Selles artiklis tahaksin vaadelda erinevaid tehnikaid võrgust VoIP-seadmete kohta teabe leidmiseks ja seejärel demonstreerida mitmeid VoIP-i rünnakuid.
Sissejuhatus
Viimastel aastatel on IP-telefoni (VoIP) kasutuselevõtt olnud kõrge. Enamik VoIP-i kasutusele võtnud organisatsioone ei tunne VoIP-i ja selle rakendamise turvaprobleeme või pole neist lihtsalt teadlikud. Nagu iga teine võrk, on ka VoIP-võrk tundlik ebaõige toimimine. Selles artiklis tahaksin vaadelda erinevaid tehnikaid võrgust VoIP-seadmete kohta teabe leidmiseks ja seejärel demonstreerida mitmeid VoIP-i rünnakuid. Ma ei laskunud meelega protokollitaseme üksikasjadesse, kuna see artikkel on mõeldud pentestijatele, kes soovivad esmalt põhitõdesid proovida. Siiski soovitan tungivalt õppida tundma VoIP-võrkudes kasutatavaid protokolle.
Võimalikud rünnakud VoIP-ile
- Teenuse keelamine (DoS)
- Mandaadi vargus ja manipuleerimine
- Rünnakud autentimissüsteemile
- Helistaja ID võltsimine
- Mees keskel ründab
- "Šamanism VLAN-ide üle" (Vlan-hüppamine)
- Passiivne ja aktiivne kuulamine
- Rämpspost Interneti-telefoni kaudu (SPIT)
- VoIP andmepüügi (vishing)
Labi konfiguratsioon VoIP testimiseks
Selle artikli VoIP-turvaprobleemide demonstreerimiseks kasutasin järgmist laborikonfiguratsiooni:
- Trixbox i(192.168.1.6) – avatud lähtekoodiga IP-PBX server
- Backtrack 4 R2 (192.168.1.4) – OS ründaja masinas
- ZoIPer ii (192.168.1.3) - pehme telefon Windowsi jaoks (kasutaja A- ohver)
- Linphone iii(192.168.1.8) – Windowsi tarkvaratelefon (kasutaja B- ohver)
Meie labori konfiguratsioon

1. pilt
Mõelge ülaltoodud labori skeemile. See on tüüpiline VoIP-võrgu konfiguratsioon väike organisatsioon ruuteriga, mis eraldab IP-aadressid seadmetele, IP-PBX süsteemile ja kasutajatele. Kui kasutaja A see võrk soovib ühendust võtta B, juhtub järgmine:
- helistama A saadetakse kasutaja autentimiseks IP-PBX serverisse.
- Pärast edukat autentimist A IP-PBX-server kontrollib kasutaja laienduse (sisenumbri) olemasolu B. Kui laiendus on olemas, suunatakse kõne ümber B.
- Vastuse põhjal B(näiteks kõne vastuvõtmine, toru katkestamine jne) IP-PBX server vastab kasutajale A.
- Kui kõik on korras A alustab suhtlemist B.
Nüüd, kui meil on suhtlusest selge pilt, jätkame lõbusa osaga – VoIP-i ründamisega.
Otsige VoIP-seadmeid
Seadme avastamine (loendamine) on iga eduka rünnaku/pentesti keskmes, kuna see annab ründajale nii vajalikud üksikasjad kui ka üldise ettekujutuse võrgu konfiguratsioonist. VoIP pole erand. VoIP-võrgus vajame meie kui ründajad teavet VoIP-lüüside/serverite, IP-PBX-süsteemide, klienditarkvara ja VoIP-telefonide ning kasutajanumbrite (laienduste) kohta. Vaatame mõningaid sagedamini kasutatavaid seadmete tuvastamise ja sõrmejälgede võtmise tööriistu. Demonstratsiooni lihtsustamiseks oletame, et teame juba seadmete IP-aadresse.
Smap
Smap iv skannib üht IP-aadressi või alamvõrku lubatud SIP-seadmete jaoks. Kasutame smappi serveri IP-PBX vastu. Joonis 2 näitab, et meil õnnestus leida server ja saada teavet selle kasutajaagendi kohta.

Joonis 2
svmap
Svmap on veel üks võimas skanner sipvicious'i tööriistakomplektist v. See tööriist võimaldab teil määrata SIP-seadmete otsimisel kasutatava päringu tüübi. Vaikimisi päringu tüüp on OPTIONS. Käitame skanneri 20 aadressist koosneval kogumil. Nagu näete, suudab svmap avastada IP-aadresse ja kasutajaagendi teavet.

Joonis 3
Swar
VoIP-seadmete otsimisel võib kasutajanumbrite järgi otsimine aidata tuvastada aktiivseid SIP-laiendeid. Svwar vi võimaldab skannida kõiki IP-aadresse. Joonis 4 näitab kasutajanumbrite skaneerimise tulemust vahemikus 200 kuni 300. Selle tulemusena saame IP-PBX serverisse registreeritud kasutajate laiendused.

Joonis 4
Niisiis, oleme käsitlenud VoIP-seadmete leidmise protsessi ja saanud huvitavaid konfiguratsiooni üksikasju. Nüüd kasutame seda teavet äsja uuritud võrgu ründamiseks.
Rünnak VoIP-ile
Nagu juba mainitud, on VoIP-võrk paljude turvaohtude ja rünnakute all. Selles artiklis vaatleme kolme kriitilist rünnakut VoIP-ile, mille eesmärk võib olla VoIP-infrastruktuuri terviklikkuse ja konfidentsiaalsuse rikkumine.
Järgmised jaotised näitavad järgmisi rünnakuid:
- Rünnak VoIP autentimise vastu
- Kuulamine ARP võltsimise kaudu
- Helistaja ID imitatsioon
1. Rünnak VoIP autentimise vastu
Kui uus või olemasolev VoIP-telefon liitub võrguga, saadab see IP-PBX-serverile REGISTER-päringu telefoniga seotud kasutaja/laienduse ID registreerimiseks. See registreerimistaotlus sisaldab oluline teave(näiteks kasutajateave, autentimisandmed jne), mis võivad ründajale või pentesterile suurt huvi pakkuda. Joonisel 5 on kujutatud jäädvustatud SIP-autentimistaotluse paketti. Pealt võetud pakett sisaldab teavet, mis on ründajale maitsev. Kasutame autentimisrünnakuks pakettandmeid.

Joonis 5
Rünnaku demonstratsioon
Rünnaku stsenaarium

Joonis 6
Samm 1: Demonstratsiooni lihtsustamiseks oletame, et meil on füüsiline juurdepääs VoIP-võrgule. Nüüd, kasutades artikli eelmistes osades kirjeldatud tööriistu ja tehnikaid, skannime ja otsime seadmeid järgmise teabe saamiseks:
- SIP-serveri IP-aadress
- Olemasolevad kasutaja ID-d ja laiendused
2. samm: Peatame Wiresharkiga kinni mitu registreerimistaotlust vii. Salvestame need faili nimega auth.pcap. Joonis 7 näitab wiresharki püüdmisfaili (auth.pcap).

Joonis 7
3. samm:
Nüüd kasutame sipcracki tööriistakomplekti viii. Komplekt on osa Backtrackist ja asub kataloogis /pentest/VoIP. Joonis 8 näitab sipcracki tööriistakasti tööriistu.
Joonis 8
4. samm: Kasutades sipdumpi, laadime autentimisandmed faili nimega auth.txt. Joonisel 9 on kujutatud Wiresharki püüdmisfaili, mis sisaldab kasutaja 200 autentimisandmeid.

Joonis 9
5. samm: Need autentimisandmed hõlmavad kasutaja ID-d, SIP-laiendit, parooliräsi (MD5) ja ohvri IP-aadressi. Nüüd kasutame parooliräside purustamiseks ettevalmistatud sõnastikurünnakut kasutades sipcracki. Joonis 10 näitab, et faili wordlist.txt kasutatakse räsimurdmise sõnaraamatuna. Salvestame häkkimise tulemused faili nimega auth.txt.

Joonis 10
6. samm: Suurepärane, nüüd on meil laienduste jaoks paroolid! Saame seda teavet kasutada oma SIP-telefonist uuesti IP-PBX-serverisse registreerumiseks. See võimaldab meil teha järgmist.
- Esinege seadusliku kasutajana ja helistage teistele tellijatele
- Kuulake ja manipuleerige ohvri (kasutaja) laiendisse tulevaid ja tulevaid seaduslikke kõnesid A V sel juhul).
2. Kuulamine läbi Arp võltsimise
Igal võrguseadmel on kordumatu MAC-aadress. Nagu ülejäänud võrguseadmed, on VoIP-telefonid MAC/ARP võltsimise suhtes haavatavad. IN see jaotis vaatame aktiivsete häälkõnede nuusutamist, kuulates ja salvestades VoIP-i otsevestlusi.
Rünnaku demonstratsioon
Rünnaku stsenaarium

Joonis 11
Samm 1: Demonstreerimise eesmärgil oletame, et oleme eelnevalt kirjeldatud võtetega ohvri IP-aadressi juba määranud. Järgmiseks ucsniffi abil ix ARP-i võltsimise tööriistana võltsime ohvri MAC-aadressi.
2. samm: Oluline on määrata võltsitava sihtmärgi MAC-aadress. Kuigi eelnevalt mainitud tööriistad suutsid MAC-aadressi määrata automaatselt, on hea tava määrata MAC iseseisvalt, eraldi viisil. Kasutame selleks nmapi x. Joonisel 12 on kujutatud ohvri IP-aadressi ja sellest tuleneva MAC-aadressi skaneerimise tulemused.
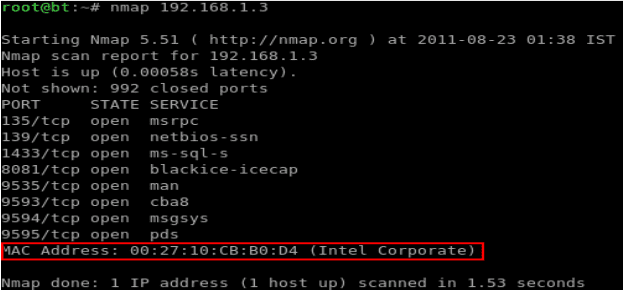
Joonis 12
3. samm: Nüüd, kui meil on ohvri MAC-aadress, kasutame nende MAC-i võltsimiseks ucsniffi. ucsniff toetab mitut võltsimisrežiimi (vaatlusrežiim, õppimisrežiim ja MiTM-režiim, st "mees keskel"). Kasutame MiTM-režiimi, määrates failis nimega targets.txt ohvri IP-aadressi ja SIP-laiendi. See režiim tagab, et ainult ohvri (kasutaja) kõned (sissetulevad ja väljaminevad). A), mõjutamata võrgu muud liiklust. Joonised 13 ja 14 näitavad, et ucsniff võltsis kasutaja MAC-i A(ARP tabelis).

Joonis 13

Joonis 14
4. samm: Petsime edukalt ohvri MAC-aadressi ja oleme nüüd valmis kuulama kasutaja sissetulevaid ja väljaminevaid kõnesid A VoIP telefoni teel.
5. samm: Nüüd, kui kasutaja B helistab kasutajale A ja alustab dialoogi, ucsniff hakkab nende vestlust salvestama. Kõne lõppedes salvestab ucsniff kogu salvestatud vestluse wav-faili. Joonis 15 näitab, et ucsniff tuvastas uue kõne laiendilt 200 laiendile 202.
Joonis 15
6. samm: Kui oleme lõpetanud, helistame uuesti ucsniffile valikuga -q, et peatada süsteemis MAC-i võltsimine ja seega tagada, et pärast rünnaku lõppemist kõik paika loksub.
7. samm: Salvestatud helifaili saab esitada mis tahes tuntud meediumipleieriga, näiteks Windowsi meedia mängija.
Helistaja ID võltsimine
See on üks lihtsamaid rünnakuid VoIP-võrkude vastu. Abonendi ID võltsimine vastab stsenaariumile, kus tundmatu kasutaja võib esineda VoIP-võrgu seadusliku kasutajana. Selle rünnaku rakendamiseks võib piisata väikesest muudatusest INVITE päringus. Moonutuste tekitamiseks on palju võimalusi korralikult SIP INVITE sõnumid (kasutades scapy, SIPp jne). Demonstreerimiseks kasutame metasploiti raamistiku abimoodulit sip_invite_spoof xi .
Rünnaku stsenaarium

Joonis 16
Samm 1: Käitame metasploiti ja laadime abimooduli voip/sip_invite_spoof.
2. samm: Järgmisena määrake suvandi MSG väärtuseks Kasutaja B. See annab meile võimaluse esineda kasutajana B. Kirjutame ka kasutaja IP-aadressi A valikus RHOSTS. Pärast mooduli seadistamist käivitame selle. Joonisel 17 on näidatud kõik konfiguratsiooniseaded.

Joonis 17
3. samm: Abistamismoodul saadab ohvrile (kasutaja A). Ohver saab minu VoIP-telefonilt kõnesid ja vastab neile, arvates, et räägib kasutajaga B. Joonisel 18 on kujutatud ohvri VoIP-telefoni ( A), mis võtab kõne vastu väidetavalt kasutajalt B(ja tegelikult minult).

Joonis 18
4. samm: Nüüd A usub, et tavaline kõne tuli B ja hakkab rääkima kellegagi, kes tutvustab end kui Kasutaja B.
Järeldus
Paljud olemasolevad turvaohud kehtivad ka VoIP-i puhul. Seadmeotsingu abil saate VoIP võrguga seotud kriitilist infot, kasutajatunnuseid/laiendusi, telefonitüüpe jne. Spetsiaalsete tööriistade abil on võimalik läbi viia autentimisründeid, varastada VoIP-kõned, kuulata pealt, manipuleerida kõnedega, saata VoIP rämpsposti, korraldada VoIP andmepüügi ja ohustada IP-PBX serverit.
Loodan, et see artikkel on olnud piisavalt informatiivne, et tuua esile VoIP-i turvaprobleemid. Tahaksin paluda lugejatel märkida, et selles artiklis ei käsitletud kõiki võimalikke tööriistu ja tehnikaid, mida kasutatakse võrgus VoIP-seadmete otsimiseks ja eeltestimiseks.
autori kohta
Sohil Garg on PwC pentester. Tema huvivaldkonnad hõlmavad uute ründevektorite väljatöötamist ja läbitungimistestimist turvalistes keskkondades. Ta osaleb erinevate rakenduste turvalisuse hindamisel. Ta on esinenud VoIP-turbeteemadel CERT-In konverentsidel, kus osalesid kõrgemad valitsus- ja kaitseametnikud. Ta avastas hiljuti ühes tootes haavatavuse suur ettevõte A, mis võimaldab privileegide suurendamist ja otsest juurdepääsu objektile.
Lingid
i http://fonality.com/trixbox/ii http://www.zoiper.com/
iii http://www.linphone.org/
iv http://www.wormulon.net/files/pub/smap-blackhat.tar.gz
v
vi http://code.google.com/p/sipvicious/
vii http://www.wireshark.org/
viii Selle tööriista leiate jaotisest Backtrack 5 jaotises /pentest/voip/sipcrack/
ix http://ucsniff.sourceforge.net/
x http://nmap.org/download.html
xi http://metasploit.com/download/
Niipea kui pakk saabub mõnda meie välisriigi või Venemaal asuvasse lattu, saate e-posti teel teate. Edaspidi saate oma pakki jälgida meie veebisaidi jaotises "Jälgimine", selleks peate sisestama oma jälgimisnumbri.
Veenduge, et sisestaksite oma IPS-profiilile õige e-posti aadress ja et teie e-posti postkast poleks täis.
Kui teie müüja (e-pood) andis teile teada, et teie pakk on jõudnud mõnda meie esindusse, kuid te ei saa seda siiski jälgida, võtke meiega võimalusel ühendust ja esitage oma paki kohta täielik teave (poe nimi, saatja ja tarneaadress identifitseerimisnumber, lahkumiskuupäev jne).
- Soovid saada seni ühe või kaks pakki:
- Kas plaanite regulaarselt (mitu korda kuus) saada välismaalt kirju, ajakirju või pakke:
- Meie teenuste tariifid meie püsiklientidele on 10-30% madalamad kui mittepüsiklientidele (olenevalt teenuse liigist).
- Välismaalt paki kohaletoimetamise tariifide arvutamine toimub vastavalt selle paki tegelikule kaalule, mitte ümardatud kaalule kilogrammide täisarvuni.
- Kehtivad kumulatiivsed allahindlused.
- Meie püsiklientidele on kirjade/pakkide pakkimine, ümberpakkimine tasuta.
- Püsiklientidele kirjade/pakkide kohaletoimetamine või edasisaatmine meie käest välismaa aadressid mis tahes muule rahvusvahelisele aadressile või mis tahes välismaal asuva isiku kätte.
- Püsiklient saab kõigist muudatustest eelnevalt infot.
- Püsiklient saab tellida endale vajaliku mittestandardse teenuse ka siis, kui seda teenust pole IPS-teenuste nimekirjas märgitud ja seda on vaja osutada väljaspool Venemaad.
- Tasuta kirjade/pakkide pikaajaline ladustamine meie välisesindustes.
- Võtke oma pakid ise meie välisesindustesse järgi.
-
Kas ma saan kasutada tellitud postkasti teie kontoris tavaposti, kirjavahetuse, arvete, tellimuste vastuvõtmiseks Moskvast või Venemaalt?
Kindlasti. Meie liitumistasu on odavam kui Vene Postil. Sel juhul ei maksa te peale liitumistasu midagi muud.
Mul on vaja pakk välismaale saata. Mille poolest erineb IPS-i saatmine teistest kullerfirmadest?
- Meie kaudu saab klient saata kolmel viisil:
- postirežiim - odavaim, kuid ka aeglasem - 10-12 tööpäeva;
- kulleri režiim keskmise tarnekiirusega - 4-5 tööpäeva (Express smart);
- Suurima kohaletoimetamise kiirusega kullerrežiim - 1-2 tööpäeva (Express business).
- Vormistame kliendile iseseisvalt kõik tollidokumendid.
- Pakume tasuta konsultatsioone mis tahes kauba saatmise logistikaprotsessi optimeerimiseks mis tahes maailma riiki.
- Meie kaudu saab klient saata kolmel viisil:
-
Mul on 4 väikest pakki. Kas saate need pakid ühte pakkida?
Me saame. Pakume pakkide koondamist. Püsiklientidele (postkastiga liitumine) - see teenus on tasuta.
Kuidas ma saan transpordi eest tasuda?
Praegu on saadaval sularahas ja sularahata makseviisid.
Millist hüvitist mulle paki kadumise korral makstakse?
Meie tarne on kõrge usaldusväärsusega. Kui see aga juhtus ja pakk oli kindlustatud - kogu kindlustussumma.
Kui kaua võtab paki kohaletoimetamine aega?
Tarneaeg võtab tavaliselt 7 kuni 12 päeva alates päevast, kui pakk saabub meie lattu vastavas riigis.
Kas ma saan hoida oma pakki teie USA/Ühendkuningriigi/Saksamaa laos 1-2 kuud? Kas selle eest tuleb maksta lisatasu?
Kui te ei telli postkasti, säilitab IPS teie pakki tasuta ainult 7 päeva alates lattu kättesaamise kuupäevast. Kui pakki hoitakse üle 7 päeva, tuleb tasuda lisatasu. IPS jätab endale õiguse oma äranägemisel utiliseerida üle 60 päeva laos hoitud pakke, mille omanikud ei ole hoiustamise eest tasunud.
Millised on IPS-iga saatmise eelised?
IPS-iga saatmise eelised:
- tarnekindlus;
- mõistlikud ja arusaadavad saatmiskulud;
- tarneaeg - 7-12 päeva;
- Moskva kontori olemasolu, kus nad on alati valmis aitama;
- võimalus osta kaupu, mis pole Venemaal saadaval;
- võimalus osta kaupu kauplustes, mis ei tarni kaupu Venemaale;
- võimalus säästa tarne pealt, kasutades saadetiste koondamise ja ümberpakendamise teenust.
-
Milliseid andmeid pean sisestama lahtrisse "Tarneaadress" e-poodidest kaupa ostes?
Peate sisestama: meie ettevõtte poolt teile antud ülemerekontori aadressi, ees- ja perekonnanime, postkasti numbri.
Kas ma pean pärast ostu sooritamist ja paki saatmist mulle antud aadressile midagi ütlema?
Peale tellimuse vormistamist tuleb meid teavitada täidetud tellimusest, esitada tellimuse andmed - manuse kirjeldus, selle kaal, maksumus. See teave on vajalik teie pakkide töötlemiseks.
Kas on mingeid investeerimispiiranguid?
IPS-iga saate saata paki mis tahes manusega, mis pole Vene Föderatsiooni õigusaktidega keelatud.
Keelatud investeeringute hulka kuuluvad:
- lõhkeained,
- tuleohtlikud esemed,
- radioaktiivsed materjalid,
- surugaas,
- tulirelvad,
- mis tahes esemeid, mis võivad pakendi olemuse tõttu põhjustada vigastusi IPS-i töötajatele või kahjustada teisi esemeid.
Saate tutvuda keelatud investeeringute täieliku nimekirjaga.
Enne e-poes ostu sooritamist palun veendu, et Sinu ost ei kuulu ohtlike kaupade kategooriasse.
Kas IPS garanteerib ostetud toote autentsuse ja kvaliteedi?
IPS ei vastuta kliendi ees tema poolt ostetud toote ehtsuse ja kvaliteedi eest. Enda turvalisuse huvides ostke tooteid ainult usaldusväärsetest veebipoodidest.
Kuidas pakki õigesti pakkida?
Vajadusel veenduge siiski, et teie pakk on korralikult pakendatud, või teavitage IPS-i, kui teie pakendile on vaja täiendavat pakkimist.
Me ei vastuta kaotsimineku või kahjustuste eest, mis võivad tekkida käsitsemise, transportimise või kohaletoimetamise käigus saatja poolt valesti pakendamise tõttu.
Milliseid dokumente pean esitama hinnangulise saatmiskulu kinnitamiseks?
Vajalik on esitada saatja koostatud arve, millel märgitud summad peavad sisaldama kõiki makse, samuti kõiki muid võimalikke tasusid.
Millistes veebipoodides saan sisseoste teha?
Mida peaksin tegema, kui müüja saatis vale kauba / vale kaubasumma?
Kuna IPS toimetab teie paki ainult Venemaale, tuleb kõik kauba pakendamise ja nõuetele vastavuse ning ümbervahetamise või tagastamise võimalusega seotud küsimused lahendada otse müüja või saatjaga.
Soovin osta ehted väärismetallidest vääriskividega. Kas see on võimalik?
Ei. Me ei tarni väärismetallidest ja/või vääriskividest esemeid.
Millal saan teada lõpliku saatmiskulu?
Alles pärast seda, kui pakk jõuab meie teie valitud välislattu.
Kui teie pakk on töödeldud, teavitatakse teid meili teel tarneaegadest ja lõplikest saatmiskuludest. Teie pakile määratakse isiklik number, saate kirjas olevate juhiste järgi tasuda saatekulu ja jälgida oma saadetise olekut.
Kui soovite saadetist koondada, peate tasuma pärast paki lõplikku vormistamist.
Postkasti telliv klient ei pea enne oma kirjade/pakkide kättesaamist IPS Moskva kontorisse makseid tegema.
Kui otsustan keelduda välismaal asuvasse IPS-i kontorisse minu nimele saabunud paki Venemaale saatmisest, kas minult võetakse mingi summa, kui pakk on vaja saatjale tagastada või see hävitada?
Kui otsustate mingil põhjusel oma paki Venemaale kohaletoimetamise peatada, võtke kiiresti ühendust oma saatjaga, et ta ei saadaks teie pakki IPS-aadressile.
Juhul, kui pakk ikka jõuab IPS lao aadressile, saame teie soovil paki tagasi saata (või edastada mõnele teisele aadressile) 10-dollarilise haldustasuga, samuti 100% tagastamise kulust / paki kohaletoimetamine.
Samuti saame paki utiliseerida 10$ haldustasuga (pakkidele kuni 15 kg). Kui pakki hoitakse kauem kui 21 päeva, võtab IPS 0,50 dollari suuruse tasu päevas paki kohta.
Mis on tarnitud paki minimaalne tasumisele kuuluv kaal?
Klientidele, kes tellivad postkasti - minimaalne arveldatav kaal on 1 nael, millele järgneb juurdekasv 0,1 naela.
Pakivedu välismaalt. Kuidas see töötab?
Pakume kõikidele oma klientidele (olgu see siis tavaklient või klient, kes soovib pakki ühekordselt kätte saada) postiaadressid kolmes maailma linnas - Londonis, New Yorgis, Hannoveris. Kõigil neist saab teie vastaja (veebipood, sõber, sugulane, kolleeg jne) teile paki saata ja 7-10 tööpäeva pärast pärast selle saabumist ühele neist aadressidest saate selle Moskvas kätte.
Kuidas ma saan aadresse?
On kaks võimalust.
IPS kontorisse tuleb sõita passiga. Siin teevad nad teie passist koopia, kirjutavad teie passi üles Kontakttelefonid ja annab teile vajaliku aadressi (Londonis, New Yorgis või Hannoveris).
Mõistlik on sõlmida leping alaliseks teenistuseks. Selleks peate postkasti tellima ja regulaarselt tegema liitumistasu. Minimaalne igakuine liitumistasu on 755,2 rubla (koos käibemaksuga 18%). (Abonemenditasu suurusi on teisigi, need sõltuvad juba liitumisteenuses sisalduvate tasuta lisateenuste komplektist). Sel juhul saate kõik kolm aadressi ja saate neid kasutada vastavalt oma soovile.
Aadressi saamiseks - kas ma võin teie juurde mitte tulla, vaid saata meilile passi koopia?
Saab, aga siis on vaja ettemaksu.
Ülaltoodud kahel juhul (vt küsimus 2) teenindame kliente sularahas - toome (st esmalt pakume teenust) ja seejärel saame kliendilt alles makse. Seetõttu on meie jaoks oluline veenduda, et meie klient on tõeline isik.
Kui soovite saata meile oma passi koopia elektrooniliselt, siis on edasise teenindamise jaoks oluline teiepoolne ettemaks summas vähemalt 4000,0 rubla. Kui pärast kättetoimetamise teenuse osutamist ja tasumist jääb Teile summa alles, tagastatakse Teile Teie esimesel nõudmisel see summa andmetele, millelt Te selle meile saatsite. Või saate seda tulevikus kasutada meie ettevõttes teenuste eest tasumiseks.
Miks tellida postkast?
Kliendist, kes tellib postkasti, saab meie püsiklient.
Püsiklientidele on järgmised eelised:
Peterburi Riiklik Ülikool
filoloogiateaduskond
Matemaatilise lingvistika osakond
V.P. Zahharov
INFOOTSING
süsteemid
Õppevahend
Peterburi
Arvustajad:
dok. tehnika. Teadused V.Sh. Rubaškin(Peterburi Riiklik Ülikool)
cand. ped. Teadused O.A. Arbatskaja(Peterburi Riiklik Kultuuri- ja Kunstiülikool)
Trükitud tellimuse alusel
Toimetus- ja kirjastusnõukogu
Peterburi Riiklik Ülikool
Zahharov V.P.
Z-38 Infootsingusüsteemid: õppemeetod. toetust. - Peterburi, 2005. - 48 lk.
Kavandatav käsiraamat sisaldab dokumentalistika põhitõdede kirjeldust teabe otsimine, distsipliini "Teabeotsingu teooria" programm, mida õpivad Peterburi Riikliku Ülikooli struktuuri- ja rakenduslingvistika osakonna 3. kursuse üliõpilased ning selle eriala laboratoorsete (praktiliste) tööde komplekt. Eraldi laboritöid kasutatakse teiste kursuste ja teiste erialade üliõpilaste õpetamiseks. Käsiraamat põhineb autori teadus- ja õppetegevusel.
Rakenduslingvistikale, infosüsteemidele ja automatiseeritud tekstitöötlussüsteemidele spetsialiseerunud bakalaureuse- ja magistriõppe üliõpilastele.
ã V.P. Zahharov, 2005
ã Peterburi
olek
Ülikool, 2005
1. Sissejuhatus teooriasse ja praktikasse
teabe otsimine
1.1. Infootsingu põhimõisted
Infootsingu süsteem (IPS) on dokumentide (dokumentide massiivid) ja infotehnoloogiate järjestatud kogum, mis on loodud teabe – tekstide (dokumentide) või andmete (faktide) salvestamiseks ja otsimiseks. Infootsingusüsteemid on mis tahes organiseeritud teabe salvestamine teatud viisil. Lisaks võivad teabeotsingusüsteemid olla mitteautomaatsed. Peaasi on objektiivne funktsioon: teabe salvestamine ja otsimine.
Sõltuvalt salvestusobjektist ja päringu tüübist eristatakse kahte tüüpi teabeotsingut: dokumentaalne ja faktograafiline - ning vastavalt kahte tüüpi IPS - dokumentaalne ja faktograafiline. Viimaseid nimetatakse ka info- ja referents-IPS-iks.
dokumentaalfilm nimetatakse IS-iks, mis teostab temaatiliste päringute otsingut dokumentide või tekstide massiivist, millele järgneb kasutajale nende dokumentide või nende koopiate alamhulk. Dokumendi mõiste võib süsteemiti erineda. Üldjuhul on tegemist teatud infoobjektiga, mis on fikseeritud (tavaliselt mõne märgisüsteemi abil) mõnele materiaalsele kandjale (paber, foto- ja filmifilm, magnetmälu jne) ning mõeldud süsteemis ruumis ja ajas edastamiseks. sotsiaalsest suhtlusest.
Faktiline IPS rakendab vahetult tegelike andmete (objektide, protsesside, nähtuste, aadresside, nimede, kvantitatiivsete andmete teaduslikud, tehnilised, majanduslikud omadused ja omadused) salvestamist, otsimist ja väljastamist.
Peamine, olemuslik erinevus dokumentaalse ja faktograafilise otsingu vahel seisneb lähenemises dokumentide semantikale. Dokumentaalsüsteemides kirjeldatakse dokumentide kui terviku tähendust nende temaatilise, ainelise sisuga. Sel juhul on oluline tuvastada ja nimetada (loetleda) peamised teemad ja objektid, millele dokument on pühendatud. Faktograafilistes süsteemides kirjeldatakse objekte, nende atribuudid ja nende atribuutide väärtused salvestatakse. Sellest tulenevad erinevused kirjelduskeeltes ja kirjelduste süsteemis salvestamises. Sellest tulenevalt on igal otsingutüübil oma otsingutööriistad.
Faktograafilised süsteemid hõlmavad rangelt reguleeritud struktuuriga dokumentide massiivi kogumist ja otsimist. Selline struktuur tuleneb kas dokumentide esialgsest intellektuaalsest töötlemisest teabe sisestamisel süsteemi või selliste dokumentide olemasolust valmis kujul teatud inimtegevuse valdkondades, näiteks raamatupidamisvormid, blanketid, teatmeteosed, ajakavad jne. . On faktipõhiseid IS-e, mis pakuvad teabe kogumist ja otsivad ainult ühte tüüpi objekte ja ainult ühte tüüpi päringuid. Samuti on rohkem arenenud faktograafilisi süsteeme, mis pakuvad sisult ja struktuurilt mitmekesiste andmete salvestamist ja otsimist, kuid see mitmekesisus on alati piiratud.
Samas pole dokumentaalse ja faktograafilise süsteemi vahel ületamatut erinevust. Üsna sageli on tõelised maksuametid näiteks segasüsteemidest, kus dokumentaalse otsingu lisavahendina kasutatakse faktilist teavet ja vastupidi. Dokumentaalsüsteemides saab tekste (dokumente) ka struktureerida, jagada fragmentideks või väljadeks ning dokumentaalse info töötlemist ja väljastamist teostada üksikute valdkondade tasandil.
On ka kolmandat tüüpi süsteeme, mida nimetatakse infoloogilisteks. Need on süsteemid, mis vastavad päringutele, millele vastatakse teabebaasis selgesõnaliselt Vastust pole. Vastust aitab saada keeleväline teadmistebaas ja olemasolevast (dokumentaalne või faktiline) algoritmiliselt genereeritud informatsioon. See uut teavet või väljastatakse vastusena päringule või kasutatakse täiendavalt otsinguks.
Dokumentaalset tüüpi teabeotsingusüsteem on dokumentide järjestatud kogum, samuti tööriistade ja meetodite kogum, mis on mõeldud dokumentaalse teabe säilitamiseks, otsimiseks ja nõudmisel väljastamiseks. Dokumentaal IPS väljastab taotlusele vastavaid dokumente teemal, teemal. Kutsutakse dokumenti, mille keskne teema või teema vastab üldiselt teabepäringu semantilisele sisule asjakohane , A semantiline omadus kahe või enama teksti vahel (antud juhul dokumendi ja teabenõude vahel) - asjakohasust . Asjakohasus on teabeotsingu teooria põhikontseptsioon. Asjakohasust on kahte tüüpi: semantiline ja formaalne. Dokumendi vastavust teabepäringu sisule nimetatakse semantiliseks asjakohasuseks ja selle dokumendi otsingupildi vastavust seda väljendavale vormistatud otsingu ettekirjutusele. infonõue, - formaalne tähtsus. Samuti nimetatakse formaalset asjakohasust dokumendi asjakohasuseks ja semantilist asjakohasust - teabe asjakohasust (tähendab "dokumendis sisalduvat teavet").
IPS-i komponente nimetatakse alamsüsteemideks. Alamsüsteemideks jaotus on vajalik ja kasulik nii arenduse eesmärgil kui ka süsteemide töötehnoloogia kirjeldamisel. Sellel võib olla erinev alus. Tavaliselt vaadeldakse kahte tüüpi IPS-i jagamist alamsüsteemideks: vastavalt funktsionaalsele põhimõttele (funktsionaalsed allsüsteemid) ja vahendite tüübi järgi (toetavad alamsüsteemid).
Kutsutakse erinevaid tööriistu, mis rakendavad IPS-i funktsioone toetavad alamsüsteemid või "tagatis". Eristatakse järgmisi alamsüsteeme: keeleline tugi, teabetugi, tehniline tugi, tarkvara, tehnoloogiline tugi, personal jne.
Teabe tugi - need on teabemassiivid (dokumendid, päringud, metaandmed), samuti nende kirjeldamise, ehitamise ja klassifitseerimise vahendid ja meetodid.
Keeleline tugi - see on loogilis-semantiline aparaat, mis koosneb teabeotsingu keelest, rakendusreeglitest (indekseerimismeetoditest), väljaandmise kriteeriumidest ja muudest keeletööriistadest.
Tarkvara - on algoritmid ja tarkvara, mis rakendavad kõiki arvuti abil teostatavaid IPS-i funktsioone.
Tehniline abi - need on tehnilised vahendid (arvutid, telekommunikatsioonivahendid), mis võimaldavad teabe salvestamist, otsimist ja edastamist.
Tehnoloogiline tugi - see on infosüsteemis infotöötluse automatiseeritud ja automatiseerimata protsesside ja protseduuride läbiviimise kogum ja kord, sealhulgas nende kirjeldus, infotehnoloogia diagrammid ning juhend- ja metoodilised materjalid.
Personali (või regulaarne) tugi - need on süsteemiga suhtlevad ja selle toimimist tagavad inimesed (hoolduspersonal).
IS jaguneb ka funktsionaalse tunnuse järgi komponentideks (allsüsteemideks), kui iga alamsüsteem täidab tehnoloogilises protsessis kindlat funktsiooni: dokumentide sisestamine, dokumentide indekseerimine, päringute sisestamine ja parandamine, päringute indekseerimine, otsing, sõnaraamatute pidamine, statistika pidamine, otsingutulemuste töötlemine, dokumentide väljastamine jne Selliseid osi nimetatakse funktsionaalsed alamsüsteemid .
Infootsingu olulised mõisted on dokument ja päring. Dokument on määratletud kui vahend, millega mis tahes viisil fikseerida eriline materjal igasugune teave faktide, sündmuste, objektiivse reaalsuse nähtuste ja inimese vaimse tegevuse kohta. Dokumentidel on erinev esitusviis. Automatiseeritud dokumentaalinfosüsteemides on see peamiselt loomulikes keeltes tekstteave masinloetaval kujul.
Päring on loomulikus keeles sõnastatud teabevajadus. "Tõlke" tulemus infonõue nimetatakse infootsingu keelde päringu otsingu pilt (POS) või otsingu järjekord (PP). Selle all mõeldakse väljendit päringu keel , mis sisaldab nii ISL-i ennast kui ka otsingu juhtelemente. Päringukeelte süntaksi ja semantika määravad dokumentide struktuur ja sisu ning süsteemi üldised ülesanded.
Infotoe kolmas osa on nn "väljaandmine", otsingutulemused. Väljaanne on saadaval kahes vormis: lühikirjeldused dokumendid ja tegelikud dokumendid.
Infootsingusüsteemide kõige olulisem komponent on teabeotsingu keel. Inimene peab massiivist vajalike dokumentide valimiseks lugema või vaatama nende sisu. Selle protseduuri kiirendamiseks ja lihtsustamiseks ilmusid mitmesugused dokumentide sisu lühendatud kirjed - annotatsioonid, kokkuvõtted, kataloogid. Kuid kõigil neil juhtudel kasutatakse dokumentide valimisel nende lühendatud kirjelduste järgi loomulikku keelt. Sellised keelemärkide "puudused" nagu homonüümia, sünonüümia, mitmetähenduslikkus on hästi teada. Paljude sõnade täpset tähendust saab mõista ainult kontekstis. See takistab loomuliku keele kasutamist kontseptuaalse teabe fikseerimiseks ja tuvastamiseks. Seetõttu nõudsid ametlikud süsteemid, mis olid loodud dokumentaalse teabe salvestamiseks hilisemaks hankimiseks, spetsiaalsete teabekeelte loomist. Infootsingu keeled on oma tähestiku, sõnavara, grammatika ja kasutusreeglitega märgisüsteemid. Märgime ainult, et kõik tehiskeeled ühel või teisel viisil loodi ja luuakse nende põhjal loomulikud keeled.
Dokumentide ja taotluste võrdlemisel on vaja välja selgitada dokumendi asjakohasus päringu suhtes ning teha otsus selle päringu kohta dokumendi väljastamise või väljastamata jätmise kohta. Reeglid, mille alusel formaalselt määratakse dokumendi ja päringu asjakohasusaste, s.o. vastavus AML-ile ja POS-ile semantilise vastavuse kriteerium (KSS) või väljastamise kriteerium .
Matemaatilised mudelid ja valemid asjakohasuse koefitsiendi arvutamiseks võivad olla väga erinevad. Praktikas IPS koos väljastamise loogiline kriteerium kui PP-de ehitamisel kasutatakse loogilisi (tõve) konjunktsiooni (&), disjunktsiooni (\/), eitusoperaatoreid (~). Sel juhul on loogilise päringu avaldis otsinguterminite kogum (tavaliselt märksõnad), mis on ühendatud loogiliste operaatorite ja sulgudega, mis näitavad operaatorite täitmise järjekorda. SP-märksõnad mängivad Boole'i muutujate rolli, mis võtavad väärtuse 1 ("tõene"), kui antud sõna sisaldub dokumendis, ja 0 ("false"), kui seda seal pole. Dokument loetakse päringu jaoks asjakohaseks, kui päringu kui terviku loogiline valem saab selle dokumendi jaoks väärtuse "tõene" ja ebaoluliseks, kui loogilise valemi arvutamise tulemus annab "väär".
Märgid (&, \/, ~), mida loogikas kasutatakse infootsingu konjunktsiooni, disjunktsiooni ja eituse tähistamiseks, asendatakse tavaliselt vastavalt operaatoritega AND, OR ja NOT. Venemaal kasutatakse sagedamini tähistusi JA, VÕI, EI. Kuid üldiselt valitakse igas konkreetses IS-is Boole'i operaatorite tähistused ja mõnikord sisestatakse kasutaja mugavuse huvides sama operaatori jaoks mitu ikooni (näiteks IPS-is "Aport" sidesõna operaatorit saab määrata järgmiste tähemärkidega: &, tühik, AND , I, +).
Tõeväärtuste operaatorite kasutamine annab dokumentide ja päringute võrdlemiseks kasutajale arusaadava loogika. Otsing (PP elementide tõe arvutamine) toimub reeglina spetsiaalsete indeksi (ümberpööratud) failide abil, mis on ehitatud dokumentaalmassiivi sõnastiku põhjal ja mida iseloomustab suur kiirus. Loogilise CSS-i selline lihtsus ja arusaadavus oli selle laialdase kasutamise põhjuseks.
Otsingu efektiivsuse hindamise probleem on keeruline probleem, mis hõlmab nii teoreetilisi kui ka praktilisi aspekte. IRS-i põhilisteks asjakohasusel põhinevateks funktsionaalseteks (tehnilisteks) näitajateks on täielikkus ja täpsus, mis põhinevad dokumentide jaotamisel asjakohasteks ja ebaolulisteks, samuti väljastatud ja väljastamata.
Otsingu täielikkus (P) (ing. Recall – R) on mõõt, mis arvutatakse arvu suhtena välja antud asjakohane dokumendid asjakohaste koguarv teabemassiivis sisalduvad dokumendid.
Otsingu täpsus (T) (inglise Precision – P) on summa suhe välja antud asjakohane dokumendid väljastatud dokumentide koguarv.
1.2. Infootsing Internetist
Üleminek 21. sajandi infoühiskonnale on toonud kaasa informatsiooni mahu ja kontsentratsiooni enneolematu kasvu globaalsetes arvutivõrkudes. See süvendas järsult teabeotsingusüsteemide (IPS) loomise ja nende tõhusa kasutamise probleemi.
Automatiseeritud teabeotsingusüsteemide ajalugu on hinnanguliselt pool sajandit. Esimeste aastate tüüpiline IS on inimene-masin süsteem, kus dokumentide sisu analüüs ja kirjeldamine (indekseerimine) toimub käsitsi, otsingud aga masinaga. Algselt moodustasid IPS-i aluse teabeotsingu keeled (ILL), mille põhielemendid on kirjeldavad sõnastikud ja tesaurused. Tänapäeval kuulub aga enamik töötavaid IS-e mittetesauruse tüüpi verbaalsete süsteemide klassi, kui indekseerimisterminid valitakse otse dokumentide tekstidest. Elektroonilise dokumentaalse teabe mahu laviinilaadne kasv, selle liigilisus, temaatiline ja keeleline mitmekesisus on nii tänapäevase infootsingu kriisi põhjus kui ka tõuke selle parandamiseks.
Internetist ressursside otsimise probleem teadvustati üsna kiiresti ja vastuseks ilmusid otsimiseks erinevad süsteemid ja tarkvaratööriistad, sealhulgas Gopher, Archie, Veronica, WAIS, WHOIS jne. Hiljuti need tööriistad asendati sõnadega "kliendid" ja "serverid" veeb WWW.
Kui proovime Interneti IP-sid klassifitseerida, saame eristada järgmisi põhitüüpe:
1. IPS verbaalne tüüp (otsingumootorid)
2. Klassifikatsioon IPS (kataloogid)
3. Elektroonilised kataloogid ("kollased" lehed jne)
4. Spetsialiseeritud IPS jaoks teatud tüübid ressursse
5. Arukad agendid.
Kõigi Interneti-ressursside globaalset arvestust pakuvad verbaalsed ja osaliselt klassifitseerimissüsteemid.
Klassifikatsioon IPS rakendada veebiruumis navigeerimist spetsiaalsete osutite alusel, mis on klassifikatsioonide alusel ehitatud temaatilised "puud". Interneti-ressursside klassifitseerimisskeemid on tavaliselt puustruktuurid, mille sõlmed on nimetatud loomuliku keele sõnadega. Erinevad liigitusskeemid erinevad üksteisest koostamise ulatuse ja metoodika poolest. Universaalsete hierarhiliste klassifikatsioonide üks puudusi on see, et need on konservatiivsed ja jäävad maha teaduse, tehnika ja elu arengust üldiselt. Klassifikatsiooniotsingu teenuste peamine probleem on klassifitseerimise automatiseerimine. Seni ülesanne automaatne klassifitseerimine ei leidnud rahuldavat lahendust. Veebisaitide ja veebilehtede registreerimist kataloogides teostavad reeglina inimesed - selle süsteemi indekseerijad ja moderaatorid. Ja seetõttu on klassifikatsioonitüüpi süsteemide andmebaasi maht suhteliselt väike, võrreldes kogu Interneti infomahuga.
Interneti-ressursside maksimaalse katvuse probleemi lahendamiseks loodi süsteemid nn metaotsing(metaotsingumootorid). Neil ei ole oma otsinguandmebaase, nad ei sisalda indekseid ja kasutavad otsimisel teiste otsingumootorite ressursse. Tänu sellele suureneb tõenäosus vajaliku info leidmiseks. Päringu saatmiseks otsingumootorisse kasutatakse spetsiaalset metaotsingu agenti, mis vastutab päringu teistele süsteemidele edastamise protsessi eest. Pärast saadud päringu töötlemist tagastab iga süsteem metaotsinguagendile komplekti kirjeldusi ja linke dokumentidele, mida ta peab asjakohaseks. see taotlus. Kogu metaotsingumootorite atraktiivsuse juures tuleks meeles pidada ka nende miinuseid ja puudusi. Esiteks puudumine ühine standard päringukeel ei võimalda metasüsteemidel saavutada sama tulemust otsingumootoritelt, mis täidavad metaotsingumootorite päringuid, mis võib saavutada edasijõudnud kasutaja iga masinaga eraldi töötades.
Peamiseks veebist teabe otsimise vahendiks tuleks tänapäeval pidada globaalset IPS-i verbaalne tüüp(otsingumootorid), indekseerimine (poolt vähemalt, väites, et on) kogu Interneti-ruum. Seda tüüpi peamistest otsingumootoritest (peamiselt andmebaasi suuruse poolest) on Google, Fast (AlltheWeb), AltaVista, HotBot, Inktomi, Teoma, WiseNut, MSN Search. hulgas Vene süsteemid peamised on kolm: Yandex (Yandex), Rambler (Rambler) ja Aport! (Aport). Otsingubaasi täielikkus ja veebisaitide indekseerimise tõhusus on kõigi Internetis olevate IRS-i peamine probleem. Reeglina annavad suurema andmebaasiga süsteemid otsingu tulemusena ja suur kogus dokumente. Suureks, nii keeleliseks kui ka programmiliseks probleemiks on interneti inforuumi mitmekeelsus ja andmete esitusvormingute mitmekesisus. Kuid peamised globaalsed süsteemid tulevad nende probleemidega toime.
Just verbaalsele IPS-ile pööratakse juhendi praktilises osas põhitähelepanu. Esiteks modelleeritakse kasutajataset, mida väljendatakse päringu keeltes ja päringu-vastuse liidestes. Tehakse erinevate Interneti-IS-de päringukeelte võrdlev analüüs.
Omapära kaasaegsed süsteemid- täisteksti otsing. Paljud Internetis leiduvad verbaalsed IPS-id arvutavad dokumentide asjakohasuse päringute jaoks, sobitades päringuelemendid veebi postitatud dokumentide täistekstidega. Mis puutub teabeotsingu keelde, siis reeglina on otsinguelemendid tavalised sõnad loomulikud keeled. Taotlused formuleeritakse spetsiaalse liidese kaudu, mida rakendatakse brauseriprogrammides kuvatavate vormide kujul.
Kasulik on mõista, kuidas need süsteemid töötavad. Igal otsingumootoril on kolm põhiosa.
Robot - alamsüsteem, mis pakub Interneti sirvimist (skannimist) ja hoiab pöördfaili (indeksiandmebaasi) ajakohasena. See tarkvarapakett on peamine tööriist võrgu teaberessursside kättesaadavuse ja oleku kohta teabe kogumiseks.
Otsi andmebaasist - nö indeks - spetsiaalselt organiseeritud registriandmebaas, mis sisaldab ennekõike ümberpööratud faili, mis koosneb indekseeritud veebidokumentidest võetud leksikaalsetest üksustest ja sisaldab nende kohta mitmesugust teavet (eriti nende asukohta dokumentides), aga ka dokumente ja saite üldiselt.
Otsingusüsteem - otsingu alamsüsteem, mis töötleb kasutaja päringut (otsingu ettekirjutus), otsib andmebaasist ja tagastab kasutajale otsingutulemused. Otsingumootor suhtleb kasutajaga läbi kasutajaliidesed- brauseriprogrammide ekraanivormid: liides päringute genereerimiseks ja liides otsingutulemuste vaatamiseks.
Indeksfail (või lihtsalt register) on omavahel ühendatud failide kogum, mis on loodud nõudmisel andmete kiireks otsimiseks. Indeks põhineb alati ümberpööratud failil. Pööratud (pöörd)ahel otsingumassiivi korraldamine põhineb põhimõttel, et dokumentidele antakse juurdepääs nende sisuidentifikaatorite kaudu (otsingu tunnused: deskriptorid, märksõnad, terminid, muud tunnused). Selline skeem saadakse dokumentide järjestikuse massiivi töötlemisel, et luua spetsiaalseid ümberpööratud abifaile - pääsupunkte.
Sellise abimassiivi iga kirje identifitseeritakse vastava sisuidentifikaatoriga (deskriptor, märksõna, lihtsalt termin, autori nimi, organisatsiooni nimi jne) ja sisaldab kõigi dokumentide nimesid (salvestusaadresse), mille otsingupiltidel see sisaldub. Iga pöördmassiivi sisuidentifikaatori (otsingu andmeelemendi) kohta saab koos dokumendi aadressi (numbri, nimega) salvestada (ja tavaliselt salvestatakse) lisateavet, näiteks: välja nimi, lause number, milles see element leiti aastal see dokument, sõna number lauses jne. Sõna asukoha fikseerimine tekstis kuni lause numbrini ja selle sõna numbrini lauses võimaldab luua paindliku päringukeele, mis võimaldab määrata dokumendis sõnade ja lausete vahelise kauguse. Positsioonitunnuseid kasutatakse ka asjakohasuskoefitsiendi arvutamisel ja dokumentide järjestamisel otsingutulemustes.
Leidmine vajalikud dokumendidümberpööratud faili kaudu ei teostata kogu massiivi pidevat skannimist, vaid vaadatakse ainult neid sisu identifikaatoreid pöördfailis, mis on määratud otsingu ettekirjutuses, st. sõnavõrdlustoimingute arv otsingus on võrdeline otsingu ettekirjutuses olevate terminite arvuga. Selline operatsioonisüsteemide viis vähendab otsinguaega ja võimaldab teil teabetarbijaid reaalajas teenindada.
Indeksiotsingud on toimingud otsinguelementide identifikaatorite loendites vastavalt otsingumudelile ja sobivuskriteeriumile. Saadud asjakohaste dokumentide loend (kaasaegses terminoloogias "vastus"), mis teisendatakse hüperteksti linkide ja muude tunnustega varustatud dokumentide lühikirjelduste järjestatud loendiks, tagastatakse kasutajale tema klientbrauseri programmis. Dokumendi pealkirjal selle lühikirjelduses klõpsamine (hüperlingi kaudu) küsib seda dokumenti kas otse serverist, kus see asub, või otsingumootori andmebaasi kaudu.
Kaasaegse IPS-i oluliseks komponendiks on nn front-end veebilehed, st. ekraanivormid, mille kaudu kasutaja suhtleb otsingumootoriga. Esilehelehti on kahte peamist tüüpi: päringulehed ja otsingutulemuste lehed.
täistekstide indekseerimine on võimalik rohkem saidid;
"pädev" töö sõnavormidega - IPS-i võime eristada sama lekseemi erinevaid sõnavorme erineval viisil, luua kanooniline vorm - lemma, ja võime eristada konkreetset vormi erinevate sõnade hulgast. sõnavormid;
otsida sõnu etteantud või meelevaldse kärpimisega nii paremale kui vasakule;
töötada fraasidega - võttes arvesse sõnade kaugust fraasides ja nende järjekorda;
tõhusad algoritmid semantilise asjakohasuse koefitsiendi arvutamiseks ja otsingutulemuste järjestamiseks.
Samuti on oluline, millist teavet ja millisel kujul saab IPS-i väljundliidestest välja võtta. Väljastamise liides (tulemuste esitamise vorm) erinevad süsteemid sisaldab järgmisi parameetreid: päringu sõnade statistika, leitud dokumentide arv, saitide arv, juhtelemendid dokumentide sorteerimiseks otsingutulemustes, dokumentide lühikirjeldus jne. Iga dokumendi kirjeldus võib omakorda sisaldama: dokumendi pealkirja, URL-i (aadressi veebis), dokumendi suurust, loomise kuupäeva, kodeeringu nime, annotatsiooni, fondi esiletõstmist päringu sõnade annotatsioonis, viidet muudele asjakohastele veebilehtedele sama sait, link kataloogi kategooriasse, kuhu leitud dokument või sait kuulub, asjakohasuse koefitsient, muud otsinguvõimalused (sarnaste dokumentide otsimine, otsimine leitud hulgast). Suurt huvi pakuvad ka sagedusomadused- teave leitud dokumentide arvu ja tuvastatud keeleüksuste kohta. Mõned süsteemid peavad päringute logi koos korduvate otsingute ja päringute statistika väljastamise võimalusega. Kasulik ja huvitav võimalus on ka dokumentide määramine teemaklassidesse.
Näidakem erinevate süsteemide, kõige populaarsemate ja kõige arenenuma keelelise toega süsteemide omadusi (vt tabel lk 14). Esiteks on need Venemaa IPS Yandex, Rambler ja Aport. Võib-olla kõige võimsama keeleaparaadi pakub infosüsteem Artifact (Integrum-TECHNO, Moskva), kuid see süsteem on kaubanduslik ja selle koostise andmebaas erineb teistest märgatavalt. Lääne süsteemidest, millest enamikul pole välja töötatud keelelisi tööriistu tekstimaterjali analüüsimiseks, võtame näiteks tuntud IPS Google ja AltaVista. Iseloomustame lühidalt nende süsteemide omadusi (sobivate võimaluste olemasolu või puudumine on tähistatud "+" ja "-" märkidega).
"Lekseemotsing" tähendab, et dokumentide ja päringute sõnade võrdlemise tulemus tunnistatakse positiivseks, kui dokument sisaldab päringust pärit sõna mis tahes vormis, mille pakub automaatne lemmatiseerimismehhanism.
"Otsi sõnavormide järgi" tähendab, et dokumentide ja päringute võrdlemise tulemus loetakse positiivseks, kui dokument sisaldab sõnavormi, mis vastab täpselt päringus olevale sõnale, mis tekib automaatse lemmatiseerimise puudumisel või on tagatud spetsiaalse mehhanismiga sõnavormide arvestus.
“Dokumendi sagedus” tähendab, et otsingu tulemusel kuvatakse teade asjakohaste dokumentide, st teatud sõna (sõnavormi) või fraasi sisaldavate dokumentide arvu kohta.
Sõnahaaval sagedus tähendab, et otsingu tulemusena antakse täiendavalt infot antud lekseemi või konkreetse sõnavormi sõnakasutuste koguarvu kohta otsingu andmebaasis (indeksis).
Otsingumootorite omadused
Märkide otsing | + (ühesõnaline päring või loogiline valem) | ||||
Otsi sõnavormide järgi | + (süntagmades: ühesõnaline päring jutumärkides või fraas jutumärkides) | ||||
Süntagmade arvestamine (lahutamatud fraasid) | |||||
Suurte ja väikeste tähtede arvestus | + (süntagmades) | ||||
Sõnade sagedus | |||||
Sagedus ühe dokumendi kohta |
1.3. Interneti IPS-i päringukeeled
Pärast mis tahes teenuse poole pöördumist töötab kasutaja brauserist lahkumata selle teenuse "kliendiga", mis pakub meile üht või teist päringukeelt. Reeglina on need keeled ilma sõnavara kontrollita. Tegelikult on meil tegemist tavalise ISL-iga, mis on rakendatud "klient-server" arhitektuuris, kuid me näeme ainult selle ISL-i "ülemist" osa - päringukeelt. Enamiku süsteemide päringukeel sisaldab nii traditsioonilisi Boole'i operaatoreid kui ka spetsiaalseid kontekstioperaatoreid, mis võtavad arvesse dokumendi struktureerimist, sõnade järjekorda tekstis ja sõnavahesid.
Päringukeel kirjeldab päringut ennast ja mõnikord ka tulemuste esitamise vormi. Võrgu IPS-i päringukeeltes saab eristada järgmisi põhikomponente.
1) Tegelikud otsinguelemendid (otsinguobjektid).
Need on kas märksõnad või muud sisuidentifikaatorid.
2) Otsinguoperaatorid.
Peaaegu kõik päringukeeled kasutavad tõeväärtusi. loogilised operaatorid JA, VÕI, EI. Nende operaatorite taotluses märgitud vorm on väga erinev ja varieerub nii üksikute teenuste lõikes kui ka sees erinevad tüübid taotlused (lihtsad, keerulised).
3) Päringu elementide normaliseerimine.
Dokumentides ja päringutes võib samu leksikaalseid üksusi esitada erineval kujul. Otsinguteenustel on viise selliste leksikaalsete üksuste normaliseerimiseks. Selle normaliseerimise saab määrata kasutaja (tuntud kui "kärbimine" või "meemärk") või seda saab teha automaatselt (viimane on eelistatud).
4) Lineaarne grammatika: otsinguelementide järjekord ja nendevaheline kaugus.
Esiteks on need "fraasid" (kõvad fraasid).
Teiseks on olemas spetsiaalsed kontekstioperaatorid (context AND), kui teatud pikkusega kontekstis peab olema täidetud päringuelementide ühise esinemise tingimus dokumendis.
5) Täiendavad otsingusõnad.
Väljundi vähendamiseks ja täpsuse parandamiseks kasutatakse erinevaid meetodeid. lisatingimused otsi kuidagi:
– otsida dokumendi teatud väljadelt (osadelt);
– otsinguala piiramine erinevate kriteeriumidega (kuupäev, andmetüüp, formaat jne).
6) Nõuded otsingutulemuste esitamise vormile.
– nõuded väljundotsingu tulemuste sortimiseks (järjestamiseks);
– väljundtulemuste tüüp;
– väljastatud dokumentide arv.
Dokumentide endi (veebilehtede) vastuvõtmiseks (vaatamiseks) ja nende vaatamiseks peate minema http-aadressile. Süsteemid annavad reeglina võimaluse vaadata konteksti – esiletõstetud päringu märksõnadega dokumendifragmente.
Otsinguprotsessi käigus antakse kasutajale tavaliselt võimalus naasta vana päringu juurde ja kas lihtsalt täpsustada, kitsendada või lülituda teisele otsingurežiimile, mis pakub keerukamaid otsingutööriistu. Üsna laialt levinud on ka teine otsingumeetod – otsi näidise järgi (otsi sarnastelt lehtedelt). Sel juhul valib otsingustrateegia süsteem ise.
2. Akadeemilise distsipliini programm
"Teabeotsingu teooria"
2.1. Organisatsiooniline ja metoodiline osa
Distsipliini programm on koostatud vastavalt riiklikule kutsekõrghariduse haridusstandardile suunal 021800 - Lingvistika.
Kursuse eesmärk on anda õpilastele infootsingu, eelkõige dokumentaalsuse, teoreetilised alused ning oskused kasutada erinevaid dokumentaalseid infosüsteeme, sh Internetti.
Kursuse eesmärgid:
tutvustada õpilastele automatiseeritud infootsingu põhimõisteid ja probleeme;
tutvustada õpilastele infootsingusüsteemide (IPS) organiseerimise ja toimimise põhiprintsiipe;
õppida erinevaid IPS-e, sealhulgas Interneti-IPS-i;
kujundada erinevate süsteemide analüüsi ja võrdlemise uurimistöö oskusi.
Kursuse koht lõpetaja erialases koolituses: Kursus on oma olemuselt propedeutiline. See on mõeldud paljudele humanitaarteaduste üliõpilastele ja selle eesmärk on anda neile põhimõtteline ettekujutus teabe salvestamise ja otsimise kohta.
Nõuded kursuse sisu valdamise tasemele
Koolituse tulemusena õpilane:
peab teadma:
infosüsteemidega seotud põhimõisted;
peamised süsteemide tüübid;
infootsingu keele mõiste;
asjakohasuse mõisted ja semantilise vastavuse kriteerium;
Interneti peamised otsingumootorid;
nende süsteemide päringukeeled ja liidesed;
peaks suutma:
otsida Internetist;
võrrelda ja analüüsida erinevaid süsteeme.
Kursuse osad:
Infootsingu põhitõed
Dokumentaalfilm IPS
Faktiline IPS
Infootsing Internetist
Jaotis 1. Infootsingu alused
Kursuse õppeaine, eesmärgid ja eesmärgid. Kursuse seos teiste erialadega.
Info, infoprotsessid, infosüsteemid, infovood, infotehnoloogiad. Infosüsteemide tüübid (AIPS, ASNTI, ACS, ASNI, AOS, CAD, ES, BZ jne).
Infootsingu põhimõisted: informatsioon, infosüsteem, infovajadus, asjakohasus.
andmed ja dokumendid. Teabedokumentide liigid. Tekstidokumendid. Dokumentide kirjeldus.
Taotlused. Taotluste tüübid. Teema otsing. Infotöötluse semantiliste protsesside automatiseerimise peamised probleemid.
Infootsingusüsteemid (IPS). IPS-i tüübid. Lühiülevaade põhitüübid: dokumentaalne, faktiline, intellektuaalne.
Bibliograafiline otsing. Bibliograafilised andmebaasid ja elektroonilised kataloogid. raamatukogu süsteemid.
Mittetekstilised infosüsteemid (geograafilised, kartograafilised jne). Otsige objekte nende kirjelduste järgi ( graafilised failid, muusikafailid ja nii edasi.). Otsige pilte ja videoteavet.
Jaotis 2. Dokumentaalne IP
Automatiseeritud dokumentaalinfosüsteemide arengulugu, arenguetapid. Integreeritud süsteemid. ASNTI. Kaasaegse lava omadused.
IPS-i komponendid. IPYA. . otsi mudeleid. Abstraktne ja konkreetne IPS.
Dokumentalistika ja faktograafilise IPS struktuur. Funktsionaalsed allsüsteemid. Struktuurne skeem dokumentaalfilm IPS.
Kahe ahelaga süsteemid. IPS täistekst. Hüperteksti infosüsteemid.
Toetavad alamsüsteemid. Tehniline abi. Tarkvara. Arvutivõrgud. Võrgu IPS ehitamise omadused.
Dokumentaalfilmi IPS matemaatiline mudel.
Otsingumassiivide korraldamine IPS-is.
Dokumentaalfilmi IPS klassifikatsioon erinevatel alustel.
Jaotis 3. Faktiline IRS
Faktiline informatsioon. Hästi struktureeritud ja halvasti struktureeritud faktiline teave.
Objekti karakteristikute tabelid.
Semantilise väljenduse keel.
Faktograafilise IPS-i efektiivsus.
Bibliograafiline otsing kui omamoodi faktograafia.
Jaotis 4. Infootsingu keeleline tugi
Keelelised teabeotsingu vahendid. IPS-i keelelise toe koosseis.
Infootsingu keele (IPL) mõiste. ILP kui IPS-i loogilis-semantilise aparaadi põhielement.
Infootsingu keeled: klassifikatsioon, tüpoloogia. Objekt-viipekeeled. Klassifikatsioonid. Tähestikuline teema ja lihvitud klassifikatsioonid.
deskriptorkeeled. verbaalsed keeled.
Semantilised ja süntagmaatilised keeled.
Keelte kirjeldamise viisid. Kirjeldavate teabeotsingu keelte komponendid (tähestik, sõnastik, grammatika).
Sõnavara normeerimine IPS-is. deskriptorsõnastikud. tesaurus. Sõnaraamatute ja tesauruste loomine. Autoriteetne kontroll kui automatiseeritud raamatukogusüsteemide keelelise toe element.
IPL-i grammatilised vahendid. paradigmaatilised ja süntagmaatilised suhted.
Dokumentide ja päringute indekseerimine. Otsige dokumentide ja päringute pilte.
Päringukeeled: mõiste ja koostis. Infovajaduste väljendamise vahendid ja meetodid. Otsimise juhised.
otsi mudeleid. otsinguoperaatorid.
Morfoloogilise normaliseerimise vahendid.
Keeletööriistad elektrooniliste dokumentide esitamine ja struktureerimine (vormingud, keeled SGML, HTML, XML). Metaandmete keeled (Dublin Core, GILS jne).
Faktograafiliste infosüsteemide keeleline tugi. Faktograafilise IRS-i IEL-i peamised üksused.
5. jagu. ISi toimimine ja toimimine
Info-, tehnoloogiline ja personali tugi.
Masinaeelse teabe töötlemise tehnoloogia. Dokumentide ja päringute indekseerimine. Otsingu funktsioonid olenevalt dokumentide tüübist.
IS töörežiimid (IRI, retrospektiivne otsing). Pakett- ja dialoogirežiimid.
Dokumentaalfilmi IPS-i peamised tehnilised omadused (poolnoot, täpsus). Otsingu tõhusust mõjutavad tegurid. IPS-i tõhususe hindamine.
Vahendid ja meetodid leksiko-semantiliste probleemide lahendamiseks IPS-is. Otsinguretseptide koostamise probleemid. Asjakohasuse tagasiside.
Otsingutulemuste pakkumine põhidokumentidega. Elektrooniline kohaletoimetamine dokumente.
Jaotis 6. Infootsing Internetist
Tähendus arvutivõrgud organiseerimise jaoks teabeteenus. Kaugdokumendi massiividele juurdepääsu meetodid ja vahendid. Protokoll Z39.50 (otsing/otsing).
Internet, selle lühikirjeldus. Internet kui elektrooniline transpordisüsteem. Internet kui globaalne inforuum.
Interneti teabeallikad. FTP serverid. GOFER. WAIS.
Hüperteksti mõiste. Hüpertekstisüsteemid enne Interneti tulekut. WWW serverid. Veebis navigeerimine. Infootsingu probleemid.
Dokumentaalsed teabeallikad. Elektroonilised dokumendid. Esitluse vormingud tekstiteave võrgus (html, pdf, ps, doc jne). Elektroonilised väljaanded.
Mittetekst infoobjektid. Elektroonilise raamatukogu kontseptsioon.
Interneti otsingumootorite tüpoloogia. Erinevad klassifitseerimise alused (katte laiuse, sisemiste tunnuste, dokumendiliikide järgi).
Interneti otsingumootorite tüpoloogia. Klassifikatsiooniteabe otsingusüsteemid (kataloogid). Verbaalsed (tekst, sõnaraamat) teabeotsingusüsteemid ( otsingumootorid).
Globaalsed teabeotsingusüsteemid ja Interneti-teenused.
Loomulikud keeled Internetis. Piirkondlik IPS. Globaalsete süsteemide piirkondlikud versioonid. Vene Internet.
Otsinguandmebaaside loomise meetodid globaalsed süsteemid. Indekseerimine ja registreerimine. Roboti indekseerijad. Indekseerimise haldustööriistad (fail robots.txt, META elemendid).
IPS-i keelelise ja infotoe iseärasused Internetis. Sõnaline ips. ILP grammatilised vahendid: süntagmaatika. Konteksti-positsioonilised operaatorid ("fraasid", kaugusoperaatorid jne).
Dokumentide järjestamise probleemid väljastamisel. Edetabeli haldamise viisid.
sisendliidesed. Päringukeeled (lihtne, laiendatud). Nende koostis, näited. Võrdlev analüüs Interneti IPS-i päringukeeled. Taotluste salvestamine (seansi ajalugu).
väljundliidesed. Otsingutulemuste esitlemine. Dokumentide (veebilehtede) kirjeldus, saitide kirjeldus. Dokumentide rühmitamine saitide järgi. Duplikaatide tuvastamine ja ühendamine.
Otsingu haldamine. otsingu statistika. Otsing leitud. Sarnasuse otsing.
Näited verbaalsest IPS-ist. Otsingumootorite võrdlev analüüs.
Silumispäringute ja verbaalses IPS-is otsimise töötuba.
Klassifikatsioon IPS. Andmebaasi moodustamise viisid klassifikatsioonisüsteemides. Registreerimine, spetsiaalsed registreerimissaidid. Otsi rubrikaatori järgi.
Klassifikatsiooni IPS-i otsingu töötuba.
Jaotis 7. Infootsingu olevik ja tulevik
Interneti ja eriti otsingumootorite kommertsialiseerimine. Reklaam. Kiire registreerimistasu.
Kohaliku IPS-i arendamine.
Unifitseerimise ja standardimise probleemid.
Tagasiside tähendab. Mitteametlikud "otsingukogukonnad".
Keelelise toe arendamine.
Tsentraliseeritud ja detsentraliseeritud hajutatud arhitektuuriga süsteemid.
Infootsingu intellektualiseerimine. Intelligentsed infosüsteemid.
Aruka töötlemise elemendid ülemaailmses Interneti-IPS-is. Arukad agendid.
metaandmete keeled, XML keeled, RDF, OWL ja muud sisu kirjeldamise tööriistad.
2.3. näidisküsimused enesekontrolli jaoks
Andke määratlused:
Väljastamise kriteeriumid
Asjakohasus
Tesaurus
IPS-i komponendid
Keelelise toe koosseis
Pöördfail
Valige õiged vastusevariandid
Märk "&" IPS Rambleris tähendab toimingut:
disjunktsioonid (VÕI)
sidesõnad (JA)
vahemaad
Märk "|" Yandexi IPS tähendab toimingut:
järgnev
sidesõnad (JA)
disjunktsioonid (VÕI)
IPS-i funktsionaalsed alamsüsteemid on:
keeleline tugi
tarkvara
tehniline abi
dokumentide sisestamine
päringu sisestus
mõttes sobitamise kriteerium
päringu keel
otsingutulemuste tagastamine
ümberpööratud failid
ISP tüübid on järgmised:
morfoloogilised keeled
deskriptorkeeled
semantilised keeled
klassifikatsioonikeeled
verbaalsed keeled
sekundaarsed keeled
objekt-funktsiooni keeled
IPS-i morfoloogilise normaliseerimise peamised meetodid:
põhineb automaatsel morfoanalüüsil
kärpimine
maskeerimine
eesliide
Semantilise vastavuse kriteerium on:
indekseerimise reeglid
normaliseerimisreeglid
täielikkuse arvutamise reeglid
järjestamise meetodid
klassifitseerimismeetodid
Indekseerimine on:
morfoloogiline normaliseerimine
otsingupildi koostamine
tõlkimine matemaatilise loogika keelde
tõlge IPL-i
asjakohasuse arvutamine
kirjeldava sõnaraamatu koostamine
IPS-i toetavad alamsüsteemid on:
keeleline tugi
tarkvara
tehniline abi
dokumentide sisestamine
päringu sisestus
mõttes sobitamise kriteerium
otsida retsepte
otsingutulemuste tagastamine
ümberpööratud failid
IIP tüübid:
objekt-funktsiooni keeled
klassifikatsioonikeeled
morfoloogilised keeled
semantilised keeled
verbaalsed keeled
sekundaarsed keeled
deskriptorkeeled
Väljastamise kriteeriumid on järgmised:
indekseerimise reeglid
normaliseerimisreeglid
asjakohasuse arvutamise reeglid
täielikkuse arvutamise reeglid
järjestamise meetodid
klassifitseerimismeetodid
2.4. Aruannete, kokkuvõtete ligikaudsed teemad,
kursusetööd
Interneti IPS-i analüüs ja kirjeldus (süsteemi valik kokkuleppel õpetajaga)
Infootsingusüsteemide terminoloogilise andmepanga loomine (identifitseerimine, terminite klassifitseerimine ja tõlgendused; tulemuseks on hüpertekstisõnastik-register või otsinguandmebaas)
Veebisõnastike ja tesauruste (nt WordNet) kasutamise võimaluste uurimine päringute indekseerimiseks teabeotsingusüsteemides
Morfoloogilise normaliseerumise mehhanismide analüüs ja kirjeldus infootsingusüsteemides
Süntagmaatiliste suhete arvestamine täisteksti IRS-is (eksperimentaalne uuring) otsingu tõhususe suurendamise vahendina
Asjakohasuse arvutused teabeotsingusüsteemides (eksperimentaalne uuring)
Täisteksti infootsingusüsteemide võrdleva efektiivsuse uuringute analüüs
Täisteksti infootsingusüsteemide keelelise toe analüüs
Teabeotsingusüsteemide elektroonilise ajakirja väljaannete analüütiline ülevaade Search Engine Report
2.5. Eksami küsimuste näidisloend
(nihe) kogu kursuse jooksul
Abstraktne ja konkreetne (päris) IPS
Verbaalsed teabeotsingusüsteemid (otsingumootorid). Nende arhitektuur. Näited verbaalsest IPS-ist
Globaalne ja piirkondlik IPS Internetis. Näited
IPL-i grammatilised vahendid. Grammatiliste suhete väljendamise viisid
deskriptorsõnastikud. tesaurus
Dokumentaalne teave Internetis. Tekstidokumendid. Keelevahendid dokumentide esitamiseks ja struktureerimiseks (otsingunurga all)
Dokumentide ja päringute indekseerimine. Indekseerimise automatiseerimine
Intelligentsed infosüsteemid
Internet kui globaalne infokeskkond. Võrgu teaberessursid. Interneti-otsingu probleemid
Infovajadus, infopäring, otsinguretsept
Infootsingusüsteemid (IPS). IPS-i tüübid. Lühiülevaade peamistest tüüpidest
Infootsingu keeled: klassifikatsioon, tüpoloogia
IPYA. deskriptorkeeled. Verbaalsed keeled
IPYA. Klassifikatsioonikeeled
Automatiseeritud dokumentaalinfosüsteemide arengulugu, arenguetapid. Kaasaegse lava omadused
Klassifikatsiooniteabe otsingusüsteemid (kataloogid). IPS klassifikatsiooni näited
Dokumentaalsete IP-de klassifitseerimine erinevatel alustel
Semantilise vastavuse kriteerium. Otsi mudeleid
Keelelised teabeotsingu vahendid. IPS-i keelelise toe koosseis
Meetodid otsinguandmebaaside loomiseks globaalsetes süsteemides (indekseerimine, registreerimine)
Sõnavara morfoloogiline normaliseerimine IPS-is
Toetavad alamsüsteemid
Objekti funktsioonide keeled
Otsingumassiivide korraldamine IPS-is
Dokumentaalfilmi IPS-i peamised tehnilised omadused (täielikkus, täpsus)
Infootsingu keele (IPL) mõiste. Klassifikatsioon (tüpoloogia) IEP
Mõisted "informatsioon" ja "süsteem". Infoprotsessid ja süsteemid. Infosüsteemide tüübid
Mitmekeelse Interneti-otsingu probleemid. Lahendused erinevates IPS-ides
Probleemid venekeelsete dokumentide otsimisel. Venekeelne IPS
Otsinguretseptide koostamise probleemid. Asjakohasuse tagasiside
Sega (hübriid) süsteemid. Metaotsingu süsteemid. Näited
Deskriptorite teabeotsingu keelte komponendid
IPS-i komponendid. Süsteemsed seosed IPS-i elementide vahel
Dokumentaalse infootsingu olemus. Asjakohasuse mõiste
Semantilised keeled
IPS-i tehnoloogia ja töörežiimid. Kahe ahelaga IPS
Interneti otsingumootorite tüpoloogia
Faktiline IPS
IPS-i funktsionaal-struktuurskeem. Funktsionaalsed allsüsteemid
IPS "Altavista" päringukeel. Otsingutulemuste esitusliides
Google IPS-i päringukeel. Otsingutulemuste esitusliides
IPS "Aport" päringukeel. Otsingutulemuste esitusliides
IPS "Rambler" päringukeel. Otsingutulemuste esitusliides
IPS "Yandex" päringukeel. Otsingutulemuste esitusliides
Kaasaegsete teabeotsingusüsteemide päringukeeled. Võrdlev analüüs
Päringu keeled. Otsimise juhised.
2.6. Kursuse tundide jaotus teemade kaupa
ja töö liigid
Teemade nimed | klassiruumi Kaasa arvatud | Iseseisev töö |
|||
Seminar | |||||
Infootsingu põhitõed | |||||
Dokumentaalfilm IPS | |||||
Faktiline IPS | |||||
Infootsingu keeleline tugi | |||||
IPS-i toimimine ja toimimine | |||||
Infootsing | |||||
Infootsingu olevik ja tulevik | |||||
KOKKU: | |||||
2.7. Voolu-, vahe- ja lõppjuhtimise vorm
Üliõpilased koostavad semestri jooksul ühel valitud teemal kirjalikke töid (konspekte), mis kursuse lõpus “kaitstakse” referaatide vormis. Kursuse lõpus - ainepunkt.
2.8. Hariduslik ja metoodiline tugi muidugi
Peamine kirjandus
Zahharov V.P. Infosüsteemid (dokumentaalfilmide otsing). SPb., 2002.
Arvutiteadus/ Toim. K.V. Tarakanova. M., 1986.
Lahuti DG. Automatiseeritud dokumentaal-faktilise teabe otsingusüsteemid // Teaduse ja tehnoloogia tulemused. Arvutiteadus. T. 12. M., 1988. S. 6–77.
Salton J. Dünaamilised raamatukogud ja infosüsteemid. M., 1979.
Salton g. Info automaatne töötlemine, salvestamine ja otsimine. M., 1973.
Cherny A.I. Sissejuhatus infootsingu teooriasse. M., 1975.
lisakirjandust
Avetisyan D.O. Infootsingu probleemid. M., 1991.
Relvad W. Digitaalsed raamatukogud. M., 2001.
Beloozerov V.N. Uued standardid teabeotsingu terminoloogiale // NTI. Ser. 1. 1997. nr 11. S. 14–21.
Voiskunsky V.G. Dokumentaalfilmide otsing ja Tagasiside// Aineotsing traditsioonilistes ja mittetraditsioonilistes teabeotsingusüsteemides. SPb., 1993. Väljaanne. 11. S. 129–141.
Voiskunsky V.G., Zahharov V.P. Dialoogide silumiskompleks // Struktuuri- ja rakenduslingvistika: Ülikoolidevaheline kogu. Probleem. 4. Peterburi, Peterburi Riiklik Ülikool, 1993. S. 197–211.
Decker S., Melnik S., Hermelen van F. Semantiline veeb: XML-i ja RDF-i rollid // avatud süsteemid. 2001. nr 9. S. 23–33.
Zahharov V.P., Mordovchenko P.G., Sahharny L.V. Keelelise toe parandamine "mittetesauruse" tüüpi IPS-is // NTI. Ser. 2. 1980. Nr 6. Lk 14–19.
Zahharov V.P., Pankov I.P. Infootsingusüsteemid // Rakenduslingvistika: õpik / Toim. toim. A.S. Gerd. Peterburi, Peterburi Riiklik Ülikool, 1996. S. 334–359.
Zahharov V.P., Pimenov E.N.. Loomuliku keele lähenemine teabeotsingusüsteemide keelelise toe loomisele // NTI. Ser. 2. 1997. nr 12.
Zmitrovitš A.I. Intelligentsed infosüsteemid. Minsk, 1997.
Kapustin V.A. Otsige teavet Internetist // Interneti maailm. 1998. nr 9. lk 54–58.
Kapustin V.A. Teabeallikad – kuidas me neid otsime? // Interneti maailm. 1998. nr 9. S. 58–61.
Kapustin V.A. Internetist teabe otsimise alused: Metoodiline juhend. SPb., 1999.
Kurnik A. Internetiotsing. SPb., 2001.
informatiivne-otsingumootorid. M., 1972.
Lahuti DG. Infosüsteemide intellektualiseerimine: teaduslik aruanne ... M., 2002.
Lyubarsky Yu.Ya. Intelligentsed infosüsteemid. M., 1990.
Masevich A.Ts. Kaks lähenemist IPS-i teooriale kaasaegsete lingvistiliste kontseptsioonide valguses // Subjektiotsing traditsioonilistes ja mittetraditsioonilistes teabeotsingusüsteemides. L., 1989. Väljaanne. 9. Lk.25–49.
Moskovitš V.A.. Teabekeeled. M., 1971.
Parkhomenko V.F. Automaatne dokumentide indekseerimise süsteem BRACKETS OS EU // M., 1983
Rakendatud Keeleteadus: õpik. SPb., 1996, lk 59–67, 92–99, 360–388.
Rubashkin V.Sh. Tähenduste kujutamine ja analüüs intelligentsetes infosüsteemides. M., 1989.
Sokolov A.V. Bibliograafilise otsingu automatiseerimine. - M., 1981.
Sokolov A.V.. Sissejuhatus sotsiaalse suhtluse teooriasse. SPb., 1996.
Sokolov A.V.. Metoodilised materjalid infootsingu tesauruste arendamise kohta. L., 1976.
Stepanov V. Bibliograafiline otsing Internetis // Bibliograafia. 1998. nr 1. S. 5–10.
Khramtsov P.B.. Interneti teabeotsingusüsteemid // Avatud süsteemid. 1996. nr 3. S. 46–49.
Khramtsov P.B.. Interneti teabeotsingusüsteemide modelleerimine ja analüüs // Avatud süsteemid. 1996. nr 6. S. 46–56.
Shemakin Yu.I., Romanov A.A.. Arvuti semantika. M., 1995.
Shemakin Yu.I. Tesaurus automatiseeritud juhtimis- ja infotöötlussüsteemides. M., 1974.
Standardid
Tüüpiline disainilahendused teadusliku ja tehnilise teabe automatiseeritud süsteemide jaoks. M., 1983.
GOST 34.601-90. Infotehnoloogia. Standardite kogum automatiseeritud süsteemid. Automatiseeritud süsteemide loomise etapid.
GOST 34.602-89. Infotehnoloogia. Automatiseeritud süsteemide standardite kogum. Tehniline ülesanne automatiseeritud süsteemi loomiseks.
GOST 7.52-85. Bibliograafiliste andmete vahetamise suhtlusvorm magnetlindil. Dokumendi otsingupilt.
GOST 7.74-96. Infootsingu keeled. Tingimused ja määratlused.
RD 34.003-90. Infotehnoloogia. Tingimused ja määratlused.
RD 34.201-89. Infotehnoloogia. Dokumentide tüübid, täielikkus ja tähistused automatiseeritud süsteemide loomisel.
RD 34.680-88. Metoodilised juhised. Infotehnoloogia. Põhisätted.
RD 34.698-90. Metoodilised juhised. Infotehnoloogia. Nõuded dokumendi sisule.
3. Töötuba (laboritöö)
Laboratoorsete tööde teostamise juhend
Laboritööde tulemused salvestatakse kõvakettale vastavasse kausta. laboritööd Lab#N, kus N on töö number. Sel juhul salvestatakse kõik need kaustad omakorda õpilase kausta, millel on järgmine tee: DISK:\ Juhendaja perekonnanimi\nnn-Perekond\, kus nnn on rühma number (identifikaator), Fam on õpilase perekonnanimi. Näiteks kõik labori nr 2 käigus loodud ja salvestatud failid ja kaustad asuvad kaustas D:\Zakharov\ML_3kurs-Ivanov\Lab#2. Laboriülesannetes kannab selle õpilase praegust kausta nime " enda kaust».
Mõnel juhul tuleks enne tööle asumist õpetaja korraldusel kopeerida (õpetaja arvutist "Võrgustiku naabruskonna" kaudu või disketilt) oma kausta ülesande täitmiseks vajalikud lisafailid.
Wordi redaktoris koostatakse tekstiaruanne vastava töö tulemustega. Dokumendiaknasse tuleb sisestada perekonnanimi, eesnimi, rühma/alarühma number, laboritöö number, töö tegemise kuupäev. Lisaks kirjutage sellesse faili soovitud töö tulemused ( vastava ülesandepunkti numbri all). Salvestage need andmed oma kausta aruandefailina nimega ReportN, kus N on töö number. Andmete kadumise vältimiseks rikete korral soovitatakse õpilaste poolt töö käigus genereeritud faile regulaarselt salvestada.
Töö tulemuste esitlemiseks õpetajale järjesta need ekraanil vasakult paremale kaskaadselt järgmistesse akendesse: kaitstud laboritööde kausta sisu (Exploreri aknas), aruande fail aknas sõna toimetaja, brauseriaken (vajadusel).
Labor nr 1
(IPS klassifikatsioon)
Avage otsingumootori Aport (ROL, Venemaa On-Line) leht. Tutvuge selle süsteemi klassifikaatoriga (rubrikaatoriga). Kirjutage ülemise taseme pealkirjad vihikusse ümber ja nummerdage need ümber. Rubrika pealkirju läbides leidke kaks muuseumi ("F. M. Dostojevski kirjandus- ja memoriaalmuuseum" ja "M. V. Lomonossovi ajaloo- ja memoriaalmuuseum Lomonosovo külas, Arhangelski oblastis"). Tutvuge kataloogis olevate saitide kohta teabe esitamise vormiga.
Iga muuseumi jaoks:
kopeerida kataloogis nimetatud muuseumide lühikirjeldused aruandefaili Report1;
märkige nende muuseumiobjektide tsiteerimisindeks (numbri kujul) ja liiga (sõnalise nime kujul);
minge muuseumi veebisaidile ja kopeerige oma kausta esimene koduleht vormingus ;
luua "järjehoidja" muuseumi veebisaidil kaustas Lemmikud.
Avage Yandexi otsingumootori leht. Tutvuge selle süsteemi klassifikaatoriga (rubrikaatoriga). Kirjutage ülemise taseme pealkirjad vihikusse ümber ja nummerdage need ümber. Märkige (ringi) pealkirjad, mis langevad kokku Aporti pealkirjadega (täielikult või osaliselt). Rubrikaatori pealkirju läbides otsige üles „F.M. kirjandus- ja memoriaalmuuseum. Dostojevski” ja „M.V. ajaloo- ja memoriaalmuuseum. Lomonosov Arhangelski oblastis Lomonosovo külas. Kopeerige nende kirjeldused Yandexi rubrikaatoris aruandefaili.
Külastage IPS Rambleri reitingusüsteemi. Tutvuge selle süsteemi klassifikaatoriga (rubrikaatoriga). Pealkirjad, mis langevad kokku Aporti pealkirjadega (täielikult või osaliselt), kirjutage vihikusse ümber. Vaadake saitide reitingut teemal "Haridus". Tutvuge kataloogis oleva teabe esitamise vormiga. Kopeerige viienda koha saidi nimi koos kvantitatiivsete näitajatega aruandefaili Report1. Vaata üksikasjalik statistika ja kopeerige statistikatabel aruandefaili.
Korrake sama Yahoo süsteemis.
Laboratoorsed tööd№ 2
(Vene keelne verbaalne IPS: võrdlev analüüs)
Töö seisneb süsteemide Aport, Yandex, Rambler võrdlevas uuringus. Õpilane peab kajastama õppetöö tulemusi tabeli kujul (lk 34) failis Report2 (tabeli orientatsioon - maastik). Lahtritesse kirjutage üles, kuidas see või teine päringukeele element või sisend/väljundliides on igas süsteemis esindatud (kõik kehtivad meetodid). Mõnel juhul saate vastata "+" või "-" märkidega (näiteks " Dokumendi kirjeldus”) või vaba teksti oma sõnadega (näiteks « Vastavad lehed sama sait" või "Sorteerimine").
Minge Aporti otsingumootori saidile (siis Yandex ja Rambler). Leidke igast süsteemist lingid selle kirjeldusele tervikuna, päringukeele kirjeldusele, liidestele ("Abi", "Abi", "Täpsem otsing" ja nii edasi . ). Linke klõpsates uurige hoolikalt taustainfot ja tehke töövihiku põhipunktidest lühidalt kokkuvõte. Pärast seda täitke iga süsteemi jaoks vastavad tabeli lahtrid (jaotised 1, 2).
Märge. Kui vastuse tekst tabeli lahtrisse ei mahu, on soovitatav teha joonealune märkus ja jätkata seda tabeli all. Pöörake tähelepanu asjaolule, et süsteemide võimalused lihtsas ja täpsemas otsingus erinevad. Peegeldage seda aruandes. Pöörake tähelepanu jaotiste "muu" olemasolule.
Naaske otsingumootori Aport (siis Yandex ja Rambler) avalehele. Sisestage päring (näiteks "Statistilised meetodid lingvistikas") tekstipäringu aknas ja otsige. Salvestage otsingutulemustega leht oma kausta vormingus "ainult html".
Uurida tulemuste esitamise vormi. Kirjutage lühidalt vihikusse otsingutulemustega veebilehel sisalduv (veebilehe struktuur). Uurige üksikute veebidokumentide esitusvormi (nende lühikirjeldusi koos lisateabega). Saadud tulemuste uurimise ja eelnevalt uuritud võrdlusteabe põhjal täitke tabeli vastavad lahtrid (jaotis 3).
Esitage oma töö oma õpetajale.
Süsteemide Aport, Yandex, Rambler võrdleva uuringu tulemused
№ | Valikud | Aport | Yandex | jään blair |
Otsi teksti järgi | ||||
Loogilised operaatorid: | ||||
sidesõna | ||||
disjunktsioon | ||||
eitus | ||||
Süntagmaatilised operaatorid: | ||||
fraasid (fraasid, läheduses olevad sõnad) | ||||
kaugus sõnades | ||||
kaugus lausetes | ||||
Morfoloogiline normaliseerimine (automaatne, kasutatud metamärke) | ||||
Otsi väljade järgi | ||||
pealkirja järgi | ||||
märksõnavälja järgi | ||||
piltide kommentaari järgi (väli ALT) | ||||
hüperlingi teksti abil | ||||
linkide aadresside järgi | ||||
saidi (serveri) domeeninime järgi | ||||
formaadi järgi | ||||
Väljastamise liides (tulemuste esitamise vorm) | ||||
päring sõna statistika | ||||
leitud dokumentide arv | ||||
leitud saitide arv | ||||
dokumentide arv tulemuste lehel | ||||
dokumentide sorteerimine väljastamise lehel | ||||
otsing leitud | ||||
dokumendi kirjeldus sisaldab järgmisi elemente: | ||||
URL (veebiaadress) | ||||
dokumendi suurus (maht) | ||||
loomise kuupäev | ||||
kodeering | ||||
abstraktne (kokkuvõte) | ||||
osutades sama saidi teistele asjakohastele veebilehtedele | ||||
otsige sarnaseid dokumente | ||||
Laboratoorsed tööd№ 3
(venekeelne verbaalne IPS: otsing)
Teemapäringu koostamine ja silumine
Tehke märkmikusse taotlus teemal “Merelahingud Suure ajal isamaa sõda". Samal ajal eemaldage teemast ebaolulised sõnad, laiendage päringut sünonüümidega, koostage loogiline päringuvalem side-, disjunktsiooni-, kaugus- ja fraasioperaatorite kohustusliku kasutamisega (kõva fraas).
Näidake palvet õpetajale.
Seejärel kirjutage üles selle variandid Aporti, Yandexi, Rambleri süsteemide keeltes.
Siluge päring reaalses otsingurežiimis, käitades järjestikuseid seansse kõigis kolmes süsteemis. Otsingu optimaalse toimivuse saavutamiseks proovige otsingu ettekirjutusi muuta. Selleks salvestage märkmikusse iga valiku kohta saadud tulemused: täpsus (esimese 20 dokumendi puhul) ja tingimuslik täielikkus (väljastamise absoluutsumma).
Naaske parima otsinguretsepti juurde ja kopeerige päringu tekst lõikelaua kaudu otsingustring(päringu sisestamise aken) aruandefaili aknasse Report3 (igas süsteemis kordamööda). Samal ajal märkige aruandes täpsuse ja täielikkuse näitajad. Salvestage esimene veebileht otsingutulemustega igas süsteemis oma kaustas vormingus "ainult html".
Sissejuhatus väliotsingusse ("Täpsem otsing")
Leidke Yandexi süsteemi abil Lev Gumiljovile pühendatud dokumendid. Salvestage leitud dokumentide ja saitide arv aruandefaili. Salvestage kausta Gumilev kausta Lemmikud loendist esimese dokumendi aadress (URL).
Seejärel lülitage täpsema otsingu režiimile ja leidke Lev Gumiljovile pühendatud dokumendid, mille kuupäev on hilisem kui 1. oktoober 2004. Märkige leitud dokumentide ja saitide uus arv uuesti aruandefaili. Salvestage esimene dokument otsingutulemuste loendist oma kaustas vormingus "veebiarhiiv, üksik fail" (*.mht).
Leidke Rambleri süsteemi kaudu dokumente teemal "Moskva linna majandus". Samal ajal määra väljundmahuks (dokumentide kirjelduste arv tulemuste lehel) 30. Sorteeri otsingutulemused kuupäeva järgi (kahanevas järjekorras) ja salvesta esimene otsingutulemustega veebileht oma kausta formaadis "ainult html"
Lülituge täpsema otsingu režiimile ja otsige dokumente samal teemal, kuid mis asuvad ainult saidil. Sorteeri otsingutulemused kuupäeva järgi (kasvavas järjekorras) ja salvesta esimene otsingutulemustega veebileht oma kausta vormingus "ainult html". Märkige aruandefailis leitud dokumentide ja saitide arv.
Otsige Yandexi süsteemi kaudu dokumente teemal "Haridus", mille saidile on link. Salvestage esimene otsingutulemustega veebileht oma kausta vormingus "ainult html". Märkige aruandefailis leitud dokumentide ja saitide arv.
Laadige alla üks leitud dokumentidest, vaadake selle html-koodi, leidke lõikepuhvri kaudu link saidile ja hüperlingi element (algusest lõpuni silt A), kopeerige see aruandefaili.
Lõikes 7 salvestatud mht-vormingus dokumenti (Lev Gumiljovi kohta) tuleks lugeda Wordis: esmalt veebilehe vormingus, seejärel vormingus “ainult tekst”. Teisel lugemisel vaata üle Wordi sisestusakna sisu (eriti faili algus ja lõpp), kopeeri sisestusakna esimene leht aruandefaili ja ole valmis selgitama, mis on mht-vorming.
Märge. Mht-vorming on kodeeritud vastavalt MIME standardile (RFC2046 ja RFC2047).
Esitage oma töö oma õpetajale.
Labor nr 4
(Globaalne verbaalne IPS: võrdlev analüüs)
Töö seisneb antud globaalsete verbaalset tüüpi Interneti IS-de võrdlevas uuringus.
Märge. Süsteemide komplekt ja nende arv võib õpetaja äranägemisel erineda.
Minge vastava otsingumootori saidile (edaspidi - süsteemi domeeninimi: www.süsteemi_nimi.com). Leidke igast süsteemist lingid selle kirjelduse kui terviku, päringukeele, liideste, töörežiimide ja muude süsteemi funktsioonide kirjeldusele. Kirjeldage lühidalt iga IPS-i kirjeldust sülearvutis.
Analüüsige ja võrrelge süsteemide võimalusi täpsema otsingu režiimis. Salvestage oma kausta täpsema otsingu liidese lehed.
Esitage analüüsi tulemused tihendatud kujul pivot tabelina (lk 38) aruandefailis Report4 (tabeli orientatsioon - maastik). Tabeli suurust saab suurendada. Kui miski tabelisse ei mahu, tee lahtrisse tabeli all olevale tekstile joonealune märkus (tabel ei ole niivõrd tulemuste esitamise vorm, kuivõrd analüüsiskeem).
Esitage oma töö oma õpetajale.
Globaalse verbaalse IPS-i võrdleva uuringu tulemused
Valikud | |||||
Loogilised operaatorid(mis ja kuidas on seatud) | |||||
Süntagmaatilised operaatorid | |||||
Otsi väljade järgi(koostage väljade loend, märkige nende olemasolu / puudumine konkreetsetes süsteemides) | |||||
väli 1 | |||||
väli 2 | |||||
……… | |||||
väli k | |||||
Otsi andmebaasi valikut | |||||
ressurss 1 | |||||
ressurss 2 | |||||
……… | |||||
ressurss k | |||||
Väljundvorming sisaldab järgmisi elemente(tooke tabeli all näide igast süsteemist) | |||||
element 1 | |||||
element 2 | |||||
……… | |||||
element k | |||||
Eriomadused või eriomadused |
Labor nr 5
(Globaalne verbaalne IPS: uurige ja otsige)
Tehke antud globaalses IPS-is otsing teemal "Arvutilingvistika" ( süsteemide komplekt ja nende arv võib õpetaja äranägemisel erineda). Otsinguretsept peaks loogiliselt välja nägema järgmine:
(komputatiivneVcomputingVcomputee) &
lkeeleteadus.
Küsi päring inglise keeles kaks korda, sidesõnana ja stabiilse fraasina (fraasina), kasutades igale süsteemile omaseid operaatorite väljendusviise (võõraste süsteemide puhul leia sobiv viiteinfo). Salvestage esimene veebileht iga otsingu tulemustega oma kaustas nimega "ainult html". Kvantitatiivsed tulemused kajastuvad tabelis:
IPS nimi | Leitud dokumendid/saidid | |||
Seminar
Dokumendihaldussüsteemide projekteerimine
Infootsingusüsteemi (IPS) kontseptsioon.
IPS-iga töötamise komponentide koostis ja tehnoloogia.
Tööl kaasaegsed ettevõtted oluline roll mängida oma teaberessursse, mida võib mõista kui projekti dokumentatsioon, kirjavahetus partneritega, sisemised korraldused ja juhised, finantsandmed ja muud dokumendid, mis on aluseks uute otsuste langetamisel ja mida kasutatakse ettevõtte juhtimisprotsessides. Ja kui spetsialiseeritud infosüsteeme saab kasutada struktureeritud andmete (nt raamatupidamis- või kauplemissüsteem või planeerimisosakonna süsteemid), mis põhinevad DBMS-i kasutamisel, siis on struktureerimata andmete jaoks vajalikud üldotstarbelised süsteemid - infootsingusüsteemi põhimõtetel töötavad elektroonilised arhiivid.
Infootsingusüsteem (IPS) – see on süsteem, mis on loodud dokumentide salvestamiseks ja otsimiseks koos tekstilise, graafilise, tabeliteabega atribuutide, dokumendi märksõnade ja sisu kohta mis tahes teemavaldkonnas. IPS-e on kahte tüüpi: faktograafilised ja dokumentograafilised süsteemid. Faktograafilised teabesüsteemid on loodud faktide, näitajate, mis tahes objektide või protsesside omaduste (näiteks töötajate, ettevõtete, aktsionäride jms teabe) salvestamiseks ja otsimiseks. Dokumentograafilised infosüsteemid erinevad selle poolest, et neis süsteemides on salvestus- ja otsinguobjektideks dokumendid, aruanded, kokkuvõtted, ülevaated, ajakirjad, raamatud jne. IPS-i abil dokumendi otsimise skript taandub tavaliselt ühest või mitmest sõnast koosneva otsingupäringu sisestamisele, mille järel esitatakse leitud dokumentide nimede loend. Kasutaja saab avada mistahes leitud dokumente ja kui otsingumootor lubab, tõstetakse otsingusõnade esinemiskohad dokumendis esile – "esile tõstetud". On võimalik eristada järgmisi organisatsiooni tunnuseid ja
dokumentograafilise IPS-i toimimine, mis eristab seda struktureeritud andmebaasihaldussüsteemidest: – Dokumente saab salvestada paberkandjal, mikrograafilisel andmekandjal või olla elektroonilises vormingus. Mikrograafiliste vormingute hulka kuuluvad mikrofilmid, mikrofišid, slaidid ja muud mikrovormid, mis on toodetud mitmesuguste dokumendikaameratega. Elektroonilisi formaate on veelgi rohkem, need sisaldavad aastal koostatud dokumente tekstitöötlusprogrammid, süsteemid Meil ja muud arvutiprogrammid, skannitud dokumentide digiteeritud kujutised jne. See eeldab nii dokumentide elektrooniliste koopiate kui ka nende paberkandjal originaalide kohustuslikku säilitamist.
Kui dokumendid on suured ja täis elektroonilised koopiad vaatamiseks või säilitamiseks pole võimalik väljastada, siis selliste dokumentide jaoks luua ja salvestada nende säilitamiseks elektroonilised aadressid.
Otsing toimub dokumendi leidmisel kahe põhimõtte kohaselt:
dokumendi atribuudid - loomise kuupäev, suurus, autor jne ning tema poolt sisu(tekst). Tavaliselt toimub otsimine dokumendi sisust kahel viisil: märksõnade ja kogu teksti järgi, mida nn. täistekst, rõhutades seega, et otsinguks kasutatakse kogu dokumendi teksti, mitte ainult selle üksikasju.
Dokumentide otsimiseks loovad ja salvestavad nad oma otsingupildid. . Dokumendiotsingu pilt (DOI) – juhtivate märksõnade (deskriptorite) koodide komplekt, mis kirjeldavad dokumendi tähendust, sisu.
Märksõnad ja nende koodid on salvestatud spetsiaalsesse sõnastikku - tesaurus.
Dokumentide otsimiseks peate looma teabeotsingu keel (IPL), mis sisaldab keele tesaurust ja grammatikat, s.o. reeglite kogum märksõnakomplekti lausete komplekti täpsustamiseks.
Dokumendi leidmiseks peate looma IPN-i kasutades otsingupäringu pilt (POZ), mis on kodeeritud märksõnade kogum, mis kirjeldab otsitavaid dokumente.
IPS-i komponentide koostoime diagramm on näidatud joonisel. 1.
Riis. 1. IPS komponentide interaktsiooni skeem
IPS koosneb järgmistest toetavatest alamsüsteemidest:
Keeleline tugi, mis sisaldab teabeotsingu keelt;
Süsteemi tehniline tugi, sealhulgas arvutid ja seadmed koopiate loomiseks, salvestamiseks, lugemiseks ja reprodutseerimiseks paberil, mikrovormingus ja elektrooniline vorm;
Teabetugi, mis koosneb dokumentide andmebaasist (DB Doc.), aadresside (DB Adr.) ja dokumentide otsingupiltide andmebaasist (DB POD) ning deskriptorite ja nende koodide loeteludest - tesaurus;
Tarkvara.
IPS-tarkvara on loodud automatiseerima järgmisi põhifunktsioone, mida see süsteem peab täitma:
AML-i andmebaasi koostamine, kodeerimine ja üleslaadimine;
Dokumentide ja nende säilitusaadresside andmebaasi allalaadimine;
Kompileerimine, POS kodeerimine;
Otsingutoimingu tegemine ja päringule vastuse väljastamine dokumendi kujul või dokumentide säilitamise aadressid arvutiekraanil, paberil, failis;
AML andmebaaside, dokumentide ja aadresside uuendamine;
tesauruse värskendus;
Viidete väljastamine.
Mõelge dokumendiotsingu valdkonnas kasutatavatele põhimõistetele.
Asjakohasus – leitud dokumendi päringule vastavuse aste . Päringu alusel leitud dokument võib päringu seisukohast olla asjakohane, st sisaldada vajalikku (nõutud) teavet, või ei pruugi sellel olla mingit seost. Esimesel juhul kutsutakse dokument välja asjakohane(inglise keeles asjakohane - "asjakohane"), teises ebaoluline või müra. Reeglina leitakse igast otsingumootorist nõudmisel mitu (sagedamini palju) dokumenti. Paljud neist ei pruugi sellega seotud olla. Ja vastupidi, mõned olulised ja asjakohased dokumendid võivad otsingus vahele jääda. On selge, et mõlema arv määrab otsingu kvaliteedi, mida saab määrata üsna täpselt. Otsingutööriistade maailmas on peamised kontseptsioonid otsingu täpsuse ja täielikkuse ideed.
Otsingu täpsus (T) määrab, milline osa päringule vastuseks antud teabest on asjakohane, s.t. on selle päringuga seotud ja on parameeter, mis näitab asjakohaste dokumentide osakaalu leitud koguarvust. See näitaja arvutatakse järgmise valemi abil:

Kui näiteks kõik nõudmisel väljastatud dokumendid on asjakohased, siis on täpsus 100%; kui vastupidi, kõik dokumendid on mürarikkad, siis on otsingu täpsus null.
Otsingu täielikkus (P)- lisaparameeter, mis näitab, milline on leitud asjakohaste dokumentide osakaal (või protsent) asjakohaste dokumentide koguarvust, s.t. mida iseloomustab suhe kogu andmebaasis saadaoleva asjakohase teabe ja selle vastuses sisalduva osa vahel, mis arvutatakse valemiga:

Kui otsingualal on tegelikult 100 dokumenti, mis sisaldavad vajalikku teavet, ja päring leidis neist ainult 30, siis on otsingu täielikkus 30%. Lisaks võetakse otsingumootorite hindamisel arvesse, millist tüüpi andmetega konkreetne süsteem töötada saab, millisel kujul otsingutulemusi esitatakse ja millisel tasemel on selles süsteemis töötamiseks vaja kasutajate koolitust. Tuleb märkida, et otsingu täpsus ja täielikkus ei sõltu mitte ainult otsingumootori omadustest, vaid ka konkreetse päringu ülesehituse õigsusest, aga ka kasutaja subjektiivsest ettekujutusest, millist teavet. ta vajab. Kui tekib probleem mitme süsteemi hindamisel ja kõige tõhusama valikul, on võimalik arvutada konkreetsete vaadeldavate süsteemide täielikkuse ja täpsuse keskmised väärtused, testides neid dokumentide võrdlusandmebaasis.
Indekseerimine dokumendid (s.o AML-i koostamine), mis tähendab tekstide eelnevat ettevalmistamist otsinguks ja mida kasutatakse peamiselt otsingu kiirendamiseks; reeglina töödeldakse mitmeks otsinguks mõeldud tekstiandmebaase eelnevalt, moodustades nn indeks(ALL ) . Indekseerimisel koostab otsingumootor tekstis leiduvatest sõnadest nimekirjad ja määrab igale sõnale oma koodi – koordinaadid tekstis (kõige sagedamini dokumendi number ja sõna number dokumendis). Otsimisel otsitakse sõna registrist ja leitud koordinaatide järgi, vajalikud dokumendid. Kui päringus on mitu sõna, tehakse nende koordinaatidega lõikumisoperatsioon . Kui palju dokumente täiendatakse, tuleb täiendada ka registrit.
Otsiüksus- see on tekstikvant, mille sees otsitakse antud otsingumootoris, mille väärtus määrab otsingu täpsuse indeksi, müra hulga ja päringule reageerimise aja. Otsinguüksus võib olla dokument, lause või lõik. IPS-i kasutamise tehnoloogias saab eristada kolme toimingute rühma:
Toimingud, mis on seotud dokumentide sisu kirjeldavate dokumentide otsingupiltide (ODD) hankimisega ja nende laadimisega andmebaasi (ODD), samuti dokumentide endi või nende salvestusaadresside laadimisega DBDoc ja BDAdr.-i;
Otsingupäringu kujutiste (POZ) koostamise toimingud tesauruse abil, tulemuste otsimine ja väljastamine leitud dokumentide või aadresside loendi vaatamiseks ja valimiseks või failide esitamiseks või printimiseks;
Infootsingusüsteemi haldamise toimingud, sh andmebaasi POD, BDDok., BDAdr uuendamine. ja tesaurus, kuna tekkis ja vajadus täiendada süsteemimälu uute dokumentide või märksõnadega. IPS-i hooldus hõlmab ka süsteemi toimimise, selle struktuuri, otsingumeetodite ja u1076 salvestatud dokumentide klasside ja tüüpide kohta sertifikaatide väljastamise korda.

 ülevaade:")































