Adakah seni bina Haswell layak dipanggil baru dan direka bentuk semula?
Selama lebih daripada lima tahun, Intel telah mengikuti strategi tick-tock, menggantikan peralihan seni bina khusus kepada norma teknologi yang lebih halus dengan keluaran seni bina baharu.
Akibatnya, setiap tahun kami mendapat sama ada seni bina baharu atau peralihan kepada teknologi proses baharu. Untuk tahun 2013, ia telah dirancang "jadi", iaitu, pelepasan seni bina baru - Haswell. Pemproses dengan seni bina baharu dihasilkan menggunakan teknologi proses yang sama seperti generasi sebelumnya Ivy Bridge: 22 nm, Tri-gate. Proses teknikal tidak berubah, manakala bilangan transistor telah meningkat, yang bermaksud bahawa kawasan akhir kristal pemproses baru juga telah meningkat - dan selepas itu, penggunaan kuasa.
Berpegang kepada tradisi, Intel pada hari pengumuman Haswell hanya memperkenalkan prestasi tinggi dan pemproses mahal Garis teras i5 dan i7. Pengumuman pemproses dwi-teras baris junior seperti biasa datang dengan kelewatan. Perlu diingat bahawa harga untuk pemproses baru kekal pada tahap yang sama seperti untuk Jambatan Ivy.
Mari kita bandingkan kawasan mati bagi generasi pemproses empat teras yang berbeza:
Seperti yang anda lihat, Haswell quad-core mempunyai keluasan hanya 177 mm², manakala ia mempunyai jambatan Utara, pengawal memori capaian rawak dan teras grafik. Oleh itu, bilangan transistor meningkat sebanyak 200 juta, dan kawasan itu bertambah sebanyak 17 mm². Jika kita bandingkan Haswell dengan 32-nanometer Jambatan Pasir, bilangan transistor meningkat sebanyak 440 juta (38%), dan kawasan berkurangan sebanyak 39 mm² (18%) disebabkan oleh peralihan kepada teknologi proses 22 nm. Pelesapan haba kekal hampir sama sepanjang tahun ini (95 W untuk SB dan 84 W untuk Haswell), dan kawasan itu telah berkurangan.
Semua ini telah membawa kepada fakta bahawa lebih banyak haba perlu dikeluarkan dari setiap milimeter persegi kristal. Jika sebelum ini adalah perlu untuk mengambil 95 W dari 216 mm², iaitu 0.44 W / mm², kini dari kawasan seluas 177 mm² perlu mengambil 84 W - 0.47 W / mm², iaitu 6.8% lebih daripada sebelumnya. Jika trend ini berterusan, ia akan menjadi sukar secara fizikal untuk mengeluarkan haba dari kawasan kecil tersebut.
Bercakap secara teori semata-mata, kita boleh mengandaikan bahawa jika dalam Broadwell, yang akan dihasilkan menggunakan teknologi proses 14 nm, bilangan transistor akan meningkat sebanyak 21%, seperti dalam peralihan dari 32 hingga 22 nm, dan kawasan akan berkurangan sebanyak 26 % (dengan jumlah yang sama, seperti dalam peralihan dari 32 hingga 22 nm), maka kita akan mendapat 1.9 bilion transistor pada kawasan seluas 131 mm². Jika pada masa yang sama pelesapan haba juga turun sebanyak 19%, maka kita mendapat 68 W, atau 0.52 W / mm².
Ini adalah pengiraan teori, dalam praktiknya ia akan berbeza - peralihan proses pembuatan dari 32 hingga 22 nm juga ditandai dengan pengenalan transistor 3D, yang mengurangkan arus kebocoran, dan dengannya pelesapan haba. Walau bagaimanapun, tiada apa yang didengar tentang peralihan dari 22 nm ke 14 nm, jadi dalam amalan nilai pelesapan haba kemungkinan besar akan menjadi lebih teruk, dan anda tidak boleh mengharapkan 0.52 W / mm². Walau bagaimanapun, walaupun tahap pelesapan haba ialah 0.52 W/mm², masalah terlalu panas setempat dan kesukaran mengeluarkan haba daripada cip kecil akan menjadi lebih teruk.
Sebenarnya, kesukaran dengan pelesapan haba pada pelesapan haba 0.52 W / mm² yang mungkin mendasari keinginan Intel untuk beralih kepada BGA atau percubaan untuk menghapuskan soket. Jika pemproses dipateri ke papan induk, maka haba akan terus dipindahkan dari kristal ke heatsink tanpa penutup perantaraan. Ini kelihatan lebih relevan memandangkan penggantian pateri dengan pes haba di bawah penutup. pemproses moden. Kita sekali lagi boleh mengharapkan kemunculan pemproses "telanjang" dengan kristal terbuka mengikut contoh Athlon XP, iaitu tanpa penutup sebagai pautan perantaraan dalam sink haba.
Ini telah dilakukan pada kad video untuk masa yang lama, dan bahaya pecah kristal diratakan oleh bingkai besi di sekelilingnya, jadi kad video tidak mempunyai "" masalah sebenar", seperti pes haba di bawah penutup pemproses. Walau bagaimanapun, overclocking akan menjadi lebih sukar, dan penyejukan yang betul pemproses "nipis" - hampir sains. Dan semua ini menanti kita tidak lama lagi, melainkan, tentu saja, keajaiban berlaku ...
Tetapi mari kita turun ke bumi dan kembali bercakap tentang Haswell. Seperti yang kita ketahui, Haswell menerima beberapa "penambahbaikan / perubahan" mengenai Sandy Bridge (dan, sewajarnya, Ivy Bridge, yang pada umumnya, pemindahan SB kepada teknologi proses yang lebih nipis):
- pengatur voltan terbina dalam;
- mod penjimatan tenaga baharu;
- meningkatkan jumlah penampan dan baris gilir;
- peningkatan dalam pemprosesan cache;
- peningkatan dalam bilangan pelabuhan pelancaran;
- menambah blok baharu, fungsi, API dalam teras grafik bersepadu;
- peningkatan dalam bilangan saluran paip dalam teras grafik.
Oleh itu, kajian semula platform baru boleh dibahagikan kepada tiga bahagian: pemproses, pemecut grafik bersepadu, chipset.
Bahagian pemproses
Perubahan pada pemproses termasuk penambahan arahan baharu dan mod penjimatan kuasa baharu, penambahan pengawal selia voltan dan perubahan pada teras pemproses itu sendiri.
Set arahan
Seni bina Haswell mempunyai set arahan baharu. Mereka boleh dibahagikan secara bersyarat kepada dua kumpulan besar: yang bertujuan untuk meningkatkan prestasi vektor dan yang bertujuan untuk segmen pelayan. Yang pertama termasuk AVX dan FMA3, manakala yang kedua termasuk maya dan memori transaksi.
Sambungan Vektor Lanjutan 2 (AVX2)
Suite AVX telah diperluaskan kepada versi AVX 2.0. Kit AVX2 menyediakan:
- sokongan untuk vektor integer 256-bit (sebelum ini hanya vektor 128-bit disokong);
- sokongan untuk mengumpul arahan, yang menghapuskan keperluan untuk lokasi berterusan data dalam ingatan; kini data "dikumpul" daripada alamat memori yang berbeza - ia akan menjadi menarik untuk melihat bagaimana ini mempengaruhi prestasi;
- menambah arahan manipulasi/operasi bit.
secara amnya, set baru lebih tertumpu pada aritmetik integer, dan keuntungan utama daripada AVX 2.0 akan kelihatan hanya dalam operasi integer.
Gabungan Gandaan-Tambah (FMA3)
FMA adalah gabungan operasi darab-tambah di mana dua nombor didarab dan ditambah dengan penumpuk. Jenis ini operasi adalah agak biasa dan membolehkan pelaksanaan pendaraban vektor dan matriks yang lebih cekap. Sokongan untuk sambungan ini harus meningkatkan prestasi operasi vektor dengan ketara. FMA3 sudah disokong pada pemproses AMD Piledriver, dan FMA4 pada Jentolak.
FMA ialah gabungan pendaraban dan penambahan: a=b×c+d.
Bagi FMA3, ini adalah arahan tiga operan, iaitu, hasilnya ditulis kepada salah satu daripada tiga operan yang mengambil bahagian dalam arahan. Hasilnya, kita mendapat operasi seperti a=b×c+a, a=a×b+c, a=b×a+c.
FMA4 ialah arahan empat operan dengan keputusan ditulis pada operan keempat. Arahannya menjadi: a=b×c+d.
Bercakap tentang FMA3: inovasi ini akan meningkatkan prestasi lebih daripada 30% jika kod itu disesuaikan dengan FMA3. Perlu diingat bahawa apabila Haswell masih jauh di kaki langit, Intel merancang untuk melaksanakan FMA4, bukan FMA3, tetapi kemudiannya mengubah keputusan yang memihak kepada FMA3. Kemungkinan besar, ia adalah kerana ini Jentolak keluar dengan sokongan FMA4: mereka mengatakan mereka tidak mempunyai masa untuk membuat semula untuk Intel (tetapi Piledriver sudah pun keluar dengan FMA3). Selain itu, Jentolak pada asalnya dirancang pada tahun 2007 dengan FMA3, tetapi selepas pengumuman rancangan Intel untuk memperkenalkan FMA4 pada tahun 2008 AMD memainkan semula keputusannya dengan melepaskan Jentolak dengan FMA4. Dan Intel kemudian menukar rancangan FMA4 kepada FMA3, kerana keuntungan daripada FMA4 berbanding FMA3 adalah kecil, dan komplikasi elektrik litar logik- ketara, yang juga meningkatkan belanjawan transistor.
Keuntungan daripada AVX2 dan FMA3 akan muncul selepas perisian disesuaikan dengan set arahan ini, jadi anda tidak seharusnya mengharapkan pertumbuhan prestasi "di sini dan sekarang". Dan oleh kerana vendor perisian agak lengai, prestasi "tambahan" perlu menunggu.
ingatan transaksi
Evolusi mikropemproses telah membawa kepada peningkatan dalam bilangan benang - pemproses desktop moden mempunyai lapan atau lebih daripadanya. Sejumlah besar benang mencipta lebih banyak kerumitan dalam pelaksanaan akses memori berbilang benang. Ia adalah perlu untuk mengawal perkaitan pembolehubah dalam RAM: ia diperlukan untuk menyekat data untuk menulis untuk beberapa utas dalam masa, untuk membenarkan membaca atau menukar data untuk utas lain. Ini adalah tugas yang sukar, dan memori transaksi telah dibangunkan untuk memastikan data dikemas kini dalam program berbilang benang. Tetapi sebelum hari ini ia telah dilaksanakan dalam perisian, yang mengurangkan prestasi.
Haswell telah memperkenalkan Sambungan Penyegerakan Transaksi (TSX) baharu - memori transaksi, yang direka untuk melaksanakan program berbilang benang dengan cekap dan meningkatkan kebolehpercayaannya. Sambungan ini membolehkan anda melaksanakan memori transaksi "dalam perkakasan", dengan itu meningkatkan prestasi keseluruhan.
Apakah memori transaksi? Ini adalah memori yang mempunyai mekanisme untuk mengurus proses selari di dalamnya untuk menyediakan akses kepada data yang dikongsi. Sambungan TSX terdiri daripada dua komponen: Hardware Lock Elision (HLE) dan Restricted Transaction Memory (RTM).
Komponen RTM ialah satu set arahan yang boleh digunakan oleh pengaturcara untuk memulakan, menamatkan dan membatalkan transaksi. Komponen HLE memperkenalkan awalan yang diabaikan oleh pemproses tanpa sokongan TSX. Awalan menyediakan penguncian pembolehubah, membenarkan proses lain menggunakan (membaca) pembolehubah terkunci dan melaksanakan kod mereka sendiri sehingga konflik penulisan data terkunci berlaku.
hidup masa ini sudah ada aplikasi yang menggunakan sambungan ini.
Virtualisasi
Kepentingan virtualisasi sentiasa berkembang: semakin banyak pelayan maya terletak pada fizikal yang sama, dan perkhidmatan awan semakin tersebar. Oleh itu, meningkatkan kelajuan teknologi virtualisasi dan persekitaran maya adalah tugas yang sangat mendesak dalam segmen pelayan. Haswell mengandungi beberapa penambahbaikan yang khusus bertujuan untuk meningkatkan prestasi persekitaran maya. Mari senaraikan mereka:
- penambahbaikan untuk mengurangkan masa peralihan daripada sistem tetamu kepada sistem hos;
- menambah bit akses ke Jadual Halaman Lanjutan (EPT);
- mengurangkan masa akses kepada TLB;
- arahan baharu untuk memanggil hypervisor tanpa melaksanakan arahan vmexit;
Akibatnya, masa peralihan antara persekitaran maya telah dikurangkan kepada kurang daripada 500 kitaran pemproses. Ini sepatutnya mengurangkan penalti prestasi keseluruhan yang dikaitkan dengan virtualisasi. Dan Xeon E3-12xx-v3 baharu mungkin akan lebih pantas dalam kelas tugasan ini berbanding Xeon E3-12xx-v2.
Pengatur voltan terbina dalam
Di Haswell, pengatur voltan telah berpindah dari papan induk ke penutup pemproses. Sebelum ini (Sandy Bridge) ia dikehendaki membekalkan pelbagai voltan kepada pemproses untuk teras grafik, untuk ejen sistem, untuk teras pemproses, dsb. Kini hanya satu voltan Vccin 1.75 V dibekalkan kepada pemproses melalui soket, yang disalurkan kepada pengatur voltan terbina dalam. Pengatur voltan terdiri daripada 20 sel, setiap sel mencipta 16 fasa dengan jumlah kekuatan arus sebanyak 25 A. Secara keseluruhan, kami mendapat 320 fasa, yang jauh lebih banyak daripada papan induk yang paling canggih. Pendekatan ini bukan sahaja memudahkan susun atur papan induk (dan oleh itu mengurangkan kosnya), tetapi juga mengawal voltan di dalam pemproses dengan lebih tepat, yang seterusnya, membawa kepada penjimatan tenaga yang lebih besar.
Ini adalah salah satu sebab utama mengapa Haswell tidak boleh serasi secara fizikal dengan soket LGA1155 lama. Ya, anda boleh bercakap tentang keinginan Intel untuk menjana wang dengan mengeluarkan platform baharu setiap tahun ( chipset baru) dan setiap dua tahun - soket baru, tetapi dalam kes ini ada sebab objektif: ketidakserasian fizikal/elektrik.
Walau bagaimanapun, anda perlu membayar untuk segala-galanya. Pengatur voltan ialah satu lagi sumber haba yang ketara dalam pemproses baharu. Dan memandangkan Haswell dihasilkan menggunakan teknologi proses yang sama seperti pendahulunya Ivy Bridge, anda harus mengharapkan pemproses menjadi lebih panas.

Secara umum, peningkatan ini akan membawa lebih banyak faedah dalam segmen mudah alih: perubahan voltan yang lebih pantas dan lebih tepat akan mengurangkan penggunaan kuasa, serta mengurus frekuensi teras pemproses dengan lebih cekap. Dan nampaknya, ini bukan kenyataan pemasaran kosong, kerana Intel akan mengumumkan pemproses mudah alih dengan penggunaan kuasa ultra-rendah.
Mod Penjimatan Kuasa Baharu
Haswell mempunyai keadaan tidur S0ix baharu yang serupa dengan keadaan S3/S4, tetapi dengan masa peralihan pemproses yang lebih pantas. keadaan bekerja. Keadaan terbiar baharu C7 juga telah ditambah.
Mod C7 disertakan dengan mematikan bahagian utama pemproses, manakala imej pada skrin kekal aktif.
Kekerapan minimum pemproses dalam keadaan melahu ialah 800 MHz, ini juga harus mengurangkan penggunaan kuasa.
Seni bina pemproses


Bahagian hadapan

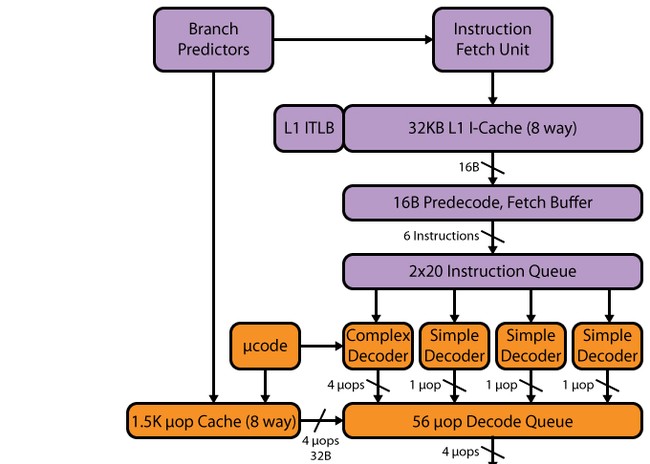
Saluran paip Haswell, seperti dalam SB, mempunyai 14–19 peringkat: 14 peringkat pada hit cache µop, 19 peringkat pada terlepas. Saiz cache µop tidak berubah berbanding SB - 1536 µop. Organisasi cache uop kekal sama seperti dalam SB - 32 set lapan baris, setiap satu dengan 6 uops. Walaupun, disebabkan peningkatan dalam bilangan peranti eksekutif, serta bilangan penimbal yang mengikuti cache uops, seseorang boleh menjangkakan peningkatan dalam cache uop - sehingga 1776 uops (mengapa jumlah ini akan dibincangkan di bawah).
Penyahkod
Penyahkod, seseorang mungkin berkata, tidak berubah - ia kekal empat trek, seperti SB. Ia terdiri daripada empat saluran selari: satu penterjemah kompleks (penyahkod kompleks) dan tiga saluran mudah (penyahkod ringkas). Penterjemah yang kompleks boleh memproses/menyahkod arahan kompleks yang menghasilkan lebih daripada satu uop. Tiga saluran lain menyahkod arahan mudah. By the way, disebabkan kehadiran makro-op penggabungan, memuatkan-dengan-melaksanakan dan memunggah arahan menjana, sebagai contoh, satu mop dan boleh dinyahkodkan dalam saluran penyahkod "mudah". arahan SSE juga menjana satu uop, supaya mereka boleh dinyahkod dalam mana-mana tiga saluran mudah. Memandangkan kemunculan AVX 256-bit, FMA3, serta peningkatan bilangan port pelancaran dan unit berfungsi, kelajuan penyahkod ini mungkin tidak mencukupi - dan ia mungkin menjadi halangan. Sebahagiannya, kesesakan ini "mengembangkan" cache mop L0m, tetapi bagaimanapun, mempunyai pemproses dengan 8 port pelancaran, Intel harus berfikir tentang mengembangkan penyahkod - khususnya, tidak ada salahnya untuk menambah bilangan saluran yang kompleks.
Penjadual, menyusun semula penimbal, unit pelaksanaan


Penyahkod diikuti oleh baris gilir arahan yang dinyahkod, dan di sini kita melihat perubahan pertama. SB mempunyai dua baris gilir 28 entri - satu baris gilir setiap benang maya Hyper-Threading (HT). Di Haswell, dua baris gilir digabungkan menjadi satu biasa untuk dua utas HT untuk 56 entri, iaitu, jumlah baris gilir tidak berubah, tetapi konsepnya telah berubah. Kini keseluruhan volum 56 rekod tersedia untuk satu utas tanpa ketiadaan yang kedua - oleh itu, kita boleh menjangkakan peningkatan dalam kedua-dua aplikasi berutas rendah dan dalam aplikasi berbilang benang (ini disebabkan oleh fakta bahawa dua utas boleh menggunakan satu barisan dengan lebih cekap).
Penampan pesanan semula juga telah mengalami perubahan - ia telah ditingkatkan daripada 168 kepada 192 penyertaan. Ini sepatutnya meningkatkan kecekapan HT dengan menjadikannya lebih berkemungkinan mempunyai uops yang "bebas". Barisan gilir mikro-op yang dinyahkod telah dinaikkan daripada 54 kepada 60. Fail daftar fizikal yang muncul dalam SB juga telah ditingkatkan - daripada 160 kepada 168 daftar untuk operan integer dan daripada 144 kepada 168 untuk operan titik terapung, yang sepatutnya memberi kesan positif prestasi pengiraan vektor.
Mari kita bawa semua data tentang perubahan dalam penimbal dan baris gilir ke dalam satu jadual.
Pada dasarnya, perubahan parameter dalam Haswell kelihatan agak dijangka, memandangkan logik biasa pembangunan seni bina pemproses Intel. Berdasarkan logik yang sama, boleh diandaikan bahawa pada generasi akan datang dimensi teras penimbal dan baris gilir akan meningkat tidak lebih daripada 14%, iaitu saiz penimbal penyusunan semula adalah sekitar 218. Tetapi ini adalah andaian teori semata-mata.
Berikutan baris gilir operasi yang dinyahkod ialah port pencetus dan dilampirkan padanya peranti berfungsi. Mari kita lihat lebih dekat pada langkah ini.
Seperti yang kita ketahui, Sandy Bridge mempunyai enam pelabuhan pelancaran, yang diwarisinya daripada Nehalem, yang seterusnya, dari Conroe. Iaitu, sejak 2006, apabila Intel menambah dua lagi port kepada empat Pentium 4, bilangan port pelancaran tidak berubah - hanya peranti berfungsi baharu telah ditambah. Benar, perlu dinyatakan bahawa P4 mempunyai sejenis seni bina NetBurst asal, di mana dua portnya boleh melakukan dua operasi setiap kitaran jam (walaupun tidak dengan semua operasi). Tetapi adalah paling tepat untuk mengesan evolusi bilangan port pelancaran bukan pada contoh P4, tetapi pada contoh PIII, kerana P4 mempunyai saluran paip yang panjang, pelancaran port dengan prestasi "berganda" dan cache jejak , dan keseluruhan seni binanya jelas berbeza daripada yang diterima umum. Dan Pentium III sangat dekat dengan Conroe dari segi susun atur fungsi pelabuhan pelancaran, dan juga mempunyai bekas pendek. Jadi secara umum kita boleh mengatakan bahawa Conroe adalah pengganti langsung PIII. Berdasarkan ini, boleh dinyatakan bahawa hanya satu pelabuhan pelancaran ditambah pada tahun 2006 berbanding PIII, yang mempunyai lima pelabuhan pelancaran.
Oleh itu, bilangan port pelancaran berkembang agak perlahan, dan jika yang baharu ditambah, maka satu demi satu. Di Haswell, mereka menambah dua sekaligus, setelah menerima sebanyak lapan pelabuhan secara keseluruhan - lebih sedikit lagi, dan kami akan sampai ke Itanium. Sehubungan itu, Haswell menunjukkan prestasi teori pada laluan pelaksanaan 8 uops/kitaran, yang mana 4 uops dibelanjakan untuk operasi aritmetik, dan 4 lagi adalah operasi ingatan. Ingat bahawa Conroe/Nehalem/SB mempunyai 6 uop/jam: 3 uop operasi aritmetik dan 3 uops operasi ingatan. Penambahbaikan ini sepatutnya meningkatkan IPC, dan dengan itu, memang terdapat perubahan yang sangat serius dalam seni bina Haswell, yang mewajarkan sepenuhnya tempatnya "begitu" dalam rancangan pembangunan Intel.
Perubahan FU dalam Haswell

Bilangan penggerak juga telah ditambah. Port keenam (ketujuh berturut-turut) baharu menambah dua unit pelaksanaan tambahan - unit aritmetik dan anjakan integer serta unit ramalan cawangan. Port ketujuh (kelapan) bertanggungjawab untuk memuat naik alamat.
Oleh itu, kami mendapat empat pelaksana aritmetik integer, manakala Sandy Bridge memberikan kami hanya tiga. Oleh itu, seseorang boleh menjangkakan peningkatan dalam kelajuan aritmetik integer. Di samping itu, secara teorinya, ini sepatutnya membolehkan kita melakukan pengiraan titik terapung dan integer secara serentak, yang seterusnya, boleh meningkatkan kecekapan NT. Dalam SB, pengiraan titik terapung telah dijalankan pada port yang sama di mana unit fungsian integer digunakan, oleh itu penyekatan besar-besaran berlaku, iaitu adalah mustahil untuk mempunyai beban "heterogen". Ia juga harus diperhatikan bahawa menambah peranti tambahan peralihan dalam Haswell akan membenarkan ramalan cawangan tanpa "menyekat" dalam pengiraan aritmetik - sebelum ini, dalam pengiraan integer, satu-satunya peramal cawangan telah disekat, iaitu sama ada penggerak aritmetik atau peramal boleh berfungsi. Port 0 dan 1 juga telah dikemas kini untuk menyokong FMA3. Ketujuh (kelapan) Port Intel diperkenalkan untuk meningkatkan kecekapan dan mengeluarkan "menyekat" - apabila port kedua dan ketiga berfungsi untuk memuatkan, port ketujuh (kelapan) boleh dipunggah, yang sememangnya mustahil sebelum ini. Penyelesaian ini diperlukan untuk memastikan kadar pelaksanaan kod AVX/FMA3 yang tinggi.
Secara umum, laluan pelaksanaan yang begitu luas mungkin membawa kepada perubahan dalam HT - menjadikannya empat aliran. Dalam co Pemproses Intel Xeon Phi, dengan laluan pelaksanaan HT yang lebih sempit, adalah berulir empat dan skala pemproses bersama dengan agak baik, seperti yang ditunjukkan oleh penyelidikan dan penanda aras. Iaitu, walaupun laluan pelaksanaan yang lebih sempit, pada dasarnya, membolehkan anda bekerja dengan berkesan dengan empat utas. Dan laluan dengan lapan port pencetus boleh menjalankan empat utas dengan agak cekap, dan lebih-lebih lagi, mempunyai empat utas boleh memuatkan lapan port pencetus dengan lebih baik. Benar, untuk kecekapan yang lebih tinggi, penampan (terutamanya penimbal susunan semula) diperlukan untuk kebarangkalian data "bebas" yang lebih besar.
Selain itu, Haswell menggandakan daya pemprosesan L1-L2, sambil mengekalkan nilai kependaman yang sama. Langkah sedemikian hanya perlu, kerana penulisan 32-bait dan bacaan 16-bait tidak akan mencukupi dengan lapan port pelancaran, serta AVX dan FMA3 256-bit.
| Jambatan Pasir | Haswell | |
| L1i | 32k, 8 hala | 32k, 8 hala |
| L1d | 32k, 8 hala | 32k, 8 hala |
| Latensi | 4 bar | 4 bar |
| Kelajuan muat turun | 32 bait/jam | 64 bait/jam |
| Kelajuan rakaman | 16 bait/jam | 32 bait/jam |
| L2 | 256k, 8 hala | 256k, 8 hala |
| Latensi | 11 bar | 11 bar |
| Lebar jalur antara L2 dan L1 | 32 bait/jam | 64 bait/jam |
| L1i TLB | 4k: 128, 4 hala 2M/4M: 8/benang | 4k: 128, 4 hala 2M/4M: 8/benang |
| L1d TLB | 4k: 128, 4 hala 2M/4M: 7/benang 1G: 4, 4 cara | 4k: 128, 4 hala 2M/4M: 7/benang 1G: 4, 4 cara |
| L2TLB | 4k: 512, 4 hala | 4k+2J dikongsi: 1024, 8 hala |
TLB L2 telah ditingkatkan kepada 1024 entri, sokongan untuk halaman dua megabait telah muncul. Peningkatan dalam TLB L2 juga mengakibatkan peningkatan persekutuan daripada empat kepada lapan.
Bagi cache L3, keadaan dengannya adalah samar-samar: dalam pemproses baharu, kelewatan akses harus meningkat disebabkan oleh kehilangan penyegerakan, kerana kini cache L3 beroperasi pada frekuensinya sendiri, dan bukan pada frekuensi teras pemproses, kerana ia adalah sebelum ini. Walaupun akses masih dilakukan pada 32 bait setiap jam. Sebaliknya, Intel bercakap tentang perubahan pada Ejen Sistem dan penambahbaikan pada blok Pengimbang Beban, yang kini boleh memproses berbilang permintaan ke cache L3 secara selari dan memisahkannya kepada permintaan data dan bukan data. Ini sepatutnya meningkatkan daya pemprosesan cache L3 (sesetengah ujian mengesahkan ini, PV cache L3 lebih tinggi sedikit daripada IB).
Prinsip cache L3 dalam Haswell agak serupa dengan Nehalem. Di Nehalem, cache L3 berada dalam Uncore dan mempunyai frekuensi tetapnya sendiri, manakala di SB cache L3 terikat pada teras pemproses - kekerapannya menjadi sama dengan frekuensi teras pemproses. Disebabkan ini, masalah timbul - sebagai contoh, apabila teras pemproses berfungsi pada frekuensi yang dikurangkan jika tiada beban (dan LLC "tertidur"), dan GPU memerlukan PS LLC yang tinggi. Iaitu, keputusan ini mengehadkan prestasi GPU, dan selain itu, ia dikehendaki membawa teras pemproses keluar daripada keadaan terbiar hanya untuk membangunkan LLC. Dalam pemproses baru untuk memperbaiki keadaan kuasa dan meningkatkan kecekapan kerja GPU dalam situasi yang diterangkan di atas, cache L3 beroperasi pada frekuensinya sendiri. Mudah alih, bukan desktop, seharusnya mendapat manfaat sepenuhnya daripada penyelesaian ini.
Perlu diingat bahawa jumlah cache mempunyai pergantungan tertentu. Cache tahap ketiga ialah dua megabait setiap teras, cache tahap kedua ialah 256 KB, iaitu lapan kali kurang daripada jumlah L3 setiap teras. Kelantangan cache tahap pertama pula adalah lapan kali kurang daripada L2 dan ialah 32 KB. Cache uop sesuai dengan perhubungan ini dengan sempurna: saiznya 1536 uops adalah 7-9 kali lebih kecil daripada L1 (adalah mustahil untuk menentukan ini dengan tepat, kerana saiz bit uop tidak diketahui, dan Intel tidak mungkin mengembangkan topik ini ). Sebaliknya, penimbal susunan semula 168 uop adalah betul-betul lapan kali lebih kecil daripada cache uop 1536 uop, walaupun, berdasarkan peningkatan meluas dalam penampan dan baris gilir, seseorang akan menjangkakan peningkatan dalam cache uop sebanyak 14%, iaitu, sehingga 1776. Oleh itu, saiz penimbal dan cache adalah bersaiz berkadar. Ini mungkin satu lagi sebab mengapa Intel tidak meningkatkan cache L1 / L2, memandangkan perkadaran dalam volum tersebut adalah yang paling berkesan dari segi peningkatan prestasi setiap kawasan. Perlu diingat bahawa dalam pemproses dengan teras grafik bahagian atas terbina dalam, terdapat memori pantas perantaraan dengan bas akses lebar, yang menyimpan semua permintaan ke RAM - kedua-dua pemproses dan pemecut video. Jumlah memori ini ialah 128 MB. Untuk teras pemproses, jika kita menganggap memori ini sebagai cache L4, volumnya sepatutnya 64 MB, dan dengan penambahan teras grafik, penggunaan 128 MB kelihatan agak logik.
Bagi pengawal memori, ia tidak menerima peningkatan dalam bilangan saluran mahupun peningkatan dalam kekerapan bekerja dengan RAM, iaitu, ia masih pengawal memori yang sama dengan akses dwi saluran pada frekuensi 1600 MHz. Keputusan ini kelihatan agak pelik, kerana peralihan dari SB ke IB meningkatkan kekerapan ICP daripada 1333 MHz kepada 1600 MHz, walaupun ini hanyalah peralihan seni bina kepada proses teknikal baharu. Dan kini kami mempunyai seni bina baharu, manakala kekerapan memori kekal pada tahap yang sama.
Ia kelihatan lebih pelik jika kita mempertimbangkan penambahbaikan dalam teras grafik - lagipun, kita masih ingat bahawa walaupun kad video junior HD2500 dalam IB menggunakan lebar jalur 25 GB / s sepenuhnya. Kini, kedua-dua prestasi CPU dan prestasi grafik telah berkembang, manakala lebar jalur memori kekal pada tahap yang sama. Melihat lebih luas, pesaing sentiasa meningkatkan lebar jalur memori dalam APUnya, dan ia lebih tinggi daripada Intel. Adalah logik untuk mengharapkan Haswell menyokong memori dengan frekuensi 1866 MHz atau 2133 MHz, yang akan meningkatkan lebar jalur kepada 30 dan 34 GB / s, masing-masing.
Akibatnya, keputusan oleh Intel ini tidak sepenuhnya jelas. Pertama, pesaing memperkenalkan sokongan untuk memori yang lebih pantas tanpa masalah khas. Kedua, kos modul memori yang beroperasi pada 1866 MHz adalah lebih tinggi sedikit berbanding dengan modul 1600 MHz, dan selain itu, tiada siapa yang mewajibkan anda membeli memori 1866 MHz - pilihannya terpulang kepada pengguna. Ketiga, tidak ada masalah dengan menyokong bukan sahaja 1866 MHz, tetapi juga 2133 MHz: sejak pengumuman Haswell, rekod dunia untuk overclocking RAM telah ditetapkan, iaitu, ICP akan "menarik" memori lebih cepat tanpa masalah. Keempat, talian pelayan Xeon E5-2500 V2 (Ivy Bridge-EP) menuntut sokongan untuk 1866 MHz, dan Intel biasanya memperkenalkan sokongan untuk standard memori yang lebih pantas dalam pasaran ini lebih lewat daripada penyelesaian desktop.
Pada dasarnya, seseorang boleh mengandaikan bahawa dalam ketiadaan persaingan, Intel tidak perlu "begitu sahaja" membina otot dan meningkatkan keunggulannya lebih banyak lagi, tetapi andaian ini sama sekali tidak betul, kerana peningkatan lebar jalur memori, sebagai peraturan. , meningkatkan prestasi teras grafik bersepadu dan hampir tidak meningkatkan prestasi pemproses. Pada masa yang sama, Intel masih ketinggalan di belakang AMD dengan tepat dalam prestasi grafik, dan dalam tahun lepas Intel sendiri memberi lebih banyak perhatian kepada grafik, dan kadar peningkatan untuknya jauh lebih tinggi daripada teras pemproses. Di samping itu, jika kita bergantung pada hasil ujian teras grafik bersepadu HD4000 generasi sebelumnya, yang menunjukkan bahawa peningkatan lebar jalur membawa kepada peningkatan prestasi grafik sehingga 30%, dan juga memandangkan teras grafik HD4600 baharu adalah nyata lebih pantas daripada HD4000, maka pergantungan prestasi teras grafik daripada PSP menjadi lebih ketara. Teras grafik baharu akan menjadi lebih terhad oleh jalur lebar memori "sempit". Merumuskan semua fakta, keputusan Intel benar-benar tidak dapat difahami: syarikat itu "mencekik" grafiknya dengan tangannya sendiri, tetapi peningkatan lebar jalur memori boleh meningkatkan prestasinya.
Kembali kepada seni bina cache, mari kita nyatakan pemikiran kosong: memandangkan cache perantaraan (cache mops) telah ditambahkan, mengapa tidak menambah cache data perantaraan lain dengan volum kira-kira 4-8 KB dan dengan kelewatan akses yang lebih rendah antara cache L1d dan peranti pelaksanaan, seperti dari P4 (sejak konsep cache uop diambil dari Netburst)? Ingat bahawa dalam P4 cache data perantaraan ini mempunyai masa capaian dua kitaran, dan satu kitaran P4 adalah sama dengan kira-kira 0.75 kitaran pemproses konvensional, iaitu, masa capaian adalah kira-kira satu setengah kitaran. Walau bagaimanapun, mungkin kita akan melihat sesuatu yang serupa sekali lagi - Intel suka mengingati yang lama yang dilupakan.
Seperti yang anda lihat, Intel mengarahkan kebanyakan perubahan seni bina untuk meningkatkan prestasi kod AVX / FMA3: ini ialah peningkatan dalam lebar jalur cache, peningkatan dalam bilangan port dan peningkatan dalam kadar muat naik / muat turun dalam laluan pelaksanaan. Akibatnya, keuntungan prestasi utama hendaklah dalam perisian yang ditulis menggunakan AVX/FMA3. Pada dasarnya, berdasarkan keputusan ujian, nampaknya ini berlaku. Prestasi kering pada frekuensi yang sama dalam aplikasi "lama" menerima peningkatan kira-kira 10% berbanding teras sebelumnya, dan aplikasi yang ditulis menggunakan set arahan baharu menunjukkan peningkatan lebih daripada 30%. Jadi faedah seni bina Haswell akan didedahkan apabila aplikasi dioptimumkan untuk set arahan baharu. Ketika itulah keunggulan Haswell berbanding SB akan terserlah.
Faedah utama daripada sebahagian besar inovasi ialah peranti mudah alih. Mereka akan dibantu oleh pendekatan baharu kepada cache L3, dan pengawal selia voltan terbina dalam, dan mod tidur baharu, dan frekuensi minimum yang lebih rendah untuk pengendalian teras pemproses.
Kesimpulan (bahagian pemproses)
Apa yang boleh anda harapkan daripada Haswell?
Disebabkan oleh peningkatan dalam bilangan pelabuhan pelancaran, kami boleh menjangkakan peningkatan dalam IPC, jadi seni bina Haswell baharu akan mempunyai sedikit kelebihan berbanding Sandy Bridge pada frekuensi yang sama walaupun sekarang, walaupun dengan perisian yang tidak dioptimumkan. Arahan AVX2/FMA3 adalah masa depan dan masa depan bergantung pada pembangun perisian: lebih cepat mereka menyesuaikan aplikasi mereka, lebih cepat pengguna akhir dapatkan peningkatan prestasi. Walau bagaimanapun, anda tidak sepatutnya bergantung pada pertumbuhan segala-galanya dan di mana-mana: Arahan SIMD digunakan terutamanya dalam bekerja dengan data multimedia dan dalam pengiraan saintifik, jadi pertumbuhan prestasi harus dijangka dengan tepat dalam tugas-tugas ini. Faedah utama daripada peningkatan kecekapan tenaga ialah sistem mudah alih, di mana isu ini sangat penting. Oleh itu, dua bidang utama di mana seni bina Intel Haswell baharu menang dengan ketara ialah peningkatan dalam prestasi SIMD dan peningkatan dalam kecekapan tenaga.
Bagi kebolehgunaan pemproses Haswell baharu, adalah wajar untuk menganalisis beberapa pilihan berbeza untuk kegunaannya: dalam komputer meja, dalam pelayan, dalam penyelesaian mudah alih, untuk pemain permainan, untuk overclocker.
Desktop
Penggunaan kuasa bukanlah aspek utama untuk pemproses desktop, jadi walaupun di Eropah dengan elektriknya yang mahal, tidak mungkin sesiapa akan beralih kepada Haswell daripada generasi terdahulu hanya kerana ini. Lebih-lebih lagi, TDP Haswell adalah lebih tinggi daripada IB, jadi penjimatan hanya akan berlaku sekiranya beban minimum. Dengan rumusan soalan sedemikian, tidak ada keraguan - ia tidak berbaloi.
Dari sudut pandangan prestasi, peralihan juga tidak kelihatan seperti perniagaan yang menguntungkan: peningkatan maksimum dalam kelajuan dalam tugas pemproses kini tidak lebih daripada 10%. Beralih kepada Haswell daripada Sandy Bridge atau Ivy Bridge hanya berbaloi jika anda merancang untuk menggunakan aplikasi dengan sokongan FMA3 dan AVX2 yang baik: Sokongan FMA3 boleh memberikan peningkatan 30% hingga 70% dalam sesetengah aplikasi. Penambahbaikan yang berkaitan dengan virtualisasi dan pengenalan memori transaksi adalah sedikit minat dan kurang digunakan untuk desktop.
Pelayan dan stesen kerja
Memandangkan pelayan berjalan secara berterusan 24 jam sehari dan mempunyai beban berterusan yang agak tinggi pada pemproses, Haswell tidak mungkin lebih baik daripada IB dari segi penggunaan kuasa bersih, walaupun ia boleh memberikan sedikit keuntungan dalam prestasi per watt. Sokongan untuk AVX2 / FMA3 tidak mungkin berguna dalam pelayan, tetapi dalam stesen kerja yang terlibat dalam pengiraan saintifik, sokongan ini akan menjadi sangat, sangat berguna - tetapi hanya jika arahan baharu disokong dalam perisian yang digunakan. Memori transaksi adalah perkara yang agak berguna, tetapi tidak selalu: ia boleh memberikan peningkatan dalam program berbilang benang dan dalam program yang berfungsi dengan pangkalan data, tetapi untuk itu penggunaan yang berkesan pengoptimuman perisian juga diperlukan.
Tetapi semua penambahbaikan yang berkaitan dengan virtualisasi mungkin mempunyai kesan yang baik, kerana persekitaran maya kini digunakan dengan sangat aktif, dan pada kebanyakan pelayan fizikal berfungsi pada beberapa yang maya. Selain itu, kelaziman virtualisasi dijelaskan bukan sahaja oleh pengurangan ketara dalam kos persekitaran maya dari segi prestasi, tetapi juga oleh kecekapan ekonomi: adalah lebih murah untuk mengekalkan banyak pelayan maya pada satu fizikal dan membolehkan penggunaan yang lebih cekap sumber, termasuk sumber pemproses.
seterusnya pasaran pelayan Penampilan Haswell harus diterima secara positif. Selepas menukar pelayan berdasarkan Xeon E3-1200v1 dan Xeon E3-1200v2 kepada pelayan dengan Xeon E3-1200v3 (Haswell), anda akan segera mendapat peningkatan kecekapan, dan selepas mengoptimumkan perisian untuk AVX2/FMA3 dan memori transaksi, prestasi akan meningkat lebih lagi.
Penyelesaian Mudah Alih
Faedah utama daripada pengenalan Haswell dalam segmen mudah alih, tentu saja, terletak pada kawasan penggunaan kuasa yang lebih baik. Berdasarkan pembentangan Intel, serta keputusan ujian yang sudah muncul di Web, benar-benar ada kesan, dan satu yang ketara.
Dari segi prestasi tulen, beralih daripada Ivy Bridge ke Haswell nampaknya bukan satu usaha yang munasabah: keuntungan bersih sepatutnya agak kecil, dan peningkatan dalam komponen individu(arahan maya atau multimedia yang sama) tidak mungkin memberi banyak kepada pengguna sistem mudah alih, kerana komputer riba dan tablet jarang mencipta persekitaran atau pengiraan saintifik yang rumit.
Secara umum, dari sudut prestasi pemproses, seseorang tidak boleh mengharapkan banyak, tetapi dalam sistem mudah alih, peningkatan dalam prestasi teras grafik pasti diperlukan. Oleh itu, jika isu penggunaan kuasa tidak kritikal untuk anda, maka anda tidak perlu serius mempertimbangkan untuk menaik taraf daripada Sandy Bridge atau Ivy Bridge - adalah lebih baik untuk meneruskan operasi sistem sedia ada sehingga ia benar-benar ketinggalan zaman. Jika anda sering menggunakan bateri, maka Haswell mampu memberikan peningkatan ketara dalam hayat bateri.
Pemain permainan
Persoalan penggunaan kuasa di kalangan pemain di Rusia, sebagai peraturan, tidak berbaloi - dan mengapa dia akan berdiri apabila kad video permainan menggunakan 200 watt atau lebih? Maya dan memori transaksi juga tidak diperlukan oleh pemain. Bukan fakta bahawa AVX2/FMA3 akan mendapat permintaan khusus untuk permainan, walaupun ia mungkin berguna dalam pengiraan fizik. Masih terdapat prestasi tulen pemproses, dan di sini perbezaan dengan Ivy Bridge yang sama adalah kecil. Akibatnya, untuk kategori pengguna ini, peralihan terus dari SB atau IB ke Haswell juga tidak kelihatan relevan. Tetapi adalah munasabah untuk bertukar kepada pemproses baharu daripada Nehalem dan Lynifield, dan lebih-lebih lagi daripada Conroe.
Overclockers
Untuk overclockers, pemproses baharu (tetapi, sudah tentu, hanya versi K yang "tidak dikunci") mungkin menarik, terutamanya jika anda boleh "mengupas"nya, iaitu, keluarkan penutup logam dan sejukkan kristal secara langsung. Jika ini tidak dilakukan, maka keputusan overclocking kelihatan lebih sederhana daripada Ivy Bridge. Selain itu, pengawal selia voltan bersepadu boleh menjadi penghalang. Baca lebih lanjut mengenainya
Menterjemah... Terjemah Cina (Mudah) Cina (Tradisional) Inggeris Perancis Jerman Itali Portugis Rusia Sepanyol Turki
Malangnya, kami tidak dapat menterjemah maklumat ini sekarang - sila cuba sebentar lagi.
pengenalan
Perisian yang direka untuk komunikasi dan penghantaran data memerlukan prestasi yang sangat tinggi, kerana sejumlah besar paket data kecil sedang dihantar. Salah satu ciri membangunkan aplikasi virtualisasi fungsi rangkaian(NFV) adalah perlu untuk menggunakan virtualisasi semaksimal mungkin, tetapi pada masa yang sama dalam kes yang perlu mengoptimumkan aplikasi untuk perkakasan yang digunakan.
Dalam artikel ini, saya akan membincangkan tiga ciri pemproses Intel® yang berguna untuk mengoptimumkan prestasi aplikasi NFV: teknologi peruntukan cache (CAT), Intel® Advanced Vector Extensions 2 (Intel® AVX2) untuk pemprosesan data vektor dan Intel® Sambungan Penyegerakan Transaksi (Intel® TSX).
Menyelesaikan Masalah Penyongsangan Keutamaan dengan CAT
Apabila fungsi keutamaan rendah mencuri sumber daripada fungsi keutamaan tinggi, kami memanggil ini "penyongsangan keutamaan".
Tidak semua fungsi maya sama penting. Sebagai contoh, untuk fungsi penghalaan, masa pemprosesan dan prestasi adalah penting, manakala untuk fungsi pengekodan media, ini tidak begitu penting. Ciri ini boleh dibenarkan untuk menggugurkan paket secara berselang-seli tanpa menjejaskan pengalaman pengguna, kerana tiada siapa yang akan menyedari penurunan kadar bingkai video daripada 20fps kepada 19fps.
Cache lalai disusun sedemikian rupa sehingga pengguna yang paling aktif menerimanya kebanyakan daripada. Tetapi pengguna yang paling aktif bukanlah aplikasi yang paling penting. Malah, sebaliknya lebih kerap berlaku. Aplikasi keutamaan tinggi dioptimumkan, volum datanya dikurangkan kepada set terkecil yang mungkin. Aplikasi keutamaan rendah tidak memerlukan banyak usaha untuk mengoptimumkan, jadi mereka cenderung menggunakan lebih banyak memori. Sesetengah fungsi ini menggunakan banyak memori. Sebagai contoh, ciri menyemak imbas paket untuk analisis statistik mempunyai keutamaan yang rendah, tetapi menggunakan banyak memori dan menggunakan banyak cache.
Pembangun sering menganggap bahawa jika mereka meletakkan satu aplikasi keutamaan tinggi dalam teras tertentu, aplikasi itu akan selamat di sana dan tidak terjejas oleh aplikasi keutamaan rendah. Malangnya, ia tidak. Setiap teras mempunyai cache L1 sendiri (L1, cache terpantas tetapi terkecil) dan cache L2 (L2, lebih besar sedikit tetapi lebih perlahan). Terdapat kawasan cache peringkat pertama yang berasingan untuk data (L1D) dan kod program (L1I, "I" bermaksud "arahan"). Cache tahap ketiga (paling perlahan) dikongsi oleh semua teras pemproses. Pada seni bina pemproses Intel® sehingga dan termasuk keluarga Broadwell, cache L3 adalah inklusif sepenuhnya, bermakna ia mengandungi semua yang terkandung dalam cache L1 dan L2. Disebabkan oleh keistimewaan cache inklusif, jika sesuatu dialih keluar daripada cache tahap ketiga, ia juga akan dialih keluar daripada cache yang sepadan pada tahap pertama dan kedua. Ini menyebabkan aplikasi keutamaan rendah yang memerlukan ruang cache L3 untuk mengusir data daripada cache L1 dan L2 bagi aplikasi keutamaan tinggi, walaupun ia berjalan pada teras yang berbeza.
Pada masa lalu, terdapat pendekatan untuk mengatasi masalah ini, yang dipanggil "pemanasan". Dalam pertikaian cache L3, "pemenang" ialah aplikasi yang paling banyak mengakses memori. Oleh itu, penyelesaiannya adalah untuk mempunyai fungsi keutamaan tinggi yang sentiasa mengakses cache, walaupun semasa melahu. Ini bukan penyelesaian yang sangat elegan, tetapi ia sering terbukti agak boleh diterima, dan sehingga baru-baru ini tiada alternatif. Tetapi kini terdapat alternatif: keluarga pemproses Intel ® Xeon ® E5 v3 memperkenalkan Teknologi Peruntukan Cache (CAT), yang membolehkan anda memperuntukkan cache mengikut aplikasi dan kelas perkhidmatan.
Kesan penyongsangan keutamaan
Untuk menunjukkan kesan penyongsangan keutamaan, saya menulis penanda aras mudah yang secara berkala menjalankan traversal senarai kombo pada utas keutamaan tinggi manakala fungsi salin dalam memori sentiasa berjalan pada utas keutamaan rendah. Benang ini diperuntukkan kepada teras yang berbeza bagi pemproses yang sama. Ini mensimulasikan perbalahan sumber kes terburuk: operasi penyalinan adalah intensif memori, jadi kemungkinan besar akan mengganggu aliran akses senarai yang lebih penting.
Berikut ialah kod dalam C.
// Bina senarai terpaut saiz N dengan corak rawak pseudo void init_pool(list_item *head, int N, int A, int B) ( int C = B; list_item *current = head; for (int i = 0; i< N - 1; i++) { current->tandakan = 0; C = (A*C + B) % N; semasa->seterusnya = (list_item*)&(head[C]); semasa = semasa->seterusnya; ) ) // Sentuh elemen N pertama dalam senarai terpaut void warmup_list(list_item* current, int N) ( bool write = (N > POOL_SIZE_L2_LINES) ? true: false; for(int i = 0; i< N - 1; i++) { current = current->seterusnya; jika (tulis) semasa->tandakan++; ) ) ukuran lompang(list_item* head, int N) ( unsigned __long long i1, i2, avg = 0; for (int j = 0; j< 50; j++) { list_item* current = head; #if WARMUP_ON while(in_copy) warmup_list(head, N); #else while(in_copy) spin_sleep(1); #endif i1 = __rdtsc(); for(int i = 0; i < N; i++) { current->tandakan++; semasa = semasa->seterusnya; ) i2 = __rdtsc(); purata += (i2-i1)/50; in_copy=true; ) keputusan=purata/N )
Ia mengandungi tiga ciri.
- Fungsi init_pool() memulakan senarai terpaut dalam kawasan memori percuma yang besar diperuntukkan dengan penjana mudah nombor pseudo-rawak. Disebabkan ini, item senarai tidak bersebelahan antara satu sama lain dalam ingatan: dalam kes ini, lokaliti spatial akan terbentuk, yang akan menjejaskan pengukuran kami, kerana beberapa elemen akan diambil secara automatik. Setiap elemen senarai adalah betul-betul satu baris cache.
- Fungsi warmup() terus berulang ke atas senarai terbina. Anda perlu mengakses data tertentu yang perlu ada dalam cache, jadi ciri ini menghalang urutan lain daripada mengusir senarai terpaut daripada cache L3.
- Fungsi measure() mengukur satu elemen senarai, kemudian sama ada tidur selama 1 milisaat atau memanggil fungsi warmup() bergantung pada ujian yang kami jalankan. Fungsi measure() kemudian meratakan hasilnya.
Hasil penanda aras mikro pada pemproses Intel® Core™ i7 Generasi ke-5 ditunjukkan dalam graf di bawah, dengan paksi-x ialah jumlah bilangan baris cache dalam kotak kombo dan paksi-y ialah purata bilangan kitaran CPU setiap kombo akses senarai. Apabila saiz senarai terpaut bertambah, ia bergerak keluar dari cache data tahap pertama ke cache tahap kedua dan kemudian ketiga, dan kemudian ke memori utama.
Garis dasar ialah garis merah-coklat, yang sepadan dengan program tanpa aliran salinan dalam memori, iaitu tiada perbalahan. Garis biru menunjukkan akibat penyongsangan keutamaan: disebabkan oleh fungsi salinan dalam memori, mengakses senarai mengambil masa yang lebih lama. Kesannya amat besar jika senarai itu sesuai dengan cache tahap pertama atau tahap kedua berkelajuan tinggi. Jika senarai terlalu besar untuk dimuatkan dalam cache L3, impaknya boleh diabaikan.
Garis hijau menunjukkan kesan memanaskan badan apabila fungsi penyalinan memori berjalan: masa capaian berkurangan dengan mendadak dan menghampiri nilai asas.
Jika kami mendayakan CAT dan memperuntukkan bahagian cache L3 kepada penggunaan eksklusif oleh setiap teras, hasilnya akan menjadi sangat hampir dengan garis dasar (terlalu hampir untuk ditunjukkan dalam rajah), yang merupakan matlamat kami.
KemasukanKUCING
Pertama sekali, pastikan platform menyokong CAT. Anda boleh menggunakan arahan CPUID dengan menyemak daun 7, subleaf 0 alamat ditambah untuk menunjukkan ketersediaan CAT.
Jika CAT didayakan dan disokong, terdapat MSR yang boleh diprogramkan untuk diperuntukkan bahagian yang berbeza cache peringkat ketiga kepada teras yang berbeza.
Setiap soket pemproses mempunyai MSR IA32_L3_MASKn (cth 0xc90, 0xc91, 0xc92, 0xc93). Daftar ini menyimpan bitmask yang menunjukkan jumlah cache L3 untuk diperuntukkan untuk setiap kelas perkhidmatan (COS). 0xc90 menyimpan peruntukan cache untuk COS0, 0xc91 untuk COS1 dan seterusnya.
Sebagai contoh, rajah ini menunjukkan beberapa topeng bit yang mungkin untuk kelas perkhidmatan yang berbeza untuk menunjukkan cara pemisahan cache boleh diatur: COS0 mendapat separuh, COS1 mendapat suku dan COS2 dan COS3 masing-masing mempunyai yang kelapan. Sebagai contoh, 0xc90 akan mengandungi 11110000 dan 0xc93 akan mengandungi 00000001.
Algoritma Direct Data I/O (DDIO) mempunyai bitmask tersembunyi sendiri yang membenarkan penstriman data daripada peranti PCIe berkelajuan tinggi seperti penyesuai rangkaian ke kawasan tertentu cache L3. Terdapat potensi konflik dengan kelas perkhidmatan yang ditakrifkan, jadi anda perlu mengambil kira perkara ini semasa membina aplikasi NFV berkeupayaan tinggi. Untuk menguji perlanggaran, gunakan ini untuk mengesan kesilapan cache. Sesetengah BIOS mempunyai tetapan yang membolehkan anda melihat dan menukar topeng DDIO.
Setiap teras mempunyai daftar MSR IA32_PQR_ASSOC (0xc8f) yang menunjukkan kelas perkhidmatan yang digunakan untuk teras tersebut. Kelas perkhidmatan lalai ialah 0, yang bermaksud bahawa bitmask dalam MSR 0xc90 digunakan. (Secara lalai, bitmask 0xc90 ditetapkan kepada 1 untuk menyediakan cache yang paling tersedia.)
Paling banyak model ringkas menggunakan CAT dalam NFV - memperuntukkan serpihan cache L3 kepada teras yang berbeza menggunakan bitmask terpencil, dan kemudian menyematkan benang atau mesin maya pada teras. Jika VM perlu berkongsi teras untuk melaksanakan, anda juga boleh melakukan pembetulan remeh untuk penjadual OS, menambah topeng cache pada urutan yang dijalankan VM dan mendayakannya secara dinamik pada setiap acara jadual.
Terdapat satu lagi cara luar biasa untuk menggunakan CAT untuk mengunci data dalam cache. Mula-mula, buat topeng cache aktif dan akses data dalam memori untuk memuatkannya ke cache peringkat ketiga. Kemudian matikan bit yang mewakili bahagian cache L3 ini dalam mana-mana bitmask CAT yang akan digunakan pada masa hadapan. Data akan dikunci dalam cache tahap ketiga, kerana kini ia tidak boleh diusir dari sana (selain DDIO). Dalam aplikasi NFV, mekanisme ini membenarkan jadual carian bersaiz sederhana untuk penghalaan dan analisis paket dikunci dalam cache L3 untuk memastikan akses berterusan.
Menggunakan Intel AVX2 untuk Pemprosesan Vektor
Arahan SIMD (satu arahan - banyak data) membolehkan anda melakukan operasi yang sama secara serentak dengan kepingan data yang berbeza. Arahan ini selalunya digunakan untuk mempercepatkan pengiraan titik terapung, tetapi versi integer, boolean dan data arahan juga tersedia.
Bergantung pada pemproses yang anda gunakan, keluarga arahan SIMD yang berbeza akan tersedia untuk anda. Saiz vektor yang diproses oleh arahan juga akan berbeza:
- SSE menyokong vektor 128-bit.
- Intel AVX2 menyokong arahan integer untuk vektor 256-bit dan melaksanakan arahan untuk operasi pengumpulan.
- Dalam sambungan AVX3 dalam perspektif seni bina Intel® akan menyokong vektor 512-bit.
Satu vektor 128-bit boleh digunakan untuk dua pembolehubah 64-bit, empat pembolehubah 32-bit, atau lapan pembolehubah 16-bit (bergantung pada arahan SIMD yang digunakan). Vektor yang lebih besar akan memuatkan lebih banyak item data. Memandangkan keperluan untuk pemprosesan tinggi dalam aplikasi NFV, arahan SIMD yang paling berkuasa (dan perkakasan berkaitan) harus sentiasa digunakan, pada masa ini Intel AVX2.
Arahan SIMD paling biasa digunakan untuk melaksanakan operasi yang sama pada vektor nilai, seperti yang ditunjukkan dalam rajah. Di sini, operasi untuk mencipta X1opY1 hingga X4opY4 ialah satu arahan memproses item data X1 hingga X4 dan Y1 hingga Y4 pada masa yang sama. Dalam contoh ini, kelajuan akan menjadi empat kali lebih cepat daripada pelaksanaan biasa (skalar), kerana empat operasi diproses pada masa yang sama. Pecutan boleh sama besar dengan vektor SIMD yang besar. Aplikasi NFV selalunya memproses berbilang aliran paket dengan cara yang sama, jadi arahan SIMD membenarkan pengoptimuman prestasi semula jadi di sini.
Untuk gelung mudah, pengkompil selalunya akan mengvektorkan operasi itu sendiri secara automatik dengan menggunakan arahan SIMD terkini yang tersedia untuk CPU (jika anda menggunakan bendera pengkompil yang betul). Anda boleh mengoptimumkan kod untuk menggunakan set arahan paling terkini yang disokong oleh perkakasan pada masa jalankan, atau anda boleh menyusun kod untuk seni bina sasaran tertentu.
Operasi SIMD juga menyokong pemuatan memori dengan menyalin sehingga 32 bait (256 bit) daripada memori ke dalam daftar. Ini membolehkan anda memindahkan data antara memori dan daftar, memintas cache, dan mengumpul data dari lokasi yang berbeza dalam ingatan. Anda juga boleh melakukan pelbagai operasi dengan vektor (menukar data dalam satu daftar) dan menyimpan vektor (menulis sehingga 32 bait daripada daftar ke memori).
Memcpy dan memmov ialah contoh rutin asas yang terkenal yang telah dilaksanakan dengan arahan SIMD dari awal kerana arahan REP MOV terlalu perlahan. Kod memcpy telah dikemas kini secara berkala perpustakaan sistem untuk menggunakan arahan SIMD terkini. Jadual pengurus CPUID digunakan untuk mendapatkan maklumat tentang versi terkini yang tersedia untuk digunakan. Pada masa yang sama, pelaksanaan generasi baru arahan SIMD di perpustakaan biasanya ditangguhkan.
Sebagai contoh, prosedur seterusnya memcpy, yang menggunakan gelung mudah, adalah berdasarkan fungsi terbina dalam (bukan kod perpustakaan), jadi pengkompil boleh mengoptimumkannya untuk versi terkini arahan SIMD.
Mm256_store_si256((__m256i*) (dest++), (__m256i*) (src++))
Ia menyusun kepada kod pemasang berikut dan mempunyai prestasi dua kali ganda daripada pustaka terkini.
C5 fd 6f 04 04 vmovdqa (%rsp,%rax,1),%ymm0 c5 fd 7f 84 04 00 00
Kod pemasangan daripada fungsi sebaris akan menyalin 32 bait (256 bit) menggunakan arahan SIMD terkini yang tersedia, manakala kod pustaka menggunakan SSE hanya akan menyalin 16 bait (128 bit).
Aplikasi NFV selalunya perlu melakukan operasi pengumpulan dengan memuatkan data daripada berbilang lokasi di lokasi memori berbeza yang tidak bersebelahan. Sebagai contoh, penyesuai rangkaian boleh cache paket masuk menggunakan DDIO. Aplikasi NFV mungkin hanya perlu mengakses sebahagian daripada pengepala rangkaian dengan alamat IP destinasi. Dengan operasi pengumpulan, aplikasi boleh mengumpul data untuk 8 paket pada masa yang sama.
Tidak perlu menggunakan fungsi sebaris atau kod pemasangan untuk operasi pengumpulan, kerana pengkompil boleh menvektorkan kod, seperti untuk atur cara yang ditunjukkan di bawah, berdasarkan ujian penjumlahan nombor dari lokasi memori pseudo-rawak.
int a; intb; untuk (i = 0; i< 1024; i++) a[i] = i; for (i = 0; i < 64; i++) b[i] = (i*1051) % 1024; for (i = 0; i < 64; i++) sum += a]; // This line is vectorized using gather.
Baris terakhir dikompil kepada kod pemasang berikut.
C5 fe 6f 40 80 vmovdqu -0x80(%rax),%ymm0 c5 ed fe f3 vpaddd %ymm3,%ymm2,%ymm6 c5 e5 ef db vpxor %ymm3,%ymm3,%ymm3 c5 d5 76 ed vpcmpeqd %ymmmpeqd ymm5,%ymm5 c4 e2 55 90 3c a0 vpgatherdd %ymm5,(%rax,%ymm4,4),%ymm7
Operasi pengumpulan tunggal adalah jauh lebih pantas daripada urutan muat turun, tetapi ini hanya masuk akal jika data sudah ada dalam cache. Jika tidak, data itu perlu diambil semula daripada memori, yang mengambil ratusan atau beribu-ribu kitaran CPU. Jika data berada dalam cache, maka kelajuan 10x mungkin
(iaitu 1000%). Jika data tiada dalam cache, kelajuan hanya 5%.
Apabila menggunakan teknik ini, adalah penting untuk menganalisis aplikasi untuk mengenal pasti kesesakan dan memahami jika aplikasi menghabiskan terlalu banyak masa untuk menyalin atau mengumpul data. Untuk mengukur prestasi program, anda boleh menggunakan .
Satu lagi ciri berguna untuk NFV dalam Intel AVX2 dan operasi SIMD lain ialah bitwise dan operasi logik. Ia digunakan untuk mempercepatkan kod penyulitan bukan standard, dan semakan bit adalah mudah untuk pembangun ASN.1 dan sering digunakan untuk data dalam telekomunikasi. Intel AVX2 boleh digunakan untuk perbandingan rentetan yang lebih pantas menggunakan algoritma lanjutan seperti MPSSEF.
Sambungan Intel AVX2 berfungsi dengan baik mesin maya. Prestasinya adalah sama, tiada keluar mesin maya yang salah.
Menggunakan Intel TSX untuk kebolehskalaan yang lebih tinggi
Salah satu masalah program selari adalah untuk mengelakkan konflik data yang boleh berlaku apabila beberapa utas cuba menggunakan item data yang sama dan sekurang-kurangnya satu utas cuba menukar data. Penguncian digunakan untuk mengelakkan hasil kekerapan yang tidak dapat diramalkan: utas pertama yang menggunakan item menyekatnya daripada utas lain sehingga ia menyelesaikan kerjanya. Tetapi pendekatan ini boleh menjadi tidak cekap jika terdapat kunci serentak yang kerap, atau jika kunci mengawal kawasan memori yang lebih besar daripada yang benar-benar diperlukan.
Sambungan Penyegerakan Transaksi Intel (TSX) menyediakan arahan pemproses untuk memintas kunci pada transaksi dalam memori perkakasan. Ini membantu mencapai kebolehskalaan yang lebih tinggi. Ia berfungsi seperti ini: apabila program memasuki bahagian yang menggunakan Intel TSX untuk menjaga lokasi memori, semua percubaan akses memori direkodkan dan pada penghujung sesi yang dilindungi, ia sama ada secara automatik komited atau secara automatik digulung semula. Pemulihan berlaku jika, semasa melaksanakan daripada utas lain, terdapat konflik akses memori yang boleh menyebabkan keadaan perlumbaan (contohnya, menulis ke lokasi dari mana transaksi lain sedang membaca data). Pulangan balik juga boleh berlaku jika kemasukan akses memori menjadi terlalu besar untuk pelaksanaan Intel TSX, jika terdapat arahan I/O atau panggilan sistem, atau jika pengecualian berlaku atau mesin maya ditutup. Panggilan I/O ditarik balik jika ia tidak dapat dilaksanakan secara spekulatif kerana gangguan dari luar. Panggilan sistem- operasi yang sangat kompleks yang menukar cincin dan deskriptor memori, sangat sukar untuk digulung semula.
Kes penggunaan biasa untuk Intel TSX ialah kawalan akses pada jadual cincang. Biasanya penguncian digunakan untuk menjamin akses kepada jadual cache, tetapi ini meningkatkan masa tamat untuk utas yang bersaing untuk akses. Mengunci selalunya terlalu kasar: seluruh jadual dikunci, walaupun situasi apabila benang cuba mengakses elemen yang sama sangat jarang berlaku. Apabila bilangan teras (dan benang) bertambah, penguncian kasar menghalang kebolehskalaan.
Seperti yang ditunjukkan dalam rajah di bawah, kunci kasar boleh menyebabkan satu utas menunggu untuk satu lagi urutan untuk melepaskan jadual cincang, walaupun utas tersebut menggunakan elemen yang berbeza. Penggunaan Intel TSX membolehkan kedua-dua utas berfungsi, keputusannya ditetapkan selepas berjaya mencapai penghujung urus niaga. Perkakasan mengesan konflik dengan cepat dan membalikkan urus niaga yang melanggar ketepatan. Apabila menggunakan Intel TSX, utas 2 tidak perlu menunggu, kedua-dua utas berjalan lebih awal. Penguncian jadual cincang ditukar kepada penguncian berbutir halus, menghasilkan prestasi yang lebih baik. Intel TSX menyokong ketepatan penjejakan untuk perlanggaran pada tahap satu baris cache (64 bait).
Intel TSX menggunakan dua antara muka pengaturcaraan untuk menentukan bahagian kod untuk melaksanakan transaksi.
- Pintasan Kunci Perkakasan (HLE) serasi ke belakang dan boleh digunakan dengan mudah untuk meningkatkan kebolehskalaan tanpa perubahan besar pada perpustakaan kunci. HLE memperkenalkan awalan untuk arahan yang disekat. Awalan arahan HLE memberi isyarat kepada perkakasan untuk memantau keadaan kunci tanpa memperolehnya. Dalam contoh di atas, mengikut langkah di atas akan menyebabkan akses kepada elemen lain jadual cincang tidak lagi menghasilkan kunci melainkan terdapat akses tulis bercanggah kepada nilai yang disimpan dalam jadual cincang. Akibatnya, akses akan disejajarkan, jadi kebolehskalaan akan ditingkatkan merentas keempat-empat utas.
- Antara muka RTM termasuk arahan eksplisit untuk memulakan (XBEGIN), melakukan (XEND), membatalkan (XABORT) dan menguji status (XTEST) transaksi. Arahan ini menyediakan perpustakaan mengunci dengan cara yang lebih fleksibel untuk melaksanakan traversal kunci. Antara muka RTM membolehkan perpustakaan menggunakan algoritma pembalikan transaksi yang fleksibel. Peluang ini boleh digunakan untuk menambah baik Prestasi Intel TSX menggunakan mulakan semula transaksi optimistik, rollback transaksi dan teknik lanjutan lain. Menggunakan arahan CPUID, pustaka boleh kembali kepada pelaksanaan kunci bukan RTM yang lebih lama sambil mengekalkan keserasian ke belakang dengan kod peringkat pengguna.
- Untuk mendapatkan maklumat tambahan mengenai HLE dan RTM, saya syorkan anda membaca artikel berikut daripada portal Zon Pembangun Intel.
Selain mengoptimumkan primitif masa dengan HLE atau RTM, ciri pelan data NFV boleh memanfaatkan Intel TSX apabila menggunakan Kit Pembangunan Data Plane (DPDK) .
Apabila menggunakan Intel TSX, kesukaran utama bukan terletak pada pelaksanaan sambungan ini, tetapi dalam menilai dan menentukan prestasinya. Terdapat kaunter prestasi yang boleh digunakan dalam program Linux* perf, dan untuk menilai kejayaan pelaksanaan Intel TSX (bilangan selesai dan bilangan kitaran yang dibatalkan).
Intel TSX harus digunakan dengan berhati-hati dan diuji secara menyeluruh dalam aplikasi NFV kerana operasi I/O dalam kawasan perlindungan Intel TSX sentiasa menyertakan rollback dan banyak ciri NFV menggunakan berbilang I/O. Kunci perbalahan harus dielakkan dalam aplikasi NFV. Jika kunci diperlukan, maka algoritma traversal kunci boleh membantu meningkatkan kebolehskalaan.
Mengenai Pengarang
Alexander Komarov ialah seorang jurutera pembangunan aplikasi dalam Kumpulan Perisian dan Perkhidmatan di Intel Corporation. Sepanjang 10 tahun yang lalu, kerja utama Alexander ialah mengoptimumkan kod untuk prestasi tertinggi pada platform pelayan Intel sedia ada dan akan datang. Kerja ini termasuk penggunaan alat pembangunan perisian Intel: pemprofil, penyusun, perpustakaan, set arahan terkini, seni bina nano dan peningkatan seni bina kepada pemproses dan set cip x86 terkini.
maklumat tambahan
Untuk maklumat lanjut tentang NFV, lihat video berikut.
#xeonSelalunya, apabila memilih pelayan atau stesen kerja pemproses tunggal, persoalan timbul tentang pemproses mana yang hendak digunakan - pelayan Xeon atau Core ix biasa. Memandangkan pemproses ini dibina berdasarkan teras yang sama, pilihannya sering jatuh pada pemproses desktop, yang biasanya mempunyai kos yang lebih rendah dengan prestasi yang serupa. Mengapakah Intel mengeluarkan pemproses Xeon E3? Mari kita fikirkan.
Spesifikasi
Sebagai permulaan, mari kita ambil model junior pemproses Xeon dari julat model semasa - Xeon E3-1220 V3. Akan bertindak sebagai lawan pemproses teras i5-4440. Kedua-dua pemproses dibuat pada teras Haswell, mempunyai kelajuan jam asas yang sama dan harga yang serupa. Perbezaan antara kedua-dua pemproses ini dibentangkan dalam jadual:Kehadiran grafik bersepadu. Pada pandangan pertama, Core i5 mempunyai kelebihan, bagaimanapun, semua papan induk pelayan mempunyai kad grafik bersepadu, yang tidak memerlukan cip grafik dalam pemproses, dan stesen kerja biasanya tidak menggunakan grafik bersepadu kerana prestasinya yang agak rendah.
Sokongan ECC. Kelajuan tinggi dan jumlah RAM yang besar meningkatkan kemungkinan ralat perisian. Biasanya ralat sedemikian tidak dapat dilihat, tetapi, walaupun ini, ia boleh menyebabkan perubahan data atau ranap sistem. Jika untuk komputer meja ralat sedemikian tidak mengerikan kerana kejadiannya yang jarang berlaku, maka dalam pelayan yang berfungsi sepanjang masa selama beberapa tahun, mereka tidak boleh diterima. Untuk membetulkannya, teknologi ECC (error-correcting code) digunakan, kecekapannya ialah 99.988%.
Anggaran kuasa haba (TDP). Malah, penggunaan kuasa pemproses pada beban maksimum. Xeon cenderung mempunyai sampul haba yang lebih kecil dan algoritma penjimatan kuasa yang lebih pintar, yang akhirnya diterjemahkan kepada bil elektrik yang lebih rendah dan penyejukan yang lebih cekap.
Cache L3. Memori cache ialah sejenis lapisan antara pemproses dan RAM, yang mempunyai kelajuan yang sangat tinggi. Lebih besar cache, lebih pantas pemproses, kerana RAM yang sangat laju pun jauh lebih perlahan daripada cache. Biasanya, pemproses Xeon mempunyai lebih banyak cache, jadi ia lebih disukai untuk aplikasi intensif sumber.
Kekerapan / Kekerapan dalam mod TurboBoost. Segala-galanya mudah di sini - semakin tinggi frekuensi, semakin pantas, semua perkara lain adalah sama, pemproses berfungsi. Kekerapan asas, iaitu, frekuensi di mana pemproses beroperasi pada beban penuh, adalah sama, tetapi dalam mod Turbo Boost, iaitu, apabila bekerja dengan aplikasi yang tidak direka untuk pemproses berbilang teras, Xeon lebih pantas.
Sokongan untuk Intel TSX-NI. Intel Transactional Synchronization Extensions New Arahan (Intel TSX-NI) membayangkan tambahan kepada sistem cache pemproses yang mengoptimumkan persekitaran pelaksanaan untuk aplikasi berbilang benang, tetapi, sudah tentu, hanya jika aplikasi ini menggunakan antara muka perisian TSX-NI. Set arahan TSX-NI memungkinkan untuk melaksanakan kerja dengan Data Besar dan pangkalan data dengan lebih berkesan - dalam kes di mana banyak rangkaian mengakses data yang sama dan situasi sekatan benang berlaku. Akses data spekulatif, yang dilaksanakan dalam TSX, membolehkan anda membina aplikasi sedemikian dengan lebih cekap dan menskalakan prestasi yang lebih dinamik dengan peningkatan bilangan utas pelaksana selari dengan menyelesaikan konflik apabila mengakses data kongsi.

Sokongan Pelaksanaan Dipercayai. Intel Trusted Execution Technology mempertingkatkan pelaksanaan arahan yang selamat melalui peningkatan perkakasan kepada pemproses dan set Cip Intel. Teknologi ini menyediakan platform pejabat digital dengan ciri keselamatan seperti pelancaran aplikasi terukur dan pelaksanaan arahan selamat. Ini dicapai dengan mewujudkan persekitaran di mana aplikasi dijalankan secara berasingan daripada aplikasi lain pada sistem.
Menambah manfaat pemproses Xeon yang lebih lama ialah lebih banyak kapasiti L3, sehingga 45MB, lebih banyak teras, sehingga 18, dan lebih banyak sokongan RAM, sehingga 768GB setiap pemproses. Dalam kes ini, penggunaan tidak melebihi 160 watt. Pada pandangan pertama, ini adalah nilai yang sangat besar, bagaimanapun, memandangkan prestasi pemproses sedemikian adalah beberapa kali lebih tinggi daripada prestasi Xeon E3-1220 V3 yang sama dengan TDP 80 W, penjimatan menjadi jelas. Ia juga harus diperhatikan bahawa tiada pemproses Keluarga teras tidak menyokong multiprocessor, iaitu, adalah mungkin untuk memasang tidak lebih daripada satu pemproses dalam satu komputer. Kebanyakan aplikasi pelayan dan stesen kerja berskala baik merentas teras, benang dan pemproses fizikal, jadi memasang dua pemproses akan hampir menggandakan prestasi.
Tarikh: 13-08-2014 22:26
Kembali pada tahun 2007 AMD melancarkan generasi baru Pemproses Phenom. Pemproses ini, seperti yang ternyata kemudiannya, mengandungi ralat dalam blok TLB (penimbal penimbal lihat-tepi terjemahan penukaran pantas alamat maya kepada yang fizikal). Syarikat itu tidak mempunyai pilihan selain menyelesaikan masalah ini dengan "patch" dalam bentuk patch BIOS, tetapi ini mengurangkan prestasi pemproses sebanyak kira-kira 15%.
Sesuatu yang serupa berlaku sekarang dengan Intel. Dalam pemproses generasi Haswell, syarikat itu telah melaksanakan sokongan untuk arahan TSX (Transactional Synchronization Extension). Ia direka untuk mempercepatkan aplikasi berbilang benang dan sepatutnya digunakan terutamanya dalam segmen pelayan. Walaupun fakta bahawa CPU Haswell telah berada di pasaran untuk masa yang lama, set ini Arahan itu praktikal tidak digunakan. Nampaknya, dalam masa terdekat dan tidak akan.
Hakikatnya ialah Intel membuat "typo", seperti yang dipanggil oleh syarikat itu sendiri, dalam arahan TSX. Kesilapan, dengan cara itu, tidak ditemui sama sekali oleh pakar gergasi pemproses. Ia boleh menyebabkan ketidakstabilan sistem. buat keputusan masalah ini satu-satunya cara syarikat boleh melakukan ini adalah dengan kemas kini BIOS yang melumpuhkan set arahan ini.
By the way, TSX dilaksanakan bukan sahaja dalam pemproses Haswell, tetapi juga dalam model pertama CPU Broadwell, yang sepatutnya muncul di bawah nama Core M. Seorang wakil syarikat mengesahkan bahawa Intel berhasrat untuk melaksanakan versi "bebas pepijat" arahan TSX pada masa hadapan dalam produknya yang seterusnya.
tag: komen
Berita sebelum ini
2014-08-13 22:23
Sony Xperia Z2 "terselamat" selepas enam minggu tinggal di dasar takungan masin
Telefon pintar sering menjadi wira cerita yang luar biasa di mana mereka mencuba peranan perisai badan poket yang menghentikan peluru dan menyelamatkan
2014-08-13 21:46
iPhone 6 telah memasuki peringkat akhir ujian
Mengikut data terkini agensi berita Gforgames, iPhone 6 telah memasuki peringkat akhir ujian sebelum pelancaran besar-besaran telefon pintar baharu ke dalam pengeluaran. Ingat bahawa iPhone 6 akan dipasang di China di kilang ...
2014-08-12 16:38
Tablet octa-core iRU M720G menyokong dwi SIM
Tablet ini mempunyai 2 GB RAM dan 16 GB memori kilat dalaman. Terdapat dua kamera di atas kapal: 8 megapiksel utama dan 2 megapiksel hadapan. iRU M720G dilengkapi dengan 3G, GPS, Wi-Fi, Bluetooth, modul radio FM, serta slot untuk dua kad SIM, yang membolehkan ia melaksanakan fungsi...
2014-08-10 18:57
LG telah mengeluarkan telefon pintar L60 yang murah di Rusia
Tanpa banyak sambutan, LG Electronics diperkenalkan di Rusia model baru Siri L III - LG L60. Telefon pintar murah ini dibentangkan dalam julat harga dari 4 hingga 5 ribu rubel dari Rusia terbesar ...
Dengan setiap generasi baharu, pemproses Intel menggabungkan lebih banyak teknologi dan ciri. Sesetengah daripada mereka terkenal kepada semua orang (yang, sebagai contoh, tidak tahu tentang hyperthreading?), Kebanyakan bukan pakar tidak tahu tentang kewujudan orang lain. Mari buka dengan baik pangkalan yang diketahui pengetahuan tentang produk Intel Automated Relational Knowledge Base (ARK) dan pilih pemproses di sana. Kita akan melihat senarai ciri dan teknologi yang banyak - apakah yang ada di sebalik nama pemasaran misteri mereka? Kami mencadangkan untuk menyelidiki isu itu, beralih Perhatian istimewa mengenai teknologi yang kurang dikenali - pastinya, terdapat banyak perkara menarik di sana.
Penukaran Berasaskan Permintaan Intel
Bersama-sama dengan Teknologi Intel SpeedStep yang Dipertingkatkan, Pensuisan Berasaskan Permintaan Intel bertanggungjawab untuk memastikan bahawa pada bila-bila masa semasa beban semasa, pemproses berjalan pada kekerapan optimum dan menerima kuasa elektrik yang mencukupi: tidak lebih dan tidak kurang daripada yang diperlukan. Oleh itu, penggunaan kuasa dan pelesapan haba dikurangkan, yang relevan bukan sahaja untuk peranti mudah alih, tetapi juga untuk pelayan - di sinilah Pertukaran Berdasarkan Permintaan digunakan.
Akses Memori Cepat Intel
Ciri pengawal memori untuk mengoptimumkan prestasi RAM. Ia adalah gabungan teknologi yang membolehkan, melalui analisis mendalam baris gilir perintah, untuk mengenal pasti arahan "bergabung" (contohnya, membaca dari halaman memori yang sama), dan kemudian menyusun semula pelaksanaan sebenar supaya "bergabung" arahan dilaksanakan satu demi satu. Di samping itu, penulisan memori keutamaan rendah dijadualkan untuk masa apabila baris gilir baca diramalkan kosong, dan akibatnya, proses menulis memori menjadi kurang mengehadkan kelajuan baca.
Akses Memori Intel Flex
Satu lagi fungsi pengawal memori, yang muncul pada zaman ketika ia adalah cip yang berasingan, pada tahun 2004. Menyediakan keupayaan untuk bekerja dalam mod segerak dengan dua modul memori pada masa yang sama, dan tidak seperti mod dwi-saluran mudah yang wujud sebelum ini, modul memori boleh saiz yang berbeza. Oleh itu, fleksibiliti dicapai dalam melengkapkan komputer dengan memori, yang ditunjukkan dalam nama.
Main Semula Arahan Intel
Teknologi yang sangat mendalam yang pertama kali muncul dalam pemproses Intel Itanium. Semasa pengendalian saluran paip pemproses, situasi mungkin berlaku apabila arahan telah pun dilaksanakan, dan data yang diperlukan belum tersedia. Arahan itu kemudiannya perlu "dimainkan semula": dikeluarkan dari penghantar dan dijalankan pada permulaannya. Yang, sebenarnya, sedang berlaku. Yang lagi satu fungsi penting IRT - pembetulan ralat rawak pada saluran paip pemproses. Baca lebih lanjut mengenai ciri yang sangat menarik ini.
Intel Teknologi WiFi Saya
Teknologi virtualisasi yang membolehkan anda menambah penyesuai WiFi maya pada fizikal sedia ada; oleh itu, ultrabook atau komputer riba anda boleh menjadi pusat akses atau pengulang sepenuhnya. Komponen perisian WiFi saya disertakan dengan pemacu Intel PROSet Wireless Software versi 13.2 dan lebih tinggi; perlu diingat bahawa hanya beberapa penyesuai WiFi yang serasi dengan teknologi. Arahan pemasangan, serta senarai keserasian perisian dan perkakasan, boleh didapati di tapak web Intel.
Teknologi Intel Smart Idle
Satu lagi teknologi penjimatan tenaga. Membolehkan anda melumpuhkan blok pemproses yang tidak digunakan pada masa ini atau mengurangkan kekerapannya. Perkara yang sangat diperlukan untuk CPU telefon pintar, di mana ia muncul - dalam pemproses Intel Atom.
Platform Imej Intel Stabil
Istilah yang merujuk kepada proses perniagaan dan bukannya teknologi. Program Intel SIPP memastikan kestabilan perisian dengan memastikan komponen dan pemacu platform utama kekal tidak berubah selama sekurang-kurangnya 15 bulan. Oleh itu, pelanggan korporat mempunyai peluang untuk menggunakan imej sistem yang digunakan sama dalam tempoh ini.
Intel QuickAssist
Satu set fungsi yang dilaksanakan perkakasan yang memerlukan sejumlah besar pengiraan, seperti penyulitan, pemampatan, pengecaman corak. Tujuan QuickAssist adalah untuk memudahkan pembangun dengan memberikan mereka "bata" yang berfungsi dan juga untuk mempercepatkan aplikasi mereka. Sebaliknya, teknologi ini memungkinkan untuk mengamanahkan tugas "berat" kepada bukan pemproses yang paling berkuasa, yang amat dihargai dalam sistem terbenam, yang sangat terhad dari segi prestasi dan penggunaan kuasa.
Intel Quick Resume
Teknologi yang dibangunkan untuk komputer berasaskan platform Intel Viiv, yang membolehkan mereka menghidupkan dan mematikan hampir serta-merta, seperti penerima TV atau pemain DVD; pada masa yang sama, dalam keadaan "mati", komputer boleh terus melaksanakan beberapa tugas yang tidak memerlukan campur tangan pengguna. Dan walaupun platform itu sendiri lancar berpindah ke penjelmaan lain, bersama-sama dengan perkembangan yang mengiringinya, garis itu masih ada di ARK, kerana ia tidak lama dahulu.
Kunci Keselamatan Intel
Istilah payung untuk arahan RDRAND 32-bit dan 64-bit yang menggunakan pelaksanaan perkakasan penjana nombor rawak Digital Random Number Generator (DRNG). Arahan digunakan untuk tujuan kriptografi untuk menghasilkan kunci rawak yang cantik dan berkualiti tinggi.
Intel TSX-NI
Teknologi dengan nama kompleks Intel Transactional Synchronization Extensions - New Instructions membayangkan tambahan kepada sistem cache pemproses yang mengoptimumkan persekitaran pelaksanaan untuk aplikasi berbilang benang, tetapi, sudah tentu, hanya jika aplikasi ini menggunakan antara muka pengaturcaraan TSX-NI . Dari sisi pengguna teknologi ini tidak kelihatan langsung, tetapi semua orang boleh membaca penerangannya dalam bahasa mudah Blog Stepan Koltsov.
Kesimpulannya, kami ingin mengingatkan anda sekali lagi bahawa Intel ARK wujud bukan sahaja sebagai tapak web, tetapi juga sebagai aplikasi luar talian untuk iOS dan Android. Jadi pada topik!

:")































