|
Быстрое внедрение ERP
Комплексные услуги |
Управление доставкой Для торговых и курьерских компаний! |
1C:ЭДО Узнайте о всех преимуществах электронного документооборота! |
Переход на «1С:ЗУП ред. 3» Фирма «1С» прекращает поддержку «1С:ЗУП 2.5»! |
Аренда сервера 1С |



Кластер серверов 1С - построение высоконагруженных систем
Заказать демонстрацию ЗаказатьВ данной статье будут рассмотрены несколько вариантов структуры 1С для высоконагруженных систем (от 200 активных пользователей), построенных на базе клиент-серверной архитектуры – их преимущества и недостатки, стоимость инсталляции и сравнительные тесты производительности каждого варианта.
Мы не будем проводить описание, оценку и сравнение общепринятых и всем давно известных классических схем построения серверной структуры 1С, таких как отдельный сервер 1С и отдельный сервер СУБД, либо кластер Microsoft SQL с кластером 1С. Таких обзоров великое множество, в том числе и проведенных самими производителями программных продуктов. Мы предложим обзор схем построения структуры 1С, которые встречались за последние несколько лет в наших ИТ-проектах для среднего и крупного бизнеса.
Требования к высоконагруженным системам 1С
Высоконагруженные системы 1С, работающие с крупными массивами данных в режиме 24/7/365 подвержены факторам риска, которые в стандартных ситуациях обычно не наблюдаются. Как следствие, для их устранения и упреждения требуется применение особенных схем архитектуры 1С и новых технологий.
Катастрофоустойчивость СУБД. В процессе проектирования архитектуры 1С делается упор на вычислительные мощности и высокую доступность сервисов, выраженную в их кластеризации. Серверы 1С:Предприятие по умолчанию способны работать в дублирующем кластере, а для кластера СУБД обычно применяется промышленная система хранения данных (СХД) и технология кластеризации (к примеру, Microsoft SQL Cluster). Однако, ситуация становится плачевной, когда проблемы случаются с самой СХД (зачастую, по нашему опыту последних лет – это проблемы программного характера). Тогда у ИТ-инженера резко возникают две проблемы – где взять актуальные данные и куда их развернуть в кратчайшие сроки, поскольку система хранения данных с нужным объемом быстрого массива дисков недоступна.
Требования к безопасности базы данных. Работая с проектами среднего и крупного бизнеса, мы регулярно сталкиваемся с требованиями по защите персональных данных (в частности, для выполнения пунктов ФЗ-152). Одним из условий выполнения этих требований является обеспечение должной сохранности персональных данных, что требует шифрования базы данных 1С.
При разработке схемы высоконагруженных систем 1С обычно обращают внимание в первую очередь на параметры дисковой системы ввода\вывода, на которой расположены базы данных. Но помимо этого, еще существует активная утилизация ресурсов ЦПУ и потребление ОЗУ сервером 1С. Зачастую именно этого типа ресурсов и не хватает, возможности аппаратной модернизации текущего сервера 1С исчерпываются и требуется добавление новых серверов 1С, работающих с единым сервером СУБД.Схемы организации кластеров серверов 1С
Схема с кластером 1С-серверов, подсоединенным к кластеру с синхронной репликацией SQL AlwaysOn по протоколу IP. Данная схема является одним из качественных вариантов решения проблемы катастрофоустойчивости базы данных 1С (см. Рисунок 1). Технология кластеризации баз SQL AlwaysOn основана на принципе онлайн-синхронизации таблиц SQL между основным и резервным серверами без вмешательства конечного пользователя. С помощью SQL Listener есть возможность переключиться на резервный сервер SQL в случае выхода из строя основного, что позволяет назвать данную систему полноценным катастрофоустойчивым кластером SQL, благодаря использованию двух независимых серверов SQL. Технология SQL Always On доступна только в версии Microsoft SQL Enterprise.

Рисунок 1 - схема кластера серверов 1С + SQL AlwaysOn
Вторая схема идентична первой, добавлено только шифрование баз SQL на основном и резервном сервере. Мы уже упоминали о том, что работа с последними ИТ-проектами показала, что компании начали гораздо больше внимания уделять вопросу безопасности данных, по различным причинам – требования ФЗ-152, рейдерские захваты серверов, утечка данных в облаке и тому подобное. Так что считаем данный вариант схемы 1С довольно актуальным (см. Рисунок 2).

Рисунок 2 - схема кластера серверов 1С + SQL AlwaysOn с шифрованием
Кластер серверов 1С "active-active", подсоединенный к единственному серверу СУБД по протоколу IP. В противовес потребностям в отказоустойчивости и безопасности – некоторым структурам в первую очередь требуется повышенная производительность, так сказать «вся вычислительная мощь». Поэтому максимальный приоритет отдается увеличению количества вычислительных кластеров сервера 1С, на которые современная платформа 1С позволяет дифференцировать различные типы вычислений и фоновые задания (см. Рисунок 3). Конечно же, комплектация основных ресурсов сервера SQL тоже должна быть на уровне, однако сам сервер баз данных представлен в единственном числе (видимо, расчет идет на своевременное резервное копирование баз).
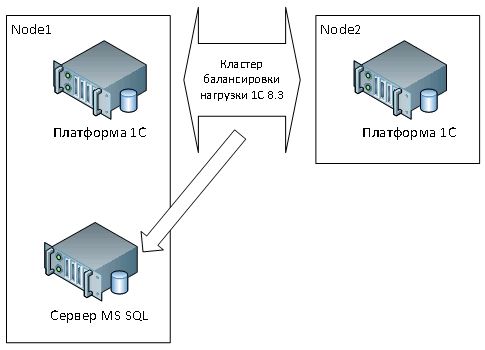
Рисунок 3 - схема кластера серверов 1С с одним сервером СУБД
Сервер 1С и СУБД на одном аппаратном сервере с SharedMemory. Поскольку наши практические тесты ориентированы на сравнение производительности разных схем, то обязательно требуется некий эталон для сравнения нескольких вариантов (см. Рисунок 4). В качестве эталона, по нашему мнению, нужно взять схему расположения сервера 1С и СУБД на одном аппаратном сервере без виртуализации с взаимодействием по SharedMemory.

Рисунок 4 - схема сервера 1С и СУБД на одном аппаратном сервере с SharedMemory
Ниже приведена общая сравнительная таблица, в которой показаны общие результаты по ключевым критериям оценки организации структуры системы 1С (см. Таблица 1).
| Критерии оценки архитектур 1С | Кластер 1С + SQL AlwaysOn |
Кластер 1С + SQL AlwaysOn с шифрованием
|
Кластер 1С с одним сервером СУБД
|
Классический 1С+СУБД SharedMemory |
| Легкость инсталляции и обслуживания | Удовл. | Удовл. | Хорошо | Отлично |
| Отказоустойчивость | Отлично | Отлично | Удовл. | Не применимо |
| Безопасность | Удовл. | Отлично | Удовл. | Удовл. |
| Бюджетность | Удовл. | Удовл. | Хорошо | Отлично |
Таблица 1 - сравнение вариантов построения систем 1С
Как видим, остается один важный критерий, значение которого предстоит выяснить – это производительность. Для этого мы проведем серию практических тестов на выделенном тестовом стенде.
Описание методики тестирования
Этап тестирования состоит из двух ключевых инструментов синтетической генерации нагрузки и имитации работы пользователей в 1С. Это тест Гилева (TPC-1C) и «Тест центр» из инструментария 1С: КИП.
Тест Гилева. Тест относится к разделу универсальных интегральных кроссплатформенных тестов. Он может применяться как для файлового, так и для клиент-серверного вариантов 1С:Предприятие. Тест оценивает количество работы в единицу времени в одном потоке и подходит для оценки скорости работы однопоточных нагрузок, включая скорость отрисовки интерфейса, влияния ресурсных затрат на обслуживание виртуальной среды, перепроведения документов, закрытия месяца, расчета зарплаты и т.п. Универсальность позволяет делать обобщенную оценку производительности не привязываясь к конкретной типовой конфигурации платформы. Результатом теста является сводная оценка измеряемой системы 1С, выраженная в условных единицах.
Специализированный «Тест центр» из инструментария 1С: КИП. Тест-центр – инструмент автоматизации многопользовательских нагрузочных испытаний информационных систем на платформе 1С:Предприятие 8. С его помощью можно моделировать работу предприятия без участия реальных пользователей, что позволяет оценивать применимость, производительность и масштабируемость информационной системы в реальных условиях. Используя инструментарий 1С: КИП, на основании процессов и контрольных примеров формируется матрица «Список Объектов макета базы ERP 2.2» для сценария тестирования производительности. В макете базы 1С: ERP 2.2 генерируются обработкой данные по Нормативно-справочной информации (НСИ):
- Несколько тысяч номенклатурных позиций;
- Несколько организаций;
- Несколько тысяч контрагентов.
Тест осуществляется в рамках нескольких групп пользователей. Группа состоит из 4 пользователей, у каждого из которых есть своя роль и перечень последовательных операций. Благодаря гибкому механизму задания параметров для тестирования, можно запускать тест на разное количество пользователей, что позволит оценить поведение системы при различных нагрузках и определить параметры, которые могут привести к снижению показателей производительности. Проводится 3 теста по 3 итерации в которых разработчик 1С запускает тест с эмуляцией работы пользователей и замеряет время выполнения каждой операции. Выполняются замеры всех трех итераций для каждой из схем структуры 1С. Результатом теста является получение среднего времени выполнения операции для каждого документа матрицы.
Показатели «Тест центра» и теста Гилева будут отражены в сводной таблице 2.
Тестовый стенд
Сервер терминального доступа – виртуальная машина, использовалась для управления инструментами тестирования:
- vCPU - 16 ядер 2.6GHz
- RAM - 32 ГБ
- I\o: Intel Sata SSD Raid1
- RAM - 96 ГБ
- I\o: Intel Sata SSD Raid1
Сервер 1С и СУБД - физический сервер
- CPU - Intel Xeon Processor E5-2670 8C 2.6GHz – 2 шт
- RAM - 96 ГБ
- I\o: Intel Sata SSD Raid1
- Роли: Сервер 1С 8.3.8.2137, Сервер MS SQL 2014 SP 2
Выводы
Можем сделать вывод, что по среднему времени выполнения операции наиболее оптимальной является схема №3 «Кластер серверов 1С "active-active", подсоединенный к единственному серверу СУБД по протоколу IP» (см. Таблица 2). Для обеспечения отказоустойчивости такой архитектуры мы рекомендуем строить классический отказоустойчивый кластер MSSQL с размещением базы данных на отдельной СХД.
Важно отметить, что наиболее оптимальное соотношение факторов минимизации простоя, отказоустойчивости и сохранности данных - у схемы №1 «Кластер 1С-серверов, подсоединенный к кластеру с синхронной репликацией SQL AlwaysOn по протоколу IP», при этом падение производительности по отношению к самому производительному варианту составляет примерно 10%.
Как мы видим по результатам тестов, синхронная репликация базы SQL AlwaysOn достаточно негативно влияет на производительность. Объясняется это тем, что система SQL ждет окончания репликации каждой транзакции на резервный сервер, не позволяя работать с базой в это время. Этого можно избежать если настроить асинхронную репликацию между MSSQL серверами, но при таких настройках мы не получим автоматического переключения приложений на резервную ноду в случае сбоя. Переключение придется выполнять вручную.
На базе облака EFSOL мы предлагаем нашим клиентам кластер серверов 1С в аренду. Это позволяет существенно сэкономить средства на построение собственной отказоустойчивой архитектуры для работы с 1С.
|
Схема архитектуры 1С |
Среднее время выполнения операции, сек | ||
MTBF (Mean Time Between Failure) — среднее время наработки на отказ.
MTTR (Mean Time To Repair) — среднее время восстановления работоспособности.
В отличие от надежности, величина которой определяется только значением MTBF, готовность зависит еще и от времени, необходимого для возврата системы в рабочее состояние.
Что такое кластер высокой готовности?
Кластер высокой готовности (далее кластер) — это разновидность кластерной системы, предназначенная для обеспечения непрерывной работы критически важных приложений или служб. Применение кластера высокой готовности позволяет предотвратить как неплановые простои, вызываемые отказами аппаратуры и программного обеспечения, так и плановые простои, необходимые для обновления программного обеспечения или профилактического ремонта оборудования.
Принципиальная схема кластера высокой готовности приведена на рисунке:
Кластер состоит из двух узлов (серверов), подключенных к общему дисковому массиву. Все основные компоненты этого дискового массива — блок питания, дисковые накопители, контроллер ввода/вывода - имеют резервирование с возможностью горячей замены. Узлы кластера соединены между собой внутренней сетью для обмена информацией о своем текущем состоянии. Электропитание кластера осуществляется от двух независимых источников. Подключение каждого узла к внешней локальной сети также дублируется.
Таким образом, все подсистемы кластера имеют резервирование, поэтому при отказе любого элемента кластер в целом останется в работоспособном состоянии. Более того, замена отказавшего элемента возможна без остановки кластера.
На обоих узлах кластера устанавливается операционная система Microsoft Windows Server 2003 Enterprise, которая поддерживает технологию Microsoft Windows Cluster Service (MSCS).
Принцип работы кластера следующий. Приложение (служба), доступность которого обеспечивается кластером, устанавливается на обоих узлах. Для этого приложения (службы) создается группа ресурсов, включающая IP-адрес и сетевое имя виртуального сервера, а также один или несколько логических дисков на общем дисковом массиве. Таким образом, приложение вместе со своей группой ресурсов не привязывается "жестко" к конретному узлу, а, напротив, может быть запущено на любом из этих узлов (причем на каждом узле одновременно может работать несколько приложений). В свою очередь, клиенты этого приложения (службы) будут "видеть" в сети не узлы кластера, а виртуальный сервер (сетевое имя и IP-адрес), на котором работает данное приложение.
Сначала приложение запускается на одном из узлов. Если этот узел по какой-либо причине прекращает функционировать, другой узел перестает получать от него сигнал активности ("heartbeat") и автоматически запускает все приложения отказавшего узла, т.е. приложения вместе со своими группами ресурсов "мигрируют" на исправный узел. Миграция приложения может продолжаться от нескольких секунд до нескольких десятков секунд и в течение этого времени данное приложение недоступно для клиентов. В зависимости от типа приложения после рестарта сеанс возобновляется автоматически либо может потребоваться повторная авторизация клиента. Никаких изменений настроек со стороны клиента не нужно. После восстановления неисправного узла его приложения могут мигрировать обратно.
Если на каждом узле кластера работают различные приложения, то в случае отказа одного из узлов нагрузка на другой узел повысится и производительность приложений упадет.
Если приложения работают только на одном узле, а другой узел используется в качестве резерва, то при отказе "рабочего" узла производительность кластера не изменится (при условии, что запасной узел не "слабее").
Основным преимуществом кластеров высокой готовности является возможность использования стандартного оборудования и программного обеспечения, что делает это решение недорогим и доступным для внедрения предприятиями малого и среднего бизнеса.
Следует отличать кластеры высокой готовности от отказоустойчивых систем ("fault-tolerant"), которые строятся по принципу полного дублирования. В таких системах серверы работают параллельно в синхронном режиме. Достоинством этих систем является малое (меньше секунды) время восстановления после отказа, а недостатком - высокая стоимость из-за необходимости применения специальных программных и аппаратных решений.
Сравнение кластера высокой готовности с обычным сервером
Как упоминалось выше, применение кластеров высокой готовности позволяет уменьшить число простоев, вызванное плановыми или неплановыми остановками работы.
Плановые остановки могут быть обусловлены необходимостью обновления программного обеспечения или проведения профилактического ремонта оборудования. На кластере эти операции можно проводить последовательно на разных узлах, не прерывая работы кластера в целом.
Неплановые остановки случаются из-за сбоев программного обеспечения или аппаратуры. В случае сбоя ПО на обычном сервере потребуется перезагрузка операционной системы или приложения, в случае с кластером приложение мигрирует на другой узел и продолжит работу.
Наименее предсказуемым событием является отказ оборудования. Из опыта известно, что сервер является достаточно надежным устройством. Но можно ли получить конкретные цифры, отражающие уровень готовности сервера и кластера?
Производители компьютерных компонентов, как правило, определяют их надежность на основании испытаний партии изделий по следующей формуле:
Например, если тестировалось 100 изделий в течение года и 10 из них вышло из строя, то MTBF, вычисленное по этой формуле, будет равно 10 годам. Т.е. предполагается, что через 10 лет все изделия выйдут из строя.
Отсюда можно сделать следующие важные выводы. Во-первых, такая методика расчета MTBF предполагает, что число отказов в единицу времени постоянно на протяжении всего срока эксплуатации. В "реальной" жизни это, конечно, не так. На самом деле, из теории надежности известно, что кривая отказов имеет следующий вид:

В зоне I проявляются отказы изделий, имеющие дефекты изготовления. В III зоне начинают сказываться усталостные изменения. В зоне II отказы вызываются случайными факторами и их число постоянно в единицу времени. Изготовители компонентов, "распространяют" эту зону на весь срок эксплуатации. Реальная статистика отказов на протяжение всего срока эксплуатации подтверждает, что эта теоретическая модель вполне близка к действительности.
Второй интересный вывод заключается в том, что понятие MTBF отражает совсем не то, что очевидно следует из его названия. "Среднее время наработки на отказ" в буквальном смысле означает время, составляющее только половину MTBF. Так, в нашем примере это "среднее время" будет не 10 лет, а пять, поскольку в среднем все экземпляры изделия проработают не 10 лет, а вполовину меньше. Т.е. MTBF, заявляемый производителем - это время, в течение которого изделие выйдет из строя с вероятностью 100%.
Итак, поскольку вероятность выхода компонента из строя на протяжении MTBF равна 1, и если MTBF измерять в годах, то вероятность выхода компонента из строя в течение одного года составит:
| P = | 1 |
| MTBF |
Очевидно, что отказ любого из недублированных компонентов сервера будет означать отказ сервера в целом.
Отказ дублированного компонента приведет к отказу сервера только при условии, что компонент-дублер тоже выйдет из строя в течение времени, необходимого для "горячей" замены компонента, отказавшего первым. Если гарантированное время замены компонента составляет 24 часа (1/365 года) (что соответствует сложившейся практике обслуживания серверного оборудования), то вероятность такого события в течение года:
| Pd = | P x P | x 2 |
| 365 |
Пояснения к формуле.
Здесь мы имеем два взаимоисключающих случая, когда оба компонента выходят из строя.
Случай (1)
- Выход из строя компонента №1 в любой момент времени в течение года (вероятность P)
- Выход из строя компонента №2 в течение 24 часов после выхода компонента №1 (вероятность P/365)
Вероятность одновременного наступления этих событий равняется произведению их вероятностей.
Для случая (2), когда сначала откажет компонент №2, а затем компонент №1, вероятность будет такой же.
Поскольку случаи (1) и (2) не могут произойти одновременно, вероятность наступления того или другого случая равна сумме их вероятностей.
Теперь, зная вероятность Pi отказа каждого из N компонентов (дублированных и недублированных) сервера, можно рассчитать вероятность отказа сервера в течение одного года.
Выполним расчет следующим образом.
Как уже говорилось выход их строя любого компонента будет означать отказ сервера в целом.
Вероятность безотказной работы любого компонента в течение года равна
| Pi" = 1 - Pi |
Вероятность безотказной работы всех компонентов в течение года равна произведению вероятностей этих независимых событий:
| Ps’ = ∏ Pi" |
Тогда вероятность выхода сервера из строя в течение года
Теперь можно определить коэффициент готовности:
| Ks = | MTBFs |
| MTBFs + MTTRs |
Перейдем к расчету. Пусть наш сервер состоит из следующих компонентов:

Рисунок 1. Состав сервера
Сведем данные производителей по надежности отдельных компонент, в следующую таблицу:
| Компоненты сервера | Заявленная надежность | Количество компонентов в сервере | Вероятность отказа с учетом дублирования |
||
| MTBF (часов) | MTBF (лет) | Вероятность отказа в те- чение года |
|||
| Блок питания | 90 000 | 10,27 | 0,09733 | 2 | 0,0000519 |
| Системная плата | 300 000 | 34,25 | 0,02920 | 1 | 0,0292000 |
| Процессор №1 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| Процессор №2 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| RAM, модуль №1 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| RAM, модуль №2 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| Жесткий диск | 400 000 | 45,66 | 0,02190 | 2 | 0,0000026 |
| Вентилятор №1 | 100 000 | 11,42 | 0,08760 | 2 | 0,0000420 |
| Вентилятор №2 | 100 000 | 11,42 | 0,08760 | 2 | 0,0000420 |
| Контроллер HDD | 300 000 | 34,25 | 0,02920 | 1 | 0,0292000 |
| Плата сопряжения | 300 000 | 34,25 | 0,02920 | 1 | 0,0292000 |
| Ленточный накопитель | 220 000 | 25,11 | 0,03982 | 1 | 0,0398182 |
| Для сервера в целом: | 0,37664 | 0,1519961 | |||
Вообще, для серверного оборудования нормальным коэффициентом готовности считается величина 99,95%, что примерно соответствует результату наших расчетов.
Выполним аналогичный расчет для кластера.
Кластер состоит из двух узлов и внешнего дискового массива. Нарушение работоспособности кластера произойдет либо в случае отказа дискового массива либо в случае одновременного отказа обеих узлов в течение времени, необходимого для восстановления узла, первым вышедшего из строя.
Предположим, что в качестве узла кластера используется рассмотренный нами сервер с коэффициентом готовности K = 99,958%, а время восстановления работоспособности узла - 24 часа.
Рассчитаем параметры надежности внешнего дискового массива:
| Компоненты массива | Заявленная надежность | Кол-во компо- нентов в массиве | Вероятность отказа с учетом дублирования |
||
| MTBF (часов) | MTBF (лет) | Вероятность отказа в те- чение года |
|||
| Блок питания | 90 000 | 10,27 | 0,09733 | 2 | 0,0000519 |
| Жесткий диск | 400 000 | 45,66 | 0,02190 | 2 | 0,0000026 |
| Вентилятор | 100 000 | 11,42 | 0,08760 | 2 | 0,0000420 |
| Контроллер HDD | 300 000 | 34,25 | 0,02920 | 2 | 0,0000047 |
| Для массива в целом: | 0,21797 | 0,0001013 | |||
Таким образом, кластер высокой готовности демонстрирует гораздо более высокую устройчивость к возможному отказу аппаратуры, нежели сервер традиционной архитектуры.
После нескольких лет молчания, решил поделиться опытом по развертыванию отказоустойчивого кластера на основе Windows Server 2012.Постановка задачи: Развернуть отказоустойчивый кластер для размещения на нем виртуальных машин, с возможностью выделения виртуальных машин в отдельные виртуальные подсети (VLAN), обеспечить высокую надежность, возможность попеременного обслуживания серверов, обеспечить доступность сервисов. Обеспечить спокойный сон отделу ИТ.
Для выполнения выше поставленной задачи нам удалось выбить себе следующее оборудование:
- Сервер HP ProLiant DL 560 Gen8 4x Xeon 8 core 64 GB RAM 2 шт.
- SAS Хранилище HP P2000 на 24 2,5» дисков 1 шт.
- Диски для хранилища 300 Gb 24 шт. //С объемом не густо, но к сожалению бюджеты такие бюджеты…
- Контроллер для подключения SAS производства HP 2 шт.
- Сетевой адаптер на 4 1Gb порта 2 шт. //Можно было взять модуль под 4 SFP, но у нас нет оборудования с поддержкой 10 Gb, гигабитного соединения вполне достаточно.
Организация подключений:

У нас на самом деле подключено в 2 разных коммутатора. Можно подключить в 4 разных. Я считаю, что достаточно 2х.
На портах коммутаторов, куда подключены сервера необходимо сменить режим интерфейса с access на trunk, для возможности разнесения по виртуальным подсетям.
Пока качаются обновления на свежеустановленную Windows Server 2012, настроим дисковое хранилище. Мы планируем развернуть сервер баз данных, посему решили 600 Гб использовать под базы данных, остальное под остальные виртуальные машины, такая вот тавтология.
Создаем виртуальные диски:
- Диск raid10 на основе Raid 1+0 из 4 дисков +1 spare
- Диск raid5 на основе Raid 5 из 16 дисков +1 spare
- 2 диска - ЗИП
Теперь необходимо создать разделы.
- raid5_quorum - Так называемый диск-свидетель (witness). Необходим для организации кластера из 2 нод.
- raid5_store - Здесь мы будем хранить виртуальные машины и их жесткие диски
- raid10_db - Здесь будет хранится жесткий диск виртуальной машины MS SQL сервера
Обязательно необходимо включить feature Microsoft Multipath IO, иначе при сервера к обоим контроллерам хранилища в системе будет 6 дисков, вместо 3х, и кластер не соберется, выдавая ошибку, мол у вас присутствуют диски с одинаковыми серийными номерами, и этот визард будет прав, хочу я вам сказать.
Подключать сервера к хранилищу советую по очереди:
- Подключили 1 сервер к 1 контроллеру хранилища
- В хранилище появится 1 подключенный хост - дайте ему имя. Советую называть так: имясервера_номер контроллера (A или B)
- И так, пока не подключите оба сервера к обоим контроллерам.
На коммутаторах, к которым подключены сервера необходимо создать 3 виртуальных подсети (VLAN):
- ClusterNetwork - здесь ходит служебная информаци кластера (хэртбит, регулирование записи на хранилище)
- LiveMigration - тут думаю все ясно
- Management - сеть для управления
На этом подготовка инфраструктуры закончена. Переходим к настройке серверов и поднятию кластера.
Заводим сервера в домен. Устанавливаем роль Hyper-V, Failover Cluster.
В настройках Multipath IO включаем поддержку SAS устройств.
Обязательно перезагружаем.
Следующие настройки необходимо выполнить на обоих серверах.
Переименуйте все 4 сетевых интерфейса в соответствии их физическим портам (у нас это 1,2,3,4).
Настраиваем NIC Teaming - Добавляем все 4 адаптера в команду, Режим (Teaming-Mode) - Switch Independent, Балансировка нагрузки (Load Balancing) - Hyper-V Port. Даем имя команде, я так и назвал Team.
Теперь необходимо поднять виртуальный коммутатор.
Открываем powershell и пишем:
New-VMSwitch "VSwitch" -MinimumBandwidthMode Weight -NetAdapterName "Team" -AllowManagementOS 0
Создаем 3 виртуальных сетевых адаптера.
В том же powershell:
Add-VMNetworkAdapter –ManagementOS –Name "Management" Add-VMNetworkAdapter –ManagementOS –Name "ClusterNetwork"Add-VMNetworkAdapter –ManagementOS –Name "Live Migration"
Эти виртуальные коммутаторы появятся в центре управления сетями и общим доступом, именно по ним и будет ходить траффик наших серверов.
Настройте адресацию в соответствии с вашими планами.
Переводим наши адапетры в соответствующие VLAN’ы.
В любимом powershell:
Set-VMNetworkAdapterVlan -ManagementOS -Access -VlanId 2 -VMNetworkAdapterName "Management" -Confirm Set-VMNetworkAdapterVlan -ManagementOS -Access -VlanId 3 -VMNetworkAdapterName "ClusterNetwork" -Confirm Set-VMNetworkAdapterVlan -ManagementOS -Access -VlanId 4 -VMNetworkAdapterName "Live Migration" -Confirm
Теперь нужно настроить QoS.
При настройке QoS by weight (по весу), что является best practice, по заявлению Microsoft, советую расставить вес так, чтобы в общей сумме получилось 100, тогда можно считать, что значение указанное в настройке есть гарантированный процент полосы пропускания. В любом случае считается процент по формуле:
Процент полосы пропускания = установленный вес * 100 / сумма всех установленных значений веса
Set-VMSwitch “VSwitch” -DefaultFlowMinimumBandwidthWeight 15
Для служебной информации кластера.
Set-VMNetworkAdapter -ManagementOS -Name “Cluster” -MinimumBandwidthWeight 30
Для управления.
Set-VMNetworkAdapter -ManagementOS -Name "Management" -MinimumBandwidthWeight 5
Для Live Migration.
Set-VMNetworkAdapter -ManagementOS -Name “Live Migration” -MinimumBandwidthWeight 50
Чтобы трафик ходил по сетям верно, необходимо верно расставить метрики.
Трафик служебной информации кластера будет ходит по сети с наименьшей метрикой.По следующей по величине метрики сети будет ходить Live Migration.
Давайте так и сделаем.
В нашем ненаглядном:
$n = Get-ClusterNetwork “ClusterNetwork” $n.Metric = 1000 $n = Get-ClusterNetwork “LiveMigration” $n.Metric = 1050$n = Get-ClusterNetwork “Management” $n.Metric = 1100
Монтируем наш диск-свидетель на ноде, с которой будем собирать кластер, форматируем в ntfs.
В оснастке Failover Clustering в разделе Networks переименуйте сети в соответствии с нашими адаптерами.
Все готово к сбору кластера.
В оснастке Failover Clustering жмем validate. Проходим проверку. После чего создаем кластер (create cluster) и выбираем конфигурацию кворума (quorum configuration) Node and Disk majority, что также считается лучшим выбором для кластеров с четным количеством нод, а учитывая, что у нас их всего две - это единственный выбор.
В разделе Storage оснастки Failover Clustering, добавьте ваши диски. А затем по очереди добавляйте их как Cluster Shared Volume (правый клик по диску). После добавления в папке C:\ClusterStorage появится символическая ссылка на диск, переименуйте ее в соответствии с названием диска, добавленного как Cluster Shared Volume.
Теперь можно создавать виртуальные машины и сохранять их на эти разделы. Надеюсь статья была Вам полезна.
Прошу сообщать об ошибках в ПМ.
Советую к прочтению: Microsoft Windows Server 2012 Полное руководство. Рэнд Моримото, Майкл Ноэл, Гай Ярдени, Омар Драуби, Эндрю Аббейт, Крис Амарис.
P.S.: Отдельное спасибо господину Салахову, Загорскому и Разборнову, которые постыдно были забыты мною при написании данного поста. Каюсь >_< XD
Если в вашей компании программным обеспечением от 1С пользуются несколько сотрудников, то достаточно закупить хороший сервер и правильно его настроить. Однако если число пользователей достигло 150-200 человек и это еще не предел, то установка кластера серверов поможет снизить нагрузку на оборудование. Конечно, установка дополнительного оборудования и подготовка специалистов для поддержки работоспособности кластера потребует некоторых финансовых и временных ресурсов, но это долговременное вложение, компенсирующее впоследствии все затраты за счет бесперебойной работы системы. При этом многое зависит от правильной настройки кластера – производительность можно увеличить в несколько раз без дорогостоящих вложений. Поэтому, перед тем как изучать функционал и закупать сервера, необходимо удостовериться, нужен ли вам кластер серверов 1С вообще.
Когда стоит устанавливать кластер серверов 1С?
При проектировании схемы работы и расчете необходимых мощностей серверов в ПО достаточно часто случаются ошибки. На начальном этапе системные администраторы могут их нивелировать с помощью увеличения количества оперативной памяти или модернизации ЦПУ и других узлов. Но всегда приходит момент, когда эти возможности иссякают, и установка кластера серверов становится фактически неизбежной. Именно она позволит решить основные проблемы высоконагруженных систем:
- Отказы оборудования и сетей. Для особо важных баз данных рекомендуется создать кластер серверов, исполняющий роль резервного;
- Недостаточная безопасность баз данных. Дополнительным преимуществом является возможность шифрования данных из ПО на платформе 1С;
- Неравномерное распределение нагрузки на узлы сервера. Решается с помощью создания нескольких «рабочих процессов», контролирующих клиентские соединения и запросы;
- Помимо решения данных проблем правильно настроенный кластер серверов 1С позволяет существенно экономить на поддержке стабильной работы приложений 1С.
Владельцы небольших компаний, столкнувшись с вышеперечисленными проблемами, также могут быть заинтересованы в установке кластера серверов. Но все же, если количество пользователей не превышает нескольких десятков и производительность ПО не вызывает жалоб, то кластер не является экономически оправданным. Намного эффективнее будет модернизировать сервер или правильно настроить ключевые параметры. Однако если компания нацелена на развитие и увеличение рабочих мест, то стоит подумать о создании кластера серверов 1С в ближайшем будущем.
Установка отказоустойчивого кластера серверов в стандартных случаях не потребует от администраторов глубоких знаний структуры и логики серверного оборудования.
Рассмотрим данный алгоритм на примере объединения двух серверов 1С 8.2 в кластер
Допустим, на сегодня у вас имеется два сервера, на одном из которых (S1C-01) установлен сервер 1С и информационные базы. Чтобы настроить отказоустойчивый кластер серверов, необходимо на сервере S1C-02 развернуть сервер 1С:Предприятие и начать рабочий процесс. Убедитесь, что в его свойствах установлен пункт «Использование» в состояние «Использовать». Регистрировать информационные базы нет необходимости.

После этого в консоли администрирования 1С необходимо добавить в раздел «Резервирование кластеров» резервный кластер с именем второго сервера – S1C-02. В аналогичный раздел второго сервера добавляем резервный кластер с именем S1C-01 и перемещаем его на верхнюю позицию. Для этого воспользуйтесь контекстным меню и командой «Переместить вверх». Необходимо добиться одинакового порядка в этих группах обоих серверов.
После вышеперечисленных действий остается лишь нажать кнопку «Действие» – «Обновить». После этого в дереве второго сервера должны появиться информационные базы, зарегистрированные на первом. Это означает, что наши действия привели к успеху и теперь у нас функционирует отказоустойчивый кластер из двух серверов.
Это один из простых примеров создания кластера серверов, не касающийся их оптимизации и корректной настройки. Для конечной реализации кластера под определенные задачи необходимо проработать вопрос о достаточности мощностей и профессиональной настройке полученного кластера.
Нагрузка на кластер и оптимизация
Тестирование нагрузки
Наиболее распространенными технологиями тестирования кластера серверов 1С считаются:
- Тест Гилева;
- Тест центр из 1С:КИП.
В первом случае мы имеем дело с инструментом, позволяющим оценить файловые и клиент-серверные базы. Он включает в себя оценку скорости работы системы, интерфейсов, длительных операций и количества ресурсов для функционирования. Большим плюсом является универсальность – нет никакой разницы, какую конфигурацию вы будете им тестировать. На выходе получается оценка в условных единицах.
Второй же функционал позволяет оценить время, затрачиваемое на определенную операцию в системе при заранее заданном количестве пользователей. При этом вы можете самостоятельно указать количество операций, их вид и последовательность – тест смоделирует реальные действия.
Исходя из полученных результатов, можно судить о том, стоит ли заниматься модернизацией или оптимизацией кластера серверов.
Самый простой путь ускорить работу 1С – увеличить характеристики серверов. Но бывали случаи, когда из-за неверных настроек после модернизации железа ситуация лишь ухудшалась. Поэтому при жалобах на зависания, рекомендуется в первую очередь проверить настройки кластера в сервисе администрирования.
Необходимо отнестись с полной ответственностью ко всем действиям. Параметры кластера могут серьезно повлиять на производительность и возможность работы, как в лучшую сторону, так и в противоположную. Каждый параметр оказывает влияние на все сервера, входящие в кластер. Поэтому перед тем, как изменять что-либо, необходимо понять, за что отвечает настройка кластера 1С.

Крайне полезный параметр для серверов, использующихся 24 часа в сутки – «Интервал перезапуска». Обычно его значение устанавливают в 86400 секунд, чтобы раз в день серверы могли перезапуститься автоматически. Это полезно для снижения отрицательных эффектов от утечки памяти и фрагментации данных на дисках при выполнении операций.
Очень важно, чтобы отказоустойчивый кластер серверов 1С был защищен от перерасхода памяти. Один неудачный запрос в цикле может забрать себе всю мощность многоядерных серверов. Чтобы воспрепятствовать этому существует два параметра кластера – «Допустимый объем памяти» и «Интервал превышения допустимого объема». Если вы правильно и точно настроите эти параметры, то обезопасите свои информационные базы от многих распространенных бед.
Ограничение процентного показателя «Допустимое отклонение количества ошибок сервера» позволит выявить рабочие процессы со слишком большим количеством ошибочных обращений. Кластер будет их принудительно завершать, если выставлена соответствующая галка. Это поможет обезопасить «безошибочные» процессы от зависаний и ожиданий.
Еще один параметр – «Выключенные процессы останавливать через» отвечает за регулярное отключение подключений к серверу через заданные промежутки времени. В 1С после завершения работы рабочие процессы висят некоторое время, чтобы данные корректно перенеслись на новые процессы. Иногда происходят сбои и на сервере остаются висеть процессы. Они тратят ресурсы и намного полезнее существенно минимизировать их количество.
Кроме оптимизации непосредственно кластера, также необходимо правильно настроить каждый сервер, входящий в него. Для удобства оптимизации сервера и проверки производительности администраторы используют агент сервера – ragent. В нем храниться информация о том, что запущено на определенном сервере. Для получения данных по используемым информационным базам необходимо обратиться к менеджеру сервера – rmngr.
Для грамотной оптимизации воспользуйтесь консолью кластера серверов и для каждого сервера настройте следующие параметры:
- Максимальный объем памяти всех рабочих процессов. Если этот показатель равен 0, то система отводит под процессы 80% оперативной памяти, если же в поле стоит 1, то все 100%. Если на одном сервере стоят вместе 1С и СУБД, то существует вероятность конфликта из-за памяти и необходимо воспользоваться этой настройкой. В ином случае достаточно будет стандартных 80% или рассчитать, сколько необходимо памяти ОС, а оставшееся количество занести в это поле;
- Безопасный расход памяти за 1 вызов. По умолчанию значение «0», означающее, что 1 рабочий процесс будет занимать менее 5% максимального объема оперативной памяти на все процессы. Значение «-1» проставлять не рекомендуется, так как оно снимет все ограничения, что чревато последствиями в виде зависаний;
- Количество информационных баз и соединений на процесс. Эти параметры управляют распределением нагрузки на рабочие процессы. Вы можете настроить их по своим требованиям, чтобы минимизировать потери при излишней нагрузке на сервер. Если установлено значение в 0, то ограничения не действуют, что опасно при большом количестве рабочих мест.

В версии 8.3 еще одной полезной характеристикой для верного распределения нагрузки на сервер является «Менеджер под каждый сервис». Этот параметр дает возможность использовать не один менеджер сервера (rmngr), а множество, каждый из которых отвечает за свою задачу. Это отличная возможность отследить, какой сервис вызывает ухудшение производительности, и измерить количество ресурсов на каждую задачу.
После установки данной характеристики агент сервера ragent перезагрузится и вместо одного rmngr.exe в консоли вы обнаружите целый список. Теперь вы сможете через диспетчер задач найти процесс, загружающий систему и заняться точечной настройкой. Отличить эти процессы друг от друга вам поможет их pid. Однако, так как это нововведение, специалисты 1С рекомендуют осторожно использовать эту возможность.
Перед тем, как принимать решение добавить кластер сервера 1С в вашу структуру, необходимо проверить настройки серверов. Возможно, существует способ исправить ситуацию без покупки дорогостоящего оборудования и обучения специалистов для настройки кластера 1С. Не редки случаи, когда профессиональное обследование и настройка сервера от сторонних специалистов позволяла работать на старых мощностях еще пару лет. Но в крупных компаниях кластер серверов 1С остается единственным решением, позволяющим сотрудникам работать 24 часа в сутки.
Введение
Кластер серверов – это группа независимых серверов под управлением службы кластеров, работающих совместно как единая система. Кластеры серверов создаются путем объединения нескольких серверов на базе Windows® 2000 Advanced Server и Windows 2000 Datacenter Server для совместной работы, обеспечивая тем самым высокий уровень доступности, масштабируемости и управляемости для ресурсов и приложений.
Задачей кластера серверов является обеспечение непрерывного доступа пользователей к приложениям и ресурсам в случаях аппаратных или программных сбоев или плановых остановках оборудования. Если один из серверов кластера оказывается недоступен по причине сбоя или его остановки для выполнения технического обслуживания, информационные ресурсы и приложения перераспределяются между остальными доступными узлами кластера.
Для кластерных систем использование термина «высокая доступность» является более предпочтительным, чем использование термина «отказоустойчивость» , поскольку технологии обеспечения отказоустойчивости предполагают более высокий уровень стойкости оборудования к внешним воздействиям и механизмов восстановления. Как правило, отказоустойчивые серверы используют высокую степень аппаратной избыточности, плюс в дополнение к этому специализированное программное обеспечение, позволяющее практически незамедлительно восстановить работу в случае любого отдельного сбоя программного или аппаратного обеспечения. Эти решения обходятся существенно дороже по сравнению с использованием кластерных технологий, поскольку организации вынуждены переплачивать за дополнительное аппаратное обеспечение, которое простаивает все основное время, и используется лишь в случае возникновения сбоев. Отказоустойчивые серверы используются для приложений, обслуживающих интенсивный поток дорогостоящих транзакций в таких сферах деятельности, как центры обработки платежных средств, банкоматы или фондовые биржи.
Хотя служба кластеров и не гарантирует безостановочной работы, она предоставляет высокий уровень доступности, достаточный для работы большинства критически важных приложений. Служба кластеров может отслеживать работу приложений и ресурсов, автоматически распознавая состояние сбоев и восстанавливая работу системы после их устранения. Это обеспечивает более гибкое управление рабочей нагрузкой внутри кластера, и повышает доступность системы в целом.
Основные преимущества, получаемые при использовании службы кластеров:
- Высокая доступность. В случае отказа какого-либо узла служба кластеров передает управление ресурсами, такими как, например, жесткие диски и сетевые адреса, действующему узлу кластера. Когда происходит программный или аппаратный сбой, программное обеспечение кластера перезапускает завершившееся с ошибкой приложение на действующем узле, или перемещает всю нагрузку отказавшего узла на оставшиеся действующие узлы. При этом пользователи могут заметить лишь кратковременную задержку в обслуживании.
- Возврат после отказа. Служба кластеров автоматически перераспределяет рабочую нагрузку в кластере, когда отказавший узел вновь становится доступным.
- Управляемость. Администратор кластера – это оснастка, которую Вы можете использовать для управления кластером как единой системой, а также для управления приложениями. Администратор кластера обеспечивает прозрачное представление работы приложений так, как если бы они выполнялись на одном сервере. Вы можете перемещать приложения на различные серверы в пределах кластера, перетаскивая объекты кластера мышью. Таким же образом можно перемещать данные. Этот способ может использоваться для ручного распределения рабочей нагрузки серверов, а также для разгрузки сервера и его последующей остановки с целью проведения планового технического обслуживания. Кроме того, Администратор кластера позволяет удаленно производить наблюдение за состоянием кластера, всех его узлов и ресурсов.
- Масштабируемость. Для того чтобы производительность кластера всегда могла соответствовать возрастающим требованиям, служба кластеров располагает возможностями масштабирования. Если общая производительность кластера становится недостаточной для обработки нагрузки, создаваемой кластерными приложениями, в кластер могут быть добавлены дополнительные узлы.
Этот документ содержит инструкции по установке службы кластеров на серверах, работающих под управлением Windows 2000 Advanced Server и Windows 2000 Datacenter Server, и описывает процесс установки службы кластеров на серверы кластерных узлов. Данное руководство не описывает установку и настройку кластерных приложений, а лишь помогает Вам пройти через весь процесс установки простого двухузлового кластера.
Системные требования для создания кластера серверов
Следующие контрольные списки помогут Вам произвести подготовку к установке. Пошаговые инструкции по установке будут представлены далее после этих списков.
Требования к программному обеспечению
- Операционная система Microsoft Windows 2000 Advanced Server или Windows 2000 Datacenter Server, установленная на всех серверах кластера.
- Установленная служба разрешения имен, такая как Domain Naming System (DNS), Windows Internet Naming System (WINS), HOSTS и т. д.
- Сервер терминалов для удаленного администрирования кластера. Данное требование не является обязательным, а рекомендуется лишь для обеспечения удобства управления кластером.
Требования к аппаратному обеспечению
- Требования, предъявляемые к аппаратному обеспечению узла кластера, аналогичны требованиям для установки операционных систем Windows 2000 Advanced Server или Windows 2000 Datacenter Server. Эти требования можно найти на странице поиска каталога Microsoft.
- Оборудование кластера должно быть сертифицировано и указано в списке совместимого аппаратного обеспечения (HCL) каталога Microsoft для службы кластеров. Последнюю версию этого списка можно на странице поиска Windows 2000 Hardware Compatibility List каталога Microsoft, выбрав категорию поиска «Cluster».
Два компьютера, удовлетворяющих требованиям списка HCL, каждый из которых имеет:
- Жесткий диск с загрузочным системным разделом и установленной операционной системой Windows 2000 Advanced Server или Windows 2000 Datacenter Server. Этот диск не должен быть подключен к шине общего запоминающего устройства, рассмотренного ниже.
- Отдельный PCI-контроллер устройств оптического канала (Fibre Channel) или SCSI для подключения внешнего общего запоминающего устройства. Этот контроллер должен присутствовать в дополнение к контроллеру загрузочного диска.
- Два сетевых PCI адаптера, установленных на каждом компьютере кластера.
- Перечисленное в списке HCL внешнее дисковое запоминающее устройство, подключенное ко всем узлам кластера. Оно будет выступать в качестве диска кластера. Рекомендуется конфигурация с использованием аппаратных RAID-массивов.
- Кабели для подключения общего запоминающего устройства ко всем компьютерам. Для получения инструкций по конфигурированию запоминающих устройств обратитесь к документации производителя. Если подключение производится к шине SCSI, Вы можете обратиться к приложению А для дополнительной информации.
- Все оборудование на компьютерах кластера должно быть полностью идентичным. Это упростит процесс конфигурирования и избавит Вас от потенциальных проблем с совместимостью.
Требования к настройке сетевой конфигурации
- Уникальное NetBIOS имя для кластера.
- Пять уникальных статических IP-адресов: два адреса для сетевых адаптеров частной сети, два – для сетевых адаптеров публичной сети, и один адрес для кластера.
- Доменная учетная запись для службы кластеров (все узлы кластера должны быть членами одного домена)
- Каждый узел должен иметь два сетевых адаптера – один для подключения к публичной сети, один – для внутрикластерного взаимодействия узлов. Конфигурация с использованием одного сетевого адаптера для одновременного подключения к публичной и частной сети не поддерживается. Наличие отдельного сетевого адаптера для частной сети необходимо для соответствия требованиям HCL.
Требования к дискам общего запоминающего устройства
- Все диски общего запоминающего устройства, включая диск кворума, должны быть физически подключены к общей шине.
- Все диски, подключенные к общей шине, должны быть доступны для каждого узла. Это можно проверить на этапе установки и конфигурирования хост-адаптера. Для подробных инструкций обратитесь к документации производителя адаптера.
- Устройствам SCSI должны быть назначены целевые уникальные номера SCSI ID, кроме этого на шине SCSI должны быть правильно установлены терминаторы, в соответствии с инструкциями производителя. 1
- Все диски общего запоминающего устройства должны быть настроены как базовые диски (не динамические)
- Все разделы дисков общего запоминающего устройства должны быть отформатированы в файловой системе NTFS.
Крайне рекомендуется объединять все диски общего запоминающего устройства в аппаратные RAID-массивы. Хотя это и не является обязательным, создание отказоустойчивых конфигураций RAID является ключевым моментом в обеспечении защиты от дисковых сбоев.
Установка кластера
Общий обзор установки
Во время процесса установки некоторые узлы будут выключены, а некоторые перезагружены. Это необходимо для того, чтобы обеспечить целостность данных, расположенных на дисках, подключенных к общей шине внешнего запоминающего устройства. Повреждение данных может произойти в тот момент, когда несколько узлов одновременно попытаются произвести запись на один и тот же диск, не защищенный программным обеспечением кластера.
Таблица 1 поможет Вам определить, какие узлы и запоминающие устройства должны быть включены на каждом этапе установки.
Это руководство описывает создание двухузлового кластера. Тем не менее, если Вы устанавливаете кластер с более чем двумя узлами, Вы можете использовать значение столбца «Узел 2» для определения состояния остальных узлов.
Таблица 1. Последовательность включения устройств при установке кластера
| Шаг | Узел 1 | Узел 2 | Устройство хранения | Комментарий |
| Установка параметров сети | Вкл. | Вкл. | Выкл. | Убедитесь, что все устройства хранения, подключенные к общей шине, выключены. Включите все узлы. |
| Настройка общих дисков | Вкл. | Выкл. | Вкл. | Выключите все узлы. Включите общее запоминающее устройство, затем включите первый узел. |
| Проверка конфигурации общих дисков | Выкл. | Вкл. | Вкл. | Выключите первый узел, включите второй узел. При необходимости повторите для узлов 3 и 4. |
| Конфигурирование первого узла | Вкл. | Выкл. | Вкл. | Выключите все узлы; включите первый узел. |
| Конфигурирование второго узла | Вкл. | Вкл. | Вкл. | После успешной конфигурации первого узла включите второй узел. При необходимости повторите для узлов 3 и 4. |
| Завершение установки | Вкл. | Вкл. | Вкл. | К этому моменту все узлы должны быть включены. |
Перед установкой программного обеспечения кластеров необходимо выполнить следующие шаги:
- Установить на каждый компьютер кластера операционную систему Windows 2000 Advanced Server или Windows 2000 Datacenter Server.
- Настроить сетевые параметры.
- Настроить диски общего запоминающего устройства.
Выполните эти шаги на каждом узле кластера прежде, чем приступать к установке службы кластеров на первом узле.
Для конфигурирования службы кластеров на сервере под управлением Windows 2000 Ваша учетная запись должна иметь права администратора на каждом узле. Все узлы кластера должны быть одновременно либо рядовыми серверами, либо контроллерами одного и того же домена. Смешанное использование рядовых серверов и контроллеров домена в кластере недопустимо.
Установка операционной системы Windows 2000
Для установки Windows 2000 на каждом узле кластера обратитесь к документации, которую Вы получили в комплекте с операционной системой.
В этом документе используется структура имен из руководства "Step-by-Step Guide to a Common Infrastructure for Windows 2000 Server Deployment" . Однако, Вы можете использовать любые имена.
Прежде, чем начинать установку службы кластеров, Вы должны выполнить вход систему под учетной записью администратора
Настройка сетевых параметров
Примечание: На этом этапе установки выключите все общие запоминающие устройства, а затем включите все узлы. Вы должны исключить возможность одновременного доступа нескольких узлов к общему запоминающему устройству до того момента, когда служба кластеров будет установлена, по крайней мере, на одном из узлов, и этот узел будет включен.
На каждом узле должно быть установлено как минимум два сетевых адаптера – один для подключения к публичной сети, и один для подключения к частной сети, состоящей из узлов кластера.
Сетевой адаптер частной сети обеспечивает взаимодействие между узлами, передачу сведений о текущем состоянии кластера и управление кластером. Сетевой адаптер публичной сети каждого узла соединяет кластер с публичной сетью, состоящей из клиентских компьютеров.
Убедитесь, что все сетевые адаптеры правильно подключены физически: адаптеры частной сети подключены только к другим адаптерам частной сети, и адаптеры публичной сети подключены к коммутаторам публичной сети. Схема подключения изображена на Рисунке 1. Выполните такую проверку на каждом узле кластера, прежде чем переходить к настройке дисков общего запоминающего устройства.
Рисунок 1: Пример двухузлового кластера
Конфигурирование сетевого адаптера частной сети
Выполните эти шаги на первом узле Вашего кластера.
- Мое сетевое окружение и выберите команду Свойства .
- Щелкните правой кнопкой мыши на значке .
Примечание: Какой сетевой адаптер будет обслуживать частную сеть, а какой публичную, зависит от физического подключения сетевых кабелей. В данном документе мы будем предполагать, что первый адаптер (Подключение по локальной сети) подключен к публичной сети, а второй адаптер (Подключение по локальной сети 2) подключен к частной сети кластера. В Вашем случае это может быть не так.
- Состояние. Окно Состояние Подключение по локальной сети 2 показывает состояние подключения и его скорость. Если подключение находится в отключенном состоянии, проверьте кабели и правильность соединения. Устраните проблему, прежде чем продолжить. Нажмите кнопку Закрыть .
- Снова щелкните правой кнопкой мыши на значке Подключение по локальной сети 2 , выберите команду Свойства и нажмите кнопку Настроить .
- Выберите вкладку Дополнительно. Появится окно, изображенное на Рисунке 2.
- Для сетевых адаптеров частной сети скорость работы должна быть выставлена вручную вместо значения, используемого по умолчанию. Укажите скорость Вашей сети в раскрывающемся списке. Не используйте значения «Auto Sense» или «Auto Select» для выбора скорости, поскольку некоторые сетевые адаптеры могут сбрасывать пакеты во время определения скорости соединения. Для задания скорости сетевого адаптера укажите фактическое значение для параметра Тип подключения или Скорость .

Рисунок 2: Дополнительные настройки сетевого адаптера
Все сетевые адаптеры кластера, подключенные к одной сети, должны быть одинаково настроены и использовать одинаковые значения параметров Дуплексный режим , Управление потоком , Тип подключения , и т. д. Даже если на разных узлах используется различное сетевое оборудование, значения этих параметров должны быть одинаковыми.
- Выберите Протокол Интернета (TCP/IP) в списке компонентов, используемых подключением.
- Нажмите кнопку Свойства .
- Установите переключатель в положение Использовать следующий IP-адрес и введите адрес 10.1.1.1 . (Для второго узла используйте адрес 10.1.1.2 ).
- Задайте маску подсети: 255.0.0.0 .
- Нажмите кнопку Дополнительно и выберите вкладку WINS. Установите значение переключателя в положение Отключить NetBIOS через TCP/IP . Нажмите OK для возврата в предыдущее меню. Выполняйте этот шаг только для адаптера частной сети.
Ваше диалоговое окно должно выглядеть, как изображено на Рисунке 3.

Рисунок 3: IP-адрес подключения к частной сети
Конфигурирование сетевого адаптера публичной сети
Примечание: Если в публичной сети работает DHCP-сервер, IP-адрес для сетевого адаптера публичной сети может назначаться автоматически. Однако для адаптеров узлов кластера этот способ использовать не рекомендуется. Мы настоятельно рекомендуем назначать постоянные IP-адреса для всех публичных и частных сетевых адаптеров узлов. В противном случае при отказе DHCP-сервера доступ к узлам кластера может оказаться невозможным. Если же Вы вынуждены использовать DHCP для сетевых адаптеров публичной сети, используйте длительные сроки аренды адресов – это даст гарантию того, что динамически назначенный адрес останется действительным, даже если DHCP-сервер окажется временно недоступным. Адаптерам частной сети всегда назначайте постоянные IP-адреса. Помните, что служба кластеров может распознавать только один сетевой интерфейс в каждой подсети. Если Вам нужна помощь в вопросах назначения сетевых адресов в Windows 2000, обратитесь к встроенной справке операционной системы.
Переименование сетевых подключений
Для ясности мы рекомендуем изменить названия сетевых подключений. Например, Вы можете изменить название подключения Подключение по локальной сети 2 на . Такой метод поможет Вам проще идентифицировать сети и правильно назначать их роли.
- Щелкните правой кнопкой мыши на значке 2.
- В контекстном меню выберите команду Переименовать .
- Введите Подключение к частной сети кластера в текстовом поле и нажмите клавишу ВВОД .
- Повторите шаги 1-3 и измените название подключения Подключение по локальной сети на Подключение к публичной сети.

Рисунок 4: Переименованные сетевые подключения
- Переименованные сетевые подключения должны выглядеть, как показано на Рисунке 4. Закройте окно Сеть и удаленный доступ к сети . Новые названия сетевых подключений автоматически реплицируются на другие узлы кластера при их включении.
Проверка сетевых соединений и разрешений имен
Для проверки работы настроенного сетевого оборудования, выполните следующие шаги для всех сетевых адаптеров каждого узла. Для этого Вы должны знать IP-адреса всех сетевых адаптеров в кластере. Вы можете получить эту информацию, выполнив команду ipconfig на каждом узле:
- Нажмите кнопку Пуск, выберите команду Выполнить и наберите команду cmd в текстовом окне. Нажмите OK .
- Наберите команду ipconfig /all и нажмите клавишу ВВОД . Вы увидите информацию о настройке IP-протокола для каждого сетевого адаптера на локальной машине.
- В случае, если у Вас еще не открыто окно командной строки, выполните шаг 1.
- Наберите команду ping ipaddress где ipaddress – это IP-адрес соответствующего сетевого адаптера на другом узле. Предположим для примера, что сетевые адаптеры имеют следующие IP-адреса:
| Номер узла | Имя сетевого подключения | IP-адрес сетевого адаптера |
| 1 | Подключение к публичной сети | 172.16.12.12 |
| 1 | Подключение к частной сети кластера | 10.1.1.1 |
| 2 | Подключение к публичной сети | 172.16.12.14 |
| 2 | Подключение к частной сети кластера | 10.1.1.2 |
В этом примере Вам нужно выполнить команды ping 172.16.12.14 и ping 10.1.1.2 с узла 1, и выполнить команды ping 172.16.12.12 и ping 10.1.1.1 с узла 2.
Чтобы проверить разрешение имен, выполните команду ping , используя в качестве аргумента имя компьютера вместо его IP-адреса. Например, чтобы проверить разрешение имени для первого узла кластера с именем hq-res-dc01, выполните команду ping hq-res-dc01 с любого клиентского компьютера.
Проверка принадлежности к домену
Все узлы кластера должны являться членами одного домена и иметь возможности сетевого взаимодействия с контроллером домена и DNS-сервером. Узлы могут быть сконфигурированы как рядовые сервера домена или как контроллеры одного и того же домена. Если Вы решите сделать один из узлов контроллером домена, то все остальные узлы кластера также должны быть сконфигурированы как контроллеры этого же домена. В этом руководстве предполагается, что все узлы являются контроллерами домена.
Примечание: Для получения ссылок на дополнительную документацию по настройке доменов, служб DNS и DHCP в Windows 2000 смотрите раздел Связанные ресурсы в конце этого документа.
- Щелкните правой кнопкой мыши Мой компьютер и выберите команду Свойства .
- Выберите вкладку Сетевая идентификация . В диалоговом окне Свойства системы Вы увидите полное имя компьютера и домена. В нашем примере домен называется reskit.com .
- Если Вы сконфигурировали узел в качестве рядового сервера, то на этом этапе Вы можете присоединить его к домену. Нажмите кнопку Свойства и следуйте инструкциям для присоединения компьютера к домену.
- Закройте окна Свойства системы и Мой компьютер .
Создание учетной записи службы кластеров
Для службы кластеров необходимо создать отдельную доменную учетную запись, от имени которой она будет запускаться. Программа установки потребует ввода учетных данных для службы кластеров, поэтому учетная запись должна быть создана до начала установки службы. Учетная запись не должна принадлежать какому-либо пользователю домена, и должна использоваться исключительно для работы службы кластеров.
- Нажмите кнопку Пуск , выберите команду Программы / Администрирование , запустите оснастку .
- Разверните категорию reskit.com , если она еще не развернута
- В списке выберите Users .
- Щелкните правой кнопкой мыши на Users , выберите в контекстном меню Создать , выберите Пользователь .
- Введите имя для учетной записи службы кластера, как показано на Рисунке 5, и нажмите кнопку Далее.

Рисунок 5: Добавление пользователя Cluster
- Установите флажки Запретить смену пароля пользователем и Срок действия пароля не ограничен . Нажмите кнопку Далее и кнопку Готово , чтобы создать пользователя.
Примечание: Если Ваша административная политика безопасности не позволяет использовать пароли с неограниченным сроком действия, Вы должны будете обновить пароль и произвести конфигурацию службы кластеров на каждом узле до истечения срока его действия.
- Щелкните правой клавишей мыши на пользователе Cluster в правой панели оснастки Active Directory – пользователи и компьютеры .
- В контекстном меню выберите команду Добавить участников в группу .
- Выберите группу Администраторы и нажмите OK . Теперь новая учетная запись имеет привилегии администратора на локальном компьютере.
- Закройте оснастку Active Directory – пользователи и компьютеры .
Настройка дисков общего запоминающего устройства
Предупреждение: Убедитесь, что, по крайней мере, на одном из узлов кластера установлена операционная система Windows 2000 Advanced Server или Windows 2000 Datacenter Server, а также настроена и работает служба кластеров. Только после этого можно загружать операционную систему Windows 2000 на остальных узлах. Если эти условия не будут выполнены, диски кластера могут быть повреждены.
Чтобы приступить к настройке дисков общего запоминающего устройства, выключите все узлы. После этого включите общее запоминающее устройство, затем включите узел 1.
Диск кворума
Диск кворума используется для хранения контрольных точек и файлов журнала восстановления базы данных кластера, обеспечивая управление кластером. Мы даем следующие рекомендации для создания диска кворума:
- Создайте небольшой раздел (размером как минимум 50 Мб), чтобы использовать его в качестве диска кворума. Обычно мы рекомендуем создавать диск кворума размером в 500 Мб.
- Выделите отдельный диск для ресурса кворума. Поскольку в случае выхода из строя диска кворума произойдет сбой работы всего кластера, мы настоятельно рекомендуем использовать аппаратный дисковый RAID-массив.
В процессе установки службы кластеров Вы будете должны назначить букву диску кворума. В нашем примере мы будем использовать букву Q .
Конфигурирование дисков общего запоминающего устройства
- Щелкните правой кнопкой мыши Мой компьютер , выберите команду Управление . В открывшемся окне раскройте категорию Запоминающие устройства .
- Выберите команду Управление дисками .
- Убедитесь, что все диски общего запоминающего устройства отформатированы в системе NTFS и имеют статус Основной . Если Вы подключите новый диск, автоматически запустится Мастер подписывания и обновления дисков . Когда мастер запустится, нажмите кнопку Обновить, чтобы продолжить его работу, после этого диск будет определен как Динамический . Чтобы преобразовать диск в базовый, щелкните правой кнопкой мыши на Диск # (где # – номер диска, с которым Вы работаете) и выберите команду Возвратить к базовому диску .
Щелкните правой кнопкой мыши область Не распределен рядом с соответствующим диском.
- Выберите команду Создать раздел
- Запустится Мастер создания раздела . Дважды нажмите кнопку Далее .
- Введите желаемый размер раздела в мегабайтах и нажмите кнопку Далее .
- Нажмите кнопку Далее , приняв предложенную по умолчанию букву диска
- Нажмите кнопку Далее для форматирования и создания раздела.
Назначение букв дискам
После того, как шина данных, диски и разделы общего запоминающего устройства сконфигурированы, необходимо назначить буквы диска для всех разделов всех дисков кластера.
Примечание: Точки подключения – это функциональная возможность файловой системы, которая позволяет Вам устанавливать файловую систему, используя существующие каталоги, без назначения буквы диска. Точки подключения не поддерживаются кластерами. Любой внешний диск, используемый в качестве ресурса кластера, должен быть разбит на NTFS разделы, и этим разделам должны быть назначены буквы диска.
- Щелкните правой кнопкой мыши требуемый раздел и выберите команду Изменение буквы диска и пути диска .
- Выберите новую букву диска.
- Повторите шаги 1 и 2 для всех дисков общего запоминающего устройства.

Рисунок 6: Разделы дисков с назначенными буквами
- По окончании процедуры окно оснастки Управление компьютером должно выглядеть, как изображено на Рисунке 6. Закройте оснастку Управление компьютером .
- Нажмите кнопку Пуск , выберите Программы / Стандартные , и запустите программу «Блокнот» .
- Наберите несколько слов и сохраните файл под именем test.txt , выбрав команду Сохранить как из меню Файл . Закройте Блокнот .
- Дважды щелкните мышью на значке Мои документы .
- Щелкните правой кнопкой мыши на файле test.txt и в контекстном меню выберите команду Копировать .
- Закройте окно.
- Откройте Мой компьютер .
- Дважды щелкните мышью на разделе диска общего запоминающего устройства.
- Щелкните правой кнопкой мыши и выберите команду Вставить .
- На диске общего запоминающего устройства должна появиться копия файла test.txt .
- Дважды щелкните мышью на файле test.txt , чтобы открыть его с диска общего запоминающего устройства. Закройте файл.
- Выделите файл и нажмите клавишу Del , чтобы удалить файл с диска кластера.
Повторите процедуру для всех дисков кластера, чтобы убедиться, что они доступны с первого узла.
Теперь выключите первый узел, включите второй узел и повторите шаги раздела Проверка работы и общего доступа к дискам . Выполните эти же шаги на всех дополнительных узлах. После того, как Вы убедитесь, что все узлы могут считывать и записывать информацию на диски общего запоминающего устройства, выключите все узлы, кроме первого, и переходите к следующему разделу.

















")






