Esimene versioon Microsofti serverid SQL-i tutvustas ettevõte juba 1988. aastal. DBMS positsioneeriti kohe relatsiooniliseks, millel oli tootja sõnul kolm eelist:
- salvestatud protseduurid, tänu millele kiirenes andmete otsimine ja säilitati selle terviklikkus mitme kasutaja režiimis;
- pidev juurdepääs administreerimiseks ilma kasutajaid katkestamata;
- avatud serveriplatvorm, mis võimaldab luua kolmanda osapoole rakendusi, mis kasutavad SQL Server.
2005, koodnimega Yukon koos täiustatud skaleerimisvõimalustega, oli esimene versioon, mis täielikult toetas .NET-tehnoloogiat. Täiustatud on hajutatud andmete tugi ning ilmunud on esimesed aruandlus- ja teabeanalüüsi tööriistad.
Integratsioon Internetiga võimaldas süsteemide loomisel aluseks võtta SQL Servers 2005 pood lihtsa ja turvalise juurdepääsuga andmetele populaarsete brauserite kaudu, kasutades toetatud sisseehitatud Firewall Enterprise'i versiooni paralleelarvutus piiramatul arvul protsessoritel.
Asendatud versioon 2005 Microsoft SQL Server 2008, mis on endiselt üks enim populaarsed serverid andmebaasid ja veidi hiljem ilmus järgmine versioon - SQL Servers 2012, mis toetab ühilduvust .NET Frameworki ja muude täiustatud infotöötlustehnoloogiate ja arenduskeskkondadega Visual Studio. Sellele juurdepääsuks loodi spetsiaalne SQL Azure'i moodul.

Transact-SQL
Alates 1992. aastast on SQL olnud andmebaasidele juurdepääsu standard. Peaaegu kõik programmeerimiskeeled kasutavad seda andmebaasile juurdepääsuks, isegi kui kasutajale tundub, et ta töötab teabega otse. Keele põhisüntaks jääb ühilduvuse tagamiseks samaks, kuid iga andmebaasihaldussüsteemi tarnija on püüdnud SQL-i lisada lisafunktsioone. Kompromissi ei õnnestunud leida ja pärast “standardisõda” jäi kaks liidrit: PL/SQL Oracle'ist ja Transact-SQL Microsoft Servers SQL-is.
T-SQL laiendab SQL-i protseduuriliselt, et pääseda juurde Microsofti serverite SQL-ile. Kuid see ei välista rakenduste arendamist "standardsetel" operaatoritel.
Automatiseerige oma äri SQL Server 2008 R2 abil
Ärirakenduste töökindel töö on selle jaoks äärmiselt oluline kaasaegne äri. Väikseimgi andmebaasi seisak võib kaasa tuua suuri kahjusid. Andmebaasi server Microsofti andmed SQL Server 2008 R2 võimaldab usaldusväärselt ja turvaliselt salvestada praktiliselt piiramatul hulgal teavet, kasutades haldustööriistu, mis on kõigile administraatoritele tuttavad. Toetatud on vertikaalne skaleerimine kuni 256 protsessorini.

Hyper-V tehnoloogia kasutab tänapäevaste mitmetuumaliste süsteemide võimsust maksimaalselt ära. Mitme virtuaalse süsteemi toetamine ühel protsessoril vähendab kulusid ja parandab skaleeritavust.
Analüüsige oma andmeid
Sest kiire analüüs reaalajas andmevoogudes kasutatakse komponenti SQL Server StreamInsight, mis on seda tüüpi ülesannete jaoks optimeeritud. NET-i baasil on võimalik arendada oma rakendusi.
Katkematu töö ja andmete turvalisus

Optimaalse jõudluse toe igal ajal tagab serverisse sisseehitatud ressursiregulaator. Administraator saab koormust hallata ja süsteem tähendab, määrake rakendustele protsessori- ja mäluressursside kasutamisele limiit. Krüpteerimisfunktsioonid pakuvad teabe paindlikku ja läbipaistvat kaitset ning peavad sellele juurdepääsu logi.
Piiramatu andmebaasi suurus
Andmete salvestamist saab kiiresti ja turvaliselt skaleerida. Kasutajad saavad kasutada valmis mallid Fast Track Date Warehouse kuni 48 TB kettamassiivide toetamiseks. Põhikonfiguratsioon toetab juhtivate ettevõtete nagu HP, EMC ja IBM seadmeid. UCS 2 standardile vastavad teabe tihendamise funktsioonid võimaldavad kettaruumi säästlikumalt kasutada.
Arendajate ja administraatorite efektiivsuse tõstmine
Uus tarkvara viisardid võimaldab teil kiiresti kõrvaldada alakasutatud serverid, parandada juhtimist ja optimeerida jõudlust ilma, et oleks vaja väliseid kolmanda osapoole spetsialiste. Jälgige rakenduste ja andmebaaside jõudlust, leidke armatuurlaudade täiustusi ning kiirendage värskendusi ja installimisi.
Tööriistad isiklikuks ärianalüüsiks
Ettevõtete vahel pole kunagi olnud üksmeelt selles, kes peaks analüüsi tegema – IT-osakonnad või kasutajad otse. Isiklik aruandlussüsteem lahendab selle probleemi kaasaegsed instrumendidäriprotsesside ohutu ja efektiivne ehitamine, analüüs ja modelleerimine. Toetab otsest juurdepääsu andmebaasidele Microsoft Office Ja SharePointi server. Ettevõtte teave saab integreerida muud tüüpi sisuga, nagu kaardid, graafika ja videod.
Mugav koostöökeskkond

Andke oma töötajatele juurdepääs teabele, koostööle ja andmete analüüsile PowerPivoti e-kaubanduse rakendusega. Exceli tabelid. Programm võimaldab analüüsida teavet ja modelleerida äriprotsesse ning avaldada aruandeid avalik juurdepääs veebis või SharePointis.
Sisemiste aruannete visuaalseks loomiseks pakutakse Report Builder 3.0 süsteemi, mis toetab paljusid formaate ja laia valikut etteantud malle.
Töötage andmebaasidega tasuta
Ettevõte pakub väikeprojekte ja alustavatele arendajatele spetsiaalseid tasuta versioon Microsoft SQL Server Express. See hõlmab samu andmebaasitehnoloogiaid, mis SQL Serveri "täis" versioonid.
Toetatakse Visual Studio ja Web Developeri arenduskeskkondi. Looge keerulisi tabeleid ja päringuid, arendage andmebaasi toega Interneti-rakendusi ja hankige otsene juurdepääs PHP teabele.
Kasutage kõiki Transact-SQL-i ja ADO.NETi ja LINQi kõige arenenumate andmetele juurdepääsu tehnoloogiaid. Toetatud on salvestatud protseduurid, päästikud ja funktsioonid.

Keskenduge äriloogika elementidele ja süsteem optimeerib andmebaasi struktuuri iseseisvalt.
Looge iga keerukusega rikkalikke aruandeid. Kasutage otsingu alamsüsteemi, integreerige aruanded Microsofti rakendused Töötage ja lisage oma dokumentidele geograafilise asukohateave.
Arendatavad rakendused võivad töötada ka ilma andmebaasiserveriga ühenduseta. Sünkroonimine toimub automaatselt, kasutades patenteeritud tehingute replikatsioonitehnoloogiat Sync Framework.
Hallake oma infrastruktuuri kõigi andmebaaside ja rakenduste halduspoliitikate abil. Levinud tööstsenaariumid vähendavad päringu optimeerimise, loomise ja taastamise aega varukoopiad ettevõtte mastaabis.
SQL Server 2008 R2 Express Edition sobib ideaalselt veebisaitide ja veebipoodide, isiklikuks kasutamiseks mõeldud programmide ja väikeettevõtete kiireks juurutamiseks. See suurepärane variant tööle ja õppima asuma.

Hallake oma andmebaase SQL Server Management Studio abil
Microsoft SQL Serverihaldus on spetsiaalne keskkond andmebaaside ja kõigi SQL Serveri elementide, sealhulgas aruandlusteenuste, loomiseks, juurdepääsuks ja haldamiseks.
Süsteem ühendab ühte liidesesse kõik haldusprogrammide võimalused alates varasemad versioonid, nagu päringuanalüsaator ja ettevõttehaldur. Administraatorid saavad tarkvara suure hulga graafiliste arendus- ja haldusobjektidega ning laiendatud keele andmebaasiga töötamiseks mõeldud skriptide loomiseks.
Microsoft Server Management Studio koodiredaktor väärib erilist tähelepanu. See võimaldab teil arendada skriptitud skripte Transact-SQL-is, programmeerida mitmemõõtmelisi andmetele juurdepääsu päringuid ja analüüsida neid, toetades tulemuste salvestamist XML-i. Päringute ja skriptide loomine on võimalik ilma võrgu või serveriga ühenduse loomiseta koos järgneva täitmise ja sünkroonimisega. Saadaval lai valik eelinstallitud mallid ja versioonikontrollisüsteem.
Objektibrauseri moodul võimaldab teil vaadata ja hallata kõiki Microsoft Serversi sisseehitatud SQL-objekte kõigis serverites ja andmebaasi eksemplarides. Lihtne juurdepääs vajalikule teabele on äärmiselt oluline kiire areng rakendused ja versioonikontroll.

Süsteem on üles ehitatud Visual Studio Isolated Shell süsteemile, mis toetab laiendatavaid sätteid ja laiendusi kolmanda osapoole arendajad. Internetis on palju kogukondi, kust leiate kogu vajaliku teabe ja koodinäiteid enda andmehaldus- ja -töötlusvahendite arendamiseks.
Uuringufirma Forrester Research andmetel oli Microsoft SQL Server 2012 andmebaasiserver 2013. aasta lõpus ettevõtete infosalvestusturul esikolmikus. Eksperdid märgivad, et Microsofti turuosa kiire kasv on tingitud korporatsiooni terviklikust lähenemisest äriprotsesside automatiseerimisele. Microsoft SQL Server on kaasaegne platvorm mis tahes tüüpi andmete haldamiseks ja säilitamiseks, mida on täiendatud analüütika ja arendusvahenditega. Eraldi väärib märkimist teiste ettevõtte toodetega, nagu Office ja SharePoint, integreerimise lihtsus.
Minu ettevõte läbis just iga-aastase ülevaatuse ja ma veensin neid lõpuks, et on aeg leida parem lahendus meie SQL-skeemi/stseenide haldamiseks. Praegu on meil käsitsi värskendamiseks vaid mõned skriptid.
Töötasin VS2008 Database Editioniga teises ettevõttes ja see on suurepärane toode. Mu ülemus palus mul vaadata Redgate'i SQL Compare'i ja otsida muid tooteid, mis võiksid olla paremad. SQL-i võrdlus on samuti suurepärane toode. Siiski näib, et nad ei toeta Perforce'i.
Kas kasutasite selleks erinevaid tooteid?
Milliseid tööriistu te SQL-i haldamiseks kasutate?
Mida peavad nõuded sisaldama enne, kui minu ettevõte ostu sooritab?
10 vastust
Ma ei usu, et on olemas tööriista, mis saaks kõigi osadega hakkama. VS Database Edition ei võimalda teil luua korralikku vabastamismehhanismi. Lahendusbrauserist üksikute skriptide käitamine ei skaleeru suurte projektide puhul piisavalt hästi.
Vähemalt, mida vajate
- IDE/redaktor
- hoidla lähtekood mille saab käivitada teie IDE-st
- erinevate skriptide nimetamine ja organiseerimine kaustadesse
- muudatuste käsitlemise, väljalasete haldamise ja juurutuste teostamise protsess.
Viimane täpp on koht, kus asjad tavaliselt purunevad. Sellepärast. Parema hallatavuse ja versioonijälgimise huvides soovite salvestada iga db-objekti oma skriptifaili. See tähendab, et iga tabel, salvestatud protseduur, vaade, indeks jne. on oma fail.
Kui midagi muutub, värskendate faili ja olete uus versioon teie hoidlas koos vajalikku teavet. Kui tegemist on mitme muudatuse liitmise versiooniga, töötlemine eraldi failid võib olla tülikas.
2 võimalust, mida kasutasin:
Lisaks kõigi üksikute andmebaasiobjektide salvestamisele oma failidesse on teil ka väljalaske skriptid, mis on üksikute skriptide konkatenatsioon. Selle puuduseks: teil on kood kahes kohas koos kõigi riskide ja puudustega. Potentsiaalne: väljalase käivitamine on sama lihtne kui ühe skripti käivitamine.
kirjutage väike tööriist, mis suudab lugeda väljalaske manifestist skripti metaandmeid ja käivitada sihtserveris manifestis määratud iga skripti. Sellel pole muud miinust, välja arvatud see, et peate koodi kirjutama. See lähenemisviis ei tööta tabelite puhul, mida ei saa tühistada ja uuesti luua (kui olete reaalajas ja teil on andmed olemas), nii et teil on tabelite jaoks muutmisskriptid. Seega on see tegelikult mõlema lähenemisviisi kombinatsioon.
Olen "skripti ise" leeris, sest kolmanda osapoole tooted viib teid ainult andmebaasi koodi haldamiseni. Mul ei ole iga objekti jaoks ühte skripti, sest objektid muutuvad aja jooksul ja üheksa korda kümnest poleks piisav lihtsalt oma "loomistabeli" skripti värskendamine kolme uue veeru saamiseks.
Andmebaaside loomine on suures osas triviaalne. Seadke hunnik CREATE skripte, järjestage need õigesti (loo andmebaas enne skeeme, skeemid enne tabeleid, tabelid enne protseduure, kutsu protseduurid enne kõnesid jne) ja tehke seda. Andmebaasi muudatuste haldamine pole nii lihtne:
- Kui lisate tabelisse veeru, ei saa te tabelit lihtsalt maha jätta ja luua seda uue veeruga, kuna see hävitab kõik teie väärtuslikud tootmisandmed.
- Kui Fred lisab tabelisse XYZ veeru ja Mary lisab tabelisse XYZ veel ühe veeru, siis milline veerg lisatakse esimesena? Jah, tabelite veergude järjekord ei oma tähtsust [sest te ei kasuta kunagi SELECT *, eks?], välja arvatud juhul, kui proovite hallata andmebaasi ja jälgida versioonide loomist, siis on teil kaks "päris" andmebaasi, mis ärge sarnanege üksteisega, muutuge tõeliseks peavaluks. Me kasutame SQL-i võrdlust mitte haldamiseks, vaid asjade ülevaatamiseks ja jälgimiseks, eriti arenduse ajal, ning need vähesed "nad on erinevad (aga see pole maager)" olukorrad võivad takistada meid oluliste erinevuste märkamast.
- Samamoodi, kui mitu projekti (arendaja) töötavad samaaegselt ja eraldi ühises andmebaasis, võib see muutuda väga keeruliseks. Võib-olla töötavad kõik projekti Next Big Thing kallal, kui äkki peab keegi hakkama projekti Last Big Thing veaparandustega. Kuidas hallata vajalikke koodimuudatusi, kui väljalaskejärjekord on muutuv ja paindlik? (Naljakad ajad tõesti.)
- Tabelistruktuuride muutmine tähendab andmete muutmist ja see võib muutuda põrgulikult keeruliseks, kui peate sellega tegelema tagasiühilduv. Lisate veeru "DeltaFactor", ok, mida sa siis teed, et täita see esoteeriline väärtus kõigi oma olemasolevate (loe: pärandandmete) jaoks? Lisate uue otsingutabeli ja vastava veeru, kuid kuidas seda olemasolevate ridade jaoks täita? Selliseid olukordi ei pruugi sageli juhtuda, kuid kui need juhtuvad, peate seda ise tegema. Kolmanda osapoole tööriistad lihtsalt ei suuda teie äriloogika vajadusi ette näha.
Põhimõtteliselt on mul iga andmebaasi jaoks CREATE-skript, millele järgneb rida ALTER-skripte, kuna meie koodibaas aja jooksul muutub. Iga skript kontrollib, kas seda saab käivitada: see on õige "tüüp" andmebaas, vajalikud eelskriptid on käivitatud, see skript juba töötab. Alles siis, kui kontrollid on läbitud, käivitab skript oma muudatused.
Tööriistana kasutame lähtekoodi haldamiseks SourceGear Fortressi, üldiseks toeks ja tõrkeotsinguks Redgate SQL Compare'i ning mitmeid SQLCMD-põhiseid koduskripte, et hulgi juurutada skripte koos muudatustega mitmes serveris ja andmebaasis ning jälgida, kes on taotlenud. milliseid andmebaasi skripte millisel ajal skriptivad. Lõpptulemus: kõik meie andmebaasid on stabiilsed ja stabiilsed ning me saame hõlpsalt tõestada, milline versioon on või oli mis tahes ajahetkel.
Nõuame, et kõik andmebaasi muudatused või lisamised sellistesse asjadesse nagu otsingutabelid tehtaks skriptis ja salvestataks allika juhtimisse. Seejärel juurutatakse need samamoodi nagu mis tahes muu versiooni juurutuskood tarkvara. Kuna meie arendajatel pole juurutamisõigusi, ei jää neil muud üle, kui luua skripte.
Tavaliselt kasutan MS Server Management Studiot SQL-i haldamiseks, andmetega töötamiseks, andmebaaside arendamiseks ja silumiseks, kui mul on vaja andmeid eksportida sql-skripti või luua mõned andmed. keeruline objekt andmebaasis kasutan EMS SQL Management Studio for SQL Server, sest seal näen selgemalt, millised kitsad koodilõigud ja visuaalne kujundus selles keskkonnas mulle lihtsamaks teevad
Mul on avatud lähtekoodiga projekt (litsentsitud LGPL-i alusel), mis püüab lahendada sellega seotud probleeme õige versioon DB skeemid (ja rohkematele) SQL Serverile (2005/2008/Azure), bsn ModuleStore'ile. Kogu protsess on väga lähedane Phillip Kelly siinse postitusega selgitatud kontseptsioonile.
Põhimõtteliselt skriptib tööriistakomplekti eraldi osa DB skeemi SQL Serveri andmebaasiobjektid standardvorminguga failideks, nii et faili sisu muudetakse ainult siis, kui objekt tegelikult muutub (erinevalt VS-i skriptimisest, mis loob ka skripte jne. , mis tähistab kõiki muudetud objekte, isegi kui need on praktiliselt identsed).
Kuid tööriistakomplekt läheb sellest kaugemale, kui kasutate .NET-i: see võimaldab manustada SQL-i skripte teeki või rakendusse (siseste ressurssidena) ja seejärel võrrelda võrreldud tekstisiseseid skripte praegune olek andmebaasis. Tabeliväliseid muudatusi (need, mis ei ole Martin Fowleri määratletud "hävitavad muudatused") saab rakendada automaatselt või nõudmisel (näiteks luua ja kustutada objekte, nagu vaated, funktsioonid, salvestatud protseduurid, tüübid, indeksid) ja muuta skripte. (mis tuleb käsitsi üles kirjutada) saab rakendada samas protsessis; luuakse ka uued tabelid ja nende seadistusandmed. Pärast värskendamist võrreldakse andmebaasi skeemi uuesti skriptidega, et tagada andmebaasi värskenduse õnnestumine enne muudatuste tegemist.
Pange tähele, et kogu skriptimis- ja võrdluskood töötab ilma SMO-ta, nii et teil pole rakendustes mooduli bsn ModuleStore kasutamisel valusat SMO-sõltuvust.
Olenevalt sellest, kuidas soovite andmebaasile juurde pääseda, pakub tööriistakomplekt veelgi enamat - see rakendab mõningaid ORM-i võimalusi ja pakub väga kena ja kasulikku esiotsa lähenemisviisi salvestatud protseduuride kutsumiseks, sealhulgas läbipaistvat XML-i tuge natiivsete .NET XML-klassidega ja ka TVP (Table-Valueed Parameters) jaoks IEnumerablena
Siin on minu skript salvestatud proc- ja udf-i ning päästikute jälgimiseks tabelis.
Looge tabel olemasoleva proci lähtekoodi salvestamiseks
Sisestage tabel kõigi olemasolevate päästiku- ja skriptiandmetega
Nende muudatuste jälgimiseks looge DDL-i päästik
/****** Objekt: tabel . Skripti kuupäev: 17.09.2014 11:36:54 ******/ ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE . ( IDENTITY(1, 1) NOT NULL , (1000) NULL , (1000) NULL , (1000) NULL , (1000) NULL , NULL , NTEXT NULL ,CONSTRAIN PRIMARY KEY CLUSTERED ( ASC , OFF, ASC , OFF, OFF , = PUHD._STAT.) VÄLJAS ,IGNORE_DUP_KEY = VÄLJAS ,ALLOW_ROW_LOCKS = ON ,ALLOW_PAGE_LOCKS = ON) ON ) ON MINNA ALTER TABLE . LISA PIIRANDUSE VAIKEKORDNE("") MISEKS MINEMINE INSERT INTO . ( , , , , ,) SELECT "sa" ,loginitialdata" ,r.ROUTINE_NAME ,r.ROUTINE_TYPE ,GETDATE() ,r.ROUTINE_DEFINITION FROM INFORMATION_SCHEMA.ROUTINES r UNION SELECT "sa",,"loginitialdata,v.TATA"LE "view" ,GETDATE() ,v.VIEW_DEFINITION FROM INFORMATION_SCHEMA.VIEWS v UNION SELECT "sa" ,,"loginitialdata" ,o.NAME , "trigger" ,GETDATE() ,m.DEFINITION FROM sys.objects o JOIN sys. sql_modules m ON o.object_id = m.object_id WHERE o.type = "TR" LOOGE ANDMEBAASIS TRIGGER FOR CREATE_PROCEDURE ,ALTER_PROCEDURE ,DROP_PROCEDURE ,CREATE_INDEX ,ALTER_INDEX ,TRIOPDREAL_INDEX ,DROPDREGAL_INDEX TRIGGER ,AL TER_TABLE ,ALTER_VIEW ,CREATE_VIEW ,DROP_VIEW AS BEGIN SET NOCOUNT ON DECLARE @data XML SET @data = Eventdata() INSERT INTO sysupdatelog VALUES (@data.value("(/EVENT_INSTANCE/LoginName)", "nvarchar(255)") ,@data.value("() /EVENT_INSTANCE /Sündmuse tüüp)", "nvarchar(255)") ,@data.value("(/SÜNDMUS/SÜNDMUS/Objektinimi)", "nvarchar(255)") ,@data.value("(/SÜNDMUS/SÜNDMUS/ObjectType)" , " nvarchar(255)") ,getdate() ,@data.value("(/EVENT_INSTANCE/TSQLCommand/CommandText)", "nvarchar(max)")) SET NOCOUNT OFF END GO SET ANSI_NULLS OFF GO SET QUOTED_OFFGOIDENTI LUBAGE ANDMEBAAS GO TRIGGER
Kui olete kunagi kirjutanud lukustusskeeme teistes andmebaasi keeltes, et lukustamise puudumisest üle saada (nagu minul), siis võis teil tekkida tunne, et peate lukustamisega ise tegelema. Kinnitan teile, et lukuhaldurit saab täielikult usaldada. SQL Server pakub aga lukkude haldamiseks mitmeid meetodeid, mida käsitleme selles jaotises üksikasjalikult.
Ärge rakendage lukustusseadeid ega muutke isolatsioonitasemeid juhuslikult – usaldage SQL Serveri lukuhaldurit, et tasakaalustada tüli ja tehingute terviklikkust. Ainult siis, kui olete täiesti kindel, et andmebaasi skeem on hästi konfigureeritud ja programmi kood on sõna otseses mõttes lihvitud, saate lukuhalduri käitumist konkreetse probleemi lahendamiseks veidi kohandada. Mõnel juhul lahendab valikupäringute lukustamata jätmine enamiku probleemidest.
Ühenduse isolatsioonitaseme määramine
Isolatsioonitase määrab ühenduse üldise või eksklusiivse blokeerimise kestuse. Eraldustaseme määramine mõjutab kõiki päringuid ja tabeleid, mida kasutatakse ühenduse kestel või seni, kuni üks isolatsioonitase on selgesõnaliselt teisega asendatud. Järgmine näide seab vaikeseadest tihedama isolatsiooni ja hoiab ära mittekorduva lugemise:
MÄÄRATA TEHINGU ISOLETAMISE TASE KORDUV LUGEMINE Kehtivad isolatsioonitasemed on:
Lugege pühendumata? serialiseeritav
Lugenud pühendunud? hetktõmmis
Korratav lugemine
Praegust isolatsioonitaset saate kontrollida andmebaasi terviklikkuse kontrolli (DBCC) käsuga:
DBCC KASUTUSVALIKUD
Tulemused on järgmised (lühendatult):
Määrake valiku väärtus
isolatsioonitaseme korratav lugemine
Isolatsioonitasemeid saab määrata ka päringu või tabeli tasemel, kasutades lukustusvalikuid.
Andmebaasi hetktõmmise taseme eraldamise kasutamine
Andmebaasi hetktõmmiste isolatsioonitaseme jaoks on kaks võimalust: hetktõmmis ja loetud hetktõmmis. Hetketõmmise isoleerimine toimib nagu korratav lugemine ilma lukustusprobleemidega tegelemata. Lugemise hetktõmmise isoleerimine jäljendab SQL Serveri vaikimisi lugemiskohustuse taset, kõrvaldades ka lukustamisprobleemid.
Kui tehingute isoleerimine on tavaliselt konfigureeritud ühenduse tasemel, siis hetktõmmise isoleerimine tuleb konfigureerida andmebaasi tasemel, kuna see
jälgib tõhusalt andmebaasi ridade versioonimist. Ridade versioonide loomine on tehnoloogia, mis loob värskendamiseks TempDB andmebaasi ridade koopiad. Lisaks TempDB andmebaasi põhilaadimisele lisab ridade versioonimine ka 14-baidise reaidentifikaatori.
Snapshot Isolation kasutamine
Järgmine väljavõte lubab hetktõmmise isolatsioonitaseme. Andmebaasi värskendamiseks ja hetktõmmise isolatsioonitaseme lubamiseks ei pea selle andmebaasiga muid ühendusi looma.
ALTER ANDMEBAASI Aesop
SEES ALLOW_SNAPSHOT_ISOLATION SISSE
| Kontrollimaks, kas hetktõmmise eraldamine on andmebaasis lubatud, käivitage järgmine SVS-päring: SELECT name, snapshot_isolation_state_desc FROM [ * sysdatabases.
Nüüd hakkab esimene tehing lugema ja jääb avatuks (st ei ole seotud): USE Aesop
ALUSTAGE TRANI VALIMISE pealkiri FROM FABLE WHERE FablD = 2
Saadakse järgmine tulemus:
Sel ajal hakkab teine tehing värskendama sama rida, mille avas esimene tehing:
SET TRANSAKTSIOONI Isolatsioonitase Snapshot;
ALUSTAGE TRAN VÄRSKENDUS Fable
SET Pealkiri = 'Kiikumine hetketõmmistega'
KUS FablD = 2;
VALI * FABLE'st, KUS FablD = 2
Tulemus on järgmine:
Kiikumine hetkepiltidega
Kas pole üllatav? Teine tehing suutis rida värskendada, kuigi esimene tehing jäi avatuks. Pöördume tagasi esimese tehingu juurde ja vaatame algandmeid:
VALIK pealkiri FROM FABLE WHERE FablD = 2
Tulemus on järgmine:
Kui avate kolmanda ja neljanda tehingu, näevad nad sama asja algne väärtus Kiilas rüütel:
Isegi pärast seda, kui teine tehing teeb muudatused, näeb esimene endiselt algset väärtust ja kõik järgnevad tehingud uut väärtust, Rocking with Snapshots.
ISOLATSIOONI kasutamine Loe tehtud hetktõmmist
Read Commited Snapshot isoleerimine on lubatud sarnase süntaksi abil:
ALTER ANDMEBAASI Aesop
SET READ_COMMITTED_SNAPSHOT ON
Sarnaselt hetktõmmise isoleerimisega, see tase Blokeerimisprobleemide eemaldamiseks kasutab see ka stringiversiooni. Võttes aluseks eelmises jaotises kirjeldatud näite, näeb sel juhul esimene tehing teise tehtud muudatusi kohe, kui need on tehtud.
Kuna Read Commited on SQL Serveri vaikimisi eraldatuse tase, on vaja ainult andmebaasi parameetreid seadistada.
Kirjutamiskonfliktide lahendamine
Tehingud, mis kirjutavad andmeid, kui hetktõmmise isolatsioonitase on määratud, võivad olla varasemate tehingute poolt blokeeritud. kinnitamata tehingud rekordid. Selline lukk ei pane uut tehingut ootama – see tekitab lihtsalt vea. Selliste olukordade lahendamiseks kasutage prooviväljendit. . . püüdke kinni, oodake paar sekundit ja proovige tehingut uuesti teha.
Blokeerimisvalikute kasutamine
Blokeerimisparameetrid võimaldavad teil blokeerimisstrateegiat ajutiselt kohandada. Kuigi isolatsioonitase mõjutab ühendust tervikuna, on lukustusvalikud konkreetse päringu iga tabeli jaoks spetsiifilised (tabel 51.5). Valik WITH (lock_option) asetatakse päringu FROM-klauslis tabeli nime järele. Iga tabeli jaoks saate määrata mitu parameetrit, eraldades need komadega.
|
Tabel 51.5. Blokeerimisvalikud |
Parameeter blokeerimine |
Kirjeldus |
Isolatsiooni tase. Ei pane ega hoia lukku. Samaväärne blokeerimise puudumisega |
Tehingu vaikeisolatsioonitase |
Isolatsiooni tase. Hoiab jagatud ja eksklusiivseid lukke kuni tehingu kinnitamiseni |
Isolatsiooni tase. Hoiab jagatud lukku kuni tehingu lõpuleviimiseni |
Jätke ootamise asemel blokeeritud read vahele |
Lubage lukustamine rea tasemel, mitte lehe, ulatuse või tabeli tasemel |
Lubage tabelitaseme lukustamise asemel lehe tasemel lukustamine |
Rea-, lehe- ja ulatusetaseme automaatne eskaleerimine lukustab tabelitaseme detailsuse |
Parameeter blokeerimine |
Kirjeldus |
Lukkude rakendamata jätmine või hooldamata jätmine. Sama mis ReadUnCommitted |
Lubage eksklusiivne laualukk. Teiste tehingute töö takistamine tabeliga |
Hoidke jagatud lukku kuni tehingu kinnitamiseni (sama, mis jadatav) |
Värskendusluku kasutamine üldise asemel ja selle hoidmine. Muude andmetesse kirjutamiste lukustamine esialgse lugemise ja kirjutamise vahel |
Eksklusiivse andmeluku hoidmine kuni tehingu kinnitamiseni |
Järgmises näites kasutatakse UPDATE lause FROM-klauslis olevat lukustussuvandit, et takistada halduril lukustuse detailsust suurendamast:
KASUTAGE toodet OBXKites UPDATE
Tootest WITH (RowLock)
SET ProductName = Tootenimi + ' Värskendatud 1
Kui päring sisaldab alampäringuid, pidage meeles, et iga päringu tabelijuurdepääs loob luku, mida saab parameetrite abil juhtida.
Indeksitaseme lukustamise piirangud
Ühenduse ja päringu tasemel rakendatakse isolatsioonitasemeid ja blokeerimisseadeid. Ainus viis Tabelitaseme lukuhaldus on lukkude detailsuse piiramine konkreetsete indeksite alusel. Süsteemi salvestatud protseduuri sp_indexoption abil saab rea- ja/või lehelukud teatud indeksi jaoks keelata, kasutades järgmist süntaksit: sp_indexoption 'indeksi_nimi 1 .
AllowRowlocks või AllowPagelocks,
See võib olla kasulik mitmel viisil erilistel puhkudel. Kui tabelis esineb sageli lehtede lukustamise tõttu ooteaegu, loob leheluku väljalülitamine reatasemel lukustuse. Luku granulaarsuse vähendamine avaldab konkurentsile positiivset mõju. Lisaks ei ole rea- ja lehetaseme lukustamine soovitav, kui tabelit värskendatakse harva, kuid seda loetakse sageli. Sellisel juhul on optimaalne lukustusaste laua tasemel. Kui värskendusi tehakse harva, siis eksklusiivne tabelite lukustamine ei tekita suuri probleeme.
Salvestatud protseduur Sp_indexoption on loodud andmeskeemi peenhäälestamiseks; sellepärast kasutab see indeksi tasemel lukustamist. Tabeli primaarvõtme lukkude piiramiseks kasutage primaarvõtme indeksi nime leidmiseks sp_help tabeli_nimi.
Järgmine käsk konfigureerib tabeli ProductCategory harva värskendatava kategorisaatorina. Käsk sp_help kuvab esmalt tabeli esmase võtmeindeksi nime: sp_help ProductCategory
Tulemus (kärbitud) on:
indeks indeks indeks
nime kirjelduse võtmed
PK_____________ Tootekategooria 79A814 03 rühmitamata, tootekategooria D
ainulaadne, esmane võti asub PEAMISEL
Võttes arvesse primaarvõtme tegelikku nime, saab süsteemi salvestatud protseduur määrata indeksi lukustamise parameetrid:
EXEC sp_indexoption
„Tootekategooria.РК__ Tootekategooria_______ 7 9A814 03”,
'AllowRowlocks', FALSE EXEC sp_indexoption
„ProductCategory.PK__ ProductCategory_______ 79A81403”,
'AllowPagelocks', FALSE
Luku ooteaegade haldamine
Kui tehing ootab lukku, jätkub see ootamine seni, kuni lukustamine muutub võimalikuks. Vaikimisi ajalõpu piirangut pole – teoreetiliselt võib see kesta igavesti.
Õnneks saate lukustuse ajalõpu määrata ühenduse suvandi lock_timeout abil. Määrake selle parameetri jaoks millisekundite arv või kui te ei soovi aega piirata, määrake selle väärtuseks -1 (mis on vaikeseade). Kui selle parameetri väärtuseks on määratud 0, lükatakse blokeeringu korral tehing kohe tagasi. Sel juhul on rakendus äärmiselt kiire, kuid ebaefektiivne.
Järgmine päring seab lukustuse ajalõpuks kaks sekundit (2000 millisekundit):
SET Lock_Timeout 2 00 0
Kui tehing ületab konfigureeritud ajalõpu limiidi, genereeritakse veanumber 1222.
Soovitan tungivalt määrata ühenduse tasemel luku ajalõpu limiit. See väärtus valitakse sõltuvalt normaalne jõudlus Andmebaas. Eelistan seada ajalõpuks viis sekundit.
Andmebaasi konkurentsi tulemuslikkuse hindamine
Väga lihtne on luua andmebaasi, mis ei tegele lukustuse ja tüliprobleemidega, kui testitakse kasutajate rühmas. Tõeline proovikivi on see, kui mitusada kasutajat värskendavad tellimusi korraga.
Võistluskatsed tuleb korralikult korraldada. Ühel tasandil peaks see sisaldama samaaegne kasutamine paljud sama lõpliku vormi kasutajad. .NET programm, mis pidevalt simuleerib
kasutaja andmete vaatamine ja värskendamine. Hea test peaks käivitama 20 skripti eksemplari, mis laadib pidevalt andmebaasi, ja seejärel laskma testimeeskonnal rakendust kasutada. Lukkude arv aitab teil näha peatükis 49 käsitletud jõudlusmonitori.
Parem on testida mitme mängijaga konkurentsi arendusprotsessi jooksul mitu korda. Nagu MCSE eksami käsiraamat ütleb: "Ärge laske reaalse maailma testil olla esikohal."
Rakenduse lukud
SQL Server kasutab väga keeruline vooluring blokeerimine. Mõnikord nõuab lukustamist muu protsess või ressurss peale andmete. Näiteks võib osutuda vajalikuks käivitada protseduur, mis põhjustab kahju, kui teine kasutaja käivitab sama protseduuri teist eksemplari.
Mitu aastat tagasi kirjutasin programmi tuumajaamaprojektide kaabeldamiseks. Kui tehase geomeetria oli kavandatud ja testitud, tutvustasid insenerid ühendit kaabelseadmed, selle asukoht ja kasutatud kaablite tüübid. Pärast mitme kaabli sisestamist kujundas programm nende paigaldamise marsruudi nii, et see oleks võimalikult lühike. Protseduuri käigus võeti arvesse ka kaabelduse ohutusprobleeme ja eraldati ühildumatud kaablid. Samal ajal, kui mitu marsruutimisprotseduuri käitatakse samaaegselt, prooviks iga eksemplar suunata samu kaableid, mille tulemuseks on valed tulemused. Rakenduste blokeerimisest on saanud selle probleemi suurepärane lahendus.
Rakenduste lukustamine avab rakendustes kasutamiseks terve maailma SQL-lukke. Selle asemel, et kasutada andmeid lukustatava ressursina, lukustavad rakenduslukud kõigi sp__GetAppLocki salvestatud protseduuris deklareeritud kasutajaressursside kasutamise.
Rakenduste lukustamist saab rakendada tehingutes; sel juhul saab blokeerimisrežiimiks olla Shared, Update, Exclusive, IntentExclusice või IntentShared. Protseduuri tagastatav väärtus näitab, kas lukk rakendati edukalt.
0. Luku paigaldamine õnnestus.
1. Lukk saadi siis, kui mõni teine protseduur selle luku vabastas.
999. Lukk jäi paigaldamata muul põhjusel.
Salvestatud protseduur sp_ReleaseApLock vabastab lukustuse. Järgmine näide demonstreerib, kuidas rakenduse lukku saab partiis või protseduuris kasutada: DEKLARERI @ShareOK INT EXEC @ShareOK = sp_GetAppLock
@Resource = 'CableWorm',
@LockMode = 'Eksklusiivne'
KUI @ShareOK< 0
...Viga koodi käsitlemisel
... Programmi kood ...
EXEC sp_ReleaseAppLock @Resource = 'CableWorm'
Kui rakenduse lukke vaadatakse kasutades haldust Studio või sp_Lock protseduurid, kuvatakse tüübiga APP. Järgmine loend on sp_Locki lühendatud väljund, mis töötab ülaltoodud koodiga samal ajal: spid dbid Objld Indld tüüp Ressursirežiimi olek
57 8 0 0 RAKENDUS Kaabel 94cl36 X GRANT
Rakenduste lukkude käsitlemisel SQL Serveris on kaks väikest erinevust.
Ummikseisu ei tuvastata automaatselt;
Kui tehing saab lukustuse mitu korda, peab see selle vabastama täpselt sama palju kordi.
Ummikud
Ummik on eriolukord, mis tekib ainult siis, kui mitme ülesandega tehingud võistlevad üksteise ressursside pärast. Näiteks esimene tehing on saanud lukustuse ressursile A ja peab lukustama ressursi B ning samal ajal peab teine tehing, mis on lukustanud ressurssi B, lukustama ressursi A.
Kõik need tehingud ootavad, kuni teine oma luku vabastab, ja kumbki ei saa seda enne lõpule viia. Kui väline mõju puudub või üks tehingutest lõpeb mingil põhjusel (näiteks ajalõpu tõttu), siis võib selline olukord kesta kuni maailma lõpuni.
Varem olid ummikud tõsine probleem, kuid SQL Server võimaldab teil selle nüüd edukalt lahendada.
Tupiku loomine
Lihtsaim viis SQL Serveris ummikseisu tekitamiseks on kasutada Management Studio päringuredaktoris kahte ühendust (joonis 51.12). Esimene ja teine tehing üritavad värskendada samu ridu, kuid vastupidises järjekorras. Kasutades kolmandat akent pGetLocksi protseduuri käivitamiseks, saate lukke jälgida.
1. Looge päringuredaktoris teine aken.
2. Asetage 2. sammu plokikood teise aknasse.
3. Asetage 1. sammu plokikood esimesse aknasse ja vajutage klahvi
4. Teises aknas käivitage samamoodi kood Samm 2.
5. Naaske esimesse aknasse ja käivitage 3. sammu plokikood.
6. Lühikese aja pärast tuvastab SQL Server ummikseisu ja lahendab selle automaatselt.
Allpool on näidiskood.
– Tehing 1 – Samm 1 KASUTAGE OBXKitesi ALUSTAGE TEHINGU VÄRSKENDAMINE Kontakt
SET LastName = 'Jorgenson'
KUS kontaktkood = 401′
Puc. 51.12. Juhtimisstuudios ummikseisu loomine kahe ühenduse abil (nende aknad asuvad ülaosas)
Nüüd on esimene tehing saanud kirjele eksklusiivse luku, mille väärtus on 101 väljal ContactCode. Teine tehing omandab rea eksklusiivse luku väärtusega 1001 väljal ProductCode ja seejärel proovib ainult lukustada kirje, mis on juba esimese tehinguga lukustatud (ContactCode=101).
– Tehing 2 – Samm 2 KASUTAGE OBXKitesi ALUSTAGE TEHINGU VÄRSKENDAMINE Tootekomplekt tootenimi
= 'DeadLocki paranduskomplekt'
WHERE tootekood = '1001'
SET FirstName = 'Neals'
KUS kontaktkood = '101'
TEHINGU TEHA
Ummikut veel ei ole, kuna tehing 2 ootab tehingu 1 lõpetamist, kuid tehing 1 ei oota veel tehingu 2 lõpetamist. Kui tehing 1 lõpetab oma töö ja täidab avalduse COMMIT TRANSACTION, siis andmeressurss vabastatakse ja tehing 2 saab turvaliselt blokeerida vajaliku ploki ja jätkata oma tegevust.
Probleem ilmneb siis, kui tehing 1 proovib värskendada rida tootekoodiga = l. Kuid see ei saa selleks vajalikku eksklusiivset lukku, kuna see kirje on lukustatud tehinguga 2:
– Tehing 1 – Samm 3 VÄRSKENDAGE tootekomplekti tootenimi
= 'DeadLock Identification Tester'
WHERE tootekood = '1001'
TEHINGU TEHA
Tehing 1 tagastab mõne sekundi pärast järgmise veateate. Tekkinud ummikseisu saab näha ka SQL Server Profileris (joonis 51.13):
Server: sõnum 1205, tase 13,
Olek 50, rea 1 tehing (protsessi ID 51) oli
lukustusressursside ummikseisus teise protsessiga ja on valitud ummikseisu ohvriks. Käivitage tehing uuesti.
Tehing 2 lõpetab oma töö nii, nagu probleemi polekski olnud:
(1 rida mõjutatud)
(1 rida mõjutatud)

Riis. 51.13. SQL Server Profiler võimaldab jälgida ummikuid sündmuse Locks:Deadlock Graph abil ja tuvastada ummikseisu põhjustava ressursi
Automaatne ummikseisu tuvastamine
Nagu ülaltoodud koodis näidatud, tuvastab SQL Server automaatselt ummikseisu, kontrollides blokeerimisprotsesse ja tühistades tehinguid.
kes tegi kõige vähem tööd. SQL Server kontrollib pidevalt ristlukkude olemasolu. Ummikseisu tuvastamise latentsusaeg võib varieeruda nullist kahe sekundini (praktikas on pikim aeg, mis ma olen pidanud seda ootama, viis sekundit).
Ummikseisude käsitlemine
Kui ummikseisu tekib, peab ummikseisu ohvriks valitud ühendus oma tehingut uuesti proovima. Kuna töö tuleb ümber teha, siis on hea, et tagasi veeretatakse tehing, millega õnnestus kõige vähem tööd teha – see on see, mida korratakse algusest peale.
Veakood 12 05 tuleks tabada kliendirakendus, mis peaks tehingu taaskäivitama. Kui kõik juhtub ootuspäraselt, siis kasutaja isegi ei kahtlusta, et ummikseisu on tekkinud.
Selle asemel, et lubada serveril endal otsustada, milline tehing „ohvriks” valida, saab tehingut ennast „mängida kingitusena”. Järgmine kood, kui tehingusse sisestatakse, teavitab SQL Serverit ummikseisu ilmnemisest see tehing tuleks tagasi pöörata:
MÄÄRATA TUKKULUKKUJPRIORITEET MAADALAKS
Ummikseisude minimeerimine
Kuigi ummikseisu on lihtne tuvastada ja käsitleda, on parem neid siiski vältida. Järgmised soovitused aitavad teil ummikseisu vältida.
Püüdke hoida tehingud lühikesed ja ilma tarbetu koodita. Kui mõni kood ei pea tehingus olema, tuleb see sellest järeldada.
Ärge kunagi muutke tehingukoodi sõltuvaks kasutaja sisendist.
Proovige luua pakette ja protseduure, mis omandavad lukud samas järjekorras. Näiteks töödeldakse kõigepealt tabelit A, seejärel tabeleid B, C jne. Seega jääb üks protseduur ootama teist ja ummikseisu ei saa definitsiooni järgi tekkida.
Kujundage füüsiline paigutus, et salvestada samaaegselt proovitud andmeid andmelehtedele võimalikult täpselt. Selle saavutamiseks kasutage normaliseerimist ja valige targalt rühmitatud indeksid. Ummistuste leviku vähendamine aitab vältida nende eskaleerumist. Väikesed ummistused aitab vältida nende konkurentsi.
Ärge suurendage isolatsiooni taset, kui see pole vajalik. Rangem isolatsioonitase pikendab sulgemiste kestust.
SQL Serveri keskkond pakub mitmeid erinevaid juhtimiskonstruktsioone, ilma milleta on võimatu kirjutada tõhusaid algoritme.
Kahe või enama meeskonna rühmitamine üks plokk tehakse märksõnade BEGIN ja END abil:
<блок_операторов>::=
Rühmitatud käske käsitleb SQL-tõlk ühe käsuna. Sarnane rühmitamine on vajalik polüvariantsete hargnevate, tingimuslike ja tsükliliste konstruktsioonide konstruktsioonide puhul. BEGIN...END plokke saab pesastada.
Mõned SQL-käsud ei tohiks käivitada koos teiste käskudega ( me räägime meeskondade kohta Reservkoopia, muudatusi tabelite struktuuris, salvestatud protseduurides ja muus sarnases), seetõttu ei ole nende ühine kaasamine konstruktsiooni BEGIN...END lubatud.
Sageli tuleb programmi teatud osa täita ainult siis, kui mõni loogiline tingimus on täidetud. Tingimuslause süntaks on näidatud allpool:
<условный_оператор>::=
IF logi_avaldis
( sql_lause | lauseblokk )
(sql_lause | lauseblokk) ]
Silmused korraldatakse järgmise konstruktsiooni abil:
<оператор_цикла>::=
WHILE log_avaldis
( sql_lause | lauseblokk )
( sql_lause | lauseblokk )
Silmuse saab sunniviisiliselt peatada, käivitades selle kehas käsu BREAK. Kui teil on vaja tsüklit uuesti käivitada, ootamata kõigi kehas olevate käskude täitmist, peate täitma käsu CONTINUE.
Mitme üksiku või pesastatud tingimuslause asendamiseks kasutage järgmist konstruktsiooni.
<оператор_поливариантных_ветвлений>::=
CASE sisend_väärtus
WHEN (võrdle_väärtust |
logi_avaldis ) SIIS
väljundi_avaldis [,...n]
[ ELSE other_out_expression ]
Kui sisendväärtus ja võrdlusväärtus on samad, tagastab konstruktsioon väljundväärtuse. Kui väärtus sisendparameeter ei leitud üheltki realt WHEN...THEN, siis tagastatakse märksõna ELSE järel määratud väärtus.
SQL-serveri andmebaasi struktuuri põhiobjektid
Vaatame andmebaasi loogilist ülesehitust.
Loogiline struktuur määrab tabelite struktuuri, nendevahelised seosed, kasutajate loendi, salvestatud protseduurid, reeglid, vaikesätted ja muud andmebaasiobjektid.
Loogiliselt on SQL Serveris olevad andmed korraldatud objektideks. Peamised SQL Serveri andmebaasiobjektid hõlmavad järgmisi objekte.
Lühiülevaade peamised andmebaasiobjektid.
Tabelid
Kõik SQL-i andmed sisalduvad kutsutavates objektides tabelid. Tabelid esindavad mis tahes teabe kogumit reaalse maailma objektide, nähtuste ja protsesside kohta. Ükski teine objekt ei salvesta andmeid, kuid neil on juurdepääs tabelis olevatele andmetele. SQL-i tabelitel on sama struktuur kui kõigi teiste DBMS-ide tabelitel ja need sisaldavad:
· read; iga rida (või kirje) esindab objekti konkreetse eksemplari atribuutide (omaduste) kogumit;
· veerud; iga veerg (väli) tähistab atribuuti või atribuutide kogumit. Stringväli on minimaalne element tabelid. Igal tabeli veerul on konkreetne nimi, andmetüüp ja suurus.
Esindus
Vaated on virtuaalsed tabelid, mille sisu määrab päring. Nagu päris tabelid, sisaldavad vaated nimega veerge ja andmeridasid. Sest lõppkasutajad vaade näeb välja nagu tabel, kuid see ei sisalda tegelikult andmeid, vaid esindab andmeid, mis asuvad ühes või mitmes tabelis. Info, mida kasutaja vaate kaudu näeb, ei salvestata andmebaasi eraldi objektina.
Salvestatud protseduurid
Salvestatud protseduurid on SQL-käskude rühm, mis on ühendatud üheks mooduliks. See käskude rühm kompileeritakse ja täidetakse ühe üksusena.
Päästikud
Päästikud on salvestatud protseduuride eriklass, mis käivitatakse automaatselt andmete lisamisel, muutmisel või tabelist kustutamisel.
Funktsioonid
Programmeerimiskeelte funktsioonid on konstruktsioonid, mis sageli sisaldavad käivitatav kood. Funktsioon teeb andmetega mõningaid toiminguid ja tagastab teatud väärtuse.
Indeksid
Indeks on tabeli või vaatega seotud struktuur, mis on loodud nendes teabe otsimise kiirendamiseks. Indeks on määratletud ühes või mitmes veerus, mida nimetatakse indekseeritud veergudeks. See sisaldab indekseeritud veeru või veergude sorteeritud väärtusi koos viidetega lähtetabeli või -vaate vastavale reale. Parem tootlikkus saavutatakse andmete sorteerimisega. Indeksite kasutamine võib otsingu jõudlust oluliselt parandada, kuid indeksite salvestamine nõuab andmebaasis lisaruumi.
©2015-2019 sait
Kõik õigused kuuluvad nende autoritele. See sait ei pretendeeri autorlusele, kuid pakub tasuta kasutamist.
Lehe loomise kuupäev: 2016-08-08
Mõnikord tahaks tõesti oma mõtted järjekorda seada, korda ajada. Ja veel parem, tähestikulises ja temaatilises järjestuses, nii et lõpuks saabuks mõtlemise selgus. Kujutage nüüd ette, milline kaos juhtuks " elektroonilised ajud» iga arvuti, millel pole selget kõigi andmete ja Microsoft SQL Serveri struktureerimist:
MS SQL Server
See tarkvaratoode on relatsiooniline andmebaasihaldussüsteem (DBMS), mille on välja töötanud Microsoft Corporation. Andmetöötluseks spetsiaalselt loodud Transact-SQL keel. Keelekäsud andmebaasi valimiseks ja muutmiseks on üles ehitatud struktureeritud päringute põhjal:

Relatsiooniandmebaasid andmed on üles ehitatud kõigi omavahelistele seostele konstruktsioonielemendid, sealhulgas nende pesitsemise tõttu. Relatsiooniandmebaasidel on sisseehitatud tugi kõige levinumate andmetüüpide jaoks. Tänu sellele integreerib SQL Server toe andmete programmiliseks struktureerimiseks päästikute ja salvestatud protseduuride abil.
Ülevaade MS SQL Serveri funktsioonidest

DBMS on osa pikast spetsiaalsest tarkvarast, mille Microsoft on arendajatele loonud. See tähendab, et kõik selle ahela lülid (rakendused) on üksteisega sügavalt integreeritud.
See tähendab, et nende tööriistad suhtlevad üksteisega hõlpsalt, mis lihtsustab oluliselt programmikoodi arendamise ja kirjutamise protsessi. Sellise seose näiteks on MS Visual Studio programmeerimiskeskkond. Selle installipakett sisaldab juba SQL Server Express Editioni.
Muidugi pole see ainus populaarne DBMS maailmaturul. Kuid just see on Windowsi kasutavate arvutite jaoks vastuvõetavam, kuna see keskendub sellele operatsioonisüsteemile. Ja mitte ainult selle pärast.
MS SQL Serveri eelised:
- omab kõrget jõudlust ja veataluvust;
- See on mitme kasutajaga DBMS ja töötab klient-server põhimõttel;
Süsteemi kliendiosa toetab kasutajapäringute koostamist ja nende saatmist serverisse töötlemiseks.
- Tihe integratsioon operatsioonisüsteem Aknad;
- Kaugühenduste tugi;
- Populaarsete andmetüüpide tugi, samuti võimalus luua käivitajaid ja salvestatud protseduure;
- Sisseehitatud tugi kasutajarollidele;
- Täiustatud andmebaasi varundusfunktsioon;
- Kõrge turvalisuse tase;
- Iga number sisaldab mitut eriväljaannet.
SQL Serveri areng
Selle populaarse DBMS-i funktsioone on kõige lihtsam näha, kui arvestada kõigi selle versioonide arengulugu. Peatume üksikasjalikumalt ainult nendel väljaannetel, milles arendajad tegid olulisi ja põhimõttelisi muudatusi:
- Microsoft SQL Server 1.0 – välja antud 1990. aastal. Eksperdid märkisid isegi siis suur kiirus andmetöötlus, demonstreeritud isegi koos maksimaalne koormus mitme kasutaja režiimis;
- SQL Server 6.0 – välja antud 1995. aastal. See versioon oli esimene maailmas, mis rakendas kursorite ja andmete replikatsiooni tuge;
- SQL Server 2000 - selles versioonis sai server täiesti uue mootori. Enamik muudatusi puudutas ainult kasutaja pool rakendused;
- SQL Server 2005 – DBMS-i skaleeritavus on suurenenud ning haldus- ja haldusprotsess on mitmeti lihtsustatud. Rakendati uus API toetuse eest tarkvaraplatvorm.NET ;
- Hilisemate väljaannete eesmärk oli arendada DBMS-i interaktsiooni tasemel pilvetehnoloogiad ja ärianalüütika tööriistad.
IN põhikomplekt Süsteem sisaldab mitmeid utiliite SQL-i seaded Server. Need sisaldavad:
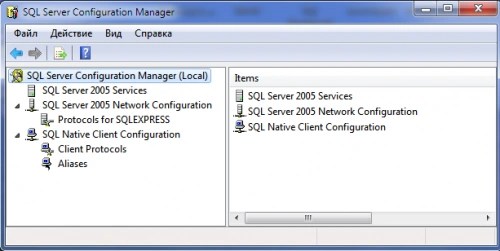
Konfiguratsioonihaldur. Võimaldab teil kõike hallata võrgusätted ja andmebaasiserveri teenused. Kasutatakse SQL Serveri konfigureerimiseks võrgus.
- SQL Serveri viga ja kasutusaruandlus:

Utiliiti kasutatakse Microsofti toele veaaruannete saatmise konfigureerimiseks.

Kasutatakse andmebaasiserveri töö optimeerimiseks. See tähendab, et saate kohandada SQL Serveri toimimist vastavalt oma vajadustele, lubades või keelates DBMS-i teatud funktsioonid ja komponendid.
Microsoft SQL Serveris sisalduvate utiliitide komplekt võib olenevalt versioonist ja väljaandest erineda tarkvarapakett. Näiteks 2008. aasta versioonis te ei leia SQL Serveri pinnaala konfiguratsioon.
Microsoft SQL Serveri käivitamine
Näiteks kasutatakse andmebaasiserveri 2005. aasta versiooni. Serverit saab käivitada mitmel viisil:
- Utiliidi kaudu SQL Serveri konfiguratsioonihaldur. Valige vasakpoolses rakenduseaknas "SQL Server 2005 teenused" ja paremal - meile vajalik andmebaasiserveri eksemplar. Märkame selle alammenüüs parem nupp valige hiirega "Start".

- Keskkonna kasutamine SQL Server Management Studio Express. See ei sisaldu Expressi väljaande installipaketis. Seetõttu tuleb see Microsofti ametlikult veebisaidilt eraldi alla laadida.
Andmebaasiserveri käivitamiseks käivitage rakendus. Dialoogiboksis " Ühendus serveriga"Valige väljal "Serveri nimi" vajalik eksemplar. Väljal " Autentimine"jätke väärtus" Windowsi autentimine" Ja klõpsake nuppu "Ühenda":

SQL Serveri halduse põhitõed
Enne MS SQL Serveri käivitamist peate end lühidalt kurssi viima selle seadistamise ja haldamise põhivõimalustega. Alustame rohkemaga üksikasjalik ülevaade mitu DBMS-i utiliiti:
- SQL Serveri pinnaala konfiguratsioon– see on koht, kuhu peaksite minema, kui teil on vaja lubada või keelata mõni andmebaasiserveri funktsioon. Akna allosas on kaks punkti: esimene vastutab võrgu parameetrid ja teises saate aktiveerida teenuse või funktsiooni, mis on vaikimisi keelatud. Näiteks lubage integreerimine .NET-platvormiga T-SQL päringute kaudu:


















")





