Первая версия Microsoft Servers SQL была представлена компанией в далеком 1988 году. СУБД сразу позиционировалась как реляционная имеющая, по заявлению производителя, три достоинства:
- хранимые процедуры, благодаря которым ускорялась выборка данных и поддерживалась их целостность в многопользовательском режиме;
- постоянный доступ к для администрирования без отключения пользователей;
- открытая платформа сервера, позволяющая создавать сторонние приложения, использующие SQL Server.
2005 под кодовым наименованием Yukon с расширенными возможностями масштабирования стал первой версией, полностью поддерживающей технологию.NET. Улучшилась поддержка распределенных данных, появились первые инструменты отчетности и анализа информации.
Интеграция с Интернетом позволила использовать SQL Servers 2005 как основу для создания систем электронной коммерции с простым и защищенным доступом к данным через популярные браузеры с использованием встроенного Firewall Версия Enterprise поддерживала параллельные вычисления на неограниченном количестве процессоров.
На смену версии 2005 пришел Microsoft SQL Server 2008, который до сих пор является одним из самых популярных серверов баз данных, а немного позже появилась и следующая версия - SQL Servers 2012 года, с поддержкой совместимости с.NET Framework и другими передовыми технологиями обработки информации и среды разработки Visual Studio. Для доступа к был создан специальный модуль SQL Azure.

Transact-SQL
С 1992 года SQL является стандартом доступа к базам данных. Практически все языки программирования для доступа к БД используют именно его, даже если пользователю кажется, что он работает с информацией напрямую. Базовый синтаксис языка остается неизменным для обеспечения совместимости, но каждый производитель систем управления базами данных старался пополнить SQL дополнительными функциями. Компромисса найти не удалось, и после «войны стандартов» остались два лидера: PL/SQL компании Oracle и Transact-SQL в Microsoft Servers SQL.
T-SQL процедурно расширяет SQL для доступа к Microsoft Servers SQL. Но это не исключает разработку приложений на «стандартных» операторах.
Автоматизируйте бизнес с помощью SQL Server 2008 R2
Надежная работа бизнес-приложений чрезвычайно важна для современного бизнеса. Малейший простой базы данных может привести к огромным убыткам. Сервер баз данных Microsoft SQL Server 2008 R2 позволяет надежно и безопасно хранить информацию практически неограниченного объема, используя знакомые всем администраторам средства управления. Поддерживается вертикальное масштабирование до 256 процессоров.

Технология Hyper-V максимально эффективно использует мощность современных многоядерных систем. Поддержка на одном процессоре множества виртуальных систем снижает издержки и улучшает масштабируемость.
Анализируйте данные
Для быстрого анализа в режиме реального времени потоков данных используется компонент SQL Server StreamInsight, оптимизированный под данный тип задач. Возможна разработка собственных приложений на основе.NET.
Бесперебойная работа и безопасность данных

Поддержку оптимальной производительности в любой момент времени обеспечивает встроенный в сервер регулятор ресурсов. Администратор может управлять нагрузкой и системными средствами, устанавливать лимит для приложений на использование ресурсов процессора и памяти. Функции шифрования обеспечивают гибкую и прозрачную защиту информации и ведут журнал доступа к ней.
Неограниченный размер базы данных
Хранилище данных можно масштабировать быстро и безопасно. Пользователи могут использовать готовые шаблоны Fast Track Date Warehouse для поддержки дисковых массивов до 48 Тб. Базовая конфигурация поддерживает оборудование ведущих фирм, таких как HP, EMC и IBM. Функции сжатия информации по стандарту UCS 2 позволяют более экономно расходовать дисковое пространство.
Повышение эффективности работы разработчиков и администраторов
Новые программные мастера позволяют быстро устранить недогруженность серверов, улучшить контроль и оптимизировать производительность без необходимости привлечения внешних сторонних специалистов. Контролируйте параметры работы приложений и баз данных, находите возможности для улучшения работы на панелях мониторинга и ускоряйте обновление и установку.
Инструменты для персонального бизнес-анализа
В компаниях никогда не было единого мнения относительно того, кто должен заниматься аналитикой - IT-отделы или непосредственно пользователи. Система создания персональных отчетов решает эту проблему посредством современных инструментов безопасного и эффективного построения, анализа и моделирования бизнес-процессов. Поддерживается прямой доступ к базам данных в Microsoft Office и SharePoint Server. Корпоративная информация может интегрироваться с материалами других типов, таких как карты, графика и видео.
Удобная среда для совместной работы

Предоставьте своим сотрудникам доступ к информации, совместной разработке и анализу данных при помощи приложения PowerPivot для электронной таблицы Excel. Программа позволяет производить анализ информации и моделирование бизнес-процессов и публиковать отчеты для общего доступа в Интернете или системе SharePoint.
Для наглядного создания внутренних отчетов предлагается система Report Builder 3.0, поддерживающая множество форматов и широкий набор предустановленных шаблонов.
Работайте с базами данных бесплатно
Компания предоставляет небольшим проектам и начинающим разработчикам специальную бесплатную версию Microsoft SQL Server Express. Сюда включены те же технологии баз данных, что и у «полных» версий SQL Server.
Поддерживаются среды разработки Visual Studio и Web Developer. Создавайте сложные таблицы и запросы, разрабатывайте интернет-приложения с поддержкой баз данных, получайте прямой доступ к информации из PHP.
Пользуйтесь всеми возможностями Transact-SQL и самыми передовыми технологиями доступа к данным ADO.NET и LINQ. Поддерживаются хранимые процедуры, триггеры и функции.

Сконцентрируйтесь на элементах бизнес-логики, а оптимизацию структуры базы данных система сделает самостоятельно.
Создавайте насыщенные отчеты любой степени сложности. Пользуйтесь подсистемой поиска, интегрируйте отчеты с приложениями Microsoft Office и добавляйте в документы информацию о географическом положении.
Разрабатываемые приложения могут работать при отсутствии подключения к серверу БД. Синхронизация производится автоматически с использованием фирменной технологии транзакционной репликации Sync Framework.
Администрируйте свою инфраструктуру, используя политики управления для всех баз данных и приложений. Общие эксплуатационные сценарии сокращают время на оптимизацию запросов, создание и восстановление резервных копий масштаба предприятия.
SQL Server 2008 R2 Express Edition идеально подходит для быстрого развертывания сайтов и интернет-магазинов, программ для персонального использования, малого бизнеса. Это отличный вариант для начала работы и обучения.

Управляйте базами данных, используя SQL Server Management Studio
Microsoft SQL Server Management представляет собой специализированную среду для создания, доступа и управления базами данных и всеми элементами SQL Server, включая службы отчетов.
Система объединяет в одном интерфейсе все возможности программ администрирования из ранних версий, таких как Query Analyzer и Enterprise Manager. Администраторы получают софт с большим набором графических объектов разработки и управления, а также расширенный язык создания сценариев работы с БД.
Редактор кода Microsoft Server Management Studio заслуживает отдельного внимания. Он позволяет разрабатывать скриптовые сценарии на Transact-SQL, программировать многомерные запросы доступа к данным и проводить их анализ с поддержкой сохранения результатов в XML. Создание запросов и сценариев возможно без подключения к сети или серверу, с последующим выполнением и синхронизацией. Имеется широкий выбор предустановленных шаблонов и система управления версиями.
Модуль «Обозреватель объектов» позволяет просматривать и управлять любыми встроенными объектами Microsoft Servers SQL на всех серверах и экземплярах баз данных. Легкий доступ к нужной информации чрезвычайно важен для быстрой разработки приложений и контроля версий.

Система построена на базе системы Visual Studio Isolated Shell, которая поддерживает расширяемые настройки и расширения сторонних разработчиков. В сети Интернет имеется множество сообществ, на которых можно найти всю необходимую информацию и примеры кода для разработки собственных инструментов управления и обработки данных.
По данным исследовательской компании Forrester Research, сервер баз данных Microsoft SQL Server 2012 вошел в тройку лидеров рынка корпоративных информационных хранилищ по итогам 2013 года. Эксперты отмечают, что быстрый рост доли рынка Microsoft обусловлен комплексным подходом корпорации к автоматизации бизнес-процессов. Microsoft SQL Server является современной платформой для управления и хранения данных любых типов, дополненной инструментами аналитики и разработки. Отдельно стоит отметить простоту интеграции с другими продуктами компании, такими как Office и SharePoint.
Моя компания только что прошла свой ежегодный процесс обзора, и я, наконец, убедил их, что настало время найти лучшее решение для управления нашей схемой/сценами SQL. В настоящее время у нас есть только несколько сценариев для ручного обновления.
Я работал с VS2008 Database Edition в другой компании, и это потрясающий продукт. Мой босс попросил меня взглянуть на SQL Compare by Redgate и искать любые другие продукты, которые могут быть лучше. Сравнение SQL также является отличным продуктом. Однако, похоже, что они не поддерживают Perforce.
Вы использовали для этого множество продуктов?
Какие инструменты вы используете для управления SQL?
Что должно быть включено в требования, прежде чем моя компания совершит покупку?
10 ответов
Я не думаю, что есть инструмент, который может обрабатывать все части. VS Database Edition не позволяет создать достойный механизм выпуска. Запуск отдельных скриптов из браузера решений недостаточно масштабируется в больших проектах.
Как минимум вам нужно
- IDE/editor
- репозиторий исходного кода, который может быть запущен с вашей IDE
- соглашение об именах и организации различных сценариев в папках
- процесс обработки изменений, управления релизами и выполнения развертываний.
Последняя пуля - это то, где вещи обычно ломаются. Вот почему. Для лучшей управляемости и отслеживания версий вы хотите сохранить каждый объект db в свой собственный файл script. То есть каждая таблица, хранимая процедура, представление, индекс и т.д. имеет свой собственный файл.
Когда что-то меняется, вы обновляете файл, и у вас есть новая версия в вашем репозитории с необходимой информацией. Когда дело доходит до объединения нескольких изменений в выпуск, обработка отдельных файлов может быть громоздкой.
2 варианта, которые я использовал:
Помимо сохранения всех отдельных объектов базы данных в своих файлах, у вас есть сценарии выпуска, которые являются конкатенацией отдельных скриптов. Недостаток этого: у вас есть код в 2 местах со всеми рисками и недостатками. Потенциал: запуск выпуска так же просто, как выполнение одиночного script.
напишите небольшой инструмент, который может читать метаданные script из манифеста выпуска и выполнить eadch script, указанный в манифесте на целевом сервере. Для этого нет недостатка, за исключением того, что вам нужно писать код. Этот подход не работает для таблиц, которые нельзя отбросить и воссоздать (как только вы живете, и у вас есть данные), поэтому для таблиц вы будете иметь скрипты изменений. Таким образом, на самом деле это будет комбинация обоих подходов.
Я нахожусь в лагере "script it yourself", поскольку сторонние продукты будут только доводить вас до управления кодом базы данных. У меня нет одного script для каждого объекта, потому что объекты меняются со временем, а девять раз из десяти просто обновляют мою "таблицу создания" script, чтобы иметь три новых столбца были бы неадекватными.
Создание баз данных по большому счету тривиально. Настройте кучу скриптов CREATE, упорядочьте их правильно (создайте базу данных перед схемами, схемы перед таблицами, таблицы перед процедурами, вызовите процедуры перед вызовами и т.д.) И сделайте это. Управление изменением базы данных не так просто:
- Если вы добавите столбец в таблицу, вы не сможете просто отбросить таблицу и создать ее с новым столбцом, потому что это приведет к уничтожению всех ваших ценных производственных данных.
- Если Fred добавляет столбец в таблицу XYZ, а Mary добавляет другой столбец в таблицу XYZ, какой столбец добавляется первым? Да, порядок столбцов в таблицах не имеет значения [потому что вы никогда не используете SELECT *, правильно?], Если вы не пытаетесь управлять базой данных и отслеживать управление версиями, после чего у вас есть две "действительные" базы данных, которые не выглядят как друг друга, становятся настоящей головной болью. Мы используем SQL-сравнение не для управления, а для обзора и отслеживания вещей, особенно во время разработки, и немногие "они разные (но это не magger)", ситуации, которые мы можем, могут помешать нам заметить различия, которые имеют значение.
- Аналогично, когда несколько проектов (разработчиков) работают одновременно и отдельно в общей базе данных, это может стать очень сложным. Возможно, все работают над проектом Next Big Thing, когда вдруг кто-то должен начать работу над исправлениями ошибок в проекте Last Big Thing. Как вы управляете требуемыми модификациями кода, когда порядок выпуска является переменным и гибким? (Действительно забавные времена.)
- Изменение структур таблиц означает изменение данных, и это может стать адски сложным, когда вам приходится иметь дело с обратной совместимостью. Вы добавляете столбец "DeltaFactor", хорошо, так что вы делаете, чтобы заполнить это эзотерическое значение для всех ваших существующих (прочитанных: устаревших) данных? Вы добавляете новую таблицу поиска и соответствующий столбец, но как вы заполняете ее для существующих строк? Такие ситуации могут случаться не часто, но когда они это делают, вы должны делать это сами. Сторонние инструменты просто не могут предвидеть потребности вашей бизнес-логики.
По сути, у меня есть CREATE script для каждой базы данных, за которой следует серия сценариев ALTER, поскольку наша база кода изменяется со временем. Каждый script проверяет, может ли он быть запущен: это правильный "вид" базы данных, были выполнены необходимые предварительные сценарии, этот script уже запущен. Только когда пройдены проверки, script выполнит свои изменения.
В качестве инструмента мы используем SourceGear Fortress для управления базовым исходным кодом, Redgate SQL Compare для общей поддержки и устранения неполадок, а также ряд домашних сценариев на основе SQLCMD для "массового" развертывания скриптов с изменениями на несколько серверов и базы данных и отслеживать, кто применял какие скрипты к базам данных в какое время. Конечный результат: все наши базы данных являются стабильными и стабильными, и мы можем с готовностью доказать, какая версия есть или была в любой момент времени.
Мы требуем, чтобы все изменения базы данных или вставки в такие вещи, как таблицы поиска, выполнялись в сценарии и сохранялись в контроле источника. Затем они развертываются таким же образом, как и любой другой код для развертывания версии программного обеспечения. Поскольку наши разработчики не имеют прав на развертывание, у них нет выбора, кроме как создавать скрипты.
Обычно я использую MS Server Management Studio для управления sql, работы с данными, разработки баз данных и отладки его, если мне нужно экспортировать некоторые данные в sql script или мне нужно создать какой-то сложный объект в базе данных, я использую EMS SQL Management Studio для SQL Server, потому что там я могу более четко видеть, что узкие разделы моего кода и визуальный дизайн в этой среде дают мне легче
У меня есть проект с открытым исходным кодом (лицензирован под LGPL), который пытается решить проблемы, связанные с правильной версией схемы DB для (и более) SQL Server (2005/2008/Azure), bsn ModuleStore . Весь процесс очень близок к понятию, объясненному сообщением Филиппа Келли здесь.
В принципе, отдельная часть набора инструментов скриптирует объекты базы данных SQL Server схемы БД в файлы со стандартным форматированием, поэтому содержимое файла изменяется только в том случае, если объект действительно изменился (в отличие от сценариев сделанный VS, который также создает скрипты и т.д., отмечая все измененные объекты, даже если они фактически идентичны).
Но набор инструментов выходит за рамки этого, если вы используете.NET: он позволяет встраивать скрипты SQL в библиотеку или приложение (в виде встроенных ресурсов), а затем сравнивать сравниваемые встроенные скрипты с текущим состоянием в базе данных. Изменения, не связанные с таблицей (те, которые не являются "деструктивными изменениями" по определение Мартина Фаулера), могут применяться автоматически или по запросу (например, создание и удаление объектов, таких как представления, функции, хранимые процедуры, типы, индексы) и сценарии изменения (которые необходимо записать вручную) могут быть применены в том же процессе; также создаются новые таблицы, а также их установочные данные. После обновления схема БД снова сравнивается с сценариями, чтобы обеспечить успешное обновление БД до того, как изменения будут совершены.
Обратите внимание, что весь код сценариев и сравнения работает без SMO, так что у вас нет болезненной зависимости SMO при использовании модуля bsn ModuleStore в приложениях.
В зависимости от того, как вы хотите получить доступ к базе данных, набор инструментов предлагает еще больше - он реализует некоторые возможности ORM и предлагает очень хороший и полезный интерфейсный подход для вызова хранимых процедур, включая прозрачную поддержку XML с собственным.NET XML классов, а также для TVP (Table-Valued Parameters) как IEnumerable
Вот мой script для отслеживания хранимых proc и udf и триггеров в таблице.
Создайте таблицу для хранения существующего исходного исходного кода proc
Ввести таблицу со всеми существующими данными триггера и script
Создайте триггер DDL для отслеживания изменений на них
/****** Object: Table . Script Date: 9/17/2014 11:36:54 AM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE . ( IDENTITY(1, 1) NOT NULL , (1000) NULL , (1000) NULL , (1000) NULL , (1000) NULL , NULL , NTEXT NULL ,CONSTRAINT PRIMARY KEY CLUSTERED ( ASC) WITH (PAD_INDEX = OFF ,STATISTICS_NORECOMPUTE = OFF ,IGNORE_DUP_KEY = OFF ,ALLOW_ROW_LOCKS = ON ,ALLOW_PAGE_LOCKS = ON) ON ) ON GO ALTER TABLE . ADD CONSTRAINT DEFAULT("") FOR GO INSERT INTO . ( , , , , ,) SELECT "sa" ,"loginitialdata" ,r.ROUTINE_NAME ,r.ROUTINE_TYPE ,GETDATE() ,r.ROUTINE_DEFINITION FROM INFORMATION_SCHEMA.ROUTINES r UNION SELECT "sa" ,"loginitialdata" ,v.TABLE_NAME ,"view" ,GETDATE() ,v.VIEW_DEFINITION FROM INFORMATION_SCHEMA.VIEWS v UNION SELECT "sa" ,"loginitialdata" ,o.NAME ,"trigger" ,GETDATE() ,m.DEFINITION FROM sys.objects o JOIN sys.sql_modules m ON o.object_id = m.object_id WHERE o.type = "TR" GO CREATE TRIGGER ON DATABASE FOR CREATE_PROCEDURE ,ALTER_PROCEDURE ,DROP_PROCEDURE ,CREATE_INDEX ,ALTER_INDEX ,DROP_INDEX ,CREATE_TRIGGER ,ALTER_TRIGGER ,DROP_TRIGGER ,ALTER_TABLE ,ALTER_VIEW ,CREATE_VIEW ,DROP_VIEW AS BEGIN SET NOCOUNT ON DECLARE @data XML SET @data = Eventdata() INSERT INTO sysupdatelog VALUES (@data.value("(/EVENT_INSTANCE/LoginName)", "nvarchar(255)") ,@data.value("(/EVENT_INSTANCE/EventType)", "nvarchar(255)") ,@data.value("(/EVENT_INSTANCE/ObjectName)", "nvarchar(255)") ,@data.value("(/EVENT_INSTANCE/ObjectType)", "nvarchar(255)") ,getdate() ,@data.value("(/EVENT_INSTANCE/TSQLCommand/CommandText)", "nvarchar(max)")) SET NOCOUNT OFF END GO SET ANSI_NULLS OFF GO SET QUOTED_IDENTIFIER OFF GO ENABLE TRIGGER ON DATABASE GO
Если вы уже когда-либо писали схемы блокировок на других языках баз данных для преодоления недостатка блокировок (как я), то у вас могло остаться чувство, что обязательно нужно самому заниматься блокировками. Позвольте вас заверить, что диспетчеру блокировок можно полностью доверять. Тем не менее SQL Server предлагает несколько методов управления блокировками, о которых мы детально поговорим в этом разделе.
Не применяйте параметры блокировки и не изменяйте уровни изоляции случайным образом - доверьте менеджеру блокировок SQL Server выполнять балансировку конкуренции и целостности транзакций. Только если вы абсолютно уверены, что схема базы данных хорошо настроена, а программный код буквально отшлифован, можете слегка подкорректировать работу диспетчера блокировок, чтобы решить конкретную проблему. В некоторых случаях настройка запросов select на отсутствие блокировок способна решить большинство проблем.
Установка уровня изоляции подключения
Уровень изоляции определяет продолжительность общей или эксклюзивной блокировки подключения. Установка уровня изоляции оказывает влияние на все запросы и все таблицы, используемые на протяжении всего подключения или до явной замены одного уровня изоляции другим. В следующем примере устанавливается более плотная изоляция, чем задана по умолчанию, и предотвращаются неповторяющиеся чтения:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ Допустимыми уровнями изоляции являются:
Read uncommited ? serializable
Read commited ? snapshot
Repeatable read
Текущий уровень изоляции можно проверить с помощью команды проверки целостности базы данных (DBCC):
DBCC USEROPTIONS
Результаты будут следующими (сокращенно):
Set Option Value
isolation level repeatable read
Уровни изоляции могут быть также установлены на уровне запроса или таблицы с помощью параметров блокировки.
Использование изоляции уровня снимков базы данных
Существуют два варианта уровня изоляции снимков базы данных: snapshot и read commited snapshot. Изоляция snapshot работает подобно repeatable read, не занимаясь вопросами блокировки. Изоляция read commited snapshot имитирует установленный по умолчанию в SQL Server уровень read commited, так же снимая вопросы блокировки.
В то время как изоляцию транзакций, как правило, устанавливают на уровне подключений, изоляция snapshot должна конфигурироваться на уровне базы данных, поскольку она
эффективно отслеживает версионность строк в базе. Версионностъ строк - это технология, которая создает для обновления копии строк в базе данных TempDB. Кроме основной загрузки базы TempDB, версионность строк также добавляет 14-байтовый идентификатор строки.
Использование изоляции Snapshot
В следующем фрагменте включается уровень изоляции snapshot. Для корректировки базы данных и включения уровня изоляции snapshot к этой базе не должны быть установлены другие подключения.
ALTER DATABASE Aesop
SET ALLOW_SNAPSHOT_ISOLATION ON
| Для проверки того, включена ли в базе данных изоляция snapshot, выполните SVS следующий запрос: SELECT name, snapshot_isolation_state_desc FROM [ * sysdatabases.
Теперь первая транзакция начинает чтение и остается открытой (т.е. не подтвержденной): USE Aesop
BEGIN TRAN SELECT Title FROM FABLE WHERE FablelD = 2
Будет получен следующий результат:
В это время вторая транзакция начинает обновление той же строки, которая открыта первой транзакцией:
SET TRANSACTION ISOLATION LEVEL Snapshot;
BEGIN TRAN UPDATE Fable
SET Title = ‘Rocking with Snapshots’
WHERE FablelD = 2;
SELECT * FROM FABLE WHERE FablelD = 2
Результат следующий:
Rocking with Snapshots
He правда ли, удивительно? Вторая транзакция смогла обновить строку, даже несмотря на то, что первая транзакция осталась открытой. Вернемся к первой транзакции и увидим исходные данные:
SELECT Title FROM FABLE WHERE FablelD = 2
Результат следующий:
Если открыть третью и четвертую транзакции, то они увидят все то же исходное значение The Bald Knight:
Даже после того как вторая транзакция подтвердит изменения, первая будет по-прежнему видеть исходное значение, а все следующие транзакции - новое, Rocking with Snapshots.
Использование ИЗОЛЯЦИИ Read Commited Snapshot
Изоляция Read Commited Snapshot включается с помощью аналогичного синтаксиса:
ALTER DATABASE Aesop
SET READ_COMMITTED_SNAPSHOT ON
Подобно изоляции Snapshot, данный уровень для снятия вопросов блокировок также использует версионность строк. Если взять за основу пример, описанный в предыдущем разделе, то в данном случае первая транзакция увидит изменения, выполненные второй, как только они будут подтверждены.
Так как Read Commited является уровнем изоляции, принятым в SQL Server по умолчанию, требуется только установка параметров базы данных.
Разрешение конфликтов записи
Транзакции, записывающие данные при установленном уровне изоляции Snapshot, могут быть заблокированы предыдущими неподтвержденными транзакциями записи. Такая блокировка не заставит новую транзакцию ожидать - просто будет сгенерирована ошибка. Для обработки подобных ситуаций используйте выражение try. . . catch, выждите пару секунд и попробуйте повторить транзакцию снова.
Использование параметров блокировки
Параметры блокировки позволяют вносить временную коррекцию в статегию блокировки. В то время как уровень изоляции оказывает влияние на подключение в целом, параметры блокировки специфичны для каждой таблицы в конкретном запросе (табл. 51.5). Параметр WITH (параметр_блокировки) помещается после имени таблицы в предложении FROM запроса. Для каждой таблицы можно задать несколько параметров, разделяя их запятыми.
|
Таблица 51.5. Параметры блокировки |
Параметр блокировки |
Описание |
Уровень изоляции. He устанавливает и не удерживает блокировку. Равносилен отсутствию блокировок |
Уровень изоляции, установленный для транзакций по умолчанию |
Уровень изоляции. Удерживает общую и эксклюзивную блокировки до момента подтверждения транзакции |
Уровень изоляции. Удерживает общую блокировку до завершения транзакции |
Пропуск заблокированных строк вместо ожидания |
Включение блокировки на уровне строк вместо уровня страницы, экстента или таблицы |
Включение блокировки на уровне страниц вместо уровня таблицы |
Автоматическая эскалация блокировок уровня строк, страниц и экстента до гранулярности уровня таблицы |
Параметр блокировки |
Описание |
Неприменение и неудержание блокировок. То же, что и ReadUnCommited |
Включение эксклюзивной блокировки таблицы. Запрет другим транзакциям работать с таблицей |
Удержание общей блокировки до подтверждения транзакции (аналогично Serializable) |
Использование блокировки обновления вместо общей и ее удержание. Блокировка других записей в данные между изначальными операциями чтения и записи |
Удержание эксклюзивной блокировки данных до подтверждения транзакции |
В следующем примере в предложении FROM инструкции UPDATE использован параметр блокировки, запрещающий диспетчеру эскалировать гранулярность блокировки:
USE OBXKites UPDATE Product
FROM Product WITH (RowLock)
SET ProductName = ProductName + ‘ Updated 1
Если запрос содержит подзапросы, не забывайте, что обращение к таблице каждого из запросов генерирует блокировку, которой можно управлять с помощью параметров.
Ограничения блокировок уровня индексов
Уровни изоляции и параметры блокировки применяются на уровне подключений и запросов. Единственным способом управления блокировками на уровне таблицы является ограничение гранулярности блокировок на основе конкретных индексов. С помощью системной хранимой процедуры sp_indexoption блокировки строк и/или страниц можно отключить для конкретного индекса, используя следующий синтаксис: sp_indexoption ‘имя_индекса 1 ,
AllowRowlocks или AllowPagelocks,
Это может пригодиться в ряде особых случаев. Если таблица часто вызывает ожидания по причине блокировок страниц, то установка для параметра allowpagelocks значения off установит блокировку на уровне строк. Уменьшенная гранулярность блокировок положительно скажется на конкуренции. К тому же, если таблица редко обновляется, но часто считывается, блокировки на уровне строк и страниц нежелательны; в этом случае оптимальным является уровень блокировки на уровне таблиц. Если обновления выполняются нечасто, то эксклюзивная блокировка таблиц не приведет к большим проблемам.
Хранимая процедура Sp_indexoption предназначена для тонкой настройки схемы данных; именно поэтому в ней используется блокировка на уровне индексов. Для ограничения блокировок по первичному ключу таблицы используйте sp_help имя_ та блицы, чтобы найти имя индекса первичного ключа.
Следующая команда конфигурирует таблицу ProductCategory как редко обновляемый классификатор. Вначале команда sp_help выводит имя индекса первичного ключа таблицы: sp_help ProductCategory
Результат (усеченный) таков:
index index index
name description keys
PK_____________ ProductCategory 79A814 03 nonclustered, ProductCategorylD
unique, primary key located on PRIMARY
Имея в наличии реальное имя первичного ключа, системная хранимая процедура может установить параметры блокировки индекса:
EXEC sp_indexoption
‘ProductCategory.РК__ ProductCategory_______ 7 9А814 03′,
‘AllowRowlocks’, FALSE EXEC sp_indexoption
‘ProductCategory.PK__ ProductCategory_______ 79A81403′,
‘AllowPagelocks’, FALSE
Управление временем ожидания блокировок
Если транзакция ожидает блокировку, то это ожидание будет продолжаться до тех пор, пока блокировка не станет возможной. По умолчанию не существует предела времени ожидания - чисто теоретически оно может длиться вечно.
К счастью, вы можете установить время ожидания блокировки с помощью параметра подключения set lock_timeout. Установите для этого параметра количество миллисекунд или, если хотите не ограничивать время, установите для него значение -1 (оно принято по умолчанию). Если для этого параметра установлено значение 0, то транзакция будет немедленно отклонена при наличии какой-либо блокировки. В этом случае приложение будет исключительно быстродействующим, но малоэффективным.
В следующем запросе время ожидания блокировки устанавливается в две секунды (2000 миллисекунд):
SET Lock_Timeout 2 00 0
Если транзакция выходит за пределы установленного предельного времени ожидания, то генерируется ошибка с номером 1222.
Настоятельно рекомендую устанавливать предельное время ожидания блокировки на уровне подключения. Эта величина выбирается в зависимости от обычной производительности базы данных. Я предпочитаю устанавливать пятисекундное время ожидания.
Оценка производительности конкуренции в базе данных
Очень легко создать базу данных, в которой не решаются вопросы соревнования блокировок и конкуренции при тестировании на группе пользователей. Реальный тест - это когда несколько сотен пользователей одновременно обновляют заказы.
Тестирование конкуренции нужно правильно организовать. На одном уровне он должен содержать одновременное использование множеством пользователей одной и той же конечной формы. Может оказаться полезной и программа.NET, которая постоянно имитирует
просмотр пользователем данных и их обновление. Хороший тест должен запускать 20 экземпляров сценария, который постоянно загружает базу данных, а затем дать возможность команде тестировщиков использовать приложение. Количество блокировок поможет увидеть монитор производительности, о котором говорилось в главе 49.
Многопользовательскую конкуренцию лучше тестировать в процессе разработки несколько раз. Как говорится в экзаменационном руководстве MCSE, “не допускайте, чтобы тест в реальных условиях был первым”.
Блокировки приложения
SQL Server использует очень сложную схему блокировок. Иногда процесс или ресурс, отличный от данных, требует блокировки. Например, может быть необходимо запускать процедуру, которая наносит вред, если другой пользователь запустил еще один экземпляр той же процедуры.
Несколько лет назад я написал программу разводки кабелей в проектах атомных электростанций. Когда геометрия предприятия была спроектирована и протестирована, инженеры вводили состав кабельного оборудования, его местоположение и типы используемых кабелей. После того как вводилось несколько кабелей, программа формировала маршрут их прокладки так, чтобы он оказался как можно более коротким. Процедура также учитывала вопросы безопасности кабельной проводки и разделяла несовместимые кабели. В то же время, если множество процедур прокладки запускалось одновременно, каждый экземпляр пытался маршрутизировать одни и те же кабели, в результате чего результат оказывался некорректным. Блокировка приложений стала отличным решением этой проблемы.
Блокировка приложений открывает целый мир блокировок SQL, предназначенных для использования в приложениях. Вместо использования данных в качестве блокируемого ресурса, блокировки приложений блокируют использование всех пользовательских ресурсов, объявленных в хранимой процедуре sp__GetAppLock.
Блокировка приложений может применяться в транзакциях; при этом может быть объявлен режим блокировки Shared, Update, Exclusive, IntentExclusice или IntentShared. Возвращаемое процедурой значение указывает, успешным ли было применение блокировки.
0. Блокировка установлена успешно.
1. Блокировка была установлена, когда другая процедура сняла свою блокировку.
999. Блокировка не была установлена по другой причине.
Хранимая процедура sp_ReleaseApLock снимает блокировку. В следующем примере продемонстрировано, как блокировка приложения может использоваться в пакете или процедуре: DECLARE @ShareOK INT EXEC @ShareOK = sp_GetAppLock
@Resource = ‘CableWorm’,
@LockMode = ‘Exclusive’
IF @ShareOK < 0
…Код обработки ошибки
… Программный код …
EXEC sp_ReleaseAppLock @Resource = ‘CableWorm’
Когда блокировки приложения просматриваются с помощью Management Studio или процедуры sp_Lock, они отображаются с типом АРР. В следующем листинге приведен сокращенный вывод процедуры sp_Lock, запущенной одновременно с приведенным выше кодом: spid dbid Objld Indld Type Resource Mode Status
57 8 0 0 APP Cabllf 94cl36 X GRANT
Следует обратить внимание на два небольших отличия в том, как блокировки приложения обрабатываются в SQL Server:
Взаимоблокировки не выявляются автоматически;
Если некоторая транзакция устанавливает блокировку несколько раз, она должна снять ее ровно такое же количество раз.
Взаимоблокировки
Взаимоблокировкой называют особую ситуацию, которая возникает только тогда, когда транзакции с множеством задач соревнуются за ресурсы друг друга. Например, первая транзакция установила блокировку ресурса А, и ей необходимо заблокировать ресурс Б, а в это же время вторая транзакция, заблокировавшая ресурс Б, нуждается в блокировке ресурса А.
Каждая из этих транзакций ожидает, пока другая снимет свою блокировку, и ни одна из них не может завершиться, пока этого не произойдет. Если не произойдет внешнего воздействия или одна из транзакций завершится по определенной причине (например, по времени ожидания), то эта ситуация может продолжаться до конца света.
Раньше взаимоблокировки представляли собой серьезную проблему, но теперь SQL Server позволяет успешно разрешить ее.
Создание взаимоблокировки
Проще всего создать ситуацию взаимоблокировки в SQL Server с помощью двух подключений в редакторе запросов утилиты Management Studio (рис. 51.12). Первая и вторая транзакции пытаются обновить одни и те же строки, однако в противоположном порядке. Используя третье окно для запуска процедуры pGetLocks, можно выполнять мониторинг блокировок.
1. Создайте в редакторе запросов второе окно.
2. Поместите код блока Шаг 2 во второе окно.
3. В первое окно поместите код блока Шаг 1 и нажмите клавишу
4. Во втором окне аналогично выполните код Шаг 2.
5. Вернитесь в первое окно и выполните код блока Шаг 3.
6. Через короткий промежуток времени SQL Server обнаружит взаимоблокировку и автоматически устранит ее.
Ниже приведен программный код примера.
– Транзакция 1 — Шаг 1 USE OBXKites BEGIN TRANSACTION UPDATE Contact
SET LastName = ‘Jorgenson’
WHERE ContactCode = 401′
Puc. 51.12. Создание ситуации взаимоблокировки в Management Studio с помощью двух подключений (их окна расположены вверху)
Теперь первая транзакция установила эксклюзивную блокировку на запись со значением 101 в поле ContactCode. Вторая транзакция установит эксклюзивную блокировку строки со значением 1001 в поле ProductCode, а затем попытается эксклюзивно заблокировать запись, уже заблокированную первой транзакцией (ContactCode=101).
– Транзакция 2 — Шаг 2 USE OBXKites BEGIN TRANSACTION UPDATE Product SET ProductName
= ‘DeadLock Repair Kit’
WHERE ProductCode = ‘1001’
SET FirstName = ‘Neals’
WHERE ContactCode = ‘101’
COMMIT TRANSACTION
Пока еще взаимоблокировки не существует, поскольку транзакция 2 ожидает завершения транзакции 1, но транзакция 1 пока еще не ожидает завершения транзакции 2. В этой ситуации, если транзакция 1 завершит свою работу и выполнит инструкцию COMMIT TRANSACTION, ресурс данных будет освобожден, и транзакция 2 благополучно получит возможность необходимой ей блокировки и продолжит свои действия.
Проблема возникает, когда транзакция 1 попытается обновить строку с ProductCode=l. Однако необходимую для этого эксклюзивную блокировку она не получит, поскольку эта запись заблокирована транзакцией 2:
– Транзакция 1 — Шаг 3 UPDATE Product SET ProductName
= ‘DeadLock Identification Tester’
WHERE ProductCode = ‘1001’
COMMIT TRANSACTION
Транзакция 1 вернет следующее текстовое сообщение об ошибке спустя пару секунд. Возникшую взаимоблокировку можно также увидеть в SQL Server Profiler (рис. 51.13):
Server: Msg 1205, Level 13,
State 50, Line 1 Transaction (Process ID 51) was
deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
Транзакция 2 завершит свою работу, будто бы проблемы и не существовало:
(1 row(s) affected)
(1 row(s) affected)

Рис. 51.13. SQL Server Profiler позволяет выполнять мониторинг взаимоблокировок с помощью события Locks:Deadlock Graph и выявлять ресурс, вызвавший взаимоблокировку
Автоматическое выявление взаимоблокировок
Как было продемонстрировано в приведенном выше коде, SQL Server автоматически выявляет ситуацию взаимоблокировки, проверяя блокирующие процессы и откатывая транзакции,
выполнившие наименьший объем работы. SQL Server постоянно проверяет существование перекрестных блокировок. Задержка выявления взаимоблокировок может варьироваться от нуля до двух секунд (на практике дольше всего мне приходилось ожидать этого пять секунд).
Обработка взаимоблокировок
Когда происходит взаимоблокировка, подключение, выбранное в качестве “жертвы” взаимоблокировки, должно повторить свою транзакцию. Так как работа должна быть переделана, хорошо, что откатывается именно та транзакция, которая успела выполнить наименьший объем работы, - именно она будет повторена сначала.
Ошибка с кодом 12 05 должна перехватываться клиентским приложением, которое и должно перезапускать транзакцию. Если все происходит как нужно, пользователь даже не заподозрит о том, что произошла взаимоблокировка.
Вместо того чтобы позволять самому серверу решать, какую из транзакций выбирать на роль “жертвы”, самой транзакции можно “сыграть в поддавки”. Следующий код, будучи помещенным в транзакцию, информирует SQL Server о том, что в случае возникновения взаимоблокировки данную транзакцию следует откатить:
SET DEADLOCKJPRIORITY LOW
Минимизация взаимоблокировок
Даже несмотря на то, что взаимоблокировки легко выявить и обработать, лучше все-таки их избегать. Приведенные ниже рекомендации помогут вам избежать взаимоблокировок.
Старайтесь делать транзакции короткими и не содержащими излишнего кода. Если некоторый код не обязательно должен присутствовать в транзакции, он должен быть выведен из нее.
Никогда не ставьте код транзакции в зависимость от ввода пользователя.
Старайтесь создавать пакеты и процедуры, устанавливающие блокировки, в одном и том же порядке. Например, вначале обрабатывается таблица А, затем таблицы Б, В и т.д. Таким образом, одна процедура будет ожидать второй и взаимоблокировки не смогут возникнуть по определению.
Планируйте физическую схему так, чтобы хранить одновременно отбираемые данные как можно ближе на страницах данных. Для этого используйте нормализацию и продуманно выбирайте кластеризованные индексы. Уменьшение разброса блокировок поможет избежать их эскалации. Небольшие блокировки помогут избежать их конкуренции.
Не увеличивайте уровень изоляции, если в этом нет необходимости. Более строгий уровень изоляции увеличивает продолжительность блокировок.
В среде SQL Server предусмотрен ряд различных управляющих конструкций, без которых невозможно написание эффективных алгоритмов.
Группировка двух и более команд в единый блок осуществляется с использованием ключевых слов BEGIN и END:
<блок_операторов>::=
Сгруппированные команды воспринимаются интерпретатором SQL как одна команда. Подобная группировка требуется для конструкций поливариантных ветвлений, условных и циклических конструкций. Блоки BEGIN...END могут быть вложенными.
Некоторые команды SQL не должны выполняться вместе с другими командами (речь идет о командах резервного копирования, изменения структуры таблиц, хранимых процедур и им подобных), поэтому их совместное включение в конструкцию BEGIN...END не допускается.
Нередко определенная часть программы должна выполняться только при реализации некоторого логического условия. Синтаксис условного оператора показан ниже:
<условный_оператор>::=
IF лог_выражение
{ sql_оператор | блок_операторов }
{sql_оператор | блок_операторов } ]
Циклы организуются с помощью следующей конструкции:
<оператор_цикла>::=
WHILE лог_выражение
{ sql_оператор | блок_операторов }
{ sql_оператор | блок_операторов }
Цикл можно принудительно остановить, если в его теле выполнить команду BREAK. Если же нужно начать цикл заново, не дожидаясь выполнения всех команд в теле, необходимо выполнить команду CONTINUE.
Для замены множества одиночных или вложенных условных операторов используется следующая конструкция:
<оператор_поливариантных_ветвлений>::=
CASE входное_значение
WHEN {значение_для_сравнения |
лог_выражение } THEN
вых_выражение [,...n]
[ ELSE иначе_вых_выражение ]
Если входное значение и значение для сравнения совпадают, то конструкция возвращает выходное значение. Если же значение входного параметра не найдено ни в одной из строк WHEN...THEN, то тогда будет возвращено значение, указанное после ключевого слова ELSE.
Основные объекты структуры базы данных SQL-сервера
Рассмотрим логическую структуру базы данных.
Логическая структура определяет структуру таблиц, взаимоотношения между ними, список пользователей, хранимые процедуры, правила, умолчания и другие объекты базы данных.
Логически данные в SQL Server организованы в виде объектов. К основным объектам базы данных SQL Server относятся следующие объекты.
Краткий обзор основных объектов баз данных.
Таблицы
Все данные в SQL содержатся в объектах, называемых таблицами . Таблицы представляют собой совокупность каких-либо сведений об объектах, явлениях, процессах реального мира. Никакие другие объекты не хранят данные, но они могут обращаться к данным в таблице. Таблицы в SQL имеют такую же структуру, что и таблицы всех других СУБД и содержат:
· cтроки; каждая строка (или запись) представляет собой совокупность атрибутов (свойств) конкретного экземпляра объекта;
· cтолбцы; каждый столбец (поле) представляет собой атрибут или совокупность атрибутов. Поле строки является минимальным элементом таблицы. Каждый столбец в таблице имеет определенное имя, тип данных и размер.
Представления
Представлениями (просмотрами) называют виртуальные таблицы, содержимое которых определяется запросом. Подобно реальным таблицам, представления содержат именованные столбцы и строки с данными. Для конечных пользователей представление выглядит как таблица, но в действительности оно не содержит данных, а лишь представляет данные, расположенные в одной или нескольких таблицах. Информация, которую видит пользователь через представление, не сохраняется в базе данных как самостоятельный объект.
Хранимые процедуры
Хранимые процедуры представляют собой группу команд SQL, объединенных в один модуль. Такая группа команд компилируется и выполняется как единое целое.
Триггеры
Триггерами называется специальный класс хранимых процедур, автоматически запускаемых при добавлении, изменении или удалении данных из таблицы.
Функции
Функции в языках программирования – это конструкции, содержащие часто исполняемый код. Функция выполняет какие-либо действия надданными и возвращает некоторое значение.
Индексы
Индекс – структура, связанная с таблицей или представлением и предназначенная для ускорения поиска информации в них. Индекс определяется для одного или нескольких столбцов, называемых индексированными столбцами. Он содержит отсортированные значения индексированного столбца или столбцов со ссылками на соответствующую строку исходной таблицы или представления. Повышение производительности достигается за счет сортировки данных. Использование индексов может существенно повысить производительность поиска, однако для хранения индексов необходимо дополнительное пространство в базе данных.
©2015-2019 сайт
Все права принадлежать их авторам. Данный сайт не претендует на авторства, а предоставляет бесплатное использование.
Дата создания страницы: 2016-08-08
Порой так хочется привести свои мысли в порядок, разложить их по полочкам. А еще лучше в алфавитной и тематической последовательности, чтобы, наконец, наступила ясность мышления. Теперь представьте, какой бы хаос творился в «электронных мозгах » любого компьютера без четкой структуризации всех данных и Microsoft SQL Server :
MS SQL Server
Данный программный продукт представляет собой систему управления базами данных (СУБД ) реляционного типа, разработанную корпорацией Microsoft . Для манипуляции данными используется специально разработанный язык Transact-SQL . Команды языка для выборки и модификации базы данных построены на основе структурированных запросов:

Реляционные базы данных построены на взаимосвязи всех структурных элементов, в том числе и за счет их вложенности. Реляционные базы данных имеют встроенную поддержку наиболее распространенных типов данных. Благодаря этому в SQL Server интегрирована поддержка программного структурирования данных с помощью триггеров и хранимых процедур.
Обзор возможностей MS SQL Server

СУБД является частью длинной цепочки специализированного программного обеспечения, которое корпорация Microsoft создала для разработчиков. А это значит, что все звенья этой цепи (приложения ) глубоко интегрированы между собой.
То есть их инструментарий легко взаимодействует между собой, что во многом упрощает процесс разработки и написания программного кода. Примером такой взаимосвязи является среда программирования MS Visual Studio . В ее инсталляционный пакет уже входит SQL Server Express Edition .
Конечно, это не единственная популярная СУБД на мировом рынке. Но именно она является более приемлемой для компьютеров, работающих под управлением Windows, за счет своей направленности именно на эту операционную систему. И не только из-за этого.
Преимущества MS SQL Server :
- Обладает высокой степенью производительности и отказоустойчивости;
- Является многопользовательской СУБД
и работает по принципу «клиент-сервер
»;
Клиентская часть системы поддерживает создание пользовательских запросов и их отправку для обработки на сервер.
- Тесная интеграция с операционной системой Windows ;
- Поддержка удаленных подключений;
- Поддержка популярных типов данных, а также возможность создания триггеров и хранимых процедур;
- Встроенная поддержка ролей пользователей;
- Расширенная функция резервного копирования баз данных;
- Высокая степень защищенности;
- Каждый выпуск включает в себя несколько специализированных редакций.
Эволюция SQL Server
Особенности этой популярной СУБД легче всего прослеживаются при рассмотрении истории эволюции всех ее версий. Более подробно мы остановимся лишь на тех выпусках, в которые разработчики вносили весомые и кардинальные изменения:
- Microsoft SQL Server 1.0 – вышел еще в 1990 году. Уже тогда эксперты отмечали высокую скорость обработки данных, демонстрируемую даже при максимальной нагрузке в многопользовательском режиме работы;
- SQL Server 6.0 – вышел в 1995 году. В этой версии впервые в мире была реализована поддержка курсоров и репликации данных;
- SQL Server 2000 – в этой версии сервер получил полностью новый движок. Большая часть изменений коснулась лишь пользовательской стороны приложения;
- SQL Server 2005 – увеличилась масштабируемость СУБД , во многом упростился процесс управления и администрирования. Был внедрен новый API для поддержки программной платформы .NET ;
- Последующие выпуски – были направлены на развитие взаимодействия СУБД на уровне облачных технологий и средств бизнес-аналитики.
В базовый комплект системы входит несколько утилит для настройки SQL Server . К ним относятся:
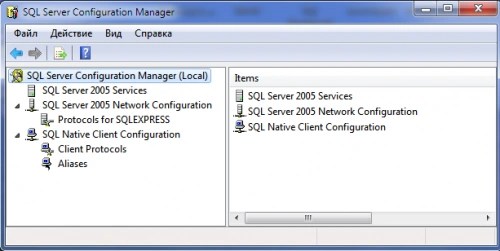
Диспетчер конфигурации. Позволяет управлять всеми сетевыми настройками и службами сервера базы данных. Используется для настройки SQL Server внутри сети.
- SQL Server Error and Usage Reporting :

Утилита служит для настройки отправки отчетов об ошибках в службу поддержки Microsoft .

Используется для оптимизации работы сервера базы данных. То есть вы можете настроить функционирование SQL Server под свои нужды, включив или отключив определенные возможности и компоненты СУБД .
Набор утилит, входящих в Microsoft SQL Server , может отличаться в зависимости от версии и редакции программного пакета. Например, в версии 2008 года вы не найдете SQL Server Surface Area Configuration .
Запуск Microsoft SQL Server
Для примера будет использована версия сервера баз данных выпуска 2005 года. Запуск сервера можно произвести несколькими способами:
- Через утилиту SQL Server Configuration Manager . В окне приложения слева выбираем «SQL Server 2005 Services », а справа — нужный нам экземпляр сервера БД . Отмечаем его и в подменю правой кнопки мыши выбираем «Start ».

- С помощью среды SQL Server Management Studio Express . Она не входит в инсталляционный пакет редакции Express . Поэтому ее нужно скачивать отдельно с официального сайта Microsoft .
Для запуска сервера баз данных запускаем приложение. В диалоговом окне «Соединение с сервером » в поле «Имя сервера » выбираем нужный нам экземпляр. В поле «Проверка подлинности » оставляем значение «Проверка подлинности Windows ». И нажимаем на кнопку «Соединить »:

Основы администрирования SQL Server
Перед тем, как запустить MS SQL Server , нужно кратко ознакомиться с основными возможностями его настройки и администрирования. Начнем с более детального обзора нескольких утилит из состава СУБД :
- SQL Server Surface Area Configuration – сюда следует обращаться, если нужно включить или отключить какую-либо возможность сервера баз данных. Внизу окна находятся два пункта: первый отвечает за сетевые параметры, а во втором можно активировать выключенную по умолчанию службу или функцию. Например, включить интеграцию с платформой .NET через запросы T-SQL :









 Инвестиционные проекты hyip")










 Инвестиционные проекты hyip")



