У цій статті я хотів би розглянути різні техніки пошуку інформації про VoIP-пристроях у мережі, а потім продемонструвати кілька атак на VoIP.
Вступ
Останні кілька років спостерігалися високі темпи впровадження IP-телефонії (VoIP). Більшість організацій, що впровадили VoIP, або ігнорують проблеми безпеки VoIP та її реалізації, або просто не знають про них. Як і будь-яка інша мережа, мережа VoIP чутлива до неправильної експлуатації. У цій статті я хотів би розглянути різні техніки пошуку інформації про VoIP-пристроях у мережі, а потім продемонструвати кілька атак на VoIP. Я свідомо не став спускатися до деталей рівня протоколу, оскільки ця стаття призначена для пентестерів, які хочуть спочатку спробувати основні прийоми. Однак я наполегливо рекомендую вивчити протоколи, які використовуються у VoIP-мережах.
Можливі атаки на VoIP
- Відмова в обслуговуванні (DoS)
- Викрадення реєстраційних даних та маніпуляція ними
- Атаки на систему аутентифікації
- Підміна (спуфінг) Caller ID
- Атаки типу "Людина посередині"
- "Шаманство над VLAN-ами" (Vlan hopping)
- Пасивне та активне прослуховування
- Спам через інтернет-телефонію (SPIT)
- VoIP фішинг (Vishing)
Конфігурація лабораторії для тестування VoIP
Щоб продемонструвати проблеми безпеки VoIP в рамках цієї статті, я використав таку конфігурацію лабораторії:
- Trixbox i(192.168.1.6) - IP-PBX сервер з відкритим вихідним кодом
- Backtrack 4 R2 (192.168.1.4) - ОС на машині атакуючого
- ZoIPer ii (192.168.1.3) - програмний телефондля Windows (користувач A- жертва)
- Linphone iii(192.168.1.8) - програмний телефон для Windows (користувач B- жертва)
Конфігурація нашої лабораторії

Малюнок 1
Розглянемо схему лабораторії, наведену вище. Це типова конфігурація VoIP-мережі невеликий організаціїз маршрутизатором, який виділяє IP-адреси пристроям, IP-PBX системі та користувачам. Якщо користувач Aданої мережі захоче зв'язатися з B, відбудеться наступне:
- Дзвінок Aнадсилається на IP-PBX сервер для автентифікації користувача.
- Після успішної автентифікації A IP-PBX сервер перевіряє наявність екстеншена (внутрішнього номера) користувача B. Якщо екстеншен присутній, дзвінок перенаправляється B.
- На підставі відповіді B(наприклад, прийом дзвінка, скидання тощо) IP-PBX сервер відповідає користувачу A.
- Якщо все гаразд, Aпочинає спілкування з B.
Тепер, коли у нас є ясна картина взаємодії, давайте перейдемо до розважальної частини – атак на VoIP.
Пошук VoIP пристроїв
Пошук пристроїв (enumerating) - є основою кожної успішної атаки/пентеста, оскільки він забезпечує атакуючого як необхідними подробицями, і загальним уявленням про конфігурації мережі. VoIP – не виняток. У VoIP-мережі нам, як атакуючим, буде корисна інформація про VoIP-шлюзи/сервери, IP-PBX системи, клієнтські програмні та VoIP-телефони та номери користувачів (екстеншенах). Давайте подивимося на деякі інструменти для пошуку пристроїв і створення відбитків (fingerprints). Для спрощення демонстрації припустимо, що вже відомі IP-адреси пристроїв.
Smap
Smap ivсканує окрему IP-адресу або підсіть на предмет увімкнених SIP-пристроїв. Давайте використовуємо smap проти IP-PBX сервера. Малюнок 2 показує, що ми змогли знайти сервер та отримати інформацію про його User-Agent.

Малюнок 2
Svmap
Svmap - інший потужний сканер із набору інструментів sipvicious v. Даний інструмент дозволяє виставити тип запиту, який використовується під час пошуку SIP-пристроїв. Тип запиту за промовчанням - OPTIONS. Давайте запустимо сканер для пула із 20 адрес. Як видно, svmap може виявляти IP-адреси та інформацію про User-Agent.

Малюнок 3
Swar
При пошуку VoIP-пристроїв для визначення діючих SIP-екстеншенів може допомогти пошук за номерами користувачів. Svwar viдозволяє сканувати повний діапазон IP-адрес. Малюнок 4 показує результат сканування номерів користувача в діапазоні від 200 до 300. В результаті отримуємо екстеншени користувачів, зареєстровані на IP-PBX сервері.

Малюнок 4
Отже, ми розглянули процес пошуку VoIP-пристроїв та отримали деякі цікаві деталі конфігурації. Тепер давайте скористаємося цією інформацією для атаки на мережу, конфігурацію якої ми щойно досліджували.
Атака на VoIP
Як вже обговорювалося, VoIP-мережа схильна до безлічі загроз безпеки та атак. У цій статті ми розглянемо три критичні атаки на VoIP, які можуть бути спрямовані на порушення цілісності та конфіденційності VoIP-інфраструктури.
У подальших розділах продемонстровано наступні атаки:
- Атака на VoIP-автентифікацію
- Прослуховування через ARP-спуфінг
- Імітація Caller ID
1. Атака на VoIP-автентифікацію
Коли новий або існуючий VoIP-телефон приєднується до мережі, він надсилає на IP-PBX сервер запит REGISTER для реєстрації асоційованого з телефоном ідентифікатора користувача/екстеншена. Цей запит на реєстрацію містить важливу інформацію(на зразок інформації про користувача, даних аутентифікації тощо) яка може представляти великий інтерес для атакуючого або пентестера. Малюнок 5 показує перехоплений пакет запиту на автентифікацію протоколу SIP. Перехоплений пакет містить ласу для інформації, що атакує. Давайте використовуємо дані пакета для атаки на автентифікацію.

Малюнок 5
Демонстрація атаки
Сценарій атаки

Малюнок 6
Крок 1:Для спрощення демонстрації припустимо, що ми маємо фізичний доступ до VoIP-мережі. Тепер, використовуючи інструменти та техніки, описані в попередніх розділах статті, ми проведемо сканування та пошук пристроїв, щоб отримати таку інформацію:
- IP-адреса SIP-сервера
- Існуючі ідентифікатори та екстеншени користувачів
Крок 2:Давайте перехопимо кілька запитів на реєстрацію за допомогою wireshark vii. Ми збережемо їх у файлі під назвою auth.pcap. Малюнок 7 показує файл wireshark з результатами перехоплення (auth.pcap).

Малюнок 7
Крок 3:
Тепер ми використовуємо набір інструментів sipcrack viii. Набір входить до складу Backtrack та знаходиться в директорії /pentest/VoIP. Малюнок 8 показує інструменти набору sipcrack.
Малюнок 8
Крок 4:Використовуючи sipdump, вивантажимо дані аутентифікації у файл з ім'ям auth.txt. Малюнок 9 показує файл захоплення wireshark, що містить автентифікаційні дані користувача 200.

Малюнок 9
Крок 5:Ці дані автентифікації включають ідентифікатор користувача, SIP-екстеншен, хеш пароля (MD5) та IP-адресу жертви. Тепер ми використовуємо sipcrack, щоб зламати хеші паролів за допомогою атаки за заготовленим словником. Малюнок 10 показує, що словником для злому хешів використовується файл wordlist.txt. Ми збережемо результати злому у файлі під назвою auth.txt.

Малюнок 10
Крок 6:Чудово тепер у нас є паролі для екстеншенів! Ми можемо використовувати цю інформацію, щоб перереєструватись на IP-PBX сервері з нашого власного SIP-телефону. Це дозволить нам виконувати такі дії:
- Видавати себе за легального користувача та дзвонити іншим абонентам
- Прослуховувати та маніпулювати легальними дзвінками, що виходять та входять на екстеншен жертви (користувача Aв даному випадку).
2. Прослуховування через Arp-спуфінг
Кожен мережний пристрій має унікальну MAC-адресу. Як і решта мережеві пристрої, VoIP телефони вразливі до спуфінгу MAC/ARP. У даному розділіми розглянемо зніфінг активних голосових дзвінків шляхом прослуховування та запису діючих розмов по VoIP.
Демонстрація атаки
Сценарій атаки

Малюнок 11
Крок 1:З метою демонстрації, давайте припустимо, що ми вже визначили IP-адресу жертви, використовуючи описані раніше техніки. Далі, використовуючи ucsniff ixяк засіб ARP-спуфінгу, ми замінимо MAC-адресу жертви.
Крок 2:Важливо визначити MAC-адресу мети, яку потрібно підмінити. Хоча інструменти, що раніше згадувалися, були здатні визначати MAC-адресу автоматично, гарною практикою буде визначити MAC незалежно, окремим способом. Давайте використовуємо для цього nmap x. Малюнок 12 показує результати сканування IP-адреси жертви та отриману в результаті MAC-адресу.
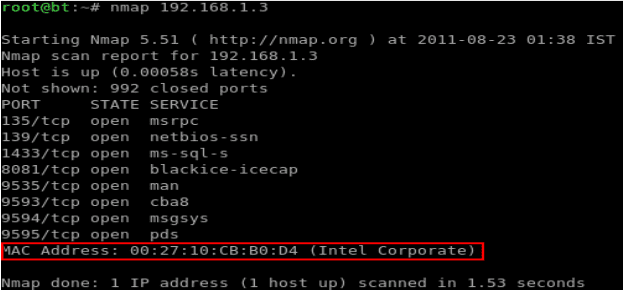
Малюнок 12
Крок 3:Тепер, коли у нас є MAC-адреса жертви, давайте використовуємо ucsniff, щоб підмінити її MAC. ucsniff підтримує кілька режимів спуфінгу (режим спостереження, режим вивчення та режим MiTM, тобто «людина-посередині»). Давайте використовуємо режим MiTM, вказавши IP-адресу жертви та SIP-екстеншен у файлі з ім'ям targets.txt. Цей режим гарантує, що прослуховуються лише дзвінки (вхідні та вихідні) жертви (користувач A), не торкаючись іншого трафіку в мережі. Малюнки 13 та 14 показують, що ucsniff підмінив MAC користувача A(В ARP-таблиці).

Малюнок 13

Малюнок 14
Крок 4:Ми успішно підмінили MAC-адресу жертви і тепер готові прослуховувати вхідні та вихідні дзвінки користувача Aза VoIP-телефоном.
Крок 5:Тепер, коли користувач Bдзвонить користувачеві Aі починає діалог, ucsniff приймається записувати їх розмову. Коли дзвінок завершується, ucsniff зберігає записану розмову повністю у wav-файл. Малюнок 15 показує, що ucsniff виявив новий дзвінок з екстеншена 200 на екстеншен 202.
Малюнок 15
Крок 6:Коли ми закінчимо, ми викликаємо ucsniff знову з ключем -q щоб припинити спуфінг MAC в системі і, таким чином, гарантувати, що після завершення атаки все стало на свої місця.
Крок 7:Збережений аудіофайл можна програти, використовуючи будь-який відомий медіаплеєр на зразок windows media Player.
Спуфінг Caller ID
Це одна із найпростіших атак на VoIP-мережі. Спуфінг ID абонента відповідає сценарію, коли невідомий користувач може видати себе легальним користувачем VoIP-мережі. Для реалізації цієї атаки може бути достатньо легких змін у запиті INVITE. Існує безліч способів формування спотворених належним чином SIP INVITE повідомлень (за допомогою scapy, SIPp тощо). Для демонстрації використовуємо допоміжний модуль sip_invite_spoof із фреймворку metasploit xi .
Сценарій атаки

Малюнок 16
Крок 1:Давайте запустимо metasploit і завантажимо допоміжний модуль voip/sip_invite_spoof.
Крок 2:Далі, встановимо значення опції MSG в User B. Це дасть нам можливість видавати себе за користувача B. Пропишемо також IP-адресу користувача Aопції RHOSTS. Після налаштування модуля ми запускаємо його. Малюнок 17 демонструє всі налаштування конфігурації.

Малюнок 17
Крок 3:Допоміжний модуль надсилатиме змінені invite-запити жертві (користувачу A). Жертва отримуватиме дзвінки з мого VoIP телефону і відповідатиме на них, думаючи, що говорить з користувачем B. Малюнок 18 показує VoIP-телефон жертви ( A), яка отримує дзвінок нібито від користувача B(А насправді від мене).

Малюнок 18
Крок 4:Тепер Aвважає, що надійшов звичайний дзвінок від Bі починає говорити з тим, хто представився як User B.
Висновок
Безліч існуючих загроз безпеки відноситься і до VoIP. Використовуючи пошук пристроїв, можна отримати критичну інформацію, що стосується VoIP-мережі, ідентифікаторів користувача/екстеншен, типів телефонів і т. д. За допомогою спеціальних інструментів, можливо проводити атаки на автентифікацію, викрадати VoIP дзвінки, підслуховувати, маніпулювати дзвінками, розсилати VoIP-спам, проводити VoIP-фішинг та компрометацію IP-PBX сервера.
Я сподіваюся, що ця стаття була достатньо інформативною, щоб звернути увагу на проблеми безпеки VoIP. Я б хотів попросити читачів відзначити, що в цій статті не обговорювалися всі можливі інструменти та техніки, які використовуються для пошуку VoIP-пристроїв у мережі та пентестингу.
про автора
Сохіл Гарг - пентестер у PwC. Області його інтересів включають розробку нових векторів атак і тестування на проникнення в середовищах, що охороняються. Він бере участь в оцінках захищеності різних програм. Він доповідав про проблеми безпеки VoIP на конференціях CERT-In, які відвідували високопосадовці та представники відомств оборони. Нещодавно він виявив вразливість у продукті великої компанії, що дає можливість підвищення привілеїв та прямого доступу до об'єкта.
Посилання
i http://fonality.com/trixbox/ii http://www.zoiper.com/
iii http://www.linphone.org/
iv http://www.wormulon.net/files/pub/smap-blackhat.tar.gz
v
vi http://code.google.com/p/sipvicious/
vii http://www.wireshark.org/
viiiЦей інструмент можна знайти у Backtrack 5 у каталозі /pentest/voip/sipcrack/
ix http://ucsniff.sourceforge.net/
x http://nmap.org/download.html
xi http://metasploit.com/download/
Як тільки посилка надійде на один із наших складів за кордоном або в Росії, ви отримаєте сповіщення електронною поштою. Надалі Ви зможете відстежити Вашу посилку на нашому сайті у розділі «Відстеження», для цього необхідно запровадити свій tracking-number.
Будь ласка, переконайтеся, що Ви правильно вказали свою поштову адресу в профілі IPS, і що Ваша електронна поштова скринька не переповнена.
Якщо ваш продавець (інтернет-магазин) повідомив Вам, що Ваша посилка прибула в один з наших офісів, але ви все ще не можете відстежити її, будь ласка, зв'яжіться з нами, надавши повну інформацію про вашу посилку (назва магазину, відправника та адресу відправлення, ідентифікаційний номер, дату відправлення тощо).
- Ви хочете отримати поки що одну-дві посилки:
- Ви плануєте регулярно (кілька разів на місяць) отримувати листи, журнали або посилки з-за кордону:
- Тарифи на наші послуги для наших постійних клієнтів нижче за тарифи для непостійних клієнтів на 10-30 % (залежно від виду послуг).
- Розрахунок тарифів за доставку посилки з-за кордону здійснюється відповідно до реальної ваги цієї посилки, а не за округлену вагу до повного числа кілограм.
- Діють накопичувальні знижки.
- Упаковка, перепакування листів/посилок для наших постійних клієнтів здійснюється безкоштовно.
- Для постійних клієнтів здійснюється доставка або пересилання листів/посилок з наших закордонних адресна будь-яку іншу міжнародну адресу або до рук будь-якій особі за кордоном.
- Постійний клієнт отримує інформацію про всі зміни наперед.
- Постійний клієнт може замовити необхідну йому нестандартну послугу, навіть якщо ця послуга не позначена в списку послуг IPS і її потрібно виконати за межами Росії.
- Безкоштовно зберігати тривалий час листи/посилки у наших закордонних офісах.
- Самостійно забирати свої посилки у наших закордонних офісах.
-
Чи можу я використовувати поштову скриньку, що абонується, у Вашому офісі для отримання звичайної пошти, кореспонденції, рахунків, підписки з Москви чи з Росії?
Звичайно. Абонентська плата у нас дешевша, ніж на Пошті Росії. У цьому випадку, крім абонентської плати, Ви більше нічого не платите.
Мені потрібно надіслати посилку за кордон. Чим послуги IPS відправлення відрізняються від інших кур'єрських компаній?
- Через нас клієнт може відправити трьома режимами:
- поштовий режим - найдешевший, але і найповільніший - 10-12 раб.
- кур'єрський режим середньої швидкості доставки - 4-5 раб.днів (Експрес-смарт);
- кур'єрський режим найвищої швидкості доставки - 1-2 раб.дня (Експрес-бізнес).
- Ми самостійно оформляємо всі документи для митниці за клієнта.
- Безкоштовно консультуємо щодо оптимізації логістичного процесу відправлення будь-якого вантажу до будь-якої країни світу.
- Через нас клієнт може відправити трьома режимами:
-
У мене 4 маленькі посилки. Ви зможете запакувати ці посилки в одну?
Зможемо. Ми забезпечимо консолідацію посилок. Для постійних клієнтів (поштова скринька, що абонують) – ця послуга безкоштовна.
Як я можу оплатити доставку?
На даний момент доступні готівковий та безготівковий метод оплати.
Яка компенсація мені буде виплачена у разі втрати посилки?
Наша доставка має високий рівень надійності. Однак, якщо таке трапилося і посилка була застрахована - повна застрахована сума.
Як довго займає доставка посилки?
Зазвичай, доставка займає від 7 до 12 днів з дня надходження посилки на наш склад у відповідній країні.
Чи можу я зберігати мою посилку на вашому складі у США/Великобританії/Німеччині протягом 1-2 місяців? Чи стягується за це додаткова плата?
Якщо Ви не абонуєте поштову скриньку, компанія IPS буде зберігати безкоштовно Вашу посилку лише протягом 7 днів з моменту надходження на склад. У разі зберігання посилки понад 7 днів стягується додаткова плата. IPS залишає за собою право на свій розсуд розпоряджатися посилками, що зберігаються на складі більш ніж на 60 днів, власники яких не здійснили оплату зберігання.
Які переваги доставки з IPS?
Переваги доставки з компанією IPS:
- надійність доставки;
- розумна та зрозуміла вартість доставки;
- виконуваний термін доставки -7-12 днів;
- наявність московського офісу, де завжди готові допомогти;
- можливість купівлі товарів, недоступних у Росії;
- можливість купівлі товарів у магазинах, які не доставляють товари до Росії;
- можливість економії на доставці, використовуючи послугу консолідації відправлення та перепакування.
-
Яку інформацію я маю вказати в полі «Адреса доставки» при купівлі товарів в інтернет-магазинах?
Ви повинні ввести: адресу нашого закордонного офісу, надану Вам нашою компанією, Ваше Прізвище та Ім'я, номер Вашої поштової скриньки.
Чи маю я щось Вам повідомити після здійснення покупки та відправки посилки на надану мені адресу?
Після здійснення замовлення необхідно повідомити нас про досконале замовлення, надати дані замовлення – опис вкладення, його вагу, вартість. Ця інформація необхідна для обробки ваших посилок.
Чи існують обмеження можливих вкладень?
З компанією IPS ви можете надіслати посилку з будь-яким вкладенням, не забороненим законодавством України.
До заборонених вкладень відносяться:
- вибухові речовини,
- легкозаймисті предмети,
- радіоактивні матеріали,
- стиснутий газ,
- вогнепальну зброю,
- будь-які предмети, які за своєю природою упаковки можуть призвести до травмування працівників IPS або спричинити пошкодження інших предметів.
З повним переліком заборонених вкладень ви зможете ознайомитись.
Перед тим як здійснити покупку в інтернет-магазині, будь ласка, переконайтеся, що ваша покупка не відноситься до категорії небезпечних вантажів.
Чи гарантує IPS справжність та якість придбаного мною продукту?
IPS не несе відповідальності перед клієнтом за справжність та якість придбаного ним товару. З метою власної безпеки, будь ласка, купуйте товари лише у перевірених інтернет-магазинах.
Як правильно запакувати посилку?
Проте, якщо це необхідно, будь ласка, забезпечте належне пакування вашого відправлення, або проінформуйте співробітників IPS про необхідність додаткового пакування вашої посилки.
Ми не несемо відповідальності за будь-які збитки та пошкодження, які можуть виникнути під час обробки, перевезення або доставки внаслідок неналежної упаковки посилки відправником.
Які документи потрібно надати для підтвердження оцінної вартості відправлення?
Необхідно надати інвойс, підготовлений відправником, зазначені у ньому суми повинні включати всі податки, і навіть інші можливі збори.
У яких інтернет-магазинах я можу купувати?
Що робити, якщо продавець надіслав не той товар/не правильну кількість товару?
Так як компанія IPS здійснює тільки доставку вашої посилки до Росії, всі питання щодо комплектації та відповідності товару, а також можливість обміну або повернення необхідно вирішувати безпосередньо з продавцем або відправником.
Я хочу придбати ювелірні виробиз дорогоцінних металів з дорогоцінним камінням. Це можливо?
Ні. Ми не доставляємо вироби з дорогоцінних металів та/або з дорогоцінним камінням.
Коли я знатиму кінцеву вартість доставки?
Тільки після того, як посилка надійде на наш, вибраний Вами закордонний склад.
Як тільки ваша посилка буде оброблена, ви будете повідомлені електронною поштою щодо термінів доставки та кінцевої вартості доставки. Вашій посилці буде надано персональний номер, ви зможете, дотримуючись інструкцій у листі, сплатити вартість доставки та відстежити статус свого відправлення.
У випадку, якщо ви хочете здійснити консолідацію вашого відправлення, необхідно робити оплату після остаточного формування посилки.
Клієнту, який абонірує поштову скриньку, не потрібно здійснювати жодних оплат до отримання своєї кореспонденції/посилок у московському офісі IPS.
Якщо я вирішив відмовитися від доставки в Росію посилки, яка прийшла на моє ім'я до закордонного офісу IPS, чи будуть з мене утримані якісь суми, якщо необхідно повернути посилку відправнику або знищити її?
Якщо з будь-якої причини ви вирішили зупинити доставку до Росії вашої посилки, будь ласка, терміново переговоріть з вашим відправником, щоб він не надсилав на адресу IPS вашу посилку.
У випадку, якщо посилка все ж таки прийшла на адресу складу IPS, ми можемо за вашою вказівкою відправити посилку назад (або переправити на іншу адресу) з утриманням 10$ адміністративного збору, а також 100% вартості витрат на повернення/доставку посилки.
Також ми можемо утилізувати посилку з утриманням 10 $ адміністративного збору (для посилок, що не перевищують 15 кг). У разі зберігання посилки більш ніж 21 день, IPS стягує оплату в розмірі $50 в день за одну посилку.
Яка мінімальна оплачувана вага посилки, що доставляється?
Для клієнтів, які абонірують поштову скриньку - мінімальна оплачувана вага становить 1 фунт з наступним кроком 0,1 фунт.
Доставка посилки з-за кордону. Як це працює?
Всім нашим клієнтам (будь то постійний клієнт або клієнт, який бажає отримати посилку одноразово) ми надаємо поштові адреси у трьох містах світу – Лондоні, Нью-Йорку, Ганновері. На будь-який з них Ваш респондент (інтернет-магазин, друг, родич, колега тощо) може надіслати Вам посилку і через – 7-10 робочих днів після того, як вона надійде на одну з цих адрес, Ви отримаєте її в Москві.
Як мені отримати адреси?
Є два варіанта:
Вам потрібно під'їхати з паспортом до офісу IPS. Тут зроблять ксерокопію Вашого паспорта, запишуть Контактні телефониі видадуть потрібну Вам адресу (у Лондоні, Нью-Йорку або Ганновері).
Вам є сенс укласти договір на постійне обслуговування. Для цього потрібно абонувати поштову скриньку та регулярно вносити абонентський платіж. Мінімальний обсяг місячної абонентської плати – 755,2руб (з урахуванням ПДВ 18%). (Є інші розміри абонентської плати, вони залежать від набору додаткових безкоштовних послуг, вже включених в абонентське обслуговування). У цьому випадку Ви отримуєте всі три адреси і можете скористатися ними на свій розсуд.
Для отримання адреси - чи можна мені до Вас не приїжджати, а надіслати копію паспорта по e-mail?
Можна, але тоді потрібна передплата.
У двох вищевказаних випадках (див. питання 2) ми обслуговуємо клієнтів у режимі післяплати - ми привозимо (тобто спочатку надаємо послугу), а потім тільки отримуємо оплату від клієнта. Тому для нас важливо переконатися, що наш клієнт є реальною особою.
Якщо Ви хочете нам надіслати копію паспорта електронно, то для подальшого обслуговування важлива передоплата від Вас у розмірі не менше ніж 4000,0 руб. Якщо після надання та оплати послуги доставки у Вас залишається сума – на першу Вашу вимогу ця сума буде Вам повернена на ті реквізити, з яких вона була надіслана Вами нам. Або надалі ви зможете використовувати її для оплати послуг у нашій компанії.
Чому вигідно абонувати поштову скриньку?
Клієнт, який абонує поштову скриньку, стає нашим постійним клієнтом.
Постійні клієнти мають такі пільги:
Санкт-Петербурзький державний університет
Філологічний факультет
Кафедра математичної лінгвістики
В.П. Захаров
ІНФОРМАЦІЙНО-ПОШУКОВІ
системи
Навчально-методичний посібник
Санкт-Петербург
Рецензенти:
докт. техн. наук В.Ш. Рубашкін(С.-Петерб. держ. ун-т)
канд. пед. наук О.А. Арбатська(С.-Петерб. держ. ун-т культ. та позов-в)
Друкується за постановою
Редакційно-видавнича рада
С.-Петербурзького державного університету
Захаров В.П.
З-38Інформаційно-пошукові системи: Навчально-метод. допомога. – СПб., 2005. – 48 с.
Пропонований посібник містить опис основ документального інформаційного пошуку, програму навчальної дисципліни «Теорія інформаційного пошуку», яка вивчається студентами 3-го курсу відділення структурної та прикладної лінгвістики Санкт-Петербурзького державного університету, та набір лабораторних (практичних) робіт з цієї дисципліни. Окремі лабораторні роботи використовуються для навчання студентів інших курсів та інших дисциплін. Посібник базується на дослідницькій та викладацькій діяльності автора.
Для студентів та аспірантів, що спеціалізуються в галузі прикладної лінгвістики, інформаційних систем та автоматизованих систем обробки тексту.
ã В.П. Захаров, 2005
ã Санкт-Петербурзький
державний
університет, 2005
1. Введення в теорію та практику
інформаційного пошуку
1.1. Основні поняття інформаційного пошуку
Інформаційно-пошукова система (ІПС) – це впорядкована сукупність документів (масивів документів) та інформаційних технологій, призначених для зберігання та пошуку інформації – текстів (документів) або даних (фактів). Інформаційно-пошуковими системами є будь-які належним чином організовані сховища інформації. Причому інформаційно-пошукові системи можуть бути неавтоматизованими. Головне це цільова функція: зберігання та пошук інформації.
Залежно від об'єкта зберігання та типу запиту розрізняють два види інформаційного пошуку: документальний та фактографічний – і, відповідно, два типи ІПС – документальні та фактографічні. Останні також називають інформаційно-довідковими ІПС.
документальними називаються ІПС, в яких реалізується пошук за тематичними запитами в масиві документів або текстів з подальшим наданням користувачеві підмножини цих документів або їх копій. Поняття документа може змінюватись від системи до системи. У загальному випадку це якийсь інформаційний об'єкт, зафіксований (зазвичай за допомогою деякої знакової системи) на якомусь матеріальному носії (папір, фото- та кіноплівка, магнітна пам'ять тощо) та призначений для передачі у просторі та часі в системі соціальних комунікацій .
Фактографічні ІПС реалізують зберігання, пошук та видачу безпосередньо фактичних даних (наукових, технічних, економічних характеристик та властивостей об'єктів, процесів, явищ, адрес, найменувань, кількісних даних тощо).
Головна, сутнісна, різниця між документальним і фактографічним пошуком полягає в підході до семантики документів. У документальних системах описується зміст документів загалом з погляду їх тематичного, предметного змісту. У цьому випадку важливо виявити та назвати (перерахувати) основні теми та об'єкти, яким присвячено документ. У фактографічних системах описуються об'єкти, фіксуються їх ознаки та значення цих ознак. Звідси розбіжності у мовах описи та способах зберігання описів у системі. Відповідно для кожного виду пошуку існують свої пошукові засоби.
Фактографічні системи передбачають накопичення та пошук у масиві документів зі строго регламентованою структурою. Така структура є результатом попередньої інтелектуальної обробки документів при введенні інформації в систему, або наявністю таких документів у готовому вигляді в конкретних сферах людської діяльності, наприклад, облікові форми, бланки, довідники, розклади тощо. Існують фактографічні ІПС, які забезпечують накопичення інформації та пошук лише за одним типом об'єктів і лише за одним типом запитів. Існують і більш розвинені фактографічні системи, що забезпечують зберігання та пошук даних, різноманітних за змістом та структурою, але ця різноманітність завжди звичайно.
Водночас між документальними та фактографічними системами немає непереборної різниці. Нерідко реальні ІПС є прикладом змішаних систем, у яких фактографічна інформація використовується як додатковий засіб документального пошуку, і навпаки. У документальних системах тексти (документи) можуть бути структуровані, розбиті на фрагменти чи поля, і обробка і видача документальної інформації може проводитися лише на рівні окремих полів.
Вирізняють ще й третій тип систем, які називають інформаційно-логічними. Це системи, що відповідають на запити, на які в інформаційній базі явному виглядівідповіді немає. Отримати відповідь допомагає екстралінгвістична база знань та інформація, що породжується алгоритмічно з наявної (документальної або фактографічної). Ця Нова інформаціяабо видається як відповідь на запит, або додатково використовується для пошуку.
Інформаційно-пошукова система документального типу є упорядкованою сукупністю документів, а також сукупністю засобів і методів, призначених для зберігання, пошуку та видачі за запитами документальної інформації. Документальна ІПС видає документи, які відповідають запиту на тему, на предмет. Документ, центральний предмет чи тема якого загалом відповідає змістовому інформаційного запиту, називається релевантним , а властивість смислової близькості між двома та більше текстами (в даному випадку - між документом та інформаційним запитом) - релевантністю . Релевантність – це фундаментальне поняття теорії інформаційного пошуку. Говорять про два види релевантності: смислову та формальну. Відповідність документа змісту інформаційного запиту називають смисловою релевантністю, а відповідність пошукового образу цього документа формалізованому пошуковому припису, що виражає даний інформаційний запит, - формальною релевантністю. Також формальну релевантність називають релевантністю документа, а смислову релевантність – релевантністю інформації (мається на увазі «інформації, що міститься в документі»).
Складові ІПС називають підсистемами. Поділ на підсистеми необхідний і корисний як у цілях розробки, так описи технології функціонування систем. Воно може мати різну основу. Зазвичай розглядають два типи розбиття ІПС на підсистеми: за функціональним принципом (функціональні підсистеми) та за типом засобів (підсистеми, що забезпечують).
Різні засоби, що реалізують функції ІПС, отримали назву забезпечують підсистем , чи «забезпечень». Виділяють такі підсистеми: лінгвістичне забезпечення, інформаційне забезпечення, технічне забезпечення, програмне забезпечення, технологічне забезпечення, кадрове забезпечення та ін.
Інформаційне забезпечення - це інформаційні масиви (документи, запити, метадані), а також засоби та способи їх опису, побудови та класифікації.
Лінгвістичне забезпечення - це логіко-семантичний апарат, що складається з інформаційно-пошукової мови, правил застосування (методик індексування), критерію видачі та інших мовних засобів.
Програмне забезпечення - це алгоритми та програмні засоби, що реалізують всі функції ІПС, які виконуються за допомогою комп'ютера.
Технічне забезпечення - це технічні засоби (комп'ютери, засоби телекомунікацій), що забезпечують зберігання, пошук та передачу інформації.
Технологічне забезпечення - це набір та порядок виконання автоматизованих та неавтоматизованих процесів та процедур обробки інформації в ІПС, включаючи їх опис, інформаційно-технологічні схеми та інструктивно-методичні матеріали.
Кадрове (або штатне) забезпечення - це люди, що взаємодіють із системою та забезпечують її експлуатацію (обслуговуючий персонал).
ІПС також ділять на складові (підсистеми) за функціональною ознакою, коли кожна підсистема виконує певну функцію в технологічному процесі: введення документів, індексування документів, введення та коригування запитів, індексування запитів, пошук, ведення словників, ведення статистики, обробка результатів пошуку, видача документів та ін. Такі частини отримали назву функціональних підсистем .
Важливі поняття в інформаційному пошуку – документ та запит. Документ визначається як засіб закріплення будь-яким способом на спеціальному матеріалібудь-якої інформації про факти, події, явища об'єктивної дійсності та розумової діяльності людини. Документи мають різну форму подання. У автоматизованих документальних ІПС це насамперед текстова інформація природними мовами в машиночитаній формі.
Запит являє собою інформаційну потребу, сформульовану природною мовою. Результат «перекладу» інформаційного запиту інформаційно-пошуковою мовою називають пошуковим чином запиту (ПОЗ) або пошуковим розпорядженням (ВП). Під цим розуміють вираз на мовою запитів , Який включає в себе як власне ІСЯ, так і засоби управління пошуком. Синтаксис та семантика мов запитів визначається структурою та наповненням документів та загальними завданнями системи.
Третя частина інформаційного забезпечення – так звана «видача», результати пошуку. Видача існує у двох видах: короткі описидокументів та власне документи.
Найважливішою компонентою інформаційно-пошукових систем є інформаційно-пошукова мова. Людина, щоб відібрати з масиву потрібні документи, повинна прочитати або переглянути їх вміст. Для прискорення та спрощення цієї процедури з'явилися різні форми скороченого запису змісту документів – анотації, реферати, каталоги. Але у всіх цих випадках при відборі документів за їх скороченими описами використовується природна мова. Добре відомі такі недоліки мовних знаків, як омонімія, синонімія, багатозначність. Точне значення багатьох слів можна зрозуміти лише у контексті. Це перешкоджає використанню природної мови для фіксації та ототожнення понятійної інформації. Тому формальні системи, призначені для зберігання документальної інформації з метою подальшого пошуку, вимагали створення спеціальних інформаційних мов. Інформаційно-пошукові мови є знаковими системами зі своїм алфавітом, лексикою, граматикою та правилами користування. Зауважимо лише, що всі штучні мови так чи інакше створювалися та створюються на основі природних мов.
При зіставленні документів та запитів потрібно визначити релевантність документа стосовно запиту та ухвалити рішення про видачу або невидачу документа на даний запит. Правила, на основі яких формально визначається ступінь релевантності документа та запиту, тобто. відповідність ПІД та ПОЗ, називаються критерієм смислової відповідності (КСС), або критерієм видачі .
Математичні моделі і формули обчислення коефіцієнта релевантності можуть бути різні. На практиці повсюдне поширення набули ІПС з логічним критерієм видачі , коли ПП будуються з використанням логічних (бульових) операторів кон'юнкції (&), диз'юнкції (\/), заперечення (~). У цьому випадку логічне вираз запиту є набором пошукових елементів (зазвичай ключових слів), об'єднаних логічними операторами і дужками, необхідними для вказівки порядку виконання операторів. Ключові слова ПП відіграють роль булевих змінних, що приймають значення 1 («істина»), якщо це слово міститься в документі, і 0 («брехня»), коли воно там відсутнє. Документ визнається релевантним запиту, якщо логічна формула запиту загалом отримує для цього документа значення «істина», і нерелевантним, якщо результат обчислення логічної формули дає «брехня».
Прийняті в логіці для позначення кон'юнкції, диз'юнкції та заперечення значки (&, \/, ~) в інформаційному пошуку зазвичай замінюють на оператори AND, OR та NOT відповідно. У Росії частіше використовуються позначення І, АБО, НЕ. Однак у загальному випадку в кожній конкретній ІПС позначення для булевих операторів вибираються свої, причому іноді для зручності користувача вводиться кілька значків для одного і того ж оператора (наприклад, в ІПС «Апорт» оператор кон'юнкції може бути заданий такими знаками: &, пробіл, AND , І, +).
Використання булевих операторів забезпечує логіку порівняння документів та запитів, зрозумілу користувачеві. Пошук (обчислення істинності для елементів ПП), як правило, проводиться за спеціальними індексними (інвертованими) файлами, побудованими на основі словника документального масиву, і характеризується високою швидкістю. Ці простота і зрозумілість логічного КСС і стали причиною його поширеності.
Проблема оцінки ефективності пошуку є комплексною проблемою, що включає як теоретичну, і практичну сторону. Головні з функціональних (технічних) показників ІПС, що базуються на релевантності, - це повнота та точність, що ґрунтуються на поділі документів на релевантні та нерелевантні, а також на видані та невидані.
Повнотою пошуку (П) (англ. Recall - R) називається міра, що обчислюється як відношення кількості виданих релевантних документів до загальної кількості релевантних документів, які у інформаційному масиві.
Точність пошуку (Т) (англ. Precision - P) - це відношення кількості виданих релевантних документів до загальної кількості документів у видачі.
1.2. Інформаційний пошук у мережі Інтернет
Перехід до інформаційного суспільства XXI століття породив безпрецедентне зростання обсягів та концентрації інформації у глобальних комп'ютерних мережах. Це різко загострило проблему створення інформаційно-пошукових систем (ІПС) та їхнього ефективного використання.
Історія автоматизованих інформаційно-пошукових систем обчислюється півстоліттям. Типова ІПС перших років – це людино-машинна система, де аналіз та опис змісту документів (індексування) виконується вручну, а пошуки проводяться машиною. Спочатку основу ІПС складали інформаційно-пошукові мови (ІПЯ), основним елементом яких є дескрипторні словники та тезауруси. Сьогодні, однак, більшість ІПС, що працюють, відноситься до класу вербальних систем безтезаурусного типу, коли індексаційні терміни вибираються безпосередньо з текстів документів. Лавиноподібне зростання обсягів електронної документальної інформації, її видове, тематичне та мовне розмаїття є як причиною кризи сучасного інформаційного пошуку, так і стимулом її вдосконалення.
Проблема пошуку ресурсів у мережі Інтернет була усвідомлена досить швидко, і у відповідь з'явилися різні системи та програмні інструменти для пошуку, серед яких слід назвати системи Gopher, Archie, Veronica, WAIS, WHOIS та ін. Останнім часомна зміну цим інструментам прийшли «клієнти» та «сервери» всесвітньої павутини WWW.
Якщо спробувати дати класифікацію ІПС мережі Інтернет, можна виділити такі основні типи:
1. ІПС вербального типу (пошукові системи – search engines)
2. Класифікаційні ІПС (каталоги – directories)
3. Електронні довідники («жовті» сторінки тощо)
4. Спеціалізовані ІПС з окремим видамресурсів
5. Інтелектуальні агенти.
Глобальний облік усіх ресурсів Інтернету забезпечується вербальними та частково класифікаційними системами.
Класифікаційні ІПСреалізують навігацію у веб-просторі на основі спеціальних покажчиків, що становлять тематичні «дерева», що будуються на основі класифікацій. Схеми класифікації ресурсів у Інтернеті - це, зазвичай, дерев'яні структури, вузли яких названі словами природної мови. Різні класифікаційні схеми відрізняються один від одного за обсягом та методологією їх складання. Одним із недоліків універсальних ієрархічних класифікацій є те, що вони консервативні та відстають від розвитку науки, техніки та життя взагалі. Головна проблема класифікаційних пошукових служб – це автоматизація класифікації. Досі завдання автоматичної класифікаціїзадовільного рішення не знайшла. Реєстрація веб-сайтів та веб-сторінок у каталогах, як правило, здійснюється людьми - індексаторами та модераторами даної системи. І тому обсяг бази даних систем класифікаційного типу порівняно невеликий проти інформаційної ємністю всього Інтернету.
Для вирішення проблеми максимального охоплення ресурсів Інтернету створюються системи, які називаються метапошуковими(metasearch engines). Вони не мають власних пошукових баз даних, не містять жодних індексів та при пошуку використовують ресурси інших пошукових систем. За рахунок цього ймовірність знаходження потрібної інформації зростає. Для передачі запиту до пошукової системи використовується спеціальний метапошуковий агент, який відповідає за процес ретрансляції запиту інші системи. Після обробки отриманого запиту кожна система повертає метапошуковому агенту безліч описів та посилань на документи, які вважає релевантними даному запиту. При всій привабливості метапошукових систем слід пам'ятати і про їх мінуси та недоліки. Насамперед відсутність єдиного стандартумови запитів не дозволяє метасистемам домагатися від пошукових систем, що виконують запити метапошукових систем, такого ж результату, якого може досягти досвідчений користувачпід час роботи з кожною машиною окремо.
Основним засобом пошуку інформації в мережі сьогодні слід вважати глобальні ІПС вербального типу(search engines), що індексують (по Крайній мірі, що претендують на це) весь Інтернет-простір. До основних пошукових систем цього типу (насамперед, за обсягом бази даних) можна віднести Google, Fast (AlltheWeb), AltaVista, HotBot, Inktomi, Teoma, WiseNut, MSN Search. Серед російських системголовними є три: Яндекс (Yandex), Рамблер (Rambler) та Апорт! (Aport). Повнота пошукової бази та оперативність індексування веб-сайтів є головною проблемою всіх ІПС в Інтернеті. Як правило, системи з більшим обсягом бази дають в результаті пошуку та Велика кількістьдокументів. Велика, як лінгвістична, і програмна проблема - багатомовність інформаційного простору Інтернету і різноманітність форматів представлення даних. Проте основні глобальні системи з цими проблемами справляються.
Саме вербальним ІПС і приділено основну увагу у практичній частині посібника. Перш за все, моделюється рівень користувача, що виражається в мовах запитів і в запитально-відповідних інтерфейсах. Здійснюється порівняльний аналіз мов запитів різних ІПС мережі Інтернет.
Особливість сучасних систем- Повнотекстовий пошук. Багато вербальних ІПС мережі Інтернет обчислюють релевантність документів запитам шляхом зіставлення елементів запиту з повними текстами документів, розміщених у мережі. Що стосується інформаційно-пошукової мови, то, як правило, як пошукові елементи виступають звичайні словаприродних мов. Запити формулюються через спеціальний інтерфейс, реалізований як екранних форм у програмах-броузерах.
Корисно уявляти, як ці системи влаштовані. У складі будь-якої пошукової системи можна виділити три основні частини.
Робот - підсистема, що забезпечує перегляд (сканування) Інтернету та підтримку інвертованого файлу (індексної бази даних) у актуальному стані. Цей програмний комплекс є основним засобом збору інформації про наявність та стан інформаційних ресурсів мережі.
Пошукова база даних - так званий індекс -спеціальним чином організована база (англ. index database), що включає, перш за все, інвертований файл, що складається з лексичних одиниць, взятих із проіндексованих веб-документів, і містить різноманітну інформацію про них (зокрема, їх позиції в документах), а також про самі документи та сайти в цілому.
Пошукова система - підсистема пошуку, що забезпечує обробку запиту (пошукового припису) користувача, пошук у базі даних та видачу результатів пошуку користувачеві. Пошукова система спілкується з користувачем через інтерфейси користувача- екранні форми програм-броузерів: інтерфейс формування запитів та інтерфейс перегляду результатів пошуку.
Індексний файл (або просто індекс) є набором пов'язаних між собою файлів, орієнтованих на швидкий пошук даних за запитом. В основі індексу лежить інвертований файл. Інвертована (інверсна) схемаОрганізація пошукового масиву заснована на принципі забезпечення доступу до документів через їх ідентифікатори змісту (пошукові ознаки: дескриптори, ключові слова, терміни, інші ознаки). Таку схему отримують шляхом обробки послідовного масиву документів для створення спеціальних допоміжних інвертованих файлів - точок доступу.
Кожен запис такого допоміжного масиву ідентифікований відповідним ідентифікатором змісту (дескриптор, ключове слово, просто термін, ім'я автора, назва організації тощо) та містить імена (адреси зберігання) всіх документів, у пошукових образах яких він міститься. Для кожного ідентифікатора змісту (пошукового елемента даних) в інвертованому масиві разом з адресою (номером, ім'ям) документа може зберігатися (і зазвичай зберігається) додаткова інформація, наприклад: ім'я поля, номер пропозиції, у складі яких даний елемент зустрівся в даному документі, номер слова у реченні і т.д. Фіксація положення слова в тексті з точністю до номера речення та номера цього слова в реченні дозволяє побудувати гнучку мову запитів, що дозволяє задавати відстань між словами та реченнями в документі. Позиційні характеристики також використовуються при обчисленні коефіцієнта релевантності та ранжирування документів у видачі.
Знаходження необхідних документівчерез инвертированный файл здійснюється не суцільним переглядом всього масиву, а переглядом лише ідентифікаторів змісту в инвертированном файлі, які в пошуковому розпорядженні, тобто. число операцій порівняння слів під час пошуку пропорційно числу термінів пошукового розпорядження. Такий спосіб роботи систем знижує час на пошук і дозволяє обслуговувати споживачів інформації у реальному масштабі часу.
Пошук в індексі - це операції над списками ідентифікаторів пошукових елементів відповідно до моделі пошуку та критерієм відповідності. Результуючий список релевантних документів (у сучасній термінології «відгук»), який перетворюється на ранжований список коротких описів документів, з гіпертекстовими посиланнями та іншими характеристиками, повертається користувачеві в його клієнтську програму-броузер. Клацніть мишею за назвою документа в його короткому описі (по гіперпосиланню) запитує цей документ або безпосередньо з сервера, на якому він знаходиться, або через базу даних пошукової системи.
Важливим компонентом сучасних ІПС є звані інтерфейсні веб-сторінки, тобто. екранні форми, якими користувач спілкується з пошуковою системою. Розрізняють два основні типи інтерфейсних сторінок: сторінки запитів та сторінки результатів пошуку.
індексування повних текстів можливе більшого числасайтів;
«грамотна» робота зі словоформами - здатність ІПС ототожнювати різні словоформи однієї і тієї ж лексеми, по-іншому, породжувати канонічну форму - лему, і можливість виділяти серед множини словоформ конкретну форму;
пошук слів із заданим або довільним усіченням, як правим, так і лівим;
робота зі словосполученнями - облік відстані між словами у словосполученнях та порядку їхнього прямування;
ефективні алгоритми обчислення коефіцієнта смислової релевантності та ранжування результатів пошуку.
Також важливо, яку інформацію та в якому вигляді можна отримати з вихідних інтерфейсів ІПС. Інтерфейс видачі (форма подання результатів) у різних системвключає такі параметри: статистика слів із запиту, кількість знайдених документів, кількість сайтів, засоби управління сортуванням документів у видачі, короткий опис документів та ін. Опис кожного документа, у свою чергу, може містити у своєму складі: назву документа, URL мережі), обсяг документа, дату створення, назва кодування, анотацію, шрифтове виділення в анотації слів із запиту, вказівку на інші релевантні веб-сторінки того ж сайту, посилання на рубрику каталогу, до якої відноситься знайдений документ або сайт, коефіцієнт релевантності, інші можливості пошуку (пошук схожих документів, пошук у знайденому). Великий інтерес становлять також частотні характеристики- відомості про кількість знайдених документів та ототожнених мовних одиниць. Деякі системи ведуть журнал запитів із можливістю повторних пошуків та видачею статистики за запитами. Корисний та цікавою можливістює також віднесення документів до тематичних класів.
Покажемо особливості різних систем, що найбільш популярні і мають найбільш розвинене лінгвістичне забезпечення (див. Табл., с. 14). Насамперед, це російські ІПС Яндекс, Рамблер та Апорт. Можливо, найбільш потужний лінгвістичний апарат має ІПС «Артефакт» (фірма «Інтегрум-ТЕХНО», м. Москва), проте ця система є комерційною та її база даних за складом помітно відрізняється від інших. Із західних систем, які здебільшого не мають розвинених лінгвістичних засобів аналізу текстового матеріалу, візьмемо добре відомі ІПС Google і AltaVista. Коротко охарактеризуємо особливості цих систем (наявність чи відсутність відповідних можливостей позначено знаками "+" та "-").
«Пошук за лексемами» означає, що результат порівняння слів документів та запитів визнається позитивним за наявності у документі будь-якої форми слова із запиту, що забезпечується механізмом автоматичної лематизації.
«Пошук за словоформами» означає, що результат порівняння документів та запитів визнається позитивним за наявності в документі словоформи, що точно збігається зі словом із запиту, що відбувається за відсутності автоматичної лематизації або забезпечується особливим механізмом обліку словоформ.
"Частота підокументна" означає, що в результаті пошуку видається повідомлення про кількість релевантних документів, тобто документів, що містять це слово (словоформу) або словосполучення.
"Частота пословна" означає, що в результаті пошуку додатково видаються відомості про загальну кількість слововжитків даної лексеми або конкретної словоформи в пошуковій базі даних (індекс).
Характеристика пошукових систем
Пошук за лексемами | + (однослівний запит або логічна формула) | ||||
Пошук за словоформами | + (у синтагмах: однослівний запит у лапках або словосполучення в лапках) | ||||
Облік синтагм (нерозривних словосоч.) | |||||
Облік великих і малих букв | + (У синтагмах) | ||||
Частота пословна | |||||
Частота підокументна |
1.3. Мови запитів ІПС Інтернет
Звернувшись до будь-якої служби, користувач, не виходячи з броузера, працює з «клієнтом» цієї служби, що надає нам ту чи іншу мову запитів. Зазвичай, це мови без контролю лексики. Фактично ми маємо справу з нормальним ІПЯ, реалізованим в архітектурі «клієнт-сервер», але бачимо лише «надводну» частину цього ІПЯ – мову запитів. Мова запитів більшості систем включає як традиційні булеви оператори, так і спеціальні контекстні оператори, що враховують структурування документа, порядок слів в тексті і відстань між словами.
Мовою запитів описується сам запит і іноді форма подання результатів. У мовах запитів мережевих ІПС можна виділити такі основні компоненти.
1) Власне пошукові елементи (об'єкти пошуку).
Це чи ключові слова, чи інші ідентифікатори змісту.
2) Пошукові оператори.
Майже у всіх мовах запитів використовуються булевські. логічні операториІ, АБО, НІ. Форма, в якій ці оператори задаються в запиті, різна, і відрізняється вона як в окремих службах, так і в різних типахзапитів (простий, складний).
3) Нормалізація елементів запиту.
Одні й самі лексичні одиниці у документах і запитах може бути представлені у різній формі. У пошукових службах є методи нормалізації таких лексичних одиниць. Ця нормалізація може задаватися самим користувачем (спосіб, відомий під назвою "усічення" (truncation) або "маскування" (wildcards)) або виконуватися автоматично (останнє краще).
4) Лінійна граматика: порядок проходження пошукових елементів та відстань між ними.
По-перше, це «фрази» (жорсткі словосполучення).
По-друге, є спеціальні контекстні оператори (контекстне І), коли умова спільного входження елементів запиту документ повинен виконуватися у контексті певної довжини.
5) Додаткові умови пошуку.
Для зменшення обсягу видачі та підвищення точності використовуються різні додаткові умовипошуку, якось:
– пошук у певних полях (частинах) документа;
– обмеження області пошуку різними критеріями (дата, тип даних, формат тощо).
6) Вимоги до форми подання результатів пошуку.
– вимоги на сортування (ранжування) результатів пошуку, що видаються;
– вид результатів, що видаються;
– кількість документів, що видаються.
Для отримання (перегляду) самих документів (веб-сторінок) та їх перегляду необхідно надіслати за адресою http. Як правило, системи надають можливість переглянути контекст - фрагменти документів з виділеними ключовими словами запиту.
У процесі пошуку користувачеві, як правило, дається можливість повернутися до старого запиту або просто уточнити, звузити його, або перейти в інший режим пошуку, що надає складніші пошукові засоби. Досить широко поширений ще один спосіб пошуку - пошук за зразком (search similar pages). У цьому стратегія пошуку вибирається самої системою.
2. Програма навчальної дисципліни
"Теорія інформаційного пошуку"
2.1. Організаційно-методичний розділ
Програма дисципліни складена відповідно до державного освітнього стандарту вищої професійної освіти за напрямом 021800 - Лінгвістика.
Ціль курсуполягає в тому, щоб дати студентам теоретичні основи інформаційного пошуку, в першу чергу, документального та навички використання різних документальних ІПС, у тому числі в мережі Інтернет.
Завдання курсу:
ознайомити студентів з основними поняттями та проблемами автоматизованого інформаційного пошуку;
ознайомити студентів з основними принципами організації та функціонування інформаційно-пошукових систем (ІПС);
вивчити різні ІПС, зокрема ІПС мережі Інтернет;
сформувати навички дослідницької роботи з аналізу та зіставлення різних систем.
Місце курсу у професійній підготовці випускника:курс має пропедевтичний характер. Він розрахований на широке коло студентів-гуманітаріїв і покликаний дати їм основне уявлення про способи зберігання та пошуку інформації.
Вимоги до рівня освоєння змісту курсу
В результаті навчання студент:
повинен знати:
основні поняття, що належать до інформаційних систем;
основні типи систем;
поняття інформаційно-пошукової мови;
поняття релевантності та критерію смислової відповідності;
основні пошукові системи Інтернету;
мови запитів та інтерфейси цих систем;
повинен вміти:
здійснювати пошук у мережі Інтернет;
порівнювати та аналізувати різні системи.
Розділи курсу:
Основи інформаційного пошуку
Документальні ІПС
Фактографічні ІПС
Інформаційний пошук у мережі Інтернет
Розділ 1. Основи інформаційного пошуку
Предмет, цілі та завдання курсу. Зв'язок курсу з іншими дисциплінами.
Інформація, інформаційні процеси, інформаційні системи, інформаційні потоки, інформаційні технології. Типи інформаційних систем (АІПС, АСНТІ, АСУ, АСНІ, АОС, САПР, ЕС, БЗ та ін.).
Основні поняття інформаційного пошуку: інформація, інформаційна система, інформаційна потреба, релевантність.
Дані та документи. Види інформаційних документів. Текстові документи Опис документів.
Запити. Типи запитів. Предметний пошук. Основні проблеми автоматизації семантичних процесів обробки інформації.
Інформаційно-пошукові системи (ІПС). Типи ІПС. Короткий оглядОсновні типи: документальні, фактографічні, інтелектуальні.
Бібліографічний пошук. Бібліографічні бази даних та електронні каталоги. Бібліотечні системи.
Нетекстові інформаційні системи (географічні, картографічні та ін.). Пошук об'єктів за їх описами ( графічні файли, музичні файлиі т.п.). Пошук зображень та відеоінформації.
Розділ 2. Документальні ІПС
Історія розвитку автоматизованих документальних ІПС, етапи розвитку. Інтегровані системи. АСНТІ. Особливості сучасного етапу.
Складові ІПС. ІПЯ. . Моделі пошуку. Абстрактна та конкретна ІПС.
Структура документальних та фактографічних ІПС. Функціональні підсистеми. Структурна схемадокументальної ІПС.
Двоконтурні системи. Повнотекстові ІПС. Гіпертекстові інформаційні системи.
Підсистеми, що забезпечують. Технічне забезпечення. Програмне забезпечення. Комп'ютерні мережі. Особливості побудови мережевих ІПС.
Математична модель документальної ІПС.
Організація пошукових масивів в ІПС.
Класифікація документальних ІПС з різних підстав.
Розділ 3. Фактографічні ІПС
Фактографічна інформація. Добре структурована та погано структурована фактографічна інформація.
Об'єктно-характеристичні таблиці.
Мова семантичної експлікації.
Ефективність фактографічних ІПС.
Бібліографічний пошук як вид фактографічного.
Розділ 4. Лінгвістичне забезпечення інформаційного пошуку
Лінгвістичні засоби інформаційного пошуку. Склад лінгвістичного забезпечення ІПС.
Поняття інформаційно-пошукової мови (ІПЯ). ІСЯ як основний елемент логіко-семантичного апарату ІПС.
Інформаційно-пошукові мови: класифікація, типологія. Об'єктно-ознакові мови. класифікації. Алфавітно-предметні та фасетні класифікації.
Дескрипторні мови. Вербальні мови.
Семантичні та синтагматичні мови.
Способи опису мов. Складові дескрипторних інформаційно-пошукових мов (алфавіт, словник, граматика).
Нормування лексики в ІПС. Дескрипторні словники. Тезаурус. Створення словників та тезаурусів. Авторитетний контроль як елемент лінгвістичного забезпечення автоматизованих бібліотечних систем.
Граматичні засоби ІСЯ. Парадигматичні та синтагматичні відносини.
Індексування документів та запитів. Пошукові образи документів та запитів.
Мови запитів: поняття та склад. Засоби та методи вираження інформаційної потреби. Пошукові розпорядження.
Моделі пошуку. Пошукові оператори.
Засоби морфологічної нормалізації.
Мовні засобиподання та структурування електронних документів (формати, мови SGML, HTML, XML). Мови мета-даних (Dublin Core, GILS та інших.).
Лінгвістичне забезпечення фактографічних ІПС. Основні одиниці ІПС фактографічних ІПС.
Розділ 5. Функціонування та експлуатація ІПС
Інформаційне, технологічне та кадрове забезпечення.
Технологія передмашинної обробки інформації. Індексування документів та запитів. Особливості пошуку, залежно від видів документів.
Режими функціонування ІПС (ІРІ, ретроспективний пошук). Пакетний та діалоговий режими.
Основні технічні характеристики документальних ІПС (повнота, точність). Чинники, що впливають на ефективність пошуку. Оцінки ефективності ІПС.
Засоби та методи вирішення лексико-семантичних проблем в ІПС. Проблеми складання пошукових розпоряджень. Зворотний зв'язок з релевантності.
Забезпечення результатів пошуку первинними документами. Електронна доставкадокументів.
Розділ 6. Інформаційний пошук у мережі Інтернет
Значення комп'ютерних мереждля організації інформаційного обслуговування. Способи та засоби доступу до віддалених документальних масивів. Протокол Z39.50 (Search/Retrieval).
Інтернет, її коротка характеристика. Інтернет як електронна транспортна система. Інтернет як глобальний інформаційний простір.
Інформаційні ресурси Інтернету. FTP сервери. GOPHER. WAIS.
Концепція гіпертексту. Гіпертекстові системи до Інтернету. WWW-сервери. Навігація у мережі. Проблеми пошуку інформації.
Документальні джерела. Електронні документи Формати подання текстової інформаціїу мережі (html, pdf, ps, doc та ін.). Електронні видання.
Нетекстові інформаційні об'єкти. Концепція електронної бібліотеки.
Типологія пошукових систем у мережі Інтернет. Різні підстави для класифікації (за шириною охоплення, внутрішніми характеристиками, за видами документів).
Типологія пошукових систем Інтернет. Класифікаційні інформаційно-пошукові системи (каталоги). Вербальні (текстові, словникові) інформаційно-пошукові системи ( пошукові машини).
Глобальні інформаційно-пошукові системи та служби Інтернету.
Природні мови в Інтернеті. Регіональні ІПС. Регіональні версії світових систем. Російськомовний Інтернет.
Методи створення пошукових баз даних у глобальних системах. Індексування та реєстрація. Роботи-індексатори. Інструменти керування індексуванням (файл robots.txt, META-елементи).
Особливості лінгвістичного та інформаційного забезпечення ІПС в Інтернет. Вербальні ІПС. Граматичні засоби ІСЯ: синтагматика. Контекстно-позиційні оператори («фрази», оператори відстані та інших.).
Проблеми ранжирування документів у видачі. Способи керування ранжуванням.
Вхідні інтерфейси. Мови запитів (прості, розширені). Їхній склад, приклади. Порівняльний аналізмов запитів ІПС мережі Інтернет. Збереження запитів (історія сеансу).
Вихідні інтерфейси. Подання результатів пошуку. Опис документів (сторінок), опис сайтів. Групування документів на сайтах. Ідентифікація та об'єднання дублів.
Управління пошуком. Статистика пошуку. Пошук у знайденому. Пошук за подобою.
Приклади вербальних ІПС. Порівняльний аналіз пошукових систем.
Практикум з налагодження запитів та пошуку у вербальних ІПС.
Класифікаційні ІПС. Способи формування бази даних у класифікаційних системах. Реєстрація, спеціальні реєстраційні сайти. Пошук за рубрикатором.
Практикум з пошуку у класифікаційних ІПС.
Розділ 7. Сьогодення та майбутнє інформаційного пошуку
Комерціалізація Інтернету загалом та пошукових служб зокрема. Реклама. Плата за прискорену реєстрацію.
Розвиток локальних ІПС.
Проблеми уніфікації та стандартизації.
Засоби зворотний зв'язок. Неформальні «пошукові спільноти».
Розвиток лінгвістичного забезпечення.
Системи з централізованою та децентралізованою розподіленою архітектурою.
Інтелектуалізація інформаційного пошуку. Інтелектуальні інформаційні системи.
Елементи інтелектуальної обробки в глобальних ІПС мережі Інтернет. Інтелектуальні агенти
Мови метаданих, мови XML, RDF, OWL та інші засоби опису змісту.
2.3. Зразкові питаннядля самоконтролю
Дати визначення:
Критерій видачі
Релевантність
Тезаурус
Складові частини ІПС
Склад лінгвістичного забезпечення
Інверсний файл
Вибрати правильні варіанти відповідей
Знак «&» в ІПС Рамблер означає операцію:
диз'юнкції (АБО)
кон'юнкції (І)
відстані
Знак «|» в ІПС Яндекс означає операцію:
слідування
кон'юнкції (І)
диз'юнкції (АБО)
Функціональні підсистеми ІПС - це:
лінгвістичне забезпечення
програмне забезпечення
технічне забезпечення
введення документів
введення запитів
критерій смислової відповідності
мова запитів
видача результатів пошуку
інвертовані файли
Типи ІПЯ - це:
морфологічні мови
дескрипторні мови
семантичні мови
класифікаційні мови
вербальні мови
вторинні мови
об'єктно-ознакові мови
Основні способи морфологічної нормалізації в ІПС:
на основі автоматичного морфоаналізу
усічення
маскування
префіксація
Критерій смислової відповідності – це:
правила індексування
правила нормалізації
правила обчислення повноти
методи ранжирування
методи класифікації
Індексування – це:
морфологічна нормалізація
складання пошукового образу
переклад на мову математичної логіки
переклад на ІПЯ
обчислення релевантності
складання дескрипторного словника
Підсистеми ІПС, що забезпечують, - це:
лінгвістичне забезпечення
програмне забезпечення
технічне забезпечення
введення документів
введення запитів
критерій смислової відповідності
пошукові розпорядження
видача результатів пошуку
інвертовані файли
Типи ІПЯ:
об'єктно-ознакові мови
класифікаційні мови
морфологічні мови
семантичні мови
вербальні мови
вторинні мови
дескрипторні мови
Критерій видачі – це:
правила індексування
правила нормалізації
правила обчислення релевантності
правила обчислення повноти
методи ранжирування
методи класифікації
2.4. Прикладна тематика доповідей, рефератів
курсових робіт
Аналіз та опис ІПС мережі Інтернет (вибір системи за погодженням з викладачем)
Створення термінологічного банку даних за інформаційно-пошуковими системами (виявлення, класифікація термінів і тлумачень; результат - гіпертекстовий словник-покажчик або пошукова база даних)
Дослідження способів використання онлайнових словників та тезаурусів (наприклад, WordNet) для індексування запитів в інформаційно-пошукових системах
Аналіз та опис механізмів морфологічної нормалізації в інформаційно-пошукових системах
Врахування синтагматичних зв'язків як засіб підвищення ефективності пошуку в повнотекстових ІПС (експериментальне дослідження)
Обчислення релевантності в інформаційно-пошукових системах (експериментальне дослідження)
Аналіз досліджень порівняльної ефективності повнотекстових інформаційно-пошукових систем
Аналіз лінгвістичного забезпечення повнотекстових інформаційно-пошукових систем
Аналітичний огляд публікацій електронного журналу з інформаційно-пошукових систем Search Engine Report
2.5. Зразковий перелік питань до іспиту
(заліку) по всьому курсу
Абстрактна та конкретна (реальна) ІПС
Вербальні інформаційно-пошукові системи (пошукові машини). Їхня архітектура. Приклади вербальних ІПС
Глобальні та регіональні ІПС у мережі Інтернет. Приклади
Граматичні засоби ІСЯ. Способи вираження граматичних відносин
Дескрипторні словники. Тезауруси
Документальна інформація у мережі Інтернет. Текстові документи Мовні засоби подання та структурування документів (під кутом пошуку)
Індексування документів та запитів. Автоматизація індексування
Інтелектуальні інформаційні системи
Інтернет як глобальне інформаційне середовище. Інформаційні ресурси мережі. Проблеми пошуку в Інтернеті
Інформаційна потреба, інформаційний запит, пошуковий розпорядження
Інформаційно-пошукові системи (ІПС). Типи ІПС. Короткий огляд основних типів
Інформаційно-пошукові мови: класифікація, типологія
ІПЯ. Дескрипторні мови. Вербальні мови
ІПЯ. Класифікаційні мови
Історія розвитку автоматизованих документальних ІПС, етапи розвитку. Особливості сучасного етапу
Класифікаційні інформаційно-пошукові системи (каталоги). Приклади класифікаційних ІПС
Класифікація документальних ІПС з різних підстав
Критерій смислової відповідності. Моделі пошуку
Лінгвістичні засоби інформаційного пошуку. Склад лінгвістичного забезпечення ІПС
Методи створення пошукових баз даних у глобальних системах (індексування, реєстрація)
Морфологічна нормалізація лексики в ІПС
Підсистеми, що забезпечують
Об'єктно-ознакові мови
Організація пошукових масивів в ІПС
Основні технічні характеристики документальних ІПС (повнота, точність)
Поняття інформаційно-пошукової мови (ІПЯ). Класифікація (типологія) ІПЯ
Поняття «інформація» та «система». Інформаційні процеси та системи. Типи інформаційних систем
Проблеми багатомовного пошуку Інтернет. Способи вирішення різних ІПС
Проблеми пошуку документів російською. Російсько-мовні ІПС
Проблеми складання пошукових розпоряджень. Зворотний зв'язок з релевантності
Змішані (гібридні) системи. Метапошукові системи. Приклади
Складові дескрипторних інформаційно-пошукових мов
Складові ІПС. Системні взаємозв'язки між елементами ІПС
Сутність документального інформаційного пошуку. Поняття релевантності
Семантичні мови
Технологія та режими функціонування ІПС. Двоконтурні ІПС
Типологія пошукових систем в Інтернет
Фактографічні ІПС
Функціонально-структурна схема ІПС. Функціональні підсистеми
Мова запитів ІПС "Altavista". Інтерфейс представлення результатів пошуку
Мова запитів ІПС Google. Інтерфейс представлення результатів пошуку
Мова запитів ІПС "Апорт". Інтерфейс представлення результатів пошуку
Мова запитів ІПС "Рамблер". Інтерфейс представлення результатів пошуку
Мова запитів ІПС «Яндекс». Інтерфейс представлення результатів пошуку
Мови запитів сучасних інформаційно-пошукових систем. Порівняльний аналіз
Мови запитів. Пошукові розпорядження.
2.6. Розподіл годинника курсу за темами
та видами роботи
Найменування тем | Аудиторні В тому числі | Самостійна робота |
|||
Семінари | |||||
Основи інформаційного пошуку | |||||
Документальні ІПС | |||||
Фактографічні ІПС | |||||
Лінгвістичне забезпечення інформаційного пошуку | |||||
Функціонування та експлуатація ІПС | |||||
Інформаційний пошук | |||||
Сьогодення та майбутнє інформаційного пошуку | |||||
РАЗОМ: | |||||
2.7. Форма поточного, проміжного та підсумкового контролю
Протягом семестру слухачі готують письмові роботи (реферати) з однієї з обраних тем, які «захищаються» наприкінці курсу як доповідей. Наприкінці курсу – залік.
2.8. Навчально-методичне забезпеченнякурсу
Основна література
Захаров В.П.Інформаційні системи (документальний пошук). СПб., 2002.
Інформатика/ За ред. К.В. Тараканова. М., 1986.
Лахуті Д.Г. Автоматизовані документально-фактографічні інформаційно-пошукові системи // Підсумки науки і техніки. Інформатики. Т. 12. М., 1988. С. 6-77.
Солтон Дж.Динамічні бібліотечно-інформаційні системи. М., 1979.
Селтон Г.Автоматична обробка, зберігання та пошук інформації. М., 1973.
Чорний А.І. Введення у теорію інформаційного пошуку. М., 1975.
додаткова література
Аветисян Д.О. Проблеми інформаційного пошуку. М., 1991.
Армс У. Електронні бібліотеки. М., 2001.
Білоозеров В.М.Нові стандарти на термінологію інформаційного пошуку // НТІ. Сер. 1. 1997. № 11. С. 14-21.
Войскунський В.Г.Документальний пошук та Зворотній зв'язок// Предметний пошук у традиційних та нетрадиційних інформаційно-пошукових системах. СПб., 1993. Вип. 11. С. 129-141.
Войскунський В.Г., Захаров В.П.Діалоговий налагоджувальний комплекс // Структурна та прикладна лінгвістика: Міжвузівська збірка. Вип. 4. СПб., СПбГУ, 1993. С. 197-211.
Декер С., Мельник С., Хермелен ван Ф. Semantic Web: ролі XML та RDF // Відкриті системи. 2001. № 9. С. 23-33.
Захаров В.П., Мордовченко П.Г., Цукровий Л.В.Удосконалення лінгвістичного забезпечення в ІПС «безтезаурусного» типу // НТІ. Сер. 2. 1980. № 6. С. 14-19.
Захаров В.П., Панков І.П.Інформаційно-пошукові системи // Прикладне мовознавство: Підручник/Відп. ред. А.С. Герд. СПб., СПбГУ, 1996. С. 334-359.
Захаров В.П., Піменов Є.М. Природно-мовний підхід до створення лінгвістичного забезпечення інформаційно-позовних систем // НТІ. Сер. 2. 1997. № 12.
Змітрович А.І.Інтелектуальні інформаційні системи. Мінськ, 1997.
Капустін В.А.Пошук інформації в Інтернет// Світ Internet. 1998. №9. С. 54-58.
Капустін В.А.Інформаційні ресурси - як ми їх шукатимемо? // Світ Internet. 1998. № 9. С. 58-61.
Капустін В.А.Основи пошуку інформації в Інтернеті: Методичний посібник. СПб., 1999.
Курник А.Пошук у Інтернет. СПб., 2001.
Інформаційно-пошукові системи. М., 1972.
Лахуті Д.Г.Інтелектуалізація інформаційних систем: Наукова доповідь… М., 2002.
Любарський Ю.Я.Інтелектуальні інформаційні системи. М., 1990.
Масевич А.Ц. Два підходи до теорії ІПС у світлі сучасних лінгвістичних концепцій // Предметний пошук у традиційних та нетрадиційних інформаційно-пошукових системах. Л., 1989. Вип. 9. С.25-49.
Москович В.А. Інформаційні мови. М., 1971.
Пархоменко В.Ф.Система автоматичного індексування документів ДУЖКИ ОС ЄС // М., 1983
Прикладнемовознавство: Підручник. СПб., 1996. С. 59-67, 92-99, 360-388.
Рубашкін В.Ш.Подання та аналіз сенсу в інтелектуальних інформаційних системах. М., 1989.
Соколов А.В.Автоматизація бібліографічного пошуку. – М., 1981.
Соколов А.В. Введення у теорію соціальної комунікації. СПб., 1996.
Соколов А.В. Методичні матеріализ розробки інформаційно-пошукових тезаурусів. Л., 1976.
Степанов В. Бібліографічний пошук до Інтернету // Бібліографія. 1998. № 1. С. 5-10.
Храмцов П.Б. Інформаційно-пошукові системи Internet // Відкриті системи. 1996. № 3. С. 46-49.
Храмцов П.Б. Моделювання та аналіз роботи інформаційно-пошукових систем Internet // Відкриті системи. 1996. № 6. С. 46-56.
Шемакін Ю.І., Романов А.А. Комп'ютерна семантика. М., 1995.
Шемакін Ю.І. Тезаурус в автоматизованих системах управління та обробки інформації. М., 1974.
Стандарти
Типові проектні рішеннядля автоматизованих систем науково-технічної інформації. М., 1983.
ГОСТ 34.601-90. Інформаційна технологія. Комплекс стандартів на автоматизовані системи. Стадії створення автоматизованих систем.
ГОСТ 34.602-89. Інформаційна технологія. Комплекс стандартів на автоматизовані системи. Технічне завданнястворення автоматизованої системи.
ГОСТ 7.52-85. Комунікативний формат для обміну бібліографічними даними на магнітній стрічці. Пошуковий образ документа.
ГОСТ 7.74-96. Інформаційно-пошукові мови. Терміни та визначення.
РД 34.003-90. Інформаційна технологія. Терміни та визначення.
РД 34.201-89. Інформаційна технологія. Види, комплектність та позначення документів при створенні автоматизованих систем.
РД 34.680-88. Методичні вказівки. Інформаційна технологія. Основні положення.
РД 34.698-90. Методичні вказівки. Інформаційна технологія. Вимоги щодо змісту документів.
3. Практикум (лабораторні роботи)
Інструкція з виконання лабораторних робіт
Результати лабораторних робіт зберігаються на жорсткому диску у відповідній папці лабораторної роботи Lab#N, де N – номер роботи. При цьому всі ці папки зберігаються в папці студента, яка має наступний шлях: ДИСК: Прізвище Викладача Nnn-Фам, де nnn – номер (ідентифікатор) групи, Фам – прізвище студента. Наприклад, усі файли та папки, що створюються та зберігаються в ході лабораторної роботи № 2 розміщуються в папці D:\Захаров\ML_3kurs-Іванова\Lab#2. У завданнях лабораторних робіт ця поточна папка студента називається « своя папка».
У ряді випадків перед початком роботи за вказівкою викладача слід скопіювати (з комп'ютера викладача через «Мережеве оточення» або з дискети) до своєї папки додаткові файли, необхідні для виконання завдання.
Текстовий звіт з результатами виконання роботи створюється в редакторі Word. У вікні документа потрібно ввести прізвище, ім'я, номер групи/підгрупи, номер лабораторної роботи, дату виконання роботи. Далі в цей файл записувати необхідні результати виконання роботи ( під номером відповідного пункту завдання). Зберігати ці дані як файл звіту з ім'ям ReportN у своїй папці, де N - номер роботи. Щоб уникнути втрати даних при збоях, що формуються студентами під час роботи, файли рекомендується регулярно зберігати.
Для пред'явлення викладачеві результатів роботи розташувати їх на екрані в наступних вікнах, розташувавши їх каскадом зліва направо: вміст папки лабораторної роботи, що захищається (у вікні Провідника), файл звіту у вікні редактора Word, вікно броузера (якщо потрібно).
Лабораторна робота №1
(Класифікаційні ІПС)
Відкрити сторінку пошукової системи Апорт (РОЛ, Russia On-Line). Ознайомитись із класифікатором (рубрикатором) даної системи. Рубрики верхнього рівня переписати в зошит та перенумерувати. Переходячи за рубриками рубрикатора, знайти два музеї («Літературно-меморіальний музей Ф.М. Достоєвського» та «Історико-меморіальний музей М.В. Ломоносова в селі Ломоносове Архангельської області»). Ознайомитись з формою представлення інформації про сайти в каталозі.
Для кожного музею:
скопіювати короткі описи вказаних музеїв у каталозі файл звіту Report1;
вказати індекс цитованості (у вигляді числа) та лігу (у вигляді словесної назви) для даних музейних сайтів;
перейти на сайт музею та першу домашню сторінку скопіювати у своїй папці у форматі ;
створити «закладку» на сайт музею у своїй папці в Обраному.
Відкрити сторінку пошукової системи Яндекс. Ознайомитись із класифікатором (рубрикатором) даної системи. Рубрики верхнього рівня переписати в зошит та перенумерувати. Позначити (обвести) рубрики, що збігаються з рубриками Апорта (повністю або частково). Переходячи за рубриками рубрикатора, знайти «Літературно-меморіальний музей Ф.М. Достоєвського» та «Історико-меморіальний музей М.В. Ломоносова у селі Ломоносове Архангельської області». Їхні описи в рубрикаторі Яндекса скопіювати у файл звіту.
Відвідати Рейтингову систему ІПС Рамблер. Ознайомитись із класифікатором (рубрикатором) даної системи. Рубрики, що збігаються з рубриками Апорта (цілком або частково), переписати в зошит. Переглянути рейтинг сайтів на тему «Освіта». Ознайомитись з формою подання інформації в каталозі. Назву сайту, що займає п'яте місце, з його кількісними показниками, скопіювати у файл звіту Report1. Подивитись докладну статистикута статтаблицю скопіювати у файл звіту.
Те саме повторити в системі Yahoo.
Лабораторна робота№ 2
(Російськомовні вербальні ІПС: порівняльний аналіз)
Робота полягає у порівняльному вивченні систем Апорт, Яндекс, Рамблер. Результати вивчення студент має відобразити у вигляді таблиці (с. 34) у файлі Report2 (орієнтація таблиці – альбомна). У осередках записати, як у кожній системі представляється той чи інший елемент мови запитів чи вхідного/вихідного інтерфейсу (всі допустимі методи). У деяких випадках можна відповідати знаками "+" або "-" (наприклад, " Опис документа») або вільним текстом своїми словами (наприклад, « Релевантні сторінкитого ж сайту»або «Сортування»).
Перейти на сайт пошукової системи Апорт (потім Яндекс та Рамблер). Знайти в кожній системі посилання на її опис загалом, на опис мови запитів, інтерфейсів («Довідка», «Допомога», «Розширений пошук»і т.п . ). Перейшовши за посиланнями, уважно вивчити довідкову інформацію та в робочому зошиту коротко закон-спектувати основні пункти. Після цього кожної системи заповнити відповідні осередки таблиці (розділи 1, 2).
Примітка.Якщо текст відповіді не міститься в осередку таблиці, рекомендується робити виноску та продовжувати її під таблицею. Зверніть увагу на те, що можливості систем у простому та розширеному пошуку різняться. Відобразити це у звіті. Звернути увагу на наявність розділів "інше".
Повернутись назад на початкову сторінку пошукової системи Апорт (потім Яндекс і Рамблер). Ввести будь-який запит (наприклад, «Статистичні методи у лінгвістиці») у вікні для текстового запиту та провести пошук. Сторінку з результатами пошуку зберегти у своїй папці у форматі «тільки html».
Вивчити форму подання результатів. Коротко записати в зошит, який міститься на веб-сторінці з результатами пошуку (структуру веб-сторінки). Вивчити форму подання окремих веб-документів (їх короткі описи додаткової інформації). На основі вивчення отриманих результатів та раніше вивченої довідкової інформації заповнити відповідні осередки таблиці (розділ 3).
Подати роботу викладачеві.
Результати порівняльного вивчення систем Апорт, Яндекс, Рамблер
№ | Параметри | Апорт | Яндекс | Рам-Блер |
Пошук за текстом | ||||
Логічні оператори: | ||||
кон'юнкція | ||||
диз'юнкція | ||||
заперечення | ||||
Синтагматичні оператори: | ||||
фрази (словосполучення, слова поряд) | ||||
відстань у словах | ||||
відстань у пропозиціях | ||||
Морфологічна нормалізація (автоматична, використовувані метасимволи) | ||||
Пошук по полях | ||||
за назвою | ||||
по полю ключових слів | ||||
за коментарем до картинок (поле ALT) | ||||
за текстом гіперпосилань | ||||
за адресами посилань | ||||
по доменному імені сайту (сервера) | ||||
за форматом | ||||
Інтерфейс видачі (форма подання результатів) | ||||
статистика слів із запиту | ||||
кількість знайдених документів | ||||
кількість знайдених сайтів | ||||
кількість документів на сторінці результатів | ||||
сортування документів на сторінці видачі | ||||
пошук у знайденому | ||||
опис документа включає такі елементи: | ||||
URL (адреса в мережі) | ||||
розмір документа (обсяг) | ||||
дата створення | ||||
кодування | ||||
анотація (короткий зміст) | ||||
вказівку на інші релевантні веб-сторінки того ж сайту | ||||
пошук схожих документів | ||||
Лабораторна робота№ 3
(Російськомовні вербальні ІПС: пошук)
Складання та налагодження тематичного запиту
Скласти у зошиті запит на тему «Морські битви під час Великої вітчизняної війни». При цьому вилучити з теми незначні слова, розширити запит синонімами, скласти логічну формулу запиту з обов'язковим використанням операторів кон'юнкції, диз'юнкції, відстані та фрази (жорстке словосполучення).
Показати запит викладачеві.
Потім записати його варіанти мовами систем Апорт, Яндекс, Рамблер.
Налагодити запит у режимі реального пошуку, проводячи послідовно сеанси у всіх трьох системах. Спробувати варіювати пошукові приписи, щоб досягти оптимальних показників пошуку. Для цього фіксувати в зошиті отримані результати за кожним варіантом: точність (за першими 20 документами) та умовну повноту (абсолютний обсяг видачі).
Повернутися до найкращого пошукового припису та текст запиту скопіювати через буфер обміну з пошукового рядка(Вікно для введення запиту) у вікно файлу звіту Report3 (по черзі в кожній системі). Вказати при цьому у звіті показники точності та повноти. Першу веб-сторінку з результатами пошуку в кожній системі зберегти у своїй папці у форматі «тільки html».
Знайомство з пошуком полями («Розширений пошук»)
Знайти за допомогою системи Яндекс документи, присвячені Леву Гумільову. Кількість знайдених документів та сайтів записати у файл звіту. Адреса (URL) першого документа зі списку зберегти в Обраному в папці Гумільов.
Потім перейти в режим розширеного пошуку та знайти документи, присвячені Левові Гумільову, з датою після 1 жовтня 2004 р. Нову кількість знайдених документів та сайтів знову записати у файл звіту. Перший документ зі списку результатів пошуку зберегти у своїй папці у форматі "Веб-архів, один файл" (*.mht).
Знайти через систему Рамблер документи на тему «Економіка міста Москви». При цьому обсяг видачі (кількість описів документів на сторінці результатів) встановити дорівнює 30. Результати пошуку відсортувати за датою (за спаданням) та першу веб-сторінку з результатами пошуку зберегти у своїй папці у форматі «тільки html»
Перейти в режим розширеного пошуку і знайти документи на тій самій темі, але знаходяться лише на сайті. Результати пошуку відсортувати за датою (за зростанням) та першу веб-сторінку з результатами пошуку зберегти у своїй папці у форматі «тільки html». Кількість знайдених документів та сайтів зафіксувати у файлі звіту.
Знайти через систему Яндекс документи на тему «Освіта», з яких є посилання на сайт. Першу веб-сторінку з результатами пошуку зберегти у своїй папці у форматі «тільки html». Кількість знайдених документів та сайтів зафіксувати у файлі звіту.
Завантажити один із знайдених документів, переглянути його html-код, знайти в ньому посилання на сайт та елемент гіперпосилання (від початкового до кінцевого тега А) через буфер обміну скопіювати у файл звіту.
Документ у форматі mht, збережений у п. 7 (про Лева Гумільова), прочитати в редакторі Word: спочатку у форматі веб-сторінки, потім у форматі «тільки текст». При другому читанні переглянути вміст вікна введення редактора Word (особливо початок і кінець файлу), скопіювати першу сторінку вікна введення файлу звіту і бути готовим пояснити, що таке формат mht.
Примітка.Формат mht кодується відповідно до стандарту MIME (RFC2046 та RFC2047).
Подати роботу викладачеві.
Лабораторна робота №4
(Глобальні вербальні ІПС: порівняльний аналіз)
Робота полягає у порівняльному вивченні заданих глобальних ІПС мережі Інтернет вербального типу.
Примітка.Набір систем та їх кількість може змінюватись на розсуд викладача.
Перейти на сайт відповідної пошукової системи (тут і далі - доменне ім'я системи: www. Назва_системи.com). Знайти у кожній системі посилання її опис загалом, на опис мови запитів, інтерфейсів, режимів роботи та інших особливостей системи. Опис кожної ІПС коротко законспектувати у зошиті.
Проаналізувати та порівняти можливості систем у режимі розширеного пошуку. Сторінки інтерфейсу розширеного пошуку зберегти у своїй папці.
Результати аналізу у стислому вигляді подати у формі зведеної таблиці (с. 38) у файлі звіту Report4 (орієнтація таблиці - альбомна). Розмір таблиці можна збільшити. Якщо щось міститься у таблиці, в осередку робити виноску на текст під таблицею (таблиця й не так форма подання результатів, скільки схема аналізу).
Подати роботу викладачеві.
Результати порівняльного вивчення глобальних вербальних ІПС
Параметри | |||||
Логічні оператори(які і як задаються) | |||||
Синтагматичні оператори | |||||
Пошук по полях(Скласти список полів, відзначати їх наявність/відсутність у конкретних системах) | |||||
поле 1 | |||||
поле 2 | |||||
……… | |||||
поле k | |||||
Вибір пошукової бази даних | |||||
ресурс 1 | |||||
ресурс 2 | |||||
……… | |||||
ресурс k | |||||
Формат видачі містить такі елементи(Під таблицею навести приклад з кожної системи) | |||||
елемент 1 | |||||
елемент 2 | |||||
……… | |||||
елемент k | |||||
Спеціальні можливості чи характерні особливості |
Лабораторна робота №5
(Глобальні вербальні ІПС: вивчення та пошук)
Провести пошук на тему «Комп'ютерна лінгвістика» в заданих глобальних ІПС ( набір систем та їх кількість може змінюватись на розсуд викладача).Пошуковий припис логічно має виглядати так:
(computationalVcomputingVcomputer) &
linguistics.
Запит по-англійськи двічі, як кон'юнкцію і як стійке словосполучення (фраза), використовуючи характерні кожної системи способи висловлювання операторів (для незнайомих систем знайти відповідну довідкову інформацію). Першу веб-сторінку з результатами кожного пошуку зберегти у своїй папці у вигляді «тільки html». Кількісні результати відобразити у таблиці:
Назва ІПС | Знайдено документи/сайти | |||
Семінар
Проектування систем керування документами
Поняття інформаційно-пошукової системи (ІПС).
Склад компонентів та технологія роботи з ІПС.
В роботі сучасних підприємств важливу рольграють його інформаційні ресурси, під якими можна розуміти проектну документацію, листування з партнерами, внутрішні накази та розпорядження, фінансові дані та інші документи, які є основою для прийняття нових рішень та використовуються в процесах управління підприємством. І якщо для зберігання структурованих даних можна застосовувати спеціалізовані інформаційні системи (типу бухгалтерської або торгової системиабо системи планового відділу), засновані на використанні СУБД, то для неструктурованих даних потрібні системи загального призначення – електронні архіви, що працюють на засадах інформаційно-пошукової системи.
Інформаційно-пошукова система (ІПС) -це система, призначена для зберігання та пошуку документів з текстовою, графічною, табличною інформацією за атрибутами, ключовими словами документа та змістом у будь-якій предметній галузі. Вирізняють ІПС двох типів: фактографічні та документографічні системи. ІПС фактографічного типу призначені для зберігання та пошуку фактів, показників, характеристик будь-яких об'єктів або процесів (наприклад, відомості про працівників, про підприємства, акціонерів тощо). Документографічні ІПС відрізняються тим, що об'єктом зберігання та пошуку в цих системах є документи, звіти, реферати, огляди, журнали, книги і т.д. Сценарій пошуку документа за допомогою ІПС зазвичай зводиться до введення запиту на пошук, що складається з одного або кількох слів, після чого подається список імен знайдених документів. Користувач може відкрити будь-який із знайдених документів і якщо пошукова система дозволяє, входження слів, що шукаються, в документі виділяються - «підсвічуються». Можна виділити такі особливості організації та
функціонування документографічної ІПС, що відрізняє її від систем управління базами структурованих даних: – Документи можуть зберігатися на папері, мікрографічних носіях або існувати в електронних форматах. Мікрографічні формати включають мікрофільми, мікрофіші, слайди та інші мікроформи, які виробляються різноманітними документними камерами. Електронні формати ще більш численні, вони включають документи, підготовлені в текстових процесорах, системах електронної поштита інших комп'ютерних програмах, оцифровані зображення пройшли сканування документів та ін. У цьому передбачається обов'язкове зберігання як електронних копій документів, і їх паперових оригіналів.
Якщо документи займають великий обсяг та повні електронні копіївидавати на перегляд або зберігати неможливо, то для таких документів створюють та зберігають електронні адреси їх зберігання.
Пошук здійснюється знаходженням документа за двома принципами:
атрибутам документа –дату створення, розміру, автору та ін. змістом(тексту). Зазвичай пошук за змістом документа виконується двома способами: за ключовими словами та по всьому тексту, який називають повнотекстовим,підкреслюючи цим, що для пошуку використовується весь текст документа, а не лише його реквізити.
Для пошуку документів створюють та зберігають їх пошукові образи . Пошуковий образ документа (ПІД) –сукупність кодів провідних ключових слів (дескрипторів), що описують зміст, зміст документа.
Ключові слова та їх коди зберігаються у спеціальному словнику – тезаурус.
Для того, щоб здійснювати пошук документів, потрібно створити інформаційно-пошукова мова (ІПЯ),до складу якого входить тезаурус та граматика мови, тобто. сукупність правил завдання безлічі висловлювань на безлічі ключових слів.
Щоб знайти документ, потрібно створити за допомогою ІПЯ пошуковий образ запиту (ПОЗ), який являє собою сукупність закодованих ключових слів, що описують документи, які потрібно знайти.
Схема взаємодії компонентів ІПС представлена на рис. 1.
Мал. 1. Схема взаємодії компонентів ІПС
ІПС складається з наступних підсистем, що забезпечують:
Лінгвістичне забезпечення, що включає до свого складу інформаційно-пошукову мову;
Технічне забезпечення системи, що включає ЕОМ та пристрої створення, зберігання, читання та розмноження копій на паперових носіях, мікроформатах і в електронної форми;
Інформаційне забезпечення, що складається з БД документів (БД Док.), адрес (БД Адр.) та БД пошукових образів документів (БД ПІД) та списків дескрипторів та їх кодів – тезаурусу;
Програмне забезпечення.
Програмне забезпечення ІПС призначене для автоматизації наступних основних функцій, які має виконувати ця система:
Складання, кодування та завантаження бази даних ПІД;
Завантаження БД документів та їх адрес зберігання;
Складання, кодування ПОЗ;
Виконання операції пошуку та видачі відповіді на запит у вигляді документа або адрес зберігання документів на екран ЕОМ, на папір, у файл;
Актуалізація баз даних ПІД, документів та адрес;
Актуалізація тезаурусу;
Видача довідок.
Розглянемо основні поняття, які у сфері пошуку документів.
Релевантністьступінь відповідності знайденого документа запиту . Знайдений за запитом документ може стосуватися запиту, т. е. містити необхідну (шукану) інформацію, і може мати жодного стосунку. У першому випадку документ називається релевантним(англійською relevant - «що стосується справи»), у другому - нерелевантним, або шумовим. Як правило, у будь-якій пошуковій системі на запит видається кілька (частіше багато) знайдених документів. Багато хто з них може оповідати не про те. І навпаки, деякі важливі, релевантні документи можуть бути пропущені при пошуку. Зрозуміло, кількість тих та інших визначає якість пошуку, яку можна визначити досить точно. Основними поняттями у світі пошукових засобів є ідеї точності та повноти пошуку.
Точність пошуку (Т)залежить від того, яка частина інформації, видана у відповідь запит, є релевантної, тобто. що стосується цього запиту і є параметром, що показує, яка частка релевантних документів у кількості знайдених. Цей показник розраховується за такою формулою:

Якщо, наприклад, всі видані на запит документи ставляться до справі, то точність дорівнює 100%; якщо, навпаки, всі шумові документи, то точність пошуку дорівнює нулю.
Повнота пошуку (П)- додатковий параметр, показує, яка частка (чи відсоток) знайдених релевантних документів у кількості релевантних документів, тобто. характеризується співвідношенням між усією релевантною інформацією, що є в базі, та тією її частиною, яка включена у відповідь і розраховується за формулою:

Якщо в області пошуку насправді є 100 документів, які містять потрібну інформацію, а за запитом знайдено їх всього 30, то повнота пошуку дорівнює 30%. Крім цього, при оцінці пошукових систем враховується, з якими типами даних може працювати та чи інша система, в якій формі надаються результати пошуку і який рівень підготовки користувачів необхідний для роботи в цій системі. Слід зазначити, що точність пошуку та її повнота залежать як від властивостей пошукової системи, а й від правильності побудови конкретного запиту, і навіть від суб'єктивного уявлення користувача у тому, яка йому інформація. Якщо стоїть проблема оцінки кількох систем та вибору найефективнішої, можна обчислити середні значення повноти та точності аналізованих конкретних систем, протестувавши їх на еталонній базі документів.
Індексаціядокументів (тобто складання ПІД), що означає попередню підготовку текстів для пошуку та застосовується головним чином для прискорення пошуку; як правило, текстові бази даних, призначені для багаторазового пошуку, обробляють заздалегідь, складаючи так званий індекс(ПІД ) . При індексації пошукова система складає списки слів, які у тексті, і приписує кожному слову його код - координати у тексті (найчастіше номер документа і номер слова у документі). Під час пошуку слово шукається в індексі, і за знайденими координатами видаються потрібні документи. Якщо слів у запиті кілька, над їх координатами провадиться операція перетину . У разі, якщо безліч документів поповнюється, доводиться поповнювати і індекс.
Одиниця пошуку- це квант тексту, не більше якого у цій пошуковій системі здійснюється пошук, від величини якого залежить показник точності пошуку, величина шуму і час відповіді запит. Одиницею пошуку може бути документ, пропозиція чи абзац. У технології використання ІПС можна виділити три групи операцій:
Операції, пов'язані з отриманням пошукових образів документів (ПІД), що описують зміст документів та завантаженням їх у базу даних (БД ПІД), а також завантаженням самих документів або їх адрес зберігання в БДДок і БДАдр.;
Операції складання пошукових образів запиту (ПОЗ) з використанням тезаурусу, пошуку та видачі результатів на перегляд та відбір чи файл або на друк знайдених документів чи списку адрес;
Операції ведення інформаційно-пошукової системи, що включають актуалізацію БД ПІД, БДДок., БДАдр. та тезаурусу внаслідок виникнення та необхідності поповнення пам'яті системи новими документами чи ключовими словами. До складу операцій ведення ІПС входить також процедура видачі довідок про роботу системи, про її структуру, методи пошуку і класи і види документів, що зберігаються.
























