Призначення.Перевірка гіпотези про належність двох дисперсій однієї генеральної сукупності і отже - їхню рівність.
Нульова гіпотеза. S 2 2 = S 1 2
Альтернативна гіпотеза. Існують наступні варіантиН А залежно від яких різняться критичні галузі:
1. S 1 2 > S 2 2 . Найбільш часто використовуваний варіант Н А. Критична область – верхній хвіст F-розподілу.
2. S 1 2< S 2 2 . Критическая область - нижний хвост F-распределения. Ввиду частого отсутствия нижнего хвоста, в таблицах критическую область обычно сводят к варианту 1, меняя местами дисперсии.
3. Двостороння S 1 2 ≠ S 2 2 .Комбінація перших двох.
Причини.Дані незалежні та розподілені за нормальним законом. Гіпотеза про рівність дисперсій двох нормальних генеральних сукупностей приймається, якщо відношення більшої дисперсії до меншої від критичного значення розподілу Фішера.
F P = S 1 2 /S 2 2
Примітка. При описуваному способі перевірки значення Fpaсч обов'язково має бути більше одиниці. Критерій чутливий до порушення припущення нормальності.
Для двосторонньої альтернативи S 1 2 ≠S 2 2 нульова гіпотеза приймається під час виконання умови:
F l - α /2< Fрасч < F α /2
приклад
Комплексним теплометричним методом визначали теплофізичні. характеристики (ТФГ) зеленого солоду. Для приготування зразків брали повітряно-сухий (середня вологість W=19%) та вологий солод чотиридобового обертання (W=45%) відповідно новою технологієюприготування карамельного солоду. Досліди показали, що теплопровідність вологого солоду приблизно в 2,5 рази більше, ніж сухого, а об'ємна теплоємність не має чіткої залежності від вологості солоду. Тому за допомогою F-критерію перевірили можливість узагальнити дані за середніми значеннями без урахування вологості.
Розрахункові дані зведено до таблиці 5.1
Таблиця 5.1
Дані для розрахунку F-критерію
Більше значення дисперсії отримано W=45%, тобто. S 2 45 = S 1 2 , S 2 19 = S 2 2 і F P = S 1 2 /S 2 2 =1,35. З таблиці 5.2 для ступеня свободи f 1 = N 1 -1 = 5 f 2 = N 2 -1 = 4 при γ = 0,95 визначаємо F КР = 6,2. Нуль гіпотеза сформульована як «У діапазоні вологості зеленого солоду від 19 до 45% її впливом на об'ємну теплоємність можна знехтувати» або «S 2 45 = S 2 19 » з довірчою ймовірністю 95% підтвердилася, оскільки Fp Приклад перевірки гіпотези щодо належності двох дисперсій однієї генеральної сукупності за критерієм Фішера за допомогою Excel Наведено дані щодо двох незалежних вибірок (табл. 5.2) ступеня водопоглинання зерна пшениці. Було проведено дослідження впливу магнітними полями низької частоти. Таблиця 5.2 Результати досліджень Перш ніж ми перевірятимемо гіпотезу про рівність середніх цих вибірок, необхідно перевірити гіпотезу про рівність дисперсій, щоб знати який із критеріїв вибрати для її перевірки. На рис. 5.1 наведено приклад перевірки гіпотези про належність двох дисперсій однієї генеральної сукупності за критерієм Фішера, використовуючи програмний продукт Microsoft Excel. Рисунок 5.1 Приклад перевірки належності двох дисперсій однієї генеральної сукупності за критерієм Фішера Вихідні дані розміщені в осередках, що знаходяться на перетині стовпців С та D з рядками 3-10. Виконаємо такі дії. 1. Визначимо, чи можна вважати закон розподілу першої та другої вибірок нормальним (стовпці С та D відповідно). Якщо ні (хоча б для однієї вибірки), необхідно використовувати непараметричний критерій, якщо так – продовжуємо. 2. Розрахуємо дисперсії для першого та другого стовпця. Для цього в осередках СП і D11 помістимо функції = ДИСП (СЗ: С10) і = ДИСП (DЗ: D10) відповідно. Результатом роботи цих функцій є розраховане значення дисперсії кожного стовпця відповідно. 3. Знаходимо розрахункове значення критерію Фішера. Для цього потрібно більшу дисперсію поділити на меншу. У комірку F13 поміщаємо формулу =C11/D11, яка виконує цю операцію. 4. Визначаємо, чи можна прийняти гіпотезу про рівність дисперсій. Існує два способи, які представлені у прикладі. За першим способом, задавшись рівнем значущості, наприклад 0,05, обчислюють критичне значення розподілу Фішера для цього значення та відповідного числа ступенів свободи. У комірку F14 вводиться функція =FPACПOBP(0,05;7;7) (де 0,05 - заданий рівень значущості; 7 - число ступенів свободи чисельника, а 7 (друге) - число ступенів свободи знаменника). Число ступенів свободи дорівнює числу експериментів мінус одиниця. Результат – 3,787051. Оскільки це значення більше за розрахунковий 1,81144, ми повинні прийняти нульову гіпотезу про рівність дисперсій. За другим варіантом розраховують для отриманого розрахункового значення критерію Фішера відповідну ймовірність. І тому в комірку F15 вводиться функція =FPACП(F13;7;7). Оскільки отримане значення 0,22566 більше, ніж 0,05, приймається гіпотеза про рівність дисперсій. Це може бути виконано спеціальною функцією. Виберіть у меню послідовно пункти Сервіс
, Аналіз даних
. З'явиться вікно такого виду (рис. 5.2). Малюнок 5.2 Вікно вибору методу обробки У цьому вікні вибираєте « Двовибірковий F-mecm для дисперсій
». Внаслідок цього з'явиться вікно виду, показаного на рис. 5.3. Тут задаються інтервали (номери осередків) першої та другої змінної, рівень значущості (альфа) і місце, де буде результат. Задайте всі необхідні параметри та натискайте OK. Результат роботи наведено на рис. 5.4 Слід зазначити, що функція перевіряє односторонній критерій і це правильно. Для випадку, коли критеріальне значення більше 1 обчислюється верхнє критичне значення. Рисунок 5.3 Вікно завдання параметрів Коли критеріальне значення менше 1, обчислюється нижнє критичне. Нагадуємо, що гіпотеза про рівність дисперсій відкидається, якщо критеріальне значення більше критичного або нижчого. Рисунок 5.4 Перевірка рівності дисперсій На цьому прикладі розглянемо, як оцінюється надійність отриманого рівняння регресії. Цей тест використовується для перевірки гіпотези у тому, що коефіцієнти регресії одночасно дорівнюють нулю, a=0 , b=0 . Іншими словами, суть розрахунків – відповісти на запитання: чи можна його використовувати для подальшого аналізу та прогнозів? Для встановлення подібності або відмінності дисперсій у двох вибірках використовуйте цей t-критерій.
де m - Число факторів в моделі. Висновки: Оскільки фактичне значення F > F табл, коефіцієнт детермінації статистично значимий ( знайдена оцінка рівняння регресії статистично надійна)
. Приклад. По сукупності 25 підприємств торгівлі вивчається залежність між ознаками: X - ціна товару А, тис. крб.; Y - прибуток торговельного підприємства, млн. руб. При оцінці регресійної моделі було отримано такі проміжні результати: ∑(y i -y x) 2 = 46000; ∑(y i -y ср) 2 = 138000. Який показник кореляції можна визначити за цими даними? Розрахуйте величину цього показника, на основі цього результату та за допомогою F-критерія Фішеразробіть висновок якість моделі регресії. F-критерій Фішера: n = 25, m = 1. Запитання: Яку статистику використовують для перевірки значущості моделі регресії? Функція ФІШЕР виконує повернення перетворення Фішера для аргументів X. Це перетворення будує функцію, яка має нормальний, а не асиметричний розподіл. Використовується функція ФІШЕР, щоб перевірити гіпотезу за допомогою коефіцієнта кореляції. При роботі з цією функцією необхідно встановити значення змінної. Відразу варто зазначити, що існують деякі ситуації, за яких дана функціяне видаватиме результатів. Це можливо, якщо змінна: Рівняння, яке використовується для математичного опису функції ФІШЕР, має вигляд: Z"=1/2*ln(1+x)/(1-x) Розглянемо застосування цієї функції на 3-х конкретних прикладах. Приклад 1. Використовуючи дані активності комерційних організацій, потрібно зробити оцінку зв'язку прибутку Y (млн крб.) і витрат X (млн крб.), що використовуються розробки продукції (наведені у таблиці 1). Таблиця 1 - Вихідні дані: Схема вирішення таких завдань виглядає так: Результати вирішення цієї задачі з функціями, що застосовуються в пакеті Excel наведені на малюнку 1. Малюнок 1 – Приклад розрахунків. Таким чином, з ймовірністю 0,95 лінійний коефіцієнт кореляції укладено в інтервалі від (-0,386) до (-0,990) зі стандартною помилкою 0,205. Приклад 2. Здійснити перевірку статистичної значущості рівняння множинної регресіїза допомогою F-критерію Фішера, зробити висновки. Для перевірки значущості рівняння в цілому висунемо гіпотезу Н 0 про статистичній незначущості коефіцієнта детермінації та протилежну їй гіпотезу Н 1 про статистичну значущість коефіцієнта детермінації: Н 1: R 2 ≠ 0. Перевіримо гіпотези за допомогою F-критерію Фішера. Показники наведені у таблиці 2. Таблиця 2 - Вихідні дані Для цього використовуємо в Excel функцію: FРОЗКЛАД (α;p;n-p-1) Знаючи, що α = 0,05, p = 2 та n = 53, отримуємо наступне значеннядля F крит (див. рисунок 2). Рисунок 2 – Приклад розрахунків. Отже можна сказати, що F расч > F крит. Через війну приймається гіпотеза Н 1 про статистичної значимості коефіцієнта детермінації. Приклад 3. Використовуючи дані 23 підприємств про: X - ціна товару А, тис. крб.; Y - прибуток торговельного підприємства, млн. руб, провадиться вивчення їх залежності. Оцінка регресійної моделі дала таке: ∑(yi-yx) 2 = 50 000; ∑(yi-yср) 2 = 130000. Який показник кореляції можна визначити за цими даними? Розрахуйте величину показника кореляції та, використовуючи критерій Фішера, зробіть висновок про якість моделі регресії. Визначимо F критий з виразу: F розрахунки = R 2 /23 * (1-R 2) де R - Коефіцієнт детермінації, рівний 0,67. Отже, розрахункове значення F расч = 46. Для визначення F крит використовуємо розподіл Фішера (див. рисунок 3). Малюнок 3 – Приклад розрахунків. Отже, отримана оцінка рівняння регресії надійна. 1. Таблиця значень F-критерію Фішера рівня значимості α = 0.05 Коли m=1 вибираємо 1 стовпець. k 2 =n-m=7-1=6 - тобто 6-й рядок - беремо табличне значення Фішера F табл = 5.99, у порівн. = разом: 7 Вплив х на у - помірний та негативний ŷ - модельне значення. А = 1/7 * 398,15 * 100% = 8,1%< 10% - прийнятне значення Модель досить точна. F розрах. = 1/0,92 = 1,6 F розрах. = 1,6< F табл. = 5,99 Має бути F розрах. > F табл Порушується дана модель, Тому це рівняння статистично не значимо. Оскільки розрахункове значення менше табличного - незначна модель. Помилка апроксимації. A = 1/7 * 0,563494 * 100% = 8,04991% 8,0% Вважаємо, що модель точна, якщо середня помилка апроксимації менше 10%. Параметрична ідентифікація парної нелінійної регресії Модель у = а * х b - статечна функція Щоб застосувати відому формулу, необхідно логарифмувати нелінійну модель. log у = log a + b log x Y=C+b*X -лінійна модель. З = 1,7605 - (- 0,298) * 1,7370 = 2,278 Повернення до вихідної моделі Ŷ=10 з *x b =10 2.278 *x -0.298 Входимо в EXCEL через "Пуск"-програми. Заносимо дані до таблиці. У "Сервіс" - "Аналіз даних" - "Регресія" - ОК Якщо в меню "Сервіс" відсутній рядок "Аналіз даних", його необхідно встановити через "Сервіс" - "Налаштування" - "Пакет аналізу даних" Прогнозування попиту продукції підприємства. Використання в MS Excel функції"Тенденція" A – попит на товар. B - час, дні Крок 1. Підготовка вихідних даних Крок 2. Продовжуємо тимчасову вісь, ставимо на 6,7 вперед; маємо право прогнозувати на 1/3 від даних. Крок 3. Виділимо діапазон A6: A7 під майбутній прогноз. Крок 4. Вставка функції Вставка діаграма нестандартні гладкі графіки діапазон готовий. Якщо кожне наступне значення нашої тимчасової осі відрізнятиметься не так на кілька відсотків, а кілька разів, тоді потрібно використовувати не функцію " Тенденція " , а функцію " Зростання " . 1. Єлісєєва "Економетрика" 2. Єлісєєва "Практикум з економетрики" 3. Карлсберг "Excel для мети аналізу" Реєстраційна статистика Значення F Коефіцієнти Стандартна помилка t-статистика Р-значення Нижні 95% Верхні 95% Нижні 95% Верхні 95% Кілька рівнянь, а кожному рівнянні - кілька змінних. Завдання оцінювання параметрів такої розгалуженої моделі вирішується за допомогою складних та химерних методів. Однак усі вони мають одну й ту саму теоретичну основу. Тож отримання початкового ставлення до змісті економетричних методів ми обмежимося у наступних параграфах розглядом простий лінійної регресії. ... Що щойно проведене порівняння ранжувань (1) і (2) здійснено недостатньо суворо. Зрозуміло, що в економетричному інструментарії фахівця з проведення експертних досліджень має бути алгоритм узгодження ранжувань, отриманих різними методами. Метод узгодження кластеризованих ранжувань Проблема, що розглядається тут, полягає у виділенні загального нестрогого порядку з набору... Здійснюється підстановкою рівняння регресії значень незалежних змінних, які визначають умови, котрим робиться прогноз. 2.2 Методи планування та прогнозування доходів бюджетів органів місцевого самоврядування Методи прогнозування та планування виражаються у способах та прийомах розробки прогнозних та планових документів та показників стосовно різних їх видів... Повертає значення, зворотне (правобічного) F-розподілу ймовірностей. Якщо p = FРАСП(x;...), то FРАСПОБР(p;...) = x. F-розподіл може використовуватися в F-тесті, який порівнює ступеня розкиду двох множин даних. Наприклад, можна проаналізувати розподіл доходів у США та Канаді, щоб визначити, чи схожі ці дві країни за рівнем щільності доходів. Важливо:Ця функція була замінена однією або декількома новими функціями, які забезпечують більш високу точністьі мають імена, які краще відображають їх призначення. Хоча ця функція все ще використовується для забезпечення зворотної сумісності, вона може стати недоступною у наступних версіях ExcelТому ми рекомендуємо використовувати нові функції. Щоб дізнатися більше про нові функції, див. статтю Функція F.ОБР та Функція F.ОБР.ПХ . FРОЗПОБР(імовірність; ступеня_свободи1;ступеня_свободи2) Аргументи функції FРАСПОБР описані нижче. Ймовірність- Обов'язковий аргумент. Імовірність пов'язана з інтегральним F-розподілом. Ступені_свободи1- Обов'язковий аргумент. Чисельник ступенів свободи. Ступені_свободи2- Обов'язковий аргумент. Знаменник ступенів волі. Якщо будь-який з аргументів не є числом, функція FРАСПОБР повертає значення помилки #ЗНАЧ!. Якщо "імовірність"< 0 или "вероятность" >1, функція FРАСПОБР повертає значення помилки #ЧИСЛО!. Якщо значення аргументу "ступеня_свободи1" або "ступеня_свободы2" не є цілим числом, воно усікається. Якщо "ступеня_свободы1"< 1 или "степени_свободы1" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!. Якщо "ступеня_свободы2"< 1 или "степени_свободы2" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!. Функцію FРАСПОБР можна використовувати визначення критичних значень F-распределения. Наприклад, результати дисперсійного аналізу зазвичай включають дані для F-статистики, F-ймовірності та критичне значення F-розподілу з рівнем значущості 0,05. Щоб визначити критичне значення F, потрібно використовувати рівень значущості як аргумент "ймовірність" функції FРАСПОБР. за заданому значеннюймовірності функція FРАСПОБР шукає значення x, для якого FРАСП(x; ступеня_свободи1;степені_свободи2) = ймовірність. Таким чином, точність функції FРАСПОБР залежить від точності FРАСП. Для пошуку функція FРАСПОБР використовує метод ітерацій. Якщо пошук закінчився після 100 ітерацій, повертається значення помилки #Н/Д. Скопіюйте зразок даних з наступної таблиці та вставте їх у комірку A1 нового листа Excel. Щоб відобразити результати формул, виділіть їх та натисніть клавішу F2, а потім - клавішу ENTER. За потреби змініть ширину стовпців, щоб побачити всі дані.Номер Номер вибірки
досвіду
2 ,
0,027
0,075
0,036
0,4
0,1
0,08
0,12
0,105
0,32
0,075
0,45
0,12
0,049
0,06
0,105
0,075




Отже, метою аналізу є отримання деякої оцінки, за допомогою якої можна було б стверджувати, що при певному рівні отримане рівняння регресії - статистично надійно. Для цього використовується коефіцієнт детермінації R 2.
Перевірка значущості моделі регресії проводиться з використанням F-критерію Фішера, розрахункове значення якого перебуває як відношення дисперсії вихідного ряду спостережень показника, що вивчається, і незміщеної оцінки дисперсії залишкової послідовності для даної моделі.
Якщо розрахункове значення з k 1 =(m) і k 2 =(n-m-1) ступенями свободи більше табличного при заданому рівні значущості, модель вважається значущою.
Оцінка статистичної значущості парної лінійної регресіїпровадиться за наступним алгоритмом:
1. Висувається нульова гіпотеза у тому, що рівняння загалом статистично незначимо: H 0: R 2 =0 лише на рівні значимості α.
2. Далі визначають фактичне значення F-критерію: ![]()
![]()
де m=1 для парної регресії.
3. Табличне значення визначається за таблицями розподілу Фішера для заданого рівня значимості, враховуючи, що число ступенів свободи для загальної суми квадратів (більшої дисперсії) дорівнює 1 і число ступенів свободи залишкової суми квадратів (меншої дисперсії) при лінійній регресії дорівнює n-2 (або через функцію Excel FРАСПОБР(імовірність; 1; n-2)).
F табл – це максимально можливе значення критерію під впливом випадкових факторів при даних ступенях свободи та рівні значущості α. Рівень значущості α - можливість відкинути правильну гіпотезу за умови, що вона вірна. Зазвичай приймається рівною 0,05 або 0,01.
4. Якщо фактичне значення F-критерію менше табличного, то кажуть, що немає підстав відхиляти нульову гіпотезу.
В іншому випадку, нульова гіпотеза відхиляється і з ймовірністю (1-α) приймається альтернативна гіпотеза про статистичну значущість рівняння в цілому.
Табличне значення критерію зі ступенями свободи k 1 =1 і k 2 =48, F табл = 4Дисперсійний аналіз
.
Показники якості рівняння регресії
Рішення. За цими даними можна визначити емпіричне кореляційне ставлення:  де ?
де ?
η 2 = 92000/138000 = 0.67, η = 0.816 (0.7< η < 0.9 - связь между X и Y высокая).
R 2 = 1 - 46000/138000 = 0.67, F = 0.67/(1-0.67)x(25 - 1 - 1) = 46. F табл (1; 23) = 4.27
Оскільки фактичне значення F > Fтабл, то знайдена оцінка рівняння регресії статистично надійна.
Відповідь: Для значущості всієї моделі загалом використовують F-статистику (критерій Фішера).Опис роботи функції ФІШЕР в Excel
Оцінка взаємозв'язку прибутку та витрат за функцією ФІШЕР
№
X Y
1
210 000 000,00 ₽ 95 000 000,00 ₽
2
1 068 000 000,00 ₽ 76 000 000,00 ₽
3
1 005 000 000,00 ₽ 78 000 000,00 ₽
4
610 000 000,00 ₽ 89 000 000,00 ₽
5
768 000 000,00 ₽ 77 000 000,00 ₽
6
799 000 000,00 ₽ 85 000 000,00 ₽
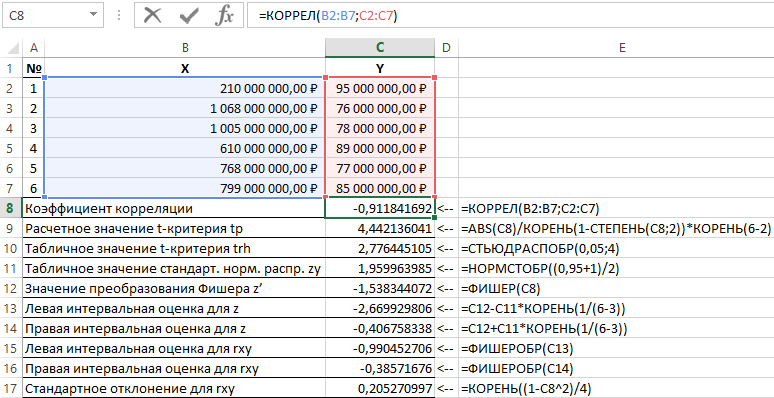
№ п/п найменування показника Формула розрахунку
1
Коефіцієнт кореляції =КОРРЕЛ(B2:B7;C2:C7)
2
Розрахункове значення t-критерію tp =ABS(C8)/КОРІНЬ(1-СТУПЕНЬ(C8;2))*КОРІНЬ(6-2)
3
Табличне значення t-критерію =СТЬЮДРАСПОБР(0,05;4)
4
Табличне значення стандартного нормального розподілу zy =НОРМСТОБР((0,95+1)/2)
5
Значення перетворення Фішера z’ =ФІШЕР(C8)
6
Ліва інтервальна оцінка для z =C12-C11*КОРІНЬ(1/(6-3))
7
Права інтервальна оцінка для z =C12+C11*КОРІНЬ(1/(6-3))
8
Ліва інтервальна оцінка для rxy =ФІШЕРОБР(C13)
9
Права інтервальна оцінка для rxy =ФІШЕРОБР(C14)
10
Стандартне відхилення для rxy =КОРІНЬ((1-C8^2)/4)
Перевірка статистичної значущості регресії за функцією FРАСПОБР
Розрахунок величини показника кореляції в Excel

1
2
3
4
5
6
8
12
24
∞
1
161,45
199,50
215,72
224,57
230,17
233,97
238,89
243,91
249,04
254,32
2
18,51
19,00
19,16
19,25
19,30
19,33
19,37
19,41
19,45
19,50
3
10,13
9,55
9,28
9,12
9,01
8,94
8,84
8,74
8,64
8,53
4
7,71
6,94
6,59
6,39
6,26
6,16
6,04
5,91
5,77
5,63
5
6,61
5,79
5,41
5, 19
5,05
4,95
4,82
4,68
4,53
4,36
6
5,99
5,14
4,76
4,53
4,39
4,28
4,15
4,00
3,84
3,67
7
5,59
4,74
4,35
4,12
3,97
3,87
3,73
3,57
3,41
3,23
8
5,32
4,46
4,07
3,84
3,69
3,58
3,44
3,28
3,12
2,93
9
5,12
4,26
3,86
3,63
3,48
3,37
3,23
3,07
2,90
2,71
10
4,96
4,10
3,71
3,48
3,33
3,22
3,07
2,91
2,74
2,54
11
4,84
3,98
3,59
3,36
3, 20
2,95
2,79
2,61
2,40
F розрах. = 28,648: 1
= 0,92
200,50: 5
1
Σ
(y - ŷ) *100%
N y
№п/п У X Y X Y*X
У I (y-ŷ) /yI
1
68,80
45,10
1,8376
1,6542
3,039758
2,736378
60,9614643
0,113932
2
61, 20
59,00
1,7868
1,7709
3,164244
3,136087
56,2711901
0,080536
3
59,90
57, 20
1,7774
1,7574
3,123603
3,088455
56,7931534
0,051867
4
56,70
61,80
1,7536
1,7910
3,140698
3, 207681
55,4990353
0,021181
5
55,00
58,80
1,7404
1,7694
3,079464
3,130776
56,3281590
0,024148
6
54,30
47, 20
1,7348
1,6739
2,903882
2,801941
60,1402577
0,107555
7
49,30
55, 20
1,6928
1,7419
2,948688
3,034216
57,3987130
0,164274
Разом 405, 20
384,30
12,3234
12,1587
21,40034
21,13553
403,391973
0,563493
Середня 57,88571
54,90
1,760486
1,736957
3,057191
3,019362
57,62742
0,080499
№ п/п A
1
11
1
2
14
2
3
13
3
4
15
4
5
17
5
6
17,9
7
18,4
7

Список літератури
додаток ВИСНОВОК ПІДСУМКІВ
Множинний R 0,947541801
R-квадрат 0,897835464
Нормований R-квадрат 0,829725774
Стандартна помилка
0,226013867
Спостереження 6
Дисперсійний аналіз
Регресія 2
1,346753196
0,673376598
13,18219855
0,032655042
Залишок 3
0,153246804
0,051082268
Разом 5
1,5
Y-перетин 4,736816539
0,651468195
7,27098664
0,005368842
2,66355399
6,810079088
2,66355399
6,810079088
Змінна X1 0,333424008
0,220082134
1,51499807
0,227014505
-0,366975566
1,033823582
-0,366975566





Синтаксис
Зауваження
приклад
























