Доброго вам дня!
Скільки б усього можна було виправити, якби знати заздалегідь, що на нас чекає...
І якщо в житті передбачити деякі події практично нереально, то ось у випадку з жорстким диском - частина проблем все ж таки, передбачити і передбачити можна!
Для цього існують спеціальні утиліти, які можуть дізнатися та проаналізувати показання SMART* диска (показати їх вам, якщо необхідно), та на основі цих даних оцінити стан здоров'я вашого диска, попутно розрахувавши скільки років він ще зможе прослужити.
Інформація вкрай корисна, до того ж подібні утиліти можуть вести моніторинг вашого диска в режимі онлайн, і щойно з'являться перші ознаки нестабільної роботи - відразу вас сповістити. Відповідно, ви вчасно встигнете зробити бекап і вжити заходів (хоча бекап потрібно робити завжди, навіть коли все добре ☺).
І так, розгляну у статті кілька способів (і кілька утиліт) аналізу стану HDD та SSD.
* Примітка:
S.M.A.R.T. (Self-Monitoring, Analysis and Reporting Technology) – спеціальна технологія оцінки стану жорсткого диска системою інтегрованої апаратної самодіагностики/самоспостереження. Основне завдання - визначити ймовірність виходу пристрою з ладу, запобігши втраті даних.
Мабуть, це одне з найпопулярніших питань, які задають усі користувачі, які вперше зіткнулися з проблемами з жорстким диском (або замислилися про безпеку зберігання своїх даних). Усіх цікавить час, який пропрацює диск до повної "зупинки". Спробуємо передбачити...
Тому, в першій частині статті я вирішив показати пару утиліт, які можуть отримати всі показання з диска та проаналізувати їх самостійно, а вам дати лише готовий результат (у другій частині статті наведу утиліти для перегляду показань SMART для самостійного аналізу).
Спосіб №1 – за допомогою Hard Disk Sentinel
Одна з найкращих утиліт для моніторингу стану дисків комп'ютера (як жорстких дисків (HDD), так і новомодних SSD). Що найбільше підкуповує у програмі - вона всі дані, отримані про стан диска самостійно проаналізує та покаже Вам вже готовий результат (дуже зручно для користувачів-початківців).
Щоб не бути голослівним, покажу відразу головне вікно програми, яке з'являється після першого запуску (аналіз диска буде зроблено відразу автоматично). Здоров'я та продуктивність диска оцінюються як 100% (в ідеалі, так і має бути), час, який диск ще пропрацює в нормальному режимі, оцінюється програмою приблизно в 1000 днів (~3 років).
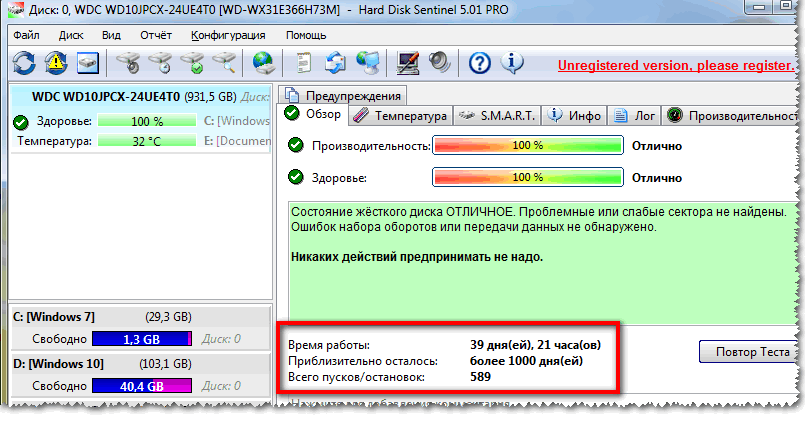
Що з диском за версією Hard Disk Sentinel
Крім цього, програма дозволяє стежити за температурою: як за поточною, так і за середньою та максимальною протягом дня, тижня, місяця. У разі виходу температури за межі "нормальності" - програма попередить Вас про це (що також дуже зручно).

Також Hard Disk Sentinel дозволяє переглянути показання SMART (щоправда, щоб оцінити їх, потрібно непогано розбиратися в дисках), отримати повну інформацію про жорсткий диск (модель, серійний номер, виробник тощо), подивитися, чим жорсткий диск завантажений (тобто · отримати відомості про продуктивність).
Загалом і в цілому, на мій скромний погляд, Hard Disk Sentinel – це одна з найкращих утиліт за контролем стану дисків у системі. Варто додати, що є кілька версій програм: професійна та стандартна (для професійної версії з розширеним функціоналом - є портативна версія програми, яка не потребує встановлення (наприклад, її можна навіть запускати з флешки)).
Hard Disk Sentinel працює у всіх популярних Windows (7, 8, 10 – 32|64 bits), підтримує російську мову в повному обсязі.
Спосіб №2 - за допомогою HDDlife
Ця програма аналогічна першій, також наочно показує поточний стан диска: його здоров'я та продуктивність (у відсотковому вираженні), його температуру, кількість відпрацьованого часу (у місяцях). У верхній частині вікна, на основі всіх цих даних, HDDlife показує підсумкове резюме на вашому диску, наприклад, в моєму випадку "ALL RIGHT" (що означає, що з диском все гаразд).
До речі, програма може працювати в режимі онлайн, стежачи за станом вашого диска, і якщо щось піде не так (при появі перших ознак проблем) - відразу ж повідомити вас про це.
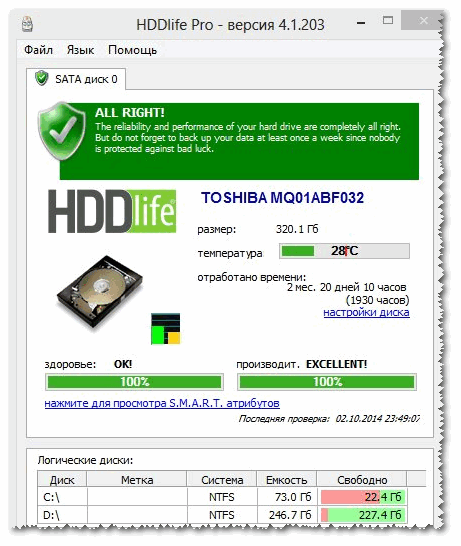
Як приклад нижче на скріншоті показаний SSD диск отримав попередження: його стан ще в допустимих межах, але надійність і продуктивність нижче середнього значення. У цьому випадку довіряти диску якихось важливих даних не варто, і по можливості, потрібно готуватися до його заміни.

До речі, у головному вікні програми, поряд із кількістю відпрацьованого часу диска, є посилання "Настоянка диска" (дозволяє змінити деякі потрібні параметри). Відкривши її, можна керувати балансом між шумом/продуктивністю дуже корисно з дисками, які сильно шумлять), і налаштувати параметри енергоспоживання (актуально для ноутбуків, у яких швидко сідає батарея).

Додаток: HDDlife працює як на ПК, так і на ноутбуках. Підтримує HDD та SSD диски. Є в наявності портативні версії програми, які не потребують встановлення. Можна настроїти так, щоб програма запускалася разом із Windows. HDDlife працює у Windows: XP, 7, 8, 10 (32|64 bits).
Як подивитися свідчення SMART
Якщо попередні утиліти самостійно оцінювали стан диска, на основі даних SMART, то наведені нижче утиліти нададуть вам більше свободи та даних для самостійного аналізу. У звітах можна буде знайти досить великий набір параметрів, на основі яких можна буде приблизно оцінити стан диска і зробити прогноз щодо його подальшої роботи.
Спосіб №1 - за допомогою CrystalDiskInfo
СrystalDiskInfo
Відмінна безкоштовна утиліта для перегляду стану та показань SMART жорсткого диска (підтримуються, зокрема, і SSD-диски). Чим підкуповує утиліта - вона надає вам повну інформацію про температуру, технічний стан диска, його характеристики тощо, причому частина даних йдуть з позначками (тобто утиліта актуальна, як для досвідчених користувачів, які самі знають "що-є- що", так і для початківців, яким потрібна підказка).
Наприклад, якщо з температурою щось не так - ви побачите на ній червоний індикатор, тобто. СrystalDiskInfo сам вам про це повідомить.
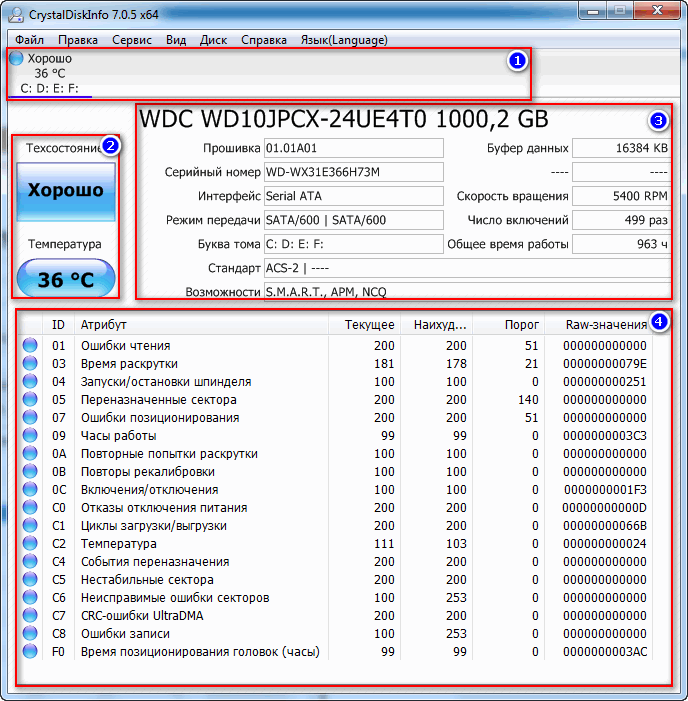
Головне вікно програми умовно можна розбити на 4 зони (див. скріншот вище):
- "1" - тут вказані всі ваші фізичні диски, встановлені на комп'ютері (ноутбуку). Поряд з кожним показана його температура, техстан, і кількість розділів на ньому (наприклад, "C: D: E: F:");
- "2" - тут показано поточну температуру диска та його техстан (програма робить аналіз на основі всіх отриманих даних з диска);
- "3" - дані про диск: серійний номер, виробник, інтерфейс, швидкість обертання та ін.;
- "4" - Свідчення SMART. До речі, чим підкуповує програма - вам необов'язково знати, що означає той чи інший параметр - якщо щось не так з будь-яким пунктом, програма помітить його жовтим або червоним кольором і повідомить вас про це.
Як приклад до вищесказаного, наведу скріншот, на якому відображено два диски: ліворуч – з яким все нормально, праворуч – у якого є проблеми з перепризначеними секторами (Тихстан - тривога!).

Як довідка (про перепризначені сектори):
коли жорсткий диск виявляє, наприклад, помилку запису, він переносить дані у спеціально відведену резервну область (а сектор цей вважатиметься «перепризначеним»). Тому на сучасних жорстких дисках не можна побачити bad-блоки – вони заховані у перепризначених секторах. Цей процес називають remapping, а перепризначений сектор - remap.
Чим більше значення перепризначених секторів – тим гірший стан поверхні дисків. Поле "raw value"містить загальну кількість перепризначених секторів.
До речі, для багатьох виробників дисків навіть один перепризначений сектор - це вже гарантійний випадок!
Щоб утиліта CrystalDiskInfoстежила у режимі онлайн за станом вашого жорсткого диска - у меню "Сервіс" поставте дві галочки: "Запуск агента" та "Автозапуск"(Див. скрін нижче).

Потім ви побачите значок програми з температурою біля годинника в треї. Загалом, за стан диска тепер можна бути спокійнішим ☺...

Спосіб №2 - за допомогою Victoria
Victoria- Одна з найзнаменитіших програм для роботи з жорсткими дисками. Основне призначення програми оцінити технічний стан накопичувача та замінити пошкоджені сектори на резервні робітники.
Утиліта безкоштовна і дозволяє працювати як під Windows, так і під DOS (що в багатьох випадках показує набагато більш точні дані про стан диска).
З мінусів: працювати з Вікторією досить складно, принаймні навмання натискати в ній кнопки я вкрай не рекомендую (можна легко знищити всі дані на диску). У мене на блозі є одна досить велика стаття, де детально розібрано, як перевірити диск за допомогою Вікторії (В тому числі, дізнатися свідчення SMART - приклад на скріншоті нижче (на якому Вікторія вказала на можливу проблему з температурою)).
Інструкція по роботі з Вікторією:
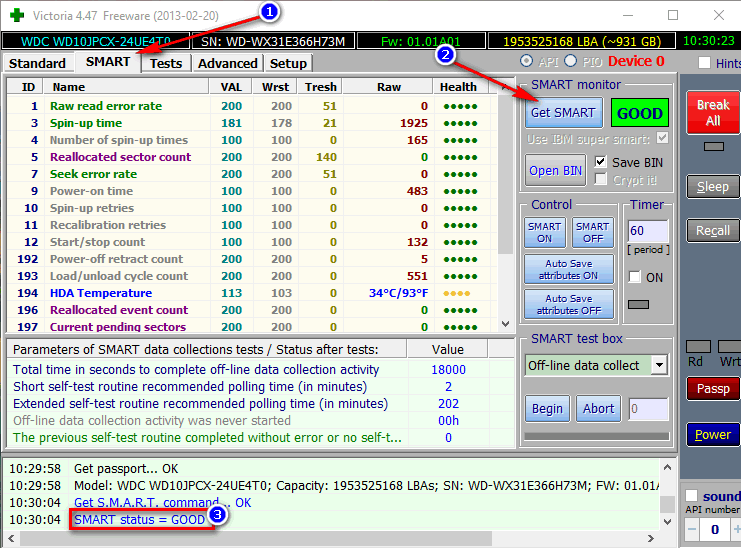
Вкладка SMART | утиліта Вікторія
На цьому закруглююсь, усім удачі!
Додатки на тему вітаються ☺
Послідовність дій за наявності S.M.A.R.T. помилки жорсткого диска або SSD. Як виправити диск та відновити втрачені дані. Під час завантаження комп'ютера або ноутбука з'являється S.M.A.R.T. помилка жорсткого диска чи SSD? Після цієї помилки комп'ютер не працює як раніше, і ви побоюєтеся про збереження ваших даних? Не знаєте, як виправити помилку?
Актуально для ОС: Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
Що робити зі помилкою SMART?
Крок 1:Припиніть використання збійного HDD
Отримання системи повідомлення про діагностику помилки не означає, що диск вже вийшов з ладу. Але у разі наявності S.M.A.R.T. помилки, треба розуміти, що диск уже в процесі виходу з ладу. Повна відмова може настати як протягом декількох хвилин, так і через місяць чи рік. Але в будь-якому випадку це означає, що ви більше не можете довірити свої дані такому диску.
Необхідно подбати про збереження ваших даних, створити резервну копію або перенести файли на інший носій інформації. Одночасно із збереженням ваших даних, необхідно вжити заходів щодо заміни жорсткого диска. Жорсткий диск, на якому було визначено S.M.A.R.T. помилки не можна використовувати - навіть якщо він повністю не вийде з ладу, він може частково пошкодити ваші дані.
Звичайно, жорсткий диск може вийти з ладу і без попереджень S.M.A.R.T. Але ця технологія дає вам перевагу попереджаючи про швидкий вихід диска з ладу.
Крок 2:Відновіть видалені дані диска
У разі виникнення SMART помилки не завжди потрібне відновлення даних із диска. У разі помилки рекомендується негайно створити копію важливих даних, оскільки диск може вийти з ладу будь-якої миті. Але бувають помилки при яких скопіювати дані вже неможливо. У такому разі можна використовувати програму для відновлення даних жорсткого диска. Hetman Partition Recovery.

Для цього:
- Завантажте програму , встановіть та запустіть її.
- За промовчанням користувачу буде запропоновано скористатися Майстром відновлення файлів. Натиснувши кнопку «Далі», програма запропонує вибрати диск, з якого потрібно відновити файли.
- Двічі клацніть на збійному диску та виберіть необхідний тип аналізу. Вибираємо «Повний аналіз»та чекаємо завершення процесу сканування диска.
- Після завершення процесу сканування вам буде надано файли для відновлення. Виділіть потрібні файли та натисніть кнопку «Відновити».
- Виберіть один із запропонованих способів збереження файлів. Не зберігайте відновлені файли на диску з помилкою.
Крок 3:Проскануйте диск на наявність «битих» секторів
Запустіть перевірку всіх розділів жорсткого диска та спробуйте виправити знайдені помилки.

Для цього відкрийте папку «Цей комп'ютер»та клацніть правою кнопкою мишки на диску з SMART помилкою. Виберіть Властивості / Сервіс / Перевіритив розділі Перевірка диска на наявність помилок.
Внаслідок сканування виявлені на диску помилки можуть бути виправлені.
Крок 4:Знизьте температуру диска
Іноді, причиною виникнення “SMART” помилки може бути перевищення максимально допустимої температури роботи диска. Така помилка може бути усунена шляхом покращення вентиляції комп'ютера. По-перше, перевірте чи обладнаний ваш комп'ютер достатньою вентиляцією і чи всі вентилятори справні.
Якщо вами виявлено та усунено проблему з вентиляцією, після чого температура роботи диска знизилася до нормального рівня, то SMART помилка може більше не виникнути.
Крок 5:
Відкрийте папку «Цей комп'ютер»та клацніть правою кнопкою мишки на диску з помилкою. Виберіть Властивості / Сервіс / Оптимізуватив розділі Оптимізація та дефрагментація диска.

Виберіть диск, який потрібно оптимізувати і клацніть Оптимізувати.
Примітка. У Windows 10 дефрагментацію та оптимізацію диска можна налаштувати таким чином, що вона здійснюватиметься автоматично.
Крок 6:Придбайте новий жорсткий диск
Якщо ви зіткнулися зі SMART помилкою жорсткого диска, придбання нового диска – це лише питання часу. Те, який жорсткий диск потрібен вам, залежить від вашого стилю роботи за комп'ютером, а також цілі з якою його використовують.
На що звернути увагу, купуючи новий диск:
- Тип диска: HDD, SSD або SSHD. Кожному типу притаманні свої плюси та мінуси, які не мають вирішального значення для одних користувачів та дуже важливі для інших. Основні з них – це швидкість читання та запису інформації, обсяг та стійкість до багаторазового перезапису.
- Розмір. Два основних форм-фактори дисків: 3,5 дюймів та 2,5 дюймів. Розмір диска визначається відповідно до місця встановлення конкретного комп'ютера або ноутбука.
- Інтерфейс. Основні інтерфейси жорстких дисків:
- SATA;
- IDE, ATAPI, ATA;
- SCSI;
- Зовнішній диск (USB, FireWire тощо).
- Технічні характеристики та продуктивність:
- Місткість;
- Швидкість читання та запису;
- Розмір буфера пам'яті чи cache;
- Час відгуку;
- Відмовостійкість.
- S.M.A.R.T. Наявність у диску даної технології допоможе визначити можливі помилки його роботи і вчасно попередити втрату даних.
- Комплектація. До цього пункту можна віднести можливу наявність кабелів інтерфейсу або живлення, а також гарантії та сервісу.
Як скинути помилку SMART?
SMART помилки можна легко скинути у BIOS (або UEFI). Але розробники всіх операційних систем категорично не рекомендують це робити. Якщо ж для вас немає цінності дані на жорсткому диску, то висновок SMART помилок можна відключити.
Для цього необхідно зробити таке:
- Перезавантажте комп'ютер, і за допомогою натискання вказаної на екрані завантаження комбінації клавіш (у різних виробників вони різні, зазвичай "F2"або "Del") Перейдіть до BIOS (або UEFI).
- Перейдіть до: Advanced > SMART settings > SMART self test. Встановіть значення Disabled.
Примітка:місце вимкнення функції вказано орієнтовно, оскільки залежно від версії BIOS або UEFI, місце розташування такої установки може незначно відрізнятися.
Чи доцільний ремонт HDD?
Важливо розуміти, що будь-який із способів усунення помилок SMART – це самообман. Неможливо повністю усунути причину виникнення помилки, оскільки основною причиною виникнення часто є фізичне зношування механізму жорсткого диска.
Для усунення або заміни неправильно працюючих складових жорсткого диска, зверніться до сервісного центру спеціальною лабораторією для роботи з жорсткими дисками.
Але вартість роботи в такому випадку буде вищою за вартість нового пристрою. Тому ремонт має сенс робити лише у разі необхідності відновлення даних із вже непрацездатного диска.
SMART помилка для диска SSD
Навіть якщо у вас немає претензій до роботи SSD диска, його працездатність поступово знижується. Причиною цього є факт того, що осередки пам'яті диска SSD мають обмежену кількість циклів перезапису. Функція зносостійкості мінімізує цей ефект, але не усуває його повністю.
SSD-диски мають свої специфічні SMART атрибути, які сигналізують про стан осередків пам'яті диска. Наприклад, "209 Remaining Drive Life", "231 SSD life left" і т.д. Ці помилки можуть виникнути у разі зниження працездатності осередків, і це означає, що збережена в них інформація може бути пошкоджена або втрачена.
Осередки SSD диска у разі виходу з ладу не відновлюються і не можуть бути замінені.
Всі сучасні накопичувачі на жорстких магнітних дисках підтримують технологію самотестування, аналізу стану та накопичення статистичних даних про погіршення власних характеристик. S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology).Основи S.M.A.R.T. були розроблені 1995 р. спільними зусиллями провідних виробниками жорстких дисків. У процесі вдосконалення обладнання накопичувачів можливості технології також допрацьовувалися, і після стандарту SMART з'явився SMART II, потім - SMART III, який, очевидно, теж не стане останнім.
Жорсткий диск у процесі свого функціонування постійно відстежує певні параметри свого стану та відображає їх у спеціальних характеристиках. атрибутах(Attribute), що зберігаються, як правило, у спеціально виділеній частині дискової поверхні, доступної тільки внутрішній мікропрограмі накопичувача - службовій зоні. Дані атрибутів можна вважати спеціальним програмним забезпеченням.
Атрибути ідентифікуються своїм цифровим номером, більшість яких однаково інтерпретується накопичувачами різних моделей. Деякі атрибути можуть бути визначені конкретним виробником обладнання та підтримуватися лише окремими моделями накопичувачів.
Атрибути складаються з кількох полів, кожне з яких має певний зміст. Як правило, програми зчитування S.M.A.R.T. видають розшифрування атрибутів у вигляді:
- Attribute- ім'я атрибуту
- ID- ідентифікатор атрибуту
- Value- поточне значення атрибуту
- Threshold- мінімальне граничне значення атрибуту
- Worst- найнижче значення атрибута за весь час роботи накопичувача
- Raw- абсолютне значення атрибуту
- Type(необов'язково) – тип атрибуту – характеризує продуктивність (PR – Performance-related), характеризує збої (ER – Error rate), лічильник подій (EC – Events count), визначено виробником або не використовується (SP – Self-preserve);
Для аналізу стану накопичувача, мабуть, найважливішим значенням атрибуту є Value- Умовне число (зазвичай від 0 до 100 або до 253), задане виробником. Значення Value спочатку встановлено максимум при виробництві накопичувача і зменшується у разі погіршення його параметрів.
Для кожного атрибуту існує граничне значення, до досягнення якого виробник гарантує його працездатність - поле Threshold. Якщо значення Value наближається або стає менше значення Threshold, - накопичувач час міняти. Перелік атрибутів та його значення жорстко не стандартизовані і визначаються виробником накопичувача, але найважливіші їх інтерпретуються однаково.
Наприклад, атрибут з ідентифікатором 5 ( Reallocated sector count) характеризуватиме кількість забракованих та перепризначених із резервної області секторів диска, і для пристроїв виробництва компанії Seagate, і для Western Digital, Samsung, Maxtor.
Жорсткий диск не має змоги, з власної ініціативи, передати дані SMART споживачеві. Їхнє зчитування виконується спеціальним програмним забезпеченням.
У налаштуваннях більшості сучасних BIOS материнських плат є пункт, що дозволяє заборонити або дозволити зчитування та аналіз атрибутів SMART у процесі виконання тестів обладнання перед виконанням початкового завантаження системи. Увімкнення опції дозволяє підпрограмі тестування обладнання BIOS вважати значення критичних атрибутів і при перевищенні порога попередити про це користувача. Як правило, без особливої деталізації:
Primary Master Hard Disk: S.M.A.R.T Status BAD!, Backup and Replace.
Виконання підпрограми BIOS припиняється, щоб привернути увагу:
Таким чином, без встановлення або запуску додаткового програмного забезпечення є можливість вчасно визначити критичний стан накопичувача (при включенні даної опції) засобами Базової Системи Введення-Виведення (BIOS).
Аналіз даних S.M.A.R.T. жорсткого диска
Для отримання даних SMART у середовищі операційної системи можуть використовуватися спеціальні програми, зокрема практично всі утиліти для тестування обладнання жорстких дисків.
Однією з найпопулярніших програм для тестування жорстких дисків є VictoriaСергія Казанського. На сайті автора знайдете останню версію програми, а також багато корисної інформації, в тому числі і докладний опис роботи з Victoria.
Програма Victoria має два різновиди - для роботи в середовищі DOS і для роботи в середовищі Windows. DOS-версія може безпосередньо працювати з контролером жорсткого диска і має значно більші можливості в порівнянні з версією для Windows. Призначення, основні можливості та порядок використання програми раніше можна було знайти на сайті автора, але з деяких пір сайт покинутий та інформації там немає.
Програма проста у використанні та дозволяє оцінити технічний стан накопичувача, виконати його тестування та деякі налаштування – рівня шуму, продуктивності, фізичного обсягу. Режими тестування поверхні накопичувача дозволяють примусово позбавитися збійних секторів за допомогою режиму Remapкількох видів. Виклик меню тестування виконується після натискання клавіші F4 (SCAN). Користувач має можливість задати область тестування:
- Start LBA:0- початок області (за замовчуванням – 0)
- End LBA:14680064- кінець області (за замовчуванням – номер останнього блоку диска)
Режим тестування:
- Лінійне читання- Послідовне читання від початкового блоку до кінцевого;
- Випадкове читання- Номер зчитуваного блоку формується випадковим чином;
- BUTTERFLY читання- Виконується читання блоків, починаючи від граничних номерів (початку і кінця), до центру області тестування. Зміна режиму здійснюється за натисканням клавіші "пробіл".
Режим обробки помилок. Цей пункт дозволяє виконати приховування дефектних блоків з використанням перепризначення (ремап) з резервної області. Вибір режиму виконується клавішею пропуску. Вибраний метод роботи з дефектами відображається у правому верхньому кутку екрана, під годинником, а також у нижньому рядку в момент запуску тесту. Змінити режим можна в та в процесі виконання сканування.
- Ignore Bad Blocks- програма не виконуватиме жодних дій при виявленні помилки.
- BB = RESTORE DATA- програма спробує відновити дані із пошкоджених секторів.
- BB = Classic REMAP- Виконується запис у пошкоджений сектор для виклику процедури перепризначення.
- BB = Advanced REMAP- Поліпшений алгоритм приховування збійних блоків. Використовується, коли допомагає класичний ремап. Програма виконує спеціальну послідовність операцій з формування ознаки кандидата на ремап (атрибут 197) у збійного блоку. Потім виконується 10-кратна запис, оброблена мікропрограмою накопичувача як звичайна обробка кандидата на ремап - якщо є помилка, виконується перепризначення, якщо немає помилки - блок вважається нормальним та видаляється з кандидатів на ремап. Даний режим дозволяє виконати приховування збійних блоків без втрати даних. Звичайно, тільки у випадках, коли накопичувач технічно справний і є вільне місце у резервній галузі для перепризначення.
- BB = Fujitsu Remap- Виконання специфічних алгоритмів, заснованих на недокументованих можливостях деяких моделей накопичувачів Fujitsu
- BB = Erase 256 sect- при виявленні збійного сектора виконується перезапис блоку з 256 секторів. Дані користувача не зберігаються.
У процесі роботи з програмою можна викликати контекстну довідку за допомогою клавіші F1
Версія Victoria For Windowsмає більш скромні можливості з налаштування накопичувача і вибору режимів тестування, і на Наразіне має підтримки російської мови, проте їй простіше користуватись і наявних можливостей цілком достатньо для зчитування таблиці SMART та оцінки технічного стану накопичувача.
Програма не вимагає встановлення, просто скачайте останню версію за посиланням Victoria v4.47 з нашого сайту.
Програма повинна виконуватись під обліковим записом з павами адміністратора. У Windows 7/8 необхідно використовувати контекстне меню “Запуск від імені адміністратора”.
Для аналізу стану SMART-атрибутів вибираємо режим роботи через програмний інтерфейс Windows – вмикаємо кнопку APIу правій верхній частині основного вікна. Потім вибираємо накопичувач для перевірки – натискаємо на кнопку Standardв основному меню програми та підсвічуємо мишкою потрібний диск у вікні зі списком.
В інформаційному вікні буде відображено паспорт накопичувача – модель, версію апаратної прошивки, серійний номер, розмір тощо. Для отримання даних SMART вибираємо пункт меню SMARTі натискаємо кнопку "Get SMART". Результат буде відображено у інформаційному вікні програми.
Короткий опис атрибутів (у дужках дано шістнадцяткове значення номера):
- 001 (1) Raw Read Error Rate- Абсолютне значення помилок зчитування. Існує деякі відмінності у формуванні значення атрибуту різними виробниками. З практики можу сказати, що накопичувачі Seagate можуть мати гігантське значення RAW цього атрибуту, реально будучи у хорошому стані, а накопичувачі Western Digital можуть мати його нульовим, маючи критичні показники за іншими характеристиками. Деякі моделі взагалі можуть не підтримувати цей атрибут.
- 003 (3) Spin Up Time- Середній час розкручування шпинделя диска від 0 RPM до робочої швидкості.
- 004 (4) Start/Stop Count- Кількість циклів запуску/зупинки шпинделя.
- 005 (5) Reallocated Sector Count- кількість перепризначених секторів. Сучасні накопичувачі мають досить велику (тисячі секторів) резервну область поверхні накопичувача для використання її у разі погіршення характеристик секторів із основної зони. Якщо накопичувач виявляє проблеми із записом/зчитуванням якогось сектора, то він автоматично переміщає його дані в резервну область, а даний сектор позначається як "перепризначений". Часто цей процес називають "remapping", або "automatic defect reassignment", він виконується мікропрограмою накопичувача і користувача (операційної системи) невидимий. Поле raw valueмістить загальну кількість перепризначених секторів. Навіть некритичне, але велике значення цього поля, може призвести до зниження швидкості обміну даними, оскільки накопичувач виконує додаткову операцію встановлення головок доріжки резервної області, зазвичай розташованої наприкінці диска.
- 007 (7) Seek Error Rate- частота появи помилок позиціонування блоку магнітних головок (БМГ). Накопичувач контролює правильність встановлення головок на необхідну доріжку поверхні. У випадку, коли установка неправильна, фіксується помилка і операція повторюється. Для цього накопичувача причиною великої кількості помилок став перегрів.
- 008 (8) Seek Time Performance- Середня швидкість позиціонування магнітних головок. Якщо значення атрибуту зменшується (уповільнення позиціонування), то велика ймовірність проблем із механічною частиною приводу головок.
- 009 (9) Power-On Hours- Кількість годинників у включеному стані. Досягнення граничного значення цього атрибуту означає вироблення накопичувачем заданої виробником напрацювання на відмову (MTBF - Mean Time Between Failures).
- 010 (0A) Spin Retry Count- Кількість повторних спроб старту шпинделя. Після ввімкнення живлення накопичувач розкручує диски і контролює досягнення робочої швидкості обертання для пристрою (наприклад 5400, 7200, 10000 об/хв) за певний час. У разі невдачі – збільшується лічильник повторів та повторюється спроба старту.
- 011 (0B) Recalibration Retries- кількість спроб рекалібрування, якщо перша спроба була невдалою. Якщо значення атрибута збільшується, то велика ймовірність проблем із механічною частиною накопичувача. Крім того, збільшення абсолютного значення даного атрибуту може бути спричинене тим, що процедура рекалібрування використовується внутрішньою мікропрограмою накопичувача для корекції інших типів помилок.
- 012 (0C) Device Power Cycle Count- Кількість циклів увімкнення/вимкнення диска.
- 184 (B8) Завершити помилку- Цей атрибут – частина технології HP SMART IV – означає, що після передачі даних через буферну пам'ять парність даних між контролером комп'ютера та жорстким диском не збігається.
- 187 (BB) Reported Uncorrectable Error- характеризує кількість помилок, які не були виправлені мікропрограмою накопичувача.
- 188 (BC) Command TimeoutКількість перерваних операцій через HDD тайм-аут. Зазвичай це значення атрибута має дорівнювати нулю, і, якщо значення набагато вище за нуль, то, швидше за все, там будуть якісь серйозні проблеми з живленням або окисленням контактів інтерфейсного кабелю.
- 189 (BD) High Fly Writes- Якщо висота польоту головки над магнітною поверхнею, навіть на короткий час перевищить оптимальну, записані нею дані, надалі, можуть не прочитатися. Сучасні накопичувачі використовують спеціально розроблену технологію контролю висоти польоту головок, що дозволяє виконувати запис даних при неоптимальній висоті. До лічильника даного атрибута додається одиниця, а запис виконується після встановлення нормальної висоти польоту. Підвищене значення даного атрибуту може бути викликане зовнішніми ударами чи вібраціями, ненормальною температурою, погіршенням характеристик магнітної поверхні чи головки.
- 190 (BE) Airflow Temperature- Температура навколишнього середовища блоку магнітних головок. Для більшості моделей цей атрибут відсутній і використовується атрибут 194.
- 191 (BF) G-sense error rate- кількість помилок, що виникають внаслідок ударних навантажень. Атрибут зберігає показання вбудованого акселерометра, який фіксує всі удари, поштовхи, падіння та навіть неакуратне встановлення диска в корпус комп'ютера. Зазвичай досить точно характеризує умови експлуатації ноутбуків - велике значення атрибуту говорить про різкі поштовхи та падіння при роботі пристрою.
- 192 (C0) Power-off retract count- кількість циклів вимкнень або аварійних відмов (включень/вимкнень живлення накопичувача).
- 193 (C1) Load/Unload Cycle- кількість циклів переміщення блоку магнітних головок у зону паркування.
- 194 (C2) HDA Temperature- Температура самого накопичувача (HDA - Hard Disk Assembly). У даному атрибуті зберігаються показання вбудованого температурного датчика, яким зазвичай є одна з магнітних головок (як правило - нижня). Дані, записані в полях атрибута, відображають поточну, мінімальну та максимальну температуру. Поле Worst показує найгіршу, досягнуту під час роботи накопичувача, температуру (можна встановити факт перегріву та її ступінь), raw value - поточну температуру. Деякі моделі накопичувачів можуть підтримувати атрибут 205 (CD) Thermal asperity rate (TAR), що фіксує кількість небезпечних перепадів температури.
- 195 (C3) Hardware ECC recovered- характеризує кількість помилок зчитування, виправлених обладнанням накопичувача із застосуванням коду корекції помилок. Подібні помилки не вимагають повторного зчитування сектора, і не призводять до втрати швидкості обміну даними, але їх велика кількість говорить про погіршення параметрів тракту зчитування.
- 196 (C4) Місцезнаходження Event Count- Число подій перепризначення збійних секторів. В полі raw valueданого атрибута зберігається загальна кількість спроб перенесення даних із нестабільних секторів у резервну область. Враховуються як успішні, і неуспішні спроби.
- 197 (C5) Current Pending Sector Count- Поточна кількість нестабільних секторів. Поле raw valueцього атрибуту показує загальну кількість секторів, які накопичувач зараз вважає кандидатами на перепризначення в резервну область (remap). Якщо надалі якийсь із цих секторів буде прочитаний успішно, то він виключається зі списку кандидатів. Якщо ж читання сектора супроводжуватиметься помилками, то накопичувач спробує відновити дані і перенести в резервну область, а сам сектор позначити як переназначений (remapped).
- 198 (C6) Невідповідний Sector Count- Лічильник помилок, що не коректуються. Це помилки, які були виправлені внутрішніми засобами корекції устаткування накопичувача. Може бути викликано несправністю окремих елементів або відсутністю вільних секторів у резервній області диска, коли виникла потреба перепризначення.
- 199 (C7) UltraDMA CRC Error Count- Лічильник помилок, що виникли під час передачі даних у режимі UltraDMA . Апаратні засоби контролю передачі з накопичувача в оперативну пам'ять виявили помилку контрольної суми. Нерідко цей тип помилки пов'язаний не так з обладнанням накопичувача, як з несправним інтерфейсним кабелем, нестабільним харчуванням, розгоном частоти шини PCI, перегріванням мікросхем чипсета материнської плати і т.п.
- 200 (C8) Write Error Rate (Multi-Zone Error Rate)- Характеризує наявність помилок під час запису даних. Може викликати погіршення стану поверхні, головок або характеристик тракту запису даних. Чим нижче значення Value, тим небезпечніше використовувати такий накопичувач.
- 220 (DC) Disk Shift- Зміщення блоку дисків щодо вертикальної осі шпинделя. В основному виникає через сильний удар або падіння накопичувача і як правило, є сигналом для його заміни.
- 228 (E4) Power-Off Retract Cycle- Кількість автоматичних паркувань магнітних головок при вимиканні живлення.
Сучасні накопичувачі підтримують як формування атрибутів S.M.A.R.T, а й ведуть додаткові журнали статистики, і навіть підтримують протокол SCT(SMART Command Transport), що забезпечує зчитування даних журналів. Журнал статистики пристрою - це доступний тільки для читання журнал SMART, що передається накопичувачем при отриманні команд READ LOG EXT, READ LOG DMA EXT або SMART READ LOG. У журналах відображається інформація про виконання вбудованих тестів S.M.A.R.T (self-test), статистика помилок, номери збійних блоків LBA тощо.
Сучасні жорсткі диски досить "розумні" пристрої і, крім основних властивих їм як пристрої зберігання та обробки даних властивостей, підтримують технологію самотестування, аналізу стану, і накопичення статистичних даних про погіршення власних характеристик S.M.A.R.T. (S elf- M onitoring A nalysis a nd R eporting T echnology). Основи S.M.A.R.T. були розроблені 1995 р. спільними зусиллями провідних виробниками жорстких дисків (HDD). У наступні роки стандарти S.M.A.R.T допрацьовувалися відповідно до змін технологій та обладнання (SMART II та SMART III) і продовжують удосконалюватися в даний час.
Жорсткий диск, починаючи з моменту його виготовлення, постійно відстежує певні параметри свого стану та відображає їх у спеціальних характеристиках - атрибутах(Attribute), що зберігаються у постійному запам'ятовуючому пристрої, як правило, у спеціально виділеній частині дискової поверхні, доступної тільки внутрішній мікропрограмі накопичувача - службовій зоні. Дані атрибутів можуть бути зчитані відповідно до специфікації ATA ( AT A ttachment) за командами підтримки SMART (SMART READ DATA та ще більше десятка команд), які передаються в накопичувач спеціальним програмним забезпеченням, як наприклад, утилітами від виробників обладнання або універсальними програмами тестування та моніторингу стану HDD (udisks, smartctl, GSmartControl, gnome-disks і т.п.). Сучасні стандарти ATA включають підтримку протоколу SCT (SMART Command Transport), що забезпечує зчитування журналів статистики пристрою. Журнал статистики пристрою - це доступний тільки для читання журнал SMART, що передається накопичувачем при отриманні команд READ LOG EXT, READ LOG DMA EXT або SMART READ LOG.
Атрибут є характеристикою певного стану жорсткого диска, яка змінюється в процесі експлуатації, приймаючи числове значення від максимального, встановленого в момент виготовлення даного пристрою, до мінімального, при досягненні якого, працездатність накопичувача не гарантується. Усі атрибути ідентифікуються своїм цифровим номером, більшість із яких однаково інтерпретується жорсткими дисками різних моделей. Деякі з них можуть використовуватися лише конкретним виробником обладнання та підтримуватися окремими моделями накопичувачів. Так, наприклад, атрибут з ідентифікатором 7 , що характеризує кількість помилок встановлення головок на потрібну доріжку поверхні диска Seek_Error_Rateнемає сенсу для твердотільних дисків (SSD) і, відповідно, не підтримується ними, а атрибут з ідентифікатором 9 , Що характеризує сумарний час роботи накопичувача за весь термін експлуатації та позначається як Power_On_Hours,підтримується як SSD, і традиційними HDD.
Атрибути складаються з декількох полів, (найчастіше позначаються як Val, Worst, Tresh, RAW), кожне з яких є певним показником, що характеризує технічний стан накопичувача на даний час. Програми зчитування S.M.A.R.T. виводять вміст атрибутів, як правило, у вигляді кількох колонок:
Pre-Failure (PF, 01h)- при досягненні граничного значення даного типу атрибутів диск потребує заміни. Іноді цей біт прапорів позначають як Life Critical (CR)або Pre-Failure warranty (PW)
O nline test (OC, 02h) – атрибут оновлює значення під час виконання off-line/on-line вбудованих тестів SMART;
P erfomance R elated (PE або PR, 04h) - атрибут характеризує продуктивність;
E rror R ate (ER, 08h) - атрибут відображає лічильники помилок обладнання;
E vent C ounts (EC, 10h) – атрибут є лічильником подій;
S elf P reserving (SP, 20h) – атрибут, що самозберігається;
Деякі програми можуть інтерпретувати прапори у вигляді текстових описів, близьких за змістом до розглянутих вище. Один атрибут може мати декілька встановлених в одиницю значень прапорів, наприклад атрибут з ідентифікатором 05
що відображає кількість перепризначених через збоїв секторів з резервної області, має встановлені прапори SP+EC+OC – лічильник подій, що самозберігається, оновлюється при автономному та інтерактивному режимі накопичувача.
Для аналізу стану накопичувача, мабуть найважливішим значенням атрибуту є Value- Умовне число (зазвичай від 0 до 100 або до 253), задане виробником. Значення Valueспочатку встановлено максимум при виробництві накопичувача і зменшується у разі погіршення його параметрів. Для кожного атрибуту існує граничне значення, при досягненні якого виробник не гарантує його працездатність - поле Threshold. Якщо значення Valueнаближається або стає менше значення Threshold, - Накопичувач пора міняти.
Перелік атрибутів та їх значення жорстко не стандартизовані та деякі з них можуть визначатися виробником накопичувача, але основна частина інтерпретується однаково. Наприклад, атрибут з ідентифікатором 05 (Reallocated sector count) характеризуватиме кількість забракованих і перепризначених із резервної області секторів диска, як для пристроїв виробництва компанії Seagate Technology, так і для пристроїв виробництва Western Digital. Набір атрибутів, що підтримуються, залежить від моделі накопичувача і може значно відрізнятися за складом для різних моделей.
Найбільш поширеним програмним засобом для отримання даних S.M.A.R.T в середовищі Linux є утиліта smartctlз комплекту smartmontools, як правило, програмного забезпечення, що входить до складу встановлюваного за умовчанням будь-якого дистрибутива. При необхідності оновити версію, а також завантажити документацію англійською мовою можна на сайті проекту smartmontools.org.
Для роботи з утилітою smartctlпотрібні права суперкористувача root.
Формат командного рядка smartctl:
smartctl параметри пристрій
Приклади використання smartctl
smartctl -help або smartctl --usage- Відобразити підказку про використання команди.
Параметри smartctl:
-V, --version, --copyright, --license- Відобразити версію, інформацію копірайту та ліцензії.
-i, --info- Відобразити ідентифікаційну інформацію для пристрою.
-g NAME, --get=NAME- Відобразити параметри налаштувань диска (all, aam, apm, lookahead, security, wcache, rcache, wcreorder)
-a, --all- Відобразити всі дані SMART зазначеного диска.
-x, --xall- Відобразити всі технічні дані для вказаного диска.
--scan- Виконати пошук дискових пристроїв.
-q TYPE, --quietmode=TYPEвстановити режим деталізації виводу для smartctl (errorsonly, silent, noserial)
-d TYPE, --device=TYPE- встановити тип пристрою (ata, scsi, sat[,auto][,N][+TYPE], usbcypress[,X], usbjmicron[,p][,x][,N], usbsunplus, marvell, areca,N /E, 3ware,N, hpt,L/M/N, megaraid,N, cciss,N, auto, test) Зазвичай установка типу пристрою потрібна в тих випадках, коли утиліта smartctlне може визначити його автоматично.
-b TYPE, --badsum=TYPE- задати реакцію виявлення помилок контрольних сум (warn, exit, ignore)
-r TYPE, --report=TYPE- опція призначена для розробників smartmontoolsта дозволяє отримати деталізовану інформацію при виконанні транзакцій функції керування пристроями вводу/виводу ioctl(ioctl, ataioctl, scsiioctl та рівень налагодження). Подробиці - man smartctl
-n MODE, --nocheck=MODE- режим заборони виконання тестів для режимів енергозбереження (never, sleep, standby, idle). Зазвичай використовується для запобігання запуску шпиндельного двигуна за командою Smartctl.
-s VALUE, --smart=VALUE- відключення або увімкнення SMART (on/off)
-o VALUE, --offlineauto=VALUE- заборона або дозвіл автоматичного виконання тестів у неінтерактивному режимі (в режимі простою накопичувача), значення, що приймаються - on/off
-S VALUE, --saveauto=VALUEавтозбереження атрибутів (on/off)
-s NAME[,VALUE], --set=NAME[,VALUE]- заборона/дозвіл параметрів обладнання накопичувача (aam,, apm,, lookahead,, security-freeze, standby,, wcache,, rcache,, wcreorder,)
-H, --health- Відобразити стан накопичувача (SMART health status)
-c, --capabilities- Відобразити інформацію про підтримувані можливості SMART зазначеного жорсткого диска.
-A, --attributes- Відобразити атрибути SMART
-f FORMAT, --format=FORMAT- задати формат атрибутів SMART (old, brief, hex[,id|val]). В основному, впливає на формат значень ідентифікаторів атрибутів, що відображаються, і формат відображення їх прапорів:
old- ідентифікатори атрибутів виводяться в десятковій системі числення, значення прапорів відображаються у шістнадцятковій та інтерпретуються у вигляді тексту.
hex- те, що й у попередньому випадку, але ідентифікатори атрибутів відображаються в шістнадцятковій системі числення.
brief- компактний висновок, ідентифікатори відображаються в десятковій системі числення, прапори відображаються у вигляді символів із розшифровкою в нижній частині таблиці:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE 1 Raw_Read_Error_Rate POSR-- 114 100 006 - 78309029 . . . . . . 254 Free_Fall_Sensor -O-CK 100 100 000 - 0 ||||||_ K auto-keep |||||__ C event count ||||___ R _____ O updated online |______ P prefailure warning
-l TYPE, --log=TYPE- відобразити вказаний журнал пристрою (selftest, selective, directory[, g|s], xerror[,N][,error], xselftest[,N][,selftest],background, sasphy[,reset], sataphy[,reset ], scttemp, scttempint,N[,p], scterc[,N,M], devstat[,N], ssd, gplog,N[,RANGE], smartlog,N[,RANGE]
-v N,OPTION , --vendorattribute=N,OPTION- встановити параметр для визначеного виробником атрибуту з ідентифікатором N
-F TYPE, --firmwarebug=TYPE- адаптація програми для обліку помилок в апаратній прошивці накопичувача (none, nologdir, samsung, samsung2, samsung3, xerrorlba, swapid)
-P TYPE, --presets=TYPE- Налаштування параметрів диска. За замовчуванням, виявивши інформацію про накопичувач у своїй базі, утиліта smartctl, використовує набір параметрів для цієї моделі. Опція use- Використовувати передустановки для цього накопичувача, ignore- не використовувати, show- відобразити налаштування для даного диска, showall- Відобразити налаштування для зазначеної моделі. Приклади:
smartctl –P ignore /dev/hdb- ігнорувати попередні установки для диска /dev/hdb;
smartctl -P show /dev/sdb- відобразити налаштування для зазначеного диска;
smartctl -P showall 'ST9250315AS'- - відобразити налаштування для зазначеної моделі диска - ST9250315AS;
smartctl -P showall 'ST3750515AS' 'SD15'- відобразити налаштування для зазначеної моделі диска ST3750515AS з прошивкою SD15;
-B [+] FILE, --drivedb = [+] FILE- прочитати та змінити базу даних моделей дисків із файлу FILE. Знак “+” перед ім'ям файлу, означає додавання нових записів до бази, перед існуючими.
За промовчанням база даних зберігається у файлі /usr/share/smartmontools/drivedb.h
DEVICE SELF-TEST OPTIONS =====
-t TEST, --test=TEST- Запустити виконання тесту TEST Run test. TEST: offline, short, long, конвеєр, праця, vendor,N, select,M-N, pending,N, afterselect,
-C, --captive- Виконання тестів в режимі захоплення накопичувача. Використовується разом із параметром -tдля тестів нев режимі offline. Використання цього параметра може викликати зайнятість пристрою на весь час виконання тесту та призвести до порушення роботи системи та втрати даних. Не варто використовувати опцію -cдля виконання тестів накопичувачів із монтованими розділами. Для SCSI пристроїв ця опція означає виконання вбудованих тестів у режимі "Foreground mode".
-X, --abort- примусово завершити тест, який виконується без ключа --captive.
Приклади використання Smartctrl.
smartctl --info /dev/sdb- Відобразити ідентифікаційну інформацію для пристрою /dev/sdb. Приклад виведення команди:
=== START OF INFORMATION SECTION === Device Model: ST9500620NS Serial Number: 9XF0AW8T Firmware Version: SN01 User Capacity: 500,107,862,016 Local Time is: Tue Oct 28 15:05:31 2014 MSK SMART support is: Available - device has SMART capability. SMART support is: Enabled
smartctl --all /dev/hdа- відобразити всі дані SMART для пристрою /dev/hda
Приклад даних, що відображаються:
=== START OF INFORMATION SECTION === Device Model: ST9500620NS Serial Number: 9XF0AW8T Firmware Version: SN01 User Capacity: 500,107,862,016 Local Time is: Tue Oct 28 15:05:45 2014 MSK SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x82) Offline data collection активність була здійснена без error. Auto Offline Data Collection: Enabled. Self-test execution status: (0) Попередній self-test routine зроблений без аварії або не self-test має будь-яку ходу. Total time to complete Offline data collection: (634) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data до введення в експлуатацію потужності. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Шорсткий self-test routine recommended polling time: (1) хвилин. Розширений self-test routine recomended polling time: (102) хвилин. Конвеянція шляху-резистентного курсу recommended polling time: (2) minutes. SCT capabilities: (0x10bd) SCT Status supported. SCT Feature Control supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST TRESH TYPE UPDATED 4202 3 Spin_Up_Time 0x0003 096 096 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 72 5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 0 7 Seek_Error_Rate 0x000s2 9 Power_On_Hours 0x0032 073 073 000 Old_age Always - 24037 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 72 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Report _age Always - 0 188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 081 048 045 Old_age Always - 19 191 G-Sense_Error_0 s - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 38 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 73 194 Temperature_Celsius 0x0022 019 052 000 Old_age Always - 19 (0 14 0 0) 195 Hardware_ECC_Recovered 0x001a 118 100 002 Old ding_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 No self-tests have been logged. SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 scanning selected spans, do NO read-scan remainder of disk. Якщо Selective self-test is pending on power-up, resume after 0 minute delay.
smartctl -A -v 9, хвилини /dev/hda- відобразити всі дані атрибутів SMART для пристрою /dev/hdaта атрибут з ідентифікатором 9 (час перебування у включеному стані) інтерпретувати як внутрішнє значення, що задається у хвилинах, а чи не в годинах.
smartctl --smart=on --offlineauto=on --saveauto=on /dev/hda- увімкнути SMART для диска /dev/hda, дозволити автоматичне виконання офлайн-тестів та самозбереження атрибутів. Команду можна виконувати на працюючій системі. Фактично це встановлення стандартних параметрів експлуатації для звичайного дискового накопичувача.
smartctl --test=long /dev/hda- Виконати розширені вбудовані тести для диска /dev/hda.Команду можна використовувати на працюючій системі. Для перегляду результатів виконання тестів використовується команда виведення внутрішнього журналу після завершення тесту
smartctl -l selftest /dev/hda
smartctl --attributes --log=selftest --quietmode=errorsonly /dev/had- Відобразити дані внутрішнього журналу самотестування та атрибути помилок.
smartctl -s on -t offline /dev/hdc- увімкнути SMART та виконати офлайн-тест для диска /dev/hdc. Якщо при тестуванні буде виявлена помилка, то інформація про неї буде записана у внутрішній журнал, переглянути який можна за допомогою параметра -l error.
smartctl -q silent -a /dev/had- Перевірити дані SMART без виведення отриманої інформації. Зазвичай використовується у скриптах. Після виконання команди перевіряється код повернення (змінна $? командної оболонки) для визначення факту виходу значення якогось атрибуту за граничну величину або наявності запису про помилки в журналах пристрою.
smartctl -q errorsonly -H -l selftest /dev/had- виводити інформацію лише за наявності помилкового стану SMART або якщо якийсь із внутрішніх тестів завершився з помилкою.
smartctl -t select,10-100 -t select,30-300 -t afterselect,on -t pending,45 /dev/hda- виконати внутрішній тест у заданій області блоків LBA і після його завершення сканувати частину диска, що залишилася. Якщо під час сканування буде вимкнено живлення, то продовжити його через 45 хвилин після ввімкнення.
smartctl --all --device=3ware,0 /dev/sda- Отримати дані SMART для першого ATA-диска, підключеного до RAID контролера 3ware.
smartctl -a -d 3ware,0 /dev/twe0- Отримати дані SMART для першого ATA-диска, підключеного до RAID контролера 3ware RAID 6000/7000/8000.
smartctl -a -d 3ware,0 /dev/twa0- Отримати дані SMART для першого ATA-диска, підключеного до RAID контролера 3ware RAID 9000
smartctl -t short -d 3ware,3 /dev/sdb- запустити виконання коротких внутрішніх тестів для 4-го диска другого дискового SCSI пристрою /dev/sdb
smartctl -a -d hpt,1/3 /dev/sda- отримати дані SMART диска, підключеного до 3 каналу першого контролера HighPoint RocketRAID
Розшифрування атрибутів S.M.A.R.T
Ідентифікатори атрибутів вказані в десятковій системі числення, а в дужках вони ж – у шістнадцятковій.
Оцінка технічного стану жорсткого диска за даними S.M.A.R.T
Набір атрибутів, що підтримуються конкретною моделлю жорсткого диска, навіть якщо він мінімальний, дозволяє з високою достовірністю визначити технічний стан та перспективи експлуатації пристрою. Можна визначити час перебування у включеному стані за значенням атрибуту 9 , а разом із значенням атрибута 12 - кількість включень/вимикань електроживлення, а отже – цілодобовий або періодичний режим експлуатації. Інтенсивність використання, температурний режим, негативні зовнішні впливи – усі ці факти легко відслідковуються за абсолютними значеннями відповідних атрибутів. Подібним чином можна оцінити і рівень зносу обладнання, якість поверхні і тракту запису/читання.
Мінімально інформативний контроль за станом дисків може виконуватися навіть на рівні BIOS. У разі досягнення критичного значення будь-якого атрибуту, що характеризує працездатність, при включеному моніторингу стану S.M.A.R.T в налаштуваннях BIOS, завантаження операційної системи припиняється і на екран виводиться повідомлення:
Primary Master Hard Disk: S.M.A.R.T Status BAD!, Backup and Replace.
Press F1 to Resume
Таким чином, без встановлення або запуску додаткового програмного забезпечення, можна вчасно визначити факт критичного стану накопичувача засобами Базової Системи Введення-Виведення (BIOS) при включенні комп'ютера.
Технічний стан жорсткого диска, що не досяг критичного порога, характеризується абсолютним значенням атрибутів, що відображають лічильники збоїв, виявлених та виправлених обладнанням накопичувача.
Зміна абсолютних значень атрибутів слід розглядати у динаміці, й у логічного взаємозв'язку друг з одним.
Виконання вбудованих тестів S.M.A.R.T
Набір вбудованих тестів S.M.A.R.T визначається виробником і може відрізнятися для різних моделей жорстких дисків. В основному, вбудовані тести SMART представлені короткими тестами (short self-test) та довгими (extended sels-test). Короткі тести виконують сканування невеликої частини дискової поверхні, визначеної виробником, і виконуються в середньому близько 1 хвилини. Довгі тести виконують сканування всієї робочої поверхні диска і можуть виконуватись, залежно від швидкодії та об'єму диска, навіть кілька годин. Також, для сучасних дисків можна виконувати селективні тести (selective self-test), параметри яких задаються користувачем і тести після транспортування пристрою (conveyance self-test). Виконання тестів можна перервати, якщо не встановлено режим захоплення накопичувача (captive) і накопичувач підтримує команду скасування тесту. Щодо режиму захоплення накопичувача при виконанні тестів captive, то скористатися ним потрібно обережно, якщо диск використовується системою.
Приклади:
smartctl --test=short /dev/sdb- Запустити короткий тест. У відповідь на команду буде виведена інформація:
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION === Sending command: "Execute SMART Short self-test routine immediately in off-line mode". Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful. Testing has begun (попередній test aborted). Please wait 1 хвилини для тесту до повного. Test will complete after Fri Dec 5 16:08:09 2014 За допомогою smartctl -X до abort test.
Що означає, що диску відправлено команду на виконання короткого тесту, диск її сприйняв успішно, тест триватиме 1 хвилину, і для примусового його припинення можна скористатися командою smartctl –X.
Результат виконання тесту можна перевірити, переглянувши журнал тестів командою smartctl –l selftest. У відповідь буде отримано інформацію журналу selftest:
=== START OF READ SMART DATA SECTION === SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Завершено без 00% 831 -
Колонки журналу: Num- номер запису.
Test_Description- Опис тесту.
Status- статус завершення (виконаний без помилок)
Remaining- відсоток часу, що залишився до завершення тесту, якщо він ще не завершений (00%)
LifeTime(hours)- час роботи накопичувача з початку експлуатації.
LBA_of_first_error- номер логічного блоку LBA, де виявлена перша помилка при виконанні тесту. У цьому прикладі помилок немає.
Для запуску довгого тесту використовується команда:
smartctl --test=long /dev/sdb
У відповідь на команду виводиться інформація про початок тесту:
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION === Sending command: "Execute SMART Extended self-test routine immediately in off-line mode". Drive command "Execute SMART Extended self-test routine immediately in off-line mode" successful. Testing has begun. Please wait 70 хвилин для тесту до повного. Test will complete after Fri Dec 5 17:15:44 2014
Як видно, довгий тест для цієї моделі накопичувача виконуватиметься 70 хвилин.
Результат виконання можна перевірити командою smartctl –l selftest /dev/sda
Список команд ATA для роботи з S.M.A.R.T
SMART_READ_VALUES 0xd0 SMART_READ_THRESHOLDS 0xd1 SMART_AUTOSAVE 0xd2 SMART_SAVE 0xd3 SMART_IMMEDIATE_OFFLINE 0xd4 SMART_READ_LOG_SECTOR 0xd5 SMART_WRITE_LOG BLE 0xd9 SMART_STATUS 0xda SMART_AUTO_OFFLINE 0xdb
Додатково на тему обладнання в Linux:
Рано чи пізно (краще, звичайно, якщо рано) будь-який користувач ставить собі питання про те, як довго ще протягне встановлений у нього на комп'ютері жорсткий диск і чи не настав час доглянути йому заміну. Дивного в цьому нічого немає, оскільки жорсткі диски через свої конструктивні особливості є найменш надійними серед комп'ютерних комплектуючих. При цьому саме на HDD у більшості користувачів зберігається левова частка найрізноманітнішої інформації: документів, знімків, різноманітних програм і т.д., внаслідок чого несподіваний вихід диска з ладу - завжди трагедія. Звичайно, нерідко інформацію на зовні «мертвих» жорстких дисках можна відновити, але не виключено, що ця операція влетить вам «у копієчку», та й нервів коштуватиме чималих. Тому набагато ефективніше спробувати запобігти втраті даних.
Як? По-перше, не забувати про регулярне резервне копіювання даних, а по-друге, контролювати стан дисків за допомогою спеціалізованих утиліт. Декілька програм такого плану в ракурсі розв'язуваних завдань ми і розглянемо в цій статті.
Контроль SMART-параметрів та температури
Усі сучасні HDD і навіть твердотілі накопичувачі (SSD) підтримують технологію S.M.A.R.T. ( від англ. Self-Monitoring, Analysis, and Reporting Technology (технологія самоконтролю, аналізу та звітності), яка була розроблена основними виробниками жорстких дисків для збільшення надійності їхньої продукції. Ця технологія базується на безперервному моніторингу та оцінці стану жорсткого диска вбудованою апаратурою самодіагностики (спеціальними сенсорами), а її основне призначення – своєчасне виявлення можливого виходу накопичувача з ладу.
Моніторинг стану HDD у реальному часі
Ряд інформаційно-діагностичних рішень для діагностики та тестування «заліза», а також спеціальні моніторингові утиліти використовують технологію S.M.A.R.T. для спостереження за поточним станом різних життєво важливих параметрів, що описують надійність та продуктивність жорстких дисків. Вони зчитують відповідні параметри безпосередньо із сенсорів та термодатчиків, якими оснащені всі сучасні жорсткі диски, аналізують отримані дані та відображають їх у вигляді короткого табличного звіту з переліком атрибутів. При цьому частина утиліт (Hard Drive Inspector, HDDlife, Crystal Disk Info тощо) не обмежується відображенням таблиці атрибутів (значення яких для непідготовлених користувачів незрозумілі) та додатково виводить коротку інформацію про стан диска у більш доступному для розуміння вигляді.
Діагностувати стан жорсткого диска за допомогою такого роду утиліт простіше простого - досить ознайомитися з короткою базовою інформацією про встановлені HDD: з основними даними про диски в Hard Drive Inspector, певним умовним відсотком здоров'я жорсткого диска HDDlife, індикатором «Техстан» в Crystal Disk Info ( 1) і т.д. У будь-якій з подібних програм надається мінімум необхідної інформації про кожен із встановлених на комп'ютері HDD: дані про модель вінчестера, його обсяг, робочу температуру, відпрацьований час, а також рівень надійності та продуктивності. Ця інформація дає можливість зробити певні висновки щодо працездатності носія.
Мал. 1. Коротка інформація про «здоров'я» робітника HDD
Слід налаштувати запуск моніторингової утиліти одночасно зі стартом операційної системи, скоригувати інтервал часу між перевірками S.M.A.R.T.-атрибутів, а також увімкнути відображення температури та «рівня здоров'я» жорстких дисків у системному треї. Після цього для контролю за станом дисків користувачеві досить буде час від часу поглядати на індикатор у системному треї, де відображатиметься коротка інформація про стан наявних у системі накопичувачів: рівень їх «здоров'я» та температуру (рис. 2). До речі, робоча температура - це не менш важливий показник ніж умовний показник здоров'я HDD, адже жорсткі диски можуть раптово вийти з ладу внаслідок банального перегріву. Тому якщо жорсткий диск нагрівається вище 50 °C, то розумніше буде забезпечити додаткове охолодження.

Мал. 2. Відображення стану жорсткого диска
у системному треї програмою HDDlife
Варто зазначити, що в ряді таких утиліт передбачена інтеграція з провідником Windows, завдяки чому на іконках локальних дисків у разі їхньої справності відображається зелений значок, а при виникненні проблем піктограма стає червоною. Тож забути про стан здоров'я жорстких дисків вам навряд чи вдасться. За такого постійного моніторингу ви не зможете пропустити момент, коли з диском почнуть виникати якісь проблеми, адже у разі виявлення утилітою критичних змін атрибутів S.M.A.R.T. та/або температури вона дбайливо сповістить про це користувача (повідомленням на екрані, звуковим повідомленням тощо – мал. 3). Завдяки цьому можна буде встигнути скопіювати дані з носія, що вселяє побоювання, завчасно.

Мал. 3. Приклад повідомлення про необхідність негайної заміни диска
Використовувати на практиці рішення S.M.A.R.T.-моніторингу для спостереження за станом жорстких дисків абсолютно необтяжливо, адже всі подібні утиліти працюють у фоновому режимі та вимагають мінімум апаратних ресурсів, тому їх функціонування жодною мірою не завадить основному робочому процесу.
Контроль S.M.A.R.T.-атрибутів
Просунуті користувачі, зрозуміло, навряд чи обмежаться для оцінки стану жорстких дисків переглядом короткого вердикту однієї з наведених вище утиліт. Воно й зрозуміло, адже за розшифровкою атрибутів S.M.A.R.T. можна виявити причину збоїв і за необхідності передбачливо вжити якихось додаткових заходів. Щоправда, для самостійного контролю S.M.A.R.T.-атрибутів потрібно хоча б коротко ознайомитися з технологією S.M.A.R.T.
До складу жорстких дисків, що підтримують цю технологію, і включені інтелектуальні процедури самодіагностики, тому вони здатні «повідомляти» про свій поточний стан. Ця діагностична інформація надається як колекція атрибутів, тобто конкретних характеристик жорсткого диска, що використовуються для аналізу його продуктивності та надійності.
Б оБільшість важливих атрибутів має той самий сенс для дисків всіх виробників. Значення даних атрибутів при нормальній роботі диска можуть змінюватись в деяких інтервалах. Для будь-якого параметра виробником визначено мінімально безпечне значення, яке не може бути перевищене за нормальних умов експлуатації. Однозначно визначити критично важливі та критично неважливі для діагностики параметри S.M.A.R.T. проблематично. Кожен із атрибутів має свою інформаційну цінність і свідчить про той чи інший аспект у роботі носія. Однак насамперед слід звертати увагу на такі атрибути:
- Raw Read Error Rate - частота помилок читання даних із диска, що виникли з вини обладнання;
- Spin Up Time – середній час розкручування шпинделя диска;
- Reallocated Sector Count – число операцій перепризначення секторів;
- Seek Error Rate – частота появи помилок позиціонування;
- Spin Retry Count – кількість повторних спроб розкрутки дисків до робочої швидкості у разі невдалості першої спроби;
- Current Pending Sector Count - кількість нестабільних секторів (тобто секторів, які очікують на процедуру перепризначення);
- Offline Scan Uncorrectable Count - загальна кількість нескоригованих помилок під час операцій читання/запису секторів.
Зазвичай атрибути S.M.A.R.T. відображаються у табличному вигляді із зазначенням імені атрибуту (Attribute), його ідентифікатора (ID) та трьох значень: поточного (Value), мінімального порогового (Threshold) та найнижчого значення атрибуту за весь час роботи накопичувача (Worst), а також абсолютного значення атрибута (Raw). Кожен атрибут має поточне значення, яке може бути будь-яким числом від 1 до 100, 200 або 253 (загальних стандартів для верхніх меж значень атрибутів не передбачено). Значення Value і Worst у абсолютно нового вінчестера збігаються (рис. 4).

Мал. 4. Атрибути S.M.A.R.T. у нового HDD
Наведена на рис. 4 інформація дозволяє зробити висновок, що теоретично справного вінчестера поточні (Value) і найгірші (Worst) значення повинні бути максимально близькими один до одного, а значення Raw у більшості параметрів (за винятком параметрів: Power-On Time, HDA Temperature і деяких інших ) має наближатися до нуля. Поточне значення може з часом змінюватися, що у більшості випадків відображає погіршення параметрів жорсткого диска, що описуються атрибутом. Це можна побачити на рис. 5 де представлені фрагменти таблиці атрибутів S.M.A.R.T. для того самого диска - дані отримані з інтервалом у півроку. Як бачимо, у новішій версії S.M.A.R.T. збільшилася частота помилок при читанні даних з диска (Raw Read Error Rate), походження яких обумовлено апаратною частиною диска, та частота помилок при позиціонуванні блоку магнітних головок (Seek Error Rate), що, можливо, свідчить про перегрівання вінчестера та його нестійке положення в кошику . Якщо поточне значення якого-небудь атрибуту наближається або стає меншим за пороговий, то жорсткий диск визнається ненадійним, і його слід терміново змінювати. Наприклад, падіння значення атрибуту Spin-Up Time (середній час розкручування шпинделя диска) нижче критичного значення, як правило, повідомляє про повне зношування механіки, внаслідок чого диск більше не в змозі підтримувати задану виробником швидкість обертання. Тому необхідно контролювати стан HDD та періодично (наприклад, раз на 2-3 місяці) проводити діагностику S.M.A.R.T. та зберігати отриману інформацію у текстовому файлі. Надалі ці дані можна буде порівняти з поточними та зробити певні висновки щодо розвитку ситуації.
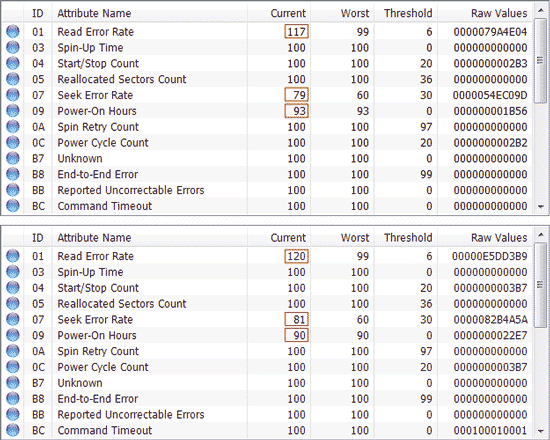
Мал. 5. Таблиці атрибутів S.M.A.R.T., одержані з піврічним інтервалом
(свіжіша версія S.M.A.R.T. внизу)
При перегляді S.M.A.R.T.-атрибутів в першу чергу варто звертати увагу на критично важливі параметри, а також параметри, виділені відмінними від базового кольору (частіше синього або зеленого) індикаторами. Залежно від поточного стану атрибуту у виведеній утилітою S.M.A.R.T. таблиці він зазвичай маркується тим чи іншим кольором, що полегшує розуміння ситуації. Зокрема, у програмі Hard Drive Inspector колірний індикатор може мати зелений, жовто-зелений, жовтий, помаранчевий або червоний колір - зелений і жовто-зелений кольори говорять про те, що все нормально (значення атрибуту не змінювалося або несуттєво змінювалося), а жовтий, помаранчевий і червоний кольори сигналізують про небезпеку (найгірше червоний колір, який говорить про те, що значення атрибуту досягло свого критичного значення). Якщо якийсь із критично важливих параметрів відзначений значком червоного кольору, потрібно терміново замінити вінчестер.
Переглянемо у програмі Hard Drive Inspector таблицю S.M.A.R.T.-атрибутів того самого диска, коротку оцінку якого моніторинговими утилітами нами було наведено раніше. З рис. 6 видно, що значення всіх атрибутів у нормі та всі параметри промарковані зеленим кольором. Аналогічну картину покажуть і утиліти HDDlife та Crystal Disk Info. Щоправда, більш професійні рішення для аналізу та діагностики HDD не такі лояльні і часто маркують S.M.A.R.T.-атрибути більш прискіпливо. Наприклад, такі відомі утиліти, як HD Tune Pro і HDD Scan, у разі з підозрою поставилися до атрибуту UltraDMA CRC Errors, що відображає кількість помилок, що виникають під час передачі інформації із зовнішнього інтерфейсу (рис. 7). Причина таких помилок зазвичай пов'язані з перекрученим і неякісним SATA-шлейфом, який, можливо, слід замінити.

Мал. 6. Таблиця S.M.A.R.T.-атрибутів, отримана у програмі Hard Drive Inspector

Мал. 7. Результати оцінки стану S.M.A.R.T.-атрибутів
утилітами HD Tune Pro та HDD Scan
Для порівняння ознайомимося з S.M.A.R.T.-атрибутами дуже древнього, але поки що працює HDD з проблемами, що періодично виникають. Програмі Crystal Disk Info довіри він не вселив - в індикаторі "Техстан" стан диска був оцінений як тривожний, а атрибут Reallocated Sector Count (Переназначені сектори) виявився виділеним жовтим кольором (рис. 8). Це дуже важливий з точки зору здоров'я диска атрибут, що позначає кількість секторів, переназначених при виявленні диском помилки читання/запису, при цій операції дані з пошкодженого сектора переносяться в резервну область. Жовтий колір індикатора у параметра говорить про те, що резервних секторів, якими можна замінити збійні, залишилося мало, і незабаром перепризначати знову з'являються збійні сектори виявиться нічим. Перевіримо також, як оцінюють стан диска серйозніші рішення, наприклад широко використовується професіоналами утиліта HDDScan, - але й тут бачимо такий самий результат (рис. 9).

Мал. 8. Оцінка проблемного жорсткого диска CrystalDiskInfo

Мал. 9. Результати S.M.A.R.T.-діагностики HDD в HDDScan
Значить, із заміною такого жорсткого диска тягнути явно не варто, хоча він ще й може деякий час послужити, правда операційну систему на цей жорсткий диск встановлювати, звичайно, не можна. Варто зазначити, що за наявності великої кількості перепризначених секторів швидкість читання/запису падає (внаслідок зайвих рухів, які доводиться здійснювати магнітною головкою), диск починає помітно гальмувати.
Сканування поверхні на bad-сектор
На жаль, на практиці одним контролем SMART-параметрів та температури не обійтися. При появі дрібних свідчень про те, що з диском щось не так (у разі періодичного зависання програм, наприклад при збереженні результатів, появі повідомлень про помилки читання тощо) необхідно просканувати поверхню диска на наявність секторів, що не читаються. Для проведення подібної перевірки носія можна скористатися, наприклад, утилітами HD Tune Pro та HDDScan або діагностичними утилітами від виробників вінчестерів, проте ці утиліти працюють лише зі своїми моделями жорстких дисків, а тому ми їх розглядати не будемо.
При використанні таких рішень існує небезпека пошкодження даних на диску, що сканується. З одного боку, з інформацією на диску, якщо накопичувач дійсно виявиться несправним, під час сканування може статися що завгодно. З іншого боку, не можна виключати некоректних дій з боку користувача, що помилково запускає сканування в режимі запису, в ході якого відбувається посекторне затирання даних з вінчестера певною сигнатурою, і на підставі швидкості цього процесу робиться висновок про стан жорсткого диска. Тому дотримання певних правил безпеки абсолютно необхідне: перед запуском утиліти потрібно створити резервну копію інформації і в ході перевірки діяти строго за інструкцією розробника відповідного ПЗ. Для отримання більш точних результатів перед скануванням краще закрити всі активні програми та вивантажити можливі фонові процеси. Крім того, слід мати на увазі, що при необхідності тестування системного HDD потрібно завантажитися з флешки і з неї запускати процес сканування або зняти жорсткий диск і приєднати його до іншого комп'ютера, з якого і запускати тестування диска.
Як приклад за допомогою HD Tune Pro перевіримо на погані сектори поверхню HDD, який вище не вселив довіри утиліті Crystal Disk Info. У цій програмі для запуску процесу сканування достатньо вибрати потрібний диск, активувати вкладку Error Scanта клацнути на кнопці Start. Після цього утиліта приступить до послідовного сканування диска, зчитуючи сектор за сектором та позначаючи на карті диска сектора різнокольоровими квадратиками. Колір квадратиків залежно від ситуації може бути зеленим (нормальні сектори) або червоним (bad-блоки) або матиме проміжний між цими кольорами відтінок. Як бачимо із рис. 10, у нашому випадку повноцінних bad-блоків утиліта не знайшла, але тим не менш наявна солідна кількість секторів з тією чи іншою затримкою читання (судячи з їхнього кольору). На додаток до нього в середній частині диска є невеликий блок секторів, колір якого близький до червоного - дані сектора поки що утилітою не визнані збійними, але вони вже близькі до цього і перейдуть у категорію збійних найближчим часом.

Мал. 10. Сканування поверхні на bad-секторі в HD Tune Pro
Протестувати носій на погані сектори у програмі HDDScan складніше, та й небезпечніше, оскільки у разі неправильно вибраного режиму інформація на диску буде безповоротно втрачена. Насамперед для запуску сканування створюють нове завдання, клацнувши по кнопці New Taskта вибравши у списку команду Suface Tests. Потім потрібно переконатися, що вибрано режим Read- цей режим встановлюється за замовчуванням і за його використання тестування поверхні жорсткого диска проводиться за читанням (тобто без видалення даних). Після цього натискають кнопку Add Test(рис. 11) і двічі клацають на створеному завданні RD-Read. Тепер у вікні можна спостерігати процес сканування диска на графіку (Graph) або на карті (Map) - рис. 12. По завершенні процесу отримаємо приблизно такі ж результати, що вище були продемонстровані утилітою HD Tune Pro, але з більш чіткою інтерпретацією: збійних секторів немає (вони відзначаються синім кольором), але в наявності три сектори з часом відгуку понад 500 мс (позначені червоним кольором), які й становлять реальну небезпеку. Що стосується шести помаранчевих секторів (час відгуку від 150 до 500 мс), то це можна вважати в межах норми, оскільки така затримка відгуку найчастіше викликається тимчасовими перешкодами у вигляді, наприклад, фонових програм, що працюють.

Мал. 11. Запуск тестування диска у програмі HDDScan

Мал. 12. Результати сканування диска в режимі Read за допомогою HDDScan
На додаток слід зазначити, що за наявності невеликої кількості bad-блоків можна спробувати покращити стан жорсткого диска, прибравши погані сектори шляхом сканування поверхні диска в режимі лінійного запису (Erase) за допомогою HDDScan. Після такої операції деякий час диск ще може експлуатуватися, але, звичайно, не системний. Однак сподіватися на диво не варто, оскільки HDD вже почав сипатися, і немає жодних гарантій, що найближчим часом кількість дефектів не зросте і накопичувач остаточно не вийде з ладу.
Програми для S.M.A.R.T.-моніторингу та тестування HDD
HD Tune Pro 5.00 та HD Tune 2.55
Розробник: EFD Software
Розмір дистрибутива: HD Tune Pro – 1,5 Мбайт; HD Tune – 628 Кбайт
Робота під управлінням: Windows XP/Server 2003/Vista/7
Спосіб поширення: HD Tune Pro – shareware (15-денна демо-версія); HD Tune – freeware (http://www.hdtune.com/download.html)
Ціна: HD Tune Pro - 34,95 дол.; HD Tune – безкоштовно (тільки для некомерційного застосування)
HD Tune - зручна утиліта для діагностики та тестування HDD/SSD (див. таблицю), а також карт пам'яті, USB-дисків та інших пристроїв зберігання даних. Програма відображає детальну інформацію про накопичувач (версія прошивки, серійний номер, об'єм диска, розмір буфера та режим передачі даних) та дозволяє встановити стан пристрою з використанням даних S.M.A.R.T. та моніторингу температури. Крім того, з її допомогою можна провести тестування поверхні диска на наявність помилок та оцінити продуктивність пристрою, провівши серію тестів (тести швидкості послідовного та випадкового читання/запису даних, тест файлової продуктивності, тест кешу та ряд Extra-тестів). Також утиліта може використовуватися для налаштування AAM та безпечного видалення даних. Програма представлена у двох редакціях: комерційній HD Tune Pro та безкоштовній полегшеній HD Tune. У редакції HD Tune доступний лише перегляд детальної інформації про диск та таблиці атрибутів S.M.A.R.T., а також сканування диска на помилки та тестування на швидкість в режимі читання (Low level benchmark – read).
За моніторинг S.M.A.R.T.-атрибутів у програмі відповідає вкладка Health – зчитування даних із сенсорів здійснюється через встановлений проміжок часу, результати відображаються у таблиці. Для будь-якого атрибуту можна переглянути історію його змін у чисельному вигляді та на графіку. Дані моніторингу автоматично записуються в балку, але жодних повідомлень користувача при критичних змінах параметрів не передбачено.
Що стосується сканування поверхні диска щодо наявності пошкоджених секторів, то за цю операцію відповідає вкладка Error Scan. Сканування може бути швидким (Quick scan) та глибоким – при швидкій перевірці перевіряється не весь диск, а лише якась його частина (зона сканування визначається через поля Start та End). Пошкоджені сектори відображаються на карті диска у вигляді червоних блоків.
HDDScan 3.3
Розробник: Artem Rubtsov
Розмір дистрибутива: 3,64 Мбайт
Робота під управлінням: Windows 2000(SP4)/XP(SP2/SP3)/Server 2003/Vista/7
Спосіб поширення: freeware (http://hddscan.com/download/HDDScan-3.3.zip)
Ціна:безкоштовно
HDDScan – утиліта для низькорівневої діагностики жорстких дисків, твердотільних накопичувачів та Flash-дисків з інтерфейсом USB. Основне призначення даної програми – тестування дисків на наявність bad-блоків та збійних секторів. Також утиліта може використовуватися для перегляду вмісту S.M.A.R.T., моніторингу температури та зміни деяких налаштувань жорсткого диска: управління шумом (AAM), управління живленням (APM), примусового запуску/зупинки шпинделя накопичувача та ін. Програма працює без встановлення та може запускатися з портативного носія наприклад флешки.
Відображення S.M.A.R.T.-атрибутів і моніторинг температури в HDDScan проводиться на вимогу. Звіт S.M.A.R.T. містить інформацію про продуктивність та «здоров'я» накопичувача у вигляді стандартної таблиці атрибутів, температура накопичувача відображається в системному треї та у спеціальному інформаційному вікні. Звіти можна роздруковувати або зберігати в MHT-файлі. Можливе проведення S.M.A.R.T.-тестів.
Перевірка поверхні диска проводиться в одному з чотирьох режимів: Verify (режим лінійної верифікації), Read (лінійного читання), Erase (лінійного запису) та Butterfly Read (режим читання Butterfly). Для перевірки диска на наявність bad-блоків зазвичай використовується тест режимі читання (Read), з допомогою якого відбувається тестування поверхні без видалення даних (висновок про стан накопичувача робиться виходячи з швидкості посекторного читання даних). При тестуванні в режимі лінійного запису (Erase) інформація на диску затирається, але цей тест може трохи підлікувати диск, позбавивши його від збійних секторів. У будь-якому з режимів тестувати можна весь диск повністю або певний його фрагмент (зона сканування визначається вказівкою початкового та кінцевого логічних секторів - Start LBA та End LBA відповідно). Результати тестування подаються у вигляді звіту (вкладка Report) і відображаються на графіку (Graph) та карті диска (Map) із зазначенням у числі іншої кількості збійних секторів (Bads) та секторів, час відгуку яких при тестуванні зайняв понад 500 мс (позначені червоним кольором) ).
Hard Drive Inspector 4.13
Розробник: AltrixSoft
Розмір дистрибутива: 2,64 Мбайт
Робота під управлінням: Windows 2000/XP/2003 Server/Vista/7
Спосіб поширення: shareware (14-денна демо-версія - http://www.altrixsoft.com/ru/download/)
Ціна: Hard Drive Inspector Professional – 600 руб.; Hard Drive Inspector for Notebooks – 800 руб.
Hard Drive Inspector - зручне рішення для S.M.A.R.T.-моніторингу зовнішніх та внутрішніх HDD. На даний момент на ринку програма пропонується у двох редакціях: базової Hard Drive Inspector Professional та портативної Hard Drive Inspector for Notebooks; остання включає всю функціональність версії Professional і в той же час враховує специфіку моніторингу жорстких дисків ноутбуків. Теоретично існує ще версія SSD, але вона поширюється лише у OEM-постачанні.
Програма забезпечує автоматичну перевірку S.M.A.R.T.-атрибутів через зазначені проміжки часу і по завершенні видає свій вердикт щодо стану накопичувача з відображенням значень деяких умовних індикаторів: «надійності», «продуктивності» та «відсутності помилок» разом з числовим значенням температури та температури. Також наводяться технічні дані про модель диска, його ємність, загальне вільне місце та час роботи в годинах (днях). У розширеному режимі можна переглянути інформацію про параметри диска (розмір буфера, назву прошивки тощо) та таблицю атрибутів S.M.A.R.T. Передбачені різні варіанти інформування користувача у разі критичних змін на диску. Додатково утиліта може бути використана для зниження рівня шуму, що виробляється жорсткими дисками, та зниження енергоспоживання HDD.
HDDlife 4.0
Розробник: BinarySense, Ltd
Розмір дистрибутива: 8,45 Мбайт
Робота під управлінням: Windows 2000/XP/2003/Vista/7/8
Спосіб поширення: shareware (15-денна демо-версія - http://hddlife.ru/ukr/downloads.html)
Ціна: HDDLife – безкоштовно; HDDLife Pro – 300 руб.; HDDlife for Notebooks – 500 руб.
HDDLife – проста утиліта, призначена для контролю стану жорстких дисків та SSD (з версії 4.0). Програма представлена у трьох редакціях: безкоштовній HDDLife та двох комерційних – базовій HDDLife Pro та портативної HDDlife for Notebooks.
Утиліта здійснює моніторинг S.M.A.R.T.-атрибутів та температури через задані проміжки часу та за результатами аналізу видає компактний звіт про стан диска із зазначенням технічних даних про модель диска та його ємність, відпрацьований час, температуру, а також відображає умовний відсоток його здоров'я та продуктивності, що дозволяє зорієнтуватися у ситуації навіть новачкам. Більш досвідчені користувачі можуть додатково подивитися таблицю S.M.A.R.T.-атрибутів. У разі проблем із жорстким диском передбачена можливість налаштування повідомлень; можна настроїти програму так, щоб при нормальному стані диска результати перевірки не відображалися. Можливе керування рівнем шуму HDD та енергоспоживанням.
CrystalDiskInfo 5.4.2
Розробник: Hiyohiyo
Розмір дистрибутива: 1,79 Мбайт
Робота під управлінням: Windows XP/2003/Vista/2008/7/8/2012
Спосіб поширення: freeware (http://crystalmark.info/download/index-e.html)
Ціна:безкоштовно
CrystalDiskInfo - проста утиліта для S.M.A.R.T.-моніторингу стану жорстких дисків (включаючи багато зовнішніх HDD) і SSD. Незважаючи на безкоштовність, програма володіє всім необхідним функціоналом для організації контролю стану дисків.
Моніторинг дисків здійснюється автоматично через вказану кількість хвилин або на вимогу. Після закінчення перевірки у системному треї відображається температура контрольованих пристроїв; детальна інформація про HDD із зазначенням значень S.M.A.R.T.-параметрів, температури та вердикту програми про стан пристроїв доступна у головному вікні утиліти. Є функціонал для налаштування порогових значень для деяких параметрів та автоматичного сповіщення користувача у разі їх перевищення. Можливе керування рівнем шуму (AAM) та живленням (APM).
На жаль, чимала частина сучасних HDD нормально працює трохи більше року, потім починаються різні проблеми, які з часом можуть призвести до втрати даних. Такої перспективи можна уникнути, якщо уважно стежити за станом жорсткого диска, наприклад, за допомогою розглянутих у статті утиліт. Однак забувати про регулярне резервування цінних даних також не варто, оскільки моніторингові утиліти, як правило, вдало прогнозують вихід диска з ладу з вини «механіки» (згідно зі статистикою компанії Seagate, через механічні компоненти виходять з ладу близько 60% HDD), але вони не в змозі передбачити загибель накопичувача через неполадки з електронними компонентами диска.

: Прості та безпечні способи Останнє оновлення для iphone 4")


")



















