Чи гідна архітектура Haswell називатися новою та переробленою?
Понад п'ять років Intel дотримується стратегії "тік-так", чергуючи переведення конкретної архітектури на більш тонкі технологічні норми з випуском нової архітектури.
У результаті щороку ми отримуємо або нову архітектуру, або перехід новий техпроцес. На 2013 рік було заплановано так, тобто випуск нової архітектури - Haswell. Процесори з новою архітектурою випускаються за тим же техпроцесом, що й попереднє покоління Ivy Bridge: 22 нм, Tri-gate. Техпроцес не змінився, у своїй кількість транзисторів збільшилося, отже, і кінцева площа кристала нового процесора теж збільшилася - а потім і енергоспоживання.
Дотримуючись традицій, Intel у день анонсу Haswell представила лише продуктивні та дорогі процесорилінійок Core i5 та i7. Анонс двоядерних процесорівмолодших лінійок як завжди йде із затримкою. Варто зауважити, що ціни на нові процесори залишилися на тому ж рівні, що й у Ivy Bridge.
Порівняємо площі кристалів різних поколінь чотириядерних процесорів:
Як бачимо, чотириядерний Haswell має площу всього 177 мм², при цьому в нього інтегровано північний міст, контролер оперативної пам'ятіта графічне ядро. Таким чином, кількість транзисторів збільшилася на 200 мільйонів, а площа зросла на 17 мм. Якщо ж порівняти Haswell із 32-нанометровими Sandy Bridgeкількість транзисторів збільшилася на 440 мільйонів (38%), а площа за рахунок переходу на техпроцес 22 нм скоротилася на 39 мм² (18%). Тепловиділення всі ці роки трималося практично на одному рівні (95 Вт у SB і 84 Вт у Haswell), а площа зменшувалась.
Все це призвело до того, що з кожного квадратного міліметра кристала доводиться відводити більше тепла. Якщо раніше з 216 мм² треба було забирати 95 Вт, тобто 0,44 Вт/мм², то тепер із площі 177 мм² треба забирати 84 Вт - 0,47 Вт/мм², що на 6,8% більше, ніж раніше. Якщо ця тенденція збережеться, то скоро просто фізично складно відводити тепло з таких маленьких площ.
Розмірковуючи суто теоретично, можна припустити, що якщо в Broadwell, який буде проводитися за техпроцесом 14 нм, кількість транзисторів зросте на 21%, як при переході з 32 на 22 нм, а площа при цьому скоротиться на 26% (на ту саму величину, що при переході з 32 на 22 нм), ми отримаємо 1.9 млрд. транзисторів площею 131 мм². Якщо при цьому тепловиділення також впаде на 19%, то ми матимемо 68 Вт, або 0,52 Вт/мм².
Це теоретичні розрахунки, на практиці буде інакше – перехід техпроцесу з 32 на 22 нм також був ознаменований запровадженням 3D-транзисторів, які знизили струми витоку, а з ними і тепловиділення. Однак про перехід з 22 нм на 14 нм поки що нічого такого не чути, так що на практиці значення тепловиділення швидше за все будуть ще гіршими, і на 0,52 Вт/мм² сподіватися не варто. Проте, навіть якщо рівень тепловиділення буде 0,52 Вт/мм², проблема локального перегріву та складність відведення тепла з маленького кристала загостряться ще більше.
До речі, саме складнощі з відведенням тепла при тепловиділенні на рівні 0,52 Вт/мм² можуть бути основою бажання Intel перейти на BGA або спроб скасувати сокет. Якщо процесор буде розпаяний на материнській платі, тепло безпосередньо передаватиметься від кристала до радіатора без проміжної кришки. Це виглядає ще більш актуальним у світлі заміни припою на термопасту під кришками сучасних процесорів. Можна знову очікувати появи «голих» процесорів з відкритими кристалами за прикладом Athlon XP, тобто без кришки як проміжної ланки в теполовідводі.
На відеокартах давно вже робиться саме так, а небезпека зколоти кристал нівелюється залізною рамкою навколо нього, тому відеокарт немає таких « актуальних проблем», як термопаста під кришкою процесора. Тим не менш, розгін стане ще складнішим заняттям, а правильне охолодження«тонших» процесорів - мало не наукою. І все це на нас чекає зовсім скоро, якщо, звичайно, не станеться диво…
Але опустимося на землю і повернемося до розмови про Haswell. Як ми знаємо, Haswell отримав низку «покращень/змін» щодо Sandy Bridge (і, відповідно, Ivy Bridge, який був, за великим рахунком, переведенням SB на більш тонкий техпроцес):
- вбудований регулятор напруги;
- нові енергозберігаючі режими;
- збільшення обсягів буферів та черг;
- збільшення пропускних здібностей кешів;
- збільшення кількості портів запуску;
- додавання нових блоків, функцій, API в інтегрованому графічному ядрі;
- збільшення кількості конвеєрів у графічному ядрі.
Отже, огляд нової платформи можна розділити втричі частини: процесор, вбудований графічний прискорювач, чипсет.
Процесорна частина
Зміни в процесорі включають додавання нових інструкцій та нових режимів енергозбереження, вбудовування регулятора напруги, а також зміни в процесорному ядрі.
Набір інструкцій
В архітектурі Haswell з'явились нові набори інструкцій. Їх можна умовно розділити на великі групи: створені задля збільшення векторної продуктивності і створені задля серверний сегмент. До перших відносяться AVX та FMA3, до других - віртуалізація та транзакційна пам'ять.
Advanced Vector Extensions 2 (AVX2)
Набір AVX було розширено до версії AVX 2.0. Набір AVX2 надає:
- підтримку 256-бітових цілих векторів (раніше була підтримка тільки 128-бітних);
- підтримку gather-інструкцій, що знімають вимогу безперервного розташування даних у пам'яті; тепер дані «збираються» з різних адрес пам'яті – цікаво буде подивитися, як це вплине на продуктивність;
- додавання інструкцій маніпуляцій/операцій над бітами.
В цілому, новий набірбільше орієнтований на цілу чисельну арифметику, і основний виграш від AVX 2.0 буде видно лише в цілих операціях.
Fused Multiply-Add (FMA3)
FMA - це операції суміщеного множення-складання, при яких множаться два числа і складаються з акумулятором. Цей типоперацій досить поширений і дозволяє більш ефективно реалізовувати множення векторів та матриць. Підтримка цього розширення має значно збільшити продуктивність векторних операцій. FMA3 вже підтримується в процесорах AMD з ядром Piledriver, а FMA4 – у Bulldozer.
FMA являє собою комбінацію операції множення та додавання: a=b×c+d.
Що стосується FMA3, то це триоперандні інструкції, тобто запис результату проводиться в один із трьох операндів, що беруть участь в інструкції. У результаті отримуємо операцію типу a=b×c+a, a=a×b+c, a=b×a+c.
FMA4 - це чотириоперадні інструкції із записом результату в четвертий операнд. Інструкція набуває вигляду: a=b×c+d.
До речі про FMA3: це нововведення дозволить збільшити продуктивність більш ніж на 30% за умови адаптації коду під FMA3. Варто зауважити, що коли Haswell був ще далеко на горизонті, Intel планувала впроваджувати FMA4, а не FMA3, але згодом змінила рішення на користь FMA3. Швидше за все, саме через це Bulldozer вийшов за допомогою FMA4: мовляв, не встигли переробити під Intel (а ось Piledriver вийшов уже з FMA3). Причому спочатку Bulldozer у 2007 році планувався саме з FMA3, але після оприлюднення планів Intel запровадити FMA4 у 2008 році AMDсвоє рішення переграла, випустивши Bulldozer із FMA4. А Intel потім змінила у планах FMA4 на FMA3, оскільки виграш від FMA4 порівняно з FMA3 невеликий, а ускладнення електричних логічних схем- Значне, що також збільшує транзисторний бюджет.
Виграш від AVX2 та FMA3 виявиться після адаптації ПЗ під ці набори інструкцій, так що зростання продуктивності «тут і зараз» чекати не варто. А оскільки виробники програмного забезпечення досить інертні, то з «додатковою» продуктивністю доведеться почекати.
Транзакційна пам'ять
Еволюція мікропроцесорів призвела до збільшення кількості потоків – сучасний десктопний процесор має їх вісім і більше. Велика кількістьпотоків створює дедалі більше складнощів при реалізації багатопоточного доступу до пам'яті. Необхідний контроль за актуальністю змінних в оперативній пам'яті: потрібно вчасно блокувати дані для запису для одних потоків, дозволяти читати або змінювати дані для інших потоків. Це складне завдання, і для підтримки актуальності даних у багатопотокових програмах було розроблено транзакційну пам'ять. Але до сьогоднішнього днявона реалізовувалася програмно, що знижувало продуктивність.
У Haswell з'явилося нове розширення Transactional Synchronization Extensions (TSX) – транзакційна пам'ять, яка призначена для ефективної реалізації багатопоточних програм та підвищення їх надійності. Це розширення дозволяє реалізувати «в залізі» транзакційну пам'ять, тим самим підвищивши загальну продуктивність.
Що таке транзакційна пам'ять? Це така пам'ять, яка має в собі механізм управління паралельними процесами для забезпечення доступу до даних, що спільно використовуються. Розширення TSX складається з двох компонентів: Hardware Lock Elision (HLE) та Restricted Transaction Memory (RTM).
Компонент RTM є набором інструкцій, за допомогою якого програміст може почати, закінчити і перервати транзакцію. Компонент HLE запроваджує префікси, які ігноруються процесорами без підтримки TSX. Префікси забезпечують блокування змінних, дозволяючи іншим процесам використовувати (зчитувати) заблоковані змінні та виконувати свій код доти, доки не станеться конфлікт запису заблокованих даних.
на Наразівже з'явилися програми з використанням цього розширення.
Віртуалізація
Важливість віртуалізації постійно зростає: все частіше віртуальних серверіврозташовані на одному фізичному, та й хмарні послуги поширюються все ширше. Тому збільшення швидкості роботи технологій віртуалізації та віртуалізованих середовищ є дуже актуальним завданням у серверному сегменті. Haswell містить деякі поліпшення, спрямовані саме на збільшення продуктивності віртуалізованих середовищ. Перерахуємо їх:
- покращення, що дозволяють скоротити час переходу з гостьових систем у host-систему;
- додалися біти доступу до Extended Page Table (EPT);
- зменшився час доступу до TLB;
- нові інструкції виклику гіпервізора без виконання команди vmexit;
У результаті час переходу між віртуалізованими середовищами скоротився і не перевищує 500 тактів процесора. Це має призводити до скорочення загальних втрат продуктивності, пов'язаних із віртуалізацією. А нові Xeon E3-12xx-v3 швидше за все будуть швидше в цьому класі завдань, ніж Xeon E3-12xx-v2.
Вбудований регулятор напруги
У Haswell регулятор напруги переїхав з материнської плати під кришку процесора. Раніше (Sandy Bridge) до процесора потрібно підводити різні напруги для графічного ядра, для системного агента, для процесорних ядер та ін. Тепер до процесора через сокет підводиться тільки одна напруга Vccin 1,75, яке надходить на вбудований регулятор напруги. Регулятор напруги являє собою 20 осередків, кожен осередок створює 16 фаз із загальною силою струму в 25 А. У сумі ми отримуємо 320 фаз, що значно більше, ніж навіть у самих наворочених материнських плат. Такий підхід дозволяє не тільки спростити розведення материнських плат (а значить, і знизити їхню вартість), а й точніше регулювати напруги всередині процесора, що, у свою чергу, веде до більшої економії електроенергії.
Це одна з основних причин, через які Haswell фізично не може бути сумісним зі старим сокетом LGA1155. Так, можна говорити про бажання Intel заробляти гроші, щороку випускаючи нову платформу. новий чіпсет) і кожні два роки – новий сокет, але в даному випадку для зміни сокету є Об'єктивні причини: фізична/електрична несумісність
Проте за все доводиться платити. Регулятор напруги – ще одне помітне джерело тепла у новому процесорі. А враховуючи, що Haswell виробляється за нормами того самого техпроцесу, що його попередник Ivy Bridge, варто очікувати, що процесор буде гаряче.

Взагалі, це покращення більшої користі принесе в мобільному сегменті: швидша і точніша зміна напруги дозволить знизити енергоспоживання, а також ефективніше керувати частотою процесорних ядер. І судячи з усього, це не порожня рекламна заява, тому що Intel збирається анонсувати мобільні процесори з наднизьким споживанням енергії.
Нові енергозберігаючі режими
У Haswell з'явилися нові стани сну S0ix, які схожі на стани S3/S4, але тільки з набагато меншим часом переходу процесора в робочий стан. Також було додано новий стан простою С7.
Режим С7 супроводжується вимкненням основної частини процесора, при цьому зображення на екрані залишається активним.
Мінімальна частота процесорів у простої становить 800 МГц, це також має зменшити енергоспоживання.
Архітектура процесора


Фронт-енд

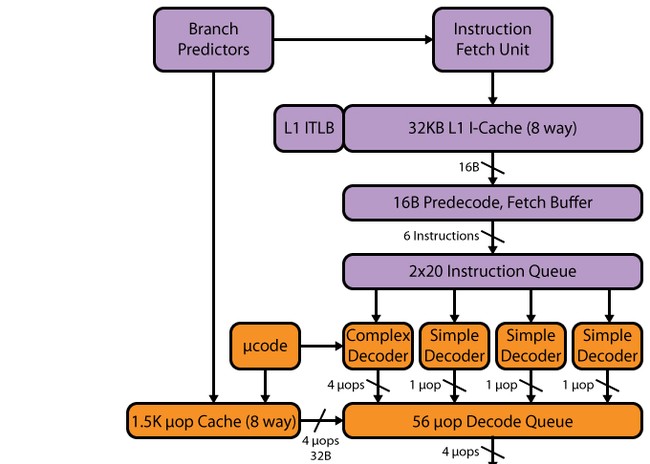
Конвеєр Haswell, як і в SB, має 14-19 стадій: 14 стадій при попаданні в µop-кеш, 19 - при промаху. Об'єм µop-кешу не змінився порівняно з SB – 1536 µop. Організація кешу мопів залишилася такою ж, як і в SB - 32 набори по вісім рядків, у кожному з яких по шість мопів. Хоча у зв'язку із збільшенням кількості виконавчих пристроїв, а також наступних після кешу мопів буферів можна було б очікувати збільшення кешу мопів – до 1776 мопів (чому саме такий обсяг – буде сказано нижче).
Декодер
Декодер, можна сказати, не змінився - залишився чотириколійним, як у SB. Він складається з чотирьох паралельних каналів: одного складного транслятора (complex decoder) та трьох простих (simple decoder). Складний транслятор може обробляти/декодувати складні інструкції, що породжують більше одного мопа. У трьох інших каналах декодуються прості інструкції. До речі, завдяки наявності злиття макрооперацій, інструкції завантаження з виконанням та вивантаження породжують, наприклад, один моп і можуть бути декодовані у «простих» каналах декодера. Інструкції SSEтеж породжують один моп, тому можуть бути декодовані у будь-якому з трьох простих каналів. Враховуючи появу 256-бітних AVX, FMA3, а також збільшену кількість портів запуску та функціональних пристроїв, такої швидкості декодера може просто не вистачити – і він може стати вузьким місцем. Частково це вузьке місце «розшиває» кеш мопів L0m, але все одно, маючи процесор з 8 портами запуску, Intel слід задуматися про розширення декодера – зокрема, не завадило б збільшити кількість складних каналів.
Планувальник, буфер переупорядкування, виконавчі пристрої


Після декодера слідує черга декодованих інструкцій, і ось тут ми бачимо першу зміну. У SB було дві черги по 28 записів – одна черга на один віртуальний потік Hyper-Threading (НТ). У Haswell дві черги поєднали в одну загальну для двох потоків HT на 56 записів, тобто обсяг черги не змінився, але змінилася концепція. Тепер весь обсяг 56 записів доступний одному потоку за відсутності другого - отже, очікується приросту як і малопоточных додатках, і у многопоточных (це пов'язані з тим, що єдину чергу два потоки можуть використовувати ефективніше).
Зміни зазнав також буфер переупорядкування - він був збільшений зі 168 до 192 записів. Це має підвищити ефективність HT за рахунок більшої ймовірності наявності «незалежних» один від одного мопів. Черга декодованих мікрооперацій збільшена з 54 до 60. Фізичні регістрові файли, які з'явилися в SB, також були збільшені - зі 160 до 168 регістрів для цілочисленних операндів і з 144 до 168 для операндів з плаваючою комою, що має позитивно позначитися на продуктивності векторів.
Зведемо всі дані про зміни в буферах та чергах у єдину таблицю.
В принципі зміни параметрів у Haswell виглядають цілком очікуваними, враховуючи загальну логікурозвитку процесорної архітектури Intel Виходячи з цієї ж логіки, можна припустити, що у наступному поколінні Core розмірибуферів та черг збільшаться не більше ніж на 14%, тобто розмір буфера переупорядкування буде в районі 218. Але це вже суто теоретичні припущення.
Слідом за чергою декодованих операцій розташовуються порти запуску та прикріплені до них функціональні пристрої. На цьому етапі зупинимося докладніше.
Як ми знаємо, Sandy Bridge мав шість портів запуску, які він успадкував від Nehalem, а той, у свою чергу, від Conroe. Тобто з 2006 року, коли Intel додала ще два порти до чотирьох чотирьом, що були в розпорядженні Рentium 4, кількість портів запуску не змінювалася - тільки додавалися нові функціональні пристрої. Щоправда, варто зазначити, що P4 мав своєрідну самобутню архітектуру NetBurst, в якій два його порти могли виконувати по дві операції за один такт (хоч і далеко не з усіма операціями). Але найбільш правильним буде простежити еволюцію кількості портів запуску не на прикладі P4, а на прикладі PIII, тому що P4 має і довгий конвеєр, і порти запуску з подвоєною продуктивністю, і кеш трас, та й вся його архітектура помітно відрізняється від загальноприйнятної. А Pentium III дуже близький за функціональною схемою портів запуску Conroe, і також має короткий контейнер. Так що в цілому можна сказати, що Conroe є прямим спадкоємцем PIII. Виходячи з цього можна заявити, що у 2006 році було додано лише один порт запуску порівняно з PIII, який мав п'ять портів запуску.
Таким чином, кількість портів запуску зростає досить повільно, а якщо додаються нові, то по одному. У Haswell додали відразу два, сумарно отримавши цілих вісім портів - ще трохи, і дійдемо до Itanium. Відповідно, Haswell показує теоретичну продуктивність на виконавчому тракті 8 моп/такт, з яких 4 мопа витрачаються на арифметичні операції, а решта 4 припадають на операції з пам'яттю. Нагадаємо, що у Conroe/Nehalem/SB було 6 моп/такт: 3 мопи арифметичних операційта 3 мопи операцій з пам'яттю. Дане покращення має підняти показник IPC, і, таким чином, в архітектурі Haswell дійсно є дуже серйозні зміни, які цілком виправдовують його місце «так» у плані розвитку Intel.
Зміни ФУ у Haswell

Кількість виконавчих пристроїв також було збільшено. Новий шостий (сьомий за рахунком) порт додав два додаткові виконавчі пристрої - пристрій цілочисленної арифметики та зсуву та пристрій передбачення переходів. Сьомий (восьмий) порт відповідає за розвантаження адреси.
Таким чином, ми отримуємо чотири виконавчі пристрої цілочисленної арифметики, тоді як Sandy Bridge нам надавав лише три. Отже, очікується збільшення швидкості цілочисленної арифметики. Крім того, теоретично це має нам дозволити одночасно виконувати і розрахунки з плаваючою комою, і цілі розрахунки, що, у свою чергу, може збільшити ефективність НТ. У SB обчислення з плаваючою комою здійснювалися на тих же портах, де використовувалися цілочисленні функціональні пристрої, тому за великим рахунком відбувалося блокування, тобто не можна було мати «різнорідне» навантаження. Також слід зазначити, що додавання додаткового пристроюпереходу в Haswell дозволить передбачати перехід без «блокування» при арифметичних обчисленнях - раніше при цілих численних обчисленнях єдиний провісник переходу блокувався, тобто була можлива робота або арифметичного виконавчого пристрою, або провісника. Порти 0 і 1 також зазнали змін - у них з'явилася підтримка FMA3. Сьомий (восьмий) порт Intelввела для підвищення ефективності та зняття «блокування» - коли другий та третій порти працюють на завантаження, сьомий (восьмий) порт може займатися вивантаженням, що раніше було просто неможливо. Це рішення необхідне для забезпечення високого темпу виконання AVX/FMA3-коду.
Взагалі, такий широкий виконавчий тракт цілком може призвести до зміни HT - зробивши її чотирипотоковою. У со процесорах Intel Xeon Phi з набагато вужчим виконавчим трактом HT є чотирипотоковим, при цьому, як показують дослідження та тести, співпроцесор досить добре масштабується. Тобто навіть вужчий виконавчий тракт у принципі дозволяє ефективно працювати із чотирма потоками. А вже тракт із вісьмома портами запуску цілком ефективно може виконувати чотири потоки, і більше того, наявність чотирьох потоків зможе краще завантажити вісім портів запуску. Щоправда, для більшої ефективності необхідно буде збільшити буфери (насамперед - буфер переупорядкування) для більшої ймовірності «незалежних» даних.
Також у Haswell вдвічі збільшили пропускну здатність L1-L2, при цьому залишилися колишні затримки. Такий захід був просто необхідний, тому що 32-байтного запису та 16-байтного читання просто не вистачило б за наявності восьми портів запуску, а також 256-бітових AVX та FMA3.
| Sandy Bridge | Haswell | |
| L1i | 32k, 8-way | 32k, 8-way |
| L1d | 32k, 8-way | 32k, 8-way |
| Латентність | 4 такти | 4 такти |
| Швидкість завантаження | 32 байти/такт | 64 байти/такт |
| Швидкість запису | 16 байт/такт | 32 байти/такт |
| L2 | 256k, 8-way | 256k, 8-way |
| Латентність | 11 тактів | 11 тактів |
| Пропускна здатність між L2 та L1 | 32 байти/такт | 64 байти/такт |
| L1i TLB | 4k: 128, 4-way 2M/4M: 8/thread | 4k: 128, 4-way 2M/4M: 8/thread |
| L1d TLB | 4k: 128, 4-way 2M/4M: 7/thread 1G: 4, 4-way | 4k: 128, 4-way 2M/4M: 7/thread 1G: 4, 4-way |
| L2 TLB | 4k: 512, 4-way | 4k+2M shared: 1024, 8-way |
TLB L2 було збільшено до 1024 записів, з'явилася підтримка двомегабайтних сторінок. Збільшення TLB L2 спричинило і збільшення асоціативності з чотирьох до восьми.
Щодо кешу третього рівня, то з ним ситуація неоднозначна: у новому процесорі затримка доступу має збільшитися через втрати при синхронізації, адже тепер кеш L3 працює на власній частоті, а не на частоті процесорних ядер, як було раніше. Хоча доступ, як і раніше, здійснюється в 32 байти за такт. З іншого боку, Intel говорить про зміни в System Agent та покращення блоку Load Balancer, який може тепер обробляти паралельно кілька запитів до кешу L3 і розділяти їх на запити до даних та «не-даних». Це має підвищити пропускну здатність кешу L3 (деякі тести підтверджують це, ПС кешу L3 виявляється трохи вище IB).
Принцип роботи кеша L3 у Haswell чимось схожий на Nehalem. У Nehalem кеш L3 був у Uncore і мав власну фіксовану частоту, а SB кеш L3 прив'язали до процесорним ядрам - його частота дорівнювала частоті процесорних ядер. Через це виникали проблеми - наприклад, коли процесорні ядра працювали на знижених частотах за відсутності навантаження (і LLC «засинав»), а GPU була потрібна висока ПС LLC. Тобто це рішення обмежувало продуктивність GPU, і до того ж потрібно виводити процесорні ядра зі стану простою лише для того, щоб розбудити LLC. У новому процесорі для покращення ситуації з енергоспоживанням та підвищення ефективності роботи GPUу вищеописаних ситуаціях кеш L3 працює у своїй частоті. Найбільшу користь із цього рішення мають мати мобільні, а не настільні рішення.
Варто зауважити, що обсяги кешів мають певну залежність. Кеша третього рівня припадає два мегабайти на ядро, кеша другого рівня - 256 КБ, що у вісім разів менше обсягу L3 на ядро. Обсяг кешу першого рівня, у свою чергу, у вісім разів менше L2 і становить 32 КБ. Кеш мопів чудово вписується в цю залежність: його об'єм у 1536 мопів у 7-9 разів менший за L1 (точно це визначити неможливо, тому що бітовий об'єм мопа невідомий, а Intel навряд чи поширюватиметься на цю тему). У свою чергу, буфер переупорядкування в 168 мопів рівно у вісім разів менший за кеш мопів у 1536 моп, хоча, виходячи з повсюдного збільшення буферів і черг, слід очікувати збільшення кешу мопів на 14%, тобто до 1776. Таким чином, обсяги буферів і кешів мають пропорційні розміри. Це, напевно, ще одна причина, чому Intel не збільшує кеші L1/L2, вважаючи такі пропорції в обсягах найбільш ефективними з точки зору збільшення продуктивності збільшення площі. Варто зауважити, що в процесорах із вбудованим топовим графічним ядром є проміжна швидка пам'ять з широкою шиною доступу, яка кешує всі запити до оперативної пам'яті - як процесора, так і відеоприскорювача. Об'єм цієї пам'яті становить 128 МБ. Для процесорних ядер, якщо розцінювати цю пам'ять як кеш L4, обсяг мав бути 64 мегабайта, і з додаванням ще й графічного ядра використання 128 МБ виглядає цілком логічним.
Що стосується контролера пам'яті, то він не отримав ні збільшення числа каналів, ні збільшення частоти роботи з оперативною пам'яттю, тобто це той самий контролер пам'яті з двоканальним доступом на частоті 1600 МГц. Таке рішення виглядає досить дивно, адже перехід із SB на IB збільшив частоту функціонування ІКП з 1333 МГц до 1600 МГц, хоча це був лише перехід архітектури на новий техпроцес. Нині ж маємо нову архітектуру, у своїй частота функціонування пам'яті залишилася колишньому рівні.
Ще дивнішим це виглядає, якщо згадати про поліпшення у графічному ядрі - адже ми пам'ятаємо, що навіть молодша відеокарта HD2500 у IB повністю утилізувала пропускну здатність у 25 ГБ/с. Тепер підросла і продуктивність ЦП, і продуктивність графіки, а пропускна здатність пам'яті залишилася на колишньому рівні. Якщо глянути ширше, то конкурент постійно збільшує пропускну здатність пам'яті у своїх гібридних процесорах, і вона вища, ніж у Intel. Логічно було очікувати Haswell підтримку пам'яті з частотою 1866 МГц чи 2133 МГц, що підвищило б пропускну здатність до 30 і 34 ГБ/с відповідно.
Як результат, це рішення Intel не зовсім зрозуміло. По-перше, конкурент ввів підтримку швидшої пам'яті без особливих проблем. По-друге, вартість модулів пам'яті, що функціонують на частоті 1866 МГц, ненабагато вище в порівнянні з 1600-мегагерцовими модулями, до того ж ніхто не зобов'язує купувати 1866-мегагерцову пам'ять - вибір залишався б за користувачем. По-третє, жодних проблем із підтримкою не те що 1866 МГц, а й 2133 МГц бути не може: з самого анонсу Haswell були поставлені світові рекорди розгону оперативної пам'яті, тобто ІКП без проблем «потягнув би» швидше пам'ять. По-четверте, в серверній лінійці Xeon E5-2500 V2 (Ivy Bridge-EP) заявлена підтримка 1866 МГц, адже Intel зазвичай впроваджує підтримку більш швидких стандартів пам'яті на цьому ринку набагато пізніше настільних рішень.
В принципі, можна було б припустити, що без конкуренції Intel немає необхідності «просто так» нарощувати м'язи і ще більше збільшувати перевагу, але це припущення абсолютно некоректно, оскільки збільшення пропускної спроможності пам'яті, як правило, збільшує продуктивність вбудованого графічного ядра і майже не підвищує продуктивність процесора. При цьому Intel поки що відстає від AMD саме у продуктивності графіки, і в Останніми рокамисама ж Intel все більше і більше приділяє увагу саме графіці, і темпи покращень для неї набагато вищі, ніж для процесорного ядра. Крім того, якщо спиратися на результати тестувань вбудованого графічного ядра попереднього покоління HD4000, які показали, що збільшення ПСП призводить до збільшення продуктивності графіки до 30%, а також враховуючи, що нове графічне ядро HD4600 помітно швидше, ніж HD4000, то залежність від ПСП стає ще явнішою. Нове графічне ядро ще більше впиратиметься у «вузьку» пропускну здатність пам'яті. Підсумовуючи всі факти, рішення Intel абсолютно незрозуміло: компанія власноруч «задушила» свою графіку, адже збільшення ПСП могло б підтягнути її продуктивність.
Повертаючись до архітектури кешів, висловимо просто думку в порожнечу: якщо вже було додано проміжний кеш (кеш мопів), то чому б не додати ще проміжний кеш даних обсягом порядку 4-8 КБ і з меншою затримкою доступу між кешем L1d і виконавчими пристроями, як у P4 (якщо концепція кеша мопів була взята саме у Netburst)? Нагадаємо, що в P4 цей проміжний кеш даних мав час доступу в два такти, причому один такт Р4 дорівнював приблизно 0,75 тактам звичайного процесора, тобто час доступу було близько півтора тактів. Втім, можливо, ми ще побачимо щось подібне – Intel любить згадувати добре забуте старе.
Як можна було помітити, більшість архітектурних змін Intel направила на збільшення продуктивності коду AVX/FMA3: це збільшення пропускної спроможності кешів, і збільшення кількості портів, і збільшення темпу вивантаження/завантаження у виконавчому тракті. У підсумку, основний виграш у продуктивності має бути саме у ПЗ, написаному з використанням AVX/FMA3. В принципі, зважаючи на результати тестів, схоже, що так воно і є. Суха продуктивність на однаковій частоті в «старих» додатках отримала приріст близько 10% порівняно з попереднім ядром, а програми, написані з використанням нових наборів інструкцій, показують приріст понад 30%. Отже, переваги архітектури Haswell будуть розкриватися в міру оптимізації додатків під нові набори інструкцій. Ось тоді перевага Haswell над SB стане очевидною.
Основний виграш від значної частини нововведень матимуть мобільні пристрої. Їм допоможуть і новий підхід до кешу L3, і вбудований регулятор напруги, нові режими сну, і нижчі мінімальні частоти функціонування процесорних ядер.
Висновок (процесорна частина)
Чого очікується від Haswell?
У зв'язку зі збільшенням кількості портів запуску очікується збільшення показника IPC, тому невелика перевага у нової архітектури Haswell над Sandy Bridge на однаковій частоті буде вже зараз, навіть за неоптимізованого програмного забезпечення. Інструкції AVX2/FMA3 - це заділ на майбутнє, і це майбутнє залежить від розробників ПЗ: чим швидше вони адаптують свої програми, тим швидше кінцевий користувачотримає приріст продуктивності. Однак не варто розраховувати на зростання всього і скрізь: SIMD-інструкції в основному використовуються в роботі з мультимедійними даними та в наукових розрахунках, тому зростання продуктивності варто очікувати саме в цих завданнях. Основний виграш від збільшення енергоефективності отримають мобільні системи, де це питання справді важливе. Таким чином, два основні напрямки, за якими нова архітектура Intel Haswell суттєво виграє – це збільшення SIMD-продуктивності та збільшення енергоефективності.
Що стосується застосування нових процесорів Haswell, то варто розібрати кілька різних варіантів їх застосування: в настільних комп'ютерах, серверах, в мобільних рішеннях, для геймерів, для оверклокерів.
Десктоп
Енергоспоживання не є ключовим аспектом для десктопного процесора, тому навіть у Європі з її дорогою електроенергією навряд чи хтось переходитиме на Haswell із попередніх поколінь лише через це. Тим більше, що TDP у Haswell вище, ніж у IB, тож економія буде лише у разі мінімальних навантажень. За такої постановки питання сумнівів бути не може - воно того не варте.
З погляду продуктивності перехід теж не виглядає такою вже вигідною справою: максимальний приріст швидкості в процесорних завданнях зараз становитиме не більше 10%. Перехід на Haswell із Sandy Bridge або Ivy Bridge буде виправданий лише в тому випадку, якщо ви плануєте використовувати програми з грамотною підтримкою FMA3 та AVX2: підтримка FMA3 може дати приріст у деяких додатках від 30% до 70%. Поліпшення, пов'язані з віртуалізацією та використанням транзакційної пам'яті, для робочого столу малоцікаві і малокорисні.
Сервери та робочі станції
Враховуючи, що сервери працюють безперервно всі 24 години на добу і мають досить високе постійне навантаження на процесор, по чистому енергоспоживання Haswell навряд чи буде кращим за IB, хоча за продуктивністю на ват і може дати деякий виграш. Підтримка AVX2/FMA3 навряд чи стане в нагоді в серверах, а ось в робочих станціях, які займаються науковими розрахунками, дана підтримкабуде дуже і дуже корисна - але лише за умови підтримки нових інструкцій у застосовуваному ПЗ. Транзакційна пам'ять - річ досить корисна, але теж не завжди: вона може дати приріст у багатопотокових програмах і програмах, що працюють з базами даних, але для неї ефективного використаннятакож потрібна оптимізація ПЗ.
А ось усі покращення, пов'язані з віртуалізацією, швидше за все дадуть непоганий ефект, оскільки віртуальні середовища зараз використовуються дуже активно, і на більшості фізичних серверівпрацює по кілька віртуальних. Причому поширеність віртуалізації пояснюється як помітним зниженням витрат віртуального середовища у плані продуктивності, а й економічної ефективністю: містити багато віртуальних серверів однією фізичному і дешевше, і дозволяє ефективніше використовувати ресурси, зокрема ресурси процесора.
Так що на серверному ринкуПоява Haswell має зустрітися позитивно. Після зміни серверів на базі Xeon E3-1200v1 і Xeon E3-1200v2 на сервери з Xeon E3-1200v3 (Haswell) ви відразу отримаєте приріст ефективності, а після оптимізації ПЗ під AVX2/FMA3 і транзакційну пам'ять продуктивність підросте ще більше.
Мобільні рішення
Основний виграш від впровадження Haswell у мобільному сегменті, звичайно ж, лежить у сфері покращеного енергоспоживання. Судячи з презентацій Intel, а також результатів тестів, які вже з'являються в Мережі, ефект справді є і помітний.
Що стосується чистої продуктивності, то перехід з Ivy Bridge на Haswell не є таким вже обґрунтованим заходом: чистий приріст повинен бути відносно невеликим, а поліпшення в окремих компонентах(ті ж віртуалізація чи мультимедійні інструкції) навряд чи багато дадуть користувачеві мобільної системи, оскільки на ноутбуках і планшетах рідко займаються створенням середовищ чи складними науковими розрахунками.
Загалом, з погляду процесорної продуктивності багато чого чекати не варто, зате в мобільних системах напевно буде затребуване зростання продуктивності графічного ядра. Тому якщо питання енергоспоживання для вас не є критично важливими, то серйозно розглядати питання апгрейду з Sandy Bridge або Ivy Bridge не варто - краще продовжувати експлуатувати наявні системи, поки вони остаточно не застаріють. Якщо ви часто працюєте від батарей, то Haswell здатний забезпечити суттєвий приріст часу автономної роботи.
Геймери
Питання енергоспоживання у геймерів у Росії, як правило, не стоїть - та й з чого йому стояти, коли геймерські відеокарти споживають по 200 і більше ват? Віртуалізація та транзакційна пам'ять геймеру теж не потрібні. Не факт, що AVX2/FMA3 будуть затребувані саме для ігор, хоча вони можуть стати в нагоді у розрахунках фізики. Залишається чиста продуктивність процесора, а тут різниця з тим самим Ivy Bridge невелика. Як результат, для цієї категорії користувачів прямий перехід із SB або IB на Haswell також не виглядає актуальним. Зате розумно переходити на нові процесори з Nehalem і Lynifield, і особливо Conroe.
Оверклокери
Для оверклокерів новий процесор (але, звісно, лише його «розблокована» K-версія) може бути цікавим, особливо якщо вдасться його «скальпувати», тобто зняти металеву кришку і охолоджувати кристал безпосередньо. Якщо цього не зробити, то результати розгону виглядають ще скромнішими, ніж у Ivy Bridge. Плюс стримуючим фактором може стати інтегрований регулятор напруги. Докладніше про це читайте
Перекладаємо... Перекласти Китайська (спрощений лист) Китайська (традиційний лист) Англійська Французька Німецька Італійська Португальська Російська Іспанська Турецька
На жаль, ми не можемо перекласти цю інформацію прямо зараз - будь ласка, повторіть спробу пізніше.
Вступ
Програмного забезпечення, призначеного для зв'язку та передачі даних, потрібна дуже висока продуктивність, оскільки йде пересилання величезної кількості дрібних пакетів даних. Одна з особливостей розробки програм віртуалізації мережевих функцій(NFV) полягає в тому, що необхідно застосовувати віртуалізацію в найбільшій можливій мірі, але при цьому в потрібних випадкахоптимізувати програми для використовуваного обладнання.
У цій статті я розповім про три можливості процесорів Intel ® , корисні для оптимізації продуктивності додатків NFV: технології виділення кешу (CAT), Intel Advanced Vector Extensions 2 (Intel AVX2) для обробки векторних даних та Intel Transactional Synchronization Extensions (Intel ® TSX).
Вирішення проблеми інверсії пріоритету за допомогою САТ
Коли функція низької пріоритету краде ресурси у високопріоритетної функції, ми називаємо це «інверсією пріоритету».
Не всі віртуальні функціїоднаково важливі. Наприклад, для функції маршрутизації важливим є час обробки та продуктивність, тоді як для функції кодування мультимедіа це не так важливо. Цій функції можна дозволити періодично втрачати пакети без впливу на зручність користувачів, оскільки все одно ніхто не помітить зниження кадрової швидкості відео з 20 до 19 кадрів в секунду.
Кеш за замовчуванням влаштований таким чином, що найбільш активний споживач отримує його найбільшу частину. Але далеко не завжди найактивніший споживач є найважливішим додатком. Насправді частіше буває вірно протилежне. Високопріоритетні програми оптимізовані, обсяг їх даних зменшено до мінімально можливого набору. На оптимізацію низькопріоритетних програм не витрачається стільки зусиль, тому вони зазвичай споживають більше пам'яті. Деякі з таких функцій споживають багато пам'яті. Наприклад, функція перегляду пакетів для статистичного аналізу має низький пріоритет, але споживає багато пам'яті та активно використовує кеш.
Розробники часто виходять з того, що якщо вони помістять один високопріоритетний додаток у певне ядро, то там цей додаток буде в безпеці, на нього не зможуть вплинути низькопріоритетні програми. На жаль, це негаразд. У кожного ядра є власний кеш першого рівня (L1, найшвидший кеш, але найменшого розміру) та кеш другого рівня (L2, дещо більше за розміром, але повільніше). Існують окремі області кешу першого рівня для даних (L1D) та для коду програм (L1I, "I" означає "інструкції"). Кеш третього рівня (найповільніший) є загальним для всіх ядер процесора. В архітектурі процесорів Intel до сімейства Broadwell включно кеш третього рівня повністю включний, тобто він містить все, що міститься в кеші першого і другого рівнів. Через особливості роботи включного кеша, якщо щось видалити з кеша третього рівня, це також буде видалено з відповідного кеша першого та другого рівнів. Це призводить до того, що низькопріоритетний додаток, якому потрібне місце в кеші третього рівня, може витіснити дані з кешу першого і другого рівнів високопріоритетної програми, навіть якщо вона працює на іншому ядрі.
У минулому для обходу цієї проблеми існував підхід, який одержав назву «прогрів». При конкуренції доступу до кешу третього рівня «переможцем» є додаток, який найчастіше звертається до пам'яті. У зв'язку з цим рішення у тому, щоб високопріоритетна функція постійно зверталася до кешу, навіть за бездіяльності. Це не дуже витончене рішення, але часто воно виявлялося цілком прийнятним, і донедавна він не мав альтернатив. Але тепер альтернатива є: у сімействі процесорів Intel Xeon E5 v3 з'явилася технологія розподілу кешу (CAT), що дає можливість виділяти кеш відповідно до додатків і класів обслуговування.
Вплив інверсії пріоритету
Для демонстрації впливу інверсії пріоритету я написав простий мікротест, який періодично запускає обхід скомпонованого списку високопріоритетному потоці, тому що в низькопріоритетному потоці постійно запущена функція копіювання в пам'яті. Ці потоки закріплені за різними ядрами одного й того самого процесора. При цьому імітується найгірший варіант змагання за доступ до ресурсів: операції копіювання потрібно багато пам'яті, тому вона з ймовірністю порушує роботу більш важливого потоку доступу до списку.
Ось код мовою С.
// Build a linked list of size N with pseudo-random pattern void init_pool(list_item *head, int N, int A, int B) (int C = B; list_item *current = head; for (int i = 0; i< N - 1; i++) { current->tick = 0; C = (A * C + B) % N; current->next = (list_item*)&(head[C]); current = current->next; ) ) // Touch first N elements in linked list void warmup_list(list_item* current, int N) ( bool write = (N > POOL_SIZE_L2_LINES) ? true: false; for(int i = 0; i< N - 1; i++) { current = current->next; if (write) current->tick++; ) ) void measure(list_item* head, int N) ( unsigned __long long i1, i2, avg = 0; for (int j = 0; j< 50; j++) { list_item* current = head; #if WARMUP_ON while(in_copy) warmup_list(head, N); #else while(in_copy) spin_sleep(1); #endif i1 = __rdtsc(); for(int i = 0; i < N; i++) { current->tick++; current = current->next; ) i2 = __rdtsc(); avg += (i2-i1)/50; in_copy = true; ) results=avg/N )
Він містить три функції.
- Функція init_pool() ініціалізує скомпонований список у великій розподіленій вільній області пам'яті за допомогою простого генераторапсевдовипадкових чисел. За рахунок цього елементи списку не знаходяться поруч один з одним у пам'яті: у такому разі утворилася б просторова локальність, що вплинуло б на наші виміри, оскільки для деяких елементів автоматично була б задіяна попереджувальна вибірка. Кожен елемент списку - один рядок кеша.
- Функція warmup() постійно оминає скомпонований список. Потрібно звертатися до певних даних, які повинні перебувати в кеші, тому ця функція не дозволяє іншим потокам витіснити скомпонований список із кешу третього рівня.
- Функція measure() вимірює обхід одного елемента списку, потім або засинає на 1 мілісекунду, або викликає функцію warmup() залежно від того, який тест ми запускаємо. Потім функція measure() усереднює результати.
Результати мікротесту на процесорі Intel Core i7 5-го покоління показані на наведеному нижче графіку, де по осі X відкладається загальна кількість рядків кеша в скомпонованому списку, а по осі Y - середня кількість циклів ЦП на кожне звернення до скомпонованого списку. У міру збільшення розміру скомпонованого списку він виходить за межі кешу даних першого рівня в кеш другого, а потім третього рівня, а потім потрапляє в основну пам'ять.
Базовий показник – червоно-коричнева лінія, вона відповідає програмі без потоку копіювання у пам'яті, тобто без конкуренції. Синя лінія показує наслідки інверсії пріоритету: через функцію копіювання в пам'яті доступ до списку займає значно більше часу. Вплив особливо великий, якщо список вміщується у високошвидкісний кеш першого рівня або кеш другого рівня. Якщо ж список настільки великий, що не вміщується до кешу третього рівня, вплив незначний.
Зелена лінія показує ефект прогріву, коли запущена функція копіювання в пам'яті: час доступу різко знижується і наближається до базового значення.
Якщо включити CAT і виділити частини кешу третього рівня в монопольне використання кожним ядром, результати будуть дуже близькі до базових (надто близькі для показу на схемі), а саме така наша мета.
УвімкненняCAT
Перш за все, переконайтеся, що платформа підтримує CAT. Можна використовувати інструкцію CPUID, перевіряючи адресу leaf 7, subleaf 0, додану для вказівки про доступність CAT.
Якщо технологія CAT увімкнена та підтримується, існують регістри MSR, які можна запрограмувати для виділення різних частинкеша третього рівня різним ядрам.
У кожного процесорного гнізда є регістри MSR IA32_L3_MASKn (наприклад, 0xc90, 0xc91, 0xc92, 0xc93). У цих регістрах зберігається бітова маска, що вказує, скільки кешу третього рівня слід виділяти кожного класу обслуговування (COS). У 0xc90 зберігається виділення кешу для COS0, 0xc91 - для COS1 і т.д.
Наприклад, на цій діаграмі показані деякі можливі маски для різних класів обслуговування, щоб продемонструвати, як можна влаштувати поділ кешу: COS0 отримує половину, COS1 отримує чверть, а COS2 і COS3 по одній восьмій частині. Наприклад, 0xc90 містив би 11110000, а 0xc93 - 00000001.
Алгоритм прямого введення-виведення даних (DDIO) має власну приховану бітову маску, що дозволяє передавати потік даних з високошвидкісних пристроїв PCIe, таких як мережні адаптери, певні області кеша третього рівня. При цьому є ймовірність виникнення конфлікту з класами обслуговування, що визначаються, тому потрібно враховувати це при створенні додатків NFV високої пропускної здатності. Для тестування утворення конфліктів використовуйте для виявлення промахів повз кеш. У деяких BIOS є налаштування, що дозволяє переглядати та змінювати маску DDIO.
Кожне ядро має регістр MSR IA32_PQR_ASSOC (0xc8f), який вказує, який клас обслуговування застосовується до цього ядра. Клас обслуговування за замовчуванням - 0, це означає, що використовується бітова маска MSR 0xc90. (За замовчуванням бітова маска 0xc90 має значення 1, щоб забезпечити максимальну доступність кеша.)
Сама проста модельвикористання CAT в NFV - виділення фрагментів кешу третього рівня різним ядрам з допомогою ізольованих бітових масок, та був закріплення потоків чи віртуальних машин за ядрами. Якщо віртуальним машинам потрібен загальний доступ до ядрів для виконання, також можна зробити тривіальне виправлення для планувальника ОС, додати маску кеша в потоки, в яких працюють віртуальні машини, та динамічно вмикати її в кожній події розкладу.
Існує ще один незвичайний спосіб використання CAT для блокування даних у кеші. Спочатку створіть активну маску кешу та зверніться до даних у пам'яті, щоб завантажити їх у кеш третього рівня. Потім відключіть біти, що представляють цю частину кеша третього рівня в будь-якій масці бітової САТ, яка буде використана в майбутньому. Дані будуть заблоковані в кеші третього рівня, оскільки їх неможливо звідти витіснити (крім DDIO). У додатку NFV цей механізм дозволяє блокувати таблиці пошуку середнього розміру для маршрутизації та аналізу пакетів у кеші третього рівня для забезпечення постійного доступу.
Використання Intel AVX2 для обробки векторів
Інструкції SIMD (одна інструкція - багато даних) дозволяють одночасно здійснювати ту саму операцію з різними фрагментами даних. Ці інструкції часто використовуються для прискорення обчислень з плаваючою комою, але також доступні версії інструкцій для роботи з цілими числами, логічними значеннями та даними.
Залежно від процесора, що використовується, вам будуть доступні різні сімейства інструкцій SIMD. Розрізнятиметься і розмір вектора, що обробляється командами:
- SSE підтримує 128-розрядні вектори.
- В Intel AVX2 підтримуються цілочисленні інструкції для 256-розрядних векторів та реалізовані інструкції для операцій збору.
- У розширеннях AVX3 у перспективних архітектурах Intel® підтримуватимуться 512-розрядні вектори.
Один 128-розрядний вектор можна використовувати для двох 64-розрядних змінних, чотирьох 32-розрядних або восьми 16-розрядних змінних (залежно від інструкцій SIMD). У великі вектори поміститься більше елементів даних. Враховуючи потребу додатків NFV у високій пропускній спроможності, слід завжди використовувати найбільш потужні інструкції SIMD (і відповідне обладнання), на сьогодні це Intel AVX2.
Інструкції SIMD найчастіше використовуються для виконання тієї самої операції з вектором значень, як показано на малюнку. Тут операція зі створення від X1opY1 до X4opY4 являє собою одну інструкцію, одночасно обробляє елементи даних з X1 X4 і Y1 Y4. У цьому прикладі прискорення буде чотириразовим порівняно із звичайним (скалярним) виконанням, оскільки одночасно обробляються чотири операції. Прискорення може бути настільки великим, наскільки великий вектор SIMD. У додатках NFV часто відбувається обробка кількох потоків пакетів однаковим способом, тому тут інструкції SIMD дозволяють природно оптимізувати продуктивність.
Для простих циклів компілятор часто сам автоматично здійснює векторизацію операцій за допомогою використання останніх інструкцій SIMD, доступних для даного ЦП (якщо використовувати потрібні прапори компілятора). Можна оптимізувати код для використання найсучаснішого набору інструкцій, які підтримує обладнання, під час виконання або можна скомпілювати код для певної цільової архітектури.
Операції SIMD також підтримують завантаження пам'ять, копіюючи до 32 байт (256 біт) з пам'яті в регістр. Це дозволяє передавати дані між пам'яттю та регістрами, минаючи кеш, і збирати дані з різних розміщень у пам'яті. Також можна виконувати різні операції з векторами (зміна даних у межах одного регістру) та збереження векторів (запис до 32 байт з регістру на згадку).
Memcpy та memmov - широко відомі приклади основних процедур, які були з самого початку реалізовані за допомогою інструкцій SIMD, оскільки інструкція REP MOV була надто повільною. Код memcpy регулярно оновлювався у системних бібліотеках, щоб використовувати останні інструкції SIMD. Для отримання даних, яка з останніх версій доступна для використання, використовувалася таблиця диспетчера CPUID. При цьому реалізація нових поколінь інструкцій SIMD у бібліотеках зазвичай запізнюється.
Наприклад, наступна процедура memcpy, що використовує простий цикл, заснована на вбудованих функціях (замість коду бібліотеки), тому компілятор може оптимізувати її для останньої версії SIMD.
Mm256_store_si256((__m256i*) (dest++), (__m256i*) (src++))
Вона компілюється в наступний асемблерний код і має вдвічі більш високу продуктивність порівняно з недавніми бібліотеками.
C5 fd 6f 04 04 vmovdqa (%rsp,%rax,1),%ymm0 c5 fd 7f 84 04 00 00 vmovdqa %ymm0,0x10000(%rsp,%rax,1)
Асемблерний код із вбудованої функції копіюватиме 32 байти (256 біт) за допомогою останніх доступних інструкцій SIMD, тоді як код бібліотеки, що використовує SSE, копіюватиме лише 16 байт (128 біт).
Додаткам NFV часто необхідно виконувати операцію збору, завантажуючи дані з кількох місць у різних місцях пам'яті, що знаходяться не поспіль. Наприклад, мережний адаптер може помістити вхідні пакети в кеш за допомогою DDIO. Додаток NFV може потребувати доступу тільки до частини мережного заголовказ IP-адресою призначення. За допомогою операції збору програма може одночасно зібрати дані для 8 пакетів.
Для операції збору немає необхідності використовувати вбудовані функції або асемблерний код, оскільки компілятор може провести векторизацію коду, як для наведеної нижче програми, на основі тесту, що підсумовує числа псевдовипадкових розташування в пам'яті.
Int a; int b; for (i = 0; i< 1024; i++) a[i] = i; for (i = 0; i < 64; i++) b[i] = (i*1051) % 1024; for (i = 0; i < 64; i++) sum += a]; // This line is vectorized using gather.
Останній рядок компілюється до наступного асемблерного коду.
C5 fe 6f 40 80 vmovdqu -0x80(%rax),%ymm0 c5 ed fe f3 vpaddd %ymm3,%ymm2,%ymm6 c5 e5 ef db vpxor %ymm3,%ymm3,%ymm3 c5 d5 76 ed vpcmpeq ymm5,%ymm5 c4 e2 55 90 3c a0 vpgatherdd %ymm5,(%rax,%ymm4,4),%ymm7
Одна операція збору значно швидше за послідовність завантажень, але це має сенс тільки у випадку, якщо дані вже знаходяться в кеші. А якщо ні, то дані доведеться отримувати з пам'яті, а для цього потрібні сотні або тисячі циклів ЦП. Якщо дані знаходяться в кеші, то можливе прискорення у 10 разів
(Тобто на 1000%). Якщо даних немає в кеші, прискорення становить лише 5 %.
При використанні подібних методик важливо аналізувати програму, щоб виявляти вузькі місця, а також розуміти, чи витрачає програма занадто багато часу на копіювання або збір даних. Для вимірювання продуктивності програм можна використовувати.
Ще одна корисна для NFV функція в Intel AVX2 та інших операціях SIMD - побітові та логічні операції. Вони використовуються для прискорення нестандартного коду шифрування, а бітова перевірка є зручною для розробників ASN.1 і часто використовується для даних у телекомунікаціях. Intel AVX2 можна використовувати для прискореного порівняння рядків за допомогою удосконалених алгоритмів, таких як MPSSEF.
Розширення Intel AVX2 добре працюють на віртуальних машинах. Продуктивність не відрізняється, немає помилкових виходів віртуальних машин.
Використання Intel TSX для більш високої масштабованості
Одна з проблем паралельних програмполягає в тому, щоб уникати конфліктів даних, які можуть відбуватися, коли кілька потоків намагаються використати той самий елемент даних і, принаймні, один потік при цьому намагається змінити дані. Щоб уникнути непередбачуваних результатів частот, використовується блокування: перший потік, що використовує елемент даних, блокує його від інших потоків аж до завершення своєї роботи. Але такий підхід може бути неефективним за наявності частих конкуруючих блокувань або, якщо блокування контролюють більшу область пам'яті, ніж це дійсно необхідно.
Intel Transactional Synchronization Extensions (TSX) надають процесорні інструкції для обходу блокування при транзакціях в апаратній пам'яті. Це допомагає досягти вищої масштабованості. Працює це так: коли програма заходить у секцію, що використовує Intel TSX для охорони розташування в пам'яті, записуються всі спроби доступу до пам'яті, а в кінці захищеного сеансу вони автоматично фіксуються або автоматично відкочуються. Відкат виконується у разі, якщо при виконанні з іншого потоку був конфлікт доступу до пам'яті, через який могла виникнути умова конкуренції (наприклад, запис у розташування, з якого читає дані інша транзакція). Відкат також може статися у випадку, якщо запис доступу до пам'яті стане занадто великим для реалізації Intel TSX, за наявності вводу-виводу або системного виклику, а також при виникненні винятків або завершенні роботи віртуальних машин. Відкат викликів введення-виводу відбувається, якщо неможливе його спекулятивне виконання через перешкоду ззовні. Системний виклик- дуже складна операція, що змінює кільця та дескриптори пам'яті, її дуже важко відкотити.
Найпоширенішим прикладом використання Intel TSX є керування доступом у таблиці хешу. Зазвичай для гарантії доступу до таблиці кеша застосовується блокування, але при цьому зростає час очікування для потоків, конкуруючих за доступ. Блокування часто є занадто грубим: блокується ціла таблиця, хоча ситуація, коли потоки намагаються отримати доступ до тих самих елементів, виникає вкрай рідко. При збільшенні кількості ядер (і потоків) грубе блокування перешкоджає масштабованості.
Як показано на схемі нижче, грубе блокування може призвести до того, що один потік чекатиме на вивільнення таблиці хеша іншим потоком, хоча ці потоки використовують різні елементи. Застосування Intel TSX дозволяє працювати обом потокам, їх результати фіксуються після успішного досягнення закінчення транзакції. Обладнання виявляє конфлікти на льоту та скасовує транзакції, що порушують правильність. При використанні Intel TSX потік 2 не повинен чекати, обидва потоки виконуються набагато раніше. Блокування по таблицях хеша перетворюється на точно настроюване блокування, що призводить до підвищення продуктивності. В Intel TSX підтримується точність відстеження для конфліктів на рівні одного рядка кешу (64 байти).
В Intel TSX використовуються два програмні інтерфейси, щоб вказувати секції коду для виконання транзакцій.
- Обхід апаратних блокувань (HLE) має зворотну сумісність, його можна використовувати без особливих труднощів для підвищення масштабованості, не піддаючи бібліотеку блокувань серйозних змін. HLE з'явилися префікси для заблокованих інструкцій. Префікс інструкції HLE дає обладнанню сигнал відстеження стану блокування без його отримання. У наведеному вище прикладі виконання описаних дій призведе до того, що доступ до інших елементів таблиці хешу більше не призводитиме до блокування, крім випадків, коли здійснюється конфліктуючий доступ на запис до значення, що зберігається в таблиці хешу. В результаті доступ буде розпаралелений, тому по всіх чотирьох потоках буде підвищено масштабованість.
- Інтерфейс RTM включає явні інструкції початку (XBEGIN), фіксування (XEND), скасування (XABORT) та тестування стану (XTEST) транзакцій. Ці інструкції надають бібліотекам блокування більш гнучкий вихід реалізації обходу блокувань. Інтерфейс RTM дозволяє бібліотекам використовувати гнучкі алгоритми скасування транзакцій. Цю можливість можна використовувати для підвищення продуктивності Intel TSX за допомогою оптимістичного перезапуску транзакцій, повернення транзакцій та інших розширених методик. За допомогою інструкції CPUID бібліотека може відкотитися до більш старої реалізації блокувань без RTM, зберігаючи зворотну сумісність із кодом на рівні користувача.
- Для отримання додаткових відомостейпро HLE та RTM рекомендую ознайомитися з наступними статтями порталу Intel Developer Zone.
Як і оптимізація примітивів синхронізації за допомогою HLE або RTM, функції плану даних NFV можуть отримати перевагу за рахунок Intel TSX при використанні пакета Data Plane Development Kit (DPDK).
При використанні Intel TSX основна складність полягає не в реалізації цих розширень, а в оцінці та визначенні їхньої продуктивності. Існують лічильники продуктивності, які можуть використовуватися в програмах Linux* perf, і для оцінки успішності виконання Intel TSX (кількість виконаних та кількість скасованих циклів).
Intel TSX слід використовувати в додатках NFV з обережністю та ретельно тестувати, оскільки операції введення-виведення в області, захищеній Intel TSX, завжди включають відкат, а багато функцій NFV використовують безліч операцій введення-виведення. У додатках NFV слід уникати конкуруючих блокувань. Якщо блокування необхідні, то алгоритми обходу блокувань допоможуть підвищити масштабованість.
про автора
Олександр Комаров працює інженером із розробки додатків у відділі Software and Services Group корпорації Intel. Протягом останніх 10 років основна робота Олександра полягала в оптимізації коду для досягнення найвищої продуктивності на існуючих та перспективних серверних платформах Intel. Така робота включає використання засобів Intel для розробки програмного забезпечення: це профільники, компілятори, бібліотеки, останні набори інструкцій, наноархітектура та вдосконалення архітектури найсучасніших процесорів архітектури x86 та наборів мікросхем.
додаткові відомості
Для отримання додаткових відомостей про NFV див. наступні відео.
#XeonДосить часто при виборі однопроцесорного сервера або робочої станції виникає питання, який процесор використовувати серверний Xeon або звичайний Core ix. Враховуючи те, що дані процесори побудовані на базі тих же ядер, вибір досить часто падає саме на настільні процесориякі зазвичай мають меншу вартість при схожій продуктивності. Чому тоді Intel випускає процесори Xeon E3? Давайте розберемося.
Технічні характеристики
Для початку візьмемо молодшу модель процесора Xeon з актуального модельного ряду - Xeon E3-1220 V3. Як опонент виступить процесор Core i5-4440. Обидва процесори виконані на ядрі Haswell, мають однакову базову тактову частоту та схожі ціни. Відмінності цих двох процесорів представлені у таблиці:Наявність вбудованої графіки. На перший погляд, Core i5 має перевагу, проте всі серверні материнські плати мають вбудовану відеокарту, якій не потрібний графічний чіп у процесорі, а робочі станції зазвичай не використовують вбудованої графіки через її відносно низьку продуктивність.
Підтримка ECC. Висока швидкість та великий обсяг оперативної пам'яті підвищують ймовірність виникнення програмних помилок. Зазвичай такі помилки виявляються непомітними, але, незважаючи на це, можуть призвести до зміни даних або падіння системи. Якщо для настільних комп'ютерівподібні помилки не страшні через їх рідкісне виникнення, то в серверах, що працюють цілодобово по кілька років, вони неприпустимі. Для їхнього виправлення використовується технологія ECC (error-correcting code), ефективність якої становить 99,988%.
Розрахункова теплова потужність (TDP). По суті, енергоспоживання процесора за максимального навантаження. Xeon'и, як правило, мають менший тепловий пакет і «розумніші» алгоритми енергозбереження, що в результаті призводить до менших рахунків за електрику та більш ефективного охолодження.
Кеш L3. Кеш-пам'ять – своєрідний прошарок між процесором і оперативною пам'яттю, що має дуже високу швидкість. Чим більший обсяг кешу, тим швидше працює процесор, тому що навіть дуже швидка оперативна пам'ять працює значно повільніше за кеш-пам'ять. Зазвичай процесори Xeon мають більший обсяг кешу, тому вони краще для ресурсомістких додатків.
Частота/Частота в режимі TurboBoost. Тут все просто – що вище частота, то швидше за інших рівних умов працює процесор. Базова частота, тобто частота, при якій працюють процесори при повному навантаженні, однакова, але в режимі Turbo Boost, тобто при роботі з програмами, не розрахованими на багатоядерні процесори, Xeon швидше.
Підтримка Intel TSX-NI. Intel Transactional Synchronization Extensions New Instructions (Intel TSX-NI) має на увазі під собою надбудову над системою роботи з кешем процесора, що оптимізує середовище виконання багатопотокових додатків, але, звичайно, тільки в тому випадку, якщо ці програми використовують програмні інтерфейси TSX-NI. Набори інструкцій TSX-NI дозволяють більш ефективно реалізувати роботу з Big Data та базами даних - у випадках, коли безліч потоків звертаються до тих самих даних і виникають ситуації блокування потоків. Спекулятивний доступ до даних, який реалізований в TSX, дозволяє ефективніше будувати такі програми і динамічніше масштабувати продуктивність зі збільшенням кількості паралельно виконуваних потоків за рахунок вирішення конфліктів при доступі до загальних даних.

Підтримка Trusted Execution. Технологія Intel Trusted Execution розширює можливості безпечного виконання команд за допомогою апаратного розширення можливостей процесорів та наборів мікросхем Intel. Ця технологія забезпечує для платформ цифрового офісу такі функції захисту, як запуск програм, що вимірюється, і захищене виконання команд. Це досягається за рахунок створення середовища, де програми виконуються ізольовано від інших програм системи.
До переваг процесорів Xeon старших моделей можна додати ще більший обсяг L3, до 45 МБ, більшу кількість ядер, до 18, і більший обсяг оперативної пам'яті, що підтримується, до 768 ГБ на процесор. При цьому споживання вбирається у 160 Вт. На перший погляд, це дуже велике значення, проте, враховуючи те, що продуктивність таких процесорів у кілька разів перевищує швидкодію того ж Xeon E3-1220 V3 з TDP 80 Вт, економія стає очевидною. Також слід зазначити, що жоден із процесорів сімейства Coreне підтримує багатопроцесорність, тобто можливе встановлення не більше одного процесора в один комп'ютер. Більшість додатків для серверів та робочих станцій чудово масштабується по ядрах, потоках і фізичних процесорах, тому установка двох процесорів дасть практично дворазовий приріст продуктивності.
Дата: 2014-08-13 22:26
У далекому 2007 році компанія AMDвипустила нове покоління процесорів Phenom. Ці процесори, як виявилося згодом, містили помилку в блоці TLB (translation look-aside buffer буфер швидкого перетвореннявіртуальних адрес у фізичні). Компанії не залишалося нічого іншого, як вирішити цю проблему за допомогою латки у вигляді патча BIOS, але це знижувало продуктивність процесора приблизно на 15%.
Щось подібне сталося тепер із Intel. У процесорах покоління Haswell компанія реалізувала підтримку вказівок TSX (Transactional Synchronization Extension). Вони призначені для прискорення багатопотокових додатків і повинні були використовуватися насамперед у серверному сегменті. Незважаючи на те, що CPU Haswell присутні на ринку вже досить давно, даний набірінструкцій мало використовувався. Певне, найближчим часом і не буде.
Справа в тому, що Intel допустила «друкарську помилку», як це називає сама компанія, в інструкціях TSX. Помилка, до речі, виявили зовсім не фахівці процесорного гіганта. Вона може спричинити нестабільність системи. Вирішити цю проблемукомпанія може лише одним способом, оновленням для BIOS, яке відключає цей набір інструкцій.
До речі, TSX реалізовані не тільки в процесорах HaswellПредставник компанії підтвердив, що Intel має намір у майбутньому реалізувати «безпомилковий» варіант інструкцій TSX у наступних своїх продуктах.
Теги: Коментувати
Попередні новини
2014-08-13 22:23
Sony Xperia Z2 "вижив" після шеститижневого перебування на дні солоного водоймища
Смартфони часто стають героями неймовірних оповідань, в яких вони приміряють на себе роль кишенькового бронежилета, який зупиняє кулю і рятує
2014-08-13 21:46
IPhone 6 перейшов у фінальну стадію тестування
За останніми данними інформаційного агентства Gforgames, iPhone 6 вступив до фінальної стадії тестування перед масовим запуском нового смартфона у виробництво. Нагадаємо, що iPhone 6 збиратиметься у Китаї на заводах...
2014-08-12 16:38
Восьмиядерний планшет iRU M720G підтримує дві SIM-картки
Планшет має 2 ГБ оперативної та 16 ГБ вбудованої флеш-пам'яті. На борту є дві камери: основна 8-мегапіксельна і фронтальна на 2 Мп. iRU M720G оснащений модулями 3G, GPS, Wi-Fi, Bluetooth, FM-радіо, а також слотом на дві SIM-картки, що дозволяє йому виконувати функції.
2014-08-10 18:57
LG випустила недорогий смартфон L60 у Росії
Без особливої помпи та фанфар компанія LG Electronics представила у Росії нову модельсерії L Series III – LG L60. Цей недорогий смартфон представлений у ціновому діапазонівід 4 до 5 тисяч рублів у найбільших...
З кожним новим поколінням процесори Intel вбирають у себе все більше технологій та функцій. Деякі з них у всіх на слуху (хто, наприклад, не знає про гіпертрединг?), про існування інших більшість нефахівців навіть не здогадуються. Відкриємо всім добре відому базузнань з продуктів Intel Automated Relational Knowledge Base (ARK) і виберемо там якийсь процесор. Ми побачимо великий список функцій та технологій - що ховається за їхніми таємничими маркетинговими найменуваннями? Пропонуємо заглибитися у питання, звертаючи особливу увагуна мало відомі технології – напевно, там знайдеться багато цікавого.
Intel Demand Based Switching
Спільно з Enhanced Intel SpeedStep Technology, технологія Intel Demand Based Switching відповідає за те, щоб у кожний момент часу при поточному завантаженні процесор працював на оптимальній частотіі отримував адекватне електричне живлення: не більше та не менше, ніж потрібно. Таким чином зменшується енергоспоживання та тепловиділення, що актуально не тільки для портативних пристроїв, Але і для серверів теж - саме там Demand Based Switching і використовується.
Intel Fast Memory Access
Функція контролера пам'яті оптимізації роботи з ОЗУ. Є комбінацією технологій, що дозволяє завдяки поглибленому аналізу черги команд виявити «сумісні» команди (наприклад, читання з однієї й тієї ж сторінки пам'яті), а потім перевпорядкувати реальне виконання таким чином, щоб команди, що «суміщаються», виконувались одна за одною. Крім того, менш пріоритетні команди запису на згадку плануються на ті моменти, коли прогнозується спустошення черги на читання, і в результаті процес запису на згадку ще менше обмежує швидкість читання.
Intel Flex Memory Access
Інша функція контролера пам'яті, що з'явилася ще за часів, коли він був окремим чіпом, у далекому 2004 році. Забезпечує можливість роботи в синхронному режимі з двома модулями пам'яті одночасно, причому на відміну від простого двоканального режиму, який існував і раніше, модулі пам'яті можуть бути різного розміру. Таким чином досягалася гнучкість в оснащенні комп'ютера пам'яттю, що відображено в назві.
Intel Instruction Replay
Дуже глибоко розташована технологія, що з'явилася вперше у процесорах Intel Itanium. У процесі роботи процесорних конвеєрів може статися така ситуація, коли інструкції вже настала черга виконуватися, а необхідні дані поки що недоступні. Інструкцію тоді необхідно «переграти»: зняти з конвеєра та запустити на його початку. Що, власне, відбувається. Ще одна важлива функція IRT - корекція випадкових помилок на процесорних конвеєрах. Докладніше про цю дуже цікаву функцію читайте.
Intel My WiFi Technology
Технологія віртуалізації, що дозволяє додати віртуальний WiFi адаптер до існуючого фізичного; таким чином, ваш ультрабук чи ноутбук може стати повноцінною точкою доступу чи повторювачем. Програмні компоненти My WiFi входять до складу драйвера Intel PROSet Wireless Software версії 13.2 та вище; Треба мати на увазі, що з технологією сумісні лише деякі WiFi адаптери. Інструкцію зі встановлення, а також перелік програмних та апаратних сумісностей можна знайти на сайті Intel.
Intel Smart Idle Technology
Ще одна технологія енергозбереження. Дозволяє вимикати блоки процесора, що не використовуються, або знижувати їх частоту. Незамінна річ для ЦПУ смартфона, яка саме там і з'явилася – у процесорах Intel Atom.
Intel Stable Image Platform
Термін, що стосується швидше бізнес-процесів, ніж технологій. Програма Intel SIPP забезпечує стабільність програмного забезпечення, гарантуючи, що основні компоненти платформ та драйвери не будуть змінюватися протягом щонайменше 15 місяців. Таким чином, корпоративні клієнтимають можливість користуватися одними тими самими образами систем, що розгортаються, протягом цього терміну.
Intel QuickAssist
Набір апаратно реалізованих функцій, що вимагають великих обсягів обчислень, наприклад, шифрування, компресія, розпізнавання шаблонів. Сенс QuickAssist – спростити завдання розробників, надавши їм функціональні «цеглинки», а також прискорити їх застосування. З іншого боку, технологія дозволяє доручити «важкі» завдання не найпотужнішим процесорам, що особливо цінується у системах, що вбудовуються, сильно обмежених і за продуктивністю, і з енергоспоживання.
Intel Quick Resume
Технологія, розроблена для комп'ютерів на базі платформи Intel Viiv, що дозволяла їм вмикатися та вимикатися практично миттєво, як ТВ-приймачі або DVD-плеєри; при цьому у «вимкненому» стані комп'ютер міг продовжувати виконання деяких завдань, що не потребують втручання користувача. І хоча сама платформа плавно перейшла в інші іпостасі разом з напрацюваннями, що супроводжували її, в ARK рядок ще присутній, адже це було не так вже й давно.
Intel Secure Key
Узагальнюючу назву для 32- та 64-бітної інструкції RDRAND, що використовує апаратну реалізацію генератора випадкових чисел Digital Random Number Generator (DRNG). Інструкція використовується в криптографічних цілях для створення красивих і високоякісних випадкових ключів.
Intel TSX-NI
Технологія зі складною назвою Intel Transactional Synchronization Extensions - New Instructions має на увазі під собою надбудову над системою роботи з кешем процесора, що оптимізує середовище виконання багатопотокових додатків, але, звичайно, тільки в тому випадку, якщо ці програми використовують програмні інтерфейси TSX-NI. З боку користувача дана технологіябезпосередньо не видно, але всі бажаючі можуть прочитати її опис доступною мовоюу блозі Степана Кольцова.
Насамкінець ще раз хочемо нагадати, що Intel ARK існує не тільки у вигляді сайту, але і як офлайновий додаток для iOS і Android. Будьте у темі!
























