Ядер багато не буває.
Сучасні GPU – це монструозні спритні бестії, здатні пережовувати гігабайти даних. Однак людина хитра і, як би не зростали обчислювальні потужності, вигадує завдання все складніше і складніше, так що настає момент, коли з сумом доводиться констатувати – потрібна оптимізацію 🙁
У цій статті описані основні поняття, щоб було легше орієнтуватися в теорії gpu-оптимізації та базові правила, для того щоб до цих понять, доводилося звертатися рідше.
Причини, за якими GPU ефективні для роботи з великими обсягами даних, що вимагають обробки:
- у них великі можливості щодо паралельного виконання завдань (багато-багато процесорів)
- висока пропускна здатність у пам'яті
Пропускна спроможність пам'яті (memory bandwidth)– це скільки інформації – біт чи гігабайт – може бути передана за одиницю часу секунду чи процесорний такт.
Одне із завдань оптимізації – задіяти по максимуму пропускну здатність – збільшити показники черезput(В ідеалі вона повинна дорівнювати memory bandwidth).
Для покращення використання пропускної спроможності:
- збільшити обсяг інформації – використовувати пропускний канал на повну (наприклад, кожен потік працює з флоат4)
- зменшувати латентність – затримку між операціями
Затримка (latency)- проміжок часу між моментами, коли контролер запросив конкретну комірку пам'яті та тим моментом, коли дані стали доступні процесору для виконання інструкцій. На саму затримку ми ніяк не можемо вплинути – ці обмеження присутні на апаратному рівні. Саме за рахунок цієї затримки процесор може одночасно обслуговувати кілька потоків - поки потік А запросив виділити йому пам'яті, потік Б може щось порахувати, а потік С чекати до нього прийдуть запитані дані.
Як знизити затримку (latency) якщо використовується синхронізація:
- зменшити кількість потоків у блоці
- збільшити кількість груп-блоків
Використання ресурсів GPU на повну – GPU Occupancy
У високолобих розмовах про оптимізацію часто миготить термін. gpu occupancyабо kernel occupancy- Він відображає ефективність використання ресурсів-потужностей відеокарти. Окремо зазначу - якщо ви навіть і використовуєте всі ресурси - це аж ніяк не означає, що ви використовуєте їх правильно.
Обчислювальні потужності GPU – це сотні процесорів жадібних до обчислень, при створенні програми – ядра (kernel) – на плечі програміста лягатиме тягар розподілу навантаження на них. Помилка може призвести до того, що більшість цих дорогоцінних ресурсів може безцільно простоювати. Зараз я поясню чому. Почати доведеться здалеку.
Нагадаю, що варп ( warp у термінології NVidia, wavefront – в термінології AMD) – набір потоків, які одночасно виконують одну і ту ж функцію-кернел на процесорі. Потоки, об'єднані програмістом в блоки, розбиваються на варпи планувальником потоків (окремо для кожного мультипроцесора) – поки один варп працює, другий чекає на обробку запитів до пам'яті і т.д. Якщо якісь із потоків варпа все ще виконують обчислення, а інші вже зробили все, що могли – має місце неефективне використання обчислювального ресурсу – в народі іменоване простоювання потужностей.
Кожна точка синхронізації, кожне розгалуження логіки може спричинити таку ситуацію простою. Максимальна дивергенція (розгалуження логіки виконання) залежить від розміру варпа. Для GPU від NVidia – це 32, для AMD – 64.
Для того щоб знизити простий мультипроцесор під час виконання варпа:
- мінімізувати час очікування бар'єрів
- мінімізувати розбіжність логіки виконання у функції-кернелі
Для ефективного розв'язання цього завдання є сенс розібратися – як відбувається формування варпів (для випадку з кількома розмірностями). Насправді порядок простий - в першу чергу X, потім Y і, в останню чергу, Z.
ядро запускається з блоками розмірністю 64×16, потоки розбиваються по варпам порядку X, Y, Z – тобто. перші 64 елементи розбиваються на два варпи, потім другі і т.д.

Ядро запускається із блоками розмірністю 16×64. У перший варп додаються перші та другі 16 елементів, у другий варп – треті та четверті тощо.
Як знижувати дивергенцію (пам'ятаєте – розгалуження – не завжди причина критичної втрати продуктивності)
- коли у суміжних потоків різні шляхи виконання - багато умов і переходів по них - шукати шляхи реструктуризації
- шукати не збалансоване завантаження потоків і рішуче її видаляти (це коли у нас мало того, що є умови, так ще через ці умови перший потік завжди щось обчислює, а п'ятий в цю умову не потрапляє і простоює)
Як використовувати ресурси GPU по максимуму
Ресурси GPU, на жаль, теж мають обмеження. І, строго кажучи, перед запуском функції-кернела є сенс визначити ліміти і при розподілі навантаження ці ліміти врахувати. Чому це важливо?
У відеокарт є обмеження на загальне число потоків, яке може виконувати один мультипроцесор, максимальна кількість потоків в одному блоці, максимальна кількість варпів на одному процесорі, обмеження різних видів пам'яті і т.п. Всю цю інформацію можна запросити як програмно, через відповідне API так і за допомогою утиліт з SDK. (Модулі deviceQuery для NVidia, CLInfo – для відеокарт AMD).
Загальна практика:
- кількість блоків/робочих груп потоків повинна бути кратна кількості потокових процесорів
- розмір блоку/робочої групи повинен бути кратний розміру варпа
При цьому слід враховувати, що абсолютний мінімум – 3-4 варпи/вейфронти крутяться одночасно на кожному процесорі, мудрі гайди радять виходити з міркування – не менше семи вейфронатів. При цьому – не забувати обмеження щодо заліза!
У голові всі ці деталі тримати швидко набридає, тому для розрахунків gpu-occupancy NVidia запропонувала несподіваний інструмент - ексельний (!) калькулятор набитий макросами. Туди можна ввести інформацію по максимальній кількості потоків для SM, кількість регістрів і розмір загальної (shared) пам'яті доступних на потоковому процесорі, і параметри запуску функцій, що використовуються - а він видає у відсотках ефективність використання ресурсів (і ви рвете на голові волосся усвідомлюючи що задіяти всі ядра вам не вистачає регістрів).
інформація щодо використання:
http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/#calculating-occupancy
GPU та операції з пам'яттю
Відеокарти оптимізовані для 128-бітових операцій із пам'яттю. Тобто. в ідеалі – кожна маніпуляція з пам'яттю, в ідеалі повинна змінювати за раз 4 чотирибайтних значення. Основна проблема для програміста полягає в тому, що сучасні компілятори для GPU не можуть оптимізувати такі речі. Це доводиться робити у коді функції і, у середньому, приносить частки-відсотка з приросту продуктивності. Набагато більший вплив на продуктивність має частота запитів до пам'яті.
Проблема в наступному - кожен запит повертає у відповідь шматочок даних розміром кратний 128 біт. А кожен потік використовує лише чверть його (у разі звичайної чотирибайтової змінної). Коли суміжні потоки одночасно працюють з даними розташованими послідовно в осередках пам'яті, це знижує загальну кількість звернень до пам'яті. Називається це явище - об'єднані операції читання та запису ( coalesced access – good! both read and write) – і за правильної організації коду ( strided access to contiguous chunk of memory – bad!) може відчутно покращити продуктивність. При організації свого ядра – пам'ятайте – суміжний доступ – у межах елементів одного рядка пам'яті, робота з елементами стовпця – це вже не так ефективно. Бажаєте більше деталей? мені сподобалася ось ця pdf – чи гуглить на предмет “ memory coalescing techniques “.
Лідируючі позиції в номінації "вузьке місце" займає інша операція з пам'яттю - копіювання даних з пам'яті хоста в ГПУ . Копіювання відбувається не аби як, а із спеціально виділеної драйвером і системою області пам'яті: при запиті на копіювання даних – система спочатку копіює туди ці дані, а вже потім заливає їх у GPU. Швидкість транспортування даних обмежена пропускною спроможністю шини PCI Express xN (де N число ліній передачі даних), через які сучасні відеокарти спілкуються з хостом.
Проте, надмірне копіювання повільної пам'яті на хості – це часом невиправдані витрати. Вихід – використовувати так звану pinned memory - Спеціальним чином позначену область пам'яті, так що операційна система не має можливості виконувати з нею якісь операції (наприклад - вивантажити у свап / перемістити на свій розсуд і т.п.). Передача даних із хоста на відеокарту здійснюється без участі операційної системи – асинхронно, через DMA (Direct Memory Access).
І, насамкінець, ще трохи про пам'ять. Пам'ять, що розділяється на мультипроцесорі зазвичай організована у вигляді банків пам'яті містять 32 бітні слова - дані. Кількість банків за доброю традицією варіюється від одного покоління GPU до іншого - 16/32 Якщо кожен потік звертається за даними в окремий банк - все гаразд. Інакше виходить кілька запитів на читання/запис до одного банку і ми отримуємо конфлікт ( shared memory bank conflict). Такі конфліктні звернення серіалізуються і виконуються послідовно, а чи не паралельно. Якщо до одного банку звертаються всі потоки - використовується "широкомовна" відповідь ( broadcast) і конфлікту немає. Існує кілька способів ефективно боротися з конфліктами доступу, мені сподобалося опис основних методик звільнення від конфліктів доступу до банків пам'яті – .
Як зробити математичні операції ще швидше? Пам'ятати що:
- обчислення подвійної точності – це високе навантаження операції з FP64 >> FP32
- константи виду 3.13 у коді, за умовчанням, інтерпретується як fp64 якщо явно не вказувати 3.14f
- для оптимізації математики не зайвим буде впоратися в гайдах - а чи немає яких прапорців компілятор
- виробники включають у свої SDK функції, які використовують особливості пристроїв для досягнення продуктивності (часто – на шкоду переносимості)
Для розробників CUDA є сенс звернути пильну увагу на концепцію cuda stream,що дозволяють запускати відразу кілька функцій-ядер на одному пристрої або поєднувати асинхронне копіювання даних з хоста на пристрій під час виконання функцій. OpenCL поки такого функціоналу не надає 🙁
Утиль для профілювання:
NVifia Visual Profiler – цікава утилітка, що аналізує ядра як CUDA так і OpenCL.
P. S. Як більш розлогий посібник з оптимізації, можу порекомендувати гуглити всілякі best practices guide для OpenCL та CUDA.
- ,
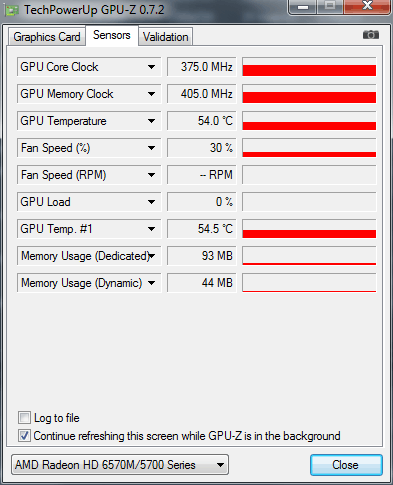
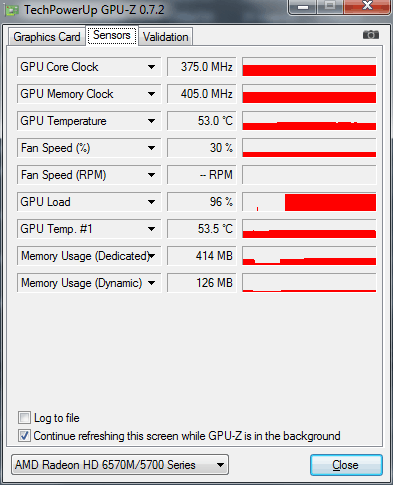
Часто постало питання: чому немає GPU прискорення в програмі Adobe Media Encoder CC? А те, що Adobe Media Encoder використовує GPU прискорення, ми з'ясували, а також відзначили нюанси його використання. Також зустрічається твердження: у програмі Adobe Media Encoder CC прибрали підтримку GPU прискорення. Це помилкова думка і випливає з того, що основна програма Adobe Premiere Pro CC тепер може працювати без прописаної та рекомендованої відеокарти, а для включення GPU движка в Adobe Media Encoder CC відеокарта повинна бути обов'язково прописана в документах: cuda_supported_cards або opencl_supported_cards. Якщо з чіпсетами nVidia все зрозуміло, просто беремо ім'я чіпсету та вписуємо його в документ cuda_supported_cards. То при використанні відеокарт AMD треба прописувати не ім'я чіпсету, а кодову назву ядра. Отже, на практиці перевіримо, як на ноутбуці ASUS N71JQ з дискретною графікою ATI Mobility Radeon HD 5730 включити GPU двигун в Adobe Media Encoder CC. Технічні дані графічного адаптера ATI Mobility Radeon HD 5730 показуються утилітою GPU-Z:
Запускаємо програму Adobe Premiere Pro CC і включаємо двигун: Mercury Playback Engine GPU Acceleration (OpenCL).
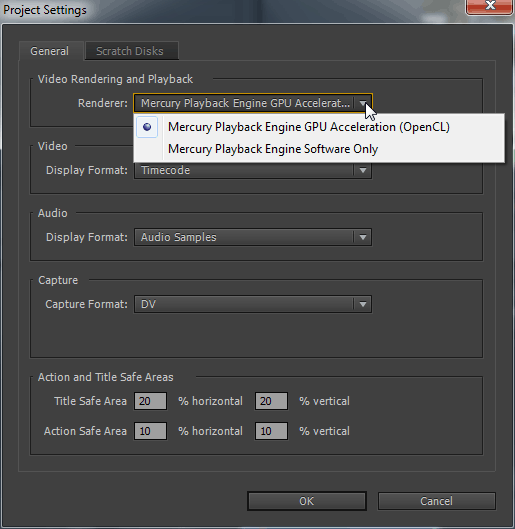
Три DSLR відео на таймлайні, один над одним, два з них, створюють ефект зображення в малюнку.

Ctrl+M, вибираємо пресет MPEG2-DVD, прибираємо чорні смуги з боків за допомогою опції Scale To Fill. Включаємо також підвищену якість для тестів без GPU: MRQ (Use Maximum Render Quality). Натискаємо кнопку: Export. Завантаження процесора до 20% та оперативної пам'яті 2.56 Гбайт.

Завантаження GPU чіпсету ATI Mobility Radeon HD 5730 складає 97% та 352Мб бортової відеопам'яті. Ноутбук тестувався під час роботи від акумулятора, тому графічне ядро/пам'ять працюють на знижених частотах: 375/810 МГц.

Підсумковий час прорахунку: 1 хвилина та 55 секунд(вкл/вимк. MRQ при використанні GPU движка, не впливає на підсумковий час прорахунку).
При встановленій галці Use Maximum Render Quality тепер натискаємо кнопку: Queue.


Тактові частоти процесора під час роботи від акумулятора: 930МГц.

Запускаємо AMEEncodingLog і дивимося підсумковий час прорахунку: 5 хвилин та 14 секунд.

Повторюємо тест, але вже при знятій галці Use Maximum Render Quality натискаємо на кнопку: Queue.
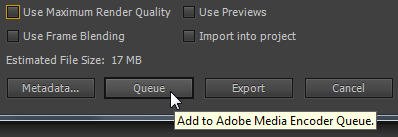

Підсумковий час прорахунку: 1 хвилина та 17 секунд.

Тепер увімкнемо GPU двигун в Adobe Media Encoder CC, запускаємо програму Adobe Premiere Pro CC, натискаємо комбінацію клавіш: Ctrl + F12, виконуємо Console > Console View і в полі Command вбиваємо GPUSniffer, натискаємо Enter.
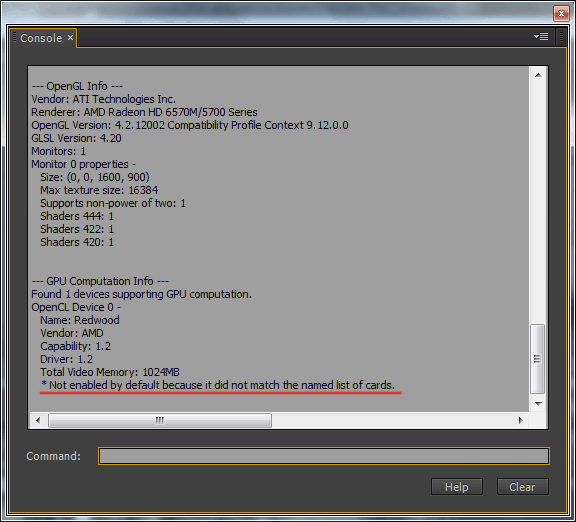
Виділяємо та копіюємо ім'я в GPU Computation Info.

У директорії програми Adobe Premiere Pro CC відкриваємо документ opencl_supported_cards і в алфавітному порядку вбиваємо кодове ім'я чіпсету, Ctrl+S.

Натискаємо кнопку: Queue, і отримуємо GPU прискорення прорахунку проекту Adobe Premiere Pro CC в Adobe Media Encoder CC.
Підсумковий час: 1 хвилина та 55 секунд.

Підключаємо ноутбук до розетки і повторюємо результати прорахунків. Queue, галка MRQ знята, без включення двигуна, завантаження оперативної пам'яті трохи підросло:

Тактові частоти процесора: 1.6ГГц під час роботи від розетки та включення режиму: Висока продуктивність.

Підсумковий час: 46 секунд.

Включаємо двигун: Mercury Playback Engine GPU Acceleration (OpenCL), як видно від мережі ноутбукова відеокарта працює на своїх базових частотах, завантаження GPU в Adobe Media Encoder CC досягає 95%.

Підсумковий час прорахунку, знизився з 1 хвилина 55 секунд, до 1 хвилини та 5 секунд.

*Для візуалізації в Adobe Media Encoder CC тепер використовується графічний процесор (GPU). Підтримуються стандарти CUDA та OpenCL. В Adobe Media Encoder CC, двигун GPU використовується для наступних процесів візуалізації:
- Зміна чіткості (від високої до стандартної та навпаки).
- Фільтр тимчасового коду.
- Перетворення формату пікселів.
- Розмежування.
Якщо візуалізується проект Premiere Pro, AME використовує установки візуалізації з GPU, задані для цього проекту. При цьому будуть використані всі можливості візуалізації з GPU, реалізовані Premiere Pro. Для візуалізації проектів AME використовується обмежений набір можливостей для візуалізації з GPU. Якщо послідовність візуалізується за допомогою оригінальної підтримки, застосовується налаштування GPU з AME, налаштування проекту ігнорується. У цьому випадку всі можливості візуалізації з GPU Premiere Pro використовуються безпосередньо в AME. Якщо проект містить VST сторонніх виробників, використовується налаштування проекту GPU. Послідовність кодується за допомогою PProHeadless, як і в попередніх версіях AME. Якщо прапорець Enable Native Premiere Pro Sequence Import (Дозволити імпорт вихідної послідовності Premiere Pro) знято, завжди використовується PProHeadless та налаштування GPU.
Читаємо про прихований розділ на системному диску ноутбука ASUS N71JQ.
Використання GPU для обчислень за допомогою C++ AMP
Досі в обговоренні прийомів паралельного програмування ми розглядали лише ядра процесора. Ми придбали деякі навички розпаралелювання програм з кількох процесорів, синхронізації доступу до спільно використовуваних ресурсів та використання високошвидкісних примітивів синхронізації без застосування блокувань.
Однак, існує ще один спосіб розпаралелювання програм - графічні процесори (GPU), що мають більшу кількість ядер, ніж навіть високопродуктивні процесори. Ядра графічних процесорів чудово підходять для реалізації паралельних алгоритмів обробки даних, а велика їхня кількість з лишком окупає незручності виконання програм на них. У цій статті ми познайомимося з одним із способів виконання програм на графічному процесорі з використанням комплекту розширень мови C++ під назвою C++ AMP.
Розширення C++ AMP засновані мовою C++ і саме тому у цій статті демонструватимуться приклади мовою C++. Однак, при помірному використанні механізму взаємодій. NET, ви зможете використовувати алгоритми C++ AMP у своїх програмах для .NET. Але про це ми поговоримо наприкінці статті.
Введення у C++ AMP
По суті, графічний процесор є таким самим процесором, як будь-які інші, але з особливим набором інструкцій, великою кількістю ядер і своїм протоколом доступу до пам'яті. Однак між сучасними графічними та звичайними процесорами існують великі відмінності, та їх розуміння є запорукою створення програм, що ефективно використовують обчислювальні потужності графічного процесора.
Сучасні графічні процесори мають дуже маленький набір інструкцій. Це передбачає деякі обмеження: відсутність можливості виклику функцій, обмежений набір типів даних, що підтримуються, відсутність бібліотечних функцій та інші. Деякі операції, такі як умовні переходи можуть коштувати значно дорожче, ніж аналогічні операції, що виконуються на звичайних процесорах. Очевидно, що перенесення великих обсягів коду з процесора на графічний процесор за таких умов потребує значних зусиль.
Кількість ядер у середньому графічному процесор значно більша, ніж у середньому звичайному процесорі. Однак деякі завдання виявляються занадто маленькими або не дозволяють розбивати себе на досить велику кількість частин, щоб можна було отримати вигоду від застосування графічного процесора.
Підтримка синхронізації між ядрами графічного процесора, що виконують одне завдання, дуже мізерна, і повністю відсутня між ядрами графічного процесора, що виконують різні завдання. Ця обставина вимагає синхронізації графічного процесора зі звичайним процесором.
Відразу постає питання, які завдання підходять для вирішення на графічному процесорі? Майте на увазі, що не всякий алгоритм підходить для виконання на графічному процесорі. Наприклад, графічні процесори не мають доступу до пристроїв вводу/виводу, тому у вас не вдасться підвищити продуктивність програми, яка отримує стрічки RSS з інтернету, за рахунок використання графічного процесора. Однак на графічний процесор можна перенести багато обчислювальних алгоритмів і забезпечити масове їх розпаралелювання. Нижче наводиться кілька прикладів таких алгоритмів (цей список далеко не повний):
збільшення та зменшення різкості зображень та інші перетворення;
швидке перетворення Фур'є;
транспонування та множення матриць;
сортування чисел;
інверсія хеша "в лоб".
Відмінним джерелом додаткових прикладів може бути блог Microsoft Native Concurrency, де наводяться фрагменти коду та пояснення до них для різних алгоритмів, реалізованих на C++ AMP.
C++ AMP - це фреймворк, що входить до складу Visual Studio 2012, що дає розробникам на C++ простий спосіб виконання обчислень на графічному процесорі і вимагає лише наявності драйвера DirectX 11. Корпорація Microsoft випустила C++ AMP як відкриту специфікацію, яку може реалізувати будь-який виробник комп'ютерів.
Фреймворк C++ AMP дозволяє виконувати код на графічних прискорювачів (accelerators), що є обчислювальними пристроями. За допомогою драйвера DirectX 11 фреймворк C++ AMP динамічно виявляє усі прискорювачі. До складу C++ AMP входять також програмний емулятор прискорювача та емулятор на базі звичайного процесора, WARP, які служить запасним варіантом у системах без графічного процесора або з графічним процесором, але без драйвера DirectX 11, і використовує кілька ядер та інструкції SIMD.
А тепер приступимо до дослідження алгоритму, який можна розпаралелити для виконання на графічному процесорі. Реалізація нижче приймає два вектори однакової довжини та обчислює поточковий результат. Важко уявити щось більш прямолінійне:
Void VectorAddExpPointwise(float* first, float* second, float* result, int length) ( for (int i = 0; i< length; ++i) { result[i] = first[i] + exp(second[i]); } }
Щоб розпаралелити цей алгоритм на звичайному процесорі, потрібно розбити діапазон ітерацій на кілька піддіапазонів і запустити по одному потоку виконання для кожного з них. Ми присвятили досить багато часу в попередніх статтях саме такому способу розпаралелювання нашого першого прикладу пошуку простих чисел - ми бачили, як це можна зробити, створюючи потоки вручну, передаючи завдання пулу потоків і використовуючи Parallel.For і PLINQ для автоматичного розпаралелювання. Згадайте також, що при розпаралелювання схожих алгоритмів на звичайному процесорі ми особливо дбали, щоб не роздробити завдання на дрібні завдання.
Для графічного процесора ці попередження непотрібні. Графічні процесори мають безліч ядер, що виконують потоки дуже швидко, а вартість перемикання контексту значно нижча, ніж у звичайних процесорах. Нижче наводиться фрагмент, який намагається використовувати функцію parallel_for_eachіз фреймворку C++ AMP:
#include
Тепер досліджуємо кожну частину коду окремо. Відразу зауважимо, що загальна форма головного циклу збереглася, але цикл, що використовувався спочатку, був замінений викликом функції parallel_for_each. Насправді принцип перетворення циклу на виклик функції або методу для нас не новий - раніше вже демонструвався такий прийом із застосуванням методів Parallel.For() і Parallel.ForEach() з бібліотеки TPL.
Далі, вхідні дані (параметри first, second та result) обгортаються екземплярами array_view. Клас array_view служить для обгортання даних, які передаються графічному процесору (прискорювачу). Його шаблонний параметр визначає тип даних та їх розмірність. Щоб виконати на графічному процесорі інструкції, що звертаються до даних, спочатку оброблюваним на звичайному процесорі, хтось чи щось має подбати про копіювання даних у графічний процесор, оскільки більшість сучасних графічних карток є окремими пристроями з власною пам'яттю. Це завдання вирішують екземпляри array_view – вони забезпечують копіювання даних на вимогу і тільки коли вони дійсно необхідні.
Коли графічний процесор виконає завдання, копіюються дані назад. Створюючи екземпляри array_view з аргументом типу const, ми гарантуємо, що first і second будуть скопійовані на згадку про графічний процесор, але не копіюватимуться назад. Аналогічно, викликаючи discard_data(), ми виключаємо копіювання результату з пам'яті звичайного процесора в пам'ять прискорювача, але ці дані копіюватимуться у зворотному напрямку.
Функція parallel_for_each приймає об'єкт extent, що визначає форму даних і функцію для застосування до кожного елемента в об'єкті extent. У цьому прикладі ми використовували лямбда-функцію, підтримка яких з'явилася в стандарті ISO C++2011 (C++11). Ключове слово restrict (amp) доручає компілятор перевірити можливість виконання тіла функції на графічному процесорі і відключає більшу частину синтаксису C++, який не може бути скомпільований в інструкції графічного процесора.
Параметр лямбда-функції, index<1>об'єкта представляє одномірний індекс. Він повинен відповідати об'єкту extent, що використовується - якби ми оголосили об'єкт extent двовимірним (наприклад, визначивши форму вихідних даних у вигляді двовимірної матриці), індекс також повинен був би бути двомірним. Приклад такої ситуації наводиться трохи нижче.
Зрештою, виклик методу synchronize()Наприкінці методу VectorAddExpPointwise гарантує копіювання результатів обчислень з array_view avResult, вироблених графічним процесором, назад у масив результату.
На цьому ми закінчуємо наше перше знайомство зі світом C++ AMP, і тепер ми готові до докладніших досліджень, а також до більш цікавих прикладів, що демонструють вигоди від використання паралельних обчислень на графічному процесорі. Складання векторів - не найкращий алгоритм і не найкращий кандидат для демонстрації використання графічного процесора через великі накладні витрати на копіювання даних. У наступному підрозділі будуть показані два цікавіші приклади.
Розмноження матриць
Перший «справжній» приклад, який ми розглянемо, – множення матриць. Для реалізації ми візьмемо простий кубічний алгоритм множення матриць, а чи не алгоритм Штрассена, має час виконання, близьке до кубічного ~O(n 2.807). Для двох матриць: матриці A розміром m x w та матриці B розміром w x n, наступна програма виконає їх множення та поверне результат - матрицю C розміром m x n:
Void MatrixMultiply(int * A, int m, int w, int * B, int n, int * C) ( for (int i = 0; i< m; ++i) { for (int j = 0; j < n; ++j) { int sum = 0; for (int k = 0; k < w; ++k) { sum += A * B; } C = sum; } } }
Розпаралелити цю реалізацію можна декількома способами, і при бажанні розпаралелити цей код для виконання на звичайному процесорі правильним вибором був прийом розпаралелювання зовнішнього циклу. Однак графічний процесор має досить велику кількість ядер і розпаралелив тільки зовнішній цикл, ми не зможемо створити достатню кількість завдань, щоб завантажити роботою всі ядра. Тому має сенс розпаралелити два зовнішні цикли, залишивши внутрішній цикл незайманим:
Void MatrixMultiply (int * A, int m, int w, int * B, int n, int * C) ( array_view
Ця реалізація все ще близько нагадує послідовну реалізацію множення матриць і приклад складання векторів, що наводилися вище, за винятком індексу, який є двовимірним і доступний у внутрішньому циклі із застосуванням оператора . Наскільки ця версія швидше за послідовну альтернативу, що виконується на звичайному процесорі? Помноження двох матриць (цілих чисел) розміром 1024 х 1024 послідовна версія на звичайному процесорі виконує в середньому 7350 мілісекунд, тоді як версія для графічного процесора – тримайтеся міцніше – 50 мілісекунд, у 147 разів швидше!
Моделювання руху частинок
Приклади розв'язання задач на графічному процесорі, представлені вище, мають дуже просту реалізацію внутрішнього циклу. Зрозуміло, що так не завжди буде. У блозі Native Concurrency, посилання на який вже наводилося вище, показується приклад моделювання гравітаційних взаємодій між частинками. Моделювання включає нескінченну кількість кроків; на кожному кроці обчислюються нові значення елементів вектора прискорень кожної частки і потім визначаються їх нові координати. Тут розпаралелювання піддається вектор частинок - при досить велику кількість частинок (від кількох тисяч і вище) можна створити досить велику кількість завдань, щоб завантажити роботою всі ядра графічного процесора.
Основу алгоритму становить реалізація визначення результату взаємодій між двома частинками, як показано нижче, яку легко можна перенести на графічний процесор:
// тут float4 - це вектори з чотирма елементами, // репрезентують частинки, що беруть участь в операціях . використовується float absDist = dist.x * dist.x + dist.y * dist.y + dist.z * dist.z; float invDist = 1.0f / sqrt (absDist); = dist*PARTICLE_MASS*invDistCube;
Вихідними даними на кожному кроці моделювання є масив з координатами та швидкостями руху частинок, а в результаті обчислень створюється новий масив з координатами та швидкостями частинок:
Struct particle ( float4 position, velocity; // реалізації конструктора, конструктора копіювання та // оператора = з restrict (amp) опущені для економії місця); void simulation_step (array
Із залученням відповідного графічного інтерфейсу, моделювання може бути дуже цікавим. Повний приклад, представлений командою розробників C++ AMP, можна знайти у блозі Native Concurrency. На моїй системі з процесором Intel Core i7 та відеокартою Geforce GT 740M, моделювання руху 10 000 частинок виконується зі швидкістю ~2.5 кадру в секунду (кроків в секунду) з використанням послідовної версії, що виконується на звичайному процесорі, та 160 кадрів в секунду з використанням оптимізований версії, що виконується на графічному процесорі – величезне збільшення продуктивності.
Перш ніж завершити цей розділ, необхідно розповісти ще одну важливу особливість фреймворку C++ AMP, яка може ще більше підвищити продуктивність коду, що виконується на графічному процесорі. Графічні процесори підтримують програмований кеш даних(часто званий пам'яттю, що розділяється (shared memory)). Значення, що зберігаються в цьому кеші, спільно використовуються всіма потоками виконання однієї мозаїці (tile). Завдяки мозаїчній організації пам'яті, програми на основі фреймворку C++ AMP можуть читати дані з пам'яті графічної карти в пам'ять мозаїки, що розділяється, і потім звертатися до них з декількох потоків виконання без повторного вилучення цих даних з пам'яті графічної карти. Доступ до пам'яті мозаїки виконується приблизно в 10 разів швидше, ніж до пам'яті графічної карти. Іншими словами, у вас є причини читання.
Щоб забезпечити виконання мозаїчної версії паралельного циклу методу parallel_for_each передається домен tiled_extent, який ділить багатовимірний об'єкт extent на багатовимірні фрагменти мозаїки, і лямбда-параметр tiled_index, що визначає глобальний та локальний ідентифікатор потоку всередині мозаїки. Наприклад, матрицю 16x16 можна розділити на фрагменти мозаїки розміром 2x2 (як показано на малюнку нижче) і потім передати функції parallel_for_each:
Extent<2>matrix(16,16); tiled_extent<2,2>tiledMatrix = matrix.tile<2,2>(); parallel_for_each (tiledMatrix, [=](tiled_index<2,2>idx) restrict (amp) ( // ...));

Кожен із чотирьох потоків виконання, що належать до однієї і тієї ж мозаїки, можуть спільно використовувати дані, що зберігаються в блоці.
При виконанні операцій з матрицями, в ядрі графічного процесора, замість стандартного індексу index<2>, як у прикладах вище, можна використовувати idx.global. Грамотне використання локальної мозаїчної пам'яті та локальних індексів може забезпечити суттєвий приріст продуктивності. Щоб оголосити мозаїчну пам'ять, поділювану всіма потоками виконання однієї мозаїці, локальні змінні можна оголосити зі специфікатором tile_static.
На практиці часто використовується прийом оголошення пам'яті, що розділяється, і ініціалізації окремих її блоків у різних потоках виконання:
Parallel_for_each(tiledMatrix, [=](tiled_index<2,2>idx) restrict(amp) ( // 32 байти спільно використовуються всіма потоками в блоці tile_static int local; // присвоїти значення елементу для цього потоку виконання local = 42; ));
Очевидно, що будь-які вигоди від використання пам'яті, що розділяється, можна отримати тільки в разі синхронізації доступу до цієї пам'яті; тобто потоки не повинні звертатися до пам'яті, доки вона не буде ініціалізована одним із них. Синхронізація потоків у мозаїці виконується за допомогою об'єктів tile_barrier(що нагадує клас Barrier з бібліотеки TPL) - вони зможуть продовжити виконання лише після виклику методу tile_barrier.Wait(), який поверне керування лише коли всі потоки викличуть tile_barrier.Wait. Наприклад:
Parallel_for_each (tiledMatrix, (tiled_index<2,2>idx) restrict(amp) ( // 32 байти спільно використовуються всіма потоками в блоці tile_static int local; // присвоїти значення елементу для цього потоку виконання local = 42; // idx.barrier - екземпляр tile_barrier idx.barrier.wait(); // Тепер цей потік може звертатися до масиву "local", // використовуючи індекси інших потоків виконання!));
Тепер саме час втілити отримані знання у конкретний приклад. Повернемося до реалізації множення матриць, виконаної без застосування мозаїчної організації пам'яті, і додамо до нього оптимізацію, що описується. Припустимо, що розмір матриці кратний числу 256 - це дозволить нам працювати з блоками 16 х 16. Природа матриць допускає можливість побічного їх множення, і ми можемо скористатися цією особливістю (фактично, розподіл матриць на блоки є типовою оптимізацією алгоритму множення матриць, що забезпечує більш ефективне використання кешу процесора).
Суть цього прийому зводиться до наступного. Щоб знайти C i,j (елемент у рядку i і в стовпці j в матриці результату), потрібно обчислити скалярний добуток між A i, * (i-й рядок першої матриці) і B *, j (j-й стовпець у другій матриці ). Однак це еквівалентно обчисленню часткових скалярних творів рядка і стовпця з подальшим підсумовуванням результатів. Ми можемо використовувати цю обставину для перетворення алгоритму множення матриць на мозаїчну версію:
Void MatrixMultiply(int * A, int m, int w, int * B, int n, int * C) ( array_view Суть оптимізації, що описується в тому, що кожен потік в мозаїці (для блоку 16 х 16 створюється 256 потоків) ініціалізує свій елемент в 16 х 16 локальних копіях фрагментів вихідних матриць A і B. Кожному потоку в мозаїці потрібно тільки один рядок і один стовпець з цих блоків, але всі потоки разом будуть звертатися до кожного рядка і кожного стовпця по 16 разів. Такий підхід суттєво знижує кількість звернень до основної пам'яті. Щоб обчислити елемент (i,j) у матриці результату, алгоритму потрібно повний i-й рядок першої матриці та j-й стовпець другої матриці. Коли потоки мозаїці 16x16, представлені на діаграмі і k=0, заштриховані області першої і другої матрицях будуть прочитані в пам'ять, що розділяється. Потік виконання, що обчислює елемент (i,j) у матриці результату, обчислить частковий скалярний добуток перших k елементів з i-го рядка та j-го стовпця вихідних матриць. У цьому прикладі застосування мозаїчної організації забезпечує величезний приріст продуктивності. Мозаїчна версія множення матриць виконується набагато швидше за просту версію і займає приблизно 17 мілісекунд (для тих же вихідних матриць розміром 1024 х 1024), що в 430 швидше за версію, що виконується на звичайному процесорі! Перш ніж закінчити обговорення фреймворку C++ AMP, нам хотілося б згадати інструменти (в Visual Studio), які є у розпорядженні розробників. Visual Studio 2012 пропонує налагоджувач для графічного процесора (GPU), що дозволяє встановлювати контрольні точки, досліджувати стек викликів, читати та змінювати значення локальних змінних (деякі прискорювачі підтримують налагодження для GPU безпосередньо; для інших Visual Studio використовує програмний симулятор), та профільник, що дає можливість оцінювати вигоди, одержувані додатком від розпаралелювання операцій із застосуванням графічного процесора. За додатковою інформацією щодо можливостей налагодження у Visual Studio звертайтеся до статті «Покроковий посібник. Налагодження програми «C++ AMP» на сайті MSDN. До цих пір у цій статті демонструвалися приклади тільки мовою C++, проте є кілька способів використовувати потужність графічного процесора в керованих додатках. Один із способів – використовувати інструменти взаємодій, що дозволяють перекласти роботу з ядрами графічного процесора на низькорівневі компоненти C++. Це рішення відмінно підходить для тих, хто бажає використовувати фреймворк C++ AMP або може використовувати вже готові компоненти C++ AMP в керованих додатках. Інший спосіб - використовувати бібліотеку, що безпосередньо працює з графічним процесором з керованого коду. Нині є кілька таких бібліотек. Наприклад, GPU.NET та CUDAfy.NET (обидві є комерційними пропозиціями). Нижче наведено приклад з репозиторію GPU.NET GitHub, що демонструє реалізацію скалярного твору двох векторів: Public static void MultiplyAddGpu(double a, double b, double c) (int ThreadId = BlockDimension.X * BlockIndex.X + ThreadIndex.X; int TotalThreads = BlockDimension.X * GridDimension.X; for (int ElementIdx = ThreadId Я дотримуюся думки, що набагато простіше та ефективніше освоїти розширення мови (на основі C++ AMP), ніж намагатися організовувати взаємодії на рівні бібліотек або вносити суттєві зміни до мови IL. Отже, після того, як ми розглянули можливості паралельного програмування в .NET і використанням GPU, напевно, ні в кого не залишилося сумнівів, що організація паралельних обчислень є важливим способом підвищення продуктивності. У багатьох серверах і робочих станціях по всьому світу залишаються безцінні обчислювальні потужності звичайних і графічних процесорів, що не використовуються, тому що додатки просто не задіють їх. Бібліотека Task Parallel Library дає нам унікальну можливість включити в роботу всі наявні ядра центрального процесора, хоча при цьому доведеться вирішувати деякі цікаві проблеми синхронізації, надмірного дроблення завдань і нерівного розподілу роботи між потоками виконання. Фреймворк C++ AMP та інші багатоцільові бібліотеки організації паралельних обчислень на графічному процесорі успішно можна використовувати для розпаралелювання обчислень між сотнями ядер графічного процесора. Нарешті, є, недосліджена раніше, можливість отримати приріст продуктивності від застосування хмарних технологій розподілених обчислень, які останнім часом перетворилися на один з основних напрямів розвитку інформаційних технологій. Сьогодні особливо активно обговорюється і багато користувачів цікавляться, з чого розпочати видобуток монет і як це взагалі відбувається. Популярність цієї індустрії вже справила відчутний вплив ринку графічних процесорів і потужна відеокарта в багатьох вже давно асоціюється не з вимогливими іграми, і з криптофермами. У цій статті ми розповімо про те, як організувати весь цей процес з нуля і почати майнути на власній фермі, що для цього використовувати і чому неможливе. Майнінг на відеокарті – це процес видобутку криптовалюти за допомогою графічних процесорів (GPU). Для цього використовують потужну відеокарту домашнього комп'ютера або спеціально зібрану ферму з декількох пристроїв в одній системі. Якщо вас цікавить, чому для цього процесу використовуються саме GPU, то відповідь дуже проста. Справа в тому, що відеокарти спочатку розробляються для обробки великої кількості даних шляхом твору однотипних операцій, як у випадку з обробкою відео. Така ж картина спостерігається і в майнінгу криптовалюти, адже тут процес хешування такий же однотипний. Для майнінгу використовуються повноцінні дискретні відеокарти. Ноутбуки або інтегрований процесор чіпи не використовуються. У мережі також зустрічаються статті про майнінг на зовнішній відеокарті, але це також працює не у всіх випадках і є не найкращим рішенням. Отже, щодо вибору відеокарти, то тут звичайною практикою є придбання AMD rx 470, rx 480, rx 570, rx 580 або Нвідіа 1060, 1070, 1080 ti. Також підійдуть, але не принесуть великого прибутку, відеокарти типу r9 280x, r9 290, 1050, 1060. Цілком точно не принесе прибутку майнінг на слабкій відеокарті на кшталт geforce gtx 460, gts 450, gtx 550ti. Якщо говорити про пам'ять, то краще брати від 2 гб. Може виявитися недостатньо навіть 1 гігабайт, не кажучи вже про 512 мегабайт. Якщо говорити про майнінг на професійній відеокарті, то він приносить приблизно стільки ж, скільки і звичайні або навіть менше. З урахуванням вартості таких ВК - це невигідно, але видобувати за їх допомогою можна, якщо вони вже є у вас. Варто також відзначити, що всі відеокарти можуть отримати приріст продуктивності завдяки розблокуванню значень, які заклав виробник. Такий процес називається розгін. Однак це небезпечно, призводить до втрати гарантії і карта може вийти з ладу, наприклад, почавши показувати артефакти. Розганяти відеокарти можна, але потрібно ознайомитися з матеріалами на цю тему та діяти з обережністю. Не варто намагатися відразу встановити всі значення на максимум, а ще краще знайти в інтернеті приклади вдалих налаштувань розгону для вашої відеокарти. Нижче наведено порівняння відеокарт. Таблиця містить найпопулярніші пристрої та їх максимальне енергоспоживання. Потрібно сказати, що ці показники можуть змінюватись в залежності від конкретної моделі відеокарти, її виробника, використовуваної пам'яті та деяких інших характеристик. Писати про застарілі показники, такі як майнінг лайткоїн на відеокарті, немає сенсу, тому розглядаються лише три найпопулярніші алгоритми для ферм на відеокартах. Якщо у вас немає бажання збирати повноцінну ферму з безлічі GPU або просто хочете випробувати цей процес на домашньому комп'ютері, то можна майнути і однією відеокартою. Жодних відмінностей немає і взагалі кількість пристроїв у системі не важлива. Більше того, можна встановити пристрої з різними чіпами або навіть від різних виробників. Потрібно лише запустити паралельно дві програми для чіпів різних компаній. Нагадаємо ще раз, що майнінг на інтегрованій відеокарті не провадиться. Майнути на GPU можна будь-яку криптовалюту, але слід розуміти, що продуктивність на різних буде відрізнятися на одній картці. Старіші алгоритми вже погано підходять для відеопроцесорів і не принесуть жодного прибутку. Відбувається це через появу на ринку нових пристроїв - так званих . Вони є значно продуктивнішими і значно підвищують складність мережі, проте їхня вартість висока і обчислюється тисячами доларів. Тому видобуток монет на SHA-256 (Біткоїн) або Scrypt (Litecoin, Dogecoin) у домашніх умовах – це погана ідея у 2018-му році. Крім LTC і DOGE, ASIC унеможливили видобуток Bitcoin (BTC), Dash та інших валют. Куди найкращим вибором стануть криптовалюти, які використовують захищені від ASIC-ів алгоритми. Так, наприклад, за допомогою GPU вийде видобувати монети на алгоритмах CryptoNight (Карбованець, Монеро, Electroneum, Bytecoin), Equihash (ZCash, Hush, Bitcoin Gold) та Ethash (Ethereum, Ethereum Classic). Список далеко не повний і постійно з'являються нові проекти цих алгоритмах. Серед них зустрічаються як форки популярніших монет, так і нові розробки. Зрідка навіть з'являються нові алгоритми, які призначені для вирішення певних завдань та можуть використовувати різне обладнання. Нижче буде розказано про те, як дізнатися про хешрейт відеокарти. Нижче наведено список того, що вам знадобиться для створення ферми: У цьому розділі буде розглянуто весь процес видобутку від вибору валюти до виведення коштів. Слід зазначити, що цей процес може дещо відрізнятися для різних пулів, програм і чипів. Ми рекомендуємо вам ознайомитись з таблицею, яка представлена вище та з розділом про підрахунок потенційного заробітку. Це дозволить розрахувати приблизний дохід і визначитися з тим, яке залізо вам більше по кишені, а також розібратися із термінами окупності вкладень. Не варто також забувати про сумісність роз'ємів живлення відеокарти та блоку живлення. Якщо використовуються різні, слід заздалегідь обзавестися відповідними перехідниками. Все це легко купується в китайських інтернет магазинах за копійки або місцеві продавці з деякою націнкою. Тепер важливо визначитися з тим, яка монета вас цікавить і яких цілей ви хочете досягти. Якщо вас цікавить заробіток у реальному часі, варто вибирати валюти з найбільшим профітом на даний момент і продавати їх відразу після отримання. Можна також майнути найпопулярніші монети і тримати їх доти, доки не відбудеться стрибок ціни. Є також свого роду стратегічний підхід, коли вибирається маловідома, але перспективна на ваш погляд валюта і ви вкладаєте потужності в неї, сподіваючись, що в майбутньому вартість значно зросте. Також мають деякі відмінності. Деякі з них вимагають реєстрації, а деяким достатньо лише адреси вашого гаманця для початку роботи. Перші зазвичай зберігають зароблені вами кошти до досягнення мінімальної виплати суми, або в очікуванні виведення вами грошей у ручному режимі. Хорошим прикладом такого пулу є Suprnova.cc. Там пропонується безліч криптовалютів і для роботи в кожному з пулів достатньо лише раз зареєструватися на сайті. Сервіс простий у налаштуванні та добре підійде новачкам. Подібну спрощену систему пропонує сайт Minergate. Ну а якщо ви не хочете реєструватися на якомусь сайті і зберігати там зароблені кошти, то вам слід вибрати який-небудь пул в офіційній темі монети, що цікавить вас на форумі BitcoinTalk. Прості пули вимагають лише вказівки адреси для нарахування крипти і надалі за допомогою адреси можна буде дізнаватися про статистику видобутку. Цей пункт не потрібний вам, якщо використовуєте пул, який вимагає реєстрацію та має вбудований гаманець. Якщо ж ви хочете отримувати виплати автоматично собі на гаманець, спробуйте почитати про створення гаманця у статті про відповідну монету. Цей процес може суттєво відрізнятися для різних проектів. Можна також просто вказувати адресу вашого гаманця на якійсь із бірж, але слід зазначити, що не всі обмінні платформи приймають транзакції з пулів. Найкращим варіантом буде створення гаманця безпосередньо на вашому комп'ютері, але якщо ви працюєте з великою кількістю валют, зберігання всіх блокчейнів буде незручно. У такому випадку варто пошукати надійні онлайн гаманці або полегшені версії, які не вимагають завантаження всього ланцюга блоків. Вибір програми для видобутку крипти залежить від вибраної монети та її алгоритму. Напевно, всі розробники такого програмного забезпечення мають теми на BitcoinTalks, де можна знайти посилання на скачування та інформацію про те, як відбуваються налаштування та запуск. Майже всі програми мають версії як для Віндовс, так і для Лінукс. Більшість таких майнерів є безкоштовними, але деякий відсоток часу вони використовують для підключення до пулу розробника. Це своєрідна комісія за використання програмного забезпечення. У деяких випадках її можна вимкнути, але це призводить до обмежень функціоналу. Налаштування програми полягає в тому, що ви вказуєте пул для майнінгу, адресу гаманця або логін, пароль (якщо є) та інші опції. Рекомендується, наприклад, виставляти максимальний ліміт температури, коли ферма відключиться, щоб не шкодити відеокартам. Регулюється швидкість вентиляторів системи охолодження та інші тонші налаштування, які навряд чи використовуватимуться новачками. Якщо ви не знаєте, яке ПЗ вибрати, перегляньте наш матеріал, присвячений або вивчіть інструкції на сайті пула. Зазвичай там завжди є розділ, присвячений початку роботи. Він містить перелік програм, які можна використовувати і конфігурації для .batфайлів. З його допомогою можна швидко розібратися з налаштуванням та розпочати майнінг на дискретній відеокарті. Можна відразу створити батники для всіх валют, з якими ви хочете працювати, щоб надалі було зручніше перемикатися між ними. Після запуску .batфайлу з налаштуваннями ви побачите консольне вікно, куди буде виводитися балка того, що відбувається. Його також можна буде знайти в папці із файлом, що запускається. У консолі ви можете ознайомитися з поточними показниками хешрейту та температурою картки. Викликати актуальні дані зазвичай дозволяють гарячі кнопки. Ви також можете побачити, якщо пристрій не знаходить хеші. У такому разі буде виведено попередження. Трапляється це, коли щось налаштовано неправильно, вибране програмне забезпечення, яке не підходить для монети, або ГПУ не функціонує належним чином. Багато майнерів також використовують засоби для віддаленого доступу до ПК, щоб стежити за роботою ферми, коли вони не там, де вона встановлена. Якщо ви використовуєте пули на кшталт Suprnova, всі кошти просто накопичуються на вашому акаунті і ви можете вивести їх у будь-який момент. Інші пули найчастіше використовують систему, коли кошти нараховуються автоматично на вказаний гаманець після отримання мінімальної суми виведення. Дізнатися, скільки ви заробили, зазвичай можна на сайті пула. Потрібно лише вказати адресу вашого гаманця або залогуватися в особистий кабінет. Сума, яку ви можете заробити, залежить від ситуації на ринку та, звичайно, загального хешрейту вашої ферми. Важливо також те, яку стратегію ви оберете. Необов'язково продавати все здобуте одразу. Можна, наприклад, зачекати на стрибок курсу намайненої монети і отримати в рази більше профіту. Однак все не так однозначно і передбачити подальший розвиток подій просто нереально. Підрахувати окупність допоможе спеціальний онлайн-калькулятор. В інтернеті їх багато, але ми розглянемо цей процес на прикладі сервісу WhatToMine. Він дозволяє отримувати дані про поточний профіт, ґрунтуючись на даних вашої ферми. Потрібно тільки вибрати відеокарти, які є у вас, а потім додати вартість електроенергії у вашому регіоні. Сайт порахує скільки ви можете заробити за день. Слід розуміти, що враховується лише поточний стан справ ринку і ситуація може змінитися будь-якої миті. Курс може впасти або піднятися, складність майнінгу стане іншою або з'являться нові проекти. Так, наприклад, може припинитися видобуток ефіру у зв'язку з можливим переходом мережі на . Якщо припинитися майнінг ефіріуму, то фермам потрібно буде кудись направити вільні потужності, наприклад, у майнінг ZCash на GPU, що вплине на курс цієї монети. Подібних сценаріїв на ринку безліч і важливо розуміти, що сьогоднішня картина може не зберегтися протягом усього терміну окупності обладнання. Однією з найбільш прихованих функцій у нещодавньому оновленні Windows 10 є можливість перевірити, які програми використовують ваш графічний процесор (GPU). Якщо ви коли-небудь відкривали диспетчер завдань, то напевно дивилися на використання вашого ЦП, щоб дізнатися, які програми найбільше вантажать ЦП. В останніх оновленнях додано аналогічну функцію, але для графічних процесорів GPU. Це допомагає зрозуміти, наскільки інтенсивним є ваше програмне забезпечення та ігри на вашому графічному процесорі, не завантажуючи програмне забезпечення сторонніх розробників. Є ще одна цікава функція, яка допомагає розвантажити ваш ЦП на GPU. Рекомендую почитати, як вибрати. На жаль, не всі відеокарти зможуть надати Windows статистику, необхідну для читання графічного процесора. Щоб переконатися, можна швидко використовувати інструмент діагностики DirectX для перевірки цієї технології. Щоб побачити використання графічного процесора для кожної програми, потрібно відкрити диспетчер завдань. Ви можете відстежувати загальне використання GPU, щоб стежити за ним при великих навантаженнях та аналізувати. У цьому випадку ви можете побачити все, що потрібно, на вкладці " Продуктивність", обравши графічний процесор.
Кожен елемент графічного процесора розбивається на окремі графіки, щоб дати ще більше інформації про те, як використовується ваш GPU. Якщо ви хочете змінити відображені графіки, ви можете клацнути маленьку стрілку поруч із назвою кожного завдання. На цьому екрані також відображається версія драйвера та дата, що є гарною альтернативою використанню DXDiag або диспетчера пристроїв.
Альтернативи обчислень на графічному процесорі В.NET
Що таке майнінг на відеокарті
Які відеокарти підійдуть для майнінгу
Найпопулярніші відеокарти для майнінгу 2020
Відеокарта
Ethash
Equihash
CryptoNight
Енергоспоживання
AMD Radeon R9 280x
11 MH/s
290 H/s
490 H/s
230W
AMD Radeon RX 470
26 MH/s
260 H/s
660 H/s
120W
AMD Radeon RX 480
29.5 MH/s
290 H/s
730 H/s
135W
AMD Radeon RX 570
27.9 MH/s
260 H/s
700 H/s
120W
AMD Radeon RX 580
30.2 MH/s
290 H/s
690 H/s
135W
Nvidia GeForce GTX 750 TI
0.5 MH/s
75 H/s
250 H/s
55W
Nvidia GeForce GTX 1050 TI
13.9 MH/s
180 H/s
300 H/s
75W
Nvidia GeForce GTX 1060
22.5 MH/s
270 H/s
430 H/s
90W
Nvidia GeForce GTX 1070
30 MH/s
430 H/s
630 H/s
120W
Nvidia GeForce GTX 1070 TI
30.5 MH/s
470 H/s
630 H/s
135W
Nvidia GeForce GTX 1080
23.3 MH/s
550 H/s
580 H/s
140W
Nvidia GeForce GTX 1080 TI
35 MH/s
685 H/s
830 H/s
190W
Чи можливий майнінг на одній відеокарті?
Які криптовалюти можна майнути на відеокартах

Що потрібно для майнінгу на відеокарті

Як налаштувати майнінг на відеокарті з нуля
Як вибрати відеокарту для майнінгу
Вибираємо криптовалюту
Вибираємо пул для майнінгу

Створюємо криптовалютний гаманець
Вибираємо та встановлюємо програму для майнінгу
Запускаємо майнінг та стежимо за статистикою

Виводимо криптовалюту
Скільки можна заробити?
Окупність відеокарт

Чому я не маю GPU в диспетчері завдань?
Включити графу GPU у диспетчері завдань

Перегляд загальної продуктивності графічного процесора





 Відновити зашифровані файли за допомогою ShadowExplorer")




















