1. Talaan ng mga halaga ng F-test ng Fisher para sa antas ng kahalagahan α = 0.05
| 1 | 2 | 3 | 4 | 5 | 6 | 8 | 12 | 24 | ∞ | |
| 1 | 161,45 | 199,50 | 215,72 | 224,57 | 230,17 | 233,97 | 238,89 | 243,91 | 249,04 | 254,32 |
| 2 | 18,51 | 19,00 | 19,16 | 19,25 | 19,30 | 19,33 | 19,37 | 19,41 | 19,45 | 19,50 |
| 3 | 10,13 | 9,55 | 9,28 | 9,12 | 9,01 | 8,94 | 8,84 | 8,74 | 8,64 | 8,53 |
| 4 | 7,71 | 6,94 | 6,59 | 6,39 | 6,26 | 6,16 | 6,04 | 5,91 | 5,77 | 5,63 |
| 5 | 6,61 | 5,79 | 5,41 | 5, 19 | 5,05 | 4,95 | 4,82 | 4,68 | 4,53 | 4,36 |
| 6 | 5,99 | 5,14 | 4,76 | 4,53 | 4,39 | 4,28 | 4,15 | 4,00 | 3,84 | 3,67 |
| 7 | 5,59 | 4,74 | 4,35 | 4,12 | 3,97 | 3,87 | 3,73 | 3,57 | 3,41 | 3,23 |
| 8 | 5,32 | 4,46 | 4,07 | 3,84 | 3,69 | 3,58 | 3,44 | 3,28 | 3,12 | 2,93 |
| 9 | 5,12 | 4,26 | 3,86 | 3,63 | 3,48 | 3,37 | 3,23 | 3,07 | 2,90 | 2,71 |
| 10 | 4,96 | 4,10 | 3,71 | 3,48 | 3,33 | 3,22 | 3,07 | 2,91 | 2,74 | 2,54 |
| 11 | 4,84 | 3,98 | 3,59 | 3,36 | 3, 20 | 2,95 | 2,79 | 2,61 | 2,40 |
Kapag m=1, pumili ng 1 column.
k 2 =n-m=7-1=6 - i.e. ang ika-6 na linya - kunin ang Fisher table value
F talahanayan =5.99, y avg. = kabuuan: 7
Ang impluwensya ng x sa y ay katamtaman at negatibo
ŷ - halaga ng modelo.
| F calc. = | 28,648: 1 | = 0,92 |
| 200,50: 5 |
A = 1/7 * 398.15 * 100% = 8.1%< 10% -
katanggap-tanggap na halaga
Ang modelo ay medyo tumpak.
F calc. = 1/0.92 =1.6
F calc. = 1.6< F табл. = 5,99
Dapat ay F calc. > F talahanayan
Nilabag modelong ito, samakatuwid ang equation na ito ay hindi makabuluhan ayon sa istatistika.
Dahil ang kinakalkula na halaga ay mas mababa kaysa sa halaga ng talahanayan, ang modelo ay hindi gaanong mahalaga.
| 1 | Σ | (y - ŷ) | *100% | |
| N | y |
Error sa pagtatantya.
A= 1/7*0.563494* 100% = 8.04991% 8.0%
Itinuturing naming tumpak ang modelo kung ang average na error sa pagtatantya ay mas mababa sa 10%.
Ang pagkakakilanlan ng parametric pair ay hindi linear regression
Model y = a * x b - power function
Upang mailapat ang kilalang formula, kinakailangan na logarithm ang nonlinear na modelo.
log y = log a + b log x
Y=C+b*X -linear na modelo.
C = 1.7605 - (- 0.298) * 1.7370 = 2.278
Bumalik sa orihinal na modelo
Ŷ=10 s *x b =10 2.278 *x -0.298
| Hindi. | U | X | Y | X | Y*X | U | Ako (y-ŷ)/yI | |
| 1 | 68,80 | 45,10 | 1,8376 | 1,6542 | 3,039758 | 2,736378 | 60,9614643 | 0,113932 |
| 2 | 61, 20 | 59,00 | 1,7868 | 1,7709 | 3,164244 | 3,136087 | 56,2711901 | 0,080536 |
| 3 | 59,90 | 57, 20 | 1,7774 | 1,7574 | 3,123603 | 3,088455 | 56,7931534 | 0,051867 |
| 4 | 56,70 | 61,80 | 1,7536 | 1,7910 | 3,140698 | 3, 207681 | 55,4990353 | 0,021181 |
| 5 | 55,00 | 58,80 | 1,7404 | 1,7694 | 3,079464 | 3,130776 | 56,3281590 | 0,024148 |
| 6 | 54,30 | 47, 20 | 1,7348 | 1,6739 | 2,903882 | 2,801941 | 60,1402577 | 0,107555 |
| 7 | 49,30 | 55, 20 | 1,6928 | 1,7419 | 2,948688 | 3,034216 | 57,3987130 | 0,164274 |
| Kabuuan | 405, 20 | 384,30 | 12,3234 | 12,1587 | 21,40034 | 21,13553 | 403,391973 | 0,563493 |
| Katamtaman | 57,88571 | 54,90 | 1,760486 | 1,736957 | 3,057191 | 3,019362 | 57,62742 | 0,080499 |
Pumasok kami sa EXCEL sa pamamagitan ng "Start" program. Ipinasok namin ang data sa talahanayan. Sa "Tools" - "Data Analysis" - "Regression" - OK
Kung ang menu ng "Mga Tool" ay walang linyang "Pagsusuri ng Data", dapat itong mai-install sa pamamagitan ng "Mga Tool" - "Mga Setting" - "Package ng Pagsusuri ng Data"
Pagtataya ng demand para sa mga produkto ng enterprise. Gamit ang function na "Trend" sa MS Excel
A ay ang demand para sa produkto. B - oras, araw
| Hindi. | A | |
| 1 | 11 | 1 |
| 2 | 14 | 2 |
| 3 | 13 | 3 |
| 4 | 15 | 4 |
| 5 | 17 | 5 |
| 6 | 17,9 | |
| 7 | 18,4 | 7 |
Hakbang 1. Paghahanda ng paunang data
Hakbang 2. Palawakin ang axis ng oras, itakda ito sa 6.7 pasulong; May karapatan kaming hulaan ang 1/3 ng data.
Hakbang 3. Piliin ang hanay na A6: A7 para sa pagtataya sa hinaharap.
Hakbang 4. Ipasok ang Function
Ipasok ang diagram na hindi karaniwang mga makinis na graph
hanay y handa na.

Kung ang bawat kasunod na halaga ng aming axis ng oras ay hindi naiiba ng ilang porsyento, ngunit sa ilang beses, kailangan mong gamitin hindi ang function na "Trend", ngunit ang function na "Growth".
Mga sanggunian
1. Eliseeva “Econometrics”
2. Eliseeva "Workshop sa econometrics"
3. Carlsberg "Excel para sa Mga Layunin ng Pagsusuri"
Aplikasyon
| KONKLUSYON NG MGA RESULTA | ||||||||
| Mga istatistika ng pagpaparehistro | ||||||||
| Maramihang R | 0,947541801 | |||||||
| R-square | 0,897835464 | |||||||
| Normalized R-squared | 0,829725774 | |||||||
| Karaniwang error | 0,226013867 | |||||||
| Mga obserbasyon | 6 | |||||||
| Pagsusuri ng pagkakaiba-iba | ||||||||
| Kahalagahan F | ||||||||
| Regression | 2 | 1,346753196 | 0,673376598 | 13,18219855 | 0,032655042 | |||
| Natitira | 3 | 0,153246804 | 0,051082268 | |||||
| Kabuuan | 5 | 1,5 | ||||||
| Odds | Karaniwang error | t-statistic | P-halaga | Ibaba 95% | Nangungunang 95% | Ibaba 95% | Nangungunang 95% |
|
| Y-intersection | 4,736816539 | 0,651468195 | 7,27098664 | 0,005368842 | 2,66355399 | 6,810079088 | 2,66355399 | 6,810079088 |
| Variable X1 | 0,333424008 | 0,220082134 | 1,51499807 | 0,227014505 | -0,366975566 | 1,033823582 | -0,366975566 | |





Naka-on sa halimbawang ito Isaalang-alang natin kung paano tinasa ang pagiging maaasahan ng resultang equation ng regression. Ang parehong pagsubok ay ginagamit upang subukan ang hypothesis na ang mga coefficient ng regression ay sabay-sabay na katumbas ng zero, a=0, b=0. Sa madaling salita, ang kakanyahan ng mga kalkulasyon ay upang sagutin ang tanong: maaari ba itong magamit para sa karagdagang pagsusuri at pagtataya?
Upang matukoy kung magkapareho o magkaiba ang mga pagkakaiba sa dalawang sample, gamitin ang t-test na ito.
Kaya, ang layunin ng pagsusuri ay upang makakuha ng ilang pagtatantya kung saan maaaring sabihin na sa isang tiyak na antas ng α ang resultang equation ng regression ay maaasahan sa istatistika. Para dito coefficient of determination R 2 ang ginagamit.
Ang pagsubok sa kahalagahan ng isang modelo ng regression ay isinasagawa gamit ang Fisher's F test, ang kinakalkula na halaga ay makikita bilang ratio ng pagkakaiba ng orihinal na serye ng mga obserbasyon ng indicator na pinag-aaralan at ang walang pinapanigan na pagtatantya ng pagkakaiba ng natitirang sequence. para sa modelong ito.
Kung ang kinakalkula na halaga na may k 1 =(m) at k 2 =(n-m-1) na antas ng kalayaan ay mas malaki kaysa sa naka-tabulate na halaga sa isang partikular na antas ng kahalagahan, kung gayon ang modelo ay itinuturing na makabuluhan.
kung saan ang m ay ang bilang ng mga kadahilanan sa modelo.
Grade istatistikal na kahalagahan Ang paired linear regression ay isinasagawa gamit ang sumusunod na algorithm:
1. Isang null hypothesis ang iniharap na ang equation sa kabuuan ay hindi gaanong mahalaga sa istatistika: H 0: R 2 =0 sa antas ng kahalagahan α.
2. Susunod na tukuyin aktwal na halaga F-test: ![]()
![]()
kung saan m=1 para sa pairwise regression.
3. Halaga ng talahanayan tinutukoy mula sa mga talahanayan ng pamamahagi ng Fisher para sa isang partikular na antas ng kahalagahan, na isinasaalang-alang na ang bilang ng mga antas ng kalayaan para sa kabuuang kabuuan ng mga parisukat (mas malaking pagkakaiba) ay 1 at ang bilang ng mga antas ng kalayaan para sa natitirang kabuuan ng mga parisukat (mas maliit na pagkakaiba-iba ) sa linear regression ay n-2 (o through Pag-andar ng Excel FDISC(probability,1,n-2)).
Ang F table ay ang pinakamataas na posibleng halaga ng criterion sa ilalim ng impluwensya ng mga random na salik na may ibinigay na antas ng kalayaan at antas ng kahalagahan α. Ang antas ng kahalagahan α ay ang posibilidad na tanggihan ang tamang hypothesis, sa kondisyon na ito ay totoo. Karaniwang kinukuha ang α na 0.05 o 0.01.
4. Kung ang aktwal na halaga ng F-test ay mas mababa sa halaga ng talahanayan, pagkatapos ay sinasabi nila na walang dahilan upang tanggihan ang null hypothesis.
Kung hindi, ang null hypothesis ay tinanggihan at may probabilidad (1-α) ang alternatibong hypothesis tungkol sa istatistikal na kahalagahan ng equation sa kabuuan ay tinatanggap.
Table value ng criterion na may degree of freedom k 1 =1 at k 2 =48, F table = 4
Mga konklusyon: Dahil ang aktwal na halaga F > F talahanayan, ang koepisyent ng pagpapasiya ay makabuluhang istatistika ( ang nahanap na pagtatantya ng equation ng regression ay maaasahan sa istatistika) .
Pagsusuri ng pagkakaiba-iba
.Mga tagapagpahiwatig ng kalidad ng regression equation
Halimbawa. Batay sa isang kabuuang 25 na negosyo sa pangangalakal, ang ugnayan sa pagitan ng mga sumusunod na katangian ay pinag-aralan: X - presyo ng produkto A, libong rubles; Y - kita negosyong pangangalakal, milyong rubles Kapag tinatasa ang modelo ng regression, ang mga sumusunod ay nakuha: mga intermediate na resulta: ∑(y i -y x) 2 = 46000; ∑(y i -y avg) 2 = 138000. Anong tagapagpahiwatig ng ugnayan ang maaaring matukoy mula sa mga datos na ito? Kalkulahin ang halaga ng tagapagpahiwatig na ito batay sa resulta at paggamit Fisher's F test gumawa ng mga konklusyon tungkol sa kalidad ng modelo ng regression.
Solusyon. Mula sa mga datos na ito matutukoy natin ang empirical correlation ratio:  , kung saan ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000.
, kung saan ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000.
η 2 = 92,000/138000 = 0.67, η = 0.816 (0.7< η < 0.9 - связь между X и Y высокая).
Fisher's F test: n = 25, m = 1.
R 2 = 1 - 46000/138000 = 0.67, F = 0.67/(1-0.67)x(25 - 1 - 1) = 46. F table (1; 23) = 4.27
Dahil ang aktwal na halaga F > Ftable, ang nahanap na pagtatantya ng equation ng regression ay maaasahan sa istatistika.
Tanong: Anong mga istatistika ang ginagamit upang subukan ang kahalagahan ng isang modelo ng regression?
Sagot: Para sa kahalagahan ng buong modelo sa kabuuan, F-statistics (Fisher's test) ang ginagamit.
Layunin. Pagsubok sa hypothesis na ang dalawang pagkakaiba ay nabibilang sa parehong pangkalahatang populasyon at, samakatuwid, ang kanilang pagkakapantay-pantay.
Null hypothesis. S 2 2 = S 1 2
Alternatibong hypothesis. meron ang mga sumusunod na opsyon N At depende sa kung aling mga kritikal na lugar ang naiiba:
1. S 1 2 > S 2 2 . Ang pinakakaraniwang ginagamit na opsyon ay H A. Ang kritikal na rehiyon ay ang itaas na buntot ng F-distribution.
2. S 1 2< S 2 2 . Критическая область - нижний хвост F-распределения. Ввиду частого отсутствия нижнего хвоста, в таблицах критическую область обычно сводят к варианту 1, меняя местами дисперсии.
3. Dalawang panig S 1 2 ≠S 2 2. Kumbinasyon ng unang dalawa.
Mga kinakailangan. Ang data ay independyente at normal na ipinamamahagi. Ang hypothesis na ang mga pagkakaiba ng dalawang normal na populasyon ay pantay ay tinatanggap kung ang ratio ng mas malaki sa mas maliit na pagkakaiba ay mas mababa kaysa sa kritikal na halaga ng pamamahagi ng Fisher.
F P = S 1 2 /S 2 2
Tandaan. Gamit ang inilarawang paraan ng pag-verify, ang halaga ng Fpasch ay dapat na mas malaki kaysa sa isa. Ang criterion ay sensitibo sa paglabag sa normality assumption.
Para sa dalawang panig na alternatibo S 1 2 ≠S 2 2 ang null hypothesis ay tinatanggap kung ang kundisyon ay natutugunan:
F l - α /2< Fрасч < F α /2
Halimbawa
Ang mga parameter ng thermophysical ay tinutukoy gamit ang isang kumplikadong pamamaraan ng thermometric. katangian (TFC) ng green malt. Upang ihanda ang mga sample, kumuha kami ng air-dry (average na kahalumigmigan W=19%) at basa ng apat na araw na may edad na malt (W=45%) alinsunod sa bagong teknolohiya paggawa ng caramel malt. Ipinakita ng mga eksperimento na ang thermal conductivity λ ng wet malt ay humigit-kumulang 2.5 beses na mas malaki kaysa sa dry malt, at ang volumetric heat capacity ay walang malinaw na pagdepende sa moisture content ng malt. Samakatuwid, gamit ang F-test, sinuri namin ang posibilidad ng pag-generalize ng data batay sa mga average na halaga nang hindi isinasaalang-alang ang kahalumigmigan.
Ang kinakalkula na data ay ibinubuod sa talahanayan 5.1
Talahanayan 5.1
Data para sa pagkalkula ng F-criterion
Ang isang mas malaking halaga ng pagpapakalat ay nakuha para sa W=45%, i.e. S 2 45 = S 1 2 , S 2 19 = S 2 2 , at F P = S 1 2 /S 2 2 =1.35. Mula sa Talahanayan 5.2 para sa antas ng kalayaan f 1 =N 1 -1=5 f 2 =N 2 -1=4 sa γ=0.95 natin tinutukoy ang F KR =6.2. Ang null hypothesis na binuo bilang "Sa hanay ng moisture content ng green malt mula 19 hanggang 45%, ang impluwensya nito sa volumetric heat capacity ay maaaring mapabayaan" o "S 2 45 = S 2 19 " na may probability na 95% ay nakumpirma, dahil ang Fp Isang halimbawa ng pagsubok ng hypothesis tungkol sa pag-aari ng dalawang variance sa parehong populasyon gamit ang Fisher criterion gamit ang Excel Ang data ay ipinakita para sa dalawang independiyenteng mga sample (Talahanayan 5.2) ng antas ng pagsipsip ng tubig ng butil ng trigo. Talahanayan 5.2 Mga resulta ng pananaliksik Bago natin subukan ang hypothesis tungkol sa pagkakapantay-pantay ng mga paraan ng mga sample na ito, kinakailangan na subukan ang hypothesis tungkol sa pagkakapantay-pantay ng mga pagkakaiba-iba upang malaman kung aling pamantayan ang pipiliin upang subukan ito. Sa Fig. Ang 5.1 ay nagpapakita ng isang halimbawa ng pagsubok sa hypothesis na ang dalawang variance ay nabibilang sa parehong populasyon gamit ang Fisher criterion gamit ang Microsoft Excel software product. Figure 5.1 Halimbawa ng pagsubok sa pagmamay-ari ng dalawang variances sa parehong populasyon gamit ang Fisher criterion Ang source data ay matatagpuan sa mga cell na matatagpuan sa intersection ng mga column C at D na may mga row 3-10. Gawin natin ang sumusunod: 1. Tukuyin natin kung ang batas sa pamamahagi ng una at pangalawang sample ay maituturing na normal (mga column C at D, ayon sa pagkakabanggit). Kung hindi (para sa hindi bababa sa isang sample), kinakailangan na gumamit ng nonparametric na pagsubok kung oo, magpapatuloy kami. 2. Kalkulahin ang mga pagkakaiba para sa una at pangalawang hanay. Upang gawin ito, sa mga cell SP at D11 inilalagay namin ang mga function =DISP(SZ:C10) at =DISP(DЗ:D10), ayon sa pagkakabanggit. Ang resulta ng mga function na ito ay ang kinakalkula na halaga ng pagkakaiba para sa bawat column, ayon sa pagkakabanggit. 3. Hanapin ang kinakalkula na halaga para sa pamantayan ng Fisher. Upang gawin ito, kailangan mong hatiin ang mas malaking pagkakaiba sa mas maliit. Sa cell F13 inilalagay namin ang formula =C11/D11, na nagsasagawa ng operasyong ito. 4. Tukuyin kung ang hypothesis ng pagkakapantay-pantay ng mga pagkakaiba ay maaaring tanggapin. Mayroong dalawang mga pamamaraan, na ipinakita sa halimbawa. Ayon sa unang paraan, sa pamamagitan ng pagtatakda ng antas ng kahalagahan, halimbawa 0.05, ang kritikal na halaga ng pamamahagi ng Fisher ay kinakalkula para sa halagang ito at ang kaukulang bilang ng mga antas ng kalayaan. Sa cell F14, ipasok ang function =FPACPOBP(0.05;7;7) (kung saan ang 0.05 ay ang tinukoy na antas ng kahalagahan; 7 ay ang bilang ng mga antas ng kalayaan ng numerator, at 7 (ikalawa) ay ang bilang ng mga antas ng kalayaan ng ang denominator). Ang bilang ng mga antas ng kalayaan ay katumbas ng bilang ng mga eksperimento na binawasan ng isa. Ang resulta ay 3.787051. Dahil ang halagang ito ay mas malaki kaysa sa kinakalkula na halaga na 1.81144, dapat nating tanggapin ang null hypothesis ng pagkakapantay-pantay ng mga pagkakaiba-iba. Ayon sa pangalawang opsyon, ang kaukulang probabilidad ay kinakalkula para sa nakuhang kinakalkula na halaga ng Fisher criterion. Upang gawin ito, ipasok ang function =FPACP(F13,7,7) sa cell F15. Dahil ang resultang halaga ng 0.22566 ay mas malaki kaysa sa 0.05, ang hypothesis ng pagkakapantay-pantay ng mga pagkakaiba ay tinatanggap. Ito ay maaaring gawin sa pamamagitan ng isang espesyal na function. Piliin ang mga item sa menu nang sunud-sunod Serbisyo
, Pagsusuri ng Datos
. Ang sumusunod na window ay lilitaw (Larawan 5.2). Figure 5.2 Window ng pagpili ng paraan ng pagproseso Sa window na ito piliin ang " Dalawang-sample na F-mecm para sa mga pagkakaiba-iba
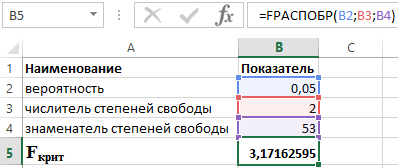
" Bilang resulta, lilitaw ang isang window tulad ng ipinapakita sa Fig. 5.3. Dito mo itatakda ang mga pagitan (mga cell number) ng una at pangalawang variable, ang antas ng kahalagahan (alpha) at ang lugar kung saan makikita ang resulta. Itakda ang lahat ng kinakailangang mga parameter at i-click ang OK. Ang resulta ng trabaho ay ipinapakita sa Fig. 5.4 Dapat tandaan na ang function ay sumusubok sa isang panig na pamantayan at ginagawa ito nang tama. Para sa kaso kapag ang criterion value ay mas malaki sa 1, ang upper critical value ay kinakalkula. Figure 5.3 Parameter setting window Kapag ang halaga ng pamantayan ay mas mababa sa 1, ang mas mababang kritikal na halaga ay kinakalkula. Ipinapaalala namin sa iyo na ang hypothesis ng pagkakapantay-pantay ng mga pagkakaiba ay tinatanggihan kung ang halaga ng pamantayan ay mas malaki kaysa sa itaas na kritikal na halaga o mas mababa kaysa sa mas mababa. Figure 5.4 Pagsubok para sa pagkakapantay-pantay ng mga pagkakaiba-iba Ang eksaktong pagsusulit ni Fisher ay isang kriterya na ginagamit upang ihambing ang dalawang kamag-anak na tagapagpahiwatig na nagpapakilala sa dalas ng isang partikular na katangian na may dalawang halaga. Ang paunang data para sa pagkalkula ng eksaktong pagsubok ni Fisher ay karaniwang pinagsama-sama sa anyo ng isang talahanayan na may apat na patlang. Ang pamantayan ay unang iminungkahi Ronald Fisher sa kanyang aklat na Design of Experiments. Nangyari ito noong 1935. Sinabi mismo ni Fischer na si Muriel Bristol ang nag-udyok sa kanya sa ideyang ito. Noong unang bahagi ng 1920s, sina Ronald, Muriel at William Roach ay nakatalaga sa England sa isang pang-eksperimentong istasyon ng agrikultura. Sinabi ni Muriel na maaari niyang matukoy ang pagkakasunud-sunod ng pagbuhos ng tsaa at gatas sa kanyang tasa. Sa oras na iyon, hindi posible na i-verify ang kawastuhan ng kanyang pahayag. Nagbunga ito ng ideya ni Fisher ng "null hypothesis". Ang layunin ay hindi upang patunayan na si Muriel ay maaaring sabihin ang pagkakaiba sa pagitan ng iba't ibang inihanda na mga tasa ng tsaa. Napagpasyahan na pabulaanan ang hypothesis na ang isang babae ay gumagawa ng isang pagpipilian nang random. Natukoy na ang null hypothesis ay hindi mapapatunayan o makatwiran. Ngunit maaari itong pabulaanan sa panahon ng mga eksperimento. 8 tasa ang inihanda. Ang unang apat ay napuno ng gatas muna, ang iba pang apat ay may tsaa. Ang mga tasa ay pinaghalo. Inalok ni Bristol na tikman ang tsaa at hatiin ang mga tasa ayon sa paraan ng paghahanda ng tsaa. Ang resulta ay dapat na dalawang grupo. Sinasabi ng kasaysayan na ang eksperimento ay isang tagumpay. Salamat sa pagsubok ng Fisher, ang posibilidad na kumikilos si Bristol nang intuitive ay nabawasan sa 0.01428. Iyon ay, posible na matukoy nang tama ang tasa sa isang kaso sa 70. Ngunit gayon pa man, walang paraan upang bawasan sa zero ang mga pagkakataong natukoy ni Madame sa pamamagitan ng pagkakataon. Kahit na dagdagan mo ang bilang ng mga tasa. Ang kwentong ito ay nagbigay ng lakas sa pagbuo ng "null hypothesis". Kasabay nito, iminungkahi ang eksaktong criterion ni Fisher, ang esensya nito ay ang pagbilang ng lahat ng posibleng kumbinasyon ng umaasa at independiyenteng mga variable. Ang eksaktong pagsubok ni Fisher ay pangunahing ginagamit para sa paghahambing maliliit na sample. Mayroong dalawang magandang dahilan para dito. Una, ang pagkalkula ng criterion ay medyo masalimuot at maaaring tumagal ng mahabang panahon o nangangailangan ng malakas na mapagkukunan ng computing. Pangalawa, ang criterion ay medyo tumpak (na makikita kahit sa pangalan nito), na nagpapahintulot na magamit ito sa mga pag-aaral na may maliit na bilang ng mga obserbasyon. Isang espesyal na lugar ang ibinigay sa eksaktong pagsusuri ni Fisher sa medisina. Ito ay isang mahalagang paraan para sa pagproseso ng medikal na data at natagpuan ang aplikasyon nito sa maraming siyentipikong pag-aaral. Salamat dito, posible na pag-aralan ang kaugnayan sa pagitan ng ilang mga kadahilanan at kinalabasan, ihambing ang dalas ng mga kondisyon ng pathological sa pagitan ng dalawang grupo ng mga paksa, atbp. Ang isang analogue ng eksaktong pagsubok ni Fisher ay ang Pearson chi-square test, habang ang eksaktong pagsubok ni Fisher ay may mas mataas na kapangyarihan, lalo na kapag naghahambing ng maliliit na sample, at samakatuwid ay may kalamangan sa kasong ito. Sabihin nating pinag-aaralan natin ang pag-asa ng dalas ng panganganak ng mga batang may congenital malformations (CDD) sa paninigarilyo ng ina sa panahon ng pagbubuntis. Para dito, dalawang grupo ng mga buntis na kababaihan ang napili, ang isa ay isang eksperimentong grupo, na binubuo ng 80 kababaihan na naninigarilyo sa unang tatlong buwan ng pagbubuntis, at ang pangalawa ay isang pangkat ng paghahambing, kabilang ang 90 kababaihan na namumuno sa isang malusog na pamumuhay sa buong pagbubuntis. Ang bilang ng mga kaso ng fetal congenital malformation na tinutukoy ng ultrasound sa experimental group ay 10, sa paghahambing na grupo - 2. Mag-compose muna kami four-field contingency table: Ang eksaktong pagsubok ni Fisher ay kinakalkula gamit ang sumusunod na formula: kung saan ang N ay ang kabuuang bilang ng mga paksa sa dalawang pangkat; ! - factorial, na produkto ng isang numero at isang pagkakasunod-sunod ng mga numero, na ang bawat isa ay mas mababa kaysa sa naunang isa sa pamamagitan ng 1 (halimbawa, 4! = 4 3 2 1) Bilang resulta ng mga kalkulasyon, nakita namin na P = 0.0137. Ang bentahe ng pamamaraan ay ang resultang criterion ay tumutugma sa eksaktong halaga ng antas ng kahalagahan p. Iyon ay, ang halaga ng 0.0137 na nakuha sa aming halimbawa ay ang antas ng kahalagahan ng mga pagkakaiba sa pagitan ng mga inihambing na grupo sa dalas ng pag-unlad ng congenital malformations ng fetus. Kinakailangan lamang na ihambing ang numerong ito sa kritikal na antas ng kahalagahan, kadalasang kinukuha sa medikal na pananaliksik bilang 0.05. Sa aming halimbawa P< 0,05, в связи с чем делаем вывод о наличии прямой взаимосвязи курения и вероятности развития ВПР плода. Частота возникновения врожденной патологии у детей курящих женщин istatistikal na makabuluhang mas mataas kaysa sa mga hindi naninigarilyo. Ibinabalik ng FISCHER function ang Fisher transform ng mga argumento sa X . Ang pagbabagong ito ay gumagawa ng isang function na may normal kaysa sa baluktot na distribusyon. Ang FISCHER function ay ginagamit upang subukan ang hypothesis gamit ang correlation coefficient. Kapag nagtatrabaho sa function na ito, dapat mong itakda ang halaga ng variable. Ito ay nagkakahalaga kaagad na tandaan na may ilang mga sitwasyon kung saan ang function na ito ay hindi magbubunga ng mga resulta. Posible ito kung ang variable ay: Ang equation na ginagamit upang ilarawan ang FISCHER function sa matematika ay: Z"=1/2*ln(1+x)/(1-x) Tingnan natin ang paggamit ng function na ito gamit ang 3 partikular na halimbawa. Halimbawa 1. Gamit ang data sa aktibidad ng mga komersyal na organisasyon, kinakailangan na gumawa ng pagtatasa ng ugnayan sa pagitan ng tubo Y (milyong rubles) at mga gastos X (milyong rubles) na ginagamit para sa pagbuo ng produkto (ipinapakita sa Talahanayan 1). Talahanayan 1 – Paunang data: Ang pamamaraan para sa paglutas ng mga naturang problema ay ang mga sumusunod: Ang mga resulta ng paglutas ng problemang ito sa mga function na ginamit sa Excel ay ipinapakita sa Figure 1. Figure 1 – Halimbawa ng mga kalkulasyon. Kaya, na may posibilidad na 0.95, ang linear correlation coefficient ay nasa hanay mula sa (–0.386) hanggang (–0.990) na may karaniwang error na 0.205. Halimbawa 2. Suriin ang istatistikal na kahalagahan ng multiple regression equation gamit ang Fisher's F test at gumawa ng mga konklusyon. Upang suriin ang kahalagahan ng equation sa kabuuan, inilagay namin ang hypothesis H 0 tungkol sa statistical insignificance ng coefficient of determination at ang kabaligtaran na hypothesis H 1 tungkol sa statistical significance ng coefficient of determination: H 1: R 2 ≠ 0. Subukan natin ang mga hypotheses gamit ang Fisher's F test. Ang mga tagapagpahiwatig ay ipinapakita sa Talahanayan 2. Talahanayan 2 - Paunang data Upang gawin ito, ginagamit namin ang function sa Excel: MAS MABILIS (α;p;n-p-1) Alam na ang α = 0.05, p = 2 at n = 53, nakuha namin ang sumusunod na halaga para sa F crit (tingnan ang Larawan 2). Figure 2 – Halimbawa ng mga kalkulasyon. Kaya masasabi natin na F kalkulado > F kritikal. Bilang resulta, tinatanggap ang hypothesis H 1 tungkol sa statistical significance ng coefficient of determination. Halimbawa 3. Paggamit ng data mula sa 23 negosyo tungkol sa: X ay ang presyo ng produkto A, libong rubles; Y ay ang kita ng isang negosyong pangkalakal, milyong rubles ang kanilang pinag-aaralan; Ang modelo ng regression ay tinatantya tulad ng sumusunod: ∑(yi-yx) 2 = 50000; ∑(yi-yср) 2 = 130000. Anong tagapagpahiwatig ng ugnayan ang maaaring matukoy mula sa mga datos na ito? Kalkulahin ang halaga ng tagapagpahiwatig ng ugnayan at, gamit ang Fisher criterion, gumuhit ng konklusyon tungkol sa kalidad ng modelo ng regression. Tukuyin natin ang F crit mula sa expression: F nakalkula = R 2 /23*(1-R 2) kung saan ang R ay ang koepisyent ng determinasyon na katumbas ng 0.67. Kaya, ang kinakalkula na halaga F calc = 46. Para matukoy ang F crit ginagamit namin ang Fisher distribution (tingnan ang Figure 3). Figure 3 – Halimbawa ng mga kalkulasyon. Kaya, ang resultang pagtatantya ng equation ng regression ay maaasahan.Numero Halimbawang numero
karanasan
2 ,
0,027
0,075
0,036
0,4
0,1
0,08
0,12
0,105
0,32
0,075
0,45
0,12
0,049
0,06
0,105
0,075




1. Kasaysayan ng pag-unlad ng pamantayan
2. Para saan ginagamit ang eksaktong pagsubok ni Fisher?
3. Sa anong mga kaso maaaring gamitin ang eksaktong pagsubok ni Fisher?
Sinusuri ng two-tailed test ang mga pagkakaiba sa dalas sa dalawang direksyon. Iyon ay, ang posibilidad ng parehong mas mataas at mas mababang dalas ng kababalaghan sa pang-eksperimentong grupo kumpara sa control group ay tinasa.4. Paano makalkula ang eksaktong pagsubok ni Fisher?
5. Paano i-interpret ang halaga ng eksaktong pagsubok ni Fisher?
Paglalarawan ng function ng FISCHER sa Excel
Pagtatantya ng kaugnayan sa pagitan ng kita at mga gastos gamit ang FISHER function
№
X Y
1
210,000,000.00 RUR 95,000,000.00 RUR
2
RUB 1,068,000,000.00 76,000,000.00 RUR
3
RUB 1,005,000,000.00 78,000,000.00 RUR
4
610,000,000.00 RUR 89,000,000.00 RUR
5
768,000,000.00 RUR 77,000,000.00 RUR
6
799,000,000.00 RUR 85,000,000.00 RUR

Hindi. Pangalan ng tagapagpahiwatig Formula ng pagkalkula
1
Koepisyent ng ugnayan =CORREL(B2:B7,C2:C7)
2
Kinakalkula ang halaga ng t-test na tp =ABS(C8)/SQRT(1-POWER(C8,2))*SQRT(6-2)
3
Halaga ng talahanayan ng t-test trh =STUDISCOVER(0.05,4)
4
Table value ng standard normal distribution zy =NORMSINV((0.95+1)/2)
5
Fisher z' transform value =FISHER(C8)
6
Kaliwang pagtatantya ng pagitan para sa z =C12-C11*ROOT(1/(6-3))
7
Tamang pagtatantya ng pagitan para sa z =C12+C11*ROOT(1/(6-3))
8
Kaliwang pagtatantya ng pagitan para sa rxy =FISHEROBR(C13)
9
Tamang pagtatantya ng pagitan para sa rxy =FISHEROBR(C14)
10
Standard deviation para sa rxy =ROOT((1-C8^2)/4)
Sinusuri ang istatistikal na kahalagahan ng regression gamit ang FASTER function
Kinakalkula ang halaga ng tagapagpahiwatig ng ugnayan sa Excel

























