Encyclopedic YouTube
-
1 / 5
Ang terminong ito sa istatistika ay unang ginamit ni Francis Galton (1886) na may kaugnayan sa pag-aaral ng pamana ng mga pisikal na katangian ng tao. Ang taas ng tao ay kinuha bilang isa sa mga katangian; ito ay natagpuan na, sa pangkalahatan, ang mga anak na lalaki ng matatangkad na ama, hindi nakakagulat, ay naging mas matangkad kaysa sa mga anak ng maiikling ama. Ang mas kawili-wili ay ang pagkakaiba-iba sa taas ng mga anak na lalaki ay mas maliit kaysa sa pagkakaiba-iba sa taas ng mga ama. Ito ay kung paano ipinakita ang ugali ng mga taas ng mga anak na lalaki na bumalik sa karaniwan ( regression to mediocrity), iyon ay, "regression". Ang katotohanang ito ay ipinakita sa pamamagitan ng pagkalkula ng average na taas ng mga anak ng mga ama na ang taas ay 56 pulgada, sa pamamagitan ng pagkalkula ng average na taas ng mga anak ng mga ama na 58 pulgada ang taas, atbp. Ang mga resulta ay pagkatapos ay naka-plot sa isang eroplano, kasama ang ordinate kung saan ang average na taas ng mga anak ay naka-plot , at sa x-axis - ang mga halaga ng average na taas ng mga ama. Ang mga punto (humigit-kumulang) ay nasa isang tuwid na linya na may positibong anggulo ng pagkahilig na mas mababa sa 45°; mahalaga na linear ang regression.
Paglalarawan
Ipagpalagay na mayroon tayong sample mula sa isang bivariate distribution ng isang pares ng random variables ( X, Y). Tuwid na linya sa eroplano ( x, y) ay isang pumipili na analogue ng function
g (x) = E (Y ∣ X = x) . (\displaystyle g(x)=E(Y\mid X=x).) E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) , (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac ( \sigma _(2))(\sigma _(1)))(x-\mu _(1)),)v a r (Y ∣ X = x) = σ 2 2 (1 − ϱ 2) . (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) Sa halimbawang ito, regression Y sa (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) Sa halimbawang ito, regression Y ay iba sa linear, kung gayon ang mga ibinigay na equation ay isang linear approximation ng totoong regression equation.
Sa pangkalahatan, ang pagbabalik ng isang random na variable sa isa pa ay hindi kinakailangang linear. Hindi rin kailangang limitahan ang iyong sarili sa ilang random na variable. Ang mga problema sa statistic regression ay kinabibilangan ng pagtukoy sa pangkalahatang anyo ng regression equation, pagbuo ng mga pagtatantya ng mga hindi kilalang parameter na kasama sa regression equation, at pagsubok ng statistical hypotheses tungkol sa regression. Ang mga problemang ito ay tinutugunan sa loob ng balangkas ng pagsusuri ng regression.
Isang simpleng halimbawa ng regression (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) Sa pamamagitan ng Y ay ang relasyon sa pagitan ng (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) At Y, na ipinapahayag ng kaugnayan: (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).)=u(Y)+ε, saan u(x)=E((\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) | Y=x), at mga random na variable Y at ε ay malaya. Kapaki-pakinabang ang representasyong ito kapag nagdidisenyo ng eksperimento upang pag-aralan ang functional connectivity y=u(x) sa pagitan ng mga hindi random na dami y At x. Sa pagsasagawa, kadalasan ang mga coefficient ng regression sa Eq. y=u(x) ay hindi alam at tinatantya mula sa pang-eksperimentong data.
Linear regression
Isipin natin ang pagtitiwala y mula sa x sa anyo ng isang unang order na linear na modelo:
y = β 0 + β 1 x + ε .(\displaystyle y=\beta _(0)+\beta _(1)x+\varepsilon .) x Ipagpalagay namin na ang mga halaga ay tinutukoy nang walang error, ang β 0 at β 1 ay ang mga parameter ng modelo, at ang ε ay ang error, ang pamamahagi nito ay sumusunod sa normal na batas na may zero mean na halaga at pare-pareho ang paglihis σ 2. Ang mga halaga ng mga parameter β ay hindi alam nang maaga at dapat na matukoy mula sa isang hanay ng mga pang-eksperimentong halaga (), i=1, …, x i, y i n
. Kaya maaari nating isulat:y i ^ = b 0 + b 1 x i , i = 1 , … , n (\displaystyle (\widehat (y_(i)))=b_(0)+b_(1)x_(i),i=1,\ tuldok, n) y kung saan nangangahulugang ang halaga na hinulaang ng modelo x, binigay b binigay 0 at 1 - mga sample na pagtatantya ng mga parameter ng modelo. Tukuyin din natin e i = y i − y i ^ (\displaystyle e_(i)=y_(i)-(\widehat (y_(i)))) - halaga ng error sa pagtatantya para sa ako (\displaystyle i)
ika obserbasyon.
Ang paraan ng least squares ay nagbibigay ng mga sumusunod na formula para sa pagkalkula ng mga parameter ng isang ibinigay na modelo at ang kanilang mga paglihis: b 1 = ∑ i = 1 n (x i − x ¯) (y i − y ¯) ∑ i = 1 n (x i − x ¯) 2 = c o v (x , y) σ x 2 ; (\displaystyle b_(1)=(\frac (\sum _(i=1)^(n)(x_(i)-(\bar (x)))(y_(i)-(\bar (y) )))(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))=(\frac (\mathrm (cov) (x,y ))(\sigma _(x)^(2)));) s b 0 = s e 1 n + x ¯ 2 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s_(b_(0))=s_(e)(\sqrt ((\frac (1)(n))+(\frac ((\bar (x))^(2))(\sum _ (i=1)^(n)(x_(i)-(\bar (x)))^(2)))));)s b 1 = s e 1 ∑ i = 1 n (x i − x ¯) 2 , (\displaystyle s_(b_(1))=s_(e)(\sqrt (\frac (1)(\sum _(i=1) )^(n)(x_(i)-(\bar (x)))^(2)))),) dito ang mga average na halaga ay tinutukoy gaya ng dati:, x ¯ = ∑ i = 1 n x i n (\displaystyle (\bar (x))=(\frac (\sum _(i=1)^(n)x_(i))(n))) At y ¯ = ∑ i = 1 n y i n (\displaystyle (\bar (y))=(\frac (\sum _(i=1)^(n)y_(i))(n))) s e
Ang 2 ay nagsasaad ng regression residual, na isang pagtatantya ng variance σ 2 kung ang modelo ay tama. Ang mga karaniwang error ng mga coefficient ng regression ay ginagamit katulad ng karaniwang error ng mean - upang mahanap ang mga pagitan ng kumpiyansa at pagsubok ng mga hypotheses. Ginagamit namin, halimbawa, ang pagsusulit ng Estudyante upang subukan ang hypothesis na ang coefficient ng regression ay katumbas ng zero, iyon ay, na ito ay hindi gaanong mahalaga para sa modelo. Mga istatistika ng mag-aaral: t = b / s b (\displaystyle t=b/s_(b)) x i, y i. Kung ang posibilidad para sa nakuhang halaga at<0,05 - гипотеза отвергается. Напротив, если нет оснований отвергнуть гипотезу о равенстве нулю, скажем, −2 degrees ng kalayaan ay medyo maliit, halimbawa, b 1 (\displaystyle b_(1)) - may dahilan upang isipin ang tungkol sa pagkakaroon ng nais na regression, hindi bababa sa form na ito, o tungkol sa pagkolekta ng mga karagdagang obserbasyon. Kung ang libreng termino ay katumbas ng zero b 0 (\displaystyle b_(0))
, pagkatapos ay ang tuwid na linya ay dumadaan sa pinanggalingan at ang pagtatantya ng slope ay katumbas ng,b = ∑ i = 1 n x i y i ∑ i = 1 n x i 2 (\displaystyle b=(\frac (\sum _(i=1)^(n)x_(i)y_(i))(\sum _(i= 1)^(n)x_(i)^(2))))
at ang karaniwang error nitos b = s e 1 ∑ i = 1 n x i 2 . binigay b binigay(\displaystyle s_(b)=s_(e)(\sqrt (\frac (1)(\sum _(i=1)^(n)x_(i)^(2)))).) x Karaniwan ang mga tunay na halaga ng mga coefficient ng regression β 0 at β 1 ay hindi alam. Tanging ang kanilang mga pagtatantya ang nalalaman y 1. Sa madaling salita, ang totoong linya ng regression ay maaaring gumana nang iba kaysa sa ginawa mula sa sample na data. Maaari mong kalkulahin ang rehiyon ng kumpiyansa para sa linya ng regression. Para sa anumang halaga kaukulang halaga karaniwang ipinamamahagi. Ang average ay ang halaga ng regression equation
y ^ (\displaystyle (\widehat (y)))Ngayon ay maaari mong kalkulahin ang -percentage confidence interval para sa halaga ng regression equation sa punto x:
y ^ − t (1 − α / 2 , n − 2) s y ^< y < y ^ + t (1 − α / 2 , n − 2) s y ^ {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{\widehat {y}}saan t(1−α/2, x i, y i−2) - t-halaga ng pamamahagi ng Mag-aaral. Ang figure ay nagpapakita ng isang regression line na ginawa gamit ang 10 puntos (solid tuldok), pati na rin ang 95% confidence region ng regression line, na nililimitahan ng mga tuldok na linya. Sa 95% na posibilidad ay masasabi nating ang totoong linya ay matatagpuan sa isang lugar sa loob ng lugar na ito. O kung hindi, kung mangolekta kami ng mga katulad na set ng data (ipinahiwatig ng mga lupon) at bumuo ng mga linya ng regression sa mga ito (ipinahiwatig sa asul), pagkatapos ay sa 95 na mga kaso sa 100 mga tuwid na linya na ito ay hindi aalis sa rehiyon ng kumpiyansa. (I-click ang larawan upang mailarawan) Pakitandaan na ang ilang mga punto ay nasa labas ng rehiyon ng kumpiyansa. Ito ay ganap na natural, dahil pinag-uusapan natin ang rehiyon ng kumpiyansa ng linya ng regression, at hindi ang mga halaga mismo. Ang pagkalat ng mga halaga ay binubuo ng pagkalat ng mga halaga sa paligid ng linya ng regression at ang kawalan ng katiyakan ng posisyon ng linyang ito mismo, lalo na:
s Y = s e 1 m + 1 n + (x − x ¯) 2 ∑ i = 1 n (x i − x ¯) 2 ;(\displaystyle s_(Y)=s_(e)(\sqrt ((\frac (1)(m))+(\frac (1)(n))+(\frac ((x-(\bar (x) )))^(2))(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))));) Dito m y kung saan nangangahulugang ang halaga na hinulaang ng modelo x- dalas ng pagsukat . AT 100 ⋅ (1 − α 2) (\displaystyle 100\cdot \left(1-(\frac (\alpha )(2))\kanan)) Dito mga halaga y-percentage confidence interval (pagtataya interval) para sa average ng
ay:< y < y ^ + t (1 − α / 2 , n − 2) s Y {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{Y}y ^ − t (1 − α / 2 , n − 2) s Y Dito Sa figure, itong 95% confidence region sa y Ang =1 ay nililimitahan ng mga solidong linya. 95% ng lahat ng posibleng halaga ng dami ay nahuhulog sa lugar na ito x.
sa pinag-aralan na hanay ng mga halaga
Ilan pang istatistika Ito ay mahigpit na mapapatunayan na kung ang kondisyon na inaasahan E (Y ∣ X = x) (\displaystyle E(Y\mid X=x)) X, Y ilang dalawang-dimensional na random na variable ( ) ay isang linear function ng x (\displaystyle x) , kung gayon ang may kundisyong inaasahan na ito ay kinakailangang kinakatawan sa anyo E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac (\ sigma _(2))(\sigma _(1)))(x-\mu _(1))) E(Y, Saan E((\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).))=μ 1 , Y)=μ 2 , var( (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).))=σ 1 2 , var( X, Y)=ρ.
)=σ 2 2 , cor( Bukod dito, para sa naunang nabanggit na linear na modelo Y = β 0 + β 1 X + ε (\displaystyle Y=\beta _(0)+\beta _(1)X+\varepsilon ) , Saan X (\displaystyle X) at mga independiyenteng random na variable, atε (\displaystyle \varepsilon) E (Y ∣ X = x) = β 0 + β 1 x (\displaystyle E(Y\mid X=x)=\beta _(0)+\beta _(1)x). Pagkatapos, gamit ang naunang nakasaad na pagkakapantay-pantay, makakakuha tayo ng mga formula para sa at: β 1 = ϱ σ 2 σ 1 (\displaystyle \beta _(1)=\varrho (\frac (\sigma _(2))(\sigma _(1)))),
β 0 = μ 2 − β 1 μ 1 (\displaystyle \beta _(0)=\mu _(2)-\beta _(1)\mu _(1))
Kung mula sa isang lugar ay kilala bilang priori na ang isang hanay ng mga random na puntos sa eroplano ay nabuo ng isang linear na modelo, ngunit may hindi kilalang coefficient β 0 (\displaystyle \beta _(0)) At β 1 (\displaystyle \beta _(1)), maaari kang makakuha ng mga pagtatantya ng punto ng mga coefficient na ito gamit ang mga tinukoy na formula. Upang gawin ito, sa halip na mga mathematical na inaasahan, mga pagkakaiba at ugnayan ng mga random na variable, ang mga formula na ito Y At (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) kailangan nating palitan ang kanilang walang pinapanigan na mga pagtatantya. Ang magreresultang mga formula ng pagtatantya ay eksaktong magkakasabay sa mga formula na nakuha batay sa paraan ng least squares.
Ang pangunahing layunin ng pagsusuri ng regression ay binubuo sa pagtukoy ng analitikal na anyo ng komunikasyon kung saan ang pagbabago sa epektibong katangian ay dahil sa impluwensya ng isa o higit pang mga katangian ng salik, at ang hanay ng lahat ng iba pang mga salik na nakakaimpluwensya rin sa epektibong katangian ay kinukuha bilang pare-pareho at karaniwang mga halaga.
Mga Problema sa Pagsusuri ng Pagbabalik:
a) Pagtatatag ng anyo ng pagtitiwala. Tungkol sa kalikasan at anyo ng ugnayan sa pagitan ng mga penomena, ang isang pagkakaiba ay ginawa sa pagitan ng positibong linear at nonlinear at negatibong linear at nonlinear na regression.
b) Pagtukoy ng regression function sa anyo ng isang mathematical equation ng isang uri o iba pa at pagtatatag ng impluwensya ng mga paliwanag na variable sa dependent variable.
c) Pagtatantya ng mga hindi kilalang halaga ng dependent variable. Gamit ang pag-andar ng regression, maaari mong kopyahin ang mga halaga ng dependent variable sa loob ng pagitan ng mga tinukoy na halaga ng mga paliwanag na variable (i.e., lutasin ang problema sa interpolation) o suriin ang kurso ng proseso sa labas ng tinukoy na agwat (i.e., lutasin ang problema sa extrapolation). Ang resulta ay isang pagtatantya ng halaga ng dependent variable.Ang paired regression ay isang equation para sa relasyon sa pagitan ng dalawang variable na y at x: , kung saan ang y ay ang dependent variable (resultative attribute); Ang x ay isang independiyenteng paliwanag na variable (feature-factor).
May mga linear at nonlinear na regression.
Mga regression na nonlinear na may kinalaman sa mga tinantyang parameter: Ang pagbuo ng isang regression equation ay bumababa sa pagtatantya ng mga parameter nito. Upang matantya ang mga parameter ng mga regression linear sa mga parameter, ang least squares method (OLS) ay ginagamit. Ang pamamaraan ng hindi bababa sa mga parisukat ay ginagawang posible upang makakuha ng mga pagtatantya ng naturang parameter kung saan ang kabuuan ng mga parisukat na paglihis ng mga aktwal na halaga ng epektibong katangian y mula sa mga teoretikal ay minimal, i.e.
Linear regression: y = a + bx + ε
Ang mga nonlinear na regression ay nahahati sa dalawang klase: mga regression na nonlinear na may kinalaman sa mga paliwanag na variable na kasama sa pagsusuri, ngunit linear na may kinalaman sa mga tinantyang parameter, at mga regression na nonlinear na may kinalaman sa mga tinantyang parameter.
Mga regression na nonlinear sa mga variable na nagpapaliwanag: .
.
Para sa mga linear at nonlinear na equation na mababawasan sa linear na mga equation, ang mga sumusunod na sistema ay nalulutas sa paggalang sa a at b:
Maaari mong gamitin ang mga handa na formula na sumusunod mula sa system na ito:
Ang lapit ng koneksyon sa pagitan ng mga phenomena na pinag-aaralan ay tinasa ng linear coefficient ng ugnayan ng pares para sa linear regression:
at correlation index - para sa nonlinear regression:
Ang kalidad ng itinayong modelo ay susuriin ng koepisyent (index) ng pagpapasiya, pati na rin ang average na error ng approximation.
Average na error sa pagtatantya - average na paglihis ng mga kinakalkula na halaga mula sa mga aktwal: .
.
Ang pinahihintulutang limitasyon ng mga halaga ay hindi hihigit sa 8-10%.
Ang average na elasticity coefficient ay nagpapakita sa kung anong porsyento sa average ang resulta y ay magbabago mula sa average na halaga nito kapag ang factor x ay nagbago ng 1% mula sa average na halaga nito:
.Ang layunin ng pagsusuri ng pagkakaiba-iba ay upang suriin ang pagkakaiba-iba ng umaasang baryabol:
,
saan ang kabuuang kabuuan ng mga squared deviations;
- ang kabuuan ng mga squared deviations dahil sa regression ("ipinaliwanag" o "factorial");
- natitirang kabuuan ng mga squared deviations.
Ang bahagi ng pagkakaiba-iba na ipinaliwanag ng regression sa kabuuang pagkakaiba ng nagresultang katangian y ay nailalarawan sa pamamagitan ng koepisyent (index) ng pagpapasiya R2:
Ang coefficient of determination ay ang parisukat ng coefficient o correlation index.Ang F-test - pagtatasa ng kalidad ng regression equation - ay binubuo ng pagsubok sa hypothesis No tungkol sa statistical insignificance ng regression equation at ang indicator ng lapit ng relasyon. Upang gawin ito, ang isang paghahambing ay ginawa sa pagitan ng aktwal na F fact at ang kritikal (tabular) F na mga halaga ng talahanayan ng Fisher F-criterion. Ang F fact ay tinutukoy mula sa ratio ng mga halaga ng kadahilanan at natitirang mga pagkakaiba-iba na kinakalkula para sa isang antas ng kalayaan:
 ,
,
kung saan ang n ay ang bilang ng mga yunit ng populasyon; m ay ang bilang ng mga parameter para sa mga variable x.
Ang F table ay ang pinakamataas na posibleng halaga ng criterion sa ilalim ng impluwensya ng mga random na salik sa ibinigay na antas ng kalayaan at antas ng kahalagahan a. Ang antas ng kahalagahan a ay ang posibilidad na tanggihan ang tamang hypothesis, dahil ito ay totoo. Karaniwan ang a ay kinukuha na katumbas ng 0.05 o 0.01.
Kung F talahanayan< F факт, то Н о - гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если F табл >F katotohanan, pagkatapos ay ang hypothesis H o ay hindi tinanggihan at ang istatistika insignificance at hindi mapagkakatiwalaan ng regression equation ay kinikilala.
Upang masuri ang statistical significance ng regression at correlation coefficients, kinakalkula ang t-test at confidence interval ng Mag-aaral para sa bawat indicator. Ang isang hypothesis ay iniharap tungkol sa random na katangian ng mga tagapagpahiwatig, i.e. tungkol sa kanilang hindi gaanong pagkakaiba mula sa zero. Ang pagtatasa ng kahalagahan ng regression at correlation coefficients gamit ang Student's t-test ay isinasagawa sa pamamagitan ng paghahambing ng kanilang mga halaga sa magnitude ng random error:
; ; .
Ang mga random na error ng linear regression na mga parameter at ang correlation coefficient ay tinutukoy ng mga formula:
Paghahambing ng aktwal at kritikal (tabular) na mga halaga ng t-statistics - t table at t fact - tinatanggap o tinatanggihan namin ang hypothesis H o.
Ang relasyon sa pagitan ng Fisher F-test at ng Student t-statistic ay ipinahayag ng pagkakapantay-pantay
Kung t talahanayan< t факт то H o отклоняется, т.е. a, b и не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора х. Если t табл >t ay isang katotohanan na ang hypothesis H o ay hindi tinatanggihan at ang random na katangian ng pagbuo ng a, b o ay kinikilala.
Upang kalkulahin ang agwat ng kumpiyansa, tinutukoy namin ang maximum na error D para sa bawat tagapagpahiwatig:
, .
Ang mga formula para sa pagkalkula ng mga agwat ng kumpiyansa ay ang mga sumusunod:
; ;
; ;
Kung ang zero ay nasa loob ng agwat ng kumpiyansa, i.e. Kung negatibo ang mababang limitasyon at positibo ang pinakamataas na limitasyon, ang tinantyang parameter ay ituturing na zero, dahil hindi ito maaaring sabay na kumuha ng parehong positibo at negatibong mga halaga.
Ang halaga ng pagtataya ay tinutukoy sa pamamagitan ng pagpapalit ng katumbas na (pagtataya) na halaga sa equation ng regression. Ang average na karaniwang error ng forecast ay kinakalkula: ,
,
saan
at isang agwat ng kumpiyansa para sa hula ay binuo: ;
;  ;
; 
saan .
.Halimbawang solusyon
Gawain Blg. 1. Para sa pitong teritoryo ng rehiyon ng Ural noong 199X, ang mga halaga ng dalawang katangian ay kilala.
Talahanayan 1.
Kinakailangan: 1. Upang makilala ang dependence ng y sa x, kalkulahin ang mga parameter ng mga sumusunod na function:
a) linear;
b) kapangyarihan (kailangan mo munang isagawa ang pamamaraan ng linearization ng mga variable sa pamamagitan ng pagkuha ng logarithm ng parehong bahagi);
c) nagpapakita;
d) isang equilateral hyperbola (kailangan mo ring malaman kung paano i-pre-linearize ang modelong ito).
2. Suriin ang bawat modelo gamit ang average na error ng approximation at Fisher's F test.Solusyon (Option No. 1)
Upang kalkulahin ang mga parameter a at b ng linear regression (maaaring gawin ang pagkalkula gamit ang isang calculator).
lutasin ang isang sistema ng mga normal na equation para sa A At b:
Batay sa paunang data, kinakalkula namin :
:
y x yx x 2 y 2 A i l 68,8 45,1 3102,88 2034,01 4733,44 61,3 7,5 10,9 2 61,2 59,0 3610,80 3481,00 3745,44 56,5 4,7 7,7 3 59,9 57,2 3426,28 3271,84 3588,01 57,1 2,8 4,7 4 56,7 61,8 3504,06 3819,24 3214,89 55,5 1,2 2,1 5 55,0 58,8 3234,00 3457,44 3025,00 56,5 -1,5 2,7 6 54,3 47,2 2562,96 2227,84 2948,49 60,5 -6,2 11,4 7 49,3 55,2 2721,36 3047,04 2430,49 57,8 -8,5 17,2 Kabuuan 405,2 384,3 22162,34 21338,41 23685,76 405,2 0,0 56,7 Wed. ibig sabihin (Kabuuan/n) 57,89 54,90 3166,05 3048,34 3383,68 Y Y 8,1 s 5,74 5,86 Y Y Y Y Y Y s 2 32,92 34,34 Y Y Y Y Y Y 

Regression equation: y = 76,88 - 0,35X. Sa isang pagtaas sa average na pang-araw-araw na sahod ng 1 kuskusin. ang bahagi ng mga gastos para sa pagbili ng mga produktong pagkain ay bumababa ng isang average na 0.35 porsyento na puntos.
Kalkulahin natin ang linear pair correlation coefficient:
Ang koneksyon ay katamtaman, kabaligtaran.
Tukuyin natin ang koepisyent ng determinasyon: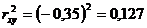
Ang 12.7% variation sa resulta ay ipinaliwanag ng variation sa x factor. Ang pagpapalit ng mga aktwal na halaga sa equation ng regression X, tukuyin natin ang teoretikal (kinakalkula) na mga halaga . Hanapin natin ang halaga ng average na error sa pagtatantya:
Sa karaniwan, ang mga kinakalkula na halaga ay lumihis mula sa aktwal na mga halaga ng 8.1%.
Kalkulahin natin ang F-criterion:
mula noong 1< F < ¥ , dapat isaalang-alang F -1 .
Ang resultang halaga ay nagpapahiwatig ng pangangailangang tanggapin ang hypothesis Pero oh ang random na kalikasan ng natukoy na pag-asa at ang hindi gaanong kahalagahan ng istatistika ng mga parameter ng equation at ang tagapagpahiwatig ng pagiging malapit ng koneksyon.
1b. Ang pagtatayo ng isang modelo ng kapangyarihan ay nauuna sa pamamaraan ng linearization ng mga variable. Sa halimbawa, ang linearization ay isinasagawa sa pamamagitan ng pagkuha ng logarithms ng magkabilang panig ng equation:
saanY=lg(y), X=lg(x), C=lg(a).Para sa mga kalkulasyon ginagamit namin ang data sa talahanayan. 1.3.
Talahanayan 1.3
(\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) Y YX Y2 X 2 A i 1 1,8376 1,6542 3,0398 3,3768 2,7364 61,0 7,8 60,8 11,3 2 1,7868 1,7709 3,1642 3,1927 3,1361 56,3 4,9 24,0 8,0 3 1,7774 1,7574 3,1236 3,1592 3,0885 56,8 3,1 9,6 5,2 4 1,7536 1,7910 3,1407 3,0751 3,2077 55,5 1,2 1,4 2,1 5 1,7404 1,7694 3,0795 3,0290 3,1308 56,3 -1,3 1,7 2,4 6 1,7348 1,6739 2,9039 3,0095 2,8019 60,2 -5,9 34,8 10,9 7 1,6928 1,7419 2,9487 2,8656 3,0342 57,4 -8,1 65,6 16,4 Kabuuan 12,3234 12,1587 21,4003 21,7078 21,1355 403,5 1,7 197,9 56,3 Average na halaga 1,7605 1,7370 3,0572 3,1011 3,0194 Y Y 28,27 8,0 σ 0,0425 0,0484 Y Y Y Y Y Y Y σ 2 0,0018 0,0023 Y Y Y Y Y Y Y Kalkulahin natin ang C at b:
Kumuha kami ng linear equation: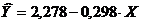 .
.
Nang maisagawa ang potentiation nito, nakukuha natin:
Ang pagpapalit ng mga aktwal na halaga sa equation na ito X, nakakakuha kami ng mga teoretikal na halaga ng resulta. Gamit ang mga ito, kakalkulahin namin ang mga tagapagpahiwatig: higpit ng koneksyon - index ng ugnayan at average na error sa pagtatantya
Ang mga katangian ng modelo ng kapangyarihan-batas ay nagpapahiwatig na inilalarawan nito ang relasyon na medyo mas mahusay kaysa sa linear function.1c. Pagbuo ng equation ng isang exponential curve
na unahan ng isang pamamaraan para sa linearizing variable sa pamamagitan ng pagkuha ng logarithms ng magkabilang panig ng equation:

Para sa mga kalkulasyon ginagamit namin ang data ng talahanayan.(\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) x Yx Y2 x 2 A i 1 1,8376 45,1 82,8758 3,3768 2034,01 60,7 8,1 65,61 11,8 2 1,7868 59,0 105,4212 3,1927 3481,00 56,4 4,8 23,04 7,8 3 1,7774 57,2 101,6673 3,1592 3271,84 56,9 3,0 9,00 5,0 4 1,7536 61,8 108,3725 3,0751 3819,24 55,5 1,2 1,44 2,1 5 1,7404 58,8 102,3355 3,0290 3457,44 56,4 -1,4 1,96 2,5 6 1,7348 47,2 81,8826 3,0095 2227,84 60,0 -5,7 32,49 10,5 7 1,6928 55,2 93,4426 2,8656 3047,04 57,5 -8,2 67,24 16,6 Kabuuan 12,3234 384,3 675,9974 21,7078 21338,41 403,4 -1,8 200,78 56,3 Wed. zn. 1,7605 54,9 96,5711 3,1011 3048,34 Y Y 28,68 8,0 σ 0,0425 5,86 Y Y Y Y Y Y Y σ 2 0,0018 34,339 Y Y Y Y Y Y Y Mga halaga ng mga parameter ng regression A at SA ay umabot sa:
Ang resultang linear equation ay: .
Gawin nating potentiate ang resultang equation at isulat ito sa karaniwang anyo:
.
Gawin nating potentiate ang resultang equation at isulat ito sa karaniwang anyo:
Susuriin namin ang pagiging malapit ng koneksyon sa pamamagitan ng index ng ugnayan:
ULAT
Takdang-aralin: isaalang-alang ang isang pamamaraan ng pagsusuri ng regression batay sa data (presyo ng pagbebenta at lugar ng tirahan) sa 23 ari-arian ng real estate.
Ang "Regression" operating mode ay ginagamit upang kalkulahin ang mga parameter ng linear regression equation at suriin ang kasapatan nito para sa prosesong pinag-aaralan.
Upang malutas ang problema ng pagsusuri ng regression sa MS Excel, pumili mula sa menu Serbisyo pangkat Pagsusuri ng Datos at tool sa pagsusuri" Regression".
Sa lalabas na dialog box, itakda ang mga sumusunod na parameter:
1. Input interval Y- ito ang hanay ng data para sa nagresultang katangian. Dapat itong binubuo ng isang column.
2. Input interval X ay isang hanay ng mga cell na naglalaman ng mga halaga ng mga kadahilanan (mga independiyenteng variable). Ang bilang ng mga saklaw ng input (mga column) ay dapat na hindi hihigit sa 16.
3. Checkbox Mga tag, ay nakatakda kung ang unang linya ng hanay ay naglalaman ng pamagat.
4. Checkbox Antas ng pagiging maaasahan ay isinaaktibo kung sa field sa tabi nito kailangan mong magpasok ng antas ng pagiging maaasahan na iba sa default. Ginagamit upang subukan ang kahalagahan ng koepisyent ng pagpapasiya R2 at mga koepisyent ng regression.
5. Constant zero. Dapat suriin ang checkbox na ito kung ang linya ng regression ay dapat dumaan sa pinanggalingan (at 0 =0).
6. Output interval/ Bagong worksheet/ Bagong workbook - tukuyin ang address ng kaliwang itaas na cell ng hanay ng output.
7. Mga checkbox sa grupo Mga natira ay nakatakda kung kinakailangang isama ang mga kaukulang column o graph sa hanay ng output.
8. Dapat gawing aktibo ang checkbox ng Normal na Probability Graph kung gusto mong magpakita ng scatter plot ng dependence ng naobserbahang Y values sa mga awtomatikong nabuong percentile interval.
Pagkatapos i-click ang OK button sa hanay ng output, nakakakuha kami ng ulat.
Gamit ang isang set ng data analysis tool, magsasagawa kami ng regression analysis ng source data.
Ang Regression analysis tool ay ginagamit upang magkasya ang mga parameter ng isang regression equation gamit ang least squares method. Ang regression ay ginagamit upang pag-aralan ang epekto sa iisang dependent variable ng mga halaga ng isa o higit pang independent variable.
TABLE REGRESSION STATISTICS
Magnitude maramihan R ay ang ugat ng coefficient of determination (R-squared). Tinatawag din itong correlation index o multiple correlation coefficient. Nagpapahayag ng antas ng pag-asa ng mga independiyenteng variable (X1, X2) at ang dependent variable (Y) at katumbas ng square root ng coefficient of determination; Sa aming kaso, ito ay katumbas ng 0.7, na nagpapahiwatig ng isang makabuluhang relasyon sa pagitan ng mga variable.
Magnitude R-squared (coefficient of determination), na tinatawag ding sukatan ng katiyakan, ay nagpapakilala sa kalidad ng nagreresultang linya ng pagbabalik. Ang kalidad na ito ay ipinahayag sa pamamagitan ng antas ng pagsusulatan sa pagitan ng pinagmumulan ng data at ng modelo ng regression (kinakalkulang data). Ang sukatan ng katiyakan ay palaging nasa pagitan.
Sa aming kaso, ang halaga ng R-square ay 0.48, i.e. halos 50%, na nagpapahiwatig ng hindi magandang akma ng linya ng regression sa orihinal na data Dahil nakitang halaga R-squared = 48%<75%, то, следовательно, также можно сделать вывод о невозможности прогнозирования с помощью найденной регрессионной зависимости. Таким образом, модель объясняет всего 48% вариации цены, что говорит о недостаточности выбранных факторов, либо о недостаточном объеме выборки.
Normalized R-squared ay ang parehong koepisyent ng pagpapasiya, ngunit nababagay para sa laki ng sample.
Normal na R-squared=1-(1-R-squared)*((n-1)/(n-k)),
pagsusuri ng regression linear equation
kung saan ang n ay ang bilang ng mga obserbasyon; k - bilang ng mga parameter. Mas mainam na gumamit ng normalized na R-squared kapag nagdaragdag ng mga bagong regressors (mga kadahilanan), dahil habang tumataas ang mga ito, tataas din ang halaga ng R-squared, ngunit hindi ito magsasaad ng pagpapabuti sa modelo. Dahil sa aming kaso ang resultang halaga ay 0.43 (na naiiba sa R-squared ng 0.05 lamang), maaari nating pag-usapan ang mataas na kumpiyansa sa R-squared coefficient.
Karaniwang error nagpapakita ng kalidad ng approximation (approximation) ng mga resulta ng pagmamasid. Sa aming kaso, ang error ay 5.1. Kalkulahin natin bilang isang porsyento: 5.1/(57.4-40.1)=0.294? 29% (Itinuturing na mas mahusay ang modelo kapag ang karaniwang error ay<30%)
Mga obserbasyon- ang bilang ng mga sinusunod na halaga ay ipinahiwatig (23).
TABLE ANALYSIS NG VARIANCE
Upang makuha ang equation ng regression, tinutukoy ang isang -statistic - isang katangian ng katumpakan ng equation ng regression, na ang ratio ng bahaging iyon ng variance ng dependent variable na ipinaliwanag ng equation ng regression sa hindi maipaliwanag (natirang) bahagi ng pagkakaiba.
Sa column df- ang bilang ng mga antas ng kalayaan k ay ibinibigay.
Para sa regression, ito ang bilang ng mga regressors (mga kadahilanan) - X1 (lugar) at X2 (iskor), i.e. k=2.
Para sa natitira, ito ay isang halaga na katumbas ng n-(m+1), i.e. ang bilang ng mga unang puntos (23) na binawasan ang bilang ng mga koepisyent (2) at binawasan ang libreng termino (1).
Sa column ng SS- ang kabuuan ng mga squared deviations mula sa average na halaga ng nagresultang katangian. Nagpapakita ito ng:
Regression sum ng squared deviations mula sa mean value ng nagresultang katangian ng theoretical values na kinakalkula gamit ang regression equation.
Ang natitirang kabuuan ng mga paglihis ng mga orihinal na halaga mula sa mga teoretikal na halaga.
Ang kabuuang kabuuan ng mga squared deviations ng mga paunang halaga mula sa nagresultang katangian.
Kung mas malaki ang regression sum ng squared deviations (o mas maliit ang natitirang kabuuan), mas maganda ang regression equation na tinatantya ang cloud ng mga orihinal na puntos. Sa aming kaso, ang natitirang halaga ay tungkol sa 50%. Dahil dito, ang equation ng regression ay napakahina na tinatantya ang ulap ng mga paunang punto.
Sa column ng MS- walang pinapanigan na mga pagkakaiba-iba ng sample, regression at nalalabi.
Sa column F Ang halaga ng mga istatistika ng pamantayan ay kinakalkula upang subukan ang kahalagahan ng equation ng regression.
Upang magsagawa ng isang istatistikal na pagsubok ng kahalagahan ng equation ng regression, ang isang null hypothesis ay nabuo tungkol sa kawalan ng isang relasyon sa pagitan ng mga variable (lahat ng mga coefficient para sa mga variable ay katumbas ng zero) at ang antas ng kahalagahan ay pinili.
Ang antas ng kabuluhan ay ang katanggap-tanggap na posibilidad ng paggawa ng isang uri I error - pagtanggi sa tamang null hypothesis bilang resulta ng pagsubok. Sa kasong ito, ang paggawa ng type I error ay nangangahulugan ng pagkilala sa isang sample na may kaugnayan sa pagitan ng mga variable sa populasyon kung sa katunayan ay wala. Karaniwan ang antas ng kahalagahan ay kinukuha na 5%. Ang paghahambing ng nakuhang halaga = 9.4 sa halaga ng talahanayan = 3.5 (ang bilang ng mga antas ng kalayaan ay 2 at 20, ayon sa pagkakabanggit), masasabi nating makabuluhan ang equation ng regression (F>Fcr).
Sa kolum ng kahalagahan F ang posibilidad ng nakuhang halaga ng mga istatistika ng pamantayan ay kinakalkula. Dahil sa aming kaso ang halagang ito = 0.00123, na mas mababa sa 0.05, maaari naming sabihin na ang regression equation (dependence) ay makabuluhan na may posibilidad na 95%.
Ang dalawang haligi na inilarawan sa itaas ay nagpapakita ng pagiging maaasahan ng modelo sa kabuuan.
Ang sumusunod na talahanayan ay naglalaman ng mga coefficient para sa mga regressor at ang kanilang mga pagtatantya.
Ang Y-intercept na linya ay hindi nauugnay sa anumang regressor; ito ay isang libreng koepisyent.
Sa column posibilidad ang mga halaga ng regression equation coefficients ay naitala. Kaya, ang equation ay nakuha:
Y=25.6+0.009X1+0.346X2
Ang equation ng regression ay dapat dumaan sa gitna ng ulap ng mga inisyal na puntos: 38.26?
Susunod, ihambing ang mga halaga ng haligi sa mga pares Mga Coefficient at Standard Error. Makikita na sa aming kaso, ang lahat ng ganap na halaga ng mga coefficient ay lumampas sa karaniwang mga error. Maaaring ipahiwatig nito ang kahalagahan ng mga regressor, gayunpaman, ito ay isang magaspang na pagsusuri. Ang column na t-statistic ay nagbibigay ng mas tumpak na pagtatantya ng kahalagahan ng mga coefficient.
Sa column na t-statistic naglalaman ng mga halaga ng t-test na kinakalkula gamit ang formula:
t=(Coefficient)/(Karaniwang error)
Ang pagsusulit na ito ay may distribusyon ng Mag-aaral na may bilang ng mga antas ng kalayaan
n-(k+1)=23-(2+1)=20
Gamit ang talahanayan ng Estudyante nakita namin ang halaga ttable = 2.086. Paghahambing
t na may ttable nakita namin na ang regressor coefficient X2 ay hindi gaanong mahalaga.
Kolum p-halaga kumakatawan sa posibilidad na ang kritikal na halaga ng istatistika ng pagsubok (estista ng t ng mag-aaral) ay lalampas sa halaga na kinakalkula mula sa sample. Sa kasong ito, inihambing namin p-halaga na may napiling antas ng kahalagahan (0.05). Makikita na tanging ang regressor coefficient X2=0.08>0.05 lamang ang maituturing na hindi gaanong mahalaga.
Ang mas mababang 95% at itaas na 95% na column ay nagbibigay ng mga limitasyon sa pagitan ng kumpiyansa na may 95% kumpiyansa. Ang bawat koepisyent ay may sariling mga limitasyon: Coefficientttable*Pamantayang error
Ang mga pagitan ng kumpiyansa ay binuo lamang para sa mga halagang makabuluhan ayon sa istatistika.
Sa mga nakaraang post, ang pagsusuri ay madalas na nakatuon sa isang solong numerical variable, tulad ng pagbabalik ng mutual fund, mga oras ng paglo-load ng Web page, o pagkonsumo ng soft drink. Sa ito at sa kasunod na mga tala, titingnan natin ang mga pamamaraan para sa paghula ng mga halaga ng isang numeric variable depende sa mga halaga ng isa o higit pang mga numeric variable.
Ang materyal ay ilalarawan gamit ang isang cross-cutting na halimbawa. Pagtataya ng dami ng benta sa isang tindahan ng damit. Ang Sunflowers chain ng mga discount na tindahan ng damit ay patuloy na lumalawak sa loob ng 25 taon. Gayunpaman, ang kumpanya ay kasalukuyang walang sistematikong diskarte sa pagpili ng mga bagong outlet. Ang lokasyon kung saan nilalayon ng isang kumpanya na magbukas ng bagong tindahan ay tinutukoy batay sa mga pansariling pagsasaalang-alang. Ang mga pamantayan sa pagpili ay ang mga kanais-nais na kondisyon sa pag-upa o ang ideya ng manager ng perpektong lokasyon ng tindahan. Isipin na ikaw ang pinuno ng mga espesyal na proyekto at departamento ng pagpaplano. Ikaw ay naatasang bumuo ng isang estratehikong plano para sa pagbubukas ng mga bagong tindahan. Ang planong ito ay dapat magsama ng pagtataya ng taunang benta para sa mga bagong bukas na tindahan. Naniniwala ka na ang retail space ay direktang nauugnay sa kita at gusto mong isama ito sa iyong proseso ng paggawa ng desisyon. Paano ka bubuo ng istatistikal na modelo upang mahulaan ang mga taunang benta batay sa laki ng isang bagong tindahan?
Karaniwan, ang pagsusuri ng regression ay ginagamit upang mahulaan ang mga halaga ng isang variable. Ang layunin nito ay bumuo ng isang istatistikal na modelo na maaaring mahulaan ang mga halaga ng isang umaasa na variable, o tugon, mula sa mga halaga ng hindi bababa sa isang independyente, o nagpapaliwanag, na variable. Sa tala na ito, titingnan natin ang simpleng linear regression - isang istatistikal na paraan na nagbibigay-daan sa iyo upang mahulaan ang mga halaga ng isang dependent variable. (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) sa pamamagitan ng mga independiyenteng variable na halaga Y. Ang mga kasunod na tala ay maglalarawan ng maraming modelo ng regression na idinisenyo upang mahulaan ang mga halaga ng isang malayang variable (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) batay sa mga halaga ng ilang dependent variables ( X 1, X 2, …, X k).
I-download ang tala sa o format, mga halimbawa sa format
Mga uri ng mga modelo ng regression
saan ρ 1 – koepisyent ng autocorrelation; Kung ρ 1 = 0 (walang autocorrelation), D≈ 2; Kung ρ 1 ≈ 1 (positibong autocorrelation), D≈ 0; Kung ρ 1 = -1 (negatibong autocorrelation), D ≈ 4.
Sa pagsasagawa, ang paggamit ng Durbin-Watson criterion ay batay sa paghahambing ng halaga D na may mga kritikal na teoretikal na halaga d L At d U para sa isang naibigay na bilang ng mga obserbasyon x i, y i, bilang ng mga independiyenteng variable ng modelo k(para sa simpleng linear regression k= 1) at antas ng kahalagahan α. Kung D< d L , ang hypothesis tungkol sa kalayaan ng mga random na paglihis ay tinanggihan (kaya, mayroong isang positibong autocorrelation); Kung D>dU, ang hypothesis ay hindi tinatanggihan (iyon ay, walang autocorrelation); Kung d L< D < d U , walang sapat na batayan para gumawa ng desisyon. Kapag ang kinakalkula na halaga D lumampas sa 2, pagkatapos ay may d L At d U Hindi ang koepisyent mismo ang inihambing D, at ang expression (4 – D).
Upang kalkulahin ang mga istatistika ng Durbin-Watson sa Excel, buksan natin ang talahanayan sa ibaba sa Fig. 14 Pag-withdraw ng balanse. Ang numerator sa expression (10) ay kinakalkula gamit ang function na =SUMMAR(array1;array2), at ang denominator =SUMMAR(array) (Fig. 16).

kanin. 16. Mga formula para sa pagkalkula ng mga istatistika ng Durbin-Watson
Sa ating halimbawa D= 0.883. Ang pangunahing tanong ay: anong halaga ng istatistika ng Durbin-Watson ang dapat ituring na sapat na maliit upang tapusin na mayroong isang positibong autocorrelation? Kinakailangan na iugnay ang halaga ng D sa mga kritikal na halaga ( d L At dU), depende sa bilang ng mga obserbasyon x i, y i at antas ng kahalagahan α (Larawan 17).

kanin. 17. Mga kritikal na halaga ng mga istatistika ng Durbin-Watson (table fragment)
Kaya, sa problema ng dami ng benta sa isang tindahan na naghahatid ng mga kalakal sa bahay, mayroong isang malayang variable ( k= 1), 15 obserbasyon ( x i, y i= 15) at antas ng kabuluhan α = 0.05. Kaya naman, d L= 1.08 at dU= 1.36. Since D = 0,883 < d L= 1.08, mayroong isang positibong autocorrelation sa pagitan ng mga residual, hindi maaaring gamitin ang hindi bababa sa mga parisukat na paraan.
Pagsubok ng Hypotheses tungkol sa Slope at Correlation Coefficient
Sa itaas, ang regression ay ginamit lamang para sa pagtataya. Upang matukoy ang mga coefficient ng regression at mahulaan ang halaga ng isang variable (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) para sa isang naibigay na variable na halaga Y Ginamit ang paraan ng least squares. Bilang karagdagan, sinuri namin ang root mean square error ng pagtatantya at ang mixed correlation coefficient. Kung ang pag-aaral ng mga nalalabi ay nagpapatunay na ang mga kondisyon ng pagkakalapat ng pamamaraan ng hindi bababa sa mga parisukat ay hindi nilalabag, at ang simpleng modelo ng linear regression ay sapat, batay sa sample na data, maaari itong maitalo na mayroong isang linear na relasyon sa pagitan ng mga variable sa ang populasyon.
Aplikasyont -pamantayan para sa slope. Sa pamamagitan ng pagsubok kung ang slope ng populasyon β 1 ay katumbas ng zero, matutukoy ng isa kung mayroong isang makabuluhang kaugnayan sa istatistika sa pagitan ng mga variable. Y At (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).). Kung ang hypothesis na ito ay tinanggihan, ito ay maaaring argued na sa pagitan ng mga variable Y At (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) mayroong isang linear na relasyon. Ang mga null at alternatibong hypotheses ay nabuo tulad ng sumusunod: H 0: β 1 = 0 (walang linear dependence), H1: β 1 ≠ 0 (may linear dependence). Sa pamamagitan ng kahulugan t-statistic ay katumbas ng pagkakaiba sa pagitan ng sample na slope at hypothetical na halaga ng slope ng populasyon, na hinati sa root mean square error ng slope estimate:
(11) t = (binigay 1 – β 1 ) / S b 1
saan binigay 1 – slope ng direktang regression sa sample na data, β1 – hypothetical slope ng direktang populasyon,
 , at mga istatistika ng pagsubok t may t-pamamahagi na may n – 2 antas ng kalayaan.
, at mga istatistika ng pagsubok t may t-pamamahagi na may n – 2 antas ng kalayaan.Suriin natin kung may makabuluhang kaugnayan sa istatistika sa pagitan ng laki ng tindahan at taunang benta sa α = 0.05. t-ang criterion ay ipinapakita kasama ng iba pang mga parameter kapag ginamit Pakete ng pagsusuri(pagpipilian Regression). Ang kumpletong resulta ng Package ng Pagsusuri ay ipinapakita sa Fig. 4, fragment na nauugnay sa t-statistics - sa Fig. 18.
kanin. 18. Mga resulta ng aplikasyon t
Dahil sa dami ng mga tindahan x i, y i= 14 (tingnan ang Fig. 3), kritikal na halaga t-Ang mga istatistika sa antas ng kahalagahan ng α = 0.05 ay matatagpuan gamit ang formula: t L=STUDENT.ARV(0.025,12) = –2.1788, kung saan ang 0.025 ay kalahati ng antas ng kahalagahan, at 12 = x i, y i – 2; t U=ESTUDYANTE.OBR(0.975,12) = +2.1788.
Since t-statistika = 10.64 > t U= 2.1788 (Larawan 19), null hypothesis H 0 tinanggihan. Sa kabilang panig, r-halaga para sa X= 10.6411, na kinakalkula ng formula =1-STUDENT.DIST(D3,12,TRUE), ay tinatayang katumbas ng zero, kaya ang hypothesis H 0 muling tinanggihan. Ang katotohanan na r-Ang halaga ng halos zero ay nangangahulugan na kung walang totoong linear na ugnayan sa pagitan ng mga laki ng tindahan at taunang benta, halos imposible itong matukoy gamit ang linear regression. Samakatuwid, mayroong makabuluhang linear na kaugnayan sa istatistika sa pagitan ng average na taunang benta ng tindahan at laki ng tindahan.

kanin. 19. Pagsubok sa hypothesis tungkol sa slope ng populasyon sa antas ng kahalagahan na 0.05 at 12 degrees ng kalayaan
AplikasyonF -pamantayan para sa slope. Ang isang alternatibong diskarte sa pagsubok ng mga hypotheses tungkol sa slope ng simpleng linear regression ay ang paggamit F-pamantayan. Paalalahanan ka namin F-test ay ginagamit upang subukan ang relasyon sa pagitan ng dalawang mga pagkakaiba-iba (para sa higit pang mga detalye, tingnan). Kapag sinusubukan ang slope hypothesis, ang sukatan ng mga random na error ay ang error variance (ang kabuuan ng mga squared error na hinati sa bilang ng mga degree ng kalayaan), kaya F-criterion ay gumagamit ng ratio ng variance na ipinaliwanag ng regression (i.e. ang value SSR, na hinati sa bilang ng mga independiyenteng variable k), sa pagkakaiba-iba ng error ( MSE = S YX 2 ).
Sa pamamagitan ng kahulugan F-statistic ay katumbas ng mean square of regression (MSR) na hinati sa error variance (MSE): F = MSR/ MSE E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac (\ sigma _(2))(\sigma _(1)))(x-\mu _(1))) MSR=SSR / k, MSE =SSE/(x i, y i– k – 1), k– bilang ng mga independiyenteng variable sa modelo ng regression. Mga istatistika ng pagsubok F may F-pamamahagi na may k At x i, y i– k – 1 antas ng kalayaan.
Para sa isang naibigay na antas ng kabuluhan α, ang tuntunin ng desisyon ay binabalangkas tulad ng sumusunod: kung F>FU, ang null hypothesis ay tinanggihan; kung hindi, hindi ito tinatanggihan. Ang mga resulta, na ipinakita sa anyo ng isang talahanayan ng buod ng pagsusuri ng pagkakaiba-iba, ay ipinapakita sa Fig. 20.

kanin. 20. Pagsusuri ng talahanayan ng pagkakaiba-iba para sa pagsubok ng hypothesis tungkol sa istatistikal na kahalagahan ng koepisyent ng regression
Ganun din t-pamantayan F-ang criterion ay ipinapakita sa talahanayan kapag ginamit Pakete ng pagsusuri(pagpipilian Regression). Buong resulta ng trabaho Pakete ng pagsusuri ay ipinapakita sa Fig. 4, fragment na may kaugnayan sa F-mga istatistika - sa Fig. 21.

kanin. 21. Mga resulta ng aplikasyon F-pamantayan na nakuha gamit ang Excel Analysis Package
Ang F-statistic ay 113.23, at r-value na malapit sa zero (cell KahalagahanF). Kung ang antas ng kahalagahan α ay 0.05, tukuyin ang kritikal na halaga F-Ang mga distribusyon na may isa at 12 degrees ng kalayaan ay maaaring makuha gamit ang formula F U=F.OBR(1-0.05;1;12) = 4.7472 (Larawan 22). Since F = 113,23 > F U= 4.7472, at r-value na malapit sa 0< 0,05, нулевая гипотеза H 0 ay tinanggihan, i.e. Ang laki ng isang tindahan ay malapit na nauugnay sa taunang benta nito.

kanin. 22. Pagsubok sa hypothesis ng slope ng populasyon sa antas ng kahalagahan na 0.05 na may isa at 12 degree ng kalayaan
Confidence interval na naglalaman ng slope β 1 . Upang subukan ang hypothesis na mayroong linear na ugnayan sa pagitan ng mga variable, maaari kang bumuo ng isang confidence interval na naglalaman ng slope β 1 at i-verify na ang hypothetical value na β 1 = 0 ay kabilang sa interval na ito. Ang sentro ng agwat ng kumpiyansa na naglalaman ng slope β 1 ay ang sample na slope binigay 1 , at ang mga hangganan nito ay ang mga dami b 1 ±tn –2 S b 1
Gaya ng ipinapakita sa Fig. 18, binigay 1 = +1,670, x i, y i = 14, S b 1 = 0,157. t 12 =ESTUDYANTE.ARV(0.975,12) = 2.1788. Kaya naman, b 1 ±tn –2 S b 1 = +1.670 ± 2.1788 * 0.157 = +1.670 ± 0.342, o + 1.328 ≤ β 1 ≤ +2.012. Kaya, may posibilidad na 0.95 na ang slope ng populasyon ay nasa pagitan ng +1.328 hanggang +2.012 (ibig sabihin, $1,328,000 hanggang $2,012,000). Dahil ang mga halagang ito ay mas malaki kaysa sa zero, mayroong istatistikal na makabuluhang linear na relasyon sa pagitan ng taunang mga benta at lugar ng tindahan. Kung ang pagitan ng kumpiyansa ay naglalaman ng zero, walang ugnayan sa pagitan ng mga variable. Bilang karagdagan, ang confidence interval ay nangangahulugan na ang bawat pagtaas sa lugar ng tindahan ng 1,000 sq. ft. ay nagreresulta sa pagtaas ng average na dami ng benta na $1,328,000 hanggang $2,012,000.
Paggamitt -pamantayan para sa koepisyent ng ugnayan. ipinakilala ang koepisyent ng ugnayan r, na isang sukatan ng ugnayan sa pagitan ng dalawang numeric na variable. Maaari itong magamit upang matukoy kung mayroong makabuluhang kaugnayan sa istatistika sa pagitan ng dalawang variable. Tukuyin natin ang koepisyent ng ugnayan sa pagitan ng mga populasyon ng parehong mga variable sa pamamagitan ng simbolo na ρ. Ang mga null at alternatibong hypotheses ay nabuo tulad ng sumusunod: H 0: ρ = 0 (walang ugnayan), H 1: ρ ≠ 0 (may ugnayan). Sinusuri ang pagkakaroon ng isang ugnayan:

saan r = + , Kung binigay 1 > 0, r = – , Kung binigay 1 < 0. Тестовая статистика t may t-pamamahagi na may n – 2 antas ng kalayaan.
Sa problema tungkol sa Sunflowers chain ng mga tindahan r 2= 0.904, a b 1- +1.670 (tingnan ang Fig. 4). Since b 1> 0, ang koepisyent ng ugnayan sa pagitan ng taunang benta at laki ng tindahan ay r= +√0.904 = +0.951. Subukan natin ang null hypothesis na walang ugnayan sa pagitan ng mga variable na ito gamit t-mga istatistika:

Sa antas ng kabuluhan na α = 0.05, ang null hypothesis ay dapat tanggihan dahil t= 10.64 > 2.1788. Kaya, maaari itong maitalo na mayroong makabuluhang kaugnayan sa istatistika sa pagitan ng taunang mga benta at laki ng tindahan.
Kapag tinatalakay ang mga hinuha tungkol sa slope ng populasyon, ang mga pagitan ng kumpiyansa at mga pagsubok sa hypothesis ay ginagamit nang magkapalit. Gayunpaman, ang pagkalkula ng agwat ng kumpiyansa na naglalaman ng koepisyent ng ugnayan ay lumalabas na mas mahirap, dahil ang uri ng pamamahagi ng sampling ng istatistika r depende sa totoong correlation coefficient.
Pagtatantya ng inaasahan sa matematika at hula ng mga indibidwal na halaga
Tinatalakay ng seksyong ito ang mga pamamaraan para sa pagtatantya ng inaasahan sa matematika ng isang tugon (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) at mga hula ng mga indibidwal na halaga (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) para sa mga ibinigay na halaga ng variable Y.
Pagbuo ng agwat ng kumpiyansa. Sa halimbawa 2 (tingnan ang seksyon sa itaas Paraan ng least squares) ginawang posible ng regression equation na mahulaan ang halaga ng variable (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) Y. Sa problema ng pagpili ng isang lokasyon para sa isang retail outlet, ang average na taunang dami ng benta sa isang tindahan na may lugar na 4000 sq. feet ay katumbas ng 7.644 million dollars, gayunpaman, ang pagtatantya ng matematikal na inaasahan ng pangkalahatang populasyon ay point-wise. Upang matantya ang mathematical na inaasahan ng populasyon, iminungkahi ang konsepto ng isang agwat ng kumpiyansa. Katulad nito, maaari nating ipakilala ang konsepto agwat ng kumpiyansa para sa mathematical na inaasahan ng tugon para sa isang naibigay na variable na halaga Y:
saan
 , =
binigay 0
+
binigay 1
X i– variable ang hinulaang halaga (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) sa Y = X i, S YX– root mean square error, x i, y i- laki ng sample, Yi- tinukoy na halaga ng variable Y, µ
Y|X =
Xi– mathematical na inaasahan ng variable (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) sa X = X i, SSX =
, =
binigay 0
+
binigay 1
X i– variable ang hinulaang halaga (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) sa Y = X i, S YX– root mean square error, x i, y i- laki ng sample, Yi- tinukoy na halaga ng variable Y, µ
Y|X =
Xi– mathematical na inaasahan ng variable (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) sa X = X i, SSX = 
Ang pagsusuri ng formula (13) ay nagpapakita na ang lapad ng agwat ng kumpiyansa ay nakasalalay sa ilang mga kadahilanan. Sa isang naibigay na antas ng kahalagahan, ang pagtaas sa amplitude ng mga pagbabago sa paligid ng linya ng regression, na sinusukat gamit ang root mean square error, ay humahantong sa pagtaas ng lapad ng agwat. Sa kabilang banda, tulad ng inaasahan ng isa, ang pagtaas sa laki ng sample ay sinamahan ng pagpapaliit ng pagitan. Bilang karagdagan, ang lapad ng agwat ay nagbabago depende sa mga halaga Yi. Kung ang variable na halaga (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) hinulaang para sa dami Y, malapit sa average na halaga , ang agwat ng kumpiyansa ay lumalabas na mas makitid kaysa sa paghula ng tugon para sa mga halaga na malayo sa karaniwan.
Sabihin nating kapag pumipili ng lokasyon ng tindahan, gusto naming bumuo ng 95% na agwat ng kumpiyansa para sa average na taunang benta ng lahat ng mga tindahan na ang lawak ay 4000 metro kuwadrado. paa:

Samakatuwid, ang average na taunang dami ng benta sa lahat ng mga tindahan na may lugar na 4,000 sq. talampakan, na may 95% na posibilidad ay nasa hanay mula 6.971 hanggang 8.317 milyong dolyar.
Kalkulahin ang agwat ng kumpiyansa para sa hinulaang halaga. Bilang karagdagan sa agwat ng kumpiyansa para sa inaasahan ng matematika ng tugon para sa isang naibigay na halaga ng variable Y, kadalasang kailangang malaman ang agwat ng kumpiyansa para sa hinulaang halaga. Bagama't ang formula para sa pagkalkula ng ganoong agwat ng kumpiyansa ay halos kapareho sa formula (13), ang agwat na ito ay naglalaman ng hinulaang halaga sa halip na ang pagtatantya ng parameter. Interval para sa hinulaang tugon (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).)X = Xi para sa isang tiyak na halaga ng variable Yi tinutukoy ng formula:

Ipagpalagay na, kapag pumipili ng lokasyon para sa isang retail outlet, gusto naming bumuo ng 95% confidence interval para sa hinulaang taunang dami ng benta para sa isang tindahan na ang lugar ay 4000 square meters. paa:

Samakatuwid, ang hinulaang taunang dami ng benta para sa isang tindahan na may lawak na 4000 sq. feet, na may 95% na posibilidad ay nasa saklaw mula 5.433 hanggang 9.854 milyong dolyar Gaya ng nakikita natin, ang agwat ng kumpiyansa para sa hinulaang halaga ng tugon ay mas malawak kaysa sa pagitan ng kumpiyansa para sa inaasahan sa matematika. Ito ay dahil ang pagkakaiba-iba sa paghula ng mga indibidwal na halaga ay mas malaki kaysa sa pagtatantya ng inaasahan sa matematika.
Mga pitfalls at etikal na isyu na nauugnay sa paggamit ng regression
Mga paghihirap na nauugnay sa pagsusuri ng regression:
- Hindi pinapansin ang mga kundisyon ng pagiging angkop ng pamamaraan ng least squares.
- Maling pagtatasa ng mga kundisyon para sa applicability ng least squares method.
- Maling pagpili ng mga alternatibong pamamaraan kapag nilabag ang mga kundisyon ng pagkakalapat ng least squares method.
- Application ng regression analysis nang walang malalim na kaalaman sa paksa ng pananaliksik.
- Extrapolating isang regression na lampas sa hanay ng paliwanag na variable.
- Pagkalito sa pagitan ng istatistikal at sanhi ng mga relasyon.
Ang malawakang paggamit ng mga spreadsheet at statistical software ay nag-alis ng mga problema sa computational na humadlang sa paggamit ng regression analysis. Gayunpaman, humantong ito sa katotohanan na ang pagsusuri ng regression ay ginamit ng mga user na walang sapat na kwalipikasyon at kaalaman. Paano malalaman ng mga gumagamit ang tungkol sa mga alternatibong pamamaraan kung marami sa kanila ang walang ideya sa lahat tungkol sa mga kondisyon ng pagiging angkop ng pamamaraang least squares at hindi alam kung paano suriin ang kanilang pagpapatupad?
Ang mananaliksik ay hindi dapat madala sa mga crunching number - pagkalkula ng shift, slope at mixed correlation coefficient. Kailangan niya ng mas malalim na kaalaman. Ilarawan natin ito sa isang klasikong halimbawa na kinuha mula sa mga aklat-aralin. Ipinakita ng Anscombe na ang lahat ng apat na set ng data na ipinapakita sa Fig. 23, ay may parehong mga parameter ng regression (Larawan 24).

kanin. 23. Apat na artipisyal na set ng data

kanin. 24. Pagsusuri ng regression ng apat na artipisyal na set ng data; tapos na sa Pakete ng pagsusuri(i-click ang larawan upang palakihin ang larawan)
Kaya, mula sa punto ng view ng pagsusuri ng regression, ang lahat ng mga set ng data na ito ay ganap na magkapareho. Kung doon natapos ang pagsusuri, mawawalan tayo ng maraming kapaki-pakinabang na impormasyon. Ito ay pinatunayan ng mga scatter plot (Larawan 25) at mga natitirang plot (Larawan 26) na binuo para sa mga set ng data na ito.

kanin. 25. Scatter plot para sa apat na data set
Ang mga scatter plot at natitirang plot ay nagpapahiwatig na ang mga data na ito ay naiiba sa bawat isa. Ang tanging set na ibinahagi sa isang tuwid na linya ay nakatakdang A. Ang plot ng mga residual na kinakalkula mula sa set A ay walang anumang pattern. Hindi ito masasabi tungkol sa set B, C at D. Ang scatter plot na naka-plot para sa set B ay nagpapakita ng binibigkas na quadratic pattern. Ang konklusyon na ito ay nakumpirma ng natitirang balangkas, na may parabolic na hugis. Ipinapakita ng scatter plot at residual plot na ang data set B ay naglalaman ng outlier. Sa sitwasyong ito, kinakailangang ibukod ang outlier mula sa set ng data at ulitin ang pagsusuri. Ang isang paraan para sa pag-detect at pag-aalis ng mga outlier sa mga obserbasyon ay tinatawag na influence analysis. Pagkatapos alisin ang outlier, ang resulta ng muling pagtatantya sa modelo ay maaaring ganap na naiiba. Ang scatterplot na naka-plot mula sa data mula sa set G ay naglalarawan ng isang hindi pangkaraniwang sitwasyon kung saan ang empirical na modelo ay lubos na nakadepende sa isang indibidwal na tugon ( X 8 = 19, (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) 8 = 12.5). Ang ganitong mga modelo ng regression ay dapat na kalkulahin nang mabuti. Kaya, ang scatter at residual plots ay isang mahalagang tool para sa pagsusuri ng regression at dapat ay isang mahalagang bahagi nito. Kung wala ang mga ito, ang pagsusuri ng regression ay hindi kapani-paniwala.

kanin. 26. Mga natitirang plot para sa apat na set ng data
Paano maiwasan ang mga pitfalls sa regression analysis:
- Pagsusuri ng mga posibleng ugnayan sa pagitan ng mga variable Y At (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) laging magsimula sa pamamagitan ng pagguhit ng scatter plot.
- Bago bigyang-kahulugan ang mga resulta ng pagsusuri ng regression, suriin ang mga kondisyon para sa pagiging angkop nito.
- I-plot ang mga residual laban sa independent variable. Ito ay magiging posible upang matukoy kung gaano kahusay ang empirical na modelo ay tumutugma sa mga resulta ng obserbasyon at upang matukoy ang isang paglabag sa pagkakaiba-iba.
- Gumamit ng mga histogram, stem-and-leaf plot, boxplot, at normal na distribution plot upang subukan ang pagpapalagay ng isang normal na pamamahagi ng error.
- Kung hindi natutugunan ang mga kundisyon para sa applicability ng least squares method, gumamit ng mga alternatibong pamamaraan (halimbawa, quadratic o multiple regression models).
- Kung natutugunan ang mga kundisyon para sa applicability ng least squares method, kinakailangang subukan ang hypothesis tungkol sa statistical significance ng regression coefficients at bumuo ng confidence intervals na naglalaman ng mathematical expectation at ang predicted response value.
- Iwasan ang paghula ng mga halaga ng dependent variable sa labas ng saklaw ng independent variable.
- Tandaan na ang mga istatistikal na relasyon ay hindi palaging sanhi-at-epekto. Tandaan na ang ugnayan sa pagitan ng mga variable ay hindi nangangahulugang mayroong sanhi-at-epekto na relasyon sa pagitan ng mga ito.
Ipagpatuloy. Gaya ng ipinapakita sa block diagram (Figure 27), inilalarawan ng tala ang simpleng linear regression na modelo, ang mga kundisyon para sa applicability nito, at kung paano subukan ang mga kundisyong ito. Isinasaalang-alang t-criterion para sa pagsubok sa istatistikal na kahalagahan ng slope ng regression. Ang isang modelo ng regression ay ginamit upang mahulaan ang mga halaga ng dependent variable. Ang isang halimbawa ay isinasaalang-alang na nauugnay sa pagpili ng lokasyon para sa isang retail outlet, kung saan ang pagtitiwala sa taunang dami ng benta sa lugar ng tindahan ay sinusuri. Ang impormasyong nakuha ay nagbibigay-daan sa iyo na mas tumpak na pumili ng isang lokasyon para sa isang tindahan at mahulaan ang taunang dami ng benta nito. Ang mga sumusunod na tala ay magpapatuloy sa pagtalakay sa pagsusuri ng regression at titingnan din ang maramihang mga modelo ng regression.

kanin. 27. Tandaan structure diagram
Ginamit ang mga materyales mula sa aklat na Levin et al. – M.: Williams, 2004. – p. 792–872
Kung ang dependent variable ay kategorya, ang logistic regression ay dapat gamitin.
Ano ang regression?
Isaalang-alang ang dalawang tuluy-tuloy na variable x=(x 1 , x 2 , .., x n), y=(y 1 , y 2 , ..., y n).
Ilagay natin ang mga punto sa isang two-dimensional na scatter plot at sabihin na mayroon tayo ugnayang linear, kung ang data ay tinatantya ng isang tuwid na linya.
Kung paniniwalaan natin yan y depende sa x, at mga pagbabago sa y ay tiyak na sanhi ng mga pagbabago sa x, matutukoy natin ang linya ng regression (regression y Sa halimbawang ito, regression x), na pinakamahusay na naglalarawan sa linear na relasyon sa pagitan ng dalawang variable na ito.
Ang istatistikal na paggamit ng salitang regression ay nagmula sa phenomenon na kilala bilang regression to the mean, na iniuugnay kay Sir Francis Galton (1889).
Ipinakita niya na kahit na ang matatangkad na ama ay may posibilidad na magkaroon ng matatangkad na anak na lalaki, ang karaniwang taas ng mga anak na lalaki ay mas maikli kaysa sa kanilang matatangkad na ama. Ang average na taas ng mga anak na lalaki ay "bumalik" at "lumipat paatras" patungo sa average na taas ng lahat ng mga ama sa populasyon. Kaya, sa karaniwan, ang matatangkad na ama ay may mas maiikli (ngunit medyo matangkad pa rin) na mga anak na lalaki, at ang maiikling ama ay may mas matatangkad (ngunit medyo maikli pa rin) na mga anak na lalaki.
Linya ng regression
Isang mathematical equation na tinatantya ang isang simple (pairwise) linear regression line:
x tinatawag na independent variable o predictor.
(\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).)- dependent variable o response variable. Ito ang halaga na inaasahan natin y(sa karaniwan) kung alam natin ang halaga x, ibig sabihin. ay ang "hulaang halaga" y»
- a- libreng miyembro (intersection) ng linya ng pagsusuri; ito ang kahulugan (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).), Kailan x=0(Larawan 1).
- binigay- slope o gradient ng tinantyang linya; kinakatawan nito ang halaga kung saan Y tataas sa karaniwan kung tataas tayo x bawat isang yunit.
- a At binigay ay tinatawag na regression coefficients ng tinantyang linya, bagaman ang terminong ito ay kadalasang ginagamit lamang para sa binigay.
Ang pairwise linear regression ay maaaring palawigin upang maisama ang higit sa isang independent variable; sa kasong ito ito ay kilala bilang maramihang pagbabalik.
Fig.1. Linear regression line na nagpapakita ng intercept a at ang slope b (ang halaga ng Y ay tumataas habang ang x ay tumataas ng isang yunit)
Paraan ng least squares
Nagsasagawa kami ng pagsusuri ng regression gamit ang isang sample ng mga obserbasyon kung saan a At binigay- mga sample na pagtatantya ng totoo (pangkalahatan) na mga parameter, α at β, na tumutukoy sa linear regression line sa populasyon (pangkalahatang populasyon).
Ang pinakasimpleng paraan para sa pagtukoy ng mga coefficient a At binigay ay paraan ng least squares(MNC).
Ang akma ay tinatasa sa pamamagitan ng pagtingin sa mga nalalabi (vertical na distansya ng bawat punto mula sa linya, hal. residual = naobserbahan y- hinulaang y, Bigas. 2).
Ang linya ng pinakamahusay na akma ay pinili upang ang kabuuan ng mga parisukat ng mga nalalabi ay minimal.

kanin. 2. Linear regression line na may mga natitirang inilalarawan (vertical dotted lines) para sa bawat punto.
Linear Regression Assumptions
Kaya, para sa bawat naobserbahang halaga, ang natitira ay katumbas ng pagkakaiba at ang katumbas na hinulaang halaga ay maaaring maging positibo o negatibo.
Maaari kang gumamit ng mga nalalabi upang subukan ang mga sumusunod na pagpapalagay sa likod ng linear regression:
- Ang mga nalalabi ay karaniwang ipinamamahagi na may mean na zero;
Kung ang mga pagpapalagay ng linearity, normality, at/o pare-parehong pagkakaiba ay kaduda-dudang, maaari nating baguhin o kalkulahin ang isang bagong linya ng regression kung saan nasiyahan ang mga pagpapalagay na ito (halimbawa, gumamit ng logarithmic transformation, atbp.).
Mga anomalyang halaga (outlier) at mga punto ng impluwensya
Ang isang "maimpluwensyang" obserbasyon, kung aalisin, ay nagbabago ng isa o higit pang mga pagtatantya ng parameter ng modelo (ibig sabihin, slope o intercept).
Ang isang outlier (isang obserbasyon na hindi naaayon sa karamihan ng mga halaga sa isang set ng data) ay maaaring maging isang "maimpluwensyang" obserbasyon at madaling makita sa pamamagitan ng pag-inspeksyon sa isang bivariate na scatterplot o natitirang plot.
Parehong para sa mga outlier at para sa "maimpluwensyang" mga obserbasyon (mga puntos), ang mga modelo ay ginagamit, kapwa may kasama at wala ang mga ito, at binibigyang pansin ang mga pagbabago sa mga pagtatantya (regression coefficients).
Kapag nagsasagawa ng pagsusuri, hindi mo dapat awtomatikong itapon ang mga outlier o mga impluwensyang puntos, dahil ang pagwawalang-bahala lamang sa mga ito ay maaaring makaapekto sa mga resultang nakuha. Palaging pag-aralan ang mga dahilan para sa mga outlier na ito at suriin ang mga ito.
Linear regression hypothesis
Kapag gumagawa ng linear regression, ang null hypothesis ay nasubok na ang pangkalahatang slope ng regression line β ay katumbas ng zero.
Kung ang slope ng linya ay zero, walang linear na relasyon sa pagitan ng at: hindi makakaapekto ang pagbabago
Upang subukan ang null hypothesis na ang totoong slope ay zero, maaari mong gamitin ang sumusunod na algorithm:
Kalkulahin ang istatistika ng pagsubok na katumbas ng ratio , na napapailalim sa isang distribusyon na may mga antas ng kalayaan, kung saan ang karaniwang error ng coefficient

 ,
, - pagtatantya ng pagpapakalat ng mga nalalabi.
- pagtatantya ng pagpapakalat ng mga nalalabi.Karaniwan, kung ang antas ng kahalagahan ay naabot, ang null hypothesis ay tinatanggihan.

kung saan ang porsyento ng punto ng pamamahagi na may mga antas ng kalayaan, na nagbibigay ng posibilidad ng isang dalawang panig na pagsubok
Ito ang agwat na naglalaman ng pangkalahatang slope na may posibilidad na 95%.
Para sa malalaking sample, sabihin nating, maaari nating tantiyahin na may halaga na 1.96 (iyon ay, ang istatistika ng pagsubok ay malamang na maipamahagi nang normal)
Pagtatasa ng kalidad ng linear regression: koepisyent ng determinasyon R 2
Dahil sa linear na relasyon at inaasahan namin na nagbabago bilang , at tawagin itong variation na dahil sa o ipinaliwanag ng regression. Ang natitirang variation ay dapat kasing liit hangga't maaari.
Kung ito ay totoo, kung gayon ang karamihan sa mga pagkakaiba-iba ay ipapaliwanag sa pamamagitan ng pagbabalik, at ang mga puntos ay malapit sa linya ng pagbabalik, ibig sabihin. ang linya ay angkop sa data.
Ang proporsyon ng kabuuang pagkakaiba na ipinaliwanag ng regression ay tinatawag koepisyent ng determinasyon, karaniwang ipinapahayag bilang isang porsyento at denoted R 2(sa ipinares na linear regression ito ang dami r 2, parisukat ng koepisyent ng ugnayan), ay nagbibigay-daan sa iyo upang masuri ang kalidad ng equation ng regression.
Ang pagkakaiba ay kumakatawan sa porsyento ng pagkakaiba na hindi maipaliwanag ng regression.
Walang pormal na pagsusulit upang suriin;
Paglalapat ng Regression Line sa Pagtataya
Maaari kang gumamit ng linya ng regression upang mahulaan ang isang halaga mula sa isang halaga sa sukdulan ng naobserbahang hanay (huwag mag-extrapolate nang lampas sa mga limitasyong ito).
Hinuhulaan namin ang ibig sabihin ng mga obserbasyon na may partikular na halaga sa pamamagitan ng pag-plug ng halagang iyon sa equation ng linya ng regression.
Kaya, kung hinuhulaan natin bilang Gamitin ang hinulaang halaga na ito at ang karaniwang error nito upang tantyahin ang agwat ng kumpiyansa para sa tunay na ibig sabihin ng populasyon.
Ang pag-uulit ng pamamaraang ito para sa iba't ibang mga halaga ay nagbibigay-daan sa iyo na bumuo ng mga limitasyon ng kumpiyansa para sa linyang ito. Ito ang banda o lugar na naglalaman ng totoong linya, halimbawa sa 95% na antas ng kumpiyansa.
Mga simpleng plano ng regression
Ang mga simpleng disenyo ng regression ay naglalaman ng isang tuluy-tuloy na predictor. Kung mayroong 3 obserbasyon na may mga predictor na halaga P, tulad ng 7, 4, at 9, at ang disenyo ay may kasamang first-order na epekto P, kung gayon ang design matrix X ay magiging

at ang regression equation gamit ang P para sa X1 ay
Y = b0 + b1 P
Kung ang isang simpleng disenyo ng regression ay naglalaman ng mas mataas na pagkakasunod-sunod na epekto sa P, tulad ng isang quadratic na epekto, kung gayon ang mga halaga sa column X1 sa design matrix ay itataas sa pangalawang kapangyarihan:

at ang equation ay kukuha ng anyo
Y = b0 + b1 P2
Sigma-constrained at overparameterized coding na mga pamamaraan ay hindi nalalapat sa mga simpleng disenyo ng regression at iba pang mga disenyo na naglalaman lamang ng tuluy-tuloy na mga predictor (dahil walang mga kategoryang predictor). Anuman ang napiling paraan ng coding, ang mga halaga ng tuluy-tuloy na mga variable ay naaayon sa pagtaas at ginagamit bilang mga halaga para sa mga variable na X. Sa kasong ito, walang ginagawang recoding. Bilang karagdagan, kapag naglalarawan ng mga plano ng regression, maaari mong alisin ang pagsasaalang-alang sa design matrix X, at gumana lamang sa equation ng regression.
Halimbawa: Simple Regression Analysis
Ginagamit ng halimbawang ito ang data na ipinakita sa talahanayan:

kanin. 3. Talaan ng inisyal na datos.
Ang data na naipon mula sa isang paghahambing ng 1960 at 1970 censuses sa random na piniling 30 county. Ang mga pangalan ng county ay ipinakita bilang mga pangalan ng pagmamasid. Ang impormasyon tungkol sa bawat variable ay ipinakita sa ibaba:

kanin. 4. Talaan ng mga variable na pagtutukoy.
Problema sa pananaliksik
Para sa halimbawang ito, susuriin ang ugnayan sa pagitan ng antas ng kahirapan at ang antas na hinuhulaan ang porsyento ng mga pamilyang nasa ibaba ng linya ng kahirapan. Samakatuwid, ituturing namin ang variable 3 (Pt_Poor) bilang dependent variable.
Maaari tayong maglagay ng hypothesis: magkaugnay ang mga pagbabago sa laki ng populasyon at ang porsyento ng mga pamilyang nasa ibaba ng linya ng kahirapan. Mukhang makatwirang asahan na ang kahirapan ay humahantong sa out-migration, kaya magkakaroon ng negatibong ugnayan sa pagitan ng porsyento ng mga taong nasa ibaba ng linya ng kahirapan at pagbabago ng populasyon. Samakatuwid, ituturing namin ang variable 1 (Pop_Chng) bilang isang predictor variable.
Tingnan ang mga resulta
Mga coefficient ng regression

kanin. 5. Regression coefficients ng Pt_Poor sa Pop_Chng.
Sa intersection ng Pop_Chng row at ng Param column.<.05 . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на.65.
ang unstandardized coefficient para sa regression ng Pt_Poor sa Pop_Chng ay -0.40374. Nangangahulugan ito na sa bawat isang yunit ng pagbaba ng populasyon, mayroong pagtaas ng antas ng kahirapan na .40374. Ang upper at lower (default) na 95% na limitasyon ng kumpiyansa para sa unstandardized coefficient na ito ay hindi kasama ang zero, kaya ang regression coefficient ay makabuluhan sa p level
Variable distribution

Ang mga koepisyent ng ugnayan ay maaaring maging labis na labis na tantiyahin o maliitin kung mayroong malalaking outlier sa data. Pag-aralan natin ang distribusyon ng dependent variable na Pt_Poor ayon sa distrito. Upang gawin ito, bumuo tayo ng histogram ng variable na Pt_Poor.
kanin. 6. Histogram ng variable na Pt_Poor.

Tulad ng nakikita mo, ang distribusyon ng variable na ito ay kapansin-pansing naiiba sa normal na distribusyon. Gayunpaman, kahit na ang dalawang county (ang dalawang kanang hanay) ay may mas mataas na porsyento ng mga pamilya na nasa ibaba ng linya ng kahirapan kaysa sa inaasahan sa ilalim ng normal na pamamahagi, lumilitaw na sila ay "sa loob ng saklaw."
kanin. 7. Histogram ng variable na Pt_Poor.
Ang paghatol na ito ay medyo subjective. Ang panuntunan ng thumb ay ang mga outlier ay dapat isaalang-alang kung ang obserbasyon (o mga obserbasyon) ay hindi nasa loob ng pagitan (mean ± 3 beses ang karaniwang paglihis). Sa kasong ito, sulit na ulitin ang pagsusuri nang may at walang outlier upang matiyak na wala silang malaking epekto sa ugnayan sa pagitan ng mga miyembro ng populasyon.
Scatterplot

Kung ang isa sa mga hypotheses ay isang priori tungkol sa relasyon sa pagitan ng mga ibinigay na variable, kung gayon ito ay kapaki-pakinabang na subukan ito sa graph ng kaukulang scatterplot.
kanin. 8. Scatter diagram.
Ang scatterplot ay nagpapakita ng malinaw na negatibong ugnayan (-.65) sa pagitan ng dalawang variable. Ipinapakita rin nito ang 95% confidence interval para sa regression line, ibig sabihin, mayroong 95% na posibilidad na ang regression line ay nasa pagitan ng dalawang dotted curve.

Pamantayan sa kahalagahan
Ang pagsubok para sa koepisyent ng pagbabalik ng Pop_Chng ay nagpapatunay na ang Pop_Chng ay malakas na nauugnay sa Pt_Poor , p<.001 .
Bottom line
Ang halimbawang ito ay nagpakita kung paano suriin ang isang simpleng disenyo ng regression. Ang mga interpretasyon ng hindi pamantayan at standardized na mga coefficient ng regression ay ipinakita din. Ang kahalagahan ng pag-aaral ng distribusyon ng tugon ng isang dependent variable ay tinalakay, at isang pamamaraan para sa pagtukoy ng direksyon at lakas ng relasyon sa pagitan ng isang predictor at isang dependent variable ay ipinapakita.
























