|
Mabilis na pagpapatupad ng ERP Mga komprehensibong serbisyo |
Pamamahala ng paghahatid Para sa mga kumpanya ng pangangalakal at courier! |
1C:EDO Alamin ang lahat ng benepisyo pamamahala ng elektronikong dokumento! |
Paglipat sa “1C:ZUP ed. 3" Ang kumpanyang "1C" ay huminto sa pagsuporta sa "1C:ZUP 2.5"! |
Magrenta ng 1C server |



1C server cluster - pagbuo ng mga high-load system
Mag-order ng isang demonstration OrderIsasaalang-alang ng artikulong ito ang ilang mga opsyon para sa istraktura ng 1C para sa mga system na may mataas na load (mula sa 200 aktibong gumagamit), na binuo batay sa arkitektura ng client-server - ang kanilang mga pakinabang at disadvantages, mga gastos sa pag-install at mga comparative na pagsubok ng pagganap ng bawat opsyon.
Hindi namin ilalarawan, susuriin at ihahambing ang karaniwang tinatanggap at matagal nang kilalang klasikal na mga scheme para sa pagbuo ng 1C server structure, gaya ng hiwalay na 1C server at hiwalay na DBMS server, o kumpol ng Microsoft SQL na may 1C cluster. Napakaraming ganoong pagsusuri, kabilang ang mga isinagawa mismo ng mga gumagawa ng produkto ng software. Mag-aalok kami ng pangkalahatang-ideya ng mga scheme ng disenyo ng istruktura ng 1C na nakatagpo sa nakalipas na ilang taon sa aming mga proyekto sa IT para sa katamtaman at malalaking negosyo.
Mga kinakailangan para sa mataas na load na 1C system
Ang mga high load na 1C system na gumagana sa malalaking halaga ng data 24/7/365 ay napapailalim sa mga risk factor na hindi karaniwang sinusunod sa mga karaniwang sitwasyon. Bilang isang resulta, upang maalis at maiwasan ang mga ito, ang paggamit ng mga espesyal na 1C architecture scheme at mga bagong teknolohiya ay kinakailangan.
DBMS disaster resistance. Sa proseso ng pagdidisenyo ng 1C na arkitektura, binibigyang-diin ang kapangyarihan sa pag-compute at mataas na kakayahang magamit ng mga serbisyo, na ipinahayag sa kanilang clustering. Bilang default, ang mga server ng 1C:Enterprise ay may kakayahang gumana sa isang kalabisan na cluster, at para sa isang DBMS cluster, isang pang-industriya na data storage system (SDS) at teknolohiya ng clustering (halimbawa, Microsoft SQL Cluster) ay karaniwang ginagamit. Gayunpaman, nagiging mahirap ang sitwasyon kapag may mga problema sa mismong storage system (kadalasan, sa aming karanasan mga nakaraang taon- ito ay mga problema programmatic). Pagkatapos ang IT engineer ay biglang nahaharap sa dalawang problema: kung saan kukuha ng up-to-date na data at kung saan ito ilalagay sa lalong madaling panahon, dahil hindi available ang isang storage system na may kinakailangang kapasidad ng isang fast disk array.
Mga kinakailangan sa seguridad ng database. Sa pagtatrabaho sa mga proyekto ng katamtaman at malalaking negosyo, regular kaming nakatagpo ng mga kinakailangan para sa proteksyon ng personal na data (sa partikular, upang sumunod sa mga talata ng Pederal na Batas-152). Isa sa mga kundisyon para matugunan ang mga kinakailangang ito ay upang matiyak ang wastong seguridad ng personal na data, na nangangailangan ng pag-encrypt ng 1C database.
Kapag bumubuo ng isang pamamaraan para sa mataas na load na mga sistema ng 1C, karaniwang binibigyang pansin nila ang mga parameter sistema ng disk I/O kung saan matatagpuan ang mga database. Ngunit bukod dito, mayroon ding aktibong paggamit ng mga mapagkukunan ng CPU at pagkonsumo ng RAM ng 1C server. Kadalasan, ang ganitong uri ng mapagkukunan ang kulang; ang mga posibilidad para sa pag-upgrade ng hardware ng kasalukuyang 1C server ay naubos at kinakailangan na magdagdag ng mga bagong 1C server na nagtatrabaho sa isang server ng DBMS.Mga scheme para sa pag-aayos ng mga cluster ng 1C server
Scheme na may cluster ng mga 1C server na konektado sa isang cluster na may kasabay na SQL AlwaysOn replication sa pamamagitan ng IP. Ang scheme na ito ay isa sa mga opsyon na may mataas na kalidad para sa paglutas ng problema ng disaster resistance ng 1C database (tingnan ang Figure 1). Ang SQL AlwaysOn database clustering technology ay batay sa prinsipyo ng online na pag-synchronize ng mga SQL table sa pagitan ng pangunahing at backup na mga server nang walang interbensyon end user. SA gamit ang SQL Ang tagapakinig ay may kakayahang lumipat sa isang backup na SQL server kung sakaling mabigo ang pangunahing isa, na nagpapahintulot sa amin na tawagan ang sistemang ito na isang ganap na disaster-proof na SQL cluster, salamat sa paggamit ng dalawang independiyenteng SQL server. Ang teknolohiyang SQL Always On ay magagamit lamang sa Mga bersyon ng Microsoft SQL Enterprise.

Figure 1 - diagram ng isang kumpol ng mga 1C server + SQL AlwaysOn
Ang pangalawang pamamaraan ay magkapareho sa una, tanging ang pag-encrypt ng mga database ng SQL sa pangunahing at mga backup na server ay idinagdag. Nabanggit na namin na ang trabaho sa kamakailang mga proyekto sa IT ay nagpakita na ang mga kumpanya ay nagsimulang magbayad ng higit na pansin sa isyu ng seguridad ng data, para sa iba't ibang mga kadahilanan - ang mga kinakailangan ng Federal Law-152, raider takeovers ng mga server, data leaks sa cloud , at mga katulad nito. Kaya't isinasaalang-alang namin ang bersyong ito ng 1C scheme na medyo may kaugnayan (tingnan ang Larawan 2).

Figure 2 - diagram ng isang cluster ng 1C + SQL AlwaysOn server na may encryption
Isang cluster ng 1C "active-active" na mga server na konektado sa isang DBMS server sa pamamagitan ng IP. Sa kaibahan sa mga pangangailangan para sa fault tolerance at seguridad, ang ilang mga istraktura ay pangunahing nangangailangan ng mas mataas na pagganap, kaya sabihin, "lahat ng kapangyarihan sa pag-compute." Samakatuwid, ang pinakamataas na priyoridad ay ibinibigay sa pagtaas ng bilang ng 1C server computing clusters, kung saan pinapayagan ng modernong 1C platform ang pagkita ng kaibahan. iba't ibang uri computing at background na mga trabaho (tingnan ang Larawan 3). Siyempre, ang hanay ng mga pangunahing mapagkukunan ng SQL server ay dapat ding maging hanggang sa pamantayan, ngunit ang database server mismo ay ipinakita sa isahan (tila, ang pagkalkula ay ginawa para sa napapanahong pag-backup ng mga database).
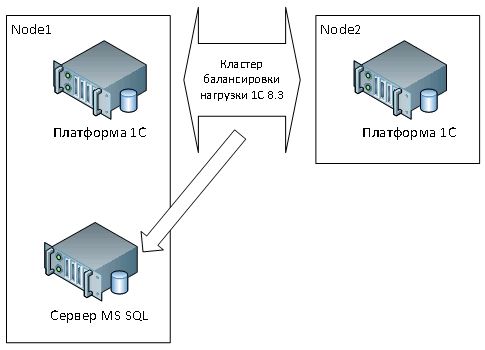
Figure 3 - diagram ng isang 1C server cluster na may isang DBMS server
1C server at DBMS sa isa server ng hardware gamit ang SharedMemory. Dahil ang aming mga praktikal na pagsusulit ay nakatuon sa paghahambing ng pagganap ng iba't ibang mga scheme, ang ilang uri ng pamantayan ay kinakailangan upang ihambing ang ilang mga pagpipilian (tingnan ang Larawan 4). Bilang isang pamantayan, sa aming opinyon, kailangan mong kunin ang layout ng 1C server at ang DBMS sa isang server ng hardware nang walang virtualization na may pakikipag-ugnayan sa pamamagitan ng SharedMemory.

Figure 4 - diagram ng 1C server at DBMS sa isang hardware server na may SharedMemory
Nasa ibaba ang pangkalahatang talahanayan ng paghahambing na nagpapakita ng pangkalahatang mga resulta para sa pangunahing pamantayan pagtatasa ng organisasyon ng istraktura ng 1C system (tingnan ang Talahanayan 1).
| Pamantayan para sa pagsusuri ng mga arkitektura ng 1C | Cluster 1C + SQL Palaging Naka-on |
Cluster 1C + SQL AlwaysOn na may encryption |
1C cluster na may isang DBMS server |
Klasikong 1C+DBMS SharedMemory |
| Dali ng pag-install at pagpapanatili | Nasiyahan | Nasiyahan | ayos lang | Mahusay |
| Pagpapahintulot sa kasalanan | Mahusay | Mahusay | Nasiyahan | Hindi naaangkop |
| Kaligtasan | Nasiyahan | Mahusay | Nasiyahan | Nasiyahan |
| Pagbabadyet | Nasiyahan | Nasiyahan | ayos lang | Mahusay |
Talahanayan 1 - paghahambing ng mga opsyon para sa pagbuo ng mga 1C system
Sa nakikita mo, isa na lang ang natitira mahalagang criterion, ang kahulugan nito ay nananatiling produktibo. Para magawa ito, magsasagawa kami ng serye ng mga praktikal na pagsubok sa isang nakalaang test bench.
Paglalarawan ng pamamaraan ng pagsubok
Ang yugto ng pagsubok ay binubuo ng dalawang pangunahing tool para sa pagbuo ng synthetic na load at pagtulad sa trabaho ng user sa 1C. Ito ang Gilev test (TPC-1C) at ang “Test Center” mula sa 1C: Instrumentation toolkit.
Pagsusulit ni Gilev. Ang pagsubok ay nabibilang sa seksyon ng unibersal na integral cross-platform na mga pagsubok. Maaari itong magamit para sa parehong mga bersyon ng file at client-server ng 1C:Enterprise. Sinusuri ng pagsubok ang dami ng trabaho sa bawat yunit ng oras sa isang thread at angkop para sa pagtatasa ng bilis ng mga single-threaded load, kabilang ang bilis ng pag-render ng interface, ang epekto ng mga gastos sa mapagkukunan sa pagpapanatili ng isang virtual na kapaligiran, pag-repost ng mga dokumento, pagsasara ng buwan, pagkalkula ng suweldo, atbp. Binibigyang-daan ka ng Universality na gumawa ng pangkalahatang pagtatasa ng pagganap nang hindi nakatali sa isang partikular na tipikal na configuration ng platform. Ang resulta ng pagsusulit ay isang buod na pagtatasa ng sinusukat na 1C system, na ipinahayag sa mga karaniwang yunit.
Espesyal na "Test Center" mula sa 1C: Instrumentation toolkit. Ang Test Center ay isang tool para sa pag-automate ng mga multi-user load test ng mga sistema ng impormasyon sa 1C:Enterprise 8 platform Sa tulong nito, maaari mong gayahin ang pagpapatakbo ng isang enterprise nang walang partisipasyon ng mga tunay na user, na nagbibigay-daan sa iyong suriin ang applicability. pagganap at scalability ng isang sistema ng impormasyon sa totoong mga kondisyon. Gamit ang 1C: KIP tool, batay sa mga proseso at pagsubok na kaso, ang matrix na "Listahan ng mga Bagay ng ERP 2.2 database layout" ay nabuo para sa senaryo ng pagsubok sa pagganap. Sa 1C: ERP 2.2 database layout, ang data ay nabuo sa pamamagitan ng pagproseso ayon sa Regulatory Reference Information (RNI):
- Ilang libong nomenclature item;
- Ilang organisasyon;
- Ilang libong katapat.
Isinasagawa ang pagsubok sa loob ng ilang grupo ng gumagamit. Ang grupo ay binubuo ng 4 na user, bawat isa ay may sariling tungkulin at isang listahan ng mga sunud-sunod na operasyon. Salamat sa flexible na mekanismo para sa pagtatakda ng mga parameter para sa pagsubok, maaari mong patakbuhin ang pagsubok iba't ibang dami mga user, na magbibigay-daan sa iyong suriin ang pag-uugali ng system sa ilalim ng iba't ibang mga pag-load at tukuyin ang mga parameter na maaaring humantong sa mahinang pagganap. 3 pagsubok ang isinasagawa sa 3 pag-ulit kung saan ang 1C developer ay nagpapatakbo ng isang pagsubok na tumutulad sa gawain ng user at sinusukat ang oras ng pagpapatupad ng bawat operasyon. Ang lahat ng tatlong mga pag-ulit ay sinusukat para sa bawat isa sa mga 1C structure scheme. Ang resulta ng pagsubok ay upang makuha ang average na oras ng pagpapatupad ng operasyon para sa bawat dokumento ng matrix.
Ang mga indicator ng "Test Center" at ang Gilev test ay makikita sa pivot table 2.
Test stand
Server pag-access sa terminal – virtual machine, na ginagamit upang pamahalaan ang mga tool sa pagsubok:
- vCPU - 16 core 2.6GHz
- RAM - 32 GB
- I\o: Intel Sata SSD Raid1
- RAM - 96 GB
- I\o: Intel Sata SSD Raid1
1C Server at DBMS - pisikal na server
- CPU - Intel Xeon Processor E5-2670 8C 2.6GHz – 2 pcs.
- RAM - 96 GB
- I\o: Intel Sata SSD Raid1
- Mga Tungkulin: 1C Server 8.3.8.2137, MS SQL Server 2014 SP 2
Mga konklusyon
Maaari naming tapusin na, batay sa average na oras ng operasyon, ang pinakamainam ay ang scheme No. 3 "Cluster ng 1C "active-active" server na konektado sa isang server ng DBMS sa pamamagitan ng IP protocol" (tingnan ang Talahanayan 2). Para matiyak ang fault tolerance ng naturang arkitektura, inirerekomenda namin ang pagbuo ng isang klasikong MSSQL failover cluster na may database na matatagpuan sa isang hiwalay na storage system.
Mahalagang tandaan na ang pinakamainam na ratio ng mga salik para sa pagliit ng downtime, fault tolerance at kaligtasan ng data ay nasa scheme No. 1 "Cluster ng 1C server na konektado sa isang cluster na may kasabay na SQL AlwaysOn replication sa pamamagitan ng IP", habang ang performance ay bumaba kumpara. sa pinaka produktibong opsyon ay humigit-kumulang 10%.
Tulad ng nakikita natin mula sa mga resulta ng pagsubok, sabay-sabay na pagtitiklop Mga database ng SQL Ang AlwaysOn ay may medyo negatibong epekto sa pagganap. Ito ay ipinaliwanag sa pamamagitan ng katotohanan na ang SQL system ay naghihintay para sa pagtatapos ng pagtitiklop ng bawat transaksyon sa backup na server, na hindi nagpapahintulot sa iyo na magtrabaho kasama ang database sa oras na ito. Maiiwasan ito sa pamamagitan ng pag-set up ng asynchronous na pagtitiklop sa pagitan ng mga server ng MSSQL, ngunit sa gayong mga setting hindi kami makakakuha ng awtomatikong paglipat ng mga application sa backup node kung sakaling mabigo. Ang switch ay kailangang gawin nang manu-mano.
Batay sa EFSOL cloud, nag-aalok kami sa aming mga kliyente 1C server cluster para sa upa. Ito ay nagbibigay-daan sa iyo upang makabuluhang makatipid ng pera sa pagbuo ng iyong sariling fault-tolerant na arkitektura para sa pagtatrabaho sa 1C.
|
1C architecture diagram |
Average na oras para makumpleto ang isang operasyon, sec | ||
MTBF (Mean Time Between Failure) - ibig sabihin ng oras sa pagitan ng mga pagkabigo.
MTTR (Mean Time To Repair) - average na oras para ibalik ang functionality.
Hindi tulad ng pagiging maaasahan, ang halaga nito ay tinutukoy lamang ng halaga ng MTBF, ang kakayahang magamit ay depende rin sa oras na kinakailangan upang ibalik ang system sa isang operating state.
Ano ang isang high availability cluster?
Ang high availability cluster (simula dito ay tinutukoy bilang cluster) ay isang uri ng cluster system na idinisenyo upang matiyak ang tuluy-tuloy na operasyon ng kritikal mahahalagang aplikasyon o mga serbisyo. Ang paggamit ng high-availability cluster ay nagbibigay-daan sa iyo na maiwasan ang parehong hindi planadong downtime na dulot ng hardware at software failure, pati na rin ang nakaplanong downtime na kinakailangan para sa mga update ng software o preventive maintenance ng equipment.
Ang schematic diagram ng isang high availability cluster ay ipinapakita sa figure:
Ang isang cluster ay binubuo ng dalawang node (server) na konektado sa isang karaniwang disk array. Ang lahat ng mga pangunahing bahagi ng disk array na ito - power supply, disk drive, I/O controller - ay kalabisan at hot-swappable. Ang mga cluster node ay konektado sa isa't isa panloob na network upang magbahagi ng impormasyon tungkol sa iyong kasalukuyang katayuan. Ang cluster ay pinapagana mula sa dalawang independiyenteng mapagkukunan. Pagkonekta sa bawat node sa isang panlabas lokal na network nadoble din.
Kaya, ang lahat ng mga subsystem ng cluster ay may redundancy, kaya kung ang anumang elemento ay nabigo, ang cluster sa kabuuan ay mananatiling operational. Bukod dito, ang pagpapalit ng isang nabigong elemento ay posible nang hindi humihinto sa kumpol.
Ang Microsoft operating system ay naka-install sa parehong mga cluster node Windows Server 2003 Enterprise, na sumusuporta sa teknolohiya ng Microsoft Windows Cluster Service (MSCS).
Ang prinsipyo ng pagpapatakbo ng kumpol ay ang mga sumusunod. Ang application (serbisyo), ang pagkakaroon ng kung saan ay ibinibigay ng kumpol, ay naka-install sa parehong mga node. Ang isang pangkat ng mapagkukunan ay nilikha para sa application na ito (serbisyo), kabilang ang isang IP address at pangalan ng network virtual server, pati na rin ang isa o higit pang mga lohikal na disk sa isang shared disk array. Kaya, ang application, kasama ang pangkat ng mga mapagkukunan nito, ay hindi "mahigpit na nakatali" sa isang tiyak na node, ngunit, sa kabaligtaran, ay maaaring ilunsad sa alinman sa mga node na ito (at maraming mga application ang maaaring tumakbo nang sabay-sabay sa bawat node). Sa turn, ang mga kliyente ng application na ito (serbisyo) ay "makikita" hindi ang mga cluster node sa network, ngunit virtual server(pangalan ng network at IP address) kung saan ito tumatakbo ang application na ito.
Una, ang application ay inilunsad sa isa sa mga node. Kung ang node na ito ay hihinto sa paggana sa anumang kadahilanan, ang kabilang node ay hihinto sa pagtanggap ng isang tibok ng puso mula dito at awtomatikong magsisimula ang lahat ng mga aplikasyon ng nabigong node, i.e. mga application, kasama ang kanilang mga resource group, "lumipat" sa malusog na node. Maaaring tumagal ang paglilipat ng application mula sa ilang segundo hanggang ilang sampu-sampung segundo, at sa panahong ito ay hindi available ang application sa mga kliyente. Depende sa uri ng aplikasyon, pagkatapos ng pag-restart ang session ay awtomatikong ipagpatuloy o maaaring kailanganin ng kliyente na muling pahintulutan. Walang mga pagbabago sa configuration ang kinakailangan sa panig ng kliyente. Kapag na-restore na ang isang nabigong node, maaaring mag-migrate pabalik ang mga application nito.
Kung tumatakbo ang bawat cluster node iba't ibang mga aplikasyon, kung ang isa sa mga node ay nabigo, ang pagkarga sa kabilang node ay tataas at ang pagganap ng aplikasyon ay bababa.
Kung ang mga application ay tumatakbo sa isang node lamang, at ang isa pang node ay ginagamit bilang isang backup, kung gayon kung ang "gumagana" na node ay nabigo, ang pagganap ng cluster ay hindi magbabago (sa kondisyon na ang backup na node ay hindi "mas mahina").
Ang pangunahing bentahe ng mga cluster na may mataas na availability ay ang kakayahang gumamit ng karaniwang hardware at software, na ginagawang mura at naa-access ang solusyon na ito para sa pagpapatupad ng maliliit at katamtamang laki ng mga negosyo.
Kinakailangang makilala ang mga cluster na may mataas na kakayahang magamit mula sa mga fault-tolerant system ("fault-tolerant"), na binuo sa prinsipyo ng kumpletong pagdoble. Sa ganitong mga sistema, ang mga server ay nagpapatakbo nang magkatulad sa isang kasabay na mode. Ang bentahe ng mga sistemang ito ay ang maikling (mas mababa sa isang segundo) na oras ng pagbawi pagkatapos ng isang pagkabigo, ngunit ang kawalan ay mataas na gastos dahil sa pangangailangang gumamit ng mga espesyal na solusyon sa software at hardware.
Paghahambing ng mataas na availability cluster sa isang regular na server
Gaya ng nabanggit sa itaas, ang paggamit ng mga cluster ng mataas na availability ay maaaring mabawasan ang downtime na dulot ng nakaplano o hindi planadong mga shutdown.
Ang mga nakaplanong shutdown ay maaaring dahil sa pangangailangang mag-update ng software o magsagawa ng preventive maintenance ng kagamitan. Sa isang cluster, ang mga operasyong ito ay maaaring isagawa nang sunud-sunod sa iba't ibang mga node nang hindi nakakaabala sa operasyon ng cluster sa kabuuan.
Nangyayari ang hindi planadong pagsasara dahil sa mga pagkabigo ng software o hardware. Sa kaganapan ng isang pagkabigo ng software sa isang regular na server, ang isang pag-reboot ng operating system o application ay kinakailangan sa kaso ng isang cluster, ang application ay lilipat sa isa pang node at patuloy na gagana.
Ang hindi mahuhulaan na kaganapan ay ang pagkabigo ng kagamitan. Alam namin mula sa karanasan na ang server ay isang medyo maaasahang device. Ngunit posible bang makuha tiyak na mga numero, na sumasalamin sa antas ng kahandaan ng server at kumpol?
Karaniwang tinutukoy ng mga tagagawa ng mga bahagi ng computer ang kanilang pagiging maaasahan batay sa batch testing gamit ang sumusunod na formula:
Halimbawa, kung 100 produkto ang sinubukan sa loob ng isang taon at 10 sa mga ito ang nabigo, ang MTBF na kinakalkula gamit ang formula na ito ay magiging 10 taon. Yung. Ipinapalagay na pagkatapos ng 10 taon ang lahat ng mga produkto ay mabibigo.
Mula dito maaari nating makuha ang mga sumusunod na mahahalagang konklusyon. Una, ang pamamaraang ito ng pagkalkula ng MTBF ay ipinapalagay na ang bilang ng mga pagkabigo sa bawat yunit ng oras ay pare-pareho sa buong buhay ng serbisyo. Sa "tunay" na buhay, siyempre, hindi ito ang kaso. Sa katunayan, mula sa teorya ng pagiging maaasahan ay kilala na ang curve ng kabiguan ay may sumusunod na anyo:

Sa zone I, lumilitaw ang mga pagkabigo ng mga produkto na may mga depekto sa pagmamanupaktura. Sa zone III, ang mga pagbabago sa pagkapagod ay nagsisimulang makaapekto. Sa zone II, ang mga pagkabigo ay sanhi ng mga random na kadahilanan at ang kanilang bilang ay pare-pareho sa bawat yunit ng oras. Ang mga tagagawa ng bahagi ay "pinahaba" ang zone na ito sa buong buhay ng serbisyo. Ang tunay na mga istatistika ng pagkabigo sa buong buhay ng serbisyo ay nagpapatunay na ang teoretikal na modelong ito ay medyo malapit sa katotohanan.
Ang pangalawang kawili-wiling konklusyon ay ang konsepto ng MTBF ay hindi sumasalamin sa kung ano ang malinaw na ipinahihiwatig ng pangalan nito. Ang ibig sabihin ng "Mean Time Between Failures" ay isang oras na kalahati lang ng MTBF. Kaya, sa aming halimbawa, ang "average na oras" na ito ay hindi magiging 10 taon, ngunit lima, dahil sa karaniwan ang lahat ng mga kopya ng produkto ay gagana hindi 10 taon, ngunit kalahati ang haba. Yung. Ang MTBF na idineklara ng tagagawa ay ang oras kung kailan mabibigo ang produkto na may 100% na posibilidad.
Kaya, dahil ang posibilidad ng isang bahagi na nabigo sa isang MTBF ay 1, at kung ang MTBF ay sinusukat sa mga taon, kung gayon ang posibilidad ng isang bahagi ay nabigo sa loob ng isang taon ay:
| P= | 1 |
| MTBF |
Malinaw, ang pagkabigo ng alinman sa mga hindi kalabisan na bahagi ng server ay mangangahulugan ng pagkabigo ng server sa kabuuan.
Ang pagkabigo ng isang dobleng bahagi ay magreresulta lamang sa isang pagkabigo ng server kung ang duplicate na bahagi ay nabigo din sa loob ng oras na kinakailangan upang mai-hot-swap ang bahagi na unang nabigo. Kung ang garantisadong oras ng pagpapalit para sa isang bahagi ay 24 na oras (1/365 ng isang taon) (na naaayon sa mga itinatag na kasanayan sa pagpapanatili ng hardware ng server), kung gayon ang posibilidad ng naturang kaganapan sa loob ng isang taon ay:
| Pd = | P x P | x 2 |
| 365 |
Mga paliwanag para sa formula.
Narito mayroon kaming dalawang magkatulad na mga kaso kung saan nabigo ang parehong mga bahagi.
Kaso (1)
- Pagkabigo ng component No. 1 sa anumang oras sa buong taon (probability P)
- Pagkabigo ng component #2 sa loob ng 24 na oras pagkatapos ng pagkabigo ng component #1 (probability P/365)
Ang posibilidad ng mga kaganapang ito na nangyayari nang sabay-sabay ay katumbas ng produkto ng kanilang mga probabilidad.
Para sa case (2), kapag nabigo muna ang component #2 at pagkatapos ay ang component #1, magiging pareho ang probabilidad.
Dahil ang mga kaso (1) at (2) ay hindi maaaring mangyari nang sabay-sabay, ang posibilidad na mangyari ang isa o ang isa ay katumbas ng kabuuan ng kanilang mga probabilidad.
Ngayon, alam ang posibilidad na Pi ng pagkabigo ng bawat isa sa mga bahagi ng N (nadoble at hindi kalabisan) ng server, maaari nating kalkulahin ang posibilidad ng pagkabigo ng server sa loob ng isang taon.
Gawin natin ang pagkalkula tulad ng sumusunod.
Tulad ng nabanggit na, ang pagkabigo ng anumang bahagi ay mangangahulugan ng pagkabigo ng server sa kabuuan.
Ang posibilidad ng walang kabiguan na operasyon ng anumang bahagi sa loob ng isang taon ay
| Pi" = 1 - Pi |
Ang posibilidad ng walang kabiguan na operasyon ng lahat ng mga bahagi sa buong taon ay katumbas ng produkto ng mga probabilidad ng mga independyenteng kaganapang ito:
| PS' = ∏ Pi" |
Pagkatapos ay ang posibilidad ng isang pagkabigo ng server sa loob ng isang taon
Ngayon ay matutukoy mo na ang availability factor:
| Ks = | Mga MTBF |
| Mga MTBF + MTTR |
Lumipat tayo sa pagkalkula. Hayaang binubuo ng aming server ang mga sumusunod na bahagi:

Larawan 1. Komposisyon ng server
Ibuod natin ang data ng mga tagagawa sa pagiging maaasahan ng mga indibidwal na bahagi sa sumusunod na talahanayan:
| Mga bahagi ng server | Inangkin ang pagiging maaasahan | Dami mga bahagi sa server | Probability pagtanggi isinasaalang-alang pagdoble |
||
| MTBF (oras) | MTBF (taon) | Probability pagtanggi sa taon |
|||
| yunit ng kuryente | 90 000 | 10,27 | 0,09733 | 2 | 0,0000519 |
| System board | 300 000 | 34,25 | 0,02920 | 1 | 0,0292000 |
| Processor #1 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| Processor #2 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| RAM, module No. 1 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| RAM, module No. 2 | 1 000 000 | 114,16 | 0,00876 | 1 | 0,0087600 |
| Hard drive | 400 000 | 45,66 | 0,02190 | 2 | 0,0000026 |
| Fan No. 1 | 100 000 | 11,42 | 0,08760 | 2 | 0,0000420 |
| Fan No. 2 | 100 000 | 11,42 | 0,08760 | 2 | 0,0000420 |
| HDD controller | 300 000 | 34,25 | 0,02920 | 1 | 0,0292000 |
| Interface board | 300 000 | 34,25 | 0,02920 | 1 | 0,0292000 |
| Tape drive | 220 000 | 25,11 | 0,03982 | 1 | 0,0398182 |
| Para sa server sa kabuuan: | 0,37664 | 0,1519961 | |||
Sa pangkalahatan, para sa kagamitan ng server ang normal na kadahilanan sa pagkakaroon ay itinuturing na 99.95%, na humigit-kumulang tumutugma sa resulta ng aming mga kalkulasyon.
Magsagawa tayo ng katulad na pagkalkula para sa isang kumpol.
Ang cluster ay binubuo ng dalawang node at isang panlabas na disk array. Ang kabiguan ng cluster ay magaganap alinman sa kaganapan ng pagkabigo ng disk array o sa kaganapan ng isang sabay-sabay na pagkabigo ng parehong mga node sa panahon na kinakailangan upang maibalik ang unang node na mabigo.
Ipagpalagay natin na ang server na isinasaalang-alang natin na may availability factor na K = 99.958% ay ginagamit bilang cluster node, at ang oras ng pagbawi para sa node ay 24 na oras.
Kalkulahin natin ang mga parameter ng pagiging maaasahan ng panlabas na hanay ng disk:
| Mga Bahagi ng Array | Inangkin ang pagiging maaasahan | Qty komposisyon Nentov sa array | Probability pagtanggi isinasaalang-alang pagdoble |
||
| MTBF (oras) | MTBF (taon) | Probability pagtanggi sa taon |
|||
| yunit ng kuryente | 90 000 | 10,27 | 0,09733 | 2 | 0,0000519 |
| Hard drive | 400 000 | 45,66 | 0,02190 | 2 | 0,0000026 |
| Fan | 100 000 | 11,42 | 0,08760 | 2 | 0,0000420 |
| HDD controller | 300 000 | 34,25 | 0,02920 | 2 | 0,0000047 |
| Para sa array sa kabuuan: | 0,21797 | 0,0001013 | |||
Kaya, ang isang high-availability cluster ay nagpapakita ng mas mataas na resilience sa posibleng pagkabigo ng hardware kaysa sa isang tradisyonal na arkitektura ng server.
Pagkatapos ng ilang taong pananahimik, nagpasya akong ibahagi ang aking karanasan sa pag-deploy ng failover cluster sa Nakabatay sa Windows Server 2012.Pahayag ng problema: Mag-deploy ng failover cluster upang mag-host ng mga virtual machine, na may kakayahang paghiwalayin ang mga virtual machine sa magkahiwalay na mga virtual subnet (VLAN), tiyakin ang mataas na pagiging maaasahan, ang kakayahang magpalit ng pagpapanatili ng server, at tiyakin ang pagkakaroon ng mga serbisyo. Tiyaking natutulog nang mapayapa ang iyong departamento ng IT.
Upang magawa ang gawain sa itaas, nakuha namin sa aming sarili ang mga sumusunod na kagamitan:
- Server ng HP ProLiant DL 560 Gen8 4x Xeon 8 core 64 GB RAM 2 pcs.
- SAS Storage HP P2000 para sa 24 2.5" na disk 1 pc.
- Mga disk para sa imbakan 300 Gb 24 na mga PC. //Hindi maganda ang volume, ngunit sa kasamaang palad, ang mga badyet ay ganoong mga badyet...
- Controller para sa Mga koneksyon sa SAS gawa ng HP 2 pcs.
- Network adapter para sa 4 1Gb port 2 pcs. //Posibleng kumuha ng module para sa 4 SFP, ngunit wala kaming kagamitan na sumusuporta sa 10 Gb na koneksyon ay sapat na.
Organisasyon ng mga koneksyon:

Talagang nakakonekta ito sa 2 magkaibang switch. Maaaring konektado sa 4 na magkakaibang. Sa tingin ko, sapat na ang 2x.
Sa mga switch port kung saan nakakonekta ang mga server, kailangang baguhin ang interface mode mula sa access sa trunk upang maipamahagi sa mga virtual subnet.
Habang nagda-download ang mga update sa bagong naka-install na Windows Server 2012, i-configure natin imbakan ng disk. Nagpaplano kaming mag-deploy ng database server, kaya nagpasya kaming gumamit ng 600 GB para sa mga database, ang iba ay para sa iba. mga virtual machine, tulad ng isang tautolohiya.
Lumikha ng mga virtual na disk:
- Raid10 disk batay sa Raid 1+0 ng 4 na disk +1 na ekstra
- Raid5 disk batay sa Raid 5 ng 16 na disk +1 na ekstra
- 2 disk - mga ekstrang bahagi
Ngayon ay kailangan mong lumikha ng mga partisyon.
- raid5_quorum - Ang tinatawag na witness disk (saksi). Kinakailangan upang ayusin ang isang kumpol ng 2 node.
- raid5_store - Dito kami mag-iimbak ng mga virtual machine at ang kanilang mga hard drive
- raid10_db - Ang hard disk ng MS SQL server virtual machine ay maiimbak dito
Kinakailangang paganahin ang tampok na Microsoft Multipath IO, kung hindi, kapag ang server ay kumonekta sa parehong mga controller ng imbakan, ang system ay magkakaroon ng 6 na disk, sa halip na 3, at ang kumpol ay hindi mag-iipon, na nagbibigay ng isang error na nagsasabi na mayroon kang mga disk na pareho. serial number, at magiging tama ang wizard na ito, gusto kong sabihin sa iyo.
Inirerekomenda ko ang pagkonekta ng mga server sa imbakan nang paisa-isa:
- Nakakonekta ang 1 server sa 1 storage controller
- 1 nakakonektang host ang lalabas sa storage - bigyan ito ng pangalan. Pinapayuhan ko kayong tawagan ito sa ganitong paraan: server name_controller number (A o B)
- At iba pa hanggang sa ikonekta mo ang parehong mga server sa parehong mga controller.
Sa mga switch kung saan nakakonekta ang mga server, kailangan mong lumikha ng 3 virtual subnets (VLAN):
- ClusterNetwork - dito napupunta ang impormasyon ng serbisyo ng cluster (tibok ng puso, regulasyon sa pagsulat ng storage)
- LiveMigration - Sa tingin ko malinaw na ang lahat dito
- Pamamahala - network para sa pamamahala
Kinukumpleto nito ang paghahanda ng imprastraktura. Magpatuloy tayo sa pag-set up ng mga server at pagpapalaki ng cluster.
Ikinonekta namin ang mga server sa domain. I-install ang papel na Hyper-V, Failover Cluster.
Sa mga setting ng Multipath IO, paganahin ang suporta para sa mga SAS device.
Tiyaking mag-reboot.
Ang mga sumusunod na setting ay dapat makumpleto sa parehong mga server.
Palitan ang pangalan ng lahat ng 4 na interface ng network ayon sa kanilang mga pisikal na port (para sa amin ito ay 1,2,3,4).
I-configure ang NIC Teaming - Idagdag ang lahat ng 4 na adapter sa team, Teaming-Mode - Switch Independent, Load Balancing - Hyper-V Port. Binibigyan namin ng pangalan ang team, iyon ang tinawag kong Team.
Ngayon ay kailangan mong itaas ang virtual switch.
Buksan ang powershell at isulat:
New-VMSwitch "VSwitch" -MinimumBandwidthMode Weight -NetAdapterName "Team" -AllowManagementOS 0
Gumagawa kami ng 3 virtual network adapters.
Sa parehong powershell:
Add-VMNetworkAdapter –ManagementOS –Pangalan "Pamamahala" Add-VMNetworkAdapter –ManagementOS –Pangalan "ClusterNetwork" Add-VMNetworkAdapter –ManagementOS –Pangalan "Live Migration"
Ang mga ito mga virtual switch lalabas sa network at sharing control center, at sa pamamagitan nila dadaloy ang trapiko ng aming mga server.
I-customize ang iyong addressing upang umangkop sa iyong mga plano.
Inilipat namin ang aming mga adaptor sa naaangkop na mga VLAN.
Sa iyong paboritong powershell:
Set-VMNetworkAdapterVlan -ManagementOS -Access -VlanId 2 -VMNetworkAdapterName "Pamamahala" -Kumpirmahin ang Set-VMNetworkAdapterVlan -ManagementOS -Access -VlanId 3 -VMNetworkAdapterName "ClusterNetwork" -Kumpirmahin ang Set-VMNetworkAdapterV "Live Migration" - Kumpirmahin
Ngayon ay kailangan mong i-configure ang QoS.
Kapag nagse-set up ng QoS ayon sa timbang, na siyang pinakamahusay na kasanayan, ayon sa Microsoft, ipinapayo ko sa iyo na itakda ang timbang upang ang kabuuang halaga ay 100, pagkatapos ay maaari nating ipagpalagay na ang halaga na tinukoy sa setting ay isang garantisadong porsyento ng bandwidth. Sa anumang kaso, ang porsyento ay kinakalkula gamit ang formula:
Porsyento ng bandwidth = nakatakdang timbang * 100 / kabuuan ng lahat itakda ang mga halaga timbang
Set-VMSwitch “VSwitch” -DefaultFlowMinimumBandwidthWeight 15
Para sa impormasyon ng serbisyo ng cluster.
Set-VMNetworkAdapter -ManagementOS -Pangalan "Cluster" -MinimumBandwidthWeight 30
Para sa pamamahala.
Set-VMNetworkAdapter -ManagementOS -Pangalan "Pamamahala" -MinimumBandwidthWeight 5
Para sa Live Migration.
Set-VMNetworkAdapter -ManagementOS -Pangalan "Live Migration" -MinimumBandwidthWeight 50
Upang dumaloy nang tama ang trapiko sa mga network, kinakailangang itakda nang tama ang mga sukatan.
Ang trapiko ng impormasyon ng serbisyo ng cluster ay maglalakbay sa network na may pinakamababang sukatan ay maglalakbay sa susunod na pinakamataas na sukatan ng network.
Gawin natin yan.
Sa ating minamahal:
$n = Get-ClusterNetwork “ClusterNetwork” $n.Metric = 1000 $n = Get-ClusterNetwork “LiveMigration” $n.Metric = 1050 $n = Get-ClusterNetwork “Management” $n.Metric = 1100
Ini-mount namin ang aming witness disk sa node kung saan namin tipunin ang cluster, i-format ito sa ntfs.
Sa snap-in ng Failover Clustering, sa seksyong Mga Network, palitan ang pangalan ng mga network upang tumugma sa aming mga adapter.
Ang lahat ay handa na upang tipunin ang kumpol.
Sa snap-in ng Failover Clustering, i-click ang validate. Sinusuri namin. Pagkatapos ay lumikha ng isang cluster at piliin ang quorum configuration Node at Disk karamihan, na isinasaalang-alang din pinakamahusay na pagpipilian para sa mga kumpol na may pantay na bilang ng mga node, at dahil mayroon lang tayong dalawa sa kanila, ito lang ang pagpipilian.
Sa seksyong Storage ng Failover Clustering snap-in, idagdag ang iyong mga disk. At pagkatapos ay idagdag ang mga ito nang paisa-isa bilang Cluster Shared Volume (right click sa disk). Pagkatapos idagdag sa folder C:\ClusterStorage lalabas simbolikong link sa disk, palitan ang pangalan nito ayon sa pangalan ng disk na idinagdag bilang Cluster Shared Volume.
Ngayon ay maaari kang lumikha ng mga virtual machine at i-save ang mga ito sa mga partisyon na ito. Umaasa ako na ang artikulo ay naging kapaki-pakinabang sa iyo.
Mangyaring iulat ang anumang mga error sa pamamagitan ng PM.
Inirerekomenda kong basahin ang: Microsoft Windows Server 2012 Complete Guide. Rand Morimoto, Michael Noel, Guy Yardeni, Omar Drouby, Andrew Abbate, Chris Amaris.
P.S.: Espesyal na pasasalamat kay G. Salakhov, Zagorsky at Razbornov, na kahiya-hiyang nakalimutan ko nang isulat ang post na ito. Nagsisisi ako >_< XD
Kung maraming empleyado sa iyong kumpanya ang gumagamit ng 1C software, kung gayon ito ay sapat na upang bumili magandang server at i-configure ito ng tama. Gayunpaman, kung ang bilang ng mga gumagamit ay umabot sa 150-200 katao at hindi ito ang limitasyon, kung gayon ang pag-install ng isang cluster ng server ay makakatulong na mabawasan ang pagkarga sa kagamitan. Siyempre, ang pag-install ng mga karagdagang kagamitan at mga espesyalista sa pagsasanay upang suportahan ang pagpapatakbo ng cluster ay mangangailangan ng ilang pinansiyal at oras na mapagkukunan, ngunit ito ay isang pangmatagalang pamumuhunan na kasunod ay nagbabayad para sa lahat ng mga gastos sa pamamagitan ng walang tigil na operasyon mga sistema. Gayunpaman, marami ang nakasalalay sa tamang setting cluster - maaaring tumaas ang produktibidad ng ilang beses nang walang mamahaling pamumuhunan. Samakatuwid, bago pag-aralan ang functionality at pagbili ng mga server, kailangan mong tiyakin kung kailangan mo ng isang cluster ng 1C server.
Kailan ka dapat mag-install ng 1C server cluster?
Kapag nagdidisenyo ng isang scheme ng trabaho at pagkalkula mga kinakailangang kapasidad server, ang mga error sa software ay madalas na nangyayari. Sa paunang yugto, maaaring i-level out ng mga system administrator ang mga ito sa pamamagitan ng pagtaas ng dami ng RAM o pag-upgrade ng CPU at iba pang mga node. Ngunit palaging dumarating ang panahon na ang mga posibilidad na ito ay natuyo, at ang pag-install ng isang server cluster ay halos hindi maiiwasan. Ito ang malulutas ang mga pangunahing problema ng mataas na load na mga sistema:
- Mga pagkabigo sa kagamitan at network. Para sa mga partikular na mahalagang database, inirerekumenda na lumikha ng isang cluster ng server na nagsisilbing backup;
- Hindi sapat na seguridad sa database. Karagdagang benepisyo ay ang kakayahang mag-encrypt ng data mula sa software sa 1C platform;
- Hindi pantay na pamamahagi ng load sa mga node ng server. Nalutas sa pamamagitan ng paglikha ng ilang "proseso ng manggagawa" na kumokontrol sa mga koneksyon at kahilingan ng kliyente;
- Bilang karagdagan sa paglutas ng mga problemang ito, ang isang maayos na na-configure na 1C server cluster ay nagbibigay-daan sa iyo upang makabuluhang makatipid sa suporta matatag na operasyon 1C application.
Mga may-ari maliliit na kumpanya, na nahaharap sa mga problema sa itaas, ay maaari ding maging interesado sa pag-install ng isang cluster ng server. Gayunpaman, kung ang bilang ng mga gumagamit ay hindi lalampas sa ilang dosena at ang pagganap ng software ay hindi nagiging sanhi ng mga reklamo, kung gayon ang kumpol ay hindi makatwiran sa ekonomiya. Ito ay magiging mas epektibo upang i-upgrade ang server o i-configure ito nang tama pangunahing mga parameter. Gayunpaman, kung ang isang kumpanya ay naglalayon sa pagbuo at pagtaas ng mga trabaho, kung gayon ito ay nagkakahalaga ng pag-iisip tungkol sa paglikha ng isang kumpol ng mga 1C server sa malapit na hinaharap.
Pag-install ng failover cluster ng mga server sa karaniwang mga kaso ay hindi mangangailangan ng mga administrador na magkaroon ng malalim na kaalaman sa istruktura at lohika ng kagamitan ng server.
Isaalang-alang natin ang algorithm na ito gamit ang halimbawa ng pagsasama-sama ng dalawang 1C 8.2 server sa isang kumpol
Sabihin nating ngayon ay mayroon kang dalawang server, kung saan ang isa (S1C-01) ay naka-install ang 1C server at mga database ng impormasyon. Para mag-configure ng failover cluster ng mga server, kailangan mong mag-deploy ng 1C:Enterprise server sa S1C-02 server at simulan ang workflow. Siguraduhin na sa mga katangian nito ang item na "Paggamit" ay nakatakda sa "Gamitin". Hindi na kailangang magrehistro ng mga base ng impormasyon.

Pagkatapos nito, sa 1C administration console kailangan mong magdagdag ng backup na cluster na may pangalan ng pangalawang server - S1C-02 - sa seksyong "Cluster Reservation". Nagdaragdag kami ng backup na cluster na pinangalanang S1C-01 sa isang katulad na seksyon ng pangalawang server at ilipat ito sa pinakamataas na posisyon. Upang gawin ito, gamitin ang menu ng konteksto at ang command na "Move up". Ito ay kinakailangan upang matiyak ang parehong pagkakasunud-sunod sa mga pangkat na ito sa parehong mga server.
Pagkatapos ng mga hakbang sa itaas, ang natitira na lang ay i-click ang "Action" - "Update" na buton. Pagkatapos nito, ang mga infobase na nakarehistro sa una ay dapat lumitaw sa puno ng pangalawang server. Nangangahulugan ito na ang aming mga aksyon ay humantong sa tagumpay at ngayon ay mayroon kaming isang failover cluster ng dalawang server.
Isa ito sa mga simpleng halimbawa paglikha ng kumpol ng server, hindi nauugnay sa kanilang pag-optimize at tamang setting. Para sa pangwakas na pagpapatupad ng isang kumpol para sa ilang mga gawain, kinakailangan upang ayusin ang isyu ng kasapatan ng kapasidad at propesyonal na pagsasaayos ng resultang kumpol.
Cluster load at optimization
Pagsubok sa pag-load
Ang pinakakaraniwang mga teknolohiya para sa pagsubok ng isang 1C server cluster ay:
- pagsubok ng Gilev;
- Test center mula sa 1C:KIP.
Sa unang kaso, nakikipag-usap kami sa isang tool na nagbibigay-daan sa amin upang suriin ang mga database ng file at client-server. Kabilang dito ang isang pagtatasa ng bilis ng system, mga interface, mahabang operasyon at ang dami ng mga mapagkukunan para sa operasyon. Ang malaking bentahe ay ang versatility nito - wala itong pinagkaiba kung anong configuration ang susuriin mo dito. Ang output ay isang pagtatantya sa mga karaniwang yunit.
Ang pangalawang pag-andar ay nagbibigay-daan sa iyo upang tantyahin ang oras na ginugol sa isang tiyak na operasyon sa system para sa isang paunang natukoy na bilang ng mga gumagamit. Kasabay nito, maaari mong independiyenteng tukuyin ang bilang ng mga operasyon, ang kanilang uri at pagkakasunud-sunod - ang pagsubok ay gayahin ang mga totoong aksyon.
Batay sa mga resultang nakuha, maaari mong hatulan kung ito ay nagkakahalaga ng pag-upgrade o pag-optimize ng cluster ng server.
Ang pinakamadaling paraan upang mapabilis ang 1C ay upang madagdagan ang mga katangian ng server. Ngunit may mga kaso kung kailan, dahil sa hindi tamang mga setting pagkatapos mag-upgrade ng hardware, lumala lamang ang sitwasyon. Samakatuwid, kung nagreklamo ka tungkol sa mga pag-freeze, inirerekomenda na suriin muna ang mga setting ng kumpol sa serbisyo ng administrasyon.
Kinakailangang tanggapin ang buong responsibilidad para sa lahat ng mga aksyon. Maaaring seryosong makaapekto sa performance at functionality ang mga setting ng cluster, gaya ng sa mas magandang panig, at sa kabaligtaran na paraan. Ang bawat setting ay nakakaapekto sa lahat ng mga server sa cluster. Samakatuwid, bago baguhin ang anumang bagay, kailangan mong maunawaan kung ano ang responsable para sa pag-set up ng isang 1C cluster.

sukdulan kapaki-pakinabang na parameter para sa mga server na ginagamit 24 oras sa isang araw – "I-restart ang pagitan". Karaniwan, ang halaga nito ay nakatakda sa 86400 segundo upang ang mga server ay awtomatikong makapag-restart isang beses sa isang araw. Ito ay kapaki-pakinabang para sa pagbabawas ng mga negatibong epekto ng memory leaks at data fragmentation sa mga disk habang tumatakbo.
Napakahalaga na ang fault-tolerant cluster ng mga 1C server ay protektado mula sa sobrang paggamit ng memorya. Maaaring alisin ng isang hindi matagumpay na kahilingan sa isang cycle ang lahat ng kapangyarihan ng mga multi-core server. Upang maiwasan ito, mayroong dalawang opsyon sa kumpol − "Pinapayagan na kapasidad ng memorya" at "Interval para sa paglampas sa pinapayagang kapasidad". Kung i-configure mo nang tama at tumpak ang mga parameter na ito, mapoprotektahan mo ang iyong mga base ng impormasyon mula sa maraming karaniwang problema.
Ang paglilimita sa porsyento ng Pagpapahintulot ng Error sa Server ay makakatulong na matukoy ang mga daloy ng trabaho na may napakaraming nabigong tawag. Pilit na tatanggalin ng cluster ang mga ito kung pipiliin ang kaukulang checkbox. Makakatulong ito na protektahan ang mga prosesong "walang error" mula sa pagbitay at paghihintay.
Isa pang parameter - "Ihinto ang mga prosesong naka-off pagkatapos" ay responsable para sa regular na pagdiskonekta ng mga koneksyon sa server sa mga tinukoy na agwat. Sa 1C, pagkatapos makumpleto ang trabaho, ang mga proseso ng trabaho ay nakabitin nang ilang oras upang ang data ay mailipat nang tama sa mga bagong proseso. Minsan nangyayari ang mga pagkabigo at nananatiling nakabitin ang mga proseso sa server. Nag-aaksaya sila ng mga mapagkukunan at mas kapaki-pakinabang ang makabuluhang bawasan ang kanilang halaga.
Bilang karagdagan sa pag-optimize ng cluster mismo, kinakailangan din na i-configure nang tama ang bawat server na kasama dito. Para sa kaginhawaan ng pag-optimize ng server at pagsuri sa pagganap, ginagamit ng mga administrador ang ahente ng server - ragent. Nag-iimbak ito ng impormasyon tungkol sa kung ano ang tumatakbo sa isang partikular na server. Upang makakuha ng data sa mga infobase na ginamit, dapat kang makipag-ugnayan sa manager ng server – rmngr.
Para sa wastong pag-optimize, gamitin ang server cluster console at i-configure ang mga sumusunod na parameter para sa bawat server:
- Pinakamataas na laki ng memorya ng lahat ng proseso ng manggagawa. Kung ang tagapagpahiwatig na ito ay 0, kung gayon ang system ay naglalaan ng 80% ng RAM para sa mga proseso, ngunit kung ang patlang ay 1, pagkatapos ay 100%. Kung naka-install ang 1C at isang DBMS sa parehong server, may posibilidad na magkaroon ng conflict dahil sa memory at kailangan mong gamitin ang setting na ito. Kung hindi, ang karaniwang 80% ay magiging sapat o kalkulahin kung gaano karaming memorya ng OS ang kailangan, at ipasok ang natitirang halaga sa field na ito;
- Ligtas na pagkonsumo ng memorya sa bawat tawag. Ang default na halaga ay "0", ibig sabihin, 1 proseso ng manggagawa ang sasakupin ng mas mababa sa 5% ng maximum na RAM para sa lahat ng mga proseso. Hindi inirerekomenda na itakda ang halagang "-1", dahil aalisin nito ang lahat ng mga paghihigpit, na puno ng mga kahihinatnan sa anyo ng mga pag-freeze;
- Bilang ng mga infobase at koneksyon sa bawat proseso. Kinokontrol ng mga setting na ito kung paano ipinamamahagi ang mga workload sa mga proseso ng trabaho. Maaari mong i-customize ang mga ito ayon sa iyong mga kinakailangan upang mabawasan ang mga pagkalugi dahil sa labis na pagkarga sa server. Kung ang halaga ay nakatakda sa 0, kung gayon ang mga paghihigpit ay hindi nalalapat, na mapanganib kung mayroong isang malaking bilang ng mga trabaho.

Sa bersyon 8.3, ang isa pang kapaki-pakinabang na tampok para sa maayos na pamamahagi ng load sa server ay "Manager para sa bawat serbisyo." Ginagawang posible ng parameter na ito na gumamit ng hindi isang server manager (rmngr), ngunit marami, na ang bawat isa ay may pananagutan para sa sarili nitong gawain. Ito ay isang magandang pagkakataon upang subaybayan kung aling serbisyo ang nagdudulot ng pagkasira ng pagganap at sukatin ang dami ng mga mapagkukunang inilalaan sa bawat gawain.
Pagkatapos i-install ang feature na ito, magre-reboot ang ragent server agent at sa halip na isang rmngr.exe lang sa console ay makakahanap ka ng buong listahan. Ngayon ay maaari mong gamitin ang task manager upang mahanap ang proseso na naglo-load sa system at gumawa ng ilang fine-tuning. Tutulungan ka ng kanilang pid na makilala ang mga prosesong ito sa isa't isa. Gayunpaman, dahil ito ay isang inobasyon, inirerekomenda ng mga eksperto sa 1C na gamitin nang mabuti ang feature na ito.
Bago magpasyang magdagdag ng 1C server cluster sa iyong istraktura, kailangan mong suriin ang mga setting ng server. Marahil ay may paraan upang itama ang sitwasyon nang hindi bumili ng mga mamahaling kagamitan at mga espesyalista sa pagsasanay upang mag-set up ng 1C cluster. Karaniwan para sa isang propesyonal na inspeksyon at pag-setup ng server mula sa mga third-party na espesyalista upang payagan kaming magtrabaho sa lumang kapasidad para sa isa pang dalawang taon. Ngunit sa malalaking kumpanya, isang kumpol ng mga 1C server ang nananatiling tanging solusyon na nagpapahintulot sa mga empleyado na magtrabaho nang 24 na oras sa isang araw.
Panimula
Ang cluster ng server ay isang pangkat ng mga independiyenteng server na pinamamahalaan ng serbisyo ng Cluster na nagtutulungan bilang isang sistema. Ang mga kumpol ng server ay nilikha sa pamamagitan ng pagsasama-sama ng ilang mga server sa Nakabatay sa Windows® 2000 Advanced Server at Windows 2000 Datacenter Server upang magtulungan, sa gayon ay nagbibigay mataas na antas availability, scalability at manageability para sa mga mapagkukunan at application.
Ang gawain ng isang cluster ng server ay tiyakin ang patuloy na pag-access ng user sa mga application at mapagkukunan sa mga kaso ng hardware o mga pagkabigo sa software o nakaplanong pagsasara ng kagamitan. Kung ang isa sa mga cluster server ay hindi available dahil sa isang pagkabigo o shutdown para sa pagpapanatili, ang mga mapagkukunan ng impormasyon at mga application ay muling ipapamahagi sa mga natitirang available na cluster node.
Para sa mga sistema ng kumpol paggamit ng terminong " mataas na kakayahang magamit» ay mas mainam kaysa sa paggamit ng terminong " pagtitiis sa kasalanan", dahil ang mga teknolohiya sa fault tolerance ay nangangailangan ng mas mataas na antas ng paglaban ng kagamitan sa mga panlabas na impluwensya at mga mekanismo ng pagbawi. Kadalasan, ginagamit ng mga fault-tolerant na server mataas na antas kalabisan ng hardware, at, bilang karagdagan dito, espesyal na software na nagbibigay-daan sa halos agarang pagpapanumbalik ng operasyon sa kaganapan ng anumang indibidwal na software o hardware. Ang mga solusyon na ito ay makabuluhang mas mahal kumpara sa paggamit ng mga teknolohiya ng kumpol, dahil ang mga organisasyon ay napipilitang mag-overpay para sa karagdagang hardware, na walang ginagawa sa halos lahat ng oras at ginagamit lamang sa kaso ng mga pagkabigo. Ginagamit ang mga fault-tolerant na server para sa mga application na humahawak ng mataas na volume ng mga transaksyong may mataas na halaga sa mga lugar gaya ng mga payment processing center, ATM, o stock exchange.
Bagama't hindi ginagarantiyahan ng serbisyo ng Cluster ang uptime, nagbibigay ito ng mataas na antas ng availability na sapat upang patakbuhin ang karamihan sa mga application na kritikal sa misyon. Maaaring subaybayan ng serbisyo ng Cluster ang pagganap ng mga application at mapagkukunan, awtomatikong kinikilala ang mga kondisyon ng pagkabigo at ibalik ang system kapag nalutas ang mga ito. Nagbibigay ito ng higit pa nababaluktot na pamamahala workload sa loob ng cluster, at pinapataas ang availability ng system sa kabuuan.
Ang mga pangunahing benepisyong makukuha sa paggamit ng serbisyo ng Cluster ay:
- Mataas na kakayahang magamit. Kung nabigo ang isang node, ililipat ng serbisyo ng Cluster ang kontrol ng mga mapagkukunan, tulad ng mga hard drive at mga address ng network, sa gumaganang cluster node. Kapag may nangyaring pagkabigo ng software o hardware, ire-restart ng cluster software ang nabigong application sa gumaganang node, o inililipat ang buong load ng nabigong node sa natitirang gumaganang node. Gayunpaman, ang mga user ay maaari lamang makapansin ng maikling pagkaantala sa serbisyo.
- Pag-refund pagkatapos ng pagtanggi. Awtomatikong ibinabahagi ng serbisyo ng Cluster ang workload sa cluster kapag naging available muli ang nabigong node.
- Kakayahang kontrolin. Ang Cluster Administrator ay isang snap-in na maaari mong gamitin upang pamahalaan ang cluster bilang isang solong system, pati na rin upang pamahalaan ang mga application. Ang Cluster Administrator ay nagbibigay ng isang transparent na view kung paano tumatakbo ang mga application na parang tumatakbo ang mga ito sa parehong server. Maaari mong ilipat ang mga application sa iba't ibang mga server sa loob ng cluster sa pamamagitan ng pag-drag ng mga cluster object gamit ang mouse. Maaari mong ilipat ang data sa parehong paraan. Ang pamamaraang ito ay maaaring gamitin upang manu-manong ipamahagi ang workload ng mga server, gayundin upang i-offload ang server at pagkatapos ay ihinto ito para sa naka-iskedyul na pagpapanatili. Bilang karagdagan, pinapayagan ka ng Cluster Administrator na malayuang subaybayan ang estado ng cluster, lahat ng mga node at mapagkukunan nito.
- Scalability. Upang matiyak na ang pagganap ng cluster ay palaging makakasabay sa dumaraming mga pangangailangan, ang serbisyo ng Cluster ay may mga kakayahan sa pag-scale. Kung ang pangkalahatang pagganap ng cluster ay nagiging hindi sapat upang mahawakan ang load na nabuo ng mga clustered application, ang mga karagdagang node ay maaaring idagdag sa cluster.
Nagbibigay ang dokumentong ito ng mga tagubilin para sa pag-install ng serbisyo ng Cluster sa mga server na nagpapatakbo ng Windows 2000 Advanced Server at Windows 2000 Datacenter Server at inilalarawan ang proseso para sa pag-install ng serbisyo ng Cluster sa mga cluster node server. Hindi inilalarawan ng gabay na ito ang pag-install at pag-configure ng mga clustered na application, ngunit gagabayan ka lamang sa buong proseso ng pag-install ng isang simpleng two-node cluster.
Mga kinakailangan ng system para sa paglikha ng isang cluster ng server
Susunod mga checklist ay tutulong sa iyo na maghanda para sa pag-install. Hakbang-hakbang na mga tagubilin Ang mga tagubilin sa pag-install ay ipapakita sa ibaba ng mga listahang ito.
Mga kinakailangan sa software
- Microsoft Windows 2000 Advanced Server o Windows 2000 Datacenter Server operating system na naka-install sa lahat ng mga server sa cluster.
- Isang naka-install na serbisyo sa paglutas ng pangalan gaya ng Domain Naming System (DNS) Windows Internet Sistema ng Pangalan (WINS), HOSTS, atbp.
- Terminal server para sa malayong pangangasiwa kumpol. Ang kinakailangang ito ay hindi sapilitan, ngunit inirerekomenda lamang upang matiyak ang kadalian ng pamamahala ng cluster.
Mga Kinakailangan sa Hardware
- Ang mga kinakailangan sa hardware ng cluster node ay kapareho ng para sa pag-install ng mga operating system ng Windows 2000 Advanced Server o Windows 2000 Datacenter Server. Ang mga kinakailangang ito ay matatagpuan sa pahina ng paghahanap Direktoryo ng Microsoft.
- Ang cluster hardware ay dapat na sertipikado at nakalista sa Microsoft Hardware Compatibility List (HCL) para sa serbisyo ng Cluster. Pinakabagong bersyon ang listahang ito ay matatagpuan sa pahina ng paghahanap Listahan ng Windows 2000 Hardware Compatibility Direktoryo ng Microsoft sa pamamagitan ng pagpili sa kategorya ng paghahanap na "Cluster".
Dalawang HCL-compliant na computer, bawat isa ay may:
- Hard drive na may boot pagkahati ng system at isang naka-install na Windows 2000 Advanced Server o Windows 2000 Datacenter Server operating system. Hindi dapat nakakonekta ang drive na ito sa shared storage bus, na tinalakay sa ibaba.
- Paghiwalayin ang PCI Fiber Channel o SCSI device controller para sa pagkonekta ng external na shared storage device. Dapat na naroroon ang controller na ito bilang karagdagan sa controller ng boot disk.
- Dalawang network PCI adapter na naka-install sa bawat computer sa cluster.
- Isang external na disk storage device na nakalista sa HCL na nakakonekta sa lahat ng node sa cluster. Ito ay kumikilos bilang isang cluster disk. Inirerekomenda ang configuration gamit ang hardware RAID arrays.
- Mga cable para sa pagkonekta ng isang karaniwang storage device sa lahat ng computer. Sumangguni sa dokumentasyon ng tagagawa para sa mga tagubilin sa pag-configure ng mga storage device. Kung ang koneksyon ay sa isang SCSI bus, maaari kang sumangguni sa Appendix A para sa karagdagang impormasyon.
- Ang lahat ng kagamitan sa mga cluster computer ay dapat na ganap na magkapareho. Pasimplehin nito ang proseso ng pagsasaayos at aalisin ang mga potensyal na isyu sa compatibility.
Mga kinakailangan para sa pag-set up ng configuration ng network
- Isang natatanging pangalan ng NetBIOS para sa cluster.
- Limang kakaiba mga static na IP address: dalawang address para sa mga adapter ng network pribadong network, dalawa para sa mga pampublikong network adapter, at isang address para sa cluster.
- Domain account para sa serbisyo ng Cluster (lahat ng cluster node ay dapat na mga miyembro ng parehong domain)
- Ang bawat node ay dapat may dalawang network adapter - isa para sa pagkonekta sa pampublikong network, isa para sa intra-cluster na komunikasyon ng mga node. Configuration gamit ang isang network adapter para sa sabay-sabay na koneksyon sa mga pampubliko at pribadong network ay hindi suportado. Ang pagkakaroon ng hiwalay na network adapter para sa pribadong network ay kinakailangan upang makasunod sa mga kinakailangan ng HCL.
Mga Kinakailangan sa Shared Storage Disk
- Ang lahat ng mga shared storage disk, kabilang ang quorum disk, ay dapat na pisikal na naka-attach sa shared bus.
- Ang lahat ng mga disk na konektado sa nakabahaging bus ay dapat ma-access ng bawat node. Maaari itong suriin sa panahon ng pag-install at pagsasaayos ng host adapter. Para sa mga detalyadong tagubilin, sumangguni sa dokumentasyon ng tagagawa ng adaptor.
- Dapat na italaga ang mga SCSI device ng mga natatanging numero ng SCSI ID, at dapat na mai-install nang tama ang mga terminator sa SCSI bus, ayon sa mga tagubilin ng manufacturer. 1
- Ang lahat ng mga shared storage disk ay dapat na i-configure bilang mga pangunahing disk (hindi dynamic)
- Dapat na naka-format ang lahat ng nakabahaging storage device na disk partition bilang file format. Sistema ng NTFS.
Lubos na inirerekomendang pagsamahin ang lahat ng shared storage drive sa mga hardware RAID array. Bagama't hindi kinakailangan, ang paggawa ng fault-tolerant na mga configuration ng RAID ay pangunahing punto sa pagbibigay ng proteksyon laban sa mga pagkabigo sa disk.
Pag-install ng cluster
Pangkalahatang-ideya ng Pag-install
Sa panahon ng proseso ng pag-install, ang ilang mga node ay isasara at ang ilan ay ire-reboot. Ito ay kinakailangan upang matiyak ang integridad ng data na matatagpuan sa mga disk na konektado sa karaniwang bus ng panlabas na storage device. Maaaring mangyari ang pagkasira ng data kapag maraming node ang sabay-sabay na sumusubok na sumulat sa parehong disk na hindi protektado ng cluster software.
Tutulungan ka ng talahanayan 1 na matukoy kung aling mga node at storage device ang dapat paganahin sa bawat yugto ng pag-install.
Inilalarawan ng gabay na ito kung paano gumawa ng dalawang-node cluster. Gayunpaman, kung nagse-set up ka ng isang cluster na may higit sa dalawang node, maaari mong gamitin ang halaga ng column "Node 2" upang matukoy ang estado ng natitirang mga node.
Talahanayan 1. Pagkakasunod-sunod ng pag-on ng mga device kapag nag-i-install ng cluster
| Hakbang | Node 1 | Node 2 | Storage device | Magkomento |
| Pagtatakda ng Mga Setting ng Network | Naka-on | Naka-on | Naka-off | Tiyaking naka-off ang lahat ng storage device na nakakonekta sa karaniwang bus. I-on ang lahat ng node. |
| Mga setting mga shared drive | Naka-on | Naka-off | Naka-on | I-off ang lahat ng node. I-on ang nakabahaging storage device, pagkatapos ay i-on ang unang node. |
| Sinusuri ang configuration ng mga shared drive | Naka-off | Naka-on | Naka-on | I-off ang unang node, i-on ang pangalawang node. Ulitin para sa mga node 3 at 4 kung kinakailangan. |
| Pag-configure ng unang node | Naka-on | Naka-off | Naka-on | I-off ang lahat ng mga node; i-on ang unang node. |
| Pag-configure ng pangalawang node | Naka-on | Naka-on | Naka-on | Matapos matagumpay na i-configure ang unang node, i-on ang pangalawang node. Ulitin para sa mga node 3 at 4 kung kinakailangan. |
| Pagkumpleto ng pag-install | Naka-on | Naka-on | Naka-on | Sa puntong ito, dapat na naka-on ang lahat ng node. |
Bago i-install ang cluster software, dapat mong kumpletuhin ang mga sumusunod na hakbang:
- I-install ang operating system ng Windows 2000 Advanced Server o Windows 2000 Datacenter Server sa bawat cluster computer.
- I-configure ang mga setting ng network.
- I-configure ang mga shared storage drive.
Kumpletuhin ang mga hakbang na ito sa bawat node sa cluster bago i-install ang serbisyo ng Cluster sa unang node.
Upang i-configure ang serbisyo ng Cluster sa isang server ng Windows 2000, ang iyong account ay dapat may mga karapatan ng administrator sa bawat node. Ang lahat ng mga cluster node ay dapat na mga server ng miyembro o mga controller ng parehong domain. Ang pinaghalong paggamit ng mga server ng miyembro at mga controller ng domain sa isang cluster ay hindi katanggap-tanggap.
Pag-install ng Windows 2000 operating system
Para sa Mga pag-install ng Windows 2000 sa bawat cluster node, sumangguni sa dokumentasyong natanggap mo kasama ng iyong operating system.
Ginagamit ng dokumentong ito ang istruktura ng pagbibigay ng pangalan mula sa manwal "Step-by-Step na Gabay sa isang Karaniwang Imprastraktura para sa Windows 2000 Server Deployment". Gayunpaman, maaari mong gamitin ang anumang mga pangalan.
Bago mo simulan ang pag-install ng serbisyo ng Cluster, dapat kang mag-log in bilang isang administrator.
Pag-configure ng mga setting ng network
Tandaan: Sa puntong ito sa pag-install, i-off ang lahat ng nakabahaging storage device, at pagkatapos ay i-on ang lahat ng node. Dapat mong alisin ang posibilidad sabay-sabay na pag-access maramihang node sa isang nakabahaging storage device hanggang sa mai-install ang serbisyo ng Cluster, ayon sa kahit man lang, sa isa sa mga node, at ang node na iyon ay paganahin.
Ang bawat node ay dapat magkaroon ng hindi bababa sa dalawang network adapter na naka-install - isa para kumonekta sa pampublikong network, at isa para kumonekta sa pribadong network na binubuo ng mga cluster node.
Ang pribadong network adapter ay nagbibigay ng inter-node na komunikasyon, komunikasyon ng kasalukuyang estado ng cluster, at pamamahala ng cluster. Ikinokonekta ng pampublikong network adapter ng bawat node ang cluster sa pampublikong network na binubuo ng mga computer ng kliyente.
Siguraduhin na ang lahat ng mga adapter ng network ay pisikal na konektado nang tama: ang mga pribadong network adapter ay konektado lamang sa iba pang mga pribadong network adapter, at ang mga pampublikong network adapter ay konektado sa mga pampublikong network switch. Ang diagram ng koneksyon ay ipinapakita sa Figure 1. Isagawa ang pagsubok na ito sa bawat node sa cluster bago mo i-configure ang mga shared storage disk.
Figure 1: Halimbawa ng dalawang-node cluster
Pag-configure ng Pribadong Network Adapter
Kumpletuhin ang mga hakbang na ito sa unang node ng iyong cluster.
- Aking kapaligiran ng network at pumili ng isang pangkat Mga Katangian.
- I-click i-right click mouse sa icon.
Tandaan: Aling network adapter ang magse-serve sa isang pribadong network at kung aling pampublikong network ang nakasalalay pisikal na koneksyon mga kable ng network. SA dokumentong ito Ipagpalagay namin na ang unang adaptor (Lokal na Koneksyon) ay konektado sa pampublikong network at ang pangalawang adaptor (Lokal na Koneksyon 2) ay konektado sa pribadong network ng cluster. Sa iyong kaso ay maaaring hindi ito ang kaso.
- Estado. Bintana Katayuan ng Koneksyon sa LAN 2 ipinapakita ang katayuan ng koneksyon at ang bilis nito. Kung ang koneksyon ay nasa disconnected state, suriin ang mga cable at koneksyon. Ayusin ang problema bago magpatuloy. I-click ang button Isara.
- Mag-right click muli sa icon Koneksyon sa LAN 2, pumili ng command Mga Katangian at pindutin ang pindutan Tune.
- Pumili ng tab Bukod pa rito. Ang window na ipinapakita sa Figure 2 ay lilitaw.
- Para sa mga pribadong network network adapter, ang bilis ay dapat na manu-manong itakda sa halip na ang default na halaga. Tukuyin ang bilis ng iyong network sa drop-down na listahan. Huwag gumamit ng mga halaga "Auto Sense" o "Auto Select" upang piliin ang bilis, dahil ang ilang mga adapter ng network ay maaaring mag-drop ng mga packet habang tinutukoy ang bilis ng koneksyon. Upang itakda ang bilis ng network adapter, tukuyin ang aktwal na halaga para sa parameter Uri ng koneksyon o Bilis.

Larawan 2: Mga karagdagang setting adaptor ng network
Ang lahat ng mga adaptor ng cluster network na konektado sa parehong network ay dapat na i-configure nang magkapareho at gamitin parehong mga halaga mga parameter Duplex mode , Kontrol sa daloy, Uri ng koneksyon, atbp. Kahit na ang iba't ibang kagamitan sa network ay ginagamit sa iba't ibang mga node, ang mga halaga ng mga parameter na ito ay dapat na pareho.
- Pumili Internet Protocol (TCP/IP) sa listahan ng mga bahagi na ginagamit ng koneksyon.
- I-click ang button Mga Katangian.
- Itakda ang switch sa posisyon Gamitin ang sumusunod na IP address at ilagay ang address 10.1.1.1 . (Para sa pangalawang node, gamitin ang address 10.1.1.2 ).
- Itakda ang subnet mask: 255.0.0.0 .
- I-click ang button Bukod pa rito at pumili ng tab PANALO. Itakda ang halaga ng switch sa posisyon Huwag paganahin ang NetBIOS sa TCP/IP. I-click OK upang bumalik sa nakaraang menu. Gawin ang hakbang na ito para lamang sa pribadong network adapter.
Ang iyong dialog box ay dapat magmukhang Figure 3.

Figure 3: IP Address ng Pribadong Network Connection
Pag-configure ng pampublikong network adapter
Tandaan: Kung ang isang DHCP server ay tumatakbo sa isang pampublikong network, ang IP address para sa network adapter sa pampublikong network ay maaaring awtomatikong italaga. Gayunpaman, ang pamamaraang ito ay hindi inirerekomenda para sa mga adaptor ng cluster node. Lubos naming inirerekomenda ang pagtatalaga ng mga permanenteng IP address sa lahat ng pampubliko at pribadong host network adapter. Kung hindi, kung nabigo ang DHCP server, maaaring imposible ang pag-access sa mga cluster node. Kung mapipilitan kang gumamit ng DHCP para sa mga adapter ng network sa isang pampublikong network, gumamit ng mahabang panahon ng pag-upa sa address - titiyakin nito na mananatiling wasto ang address na nakatalaga sa dinamikong paraan kahit na pansamantalang hindi available ang DHCP server. Palaging magtalaga ng mga permanenteng IP address sa mga pribadong network adapter. Tandaan na isa lang ang makikilala ng serbisyo ng Cluster interface ng network sa bawat subnet. Kung kailangan mo ng tulong sa mga appointment mga address ng network sa Windows 2000, sumangguni sa built-in na Help ng operating system.
Pagpapalit ng pangalan ng mga koneksyon sa network
Para sa kalinawan, inirerekomenda naming baguhin ang mga pangalan ng iyong mga koneksyon sa network. Halimbawa, maaari mong baguhin ang pangalan ng koneksyon Koneksyon sa LAN 2 sa . Tutulungan ka ng paraang ito na mas madaling matukoy ang mga network at italaga nang tama ang kanilang mga tungkulin.
- Mag-right click sa icon 2.
- Sa menu ng konteksto, piliin ang command Palitan ang pangalan.
- Pumasok Kumonekta sa pribadong network ng cluster sa text field at pindutin ang key PUMASOK.
- Ulitin ang hakbang 1-3 at palitan ang pangalan ng koneksyon Koneksyon sa lokal na network sa Kumonekta sa isang pampublikong network.

Figure 4: Pinalitan ang pangalan ng mga koneksyon sa network
- Ang pinalitan ng pangalan na mga koneksyon sa network ay dapat magmukhang Figure 4. Isara ang window Network at malayuang pag-access sa network. Ang mga bagong pangalan ng koneksyon sa network ay awtomatikong ginagaya sa iba pang mga node sa cluster kapag naka-on ang mga ito.
Pagsusulit mga koneksyon sa network at resolusyon ng pangalan
Upang subukan ang pagpapatakbo ng naka-configure na kagamitan sa network, kumpletuhin ang mga sumusunod na hakbang para sa lahat ng mga adapter ng network sa bawat node. Upang gawin ito, dapat mong malaman ang mga IP address ng lahat ng mga adapter ng network sa cluster. Makukuha mo ang impormasyong ito sa pamamagitan ng pagpapatakbo ng command ipconfig sa bawat node:
- I-click ang button Magsimula, pumili ng koponan Ipatupad at i-type ang command cmd sa text window. I-click OK.
- I-type ang command ipconfig /all at pindutin ang key PUMASOK. Makakakita ka ng impormasyon sa pagsasaayos ng IP protocol para sa bawat network adapter na naka-on lokal na makina.
- Kung wala ka pang nakabukas na command prompt window, sundin ang hakbang 1.
- I-type ang command ping ipaddress saan ipaddress ay ang IP address ng kaukulang network adapter sa isa pang node. Halimbawa, ipagpalagay na ang mga network adapter ay may mga sumusunod na IP address:
| Numero ng node | Pangalan koneksyon sa network | IP address ng adapter ng network |
| 1 | Kumokonekta sa isang pampublikong network | 172.16.12.12 |
| 1 | Kumonekta sa pribadong network ng cluster | 10.1.1.1 |
| 2 | Kumokonekta sa isang pampublikong network | 172.16.12.14 |
| 2 | Kumonekta sa pribadong network ng cluster | 10.1.1.2 |
Sa halimbawang ito kailangan mong patakbuhin ang mga utos ping 172.16.12.14 At ping 10.1.1.2 mula sa node 1, at isagawa ang mga utos ping 172.16.12.12 At ping 10.1.1.1 mula sa node 2.
Upang suriin ang resolution ng pangalan, patakbuhin ang command ping, gamit ang pangalan ng computer bilang argumento sa halip na ang IP address nito. Halimbawa, upang suriin ang resolution ng pangalan para sa unang cluster node na pinangalanang hq-res-dc01, patakbuhin ang command ping hq-res-dc01 mula sa alinman computer ng kliyente.
Sinusuri ang domain membership
Ang lahat ng cluster node ay dapat na mga miyembro ng parehong domain at may mga kakayahan sa networking na may isang domain controller at DNS server. Maaaring i-configure ang mga node bilang mga server ng domain ng miyembro o bilang mga controller ng parehong domain. Kung magpasya kang gawing domain controller ang isa sa mga node, dapat ding i-configure ang lahat ng iba pang node sa cluster bilang mga controller ng domain ng parehong domain. Ipinapalagay ng gabay na ito na ang lahat ng mga host ay mga controller ng domain.
Tandaan: Para sa mga link sa karagdagang dokumentasyon sa pag-configure ng mga domain, DNS, at mga serbisyo ng DHCP sa Windows 2000, tingnan ang Mga Kaugnay na Mapagkukunan sa dulo ng dokumentong ito.
- I-right click Ang computer ko at pumili ng isang pangkat Mga Katangian.
- Pumili ng tab Pagkakakilanlan sa network. Sa dialog box Mga Katangian ng System makikita mo buong pangalan computer at domain. Sa aming halimbawa, ang domain ay tinatawag restit.com.
- Kung na-configure mo ang node bilang isang server ng miyembro, sa yugtong ito maaari mo itong isama sa domain. I-click ang button Mga Katangian at sundin ang mga tagubilin upang isama ang computer sa domain.
- Isara ang mga bintana Mga Katangian ng System At Ang computer ko.
Gumawa ng Cluster service account
Para sa serbisyo ng Cluster, dapat kang lumikha ng hiwalay na domain account kung saan ito ilulunsad. Hihilingin sa iyo ng installer na maglagay ng mga kredensyal para sa serbisyo ng Cluster, kaya dapat gumawa ng account bago i-install ang serbisyo. Ang account ay hindi dapat pagmamay-ari ng sinumang gumagamit ng domain, at dapat gamitin lamang para sa pagpapatakbo ng serbisyo ng Cluster.
- I-click ang button Magsimula, pumili ng command Mga Programa / Pangangasiwa, patakbuhin ang snap-in.
- Palawakin ang kategorya restit.com, kung hindi pa ito nai-deploy
- Pumili mula sa listahan Mga gumagamit.
- I-right click sa Mga gumagamit, pumili mula sa menu ng konteksto Lumikha, piliin Gumagamit.
- Maglagay ng pangalan para sa cluster service account tulad ng ipinapakita sa Figure 5 at i-click Susunod.

Figure 5: Pagdaragdag ng Cluster User
- Lagyan ng tsek ang mga kahon Pigilan ang user na baguhin ang password At Walang expiration date ang password. I-click ang button Susunod at isang pindutan handa na upang lumikha ng isang gumagamit.
Tandaan: Kung ang iyong administratibong patakaran sa seguridad ay hindi nagpapahintulot sa iyo na gumamit ng mga password gamit ang walang limitasyong panahon aksyon, kakailanganin mong i-update ang password at i-configure ang serbisyo ng Cluster sa bawat node bago ito mag-expire.
- Mag-right click sa user Cluster V kanang panel rigging Active Directory - Mga User at Computer.
- Sa menu ng konteksto, piliin ang command Magdagdag ng mga miyembro sa isang grupo.
- Pumili ng pangkat Mga tagapangasiwa at pindutin OK. Ang bagong account ay mayroon na ngayong mga pribilehiyo ng administrator sa lokal na computer.
- Isara ang snap Active Directory - Mga User at Computer.
Pag-configure ng mga shared storage drive
Babala: Siguraduhin na kahit isa sa mga cluster node ay tumatakbo sa Windows 2000 Advanced Server o Windows 2000 Datacenter Server operating system at na ang serbisyo ng Cluster ay na-configure at tumatakbo. Pagkatapos lamang nito mai-load ang operating system ng Windows 2000 sa natitirang mga node. Kung hindi matugunan ang mga kundisyong ito, maaaring masira ang mga cluster disk.
Upang simulan ang pag-set up ng mga shared storage drive, i-off ang lahat ng node. Pagkatapos nito, i-on ang nakabahaging storage device, pagkatapos ay i-on ang node 1.
Quorum disk
Ang quorum disk ay ginagamit upang mag-imbak ng mga checkpoint at recovery log files ng cluster database, na nagbibigay ng cluster management. Ginagawa namin ang mga sumusunod na rekomendasyon para sa paglikha ng isang quorum disk:
- Gumawa ng maliit na partition (hindi bababa sa 50 MB ang laki) para gamitin bilang quorum disk. Karaniwan naming inirerekumenda ang paglikha ng isang quorum disk na 500 MB ang laki.
- Maglaan ng hiwalay na disk para sa mapagkukunan ng korum. Dahil kung mabibigo ang isang quorum disk, mabibigo ang buong cluster, lubos naming inirerekomenda ang paggamit ng hardware disk RAID array.
Sa panahon ng proseso ng pag-install ng serbisyo ng Cluster, kakailanganin mong magtalaga ng sulat sa quorum drive. Sa ating halimbawa ay gagamitin natin ang liham Q.
Pag-configure ng mga shared storage drive
- I-right click Ang computer ko, pumili ng command Kontrolin. Sa window na bubukas, palawakin ang kategorya Mga storage device.
- Pumili ng isang koponan Pamamahala ng Disk.
- Tiyaking naka-format ang lahat ng shared storage drive bilang NTFS at may status Basic. Kung kumonekta ka bagong disk, ay awtomatikong magsisimula Disk Signing at Update Wizard. Kapag nagsimula ang wizard, i-click ang pindutan Update, upang ipagpatuloy ang operasyon nito, pagkatapos nito ang disk ay makikilala bilang Dynamic. Upang i-convert ang disk sa basic, i-right click sa Disk #(Saan # – numero ng disk na pinagtatrabahuhan mo) at piliin ang command Bumalik sa pangunahing disk.
I-right click ang lugar Hindi ipinamahagi sa tabi ng kaukulang disk.
- Pumili ng isang koponan Lumikha ng isang seksyon
- Magsisimula Wizard sa Paglikha ng Partition. Pindutin ang pindutan ng dalawang beses Susunod.
- Ipasok ang nais na laki ng partisyon sa megabytes at i-click ang pindutan Susunod.
- I-click ang button Susunod, tinatanggap ang default na drive letter na iminungkahi
- I-click ang button Susunod para mag-format at gumawa ng partition.
Pagtatalaga ng mga drive letter
Pagkatapos ma-configure ang data bus, mga disk, at shared storage partition, dapat kang magtalaga ng mga drive letter sa lahat ng partition sa lahat ng disk sa cluster.
Tandaan: Ang mga mount point ay isang feature ng file system na nagbibigay-daan sa iyong magtakda file system gamit ang mga kasalukuyang direktoryo, nang hindi nagtatalaga ng drive letter. Ang mga mount point ay hindi sinusuportahan ng mga cluster. Anuman panlabas na drive na ginamit bilang isang mapagkukunan ng kumpol ay dapat hatiin sa Mga partisyon ng NTFS, at ang mga partisyon na ito ay dapat magtalaga ng mga drive letter.
- I-right-click ang nais na partition at piliin Pagbabago ng drive letter at drive path.
- Pumili ng bagong drive letter.
- Ulitin ang hakbang 1 at 2 para sa lahat ng shared storage drive.

Figure 6: Mga partisyon ng disk na may mga nakatalagang titik
- Sa dulo ng pamamaraan, ang snap window Pamamahala ng kompyuter dapat magmukhang Figure 6. Isara ang snap-in Pamamahala ng kompyuter.
- I-click ang button Magsimula, piliin Mga programa / Pamantayan, at patakbuhin ang programa " Notebook".
- Mag-type ng ilang salita at i-save ang file sa ilalim ng pangalan test.txt sa pamamagitan ng pagpili ng utos I-save bilang mula sa menu file. Isara Notebook.
- Mag-double click sa icon Aking mga dokumento.
- Mag-right click sa file test.txt at sa menu ng konteksto piliin ang utos Kopyahin.
- Isara ang bintana.
- Bukas Ang computer ko.
- I-double click ang shared storage drive partition.
- I-right click at piliin ang command Ipasok.
- Dapat lumabas ang isang kopya ng file sa shared storage drive test.txt.
- I-double click ang file test.txt upang buksan ito mula sa isang shared storage drive. Isara ang file.
- Piliin ang file at pindutin ang key Sinabi ni Del para magtanggal ng file mula sa cluster disk.
Ulitin ang pamamaraan para sa lahat ng mga disk sa cluster upang matiyak na naa-access ang mga ito mula sa unang node.
Ngayon i-off ang unang node, i-on ang pangalawang node at ulitin ang mga hakbang sa seksyon Sinusuri ang operasyon at pagbabahagi ng mga disk. Sundin ang parehong mga hakbang na ito sa lahat ng karagdagang node. Sa sandaling sigurado ka na ang lahat ng node ay makakapagbasa at makakasulat ng impormasyon sa mga shared storage drive, i-off ang lahat ng node maliban sa una at magpatuloy sa susunod na seksyon.
























