ในการทำงานในแต่ละวัน คุณพบข้อผิดพลาดที่ค่อนข้างคล้ายกันเมื่อเขียนแบบสอบถาม
ในบทความนี้ ฉันอยากจะยกตัวอย่างวิธีที่จะไม่เขียนคำสั่ง
- เลือกช่องทั้งหมด
เลือก * จากตารางเมื่อเขียนแบบสอบถาม อย่าใช้การเลือกช่องทั้งหมด - "*" ระบุเฉพาะฟิลด์ที่คุณต้องการจริงๆ วิธีนี้จะช่วยลดปริมาณข้อมูลที่ดึงและส่ง นอกจากนี้อย่าลืมเกี่ยวกับการครอบคลุมดัชนีด้วย แม้ว่าคุณต้องการฟิลด์ทั้งหมดในตารางจริงๆ แต่ก็เป็นการดีกว่าที่จะแสดงรายการเหล่านั้น ประการแรกจะปรับปรุงความสามารถในการอ่านโค้ด เมื่อใช้เครื่องหมายดอกจัน จะเป็นไปไม่ได้ที่จะทราบว่าช่องใดอยู่ในตารางโดยไม่ดู ประการที่สอง เมื่อเวลาผ่านไป จำนวนคอลัมน์ในตารางของคุณอาจเปลี่ยนแปลง และหากวันนี้มีคอลัมน์ INT ห้าคอลัมน์ ฟิลด์ TEXT และ BLOB อาจถูกเพิ่มในหนึ่งเดือน ซึ่งจะทำให้การเลือกช้าลง
- คำขอเป็นรอบ
คุณต้องเข้าใจอย่างชัดเจนว่า SQL เป็นภาษาที่ใช้ในการตั้งค่า บางครั้งโปรแกรมเมอร์ที่คุ้นเคยกับการคิดในแง่ของภาษาขั้นตอนพบว่าเป็นการยากที่จะเปลี่ยนความคิดเป็นภาษาของเซต ซึ่งสามารถทำได้ค่อนข้างง่ายโดยใช้กฎง่ายๆ - "อย่าดำเนินการค้นหาในวง" ตัวอย่างวิธีการนี้สามารถทำได้:1. ตัวอย่าง
$news_ids = get_list("เลือก news_id จาก today_news ");
ในขณะที่($news_id = get_next($news_ids))
$news = get_row("เลือกหัวข้อ, เนื้อหาจากข่าว WHERE news_id = ". $news_id);กฎนั้นง่ายมาก - ยิ่งมีคำขอน้อยเท่าไรก็ยิ่งดีเท่านั้น (แม้ว่าจะมีข้อยกเว้นเช่นเดียวกับกฎอื่นๆ ก็ตาม) อย่าลืมเกี่ยวกับโครงสร้าง IN() โค้ดด้านบนสามารถเขียนได้ในแบบสอบถามเดียว:
เลือกชื่อ เนื้อหา จาก today_news INNER JOIN ข่าว USING(news_id)2. ส่วนแทรก
$log = parse_log();
ในขณะที่($บันทึก = ถัดไป($log))
query("INSERT INTO บันทึกค่า SET = ". $log["value"]);!}การเชื่อมต่อและดำเนินการหนึ่งแบบสอบถามจะมีประสิทธิภาพมากกว่ามาก:
INSERT INTO logs (value) ค่า (...), (...)3. อัปเดต
บางครั้งคุณจำเป็นต้องอัปเดตหลายแถวในตารางเดียว หากค่าที่อัปเดตเหมือนกันทุกอย่างก็ง่าย:
อัพเดทข่าว SET title="test" WHERE id IN (1, 2, 3).!}หากค่าที่กำลังเปลี่ยนแปลงแตกต่างกันในแต่ละเรคคอร์ด สามารถทำได้โดยใช้แบบสอบถามต่อไปนี้:
อัพเดทข่าว ตลท
หัวเรื่อง = กรณี
เมื่อ news_id = 1 แล้ว "aa"
เมื่อ news_id = 2 แล้ว "bb" สิ้นสุด
ที่ news_id ใน (1, 2)การทดสอบของเราแสดงให้เห็นว่าคำขอดังกล่าวเร็วกว่าคำขอแยกกันหลายรายการถึง 2-3 เท่า
- ดำเนินการกับฟิลด์ที่มีการจัดทำดัชนี
เลือก user_id จากผู้ใช้ โดยที่ blogs_count * 2 = $valueแบบสอบถามนี้จะไม่ใช้ดัชนี แม้ว่าคอลัมน์ blogs_count จะถูกจัดทำดัชนีก็ตาม สำหรับดัชนีที่จะใช้ ไม่ต้องทำการแปลงใดๆ บนฟิลด์ที่จัดทำดัชนีในแบบสอบถาม สำหรับคำขอดังกล่าว ให้ย้ายฟังก์ชันการแปลงไปยังส่วนอื่น:
เลือก user_id จากผู้ใช้ โดยที่ blogs_count = $value / 2;ตัวอย่างที่คล้ายกัน:
เลือก user_id จากผู้ใช้ WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(ลงทะเบียน)<= 10;จะไม่ใช้ดัชนีในฟิลด์ที่ลงทะเบียนในขณะที่
เลือก user_id จากผู้ใช้ที่ลงทะเบียน >= DATE_SUB (CURRENT_DATE, INTERVAL 10 DAY);
จะ. - กำลังดึงแถวเพื่อนับจำนวนเท่านั้น
$result = mysql_query("SELECT * FROM table", $link);
$num_rows = mysql_num_rows($ผลลัพธ์);
หากคุณต้องการเลือกจำนวนแถวที่ตรงตามเงื่อนไขบางประการ ให้ใช้ เลือกแบบสอบถาม COUNT(*) จากตาราง แทนที่จะเลือกแถวทั้งหมดเพื่อนับจำนวน - กำลังเรียกแถวพิเศษ
$result = mysql_query("SELECT * FROM table1", $link);
ในขณะที่($row = mysql_fetch_assoc($result) && $i< 20) {
…
}
หากคุณต้องการดึงข้อมูลเพียง n แถว ให้ใช้ LIMIT แทนที่จะทิ้งแถวเพิ่มเติมในแอปพลิเคชัน - ใช้ ORDER BY RAND()
SELECT * จากตาราง ORDER BY RAND() จำกัด 1;หากตารางมีมากกว่า 4-5,000 แถว ORDER BY RAND() จะทำงานช้ามาก การเรียกใช้สองแบบสอบถามจะมีประสิทธิภาพมากกว่ามาก:
หากตารางมีคีย์หลักแบบเพิ่มค่าอัตโนมัติและไม่มีช่องว่าง:
$rnd = rand(1, query("SELECT MAX(id) FROM table");
$row = query("SELECT * FROM table WHERE id = ".$rnd);หรือ:
$cnt = query("SELECT COUNT(*) FROM table");
$row = query("SELECT * FROM table LIMIT ".$cnt.", 1");
อย่างไรก็ตาม ซึ่งอาจช้าได้หากมีแถวจำนวนมากในตาราง - ใช้ JOIN จำนวนมาก
เลือก
v.video_id
ก.ชื่อ
g.ประเภท
จาก
วิดีโอ AS v
เข้าร่วมทางซ้าย
link_actors_videos AS la ON la.video_id = v.video_id
เข้าร่วมทางซ้าย
นักแสดง AS a ON a.actor_id = la.actor_id
เข้าร่วมทางซ้าย
link_genre_video AS lg บน lg.video_id = v.video_id
เข้าร่วมทางซ้าย
ประเภท AS g ON g.genre_id = lg.genre_idต้องจำไว้ว่าเมื่อเชื่อมต่อตารางแบบหนึ่งต่อหลายแถวจำนวนแถวที่เลือกจะเพิ่มขึ้นตามแต่ละ JOIN ถัดไป ในกรณีเช่นนี้ การแยกแบบสอบถามดังกล่าวออกเป็นหลาย ๆ แถวจะเร็วกว่า
- ใช้ LIMIT
เลือก... จากตาราง จำกัด $start, $per_pageหลายๆ คนคิดว่าแบบสอบถามดังกล่าวจะส่งกลับ $per_page ของระเบียน (ปกติคือ 10-20) ดังนั้นจึงจะทำงานได้อย่างรวดเร็ว มันจะทำงานได้อย่างรวดเร็วสำหรับสองสามหน้าแรก แต่ถ้าจำนวนบันทึกมีขนาดใหญ่ และคุณต้องดำเนินการ SELECT... FROM table LIMIT 1000000, 1000020 แบบสอบถาม จากนั้นในการดำเนินการค้นหาดังกล่าว MySQL จะเลือก 1000020 ระเบียนก่อน ทิ้งล้านแรกแล้วส่งคืน 20 สิ่งนี้ อาจจะไม่เร็วเลย ไม่มีวิธีแก้ไขปัญหาเล็กน้อย หลายๆ คนก็จำกัดปริมาณ หน้าที่มีอยู่ จำนวนที่เหมาะสม- คุณยังสามารถเพิ่มความเร็วการสืบค้นดังกล่าวได้โดยใช้ดัชนีที่ครอบคลุมหรือ โซลูชันของบุคคลที่สาม(เช่น สฟิงซ์)
- ไม่ได้ใช้ ON DUPLICATE KEY UPDATE
$row = query("SELECT * FROM table WHERE id=1");ถ้า($แถว)
แบบสอบถาม ("อัปเดตตาราง SET คอลัมน์ = คอลัมน์ + 1 WHERE id = 1")
อื่น
query("INSERT INTO table SET column = 1, id=1");โครงสร้างที่คล้ายกันสามารถแทนที่ได้ด้วยแบบสอบถามเดียว โดยมีเงื่อนไขว่าต้องมีคีย์หลักหรือคีย์เฉพาะสำหรับฟิลด์ id:
แทรกลงในคอลัมน์ SET ของตาราง = 1, id = 1 บนคอลัมน์การอัปเดตคีย์ซ้ำ = คอลัมน์ + 1
MySQL ยังคงเป็นฐานข้อมูลเชิงสัมพันธ์ที่ได้รับความนิยมมากที่สุดในโลก แต่ก็เป็นฐานข้อมูลที่ไม่ได้รับการปรับให้เหมาะสมที่สุดเช่นกัน หลายๆ คนยังคงใช้การตั้งค่าเริ่มต้นโดยไม่ต้องเจาะลึกลงไปอีก ในบทความนี้ เราจะดูเคล็ดลับการเพิ่มประสิทธิภาพ MySQL รวมกับคุณสมบัติใหม่บางอย่างที่ออกมาค่อนข้างเร็ว
การเพิ่มประสิทธิภาพการกำหนดค่า
สิ่งแรกที่ผู้ใช้ MySQL ทุกคนควรทำเพื่อปรับปรุงประสิทธิภาพคือปรับแต่งการกำหนดค่า อย่างไรก็ตาม คนส่วนใหญ่ข้ามขั้นตอนนี้ บี 5.7 ( รุ่นปัจจุบัน) การตั้งค่าเริ่มต้นนั้นดีกว่ารุ่นก่อนมาก แต่การปรับปรุงยังคงเป็นไปได้และง่ายดาย
เราหวังว่าคุณจะใช้ Linux หรือบางอย่างเช่น Vagrant -box (เช่น Homestead Enhanced ของเรา) และด้วยเหตุนี้ ไฟล์การกำหนดค่าของคุณจะอยู่ใน /etc/mysql/my.cnf เป็นไปได้ว่าการติดตั้งของคุณจะโหลดจริง ไฟล์เพิ่มเติมการกำหนดค่าในอันนี้ ดังนั้นลองดูว่าไฟล์ my.cnf มีไม่มาก ให้ลองค้นหาใน /etc/mysql/mysql.conf.d/mysqld.cnf
การปรับจูนด้วยตนเอง
การตั้งค่าต่อไปนี้ควรทำตั้งแต่แกะกล่อง ตามเคล็ดลับเหล่านี้ ให้เพิ่มไฟล์ปรับแต่งในส่วนนี้:
Innodb_buffer_pool_size = 1G # (ที่นี่เปลี่ยนประมาณ 50% -70% ของ RAM ทั้งหมด) innodb_log_file_size = 256M innodb_flush_log_at_trx_commit = 1 # สามารถเปลี่ยนเป็น 2 หรือ 0 innodb_flush_method = O_DIRECT
- innodb_buffer_pool_size . บัฟเฟอร์พูลเป็น "คลังสินค้า" ประเภทหนึ่งสำหรับการแคชข้อมูลและดัชนีในหน่วยความจำ มันถูกใช้เพื่อจัดเก็บข้อมูลที่เข้าถึงบ่อยไว้ในหน่วยความจำ และเมื่อคุณใช้เซิร์ฟเวอร์เฉพาะหรือเซิร์ฟเวอร์เสมือน ซึ่งฐานข้อมูลมักเป็นจุดคอขวด ก็สมเหตุสมผลที่จะให้ RAM ส่วนใหญ่แก่ฐานข้อมูล ดังนั้นเราจึงให้ 50-70% ของ RAM ทั้งหมด มีคำแนะนำในการตั้งค่าพูลนี้ในเอกสารประกอบ MySQL
- innodb_log_file_size . การตั้งค่าขนาดไฟล์บันทึกอธิบายไว้อย่างดี แต่โดยสรุปคือจำนวนข้อมูลที่จัดเก็บไว้ในบันทึกก่อนที่จะถูกล้าง โปรดทราบว่าบันทึกในกรณีนี้ไม่ใช่บันทึกข้อผิดพลาด แต่เป็นสแน็ปช็อตเดลต้าของการเปลี่ยนแปลงที่ยังไม่ได้ถูกล้างลงดิสก์ในไฟล์ Innodb หลัก MySQL เขียนถึง พื้นหลังแต่สิ่งนี้ยังคงส่งผลต่อประสิทธิภาพในขณะที่บันทึก ไฟล์บันทึกขนาดใหญ่มีความหมายมากกว่านั้น ประสิทธิภาพสูงเนื่องจากจุดตรวจใหม่และจุดตรวจขนาดเล็กที่สร้างขึ้นมีจำนวนน้อย แต่ในขณะเดียวกันก็ใช้เวลาในการกู้คืนนานขึ้นในกรณีที่เกิดความผิดพลาด (ต้องเขียนข้อมูลเพิ่มเติมลงในฐานข้อมูล)
- มีการอธิบาย innodb_flush_log_at_trx_commit และแสดงสิ่งที่เกิดขึ้นกับไฟล์บันทึก ค่า 1 นั้นปลอดภัยที่สุด เนื่องจากบันทึกจะถูกล้างลงดิสก์หลังจากแต่ละธุรกรรม ด้วยค่า 0 และ 2 รับประกัน ACID น้อยกว่า แต่ประสิทธิภาพจะสูงกว่า ความแตกต่างไม่มากพอที่จะเกินดุลผลประโยชน์ด้านความมั่นคงที่ 1
- innodb_flush_method เหนือสิ่งอื่นใดเมื่อพูดถึงการล้างข้อมูล การตั้งค่านี้จะต้องตั้งค่าเป็น O_DIRECT - เพื่อหลีกเลี่ยงการบัฟเฟอร์ซ้ำซ้อน ฉันแนะนำให้คุณทำเช่นนี้เสมอในขณะที่ระบบ I/O ยังคงช้ามาก แม้ว่าโฮสติ้งส่วนใหญ่ เช่น DigitalOcean คุณจะมีไดรฟ์ SSD ดังนั้นระบบ I/O จึงมีประสิทธิผลมากกว่า
มีเครื่องมือจาก Percona ที่จะช่วยให้เราค้นหาปัญหาที่เหลือโดยอัตโนมัติ โปรดทราบว่าหากเรารันโดยไม่มีการตั้งค่าด้วยตนเอง จะมีการกำหนดเพียง 1 ใน 4 การตั้งค่าเท่านั้น เนื่องจากอีก 3 รายการขึ้นอยู่กับการตั้งค่าของผู้ใช้และ สิ่งแวดล้อมการใช้งาน
ตัวตรวจสอบตัวแปร
การติดตั้งตัวตรวจสอบตัวแปรบน Ubuntu:
รับ https://repo.percona.com/apt/percona-release_0.1-4.$(lsb_release -sc)_all.deb sudo dpkg -i percona-release_0.1-4.$(lsb_release -sc)_all. deb sudo apt-get อัปเดต sudo apt-get ติดตั้ง percona-toolkit
สำหรับระบบอื่นๆ ให้ปฏิบัติตามคำแนะนำเหล่านี้
จากนั้นรันชุดเครื่องมือ:
Pt-variable-advisor h=localhost,u=homestead,p=secret
คุณจะเห็นผลลัพธ์นี้:
# คำเตือน Delay_key_write: บล็อกดัชนี MyISAM จะไม่ถูกล้างจนกว่าจะจำเป็น # หมายเหตุ max_binlog_size: max_binlog_size เล็กกว่าค่าเริ่มต้นที่ 1GB # หมายเหตุ sort_buffer_size-1: โดยทั่วไปตัวแปร sort_buffer_size ควรปล่อยให้เป็นค่าเริ่มต้น เว้นแต่ผู้เชี่ยวชาญจะพิจารณาว่าจำเป็นต้องเปลี่ยนแปลง # หมายเหตุ innodb_data_file_path: ไฟล์ InnoDB ที่ขยายอัตโนมัติอาจใช้พื้นที่ดิสก์จำนวนมากซึ่งยากต่อการเรียกคืนในภายหลัง # คำเตือน log_bin: การบันทึกไบนารี่ถูกปิดใช้งาน ดังนั้น ณ เวลานั้น การกู้คืนและการจำลองแบบ ไม่ได้เป็นไปได้.
บันทึก นักแปล:
ของฉัน เครื่องท้องถิ่นนอกจากนี้ ยังได้ออกคำเตือนดังต่อไปนี้:
ความจริงที่ว่าพารามิเตอร์ innodb_flush_method จำเป็นต้องตั้งค่าเป็น O_DIRECT และเหตุใดจึงมีการกล่าวถึงข้างต้น และหากคุณทำตามลำดับการปรับแต่งเหมือนในบทความ คุณจะไม่เห็นคำเตือนนี้
ไม่มีสิ่งเหล่านี้ ( ประมาณ: ระบุโดยผู้เขียน) คำเตือนไม่สำคัญ ไม่จำเป็นต้องแก้ไข สิ่งเดียวที่สามารถแก้ไขได้คือการตั้งค่าบันทึกไบนารีสำหรับการจำลองและสแน็ปช็อต
หมายเหตุ: ในเวอร์ชันใหม่ ขนาด Binlog เริ่มต้นคือ 1G และคำเตือนนี้จะไม่เกิดขึ้น
Max_binlog_size = 1G log_bin = /var/log/mysql/mysql-bin.log server-id=master-01 binlog-format = "ROW"
- max_binlog_size . กำหนดว่าบันทึกไบนารีจะมีขนาดใหญ่เพียงใด พวกเขาบันทึกธุรกรรมและคำขอของคุณและทำจุดตรวจ หากธุรกรรมเกินขนาดสูงสุด บันทึกอาจมีขนาดเกินเมื่อบันทึกลงดิสก์ มิฉะนั้น MySQL จะรองรับภายในขีดจำกัดนี้
- log_bin. ตัวเลือกนี้เปิดใช้งานการบันทึกแบบไบนารีโดยทั่วไป หากไม่มีสิ่งนี้ สแนปช็อตหรือการจำลองแบบก็เป็นไปไม่ได้ โปรดทราบว่าสิ่งนี้อาจส่งผลกระทบอย่างมากต่อพื้นที่ดิสก์ของคุณ รหัสเซิร์ฟเวอร์คือ ตัวเลือกที่จำเป็นเมื่อเปิดใช้งานการบันทึกแบบไบนารี ดังนั้นบันทึกจะ "รู้" ว่ามาจากเซิร์ฟเวอร์ใด (สำหรับการจำลองแบบ) และรูปแบบ binlog เป็นเพียงวิธีการเขียนเท่านั้น
อย่างที่คุณเห็น MySQL ใหม่มีค่าเริ่มต้นที่เกือบจะพร้อมสำหรับการใช้งานจริง แน่นอนว่าแต่ละแอปพลิเคชันมีความแตกต่างกันและมีลูกเล่นและการปรับแต่งเพิ่มเติมที่นำไปใช้
MySQL จูนเนอร์
เครื่องมือสนับสนุน: Percona Toolkit สำหรับระบุดัชนีที่ซ้ำกัน
Percona Toolkit ที่เราติดตั้งไว้ก่อนหน้านี้ยังมีเครื่องมือสำหรับตรวจจับดัชนีที่ซ้ำกัน ซึ่งอาจมีประโยชน์เมื่อใช้ CMS ของบุคคลที่สาม หรือเพียงตรวจสอบตัวเองว่าคุณเพิ่มดัชนีมากเกินไปโดยไม่ได้ตั้งใจหรือไม่ ตัวอย่างเช่น การติดตั้ง WordPress เริ่มต้นมีดัชนีที่ซ้ำกันในตาราง wp_posts:
Pt-duplicate-key-checker h=localhost,u=homestead,p=secret # ############################### ########################################## # homestead.wp_posts # #### ################################################### ################## # คีย์ type_status_date ลงท้ายด้วยคำนำหน้าของดัชนีคลัสเตอร์ # คำจำกัดความของคีย์: # KEY `type_status_date` (`post_type`,`post_status`,`post_date` ,`ID`), # PRIMARY KEY (`ID`), # ประเภทคอลัมน์: # `post_type` varchar(20) เปรียบเทียบ utf8mb4_unicode_520_ci ไม่ใช่ค่าเริ่มต้นที่เป็นค่าว่าง "post" # `post_status` varchar(20) เปรียบเทียบ utf8mb4_unicode_520_ci ไม่ใช่ค่าเริ่มต้นที่เป็นค่าว่าง "เผยแพร่ " " # `post_date` datetime ไม่ใช่ค่าเริ่มต้นที่เป็นโมฆะ "0000-00-00 00:00:00" # `id` bigint(20) ไม่ได้ลงนาม ไม่ใช่ null auto_increation # หากต้องการย่อดัชนีคลัสเตอร์ที่ซ้ำกันนี้ให้สั้นลง ให้ดำเนินการ: ALTER TABLE `homestead` ` wp_posts` DROP INDEX `type_status_date`, เพิ่ม INDEX `type_status_date` (`post_type`,`post_status`,`post_date`);
ดังที่เห็นได้จาก บรรทัดสุดท้ายเครื่องมือนี้ยังให้คำแนะนำเกี่ยวกับวิธีกำจัดดัชนีที่ซ้ำกันอีกด้วย
เครื่องมือช่วยเหลือ: Percona Toolkit สำหรับดัชนีที่ไม่ได้ใช้
Percona Toolkit ยังสามารถตรวจจับดัชนีที่ไม่ได้ใช้ได้อีกด้วย หากคุณกำลังบันทึกการสืบค้นที่ช้า (ดูส่วนคอขวดด้านล่าง) คุณสามารถเรียกใช้ยูทิลิตีได้และจะตรวจสอบว่าการสืบค้นเหล่านั้นใช้ดัชนีบนตารางหรือไม่และอย่างไร
Pt-index-การใช้งาน /var/log/mysql/mysql-slow.log
สำหรับข้อมูลโดยละเอียดเกี่ยวกับการใช้ยูทิลิตี้นี้ โปรดดูที่
คอขวด
ในส่วนนี้อธิบายวิธีการตรวจหาและตรวจสอบปัญหาคอขวดของฐานข้อมูล
ขั้นแรก เรามาเปิดใช้งานการบันทึกการสืบค้นที่ช้า:
Slow_query_log = /var/log/mysql/mysql-slow.log long_query_time = 1 บันทึกแบบสอบถามไม่ได้ใช้ดัชนี = 1
ต้องเพิ่มบรรทัดด้านบนในการกำหนดค่า mysql ฐานข้อมูลจะติดตามคำค้นหาที่ใช้เวลาดำเนินการมากกว่า 1 วินาทีและคำค้นหาที่ไม่ได้ใช้ดัชนี
เมื่อมีข้อมูลบางส่วนในบันทึกนี้ คุณสามารถวิเคราะห์ข้อมูลดังกล่าวเพื่อใช้ดัชนีได้โดยใช้ยูทิลิตี pt-index-usage ด้านบน หรือใช้ pt-query-digest ซึ่งจะแสดงผลดังนี้:
Pt-query-digest /var/log/mysql/mysql-slow.log # เวลาผู้ใช้ 360ms, เวลาระบบ 20ms, 24.66M rss, 92.02M vsz # วันที่ปัจจุบัน: พฤหัสบดี 13 ก.พ. 22:39:29 2014 # ชื่อโฮสต์: * # ไฟล์: mysql-slow.log # โดยรวม: ทั้งหมด 8 รายการ, 6 รายการที่ไม่ซ้ำกัน, 1.14 QPS, การทำงานพร้อมกัน 0.00 เท่า ________________ # ช่วงเวลา: 2014-02-13 22:23:52 ถึง 22:23:59 # แอตทริบิวต์รวมขั้นต่ำเฉลี่ยสูงสุด ค่ามัธยฐานมาตรฐาน 95% # ============ ======= ======= ======= ======= ===== == ======= ======= # เวลาดำเนินการ 3ms 267us 406us 343us 403us 39us 348us # เวลาล็อค 827us 88us 125us 103us 119us 12us 98us # แถวที่ส่ง 36 1 15 4.50 14.52 4.18 3.89 # แถว ตรวจสอบ 87 4 30 10.88 28.75 7.37 7.70 # ขนาดแบบสอบถาม 2.15k 153 296 245.11 284.79 48.90 258.32 # === = === ========== === ===== ====== = ==== =============== # โปรไฟล์ # อันดับ Query ID เวลาตอบสนอง โทร R/Call V/M Item # ==== ==== ====== ====== ===== ====== === == =============== # 1 0x728E539F7617C14D 0.0011 41.0% 3 0.0004 0.00 เลือก blog_article # 2 0x1290EEE0B201F3FF 0.0003 12.8% 1 0.0003 0.00 เลือกพอร์ตโฟลิโอ _item # 3 0x31DE4535BDBFA465 0.0003 12.6% 1 0.0003 0.00 SELECT 8F848005A09C9588 0.0003 11.8% 1 0.0003 0.00 SELECT Blog_Category # 6 0x55F49 C753CA2ED64 0.0003 9.7% 1 0.0003 0.00 SELECT blog_article # ==== ============ ====== ============ ===== ==== == ===== =============== # แบบสอบถาม 1: 0 QPS, 0x การทำงานพร้อมกัน, ID 0x728E539F7617C14D ที่ไบต์ 736 ______ # คะแนน: V/M = 0.00 # ช่วงเวลา: เหตุการณ์ทั้งหมดเกิดขึ้นที่ 2014-02-13 22:23:52 # คุณลักษณะ pct รวมขั้นต่ำสูงสุดเฉลี่ย 95 % stddev median # ============ === ======= == ===== ======= ======= === ==== ======= ======= # นับ 37 3 # เวลาดำเนินการ 40 1ms 352us 406us 375us 403us 22us 366us # เวลาล็อค 42 351us 103us 125us 117us 119us 9us 119us # แถวที่ส่ง 25 9 1 4 3 3.89 1.37 3.89 # แถวที่ตรวจสอบ 24 21 5 8 7 7.70 1.29 0 # ขนาดแบบสอบถาม 47 1.02k 261 262 261.25 258.32 0 258.32 # สตริง: # โฮสต์โฮสต์ท้องถิ่น# ผู้ใช้ * # การกระจาย Query_time # 1us # 10us # 100us ##################################### ########################## # 1ms # 10ms # 100ms # 1s # 10s+ # Tables # แสดงสถานะตารางเช่น "blog_article"\G # SHOW สร้างตาราง `blog_article`\G # EXPLAIN /*!50100 PARTITIONS*/ SELECT b0_.id AS id0, b0_.slug AS slug1, b0_.title AS title2, b0_.excerpt AS excerpt3, b0_.external_link AS external_link4, b0_.description AS description5, b0_.สร้าง AS สร้างแล้ว 6, b0_.อัปเดต AS อัปเดต 7 จาก blog_article b0_ เรียงลำดับตาม b0_.สร้าง DESC จำกัด 10
หากคุณต้องการวิเคราะห์บันทึกเหล่านี้ด้วยตนเอง คุณก็ทำเช่นเดียวกันได้ แต่ก่อนอื่นคุณจะต้องส่งออกบันทึกเป็นรูปแบบที่แยกวิเคราะห์ได้มากขึ้น ซึ่งสามารถทำได้เช่นนี้:
Mysqldumpslow /var/log/mysql/mysql-slow.log
กับ พารามิเตอร์เพิ่มเติมคุณสามารถกรองข้อมูลเพื่อส่งออกเฉพาะสิ่งที่คุณต้องการได้ ตัวอย่างเช่น ข้อความค้นหา 10 อันดับแรก จัดเรียงตามเวลาดำเนินการโดยเฉลี่ย:
Mysqldumpslow -t 10 -s ที่ /var/log/mysql/localhost-slow.log
บทสรุป
ในโพสต์การเพิ่มประสิทธิภาพ MySQL ที่ครอบคลุมนี้ เราได้กล่าวถึงแล้ว วิธีการต่างๆและเทคนิคที่เราสามารถทำให้ MySQL ของเราบินได้
เราค้นพบการเพิ่มประสิทธิภาพการกำหนดค่า เราอัปเกรดดัชนี และกำจัดปัญหาคอขวดบางอย่าง ทั้งหมดนี้เป็นเพียงทฤษฎีเท่านั้น อย่างไรก็ตาม ทั้งหมดนี้ใช้ได้กับการใช้งานในโลกแห่งความเป็นจริง
จากผู้เขียน:เพื่อนคนหนึ่งของฉันตัดสินใจเพิ่มประสิทธิภาพรถของเขา ก่อนอื่นเขาถอดล้อออกหนึ่งล้อจึงตัดหลังคาออก จากนั้นก็ตัดเครื่องยนต์... โดยทั่วไปตอนนี้เขาเดินแล้ว ทั้งหมดนี้ล้วนเป็นผลมาจากแนวทางที่ผิด! ดังนั้น เพื่อให้ DBMS ของคุณทำงานต่อไปได้ การเพิ่มประสิทธิภาพ MySQL จะต้องดำเนินการอย่างถูกต้อง
ควรเพิ่มประสิทธิภาพเมื่อใดและเพราะเหตุใด
มันไม่คุ้มที่จะเข้าไปที่การตั้งค่าเซิร์ฟเวอร์และเปลี่ยนค่าพารามิเตอร์อีกครั้ง (โดยเฉพาะถ้าคุณไม่รู้ว่าสิ่งนี้จะจบลงอย่างไร) หากเราพิจารณาหัวข้อนี้จาก "หอระฆัง" ในการปรับปรุงประสิทธิภาพของแหล่งข้อมูลบนเว็บก็ถือว่าครอบคลุมมากจนจำเป็นต้องทุ่มเทให้กับสิ่งพิมพ์ทางวิทยาศาสตร์ทั้งหมดใน 7 เล่ม
แต่เห็นได้ชัดว่าฉันไม่มีความอดทนแบบนั้นในฐานะนักเขียน และคุณในฐานะผู้อ่านก็เช่นกัน เราจะทำให้มันง่ายขึ้นและพยายามเจาะลึกเพียงเล็กน้อยในการเพิ่มประสิทธิภาพเซิร์ฟเวอร์ MySQL และส่วนประกอบต่างๆ ด้วยการตั้งค่าพารามิเตอร์ DBMS ทั้งหมดอย่างเหมาะสม คุณสามารถบรรลุเป้าหมายหลายประการ:
เพิ่มความเร็วของการดำเนินการค้นหา
ส่งเสริม ประสิทธิภาพโดยรวมเซิร์ฟเวอร์
ลดเวลาในการรอโหลดหน้าทรัพยากร
ลดการใช้ความจุของเซิร์ฟเวอร์โฮสติ้ง
ลดจำนวนเนื้อที่ดิสก์ที่ใช้
เราจะพยายามแบ่งหัวข้อการเพิ่มประสิทธิภาพทั้งหมดออกเป็นหลายจุด เพื่อให้ชัดเจนไม่มากก็น้อยว่าอะไรทำให้ "หม้อเดือด"
ทำไมต้องตั้งค่าเซิร์ฟเวอร์
ใน MySQL การเพิ่มประสิทธิภาพการทำงานควรเริ่มต้นจากเซิร์ฟเวอร์ ก่อนอื่น คุณควรเร่งการดำเนินการและลดเวลาที่ใช้ในการประมวลผลคำขอ วิธีการสากลในการบรรลุเป้าหมายข้างต้นทั้งหมดคือการเปิดใช้งานการแคช ไม่รู้ว่า “มันคืออะไร”? ตอนนี้ฉันจะอธิบายทุกอย่าง
หากเปิดใช้งานการแคชบนอินสแตนซ์เซิร์ฟเวอร์ของคุณ ระบบมายเอสคิวแอล"จดจำ" ข้อความค้นหาที่ผู้ใช้ป้อนโดยอัตโนมัติ และครั้งต่อไปก็เกิดขึ้นอีก ผลลัพธ์นี้คำขอ (สำหรับการสุ่มตัวอย่าง) จะไม่ถูกประมวลผล แต่นำมาจากหน่วยความจำระบบ ปรากฎว่าด้วยวิธีนี้เซิร์ฟเวอร์จะ "ประหยัดเวลา" ในการตอบกลับ และส่งผลให้ความเร็วในการตอบสนองของไซต์เพิ่มขึ้น นอกจากนี้ยังใช้กับความเร็วในการดาวน์โหลดโดยรวมด้วย
ใน MySQL การเพิ่มประสิทธิภาพคิวรีใช้ได้กับกลไกและ CMS ที่ทำงานบนพื้นฐานของ DBMS และ PHP นี้ ในกรณีนี้ โค้ดที่เขียนด้วยภาษาโปรแกรม เพื่อสร้างเว็บเพจแบบไดนามิก จะต้องร้องขอส่วนโครงสร้างและเนื้อหาบางส่วน (บันทึก เอกสารสำคัญ และอนุกรมวิธานอื่นๆ) จากฐานข้อมูล
ด้วยการเปิดใช้งานการแคชใน MySQL การเรียกใช้คำสั่งไปยังเซิร์ฟเวอร์ DBMS จึงรวดเร็วยิ่งขึ้นมาก ด้วยเหตุนี้ความเร็วในการโหลดทรัพยากรทั้งหมดโดยรวมจึงเพิ่มขึ้น และสิ่งนี้มีผลดีต่อทั้งประสบการณ์ผู้ใช้และตำแหน่งของเว็บไซต์ในผลการค้นหา
เปิดใช้งานและกำหนดค่าการแคช
แต่ขอกลับจากทฤษฎีที่ "น่าเบื่อ" ไปสู่การปฏิบัติที่น่าสนใจกันดีกว่า การเพิ่มประสิทธิภาพเพิ่มเติม ฐานข้อมูล MySQLดำเนินการต่อด้วยการตรวจสอบสถานะแคชบนเซิร์ฟเวอร์ฐานข้อมูลของคุณ ในการดำเนินการนี้ เราจะแสดงค่าของตัวแปรระบบทั้งหมดโดยใช้คำขอพิเศษ:
มันเป็นเรื่องที่แตกต่างอย่างสิ้นเชิง
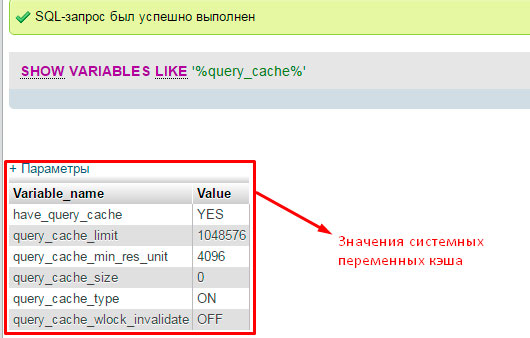
เรามาสร้างภาพรวมเล็กน้อยของค่าที่ได้รับซึ่งจะเป็นประโยชน์สำหรับเราในการเพิ่มประสิทธิภาพฐานข้อมูล MySQL:
have_query_cache – ค่าระบุว่าแคชการสืบค้นเป็น "เปิด" หรือไม่
query_cache_type - แสดงประเภทแคชที่ใช้งานอยู่ เราต้องการค่า "ON" สิ่งนี้บ่งชี้ว่าแคชถูกเปิดใช้งานสำหรับการเลือกทุกประเภท (คำสั่ง SELECT) ยกเว้นที่ใช้พารามิเตอร์ SQL_NO_CACHE (ห้ามไม่ให้บันทึกข้อมูลเกี่ยวกับแบบสอบถามนี้)
เรามีการตั้งค่าทั้งหมดอย่างถูกต้อง
เราวัดแคชสำหรับดัชนีและคีย์
ตอนนี้คุณต้องตรวจสอบจำนวน RAM ที่จัดสรรสำหรับดัชนีและคีย์ ขอแนะนำให้ตั้งค่าพารามิเตอร์นี้ซึ่งสำคัญสำหรับการเพิ่มประสิทธิภาพฐานข้อมูล MySQL เป็น 20-30% ของจำนวน RAM ที่มีให้กับเซิร์ฟเวอร์ ตัวอย่างเช่น หากจัดสรรพื้นที่ 4 “เฮกตาร์” สำหรับอินสแตนซ์ DBMS คุณก็ตั้งค่าได้ 32 “เมตร” แต่ทั้งหมดขึ้นอยู่กับลักษณะของฐานข้อมูลเฉพาะและโครงสร้าง (ประเภท) ของตาราง
หากต้องการตั้งค่าพารามิเตอร์ คุณต้องแก้ไขเนื้อหา ไฟล์การกำหนดค่า my.ini ซึ่งในเดนเวอร์อยู่ที่เส้นทางต่อไปนี้: F:\Webserver\usr\local\mysql-5.5

เปิดไฟล์โดยใช้ Notepad จากนั้นเราจะค้นหาพารามิเตอร์ key_buffer_size และตั้งค่าขนาดที่เหมาะสมที่สุดสำหรับระบบพีซีของคุณ (ขึ้นอยู่กับ RAM “เฮกตาร์”) หลังจากนี้ คุณจะต้องรีสตาร์ทเซิร์ฟเวอร์ฐานข้อมูล

DBMS ใช้ระบบย่อยเพิ่มเติมหลายระบบ ( ระดับล่าง) และการตั้งค่าพื้นฐานทั้งหมดก็ระบุไว้ในนั้นด้วย ไฟล์นี้การกำหนดค่า ดังนั้น หากคุณต้องการเพิ่มประสิทธิภาพ MySQL InnoDB ยินดีต้อนรับที่นี่ เราจะศึกษาหัวข้อนี้โดยละเอียดยิ่งขึ้นในเอกสารฉบับถัดไปของเรา
การวัดระดับของดัชนี
การใช้ดัชนีในตารางจะเพิ่มความเร็วในการประมวลผลและสร้างการตอบสนอง DBMS ให้กับแบบสอบถามที่ป้อนอย่างมาก MySQL “วัด” ระดับของดัชนีและการใช้งานคีย์ในแต่ละฐานข้อมูลอย่างต่อเนื่อง เพื่อรับ มูลค่าที่กำหนดใช้แบบสอบถาม:
แสดงสถานะเช่น "handler_read%"
แสดงสถานะเช่น "handler_read%" |

ในผลลัพธ์ที่ได้ เราสนใจค่าในบรรทัด Handler_read_key หากตัวเลขที่ระบุมีจำนวนน้อย แสดงว่าแทบไม่เคยมีการใช้ดัชนีในฐานข้อมูลนี้เลย และนี่ก็แย่ (เหมือนเรา)
→ การเพิ่มประสิทธิภาพ แบบสอบถาม MySQL
MySQLมีฟังก์ชั่นการจัดเรียงที่หลากหลาย ( สั่งซื้อโดย) กลุ่ม ( จัดกลุ่มตาม) สมาคม ( เข้าร่วมทางซ้ายหรือ เข้าร่วมอย่างถูกต้อง) และอื่นๆ ทั้งหมดนี้สะดวกอย่างแน่นอน แต่ต้องอยู่ในเงื่อนไขของการร้องขอครั้งเดียว ตัวอย่างเช่น หากคุณจำเป็นต้องขุดบางอย่างลงในฐานข้อมูลเป็นการส่วนตัวโดยใช้ตารางและลิงก์จำนวนมาก นอกเหนือจากฟังก์ชันข้างต้นแล้ว คุณยังสามารถใช้ตัวดำเนินการแบบมีเงื่อนไขได้อีกด้วย ถ้า. ข้อผิดพลาดหลักสำหรับโปรแกรมเมอร์มือใหม่นี่คือความปรารถนาที่จะใช้คำสั่งดังกล่าวในโค้ดการทำงานของไซต์ ในกรณีนี้ คำถามที่ซับซ้อนย่อมสวยงามแต่เป็นอันตราย ประเด็นก็คือการเรียงลำดับ การจัดกลุ่ม ยูเนี่ยน หรือตัวดำเนินการคิวรีแบบซ้อนไม่สามารถดำเนินการได้ใน RAM และใช้ ฮาร์ดไดรฟ์เพื่อสร้างตารางชั่วคราว และอย่างที่ทราบกันดีว่าฮาร์ดไดรฟ์คือปัญหาคอขวดของเซิร์ฟเวอร์
กฎสำหรับการเพิ่มประสิทธิภาพการสืบค้น mysql
1. หลีกเลี่ยงคำถามที่ซ้อนกัน
นี่เป็นข้อผิดพลาดที่ร้ายแรงที่สุด กระบวนการหลักจะรอให้กระบวนการลูกดำเนินการเสมอ และในเวลานี้ยังคงเชื่อมต่อกับฐานข้อมูล ใช้ดิสก์ และโหลด iowait คำขอแบบขนานสองครั้งไปยังฐานข้อมูลและดำเนินการกรองที่จำเป็นในล่ามเซิร์ฟเวอร์ ( ภาษาเพิร์ล, PHP ฯลฯ) จะถูกดำเนินการตามลำดับความสำคัญเร็วกว่าขนาดที่ซ้อนกัน
ตัวอย่างในภาษา Perlสิ่งที่ไม่ควรทำ:
$sth ของฉัน = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(2,3,7)");
$sth->ดำเนินการ();
ในขณะที่ (my @row = $sth->fetchrow_array()) ( my $groupNAME = $dbh->selectrow_array("SELECT groupNAME FROM groups WHERE groupID = $row"); ### สมมติว่าคุณต้องรวบรวมชื่อของ group ### และเพิ่มลงที่ส่วนท้ายของอาร์เรย์ข้อมูล push @row => $groupNAME; ### Do else... )
หรือไม่ว่าในกรณีเช่นนี้:
$sth = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(SELECT groupID FROM groups WHERE groupNAME = "First" OR groupNAME = "Second" OR groupNAME = "Seventh")");
หากจำเป็นต้องดำเนินการดังกล่าว ในทุกกรณี ควรใช้แฮช อาร์เรย์ หรือเส้นทางการกรองอื่นๆ จะดีกว่า
ตัวอย่างในภาษา Perl อย่างที่ฉันมักจะทำ:
%กลุ่มของฉัน;
$sth ของฉัน = $dbh->prepare("เลือก groupID,groupNAME จากกลุ่ม WHERE groupID IN(2,3,7)");
$sth->ดำเนินการ();
ในขณะที่ (my @row = $sth->fetchrow_array()) ( $groups($row) = $row; ) ### ทีนี้มาทำการดึงข้อมูลหลักโดยไม่มีแบบสอบถามย่อย my $sth2 = $dbh->prepare("SELECT elementID ,elementNAME,groupID จาก tbl โดยที่ groupID IN (2,3,7)");
$sth2->ดำเนินการ();
ในขณะที่ (my @row = $sth2->fetchrow_array()) ( push @row => $groups($row); ### มาทำอย่างอื่นกันดีกว่า... ) 2. ห้ามเรียงลำดับ จัดกลุ่ม หรือกรองข้อมูลในฐานข้อมูลหากเป็นไปได้ อย่าใช้ตัวดำเนินการ ORDER BY, GROUP BY หรือ JOIN ในการสืบค้นของคุณ พวกเขาทั้งหมดใช้ตารางชั่วคราว หากจำเป็นต้องเรียงลำดับหรือจัดกลุ่มเพื่อแสดงองค์ประกอบต่างๆ เช่น ตามตัวอักษร การดำเนินการเหล่านี้ในตัวแปรล่ามจะดีกว่า
ตัวอย่าง Perl ของวิธีที่จะไม่เรียงลำดับ:
แม้ว่าการเรียงลำดับในฐานข้อมูลสามารถละทิ้งได้ในบางกรณี แต่ WHERE ไม่น่าจะเป็นไปได้ ดังนั้นสำหรับฟิลด์ที่จะเปรียบเทียบจึงจำเป็นต้องตั้งค่าดัชนี พวกเขาทำได้ง่าย
ด้วยการร้องขอนี้:
แก้ไขตาราง `any_db`.`any_tbl` เพิ่มดัชนี `text_index`(`text_fld`(255));
โดยที่ 255 คือความยาวของคีย์ สำหรับข้อมูลบางประเภทก็ไม่จำเป็น ดูเอกสารประกอบ MySQL สำหรับรายละเอียด
บางครั้งเมื่อคุณสร้างแบบสอบถาม คุณทราบอยู่แล้วว่าคุณต้องการเพียงแถวเดียวในตารางเท่านั้น คุณสามารถสร้างการเลือกตามเรกคอร์ดที่ไม่ซ้ำได้ หรือคุณสามารถเรียกใช้การตรวจสอบเพื่อดูว่ามีบันทึกจำนวนเท่าใดที่ตรงตามเงื่อนไขของคุณ
ในกรณีเช่นนี้ การใช้วิธี LIMIT 1 สามารถปรับปรุงประสิทธิภาพได้อย่างมาก:
// มีข้อมูลของคนจากแคลิฟอร์เนียในฐานข้อมูลหรือไม่? // ไม่ ไม่มีเลย!: $r = mysql_query("SELECT * FROM user WHERE state = "California""); if (mysql_num_rows($r) > 0) ( // ... รหัสอื่น ๆ ) // คำตอบเชิงบวก $r = mysql_query("SELECT 1 FROM user WHERE state = "California" LIMIT 1"); ถ้า (mysql_num_rows($r) > 0) ( // ... รหัสอื่น ๆ )
2. การเพิ่มประสิทธิภาพการทำงานกับฐานข้อมูลโดยใช้การประมวลผลแคชแบบสอบถาม
เซิร์ฟเวอร์ MySQL ส่วนใหญ่รองรับการแคชแบบสอบถาม นี่คือหนึ่งในที่สุด วิธีการที่มีประสิทธิภาพการปรับปรุงประสิทธิภาพที่กลไกจัดการฐานข้อมูลจัดการได้โดยไม่มีปัญหา
เมื่อมีการดำเนินการแบบสอบถามเดียวกันหลายครั้ง ผลลัพธ์จะได้รับจากแคช โดยไม่ต้องประมวลผลตารางทั้งหมดอีกครั้ง สิ่งนี้จะช่วยเร่งกระบวนการให้เร็วขึ้นอย่างมาก
// หากไม่รองรับแคชการสืบค้น $r = mysql_query("เลือกชื่อผู้ใช้จากผู้ใช้ WHERE signup_date >= CURDATE()"); // รองรับแคช! $today_date = date("Y-m-d"); $r = mysql_query("เลือกชื่อผู้ใช้จากผู้ใช้ WHERE signup_date >= "$today_date"");
3. การจัดทำดัชนีช่องค้นหา
ดัชนีไม่ได้มีวัตถุประสงค์เพื่อกำหนดให้กับคีย์หลักหรือคีย์เฉพาะเท่านั้น หากมีคอลัมน์ในตารางที่คุณค้นหา คอลัมน์เหล่านั้นควรได้รับการจัดทำดัชนีเกือบแน่นอน
ดังที่คุณสามารถจินตนาการได้ กฎนี้ยังใช้กับส่วนของสตริงการค้นหาด้วย เช่น “last_name LIKE '%'” เมื่อค้นหาที่จุดเริ่มต้นของแถว MySQL สามารถใช้การจัดทำดัชนีในคอลัมน์นั้นได้
คุณต้องเข้าใจด้วยว่าแบบสอบถามประเภทใดที่ไม่สามารถใช้ดัชนีปกติได้ ตัวอย่างเช่น เมื่อค้นหาคำ (เช่น "WHERE post_content LIKE '%tomato%"") การใช้ดัชนีปกติจะไม่ให้อะไรเลย ในกรณีนี้ จะดีกว่าถ้าใช้ ค้นหา MySQLเพื่อการปฏิบัติตามข้อกำหนดอย่างสมบูรณ์หรือสร้างดัชนีของคุณเอง
4. การจัดทำดัชนีและการใช้คอลัมน์ประเภทเดียวกันเมื่อเข้าร่วม
หากแอปพลิเคชันของคุณมีคำถามเข้าร่วมจำนวนมาก คุณต้องแน่ใจว่าคอลัมน์ในทั้งสองตารางที่คุณเข้าร่วมนั้นได้รับการจัดทำดัชนีแล้ว สิ่งนี้ส่งผลต่อการเพิ่มประสิทธิภาพภายใน การดำเนินงาน MySQLโดยสมาคม
นอกจากนี้ คอลัมน์ที่ผสานต้องเป็นชนิดเดียวกัน ตัวอย่างเช่น หากคุณรวมคอลัมน์ประเภท DECIMAL จากตารางหนึ่งและคอลัมน์ประเภท INT จากอีกตารางหนึ่ง MySQL จะไม่สามารถใช้งานได้เช่นกัน อย่างน้อยหนึ่งในดัชนี
แม้แต่การเข้ารหัสอักขระก็ต้องเป็นประเภทเดียวกันสำหรับแถวที่สอดคล้องกันของคอลัมน์ที่จะรวม
// กำลังมองหาบริษัทที่ตั้งอยู่ในสถานะของฉัน $r = mysql_query("SELECT company_name FROM users LEFT JOIN companies ON (users.state = companies.state) WHERE users.id = $user_id"); // ทั้งสองคอลัมน์สถานะจะต้องได้รับการจัดทำดัชนี // และทั้งคู่จะต้องเป็นประเภทเดียวกันและมีการเข้ารหัสอักขระเหมือนกันสำหรับแถวที่เกี่ยวข้อง // หรือ MySQL จะต้องสแกนทั้งตาราง
5. หากเป็นไปได้ ให้หลีกเลี่ยงการใช้คำสั่ง SELECT *
ยิ่งมีการประมวลผลข้อมูลในตารางระหว่างการสืบค้นมากขึ้นเท่าใด การสืบค้นก็จะยิ่งทำงานช้าลงเท่านั้น เวลากำลังจะหมดลง การดำเนินงานของดิสก์- นอกจากนี้ เมื่อเซิร์ฟเวอร์ฐานข้อมูลถูกแชร์กับเว็บเซิร์ฟเวอร์ การถ่ายโอนข้อมูลระหว่างเซิร์ฟเวอร์ก็จะเกิดความล่าช้า
// ข้อความค้นหาที่ไม่ต้องการ $r = mysql_query("SELECT * FROM user WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "ยินดีต้อนรับ ($d["ชื่อผู้ใช้"])"; // ควรใช้โค้ดต่อไปนี้: $r = mysql_query("SELECT username FROM user WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "ยินดีต้อนรับ ($d["ชื่อผู้ใช้"])";
6. กรุณาอย่าใช้วิธีการเรียงลำดับ ORDER BY RAND()
นี่เป็นหนึ่งในเทคนิคที่ดูเหมือนจะดีในตอนแรก และโปรแกรมเมอร์หน้าใหม่หลายคนก็ตกหลุมรักมัน คุณไม่สามารถจินตนาการได้เลยว่าคุณกำลังวางกับดักแบบไหนให้กับตัวเองทันทีที่คุณเริ่มใช้ตัวกรองนี้ในการสืบค้น
หากคุณต้องการจัดเรียงสตริงในผลการค้นหาจริงๆ มีวิธีที่มีประสิทธิภาพมากกว่านี้มาก สมมติว่าคุณต้องเพิ่ม รหัสเพิ่มเติมตามคำขอ แต่เนื่องจากกับดักนี้ คุณจะไม่สามารถทำเช่นนี้ได้ ซึ่งจะส่งผลให้ประสิทธิภาพของการประมวลผลข้อมูลลดลงเมื่อฐานข้อมูลมีขนาดใหญ่ขึ้น
ปัญหาคือ MySQL จะดำเนินการ RAND() (ซึ่งใช้ทรัพยากรการประมวลผลของเซิร์ฟเวอร์) ก่อนที่จะเรียงลำดับสำหรับแต่ละแถวในตาราง ในกรณีนี้ จะมีการเลือกเพียงแถวเดียวเท่านั้น
// รหัสใดที่ไม่ควรใช้: $r = mysql_query("เลือกชื่อผู้ใช้จากผู้ใช้ ORDER BY RAND() จำกัด 1"); // มันจะถูกต้องกว่าถ้าใช้โค้ดต่อไปนี้: $r = mysql_query("SELECT count(*) FROM user"); $d = mysql_fetch_row($r); $แรนด์ = mt_rand(0,$d - 1); $r = mysql_query("เลือกชื่อผู้ใช้จากผู้ใช้จำกัด $rand, 1");
ด้วยวิธีนี้ คุณจะเลือกผลการค้นหาน้อยลง หลังจากนั้นคุณสามารถใช้วิธี LIMIT ที่อธิบายไว้ในจุดที่ 1 ได้
7. ใช้คอลัมน์ ENUM แทน VARCHAR
คอลัมน์ ENUM มีขนาดเล็กมากจึงประมวลผลได้รวดเร็ว ภายในฐานข้อมูล เนื้อหาจะถูกจัดเก็บในรูปแบบ TINYINT แต่สามารถมีและแสดงค่าใดๆ ได้ ดังนั้นจึงสะดวกมากที่จะตั้งค่าบางฟิลด์ในนั้น
หากคุณมีบางช่องที่มีหลายช่อง ความหมายที่แตกต่างกันประเภทเดียวกัน ควรใช้ ENUM แทนคอลัมน์ VARCHAR ตัวอย่างเช่น อาจเป็นคอลัมน์ "สถานะ" ซึ่งมีเพียงค่าต่างๆ เช่น "ใช้งานอยู่", "ไม่ใช้งาน", "รอดำเนินการ", " หมดอายุแล้ว"ฯลฯ
เป็นไปได้ที่จะกำหนดสถานการณ์ที่ MySQL จะ "แจ้ง" ให้คุณเปลี่ยนโครงสร้างตาราง เมื่อคุณมีฟิลด์ VARCHAR ระบบอาจแนะนำให้เปลี่ยนรูปแบบคอลัมน์เป็น ENUM โดยอัตโนมัติ ซึ่งสามารถทำได้โดยการเรียกฟังก์ชัน PROCEDURE ANALYSE()
ใช้ฟิลด์เพื่อจัดเก็บที่อยู่ IP พิมพ์ไม่ได้ลงนามอินเตอร์เนชั่นแนล
นักพัฒนาจำนวนมากสร้างฟิลด์ VARCHAR(15) เพื่อจุดประสงค์นี้ ในขณะที่ที่อยู่ IP สามารถเก็บไว้ในฐานข้อมูลเป็นเลขทศนิยมได้ ฟิลด์ประเภท INT ให้ความสามารถในการจัดเก็บข้อมูลได้ถึง 4 ไบต์และในขณะเดียวกันก็สามารถตั้งค่าได้ ขนาดคงที่สาขา
คุณต้องตรวจสอบให้แน่ใจว่าคอลัมน์ของคุณอยู่ในรูปแบบ UNSIGNED INT เนื่องจากที่อยู่ IP ระบุไว้ใน 32 บิต
ในการสืบค้น คุณสามารถใช้พารามิเตอร์ INET_ATON() เพื่อแปลงที่อยู่ IP เป็นได้ ตัวเลขทศนิยมและ INET_NTOA() เป็นสิ่งที่ตรงกันข้าม PHP มีฟังก์ชันอื่นๆ ที่คล้ายกัน long2ip() และ ip2long()
8. การแบ่งส่วนแนวตั้ง (การแยก)
การแบ่งพาร์ติชันในแนวตั้งเป็นกระบวนการแบ่งโครงสร้างตารางในแนวตั้งเพื่อเพิ่มประสิทธิภาพการทำงานของฐานข้อมูล
ตัวอย่างที่ 1: สมมติว่าคุณมีตารางของผู้ใช้ที่มีที่อยู่บ้านของพวกเขา เหนือสิ่งอื่นใด ข้อมูลนี้ถูกใช้น้อยมาก คุณสามารถแยกตารางของคุณและจัดเก็บข้อมูลที่อยู่ในตารางอื่นได้
ด้วยวิธีนี้ ตารางผู้ใช้หลักของคุณจะมีขนาดลดลงอย่างเห็นได้ชัด และอย่างที่คุณทราบ ตารางขนาดเล็กจะถูกประมวลผลได้เร็วกว่า
ตัวอย่างที่ 2: คุณมีช่องในตาราง “last_login” (เข้าสู่ระบบครั้งล่าสุด) มีการอัปเดตทุกครั้งที่ผู้ใช้เข้าสู่ระบบด้วยชื่อผู้ใช้ของตน แต่ทุกการเปลี่ยนแปลงในตารางจะถูกเขียนลงในแคชแบบสอบถามสำหรับตารางนั้น ซึ่งจัดเก็บไว้ในดิสก์ คุณสามารถย้ายฟิลด์นี้ไปยังตารางอื่นเพื่อลดจำนวนการเรียกไปยังตารางผู้ใช้หลักของคุณ
อย่างไรก็ตาม คุณต้องแน่ใจว่าทั้งสองตารางที่เกิดจากการแบ่งพาร์ติชั่นจะไม่ถูกใช้บ่อยเท่ากันในอนาคต มิฉะนั้นจะลดประสิทธิภาพลงอย่างมาก
9. คอลัมน์เล็กจะเร็วกว่า
สำหรับเอ็นจิ้นฐานข้อมูล พื้นที่ดิสก์บางทีอาจเป็นปัญหาคอขวด ดังนั้นการจัดเก็บข้อมูลให้มีขนาดกะทัดรัดมากขึ้นโดยทั่วไปจะเป็นประโยชน์จากมุมมองของประสิทธิภาพ ซึ่งจะช่วยลดจำนวนการเข้าถึงดิสก์
เอกสาร MySQL สรุปข้อกำหนดด้านพื้นที่จัดเก็บข้อมูลจำนวนหนึ่ง ประเภทต่างๆข้อมูล. หากตารางไม่คาดว่าจะมีระเบียนมากเกินไป ก็ไม่มีเหตุผลที่จะจัดเก็บคีย์หลักในช่องต่างๆ เช่น INT, MEDIUMINT, SMALLINT และใน ในบางกรณีแม้แต่ TINYINT หากคุณไม่ต้องการส่วนประกอบเวลา (ชั่วโมง: นาที) ในรูปแบบวันที่ ให้ใช้ฟิลด์ประเภท DATE แทน DATETIME
อย่างไรก็ตาม ตรวจสอบให้แน่ใจว่าคุณปล่อยให้ตัวเองมีพื้นที่เพียงพอสำหรับการพัฒนาในอนาคต มิฉะนั้นเมื่อถึงจุดหนึ่งอาจเกิดการล่มสลายได้
























