สถาปัตยกรรมของ Haswell สมควรได้รับการเรียกว่าใหม่และออกแบบใหม่หรือไม่
เป็นเวลากว่าห้าปีที่ Intel ได้ปฏิบัติตามกลยุทธ์แบบ Tick-tock โดยสลับการเปลี่ยนแปลงของสถาปัตยกรรมเฉพาะไปสู่บรรทัดฐานทางเทคโนโลยีที่ซับซ้อนยิ่งขึ้นด้วยการเปิดตัวสถาปัตยกรรมใหม่
เป็นผลให้ทุกปีเราจะได้รับสถาปัตยกรรมใหม่หรือการเปลี่ยนไปสู่กระบวนการทางเทคนิคใหม่ “ ดังนั้น” มีการวางแผนในปี 2556 นั่นคือการเปิดตัวสถาปัตยกรรมใหม่ - แฮสเวลล์ โปรเซสเซอร์ที่มีสถาปัตยกรรมใหม่ผลิตโดยใช้เทคโนโลยีกระบวนการเดียวกันกับ Ivy Bridge รุ่นก่อนหน้า: 22 นาโนเมตร, Tri-gate กระบวนการทางเทคนิคไม่เปลี่ยนแปลง แต่จำนวนทรานซิสเตอร์เพิ่มขึ้นซึ่งหมายความว่าพื้นที่สุดท้ายของคริสตัลของโปรเซสเซอร์ใหม่ก็เพิ่มขึ้นเช่นกัน - และหลังจากนั้นก็การใช้พลังงาน
ตามประเพณี Intel นำเสนอเฉพาะประสิทธิผลและ โปรเซสเซอร์ราคาแพงสาย Core i5 และ i7 ประกาศ โปรเซสเซอร์ดูอัลคอร์สายจูเนียร์ก็ล่าช้าเช่นเคย เป็นที่น่าสังเกตว่าราคาสำหรับโปรเซสเซอร์ใหม่ยังคงอยู่ในระดับเดียวกับ สะพานไม้เลื้อย.
มาเปรียบเทียบพื้นที่ดายของโปรเซสเซอร์ Quad-Core รุ่นต่างๆ กัน:
อย่างที่คุณเห็น Haswell แบบ quad-core มีพื้นที่เพียง 177 มม. ² ในขณะที่มันถูกรวมเข้าด้วยกัน สะพานเหนือ, ผู้ควบคุม หน่วยความจำเข้าถึงโดยสุ่มและคอร์กราฟิก ดังนั้นจำนวนทรานซิสเตอร์จึงเพิ่มขึ้น 200 ล้านและพื้นที่เพิ่มขึ้น 17 ตารางมิลลิเมตร หากเราเปรียบเทียบ Haswell กับ 32nm สะพานแซนดี้จากนั้นจำนวนทรานซิสเตอร์เพิ่มขึ้น 440 ล้าน (38%) และพื้นที่เนื่องจากการเปลี่ยนไปใช้เทคโนโลยีการผลิต 22 นาโนเมตรลดลง 39 มม. ² (18%) การกระจายความร้อนยังคงเกือบเท่าเดิมตลอดหลายปีที่ผ่านมา (95 W สำหรับ SB และ 84 W สำหรับ Haswell) และพื้นที่ก็ลดลง
ทั้งหมดนี้ส่งผลให้คริสตัลทุกตารางมิลลิเมตรต้องระบายความร้อนออกไปมากขึ้น หากก่อนหน้านี้จาก 216 มม.² จำเป็นต้องใช้ 95 W นั่นคือ 0.44 W/mm² ตอนนี้จากพื้นที่ 177 mm² จำเป็นต้องใช้ 84 W - 0.47 W/mm² ซึ่งมากกว่าเดิม 6.8% . หากแนวโน้มนี้ยังคงดำเนินต่อไป อีกไม่นานการขจัดความร้อนออกจากพื้นที่เล็กๆ ดังกล่าวก็จะเป็นเรื่องยากทางกายภาพ
ตามทฤษฎีแล้วเราสามารถสรุปได้ว่าหากใน Broadwell ซึ่งจะผลิตโดยใช้เทคโนโลยีการผลิต 14 นาโนเมตร จำนวนทรานซิสเตอร์จะเพิ่มขึ้น 21% ในขณะที่ในช่วงเปลี่ยนผ่านจาก 32 เป็น 22 นาโนเมตร และพื้นที่จะลดลง 26 % (เท่ากับปริมาณเมื่อย้ายจาก 32 เป็น 22 นาโนเมตร) เราจะได้ทรานซิสเตอร์ 1.9 พันล้านตัวบนพื้นที่ 131 มม. ² หากการกระจายความร้อนลดลง 19% เราจะได้ 68 วัตต์หรือ 0.52 วัตต์/มม.²
เหล่านี้เป็นการคำนวณทางทฤษฎีในทางปฏิบัติมันจะแตกต่างออกไป - การเปลี่ยนกระบวนการทางเทคโนโลยีจาก 32 เป็น 22 นาโนเมตรก็ถูกทำเครื่องหมายด้วยการนำทรานซิสเตอร์ 3 มิติมาใช้ซึ่งช่วยลดกระแสรั่วไหลและทำให้เกิดความร้อนด้วย อย่างไรก็ตาม ยังไม่มีใครได้ยินเรื่องแบบนี้เกี่ยวกับการเปลี่ยนจาก 22 นาโนเมตรเป็น 14 นาโนเมตร ดังนั้นในทางปฏิบัติแล้วค่าการกระจายความร้อนน่าจะยิ่งแย่ลงไปอีก และคุณไม่ควรหวังว่าจะได้ 0.52 W/mm² อย่างไรก็ตาม แม้ว่าระดับการกระจายความร้อนจะอยู่ที่ 0.52 วัตต์/มม.² แต่ปัญหาความร้อนสูงเกินไปในท้องถิ่นและความยากในการขจัดความร้อนออกจากผลึกขนาดเล็กก็จะรุนแรงยิ่งขึ้น
อย่างไรก็ตาม มันเป็นความยากลำบากในการกระจายความร้อนด้วยระดับการกระจายความร้อน 0.52 W/mm² ซึ่งอาจเป็นไปตามความปรารถนาของ Intel ที่จะเปลี่ยนไปใช้ BGA หรือความพยายามที่จะยกเลิกซ็อกเก็ต หากบัดกรีโปรเซสเซอร์เข้ากับเมนบอร์ด ความร้อนจะถูกถ่ายโอนโดยตรงจากชิปไปยังฮีทซิงค์โดยไม่มีฝาปิดตรงกลาง สิ่งนี้ดูมีความเกี่ยวข้องมากขึ้นในแง่ของการเปลี่ยนการบัดกรีด้วยแผ่นระบายความร้อนใต้ฝาครอบ โปรเซสเซอร์ที่ทันสมัย- เราคาดหวังได้อีกครั้งว่าโปรเซสเซอร์ "เปลือย" ที่มีคริสตัลแบบเปิดเป็นไปตามตัวอย่างของ Athlon XP กล่าวคือ โดยไม่มีฝาปิดเป็นตัวเชื่อมกลางในแผงระบายความร้อน
สิ่งนี้ทำกับการ์ดแสดงผลมาเป็นเวลานานแล้ว และอันตรายจากการบิ่นคริสตัลก็ถูกบรรเทาลงด้วยโครงเหล็กที่อยู่รอบ ๆ ซึ่งเป็นสาเหตุที่การ์ดแสดงผลไม่มีเช่นนี้ " ปัญหาในปัจจุบัน" เช่นเดียวกับแผ่นระบายความร้อนใต้ฝาครอบโปรเซสเซอร์ อย่างไรก็ตามการโอเวอร์คล็อกจะยิ่งยากขึ้นและ การระบายความร้อนที่เหมาะสมโปรเซสเซอร์ที่ "บางกว่า" แทบจะเป็นวิทยาศาสตร์เลยทีเดียว และทั้งหมดนี้รอเราอยู่ในไม่ช้า เว้นเสียแต่ว่าจะมีปาฏิหาริย์เกิดขึ้น...
แต่มาลงสู่พื้นโลกแล้วกลับมาพูดถึงแฮสเวลล์กันดีกว่า ดังที่เราทราบ Haswell ได้รับ "การปรับปรุง/การเปลี่ยนแปลง" หลายประการที่เกี่ยวข้องกับ Sandy Bridge (และด้วยเหตุนี้ Ivy Bridge ซึ่งโดยส่วนใหญ่แล้ว การโอน SB ไปยังกระบวนการทางเทคนิคที่ละเอียดอ่อนยิ่งขึ้น):
- เครื่องปรับแรงดันไฟฟ้าในตัว
- โหมดประหยัดพลังงานใหม่
- การเพิ่มปริมาณบัฟเฟอร์และคิว
- เพิ่มความจุแคช
- การเพิ่มจำนวนพอร์ตการเปิดตัว
- การเพิ่มบล็อกใหม่ ฟังก์ชัน APIs ในคอร์กราฟิกแบบรวม
- การเพิ่มจำนวนไปป์ไลน์ในคอร์กราฟิก
ดังนั้นการตรวจสอบแพลตฟอร์มใหม่จึงสามารถแบ่งออกเป็นสามส่วน: โปรเซสเซอร์, ตัวเร่งกราฟิกแบบรวม, ชิปเซ็ต
ส่วนโปรเซสเซอร์
การเปลี่ยนแปลงโปรเซสเซอร์รวมถึงการเพิ่มคำสั่งใหม่และโหมดประหยัดพลังงานใหม่ การรวมตัวควบคุมแรงดันไฟฟ้า รวมถึงการเปลี่ยนแปลงแกนโปรเซสเซอร์เอง
ชุดคำสั่ง
สถาปัตยกรรม Haswell นำเสนอชุดคำสั่งใหม่ พวกเขาสามารถแบ่งออกเป็นสองกลุ่มใหญ่: กลุ่มที่มุ่งเป้าไปที่การเพิ่มประสิทธิภาพเวกเตอร์และกลุ่มที่มุ่งเป้าไปที่ส่วนของเซิร์ฟเวอร์ อดีตประกอบด้วย AVX และ FMA3 ส่วนหลัง - การจำลองเสมือนและหน่วยความจำทรานแซคชัน
ส่วนขยายเวกเตอร์ขั้นสูง 2 (AVX2)
ชุด AVX ได้รับการขยายเป็นเวอร์ชัน AVX 2.0 ชุด AVX2 มอบ:
- รองรับเวกเตอร์จำนวนเต็ม 256 บิต (ก่อนหน้านี้รองรับเฉพาะ 128 บิต)
- รองรับการรวบรวมคำสั่งซึ่งลบข้อกำหนดสำหรับตำแหน่งข้อมูลที่ต่อเนื่องกันในหน่วยความจำ ตอนนี้ข้อมูลถูก "รวบรวม" จากที่อยู่หน่วยความจำที่แตกต่างกัน - น่าสนใจที่จะเห็นว่าสิ่งนี้ส่งผลต่อประสิทธิภาพอย่างไร
- เพิ่มคำแนะนำสำหรับการจัดการ/การดำเนินการกับบิต
โดยทั่วไป, ชุดใหม่มุ่งเน้นไปที่เลขคณิตจำนวนเต็มมากกว่า และประโยชน์หลักจาก AVX 2.0 จะมองเห็นได้เฉพาะในการดำเนินการจำนวนเต็มเท่านั้น
ผสมคูณ-บวก (FMA3)
FMA เป็นการดำเนินการบวกคูณคูณกัน โดยจะมีการคูณตัวเลขสองตัวและเพิ่มเข้าในตัวสะสม ประเภทนี้การดำเนินการค่อนข้างธรรมดาและช่วยให้คุณใช้การคูณเวกเตอร์และเมทริกซ์ได้อย่างมีประสิทธิภาพมากขึ้น การสนับสนุนส่วนขยายนี้ควรเพิ่มประสิทธิภาพการทำงานของเวกเตอร์อย่างมาก FMA3 ได้รับการสนับสนุนแล้วในโปรเซสเซอร์ AMD ที่มี Piledriver core และ FMA4 ได้รับการสนับสนุนใน Bulldozer แล้ว
FMA คือการรวมกันของการดำเนินการคูณและการบวก: a=b×c+d
สำหรับ FMA3 คำสั่งเหล่านี้เป็นคำสั่งสามตัวถูกดำเนินการ นั่นคือ ผลลัพธ์จะถูกเขียนไปยังหนึ่งในสามตัวถูกดำเนินการที่เข้าร่วมในคำสั่ง เป็นผลให้เราได้การดำเนินการเช่น a=b×c+a, a=a×b+c, a=b×a+c
FMA4 เป็นคำสั่งตัวถูกดำเนินการสี่คำสั่งโดยเขียนผลลัพธ์ไปยังตัวถูกดำเนินการที่สี่ คำสั่งอยู่ในรูปแบบ: a=b×c+d
เมื่อพูดถึง FMA3: นวัตกรรมนี้จะช่วยเพิ่มผลผลิตได้มากกว่า 30% หากโค้ดถูกปรับให้เข้ากับ FMA3 เป็นที่น่าสังเกตว่าเมื่อ Haswell ยังอยู่บนขอบฟ้า Intel กำลังวางแผนที่จะใช้ FMA4 แทนที่จะเป็น FMA3 แต่ต่อมาได้เปลี่ยนการตัดสินใจไปใช้ FMA3 เป็นไปได้มากว่าเป็นเพราะเหตุนี้ Bulldozer จึงออกมาพร้อมกับการรองรับ FMA4: พวกเขาบอกว่าพวกเขาไม่มีเวลาแปลงเป็น Intel (แต่ Piledriver ออกมาพร้อมกับ FMA3) ยิ่งไปกว่านั้น Bulldozer ในตอนแรกในปี 2550 ได้รับการวางแผนด้วย FMA3 แต่หลังจากการประกาศแผนการของ Intel ที่จะเปิดตัว FMA4 ในปี 2551 ปีเอเอ็มดีเปลี่ยนใจด้วยการปล่อย Bulldozer ด้วย FMA4 จากนั้น Intel ก็เปลี่ยน FMA4 เป็น FMA3 ในแผน เนื่องจากผลประโยชน์จาก FMA4 เมื่อเทียบกับ FMA3 นั้นน้อยมาก และมีความซับซ้อนทางไฟฟ้า วงจรลอจิก- สำคัญซึ่งเพิ่มงบประมาณทรานซิสเตอร์ด้วย
ผลลัพธ์ที่ได้รับจาก AVX2 และ FMA3 จะปรากฏขึ้นหลังจากที่ซอฟต์แวร์ถูกปรับให้เข้ากับชุดคำสั่งเหล่านี้ ดังนั้นคุณจึงไม่ควรคาดหวังว่าประสิทธิภาพจะเพิ่มขึ้น “ที่นี่และเดี๋ยวนี้” และเนื่องจากผู้ผลิตซอฟต์แวร์ค่อนข้างเฉื่อยชา ประสิทธิภาพ "เพิ่มเติม" จึงต้องรอ
หน่วยความจำทรานแซคชัน
วิวัฒนาการของไมโครโปรเซสเซอร์ทำให้จำนวนเธรดเพิ่มขึ้น - โปรเซสเซอร์เดสก์ท็อปสมัยใหม่มีแปดเธรดขึ้นไป จำนวนมากเธรดสร้างปัญหามากขึ้นเรื่อย ๆ เมื่อใช้การเข้าถึงหน่วยความจำแบบมัลติเธรด จำเป็นต้องควบคุมความเกี่ยวข้องของตัวแปรใน RAM: จำเป็นต้องบล็อกข้อมูลสำหรับการเขียนในเวลาที่เหมาะสมสำหรับเธรดบางรายการ และอนุญาตให้อ่านหรือเปลี่ยนแปลงข้อมูลสำหรับเธรดอื่น ๆ นี่เป็นงานที่ยาก และหน่วยความจำทรานแซคชันได้รับการพัฒนาเพื่อให้ข้อมูลใหม่ในโปรแกรมแบบมัลติเธรด แต่ก่อน วันนี้มันถูกนำไปใช้ในซอฟต์แวร์ซึ่งทำให้ประสิทธิภาพลดลง
Haswell มี Transactional Synchronization Extensions (TSX) ใหม่ - หน่วยความจำทรานแซคชันซึ่งได้รับการออกแบบมาเพื่อใช้งานโปรแกรมแบบมัลติเธรดอย่างมีประสิทธิภาพและเพิ่มความน่าเชื่อถือ ส่วนขยายนี้ช่วยให้คุณใช้หน่วยความจำทรานแซคชัน “ในฮาร์ดแวร์” ซึ่งจะช่วยเพิ่มประสิทธิภาพโดยรวม
หน่วยความจำทรานแซคชันคืออะไร? นี่คือหน่วยความจำที่มีกลไกภายในตัวสำหรับการจัดการกระบวนการแบบขนานเพื่อให้สามารถเข้าถึงข้อมูลที่ใช้ร่วมกันได้ ส่วนขยาย TSX ประกอบด้วยสององค์ประกอบ: Hardware Lock Elision (HLE) และ Restricted Transaction Memory (RTM)
ส่วนประกอบ RTM คือชุดคำสั่งที่โปรแกรมเมอร์สามารถใช้เพื่อเริ่มต้น สิ้นสุด และยกเลิกธุรกรรม ส่วนประกอบ HLE แนะนำคำนำหน้าที่ถูกละเลยโดยโปรเซสเซอร์ที่ไม่รองรับ TSX คำนำหน้าจัดให้มีการล็อคตัวแปร ซึ่งช่วยให้กระบวนการอื่นใช้ (อ่าน) ตัวแปรที่ถูกล็อค และรันโค้ดของพวกเขาจนกว่าข้อขัดแย้งในการเขียนข้อมูลที่ล็อคจะเกิดขึ้น
บน ช่วงเวลานี้แอปพลิเคชันที่ใช้ส่วนขยายนี้ปรากฏแล้ว
การจำลองเสมือน
ความสำคัญของระบบเสมือนจริงมีการเติบโตอย่างต่อเนื่อง: มีจำนวนมากขึ้นเรื่อยๆ เซิร์ฟเวอร์เสมือนตั้งอยู่ในที่เดียว และบริการคลาวด์กำลังแพร่หลายมากขึ้น ดังนั้นการเพิ่มความเร็วของเทคโนโลยีเวอร์ช่วลไลเซชั่นและสภาพแวดล้อมเวอร์ชวลไลซ์จึงเป็นงานเร่งด่วนมากในส่วนเซิร์ฟเวอร์ Haswell มีการปรับปรุงหลายอย่างที่มุ่งเพิ่มประสิทธิภาพการทำงานของสภาพแวดล้อมเสมือนจริงโดยเฉพาะ มาแสดงรายการกัน:
- การปรับปรุงเพื่อลดเวลาที่ใช้ในการเปลี่ยนจากระบบเกสต์เป็นระบบโฮสต์
- เพิ่มบิตการเข้าถึงไปยัง Extended Page Table (EPT);
- เวลาการเข้าถึง TLB ลดลง
- คำแนะนำใหม่สำหรับการเรียกไฮเปอร์ไวเซอร์โดยไม่ต้องดำเนินการคำสั่ง vmexit
เป็นผลให้ระยะเวลาในการเปลี่ยนแปลงระหว่างสภาพแวดล้อมเสมือนจริงลดลงเหลือน้อยกว่า 500 รอบของโปรเซสเซอร์ สิ่งนี้น่าจะส่งผลให้ค่าใช้จ่ายด้านประสิทธิภาพโดยรวมที่เกี่ยวข้องกับการจำลองเสมือนลดลง และ Xeon E3-12xx-v3 ใหม่น่าจะเร็วกว่า Xeon E3-12xx-v2 ในงานระดับนี้
เครื่องปรับแรงดันไฟฟ้าในตัว
ใน Haswell ตัวควบคุมแรงดันไฟฟ้าถูกย้ายจากเมนบอร์ดใต้ฝาครอบโปรเซสเซอร์ ก่อนหน้านี้ (Sandy Bridge) จำเป็นต้องจ่ายแรงดันไฟฟ้าที่แตกต่างกันให้กับโปรเซสเซอร์ แกนกราฟิกสำหรับตัวแทนระบบสำหรับคอร์โปรเซสเซอร์ ฯลฯ ขณะนี้มีเพียงแรงดันไฟฟ้า Vccin 1.75 V เท่านั้นที่จ่ายให้กับโปรเซสเซอร์ผ่านซ็อกเก็ตซึ่งจ่ายให้กับตัวควบคุมแรงดันไฟฟ้าในตัว ตัวควบคุมแรงดันไฟฟ้าประกอบด้วย 20 เซลล์ แต่ละเซลล์สร้าง 16 เฟส รวมกระแส 25 A โดยรวมแล้วเราได้ 320 เฟส ซึ่งมากกว่าเมนบอร์ดที่ซับซ้อนที่สุดอย่างเห็นได้ชัด วิธีการนี้ไม่เพียงช่วยให้การจัดวางเมนบอร์ดง่ายขึ้น (และลดต้นทุน) แต่ยังช่วยควบคุมแรงดันไฟฟ้าภายในโปรเซสเซอร์ได้แม่นยำยิ่งขึ้น ซึ่งในทางกลับกันจะนำไปสู่การประหยัดพลังงานมากขึ้น
นี่เป็นหนึ่งในสาเหตุหลักที่ทำให้ Haswell ไม่สามารถใช้งานร่วมกับซ็อกเก็ต LGA1155 รุ่นเก่าได้ ใช่ เราสามารถพูดคุยเกี่ยวกับความปรารถนาของ Intel ที่จะสร้างรายได้ด้วยการเปิดตัวแพลตฟอร์มใหม่ทุกปี ( ชิปเซ็ตใหม่) และทุก ๆ สองปี - ซ็อกเก็ตใหม่ แต่ในกรณีนี้ก็มี เหตุผลวัตถุประสงค์: ความไม่เข้ากันทางกายภาพ/ทางไฟฟ้า
อย่างไรก็ตามทุกอย่างมีราคา ตัวควบคุมแรงดันไฟฟ้าเป็นอีกหนึ่งแหล่งความร้อนที่เห็นได้ชัดเจนในโปรเซสเซอร์ใหม่ และเนื่องจาก Haswell ผลิตขึ้นโดยใช้เทคโนโลยีกระบวนการเดียวกันกับ Ivy Bridge รุ่นก่อน เราควรคาดหวังว่าโปรเซสเซอร์จะร้อนขึ้น

โดยทั่วไปการปรับปรุงนี้จะเป็นประโยชน์มากขึ้นในกลุ่มอุปกรณ์พกพา: การเปลี่ยนแปลงแรงดันไฟฟ้าที่เร็วขึ้นและแม่นยำยิ่งขึ้นจะช่วยลดการใช้พลังงานรวมถึงการควบคุมความถี่ของแกนประมวลผลได้อย่างมีประสิทธิภาพมากขึ้น และเห็นได้ชัดว่านี่ไม่ใช่คำแถลงทางการตลาดที่ว่างเปล่า เนื่องจาก Intel กำลังจะประกาศโปรเซสเซอร์มือถือที่ใช้พลังงานต่ำมาก
โหมดประหยัดพลังงานใหม่
Haswell มีสถานะสลีป S0ix ใหม่ ซึ่งคล้ายกับสถานะ S3/S4 แต่มีเวลาในการเปลี่ยน CPU ที่เร็วกว่ามาก สภาพการทำงาน- เพิ่มสถานะไม่ได้ใช้งาน C7 ใหม่แล้ว
โหมด C7 จะมาพร้อมกับการปิดส่วนหลักของโปรเซสเซอร์ในขณะที่ภาพบนหน้าจอยังคงทำงานอยู่
ความถี่ว่างขั้นต่ำของโปรเซสเซอร์คือ 800 MHz ซึ่งควรลดการใช้พลังงานด้วย
สถาปัตยกรรมโปรเซสเซอร์


ส่วนหน้า

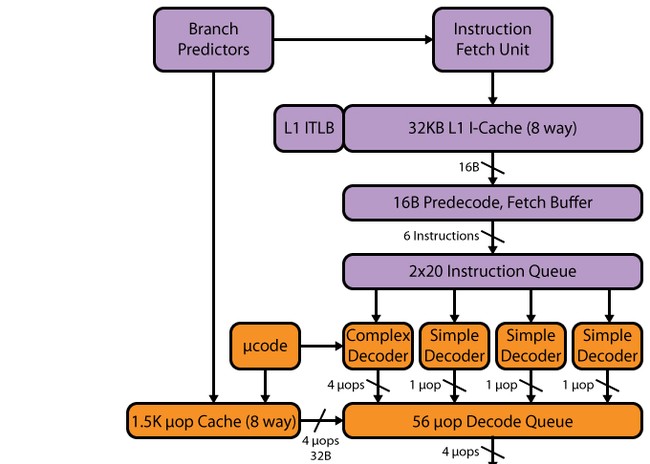
ไปป์ไลน์ Haswell เช่นเดียวกับใน SB มี 14–19 สเตจ: 14 สเตจสำหรับการโจมตีแคช µop, 19 สเตจสำหรับการพลาด ขนาดของแคช µop ไม่มีการเปลี่ยนแปลงเมื่อเปรียบเทียบกับ SB - 1536 µop การจัดระเบียบแคช uop ยังคงเหมือนกับใน SB - 32 ชุดแปดบรรทัดแต่ละบรรทัดมีหก uops แม้ว่าเนื่องจากจำนวนอุปกรณ์ดำเนินการที่เพิ่มขึ้นรวมถึงบัฟเฟอร์ที่ตามมาหลังจากแคช uop เราจึงสามารถคาดหวังได้ว่าแคช uop จะเพิ่มขึ้นมากถึง 1,776 uops (เหตุใดจึงมีการกล่าวถึงวอลุ่มนี้อย่างชัดเจนด้านล่าง)
เครื่องถอดรหัส
อาจกล่าวได้ว่าตัวถอดรหัสไม่ได้เปลี่ยนแปลง - มันยังคงเป็นสี่ทางเช่นเดียวกับ SB ประกอบด้วยสี่ช่องทางคู่ขนาน: ตัวแปลที่ซับซ้อนหนึ่งตัว (ตัวถอดรหัสที่ซับซ้อน) และตัวถอดรหัสธรรมดาสามตัว (ตัวถอดรหัสแบบง่าย) นักแปลที่ซับซ้อนสามารถประมวลผล/ถอดรหัสคำสั่งที่ซับซ้อนที่สร้างมากกว่าหนึ่ง uop สามช่องที่เหลือจะถูกถอดรหัส คำแนะนำง่ายๆ- อย่างไรก็ตาม เนื่องจากมีการผสานการทำงานของมาโครเข้าด้วยกัน การโหลดด้วยคำสั่งการดำเนินการและการขนถ่ายจึงถูกสร้างขึ้น เช่น หนึ่ง uop และสามารถถอดรหัสได้ในช่องสัญญาณตัวถอดรหัส "ธรรมดา" คำแนะนำ SSEยังสร้างหนึ่ง uop เพื่อให้สามารถถอดรหัสได้ในสามช่องทางง่ายๆ ด้วยการถือกำเนิดของ AVX, FMA3 256 บิต รวมถึงจำนวนพอร์ตทริกเกอร์และอุปกรณ์ฟังก์ชั่นที่เพิ่มขึ้น ความเร็วตัวถอดรหัสนี้อาจไม่เพียงพอ และอาจกลายเป็นคอขวดได้ คอขวดบางส่วนนี้ถูก "ขยาย" โดยแคช L0m uop แต่ยังคงมีโปรเซสเซอร์ที่มีพอร์ตการเปิดตัว 8 พอร์ต Intel ควรพิจารณาที่จะขยายตัวถอดรหัส - โดยเฉพาะอย่างยิ่งการเพิ่มจำนวนช่องสัญญาณที่ซับซ้อนจะไม่เจ็บ
ตัวกำหนดเวลา, บัฟเฟอร์การเรียงลำดับใหม่, หน่วยการดำเนินการ


หลังจากที่ตัวถอดรหัสมาถึงคิวคำสั่งที่ถอดรหัส และที่นี่เราเห็นการเปลี่ยนแปลงแรก SB มีสองคิวจาก 28 รายการ - หนึ่งคิวต่อเธรด Hyper-Threading (HT) เสมือน ใน Haswell สองคิวถูกรวมเป็นหนึ่งเดียวสำหรับสองเธรด HT ที่มี 56 รายการ นั่นคือปริมาณของคิวไม่เปลี่ยนแปลง แต่แนวคิดเปลี่ยนไป ขณะนี้ปริมาณการบันทึกทั้งหมด 56 รายการพร้อมใช้งานในหนึ่งเธรดโดยไม่มีวินาที - ดังนั้นเราจึงคาดหวังได้ว่าจะเพิ่มขึ้นทั้งในแอปพลิเคชันแบบเธรดต่ำและแบบมัลติเธรด (นี่เป็นเพราะความจริงที่ว่าสองเธรดสามารถใช้ คิวเดียวได้อย่างมีประสิทธิภาพมากขึ้น)
บัฟเฟอร์การเรียงลำดับใหม่ก็เปลี่ยนไปเช่นกัน - เพิ่มขึ้นจาก 168 เป็น 192 รายการ สิ่งนี้ควรปรับปรุงประสิทธิภาพของ HT เนื่องจากมีแนวโน้มที่จะมี uops ที่ "เป็นอิสระ" ซึ่งกันและกันมากขึ้น คิว micro-op ที่ถอดรหัสได้เพิ่มขึ้นจาก 54 เป็น 60 ไฟล์รีจิสเตอร์ทางกายภาพที่ปรากฏใน SB ก็เพิ่มขึ้นเช่นกัน - จาก 160 เป็น 168 รีจิสเตอร์สำหรับตัวถูกดำเนินการจำนวนเต็มและจาก 144 เป็น 168 สำหรับตัวถูกดำเนินการจุดลอยตัว ซึ่งควรมีค่าบวก ผลกระทบต่อประสิทธิภาพการคำนวณเวกเตอร์
มาสรุปข้อมูลทั้งหมดเกี่ยวกับการเปลี่ยนแปลงในบัฟเฟอร์และคิวลงในตารางเดียว
โดยหลักการแล้ว การเปลี่ยนแปลงพารามิเตอร์ใน Haswell ดูค่อนข้างคาดหวัง ตรรกะทั่วไปการพัฒนาสถาปัตยกรรมโปรเซสเซอร์ของ Intel บนพื้นฐานตรรกะเดียวกันเราสามารถสรุปได้ว่าในรุ่นต่อไป ขนาดแกนบัฟเฟอร์และคิวจะเพิ่มขึ้นไม่เกิน 14% นั่นคือขนาดของบัฟเฟอร์การเรียงลำดับใหม่จะอยู่ที่ประมาณ 218 แต่สิ่งเหล่านี้เป็นเพียงสมมติฐานทางทฤษฎีเท่านั้น
การดำเนินการตามคิวของการถอดรหัสคือพอร์ตทริกเกอร์และพอร์ตที่ต่ออยู่ อุปกรณ์การทำงาน- ในขั้นตอนนี้เราจะดูรายละเอียดเพิ่มเติม
ดังที่เราทราบ Sandy Bridge มีท่าปล่อยจรวด 6 แห่ง ซึ่งสืบทอดมาจาก Nehalem และต่อมาจาก Conroe นั่นคือตั้งแต่ปี 2549 เมื่อ Intel เพิ่มพอร์ตอีกสองพอร์ตในสี่พอร์ตที่มีใน Pentium 4 จำนวนพอร์ตการเปิดตัวไม่เปลี่ยนแปลง - มีเพียงอุปกรณ์ที่ใช้งานได้ใหม่เท่านั้นที่เพิ่มเข้ามา อย่างไรก็ตาม เป็นที่น่าสังเกตว่า P4 มีสถาปัตยกรรม NetBurst ดั้งเดิม ซึ่งพอร์ตทั้งสองพอร์ตสามารถดำเนินการสองรายการในรอบสัญญาณนาฬิกาเดียว (แม้ว่าจะไม่ใช่กับการดำเนินการทั้งหมดก็ตาม) แต่จะเป็นการถูกต้องที่สุดในการติดตามวิวัฒนาการของจำนวนพอร์ตการเปิดตัวที่ไม่ได้ใช้ตัวอย่างของ P4 แต่ใช้ตัวอย่างของ PIII เนื่องจาก P4 มีไปป์ไลน์ที่ยาวและเปิดใช้งานพอร์ตที่มีประสิทธิภาพ "สองเท่า" และแคชการติดตาม และสถาปัตยกรรมทั้งหมดแตกต่างอย่างเห็นได้ชัดจากสถาปัตยกรรมที่ยอมรับโดยทั่วไป และ Pentium III นั้นใกล้เคียงกันมากในแง่ของรูปแบบการทำงานของพอร์ตส่งไปยัง Conroe และยังมีคอนเทนเนอร์ขนาดสั้นอีกด้วย โดยทั่วไปเราสามารถพูดได้ว่า Conroe เป็นผู้สืบทอดโดยตรงของ PIII จากข้อมูลนี้ สามารถระบุได้ว่าในปี พ.ศ. 2549 มีการเพิ่มพอร์ตปล่อยเพียง 1 พอร์ตเท่านั้น เมื่อเทียบกับ PIII ซึ่งมีพอร์ตปล่อย 5 พอร์ต
ดังนั้นจำนวนพอร์ตการเปิดตัวจึงเติบโตค่อนข้างช้า และหากมีการเพิ่มพอร์ตใหม่ก็จะเพิ่มขึ้นทีละพอร์ต แฮสเวลล์เพิ่มสองพอร์ตพร้อมกัน ทำให้มีพอร์ตทั้งหมดแปดพอร์ต - เพิ่มเพียงเล็กน้อยเท่านั้น แล้วเราจะไปถึงอิเทเนียม ดังนั้น Haswell จึงแสดงประสิทธิภาพทางทฤษฎีบนเส้นทางการดำเนินการ 8 UOP/รอบ โดย 4 UOP ถูกใช้ไปกับการดำเนินการทางคณิตศาสตร์ และอีก 4 รายการที่เหลือใช้กับการทำงานของหน่วยความจำ จำได้ว่า Conroe/Nehalem/SB มี 6 mops/จังหวะ: 3 mops การดำเนินการทางคณิตศาสตร์และโมดูลการทำงานของหน่วยความจำ 3 โมดูล การปรับปรุงนี้ควรเพิ่มคะแนน IPC และดังนั้นจึงมีการเปลี่ยนแปลงที่ร้ายแรงมากในสถาปัตยกรรม Haswell ซึ่งพิสูจน์ให้เห็นถึงตำแหน่ง "เช่นนั้น" ในแผนการพัฒนาของ Intel อย่างเต็มที่
การเปลี่ยนแปลง FU ในแฮสเวลล์

จำนวนตัวกระตุ้นก็เพิ่มขึ้นเช่นกัน พอร์ตที่หก (เจ็ด) ใหม่ได้เพิ่มแอคทูเอเตอร์เพิ่มเติมสองตัว - อุปกรณ์เลขคณิตจำนวนเต็มและอุปกรณ์เปลี่ยนเกียร์ และอุปกรณ์ทำนายสาขา พอร์ตที่เจ็ด (แปด) มีหน้าที่รับผิดชอบในการขนถ่ายที่อยู่
ดังนั้นเราจึงได้หน่วยดำเนินการทางคณิตศาสตร์จำนวนเต็มสี่หน่วย ในขณะที่ Sandy Bridge ให้มาเพียงสามหน่วยเท่านั้น ดังนั้นเราจึงสามารถคาดหวังได้ว่าความเร็วของเลขคณิตจำนวนเต็มจะเพิ่มขึ้น นอกจากนี้ ตามทฤษฎีแล้ว สิ่งนี้น่าจะช่วยให้เราคำนวณทั้งจุดลอยตัวและจำนวนเต็มพร้อมกันได้ ซึ่งในทางกลับกัน ก็สามารถเพิ่มประสิทธิภาพของ NT ได้ ใน SB การคำนวณจุดลอยตัวจะดำเนินการบนพอร์ตเดียวกันกับที่ใช้อุปกรณ์ฟังก์ชันจำนวนเต็ม ดังนั้นจึงเกิดการบล็อกขนาดใหญ่ กล่าวคือ คุณไม่สามารถมีโหลด "ต่างกัน" ได้ ก็ควรสังเกตด้วยว่าการเพิ่ม อุปกรณ์เพิ่มเติมการเปลี่ยนแปลงใน Haswell จะทำให้สามารถทำนายการเปลี่ยนแปลงโดยไม่ต้อง "บล็อก" ในระหว่างการคำนวณทางคณิตศาสตร์ - ก่อนหน้านี้ ในระหว่างการคำนวณจำนวนเต็ม ตัวทำนายสาขาเพียงตัวเดียวถูกบล็อก นั่นคือ มันเป็นไปได้ที่จะดำเนินการทั้งหน่วยดำเนินการทางคณิตศาสตร์หรือตัวทำนาย พอร์ต 0 และ 1 ก็มีการเปลี่ยนแปลงเช่นกัน - ตอนนี้รองรับ FMA3 แล้ว ที่เจ็ด (แปด) พอร์ตอินเทลได้รับการแนะนำเพื่อเพิ่มประสิทธิภาพและลบ "การบล็อก" - เมื่อพอร์ตที่สองและสามทำงานเพื่อการโหลดพอร์ตที่เจ็ด (แปด) สามารถมีส่วนร่วมในการขนถ่ายซึ่งก่อนหน้านี้เป็นไปไม่ได้เลย โซลูชันนี้จำเป็นเพื่อให้แน่ใจว่าโค้ด AVX/FMA3 มีความเร็วในการดำเนินการสูง
โดยทั่วไป เส้นทางผู้บริหารที่กว้างไกลเช่นนี้อาจนำไปสู่การเปลี่ยนแปลงใน HT ซึ่งทำให้เป็นแบบสี่เธรด ในร่วม โปรเซสเซอร์อินเทล Xeon Phi ที่มีเส้นทางการดำเนินการ HT ที่แคบกว่ามากเป็นแบบสี่เธรด และตามการศึกษาและการทดสอบแสดงให้เห็นว่า โปรเซสเซอร์ร่วมปรับขนาดได้ค่อนข้างดี โดยหลักการแล้ว แม้แต่เส้นทางการดำเนินการที่แคบกว่าก็ช่วยให้คุณทำงานได้อย่างมีประสิทธิภาพด้วยสี่เธรด และพาธที่มีแปดพอร์ตเรียกใช้งานสามารถรันสี่เธรดได้อย่างมีประสิทธิภาพ และยิ่งไปกว่านั้น การมีสี่เธรดสามารถโหลดพอร์ตเรียกใช้งานแปดพอร์ตได้ดีขึ้น จริงอยู่ เพื่อประสิทธิภาพที่มากขึ้น จำเป็นต้องเพิ่มบัฟเฟอร์ (โดยหลักคือบัฟเฟอร์การเรียงลำดับใหม่) เพื่อความน่าจะเป็นที่ข้อมูล "อิสระ" มากขึ้น
Haswell ยังเพิ่มปริมาณงาน L1-L2 เป็นสองเท่า ในขณะที่ยังคงค่าความหน่วงเท่าเดิม มาตรการนี้มีความจำเป็นเพียงอย่างเดียว เนื่องจากการเขียนแบบ 32 ไบต์และการอ่านแบบ 16 ไบต์จะไม่เพียงพอหากมีพอร์ตเรียกใช้งานแปดพอร์ต เช่นเดียวกับ AVX และ FMA3 256 บิต
| สะพานแซนดี้ | แฮสเวลล์ | |
| L1i | 32,000 8 เวย์ | 32,000 8 เวย์ |
| L1d | 32,000 8 เวย์ | 32,000 8 เวย์ |
| เวลาแฝง | 4 มาตรการ | 4 มาตรการ |
| ความเร็วดาวน์โหลด | 32 ไบต์/นาฬิกา | 64 ไบต์/นาฬิกา |
| ความเร็วในการเขียน | 16 ไบต์/รอบ | 32 ไบต์/นาฬิกา |
| L2 | 256,000 8 ทิศทาง | 256,000 8 ทิศทาง |
| เวลาแฝง | 11 มาตรการ | 11 มาตรการ |
| แบนด์วิธระหว่าง L2 และ L1 | 32 ไบต์/นาฬิกา | 64 ไบต์/นาฬิกา |
| L1i ทีแอลบี | 4k: 128, 4 ทิศทาง 2M/4M: 8/ด้าย | 4k: 128, 4 ทิศทาง 2M/4M: 8/ด้าย |
| L1d ทีแอลบี | 4k: 128, 4 ทิศทาง 2M/4M: 7/ด้าย 1G: 4, 4 ทิศทาง | 4k: 128, 4 ทิศทาง 2M/4M: 7/ด้าย 1G: 4, 4 ทิศทาง |
| L2 ทีแอลบี | 4k: 512, 4 ทิศทาง | 4k+2M แชร์: 1024, 8-way |
TLB L2 เพิ่มขึ้นเป็น 1,024 รายการ และรองรับเพจขนาด 2 เมกะไบต์ การเพิ่มขึ้นของ TLB L2 ยังนำมาซึ่งความสัมพันธ์ที่เพิ่มขึ้นจากสี่เป็นแปด
สำหรับแคชระดับที่สามสถานการณ์นั้นไม่ชัดเจน: ในโปรเซสเซอร์ใหม่เวลาแฝงในการเข้าถึงควรเพิ่มขึ้นเนื่องจากการสูญเสียการซิงโครไนซ์เนื่องจากตอนนี้แคช L3 ทำงานที่ความถี่ของตัวเองและไม่ใช่ที่ความถี่ของแกนประมวลผล เหมือนเมื่อก่อน แม้ว่าการเข้าถึงจะยังคงดำเนินการที่ 32 ไบต์ต่อรอบสัญญาณนาฬิกา ในทางกลับกัน Intel กำลังพูดถึงการเปลี่ยนแปลงใน System Agent และการปรับปรุงบล็อก Load Balancer ซึ่งขณะนี้สามารถประมวลผลคำขอแคช L3 หลายรายการพร้อมกัน และแยกออกเป็นคำขอข้อมูลและคำขอที่ไม่ใช่ข้อมูล สิ่งนี้ควรเพิ่มปริมาณงานของแคช L3 (การทดสอบบางอย่างยืนยันสิ่งนี้ แบนด์วิดท์แคช L3 นั้นสูงกว่า IB เล็กน้อย)
หลักการทำงานของแคช L3 ใน Haswell ค่อนข้างคล้ายกับ Nehalem ใน Nehalem แคช L3 ตั้งอยู่ใน Uncore และมีความถี่คงที่ของตัวเองในขณะที่แคช L3 ใน SB นั้นเชื่อมโยงกับคอร์โปรเซสเซอร์ - ความถี่ของมันจะเท่ากับความถี่ของคอร์โปรเซสเซอร์ ด้วยเหตุนี้จึงเกิดปัญหา - ตัวอย่างเช่นเมื่อแกนประมวลผลทำงานที่ความถี่ลดลงเมื่อไม่มีโหลด (และ LLC "หลับไป") และ GPU ต้องการ PS LLC ที่สูง นั่นคือโซลูชันนี้จำกัดประสิทธิภาพของ GPU และยังต้องการให้แกนประมวลผลของโปรเซสเซอร์ถูกนำออกจากสถานะไม่ได้ใช้งานเพียงเพื่อปลุก LLC โปรเซสเซอร์ใหม่เพื่อปรับปรุงการใช้พลังงานและประสิทธิภาพ การทำงานของจีพียูในสถานการณ์ข้างต้น แคช L3 จะทำงานที่ความถี่ของตัวเอง โซลูชันบนมือถือมากกว่าเดสก์ท็อปควรได้รับประโยชน์สูงสุดจากโซลูชันนี้
เป็นที่น่าสังเกตว่าขนาดแคชมีการพึ่งพาอาศัยกัน แคชระดับที่สามคือสองเมกะไบต์ต่อคอร์ แคชระดับที่สองคือ 256 KB ซึ่งน้อยกว่าปริมาณ L3 ต่อคอร์ถึงแปดเท่า ในทางกลับกัน ปริมาตรของแคชระดับแรกจะเล็กกว่า L2 ถึงแปดเท่าและมีขนาด 32 KB แคช uop เข้ากันได้อย่างสมบูรณ์แบบกับการพึ่งพานี้: ปริมาตร 1,536 uops นั้นเล็กกว่า L1 7-9 เท่า (เป็นไปไม่ได้ที่จะระบุสิ่งนี้ได้อย่างแม่นยำเนื่องจากไม่ทราบขนาดบิตของ uop และ Intel ไม่น่าจะขยายในหัวข้อนี้ ). ในทางกลับกัน บัฟเฟอร์การเรียงลำดับใหม่ที่ 168 uops นั้นเล็กกว่าแคช uop ที่ 1536 uops ถึงแปดเท่าอย่างแน่นอน แม้ว่าเมื่อพิจารณาจากการเพิ่มขึ้นของบัฟเฟอร์และคิวอย่างกว้างขวาง เราก็คาดหวังว่าแคช uop จะเพิ่มขึ้น 14% นั่นคือ จนถึงปี 1776 ดังนั้น ปริมาตรของบัฟเฟอร์และแคชจึงมีขนาดตามสัดส่วน นี่อาจเป็นอีกสาเหตุหนึ่งว่าทำไม Intel ไม่เพิ่มแคช L1/L2 โดยพิจารณาว่าสัดส่วนในปริมาณดังกล่าวจะมีประสิทธิภาพมากที่สุดในแง่ของการเพิ่มประสิทธิภาพต่อการเพิ่มพื้นที่ เป็นที่น่าสังเกตว่าโปรเซสเซอร์ที่มีคอร์กราฟิกระดับบนสุดในตัวมีหน่วยความจำที่รวดเร็วระดับกลางพร้อมบัสการเข้าถึงที่กว้างซึ่งแคชคำขอทั้งหมดไปยัง RAM - ทั้งโปรเซสเซอร์และตัวเร่งความเร็ววิดีโอ ปริมาตรของหน่วยความจำนี้คือ 128 MB สำหรับคอร์โปรเซสเซอร์ หากเราถือว่าหน่วยความจำนี้เป็นแคช L4 โวลุ่มควรเป็น 64 เมกะไบต์ และด้วยการเพิ่มคอร์กราฟิก การใช้ 128 MB จึงดูสมเหตุสมผล
สำหรับตัวควบคุมหน่วยความจำนั้นไม่ได้รับการเพิ่มจำนวนช่องสัญญาณหรือเพิ่มความถี่ในการทำงานของ RAM นั่นคือยังคงเป็นตัวควบคุมหน่วยความจำเดียวกันกับการเข้าถึงแบบดูอัลแชนเนลที่ความถี่ 1600 MHz การตัดสินใจครั้งนี้ดูค่อนข้างแปลกเนื่องจากการเปลี่ยนจาก SB เป็น IB เพิ่มความถี่การทำงานของ ICP จาก 1333 MHz เป็น 1600 MHz แม้ว่านี่จะเป็นเพียงการเปลี่ยนสถาปัตยกรรมไปเป็นกระบวนการทางเทคนิคใหม่ก็ตาม และตอนนี้เรามีสถาปัตยกรรมใหม่ในขณะที่ความถี่การทำงานของหน่วยความจำยังคงอยู่ที่ระดับเดิม
สิ่งนี้อาจดูแปลกไปหากเราจำการปรับปรุงคอร์กราฟิกได้ ท้ายที่สุดแล้ว เราจำได้ว่าแม้แต่การ์ดวิดีโอ HD2500 ระดับล่างใน IB ก็ใช้แบนด์วิดท์ 25 GB/s อย่างสมบูรณ์ ขณะนี้ทั้งประสิทธิภาพของ CPU และประสิทธิภาพกราฟิกเพิ่มขึ้น ในขณะที่แบนด์วิดท์หน่วยความจำยังคงอยู่ที่ระดับเดียวกัน ในระดับที่กว้างขึ้น คู่แข่งจะเพิ่มแบนด์วิธหน่วยความจำใน APU ของตนอย่างต่อเนื่อง และสูงกว่าของ Intel เป็นเรื่องที่สมเหตุสมผลหากคาดว่า Haswell จะรองรับหน่วยความจำที่มีความถี่ 1866 MHz หรือ 2133 MHz ซึ่งจะเพิ่มแบนด์วิดท์เป็น 30 และ 34 GB/s ตามลำดับ
ด้วยเหตุนี้การตัดสินใจของ Intel จึงไม่ชัดเจนนัก ประการแรก คู่แข่งแนะนำการรองรับหน่วยความจำที่เร็วขึ้นโดยไม่ต้องใช้ ปัญหาพิเศษ- ประการที่สองค่าใช้จ่ายของโมดูลหน่วยความจำที่ทำงานที่ความถี่ 1866 MHz นั้นไม่สูงกว่ามากนักเมื่อเทียบกับโมดูล 1600 MHz และนอกจากนี้ไม่มีใครจำเป็นต้องซื้อหน่วยความจำ 1866 MHz - ตัวเลือกจะขึ้นอยู่กับผู้ใช้ ประการที่สามไม่มีปัญหาใด ๆ กับการรองรับไม่เพียง แต่ 1866 MHz แต่ยัง 2133 MHz ด้วย: นับตั้งแต่การประกาศของ Haswell ได้มีการสร้างสถิติโลกสำหรับการโอเวอร์คล็อก RAM นั่นคือ IKP จะสามารถจัดการหน่วยความจำได้เร็วขึ้นโดยไม่ต้อง ปัญหาใด ๆ ประการที่สี่ กลุ่มเซิร์ฟเวอร์ Xeon E5-2500 V2 (Ivy Bridge-EP) อ้างว่ารองรับ 1866 MHz แต่โดยปกติแล้ว Intel จะแนะนำการสนับสนุนสำหรับมาตรฐานหน่วยความจำที่เร็วกว่าในตลาดนี้ช้ากว่าโซลูชันเดสก์ท็อปมาก
โดยหลักการแล้วใคร ๆ ก็สามารถสรุปได้ว่าหากไม่มีการแข่งขัน Intel ไม่จำเป็นต้อง "เป็นเช่นนั้น" สร้างกล้ามเนื้อและเพิ่มความเหนือกว่าอีกต่อไป แต่สมมติฐานนี้ไม่ถูกต้องอย่างแน่นอน เนื่องจากตามกฎแล้วการเพิ่มแบนด์วิดท์หน่วยความจำจะเพิ่มขึ้น ประสิทธิภาพของคอร์กราฟิกแบบรวมและแทบจะไม่เพิ่มประสิทธิภาพของโปรเซสเซอร์ ในขณะเดียวกัน Intel ยังคงตามหลัง AMD ในด้านประสิทธิภาพกราฟิกและ ปีที่ผ่านมา Intel เองให้ความสำคัญกับกราฟิกมากขึ้นเรื่อย ๆ และอัตราการปรับปรุงนั้นสูงกว่าคอร์โปรเซสเซอร์มาก นอกจากนี้ หากเราอาศัยผลการทดสอบคอร์กราฟิกแบบรวมของ HD4000 รุ่นก่อนหน้า ซึ่งแสดงให้เห็นว่าแบนด์วิธหน่วยความจำที่เพิ่มขึ้นส่งผลให้ประสิทธิภาพกราฟิกเพิ่มขึ้นถึง 30% และยังคำนึงถึงว่าใหม่ คอร์กราฟิก HD4600 นั้นเร็วกว่า HD4000 อย่างเห็นได้ชัดดังนั้นการพึ่งพาประสิทธิภาพของคอร์กราฟิกจาก PSP จึงชัดเจนยิ่งขึ้น คอร์กราฟิกใหม่จะถูกจำกัดมากยิ่งขึ้นด้วยแบนด์วิธหน่วยความจำ "แคบ" เมื่อสรุปข้อเท็จจริงทั้งหมดแล้ว การตัดสินใจของ Intel นั้นไม่สามารถเข้าใจได้อย่างสมบูรณ์: บริษัท เองก็ "รัดคอ" กราฟิกของตน แต่การเพิ่มแบนด์วิดท์สามารถปรับปรุงประสิทธิภาพได้
กลับมาที่สถาปัตยกรรมของแคช เรามาโยนความคิดทิ้งไปในช่องว่าง: เนื่องจากมีการเพิ่มแคชระดับกลาง (แคชซับ) แล้วทำไมไม่เพิ่มแคชข้อมูลระดับกลางขนาดประมาณ 4-8 KB และด้วยการเข้าถึงที่ต่ำกว่า เวลาแฝงระหว่างแคช L1d และอุปกรณ์ผู้บริหาร เช่นจาก P4 (เนื่องจากแนวคิดของแคช uop ถูกนำมาจาก Netburst) โปรดจำไว้ว่าใน P4 แคชข้อมูลระดับกลางนี้มีเวลาในการเข้าถึงสองรอบนาฬิกา และหนึ่งรอบ P4 เท่ากับประมาณ 0.75 รอบนาฬิกาของโปรเซสเซอร์ทั่วไป นั่นคือ เวลาในการเข้าถึงประมาณหนึ่งรอบนาฬิกาครึ่ง อย่างไรก็ตาม บางทีเราอาจจะได้เห็นสิ่งที่คล้ายกันอีกครั้ง - Intel ชอบที่จะจดจำสิ่งเก่า ๆ ที่ถูกลืมไปอย่างดี
อย่างที่คุณเห็น Intel มุ่งเป้าไปที่การเปลี่ยนแปลงทางสถาปัตยกรรมส่วนใหญ่โดยเพิ่มประสิทธิภาพของโค้ด AVX/FMA3: ซึ่งรวมถึงการเพิ่มปริมาณงานแคช การเพิ่มจำนวนพอร์ต และการเพิ่มอัตราการอัพโหลด/โหลดใน เส้นทางการดำเนินการ ด้วยเหตุนี้ ประสิทธิภาพหลักที่เพิ่มขึ้นควรมาจากซอฟต์แวร์ที่เขียนโดยใช้ AVX/FMA3 โดยหลักการแล้วเมื่อพิจารณาจากผลการทดสอบแล้วดูเหมือนว่าเป็นเช่นนั้น ประสิทธิภาพแบบแห้งที่ความถี่เดียวกันในแอปพลิเคชัน "เก่า" ได้รับการเพิ่มขึ้นประมาณ 10% เมื่อเทียบกับคอร์ก่อนหน้า และแอปพลิเคชันที่เขียนโดยใช้ชุดคำสั่งใหม่แสดงการเพิ่มขึ้นมากกว่า 30% ดังนั้นประโยชน์ของสถาปัตยกรรม Haswell จะถูกเปิดเผยเมื่อแอปพลิเคชันได้รับการปรับให้เหมาะสมสำหรับชุดคำสั่งใหม่ นั่นคือเวลาที่ความเหนือกว่าของ Haswell เหนือ SB จะปรากฏชัดเจน
ประโยชน์หลักจากส่วนสำคัญของนวัตกรรมนี้คืออุปกรณ์พกพา พวกเขาจะได้รับความช่วยเหลือจากแนวทางใหม่ในแคช L3, ตัวควบคุมแรงดันไฟฟ้าในตัว, โหมดสลีปใหม่และความถี่การทำงานขั้นต่ำที่ลดลงของคอร์โปรเซสเซอร์
สรุป (ส่วนโปรเซสเซอร์)
คุณคาดหวังอะไรจากแฮสเวลล์?
เนื่องจากจำนวนพอร์ตการเปิดตัวที่เพิ่มขึ้น เราจึงสามารถคาดหวังได้ว่า IPC จะเพิ่มขึ้น ดังนั้นสถาปัตยกรรม Haswell ใหม่จะมีข้อได้เปรียบเหนือ Sandy Bridge เล็กน้อยที่ความถี่เดียวกันแม้ในขณะนี้ แม้ว่าซอฟต์แวร์จะไม่ได้เพิ่มประสิทธิภาพก็ตาม คำสั่ง AVX2/FMA3 เป็นรากฐานสำหรับอนาคต และอนาคตนี้ขึ้นอยู่กับนักพัฒนาซอฟต์แวร์ ยิ่งพวกเขาปรับแอปพลิเคชันได้เร็วเท่าไรก็ยิ่งเร็วขึ้นเท่านั้น ผู้ใช้จะได้รับการเพิ่มประสิทธิภาพ อย่างไรก็ตาม คุณไม่ควรคาดหวังการเติบโตในทุกสิ่งและทุกที่: คำสั่ง SIMD ส่วนใหญ่จะใช้ในการทำงานกับข้อมูลมัลติมีเดียและการคำนวณทางวิทยาศาสตร์ ดังนั้นงานเหล่านี้จึงควรคาดหวังการเติบโตของประสิทธิภาพ ประโยชน์หลักจากการเพิ่มประสิทธิภาพการใช้พลังงานจะอยู่ที่ระบบเคลื่อนที่ ซึ่งปัญหานี้มีความสำคัญมาก ดังนั้นสองประเด็นหลักที่สถาปัตยกรรม Intel Haswell ใหม่มีประโยชน์อย่างมากคือการเพิ่มประสิทธิภาพ SIMD และประสิทธิภาพการใช้พลังงานที่เพิ่มขึ้น
สำหรับการบังคับใช้โปรเซสเซอร์ Haswell ใหม่นั้นคุ้มค่าที่จะตรวจสอบตัวเลือกต่าง ๆ สำหรับการใช้งาน: ในคอมพิวเตอร์เดสก์ท็อป, ในเซิร์ฟเวอร์, ในโซลูชันมือถือ, สำหรับนักเล่นเกม, สำหรับโอเวอร์คล็อกเกอร์
เดสก์ทอป
การใช้พลังงานไม่ใช่สิ่งสำคัญสำหรับโปรเซสเซอร์เดสก์ท็อป ดังนั้นแม้แต่ในยุโรปที่ไฟฟ้ามีราคาแพง ก็ไม่น่าจะมีใครเปลี่ยนมาใช้ Haswell จากรุ่นก่อนๆ เพียงเพราะเหตุนี้ นอกจากนี้ TDP ของ Haswell ยังสูงกว่า IB ดังนั้นการประหยัดจะเกิดขึ้นเฉพาะในกรณีที่มีโหลดน้อยที่สุดเท่านั้น เมื่อถามคำถามในลักษณะนี้ ไม่ต้องสงสัยเลย - มันไม่คุ้มค่า
จากมุมมองของประสิทธิภาพ การเปลี่ยนแปลงก็ดูไม่เหมือนข้อตกลงที่ให้ผลกำไรเช่นกัน ความเร็วสูงสุดที่เพิ่มขึ้นในงานตัวประมวลผลจะไม่เกิน 10% การเปลี่ยนมาใช้ Haswell จาก Sandy Bridge หรือ Ivy Bridge จะได้รับการพิสูจน์ก็ต่อเมื่อคุณวางแผนที่จะใช้แอปพลิเคชันที่รองรับ FMA3 และ AVX2: การสนับสนุน FMA3 สามารถเพิ่มในบางแอปพลิเคชันจาก 30% เป็น 70% การปรับปรุงที่เกี่ยวข้องกับการจำลองเสมือนและการใช้งานหน่วยความจำทรานแซคชันนั้นไม่ค่อยน่าสนใจและใช้สำหรับเดสก์ท็อป
เซิร์ฟเวอร์และเวิร์กสเตชัน
เมื่อพิจารณาว่าเซิร์ฟเวอร์ทำงานอย่างต่อเนื่องตลอด 24 ชั่วโมงต่อวันและมีโหลดบนโปรเซสเซอร์ค่อนข้างคงที่ Haswell ไม่น่าจะดีกว่า IB ในแง่ของการใช้พลังงานล้วนๆ แม้ว่าอาจให้ประสิทธิภาพเพิ่มขึ้นบ้างในแง่ของประสิทธิภาพต่อวัตต์ก็ตาม การรองรับ AVX2/FMA3 ไม่น่าจะมีประโยชน์ในเซิร์ฟเวอร์ แต่ในเวิร์กสเตชันที่เกี่ยวข้องกับการคำนวณทางวิทยาศาสตร์ การสนับสนุนนี้จะมีประโยชน์มาก - แต่เฉพาะในกรณีที่ซอฟต์แวร์ที่ใช้รองรับคำแนะนำใหม่เท่านั้น หน่วยความจำทรานแซคชันค่อนข้างมีประโยชน์ แต่ก็ไม่เสมอไป: สามารถเพิ่มโปรแกรมแบบมัลติเธรดและในโปรแกรมที่ทำงานกับฐานข้อมูลได้มากขึ้น แต่สำหรับ การใช้งานที่มีประสิทธิภาพการเพิ่มประสิทธิภาพซอฟต์แวร์ก็เป็นสิ่งจำเป็นเช่นกัน
แต่การปรับปรุงทั้งหมดที่เกี่ยวข้องกับการจำลองเสมือนมักจะให้ผลดี เนื่องจากขณะนี้สภาพแวดล้อมเสมือนมีการใช้งานอย่างแข็งขัน และในส่วนใหญ่ ฟิสิคัลเซิร์ฟเวอร์ใช้งานได้กับหลายเสมือน ยิ่งไปกว่านั้น ความชุกของการจำลองเสมือนนั้นไม่เพียงอธิบายโดยการลดต้นทุนของสภาพแวดล้อมเสมือนอย่างเห็นได้ชัดในแง่ของประสิทธิภาพ แต่ยังรวมถึงประสิทธิภาพเชิงเศรษฐกิจด้วย: การบำรุงรักษาเซิร์ฟเวอร์เสมือนจำนวนมากในเครื่องเดียวนั้นถูกกว่า และช่วยให้มีประสิทธิภาพมากขึ้น การใช้ทรัพยากร รวมถึงทรัพยากรของโปรเซสเซอร์
เร็วๆ นี้ ตลาดเซิร์ฟเวอร์รูปร่างหน้าตาของแฮสเวลล์ควรได้รับการต้อนรับในแง่บวก หลังจากเปลี่ยนเซิร์ฟเวอร์ที่ใช้ Xeon E3-1200v1 และ Xeon E3-1200v2 เป็นเซิร์ฟเวอร์ที่ใช้ Xeon E3-1200v3 (Haswell) คุณจะได้รับประสิทธิภาพที่เพิ่มขึ้นทันที และหลังจากปรับซอฟต์แวร์ให้เหมาะสมสำหรับ AVX2/FMA3 และหน่วยความจำทรานแซคชันแล้ว ประสิทธิภาพจะเพิ่มขึ้น มากไปกว่านั้น.
โซลูชั่นมือถือ
แน่นอนว่าประโยชน์หลักจากการเปิดตัว Haswell ในกลุ่มอุปกรณ์พกพานั้นอยู่ที่การใช้พลังงานที่ดีขึ้น ตัดสินโดยการนำเสนอของ Intel รวมถึงผลการทดสอบที่ปรากฏบนอินเทอร์เน็ตแล้วมีผลจริงๆและเป็นสิ่งที่สังเกตได้ชัดเจน
ในแง่ของประสิทธิภาพที่แท้จริง การเปลี่ยนจาก Ivy Bridge เป็น Haswell ดูเหมือนจะไม่สมเหตุสมผลนัก: กำไรสุทธิควรค่อนข้างน้อย และการปรับปรุงใน ส่วนประกอบแต่ละส่วน(คำสั่งการจำลองเสมือนหรือมัลติมีเดียเดียวกัน) ไม่น่าจะให้ประโยชน์แก่ผู้ใช้ระบบมือถือได้มากนักเนื่องจากแทบจะไม่สร้างสภาพแวดล้อมหรือการคำนวณทางวิทยาศาสตร์ที่ซับซ้อนบนแล็ปท็อปและแท็บเล็ต
โดยทั่วไปแล้ว ในแง่ของประสิทธิภาพของโปรเซสเซอร์ คุณไม่ควรคาดหวังอะไรมาก แต่ระบบมือถือจะต้องการเพิ่มประสิทธิภาพของคอร์กราฟิกอย่างแน่นอน ดังนั้น หากปัญหาการใช้พลังงานไม่สำคัญสำหรับคุณอย่างยิ่ง คุณไม่ควรพิจารณาอัปเกรดจาก Sandy Bridge หรือ Ivy Bridge อย่างจริงจัง - ควรใช้ระบบที่มีอยู่ต่อไปจนกว่าระบบจะล้าสมัยไปโดยสิ้นเชิง หากคุณใช้แบตเตอรี่บ่อยครั้ง Haswell จะช่วยยืดอายุการใช้งานแบตเตอรี่ได้อย่างมาก
นักเล่นเกม
ตามกฎแล้วปัญหาการใช้พลังงานในหมู่นักเล่นเกมในรัสเซียไม่ใช่ปัญหา - และเหตุใดจึงควรเป็นเช่นนั้นเมื่อการ์ดแสดงผลการเล่นเกมใช้ 200 วัตต์ขึ้นไป เกมเมอร์ยังไม่จำเป็นต้องใช้ระบบเสมือนจริงและหน่วยความจำทรานแซคชันอีกด้วย ไม่ใช่ความจริงที่ว่า AVX2/FMA3 จะเป็นที่ต้องการสำหรับเกมโดยเฉพาะ แม้ว่าอาจมีประโยชน์ในการคำนวณทางฟิสิกส์ก็ตาม สิ่งที่เหลืออยู่คือประสิทธิภาพที่แท้จริงของโปรเซสเซอร์ และนี่คือความแตกต่างระหว่าง Ivy Bridge แบบเดียวกันที่มีเพียงเล็กน้อย ด้วยเหตุนี้ สำหรับผู้ใช้ประเภทนี้ การเปลี่ยนจาก SB หรือ IB ไปเป็น Haswell โดยตรงจึงไม่เกี่ยวข้องกัน แต่มันสมเหตุสมผลที่จะเปลี่ยนไปใช้โปรเซสเซอร์ใหม่จาก Nehalem และ Lynifield และยิ่งกว่านั้นคือ Conroe
โอเวอร์คล็อกเกอร์
สำหรับโอเวอร์คล็อกเกอร์โปรเซสเซอร์ใหม่ (แต่แน่นอนว่ามีเพียงเวอร์ชัน K ที่ "ปลดล็อค" เท่านั้น) อาจน่าสนใจโดยเฉพาะอย่างยิ่งหากเป็นไปได้ที่จะ "หนังศีรษะ" นั่นคือถอดฝาครอบโลหะออกและทำให้คริสตัลเย็นลงโดยตรง หากยังไม่เสร็จสิ้นผลลัพธ์ของการโอเวอร์คล็อกจะดูเรียบง่ายกว่าของ Ivy Bridge นอกจากนี้ตัวควบคุมแรงดันไฟฟ้าในตัวอาจเป็นปัจจัยจำกัดได้ อ่านเพิ่มเติมเกี่ยวกับเรื่องนี้
เราแปล... แปลภาษาจีน (ตัวย่อ) จีน (ตัวเต็ม) อังกฤษ ฝรั่งเศส เยอรมัน อิตาลี โปรตุเกส รัสเซีย สเปน ตุรกี
ขออภัย เราไม่สามารถแปลข้อมูลนี้ได้ในขณะนี้ - โปรดลองอีกครั้งในภายหลัง
การแนะนำ
ซอฟต์แวร์ที่ออกแบบมาเพื่อการสื่อสารและการถ่ายโอนข้อมูลต้องการประสิทธิภาพสูงมาก เนื่องจากมีการถ่ายโอนแพ็กเก็ตข้อมูลขนาดเล็กจำนวนมาก หนึ่งในคุณสมบัติของการพัฒนาแอพพลิเคชั่นเสมือนจริง ฟังก์ชั่นเครือข่าย(NFV) คือมีความจำเป็นต้องใช้การจำลองเสมือนให้มากที่สุดเท่าที่จะเป็นไปได้ แต่ในขณะเดียวกัน กรณีที่จำเป็นปรับแอพพลิเคชั่นให้เหมาะสมสำหรับฮาร์ดแวร์ที่ใช้
ในบทความนี้ ผมจะเน้นคุณลักษณะสามประการของโปรเซสเซอร์ Intel® ที่มีประโยชน์ในการปรับประสิทธิภาพของแอปพลิเคชัน NFV ให้เหมาะสม: Cache Allocation Technologies (CAT), Intel® Advanced Vector Extensions 2 (Intel® AVX2) สำหรับการประมวลผลเวกเตอร์ และ Intel® ส่วนขยายการซิงโครไนซ์ธุรกรรม (Intel® TSX)
การแก้ปัญหาการกลับลำดับความสำคัญโดยใช้ CAT
เมื่อฟังก์ชันที่มีลำดับความสำคัญต่ำขโมยทรัพยากรจากฟังก์ชันที่มีลำดับความสำคัญสูง เราจะเรียกสิ่งนี้ว่า "การผกผันลำดับความสำคัญ"
ไม่ทั้งหมด ฟังก์ชั่นเสมือนสำคัญไม่แพ้กัน ตัวอย่างเช่น ฟังก์ชันการกำหนดเส้นทางมีความสำคัญต่อเวลาและประสิทธิภาพในการประมวลผล ในขณะที่ฟังก์ชันการเข้ารหัสสื่อไม่สำคัญเท่ากับ คุณลักษณะนี้อาจอนุญาตให้ดรอปแพ็กเก็ตเป็นระยะๆ โดยไม่กระทบต่อประสบการณ์ผู้ใช้ เนื่องจากจะไม่มีใครสังเกตเห็นการลดลงของอัตราเฟรมวิดีโอจาก 20 เป็น 19 เฟรมต่อวินาทีอยู่ดี
แคชเริ่มต้นได้รับการออกแบบในลักษณะที่ผู้บริโภคที่ใช้งานมากที่สุดจะได้รับ ส่วนที่ใหญ่ที่สุด- แต่ผู้บริโภคที่กระตือรือร้นที่สุดไม่ใช่แอปพลิเคชันที่สำคัญที่สุดเสมอไป ในความเป็นจริงสิ่งที่ตรงกันข้ามมักเป็นจริง แอปพลิเคชันที่มีลำดับความสำคัญสูงได้รับการปรับให้เหมาะสม โดยปริมาณข้อมูลจะลดลงเหลือน้อยที่สุด แอปพลิเคชันที่มีลำดับความสำคัญต่ำไม่จำเป็นต้องใช้ความพยายามในการปรับให้เหมาะสมมากนัก ดังนั้นจึงมีแนวโน้มที่จะใช้หน่วยความจำมากกว่า ฟังก์ชันบางอย่างเหล่านี้ใช้หน่วยความจำมาก ตัวอย่างเช่น ฟังก์ชันการดูแพ็กเก็ตสำหรับการวิเคราะห์ทางสถิติมีลำดับความสำคัญต่ำ แต่ใช้หน่วยความจำจำนวนมากและใช้แคชมาก
นักพัฒนามักคิดว่าหากพวกเขาใส่แอปพลิเคชันที่มีลำดับความสำคัญสูงตัวใดตัวหนึ่งลงในเคอร์เนลเฉพาะ แอปพลิเคชันนั้นก็จะปลอดภัยที่นั่น และไม่ได้รับผลกระทบจากแอปพลิเคชันที่มีลำดับความสำคัญต่ำ น่าเสียดายที่มันไม่ใช่ แต่ละคอร์มีแคชระดับ 1 ของตัวเอง (L1 ซึ่งเป็นแคชที่เร็วที่สุดแต่เล็กที่สุด) และแคชระดับ 2 (L2 ใหญ่กว่าเล็กน้อยแต่ช้ากว่า) มีพื้นที่แคช L1 แยกต่างหากสำหรับข้อมูล (L1D) และรหัสโปรแกรม (L1I, "I" ย่อมาจากคำแนะนำ) แคชระดับที่สาม (ช้าที่สุด) นั้นเป็นเรื่องปกติสำหรับคอร์โปรเซสเซอร์ทั้งหมด บนสถาปัตยกรรมโปรเซสเซอร์ Intel® จนถึงตระกูล Broadwell แคช L3 นั้นครอบคลุมอย่างครบถ้วน ซึ่งหมายความว่าแคชจะมีทุกสิ่งที่มีอยู่ในแคช L1 และ L2 เนื่องจากวิธีการทำงานของแคชแบบรวม หากมีสิ่งใดถูกลบออกจากแคชระดับที่สาม สิ่งนั้นจะถูกลบออกจากแคชระดับที่หนึ่งและสองที่เกี่ยวข้องด้วย ซึ่งหมายความว่าแอปพลิเคชันที่มีลำดับความสำคัญต่ำซึ่งต้องการพื้นที่ในแคช L3 สามารถแทนที่ข้อมูลจากแคช L1 และ L2 ของแอปพลิเคชันที่มีลำดับความสำคัญสูง แม้ว่าแอปพลิเคชันจะทำงานบนคอร์อื่นก็ตาม
ในอดีตมีแนวทางแก้ไขปัญหานี้ที่เรียกว่า “อุ่นเครื่อง” เมื่อการเข้าถึงแคช L3 แข่งขันกัน “ผู้ชนะ” คือแอปพลิเคชันที่เข้าถึงหน่วยความจำบ่อยที่สุด ดังนั้นวิธีแก้ปัญหาคือให้ฟังก์ชันที่มีลำดับความสำคัญสูงเข้าถึงแคชอย่างต่อเนื่อง แม้ว่าจะไม่ได้ใช้งานก็ตาม นี่ไม่ใช่วิธีแก้ปัญหาที่หรูหรานัก แต่มักจะเป็นที่ยอมรับ และจนกระทั่งเมื่อไม่นานมานี้ก็ไม่มีทางเลือกอื่น แต่ตอนนี้มีทางเลือกอื่น: ตระกูลโปรเซสเซอร์ Intel® Xeon® E5 v3 เปิดตัว Cache Allocation Technology (CAT) ซึ่งช่วยให้คุณสามารถจัดสรรแคชตามแอปพลิเคชันและคลาสของบริการ
ผลกระทบของการผกผันลำดับความสำคัญ
เพื่อแสดงให้เห็นถึงผลกระทบของการผกผันลำดับความสำคัญ ฉันเขียน microbench ธรรมดาที่รันการข้ามรายการแบบเชื่อมโยงบนเธรดที่มีลำดับความสำคัญสูงเป็นระยะ ๆ ในขณะที่เธรดที่มีลำดับความสำคัญต่ำกำลังรันฟังก์ชันการคัดลอกในหน่วยความจำอย่างต่อเนื่อง เธรดเหล่านี้ถูกกำหนดให้กับคอร์ที่แตกต่างกันของโปรเซสเซอร์เดียวกัน นี่เป็นการจำลองกรณีที่เลวร้ายที่สุดของการช่วงชิงทรัพยากร: การคัดลอกต้องใช้หน่วยความจำจำนวนมาก ดังนั้นจึงมีแนวโน้มที่จะขัดขวางเธรดที่สำคัญกว่าในการเข้าถึงรายการ
นี่คือรหัสในภาษา C
// สร้างรายการเชื่อมโยงขนาด N ด้วยรูปแบบสุ่มหลอก void init_pool(list_item *head, int N, int A, int B) ( int C = B; list_item *current = head; for (int i = 0; i< N - 1; i++) { current->ติ๊ก = 0; C = (A*C + B) % N; ปัจจุบัน -> ถัดไป = (list_item*)&(หัว[C]); ปัจจุบัน = ปัจจุบัน -> ถัดไป; ) ) // แตะ N องค์ประกอบแรกในรายการที่เชื่อมโยง void warmup_list(list_item* current, int N) ( bool write = (N > POOL_SIZE_L2_LINES) ? true: false; for(int i = 0; i< N - 1; i++) { current = current->ต่อไป;< 50; j++) { list_item* current = head; #if WARMUP_ON while(in_copy) warmup_list(head, N); #else while(in_copy) spin_sleep(1); #endif i1 = __rdtsc(); for(int i = 0; i < N; i++) { current->ถ้า (เขียน) ปัจจุบัน -> ติ๊ก ++; ) ) การวัดเป็นโมฆะ (list_item* head, int N) ( ไม่ได้ลงนาม __long long i1, i2, avg = 0; for (int j = 0; j
ติ๊ก++; ปัจจุบัน = ปัจจุบัน -> ถัดไป; ) i2 = __rdtsc(); เฉลี่ย += (i2-i1)/50; in_copy = จริง; ) ผลลัพธ์=ค่าเฉลี่ย/N )
- ประกอบด้วยสามฟังก์ชัน ฟังก์ชัน init_pool() จะเริ่มต้นรายการเชื่อมโยงในพื้นที่หน่วยความจำว่างขนาดใหญ่ที่ได้รับการจัดสรรโดยใช้เครื่องกำเนิดไฟฟ้าง่ายๆ
- ตัวเลขสุ่มเทียม วิธีนี้จะป้องกันไม่ให้รายการอยู่ใกล้กันในหน่วยความจำ ซึ่งจะทำให้เกิดตำแหน่งเชิงพื้นที่ ซึ่งจะส่งผลต่อการวัดของเรา เนื่องจากบางรายการจะถูกดึงข้อมูลล่วงหน้าโดยอัตโนมัติ แต่ละองค์ประกอบรายการจะมีหนึ่งบรรทัดแคชเท่านั้น
- ฟังก์ชัน warmup() จะวนซ้ำรายการที่สร้างขึ้นอย่างต่อเนื่อง มีข้อมูลเฉพาะที่จำเป็นต้องเข้าถึงซึ่งควรอยู่ในแคช ดังนั้นฟังก์ชันนี้จึงป้องกันไม่ให้เธรดอื่นลบรายการที่แต่งออกจากแคช L3
ฟังก์ชัน Measure() จะวัดการข้ามผ่านขององค์ประกอบรายการหนึ่ง จากนั้นจะพักเป็นเวลา 1 มิลลิวินาที หรือเรียกใช้ฟังก์ชัน warmup() ขึ้นอยู่กับการทดสอบที่เรากำลังดำเนินการอยู่ จากนั้นฟังก์ชัน Measure() จะเฉลี่ยผลลัพธ์
ตัวบ่งชี้พื้นฐานคือเส้นสีน้ำตาลแดงซึ่งสอดคล้องกับโปรแกรมที่ไม่มีเธรดการคัดลอกในหน่วยความจำนั่นคือไม่มีการแข่งขัน เส้นสีน้ำเงินแสดงผลที่ตามมาของการกลับลำดับความสำคัญ: เนื่องจากฟังก์ชันคัดลอกหน่วยความจำ การเข้าถึงรายการจึงใช้เวลานานกว่ามาก ผลกระทบจะมีขนาดใหญ่เป็นพิเศษหากรายการพอดีกับแคช L1 หรือ L2 ความเร็วสูง หากรายการมีขนาดใหญ่จนไม่พอดีกับแคชระดับที่สาม ผลกระทบก็ไม่มีนัยสำคัญ
เส้นสีเขียวแสดงผลการอุ่นเครื่องเมื่อฟังก์ชันคัดลอกหน่วยความจำกำลังทำงาน: เวลาในการเข้าถึงลดลงอย่างรวดเร็วและเข้าใกล้ค่าฐาน
หากเราเปิดใช้งาน CAT และจัดสรรส่วนของแคช L3 ให้กับแต่ละคอร์เพื่อการใช้งานเฉพาะ ผลลัพธ์ที่ได้จะใกล้เคียงกับพื้นฐานมาก (ใกล้เกินไปที่จะแสดงในแผนภาพ) ซึ่งเป็นเป้าหมายของเรา
การรวมแมว
ก่อนอื่น ตรวจสอบให้แน่ใจว่าแพลตฟอร์มรองรับ CAT คุณสามารถใช้คำสั่ง CPUID ได้โดยตรวจสอบที่อยู่ leaf 7, subleaf 0 ที่เพิ่มเพื่อระบุความพร้อมของ CAT
หากเปิดใช้งานและรองรับเทคโนโลยี CAT จะมีรีจิสเตอร์ MSR ที่สามารถตั้งโปรแกรมให้จัดสรรได้ ส่วนต่างๆแคชระดับที่สามสำหรับคอร์ที่แตกต่างกัน
ซ็อกเก็ตโปรเซสเซอร์แต่ละตัวมีการลงทะเบียน MSR IA32_L3_MASKn (เช่น 0xc90, 0xc91, 0xc92, 0xc93) รีจิสเตอร์เหล่านี้จะจัดเก็บบิตมาสก์ซึ่งระบุจำนวนแคช L3 ที่ควรจัดสรรสำหรับบริการแต่ละคลาส (COS) 0xc90 เก็บการจัดสรรแคชสำหรับ COS0, 0xc91 สำหรับ COS1 เป็นต้น
ตัวอย่างเช่น แผนภาพนี้แสดงบิตมาสก์ที่เป็นไปได้สำหรับคลาสบริการที่แตกต่างกัน เพื่อสาธิตวิธีการแบ่งแคช: COS0 ได้รับครึ่งหนึ่ง COS1 ได้รับหนึ่งในสี่ และ COS2 และ COS3 ต่างก็ได้รับหนึ่งในแปด ตัวอย่างเช่น 0xc90 จะมี 11110000 และ 0xc93 จะมี 00000001
อัลกอริธึม Direct Data Input/Output (DDIO) มีบิตมาสก์ที่ซ่อนอยู่ซึ่งช่วยให้ถ่ายโอนข้อมูลจากอุปกรณ์ PCIe ความเร็วสูง เช่น อะแดปเตอร์เครือข่าย ไปยังพื้นที่เฉพาะของแคช L3 อาจมีข้อขัดแย้งกับคลาสของบริการที่กำหนด ดังนั้นจึงต้องคำนึงถึงเรื่องนี้เมื่อสร้างแอปพลิเคชัน NFV ที่มีปริมาณงานสูง หากต้องการทดสอบข้อขัดแย้ง ใช้เพื่อตรวจหาการพลาดแคช BIOS บางตัวมีการตั้งค่าที่ให้คุณดูและเปลี่ยนมาสก์ DDIO ได้
แต่ละคอร์มี MSR register IA32_PQR_ASSOC (0xc8f) ซึ่งระบุคลาสของบริการที่ใช้กับคอร์นั้น คลาสบริการเริ่มต้นคือ 0 ซึ่งหมายความว่ามีการใช้บิตมาสก์ใน MSR 0xc90 (ตามค่าเริ่มต้น บิตมาสก์ 0xc90 จะถูกตั้งค่าเป็น 1 เพื่อให้แน่ใจว่าแคชมีความพร้อมใช้งานสูงสุด)
ที่สุด โมเดลที่เรียบง่ายการใช้ CAT ใน NFV เป็นการจัดสรรก้อนแคช L3 ให้กับคอร์ที่แตกต่างกันโดยใช้มาสก์บิตที่แยกได้ จากนั้นจึงกำหนดเธรดหรือเครื่องเสมือนให้กับคอร์ หาก VM จำเป็นต้องแชร์คอร์เพื่อดำเนินการ ก็เป็นไปได้ที่จะทำการแก้ไขเล็กน้อยกับตัวกำหนดเวลา OS เพิ่มแคชมาสก์ให้กับเธรดที่ VM กำลังทำงานอยู่ และเปิดใช้งานแบบไดนามิกในทุกเหตุการณ์การจัดกำหนดการ
มีอีกวิธีที่ผิดปกติในการใช้ CAT เพื่อล็อคข้อมูลในแคช ขั้นแรก สร้างแคชมาสก์ที่ใช้งานอยู่ และเข้าถึงข้อมูลในหน่วยความจำเพื่อโหลดลงในแคช L3 จากนั้นปิดการใช้งานบิตที่แสดงถึงส่วนนี้ของแคช L3 ในบิตมาสก์ CAT ใด ๆ ที่จะใช้ในอนาคต ข้อมูลจะถูกล็อคไว้ในแคช L3 เนื่องจากขณะนี้ไม่สามารถลบออกได้ (นอกเหนือจาก DDIO) ในแอปพลิเคชัน NFV กลไกนี้อนุญาตให้ล็อกตารางการค้นหาขนาดกลางสำหรับการกำหนดเส้นทางและการแยกวิเคราะห์แพ็กเก็ตในแคช L3 เพื่อให้แน่ใจว่ามีการเข้าถึงอย่างต่อเนื่อง
การใช้ Intel AVX2 สำหรับการประมวลผลเวกเตอร์
คำสั่ง SIMD (หนึ่งคำสั่ง ข้อมูลจำนวนมาก) ช่วยให้คุณสามารถดำเนินการเดียวกันกับข้อมูลส่วนต่างๆ ได้ในเวลาเดียวกัน คำแนะนำเหล่านี้มักใช้เพื่อเพิ่มความเร็วในการคำนวณจุดลอยตัว แต่ก็มีคำสั่งเวอร์ชันจำนวนเต็ม บูลีน และข้อมูลด้วย
ขึ้นอยู่กับโปรเซสเซอร์ที่คุณใช้ คุณจะมีตระกูลคำสั่ง SIMD ที่แตกต่างกันสำหรับคุณ ขนาดของเวกเตอร์ที่ประมวลผลโดยคำสั่งจะแตกต่างกันเช่นกัน:
- SSE รองรับเวกเตอร์ 128 บิต
- Intel AVX2 รองรับคำสั่งจำนวนเต็มสำหรับเวกเตอร์ 256 บิต และใช้คำสั่งสำหรับการดำเนินการรวบรวม
- ในส่วนขยาย AVX3 ในอนาคต สถาปัตยกรรมของอินเทล® รองรับเวกเตอร์ 512 บิต
เวกเตอร์ 128 บิตหนึ่งตัวสามารถใช้กับตัวแปร 64 บิตสองตัว ตัวแปร 32 บิตสี่ตัว หรือตัวแปร 16 บิตแปดตัว (ขึ้นอยู่กับคำสั่ง SIMD ที่ใช้) เวกเตอร์ขนาดใหญ่จะรองรับองค์ประกอบข้อมูลได้มากขึ้น เนื่องจากความต้องการปริมาณงานสูงของแอปพลิเคชัน NFV คุณควรใช้คำสั่ง SIMD ที่ทรงพลังที่สุด (และฮาร์ดแวร์ที่เกี่ยวข้อง) ซึ่งปัจจุบันคือ Intel AVX2
คำสั่ง SIMD มักใช้เพื่อดำเนินการเดียวกันกับเวกเตอร์ของค่าดังแสดงในรูป ในที่นี้ การดำเนินการสร้าง X1opY1 ถึง X4opY4 เป็นคำสั่งเดียว ซึ่งประมวลผลรายการข้อมูล X1 ถึง X4 และ Y1 ถึง Y4 ไปพร้อมๆ กัน ในตัวอย่างนี้ การเร่งความเร็วจะเร็วกว่าการดำเนินการปกติ (สเกลาร์) ถึงสี่เท่า เนื่องจากมีการประมวลผลสี่การดำเนินการพร้อมกัน การเร่งความเร็วอาจมีขนาดใหญ่เท่ากับเวกเตอร์ SIMD ที่มีขนาดใหญ่ แอปพลิเคชัน NFV มักจะประมวลผลสตรีมแพ็กเก็ตหลายรายการในลักษณะเดียวกัน ดังนั้นคำสั่ง SIMD จึงมอบวิธีธรรมชาติในการเพิ่มประสิทธิภาพการทำงาน
สำหรับลูปแบบง่าย คอมไพลเลอร์มักจะกำหนดเวคเตอร์การดำเนินการโดยอัตโนมัติโดยใช้คำสั่ง SIMD ล่าสุดที่มีให้สำหรับ CPU ที่กำหนด (หากคุณใช้แฟล็กคอมไพเลอร์ที่ถูกต้อง) คุณสามารถปรับโค้ดของคุณให้เหมาะสมเพื่อใช้ชุดคำสั่งที่ทันสมัยที่สุดที่ฮาร์ดแวร์รองรับขณะรันไทม์ หรือคุณสามารถคอมไพล์โค้ดสำหรับสถาปัตยกรรมเป้าหมายเฉพาะได้
การทำงานของ SIMD ยังรองรับการโหลดหน่วยความจำ โดยคัดลอกได้สูงสุด 32 ไบต์ (256 บิต) จากหน่วยความจำไปยังรีจิสเตอร์ ซึ่งช่วยให้สามารถถ่ายโอนข้อมูลระหว่างหน่วยความจำและรีจิสเตอร์ ข้ามแคช และรวบรวมข้อมูลจากตำแหน่งต่างๆ ในหน่วยความจำได้ คุณยังสามารถดำเนินการต่างๆ ด้วยเวกเตอร์ (เปลี่ยนข้อมูลภายในรีจิสเตอร์เดียว) และจัดเก็บเวกเตอร์ (เขียนได้ถึง 32 ไบต์จากรีจิสเตอร์ไปยังหน่วยความจำ)
Memcpy และ memmov เป็นตัวอย่างที่รู้จักกันดีของรูทีนพื้นฐานที่นำมาใช้โดยใช้คำสั่ง SIMD ตั้งแต่ต้น เนื่องจากคำสั่ง REP MOV ช้าเกินไป รหัส memcpy ได้รับการอัปเดตเป็นประจำ ไลบรารีระบบเพื่อใช้คำแนะนำ SIMD ล่าสุด ตารางตัวจัดการ CPUID ถูกใช้เพื่อรับข้อมูลเกี่ยวกับเวอร์ชันล่าสุดที่พร้อมใช้งาน ในขณะเดียวกัน การใช้งานคำสั่ง SIMD รุ่นใหม่ในไลบรารีมักจะล่าช้า
ตัวอย่างเช่น, ขั้นตอนต่อไป memcpy ซึ่งใช้การวนซ้ำอย่างง่ายจะขึ้นอยู่กับฟังก์ชันในตัว (แทนโค้ดไลบรารี) ดังนั้นคอมไพเลอร์สามารถปรับให้เหมาะสมสำหรับคำสั่ง SIMD เวอร์ชันล่าสุด
Mm256_store_si256((__m256i*) (ปลายทาง++), (__m256i*) (src++))
มันคอมไพล์เป็นโค้ดแอสเซมบลีต่อไปนี้และมีประสิทธิภาพเป็นสองเท่าของไลบรารีล่าสุด
C5 fd 6f 04 04 vmovdqa (%rsp,%rax,1),%ymm0 c5 fd 7f 84 04 00 00 vmovdqa %ymm0.0x10000(%rsp,%rax,1)
รหัสแอสเซมบลีจากฟังก์ชันอินไลน์จะคัดลอก 32 ไบต์ (256 บิต) โดยใช้คำสั่ง SIMD ล่าสุดที่มีอยู่ ในขณะที่รหัสไลบรารีที่ใช้ SSE จะคัดลอกเพียง 16 ไบต์ (128 บิต)
แอปพลิเคชัน NFV มักจะจำเป็นต้องดำเนินการรวบรวมโดยการโหลดข้อมูลจากหลายตำแหน่งในตำแหน่งหน่วยความจำที่แตกต่างกันซึ่งไม่ต่อเนื่องกัน ตัวอย่างเช่น อะแดปเตอร์เครือข่ายสามารถแคชแพ็กเก็ตขาเข้าโดยใช้ DDIO แอปพลิเคชัน NFV อาจต้องการการเข้าถึงเพียงบางส่วนเท่านั้น ส่วนหัวของเครือข่ายด้วยที่อยู่ IP ปลายทาง ด้วยการดำเนินการรวบรวมข้อมูลแอปพลิเคชันสามารถรวบรวมข้อมูลได้ 8 แพ็กเก็ตในเวลาเดียวกัน
ไม่จำเป็นต้องใช้ฟังก์ชันอินไลน์หรือโค้ดแอสเซมบลีสำหรับการดำเนินการรวบรวม เนื่องจากคอมไพลเลอร์สามารถกำหนดเวคเตอร์โค้ดได้ เช่นเดียวกับโปรแกรมที่แสดงด้านล่าง โดยอิงจากการทดสอบผลรวมตัวเลขจากตำแหน่งสุ่มหลอกในหน่วยความจำ
อินท์เอ; อินท์ข; สำหรับ (i = 0; i< 1024; i++) a[i] = i; for (i = 0; i < 64; i++) b[i] = (i*1051) % 1024; for (i = 0; i < 64; i++) sum += a]; // This line is vectorized using gather.
บรรทัดสุดท้ายถูกคอมไพล์เป็นโค้ดแอสเซมบลีต่อไปนี้
C5 fe 6f 40 80 vmovdqu -0x80(%rax),%ymm0 c5 ed fe f3 vpaddd %ymm3,%ymm2,%ymm6 c5 e5 ef db vpxor %ymm3,%ymm3,%ymm3 c5 d5 76 ed vpcmpeqd %ymm5,% ymm5,% ymm5 c4 e2 55 90 3c a0 vpgatherdd % ymm5, (% rax,% ymm4,4),% ymm7
การดำเนินการรวบรวมเดี่ยวจะเร็วกว่าลำดับการดาวน์โหลดอย่างมาก แต่จะสมเหตุสมผลก็ต่อเมื่อข้อมูลอยู่ในแคชแล้วเท่านั้น มิฉะนั้น จะต้องดึงข้อมูลจากหน่วยความจำ ซึ่งต้องใช้รอบ CPU หลายร้อยหรือหลายพันรอบ หากข้อมูลอยู่ในแคช จะสามารถเร่งความเร็วได้ 10 เท่า
(เช่น 1,000%) หากข้อมูลไม่อยู่ในแคช ความเร็วจะอยู่ที่ 5% เท่านั้น
เมื่อใช้เทคนิคเช่นนี้ สิ่งสำคัญคือต้องวิเคราะห์แอปพลิเคชันเพื่อระบุปัญหาคอขวด และเพื่อทำความเข้าใจว่าแอปพลิเคชันใช้เวลามากเกินไปในการคัดลอกหรือรวบรวมข้อมูลหรือไม่ คุณสามารถใช้ได้ .
คุณสมบัติที่มีประโยชน์อีกประการหนึ่งสำหรับ NFV ใน Intel AVX2 และการทำงานของ SIMD อื่น ๆ ก็คือระดับบิตและ การดำเนินการเชิงตรรกะ- ใช้เพื่อเร่งความเร็วโค้ดการเข้ารหัสที่ไม่ได้มาตรฐาน และการตรวจสอบบิตก็สะดวกสำหรับนักพัฒนา ASN.1 และมักใช้สำหรับข้อมูลในโทรคมนาคม สามารถใช้ Intel AVX2 เพื่อการเปรียบเทียบสตริงที่รวดเร็วยิ่งขึ้นโดยใช้อัลกอริธึมขั้นสูง เช่น MPSSEF
ส่วนขยาย Intel AVX2 ทำงานได้ดี เครื่องเสมือน- ประสิทธิภาพยังคงเหมือนเดิมและไม่มีข้อผิดพลาดในการออกจากเครื่องเสมือน
การใช้ Intel TSX เพื่อความสามารถในการขยายขนาดที่สูงขึ้น
หนึ่งในปัญหา โปรแกรมคู่ขนานคือการหลีกเลี่ยงการชนกันของข้อมูล ซึ่งอาจเกิดขึ้นเมื่อหลายเธรดพยายามใช้รายการข้อมูลเดียวกัน และอย่างน้อยหนึ่งเธรดพยายามเปลี่ยนแปลงข้อมูล เพื่อหลีกเลี่ยงผลลัพธ์ความถี่ที่คาดเดาไม่ได้ ระบบจะใช้การล็อค: เธรดแรกที่ใช้รายการข้อมูลจะบล็อกเธรดจากเธรดอื่นจนกว่างานจะเสร็จสิ้น แต่วิธีนี้อาจไม่ได้ผลหากมีการล็อคที่แข่งขันกันบ่อยครั้งหรือหากการล็อคนั้นควบคุมพื้นที่หน่วยความจำที่ใหญ่กว่าที่จำเป็นจริงๆ
Intel Transactional Synchronization Extensions (TSX) ให้คำแนะนำแก่โปรเซสเซอร์ในการเลี่ยงผ่านการล็อกธุรกรรมในหน่วยความจำฮาร์ดแวร์ สิ่งนี้ช่วยให้บรรลุความสามารถในการขยายขนาดที่สูงขึ้น วิธีการทำงานคือเมื่อโปรแกรมเข้าสู่ส่วนที่ใช้ Intel TSX เพื่อปกป้องตำแหน่งหน่วยความจำ ความพยายามในการเข้าถึงหน่วยความจำทั้งหมดจะถูกบันทึกไว้ และเมื่อสิ้นสุดเซสชันที่ได้รับการป้องกัน ความพยายามในการเข้าถึงหน่วยความจำทั้งหมดจะถูกคอมมิตโดยอัตโนมัติหรือย้อนกลับโดยอัตโนมัติ การย้อนกลับจะดำเนินการหากมีข้อขัดแย้งในการเข้าถึงหน่วยความจำที่อาจทำให้เกิดสภาวะการแข่งขัน (เช่น การเขียนไปยังตำแหน่งที่ธุรกรรมอื่นกำลังอ่านข้อมูล) ขณะดำเนินการจากเธรดอื่น การย้อนกลับอาจเกิดขึ้นได้หากบันทึกการเข้าถึงหน่วยความจำมีขนาดใหญ่เกินไปสำหรับการใช้งาน Intel TSX หากมีคำสั่ง I/O หรือการเรียกของระบบ หรือหากมีข้อยกเว้นเกิดขึ้นหรือเครื่องเสมือนถูกปิด การเรียก I/O จะถูกย้อนกลับเมื่อไม่สามารถดำเนินการคาดเดาได้เนื่องจากการรบกวนจากภายนอก การโทรของระบบ- การดำเนินการที่ซับซ้อนมากซึ่งเปลี่ยนวงแหวนและตัวอธิบายหน่วยความจำ เป็นการยากมากที่จะย้อนกลับ
กรณีการใช้งานทั่วไปสำหรับ Intel TSX คือการควบคุมการเข้าถึงบนตารางแฮช โดยทั่วไปแล้ว การล็อกตารางแคชจะใช้เพื่อรับประกันการเข้าถึงตารางแคช แต่จะเพิ่มเวลาแฝงสำหรับเธรดที่แข่งขันกันเพื่อเข้าถึง การล็อคมักจะหยาบเกินไป: ทั้งตารางถูกล็อค แม้ว่าเธรดจะพยายามเข้าถึงองค์ประกอบเดียวกันนั้นยากมากก็ตาม เมื่อจำนวนคอร์ (และเธรด) เพิ่มขึ้น การล็อคแบบหยาบจะเป็นอุปสรรคต่อความสามารถในการขยายขนาด
ดังที่แสดงในแผนภาพด้านล่าง การบล็อกแบบหยาบอาจทำให้เธรดหนึ่งต้องรออีกเธรดหนึ่งเพื่อปล่อยตารางแฮช แม้ว่าเธรดนั้นจะใช้องค์ประกอบที่แตกต่างกันก็ตาม การใช้ Intel TSX ช่วยให้ทั้งสองเธรดทำงานได้ ผลลัพธ์จะถูกบันทึกหลังจากสิ้นสุดการทำธุรกรรมสำเร็จ ฮาร์ดแวร์ตรวจจับข้อขัดแย้งได้ทันทีและยกเลิกธุรกรรมที่ละเมิด เมื่อใช้ Intel TSX เธรด 2 ไม่จำเป็นต้องรอ ทั้งสองเธรดจะดำเนินการเร็วกว่ามาก การล็อคตารางแฮชจะถูกแปลงเป็นการล็อคที่ได้รับการปรับแต่ง ส่งผลให้ประสิทธิภาพการทำงานดีขึ้น Intel TSX รองรับความแม่นยำในการติดตามการโต้แย้งที่ระดับแคชบรรทัดเดียว (64 ไบต์)
Intel TSX ใช้อินเทอร์เฟซการเขียนโปรแกรมสองตัวเพื่อระบุส่วนของโค้ดเพื่อทำธุรกรรม
- Hardware Lock Bypass (HLE) มีความเข้ากันได้แบบย้อนหลัง และสามารถนำมาใช้ได้อย่างง่ายดายเพื่อปรับปรุงความสามารถในการปรับขนาดโดยไม่ต้องทำการเปลี่ยนแปลงที่สำคัญกับไลบรารีการล็อค ขณะนี้ HLE มีคำนำหน้าสำหรับคำสั่งที่ถูกบล็อก คำนำหน้าคำสั่ง HLE จะส่งสัญญาณให้ฮาร์ดแวร์ตรวจสอบสถานะของการล็อคโดยไม่ต้องรับมัน ในตัวอย่างข้างต้น การทำตามขั้นตอนที่อธิบายไว้จะช่วยให้มั่นใจได้ว่าการเข้าถึงรายการตารางแฮชอื่นๆ จะไม่ส่งผลให้เกิดการล็อคอีกต่อไป เว้นแต่จะมีการเข้าถึงการเขียนที่ขัดแย้งกันกับค่าที่จัดเก็บไว้ในตารางแฮช เป็นผลให้การเข้าถึงเป็นแบบขนาน ดังนั้นความสามารถในการปรับขนาดจะเพิ่มขึ้นในทั้งสี่เธรด
- อินเทอร์เฟซ RTM มีคำแนะนำที่ชัดเจนในการเริ่มต้น (XBEGIN), คอมมิต (XEND), ยกเลิก (XABORT) และทดสอบสถานะ (XTEST) ของธุรกรรม คำแนะนำเหล่านี้ช่วยให้ไลบรารีการล็อกมีวิธีการที่ยืดหยุ่นมากขึ้นในการใช้การบายพาสการล็อก อินเทอร์เฟซ RTM ช่วยให้ไลบรารีสามารถใช้อัลกอริธึมการยกเลิกธุรกรรมที่ยืดหยุ่นได้ คุณลักษณะนี้สามารถใช้เพื่อปรับปรุงได้ ประสิทธิภาพของอินเทล TSX ใช้การรีสตาร์ทธุรกรรมในแง่ดี การย้อนกลับธุรกรรม และเทคนิคขั้นสูงอื่นๆ เมื่อใช้คำสั่ง CPUID ไลบรารีสามารถย้อนกลับไปใช้การล็อกแบบไม่ใช่ RTM แบบเก่า ในขณะที่ยังคงรักษาความเข้ากันได้แบบย้อนหลังกับโค้ดระดับผู้ใช้
- สำหรับการได้รับ ข้อมูลเพิ่มเติมฉันขอแนะนำให้อ่านบทความต่อไปนี้ในพอร์ทัล Intel Developer Zone เกี่ยวกับ HLE และ RTM
เช่นเดียวกับการเพิ่มประสิทธิภาพการซิงโครไนซ์ดั้งเดิมโดยใช้ HLE หรือ RTM คุณลักษณะแผนข้อมูล NFV จะได้รับประโยชน์จาก Intel TSX เมื่อใช้ Data Plane Development Kit (DPDK)
เมื่อใช้ Intel TSX ความท้าทายหลักไม่ได้อยู่ที่การนำส่วนขยายเหล่านี้ไปใช้ แต่เป็นการประเมินและกำหนดประสิทธิภาพ มีตัวนับประสิทธิภาพที่สามารถใช้ได้ โปรแกรมลินุกซ์* perf และเพื่อประเมินความสำเร็จของการดำเนินการ Intel TSX (จำนวนเสร็จสมบูรณ์และจำนวนรอบที่ยกเลิก)
ควรใช้ Intel TSX ด้วยความระมัดระวังและการทดสอบอย่างรอบคอบในแอปพลิเคชัน NFV เนื่องจากการดำเนินการ I/O ในพื้นที่ที่ได้รับการคุ้มครองโดย Intel TSX เกี่ยวข้องกับการย้อนกลับเสมอ และคุณลักษณะ NFV จำนวนมากใช้การดำเนินการ I/O จำนวนมาก ควรหลีกเลี่ยงการล็อคพร้อมกันในแอปพลิเคชัน NFV หากจำเป็นต้องล็อก อัลกอริธึมบายพาสการล็อกจะช่วยปรับปรุงความสามารถในการปรับขนาดได้
เกี่ยวกับผู้เขียน
Alexander Komarov ทำงานเป็นวิศวกรพัฒนาแอปพลิเคชันในกลุ่มซอฟต์แวร์และบริการของ Intel Corporation ในช่วง 10 ปีที่ผ่านมา งานหลักของ Alexander คือการเพิ่มประสิทธิภาพโค้ดเพื่อให้ได้ประสิทธิภาพสูงสุดบนแพลตฟอร์มเซิร์ฟเวอร์ Intel ที่มีอยู่และในอนาคต งานนี้รวมถึงการใช้เครื่องมือพัฒนาซอฟต์แวร์ของ Intel เช่น โปรไฟล์เซอร์ คอมไพเลอร์ ไลบรารี ชุดคำสั่งล่าสุด สถาปัตยกรรมนาโน และการปรับปรุงสถาปัตยกรรมให้กับโปรเซสเซอร์และชิปเซ็ต x86 ล่าสุด
ข้อมูลเพิ่มเติม
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับ NFV โปรดดูวิดีโอต่อไปนี้
#ซีออนบ่อยครั้งเมื่อเลือกเซิร์ฟเวอร์หรือเวิร์กสเตชันที่มีโปรเซสเซอร์ตัวเดียวจะมีคำถามเกิดขึ้นว่าควรใช้โปรเซสเซอร์ตัวใด - เซิร์ฟเวอร์ Xeon หรือ Core ix ปกติ เมื่อพิจารณาว่าโปรเซสเซอร์เหล่านี้สร้างขึ้นบนคอร์เดียวกัน ตัวเลือกมักจะตกอยู่ โปรเซสเซอร์เดสก์ท็อปซึ่งมักจะมีต้นทุนที่ต่ำกว่าแต่มีประสิทธิภาพใกล้เคียงกัน เหตุใด Intel จึงเปิดตัวโปรเซสเซอร์ Xeon E3 ลองคิดดูสิ
ข้อมูลจำเพาะ
เริ่มต้นด้วยการนำโปรเซสเซอร์ Xeon รุ่นจูเนียร์จากกลุ่มรุ่นปัจจุบัน - Xeon E3-1220 V3 ฝ่ายตรงข้ามก็จะเป็น โปรเซสเซอร์หลัก i5-4440. โปรเซสเซอร์ทั้งสองใช้คอร์ Haswell มีความเร็วสัญญาณนาฬิกาพื้นฐานเท่ากันและราคาใกล้เคียงกัน ความแตกต่างระหว่างโปรเซสเซอร์ทั้งสองนี้แสดงอยู่ในตาราง:ความพร้อมใช้งานของกราฟิกในตัว- เมื่อมองแวบแรก Core i5 มีข้อได้เปรียบ แต่มาเธอร์บอร์ดเซิร์ฟเวอร์ทั้งหมดมีการ์ดกราฟิกในตัวที่ไม่ต้องใช้ชิปกราฟิกในโปรเซสเซอร์ และโดยทั่วไปเวิร์กสเตชันจะไม่ใช้กราฟิกในตัวเนื่องจากประสิทธิภาพค่อนข้างต่ำ
การสนับสนุนอีซีซี- ความเร็วสูงและ RAM จำนวนมากเพิ่มความเป็นไปได้ ข้อผิดพลาดของซอฟต์แวร์- โดยทั่วไปแล้ว ข้อผิดพลาดดังกล่าวจะไม่ปรากฏให้เห็น แต่ถึงอย่างไรก็ตาม ข้อผิดพลาดเหล่านี้ก็สามารถนำไปสู่การเปลี่ยนแปลงข้อมูลหรือระบบล่มได้ ถ้าเพื่อ คอมพิวเตอร์ตั้งโต๊ะแม้ว่าข้อผิดพลาดดังกล่าวจะไม่เป็นอันตรายเนื่องจากเกิดขึ้นไม่บ่อยนัก แต่ก็ยอมรับไม่ได้ในเซิร์ฟเวอร์ที่ทำงานตลอดเวลาเป็นเวลาหลายปี เพื่อแก้ไขจะใช้เทคโนโลยี ECC (รหัสแก้ไขข้อผิดพลาด) ซึ่งมีประสิทธิภาพ 99.988%
กำลังการออกแบบเชิงความร้อน (TDP)- โดยพื้นฐานแล้ว การใช้พลังงานของโปรเซสเซอร์ที่โหลดสูงสุด โดยทั่วไปแล้ว Xeons จะมีซองระบายความร้อนที่เล็กกว่าและมีอัลกอริธึมการประหยัดพลังงานที่ชาญฉลาดกว่า ซึ่งท้ายที่สุดจะส่งผลให้ค่าไฟฟ้าลดลงและการระบายความร้อนที่มีประสิทธิภาพมากขึ้น
แคช L3- หน่วยความจำแคชเป็นชั้นระหว่างโปรเซสเซอร์และ RAM ซึ่งมีความเร็วสูงมาก ยิ่งขนาดแคชมีขนาดใหญ่เท่าใด โปรเซสเซอร์ก็จะทำงานเร็วขึ้นเท่านั้น เนื่องจากแม้แต่ RAM ที่เร็วมากก็ยังช้ากว่าหน่วยความจำแคชอย่างมาก โดยทั่วไปโปรเซสเซอร์ Xeon จะมีขนาดแคชที่ใหญ่กว่า ทำให้เหมาะสำหรับแอปพลิเคชันที่ใช้ทรัพยากรมาก
ความถี่ / ความถี่ในโหมด TurboBoost- ทุกอย่างเรียบง่ายที่นี่ - ยิ่งความถี่สูงเท่าไร โปรเซสเซอร์ก็จะทำงานเร็วขึ้นเท่านั้น สิ่งอื่นๆ ทั้งหมดก็เท่าเทียมกัน ความถี่พื้นฐานคือความถี่ที่โปรเซสเซอร์ทำงานภายใต้โหลดเต็มจะเหมือนกัน แต่ในโหมด Turbo Boost นั่นคือเมื่อทำงานกับแอปพลิเคชันที่ไม่ได้ออกแบบมาสำหรับโปรเซสเซอร์แบบมัลติคอร์ Xeon จะเร็วกว่า
รองรับ Intel TSX-NI- คำแนะนำใหม่ของ Intel Transactional Synchronization Extensions (Intel TSX-NI) หมายถึงส่วนเสริมของระบบแคชโปรเซสเซอร์ที่ปรับสภาพแวดล้อมการทำงานของแอพพลิเคชั่นแบบมัลติเธรดให้เหมาะสม แต่แน่นอนว่าเฉพาะในกรณีที่แอพพลิเคชั่นเหล่านี้ใช้ อินเทอร์เฟซซอฟต์แวร์ TSX-NI ชุดคำสั่ง TSX-NI ช่วยให้คุณสามารถใช้งาน Big Data และฐานข้อมูลได้อย่างมีประสิทธิภาพมากขึ้น ในกรณีที่มีเธรดจำนวนมากเข้าถึงข้อมูลเดียวกันและเกิดสถานการณ์การบล็อกเธรด การเข้าถึงข้อมูลที่เก็งกำไรซึ่งมีการใช้งานใน TSX ช่วยให้คุณสร้างแอปพลิเคชันดังกล่าวได้อย่างมีประสิทธิภาพมากขึ้นและปรับขนาดประสิทธิภาพแบบไดนามิกมากขึ้น เมื่อเพิ่มจำนวนเธรดที่ดำเนินการพร้อมกันโดยการแก้ไขข้อขัดแย้งเมื่อเข้าถึงข้อมูลที่แชร์

การสนับสนุนการดำเนินการที่เชื่อถือได้- Intel Trusted Execution Technology ปรับปรุงการดำเนินการคำสั่งอย่างปลอดภัยผ่านการปรับปรุงฮาร์ดแวร์ให้กับโปรเซสเซอร์และฮาร์ดแวร์ ชิปอินเทล- เทคโนโลยีนี้มอบแพลตฟอร์มสำนักงานดิจิทัลที่มีคุณสมบัติด้านความปลอดภัย เช่น การเปิดแอปพลิเคชันที่วัดผลได้ และการดำเนินการคำสั่งที่ปลอดภัย ซึ่งสามารถทำได้โดยการสร้างสภาพแวดล้อมที่แอปพลิเคชันทำงานโดยแยกจากแอปพลิเคชันอื่นๆ บนระบบ
ข้อดีของโปรเซสเซอร์ Xeon รุ่นเก่า ได้แก่ ความจุ L3 ที่ใหญ่ขึ้น สูงสุด 45 MB มีคอร์มากขึ้น สูงสุด 18 คอร์ และ RAM ที่รองรับมากขึ้น สูงสุด 768 GB ต่อโปรเซสเซอร์ ขณะเดียวกันก็กินไฟได้ไม่เกิน 160 วัตต์ เมื่อมองแวบแรกนี่เป็นค่าที่สูงมาก แต่เมื่อพิจารณาว่าประสิทธิภาพของโปรเซสเซอร์ดังกล่าวนั้นสูงกว่าประสิทธิภาพของ Xeon E3-1220 V3 รุ่นเดียวกันหลายเท่าที่มี TDP ที่ 80 W การประหยัดก็ชัดเจน ควรสังเกตด้วยว่าไม่มีโปรเซสเซอร์ตัวใด ครอบครัวหลักไม่รองรับการประมวลผลหลายตัวนั่นคือสามารถติดตั้งโปรเซสเซอร์ได้ไม่เกินหนึ่งตัวในคอมพิวเตอร์เครื่องเดียว แอปพลิเคชันส่วนใหญ่สำหรับเซิร์ฟเวอร์และเวิร์กสเตชันปรับขนาดได้ดีทั้งคอร์ เธรด และโปรเซสเซอร์ทางกายภาพ ดังนั้นการติดตั้งโปรเซสเซอร์สองตัวจะทำให้ประสิทธิภาพเพิ่มขึ้นเกือบสองเท่า
วันที่: 13-08-2014 22:26 น
ย้อนกลับไปในปี 2550 บริษัทเอเอ็มดีเปิดตัวคนรุ่นใหม่ โปรเซสเซอร์ฟีนอม- ตามที่ปรากฎในภายหลัง โปรเซสเซอร์เหล่านี้มีข้อผิดพลาดในบล็อก TLB (บัฟเฟอร์มองข้ามการแปลการแปล การแปลงอย่างรวดเร็วที่อยู่เสมือนไปยังที่อยู่จริง) บริษัทไม่มีทางเลือกอื่นนอกจากต้องแก้ไขปัญหานี้ผ่านแพตช์ในรูปแบบของแพตช์ BIOS แต่ประสิทธิภาพของโปรเซสเซอร์ลดลงประมาณ 15%
สิ่งที่คล้ายกันนี้เกิดขึ้นกับ Intel แล้ว ในโปรเซสเซอร์รุ่น Haswell บริษัทได้ดำเนินการสนับสนุนคำสั่ง TSX (Transactional Synchronization Extension) ได้รับการออกแบบมาเพื่อเร่งความเร็วแอปพลิเคชันแบบมัลติเธรด และควรใช้ในส่วนเซิร์ฟเวอร์เป็นหลัก แม้ว่าซีพียู Haswell จะออกสู่ตลาดมาเป็นเวลานานแล้ว ชุดนี้แทบไม่มีการใช้คำแนะนำเลย เห็นได้ชัดว่ามันจะไม่เกิดขึ้นในอนาคตอันใกล้นี้
ความจริงก็คือ Intel ได้ "พิมพ์ผิด" ตามที่บริษัทเรียกมันเองในคำสั่ง TSX ผู้เชี่ยวชาญจากยักษ์ใหญ่โปรเซสเซอร์ไม่ได้ค้นพบข้อผิดพลาดนี้ อาจทำให้ระบบไม่เสถียรได้ ตัดสินใจ ปัญหานี้บริษัทสามารถทำได้ด้วยวิธีเดียวเท่านั้น โดยการอัปเดต BIOS ซึ่งจะปิดใช้งานชุดคำสั่งนี้
อย่างไรก็ตาม TSX ไม่เพียงแต่ถูกนำมาใช้เท่านั้น โปรเซสเซอร์แฮสเวลล์แต่ยังอยู่ใน Broadwell CPU รุ่นแรกด้วย ซึ่งควรปรากฏภายใต้ชื่อ Core M ตัวแทนบริษัทยืนยันว่า Intel ตั้งใจที่จะใช้คำสั่ง TSX เวอร์ชัน "ปราศจากข้อผิดพลาด" ในผลิตภัณฑ์ถัดไปในอนาคต
แท็ก: ความคิดเห็น
ข่าวก่อนหน้า
2014-08-13 22:23
Sony Xperia Z2 “รอดชีวิต” หลังจากพักอยู่ที่ก้นบ่อน้ำเค็มเป็นเวลาหกสัปดาห์
สมาร์ทโฟนมักจะกลายเป็นฮีโร่ของเรื่องราวอันน่าทึ่งที่พวกเขาได้ลองสวมบทบาทเป็นชุดเกราะพกพา หยุดกระสุน และช่วยชีวิต
2014-08-13 21:46
iPhone 6 ได้เข้าสู่ขั้นตอนการทดสอบขั้นสุดท้ายแล้ว
ตามข้อมูลล่าสุด สำนักข่าว Gforgames, iPhone 6 ได้เข้าสู่ขั้นตอนการทดสอบขั้นสุดท้ายก่อนการเปิดตัวสมาร์ทโฟนรุ่นใหม่สู่การผลิตจำนวนมาก เราขอเตือนคุณว่า iPhone 6 จะถูกประกอบในโรงงานในจีน...
2014-08-12 16:38
แท็บเล็ต Octa-core iRU M720G รองรับซิมการ์ดคู่
แท็บเล็ตมี RAM 2 GB และหน่วยความจำแฟลชในตัว 16 GB มีกล้องสองตัวบนเครื่อง: กล้องหลัก 8 ล้านพิกเซลและกล้องหน้า 2 ล้านพิกเซล iRU M720G มาพร้อมกับโมดูล 3G, GPS, Wi-Fi, Bluetooth, วิทยุ FM รวมถึงช่องสำหรับสองซิมการ์ด ซึ่งช่วยให้สามารถ...
2014-08-10 18:57
LG ได้เปิดตัวสมาร์ทโฟนราคาไม่แพง L60 ในรัสเซีย
LG Electronics นำเสนอในรัสเซียโดยไม่ต้องเอิกเกริกและประโคมข่าวมากนัก รุ่นใหม่ L Series III - LG L60. สมาร์ทโฟนราคาไม่แพงเครื่องนี้นำเสนอใน ช่วงราคาจาก 4 ถึง 5 พันรูเบิลจากบริษัทรัสเซียที่ใหญ่ที่สุด...
ด้วยโปรเซสเซอร์รุ่นใหม่แต่ละรุ่น โปรเซสเซอร์ Intel ได้รวมเอาเทคโนโลยีและฟังก์ชันต่างๆ เพิ่มมากขึ้น บางคนเป็นที่รู้จักกันดี (เช่นใครไม่รู้เกี่ยวกับไฮเปอร์เธรด) ในขณะที่ผู้ที่ไม่ใช่ผู้เชี่ยวชาญส่วนใหญ่ไม่รู้ด้วยซ้ำเกี่ยวกับการมีอยู่ของผู้อื่น มาเปิดให้ทุกคนดูกัน ฐานที่รู้จักความรู้เกี่ยวกับผลิตภัณฑ์ Intel Automated Relational Knowledge Base (ARK) และเลือกโปรเซสเซอร์ที่นั่น เราจะเห็นรายการคุณสมบัติและเทคโนโลยีมากมาย - อะไรอยู่เบื้องหลังชื่อทางการตลาดที่ลึกลับของพวกเขา? เราขอเชิญคุณให้เจาะลึกถึงประเด็นนี้โดยเปลี่ยน ความสนใจเป็นพิเศษเกี่ยวกับเทคโนโลยีที่ไม่ค่อยมีใครรู้จัก - จะมีสิ่งที่น่าสนใจมากมายอยู่ที่นั่นอย่างแน่นอน
การสลับตามความต้องการของ Intel
เมื่อรวมกับเทคโนโลยี Intel SpeedStep ที่ปรับปรุงแล้ว เทคโนโลยี Intel Demand Based Switching มีหน้าที่รับผิดชอบในการรับรองว่าโปรเซสเซอร์ทำงานที่ ความถี่ที่เหมาะสมที่สุดและได้รับกำลังไฟฟ้าเพียงพอไม่มากและไม่น้อยไปกว่าที่กำหนด ซึ่งจะช่วยลดการใช้พลังงานและการสร้างความร้อนซึ่งไม่เพียงแต่มีความสำคัญเท่านั้น อุปกรณ์พกพาแต่สำหรับเซิร์ฟเวอร์ด้วย - นั่นคือที่ที่ใช้การสลับตามความต้องการ
การเข้าถึงหน่วยความจำที่รวดเร็วของ Intel
ฟังก์ชั่นตัวควบคุมหน่วยความจำเพื่อเพิ่มประสิทธิภาพการทำงานกับ RAM เป็นการผสมผสานเทคโนโลยีที่ช่วยให้สามารถระบุคำสั่ง "ที่ทับซ้อนกัน" (เช่น การอ่านจากหน้าหน่วยความจำเดียวกัน) ผ่านการวิเคราะห์เชิงลึกของคิวคำสั่ง จากนั้นจึงจัดลำดับการดำเนินการจริงใหม่ เพื่อให้คำสั่ง "ที่ทับซ้อนกัน" ดำเนินการทีละรายการ นอกจากนี้ คำสั่งการเขียนหน่วยความจำที่มีลำดับความสำคัญต่ำกว่าจะถูกกำหนดเวลาเมื่อคิวการอ่านถูกคาดการณ์ว่าจะว่างเปล่า ทำให้กระบวนการเขียนหน่วยความจำมีข้อจำกัดในเรื่องความเร็วในการอ่านน้อยลงอีกด้วย
การเข้าถึงหน่วยความจำ Intel Flex
อีกฟังก์ชันหนึ่งของตัวควบคุมหน่วยความจำ ซึ่งปรากฏย้อนกลับไปในสมัยที่เป็นชิปแยก ย้อนกลับไปในปี 2004 ให้ความสามารถในการทำงานในโหมดซิงโครนัสด้วยโมดูลหน่วยความจำสองโมดูลพร้อมกัน และไม่เหมือนกับโหมดดูอัลแชนเนลธรรมดาที่มีอยู่ก่อนหน้านี้ โมดูลหน่วยความจำสามารถ ขนาดที่แตกต่างกัน- ด้วยวิธีนี้จึงเกิดความยืดหยุ่นในการเตรียมคอมพิวเตอร์ด้วยหน่วยความจำซึ่งสะท้อนให้เห็นในชื่อ
เล่นซ้ำคำสั่ง Intel
เทคโนโลยีล้ำลึกที่ปรากฏครั้งแรกในโปรเซสเซอร์ Intel Itanium ในระหว่างการทำงานของไปป์ไลน์ตัวประมวลผล สถานการณ์อาจเกิดขึ้นเมื่อมีการดำเนินการคำสั่งแล้ว แต่ยังไม่มีข้อมูลที่จำเป็น จากนั้นจำเป็นต้อง "เล่นซ้ำ" คำสั่ง: นำออกจากสายพานลำเลียงและรันตั้งแต่เริ่มต้น ซึ่งเป็นสิ่งที่เกิดขึ้น อีกอันหนึ่ง ฟังก์ชั่นที่สำคัญ IRT – การแก้ไขข้อผิดพลาดแบบสุ่มบนไปป์ไลน์ของโปรเซสเซอร์ อ่านเพิ่มเติมเกี่ยวกับคุณสมบัติที่น่าสนใจนี้
เทคโนโลยี Intel My WiFi
เทคโนโลยีการจำลองเสมือนที่ช่วยให้คุณสามารถเพิ่มอแด็ปเตอร์ WiFi เสมือนเข้ากับฟิสิคัลที่มีอยู่ ดังนั้นอัลตร้าบุ๊กหรือแล็ปท็อปของคุณจึงสามารถกลายเป็นจุดเข้าใช้งานหรือทวนสัญญาณเต็มรูปแบบได้ ส่วนประกอบซอฟต์แวร์ My WiFi มาพร้อมกับไดรเวอร์ซอฟต์แวร์ Intel PROSet Wireless เวอร์ชัน 13.2 และสูงกว่า โปรดทราบว่ามีเพียงอแด็ปเตอร์ WiFi บางตัวเท่านั้นที่สามารถใช้งานร่วมกับเทคโนโลยีนี้ได้ คำแนะนำในการติดตั้ง รวมถึงรายการความเข้ากันได้ของซอฟต์แวร์และฮาร์ดแวร์มีอยู่ในเว็บไซต์ Intel
เทคโนโลยี Intel Smart Idle
อีกหนึ่งเทคโนโลยีประหยัดพลังงาน ช่วยให้คุณสามารถปิดการใช้งานบล็อกตัวประมวลผลที่ไม่ได้ใช้ในปัจจุบันหรือลดความถี่ของมัน สิ่งที่ขาดไม่ได้สำหรับซีพียูของสมาร์ทโฟนซึ่งตรงกับที่ปรากฏในโปรเซสเซอร์ Intel Atom
แพลตฟอร์มภาพที่เสถียรของ Intel
คำที่อ้างถึงกระบวนการทางธุรกิจมากกว่าเทคโนโลยี โปรแกรม Intel SIPP ช่วยให้มั่นใจถึงความเสถียรของซอฟต์แวร์โดยทำให้ส่วนประกอบแพลตฟอร์มหลักและไดรเวอร์ไม่เปลี่ยนแปลงเป็นเวลาอย่างน้อย 15 เดือน ดังนั้น, ลูกค้าองค์กรมีโอกาสที่จะใช้อิมเมจระบบที่ปรับใช้เดียวกันในช่วงเวลานี้
อินเทล QuickAssist
ชุดฟังก์ชันที่ใช้ฮาร์ดแวร์ซึ่งต้องการการคำนวณจำนวนมาก เช่น การเข้ารหัส การบีบอัด การจดจำรูปแบบ จุดประสงค์ของ QuickAssist คือการทำให้สิ่งต่าง ๆ ง่ายขึ้นสำหรับนักพัฒนาโดยมอบบล็อคส่วนประกอบที่ใช้งานได้และเพิ่มความเร็วให้กับแอปพลิเคชันของพวกเขา ในทางกลับกัน เทคโนโลยีนี้ช่วยให้คุณมอบหมายงาน "หนัก" ให้กับโปรเซสเซอร์ที่ไม่ใช่ที่ทรงพลังที่สุดได้ ซึ่งมีคุณค่าอย่างยิ่งในระบบฝังตัวที่ถูกจำกัดอย่างรุนแรงทั้งในด้านประสิทธิภาพและการใช้พลังงาน
Intel ประวัติย่อด่วน
เทคโนโลยีที่พัฒนาขึ้นสำหรับคอมพิวเตอร์บนพื้นฐานของ แพลตฟอร์มของอินเทล Viiv ซึ่งช่วยให้พวกเขาสามารถเปิดและปิดได้เกือบจะในทันที เช่น เครื่องรับโทรทัศน์หรือเครื่องเล่นดีวีดี ในเวลาเดียวกันในสถานะ "ปิด" คอมพิวเตอร์สามารถทำงานบางอย่างต่อไปได้โดยไม่จำเป็นต้องให้ผู้ใช้ดำเนินการ และถึงแม้ว่าตัวแพลตฟอร์มเองจะเปลี่ยนไปเป็นรูปแบบอื่น ๆ ได้อย่างราบรื่นพร้อมกับการพัฒนาที่มาพร้อมกับมัน แต่บรรทัดนี้ยังคงอยู่ใน ARK เนื่องจากเมื่อไม่นานมานี้
คีย์การรักษาความปลอดภัยของ Intel
ชื่อทั่วไปสำหรับคำสั่ง RDRAND แบบ 32 และ 64 บิตที่ใช้การใช้งานฮาร์ดแวร์ของ Digital Random Number Generator (DRNG) คำสั่งนี้ใช้เพื่อวัตถุประสงค์ในการเข้ารหัสเพื่อสร้างคีย์สุ่มที่สวยงามและมีคุณภาพสูง
อินเทล TSX-NI
เทคโนโลยีที่มีชื่อที่ซับซ้อน Intel Transactional Synchronization Extensions - คำแนะนำใหม่แสดงถึงส่วนเสริมของระบบแคชโปรเซสเซอร์ที่ปรับสภาพแวดล้อมการทำงานของแอปพลิเคชันแบบมัลติเธรดให้เหมาะสมที่สุด แต่แน่นอนว่าเฉพาะในกรณีที่แอปพลิเคชันเหล่านี้ใช้อินเทอร์เฟซการเขียนโปรแกรม TSX-NI จากฝั่งผู้ใช้ เทคโนโลยีนี้ไม่สามารถมองเห็นได้โดยตรง แต่ใครๆ ก็สามารถอ่านคำอธิบายได้ ภาษาที่สามารถเข้าถึงได้ในบล็อกของ Stepan Koltsov
โดยสรุป เราขอเตือนคุณอีกครั้งว่า Intel ARK ไม่เพียงมีอยู่ในฐานะเว็บไซต์เท่านั้น แต่ยังเป็นแอปพลิเคชันออฟไลน์สำหรับ iOS และ Android อีกด้วย อยู่ในหัวข้อ!
























