- Tafsiri
Makala inahusu nini?
Binafsi, ninajifunza vyema zaidi na msimbo mdogo wa kufanya kazi ambao ninaweza kucheza nao. Katika somo hili, tutajifunza algorithm ya uenezaji nyuma kwa kutumia mtandao mdogo wa neural unaotekelezwa katika Python kama mfano.Nipe kanuni!
X = np.array([ ,,, ]) y = np.array([]).T syn0 = 2*np.random.random((3,4)) - 1 syn1 = 2*np.random.nasibu ((4,1)) - 1 kwa j katika xrange(60000): l1 = 1/(1+np.exp(-(np.dot(X,syn0))))) l2 = 1/(1+np. exp(-(np.dot(l1,syn1)))) l2_delta = (y - l2)*(l2*(1-l2)) l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1) )) syn1 += l1.T.dot(l2_delta) syn0 += X.T.dot(l1_delta)Imebanwa sana? Wacha tuigawanye katika sehemu rahisi zaidi.
Sehemu ya 1: Mtandao mdogo wa neural wa toy
Mtandao wa neva uliofunzwa kupitia majaribio ya uenezaji nyuma ya kutumia data ya ingizo kutabiri data ya matokeo.Wacha tuseme tunahitaji kutabiri jinsi safu wima ya pato itaonekana kulingana na data ya ingizo. Tatizo hili linaweza kutatuliwa kwa kuhesabu mawasiliano ya takwimu kati yao. Na tungeona kuwa safu wima ya kushoto inahusiana 100% na matokeo.
Uenezaji wa nyuma, katika hali yake rahisi, huhesabu takwimu sawa ili kuunda mfano. Tujaribu.
Mtandao wa neva katika tabaka mbili
import numpy as np # Sigmoid def nonlin(x,deriv=False): if(deriv==True): rudisha f(x)*(1-f(x)) rudisha 1/(1+np.exp(-x) )) # seti ya data ya ingizo X = np.array([ , , , ]) # data towe y = np.array([]).T # fanya nambari nasibu maalum zaidi np.random.seed(1) # anzisha uzani kwa njia nasibu na wastani 0 syn0 = 2*np.random.random((3,1)) - 1 kwa iter katika xrange(10000): # uenezi wa mbele l0 = X l1 = nonlin(np.dot(l0,syn0) )) # Tulikosea kwa kiasi gani? l1_error = y - l1 # zidisha hii kwa mteremko wa sigmoid # kulingana na maadili katika l1 l1_delta = l1_error * nonlin(l1,True) # !!! # sasisha uzani syn0 += np.dot(l0.T,l1_delta) # !!! chapisha "Pato baada ya mafunzo:" chapisha l1Pato baada ya mafunzo: [[ 0.00966449] [0.00786506] [0.99358898] [0.99211957]]
Vigezo na maelezo yao.
"*" - kuzidisha kwa busara - vekta mbili za saizi sawa huzidisha maadili yanayolingana, na matokeo ni vekta ya saizi sawa.
"-" - uondoaji wa kipengee wa vekta
x.dot(y) - ikiwa x na y ni vekta, basi matokeo yatakuwa bidhaa ya scalar. Ikiwa hizi ni matrices, basi matokeo ni kuzidisha matrix. Ikiwa tumbo ni moja tu yao, ni kuzidisha kwa vekta na tumbo.
- linganisha l1 baada ya marudio ya kwanza na baada ya mwisho
- angalia utendakazi wa nonlin.
- angalia jinsi l1_error inavyobadilika
- mstari wa 36 - viungo kuu vya siri vinakusanywa hapa (alama !!!)
- mstari wa 39 - mtandao mzima unajiandaa kwa operesheni hii (iliyowekwa alama !!!)
Hebu tuvunje kanuni kwa mstari
ingiza numpy kama npInaagiza numpy, maktaba ya aljebra ya mstari. Uraibu wetu pekee.
Def nonlin(x,deriv=False):
Kutokuwa na mshikamano wetu. Kitendaji hiki maalum huunda "sigmoid". Inalingana na nambari yoyote iliyo na thamani kutoka 0 hadi 1 na inabadilisha nambari kuwa uwezekano, na pia ina sifa zingine kadhaa muhimu kwa mafunzo ya mitandao ya neural.
Ikiwa(deriv==Kweli):
Chaguo hili la kukokotoa linaweza pia kutoa derivative ya sigmoid (deriv=Kweli). Hii ni moja ya mali zake za manufaa. Ikiwa matokeo ya chaguo la kukokotoa ni tofauti ya nje, basi derivative itakuwa nje * (1-out). Ufanisi.
X = np.array([ , ...
Kuanzisha safu ya data ya ingizo kama matrix numpy. Kila mstari ni mfano wa mafunzo. Safu ni nodi za kuingiza. Tunamaliza na nodi 3 za kuingiza kwenye mtandao na mifano 4 ya mafunzo.
Y = np.array([]).T
Huanzisha data ya pato. ".T" - kipengele cha uhamisho. Baada ya tafsiri, matrix y ina safu 4 na safu moja. Kama ilivyo kwa data ya uingizaji, kila safu ni mfano wa mafunzo, na kila safu (moja kwa upande wetu) ni nodi ya pato. Inabadilika kuwa mtandao una pembejeo 3 na pato 1.
Mbegu.nasibu(1)
Shukrani kwa hili, usambazaji wa random utakuwa sawa kila wakati. Hii itaturuhusu kufuatilia mtandao kwa urahisi zaidi baada ya kufanya mabadiliko kwenye msimbo.
Syn0 = 2*np.random.random((3,1)) - 1
Matrix ya uzito wa mtandao. syn0 inamaanisha "synapse zero". Kwa kuwa tuna tabaka mbili tu, pembejeo na pato, tunahitaji tumbo moja la uzito ambalo litawaunganisha. Kipimo chake ni (3, 1), kwa kuwa tuna pembejeo 3 na pato 1. Kwa maneno mengine, l0 ina ukubwa wa 3 na l1 ina ukubwa wa 1. Kwa kuwa tunaunganisha nodes zote katika l0 kwa nodes zote katika l1, tunahitaji matrix ya mwelekeo (3, 1).
Kumbuka kuwa imeanzishwa kwa nasibu na wastani ni sifuri. Kuna nadharia ngumu zaidi nyuma ya hii. Kwa sasa tutachukua hili kama pendekezo. Pia kumbuka kuwa mtandao wetu wa neva ndio matrix hii. Tuna "tabaka" l0 na l1, lakini hizi ni maadili ya muda kulingana na seti ya data. Hatuzihifadhi. Mafunzo yote yanahifadhiwa katika syn0.
Kwa iter katika xrange(10000):
Hapa ndipo nambari kuu ya mafunzo ya mtandao huanza. Kitanzi cha msimbo hurudiwa mara nyingi na kuboresha mtandao kwa seti ya data.
Safu ya kwanza, l0, ni data tu. X ina mifano 4 ya mafunzo. Tutazishughulikia zote mara moja - hii inaitwa mafunzo ya kikundi. Kwa jumla tunayo mistari 4 tofauti ya l0, lakini inaweza kuzingatiwa kama mfano mmoja wa mafunzo - katika hatua hii haijalishi (unaweza kupakia 1000 au 10000 kati yao bila mabadiliko yoyote katika nambari).
L1 = nonlin(np.dot(l0,syn0))
Hii ni hatua ya utabiri. Tunaruhusu mtandao ujaribu kutabiri matokeo kulingana na pembejeo. Kisha tutaona jinsi anavyofanya ili tuweze kuiboresha kwa kuboresha.
Kuna hatua mbili kwa kila mstari. Ya kwanza hufanya kuzidisha matrix ya l0 na syn0. Ya pili hupitisha pato kupitia sigmoid. Vipimo vyao ni kama ifuatavyo:
(4 x 3) nukta (3 x 1) = (4 x 1)
Kuzidisha kwa matrix kunahitaji kwamba vipimo viwe sawa katikati ya mlinganyo. Matrix ya mwisho ina idadi sawa ya safu kama ya kwanza, na idadi sawa ya safuwima kama ya pili.
Tulipakia mifano 4 ya mafunzo na tukapata makadirio 4 (matrix 4x1). Kila pato linalingana na nadhani ya mtandao kwa ingizo fulani.
L1_kosa = y - l1
Kwa kuwa l1 ina ubashiri, tunaweza kulinganisha tofauti zao na ukweli kwa kutoa l1 kutoka kwa jibu sahihi y. l1_error ni vekta ya nambari chanya na hasi zinazoashiria mtandao "kosa".
Na hapa ni kiungo cha siri. Mstari huu unahitaji kuchanganuliwa kipande kwa kipande.
Sehemu ya kwanza: derivative
Nonlin(l1,Kweli)
L1 inawakilisha pointi hizi tatu, na kanuni hutoa mteremko wa mistari iliyoonyeshwa hapa chini. Kumbuka kuwa kwa thamani kubwa kama x=2.0 (kijani kitone) na thamani ndogo sana kama x=-1.0 (zambarau) mistari ina mteremko mdogo. Pembe kubwa zaidi kwa uhakika x=0 (bluu). Hii inaleta tofauti kubwa. Pia kumbuka kuwa derivatives zote huanzia 0 hadi 1.

Usemi kamili: derivative yenye uzito wa makosa
L1_delta = l1_error * nonlin(l1,True)
Kwa hisabati, kuna njia sahihi zaidi, lakini kwa upande wetu hii pia inafaa. l1_error ni (4,1) matrix. nonlin(l1,True) inarudisha (4,1) matrix. Hapa tunazizidisha kipengele kwa kipengele, na kwenye pato tunapata pia matrix (4,1), l1_delta.
Kwa kuzidisha derivatives kwa makosa, tunapunguza makosa ya utabiri uliofanywa kwa ujasiri wa juu. Ikiwa mteremko wa mstari ulikuwa mdogo, basi mtandao ulikuwa na thamani kubwa sana au ndogo sana. Ikiwa nadhani ya mtandao iko karibu na sifuri (x=0, y=0.5), basi haina ujasiri haswa. Tunasasisha utabiri huu usio na uhakika na kuacha ubashiri wa imani ya juu pekee kwa kuuzidisha kwa thamani karibu na sifuri.
Syn0 += np.dot(l0.T,l1_delta)
Tuko tayari kusasisha mtandao. Hebu tuangalie mfano mmoja wa mafunzo. Ndani yake tutasasisha uzani. Sasisha uzani wa kushoto kabisa (9.5)

Weight_update = input_value * l1_delta
Kwa uzani wa kushoto kabisa itakuwa 1.0 * l1_delta. Labda hii itaongeza tu 9.5 kidogo. Kwa nini? Kwa sababu utabiri ulikuwa tayari kujiamini, na utabiri ulikuwa sahihi kivitendo. Hitilafu ndogo na mteremko mdogo wa mstari unamaanisha sasisho ndogo sana.

Lakini kwa kuwa tunafanya mafunzo ya kikundi, tunarudia hatua iliyo hapo juu kwa mifano yote minne ya mafunzo. Kwa hivyo inaonekana sawa na picha hapo juu. Kwa hivyo mstari wetu hufanya nini? Huhesabu masasisho ya uzito kwa kila uzani, kwa kila mfano wa mafunzo, hujumlisha na kusasisha uzani wote - yote kwa mstari mmoja.
Baada ya kutazama sasisho la mtandao, turudi kwenye data yetu ya mafunzo. Wakati pembejeo na pato ni 1, tunaongeza uzito kati yao. Wakati pembejeo ni 1 na pato ni 0, tunapunguza uzito.
Pato la Kuingiza 0 0 1 0 1 1 1 1 1 0 1 1 0 1 1 0
Kwa hivyo katika mifano yetu minne ya mafunzo hapa chini, uzani wa pembejeo ya kwanza inayohusiana na pato itaongezeka au kubaki thabiti, na uzani mwingine mbili utaongezeka na kupungua kulingana na mifano. Athari hii inachangia ujifunzaji wa mtandao kulingana na uunganisho wa data ya pembejeo na matokeo.
Sehemu ya 2: kazi ngumu zaidi
Pato la Kuingiza 0 0 1 0 0 1 1 1 1 0 1 1 1 1 1 0Wacha tujaribu kutabiri data ya pato kulingana na safu wima tatu za data. Hakuna safu wima yoyote kati ya ingizo inayohusiana 100% na matokeo. Safu ya tatu haijaunganishwa na chochote, kwani ina zile njia zote. Walakini, hapa unaweza kuona muundo - ikiwa moja ya safu wima mbili za kwanza (lakini sio zote mbili mara moja) ina 1, basi matokeo pia yatakuwa sawa na 1.
Huu ni muundo usio na mstari kwa sababu hakuna mawasiliano ya moja kwa moja kati ya safu wima. Mechi inategemea mchanganyiko wa ingizo, safu wima 1 na 2.
Inafurahisha, utambuzi wa muundo ni kazi inayofanana sana. Ikiwa una picha 100 za baiskeli na mabomba ya ukubwa sawa, uwepo wa saizi fulani katika maeneo fulani hauhusiani moja kwa moja na uwepo wa baiskeli au bomba kwenye picha. Kwa takwimu, rangi yao inaweza kuonekana bila mpangilio. Lakini michanganyiko mingine ya saizi sio nasibu - zile zinazounda picha ya baiskeli (au bomba).


Mkakati
Ili kuchanganya saizi kuwa kitu ambacho kinaweza kuwa na mawasiliano ya moja kwa moja kwa pato, unahitaji kuongeza safu nyingine. Safu ya kwanza inachanganya ingizo, ya pili inapeana mechi kwa matokeo kwa kutumia pato la safu ya kwanza kama ingizo. Makini na meza.Ingizo (l0) Vizito vilivyofichwa (l1) Pato (l2) 0 0 1 0.1 0.2 0.5 0.2 0 0 1 1 0.2 0.6 0.7 0.1 1 1 0 1 0.3 0.2 0.3 0.9 3 1 1 1 1 1 .
Kwa kugawa uzani kwa nasibu, tunapata maadili yaliyofichwa ya safu ya 1. Inafurahisha, safu ya pili ya uzani uliofichwa tayari ina uhusiano mdogo na matokeo. Sio bora, lakini huko. Na hii pia ni sehemu muhimu ya mchakato wa mafunzo ya mtandao. Mafunzo yataimarisha tu uwiano huu. Itasasisha syn1 ili kugawa ramani yake kwa data ya matokeo, na syn0 ili kupata data ya ingizo vyema.
Mtandao wa neva katika tabaka tatu
import numpy as np def nonlin(x,deriv=False): if(deriv==True): rudisha f(x)*(1-f(x)) rudisha 1/(1+np.exp(-x)) X = np.array([, , ]) y = np.array([, , , ]) np.random.seed(1) # anzisha uzani bila mpangilio, kwa wastani - 0 syn0 = 2*np.nasibu. nasibu ((3,4)) - 1 syn1 = 2*np.random.random((4,1)) - 1 kwa j katika xrange(60000): # nenda mbele kupitia safu 0, 1 na 2 l0 = X l1 = nonlin(np.dot(l0,syn0)) l2 = nonlin(np.dot(l1,syn1)) # tulikuwa na makosa kiasi gani kuhusu thamani inayohitajika? l2_error = y - l2 ikiwa (j% 10000) == 0: chapisha "Kosa:" + str(np.mean(np.abs(l2_error))) # ni njia gani unapaswa kusonga? # ikiwa tulikuwa na uhakika katika utabiri huo, basi hatuhitaji kuubadilisha sana l2_delta = l2_error*nonlin(l2,deriv=True) # ni kiasi gani maadili ya l1 huathiri makosa katika l2? l1_error = l2_delta.dot(syn1.T) # tunapaswa kuelekea upande gani ili kufikia l1? # ikiwa tulikuwa na uhakika katika utabiri, basi hatuhitaji kuubadilisha sana l1_delta = l1_error * nonlin(l1,deriv=True) syn1 += l1.T.dot(l2_delta) syn0 += l0.T.dot (l1_delta)Hitilafu:0.496410031903 Hitilafu:0.00858452565325 Hitilafu:0.00578945986251 Hitilafu:0.00462917677677 Hitilafu:0.0039587652802720507027250767255076507650765027507650765076507650765076.
Vigezo na maelezo yao
X ni matrix ya seti ya data ya pembejeo; masharti - mifano ya mafunzoy - matrix ya seti ya data ya pato; masharti - mifano ya mafunzo
l0 - safu ya kwanza ya mtandao iliyofafanuliwa na data ya pembejeo
l1 - safu ya pili ya mtandao, au safu iliyofichwa
l2 ndio safu ya mwisho, hii ndio nadharia yetu. Unapofanya mazoezi, unapaswa kupata karibu na jibu sahihi.
syn0 - safu ya kwanza ya uzani, Synapse 0, inachanganya l0 na l1.
syn1 - Safu ya pili ya uzani, Synapse 1, inachanganya l1 na l2.
l2_error - hitilafu ya mtandao kwa maneno ya kiasi
l2_delta - kosa la mtandao, kulingana na ujasiri wa utabiri. Inakaribia kufanana na makosa, isipokuwa kwa utabiri wa uhakika
l1_kosa - kwa kupima l2_delta na uzani kutoka kwa syn1, tunahesabu kosa katika safu ya kati/iliyofichwa.
l1_delta - makosa ya mtandao kutoka kwa l1, yaliyowekwa na ujasiri wa utabiri. Inakaribia kufanana na l1_error, isipokuwa kwa utabiri wa uhakika
Nambari inapaswa kuwa wazi - ni utekelezaji wa awali wa mtandao, uliowekwa katika tabaka mbili, moja juu ya nyingine. Pato la safu ya kwanza l1 ni pembejeo ya safu ya pili. Kuna kitu kipya tu kwenye mstari unaofuata.
L1_error = l2_delta.dot(syn1.T)
Hutumia makosa yaliyowekewa uzani wa imani ya utabiri kutoka l2 kukokotoa kosa kwa l1. Tunapata, mtu anaweza kusema, kosa lililowekwa na michango - tunahesabu ni kiasi gani maadili kwenye nodi l1 yanachangia makosa katika l2. Hatua hii inaitwa kurudi nyuma. Kisha tunasasisha syn0 kwa kutumia algoriti sawa na mtandao wa neva wa safu mbili.
James Loy, Georgia Tech. Mwongozo wa mwanzilishi wa kuunda mtandao wako wa neural huko Python.
Motisha: Kulingana na uzoefu wa kibinafsi katika kusoma ujifunzaji wa kina, niliamua kuunda mtandao wa neva kutoka mwanzo bila maktaba changamano ya mafunzo kama vile, kwa mfano,. Ninaamini kuwa kwa Mwanasayansi wa Data anayeanza ni muhimu kuelewa muundo wa ndani.
Nakala hii ina yale niliyojifunza na natumai itakuwa muhimu kwako pia! Nakala zingine muhimu juu ya mada:
Mtandao wa neva ni nini?
Nakala nyingi kwenye mitandao ya neva huchora ulinganifu na ubongo wakati wa kuzielezea. Ni rahisi kwangu kuelezea mitandao ya neural kama kazi ya hisabati ambayo huweka pembejeo fulani kwa matokeo unayotaka, bila kuingia kwa undani sana.
Mitandao ya Neural inajumuisha vipengele vifuatavyo:
- safu ya pembejeo, x
- wingi wa kiholela tabaka zilizofichwa
- safu ya pato, ŷ
- seti mizani Na uhamisho kati ya kila safu W Na b
- uteuzi kwa kila safu iliyofichwa σ ; katika kazi hii tutatumia kazi ya uanzishaji ya Sigmoid
Mchoro hapa chini unaonyesha usanifu wa mtandao wa neural wa safu mbili (kumbuka kuwa safu ya pembejeo kawaida haijumuishwi wakati wa kuhesabu idadi ya tabaka kwenye mtandao wa neva).
Kuunda darasa la Mtandao wa Neural huko Python ni rahisi:
Mafunzo ya mtandao wa neva
Utgång ŷ mtandao rahisi wa safu mbili wa neva:
Katika mlinganyo ulio hapo juu, uzani W na upendeleo b ndio vigeu pekee vinavyoathiri pato ŷ.
Kwa kawaida, maadili sahihi ya uzani na upendeleo huamua usahihi wa utabiri. Mchakato wa kurekebisha uzani na upendeleo kutoka kwa data ya ingizo hujulikana kama .
Kila marudio ya mchakato wa kujifunza huwa na hatua zifuatazo
- kukokotoa matokeo yaliyotabiriwa ŷ, inayoitwa uenezaji wa mbele
- kusasisha uzani na upendeleo, unaoitwa
Grafu iliyofuatana hapa chini inaonyesha mchakato:

Usambazaji wa moja kwa moja
Kama tulivyoona kwenye grafu hapo juu, uenezi wa mbele ni hesabu rahisi tu, na kwa mtandao wa msingi wa safu-2, matokeo ya mtandao wa neural hutolewa na:
Wacha tuongeze kazi ya uenezi wa mbele kwa nambari yetu ya Python kufanya hivi. Kumbuka kuwa kwa unyenyekevu, tumechukulia punguzo kuwa 0.
Hata hivyo, tunahitaji njia ya kutathmini "wema" wa utabiri wetu, yaani, jinsi utabiri wetu ulivyo mbali). Kazi ya kupoteza inaturuhusu tu kufanya hivi.
Kazi ya kupoteza
Kuna vitendaji vingi vya upotezaji vinavyopatikana, na asili ya shida yetu inapaswa kuamuru chaguo letu la utendaji wa upotezaji. Katika kazi hii tutatumia jumla ya makosa ya mraba kama kazi ya kupoteza.

Jumla ya makosa ya mraba ni wastani wa tofauti kati ya kila thamani iliyotabiriwa na halisi.
Kusudi la kujifunza ni kupata seti ya uzani na upendeleo ambao hupunguza utendaji wa upotezaji.
Uenezaji wa nyuma
Sasa kwa kuwa tumepima makosa katika utabiri wetu (hasara), tunahitaji kutafuta njia kueneza kosa nyuma na sasisha uzani na upendeleo wetu.
Ili kujua kiasi kinachofaa kurekebisha uzani na upendeleo, tunahitaji kujua derivative ya kazi ya kupoteza kwa heshima na uzani na upendeleo.
Tukumbuke kutokana na uchambuzi huo Derivative ya chaguo za kukokotoa ni mteremko wa chaguo la kukokotoa.

Ikiwa tunayo derivative, basi tunaweza kusasisha uzani na upendeleo kwa kuziongeza/kuzipunguza (tazama mchoro hapo juu). Inaitwa.
Hata hivyo, hatuwezi kukokotoa moja kwa moja derivative ya chaguo la kukokotoa la upotevu kuhusiana na uzani na upendeleo kwa sababu mlinganyo wa utendaji wa upotezaji hauna uzani na upendeleo. Kwa hivyo tunahitaji sheria ya mnyororo kusaidia kuhesabu.
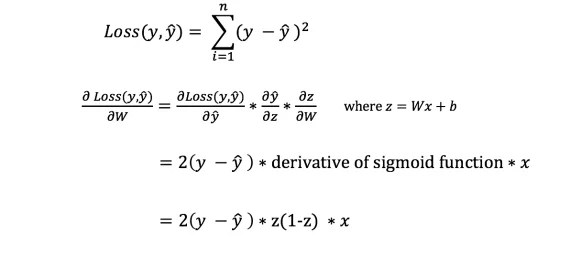
Phew! Hili lilikuwa gumu, lakini lilituruhusu kupata kile tulichohitaji — chini (mteremko) wa utendaji wa upotevu kwa heshima na uzani. Sasa tunaweza kurekebisha uzito ipasavyo.
Wacha tuongeze kazi ya uenezaji nyuma kwa nambari yetu ya Python:
Kuangalia uendeshaji wa mtandao wa neva
Sasa kwa kuwa tunayo nambari yetu kamili ya Python ya kufanya uenezaji wa mbele na nyuma, wacha tupitie mtandao wetu wa neva na mfano na tuone jinsi inavyofanya kazi.
 Seti bora ya mizani
Seti bora ya mizani Mtandao wetu wa neva lazima ujifunze seti bora ya uzani ili kuwakilisha utendaji huu.
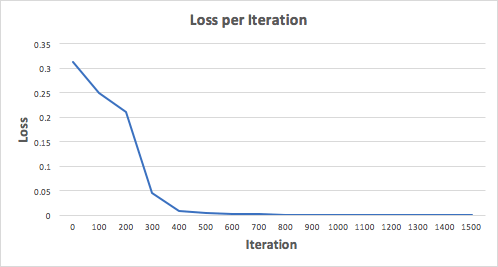
Wacha tufunze mtandao wa neva kwa marudio 1500 na tuone kitakachotokea. Kuangalia njama ya upotezaji wa kurudia hapa chini, tunaweza kuona wazi kuwa upotezaji wa monotonically hupungua hadi kiwango cha chini. Hii inalingana na algoriti ya mteremko wa daraja tuliojadili hapo awali.
Wacha tuangalie utabiri wa mwisho (pato) kutoka kwa mtandao wa neva baada ya marudio 1500.

Tulifanya! Algorithm yetu ya uenezaji wa mbele na nyuma imeonyesha kuwa mtandao wa neva hufanya kazi kwa mafanikio, na utabiri huungana kwenye maadili ya kweli.
Kumbuka kuwa kuna tofauti kidogo kati ya utabiri na maadili halisi. Hili ni jambo la kuhitajika kwa sababu huzuia kufifia kupita kiasi na huruhusu mtandao wa neva kufanya jumla bora kwa data isiyoonekana.
Mawazo ya Mwisho
Nilijifunza mengi katika mchakato wa kuandika mtandao wangu wa neural kutoka mwanzo. Ingawa maktaba za kujifunza kwa kina kama TensorFlow na Keras hukuruhusu kuunda mitandao ya kina bila kuelewa kikamilifu utendakazi wa ndani wa mtandao wa neva, ninaona inasaidia kwa Wanasayansi wanaotaka kuwa na data kupata uelewa wa kina kuzihusu.
Nimewekeza wakati wangu mwingi wa kibinafsi katika kazi hii, na natumai itakuwa muhimu kwako!
Sehemu hii ina viungo vya makala kutoka kwa RuNet kuhusu mitandao ya neural ni nini. Nakala nyingi zimeandikwa katika lugha asilia na hai na zinaeleweka sana. Hata hivyo, hapa, kwa sehemu kubwa, tu msingi sana, miundo rahisi zaidi, huzingatiwa. Hapa unaweza pia kupata viungo vya fasihi kwenye mitandao ya neva. Vitabu na vitabu, kama inavyopaswa kuwa, vimeandikwa kwa lugha ya kitaaluma au sawa na vina mifano isiyoeleweka, isiyoeleweka ya kujenga mitandao ya neural, mafunzo yao, nk. Ikumbukwe kwamba istilahi katika makala tofauti "huelea", kama inavyoweza. kuonekana kutoka kwa maoni hadi kwenye makala. Kwa sababu hii, mwanzoni kunaweza kuwa na "fujo kichwani."
- Jinsi mkulima wa Kijapani alivyopanga matango kwa kujifunza kwa kina na TensorFlow
- Mitandao ya Neural katika picha: kutoka kwa neuroni moja hadi usanifu wa kina
- Mfano wa programu ya mtandao wa neva na msimbo wa chanzo katika C++.
- Utekelezaji wa mtandao wa neural wa safu moja - perceptron kwa tatizo la uainishaji wa gari
- Pakua vitabu kwenye mitandao ya neva. Afya!
- Teknolojia za soko la hisa: Dhana 10 potofu kuhusu mitandao ya neva
- Algorithm ya kufunza mtandao wa neva wa safu nyingi kwa kutumia mbinu ya uenezaji nyuma
Mitandao ya Neural huko Python
Unaweza kusoma kwa ufupi juu ya maktaba gani zipo za Python. Kuanzia hapa nitachukua mifano ya majaribio ili kuhakikisha kuwa kifurushi kinachohitajika kimewekwa kwa usahihi.
tensorflow
Lengo kuu la TensorFlow ni jedwali la mtiririko wa data ambalo linawakilisha ukokotoaji. Vipeo vya grafu vinawakilisha utendakazi, na kingo zinawakilisha tensor (safu za multidimensional ambazo ni msingi wa TensorFlow). Grafu ya mtiririko wa data kwa ujumla wake ni maelezo kamili ya hesabu ambazo hutekelezwa ndani ya kipindi na kutekelezwa kwenye vifaa (CPU au GPU). Kama mifumo mingi ya kisasa ya kompyuta ya kisayansi na ujifunzaji wa mashine, TensorFlow ina API iliyohifadhiwa vizuri ya Python, ambapo tensorer huwakilishwa kama safu zinazojulikana za NumPy ndarray. TensorFlow hufanya hesabu kwa kutumia C++ iliyoboreshwa zaidi na pia inasaidia API asili za C na C++.
- Utangulizi wa kujifunza kwa mashine na tensorflow. Kufikia sasa, ni nakala ya kwanza tu kati ya nne iliyotangazwa ambayo imechapishwa.
- TensorFlow inakatisha tamaa. Mafunzo ya kina ya Google hayana "kina"
- Kujifunza kwa Mashine kwa Muhtasari: Uainishaji wa Maandishi kwa Mitandao ya Neural na TensorFlow
- Maktaba ya kujifunza mashine ya Google TensorFlow - maonyesho ya kwanza na kulinganisha na utekelezaji wetu wenyewe
Kufunga tensorflow imeelezewa vizuri katika makala kwenye kiungo cha kwanza. Walakini, Python 3.6.1 sasa imetolewa. Haitawezekana kuitumia. Angalau salfa kwa sasa (06/03/2017). Inahitaji toleo la 3.5.3, ambalo linaweza kupakuliwa. Hapo chini nitatoa mlolongo ambao ulinifanyia kazi (tofauti kidogo na nakala kutoka kwa Habr). Haijulikani kwa nini, lakini Python 64-bit imeundwa kwa processor ya AMD, mtawaliwa, na kila kitu kingine kwa hiyo. Baada ya kusakinisha Phyton, usisahau kuweka ufikiaji kamili kwa watumiaji ikiwa Python iliwekwa kwa kila mtu.
pip install --upgrade pip
pip install -U setuptools za bomba
pip3 install --upgrade tensorflow
pip3 install --upgrade tensorflow-gpu
pip install matplotlib /*Pakua 8.9 MB na faili kadhaa ndogo zaidi */
bomba kufunga jupyter
"Python uchi" inaweza kuonekana kuwa haipendezi. Kwa hiyo, hapa chini ni maagizo ya kufunga katika mazingira ya Anaconda. Huu ni muundo mbadala. Python tayari imeunganishwa ndani yake.
Wavuti tena ina toleo jipya la Python 3.6, ambalo bidhaa mpya ya Google bado haiauni. Kwa hiyo, mara moja nilichukua toleo la awali kutoka kwenye kumbukumbu, yaani Anaconda3-4.2.0 - linafaa. Usisahau kuangalia kisanduku cha usajili cha Python 3.5. Hasa, kabla ya kufunga Anaconda, ni bora kufunga terminal, vinginevyo itaendelea kufanya kazi na PATH iliyopitwa na wakati. Pia, usisahau kubadilisha haki za upatikanaji wa mtumiaji, vinginevyo hakuna kitu kitafanya kazi.
conda create -n tensorflow
kuamsha tensorflow
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.1.0-cp35-cp35m-win_amd64.whl /*Imepakuliwa kutoka kwa Mtandao 19.4 MB, kisha 7 , 7 MB na nyingine 0.317 MB*/
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/gpu/tensorflow_gpu-1.1.0-cp35-cp35m-win_amd64.whl /*Pakua 48.6 MB */
Picha ya skrini ya usakinishaji: kila kitu kinakwenda vizuri katika Anaconda.
Vivyo hivyo kwa faili ya pili.
Naam, kwa kumalizia: ili yote haya yafanye kazi, unahitaji kufunga kifurushi cha CUDA Toolkits kutoka NVIDEA (katika kesi ya kutumia GPU). Toleo la sasa linalotumika ni 8.0. Utahitaji pia kupakua na kufungua maktaba ya cuDNN v5.1 kwenye folda ya CUDA, lakini sio toleo jipya zaidi! Baada ya ghiliba hizi zote, TensorFlow itafanya kazi.

Theano
- Mtandao wa neva wa kawaida katika mistari 10 ya msimbo ulitathmini maoni kutoka kwa watazamaji wa kipindi kipya cha "Star Wars"
Kifurushi cha Theano kimejumuishwa kwenye PyPI ya Python mwenyewe. Kwa yenyewe ni ndogo - 3.1 MB, lakini inavuta MB 15 nyingine ya utegemezi - scipy. Ili kusakinisha ya mwisho, unahitaji pia moduli ya lapack... Kwa ujumla, kusakinisha kifurushi cha theano chini ya Windows kutamaanisha "kucheza kwa tambourini." Hapo chini nitajaribu kuonyesha mlolongo wa vitendo ili kufanya kifurushi kifanye kazi.
Wakati wa kutumia Anaconda, "kucheza na tambourini" wakati wa ufungaji sio muhimu. Amri inatosha:
conda install theano
na mchakato unafanyika moja kwa moja. Kwa njia, vifurushi vya GCC pia vinapakiwa.

Scikit-Jifunze
Chini ya Python 3.5.3, tu toleo la awali la 0.17.1 limewekwa na kuzinduliwa, ambalo unaweza kuchukua. Kuna kisakinishi cha kawaida. Hata hivyo, haitafanya kazi moja kwa moja chini ya Windows - unahitaji maktaba ya scipy.
Inasakinisha Vifurushi vya Msaidizi
Ili vifurushi viwili hapo juu vifanye kazi (tunazungumza juu ya "uchi" Phyton), unahitaji kufanya hatua za awali.
SciPy
Ili kuzindua Scikit-Learn na Theano, kama tayari imekuwa wazi kutoka hapo juu, utahitaji "kucheza na tari." Jambo la kwanza ambalo Yandex inatupa ni ghala la hekima, ingawa kwa Kiingereza, rasilimali stackoverflow.com, ambapo tunapata kiunga cha kumbukumbu bora ya karibu vifurushi vyote vya Python vilivyoundwa kwa Windows - lfd.uci.edu
Hapa kuna mikusanyiko iliyo tayari kusanikisha ya vifurushi ambavyo unavutiwa navyo kwa sasa, vilivyokusanywa kwa matoleo tofauti ya Python. Kwa upande wetu, matoleo ya faili yanahitajika ambayo yana kamba "-cp35-win_amd64" kwa jina lao kwa sababu hiki ni kifurushi cha Python ambacho kilitumika kwa usakinishaji. Kwenye stakowerflow, ukitafuta, unaweza pia kupata "maagizo" ya kusakinisha vifurushi vyetu mahususi.
pip install --upgrade --ignore-installed http://www.lfd.uci.edu/~gohlke/pythonlibs/vu0h7y4r/numpy-1.12.1+mkl-cp35-cp35m-win_amd64.whl
pip install --upgrade --ignore-insalled http://www.lfd.uci.edu/~gohlke/pythonlibs/vu0h7y4r/scipy-0.19.0-cp35-cp35m-win_amd64.whl
pip --upgrade --ignore-installed pandas
pip install --upgrade --ignore-installed matplotlib
Vifurushi viwili vya mwisho vilionekana kwenye mnyororo wangu kwa sababu ya "kucheza kwa matari" kwa watu wengine. Sikuwaona katika utegemezi wa vifurushi vilivyowekwa, lakini inaonekana baadhi ya vipengele vyao vinahitajika kwa mchakato wa kawaida wa ufungaji.
Lapack/Blas
Maktaba hizi mbili zinazohusiana za kiwango cha chini, zilizoandikwa huko Fortran, zinahitajika ili kusakinisha kifurushi cha Theano. Scikit-Learn pia inaweza kufanya kazi kwa wale ambao tayari wamesakinishwa "kwa siri" kwenye vifurushi vingine (tazama hapo juu). Kweli, ikiwa toleo la Theano 0.17 limesakinishwa kutoka kwa faili ya exe, itafanya kazi pia. Angalau katika Anaconda. Hata hivyo, maktaba hizi pia zinaweza kupatikana kwenye mtandao. Kwa mfano . Miundo ya hivi karibuni zaidi. Hii inafaa kwa kuendesha kifurushi kilichomalizika cha toleo la awali. Kuunda kifurushi kipya kutahitaji matoleo mapya.
Ikumbukwe pia kuwa katika muundo mpya kabisa wa Anaconda, kifurushi cha Theano kimewekwa rahisi zaidi - kwa amri moja, lakini kuwa waaminifu, katika hatua hii (sifuri) ya kusimamia mitandao ya neural, nilipenda TensorFlow zaidi, na ni. bado sio rafiki na matoleo mapya ya Python.
Asili: Kuunda Mtandao wa Neural katika Python
Mwandishi: John Serrano
Tarehe ya kuchapishwa: Mei 26, 2016
Tafsiri: A. Panin
Tarehe ya kutafsiri: Desemba 6, 2016
Mitandao ya Neural ni programu ngumu sana, zinazoeleweka tu kwa wasomi na fikra, ambazo kwa ufafanuzi haziwezi kufanyiwa kazi na watengenezaji wa kawaida, bila kunitaja. Hiyo ndivyo unavyofikiri, sawa?
Kweli, sio hivyo hata kidogo. Baada ya mazungumzo bora ya Louis Monier na Greg Renard katika Chuo cha Holberton, niligundua kuwa mitandao ya neva ni rahisi vya kutosha kwa msanidi programu yeyote kuelewa na kutekeleza. Bila shaka, mitandao ngumu zaidi ni miradi mikubwa yenye usanifu wa kifahari na ngumu, lakini dhana za msingi pia ni wazi zaidi au chini. Kutengeneza mtandao wowote wa neva kutoka mwanzo kunaweza kuwa changamoto, lakini kwa bahati nzuri kuna maktaba kadhaa nzuri ambazo zinaweza kukufanyia kazi zote za kiwango cha chini.
Katika muktadha huu, neuroni ni chombo rahisi. Inakubali maadili kadhaa ya pembejeo na ikiwa jumla ya maadili haya yanazidi kikomo maalum, inawashwa. Katika kesi hii, kila thamani ya pembejeo inazidishwa na uzito wake. Mchakato wa kujifunza kimsingi ni mchakato wa kuweka uzani wa thamani ili kutoa maadili yanayohitajika. Mitandao ambayo itajadiliwa katika makala hii inaitwa mitandao ya "feedforward", ambayo ina maana kwamba neurons ndani yake hupangwa kwa tabaka, na data zao za pembejeo zinatoka kwa kiwango cha awali na data zao za matokeo zinatumwa kwa ngazi inayofuata.

Kuna aina nyingine za mitandao ya neva, kama vile mitandao ya neva inayojirudia, ambayo imepangwa kwa njia tofauti, lakini hiyo ni mada ya makala nyingine.
Neuroni inayofanya kazi kulingana na kanuni iliyoelezwa hapo juu inaitwa perceptron na inategemea mfano wa asili wa niuroni bandia, ambao hutumiwa mara chache sana leo. Shida ya perceptrons ni kwamba mabadiliko madogo katika maadili ya pembejeo yanaweza kusababisha mabadiliko makubwa katika thamani ya pato kwa sababu ya kazi ya uanzishaji ya hatua kwa hatua. Katika kesi hii, kupungua kidogo kwa thamani ya pembejeo kunaweza kusababisha ukweli kwamba thamani ya ndani haitazidi kikomo kilichowekwa na neuron haitaamilishwa, ambayo itasababisha mabadiliko makubwa zaidi katika hali ya neurons zifuatazo. . Kwa bahati nzuri, tatizo hili linatatuliwa kwa urahisi na kipengele cha uanzishaji laini kinachopatikana kwenye mitandao ya kisasa zaidi.


Hata hivyo, mtandao wetu wa neva utakuwa rahisi sana kwamba perceptrons zinafaa kabisa kwa uumbaji wake. Tutaunda mtandao unaofanya kazi ya kimantiki NA. Hii ina maana kwamba tutahitaji niuroni mbili za pembejeo na niuroni moja ya pato, pamoja na niuroni kadhaa katika safu ya kati "iliyofichwa". Mchoro hapa chini unaonyesha usanifu wa mtandao huu, ambao unapaswa kuwa wazi kabisa.

Monier na Renard walitumia hati ya convnet.js kuunda mitandao ya onyesho kwa mazungumzo yao. Convnet.js inaweza kutumika kuunda mitandao ya neva moja kwa moja kwenye kivinjari chako cha wavuti, ikikuruhusu kuchunguza na kuirekebisha kwenye takriban jukwaa lolote. Bila shaka, utekelezaji huu katika JavaScript pia una vikwazo muhimu, moja ambayo ni kasi ya chini. Naam, kwa madhumuni ya makala hii tutatumia maktaba ya FANN (Fast Artifical Neural Networks). Katika kesi hii, katika kiwango cha lugha ya programu ya Python, moduli ya pyfann itatumika, ambayo ina vifungo vya maktaba ya FANN. Unapaswa kusakinisha kifurushi cha programu na moduli hii sasa hivi.
Kuagiza moduli ya kufanya kazi na maktaba ya FANN hufanywa kama ifuatavyo:
>>> kutoka kwa pyfann import libfann
Sasa tunaweza kuanza! Operesheni ya kwanza ambayo itabidi tufanye ni kuunda mtandao tupu wa neva.
>>> neural_net = libfann.neural_network()
Kitu kilichoundwa cha neural_net hakina nyuroni kwa sasa, kwa hivyo hebu tujaribu kuunda zingine. Kwa kusudi hili tutatumia kazi ya libfann.create_standard_array(). Kitendaji cha create_standard_array() huunda mtandao wa neva ambapo niuroni zote zimeunganishwa kwa niuroni kutoka kwa tabaka za jirani, kwa hivyo inaweza kuitwa mtandao "uliounganishwa kikamilifu". Uundaji_standard_array() chaguo za kukokotoa huchukua kama kigezo safu yenye thamani za nambari zinazolingana na idadi ya niuroni katika kila ngazi. Kwa upande wetu hii ni safu.
>>> neural_net.create_standard((2, 4, 1))
Baada ya hayo, tutalazimika kuweka thamani ya kiwango cha kujifunza. Thamani hii inalingana na idadi ya mabadiliko ya uzito ndani ya kurudia mara moja. Tutaweka kiwango cha juu cha kujifunza cha 0.7, kwa kuwa tutakuwa tunatatua tatizo rahisi kwa kutumia mtandao wetu.
>>> neural_net.set_learning_rate(0.7)
Sasa ni wakati wa kufunga kazi ya uanzishaji, madhumuni ambayo yalijadiliwa hapo juu. Tutatumia modi ya kuwezesha SIGMOID_SYMMETRIC_STEPWISE, ambayo inalingana na kitendakazi cha hatua ya tanjiti ya hyperbolic. Haina usahihi na kasi zaidi kuliko kitendakazi cha kawaida cha hyperbolic na inafaa kwa kazi yetu.
>>> neural_net.set_activation_function_output(libfann.SIGMOID_SYMMETRIC_STEPWISE)
Hatimaye, tunahitaji kuendesha algorithm ya mafunzo ya mtandao na kuhifadhi data ya mtandao kwenye faili. Kazi ya mafunzo ya mtandao inachukua hoja nne: jina la faili iliyo na data ambayo mafunzo yatategemea, idadi kubwa ya majaribio ya kuendesha algorithm ya mafunzo, idadi ya shughuli za mafunzo kabla ya kutoa data kuhusu hali ya mtandao, na kiwango cha makosa.
>>> neural_network.train_on_file("na.data", 10000, 1000, .00001) >>> neural_network.save("na.net")
Faili ya "na.data" inapaswa kuwa na data ifuatayo:
4 2 1 -1 -1 -1 -1 1 -1 1 -1 -1 1 1 1
Mstari wa kwanza una maadili matatu: idadi ya mifano katika faili, idadi ya maadili ya pembejeo, na idadi ya maadili ya pato. Ifuatayo ni mifano ya mistari, ambapo mistari iliyo na thamani mbili ina thamani za ingizo, na mistari yenye thamani moja inaonyesha thamani za pato.
Umemaliza mafunzo ya mtandao kwa mafanikio na sasa unataka kuyajaribu, sivyo? Lakini kwanza tutalazimika kupakia data ya mtandao kutoka kwa faili ambayo ilihifadhiwa hapo awali.
>>> neural_net = libfann.neural_net() >>> neural_net.create_from_file("na.net")
Baada ya hapo tunaweza kuiwasha kwa njia sawa:
>>> chapisha neural_net.run()
Matokeo yanapaswa kuwa [-1.0] au thamani sawa, kulingana na data ya mtandao inayozalishwa wakati wa mchakato wa mafunzo.
Hongera! Umefundisha kompyuta yako jinsi ya kufanya shughuli za kimsingi za kimantiki!
- Tafsiri
Makala inahusu nini?
Binafsi, ninajifunza vyema zaidi na msimbo mdogo wa kufanya kazi ambao ninaweza kucheza nao. Katika somo hili, tutajifunza algorithm ya uenezaji nyuma kwa kutumia mtandao mdogo wa neural unaotekelezwa katika Python kama mfano.Nipe kanuni!
X = np.array([ ,,, ]) y = np.array([]).T syn0 = 2*np.random.random((3,4)) - 1 syn1 = 2*np.random.nasibu ((4,1)) - 1 kwa j katika xrange(60000): l1 = 1/(1+np.exp(-(np.dot(X,syn0))))) l2 = 1/(1+np. exp(-(np.dot(l1,syn1)))) l2_delta = (y - l2)*(l2*(1-l2)) l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1) )) syn1 += l1.T.dot(l2_delta) syn0 += X.T.dot(l1_delta)Imebanwa sana? Wacha tuigawanye katika sehemu rahisi zaidi.
Sehemu ya 1: Mtandao mdogo wa neural wa toy
Mtandao wa neva uliofunzwa kupitia majaribio ya uenezaji nyuma ya kutumia data ya ingizo kutabiri data ya matokeo.Wacha tuseme tunahitaji kutabiri jinsi safu wima ya pato itaonekana kulingana na data ya ingizo. Tatizo hili linaweza kutatuliwa kwa kuhesabu mawasiliano ya takwimu kati yao. Na tungeona kuwa safu wima ya kushoto inahusiana 100% na matokeo.
Uenezaji wa nyuma, katika hali yake rahisi, huhesabu takwimu sawa ili kuunda mfano. Tujaribu.
Mtandao wa neva katika tabaka mbili
import numpy as np # Sigmoid def nonlin(x,deriv=False): if(deriv==True): rudisha f(x)*(1-f(x)) rudisha 1/(1+np.exp(-x) )) # seti ya data ya ingizo X = np.array([ , , , ]) # data towe y = np.array([]).T # fanya nambari nasibu maalum zaidi np.random.seed(1) # anzisha uzani kwa njia nasibu na wastani 0 syn0 = 2*np.random.random((3,1)) - 1 kwa iter katika xrange(10000): # uenezi wa mbele l0 = X l1 = nonlin(np.dot(l0,syn0) )) # Tulikosea kwa kiasi gani? l1_error = y - l1 # zidisha hii kwa mteremko wa sigmoid # kulingana na maadili katika l1 l1_delta = l1_error * nonlin(l1,True) # !!! # sasisha uzani syn0 += np.dot(l0.T,l1_delta) # !!! chapisha "Pato baada ya mafunzo:" chapisha l1Pato baada ya mafunzo: [[ 0.00966449] [0.00786506] [0.99358898] [0.99211957]]
Vigezo na maelezo yao.
"*" - kuzidisha kwa busara - vekta mbili za saizi sawa huzidisha maadili yanayolingana, na matokeo ni vekta ya saizi sawa.
"-" - uondoaji wa kipengee wa vekta
x.dot(y) - ikiwa x na y ni vekta, basi matokeo yatakuwa bidhaa ya scalar. Ikiwa hizi ni matrices, basi matokeo ni kuzidisha matrix. Ikiwa tumbo ni moja tu yao, ni kuzidisha kwa vekta na tumbo.
- linganisha l1 baada ya marudio ya kwanza na baada ya mwisho
- angalia utendakazi wa nonlin.
- angalia jinsi l1_error inavyobadilika
- mstari wa 36 - viungo kuu vya siri vinakusanywa hapa (alama !!!)
- mstari wa 39 - mtandao mzima unajiandaa kwa operesheni hii (iliyowekwa alama !!!)
Hebu tuvunje kanuni kwa mstari
ingiza numpy kama npInaagiza numpy, maktaba ya aljebra ya mstari. Uraibu wetu pekee.
Def nonlin(x,deriv=False):
Kutokuwa na mshikamano wetu. Kitendaji hiki maalum huunda "sigmoid". Inalingana na nambari yoyote iliyo na thamani kutoka 0 hadi 1 na inabadilisha nambari kuwa uwezekano, na pia ina sifa zingine kadhaa muhimu kwa mafunzo ya mitandao ya neural.
Ikiwa(deriv==Kweli):
Chaguo hili la kukokotoa linaweza pia kutoa derivative ya sigmoid (deriv=Kweli). Hii ni moja ya mali zake za manufaa. Ikiwa matokeo ya chaguo la kukokotoa ni tofauti ya nje, basi derivative itakuwa nje * (1-out). Ufanisi.
X = np.array([ , ...
Kuanzisha safu ya data ya ingizo kama matrix numpy. Kila mstari ni mfano wa mafunzo. Safu ni nodi za kuingiza. Tunamaliza na nodi 3 za kuingiza kwenye mtandao na mifano 4 ya mafunzo.
Y = np.array([]).T
Huanzisha data ya pato. ".T" - kipengele cha uhamisho. Baada ya tafsiri, matrix y ina safu 4 na safu moja. Kama ilivyo kwa data ya uingizaji, kila safu ni mfano wa mafunzo, na kila safu (moja kwa upande wetu) ni nodi ya pato. Inabadilika kuwa mtandao una pembejeo 3 na pato 1.
Mbegu.nasibu(1)
Shukrani kwa hili, usambazaji wa random utakuwa sawa kila wakati. Hii itaturuhusu kufuatilia mtandao kwa urahisi zaidi baada ya kufanya mabadiliko kwenye msimbo.
Syn0 = 2*np.random.random((3,1)) - 1
Matrix ya uzito wa mtandao. syn0 inamaanisha "synapse zero". Kwa kuwa tuna tabaka mbili tu, pembejeo na pato, tunahitaji tumbo moja la uzito ambalo litawaunganisha. Kipimo chake ni (3, 1), kwa kuwa tuna pembejeo 3 na pato 1. Kwa maneno mengine, l0 ina ukubwa wa 3 na l1 ina ukubwa wa 1. Kwa kuwa tunaunganisha nodes zote katika l0 kwa nodes zote katika l1, tunahitaji matrix ya mwelekeo (3, 1).
Kumbuka kuwa imeanzishwa kwa nasibu na wastani ni sifuri. Kuna nadharia ngumu zaidi nyuma ya hii. Kwa sasa tutachukua hili kama pendekezo. Pia kumbuka kuwa mtandao wetu wa neva ndio matrix hii. Tuna "tabaka" l0 na l1, lakini hizi ni maadili ya muda kulingana na seti ya data. Hatuzihifadhi. Mafunzo yote yanahifadhiwa katika syn0.
Kwa iter katika xrange(10000):
Hapa ndipo nambari kuu ya mafunzo ya mtandao huanza. Kitanzi cha msimbo hurudiwa mara nyingi na kuboresha mtandao kwa seti ya data.
Safu ya kwanza, l0, ni data tu. X ina mifano 4 ya mafunzo. Tutazishughulikia zote mara moja - hii inaitwa mafunzo ya kikundi. Kwa jumla tunayo mistari 4 tofauti ya l0, lakini inaweza kuzingatiwa kama mfano mmoja wa mafunzo - katika hatua hii haijalishi (unaweza kupakia 1000 au 10000 kati yao bila mabadiliko yoyote katika nambari).
L1 = nonlin(np.dot(l0,syn0))
Hii ni hatua ya utabiri. Tunaruhusu mtandao ujaribu kutabiri matokeo kulingana na pembejeo. Kisha tutaona jinsi anavyofanya ili tuweze kuiboresha kwa kuboresha.
Kuna hatua mbili kwa kila mstari. Ya kwanza hufanya kuzidisha matrix ya l0 na syn0. Ya pili hupitisha pato kupitia sigmoid. Vipimo vyao ni kama ifuatavyo:
(4 x 3) nukta (3 x 1) = (4 x 1)
Kuzidisha kwa matrix kunahitaji kwamba vipimo viwe sawa katikati ya mlinganyo. Matrix ya mwisho ina idadi sawa ya safu kama ya kwanza, na idadi sawa ya safuwima kama ya pili.
Tulipakia mifano 4 ya mafunzo na tukapata makadirio 4 (matrix 4x1). Kila pato linalingana na nadhani ya mtandao kwa ingizo fulani.
L1_kosa = y - l1
Kwa kuwa l1 ina ubashiri, tunaweza kulinganisha tofauti zao na ukweli kwa kutoa l1 kutoka kwa jibu sahihi y. l1_error ni vekta ya nambari chanya na hasi zinazoashiria mtandao "kosa".
Na hapa ni kiungo cha siri. Mstari huu unahitaji kuchanganuliwa kipande kwa kipande.
Sehemu ya kwanza: derivative
Nonlin(l1,Kweli)
L1 inawakilisha pointi hizi tatu, na kanuni hutoa mteremko wa mistari iliyoonyeshwa hapa chini. Kumbuka kuwa kwa thamani kubwa kama x=2.0 (kijani kitone) na thamani ndogo sana kama x=-1.0 (zambarau) mistari ina mteremko mdogo. Pembe kubwa zaidi kwa uhakika x=0 (bluu). Hii inaleta tofauti kubwa. Pia kumbuka kuwa derivatives zote huanzia 0 hadi 1.
Usemi kamili: derivative yenye uzito wa makosa
L1_delta = l1_error * nonlin(l1,True)
Kwa hisabati, kuna njia sahihi zaidi, lakini kwa upande wetu hii pia inafaa. l1_error ni (4,1) matrix. nonlin(l1,True) inarudisha (4,1) matrix. Hapa tunazizidisha kipengele kwa kipengele, na kwenye pato tunapata pia matrix (4,1), l1_delta.
Kwa kuzidisha derivatives kwa makosa, tunapunguza makosa ya utabiri uliofanywa kwa ujasiri wa juu. Ikiwa mteremko wa mstari ulikuwa mdogo, basi mtandao ulikuwa na thamani kubwa sana au ndogo sana. Ikiwa nadhani ya mtandao iko karibu na sifuri (x=0, y=0.5), basi haina ujasiri haswa. Tunasasisha utabiri huu usio na uhakika na kuacha ubashiri wa imani ya juu pekee kwa kuuzidisha kwa thamani karibu na sifuri.
Syn0 += np.dot(l0.T,l1_delta)
Tuko tayari kusasisha mtandao. Hebu tuangalie mfano mmoja wa mafunzo. Ndani yake tutasasisha uzani. Sasisha uzani wa kushoto kabisa (9.5)
Weight_update = input_value * l1_delta
Kwa uzani wa kushoto kabisa itakuwa 1.0 * l1_delta. Labda hii itaongeza tu 9.5 kidogo. Kwa nini? Kwa sababu utabiri ulikuwa tayari kujiamini, na utabiri ulikuwa sahihi kivitendo. Hitilafu ndogo na mteremko mdogo wa mstari unamaanisha sasisho ndogo sana.
Lakini kwa kuwa tunafanya mafunzo ya kikundi, tunarudia hatua iliyo hapo juu kwa mifano yote minne ya mafunzo. Kwa hivyo inaonekana sawa na picha hapo juu. Kwa hivyo mstari wetu hufanya nini? Huhesabu masasisho ya uzito kwa kila uzani, kwa kila mfano wa mafunzo, hujumlisha na kusasisha uzani wote - yote kwa mstari mmoja.
Baada ya kutazama sasisho la mtandao, turudi kwenye data yetu ya mafunzo. Wakati pembejeo na pato ni 1, tunaongeza uzito kati yao. Wakati pembejeo ni 1 na pato ni 0, tunapunguza uzito.
Pato la Kuingiza 0 0 1 0 1 1 1 1 1 0 1 1 0 1 1 0
Kwa hivyo katika mifano yetu minne ya mafunzo hapa chini, uzani wa pembejeo ya kwanza inayohusiana na pato itaongezeka au kubaki thabiti, na uzani mwingine mbili utaongezeka na kupungua kulingana na mifano. Athari hii inachangia ujifunzaji wa mtandao kulingana na uunganisho wa data ya pembejeo na matokeo.
Sehemu ya 2: kazi ngumu zaidi
Pato la Kuingiza 0 0 1 0 0 1 1 1 1 0 1 1 1 1 1 0Wacha tujaribu kutabiri data ya pato kulingana na safu wima tatu za data. Hakuna safu wima yoyote kati ya ingizo inayohusiana 100% na matokeo. Safu ya tatu haijaunganishwa na chochote, kwani ina zile njia zote. Walakini, hapa unaweza kuona muundo - ikiwa moja ya safu wima mbili za kwanza (lakini sio zote mbili mara moja) ina 1, basi matokeo pia yatakuwa sawa na 1.
Huu ni muundo usio na mstari kwa sababu hakuna mawasiliano ya moja kwa moja kati ya safu wima. Mechi inategemea mchanganyiko wa ingizo, safu wima 1 na 2.
Inafurahisha, utambuzi wa muundo ni kazi inayofanana sana. Ikiwa una picha 100 za baiskeli na mabomba ya ukubwa sawa, uwepo wa saizi fulani katika maeneo fulani hauhusiani moja kwa moja na uwepo wa baiskeli au bomba kwenye picha. Kwa takwimu, rangi yao inaweza kuonekana bila mpangilio. Lakini michanganyiko mingine ya saizi sio nasibu - zile zinazounda picha ya baiskeli (au bomba).
Mkakati
Ili kuchanganya saizi kuwa kitu ambacho kinaweza kuwa na mawasiliano ya moja kwa moja kwa pato, unahitaji kuongeza safu nyingine. Safu ya kwanza inachanganya ingizo, ya pili inapeana mechi kwa matokeo kwa kutumia pato la safu ya kwanza kama ingizo. Makini na meza.Ingizo (l0) Vizito vilivyofichwa (l1) Pato (l2) 0 0 1 0.1 0.2 0.5 0.2 0 0 1 1 0.2 0.6 0.7 0.1 1 1 0 1 0.3 0.2 0.3 0.9 3 1 1 1 1 1 .
Kwa kugawa uzani kwa nasibu, tunapata maadili yaliyofichwa ya safu ya 1. Inafurahisha, safu ya pili ya uzani uliofichwa tayari ina uhusiano mdogo na matokeo. Sio bora, lakini huko. Na hii pia ni sehemu muhimu ya mchakato wa mafunzo ya mtandao. Mafunzo yataimarisha tu uwiano huu. Itasasisha syn1 ili kugawa ramani yake kwa data ya matokeo, na syn0 ili kupata data ya ingizo vyema.
Mtandao wa neva katika tabaka tatu
import numpy as np def nonlin(x,deriv=False): if(deriv==True): rudisha f(x)*(1-f(x)) rudisha 1/(1+np.exp(-x)) X = np.array([, , ]) y = np.array([, , , ]) np.random.seed(1) # anzisha uzani bila mpangilio, kwa wastani - 0 syn0 = 2*np.nasibu. nasibu ((3,4)) - 1 syn1 = 2*np.random.random((4,1)) - 1 kwa j katika xrange(60000): # nenda mbele kupitia safu 0, 1 na 2 l0 = X l1 = nonlin(np.dot(l0,syn0)) l2 = nonlin(np.dot(l1,syn1)) # tulikuwa na makosa kiasi gani kuhusu thamani inayohitajika? l2_error = y - l2 ikiwa (j% 10000) == 0: chapisha "Kosa:" + str(np.mean(np.abs(l2_error))) # ni njia gani unapaswa kusonga? # ikiwa tulikuwa na uhakika katika utabiri huo, basi hatuhitaji kuubadilisha sana l2_delta = l2_error*nonlin(l2,deriv=True) # ni kiasi gani maadili ya l1 huathiri makosa katika l2? l1_error = l2_delta.dot(syn1.T) # tunapaswa kuelekea upande gani ili kufikia l1? # ikiwa tulikuwa na uhakika katika utabiri, basi hatuhitaji kuubadilisha sana l1_delta = l1_error * nonlin(l1,deriv=True) syn1 += l1.T.dot(l2_delta) syn0 += l0.T.dot (l1_delta)Hitilafu:0.496410031903 Hitilafu:0.00858452565325 Hitilafu:0.00578945986251 Hitilafu:0.00462917677677 Hitilafu:0.0039587652802720507027250767255076507650765027507650765076507650765076.
Vigezo na maelezo yao
X ni matrix ya seti ya data ya pembejeo; masharti - mifano ya mafunzoy - matrix ya seti ya data ya pato; masharti - mifano ya mafunzo
l0 - safu ya kwanza ya mtandao iliyofafanuliwa na data ya pembejeo
l1 - safu ya pili ya mtandao, au safu iliyofichwa
l2 ndio safu ya mwisho, hii ndio nadharia yetu. Unapofanya mazoezi, unapaswa kupata karibu na jibu sahihi.
syn0 - safu ya kwanza ya uzani, Synapse 0, inachanganya l0 na l1.
syn1 - Safu ya pili ya uzani, Synapse 1, inachanganya l1 na l2.
l2_error - hitilafu ya mtandao kwa maneno ya kiasi
l2_delta - kosa la mtandao, kulingana na ujasiri wa utabiri. Inakaribia kufanana na makosa, isipokuwa kwa utabiri wa uhakika
l1_kosa - kwa kupima l2_delta na uzani kutoka kwa syn1, tunahesabu kosa katika safu ya kati/iliyofichwa.
l1_delta - makosa ya mtandao kutoka kwa l1, yaliyowekwa na ujasiri wa utabiri. Inakaribia kufanana na l1_error, isipokuwa kwa utabiri wa uhakika
Nambari inapaswa kuwa wazi - ni utekelezaji wa awali wa mtandao, uliowekwa katika tabaka mbili, moja juu ya nyingine. Pato la safu ya kwanza l1 ni pembejeo ya safu ya pili. Kuna kitu kipya tu kwenye mstari unaofuata.
L1_error = l2_delta.dot(syn1.T)
Hutumia makosa yaliyowekewa uzani wa imani ya utabiri kutoka l2 kukokotoa kosa kwa l1. Tunapata, mtu anaweza kusema, kosa lililowekwa na michango - tunahesabu ni kiasi gani maadili kwenye nodi l1 yanachangia makosa katika l2. Hatua hii inaitwa kurudi nyuma. Kisha tunasasisha syn0 kwa kutumia algoriti sawa na mtandao wa neva wa safu mbili.




 Jinsi ya kuunganisha hdd ya kawaida kwenye kompyuta")



















