Elke site is een verhaal met een begin en een einde. Maar hoe kun je de fasen van de vorming van een project, de levenscyclus ervan, traceren? Voor deze doeleinden is er een speciale dienst, een webarchief. In dit artikel zullen we het hebben over de presentatie van dergelijke bronnen, hun gebruik en mogelijkheden.
Wat is een webarchief en waarom is het nodig?
Een webarchief is een gespecialiseerde site die is ontworpen om informatie over verschillende internetbronnen te verzamelen. De robot slaat kopieën van projecten automatisch en handmatig op, alles hangt alleen af van de site en het gegevensverzamelingssysteem.
Momenteel zijn er enkele tientallen sites met vergelijkbare mechanismen en taken. Sommigen van hen worden als particulier beschouwd, andere zijn non-profitprojecten die voor het publiek toegankelijk zijn. Ook verschillen de middelen van elkaar in de bezoekfrequentie, de volledigheid van de opgeslagen informatie en de mogelijkheden om gebruik te maken van de ontvangen historie.
Zoals sommige experts opmerken, worden pagina's voor het opslaan van informatiestromen beschouwd als een belangrijk onderdeel van Web 2.0. Dat wil zeggen, een deel van de ideologie van de ontwikkeling van internet, die voortdurend in ontwikkeling is. Het verzamelmechanisme is erg middelmatig, maar er zijn geen geavanceerde methoden of analogen meer. Met behulp van een webarchief kunt u verschillende problemen oplossen: het bijhouden van informatie in de loop van de tijd, het herstellen van een verloren site, het zoeken naar informatie.
Hoe webarchief gebruiken?

Zoals hierboven vermeld, is een webarchief een site die een bepaald soort zoekservice in de geschiedenis biedt. Om het project te gebruiken, moet u:
- Ga naar een gespecialiseerde bron (bijvoorbeeld web.archive.org).
- Voer informatie voor de zoekopdracht in het speciale veld in. Dit kan een domeinnaam of een trefwoord zijn.
- Krijg relevante resultaten. Dit zijn een of meer sites, die elk een vaste crawldatum hebben.
- Door op een datum te klikken, gaat u naar de betreffende bron en gebruikt u de informatie voor persoonlijke doeleinden.
We zullen het later hebben over gespecialiseerde sites voor het zoeken naar historische gegevens van projecten, dus blijf bij ons.
Projecten die sitegeschiedenis bieden

Tegenwoordig zijn er verschillende projecten die diensten leveren voor het vinden van opgeslagen kopieën. Hier zijn er enkele:
- De meest populaire en veelgevraagde onder gebruikers is web.archive.org. De gepresenteerde site wordt beschouwd als de oudste op internet; de oprichting ervan dateert uit 1996. De dienst verzamelt gegevens automatisch en handmatig, en alle informatie wordt gehost op grote buitenlandse servers.
- De tweede meest populaire site is peeep.us. De hulpbron is erg interessant, omdat deze kan worden gebruikt om een kopie van de informatiestroom op te slaan die alleen voor u toegankelijk is. Merk op dat het project met alle domeinnamen werkt en de grenzen van het gebruik van webarchief verlegt. Wat de volledigheid van de informatie betreft, slaat de gepresenteerde site geen afbeeldingen en frames op. Sinds 2015 is het ook opgenomen in de lijst met verboden producten in Rusland.
- Een soortgelijk project als het hierboven beschreven project is archive.is. De verschillen omvatten de volledigheid van het verzamelen van informatie, evenals de mogelijkheid om pagina's van sociale netwerken op te slaan. Als u dus een bericht of interessante informatie kwijt bent, kunt u in het webarchief zoeken.
Mogelijkheid om webarchief te gebruiken

Nu weet iedereen wat een webarchief is en welke sites diensten aanbieden voor het opslaan van kopieën van projecten. Maar velen begrijpen nog steeds niet hoe ze de gepresenteerde informatie moeten gebruiken. De mogelijkheden van archiefgegevens worden als volgt uitgedrukt:
- Een domeinnaam kiezen. Het is geen geheim dat veel webmasters al geüpgradede domeinen gebruiken. Het is de moeite waard om te begrijpen dat ervaren gebruikers niet alleen doelparameters volgen, maar ook de geschiedenis van eerder gebruik. Elke netwerkgebruiker wil weten wat hij koopt: of er eerder verboden of sancties waren, of het project onderworpen was aan filters.
- Een site herstellen vanuit archieven. Soms gebeurt er een ramp die het voortbestaan van uw eigen project bedreigt. Het ontbreken van tijdige back-ups in het hostingprofiel en een accidentele fout kunnen tot een tragedie leiden. Als dit gebeurt, wees dan niet boos, want u kunt het webarchief gebruiken. We zullen het hieronder hebben over het herstelproces.
- Zoek naar unieke inhoud. Elke dag verdwijnen er sites vol inhoud op internet. Dit gebeurt met een bijzondere consistentie, waardoor een enorme informatiestroom verloren gaat. Na verloop van tijd vallen dergelijke pagina's uit de index en kan een vindingrijke webmaster de informatie lenen voor een persoonlijk project. Natuurlijk is er een zoekprobleem, maar dat is van secundair belang.
We hebben gekeken naar de belangrijkste functies die webarchieven bieden, nu is het tijd om verder te gaan met een meer gedetailleerde studie van afzonderlijke elementen.
Een website herstellen vanuit een webarchief

Niemand is immuun voor problemen met websites. De meeste problemen worden opgelost met behulp van back-ups. Maar wat als er geen opgeslagen kopie op de hostingserver staat? Gebruik het webarchief. Om dit te doen moet u:
- Ga naar de gespecialiseerde hulpbron waar we het eerder over hadden.
- Voer uw eigen domeinnaam in de zoekbalk in en open het project in een nieuw venster.
- Kies de meest succesvolle foto, die zich dichter bij de probleemdatum bevindt en een volwaardig beeld heeft.
- Herstel interne links naar directe links. Gebruik hiervoor de link “http://web.archive.org/web/any_sequence_number_id_/Site name”.
- Kopieer verloren informatie of ontwerpgegevens om te gebruiken voor herstel.
Merk op dat het proces enigszins vervelend is, gezien de snelheid van het archief. Daarom raden we eigenaren van grote webbronnen aan vaker back-ups te maken, wat tijd en zenuwen bespaart.
Wij zijn op zoek naar unieke content voor onze eigen website

Sommige webmasters gebruiken een interessante manier om nieuwe inhoud te verkrijgen die niemand nodig heeft. Elke dag raken honderden sites in de vergetelheid en daarmee gaat ook informatie verloren. Om contenteigenaar te worden, moet je het volgende doen:
- Voer URL in
https://www.nic.ru/auction/forbuyer/download_list.shtml#buying in de zoekbalk. - Download op de domeinnaamveilingwebsite bestanden met de naam ru.
- Open de ontvangen bestanden met behulp van Excel en begin met selecteren op basis van de beschikbaarheid van ontwerpinformatie.
- Voer de gevonden projecten in de lijst op de zoekpagina van het webarchief in.
- Open de momentopname en krijg toegang tot de informatiestroom.
We raden aan de inhoud te controleren op plagiaat, hierdoor kunt u echt waardevolle teksten vinden. En dat is alles! Nu kent iedereen de mogelijkheden en methoden van het gebruik van een webarchief. Gebruik kennis verstandig en winstgevend.
Wanneer u snel websitebronnen van een server moet downloaden, biedt zelfs een relatief snelle SSH-tunnel niet de vereiste snelheid. En je moet heel, heel lang wachten. En veel hostingproviders bieden deze toegang niet, maar dwingen je genoegen te nemen met FTP, wat vele malen langzamer is.
Voor mezelf persoonlijk heb ik een uitweg gevonden. Een klein script wordt naar de server geüpload en gestart. Na enige tijd ontvangen we een archief met alle bronnen. En één bestand wordt, zelfs via eeuwenoude FTP, veel sneller gedownload dan honderd kleine.
Eerder op de pagina's van deze blog stond de zipArchive-bibliotheek. Toen was het echter een kwestie van het archief uitpakken.
Eerst moeten we uitzoeken of de server zipArchive ondersteunt. Deze populaire bibliotheek is op de overgrote meerderheid van de hostingsites geïnstalleerd.
De bibliotheek is strikt beperkt door php- en serverparameters. Enorme databases en fotobanken kunnen niet worden gearchiveerd. Zelfs de basis van het goede oude 1C-programma voor boekhouding. Het lijkt erop dat ze alleen tekstgegevens mogen bevatten. Maar nee.
Ik raad u aan de bibliotheek alleen te gebruiken bij het archiveren van relatief kleine sites met een groot aantal kleine bestanden.
Laten we eens kijken of de bibliotheek beschikbaar is om mee te werken
If (!extension_loaded("zip")) ( retourneert false; )
Als alles goed is, wordt het script verder uitgevoerd.
Een kleine offtopic voor dergelijke controles. Controles moeten op deze manier worden uitgevoerd, waarbij grote structuren met geneste haakjes worden vermeden. Op deze manier zal de code meer atomair zijn en gemakkelijker te debuggen. Vergelijken
If(a==b)( if(c==d)( if(e==f)( echo "Aan alle voorwaarden voldaan"; )else echo "e<>f"; )anders echo "c<>d"; )anders echo "a<>B;
en deze code
If(a!=b) exit("a<>B); if(c!=d) exit("c<>D); if(e!=f) exit("e<>F); echo "Aan alle voorwaarden voldaan";
De code is mooier en groeit niet uit tot enorme geneste structuren.
Sorry voor de off-topic, maar ik wilde deze vondst toch even delen.
Laten we nu een object en een archief maken.
$zip = nieuw ZipArchive(); if (!$zip->open($destination, ZIPARCHIVE::CREATE)) ( return false; )
waarbij $destination het volledige pad naar het archief is. Als het archief al is aangemaakt, worden de bestanden eraan toegevoegd.
$zip->addEmptyDir(str_replace($source . "/", "", $file . "/"));
waar $source het volledige pad is naar onze categorie (die we aanvankelijk hebben gearchiveerd), is $file het volledige pad naar de huidige map. Dit wordt gedaan zodat het archief geen volledige paden bevat, maar alleen relatieve paden.
Het toevoegen van een bestand werkt op dezelfde manier, maar u moet het eerst in een string lezen.
$zip->addFromString(str_replace($source . "/", "", $file), file_get_contents($file));
Aan het einde moet je het archief sluiten.
Retourneer $zip->close();
Ik denk niet dat het nodig is om uit te leggen hoe je door alle bestanden en submappen in een map moet bladeren. Google het eens, zoiets Recursieve doorloop van mappen in php
Deze optie beviel mij
Functie Zip($source, $destination)( if (!extension_loaded("zip') || !file_exists($source)) ( retourneert false; ) $zip = new ZipArchive(); if (!$zip->open( $destination, ZIPARCHIVE::CREATE)) ( retourneert false; ) $source = str_replace("\\", "/", realpath($source) if (is_dir($source) === true)( $files = new RecursiveIteratorIterator(nieuwe RecursiveDirectoryIterator($source), RecursiveIteratorIterator::SELF_FIRST); foreach ($bestanden als $file)( $file = str_replace("\\", "/", $file); // Negeer "." en ".." mappen if(in_array(substr($file, strrpos($file, "/")+1), array(".", ".."))) continue $file = realpath($file ); $file = str_replace("\\", "/", $file); (is_dir($file) === true)( $zip->addEmptyDir(str_replace($source . "/", "" , $file . "/")); else if (is_file($file) === true)( $zip->addFromString(str_replace($source . "/", "", $file), file_get_contents($ file)); ) )else if (is_file($source) === true)( $zip->addFromString(basename($source), file_get_contents($source)); ) return $zip->close(); )
Het is duidelijk dat het voor sjabloonmakers eenvoudiger is om standaardfuncties en WordPress-sjabloontags te gebruiken om standaardweergaven van alle sitepagina’s weer te geven, maar dit zorgt voor een uniforme uitstraling en een gevoel van overgang naar dezelfde pagina's van de site.
Ik laat je meteen zien wat we als resultaat krijgen.
Type WordPress-archieven: categoriearchief vóór wijzigingen  Archief van secties met verwijderde thumbnails en een link voor meer details.
Archief van secties met verwijderde thumbnails en een link voor meer details.
Belangrijk! Omdat deze taak wordt opgelost door de sjablooncode te wijzigen, doen we vóór het werk (database + sitebestanden). Daarnaast maken we twee kopieën van de werksjabloon, één voor bewerking, de tweede voor het herstellen van onjuiste bewerking.
Het uiterlijk van WordPress-archieven wijzigen
Om het uiterlijk van WordPress-archieven te veranderen, moet u zoeken, of beter gezegd, bepalen welk bestand in uw werksjabloon archieven weergeeft. In de meeste sjablonen worden alle archieven in één enkel bestand uitgevoerd, genaamd (archive.php).
Ik herhaal, om te voorkomen dat we de site kwijtraken, gebruiken we niet de editor in het beheerderspaneel van de site, maar bewerken we eerder gemaakte back-ups van de sjabloonbestanden.
Open in een teksteditor (zoals Notepad++) het bestand archive.php en begin met bewerken. In het archive.php-bestand (aan het einde van het bestand) zoeken we naar een functie die de archiefblog weergeeft:

Naam is de naam van het bestand dat wordt gebruikt om de archiefblog uit te voeren.
Het eerste idee voor het voltooien van de taak is eenvoudig: we moeten de code wijzigen van het bestand dat archieven uitvoert (content.php), namelijk verschillende functies ervan verwijderen, en daardoor het uiterlijk van alle archieven van de site veranderen (categorieën, auteurs, datums, enz.).
Maar de vraag rijst: als we de code van het sjabloonbestand wijzigen, zal deze na de eerste update van de sjabloon terugkeren naar de vorige staat, dit hebben we niet nodig. Daarom zullen we het content.php-bestand niet bewerken, maar kopiëren en ons eigen bestand maken onder een andere naam, bijvoorbeeld content-cat.php, en het bewerken.
We zoeken naar een functie in het bestand die thumbnails weergeeft. De miniatuurfunctie staat bovenaan. We verwijderen de miniatuuruitvoer.

ofen verwijder de regel met ‘Lees meer’, ‘sjabloonnaam’.

We slaan het gemaakte en bewerkte content-cat.php-bestand op en uploaden het naar de sitemap in de werkende sjabloonmap. Dit bestand verschijnt in het beheerderspaneel van de site op het tabblad Uiterlijk → Editor.
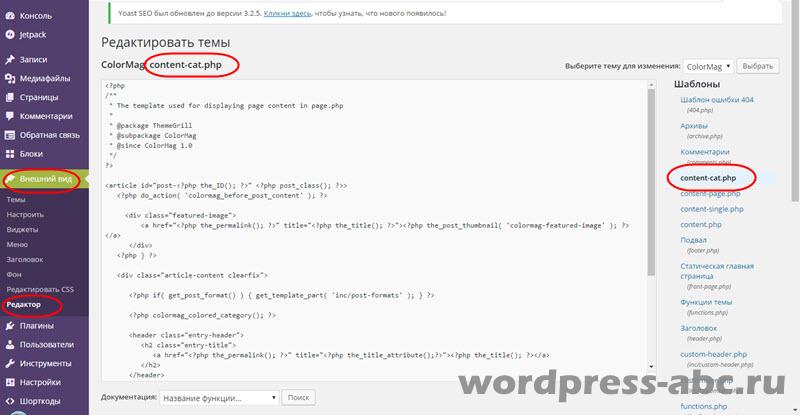
Laten we verder gaan met de tweede stap. In het bestand dat archieven uitvoert (archive.php), wijzigt u de inhoud van de bestandsnaam in content-cat .

We bewaren en bekijken het resultaat. Als er iets mis is, toont het systeem een fout, een foutbestand en een foutregel. Om de fout te corrigeren, plaatst u de opgeslagen back-upsjabloonbestanden terug op hun plaats en herhaalt u alles opnieuw.
Advies. Als je meer wilt lezen over template-tags en standaard WordPress-functies, let dan op deze site: https://wp-kama.ru. Dit is geen advertentie of zelfs maar een link, deze site is duidelijker dan de officiële WordPress-site in de sectie met templates en feature-tags.
Bij de ontwikkeling van het onderwerp
Naar mijn mening vereist het onderwerp aankondigingen op WordPress-sites voortzetting. In de komende berichten zal ik de onderwerpen bespreken: en.
WordPress-codex
Verborgen tekst
de_post_thumbnail-functie
Functie
de_post_thumbnail
Doel
De functie_post_thumbnail voert de html-code van de miniatuurafbeelding van het bericht uit, een lege waarde als er geen afbeelding is.
Sollicitatie
Deze sjabloontag, de functie_post_thumbnail, moet intern worden gebruikt
Gebruik
the_post_thumbnail(string|array $size = "post-thumbnail", string|array $attr = "")Bron
Bestand: wp-includes/post-thumbnail-template.php
Functie the_post_thumbnail($size = "post-thumbnail", $attr = "") ( echo get_the_post_thumbnail(null, $size, $attr); )
Opties
$grootte (tekenreeks/matrix)
De grootte van de thumbnail die u wilt ontvangen. Het kan een string zijn met voorwaardelijke afmetingen: thumbnail, medium, large, full of een array van twee elementen (afbeeldingsbreedte en -hoogte): array(60, 60).
Standaard: ‘post-thumbnail’, dat wil zeggen de grootte die voor het huidige thema is ingesteld door de functie set_post_thumbnail_size()
$attr (tekenreeks/matrix)
Een array met attributen die moeten worden toegevoegd aan de resulterende html img-tag (alt is een alternatieve naam).
Standaard:
























