In het dagelijkse werk kom je redelijk vergelijkbare fouten tegen bij het schrijven van queries.
In dit artikel wil ik voorbeelden geven van hoe je GEEN queries schrijft.
- Selecteer alle velden
SELECT * UIT tabelGebruik bij het schrijven van query's geen selectie van alle velden - "*". Vermeld alleen de velden die u echt nodig heeft. Hierdoor wordt de hoeveelheid opgehaalde en verzonden gegevens verminderd. Vergeet ook de dekking van indexen niet. Zelfs als u alle velden in de tabel daadwerkelijk nodig heeft, is het beter om ze op te sommen. Ten eerste verbetert het de leesbaarheid van de code. Als u een asterisk gebruikt, is het onmogelijk om te weten welke velden in de tabel staan zonder ernaar te kijken. Ten tweede kan het aantal kolommen in uw tabel na verloop van tijd veranderen, en als er vandaag vijf INT-kolommen zijn, kunnen binnen een maand TEXT- en BLOB-velden worden toegevoegd, wat de selectie zal vertragen.
- Verzoeken in een cyclus.
U moet duidelijk begrijpen dat SQL een set-operationele taal is. Soms vinden programmeurs die gewend zijn te denken in termen van procedurele talen het moeilijk om hun denken te verschuiven naar de taal van sets. Dit kan heel eenvoudig worden gedaan door een eenvoudige regel aan te nemen: “voer zoekopdrachten nooit in een lus uit.” Voorbeelden van hoe dit gedaan kan worden:1. Monsters
$news_ids = get_list("SELECT news_id FROM today_news ");
while($news_id = get_next($news_ids))
$news = get_row("SELECT titel, body FROM nieuws WHERE news_id = ". $news_id);De regel is heel eenvoudig: hoe minder verzoeken, hoe beter (hoewel hier, zoals op elke regel, uitzonderingen op bestaan). Vergeet de IN()-constructie niet. De bovenstaande code kan in één query worden geschreven:
SELECT titel, body FROM today_news INNER JOIN news USING(news_id)2. Inzetstukken
$log = parse_log();
while($record = volgende($log))
query("INSERT INTO logt SET value = ". $log["value"]);!}Het is veel efficiënter om één query samen te voegen en uit te voeren:
INSERT INTO logs (waarde) VALUES (...), (...)3. Updates
Soms moet u meerdere rijen in één tabel bijwerken. Als de bijgewerkte waarde hetzelfde is, is alles eenvoudig:
UPDATE nieuws SET title="test" WHERE id IN (1, 2, 3).!}Als de waarde die wordt gewijzigd voor elk record verschillend is, dan kan dit met de volgende query:
UPDATE nieuws SET
titel = GEVAL
WANNEER news_id = 1 DAN "aa"
WANNEER news_id = 2 DAN "bb" EINDE
WAAR nieuws_id IN (1, 2)Uit onze tests blijkt dat zo’n verzoek 2-3 keer sneller gaat dan meerdere afzonderlijke verzoeken.
- Bewerkingen uitvoeren op geïndexeerde velden
SELECT user_id VAN gebruikers WAAR blogs_count * 2 = $valueDeze query maakt geen gebruik van de index, zelfs niet als de kolom blogs_count is geïndexeerd. Om een index te kunnen gebruiken, mogen er geen transformaties worden uitgevoerd op het geïndexeerde veld in de query. Verplaats voor dergelijke verzoeken de conversiefuncties naar een ander deel:
SELECTEER user_id VAN gebruikers WAAR blogs_count = $value / 2;Soortgelijk voorbeeld:
SELECT user_id FROM gebruikers WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(geregistreerd)<= 10;Zal geen index gebruiken op het geregistreerde veld, terwijl
SELECT user_id FROM gebruikers WAAR geregistreerd >= DATE_SUB(CURRENT_DATE, INTERVAL 10 DAY);
zullen. - Rijen alleen ophalen om hun aantal te tellen
$result = mysql_query("SELECT * FROM tabel", $link);
$num_rows = mysql_num_rows($result);
Als u het aantal rijen wilt selecteren dat aan een bepaalde voorwaarde voldoet, gebruikt u SELECT-vraag COUNT(*) FROM tabel, in plaats van alle rijen te selecteren om alleen het aantal te tellen. - Extra rijen ophalen
$result = mysql_query("SELECT * UIT tabel1", $link);
while($row = mysql_fetch_assoc($result) && $i< 20) {
…
}
Als u slechts n ophaalrijen nodig heeft, gebruik dan LIMIT in plaats van de extra rijen in de toepassing weg te gooien. - ORDER BY RAND() gebruiken
SELECT * FROM tabel ORDER BY RAND() LIMIT 1;Als de tabel meer dan 4-5 duizend rijen heeft, werkt ORDER BY RAND() erg langzaam. Het zou veel efficiënter zijn om twee query's uit te voeren:
Als de tabel een primaire sleutel auto_increment heeft en geen gaten bevat:
$rnd = rand(1, query("SELECT MAX(id) FROM tabel"));
$row = query("SELECT * FROM tabel WHERE id = ".$rnd);Of:
$cnt = query("SELECT COUNT(*) FROM tabel");
$row = query("SELECT * FROM tabel LIMIT ".$cnt.", 1");
wat echter ook langzaam kan zijn als de tabel een zeer groot aantal rijen bevat. - Een groot aantal JOIN's gebruiken
SELECTEER
v.video_id
een.naam,
g.genre
VAN
video's AS v
LINKS AANMELDEN
link_actors_videos AS la ON la.video_id = v.video_id
LINKS AANMELDEN
acteurs AS a ON a.actor_id = la.actor_id
LINKS AANMELDEN
link_genre_video AS lg AAN lg.video_id = v.video_id
LINKS AANMELDEN
genres AS g ON g.genre_id = lg.genre_idHoud er rekening mee dat bij het één-op-veel verbinden van tabellen het aantal rijen in de selectie bij elke volgende JOIN zal toenemen. In dergelijke gevallen is het sneller om een dergelijke zoekopdracht in meerdere eenvoudige te splitsen.
- LIMIT gebruiken
SELECT… FROM tabel LIMIT $start, $per_pageVeel mensen denken dat een dergelijke zoekopdracht $per_pagina aan records oplevert (meestal 10-20) en daarom snel zal werken. Het zal snel werken gedurende de eerste paar pagina's. Maar als het aantal records groot is en u een SELECT... FROM tabel LIMIT 1000000, 1000020-query moet uitvoeren, dan zal MySQL, om zo'n query uit te voeren, eerst 1000020 records selecteren, de eerste miljoen weggooien en 20 retourneren. misschien helemaal niet snel. Er zijn geen triviale manieren om het probleem op te lossen. Velen beperken eenvoudigweg de hoeveelheid beschikbare pagina's redelijk aantal. U kunt dergelijke zoekopdrachten ook versnellen door gebruik te maken van dekkingsindexen of oplossingen van derden(bijvoorbeeld sfinx).
- Wordt niet gebruikt bij DUPLICATE KEY UPDATE
$row = query("SELECT * FROM tabel WHERE id=1");Als($rij)
query("UPDATE tabel SET kolom = kolom + 1 WHERE id=1")
anders
query("INSERT INTO tabel SET kolom = 1, id=1");Een soortgelijke constructie kan worden vervangen door één query, op voorwaarde dat er een primaire of unieke sleutel is voor het id-veld:
INSERT INTO tabel SET kolom = 1, id=1 ON DUPLICATE KEY UPDATE kolom = kolom + 1
MySQL is nog steeds de populairste relationele database ter wereld, maar ook de minst geoptimaliseerde. Veel mensen blijven bij de standaardinstellingen zonder dieper te graven. In dit artikel zullen we enkele MySQL-optimalisatietips bekijken, gecombineerd met enkele nieuwe functies die relatief recentelijk zijn uitgekomen.
Configuratie-optimalisatie
Het eerste dat elke MySQL-gebruiker moet doen om de prestaties te verbeteren, is de configuratie aanpassen. De meeste mensen slaan deze stap echter over. B 5,7 ( huidige versie) standaardinstellingen zijn veel beter dan die van zijn voorgangers, maar het verbeteren ervan is nog steeds mogelijk en eenvoudig.
We hopen dat je Linux of iets als Vagrant -box (zoals onze Homestead Verbeterd) gebruikt en dat je configuratiebestand zich dienovereenkomstig in /etc/mysql/my.cnf bevindt. Het is mogelijk dat uw installatie daadwerkelijk wordt geladen extra bestand configuraties in deze. Dus kijk, als het bestand my.cnf niet veel bevat, kijk dan in /etc/mysql/mysql.conf.d/mysqld.cnf .
Handmatig afstemmen
De volgende instellingen moeten standaard worden uitgevoerd. Voeg volgens deze tips toe aan het configuratiebestand in de sectie:
Innodb_buffer_pool_size = 1G # (hier verander je ongeveer 50%-70% van het totale RAM) innodb_log_file_size = 256M innodb_flush_log_at_trx_commit = 1 # kan worden gewijzigd in 2 of 0 innodb_flush_method = O_DIRECT
- innodb_buffer_pool_size . De bufferpool is een soort ‘magazijn’ voor het cachen van gegevens en indexen in het geheugen. Het wordt gebruikt om veelgebruikte gegevens in het geheugen op te slaan. En als u een dedicated of virtuele server gebruikt, waarbij de database vaak het knelpunt is, is het zinvol om deze het grootste deel van het RAM-geheugen te geven. Daarom geven we het 50-70% van het totale RAM-geheugen. Er is een handleiding voor het opzetten van deze pool in de MySQL-documentatie.
- innodb_log_bestandsgrootte . Het instellen van de logbestandsgrootte is goed beschreven, maar in een notendop gaat het om de hoeveelheid gegevens die in de logs wordt opgeslagen voordat deze worden gewist. Houd er rekening mee dat het logbestand in dit geval geen foutrecords is, maar een soort delta-snapshot van wijzigingen die nog niet naar schijf zijn gespoeld in de belangrijkste innodb-bestanden. MySQL schrijft naar achtergrond, maar dit heeft nog steeds invloed op de prestaties op het moment van opnemen. Een groot logbestand betekent meer hoge prestaties vanwege het kleine aantal nieuwe en kleine gecreëerde controlepunten, maar tegelijkertijd een langere hersteltijd in geval van een crash (er moeten meer gegevens in de database worden herschreven).
- innodb_flush_log_at_trx_commit wordt beschreven en laat zien wat er met het logbestand gebeurt. Waarde 1 is het veiligst, omdat het logboek na elke transactie naar schijf wordt gewist. Bij waarden 0 en 2 is ACID minder gegarandeerd, maar zijn de prestaties hoger. Het verschil is niet groot genoeg om op te wegen tegen de stabiliteitsvoordelen bij 1.
- innodb_flush_methode . Als klap op de vuurpijl als het gaat om het opschonen van gegevens, moet deze instelling worden ingesteld op O_DIRECT - om dubbele buffering te voorkomen. Ik raad u aan dit altijd te doen zolang het I/O-systeem erg traag blijft. Hoewel je op de meeste hostingsites, zoals DigitalOcean, over SSD-schijven beschikt, zal het I/O-systeem productiever zijn.
Er is een tool van Percona waarmee we de resterende problemen automatisch kunnen opsporen. Houd er rekening mee dat als we het zouden uitvoeren zonder deze handmatige instelling, slechts 1 van de 4 instellingen zou worden gedefinieerd, aangezien de andere 3 afhankelijk zijn van de voorkeuren van de gebruiker en omgeving toepassingen.
Variabele inspecteur
Variabele-inspecteur installeren op Ubuntu:
Wget https://repo.percona.com/apt/percona-release_0.1-4.$(lsb_release -sc)_all.deb sudo dpkg -i percona-release_0.1-4.$(lsb_release -sc)_all. deb sudo apt-get update sudo apt-get install percona-toolkit
Voor andere systemen volgt u deze instructies.
Voer vervolgens de toolkit uit:
Pt-variabele-adviseur h=localhost,u=homestead,p=geheim
Je zult dit resultaat zien:
# WARN delay_key_write: MyISAM-indexblokken worden nooit leeggemaakt totdat dit nodig is. # OPMERKING max_binlog_size: De max_binlog_size is kleiner dan de standaardwaarde van 1GB. # OPMERKING sort_buffer_size-1: De sort_buffer_size variabele moet over het algemeen op de standaardwaarde blijven staan, tenzij een expert bepaalt dat het nodig is om deze te wijzigen. # OPMERKING innodb_data_file_path: Het automatisch uitbreiden van InnoDB-bestanden kan veel schijfruimte in beslag nemen, wat later erg moeilijk terug te winnen is. # WARN log_bin: Binaire logboekregistratie is uitgeschakeld, dus op een bepaald tijdstip herstel en replicatie zijn niet mogelijk.
Opmerking vertaler:
Op de mijne lokale machine Daarnaast heeft zij ook de volgende waarschuwing afgegeven:
Het feit dat de parameter innodb_flush_method moet worden ingesteld op O_DIRECT en waarom werd hierboven besproken. En als u de afstemmingsvolgorde hebt gevolgd zoals in het artikel, ziet u deze waarschuwing niet.
Geen van deze ( ca.: aangegeven door de auteur) waarschuwingen zijn niet kritisch en hoeven niet te worden gecorrigeerd. Het enige dat kan worden gecorrigeerd, is het opzetten van een binair logboek voor replicatie en snapshots.
Let op: in nieuwe versies is de standaard binloggrootte 1G en deze waarschuwing zal niet verschijnen.
Max_binlog_size = 1G log_bin = /var/log/mysql/mysql-bin.log server-id=master-01 binlog-format = "RIJ"
- max_binlog_size . Bepaalt hoe groot de binaire logboeken zullen zijn. Ze registreren uw transacties en verzoeken en maken controlepunten. Als een transactie het maximum overschrijdt, kan het logbestand groter zijn wanneer het op schijf wordt opgeslagen; anders ondersteunt MySQL het binnen deze limiet.
- log_bin. Met deze optie wordt binaire logboekregistratie in het algemeen ingeschakeld. Zonder dit zijn snapshots of replicaties onmogelijk. Houd er rekening mee dat dit een grote impact kan hebben op uw schijfruimte. server-id is vereiste optie bij het inschakelen van binaire logboekregistratie, zodat de logs "weten" van welke server ze afkomstig zijn (voor replicatie), en het binlog-formaat is eenvoudigweg de manier waarop ze zijn geschreven.
Zoals u kunt zien, heeft de nieuwe MySQL standaardinstellingen die bijna productieklaar zijn. Natuurlijk is elke applicatie anders en zijn er extra trucs en aanpassingen die daarop van toepassing zijn.
MySQL-tuner
Ondersteunende tools: Percona Toolkit voor het identificeren van dubbele indexen
De Percona Toolkit die we eerder hebben geïnstalleerd, bevat ook een tool voor het detecteren van dubbele indexen, wat handig kan zijn bij het gebruik van CMS'en van derden of om zelf te controleren of u per ongeluk meer indexen hebt toegevoegd dan nodig. De standaard WordPress-installatie heeft bijvoorbeeld dubbele indexen in de wp_posts-tabel:
Pt-duplicate-key-checker h=localhost,u=homestead,p=geheim # ########################## #################################### # homestead.wp_posts # #### ########################################## ################# # Sleuteltype_status_date eindigt met een voorvoegsel van de geclusterde index # Sleuteldefinities: # KEY `type_status_date` (`post_type`,`post_status`,`post_date` ,`ID`), # PRIMARY KEY (`ID`), # Kolomtypen: # `post_type` varchar(20) collate utf8mb4_unicode_520_ci niet null standaard "post" # `post_status` varchar(20) collate utf8mb4_unicode_520_ci niet null standaard "publish " " # `post_date` datetime not null default "0000-00-00 00:00:00" # `id` bigint(20) unsigned not null auto_increment # Om deze dubbele geclusterde index in te korten, voert u het volgende uit: ALTER TABLE `homestead`. ` wp_posts` DROP INDEX `type_status_date`, ADD INDEX `type_status_date` (`post_type`,`post_status`,`post_date`);
Zoals blijkt uit laatste regel, geeft deze tool u ook tips over hoe u dubbele indexen kunt verwijderen.
Hulptools: Percona Toolkit voor ongebruikte indexen
Percona Toolkit kan ook ongebruikte indexen detecteren. Als u langzame query's registreert (zie het gedeelte over knelpunten hieronder), kunt u het hulpprogramma uitvoeren en controleren of en hoe die query's indexen op tabellen gebruiken.
Pt-index-gebruik /var/log/mysql/mysql-slow.log
Voor gedetailleerde informatie over het gebruik van dit hulpprogramma, zie .
Knelpunten
In deze sectie wordt beschreven hoe u databaseknelpunten kunt detecteren en bewaken.
Laten we eerst het loggen van langzame queries inschakelen:
Slow_query_log = /var/log/mysql/mysql-slow.log long_query_time = 1 log-queries-not-using-indexes = 1
De bovenstaande regels moeten worden toegevoegd aan de mysql-configuratie. De database houdt zoekopdrachten bij die meer dan 1 seconde in beslag namen en zoekopdrachten die geen indexen gebruiken.
Zodra er wat gegevens in dit logboek staan, kunt u deze analyseren op indexgebruik met behulp van het bovenstaande hulpprogramma pt-index-usage, of met pt-query-digest, dat ongeveer zo zal opleveren:
Pt-query-digest /var/log/mysql/mysql-slow.log # 360ms gebruikerstijd, 20ms systeemtijd, 24,66M rss, 92,02M vsz # Huidige datum: do 13 februari 22:39:29 2014 # Hostnaam: * # Bestanden: mysql-slow.log # Totaal: 8 totaal, 6 uniek, 1,14 QPS, 0,00x gelijktijdigheid ________________ # Tijdbereik: 2014-02-13 22:23:52 tot 22:23:59 # Attribuut totaal min max gem. 95% stddev mediaan # ============ ======= ======= ======= ======= ===== == ======= ======= # Uitvoeringstijd 3 ms 267us 406us 343us 403us 39us 348us # Vergrendelingstijd 827us 88us 125us 103us 119us 12us 98us # Verzonden rijen 36 1 15 4,50 14,52 4,18 3,89 # Rij s onderzoeken 87 4 30 10,88 28,75 7,37 7,70 # Querygrootte 2,15k 153 296 245,11 284,79 48,90 258,32 # === = === ========== === ===== ====== = ==== =============== # Profiel # Rang Zoekopdracht ID Reactietijd Oproepen R/Call V/M Item # ==== ==== ====== ====== ===== ====== === == =============== # 1 0x728E539F7617C14D 0,0011 41,0% 3 0,0004 0,00 SELECTEER blog_artikel # 2 0x1290EEE0B201F3FF 0,0003 12,8% 1 0,0003 0,00 SELECTEER portfolio_item # 3 0x31DE4535BDBFA465 0,0003 12,6% 1 0,0003 0,00 SELECTEER portfolio_item # 4 0xF14E15D0F47A5742 0,0003 12,1% 1 0,0003 0,00 SELECTEER portfolio_categorie # 5 0x8F848005A09C9588 0,0003 11,8% 1 0,0003 0,00 SELECTEER blog_categorie # 6 0x55F49 C753CA2ED64 0,0003 9,7% 1 0,0003 0,00 SELECTEER blog_artikel # ==== ============ ====== ============ ===== ==== == ===== =============== # Query 1: 0 QPS, 0x gelijktijdigheid, ID 0x728E539F7617C14D bij byte 736 ______ # Scores: V/M = 0,00 # Tijdsbereik: alle gebeurtenissen hebben plaatsgevonden op 13-02-2014 22:23:52 # Attribuut pct totaal min max avg 95 % stddev mediaan # ============ === ======= == ===== ======= ======= === ==== ======= ======= # Aantal 37 3 # Uitvoeringstijd 40 1ms 352us 406us 375us 403us 22us 366us # Vergrendeltijd 42 351us 103us 125us 117us 119us 9us 119us # Verzonden rijen 25 9 1 4 3 3,89 1,37 3,89 # Rijen onderzoeken 24 21 5 8 7 7,70 1,29 7,7 0 # Querygrootte 47 1,02k 261 262 261,25 258,32 0 258,32 # Snaar: # Hosts localhost# Gebruikers * # Query_time distributie # 1us # 10us # 100us ############################### ####################### # 1ms # 10ms # 100ms # 1s # 10s+ # Tabellen # TOON TABELSTATUS ZOALS "blog_artikel"\G # TOON MAAK TABEL `blog_artikel`\G # UITLEG /*!50100 PARTITIES*/ SELECTEER b0_.id AS id0, b0_.slug AS slug1, b0_.title AS title2, b0_.excerpt AS excerpt3, b0_.external_link AS external_link4, b0_.description AS beschrijving5, b0_.gemaakt AS gemaakt6, b0_.bijgewerkt AS bijgewerkt7 VAN blog_artikel b0_ BESTEL OP b0_.gemaakt BESCHRIJVINGSLIMIET 10
Als u deze logboeken liever handmatig analyseert, kunt u hetzelfde doen, maar eerst moet u het logboek exporteren naar een beter parseerbaar formaat. Dit kan als volgt worden gedaan:
Mysqldumpslow /var/log/mysql/mysql-slow.log
MET aanvullende parameters U kunt de gegevens filteren om alleen te exporteren wat u nodig heeft. De top 10 van zoekopdrachten gesorteerd op gemiddelde uitvoeringstijd:
Mysqldumpslow -t 10 -s op /var/log/mysql/localhost-slow.log
Conclusie
In deze uitgebreide MySQL-optimalisatiepost hebben we het besproken verschillende methoden en technieken waarmee we onze MySQL kunnen laten vliegen.
We hebben configuratie-optimalisatie bedacht, we hebben de indexen geüpgraded en we hebben een aantal knelpunten weggenomen. Dit was allemaal grotendeels theorie, maar het is allemaal toepasbaar op toepassingen in de echte wereld.
Van de auteur: een van mijn vrienden besloot zijn auto te optimaliseren. Eerst demonteerde hij één wiel, dus sneed hij het dak eraf, daarna de motor... Over het algemeen loopt hij nu. Dit zijn allemaal gevolgen van een verkeerde aanpak! Om ervoor te zorgen dat uw DBMS blijft werken, moet MySQL-optimalisatie daarom correct worden uitgevoerd.
Wanneer optimaliseren en waarom?
Het is niet de moeite waard om naar de serverinstellingen te gaan en de parameterwaarden opnieuw te wijzigen (vooral als je niet weet hoe dit zou kunnen eindigen). Als we dit onderwerp bekijken vanuit de “klokkentoren” van het verbeteren van de prestaties van webbronnen, dan is het zo uitgebreid dat er een hele wetenschappelijke publicatie in 7 delen aan moet worden gewijd.
Maar ik heb duidelijk niet zoveel geduld als schrijver, en jij als lezer ook niet. We zullen het eenvoudiger doen en proberen ons slechts een klein beetje te verdiepen in het struikgewas van de optimalisatie van de MySQL-server en zijn componenten. Door alle DBMS-parameters optimaal in te stellen, kunnen verschillende doelen worden bereikt:
Verhoog de snelheid van het uitvoeren van query's.
Bevorderen algemene prestaties server.
Verkort de wachttijd voordat bronpagina's zijn geladen.
Verminder het verbruik van de capaciteit van de hostingserver.
Verminder de hoeveelheid schijfruimte die wordt verbruikt.
We zullen proberen het hele onderwerp optimalisatie in verschillende punten op te splitsen, zodat het min of meer duidelijk is wat de ‘pot kookt’.
Waarom een server opzetten?
In MySQL moet prestatie-optimalisatie beginnen vanaf de server. Allereerst moet u de werking ervan versnellen en de tijd die nodig is om verzoeken te verwerken, verkorten. Een universeel middel om alle bovengenoemde doelen te bereiken is het inschakelen van caching. Weet je niet “wat is het”? Nu zal ik alles uitleggen.
Als caching is ingeschakeld op uw serverinstantie, dan MySQL-systeem onthoudt automatisch de door de gebruiker ingevoerde zoekopdracht. En de volgende keer gebeurt het weer dit resultaat verzoek (voor bemonstering) wordt niet verwerkt, maar uit het systeemgeheugen gehaald. Het blijkt dat de server op deze manier tijd ‘bespaart’ bij het geven van een antwoord, en als gevolg daarvan neemt de reactiesnelheid van de site toe. Dit geldt ook voor de algehele downloadsnelheid.
In MySQL is query-optimalisatie van toepassing op die motoren en CMS die op basis van dit DBMS en PHP werken. In dit geval vraagt de code die in een programmeertaal is geschreven om een dynamische webpagina te genereren een deel van de structurele delen en inhoud ervan (records, archieven en andere taxonomieën) uit de database.
Dankzij ingeschakelde caching in MySQL gaat het uitvoeren van queries naar de DBMS-server veel sneller. Hierdoor neemt de laadsnelheid van de gehele bron als geheel toe. En dit heeft een positief effect op zowel de gebruikerservaring als de positie van de site in de zoekresultaten.
Caching inschakelen en configureren
Maar laten we teruggaan van de “saaie” theorie naar de interessante praktijk. Verdere optimalisatie MySQL-databases Laten we doorgaan met het controleren van de cachingstatus op uw databaseserver. Om dit te doen, zullen we op speciaal verzoek de waarden van alle systeemvariabelen weergeven:
Het is een heel andere zaak.
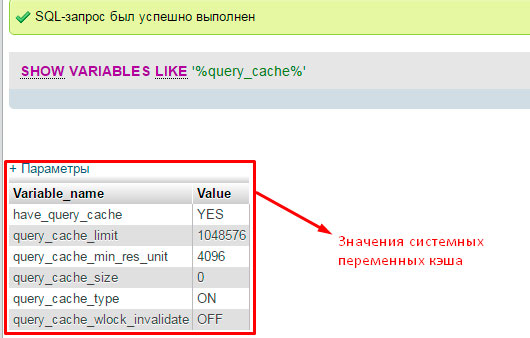
Laten we een klein overzicht maken van de verkregen waarden, die voor ons nuttig zullen zijn bij het optimaliseren van MySQL-databases:
have_query_cache – de waarde geeft aan of het cachen van zoekopdrachten “AAN” is of niet.
query_cache_type – geeft het actieve cachetype weer. We hebben de waarde "AAN" nodig. Dit geeft aan dat caching is ingeschakeld voor alle soorten selectie (SELECT-opdracht). Behalve voor degenen die de parameter SQL_NO_CACHE gebruiken (verbiedt het opslaan van informatie over deze query).
We hebben alle instellingen correct ingesteld.
We meten de cache voor indexen en sleutels
Nu moet u controleren hoeveel RAM is toegewezen voor indexen en sleutels. Het wordt aanbevolen om deze parameter, belangrijk voor het optimaliseren van de MySQL-database, in te stellen op 20-30% van de hoeveelheid RAM die beschikbaar is voor de server. Als er bijvoorbeeld 4 “hectare” is toegewezen voor een DBMS-instantie, kunt u gerust 32 “meters” instellen. Maar het hangt allemaal af van de kenmerken van een bepaalde database en de structuur (types) van tabellen.
Om de parameterwaarde in te stellen, moet u de inhoud bewerken configuratiebestand my.ini, dat zich in Denver op het volgende pad bevindt: F:\Webserver\usr\local\mysql-5.5

Open het bestand met Kladblok. Vervolgens vinden we daarin de parameter key_buffer_size en stellen we de optimale grootte voor uw pc-systeem in (afhankelijk van de “hectare” RAM). Hierna moet u de databaseserver opnieuw opstarten.

Het DBMS gebruikt verschillende aanvullende subsystemen ( lager niveau), en al hun basisinstellingen zijn ook gespecificeerd in dit bestand configuraties. Daarom, als u MySQL InnoDB moet optimaliseren, welkom hier. We zullen dit onderwerp in meer detail bestuderen in een van onze volgende materialen.
Het meten van het niveau van indexen
Het gebruik van indexen in tabellen verhoogt de verwerkingssnelheid en het genereren van een DBMS-antwoord op een ingevoerde vraag aanzienlijk. MySQL “meet” voortdurend het niveau van index- en sleutelgebruik in elke database. Om te ontvangen gegeven waarde gebruik zoekopdracht:
TOON STATUS ZOALS "handler_read%"
TOON STATUS ZOALS "handler_read%" |

In het resulterende resultaat zijn we geïnteresseerd in de waarde in de regel Handler_read_key. Als het daar aangegeven aantal klein is, geeft dit aan dat indexen vrijwel nooit in deze database worden gebruikt. En dit is slecht (zoals het onze).
→ Optimalisatie MySQL-query's
MySQL heeft een breed scala aan functies voor verschillende sorteringen ( BESTEL DOOR), groepen ( GROEP DOOR), verenigingen ( LINKS AANMELDEN of RECHTS MOETEN) enzovoort. Ze zijn allemaal zeker handig, maar onder voorwaarden van eenmalige verzoeken. Als u bijvoorbeeld persoonlijk iets in de database moet opgraven met behulp van een aantal tabellen en links, dan kunt en moet u naast de bovenstaande functies zelfs voorwaardelijke operatoren gebruiken ALS. Belangrijkste fout Voor beginnende programmeurs is dit de wens om dergelijke vragen toe te passen in de werkende code van de site. In dit geval is een complexe vraag zeker mooi, maar schadelijk. Het punt is dat operatoren voor sorteren, groeperen, samenvoegen of geneste query's niet in RAM kunnen worden uitgevoerd en gebruikt harde schijf om tijdelijke tabellen te maken. En de harde schijf is, zoals u weet, het knelpunt van de server.
Regels voor het optimaliseren van mysql-query's
1. Vermijd geneste zoekopdrachten
Dit is de ernstigste fout. Het ouderproces wacht altijd tot het onderliggende proces is voltooid en houdt op dit moment een verbinding met de database, gebruikt de schijf en laadt iowait. Twee parallelle verzoeken aan de database en het uitvoeren van de nodige filtering in de serverinterpreter ( Perl, PHP, enz.) zal een orde van grootte sneller worden uitgevoerd dan de geneste versie.
Voorbeelden in perl wat je niet moet doen:
Mijn $sth = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(2,3,7)");
$sth->execute();
while (my @row = $sth->fetchrow_array()) ( my $groupNAME = $dbh->selectrow_array("SELECT groupNAME FROM groups WHERE groupID = $row"); ### Laten we zeggen dat je de namen moet verzamelen van groups ### en voeg ze toe aan het einde van de data-array push @row => $groupNAME; ### Doe iets anders... )
of in geen geval zoals dit:
Mijn $sth = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(SELECT groupID FROM groups WHERE groupNAME = "Eerste" OR groupNAME = "Tweede" OF groupNAME = "Zevende")");
Als dergelijke acties nodig zijn, is het in alle gevallen beter om een hash, array of een ander filterpad te gebruiken.
Een voorbeeld in perl, zoals ik meestal doe:
Mijn %groepen;
my $sth = $dbh->prepare("SELECT groupID,groupNAME FROM groepen WHERE groupID IN(2,3,7)");
$sth->execute();
while (my @row = $sth->fetchrow_array()) ( $groups($row) = $row; ) ### Laten we nu de hoofdophaalactie uitvoeren zonder de subquery my $sth2 = $dbh->prepare("SELECT elementID,elementNAAM,groepID VAN tbl WHERE groepsID IN(2,3,7)");
$sth2->execute();
while (my @row = $sth2->fetchrow_array()) ( push @row => $groups($row); ### Laten we iets anders doen... ) 2. Sorteer, groepeer of filter niet in de database Gebruik indien mogelijk niet de operatoren ORDER BY, GROUP BY of JOIN in uw zoekopdrachten. Ze gebruiken allemaal tijdelijke tabellen. Als sorteren of groeperen alleen nodig is om elementen weer te geven, bijvoorbeeld alfabetisch, is het beter om deze acties uit te voeren in interpretervariabelen.
Perl-voorbeelden van hoe u niet moet sorteren:
Hoewel het sorteren in de database in sommige gevallen kan worden achterwege gelaten, is het onwaarschijnlijk dat WHERE mogelijk is. Daarom is het voor de velden die worden vergeleken noodzakelijk om indexen in te stellen. Ze zijn gemakkelijk te doen.
Met dit verzoek:
ALTER TABEL `any_db`.`any_tbl` ADD INDEX `text_index`(`text_fld`(255));
Waarbij 255 de sleutellengte is. Voor sommige gegevenstypen is dit niet vereist. Zie de MySQL-documentatie voor meer informatie.
Wanneer u een query maakt, weet u soms al dat u slechts één unieke rij in de tabel nodig heeft. U kunt een selectie maken op basis van een uniek record. Of u kunt eenvoudigweg een controle uitvoeren om te zien of er een aantal records bestaat die aan uw voorwaarde voldoen.
In dergelijke gevallen kan het gebruik van de LIMIT 1-methode de prestaties aanzienlijk verbeteren:
// zijn er gegevens voor mensen uit Californië in de database? // NEE, die zijn er niet!: $r = mysql_query("SELECT * FROM gebruiker WHERE state = "California""); if (mysql_num_rows($r) > 0) ( // ... andere code ) // Positief antwoord $r = mysql_query("SELECT 1 FROM gebruiker WHERE state = "California" LIMIT 1"); if (mysql_num_rows($r) > 0) ( // ... andere code )
2. Optimalisatie van het werken met de database met behulp van query-cacheverwerking
De meeste MySQL-servers ondersteunen query-caching. Dit is een van de meest effectieve methoden prestatieverbeteringen die de database-engine zonder problemen verwerkt.
Wanneer dezelfde zoekopdracht meerdere keren wordt uitgevoerd, wordt het resultaat uit de cache gehaald. Zonder dat u alle tabellen opnieuw hoeft te verwerken. Dit versnelt het proces aanzienlijk.
// als querycache NIET wordt ondersteund $r = mysql_query("SELECT gebruikersnaam VAN gebruiker WHERE signup_date >= CURDATE()"); // cache ondersteund! $today_date = date("J-m-d"); $r = mysql_query("SELECT gebruikersnaam VAN gebruiker WAAR signup_date >= "$today_date"");
3. Indexeren van zoekvelden
Indexen zijn niet alleen bedoeld om te worden toegewezen aan primaire of unieke sleutels. Als er kolommen in een tabel staan waarnaar u zoekt, moeten deze vrijwel zeker worden geïndexeerd.
Zoals u zich kunt voorstellen, geldt deze regel ook voor delen van de zoekreeks: zoals “achternaam LIKE ‘%’”. Bij het zoeken aan het begin van een rij kan MySQL indexering op die kolom gebruiken.
U moet ook begrijpen welke soorten zoekopdrachten geen reguliere indexen kunnen gebruiken. Wanneer u bijvoorbeeld naar een woord zoekt (bijvoorbeeld 'WHERE post_content LIKE '%tomato%''), levert het gebruik van een gewone index u niets op. In dit geval is het beter om MySQL-zoekopdracht voor volledige naleving of maak uw eigen index.
4. Kolommen van hetzelfde type indexeren en gebruiken bij het samenvoegen
Als uw toepassing veel join-query's bevat, moet u ervoor zorgen dat de kolommen in beide tabellen waaraan u deelneemt, worden geïndexeerd. Dit heeft invloed op de optimalisatie van intern MySQL-bewerkingen door associatie.
Bovendien moeten de kolommen die worden samengevoegd van hetzelfde type zijn. Als u bijvoorbeeld een kolom van het type DECIMAL uit de ene tabel en een kolom van het type INT uit een andere tabel samenvoegt, kan MySQL geen van beide gebruiken. ten minsteéén van de indexen.
Zelfs de tekencodering moet van hetzelfde type zijn voor de corresponderende rijen van de kolommen die worden samengevoegd.
// op zoek naar bedrijven in mijn staat $r = mysql_query("SELECTeer bedrijfsnaam VAN gebruikers LINKS JOIN bedrijven AAN (users.state = bedrijven.staat) WAAR gebruikers.id = $user_id"); // beide statuskolommen moeten worden geïndexeerd // en ze moeten allebei van hetzelfde type zijn en dezelfde tekencodering hebben voor de overeenkomstige rijen // anders moet MySQL de hele tabel scannen
5. Vermijd indien mogelijk het gebruik van SELECT *-query's
Hoe meer gegevens in een tabel tijdens een query worden verwerkt, hoe langzamer de query zelf wordt uitgevoerd. De tijd dringt schijfbewerkingen. Wanneer de databaseserver wordt gedeeld met de webserver, treden er bovendien vertragingen op bij de gegevensoverdracht tussen de servers.
// ongewenste zoekopdracht $r = mysql_query("SELECT * FROM gebruiker WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "Welkom ($d["gebruikersnaam"])"; // het is beter om de volgende code te gebruiken: $r = mysql_query("SELECT gebruikersnaam FROM gebruiker WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "Welkom ($d["gebruikersnaam"])";
6. Gebruik alstublieft niet de sorteermethode ORDER BY RAND().
Dit is een van die trucs die op het eerste gezicht goed lijken, en veel nieuwe programmeurs trappen erin. U kunt zich niet eens voorstellen wat voor soort val u voor uzelf uitzet zodra u dit filter in zoekopdrachten gaat gebruiken.
Als u echt bepaalde tekenreeksen in uw zoekresultaten moet sorteren, zijn er veel efficiëntere manieren om dit te doen. Stel dat u iets moet toevoegen extra code aan het verzoek voldoen, maar vanwege deze valkuil kunt u dit niet doen, wat zal leiden tot een afname van de efficiëntie van de gegevensverwerking naarmate de database groter wordt.
Het probleem is dat MySQL een RAND()-bewerking uitvoert (die servercomputerbronnen gebruikt) voordat elke rij in de tabel wordt gesorteerd. In dit geval wordt slechts één rij geselecteerd.
// welke code mag NIET worden gebruikt: $r = mysql_query("SELECT gebruikersnaam FROM gebruiker ORDER BY RAND() LIMIT 1"); // het zou juister zijn om de volgende code te gebruiken: $r = mysql_query("SELECT count(*) FROM user"); $d = mysql_fetch_row($r); $rand = mt_rand(0,$d - 1); $r = mysql_query("SELECTEER gebruikersnaam VAN gebruiker LIMIT $rand, 1");
Zo selecteert u minder zoekresultaten, waarna u de LIMIT-methode kunt toepassen zoals beschreven in punt 1.
7. Gebruik ENUM-kolommen in plaats van VARCHAR
ENUM kolommen zijn zeer compact en daardoor snel te verwerken. In de database wordt de inhoud opgeslagen in TINYINT-formaat, maar ze kunnen alle waarden bevatten en weergeven. Daarom is het erg handig om bepaalde velden erin in te stellen.
Als u een veld heeft dat er meerdere bevat verschillende betekenissen van hetzelfde type is, is het beter om ENUM te gebruiken in plaats van VARCHAR-kolommen. Dit kan bijvoorbeeld een kolom ‘Status’ zijn, die alleen waarden bevat zoals ‘actief’, ‘inactief’, ‘in behandeling’, ‘ verlopen"enz.
Het is zelfs mogelijk om een scenario in te stellen waarin MySQL u zal “vragen” om de tabelstructuur te wijzigen. Als u een VARCHAR-veld heeft, kan het systeem automatisch aanbevelen om de kolomindeling te wijzigen in ENUM. Dit kunt u doen door de functie PROCEDURE ANALYSE() aan te roepen.
Gebruik velden om IP-adressen op te slaan typ NIET ONDERTEKEND INT
Veel ontwikkelaars creëren voor dit doel VARCHAR(15)-velden, terwijl IP-adressen als decimale getallen in de database kunnen worden opgeslagen. Velden van het type INT bieden de mogelijkheid om maximaal 4 bytes aan informatie op te slaan en kunnen tegelijkertijd worden ingesteld vaste maat velden.
U moet ervoor zorgen dat uw kolommen de indeling UNSIGNED INT hebben, aangezien het IP-adres is opgegeven in 32 bits.
In query's kunt u de parameter INET_ATON() gebruiken om IP-adressen naar te converteren decimale getallen, en INET_NTOA() is het tegenovergestelde. PHP heeft andere vergelijkbare functies long2ip() en ip2long().
8. Verticaal snijden (scheiding)
Verticale partities zijn het proces waarbij een tabelstructuur verticaal wordt verdeeld om de databaseprestaties te optimaliseren.
Voorbeeld 1: Stel dat u een tabel met gebruikers heeft die onder andere hun thuisadressen bevat. Deze informatie wordt zeer zelden gebruikt. U kunt uw tabel splitsen en de adresgegevens in een andere tabel opslaan.
Op deze manier wordt uw hoofdgebruikerstabel merkbaar kleiner. En zoals u weet worden kleinere tabellen sneller verwerkt.
Voorbeeld 2: U heeft een veld in uw tabel “last_login” (laatste login). Het wordt elke keer bijgewerkt wanneer de gebruiker inlogt met zijn gebruikersnaam. Maar elke wijziging aan een tabel wordt naar de querycache voor die tabel geschreven, die op schijf wordt opgeslagen. U kunt dit veld naar een andere tabel verplaatsen om het aantal oproepen naar uw hoofdgebruikerstabel te verminderen.
U moet er echter zeker van zijn dat beide tabellen die het gevolg zijn van het partitioneren, in de toekomst niet even vaak zullen worden gebruikt. Anders zullen de prestaties aanzienlijk afnemen.
9. Kleinere kolommen zijn sneller
Voor database-engines schijfruimte, misschien wel het knelpunt. Daarom is het compacter opslaan van informatie over het algemeen gunstig vanuit het oogpunt van prestaties. Dit vermindert het aantal schijftoegangen.
De MySQL-documenten schetsen een aantal opslagvereisten verschillende soorten gegevens. Als de tabel naar verwachting niet te veel records bevat, is er geen reden om de primaire sleutel op te slaan in velden als INT, MEDIUMINT, SMALLINT en in in sommige gevallen zelfs TINYINT. Als u geen tijdcomponenten (uren: minuten) nodig heeft in het datumformaat, gebruik dan velden van het type DATE in plaats van DATETIME.
Zorg er echter voor dat je jezelf in de toekomst voldoende ruimte laat voor ontwikkeling. Anders kan er op een gegeven moment zoiets als een ineenstorting optreden.
























