Wanneer u zoekwoordgegevens ontvangt, kunt u statistieken of prognoses kiezen. Deze gegevens komen overeen met de locatie, het datumbereik en de targetinginstellingen voor het zoeknetwerk die u selecteert in het venster Targeting. Met behulp van statistieken en prognoses krijgt u inzicht in hoe u zoekwoorden het beste kunt groeperen en welke biedingen u kunt kiezen.
In dit artikel leert u hoe u statistieken en prognoses voor zoekwoorden kunt verkrijgen, dergelijke gegevens kunt analyseren en targeting en filterresultaten kunt instellen.
Instructies
Indicatoren en prognoses op trefwoorden
Gebruik zoektypen voor zoekwoorden om nauwkeurigere verkeersprognoses te krijgen. Door bijvoorbeeld een zoekwoordzin toe te voegen met een exacte overeenkomst [elite resort regio Krasnodar], kunt u de effectiviteit van zoekopdrachten die specifiek daarvoor bedoeld zijn, evalueren.
Indicatoren voor de afgelopen periode
Voorspellingen
Bij het berekenen van het aantal vertoningen dat u in de toekomst mogelijk ontvangt, wordt rekening gehouden met uw bod, budget, tijd van het jaar en statistieken over de advertentiekwaliteit. Zoekwoordprognoses, bekeken in Planner, bestaan uit een overzichtsdiagram, een tabel met gedetailleerde gegevens en biedingsaanbevelingen op basis van uw bedrijfsdoelen.
Betekenis van indicatoren in prognoses voor trefwoorden
- Klikken. Het aantal klikken dat een advertentie met een bepaald zoekwoord per dag kan ontvangen.
- Prijs. Mogelijk gemiddeld bedrag dat per dag aan dit zoekwoord wordt besteed.
- Indrukken. Hoeveel vertoningen kan een advertentie per dag ontvangen. Elke keer dat deze op een zoekresultatenpagina verschijnt, wordt er een vertoning geregistreerd.
- CTR. De verhouding tussen het aantal potentiële klikken op een advertentie en het mogelijke aantal vertoningen.
- Gemiddelde kosten per klik. Het gemiddelde bedrag dat u naar verwachting per klik betaalt. Het uiteindelijke bedrag dat u per klik betaalt, wordt automatisch aangepast en heet de werkelijke kosten per klik. Dit betekent dat het bedrag de minimaal aanvaardbare waarde met niet meer dan 60 kopeken zal overschrijden. Dit percentage kan daarom lager zijn dan het gemiddelde van alle ingevoerde zoekwoorden of de huidige CPC op advertentiegroepniveau.
Opmerking
Houd er rekening mee dat sommige statistieken (zoals maandelijkse zoekopdrachten) alleen worden verstrekt voor exacte matchdoeleinden. Bijvoorbeeld bij het controleren van het aantal maandelijkse zoekopdrachten op een trefwoord donkere chocolade U ziet dezelfde statistieken voor zowel brede zoekwoorden, zinsdeelzoekwoorden als exacte zoekwoorden donkere chocolade. Aan de andere kant wordt bij het verkrijgen van verkeersprognoses (aantal en kosten van klikken) rekening gehouden met deze instellingen. Bij het evalueren van een lijst met brede zoekwoorden houdt het systeem bijvoorbeeld rekening met mogelijke overlappingen daartussen.
Pagina Planoverzicht
Op de pagina Planoverzicht worden prognoses voor uw plan weergegeven, opgesplitst op best presterende zoekwoorden, locaties en apparaten. De informatie wordt op een eenvoudige en begrijpelijke manier gepresenteerd en u kunt de parameters van elke prognose wijzigen om de potentiële uitkomst van het plan in detail te analyseren.
Het standaardtarief wordt ook vermeld bovenaan de pagina Planoverzicht. U kunt deze waarde wijzigen door deze in het daarvoor bestemde veld in te voeren of door het gewenste punt op de kaart te selecteren. Zo krijgt u inzicht in de manier waarop uw bodbedrag de prestaties van uw zoekwoorden beïnvloedt. Het standaardpercentage wordt beïnvloed door de volgende factoren:
- vorig plan (indien van toepassing);
- De gemiddelde maximum CPC voor alle advertentiegroepen in het account die handmatige biedingen hebben;
- De gemiddelde maximum CPC voor alle advertentiegroepen voor handmatig bieden die dezelfde valuta gebruiken.
Problemen met verkeersvoorspellingen oplossen
Soms kunnen verkeersvoorspellingen lager zijn dan u had verwacht of afwijken van de werkelijke gegevens. In sommige gevallen wordt de voorspelling helemaal niet weergegeven.
Hieronder worden de oorzaken van dergelijke problemen beschreven en hoe u deze kunt oplossen.
De beoordelingen zijn te laag
In de Zoekwoordplanner kunt u schattingen bekijken van het aantal klikken en vertoningen dat u op een dag kunt krijgen. Om uw resultaten te verbeteren, hoeft u meestal alleen maar uw CPC te verhogen. Deze oplossing werkt echter niet altijd. De redenen staan hieronder vermeld.
- Statistieken over de effectiviteit van advertenties. Keyword Planner gebruikt deze gegevens en informatie over advertenties met vergelijkbare zoekwoorden. Als de algehele CTR voor voorgaande perioden consistent laag was, heeft dit invloed op de huidige prognose. Probeer de CTR te verhogen, wat op de lange termijn zal leiden tot betere prognoses.
- Zoekanalyse. We houden trefwoorden en zoekpatronen bij om de verkeersvolumes beter te kunnen voorspellen. Een lage ranking kan te wijten zijn aan het feit dat een bepaald trefwoord of een bepaalde zinsnede zelden wordt vermeld in zoekopdrachten. Probeer in dit geval andere zoekwoorden of combinaties daarvan toe te voegen. Om dit te doen, klikt u op "Zoekwoordopties" in het paginaselectiemenu aan de linkerkant.
- Regels voor het advertentienetwerk van Google. De zoekpartners van Google kunnen verschillende vereisten voor advertentietypen stellen. Op sommige sites kunt u dus alleen advertenties weergeven die geschikt zijn voor welk publiek dan ook. De Zoekwoordplanner past zijn prognose aan om rekening te houden met mogelijke verschillen in de regels, zodat verkeersschattingen niet altijd goed het potentieel voor zoekadvertenties weerspiegelen.
Het daadwerkelijke verkeer wijkt af van de voorspellingen van de Zoekwoordplanner
De verkeersvoorspelling voor Google Zoeken en partnersites is gebaseerd op gegevens van een dynamisch advertentieweergavesysteem. Daarom kunnen de werkelijke resultaten in een aantal situaties wezenlijk verschillen van de voorspelde resultaten.
- U heeft onlangs een Google Ads-account gemaakt. Voorspellingen voor nieuwe accounts zijn gebaseerd op gemiddelde statistieken voor alle adverteerders, omdat we nog niets over uw bedrijf weten. Geschatte waarden worden weergegeven totdat nauwkeurige gegevens over advertentieprestaties beschikbaar zijn.
- Uw advertenties worden weergegeven in het Display Netwerk. De prognose geldt alleen voor het zoeknetwerk, met uitzondering van verkeer uit het Display Netwerk, inclusief handmatig geselecteerde plaatsingen. Wanneer advertenties in het Display Netwerk worden weergegeven, zal het werkelijke verkeersvolume waarschijnlijk hoger zijn.
- U heeft een te klein doelgebied geselecteerd. Als het systeem niet over voldoende gegevens beschikt voor een geselecteerd klein gebied, is de voorspelling mogelijk niet nauwkeurig.
- U gebruikt in meerdere campagnes dezelfde of zeer vergelijkbare zoekwoorden. Als er meerdere advertenties aan een specifiek zoekwoord zijn gekoppeld, wordt er slechts één weergegeven. Dit betekent dat vergelijkbare of identieke zoekwoorden in verschillende advertentiegroepen of campagnes met elkaar zullen concurreren. De Zoekwoordplanner houdt waar mogelijk rekening met de concurrentie tussen vergelijkbare en identieke zoekwoorden binnen dezelfde campagne, maar schattingen voor dergelijke termen kunnen minder nauwkeurig zijn. De Zoekwoordplanner vergelijkt geen zoekwoorden die in verschillende campagnes worden gebruikt, dus er wordt bij het berekenen van de scores helemaal geen rekening gehouden met de concurrentie tussen campagnes.
- Een zoekwoordenplan of -lijst presenteert gerelateerde zoekwoorden. Wanneer u vraagt om een schatting van het aantal klikken voor verschillende nauw verwante zoekwoorden, probeert Planner de verdeling van het verkeer daartussen te voorspellen, waardoor de resulterende schattingen mogelijk minder nauwkeurig zijn.
- De dagelijkse schatting wordt berekend op basis van de wekelijkse schatting. Om een voorspelling te maken, wordt een schatting voor een week gemaakt, die vervolgens gelijkmatig over de dagen wordt verdeeld. Omdat het verkeer gedurende de week sterk fluctueert, kunt u het beste naar het weekgemiddelde kijken.
Yandex.Wordstat(https://wordstat.yandex.ru/) is een zeer nuttige en gratis (!) Yandex-service gemaakt om trefwoorden te selecteren voor, en doe ook nog veel andere leuke dingen. Deze service is over het algemeen erg nuttig. In dit artikel zullen we erachter komen hoe u Wordstat gebruikt en we zullen bekendmaken wat er gedaan kan worden met de gegevens die via deze dienst zijn verkregen.
Veel mensen geloven dat ten onrechte Yandex Wordstat is alleen nodig om vervolgens de meest populaire ontvangen verzoeken te gebruiken, die op de site worden geplaatst. Maar dit is niet waar: Wordstat - multifunctioneel hulpmiddel, ondanks al zijn eenvoud. U kunt het bijvoorbeeld gebruiken om de structuur van zowel individuele pagina's als de site zelf als geheel te creëren.
Hoe Yandex Wordstat gebruiken?
Makkelijker kan het niet! Deze tool is zo eenvoudig te gebruiken dat zelfs een beginner ermee overweg kan. Bovendien werkt Wordstat prima op moderne mobiele apparaten. Alle noodzakelijke acties kosten u niet meer dan een minuut. Volg deze stappen om aan de slag te gaan met deze service:
- Log in op uw Yandex-mail;
- Volg de link https://wordstat.yandex.ru/;
- Voer het gewenste woord of de gewenste zin in de regel in en klik op de knop “Selecteren” (aan de rechterkant).
Zorg er eerst voor dat u een geregistreerd e-mailaccount op Yandex heeft. Als u er geen heeft, is er geen reden om naar andere diensten te zoeken: het registreren van een Yandex-e-mailaccount duurt slechts een paar minuten. Klik in de rechterbovenhoek van het scherm op de knop 'Mail' en volg vervolgens de instructies door de velden in het voorgestelde formulier in te vullen.
Log in op uw nieuwe of oude account en volg de link https://wordstat.yandex.ru/. Als het je lukt om dit adres te vergeten, kun je eenvoudigweg "Wordstat" in het Russisch in de zoekbalk typen en de eerste link volgen - je zult je niet vergissen.
Dit is hoe Yandex.Wordstat er in eerste instantie uitziet.
We voeren het gewenste woord of de gewenste zin in de regel in, klikken op "Selecteren" en binnen een paar seconden krijgen we het resultaat. Wordstat is een erg handige dienst omdat het selecteert trefwoorden in verschillende letters en cijfers, en weet ze ook in afzonderlijke woorden op te splitsen. Daarom is het voldoende om een zin in de nominatief in de regel in te voeren. Als we bijvoorbeeld 'populaire zoekopdrachten' typen, krijgen we zowel 'zoeken naar populaire zoekopdrachten' als 'populaire ZOEKzoekopdrachten' te zien.

In de zoekresultaten kunnen de eindes van woorden verschillen en kan de gezochte zin worden opgesplitst in andere woorden.
Het tabblad ‘Alles’ is in eerste instantie bovenaan geopend en kan worden omgeschakeld naar ‘Alleen mobiel’. Uit de naam van de knop blijkt duidelijk dat we in het tweede geval verzoeken zullen zien die uitsluitend door Yandex zijn verzameld op basis van verkeer van mobiele apparaten (telefoons, smartphones, tablets, enz.).
Hulptekens om uw verzoek te verduidelijken
Net als zoekmachines kunt u met Wordstat syntaxis gebruiken om uw zoekopdracht te verfijnen. De onderstaande tabel toont duidelijk de belangrijkste symbolen en hun betekenis, waarbij xxx en yyy willekeurige woorden zijn.
Teken minus (« — ") vóór een woord betekent dat alle zinsneden waarin het voorkomt uit de resulterende lijst worden verwijderd. Bijvoorbeeld door ‘populaire zoekopdrachten’ in Wordstat in te voeren -woorden“Laten we zinsneden als “populaire zoekwoorden”, “populaire woorden in zoekopdrachten” en andere weglaten.
Teken plus (« + ") vóór een woord betekent de verplichte aanwezigheid ervan in uitgegeven zoekopdrachten. Dit geldt voor voorzetsels en voegwoorden, omdat Wordstat in de normale modus veel functionele delen van de spraak ‘opeet’, dat wil zeggen dat het deze volledig negeert. Meer precies merkt de dienst GEEN korte voegwoorden en voorzetsels op (“en”, “naar”...), terwijl langere nog steeds de aandacht waard zijn (“voor”, “ook”...). Als we bijvoorbeeld de zinsnede 'populaire zoekopdrachten in Yandex' in een regel invoeren, vinden we in de lijst, naast andere zoekopdrachten, 'populaire Yandex-zoekopdrachten' en 'populaire Yandex-zoekopdrachten' en andere zinnen zonder het voorzetsel "in". En als we ‘populaire zoekopdrachten +v Yandex", dan krijgen we alleen wat we zochten, zonder onnodig "afval".
Teken citaten(«» ) kunt u alleen resultaten zien met de woorden die erin zijn geschreven (geciteerd). Houd er rekening mee dat hun volgorde en eindes kunnen variëren.
Uitroepteken (« ! “) vóór een woord betekent dat we in de uitvoer de exacte verschijning van het woord krijgen (in het aantal en de hoofdlettergrootte die we nodig hebben).
Sorteren op regio
Met Wordstat kunt u ook op regio sorteren. Om dit te doen, zoekt u rechts onder de regel de knop "Alle regio's" en plaatst u in het venster dat verschijnt de nodige selectievakjes. Overigens vindt u in hetzelfde venster aan de rechterkant een zeer handige “Quick Select” -optie. Hiermee kunt u snel (met één klik) een bestemming aanwijzen woord keuze een van de vier meest voorkomende geografische opties: Moskou en de regio; Sint-Petersburg en regio; Oekraïne; Rusland, GOS en Georgië.
Hoe overstappen op laagfrequente zoekopdrachten?
Hieronder (na de ontvangen lijst) ziet u direct een overgang naar de volgende pagina. Helaas kun je niet met één klik naar het einde van de dienst gaan, omdat je maar door één pagina tegelijk kunt scrollen. Tegenover de gemarkeerde zoekopdrachten toont Wordstat hun aantal en verzamelt alle zinnen, oftewel, die de afgelopen maand minstens vijf keer zijn doorzocht. Let op: als u pagina's te snel omslaat, of als u lang aan de dienst besteedt, a captcha. Als Yandex je dwingt de alfanumerieke code in te voeren die op de afbeelding wordt aangegeven, wil het er alleen zeker van zijn dat je geen robot bent, maar een levend persoon.
In Wordstat kunt u slechts één pagina vooruit scrollen. Om naar de tiende pagina te gaan, moet u negen keer op de knop “Volgende” klikken.
Als u, om verder te werken met populaire zoekopdrachten, de resulterende statistieken in Excel moet plakken, drukt u op Ctrl+C, markeert u met de muis alle benodigde gegevens in de browser en klikt u vervolgens in Excel met de rechtermuisknop en selecteert u "Plakken als" => “Tekst zonder opmaak”. Hierdoor ziet uw tafel er mooi en verzorgd uit.
Wat te doen met zeer populaire zoekopdrachten?
Bij het gebruik van Wordstat is er één ‘maar’ die alleen relevant is voor superpopulaire zoekopdrachten: deze service toont nooit gegevens die zich voorbij de 40e pagina van de ontvangen zinnen bevinden. Als we bijvoorbeeld de zinsnede 'film downloaden' in een regel typen, ontvangen we een groot aantal verzoeken: bijna vijf miljoen! Uiteraard zien we in dit geval het einde van de zoekresultaten niet op pagina veertig.
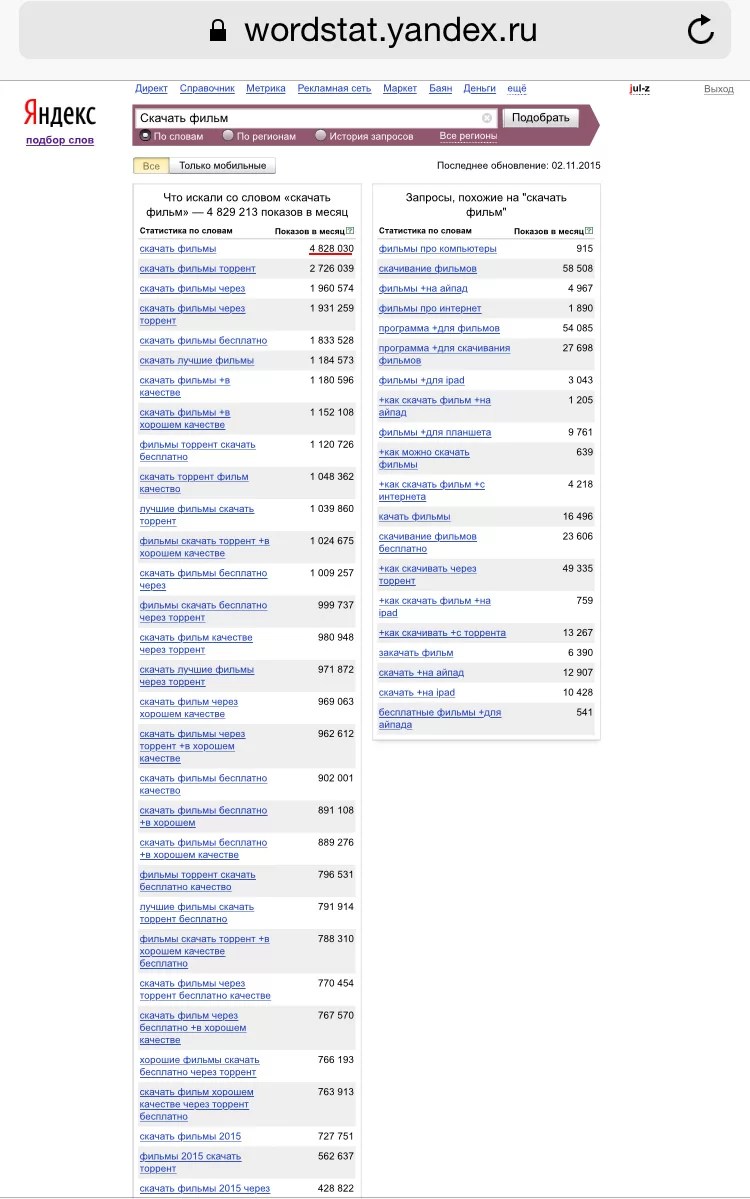
“Film downloaden” is een zeer populair verzoek. Zelfs SUPER populair.
Maar nogmaals, er is een uitweg. Als u verder moet “kijken”, kunt u een van de oplossingen van derden voor Wordstat gebruiken (deze tool heet parser). Er zijn er nogal wat, dus we zullen de bekendste noemen: Key Collector, YandexKeyParser, Yandex Wordstat Helper (« Helper » ) en Yandex Wordstat Assistent. In de volgende artikelen zullen we schrijven over hoe u dergelijke tools kunt gebruiken en hoe u precies een websitestructuur kunt maken met behulp van de meest populaire zoekopdrachten.
Nadat we de lijst met gezochte zoekopdrachten hebben ontvangen, zien we aan de rechterkant een kolom met de naam “Zoekopdrachten vergelijkbaar met “xxx” (xxx is de zin die we hebben ingevoerd). Wordstat selecteert automatisch zinnen die ook interessant en nuttig kunnen zijn voor de gebruiker. Het principe van hun selectie is als volgt: de service toont ons de woorden waarnaar mensen in Yandex hebben gezocht, samen met de vraag die we hebben getypt. Met andere woorden, vanuit Wordstat kunnen we ontdekken hoe mensen hun problemen proberen op te lossen (of aan hun behoeften te voldoen) op internet.
Door op een van de zinnen te klikken, zullen we zien dat de geselecteerde zoekopdracht naar de regel is verplaatst, dat wil zeggen dat we onmiddellijk een nieuw resultaat voor de nieuwe zoekopdracht hebben ontvangen. We kunnen niet zeggen dat deze optie altijd voor iedereen nuttig zal zijn, want als we bijvoorbeeld het woord 'zegels' in een regel typen, zullen we in de kolom aan de rechterkant nogal vreemde zinnen zien. Het is onwaarschijnlijk dat iemand ruzie zou maken met het feit dat "vragen aan klasgenoten" en "gissende antwoorden" een nogal indirecte relatie hebben met katten. 🙂 Maar dit is alleen op het eerste gezicht, omdat mensen precies naar deze zinnen zochten, wat betekent dat dit erg belangrijk kan zijn voor statistieken. Deze functie kan dus erg handig zijn, bijvoorbeeld voor het uitbreiden van onderwerpquery's.
Wat kun je nog meer zien in Wordstat?
Houd er rekening mee dat er onder de regel aan de linkerkant 3 opties zijn voor het uitgeven van Wordstat: "Volgens", "Per regio" En "Vraaggeschiedenis" Met de laatste functie kunt u de seizoensgebondenheid van verzoeken bepalen. Daar kunt u grafieken per maand of week bekijken en deze gebruiken om trends van het afgelopen jaar te volgen. Standaard is de service ingesteld op de functie "By Words", omdat deze als de meest populaire wordt beschouwd. We zullen het nu in detail analyseren, en we zullen iets later twee andere functies van Wordstat bespreken.
Wat moet u onthouden over de Yandex Wordstat-service?
- Deze tool is volledig gratis;
- Om het te gebruiken, moet u geregistreerd zijn in Yandex;
- Met Wordstat kunt u trefwoorden voor teksten selecteren;
- De terugkeer van populaire zoekopdrachten over veel onderwerpen zal elke maand of afhankelijk van het seizoen heel anders zijn (als u bijvoorbeeld de zoekopdracht “nieuws” of “waar naartoe” invoert, ontvangt u voortdurend een andere lijst);
- Wordstat is niet beperkt tot het gedeelte 'Op woorden'.
Bestudeer publieksverzoeken en Yandex Wordstat zal u voorzien hulp in deze moeilijke kwestie. Succes!
Doel: Yandex Wordstat is een van de belangrijkste hulpmiddelen om de huidige vraag naar een specifiek onderwerp te bepalen en dienovereenkomstig een actuele semantische kern te vormen. Het wordt actief gebruikt door SEO-optimizers, copywriters en webmasters.
Zoeken naar trefwoorden met Yandex Wordstat is tegenwoordig een van de snelste en handigste manieren om sleutels voor de semantische kern te selecteren. Uit ervaring betekent het kiezen van trefwoorden in deze online service van Yandex het verzamelen van 30 tot 40% van de volledige semantische kern. Bovendien kunt u in Yandex naar trefwoorden zoeken door zoeksuggesties te selecteren, maar dit is een onderwerp voor een ander artikel. De dienst is geheel gratis.
Naast selectie kunt u in Yandex Wordstat een handige analyse van zoekopdrachten uitvoeren, hoeveel zoekopdrachten er zijn gericht en veel gevraagd zijn - de service heeft hiervoor veel functionaliteit. Zoekwoordanalyse in Yandex Wordstat komt neer op:
- Analyse van de woordfrequentie (querypopulariteit) voor 3 zoekopties: breed, woordgroep, exact.
- Populariteit van zoekopdrachten in verschillende regio's
- Het bepalen van de seizoensgebondenheid van een zoekterm met behulp van de tool Querygeschiedenis.
Geval 1. Om het werken met de service te automatiseren, zijn er een aantal tools: Sleutelverzamelaar(betaald), SlowakijeYOB(gratis versie van KeyCollector), trefwoordparser "Magadan"(betaalde en gratis versie), extensie voor Mozilla Firefox en Google Chrome voor Yandex Wordstat-helper, AllesInzender(module “zoekwoordselectie”), YWSCheck.

Hieronder gaan we dieper in op de zoekwoordstatistieken van Yandex Wordstat ( wordstat.yandex.ru), als het belangrijkste hulpmiddel voor het selecteren van statistieken van Yandex-query's en de woorden zelf. U kunt echter de benodigde populaire zoekopdrachten selecteren met een andere service van Yandex - Direct ( direct.yandex.ru). Het is gemaakt voor advertentiecampagnes en stelt u in staat de weergave van advertentieblokken die voor bepaalde zoektermen worden weergegeven, te verfijnen.
Hoewel beide diensten dezelfde informatiebasis gebruiken en een aantal vergelijkbare functies hebben, zijn hun doeleinden totaal verschillend.
Geval 2.
- Informatie in de dienst wordt één keer per maand bijgewerkt.
- Het maximale aantal pagina's met resultaten is 40.
- De minimale frequentie is 1.
1. Bekijk zoekopdrachtstatistieken met Yandex Wordstat
Om te profiteren hulpmiddel voor het selecteren van populaire trefwoorden en het bekijken van statistieken van Yandex-zoekopdrachten, moet u een geregistreerde gebruiker zijn en autoriseren. Als hier geen problemen mee zijn, kunt u door naar de pagina https://wordstat.yandex.ru/ te gaan onmiddellijk aan de slag.
Voer de zoekopdracht waarin u geïnteresseerd bent in de zoekbalk in. Als u bijvoorbeeld van plan bent een informatieve website over landschapsarchitectuur te maken, typt u 'landschapsontwerp'.
Na een paar seconden ziet u in de linkerkolom statistieken voor de ingevoerde sleutelzin. Op de eerste regel wordt de zin en het aantal vertoningen per maand weergegeven.
Aandacht! De frequentie in Yandex Wordstat en Direct is niet hoe vaak een bepaalde zoekopdracht in de Yandex-zoekbalk is ingevoerd, maar hoe vaak een Yandex Direct-advertentie voor een bepaalde zoekopdracht is verschenen - dit moet onthouden worden!
Alle onderstaande zinnen zijn verdunde woordvormen van de ingevoerde sleutel. U moet het aantal vertoningen daarvoor niet bij elkaar optellen, aangezien deze allemaal zijn opgenomen in het totale aantal dat op de eerste regel wordt aangegeven.

Door op een van deze te klikken, bijvoorbeeld op 'landschapsontwerp van een site', kunt u specifieke statistieken voor dit gebied bekijken, met allerlei extra woorden.
Geval 3. Om de Yandex-beperking op het aantal zoekopties te omzeilen, kunt u ernaar zoeken in verschillende vormen, bijvoorbeeld: schoonmaken, schoonmaken, schoonmaken, schoonmaken, etc. Hierdoor krijg je meer zoekvraagmogelijkheden dan wanneer je alleen maar zou vragen: schoonmaken

Op de rechter regel worden vergelijkbare zoekopdrachten en Yandex-querystatistieken voor hen weergegeven. Dit is erg handig bij het samenstellen en uitbreiden van de semantische kern als de hoofdzoekzin bijvoorbeeld geen breed bereik heeft.
Geval 4. Bedenk dat frequentie-indicatoren vaak overdreven zijn en niet altijd overeenkomen met de werkelijke vraag. Redenen:
- website-eigenaren en SEO-bedrijven controleren dagelijks de zichtbaarheid van hun sites
- werkzaamheden van verschillende diensten voor het controleren van posities, het stimuleren van gedragsfactoren, het groeperen van zoekopdrachten
2. Regio-instelling Als u een website maakt die zich richt op een specifieke regio (bijvoorbeeld de website van een waterleveringsbedrijf in Moskou

Geval 5. Voor grote regio's: Moskou, Moskou, St. Petersburg, kunt u de regio Rusland instellen en na het verzamelen alle regio's verwijderen behalve degene die u nodig hebt (op internet kunt u veel lijsten met regio's in Rusland vinden , Wit-Rusland, Oekraïne). Op deze manier kunt u een bredere lijst met sleutelzinnen krijgen.
In het rapport “per regio” kunt u zien in welke regio’s dit verzoek populairder is. En als u op de knop “ kaart» kunt u op de wereldkaart visueel zien hoe vaak de zin wordt gebruikt.
Geval 6. Wanneer u over een land zweeft, kan het percentage meer dan 100 zijn. “Regionale populariteit” is het aandeel dat een regio inneemt in vertoningen voor een bepaald woord, gedeeld door het aandeel van alle vertoningen van zoekresultaten die op deze regio vielen . De populariteit van een woord/zin gelijk aan 100% betekent dat dit woord zich door niets onderscheidt in deze regio. Als de populariteit meer dan 100% is, betekent dit dat er in deze regio meer belangstelling is voor dit woord; als deze minder dan 100% is, betekent dit een verminderde belangstelling.

Deze gegevens kunnen worden gebruikt om contextuele advertenties te maken en te beslissen of er voor bepaalde regio's afzonderlijke advertentiecampagnes moeten worden gemaakt.
3. Seizoensgebondenheid
Met de tool Querygeschiedenis kunt u:
- Bekijk gedetailleerde statistieken per maand, week.
- Beoordeel de seizoensgebondenheid van een bepaald onderwerp.
- Bepaal of de zin een “dummy” is (het aantal vertoningen wordt in korte tijd door webmasters verhoogd).
Door een zoekterm in te voeren en op “Querygeschiedenis” te klikken, kunt u vertoningsstatistieken voor het jaar bekijken. Als we bijvoorbeeld onze zoekopdracht 'landschapsontwerp' hebben ingevoerd in de Yandex Wordstat-zoekopdracht, zullen we zien dat dit onderwerp alleen in de lente- en zomermaanden op het hoogtepunt van populariteit is. En tegen het nieuwe jaar overschrijdt de frequentie amper 100.000 vertoningen per maand.

Geval 7. Met seizoensinvloeden kunt u 'opgeblazen'/dummy-zoekopdrachten vinden, bijvoorbeeld als de frequentie van een zin een heel jaar lang 0 is en de frequentie in de afgelopen 1-2 maanden 3000 is geworden. Een uitzondering op de regel Dit kunnen voor de hand liggende seizoensvragen zijn, bijvoorbeeld: koop een grote kunstkerstboom, koop nieuwjaarsspeelgoed, uiteraard zal in de zomer de frequentie van dergelijke verzoeken nul zijn. Een uitzondering kunnen belangrijk nieuws en gebeurtenissen zijn, bijvoorbeeld: de overwinning van een onbekende atleet op de Olympische Spelen.
Bij het analyseren van sprongen in een grafiek is het raadzaam om meerdere verzoeken van een groep te analyseren om de algemene trends in de groei en ondergang van de grafiek te begrijpen.

Yandex Wordstat zal nuttig zijn voor beginnende webmasters die hun eerste website maken. Met zijn hulp kunnen ze sleutelzinnen met een stabiele populariteit selecteren. Hierdoor zijn ze niet afhankelijk van de tijd van het jaar en hebben ze een stabieler inkomen.
Geval 8. Wordstat-operatoren werken hier niet! Houd er rekening mee dat dit rapport geen zoekopdrachttaaloperatoren ondersteunt. Seizoensgebondenheid van het verzoek Yandex verstrekt geen informatie met behulp van de operatoren “aanhalingstekens”, “uitroepteken” en alle andere. In dit rapport geeft Yandex informatie over het breedste zoektype.
4. Operators in Yandex Wordstat voor het selecteren van trefwoorden
Het zoekformulier in Wordstat ondersteunt 5 operatoren, waarmee u kunt: “Zoekopdrachten verfijnen”, “Onnodige woorden uitsluiten”, “Gegevens voor meerdere zoekopdrachten combineren”:
- Operator "-". Als u het voor een bepaald woord plaatst, verdwijnen alle zoekopdrachten die dit woord bevatten uit de selectie. Voorbeeld: Koop een gebruikte bmx-fiets in Moskou
- Operator "(|)". Het wordt gebruikt om synoniemen aan de selectie toe te voegen. De constructie “Vliegtickets naar (Istanbul|Antalya)” is bijvoorbeeld gelijk aan twee zoekopdrachten: “Vliegtickets naar Istanbul” en “Vliegtickets naar Antalya”.
- Operator "!" - exacte overeenkomst. Dit is nodig zodat de woorden die u invoert in de exacte vorm door de dienst in aanmerking worden genomen, zonder dat de uitgangen of verbuigingen worden gewijzigd.
- De quote-operator "" is een zoekwoordgroep. Door de gewenste zin tussen aanhalingstekens te plaatsen, kunt u alle verdunde zoekopdrachten die extra woorden bevatten uit de selectie verwijderen en alleen de exacte vorm en woordvormen achterlaten.
- Operator "+". Voegwoorden en voorzetsels worden alleen in aanmerking genomen als ze worden voorafgegaan door deze operator. Anders worden ze door Yandex genegeerd.

Voorbeeld. Verschil in frequentie van verschillende wedstrijden voor “alle regio’s”:
- Brede match - schoonmaak appartement - 15.912 vertoningen per maand
- Zoekwoordmatch - 'schoonmaak appartement' - 1.963 vertoningen per maand
- Exacte match - “!schoonmaak!appartementen” - 1.057 vertoningen per maand
Geval 9. Bij het selecteren van zoekopdrachten voor een site is het noodzakelijk om de frequentie bovendien te controleren op exacte overeenkomst, aangezien de uitdrukkingen “nulls” heel gebruikelijk zijn, maar bij brede overeenkomst zeer indrukwekkende waarden kunnen hebben.
5. Denk na over de volgorde van de woorden in de zoekopdracht
Als er 2 zoekopdrachten in de kernel zijn die dezelfde woorden bevatten, alleen in een andere volgorde, dan kan nu iedereen ontdekken welke van de twee opties gebruikers vaker vragen, bijvoorbeeld:
Het was vóór het verschijnen van de operator: "!koop!een kerstboom" - "469 vertoningen per maand" of "koop een kerstboom" - "469 vertoningen per maand"

Het werd bij gebruik van de operator: "koop een kerstboom" - "442 vertoningen per maand" of "koop een kerstboom" - "27 vertoningen per maand"

Conclusie: de vraag ‘koop een kerstboom’ wordt vaker gesteld dan ‘koop een kerstboom’.
De “echte” frequentie is 442 vertoningen per maand voor de meest populaire optie: “koop een kerstboom”.
*controle werd uitgevoerd op 26 september 2016.
* voorheen moest u om de juiste spelling te bepalen een beroep doen op de diensten van de Keyword Planner-tool - adwords.google.com
Operator ""(vierkante haakjes). Hiermee kunt u de volgorde van woorden in een zoekopdracht vastleggen. In dit geval wordt rekening gehouden met alle woordvormen en stopwoorden.
Voor de zinsnede “tickets [van Moskou naar Parijs]” wordt de advertentie bijvoorbeeld weergegeven voor de zoekopdrachten “vliegtickets van Moskou naar Parijs”, “tickets van Moskou naar Parijs”, maar niet voor de zoekopdrachten “tickets van Parijs naar Moskou”, “tickets Moskou naar Parijs" of "hoe vlieg je van Moskou naar Parijs."
Vaak ontstaat de taak om alle zoekopdrachten van 2, 3 of 4 woorden te verzamelen, inclusief de belangrijkste markervragen. Hier zijn twee voorbeelden van hoe u dit kunt doen:
Voorbeeld 1: als u alle zoekopdrachten van drie woorden in een onderwerp met de woorden schoonmaken wilt verzamelen, moet u de volgende regel maken: 'schoonmaken schoonmaken schoonmaken'.

Een compactere alternatieve lijn:
(opschonen ~3) - parseert alle zoekopdrachten van 3 woorden met het woord opschonen
(opschonen ~4) - parseert alle zoekopdrachten van 4 woorden met het woord opschonen

Voorbeeld 2: Als de hoofdvraag uit twee woorden bestaat en u alle zoekopdrachten van vier woorden ermee moet parseren, dan moet u de volgende regel genereren: "schoonmaak schoonmaak schoonmaak appartementen".

Een compactere alternatieve lijn:(schoonmaak ~4) appartementen
7. Kenmerken van Yandex Wordstat
Het nadeel van het direct parseren van Yandex Wordstat zijn de technische beperkingen die de service zelf oplegt:
- Bij het controleren van frequenties is het noodzakelijk om afzonderlijke zoekopdrachten te maken voor elke zin die wordt gecontroleerd. Hierdoor neemt de tijd voor het verzamelen van informatie toe.
- Als er een groot aantal verzoeken is, zijn er mogelijk extra proxyservers nodig de dienst kan sancties opleggen in de vorm van een eeuwige captcha of een ban (u kunt ook proberen het IP-adres te wijzigen door de internetverbinding te resetten als het IP-adres dynamisch wordt uitgegeven door de provider).
8. Browserplug-ins voor eenvoudig werken met Yandex Wordstat
- Yandex Wordstat Helper - Een extensie voor Mozilla Firefox en Google Chrome waarmee u het verzamelen van woorden aanzienlijk kunt versnellen met behulp van de service wordstat.yandex.ru.
- Yandex Wordstat Assistant - Een extensie voor Google Chrome, Yandex.Browser en Opera-browsers, waarmee u het handmatig verzamelen van woorden aanzienlijk kunt versnellen met behulp van de Yandex-woordselectieservice (wordstat).

9. Selectie van zoektermen met Yandex Direct
Yandex Direct is een contextuele advertentiedienst en het leeuwendeel van de gebruikers zijn verkopers van goederen en diensten en adverteerders. Ondanks het feit dat het ‘op maat’ is voor het uitvoeren van advertentiecampagnes, kunt u met deze service ook Yandex-statistieken bekijken over populaire zoekwoorden of producten die gebruikers willen kopen. Maar aangezien dit een uitsluitend commerciële tool is, kunt u hier ook uw promotiewinst voor specifieke verzoeken berekenen.
Selectie van trefwoorden voor Yandex Direct kan worden gedaan met behulp van de volgende instructies:
- Ga naar de pagina https://direct.yandex.ru/.
- Klik op de knop " Plaats een advertentie" en klik op "de service gebruiken".
- Vul de informatie over de advertentiecampagne in en ga door naar de volgende fase van het opzetten ervan (de knop ‘volgende’ onderaan de pagina).
- Ga verder met het invullen van het veld 'nieuwe zoekwoorden'.

Door op de knop ‘Woorden selecteren’ te klikken en een zoekterm in te voeren, krijgt u dezelfde statistieken te zien als in de woordselectieservice. Hier kan dat toevoegen specifieke Yandex Direct-sleutelzinnen, zodat uw advertentie hiermee wordt weergegeven. Er zijn ook tips beschikbaar om uw advertentiecampagne te verfijnen.

Geval 10. Een zeer snelle verzameling van zoekopdrachten wordt binnen een paar minuten in het KeyCollector-programma geïmplementeerd. Als u over voldoende accounts beschikt, kunt u duizenden zinnen verzamelen.
10. Extra service voor budgetprognose in Direct
Zoals we hebben gezien, zijn de Wordstat- en Yandex-services gemaakt om totaal verschillende problemen op te lossen. Als Wordstat wordt gebruikt door webmasters en SEO's die geld proberen te verdienen met adverteren, dan wordt Direct ook door adverteerders gebruikt om hun campagnes op te bouwen.
De Yandex Direct-functionaliteit bevat echter een zeer populaire tool voor zowel webmasters als adverteerders - “ budgetprognose". De eerstgenoemden kunnen de potentiële winst van de site realistisch inschatten als deze is opgenomen in het Yandex Advertising Network, terwijl de laatstgenoemden hun advertentiekosten kunnen schatten.

Geval 11. In de interface worden in het venster "Hints" alleen frequentiequery's "geen dummies" weergegeven, met behulp waarvan u alle belangrijke initiële zinnen in het onderwerp kunt verzamelen, die verder kunnen worden uitgebreid.
Door een groep zoekwoorden toe te voegen, kunt u niet alleen hun frequentie (“Impressievoorspelling”) zien, maar ook de kosten van het klikken op een advertentie, evenals de CTR (klikfrequentie).

11. Kenmerken van Yandex Direct
- U kunt zowel een batchverzameling van zinnen uit de linker- als rechterkolom gebruiken, als verduidelijking van alle soorten frequenties voor zinnen die beschikbaar zijn in de tabel. Deze modus vermindert het aantal oproepen naar de dienst en verhoogt de incassosnelheid aanzienlijk.
- Wanneer u via Yandex Direct zinnen uit de linker- of rechterkolom ophaalt, retourneert de service mogelijk minder zinnen dan deze voornamelijk uit Yandex.Wordstat produceert.
- Bij het verzamelen van frequenties in KeyCollector via de Yandex.Direct-interface wordt een enorme snelheid van gegevensverzameling bereikt (tot 1000 zinnen per minuut voor 1 stream).
Hallo, beste lezers van de blogsite. Vandaag zal ik proberen je te vertellen over een dergelijk concept als de semantische kern, ik zal het tenminste proberen, omdat het onderwerp vrij specifiek is en waarschijnlijk niet voor iedereen interessant zal zijn, hoewel...
En de interne pagina's van de site, waarvan het statische gewicht niet erg hoog is, kunnen worden geoptimaliseerd voor laagfrequente zoekopdrachten (LF), die, zoals ik al meer dan eens heb genoemd, met een succesvolle combinatie van omstandigheden kunnen worden gepromoot vrijwel zonder tussenkomst van externe optimalisatie (aankoop van backlinks naar deze artikelen).
Maar nu we het toch over dit onderwerp hebben frequentie aanvragen, zonder welke het onwaarschijnlijk is dat we een semantische kern kunnen samenstellen, dan zal ik mezelf toestaan u hier een beetje aan te herinneren en hoe u hun frequentie kunt bepalen. Alle zoekopdrachten die gebruikers in de zoekbalk van Yandex, Google of een andere zoekmachine typen, kunnen dus vrij grofweg in drie groepen worden verdeeld:
- hoge frequentie (HF)
- middenfrequentie (MF)
- lage frequentie (LF)
Het zal mogelijk zijn om een sleutelzin aan een bepaalde groep toe te wijzen op basis van het aantal dergelijke verzoeken dat door gebruikers gedurende de maand is gedaan. Maar voor verschillende onderwerpen kunnen de grenzen behoorlijk verschillen. Het punt hier is dat we bij het selecteren van trefwoorden in wezen niet geïnteresseerd zijn in de frequentie van hun inbreng door gebruikers, maar in hoe moeilijk zal het zijn om vooruit te komen volgens hen (hoeveel optimizers proberen hetzelfde te doen als jij).
Daarom zal het mogelijk zijn om nog drie gradaties te introduceren, die van groot belang zullen zijn voor het samenstellen van de semantische kern:
- zeer competitief (VC)
- gemiddeld competitief (SC)
- laag competitief (NC)
Maar het bepalen van de concurrentiekracht van een bepaald zoekwoord of een bepaalde zin is niet altijd eenvoudig. Om de zaken te vereenvoudigen worden daarom vaak parallellen getrokken en wordt VC geïdentificeerd met HF, MF met SC en LF met NC. In de meeste gevallen zal een dergelijke generalisatie gerechtvaardigd zijn, maar zoals bekend zijn er uitzonderingen op elke regel, en bij sommige onderwerpen kunnen NP's zeer competitief blijken te zijn, en je zult dit meteen zien aan hoe moeilijk het zal zijn om ga naar de TOP voor deze trefwoorden.
Dergelijke botsingen zijn mogelijk bij onderwerpen waar er extreem veel concurrentie is en er een strijd is voor elke individuele bezoeker, waardoor ze zelfs voor zeer laagfrequente vragen eruit worden gehaald. Hoewel dit niet alleen inherent kan zijn aan commerciële onderwerpen. Bij het samenstellen van een semantische kern moeten informatiesites over het onderwerp “WordPress” er bijvoorbeeld rekening mee houden dat zelfs zoekopdrachten met een frequentie onder de 100 (honderd vertoningen per maand) zeer concurrerend kunnen zijn, om de eenvoudige reden dat er een heleboel sites over dit onderwerp, omdat zelfs zulke “domme jongens” zoals ik iets over dit onderwerp proberen te schrijven.
Maar we zullen niet zo diep op de details ingaan en bij het samenstellen van de semantische kern gaan we ervan uit dat de concurrentie (hoeveel optimizers proberen hun projecten voor deze sleutel te promoten) en de frequentie (hoe vaak gebruikers ze in de zoekbalk invoeren) rechtstreeks van elkaar verschillen. afhankelijk van elkaar. Welnu, we kunnen op de een of andere manier de frequentie van bepaalde zoekwoorden bepalen, toch?
Je kunt er meerdere hiervoor gebruiken, maar ik vind de Yandex-tool het leukst. Voorheen was het alleen bedoeld om adverteerders in staat te stellen de teksten van hun contextuele advertenties correct samen te stellen, rekening houdend met de woorden waar gebruikers deze zoekmachine het vaakst om vragen.
Maar dan toegang tot online trefwoordselectieservice genaamd Yandex Wordstat (Wordstat.Yandex.ru) stond open voor iedereen, waar dezelfde mensen niet nalaten gebruik van te maken. Waarom zijn wij nog slechter?
Yandex Wordstat - waar u op moet letten bij het verzamelen van zaden
Laten we dus naar deze wonderservice van Yandex gaan, die "trefwoordstatistieken" wordt genoemd en zich bevindt op Wordstat.Yandex.ru. Deze service is gemaakt en gepositioneerd als een onmisbaar hulpmiddel voor het werken met Yandex Direct, maar ook voor SEO-promotie van uw website voor deze zoekmachine. Maar in feite is het de krachtigste tool geworden voor het analyseren van trefwoorden in RuNet.
Daarom, naast het directe doel ervan Yandex Wordstat kan ook met succes worden gebruikt:
- Bij het werken met Google Adwords
- Om te zoeken naar populaire hashtags op sociale netwerken
- Om gegevens te verkrijgen over de vraag naar een bepaald product
- Om de sitestructuur op te bouwen
- Om naar soortgelijke woorden te zoeken
- Om de vraag naar goederen of diensten in een andere regio te testen bij het zoeken naar nieuwe markten
- Om het succes van offline adverteren te analyseren door de frequentie van vermeldingen van merkwoorden te analyseren
Met dit alles kan worden gezegd dat de Wordstat-interface spartaans is, maar dit is misschien alleen maar ten goede. Als u meer wilt, kunt u verschillende programma's gebruiken om op afstand met deze service te werken, of een plug-in zoals Yandex Wordstat Assistant in uw browser installeren.
Nadat Yandex de verdeling van zoekresultaten afhankelijk van de regio heeft geïntroduceerd, heeft u de mogelijkheid om de frequentie te zien van het invoeren van bepaalde zoekopdrachten voor elke regio afzonderlijk (hiervoor heeft u nodig regio selecteren door naar het juiste tabblad te gaan).

Als regionaliteit u niet stoort, is het zinvol om naar de statistieken op het eerste tabblad te kijken zonder rekening te houden met geoafhankelijkheid. In principe is dit niet zo belangrijk in de fase van het bestuderen van de principes van het samenstellen van een semantische kern voor een site. Evenals de onlangs verschenen mogelijkheid om statistieken alleen voor mobiele gebruikers (met tablets en smartphones) afzonderlijk te bekijken. Dit kan relevant zijn in het licht van de exponentiële groei van mobiel verkeer.
In ieder geval moet u eerst voor uzelf toewijzen een aantal basissleutelwoorden (maskers) over het onderwerp van uw toekomstige project, van waaruit we verder zullen dansen en alle andere trefwoorden zullen selecteren met Yandex Wordstat. Waar kan ik ze krijgen? Denk of kijk eens naar de concurrenten die u kent in uw niche (er is een dienst genaamd Serpstat die u hierbij kan helpen).
En eenvoudige logica is vaak erg handig. Als uw toekomstige site bijvoorbeeld over het onderwerp "Joomla" gaat, dan zou het voor het compileren van een semantische kern heel logisch zijn om dit trefwoord eerst in Yandex.Wordstat in te voeren. De logica is eenvoudig. Als de site gebaseerd is op SEO, kunnen er veel initiële sleutels zijn (SEO, websitepromotie, promotie, optimalisatie, enz.).
Welnu, we nemen een andere zin als voorbeeld: “wordstat”. Laten we eens kijken wat deze online service ons over zichzelf vertelt. Hier is het de moeite waard om meteen een paar opmerkingen te maken.
Wat u moet weten en begrijpen om WordStat succesvol te kunnen gebruiken
- Ten eerste, om een aanzienlijke toestroom van bezoekers te kunnen ontvangen voor de door u gekozen sleutel, uw site zou in de Top 10 moeten staan(na de eerste tien levensjaren zijn er helaas vrijwel geen) zoekresultaten (sikkel - zie). Stel je voor dat er honderden of zelfs duizenden mensen bereid zijn (concurrenten). Daarom is de zaadkern slechts een noodzakelijke voorwaarde voor het succes van de site, maar helemaal niet voldoende.
- Ten tweede krijgt nu bijna elke gebruiker zijn eigen resultaten, enigszins verschillend van wat zelfs zijn buurman op de vloer ziet. Er wordt rekening gehouden met de voorkeuren en wensen van deze specifieke gebruiker als Yandex ze eerder heeft kunnen identificeren (nou ja, en de regio natuurlijk, als het verzoek geo-afhankelijk is - bijvoorbeeld "pizzabezorging"). Standpunten hierbij zijn de “gemiddelde temperatuur in het ziekenhuis” en zullen niet altijd leiden tot de verwachte toestroom van bezoekers. Wil je het echte plaatje zien? Gebruik het.
- Ten derde: zelfs als u in de Top 10-resultaten komt (weergegeven aan de meerderheid van uw doelgroep), zal het aantal overgangen naar uw site sterk afhankelijk zijn van twee dingen: positie (de eerste en tiende kunnen qua klikfrequentie verschillen per tientallen keren) en de aantrekkelijkheid van uw (informatie over de pagina van uw site die wordt weergegeven in de resultaten voor dit specifieke verzoek).
- De zoekopdrachten die u hebt gekozen voor promotie en vorming van de semantische kern zijn eenvoudig het kunnen wel eens dummies blijken te zijn. Hoewel dummies kunnen worden geïdentificeerd en uitgeroeid, vallen beginners vaak voor dit aas. Lees hieronder hoe u dit kunt zien en corrigeren.
- Er bestaat zoiets als bedriegen zoekopdrachten. Persoonlijk kan ik niemand bedenken die dit nodig heeft en waarom, maar zulke verzoeken komen wel voor. Als u ermee begint reclame te maken, krijgt u niet het verkeer waarop u kunt rekenen op basis van Yandex Wordstat-gegevens. Lees hieronder nogmaals hoe u bedrog kunt identificeren.
- Geef uw regio op (als u een regionaal bedrijf of regionale verzoeken heeft) bij het bekijken van de statistieken, anders krijgt u mogelijk een beeld dat volledig in strijd is met de werkelijkheid.
- Zorg ervoor dat u bij het analyseren van uw promotieresultaten rekening houdt met de seizoensgebondenheid van uw verzoeken (indien van toepassing). In Wordstat is de seizoensinvloed duidelijk zichtbaar op het tabblad “Querygeschiedenis”. U moet geen rekening houden met seizoensgebonden ups en downs als factor in uw mislukkingen of successen in promotie.
- Rechtstreeks werken met de service-interface is handig voor een klein aantal verzoeken, maar dan wordt het een “marteling”. Daarom is het belangrijkste probleem voor het succesvolle gebruik van Wordstat de automatisering van routinematige handelingen. Hoe en waarmee te automatiseren wordt hieronder beschreven.
- Als u leert hoe u Wordstat-operatoren correct gebruikt, kan het rendement aanzienlijk worden verhoogd. Dit zijn citaten, een plusteken en inzicht in wat deze service oplevert bij het invoeren van ongebruikelijke zoekopdrachten. Lees hierover hieronder en in de sectie “Geheimen van YanVo”
Bang? Zelfs ik was bang, ondanks het feit dat mijn blog in de Top staat voor honderden verzoeken (vrij frequent) (en niet in de laatste plaats vanwege het feit dat ik vrijwel onmiddellijk vanuit de semantische kern begon te werken, zij het in een enigszins uitgeklede vorm). versie - aanwijzingen selecteren voor een toekomstig artikel onmiddellijk voordat u het schrijft). Maar als ik nu zou beginnen (zelfs met de huidige ervaring), zou ik niet geloven dat ik ‘door zou kunnen breken’. Is het waar! Ik denk dat ik vooral geluk heb gehad.
Wordstat-operatoren in voorbeelden
Laten we dus de laatste twee punten eens nader bekijken: dummies en nepverzoeken. Ben je klaar? Nou, dan gaan we weg. Laten we beginnen met dummy verzoeken. Herinner je je het voorbeeld nog dat we hierboven gebruikten? Voer het woord VORDSTAT in de regel van deze service in en klik op de knop “Selecteren”.

U moet dus begrijpen dat het getal dat voor dit woord (of een andere zin) wordt weergegeven helemaal niet het werkelijke aantal verzoeken om deze sleutel weerspiegelt. Weergegeven (let op!) is het totale aantal opgevraagde zinnen per maand waarin het woord “Wordstat” werd gevonden, en niet het aantal zoekopdrachten waarin dit enkele woord (of zin, als u een sleutelzin in het Wordstat-formulier hebt ingevoerd) voorkomt. . Eigenlijk blijkt dit duidelijk uit de schermafbeelding: "Wat zocht je met het woord...".
Maar Yandex Wordstat beschikt over de juiste tools waarmee u het kaf van het koren kunt scheiden (dummy's kunt identificeren of frequentie-informatie kunt verkrijgen die geschikt is voor de werkelijkheid) en de gegevens kunt verkrijgen die we nodig hebben. Deze zijn verschillend exploitanten, die u aan uw verzoek kunt toevoegen en een verfijnd resultaat kunt krijgen.

Operators voor aanhalingstekens en uitroeptekens - dummies uitfilteren in Wordstat
Zoals u kunt zien, zijn er weinig hoofdoperatoren en de belangrijkste zijn dat naar mijn mening wel een sleutelzin tussen aanhalingstekens plaatsen en een uitroepteken voor het woord plaatsen. Hoewel voor zeer competitieve onderwerpen de nieuwe Wordstat-operator in de vorm van vierkante aanhalingstekens ook relevant kan zijn. Soms is het belangrijk om te weten hoe gebruikers woorden het vaakst rangschikken in de zoekopdracht die u nodig heeft (bijvoorbeeld 'koop een appartement' of nog steeds 'koop een appartement'). Ik gebruik het echter nog niet.
Dus, Wordstat-operator "aanhalingstekens" kunt u het aantal vermeldingen van deze specifieke zin in de Yandex-zoekregel gedurende de maand tellen, maar tegelijkertijd worden alle mogelijke woordvormen in aanmerking genomen en geteld - een ander getal, hoofdlettergebruik, enz. (Er wordt bijvoorbeeld geen rekening gehouden met Yandex Wordstat-query's, maar in ons voorbeeld alleen met Wordstat). In wezen is dit hetzelfde waar we in het artikel over hebben gesproken. Het frequentiecijfer na zo'n eenvoudige handeling zal aanzienlijk afnemen:

Die. dit is het aantal keren per maand dat gebruikers één enkel woord VORDSTAT in al zijn woordvormen (als ze überhaupt bestaan) in de Yandex-zoekbalk hebben ingevoerd. Dit verzoek is natuurlijk helemaal geen dummy, maar een volwaardige RF, maar er zijn gevallen waarin het simpelweg plaatsen van een zin tussen aanhalingstekens de frequentie reduceert van enkele duizenden tot enkele tientallen of zelfs eenheden (probeer bijvoorbeeld de zinsnede “ 100 verdienen” met of zonder offertes). Dit was echt een dummy.
De tweede belangrijke operator in Wordstat is uitroepteken vóór het woord, waardoor deze service alleen woorden zal tellen in de exacte spelling waarin u ze hebt ingevoerd (zonder rekening te houden met woordvormen). Zoals ik had verwacht, heeft het installeren van de uitroeptekenoperator voor het woord “Joomla” geen aanpassingen toegevoegd, maar dit is alleen te wijten aan de specifieke kenmerken van dit specifieke zoekwoord.
Nou ja, maar voor de sleutelzin ‘sitepromotie’ zal het verschil duidelijk en opvallend zijn:

En voeg "!" vóór elk woord zonder een spatie toe te voegen:

Waar komt dit verschil in aantallen vandaan? Het is duidelijk dat er verzoeken zijn met dezelfde trefwoorden, maar in een andere woordvorm, waardoor de resterende getallen worden opgeslokt. Voor ons voorbeeld is het gemakkelijk te raden dat het meervoud zal zijn:

Door een zin tussen aanhalingstekens te plaatsen en voor elk woord een uitroepteken te plaatsen, kunt u dus totaal verschillende frequentiewaarden verkrijgen. Op deze manier kun je niet alleen dummy's verwijderen, maar ook ideeën opdoen over de woordvormen van de zin, die het wenselijk zou zijn om vaker in de tekst te gebruiken, en welke minder vaak (maar vergeet de synoniemen niet) . Hoewel ik persoonlijk niet veel verschil zie bij het toevoegen van uitroeptekens, ben ik tevreden met simpele aanhalingstekens.
Hoe u snel rommel kunt verwijderen en alleen gerichte vragen kunt achterlaten
Er is nog een operator waarmee je alle onnodige dingen kunt afsnijden en de echte frequentie van de zin kunt zien. Dit "+" vóór een woord. Het betekent dat dit woord aanwezig moet zijn in de zin. Waarom zou dit nodig kunnen zijn? Nou, het gaat allemaal om de eigenaardigheden van de Yandex-zoekmachine.
Standaard houdt de rangschikking (en dus de Wordstat-statistieken) geen rekening met voegwoorden, voorzetsels, tussenwerpsels, enz. woorden. Dit wordt gedaan voor de eenvoud, maar vaak zijn we geïnteresseerd in het vooruitzicht op promotie, specifiek onder een zinsnede met een voorzetsel of voegwoord. Dit is waar de plustekenoperator van pas komt.
Trouwens, min operator kunt u onmiddellijk zoekwoorden verwijderen uit de zoekwoorden die niet voor u bedoeld zijn. Een dergelijke zoekopdracht naar WordStat levert bijvoorbeeld onmiddellijk het gewenste resultaat op:
Smartphones (+naar|+van|+naar) -downloaden -games -Internet -mts -foto

Om dit verzoek niet drie keer te herhalen, wordt hier de operator gebruikt "verticale balk", waarmee u zinnen met drie voorzetsels tegelijk kunt verzamelen (naar, met, aan). Welnu, woorden met een minteken (stopwoorden) zijn nodig om zinsneden te verwijderen.
Hier is nog een voorbeeld van het gebruik van operators voor hetzelfde doel:
Wasmachines (machines) (Samsung) -reparatie -fouten -review -codes -video -reserveonderdelen -storingen
Het is erg handig en snel om onnodige dingen af te snijden en tijd te besparen.
Selectie van trefwoorden in Yandex Wordstat
Het wordt u waarschijnlijk al duidelijk dat de basissleutelzinnen (maskers) die u zelf kunt formuleren op basis van het toekomstige onderwerp van uw project, met behulp van Wordstat moeten worden uitgebreid. En ook hier lijkt er sprake te zijn van twee richtingen bij het verkrijgen van nieuwe zoekwoorden om een volledige semantische kern samen te stellen.
- Ten eerste kunt u gebruik maken van de geavanceerde opties die Wordstat biedt in de linkerkolom jouw raam. Er zullen zoekopdrachten zijn die woorden uit uw masker bevatten (bijvoorbeeld 'constructie', als uw project een relevant onderwerp heeft). Ze worden gesorteerd in aflopende volgorde van gebruik door gebruikers in de Yandex-zoekbalk per maand.
Wat is hier belangrijk? Het is belangrijk om onmiddellijk de uitgebreide sleutelopties te benadrukken die voor uw project bedoeld zijn. Doel- dit zijn zoekopdrachten waarvan de inhoud meteen duidelijk maakt dat de gebruiker die deze invoert, precies zoekt naar wat u hem op uw website kunt aanbieden en die u wilt promoten.
De zoekopdracht ‘core’ is bijvoorbeeld zeer hoogfrequent, maar ik heb deze helemaal niet nodig, omdat dit absoluut niet het doelzoekwoord is voor deze publicatie. Je weet nooit waar gebruikers naar op zoek zijn als ze het in de Yandex-zoekbalk invoeren, nou ja, zeker niet "semantisch", wat trouwens een goed voorbeeld zal zijn van een doelzoekopdracht met betrekking tot dit artikel.
Maar u moet doelsleutels kiezen met betrekking tot de hele toekomstige site, hoewel het soms handig kan zijn om algemene zoekopdrachten te promoten, maar dit is eerder de uitzondering op de regel.
Doelzinnen zullen minder vaak voorkomen en gebruikers die uit zoekresultaten voor hen komen, zullen op zijn minst iets kunnen vinden dat lijkt op wat ze wilden vinden, wat betekent dat ze uw project niet onmiddellijk zullen verlaten, waardoor uw resultaten verslechteren. En zulke bezoekers zijn voor u heel belangrijk, omdat zij de door u gewenste actie kunnen uitvoeren (een aankoop doen of een dienst bestellen).
Ik denk dat het niet nodig is om verder te praten over de selectie van precies zulke trefwoorden uit de Yandex-statistieken - alles is je al duidelijk. De enige ‘maar’. Alle zinnen uit de rechterkolom van Wordstat zijn weer voor jou moet controleren op fopspenen, namelijk, plaats ze tussen aanhalingstekens (statistieken met uitroeptekens kunnen later worden bekeken en geanalyseerd). Als de frequentie niet naar nul neigt, voeg deze dan toe aan de voorraad.

Het is je waarschijnlijk opgevallen dat voor veel zinnen de lijst in de linkerkolom niet beperkt is tot één pagina (onderaan staat een knop “volgende”). Het maximum dat Wordstat oplevert is naar mijn mening 2000 zoekopdrachten. En ze zullen allemaal op dummies moeten worden gecontroleerd. Kun jij het aan? Maar dit is slechts een van de vele ‘maskers’ (initiële sleutels) van je semantische kern. Je kunt er immers ‘je paarden verplaatsen’.
Maar wees niet ontmoedigd, want er is een manier. Via de link vindt u een gedetailleerd artikel, en als hierna nog steeds iets niet duidelijk is, gooi dan een steen naar mij.
- De tweede nuance bij het selecteren van frases voor de semantische kern is de mogelijkheid om de zogenaamde te gebruiken verenigingen uit Yandex Wordstat-statistieken. Dezelfde associatieve vragen worden gegeven in de rechterkolom zijn hoofdvenster.

Hier is het waarschijnlijk belangrijk om te begrijpen hoe deze zeer associatieve zoekopdrachten in Yandex-statistieken worden gevormd en waar ze vandaan komen. Feit is dat de zoekmachine het gedrag analyseert van de gebruiker die naar iets zoekt.
Als de gebruiker bijvoorbeeld, na (of vóór) het typen van onze sleutelzin ‘semantische kern’, een andere zoekopdracht in de zoekregel heeft ingevoerd (dit wordt één zoeksessie genoemd), dan kan Yandex ervan uitgaan dat deze zoekopdrachten op de een of andere manier met elkaar verbonden zijn. ander.
Als dezelfde associatieve connectie wordt waargenomen bij sommige andere gebruikers, wordt deze zoekopdracht, samen met de hoofdvraag, weergegeven in de rechterkolom van Wordstat. Het enige dat u hoeft te doen, is deze gegevens gebruiken om de semantische kern van uw site uit te breiden.
Alle verenigingen krijgen een indicatie van de frequentie van hun aanvraag gedurende de maand. Maar het zal natuurlijk algemeen zijn, d.w.z. je zult ook dummy's moeten identificeren, opnieuw door al deze zinnen tussen aanhalingstekens aan te vinken (Slovoeb of Key Collector kunnen je helpen - lees erover via de link hierboven).
Sommige associatieve vragen zijn waarschijnlijk bij u opgekomen, maar er zullen altijd andere zijn die u over het hoofd hebt gezien. Welnu, hoe meer doelzoekwoorden uw semantische kern bevat, hoe meer correcte bezoekers u naar uw website kunt trekken met de juiste interne en externe optimalisatie.
We gaan er dus van uit dat u op basis van basismaskers (trefwoorden die het onderwerp van uw toekomstige project duidelijk definiëren) en de mogelijkheden van Yandex Wordstat een voldoende aantal zinnen voor de semantische kern kon typen. Nu moet u ze duidelijk scheiden op basis van gebruiksfrequentie.
Geheime technieken voor het werken met WordStat
Natuurlijk is deze titel enigszins helder, maar toch zijn het de hieronder beschreven “geheimen” die je kunnen helpen deze tool 200% te gebruiken. Het is alleen zo dat als u hier geen rekening mee houdt, u tijd, geld en moeite kunt verspillen.
Hoe u de zoekopdrachtboost in Wordstat kunt zien
Het is echter duidelijk dat Wordstat voor sommige trefwoorden onjuiste informatie verstrekt. Heeft dit te maken met eventuele fraudemogelijkheden en hoe u deze kunt identificeren? fopspenen Ik zal het proberen uit te leggen. Natuurlijk kan het op deze manier controleren van alle zinnen vervelend zijn en vereist het waarschijnlijk alleen maar ervaring (onderbuikgevoel), maar het werkt best goed.
Persoonlijk ga ik ervan uit dat ze in de regel niet jarenlang vals spelen, wat betekent dat de afwijking van de gemiddelde frequentiewaarde in de grafiek kan worden gevolgd "Geschiedenis opvragen"(de schakelaar is verborgen onder de query-invoerregel van de Yandex Wordstat-service). Ik heb bijvoorbeeld onlangs zoekopdrachten geprobeerd die verband hielden met het 'affiliatieprogramma' en kwam zojuist valsspelen tegen (van bijna alle trefwoorden die verband hielden met het onderwerp).

Het is alleen zo dat ik al heel lang met deze verzoeken werk en dat ik de ‘afstemming’ grofweg ken. Daar werd de HF een of twee keer verkeerd berekend, maar hier is het niet de sleutel, het is de HF. Maar kijk maar eens naar de geschiedenis van de frequentie van dit verzoek in Wordstat (vergeet alleen niet eerst de aanhalingstekens te verwijderen) en alles wordt duidelijk (ze begonnen aan het begin van de zomer te draaien):

Bovendien is de frequentie van de verzoeken in een paar maanden met bijna twee ordes van grootte toegenomen, en een paar jaar daarvoor was deze stabiel en onderging zelfs geen bijzondere seizoensschommelingen. Duidelijk bedrog - ik weet niet waarom, maar ze verdraaien alle bijbehorende sleutels.
Hoe u het verzamelen van trefwoorden in de Yandex-service automatiseert
In principe kun je via de webinterface werken, maar het is erg vervelend. Er zijn programma's (betaald en gratis) die hiervoor geschikt zijn. Er zijn zelfs browserextensies waarmee je de routine een beetje kunt verslaan. Ik zal ze even opsommen:
Waarom is de frequentie van zoekopdrachten met herhaalde woorden zo hoog?
Als je je al min of meer hebt verdiept in de problemen van het compileren van een zaadje en veel zoekopdrachten in Wordestat hebt geparseerd, dan ben je waarschijnlijk vreemde zoekopdrachten tegengekomen met herhaalde woorden, die om de een of andere reden een hoge frequentie hebben, zelfs als ze tussen aanhalingstekens en uitroeptekens worden vóór de woorden geplaatst.

Ook als je er nog een paar keer ‘watch’ aan toevoegt, blijft de frequentie vrijwel even hoog. Moeten we Yandex dus vertrouwen en artikelen optimaliseren voor dergelijke onzin? Niet op je nelly. Dit is een ander type "fopspeen". In feite neemt Wordstat slechts één van de herhaalde woorden waar, maar vervangt de rest “mentaal” door andere mogelijke woorden met hetzelfde aantal tekens. Over het algemeen moet u, ondanks de grote aantallen, geen aandacht besteden aan verzoeken met herhaalde woorden. Dit is een fantoom.
We zijn de compilatie van de semantische kern aan het voltooien
Zoals ik hierboven al zei, zullen we standaard rekening houden met HF en VK, wat betekent dat u, om ze te promoten, die pagina's van uw site moet kiezen die het grootste statische gewicht hebben. Deze wordt gegenereerd via inkomende links naar deze pagina.
Het is belangrijk om te begrijpen dat bij de berekening ervan geen rekening wordt gehouden met de inhoud van de ankerlink en dat het niet uitmaakt of deze extern of intern is. Lees er meer over via de gegeven link.
Dat. voor promotie volgens de hoogste frequenties Voor zoekopdrachten (uit de gecompileerde semantische kern) is de hoofdpagina het meest geschikt, omdat in de regel links van alle andere pagina's van uw bron ernaar zullen leiden (met een normale structuur), evenals de meeste externe links, vooral die op natuurlijke wijze zijn verkregen. Het statische gewicht van de belangrijkste voor de meeste bronnen zal dus het hoogst zijn (voorheen kon dit worden begrepen door de werkbalkwaarde van Google PageRank te lezen, die daarvoor altijd hoger zal zijn dan voor interne bronnen, maar nu heeft Google besloten te stoppen met delen deze informatie bij ons).
Onder andere gelijke omstandigheden (dezelfde kwaliteit van interne en externe optimalisatie) zullen zoekmachines hoger scoren op de pagina waarvan het statische gewicht groter is. Als u daarom een interne pagina (met een duidelijk lager statusgewicht) kiest voor promotie op HF, zullen concurrenten een voordeel ten opzichte van u hebben als zij reclame maken met dezelfde trefwoorden, maar dan op de hoofdpagina van hun site. Hoewel de beste manier zou zijn om de Top 10 voor het zoekwoord te analyseren, moet u het aantal belangrijkste bepalen dat aan de ranglijst deelneemt (dit geeft overigens indirect het concurrentievermogen van het verzoek aan).
Als de interne linkstructuur van uw toekomstige project andere pagina's bevat met een groot statisch gewicht (secties, categorieën, enz.), dan moet u deze in de semantische kern markeren als potentiële kandidaten voor optimalisatie voor min of meer hoge en middenklassen. -frequentiequery's van de door u geselecteerde zoekopdrachten.
Op deze manier kunt u profiteren van de functies van statische gewichtsverdeling op uw site en, in overeenstemming hiermee, voor elke pagina de meest geschikte zoekopdrachten selecteren in termen van frequentie, d.w.z. stel een volledig semantische kern samen: matchparenverzoek - pagina.
Wanneer u echter een pagina optimaliseert voor promotie met een trefwoord met een hoge of gemiddelde frequentie, kunt u ook een trefwoord met een lagere frequentie toevoegen, dat wordt verkregen door de hoofdsleutel te verdunnen. Maar nogmaals, niet alle sleutels kunnen op dezelfde landingspagina tot buren worden gemaakt. Een analyse van uw directe concurrenten in de Top 10 voor uw belangrijkste zoekwoordzin zal u helpen te begrijpen welke samen kunnen worden gebruikt en welke niet. Als ze in de Top staan, betekent dit dat de zoekopdracht hun versie van het zaad leuk vindt.
Het is echter gemakkelijk gezegd, maar moeilijk om te doen. Probeer de resultaten van honderden (duizenden) zoekopdrachten uit uw voorlopige semantische kern te doorzoeken om te zien of ze compatibel of incompatibel zijn. Hier kunnen “de paarden zeker verplaatst worden.” Maar ook hier kom ik u te hulp door een link te geven naar een gedetailleerde publicatie over. Een klein programma vereenvoudigt echt alles.

Bij het uitvoeren van externe optimalisatie (aankoop en plaatsen van links met de nodige ankers) moet u opnieuw rekening houden met de gecreëerde semantische kern en backlinks plaatsen rekening houdend met de trefwoorden waarvoor deze pagina van uw site is geoptimaliseerd. Vergeet niet dat het in het tijdperk van Minusinsk en Penguin beter is om één backlink te plaatsen met een directe toegang, maar vanaf een zeer gedurfde en thematische site, en “verwatering” met niet-ankers, artikeltitels, enz. Het is de moeite waard om meer te doen.
In de praktijk zal uw semantische kern waarschijnlijk een nogal vertakt schema van pagina's vertegenwoordigen met daarvoor geselecteerde trefwoorden, waarvoor ze zullen worden geoptimaliseerd en gepromoot. Er zal ook een diagram zijn van interne koppelingen voor het oppompen van de benodigde pagina's met statisch gewicht.
Over het algemeen zal al het mogelijke worden opgenomen en overwogen; het enige dat overblijft is het starten van het bouwen (of hermodelleren) van een website op basis van dit project (semantische kern). Persoonlijk heb ik de laatste tijd altijd de regel gevolgd om het van tevoren samen te stellen, omdat blindelings werken misschien geen winstgevende activiteit is - ik zal mijn energie verspillen, en degenen die het materiaal interessant en nuttig zullen vinden, zullen het ook niet in Yandex of Google vinden ...
Als we het over deze blog hebben, ga ik voordat ik een artikel schrijf altijd naar Wordstat en kijk hoe gebruikers hun vragen formuleren over het onderwerp waarover ik wil schrijven. Het is dus waarschijnlijker dat ik mijn lezer vind, die, met een succesvolle publicatie, een vaste lezer kan worden. Dit is voor niemand slecht, behalve dat je er wat tijd aan moet besteden.
Welnu, in het geval van een project over een nieuw onderwerp voor u, en vooral als u een beginnende optimizer bent, kan het samenstellen van een dergelijke kern en het selecteren van geschikte trefwoorden u aanzienlijk helpen en onnodige fouten voorkomen. Niet iedereen heeft echter de tijd en energie om dergelijk werk uit te voeren, maar doe het toch absoluut noodzakelijk. Maar als er vraag is, zal er ook aanbod zijn. Er zullen altijd mensen zijn die dit voor je willen doen; een ander ding is dat ze misschien niet altijd eerlijk en ijverig zijn.
Veel geluk voor jou! Tot binnenkort op de pagina's van de blogsite
Je kunt meer video's bekijken door naar te gaan");">

Misschien ben je geïnteresseerd
 Statistieken van zoekopdrachten van Yandex, Google en Rambler, hoe en waarom met Wordstat werken
Statistieken van zoekopdrachten van Yandex, Google en Rambler, hoe en waarom met Wordstat werken  Rekening houdend met de morfologie van de taal en andere problemen die door zoekmachines worden opgelost, evenals met het verschil tussen hoogfrequente, middenfrequente en laagfrequente zoekopdrachten
Rekening houdend met de morfologie van de taal en andere problemen die door zoekmachines worden opgelost, evenals met het verschil tussen hoogfrequente, middenfrequente en laagfrequente zoekopdrachten
Door websites te maken verwacht hun maker dat het aantal bezoekers elke dag zal toenemen en de winst zal groeien. Maar vaak gebeurt dit niet. Waarom? Ik heb tenslotte alle punten bestudeerd en met behulp van Wordstat werd rekening gehouden met de statistieken van trefwoorden en werden ze volgens alle regels in de tekst ingevoerd.
Voor een goede optimalisatie is het noodzakelijk om een uitgebreide analyse uit te voeren van de zoekopdrachten die voor het zoeken worden gebruikt. En de selectie en implementatie van sleutelzinnen moet overeenkomen met een bepaald algoritme. Het groene licht ‘het zal wel lukken’ zal in de toekomst een wrede grap zijn. De zoekwoorden zelf worden niet correct geselecteerd en werken niet voor u.
Yandex Wordstat-statistieken: wat moet u weten?
Statistieken geven zoekopdrachten weer waarnaar internetgebruikers het vaakst zoeken in zoekmachines. Waarom is het nodig? De hoofdtaak is het samenstellen van een semantische kern. Mensen wenden zich ertoe om een tekst/artikel ‘op maat’ te maken voor een specifiek zoekwoord. Dit is nodig om een website/blog/andere bron te promoten.
Yandex-query's voor trefwoorden in Wordstat worden gecombineerd door mogelijke woordvormen, zonder rekening te houden met voorzetsels en zinnen in vragende vorm. Hoe werkt dit? Voer het benodigde woord in de service in en na een paar seconden kun je het aantal verzoeken in Yandex achterhalen: zinnen waarin het woord tegenkwam, worden weergegeven.
Afhankelijk van de specificatie krijgt u verschillende resultaten. U kunt op verschillende manieren naar Yandex-woorden zoeken met behulp van zoekopdrachten. Bijvoorbeeld de ‘pure’ spelling van een woord of woordgroep: als u zoekstatistieken in de zoekbalk invoert, zal het resultaat allerlei woordvormen zijn. Het totaal aantal vertoningen bedraagt 31535.
Welke operators moet ik gebruiken voor instantiatie?

De oplossing voor de vraag hoe u het aantal verzoeken op Yandex kunt achterhalen, is eenvoudig. Het is voldoende om speciale operators te gebruiken bij het zoeken.
- Citaten. Plaats de zin waarin u geïnteresseerd bent tussen aanhalingstekens en ontvang alleen dit trefwoord in verschillende woordvormen.
- Uitroepteken. Het wordt vóór elk woord geplaatst en zorgt ervoor dat u resultaten kunt krijgen op basis van de exacte gebeurtenis.
- Met een minteken (-) kunt u woorden uitsluiten.
- Wordstat yandex ru-statistieken kunnen resultaten weergeven met voorzetsels en voegwoorden. Om er voor te zorgen dat er rekening mee wordt gehouden, moet u de plus (+) gebruiken. Op dat moment zal de service verzoeken bij hen weergeven.
- Haakjes worden gebruikt om woorden en woordvormen tot zinsdelen te combineren.
- Een operator | betekent "of". Het is zinvol om te gebruiken als er verschillende vergelijkbare opties zijn.
De laatste twee zijn nodig bij het samenstellen van meerdere sleutelgroepen voor één aanvraag. Alle operators worden op verschillende manieren gecombineerd om tijd te besparen bij het selecteren van semantiek en het uitvoeren van statistische analyses.
Hoe u het aantal verzoeken in Yandex kunt achterhalen: extra functies
Wordstat Yandex trefwoordstatistieken geven niet alleen afgeleide gegevens weer van de woorden waarnaar u zoekt, maar ook zoekopdrachten met associaties die door gebruikers zijn gebruikt in combinatie met uw zoekopdrachten. Wat geeft dit? Deze functie helpt de semantische kern uit te breiden, waardoor u de bron zo competent mogelijk kunt optimaliseren.
U kunt aanvragen ook per regio volgen. Hoe vaak uw zoekwoord werd gebruikt in een bepaalde plaats, stad, regio, enz. Het tabblad “Op de kaart” toont de frequentie van het verzoek in de wereld.
Om het aantal verzoeken voor trefwoorden in Yandex in een bepaalde periode bij te houden, kunt u de gegevens in bijdragen “per maand”, “per week” analyseren. Dit is gerechtvaardigd voor seizoensgebonden verzoeken.

Yandex-statistieken op trefwoorden en de functies ervan
Om correct conclusies te kunnen trekken en geen tijd te verspillen aan analyse, moet u bij het selecteren van sleutelzinnen rekening houden met het volgende:
- Het aantal trefwoordverzoeken in Yandex weerspiegelt niet het aantal mensen dat het verzoek indient. Het moet duidelijk zijn dat statistieken alleen het aantal vertoningen tonen dat de gezochte zoekopdracht bevat.
- De standaardinstellingen zijn om resultaten van de afgelopen maand weer te geven. Houd er bij het analyseren rekening mee dat er seizoensgebonden verzoeken en tijdelijke ‘interessepieken’ zijn op basis van hobby’s. Dit betekent dat de zoekgegevens gedurende deze periode kunnen afwijken van het werkelijke beeld.
- Gebruik altijd Wordstat-operatoren. De gegevens die worden weergegeven tonen immers het totaal aantal van alle trefwoorden. Geen bijzonderheden. Ze zijn essentieel voor de nauwkeurigheid. Als u ze negeert, betekent dit dat u de verkeerde conclusies trekt en energie en tijd verspilt.
Met het juiste gebruik van de service en al zijn “trucs” en hulpmiddelen, kunt u het aantal verzoeken om trefwoorden achterhalen, wat een belangrijk onderdeel zal worden bij het promoten van uw bron. En om het handmatig verzamelen van zoekopdrachten uit Wordstat te vereenvoudigen, raden we u aan Yandex Wordstat Assistant te gebruiken - een browserextensie waarmee u de benodigde woorden zonder onnodige arbeid kunt kopiëren. We hebben het gemaakt in een websitepromotiestudio in Moskou: http://semantica.in/ (op de website in de sectie Tools vindt u de benodigde extensie). Trouwens, de jongens hebben een interessante blog - bestudeer het ook, je zult veel nuttige dingen vinden voor een beginnende optimizer.
Hoe de resultaten analyseren?
We hebben het algemene principe besproken van hoe u het aantal verzoeken in Yandex kunt controleren. Laten we het nu hebben over het zoekvolume. Dit is een belangrijk punt bij het bouwen van een algoritme voor het selecteren van een semantische kern en het promoten van een website.
Verdeel zoekopdrachten in zoekmachines dus in drie groepen: hoogfrequent (HF), middenfrequent (MF) en laagfrequent (LF). Yandex-querystatistieken geven alle zoekopdrachten weer. Hoe kom je erachter welke welke is en wat je het beste kunt gebruiken voor promotie? Er is geen strikte classificatie naar frequentie.
Veel mensen interpreteren de resultaten verkregen op Wordstat verkeerd. En soms worden verzoeken met een lage frequentie of zelfs dummies verward met verzoeken met een hoge frequentie. En dat allemaal omdat ze het gebruik van operators negeren.
Om het aantal verzoeken in Yandex te controleren aan de hand van het aantal keren dat de gevraagde zin is ingevoerd, en niet alleen de zoekresultaten, moet u de hierboven beschreven gebruiken!, “”. En indien nodig andere hulpmiddelen. Zo wordt het ‘afval’ opgeruimd.
Er is ook een aanvullende indeling in hoogcompetitief (HC), gemiddeld competitief (SC) en laagcompetitief (NK). De beste combinatie wordt beschouwd als een hoogfrequent en tegelijkertijd laag- of gemiddeld concurrerend verzoek.
Onthoud ook dat het controleren van de querystatistieken in Yandex slechts het halve werk is. Voor optimale en effectieve promotie in artikelen die op uw bron zullen worden gepubliceerd, moet u alle soorten sleutelzoekopdrachten gebruiken, ongeacht de frequentie. Natuurlijk heeft niemand ‘dummies’ nodig, maar de aanwezigheid van hoge, midden- en dieptepunten in de teksten is verplicht. En sleutelzinnen met ‘staarten’ zullen uw ranking verhogen.

In het artikel hebben we gekeken hoe je het aantal verzoeken kunt achterhalen met Wordstat. Bedenk echter dat de termen zeer competitief, matig competitief en weinig competitief geen duidelijke kwantitatieve betekenis hebben. Voor elk onderwerp kunnen ze variëren, afhankelijk van de specifieke kenmerken, seizoensinvloeden en populariteit van het gebied waarin ze worden toegepast. En websitepromotie wordt mede bepaald door de specifieke marktsituatie.
Weten hoe u het aantal zoekopdrachten naar trefwoorden kunt controleren, is slechts een van de belangrijkste componenten van het optimalisatieproces. Het is niet genoeg om de juiste woorden en zinnen te vinden, je moet ze verstandig gebruiken. Wat is hiervoor nodig?
Gebruikers en bezoekers van uw bron die met behulp van zoektermen naar de site zijn gekomen, moeten nuttige en interessante informatie zien en, belangrijker nog, de informatie waarop ze rekenen. Dit is de enige manier waarop je ze kunt aantrekken, en ze zullen bij je terug willen komen. En je kunt dit beter aan professionals toevertrouwen!
Dat is alles wat u moet weten voor een juiste semantiekselectie en effectieve promotie. Succes!
























