
Kunstmatige intelligentie, neurale netwerken, machinaal leren: wat betekenen al deze momenteel populaire concepten eigenlijk? Voor de meeste niet-ingewijden, wat ik zelf ben, leken ze altijd iets fantastisch, maar in feite ligt hun essentie aan de oppervlakte. Ik loop al lang met het idee om in eenvoudige taal te schrijven over kunstmatige neurale netwerken. Ontdek het zelf en vertel anderen wat deze technologie is, hoe het werkt, overweeg de geschiedenis en vooruitzichten ervan. In dit artikel probeerde ik niet in het onkruid te duiken, maar eenvoudig en in de volksmond te praten over deze veelbelovende richting in de wereld van de geavanceerde technologie.

Kunstmatige intelligentie, neurale netwerken, machinaal leren: wat betekenen al deze momenteel populaire concepten eigenlijk? Voor de meeste niet-ingewijden, wat ik zelf ben, leken ze altijd iets fantastisch, maar in feite ligt hun essentie aan de oppervlakte. Ik loop al lang met het idee om in eenvoudige taal te schrijven over kunstmatige neurale netwerken. Ontdek het zelf en vertel anderen wat deze technologie is, hoe het werkt, overweeg de geschiedenis en vooruitzichten ervan. In dit artikel probeerde ik niet in het onkruid te duiken, maar eenvoudig en in de volksmond te praten over deze veelbelovende richting in de wereld van de geavanceerde technologie.
Een beetje geschiedenis
Voor het eerst ontstond het concept van kunstmatige neurale netwerken (ANN) in een poging hersenprocessen te simuleren. De creatie van het McCulloch-Pitts neurale netwerkmodel in 1943 kan worden beschouwd als de eerste serieuze doorbraak op dit gebied. Wetenschappers hebben voor het eerst een model van een kunstneuron ontwikkeld. Ze stelden ook het ontwerp voor van een netwerk van deze elementen om logische bewerkingen uit te voeren. Maar het allerbelangrijkste is dat wetenschappers hebben bewezen dat een dergelijk netwerk in staat is om te leren.

De volgende belangrijke stap was de ontwikkeling door Donald Hebb van het eerste algoritme voor het berekenen van ANN in 1949, dat fundamenteel werd voor de daaropvolgende decennia. In 1958 ontwikkelde Frank Rosenblatt de parceptron, een systeem dat hersenprocessen imiteert. Ooit had de technologie geen analogen en is ze nog steeds van fundamenteel belang in neurale netwerken. In 1986 verbeterden Amerikaanse en Sovjet-wetenschappers vrijwel gelijktijdig, onafhankelijk van elkaar, de fundamentele methode voor het trainen van een meerlaags perceptron aanzienlijk. In 2007 beleefden neurale netwerken een wedergeboorte. De Britse computerwetenschapper Geoffrey Hinton ontwikkelde eerst een deep learning-algoritme voor meerlaagse neurale netwerken, dat nu bijvoorbeeld wordt gebruikt om zelfrijdende auto’s te besturen.
Kort over het belangrijkste
In de algemene zin van het woord zijn neurale netwerken wiskundige modellen die werken volgens het principe van netwerken van zenuwcellen in een dierlijk organisme. ANN's kunnen worden geïmplementeerd in zowel programmeerbare als hardwareoplossingen. Om de zaken begrijpelijker te maken, kan een neuron worden gezien als een cel met veel invoergaten en één uitvoergat. Hoe meerdere binnenkomende signalen worden omgezet in een uitgangssignaal, wordt bepaald door het berekeningsalgoritme. Aan elke neuroningang worden effectieve waarden geleverd, die vervolgens worden verdeeld langs interneuronverbindingen (synopses). Synapsen hebben één parameter: gewicht, waardoor de invoerinformatie verandert bij het verplaatsen van het ene neuron naar het andere. De eenvoudigste manier om het werkingsprincipe van neurale netwerken voor te stellen is door kleuren te mengen. Blauwe, groene en rode neuronen hebben verschillende gewichten. De informatie van het neuron waarvan het gewicht groter is, zal dominant zijn in het volgende neuron.

Het neurale netwerk zelf is een systeem van veel van dergelijke neuronen (processors). Individueel zijn deze processors vrij eenvoudig (veel eenvoudiger dan een pc-processor), maar wanneer ze op een groter systeem zijn aangesloten, zijn neuronen in staat zeer complexe taken uit te voeren.
Afhankelijk van het toepassingsgebied kan een neuraal netwerk op verschillende manieren worden geïnterpreteerd. Vanuit het oogpunt van machine learning is een ANN bijvoorbeeld een patroonherkenningsmethode. Vanuit wiskundig oogpunt is dit een probleem met meerdere parameters. Vanuit het oogpunt van cybernetica - een model van adaptieve controle van robotica. Voor kunstmatige intelligentie is ANN een fundamenteel onderdeel voor het modelleren van natuurlijke intelligentie met behulp van computationele algoritmen.
Het belangrijkste voordeel van neurale netwerken ten opzichte van conventionele computeralgoritmen is hun vermogen om te leren. In de algemene zin van het woord gaat leren over het vinden van de juiste koppelingscoëfficiënten tussen neuronen, het samenvatten van gegevens en het identificeren van complexe afhankelijkheden tussen invoer- en uitvoersignalen. Succesvolle training van een neuraal netwerk betekent in feite dat het systeem in staat zal zijn het juiste resultaat te identificeren op basis van gegevens die niet in de trainingsset voorkomen.

Huidige situatie
En hoe veelbelovend deze technologie ook mag zijn, ANN’s staan nog steeds ver verwijderd van de mogelijkheden van het menselijk brein en denken. Neurale netwerken worden echter al op veel gebieden van menselijke activiteit gebruikt. Tot nu toe zijn ze niet in staat om zeer intelligente beslissingen te nemen, maar ze kunnen wel een persoon vervangen waar hij voorheen nodig was. Onder de vele toepassingsgebieden van ANN kunnen we vermelden: de creatie van zelflerende productieprocessystemen, onbemande voertuigen, beeldherkenningssystemen, intelligente beveiligingssystemen, robotica, kwaliteitsbewakingssystemen, spraakinteractie-interfaces, analysesystemen en nog veel meer. Dit wijdverbreide gebruik van neurale netwerken is onder meer te danken aan de opkomst van verschillende methoden om ANN-training te versnellen.

Tegenwoordig is de markt voor neurale netwerken enorm: miljarden en miljarden dollars. Zoals de praktijk laat zien, verschillen de meeste neurale netwerktechnologieën over de hele wereld weinig van elkaar. Het gebruik van neurale netwerken is echter een zeer dure activiteit, die in de meeste gevallen alleen grote bedrijven zich kunnen veroorloven. Het ontwikkelen, trainen en testen van neurale netwerken vergt grote rekenkracht, en het is duidelijk dat grote spelers op de IT-markt hier volop over beschikken. Tot de belangrijkste bedrijven die de ontwikkelingen op dit gebied leiden, behoren de Google DeepMind-divisie, de Microsoft Research-divisie, IBM, Facebook en Baidu.
Dit is natuurlijk allemaal goed: neurale netwerken ontwikkelen zich, de markt groeit, maar tot nu toe is het grootste probleem niet opgelost. De mensheid is er niet in geslaagd een technologie te creëren die zelfs maar de mogelijkheden van het menselijk brein benadert. Laten we eens kijken naar de belangrijkste verschillen tussen het menselijk brein en kunstmatige neurale netwerken.
Waarom zijn neurale netwerken nog steeds ver verwijderd van het menselijk brein?
Het belangrijkste verschil, dat het principe en de efficiëntie van het systeem radicaal verandert, is de verschillende overdracht van signalen in kunstmatige neurale netwerken en in een biologisch netwerk van neuronen. Feit is dat neuronen in een ANN waarden doorgeven die echte waarden zijn, dat wil zeggen getallen. In het menselijk brein worden impulsen met een vaste amplitude overgedragen, en deze impulsen zijn vrijwel onmiddellijk. Dit leidt tot een aantal voordelen van het menselijke netwerk van neuronen.

Ten eerste zijn de communicatielijnen in de hersenen veel efficiënter en zuiniger dan die in het ANN. Ten tweede zorgt het pulscircuit voor een gemakkelijke implementatie van de technologie: het is voldoende om analoge circuits te gebruiken in plaats van complexe computermechanismen. Uiteindelijk zijn gepulseerde netwerken immuun voor audio-interferentie. Reële cijfers zijn onderhevig aan ruis, wat de kans op fouten vergroot.
Kortom
Natuurlijk heeft de ontwikkeling van neurale netwerken de afgelopen tien jaar een ware hausse gekend. Dit komt vooral doordat het ANN-trainingsproces veel sneller en eenvoudiger is geworden. Er worden ook actief zogenaamde ‘voorgetrainde’ neurale netwerken ontwikkeld, die het proces van de introductie van technologie aanzienlijk kunnen versnellen. En als het nog te vroeg is om te zeggen of neurale netwerken op een dag in staat zullen zijn de capaciteiten van het menselijk brein volledig te reproduceren, wordt de waarschijnlijkheid dat ANN’s in het komende decennium mensen in een kwart van de bestaande beroepen zullen kunnen vervangen steeds groter. .
Voor wie meer wil weten
- De Grote Neurale Oorlog: wat Google werkelijk van plan is
- Hoe cognitieve computers onze toekomst kunnen veranderen
Goedemiddag, mijn naam is Natalia Efremova en ik ben onderzoekswetenschapper bij NtechLab. Vandaag zal ik het hebben over de soorten neurale netwerken en hun toepassingen.
Eerst zal ik enkele woorden zeggen over ons bedrijf. Het bedrijf is nieuw, misschien weten velen van jullie nog niet wat we doen. Vorig jaar wonnen we de MegaFace-wedstrijd. Dit is een internationale wedstrijd voor gezichtsherkenning. In hetzelfde jaar werd ons bedrijf geopend, dat wil zeggen dat we ongeveer een jaar op de markt zijn, zelfs iets langer. Daarom zijn wij een van de toonaangevende bedrijven op het gebied van gezichtsherkenning en biometrische beeldverwerking.
Het eerste deel van mijn rapport zal gericht zijn aan degenen die onbekend zijn met neurale netwerken. Ik ben direct betrokken bij deep learning. Ik ben al meer dan 10 jaar werkzaam in dit vakgebied. Hoewel het iets minder dan tien jaar geleden verscheen, waren er enkele beginselen van neurale netwerken die vergelijkbaar waren met het deep learning-systeem.
De afgelopen tien jaar hebben deep learning en computervisie zich in een ongelooflijk tempo ontwikkeld. Alles wat op dit gebied van belang is, is de afgelopen zes jaar gebeurd.
Ik zal het hebben over praktische aspecten: waar, wanneer, wat te gebruiken op het gebied van deep learning voor beeld- en videoverwerking, voor beeld- en gezichtsherkenning, aangezien ik in een bedrijf werk dat dit doet. Ik zal je iets vertellen over emotieherkenning en welke benaderingen worden gebruikt in games en robotica. Ik zal ook praten over de niet-standaard toepassing van deep learning, iets dat nog maar net in wetenschappelijke instellingen opkomt en in de praktijk nog weinig wordt gebruikt, hoe het kan worden toegepast en waarom het moeilijk is toe te passen.
Het rapport zal uit twee delen bestaan. Omdat de meesten bekend zijn met neurale netwerken, zal ik eerst kort bespreken hoe neurale netwerken werken, wat biologische neurale netwerken zijn, waarom het belangrijk voor ons is om te weten hoe het werkt, wat kunstmatige neurale netwerken zijn en welke architecturen op welke gebieden worden gebruikt. .
Ik bied meteen mijn excuses aan, ik zal een beetje overslaan naar de Engelse terminologie, omdat ik het meeste niet eens weet van hoe het in het Russisch wordt genoemd. Misschien jij ook.
Het eerste deel van het rapport zal dus gewijd zijn aan convolutionele neurale netwerken. Ik zal je vertellen hoe convolutionele neurale netwerken (CNN) en beeldherkenning werken aan de hand van een voorbeeld uit gezichtsherkenning. Ik zal je iets vertellen over terugkerende neurale netwerken (RNN) en versterkend leren aan de hand van het voorbeeld van deep learning-systemen.
Als niet-standaardtoepassing van neurale netwerken zal ik het hebben over hoe CNN in de geneeskunde werkt om voxelbeelden te herkennen, en hoe neurale netwerken worden gebruikt om armoede in Afrika te herkennen.
Wat zijn neurale netwerken
Het prototype voor het creëren van neurale netwerken waren, vreemd genoeg, biologische neurale netwerken. Velen van jullie weten misschien hoe je een neuraal netwerk moet programmeren, maar ik denk dat sommigen niet weten waar het vandaan komt. Tweederde van alle zintuiglijke informatie die tot ons komt, komt van de visuele waarnemingsorganen. Meer dan een derde van het oppervlak van onze hersenen wordt ingenomen door de twee belangrijkste visuele gebieden: het dorsale visuele pad en het ventrale visuele pad.Het dorsale visuele pad begint in de primaire visuele zone, bij onze kruin, en gaat verder omhoog, terwijl het ventrale pad aan de achterkant van ons hoofd begint en ongeveer achter de oren eindigt. Alle belangrijke patroonherkenning die in ons plaatsvindt, alles wat betekenis heeft en waarvan we ons bewust zijn, vindt precies daar plaats, achter de oren.
Waarom is dit belangrijk? Omdat het vaak nodig is om neurale netwerken te begrijpen. Ten eerste praat iedereen hierover, en ik ben er al aan gewend dat dit gebeurt, en ten tweede is het een feit dat alle gebieden die in neurale netwerken worden gebruikt voor beeldherkenning precies naar ons toe kwamen via het ventrale visuele pad, waar elk een klein zone is verantwoordelijk voor zijn strikt gedefinieerde functie.
Het beeld komt vanuit het netvlies naar ons toe, gaat door een reeks visuele zones en eindigt in de temporele zone.
In de verre jaren 60 van de vorige eeuw, toen de studie van de visuele delen van de hersenen nog maar net begon, werden de eerste experimenten op dieren uitgevoerd, omdat er geen fMRI was. De hersenen werden bestudeerd met behulp van elektroden die in verschillende visuele gebieden waren geïmplanteerd.
Het eerste visuele gebied werd in 1962 bestudeerd door David Hubel en Thorsten Wiesel. Ze voerden experimenten uit met katten. De katten kregen verschillende bewegende objecten te zien. Waar de hersencellen op reageerden was de prikkel die het dier herkende. Zelfs nu nog worden veel experimenten op deze draconische manieren uitgevoerd. Maar toch is dit de meest effectieve manier om erachter te komen wat elke kleine cel in onze hersenen doet.
Op dezelfde manier werden veel meer belangrijke eigenschappen van de visuele gebieden ontdekt, die we nu gebruiken bij deep learning. Een van de belangrijkste eigenschappen is de toename van de receptieve velden van onze cellen terwijl we van de primaire visuele gebieden naar de temporale kwabben gaan, dat wil zeggen de latere visuele gebieden. Het receptieve veld is dat deel van het beeld dat elke cel van onze hersenen verwerkt. Elke cel heeft zijn eigen receptieve veld. Dezelfde eigenschap blijft behouden in neurale netwerken, zoals jullie waarschijnlijk allemaal weten.
Naarmate de receptieve velden toenemen, nemen ook de complexe stimuli toe die neurale netwerken doorgaans herkennen.

Hier zie je voorbeelden van de complexiteit van stimuli, de verschillende tweedimensionale vormen die worden herkend in de gebieden V2, V4 en verschillende delen van de tijdelijke velden bij makaken. Ook worden er een aantal MRI-experimenten uitgevoerd.

Hier kunt u zien hoe dergelijke experimenten worden uitgevoerd. Dit is een deel van 1 nanometer van de IT-cortexzones van de aap bij het herkennen van verschillende objecten. Waar het wordt herkend, is gemarkeerd.
Laten we het samenvatten. Een belangrijke eigenschap die we willen overnemen van de visuele gebieden is dat de omvang van de receptieve velden toeneemt, en de complexiteit van de objecten die we herkennen toeneemt.
Computervisie
Voordat we dit leerden toepassen op computervisie, bestond het over het algemeen niet als zodanig. Het werkte in ieder geval niet zo goed als nu.We dragen al deze eigenschappen over naar het neurale netwerk, en nu werkt het, als je geen kleine uitweiding over de datasets toevoegt, waarover ik je later zal vertellen.
Maar eerst iets over de eenvoudigste perceptron. Het wordt ook gevormd naar het beeld en de gelijkenis van onze hersenen. Het eenvoudigste element dat op een hersencel lijkt, is een neuron. Heeft invoerelementen die standaard van links naar rechts zijn gerangschikt, soms van onder naar boven. Aan de linkerkant bevinden zich de invoerdelen van het neuron, aan de rechterkant de uitvoerdelen van het neuron.
De eenvoudigste perceptron kan alleen de eenvoudigste bewerkingen uitvoeren. Om complexere berekeningen uit te voeren, hebben we een structuur met meer verborgen lagen nodig.

In het geval van computervisie hebben we nog meer verborgen lagen nodig. En alleen dan zal het systeem op betekenisvolle wijze herkennen wat het ziet.
Ik zal je dus vertellen wat er gebeurt tijdens beeldherkenning aan de hand van het voorbeeld van gezichten.
Als we naar deze foto kijken en zeggen dat deze precies het gezicht van het beeld laat zien, is dat vrij eenvoudig. Vóór 2010 was dit echter een ongelooflijk moeilijke taak voor computervisie. Degenen die eerder met dit probleem te maken hebben gehad, weten waarschijnlijk hoe moeilijk het was om het object dat we op de foto willen vinden zonder woorden te beschrijven.
We moesten dit op een geometrische manier doen, het object beschrijven, de relaties van het object beschrijven, hoe deze delen zich tot elkaar kunnen verhouden, dan dit beeld op het object vinden, ze vergelijken en uitzoeken wat we slecht herkenden. Het was meestal iets beter dan het opgooien van een muntje. Iets beter dan kansniveau.
Dit is niet hoe het nu werkt. We verdelen ons beeld in pixels of in bepaalde vlakken: 2x2, 3x3, 5x5, 11x11 pixels - zoals handig is voor de makers van het systeem waarin ze dienen als invoerlaag voor het neurale netwerk.
Signalen van deze invoerlagen worden van laag naar laag verzonden met behulp van synapsen, waarbij elke laag zijn eigen specifieke coëfficiënten heeft. We gaan dus van laag naar laag, van laag naar laag, totdat we het gezicht hebben herkend.
Conventioneel kunnen al deze delen in drie klassen worden verdeeld, we zullen ze X, W en Y aanduiden, waarbij X ons invoerbeeld is, Y een reeks labels is en we onze gewichten moeten bepalen. Hoe berekenen we W?
Gegeven onze X en Y lijkt dit eenvoudig. Wat echter met een asterisk wordt aangegeven, is een zeer complexe niet-lineaire operatie, die helaas geen inverse heeft. Zelfs met twee gegeven componenten van de vergelijking is het erg moeilijk om deze te berekenen. Daarom moeten we er geleidelijk, met vallen en opstaan, door het gewicht W te selecteren, voor zorgen dat de fout zoveel mogelijk afneemt, bij voorkeur zodat deze gelijk wordt aan nul.

Dit proces vindt iteratief plaats, we verminderen voortdurend totdat we de waarde van gewicht W vinden die voldoende bij ons past.
Overigens behaalde geen enkel neuraal netwerk waarmee ik werkte een fout gelijk aan nul, maar het werkte redelijk goed.

Dit is het eerste netwerk dat de internationale ImageNet-wedstrijd in 2012 heeft gewonnen. Dit is het zogenaamde AlexNet. Dit is het netwerk dat voor het eerst verklaarde dat er convolutionele neurale netwerken bestaan, en sindsdien hebben convolutionele neurale netwerken hun positie in alle internationale competities nooit opgegeven.
Ondanks het feit dat dit netwerk vrij klein is (het heeft slechts 7 verborgen lagen), bevat het 650 duizend neuronen met 60 miljoen parameters. Om iteratief de benodigde gewichten te leren vinden, hebben we veel voorbeelden nodig.
Het neurale netwerk leert van het voorbeeld van een afbeelding en een label. Net zoals ons in de kindertijd wordt geleerd ‘dit is een kat en dit is een hond’, worden neurale netwerken getraind op een groot aantal afbeeldingen. Maar feit is dat er tot 2010 geen dataset bestond die groot genoeg was om een dergelijk aantal parameters te leren om afbeeldingen te herkennen.
De grootste databases die vóór die tijd bestonden waren PASCAL VOC, die slechts 20 objectcategorieën had, en Caltech 101, ontwikkeld door het California Institute of Technology. De laatste had 101 categorieën, en dat was veel. Degenen die hun objecten in geen van deze databases konden vinden, moesten hun databases kapot maken, wat, zal ik zeggen, vreselijk pijnlijk is.
In 2010 verscheen echter de ImageNet-database, die 15 miljoen afbeeldingen bevatte, verdeeld in 22 duizend categorieën. Dit loste ons probleem van het trainen van neurale netwerken op. Nu kan iedereen met een academisch adres eenvoudig naar de website van de basis gaan, toegang aanvragen en deze basis ontvangen voor het trainen van hun neurale netwerken. Ze reageren vrij snel, naar mijn mening, de volgende dag.
Vergeleken met eerdere datasets is dit een zeer grote database.

Het voorbeeld laat zien hoe onbeduidend alles wat eraan voorafging, was. Gelijktijdig met de ImageNet-basis verscheen de ImageNet-competitie, een internationale uitdaging waaraan alle teams die willen meedoen, kunnen deelnemen.
Dit jaar werd het winnende netwerk in China gecreëerd en telde het 269 lagen. Ik weet niet hoeveel parameters er zijn, ik vermoed dat het er ook veel zijn.
Diepe neurale netwerkarchitectuur
Conventioneel kan het in twee delen worden verdeeld: degenen die studeren en degenen die niet studeren.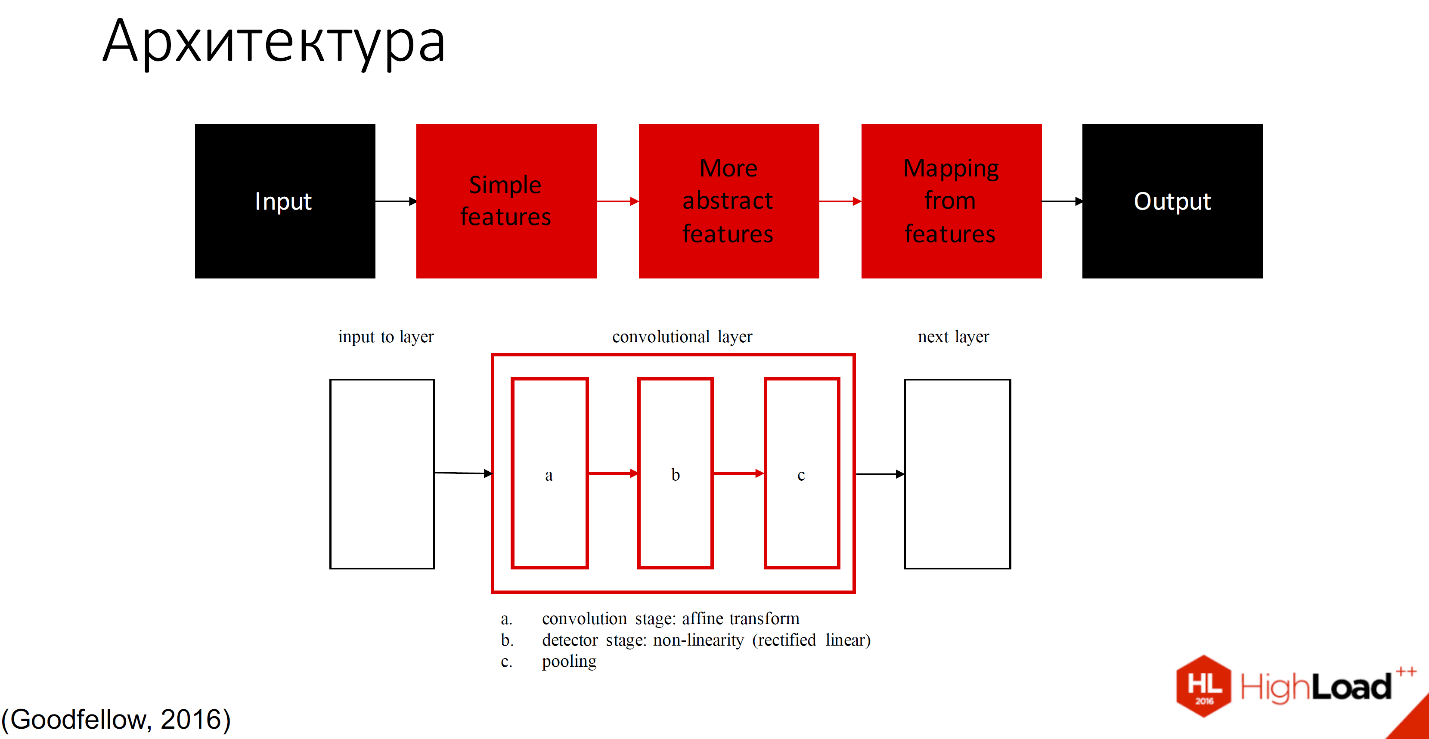
Zwart geeft de delen aan die niet leren; alle andere lagen zijn in staat om te leren. Er zijn veel definities van wat zich binnen elke convolutionele laag bevindt. Een van de geaccepteerde notaties is dat één laag met drie componenten is verdeeld in een convolutiefase, een detectorfase en een poolingfase.
Ik zal niet in details treden; er zullen nog veel meer rapporten zijn die in detail zullen bespreken hoe dit werkt. Ik zal het je vertellen met een voorbeeld.
Omdat de organisatoren mij vroegen om veel formules niet te noemen, heb ik ze volledig weggegooid.

Het invoerbeeld valt dus in een netwerk van lagen, die filters van verschillende groottes en variërende complexiteit van de elementen die ze herkennen kunnen worden genoemd. Deze filters vormen hun eigen index of reeks functies, die vervolgens in de classificator worden opgenomen. Meestal is dit SVM of MLP - meerlaagse perceptron, afhankelijk van wat het beste bij u past.
Op dezelfde manier als een biologisch neuraal netwerk worden objecten van verschillende complexiteit herkend. Naarmate het aantal lagen toenam, verloor het allemaal het contact met de cortex, omdat er een beperkt aantal zones in het neurale netwerk is. 269 of vele, vele zones van abstractie, dus er blijft alleen een toename van de complexiteit, het aantal elementen en receptieve velden behouden.

Als we naar het voorbeeld van gezichtsherkenning kijken, zal ons receptieve veld van de eerste laag klein zijn, dan een beetje groter, groter, enzovoort, totdat we uiteindelijk het hele gezicht kunnen herkennen.

Vanuit het perspectief van wat zich in onze filters bevindt, zullen er eerst schuine stokjes zijn plus een beetje kleur, dan delen van gezichten, en dan zullen hele gezichten door elke cel van de laag worden herkend.
Er zijn mensen die beweren dat een persoon altijd beter herkent dan een netwerk. Is dit waar?
In 2014 besloten wetenschappers te testen hoe goed we herkennen in vergelijking met neurale netwerken. Ze namen de twee beste netwerken van dit moment - AlexNet en het netwerk van Matthew Ziller en Fergus, en vergeleken deze met de reactie van verschillende delen van de hersenen van een makaak, die ook leerde sommige objecten te herkennen. De voorwerpen kwamen uit de dierenwereld zodat de aap niet in de war zou raken, en er werden experimenten uitgevoerd om te kijken wie het beter kon herkennen.
Omdat het onmogelijk is om een duidelijke reactie van de aap te krijgen, werden er elektroden in geïmplanteerd en werd de reactie van elk neuron direct gemeten.
Het bleek dat hersencellen onder normale omstandigheden net zo goed reageerden als het toenmalige state-of-the-art model, dat wil zeggen het netwerk van Matthew Ziller.
Met een toename van de snelheid waarmee objecten worden weergegeven en een toename van de hoeveelheid ruis en objecten in het beeld, neemt de herkenningssnelheid en kwaliteit van onze hersenen en die van primaten echter aanzienlijk af. Zelfs het eenvoudigste convolutionele neurale netwerk kan objecten beter herkennen. Dat wil zeggen: officieel werken neurale netwerken beter dan onze hersenen.
Klassieke problemen van convolutionele neurale netwerken
Er zijn er eigenlijk niet veel; ze behoren tot drie klassen. Daartoe behoren taken als objectidentificatie, semantische segmentatie, gezichtsherkenning, herkenning van menselijke lichaamsdelen, semantische randdetectie, het benadrukken van aandachtsobjecten in een beeld en het benadrukken van oppervlaktenormalen. Ze kunnen grofweg worden onderverdeeld in 3 niveaus: van taken op het laagste niveau tot taken op het hoogste niveau.
Laten we, met behulp van deze afbeelding als voorbeeld, kijken naar wat elke taak doet.
- Grenzen definiëren- Dit is de taak op het laagste niveau waarvoor convolutionele neurale netwerken al klassiek worden gebruikt.
- Bepalen van de vector naar de normaal stelt ons in staat een driedimensionaal beeld te reconstrueren uit een tweedimensionaal beeld.
- Opvallendheid, het identificeren van aandachtsobjecten- dit is waar iemand op zou letten als hij naar deze foto kijkt.
- Semantische segmentatie Hiermee kunt u objecten in klassen verdelen op basis van hun structuur, zonder iets over deze objecten te weten, dat wil zeggen zelfs voordat ze worden herkend.
- Semantische grensmarkering- dit is de selectie van grenzen verdeeld in klassen.
- Het benadrukken van menselijke lichaamsdelen.
- En de taak op het hoogste niveau is herkenning van de objecten zelf, die we nu zullen overwegen aan de hand van het voorbeeld van gezichtsherkenning.
Gezichtsherkenning
Het eerste wat we doen is een gezichtsdetector over de afbeelding laten lopen om een gezicht te vinden. Vervolgens normaliseren we het gezicht, centreren we het en voeren het uit voor verwerking in een neuraal netwerk. Daarna verkrijgen we een set of vector van kenmerken die uniek zijn beschrijft de kenmerken van dit gezicht.
Vervolgens kunnen we deze kenmerkvector vergelijken met alle kenmerkvectoren die in onze database zijn opgeslagen, en een verwijzing krijgen naar een specifieke persoon, naar zijn naam, naar zijn profiel - alles wat we in de database kunnen opslaan.
Dit is precies hoe ons FindFace-product werkt: het is een gratis service waarmee u naar de profielen van mensen in de VKontakte-database kunt zoeken.
Daarnaast hebben wij een API voor bedrijven die onze producten willen uitproberen. Wij leveren diensten voor gezichtsdetectie, verificatie en gebruikersidentificatie.
We hebben nu 2 scenario’s ontwikkeld. De eerste is identificatie, het zoeken naar een persoon in een database. De tweede is verificatie, dit is een vergelijking van twee afbeeldingen met een bepaalde waarschijnlijkheid dat dit dezelfde persoon is. Daarnaast ontwikkelen we momenteel emotieherkenning, beeldherkenning op video en liveness-detectie - dit is inzicht of de persoon voor de camera of een foto leeft.
Enkele statistieken. Bij het identificeren, bij het doorzoeken van 10.000 foto's, hebben we een nauwkeurigheid van ongeveer 95%, afhankelijk van de kwaliteit van de database, en een nauwkeurigheid van 99% bij de verificatie. En daarnaast is dit algoritme zeer resistent tegen veranderingen: we hoeven niet naar de camera te kijken, we kunnen obstakels hebben: een bril, een zonnebril, een baard, een medisch masker. In sommige gevallen kunnen we zelfs de ongelooflijke uitdagingen voor computervisie overwinnen, zoals een bril en een masker.
Zeer snel zoeken, het duurt 0,5 seconde om 1 miljard foto's te verwerken. Wij hebben een unieke snelzoekindex ontwikkeld. We kunnen ook werken met beelden van lage kwaliteit afkomstig van CCTV-camera's. Wij kunnen dit allemaal realtime verwerken. Je kunt foto's uploaden via de webinterface, via Android, iOS en zoeken door 100 miljoen gebruikers en hun 250 miljoen foto's.
Zoals ik al zei, behaalden we de eerste plaats in de MegaFace-wedstrijd - een analoog voor ImageNet, maar dan voor gezichtsherkenning. Het loopt al een aantal jaren, vorig jaar waren we de beste onder de 100 teams van over de hele wereld, inclusief Google.
Terugkerende neurale netwerken
We gebruiken terugkerende neurale netwerken als het niet genoeg is om alleen een afbeelding te herkennen. In gevallen waarin het voor ons belangrijk is om de consistentie te behouden, hebben we de volgorde nodig van wat er gebeurt en gebruiken we gewone terugkerende neurale netwerken.Dit wordt gebruikt voor natuurlijke taalherkenning, videoverwerking en zelfs voor beeldherkenning.
Ik zal het niet hebben over natuurlijke taalherkenning – na mijn rapport zullen er nog twee volgen die gericht zullen zijn op natuurlijke taalherkenning. Daarom zal ik het hebben over het werk van terugkerende netwerken aan de hand van het voorbeeld van emotieherkenning.
Wat zijn terugkerende neurale netwerken? Dit is ongeveer hetzelfde als gewone neurale netwerken, maar dan met feedback. We hebben feedback nodig om de vorige toestand van het systeem door te geven aan de input van het neurale netwerk of aan enkele van zijn lagen.
Laten we zeggen dat we emoties verwerken. Zelfs in een glimlach – een van de eenvoudigste emoties – zijn er meerdere momenten: van een neutrale gezichtsuitdrukking tot het moment waarop we een volle glimlach hebben. Ze volgen elkaar opeenvolgend op. Om dit goed te begrijpen, moeten we kunnen observeren hoe dit gebeurt, en wat er in het vorige frame stond, overbrengen naar de volgende stap van het systeem.

In 2005 presenteerde een team uit Montreal tijdens de Emotion Recognition in the Wild-wedstrijd een terugkerend systeem specifiek voor het herkennen van emoties, dat er heel eenvoudig uitzag. Het had slechts een paar convolutionele lagen en werkte uitsluitend met video. Dit jaar voegden ze ook audioherkenning toe en geaggregeerde frame-voor-frame gegevens verkregen uit convolutionele neurale netwerken, audiosignaalgegevens met de werking van een terugkerend neuraal netwerk (met statusretour) en behaalden ze de eerste plaats in de competitie.
Versterkend leren
Het volgende type neurale netwerken, dat de laatste tijd heel vaak wordt gebruikt, maar niet zoveel publiciteit heeft gekregen als de vorige twee typen, is diep versterkend leren.Feit is dat we in de vorige twee gevallen databases gebruiken. We hebben óf gegevens van gezichten, óf gegevens van foto’s, óf gegevens met emoties uit video’s. Als we dit niet hebben, als we het niet kunnen filmen, hoe kunnen we een robot dan leren objecten op te pakken? We doen dit automatisch, we weten niet hoe het werkt. Nog een voorbeeld: het samenstellen van grote databases in computerspellen is moeilijk, en het kan ook niet veel eenvoudiger.
Iedereen heeft waarschijnlijk gehoord van het succes van diep versterkend leren in Atari en Go.
Wie heeft er van Atari gehoord? Nou, iemand heeft het gehoord, oké. Ik denk dat iedereen wel eens van AlphaGo heeft gehoord, dus ik ga niet eens vertellen wat daar precies gebeurt.

Wat is er aan de hand bij Atari? De architectuur van dit neurale netwerk wordt links weergegeven. Ze leert door met zichzelf te spelen om de maximale beloning te krijgen. De maximale beloning is de snelst mogelijke uitkomst van het spel met de hoogst mogelijke score.
Rechtsboven bevindt zich de laatste laag van het neurale netwerk, die het volledige aantal toestanden van het systeem weergeeft, dat slechts twee uur lang tegen zichzelf speelde. Gewenste uitkomsten van het spel met de maximale beloning worden in rood weergegeven, en ongewenste uitkomsten in blauw. Het netwerk bouwt een bepaald veld op en beweegt zich door de getrainde lagen naar de staat die het wil bereiken.
In de robotica is de situatie een beetje anders. Waarom? Hier hebben we verschillende moeilijkheden. Ten eerste hebben we niet veel databases. Ten tweede moeten we drie systemen tegelijk coördineren: de perceptie van de robot, zijn acties met behulp van manipulatoren en zijn geheugen - wat er in de vorige stap is gedaan en hoe het is gedaan. Over het algemeen is dit allemaal erg moeilijk.
Feit is dat geen enkel neuraal netwerk, zelfs deep learning op dit moment, deze taak niet effectief genoeg aankan, dus deep learning is slechts een deel van wat robots moeten doen. Sergei Levin heeft bijvoorbeeld onlangs een systeem geleverd dat een robot leert objecten te grijpen.

Hier zijn de experimenten die hij uitvoerde met zijn veertien robotarmen.
Wat is hier aan de hand? In deze bassins die je voor je ziet, bevinden zich verschillende voorwerpen: pennen, gummen, kleinere en grotere mokken, vodden, verschillende texturen, verschillende hardheden. Het is onduidelijk hoe je een robot kunt leren ze te vangen. Urenlang, en zelfs wekenlang, trainden de robots om deze objecten te kunnen pakken, en hierover werden databases samengesteld.
Databases zijn een soort reactie uit de omgeving die we moeten verzamelen om de robot te kunnen trainen om in de toekomst iets te doen. In de toekomst zullen robots leren van deze reeks systeemtoestanden.
Niet-standaard toepassingen van neurale netwerken
Helaas is dit het einde, ik heb niet veel tijd. Ik zal u vertellen over de niet-standaardoplossingen die momenteel bestaan en die, volgens veel voorspellingen, in de toekomst enige toepassing zullen hebben.Wetenschappers van Stanford kwamen onlangs met een zeer ongebruikelijke toepassing van een neuraal netwerk van CNN om armoede te voorspellen. Wat deden ze?
Het concept is eigenlijk heel eenvoudig. Feit is dat in Afrika het armoedeniveau alle denkbare en onvoorstelbare grenzen overschrijdt. Ze hebben niet eens de mogelijkheid om sociaal-demografische gegevens te verzamelen. Daarom hebben we sinds 2005 helemaal geen gegevens over wat daar gebeurt.
Wetenschappers verzamelden dag- en nachtkaarten van satellieten en voerden deze gedurende een bepaalde periode door naar een neuraal netwerk.
Het neurale netwerk was vooraf geconfigureerd op ImageNet. Dat wil zeggen dat de eerste filterlagen zo waren geconfigureerd dat het een aantal zeer eenvoudige dingen kon herkennen, bijvoorbeeld daken van huizen, om nederzettingen te zoeken op kaarten overdag vergeleken met nachtelijke kaarten verlichting van hetzelfde deel van het oppervlak om te zeggen hoeveel geld de bevolking heeft om op zijn minst hun huizen 's nachts te verlichten.

Hier zie je de resultaten van de voorspelling gebouwd door het neurale netwerk. De voorspelling werd gedaan met verschillende resoluties. En je ziet – het allerlaatste frame – echte gegevens verzameld door de Oegandese overheid in 2005.
Je kunt zien dat het neurale netwerk een redelijk nauwkeurige voorspelling heeft gedaan, zelfs met een kleine verschuiving sinds 2005.
Natuurlijk waren er bijwerkingen. Wetenschappers die zich bezighouden met deep learning zijn altijd verrast als ze verschillende bijwerkingen ontdekken. Bijvoorbeeld het feit dat het netwerk water, bossen, grote bouwplaatsen, wegen heeft leren herkennen - dit alles zonder leraren, zonder vooraf gebouwde databases. Over het algemeen geheel zelfstandig. Er waren bepaalde lagen die bijvoorbeeld op wegen reageerden.
En de laatste toepassing waar ik het over wil hebben is de semantische segmentatie van 3D-beelden in de geneeskunde. Over het algemeen is medische beeldvorming een complex vakgebied waar heel moeilijk mee te werken is.
Hiervoor zijn verschillende redenen.
- We hebben heel weinig databases. Het is niet zo eenvoudig om een foto van een brein te vinden, sterker nog, een beschadigd brein, en het is ook onmogelijk om het ergens vandaan te halen.
- Zelfs als we zo'n foto hebben, moeten we een dokter meenemen en hem dwingen alle meerlaagse afbeeldingen handmatig te plaatsen, wat erg tijdrovend en uiterst inefficiënt is. Niet alle artsen hebben de middelen om dit te doen.
- Er is een zeer hoge nauwkeurigheid vereist. Het medische systeem mag geen fouten maken. Bij het herkennen werden katten bijvoorbeeld niet herkend - geen probleem. En als we de tumor niet herkennen, dan is dit niet zo goed meer. De eisen aan de systeembetrouwbaarheid zijn hier bijzonder streng.
- Afbeeldingen bestaan uit driedimensionale elementen: voxels, geen pixels, wat extra complexiteit voor systeemontwikkelaars met zich meebrengt.
Waar het wordt gebruikt: het vaststellen van schade na een botsing, het zoeken naar een tumor in de hersenen, in de cardiologie om te bepalen hoe het hart werkt.

Hier is een voorbeeld voor het bepalen van het volume van de placenta.
Automatisch werkt het goed, maar niet goed genoeg om in productie te gaan, dus het is nog maar net begonnen. Er zijn verschillende startups die dergelijke medische visiesystemen ontwikkelen. Over het algemeen zullen er in de nabije toekomst veel startups in deep learning zijn. Ze zeggen dat durfkapitalisten de afgelopen zes maanden meer budget hebben toegewezen aan deep learning-startups dan in de afgelopen vijf jaar.
Dit gebied ontwikkelt zich actief, er zijn veel interessante richtingen. We leven in interessante tijden. Als je betrokken bent bij deep learning, dan is het waarschijnlijk tijd om je eigen startup te openen.
Nou, ik zal het waarschijnlijk hier afronden. Hartelijk dank.
Een kunstmatig neuraal netwerk is een verzameling neuronen die met elkaar interageren. Ze zijn in staat gegevens te ontvangen, verwerken en creëren. Het is net zo moeilijk voor te stellen als de werking van het menselijk brein. Het neurale netwerk in onze hersenen werkt zo dat je dit nu kunt lezen: onze neuronen herkennen letters en zetten deze onder woorden.
Een kunstmatig neuraal netwerk is als een brein. Het was oorspronkelijk geprogrammeerd om enkele complexe computerprocessen te vereenvoudigen. Tegenwoordig hebben neurale netwerken veel meer mogelijkheden. Sommige daarvan staan op je smartphone. Een ander deel heeft al in zijn database vastgelegd dat jij dit artikel hebt geopend. Hoe dit allemaal gebeurt en waarom, lees verder.
Hoe het allemaal begon
Mensen wilden echt begrijpen waar iemands geest vandaan komt en hoe de hersenen werken. Halverwege de vorige eeuw besefte de Canadese neuropsycholoog Donald Hebb dit. Hebb bestudeerde de interactie van neuronen met elkaar, onderzocht het principe waarmee ze worden gecombineerd tot groepen (in wetenschappelijke termen - ensembles) en stelde het eerste algoritme in de wetenschap voor voor het trainen van neurale netwerken.
Een paar jaar later modelleerde een groep Amerikaanse wetenschappers een kunstmatig neuraal netwerk dat vierkante vormen van andere vormen kon onderscheiden.
Hoe werkt een neuraal netwerk?
Onderzoekers hebben ontdekt dat een neuraal netwerk een verzameling neuronenlagen is, die elk verantwoordelijk zijn voor het herkennen van een specifiek criterium: vorm, kleur, grootte, textuur, geluid, volume, enz. Jaar na jaar, als resultaat van miljoenen experimenten en talloze berekeningen, toevoegingen werden toegevoegd aan het eenvoudigste netwerk van nieuwe en nieuwe lagen neuronen. Ze werken om de beurt. De eerste bepaalt bijvoorbeeld of een vierkant vierkant is of niet, de tweede begrijpt of een vierkant rood is of niet, de derde berekent de grootte van het vierkant, enzovoort. Geen vierkanten, geen rode en vormen van ongepast formaat komen terecht in nieuwe groepen neuronen en worden door hen onderzocht.
Wat zijn neurale netwerken en wat kunnen ze doen?
Wetenschappers hebben neurale netwerken ontwikkeld zodat ze onderscheid kunnen maken tussen complexe beelden, video’s, teksten en spraak. Er zijn tegenwoordig veel soorten neurale netwerken. Ze worden geclassificeerd afhankelijk van de architectuur: sets van dataparameters en het gewicht van deze parameters, een bepaalde prioriteit. Hieronder staan er enkele.
Convolutionele neurale netwerken
Neuronen zijn verdeeld in groepen, elke groep berekent een kenmerk dat eraan wordt gegeven. In 1993 toonde de Franse wetenschapper Yann LeCun de wereld LeNet 1, het eerste convolutionele neurale netwerk dat snel en nauwkeurig met de hand op papier geschreven getallen kon herkennen. Kijk zelf:
Tegenwoordig worden convolutionele neurale netwerken voornamelijk gebruikt voor multimediadoeleinden: ze werken met afbeeldingen, audio en video.
Terugkerende neurale netwerken
Neuronen onthouden achtereenvolgens informatie en bouwen verdere acties op basis van deze gegevens. In 1997 hebben Duitse wetenschappers de eenvoudigste terugkerende netwerken gewijzigd in netwerken met een lang kortetermijngeheugen. Op basis daarvan werden vervolgens netwerken met gecontroleerde terugkerende neuronen ontwikkeld.
Tegenwoordig worden met behulp van dergelijke netwerken teksten geschreven en vertaald, worden bots geprogrammeerd om betekenisvolle dialogen met mensen te voeren, en worden pagina- en programmacodes gemaakt.
Het gebruik van dit soort neurale netwerken biedt de mogelijkheid om gegevens te analyseren en te genereren, databases samen te stellen en zelfs voorspellingen te doen.
In 2015 bracht SwiftKey 's werelds eerste toetsenbord uit dat draait op een terugkerend neuraal netwerk met gecontroleerde neuronen. Vervolgens gaf het systeem hints tijdens het typen op basis van de laatst ingevoerde woorden. Vorig jaar hebben ontwikkelaars een neuraal netwerk getraind om de context van de getypte tekst te bestuderen, en de hints werden betekenisvol en nuttig:

Gecombineerde neurale netwerken (convolutioneel + terugkerend)
Dergelijke neurale netwerken kunnen begrijpen wat er in het beeld staat en dit beschrijven. En omgekeerd: teken afbeeldingen volgens de beschrijving. Het meest opvallende voorbeeld werd gedemonstreerd door Kyle MacDonald, die een neuraal netwerk meenam voor een wandeling door Amsterdam. Het netwerk bepaalde onmiddellijk wat zich ervoor bevond. En bijna altijd precies:

Neurale netwerken zijn voortdurend zelflerend. Via dit proces:
1. Skype heeft simultaanvertaalmogelijkheden voor 10 talen geïntroduceerd. Waaronder, voor een moment, Russisch en Japans - enkele van de moeilijkste ter wereld. Natuurlijk vereist de kwaliteit van de vertaling een serieuze verbetering, maar juist het feit dat je nu in het Russisch met collega's uit Japan kunt communiceren en er zeker van kunt zijn dat je begrepen wordt, is inspirerend.
2. Yandex heeft twee zoekalgoritmen gemaakt op basis van neurale netwerken: “Palekh” en “Korolev”. De eerste hielp bij het vinden van de meest relevante sites voor laagfrequente zoekopdrachten. "Palekh" bestudeerde de paginakoppen en vergeleek hun betekenis met de betekenis van de verzoeken. Gebaseerd op Palekh verscheen Korolev. Dit algoritme evalueert niet alleen de titel, maar ook de volledige tekstinhoud van de pagina. De zoekopdracht wordt nauwkeuriger en site-eigenaren beginnen pagina-inhoud intelligenter te benaderen.
3. SEO-collega's van Yandex creëerden een muzikaal neuraal netwerk: het componeert poëzie en schrijft muziek. De neurogroep heet symbolisch Neurona, en heeft al zijn eerste album:

4. Google Inbox gebruikt neurale netwerken om op berichten te reageren. De technologische ontwikkeling is in volle gang en vandaag de dag bestudeert het netwerk al correspondentie en genereert het mogelijke antwoordopties. U hoeft geen tijd te verspillen met typen en bent niet bang om een belangrijke afspraak te vergeten.

5. YouTube gebruikt neurale netwerken om video's te rangschikken, en wel volgens twee principes tegelijk: het ene neurale netwerk bestudeert video's en de reacties van het publiek daarop, het andere doet onderzoek naar gebruikers en hun voorkeuren. Daarom zijn YouTube-aanbevelingen altijd actueel.
6. Facebook werkt actief aan DeepText AI, een communicatieprogramma dat jargon begrijpt en chats ontdoet van obsceen taalgebruik.
7. Apps zoals Prisma en Fabby, gebouwd op neurale netwerken, maken afbeeldingen en video's:

Colorize herstelt kleuren in zwart-witfoto's (verras oma!).

MakeUp Plus selecteert de perfecte lippenstift voor meisjes uit een echt aanbod van echte merken: Bobbi Brown, Clinique, Lancome en YSL zijn al actief.

8.
Apple en Microsoft zijn voortdurend bezig met het upgraden van hun neurale Siri en Contana. Voorlopig voeren ze alleen onze bevelen uit, maar in de nabije toekomst zullen ze het initiatief gaan nemen: aanbevelingen doen en anticiperen op onze wensen.
Wat staat ons nog meer te wachten in de toekomst?
Zelflerende neurale netwerken kunnen mensen vervangen: ze beginnen met copywriters en proeflezers. Robots creëren nu al teksten met betekenis en zonder fouten. En ze doen het veel sneller dan mensen. Ze gaan verder met callcentermedewerkers, technische ondersteuning, moderators en beheerders van openbare pagina's op sociale netwerken. Neurale netwerken zijn al in staat een script te leren en dit met hun stem te reproduceren. Hoe zit het met andere gebieden?
Agrarische sector
Het neurale netwerk zal in speciale apparatuur worden geïmplementeerd. Oogstmachines zullen de automatische piloot gebruiken, planten scannen en de bodem bestuderen, waarbij gegevens naar een neuraal netwerk worden verzonden. Zij beslist of ze water geeft, bemest of sproeit tegen ongedierte. In plaats van een paar dozijn werknemers heb je maximaal twee specialisten nodig: een supervisor en een technische.
Geneesmiddel
Microsoft werkt momenteel actief aan het ontwikkelen van een geneesmiddel tegen kanker. Wetenschappers houden zich bezig met bioprogrammering - ze proberen het proces van het ontstaan en de ontwikkeling van tumoren te digitaliseren. Als alles lukt, zullen programmeurs een manier kunnen vinden om een dergelijk proces te blokkeren, en zal er naar analogie een medicijn worden gecreëerd.
Marketing
Marketing is zeer persoonlijk. Nu al kunnen neurale netwerken binnen enkele seconden bepalen welke inhoud aan welke gebruiker moet worden getoond en tegen welke prijs. In de toekomst zal de deelname van de marketeer aan het proces tot een minimum worden beperkt: neurale netwerken zullen zoekopdrachten voorspellen op basis van gegevens over gebruikersgedrag, de markt scannen en de meest geschikte aanbiedingen bieden tegen de tijd dat iemand aan kopen denkt.
E-commerce
E-commerce zal overal worden geïmplementeerd. Je hoeft niet meer via een link naar de online winkel: je koopt alles met één klik waar je het ziet. U leest dit artikel bijvoorbeeld enkele jaren later. Je vindt de lippenstift in de schermafbeelding van de MakeUp Plus-applicatie erg mooi (zie hierboven). Je klikt erop en gaat direct naar de winkelwagen. Of bekijk een video over het nieuwste model Hololens (mixed reality bril) en plaats direct een bestelling direct via YouTube.
Op vrijwel elk gebied zullen specialisten met kennis of op zijn minst begrip van de structuur van neurale netwerken, machine learning en kunstmatige intelligentiesystemen worden gewaardeerd. We zullen bestaan met robots naast elkaar. En hoe meer we over hen weten, hoe rustiger ons leven zal zijn.
P.S. Zinaida Falls is een neuraal netwerk van Yandex dat poëzie schrijft. Beoordeel het werk dat de machine schreef na training door Majakovski (spelling en interpunctie behouden):
« Dit»
Dit
gewoon alles
iets
in de toekomst
en macht
die persoon
is alles in de wereld of niet
er is overal bloed
met elkaar omgaan
dik worden
glorie aan
land
met een knal in de snavel
Indrukwekkend, toch?
De kwesties van kunstmatige intelligentie en neurale netwerken worden momenteel populairder dan ooit tevoren. Veel gebruikers komen steeds vaker bij ons terecht met vragen over hoe neurale netwerken werken, wat ze zijn en wat het principe van hun werking is?
Deze vragen zijn, samen met hun populariteit, ook aanzienlijk complex, omdat de processen complexe machine learning-algoritmen zijn die voor verschillende doeleinden zijn ontworpen, van het analyseren van veranderingen tot het modelleren van de risico's die aan bepaalde acties zijn verbonden.
Wat zijn neurale netwerken en hun typen?
De eerste vraag die voor geïnteresseerden opkomt is: wat is een neuraal netwerk? In de klassieke definitie is dit een bepaalde reeks neuronen die met elkaar verbonden zijn door synapsen. Neurale netwerken zijn een vereenvoudigd model van biologische analogen.
Een programma met een neurale netwerkstructuur stelt de machine in staat invoergegevens te analyseren en het resultaat uit bepaalde bronnen te onthouden. Vervolgens maakt een dergelijke aanpak het mogelijk om het resultaat dat overeenkomt met de huidige dataset uit het geheugen op te halen, als dit al beschikbaar was in de ervaring van netwerkcycli. 
Veel mensen beschouwen een neuraal netwerk als een analoog van het menselijk brein. Aan de ene kant kan dit oordeel als dicht bij de waarheid worden beschouwd, maar aan de andere kant is het menselijk brein een te complex mechanisme om het met behulp van een machine, zelfs met een fractie van een seconde, opnieuw te kunnen creëren. procent. Een neuraal netwerk is in de eerste plaats een programma dat gebaseerd is op het principe van de hersenen, maar op geen enkele manier analoog is.
Een neuraal netwerk bestaat uit een aantal neuronen, die elk informatie ontvangen, verwerken en doorgeven aan een ander neuron. Elk neuron verwerkt het signaal op precies dezelfde manier.
Hoe krijg je dan andere resultaten? Het draait allemaal om de synapsen die neuronen met elkaar verbinden. Eén neuron kan een groot aantal synapsen hebben die het signaal versterken of verzwakken, en ze hebben het vermogen om hun kenmerken in de loop van de tijd te veranderen.
Het zijn de correct geselecteerde parameters van synapsen die het mogelijk maken om het juiste resultaat te verkrijgen van het transformeren van de invoergegevens aan de uitgang.
Nadat we in algemene termen hebben gedefinieerd wat een neuraal netwerk is, kunnen we de belangrijkste typen van hun classificatie identificeren. Voordat u doorgaat met de classificatie, is het noodzakelijk om één verduidelijking in te voeren. Elk netwerk heeft een eerste laag neuronen, de invoerlaag.
Het voert geen berekeningen of transformaties uit; zijn taak is slechts één ding: invoersignalen ontvangen en distribueren naar andere neuronen. Dit is de enige laag die alle soorten neurale netwerken gemeen hebben; hun verdere structuur is het criterium voor de hoofdindeling.
- Enkellaags neuraal netwerk. Dit is een structuur voor de interactie van neuronen, waarbij, nadat de invoergegevens de eerste invoerlaag binnenkomen, het eindresultaat onmiddellijk wordt overgedragen naar de uitvoerlaag. In dit geval wordt geen rekening gehouden met de eerste invoerlaag, aangezien deze geen andere acties uitvoert dan ontvangst en distributie, dit is hierboven al vermeld. En de tweede laag voert alle benodigde berekeningen en bewerkingen uit en levert direct het eindresultaat op. Invoerneuronen worden gecombineerd met de hoofdlaag door synapsen met verschillende wegingscoëfficiënten, waardoor de kwaliteit van verbindingen wordt gewaarborgd.
- Meerlaags neuraal netwerk. Zoals duidelijk blijkt uit de definitie kent dit type neuraal netwerk naast de input- en outputlagen ook tussenlagen. Hun aantal hangt af van de complexiteit van het netwerk zelf. Het lijkt meer op de structuur van een biologisch neuraal netwerk. Dit soort netwerken zijn vrij recent ontwikkeld; alle processen werden geïmplementeerd met behulp van enkellaagse netwerken. Dienovereenkomstig heeft een dergelijke oplossing veel meer mogelijkheden dan zijn voorouder. In het informatieverwerkingsproces vertegenwoordigt elke tussenlaag een tussenstadium van informatieverwerking en -distributie.
Afhankelijk van de richting van de informatieverdeling over synapsen van het ene neuron naar het andere, kunnen netwerken ook in twee categorieën worden ingedeeld.
- Directe voortplantingsnetwerken of unidirectioneel, dat wil zeggen een structuur waarin het signaal strikt van de invoerlaag naar de uitvoerlaag beweegt. Signaalbeweging in de tegenovergestelde richting is onmogelijk. Dergelijke ontwikkelingen zijn vrij wijdverspreid en lossen momenteel met succes problemen op zoals herkenning, voorspellingen of clustering.
- Netwerken met feedback of terugkerend. Dergelijke netwerken zorgen ervoor dat het signaal niet alleen in de voorwaartse richting kan reizen, maar ook in de omgekeerde richting. Wat geeft dit? In dergelijke netwerken kan op basis hiervan het resultaat van de output worden teruggestuurd naar de input, de output van het neuron wordt bepaald door de gewichten en inputsignalen, en wordt aangevuld door de eerdere outputs, die weer worden teruggestuurd naar de input. Dergelijke netwerken kenmerken zich door de functie van het kortetermijngeheugen, op basis waarvan signalen tijdens de verwerking worden hersteld en aangevuld.
Dit zijn niet de enige opties voor het classificeren van netwerken.
Ze kunnen worden onderverdeeld in homogeen en hybride op basis van de soorten neuronen waaruit het netwerk bestaat. En ook heteroassociatief of autoassociatief, afhankelijk van de netwerktrainingsmethode, met of zonder docent. U kunt netwerken ook classificeren op basis van hun doel.
Waar worden neurale netwerken gebruikt?
Neurale netwerken worden gebruikt om een verscheidenheid aan problemen op te lossen. Als we taken beschouwen op basis van de mate van complexiteit, dan is een gewoon computerprogramma geschikt voor het oplossen van de eenvoudigste problemen, meer nog  Bij complexe problemen die een eenvoudige voorspelling of een benaderende oplossing van vergelijkingen vereisen, worden programma's gebruikt die statistische methoden gebruiken.
Bij complexe problemen die een eenvoudige voorspelling of een benaderende oplossing van vergelijkingen vereisen, worden programma's gebruikt die statistische methoden gebruiken.
Maar taken van een nog complexer niveau vereisen een geheel andere aanpak. Dit geldt met name voor patroonherkenning, spraakherkenning of complexe voorspelling. In het hoofd van een persoon vinden dergelijke processen onbewust plaats, dat wil zeggen dat iemand tijdens het herkennen en onthouden van beelden zich niet bewust is van hoe dit proces plaatsvindt en er daarom geen controle over heeft.
Het zijn precies deze problemen die neurale netwerken helpen oplossen, dat wil zeggen dat ze zijn gemaakt om processen uit te voeren waarvan de algoritmen onbekend zijn.
Zo worden neurale netwerken veel gebruikt op de volgende gebieden:
- erkenning, en deze richting is momenteel de breedste;
- bij het voorspellen van de volgende stap is deze functie toepasbaar in de handel en op aandelenmarkten;
- classificatie van invoergegevens door parameters; deze functie wordt uitgevoerd door kredietrobots, die een beslissing kunnen nemen bij het goedkeuren van een lening aan een persoon, op basis van een invoerset van verschillende parameters.
De mogelijkheden van neurale netwerken maken ze erg populair. Ze kunnen veel dingen leren, zoals spelletjes spelen, een bepaalde stem herkennen, enzovoort. Gebaseerd op het feit dat kunstmatige netwerken zijn gebouwd op het principe van biologische netwerken, kunnen ze alle processen leren die een persoon onbewust uitvoert.
Wat is een neuron en een synaps?
Dus wat is een neuron in termen van kunstmatige neurale netwerken? Dit concept verwijst naar een eenheid die berekeningen uitvoert. Het ontvangt informatie van de invoerlaag van het netwerk, voert er eenvoudige berekeningen mee uit en stuurt deze door naar het volgende neuron. 
Het netwerk bevat drie soorten neuronen: input, verborgen en output. Bovendien, als het netwerk uit één laag bestaat, bevat het geen verborgen neuronen. Daarnaast zijn er verschillende eenheden die verplaatsingsneuronen en contextneuronen worden genoemd.
Elk neuron heeft twee soorten gegevens: invoer en uitvoer. In dit geval heeft de eerste laag invoergegevens die gelijk zijn aan uitvoergegevens. In andere gevallen ontvangt de neuroninvoer de totale informatie van de voorgaande lagen en doorloopt deze vervolgens een normalisatieproces, dat wil zeggen dat alle waarden die buiten het gewenste bereik vallen, worden getransformeerd door de activeringsfunctie.
Zoals hierboven vermeld, is een synaps een verbinding tussen neuronen, die elk hun eigen mate van gewicht hebben. Dankzij deze functie verandert de invoerinformatie tijdens het transmissieproces. Tijdens de verwerking zal de informatie die door de synaps met een groot gewicht wordt verzonden, dominant zijn.
Het blijkt dat het resultaat niet wordt beïnvloed door neuronen, maar door synapsen die een bepaald gewicht toekennen aan de invoergegevens, aangezien de neuronen zelf elke keer precies dezelfde berekeningen uitvoeren.
In dit geval worden de gewichten in willekeurige volgorde ingesteld.
Werkingsschema van een neuraal netwerk
Om het werkingsprincipe van een neuraal netwerk voor te stellen, zijn geen speciale vaardigheden vereist. De invoerlaag van neuronen ontvangt bepaalde informatie. Het wordt via synapsen naar de volgende laag overgedragen, waarbij elke synaps zijn eigen gewichtscoëfficiënt heeft, en elk volgend neuron meerdere inkomende synapsen kan hebben.
Als gevolg hiervan is de informatie die door het volgende neuron wordt ontvangen de som van alle gegevens, elk vermenigvuldigd met zijn eigen gewichtscoëfficiënt. De resulterende waarde wordt vervangen door de activeringsfunctie en er wordt uitvoerinformatie verkregen, die verder wordt verzonden totdat deze de uiteindelijke uitvoer bereikt. De eerste lancering van het netwerk levert niet de juiste resultaten op, omdat het netwerk nog niet is getraind.
De activeringsfunctie wordt gebruikt om de invoergegevens te normaliseren. Er zijn veel van dergelijke functies, maar er zijn verschillende belangrijke functies die het meest worden gebruikt. Hun grootste verschil is het bereik van waarden waarin ze opereren.
- De lineaire functie f(x) = x, de eenvoudigste van allemaal, wordt alleen gebruikt voor het testen van het gecreëerde neurale netwerk of voor het verzenden van gegevens in de oorspronkelijke vorm.
- Sigmoid wordt beschouwd als de meest voorkomende activeringsfunctie en heeft de vorm f(x) = 1 / 1+e-×; Bovendien ligt het bereik van de waarden van 0 tot 1. Het wordt ook wel de logistieke functie genoemd.
- Om negatieve waarden te dekken, wordt een hyperbolische tangens gebruikt. F(x) = e²× - 1 / e²× + 1 - dit is de vorm van deze functie en het bereik ervan is van -1 tot 1. Als het neurale netwerk niet voorziet in het gebruik van negatieve waarden, dan mag niet worden gebruikt.
Om het netwerk de data te geven waarmee het gaat werken, zijn trainingssets nodig.
Integratie is een meter die met elke trainingsset toeneemt.Het tijdperk is een indicator van de training van een neuraal netwerk; deze indicator neemt toe elke keer dat het netwerk een cyclus van een volledige set trainingssets doorloopt.
Om het netwerk correct te trainen, moet u daarom sets uitvoeren, waarbij u de tijdperkindicator consequent verhoogt.
Tijdens de training worden fouten ontdekt. Dit is het procentuele verschil tussen het verkregen en het gewenste resultaat. Deze indicator zou moeten afnemen naarmate de epoch-indicator toeneemt, anders is er ergens een ontwikkelaarsfout.
Wat is een bias-neuron en waar dient het voor?
In neurale netwerken is er een ander type neuron: een verplaatsingsneuron. Het verschilt van het hoofdtype neuronen doordat de input en output in ieder geval gelijk zijn aan één. Bovendien hebben dergelijke neuronen geen invoersynapsen.
De rangschikking van dergelijke neuronen vindt één per laag plaats en niet meer, en ze kunnen niet met elkaar synapsen. Het is niet aan te raden dergelijke neuronen op de uitvoerlaag te plaatsen.
 Waar zijn ze voor? Er zijn situaties waarin het neurale netwerk simpelweg niet in staat zal zijn de juiste oplossing te vinden, omdat het gewenste punt buiten bereik is. Dit is precies de reden waarom dergelijke neuronen nodig zijn om het definitiegebied te kunnen verschuiven.
Waar zijn ze voor? Er zijn situaties waarin het neurale netwerk simpelweg niet in staat zal zijn de juiste oplossing te vinden, omdat het gewenste punt buiten bereik is. Dit is precies de reden waarom dergelijke neuronen nodig zijn om het definitiegebied te kunnen verschuiven.
Dat wil zeggen dat het gewicht van de synaps de buiging van de functiegrafiek verandert, terwijl het verplaatsingsneuron een verschuiving langs de X-coördinaatas mogelijk maakt, zodat het neurale netwerk een gebied kan vastleggen dat voor hem ontoegankelijk is zonder een verschuiving. In dit geval kan de verschuiving zowel naar rechts als naar links worden uitgevoerd. Shift-neuronen worden meestal niet schematisch gemarkeerd; bij het berekenen van de invoerwaarde wordt standaard rekening gehouden met hun gewicht.
Bovendien kunt u met bias-neuronen een resultaat krijgen in het geval dat alle andere neuronen 0 als uitgangsparameter produceren. In dit geval wordt, ongeacht het gewicht van de synaps, precies deze waarde naar elke volgende laag verzonden.
De aanwezigheid van een verplaatsingsneuron stelt je in staat de situatie te corrigeren en een ander resultaat te krijgen. De haalbaarheid van het gebruik van verplaatsingsneuronen wordt bepaald door het netwerk met en zonder deze te testen en de resultaten te vergelijken.
Maar het is belangrijk om te onthouden dat het voor het bereiken van resultaten niet voldoende is om een neuraal netwerk te creëren. Het moet ook worden getraind, wat ook een speciale aanpak vereist en zijn eigen algoritmen heeft. Dit proces kan nauwelijks eenvoudig worden genoemd, omdat de implementatie ervan bepaalde kennis en inspanning vereist.
Met vriendelijke groet, Nastya TsjechovaDienovereenkomstig neemt het neurale netwerk twee getallen als invoer en moet het een ander getal uitvoeren: het antwoord. Nu over de neurale netwerken zelf.
Wat is een neuraal netwerk?
Een neuraal netwerk is een reeks neuronen die met elkaar zijn verbonden door synapsen. De structuur van een neuraal netwerk kwam rechtstreeks vanuit de biologie naar de programmeerwereld. Dankzij deze structuur krijgt de machine de mogelijkheid om verschillende informatie te analyseren en zelfs te onthouden. Neurale netwerken zijn ook in staat om niet alleen binnenkomende informatie te analyseren, maar deze ook uit hun geheugen te reproduceren. Voor degenen die geïnteresseerd zijn, bekijk zeker 2 video's van TED Talks: Video 1 , Video 2). Met andere woorden: een neuraal netwerk is een machinale interpretatie van het menselijk brein, dat miljoenen neuronen bevat die informatie doorgeven in de vorm van elektrische impulsen.
Welke soorten neurale netwerken zijn er?
Voor nu zullen we voorbeelden bekijken van het meest basale type neurale netwerken: een feed-forward-netwerk (hierna een feed-forward-netwerk genoemd). Ook in volgende artikelen zal ik meer concepten introduceren en vertellen over terugkerende neurale netwerken. SPR is, zoals de naam al aangeeft, een netwerk met een opeenvolgende verbinding van neurale lagen; informatie stroomt altijd in slechts één richting.
Waar zijn neurale netwerken voor?
Neurale netwerken worden gebruikt om complexe problemen op te lossen waarvoor analytische berekeningen nodig zijn, vergelijkbaar met wat het menselijk brein doet. De meest voorkomende toepassingen van neurale netwerken zijn:
Classificatie- verdeling van gegevens per parameters. U krijgt bijvoorbeeld een aantal mensen als input en u moet beslissen aan wie u eer wilt geven en aan wie niet. Dit werk kan worden gedaan door een neuraal netwerk, dat informatie analyseert zoals leeftijd, solvabiliteit, kredietgeschiedenis, enz.
Voorspelling- het vermogen om de volgende stap te voorspellen. Bijvoorbeeld de stijging of daling van aandelen op basis van de situatie op de aandelenmarkt.
Herkenning- Momenteel het meest wijdverspreide gebruik van neurale netwerken. Gebruikt in Google wanneer u naar een foto zoekt of in telefooncamera's wanneer het de positie van uw gezicht detecteert en markeert, en nog veel meer.
Laten we, om te begrijpen hoe neurale netwerken werken, eens kijken naar de componenten en hun parameters.
Wat is een neuron?
Een neuron is een rekeneenheid die informatie ontvangt, er eenvoudige berekeningen op uitvoert en deze verder verzendt. Ze zijn onderverdeeld in drie hoofdtypen: invoer (blauw), verborgen (rood) en uitvoer (groen). Er is ook een verplaatsingsneuron en een contextneuron, waarover we het in het volgende artikel zullen hebben. In het geval dat een neuraal netwerk uit een groot aantal neuronen bestaat, wordt de term laag geïntroduceerd. Dienovereenkomstig is er een invoerlaag die informatie ontvangt, n verborgen lagen (meestal niet meer dan 3) die deze verwerken, en een uitvoerlaag die het resultaat uitvoert. Elk neuron heeft 2 hoofdparameters: invoergegevens en uitvoergegevens. In het geval van een inputneuron: input=output. In de rest bevat het invoerveld de totale informatie van alle neuronen uit de vorige laag, waarna deze wordt genormaliseerd met behulp van de activeringsfunctie (laten we het ons nu maar voorstellen als f(x)) en in het uitvoerveld terechtkomt.
Belangrijk om te onthouden dat neuronen werken met getallen in het bereik of [-1,1]. Maar hoe, zo vraagt u zich af, verwerkt u dan getallen die buiten dit bereik vallen? Op dit moment is het eenvoudigste antwoord om 1 te delen door dat getal. Dit proces wordt normalisatie genoemd en wordt vaak gebruikt in neurale netwerken. Hierover later meer.
Wat is een synaps?
Een synaps is een verbinding tussen twee neuronen. Synapsen hebben 1 parameter: gewicht. Dankzij dit verandert de ingevoerde informatie wanneer deze van het ene neuron naar het andere wordt overgedragen. Laten we zeggen dat er drie neuronen zijn die informatie doorgeven aan de volgende. Dan hebben we 3 gewichten die overeenkomen met elk van deze neuronen. Voor het neuron waarvan het gewicht groter is, zal die informatie dominant zijn in het volgende neuron (bijvoorbeeld bij het mengen van kleuren). In feite is de reeks gewichten van een neuraal netwerk of de gewichtsmatrix een soort brein van het hele systeem. Dankzij deze gewichten wordt de invoerinformatie verwerkt en omgezet in een resultaat.
Belangrijk om te onthouden, dat tijdens de initialisatie van het neurale netwerk de gewichten in willekeurige volgorde worden geplaatst.
Hoe werkt een neuraal netwerk?
Dit voorbeeld toont een deel van een neuraal netwerk, waarbij de letters I invoerneuronen aanduiden, de letter H een verborgen neuron aanduidt en de letter w gewichten aanduidt. De formule laat zien dat de invoerinformatie de som is van alle invoergegevens vermenigvuldigd met hun overeenkomstige gewichten. Dan geven we 1 en 0 als invoer. Stel dat w1=0,4 en w2 = 0,7. De invoergegevens van neuron H1 zijn als volgt: 1*0,4+0*0,7=0,4. Nu we de invoer hebben, kunnen we de uitvoer verkrijgen door de invoer in de activeringsfunctie te pluggen (daarover later meer). Nu we de output hebben, geven we deze door. En dus herhalen we dit voor alle lagen totdat we het uitgangsneuron bereiken. Nu we voor het eerst een dergelijk netwerk hebben gelanceerd, zullen we zien dat het antwoord verre van correct is, omdat het netwerk niet is getraind. Om de resultaten te verbeteren gaan wij haar trainen. Maar voordat we leren hoe we dit moeten doen, introduceren we eerst een paar termen en eigenschappen van een neuraal netwerk.
Activeringsfunctie
Een activeringsfunctie is een manier om invoergegevens te normaliseren (we hebben hier eerder over gesproken). Dat wil zeggen, als u een groot getal aan de ingang heeft en dit door de activeringsfunctie stuurt, krijgt u een uitvoer in het bereik dat u nodig heeft. Er zijn nogal wat activeringsfuncties, dus we zullen de meest elementaire overwegen: lineair, sigmoïde (logistiek) en hyperbolische tangens. Hun belangrijkste verschillen zijn het bereik van waarden.
Lineaire functie
Deze functie wordt bijna nooit gebruikt, behalve wanneer u een neuraal netwerk moet testen of een waarde moet doorgeven zonder conversie.
Sigmoïd
Dit is de meest voorkomende activeringsfunctie en het bereik van waarden is . Dit is waar de meeste voorbeelden op internet worden getoond, en wordt ook wel de logistieke functie genoemd. Dienovereenkomstig, als er in uw geval negatieve waarden zijn (aandelen kunnen bijvoorbeeld niet alleen stijgen, maar ook dalen), dan heeft u een functie nodig die ook negatieve waarden vastlegt.
Hyperbolische raaklijn
Het heeft alleen zin om de hyperbolische tangens te gebruiken als uw waarden zowel negatief als positief kunnen zijn, aangezien het bereik van de functie [-1,1] is. Het is niet raadzaam om deze functie alleen bij positieve waarden te gebruiken, omdat dit de resultaten van uw neurale netwerk aanzienlijk zal verslechteren.
Trainingsset
Een trainingsset is een reeks gegevens waarop een neuraal netwerk werkt. In ons geval van uitzonderlijk of (xor) hebben we slechts 4 verschillende uitkomsten, dat wil zeggen dat we 4 trainingssets hebben: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Iteratie
Dit is een soort teller die toeneemt elke keer dat het neurale netwerk één trainingsset doorloopt. Met andere woorden: dit is het totale aantal trainingssets dat door het neurale netwerk is voltooid.
tijdperk
Wanneer het neurale netwerk wordt geïnitialiseerd, wordt deze waarde ingesteld op 0 en heeft deze een handmatig ingesteld plafond. Hoe groter het tijdperk, hoe beter het netwerk is getraind en dus ook het resultaat ervan. Het tijdperk neemt toe elke keer dat we de hele set trainingssets doorlopen, in ons geval vier sets of vier iteraties.
Belangrijk verwar iteratie niet met tijdperk en begrijp de volgorde van hun toename. Eerste n
zodra de iteratie toeneemt, en dan het tijdperk, en niet andersom. Met andere woorden: je kunt een neuraal netwerk niet eerst op slechts één set trainen, dan op een andere, enzovoort. Je moet elke set één keer per tijdperk trainen. Zo voorkom je fouten in de berekeningen.Fout
Fout is een percentage dat het verschil weergeeft tussen de verwachte en ontvangen antwoorden. De fout wordt elk tijdperk gevormd en moet afnemen. Als dit niet gebeurt, doe je iets verkeerd. De fout kan op verschillende manieren worden berekend, maar we zullen slechts drie hoofdmethoden beschouwen: Mean Squared Error (hierna MSE), Root MSE en Arctan. Er is geen gebruiksbeperking zoals bij de activeringsfunctie, en u bent vrij om elke methode te kiezen die u de beste resultaten oplevert. Houd er alleen rekening mee dat elke methode fouten anders telt. Bij Arctan zal de fout bijna altijd groter zijn, omdat het werkt volgens het principe: hoe groter het verschil, hoe groter de fout. De root-MSE heeft de kleinste fout, dus het is het gebruikelijkst om een MSE te gebruiken die het evenwicht in de foutberekening handhaaft.
Root-MSE
Het principe van rekenfouten is in alle gevallen hetzelfde. Voor elke set tellen we de fout door het resultaat af te trekken van het ideale antwoord. Vervolgens kwadrateren we het of berekenen we de kwadratische raaklijn uit dit verschil, waarna we het resulterende getal delen door het aantal sets.
Taak
Om uzelf te testen, berekent u nu de output van een bepaald neuraal netwerk met behulp van sigmoid en de fout ervan met behulp van MSE.
Gegevens: I1=1, I2=0, w1=0,45, w2=0,78,w3=-0,12,w4=0,13,w5=1,5,w6=-2,3.




































