Instrumenttests, configuratiebestanden en logbestanden moeten allemaal leesbaar zijn voor mensen. YAML (YAML Not Markup Language) heeft minder uitgebreide gegevens dan het XML-serialisatieformaat en is een populair formaat geworden onder softwareontwikkelaars, vooral omdat het gemakkelijker is voor menselijk begrip. YAML-bestanden zijn eenvoudigweg tekstbestanden die gegevens bevatten die zijn geschreven volgens de YAML-syntaxisregels en hebben meestal de bestandsextensie .yml. In dit artikel maak je kennis met de basisprincipes van YAML en hoe je de YAML-parser van PHP in je projecten kunt integreren.
Gebruik YAML voor PHP-projecten
YAML-syntaxis begrijpen
YAML ondersteunt geavanceerde functies zoals referenties en aangepaste gegevenstypen, maar als PHP-ontwikkelaar zult u meestal geïnteresseerd zijn in de manier waarop YAML opgesomde arrays (reeksen in YAML-terminologie) en associatieve arrays (toewijzingen) representeert.
Hier ziet u hoe een enum wordt weergegeven in een YAML-array:
- "William O'Neal" - vals
Elk array-element wordt weergegeven na een koppelteken en een spatie. De syntaxis voor het weergeven van waarden is vergelijkbaar met PHP (tekenreeksen aanhalen, enz.)
Het bovenstaande is gelijk aan de volgende PHP:
Normaal gesproken verschijnt elk element op een eigen regel in YAML, maar de vermelde arrays kunnen op één regel worden uitgedrukt met behulp van haakjes:
[2, "William O'Neal", vals ]
De volgende code laat zien hoe een associatieve array wordt weergegeven in YAML:
Id: 2 naam: "William O'Neal" isActive: false
De eerste elementsleutel specificeert een dubbele punt en een of meer spaties, en vervolgens wordt de waarde gespecificeerd. Slechts één spatie na de dubbele punt is voldoende, maar u kunt desgewenst meer ruimte gebruiken voor een betere leesbaarheid.
De equivalente PHP-array van de bovenstaande YAML is:
2, "naam" => "William O"Neal", "isActive" => false);?>
En net als bij opgesomde arrays, kun je associatieve arrays op één regel uitdrukken met behulp van accolades:
(id: 2, naam: "William O'Neal", isActive: false )
Met een of meer spaties voor inspringing kunt u een multidimensionale array als volgt weergeven:
Boven het YAML-blok is dit gelijk aan de volgende PHP:
array(0 => array("id" => 1, "name" => "Brad Taylor", "isActive" => true), 1 => array("id" => 2, "name" => " William O"Neill", "isActive" => false)));?>
Met YAML kunt u ook een verzameling gegevenselementen in één document weergeven zonder dat u een hoofdknooppunt nodig heeft. Het volgende voorbeeld bevat de inhoud van Article.yml, waarin meerdere multidimensionale arrays in één bestand worden weergegeven.
Auteur: 0: ( id: 1, naam: "Brad Taylor", isActive: true ) 1: ( id: 2, naam: "William O"Neal", isActive: false ) categorie: 0: ( id: 1, naam : "PHP" ) 1: ( id: 2, naam: "YAML" ) 2: ( id: 3, naam: "XML") artikel: 0: id: 1 title: "Hoe YAML te gebruiken in een PHP-project" inhoud: > YAML is een minder uitgebreid gegevensserialisatieformaat. Daarachter staat "YAML is geen opmaaktaal". YAML is een populair gegevensserialisatieformaat onder softwareontwikkelaars, vooral omdat het voor mensen leesbaar is. auteur: 1 status: 2 artikelCategorie : 0 : ( artikelId: 1, categorieId: 1 ) 1: ( artikelId: 1, categorieId: 2 )
Hoewel de meeste YAML-syntaxis intuïtief en gemakkelijk te onthouden is, is er één belangrijke regel waar u op moet letten. De uitlijning moet gebeuren met één of meerdere spaties; Tabbladen zijn niet toegestaan. U kunt de IDE configureren om spaties in plaats van tabs in te voegen wanneer u op de Tab-toets drukt, wat een gebruikelijke configuratie is onder softwareontwikkelaars om ervoor te zorgen dat de code correct wordt ingesprongen en verschijnt wanneer deze in andere editors wordt bekeken.
U kunt meer geavanceerde functies en syntaxis leren, en wat YAML ondersteunt, door de officiële documenten, Symfony of Wiki te lezen.
YAML mag geen alternatief zijn voor XML
Als u YAML onderzoekt met uw favoriete zoekmachine, zult u ongetwijfeld het onderwerp 'YAML versus XML' hebben, en natuurlijk zult u, wanneer u YAML voor het eerst ziet, de voorkeur geven boven XML, omdat het gemakkelijker is lezen en schrijven YAML zou echter een ander hulpmiddel moeten zijn in het arsenaal van een ontwikkelaar en mag geen alternatief zijn voor XML. Hier zijn enkele voordelen van YAML en XML.
Voordelen van YAML
- Minder gedetailleerd, gemakkelijker samen te stellen en beter leesbaar
- Heeft geen boomstructuur met één bovenliggend knooppunt
Voordelen van XML
- Meer ingebouwde ondersteuning voor PHP vergeleken met YAML
- XML is de de facto standaard geworden voor communicatie tussen communicatietoepassingen
- XML-tags kunnen attributen hebben die meer gedetailleerde informatie over de privégegevens bieden
Hoewel uitgebreid, is XML beter leesbaar en onderhoudbaar als de elementhiërarchie diep is vergeleken met de op ruimte gebaseerde hiërarchierepresentatie van YAML.
Gezien de voordelen in beide talen lijkt YAML geschikter voor het verzamelen van verschillende datasets en wanneer mensen ook een van de dataconsumenten zijn.
Selecteer Parser PHP YAML
De YAML-parser heeft twee functionaliteiten, een soort laadfunctie die YAML naar een array converteert, en een dumpfunctie die de array naar YAML converteert.
Momenteel een PHP YAML-parser, beschikbaar als PECL-extensie en niet gebundeld met PHP. Daarnaast zijn er analysers geschreven in pure PHP, wat iets langzamer zou zijn vergeleken met de PECL-extensie.
Hieronder staan enkele YAML-parsers voor PHP:
- Wordt niet geleverd met PHP
- Vereist root-toegang tot de server voor installatie
- Geïmplementeerd in PHP
- Werkt in PHP 5.2.4+
- Noodzaak om raamwerken uit Symfony te extraheren
- Geïmplementeerd in PHP
- Werkt in PHP 5.3.2+
- Geïmplementeerd in PHP
- Werkt in PHP 5+
Ik geef er de voorkeur aan om Symfony 1.4 YAML-componenten te kiezen vanwege draagbaarheid (het werkt met PHP 5.2.4+) en verlossing (Symfony 1.4 en PHP-framework geïnstalleerd). Nadat u het YAML-archief van Symfony-componenten hebt uitgepakt, zijn de YAML-klassen beschikbaar onder lib/yaml . De statische methoden load() en dump() zijn beschikbaar via de klasse sfYaml.
Integratie in het Parser PHP YAML-project
Wanneer u een klasse of bibliotheek van derden in uw PHP-project moet integreren, is het een goede gewoonte om een wrapper en tests te maken. Het wijzigen van een bibliotheek van derden met minimale wijzigingen aan de projectcode (alleen de shell mag van toepassing zijn op de projectcode) en met het vertrouwen dat de wijzigingen geen enkele functionaliteit zullen vertragen (testen).
Hieronder vindt u een test (YamlParserTest.php) die is gemaakt voor de wrapper-klasse (YamlParser.php). Vereist om de test uit te voeren en te onderhouden. U kunt desgewenst meerdere tests toevoegen, voor ongeldige bestandsnamen en andere bestandsextensies dan .yml en andere tests op basis van scripts die u in uw project tegenkomt.
yamlParser = nieuwe YamlParser();"; $content = "YAML is a less-verbose data serialization format. " . "It stands for \"YAML Ain"t Markup Language\". " . "YAML has been a popular data serialization format among " . "software developers mainly because it"s human-readable.\n"; $expectedArticle = array("id" => 1, "title" => $title, "content" => $content, "author" => 1, "status" => 2); $this->assertEquals($expectedArticle, $actualArticle); } /** * @expectedException YamlParserException */ public function testExceptionForWrongSyntax() { $this->yamlParser->load("wrong-syntax.yml"); } }?> !}
) publieke functie testMainArrayKeys() ( $parsedYaml = $this->yamlParser->load("article.yml"); $mainArrayKeys = array_keys($parsedYaml); $expectedKeys = array("auteur", "categorie", "artikel ", "articleCategory"); $this->assertEquals($expectedKeys, $mainArrayKeys); ) public function testSecondLevelElement() ( $parsedYaml = $this->yamlParser->load("article.yml"); $actual Article = $ parsedYaml["article"]; $title = "Hoe u YAML gebruikt in uw volgende PHP-project
En hier is de wrapper-klasse:< 0) { parent::__construct($message, $code); } else { parent::__construct($message, $code, $previous); } } }?>
getMessage(), $e->getCode(), $e);
) ) public function dump($array) ( try ( return sfYaml::dump($array); ) catch (Exception $e) ( throw new YamlParserException($e->getMessage(), $e->getCode(), $e); ) ) ) klasse YamlParserException breidt uitzondering uit ( publieke functie __construct($message = "", $code = 0, $previous = NULL) ( if (version_compare(PHP_VERSION, "5.3.0")
P.S.
Dus nu heb je kennis over wat YAML is en hoe je PHP-arrays in YAML kunt weergeven, en hoe je de PHP YAML-parser in je projecten kunt integreren. Door wat tijd te besteden aan de YAML-syntaxis, kunt u het potentieel van de mogelijkheden die het biedt begrijpen. Je kunt ook overwegen om Symfony 1.4 en 2 te leren, waarin uitgebreid gebruik wordt gemaakt van YAML.
JSON (JavaScript Object Notation) is een formaat voor de uitwisseling van tekstgegevens, gebaseerd op JavaScript en dat veel wordt gebruikt in deze taal. Net als veel andere tekstformaten is JSON gemakkelijk te lezen door mensen. Ondanks zijn oorsprong in JavaScript (meer precies, uit een subset van de taal van de ECMA-262-standaard uit 1999), wordt het formaat als taalonafhankelijk beschouwd en kan het met vrijwel elke programmeertaal worden gebruikt. Voor veel talen is er kant-en-klare code voor het maken en verwerken van gegevens in JSON-formaat.
YAML is een door mensen leesbaar dataserialisatieformaat, conceptueel dicht bij opmaaktalen, maar gericht op het gemak van input-output van typische datastructuren van veel programmeertalen. De naam YAML is een recursief acroniem voor YAML Ain't Markup Language ("YAML is geen opmaaktaal"). De naam weerspiegelt de ontwikkelingsgeschiedenis: in de beginfase heette de taal Yet Another Markup Language ("Another Markup Language") ”) en werd zelfs beschouwd als XML van een concurrent, maar werd later hernoemd om de nadruk te leggen op gegevens in plaats van documentmarkeringen.
Dus wat we nodig hebben:
- maak dezelfde complexe JSON en YAML
- bepaal de parameters waarmee we zullen vergelijken
- Deserialiseer objecten in Java ongeveer 30 keer
- snelheidsresultaten vergelijken
- vergelijk de leesbaarheid van bestanden
- vergelijk gebruiksgemak met het formaat
Uiteraard gaan we niet onze eigen parsers schrijven, dus selecteren we eerst voor elk formaat een bestaande parser.
Voor json gebruiken we gson (van Google), en voor yaml gebruiken we snakeyaml (van ik weet niet wie).
Zoals je kunt zien, is alles eenvoudig, je hoeft alleen maar een vrij complex model te maken dat de complexiteit van configuratiebestanden simuleert, en een module te schrijven die yaml- en json-parsers test. Laten we beginnen.
We hebben een model nodig van ongeveer deze complexiteit: 20 attributen van verschillende typen + 5 verzamelingen van elk 5-10 elementen + 5 geneste objecten van elk 5-10 elementen en 5 verzamelingen.
Deze fase van de hele vergelijking kan gerust de meest vervelende en oninteressante worden genoemd. Er zijn klassen gemaakt met stille namen zoals Model, Emdedded1, enz. Maar we streven niet naar leesbaarheid van code (tenminste in dit deel), dus laten we dat zo.
bestand.json
"embedded2": ( "strel1": "el1", "strel2": "el2", "strel4": "el4", "strel5": "el5", "strel6": "el6", "strel7": " el7", "intel1": 1, "intel2": 2, "intel3": 3, "lijst1": [ 1, 2, 3, 4, 5 ], "lijst2": [ 1, 2, 3, 4, 5, 6, 7 ], "lijst3": [ "1", "2", "3", "4" ], "lijst4": [ "1", "2", "3", "4", "5", "6" ], "map1": ( "3": 3, "2": 2, "1": 1), "map2": ("1": "1", "2": "2", "3": "3") )
bestand.yml
embedded2: intel1: 1 intel2: 2 intel3: 3 lijst1: - 1 - 2 - 3 - 4 - 5 lijst2: - 1 - 2 - 3 - 4 - 5 - 6 - 7 lijst3: - "1" - "2" - "3" - "4" lijst4: - "1" - "2" - "3" - "4" - "5" - "6" kaart1: "3": 3 "2": 2 "1": 1 kaart2: 1: "1" 2: "2" 3: "3" strel1: el1 strel2: el2 strel4: el4 strel5: el5 strel6: el6 strel7: el7
Ik ben het ermee eens dat menselijke leesbaarheid een nogal subjectieve parameter is. Maar toch is yaml naar mijn mening een beetje aangenamer voor het oog en intuïtiever.
yaml-parser
public class BookYAMLPaser implementeert Parser
json-parser
openbare klasse BookJSONParser implementeert Parser
Zoals we kunnen zien, worden beide formaten ondersteund in Java. Maar voor json is de keuze veel ruimer, dat valt niet te ontkennen.
De parsers zijn klaar, laten we nu eens kijken naar de implementatie van de vergelijking. Ook hier is alles uiterst eenvoudig en duidelijk. Er is een eenvoudige methode die objecten uit een bestand 30 keer deserialiseert. Mocht iemand interesse hebben, de code staat onder de spoiler.
testcode
public static void main(String args) ( String jsonFilename = "file.json"; String yamlFilename = "file.yml"; BookJSONParser jsonParser = new BookJSONParser(jsonFilename); jsonParser.serialize(new Book(new Author("name", "123-123-123"), 123, "dfsas")); BookYAMLPaser yamlParser = new BookYAMLPaser(yamlBestandsnaam); , "dfsas")); //json-deserialisatie StopWatch stopWatch = nieuwe StopWatch();< LOOPS; i++) { Book e = jsonParser.deserialize(); } stopWatch.stop(); System.out.println("json worked: " + stopWatch.getTime()); stopWatch.reset(); //yaml deserialization stopWatch.start(); for (int i = 0; i < LOOPS; i++) { Book e; e = yamlParser.deserialize(); } stopWatch.stop(); System.out.println("yaml worked: " + stopWatch.getTime()); }
Als resultaat krijgen we het volgende resultaat:
json werkte: 278 yaml werkte: 669

Zoals u kunt zien, worden json-bestanden ongeveer drie keer sneller geparseerd. Maar het absolute verschil is op onze schaal niet van cruciaal belang. Daarom is dit geen sterk pluspunt in het voordeel van json.
Dit gebeurt omdat json direct wordt geparseerd, dat wil zeggen dat het karakter voor karakter wordt gelezen en onmiddellijk in een object wordt opgeslagen. Het blijkt dat het object in één keer door het bestand wordt gevormd. Eigenlijk weet ik niet hoe deze parser precies werkt, maar over het algemeen is het schema als volgt.
En yaml is op zijn beurt meer afgemeten. De gegevensverwerkingsfase is verdeeld in 3 fasen. Eerst wordt een boom met objecten gebouwd. Dan wordt het op de een of andere manier getransformeerd. En pas na deze fase wordt het omgezet in de benodigde datastructuren.
Een kleine vergelijkende tabel ("+" - voordeel, "-" - vertraging, "+-" - geen duidelijk voordeel):
Hoe kan dit worden samengevat?
Alles is hier duidelijk, als snelheid belangrijk voor je is - dan json, als menselijke leesbaarheid - yaml. Je hoeft alleen maar te beslissen wat belangrijker is. Voor ons werd het de tweede.
In feite kunnen er nog veel meer verschillende argumenten ten gunste van elk van de formaten worden aangevoerd, maar ik denk dat deze twee punten nog steeds het belangrijkst zijn.
Verder had ik bij het werken met yaml te maken met niet erg goede afhandeling van uitzonderingen, vooral voor syntaxisfouten. Ook moest ik verschillende yaml-bibliotheken testen. Ten slotte was het nodig om een soort validatie te schrijven. We hebben validatie geprobeerd met behulp van schema's (waarbij we Ruby-edelstenen moesten aanroepen) en bonenvalidatie op basis van jsr-303. Als u geïnteresseerd bent in een van deze onderwerpen, beantwoord ik graag uw vragen.
Bedankt voor uw aandacht :)
getMessage(), $e->getCode(), $e);
Tegen het einde van het schrijven van het artikel kwam ik de volgende vergelijking van yaml en json tegen.
Stanislav Sjasjevitsj

Content parser is onze wereldwijde en geavanceerde oplossing waarmee u catalogi, pagina's en RSS-feeds kunt parseren. Het lijkt erop, wat kun je nog meer vragen van deze module?! Maar dat was niet het geval. Onze klanten staan niet stil en vragen voortdurend van ons om oplossingen te ontwikkelen. En daar zijn wij alleen maar blij mee. En nu willen we aankondigen dat we aan een ander zeer belangrijk verzoek van onze klanten hebben voldaan: het parseren van XML-bestanden. Nu kan de Parser niet alleen werken met rss, pagina, catalogus gegevenstypen, maar ook met xml. En het allerbelangrijkste: de implementatie van dergelijke nuttige functionaliteit heeft op geen enkele manier invloed op de kosten van de oplossing. Oplossing prijs in 14
990 wrijven. zal onveranderd blijven.
Parseren xml Met bestanden kunt u zo'n handig formaat voor online winkels ontleden als YML bestanden. Dat is waarom xml de parser is standaard geconfigureerd voor parseren yml uitgifte. Maar onze klanten hebben misschien meteen een vraag: wat is je download? YML bestanden verschilt van vergelijkbare oplossingen op de Marktplaats. Hier is een lijst met enkele voordelen van onze module ten opzichte van analogen:
- mogelijkheid om valuta's om te rekenen en te herberekenen
- mogelijkheid om prijzen te wijzigen
- mogelijkheid om productnamen en eigenschappen te bewerken
- mogelijkheid om standaardeigenschappen op te geven
- mogelijkheid tot autorisatie op een server van derden
- voer verschillende acties uit op elementen die niet in de huidige upload zitten (niets doen, verwijderen, deactiveren)
- automatische tekstvertaling
- mogelijkheid tot periodieke lancering (agenten, kronen)
- mogelijkheid om velden en eigenschappen op te geven die moeten worden bijgewerkt
- mogelijkheid om een proxyserver te gebruiken
De essentie van parseren blijft hetzelfde: verwerken xml bestand gaat via selectors en attributen. Dus als u de parser al hebt geconfigureerd catalogus, dan zal het opzetten van een nieuw type parser eenvoudig en gemakkelijk voor u zijn.
Laten we nu de functionaliteit van het nieuwe gegevenstype eens nader bekijken:
Parser-tabblad:

Parser-type– dienovereenkomstig is er een type parser: rss, pagina, catalogus, xml
Parser-modus– de modus waarin de parser werkt. Er zijn twee bedieningsmodi: debuggen en werken. Standaard wordt de foutopsporingsmodus gebruikt voor foutopsporing. In deze modus moet de parser worden geconfigureerd. In de debug-modus worden de eerste 30 elementen van het XML-bestand geparseerd.
Het is vermeldenswaard dat als u de module “Content Parser” in de proefversie gebruikt, de parser alleen in de foutopsporingsmodus werkt.
Extra XML-bestands-URL's- u kunt ook andere XML-bestands-URL's in de upload opnemen. Om dit te doen, voert u ze eenvoudigweg op een nieuwe regel in.
Catalogusinformatieblok-ID– een informatieblok waarin secties en producten worden geladen.
Sectie-ID– sectie van het informatieblok waarin secties en producten worden geladen.
Aantal producten dat in één parserstap is gelost– het aantal producten dat de parser in één stap verwerkt. Standaard 300
Parser-stap– een concept dat optreedt wanneer de parser handmatig wordt gestart. In dit geval omvat elke stap het verbreken en opnieuw verbinden met het uploadkanaal. Varieer deze waarde afhankelijk van uw hostingmogelijkheden. Als de parser vanuit een agent (kroon) wordt uitgevoerd, wordt de parserstap genegeerd en wordt het ontladen in één verzoek uitgevoerd.
Actief, Sorteren, Titel, Laatste looptijd– velden zijn intuïtief en vereisen geen commentaar.
Codering- XML-bestandscodering. Verouderd veld. Op dit moment wordt de codering automatisch bepaald, maar als er problemen zijn met de codering, is het raadzaam deze handmatig op te geven.
Tabblad Basisinstellingen - Categorieën

Voorbeeld XML-bestand voor categorieën:

Kenmerkkiezer voor categorienaam– geeft het pad naar de categorienaam aan. Indien leeg, wordt de naam overgenomen van de waarde van de categorie zelf
Kenmerkkiezer met categorie-ID– pad naar de categorie-ID.
Kenmerkkiezer die de ID van de bovenliggende categorie bevat– om het nesten van secties te organiseren, moet u let opgeven aan de waarde van de bovenliggende categorie-ID.
Tabblad Basisinstellingen - Producten

Voorbeeld XML-bestand voor producten:

Specifieke productkiezer– pad naar de container van een specifiek product
Kenmerkkiezer met product-ID– pad naar product-ID
Kenmerkkiezer voor productnaam– pad naar de productnaam
Prijskenmerkkiezer– container met daarin de prijswaarde van het product
Beschrijving attribuutkiezer– bevat een beschrijving van het product
Voorbeeldafbeelding van selectorkenmerk– pad naar de afbeelding
Gedetailleerde afbeeldingsattribuutselector– pad naar de afbeelding
Tabblad Eigenschappen

Extra eigendom foto's– als er extra is afbeeldingen, dan moet u de velden specificeren waarin de afbeeldingen zullen worden geüpload.
Selector-attribuut van aanvullende opsomming. foto's– de selector en het extra attribuut worden aangegeven. foto's. Voorbeeld foto. Gespecificeerd ten opzichte van de productselector.
Standaard eigenschapswaarden– u kunt eigenschapswaarden opgeven die standaard automatisch worden ingevoerd bij het maken van producten
Parseren via selector– u kunt een specifieke eigenschappenkiezer opgeven die zich in de productkiezer in xml bevindt. Bijvoorbeeld: leverancier, streepjescode
Tekens verwijderen– u kunt ook onnodige tekens in eigenschappen (maateenheden, enz.) verwijderen
Parseren van eigenschappen en automatische creatie- hiermee kunt u automatisch eigenschappen maken, invullen en bijwerken die in het XML-bestand worden vermeld.
In dit geval zijn eigenschappen uniek qua naam.
Automatisch aanmaken van eigenschappen– als het selectievakje is aangevinkt, wordt de eigenschap aangemaakt als deze niet bestaat. Als de woning al bestaat
Kenmerkselector voor eigendomsopsomming– een algemene selector met informatie over het onroerend goed
Kenmerkkiezer voor eigenschapsnaam– pad waar de eigenschapsnaam zich bevindt. We herinneren u eraan dat dit een belangrijke parameter is, aangezien de unicatie in dit geval op deze parameter is gebaseerd.
Kenmerkselector voor eigenschapswaarde– pad naar de waarde van het onroerend goed. Als er niets is opgegeven, wordt de waarde rechtstreeks uit de eigenschappenkiezer gehaald
Selecteer het type eigenschappen dat u wilt maken– als de eigenschappen niet zijn gemaakt, worden ze wel gemaakt. U moet het type nieuwe eigenschappen selecteren uit de waarden: Lijst of Tekenreeks.
Tekens verwijderen– hiermee kunt u onnodige tekens uit eigenschappen verwijderen.
Veld- en eigenschapssymbolen toevoegen/verwijderen– functionaliteit waarmee u symbolen en namen van een product, evenals de eigenschappen ervan, kunt toevoegen en verwijderen.
Tabbladen Handelscatalogus, Aanvullende instellingen, Updates/uniciteit, Logs, Video-instructies identiek aan de typeparser catalogus. Daarom zullen we ze niet in detail bespreken.
Tabblad Handelscatalogus

Op het tabblad kun je flexibel met prijzen werken:
Geef prijs- en valutaparameters op
Valuta omzetten
Wijzig prijzen
Ronde prijzen
Tabblad Extra instellingen:
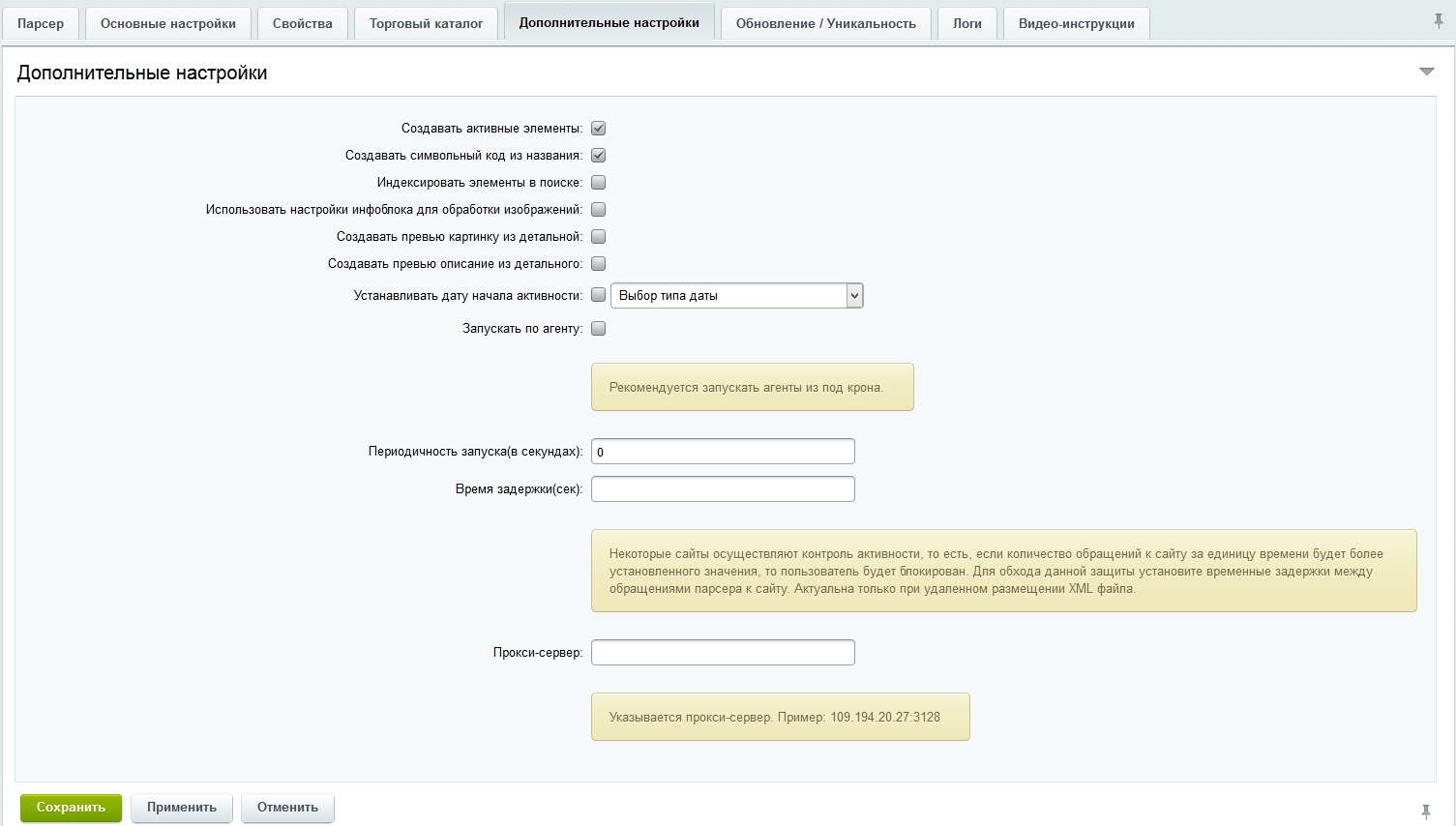
Tabblad Update/uniciteit:

Op het tabblad kunt u uniciteitsparameters instellen en het bijwerken van productvelden configureren.
(PECL yaml >= 0,4,0)
yaml_parse — Parseert een YAML-stream
Beschrijving
yaml_parse (tekenreeks $invoer [, int $ pos = 0 [, int &$ndocs [, array $callbacks = NUL ]]]) : gemengd
Converteert een YAML-stream geheel of gedeeltelijk en schrijft deze naar een variabele.
Lijst met parameters
Lijn voor parseren als een YAML-stream.
Document voor parseren ( -1 voor alle documenten, 0 voor het eerste document, ...).
Als ndocs wordt gevonden, wordt dit vervangen door het aantal documenten in de YAML-stream.
Waarden retourneren
Retourneert de waarde die is gecodeerd in de invoer in het juiste PHP-type of ONWAAR in geval van een fout. Als de pos-parameter gelijk is aan -1 , wordt een array geretourneerd met één item voor elk document dat in de stream wordt gevonden.
Voorbeelden
Voorbeeld #1 Gebruiksvoorbeeld yaml_parse()
$yaml =<<
factuur: 34843
datum: "23-01-2001"
factureren aan: &id001
gegeven: Chris
familie: Dumars
adres:
lijnen: |-
458 Walkman Dr.
Suite #292
stad: Koninklijke Eik
staat: MI
post: 48046
site: zxibit.esy.es
verzendadres: *id001
product:
- SKU: BL394D
hoeveelheid: 4
omschrijving: Basketbal
prijs: 450
- SKU: BL4438H
hoeveelheid: 1
beschrijving: Super Hoop
prijs: 2392
belasting: 251,420000
totaal: 4443,520000
opmerkingen: Laat in de middag is het beste. Back-upcontact is Nancy Billsmer @ 338-4338.
...
EOD;
$parsed = yaml_parse ($yaml);
var_dump ($geparseerd);
?>
Het resultaat van het uitvoeren van dit voorbeeld zal ongeveer zo zijn:
array(8) ( ["factuur"]=> int(34843) ["datum"]=> string(10) "23-01-2001" ["factuur-aan"]=> &array(3) ( [" gegeven"]=> string(5) "Chris" ["familie"]=> string(6) "Dumars" ["adres"]=> array(4) ( ["lijnen"]=> string(34) " 458 Walkman Dr. Suite #292" ["city"]=> string(9) "Royal Oak" ["state"]=> string(2) "MI" ["post"]=> int(48046) ) [ "verzenden naar"]=> &array(3) ( ["gegeven"]=> string(5) "Chris" ["familie"]=> string(6) "Dumars" ["adres"]=> array ( 4) ( ["lines"]=> string(34) "458 Walkman Dr. Suite #292" ["city"]=> string(9) "Royal Oak" ["state"]=> string(2) " MI" ["postal"]=> int(48046) ) ["product"]=> array(2) ( => array(4) ( ["sku"]=> string(6) "BL394D" [ " aantal"]=> int(4) ["beschrijving"]=> string(10) "Basketbal" ["prijs"]=> int(450) ) => array(4) ( ["sku"]=> string (7) "BL4438H" ["hoeveelheid"]=> int(1) ["beschrijving"]=> string(10) "Super Hoop" ["prijs"]=> int(2392) ) ) ["belasting" ] => float(251.42) ["totaal"]=> float(4443.52) ["comments"]=> string(68) "Laat in de middag is het beste. Back-upcontact is Nancy Billsmer @ 338-4338." )
Met de plug-in kunt u producten uit andere winkels importeren via de Yandex XML-feed, die door winkels wordt gebruikt om te handelen op Yandex.Market.
Producten worden geïmporteerd in de WP Shop-plug-instructuur. Er is automatische synchronisatie van producten met de bron, die handmatig of via cron kan worden gestart.
Een onmisbaar hulpmiddel voor:
1. De winkel overbrengen van andere zoekmachines naar WordPress WP-Shop
2. Het bouwen van aangesloten winkels om geld te verdienen aan aangesloten commissies met behulp van het CPS-model
De applicatie vereist dat IonCube Loader werkt!
Willekeurig onderdeel 1
Veelgestelde vragen
Installatie-instructies- Upload plug-in “WP Shop YML Parser” naar de map /wp-content/plugins/
- Activeer de plug-in “WP Shop YML Parser” via het menu ‘Plugins’ in WordPress
- Bekijk de volledige gebruikershandleiding voor het instellen van uw “WP Shop YML Parser”
Bezoek de site wp-shop.ru voor hulp.
Recensies
Neem in geen geval contact op met deze ontwikkelaars en koop niets van hen. De functionaliteit die ze beloven in de pro-versie is een leugen. Ze nemen eenvoudigweg uw geld aan en weigeren vervolgens alles, inclusief ondersteuning. Kijk maar naar hun kromme website en halflevende documentatie en je zult zelf alles begrijpen!
Wijzigingslog
Versie: 0.9
-project_als_veld
-id_as_veld
Versie: 0.8
-template_price (aangepast prijskaartje)
Versie: 0.7
-fields_update — nieuwe instelling om aangepaste velden in projecten bij te werken
Versie: 0.6
-Voorbeeld van XML-parser vervangen door SAX-parser die beter is voor geheugenbeheer
Versie: 0.5
-verbeteringen
Versie: 0.4
-bulkanalyse
-kloon project op categorie
Versie: 0.3
-link naar documenten
Versie: 0.2
-lokale feeds inschakelen
- bron als bestand inschakelen
- toevoeging yml-opties
Versie: 0.1
-eerste uitgave
























