SQL позволяет вкладывать запросы друг в друга. Обычно подзапрос возвращает одно значение, которое проверяется на предмет истинности предиката.
Виды условий поиска:
. Сравнение с результатом вложенного запроса (=, >=)
. Проверка на принадлежность результатам подзапроса (IN)
. Проверка на существование (EXISTS)
. Многократное (количественное) сравнение (ANY, ALL)
Примечания по вложенным запросам:
. Подзапрос должен выбирать только один столбец (за исключением подзапроса с предикатом EXISTS), и тип данных его результата должен соответствовать типу данных значения, указанному в предикате.
. В ряде случаев можно использовать ключевое слово DISTINCT для гарантии получения единственного значения.
. Во вложенном запросе нельзя включать раздел ORDER BY и UNION.
. Подзапрос может находиться и лева и справа от условия поиска.
. В подзапросах могут использоваться функции агрегирования без раздела GROUP BY, которые автоматически выдают специальное значение для любого количества строк, специальный предикат IN, а также выражения, основанные на столбцах.
. По возможности следует вместо подзапросов использовать соединение таблиц JOIN.
Примеры на вложенные запросы :
SELECT * FROM Orders WHERE SNum=(SELECT SNum FROM SalesPeople WHERE SName=’Motika’)
SELECT * FROM Orders WHERE SNum IN (SELECT SNum FROM SalesPeople WHERE City=’London’)
SELECT * FROM Orders WHERE SNum=(SELECT DISTINCT SNum FROM Orders WHERE CNum=2001)
SELECT * FROM Orders WHERE Amt>(SELECT AVG(Amt) FROM Orders WHERE Odate=10/04/1990)
SELECT * FROM Customer WHERE CNum=(SELECT SNum+1000 FROM SalesPeople WHERE SName=’Serres’)
2) Связанные подзапросы
В SQL можно создавать подзапросы со ссылкой на таблицу из внешнего запроса. В этом случае подзапрос выполняется многократно, по одному разу для каждой строки таблицы из внешнего запроса. Поэтому важно, чтобы подзапрос использовал индекс. Подзапрос может обращаться к той же таблице, чтоб и внешний. Если внешний запрос возвращает относительно небольшое число строк, то связанный подзапрос будет работать быстрее несвязанного. Если подзапрос возвращает небольшое число строк, то связанный запрос выполнится медленнее несвязанного.
Примеры на связанные подзапросы:
SELECT * FROM SalesPeople Main WHERE 1(SELECT AVG(Amt) FROM Orders O2 WHERE O2.CNum=O1.CNum) //возвращает все заказы, величина которых превосходит среднюю величины заказа для данного покупателя
3) Предикат EXISTS
Синтаксическая форма: EXISTS ()
Предикат использует подзапрос в качестве аргумента и оценивает его как истинный, если в подзапросе есть выходные данные, а в противном случае как ложный. Выполняется подзапрос один раз и может содержать несколько столбцов, поскольку их значения не проверяются, а просто фиксируется результат наличия строк.
Примечания по предикату EXISTS:
. EXISTS – предикат, возвращающий значение TRUE или FALSE, и его можно применять отдельно или вместе с другими булевыми выражениями.
. EXISTS не может использовать функции агрегирования в своем подзапросе.
. В коррелирующих (связанных, зависимых – Correlated) подзапросах предикат EXISTS выполняется для каждой строки внешней таблицы.
. Можно комбинировать предикат EXISTS с соединениями таблиц.
Примеры на предикат EXISTS:
SELECT * FROM Customer WHERE EXISTS(SELECT * FROM Customer WHERE City=’San Jose’) – возвращает всех покупателей, если кто-то из них проживает в San Jose.
SELECT DISTINCT SNum FROM Customer First WHERE NOT EXISTS (SELECT * FROM Customer Send WHERE Send.SNum=First.SNum AND Send.CNumFirst.CNum) – возвращает номера продавцов, обслуживших только одного покупателя.
SELECT DISTINCT F.SNum, SName, F.City FROM SalesPeople F, Customer S WHERE EXISTS (SELECT * FROM Customer T WHERE S.SNum=T.SNum AND S.CNumT.CNum AND F.SNum=S.SNum) – возвращает номера, имена и города проживания всех продавцов, обслуживших нескольких покупателей.
SELECT * FROM SalesPeople Frst WHERE EXISTS (SELECT * FROM Customer Send WHERE Frst.SNum=Send.SNum AND 1
4) Предикаты количественного сравнения
Синтаксическая форма: {=|>|=|} ANY|ALL ()
Эти предикаты используют в качестве аргумента подзапрос, однако, по сравнению с предикатом EXISTS, они применяются в конъюнкции с предикатами отношения (=,>=). В этом смысле они сходны с предикатом IN, но применяются только с подзапросами. Стандарт допускает использовать вместо ANY ключевое слово SOME, однако не все СУБД его поддерживают.
Примечания по предикатам сравнения:
. Предикат ALL принимает значение TRUE, если каждое значение, выбранное в процессе выполнения подзапроса, удовлетворяет условию, заданному в предикате внешнего запроса. Чаще всего он используется с неравенствами.
. Предикат ANY принимает значение TRUE, если хотя бы одно значение, выбранное в процессе выполнения подзапроса, удовлетворяет условию, заданному в предикате внешнего запроса. Чаще всего он используется с неравенствами.
. Если подзапрос не возвращает строк, то ALL автоматически принимает значение TRUE (считается, что условие сравнения выполняется), а для ANY – FALSE.
. Если сравнение не имеет значения TRUE ни для одной строки и есть одна или несколько строк с NULL значением, то ANY возвращает UNKNOWN.
. Если сравнение не имеет значения FALSE ни для одной строки и есть одна или несколько строк с NULL значением, то ALL возвращает UNKNOWN.
Примеры на предикат количественного сравнения:
SELECT * FROM SalesPeople WHERE City=ANY(SELECT City FROM Customer)
SELECT * FROM Orders WHERE Amt ALL(SELECT Rating FROM Customer WHERE City=’Rome’)
5) Предикат уникальности
UNIQUE|DISTINCT ()
Предикат служит для проверка уникальности (отсутствия дублей) в выходных данных подзапроса. Причем в предикате UNIQUT строки с NULL значениями считаются уникальными, а в предикате DISTINCT два неопределенных значения считаются равными друг другу.
6) Предикат совпадений
MATCH ()
Предикат MATCH проверяет, будет ли значение строки запроса совпадать со значением любой строки, полученной в результате подзапроса. От предикатов IN И ANY такой подзапрос отличается тем, что позволяет обрабатывать «частичные» (PARTIAL) совпадения, которые могут встречаться среди строк, имеющих часть NULL-значений.
7) Запросы в разделе FROM
Фактически допустимо использовать подзапрос везде, где допускается ссылка на таблицу.
SELECT CName, Tot_Amt FROM Customer, (SELECT CNum, SUM(Amt) AS Tot_Amt FROM Orders GROUP BY CNum) WHERE City=’London’ AND Customer.CNum=Orders.CNum
//подзапрос возвращает суммарную величину заказов, сделанных каждым покупателем из Лондона.
8) Рекурсивные запросы
WITH RECURSIVE
Q1 AS SELECT … FROM … WHERE …
Q2 AS SELECT … FROM … WHERE …
В прошлом уроке мы столкнулись с одним неудобством. Когда мы хотели узнать, кто создал тему "велосипеды", и делали соответствующий запрос:
Вместо имени автора, мы получали его идентификатор. Это и понятно, ведь мы делали запрос к одной таблице - Темы, а имена авторов тем хранятся в другой таблице - Пользователи. Поэтому, узнав идентификатор автора темы, нам надо сделать еще один запрос - к таблице Пользователи, чтобы узнать его имя:

В SQL предусмотрена возможность объединять такие запросы в один путем превращения одного из них в подзапрос (вложенный запрос). Итак, чтобы узнать, кто создал тему "велосипеды", мы сделаем следующий запрос:
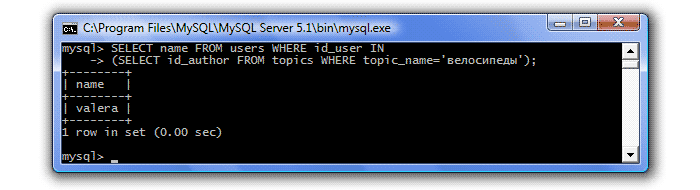
То есть, после ключевого слова WHERE , в условие мы записываем еще один запрос. MySQL сначала обрабатывает подзапрос, возвращает id_author=2, и это значение передается в предложение WHERE внешнего запроса.
В одном запросе может быть несколько подзапросов, синтаксис у такого запроса следующий: Обратите внимание, что подзапросы могут выбирать только один столбец, значения которого они будут возвращать внешнему запросу. Попытка выбрать несколько столбцов приведет к ошибке.
Давайте для закрепления составим еще один запрос, узнаем, какие сообщения на форуме оставлял автор темы "велосипеды":

Теперь усложним задачу, узнаем, в каких темах оставлял сообщения автор темы "велосипеды":

Давайте разберемся, как это работает.
- Сначала MySQL выполнит самый глубокий запрос:
- Полученный результат (id_author=2) передаст во внешний запрос, который примет вид:
- Полученный результат (id_topic:4,1) передаст во внешний запрос, который примет вид:
- И выдаст окончательный результат (topic_name: о рыбалке, о рыбалке). Т.е. автор темы "велосипеды" оставлял сообщения в теме "О рыбалке", созданной Сергеем (id=1) и в теме "О рыбалке", созданной Светой (id=4).
- Не рекомендуется создавать запросы со степенью вложения больше трех. Это приводит к увеличению времени выполнения и к сложности восприятия кода.
- Приведенный синтаксис вложенных запросов, скорее наиболее употребительный, но вовсе не единственный. Например,
мы могли бы вместо запроса
написать
Т.е. мы можем использовать любые операторы, используемые с ключевым словом WHERE (их мы изучали в прошлом уроке).
Объединение таблиц.
В запросе можно объединять данные из одной или нескольких таблиц. Такое объединение таблиц называется соединением (связыванием) таблиц. Различают внутреннее и внешнее соединения.
Внутреннее соединение – это соединение, при котором результирующий набор получается путем перечисления нужных полей из разных таблиц после слова SELECT. При этом таблицы должны находиться в отношении «один-к-одному».
Например,
SELECT R.fam, R.birthday,A.Foto
FROM Rabotniki R, Advanced A
где таблицы Rabotniki и Advanced содержат основные и дополнительные сведения о работниках предприятия. Связь «один-к-одному». Таблице Rabotniki дан псевдоним R, а таблице Advanced дан псевдоним A.
В предыдущем примере перед именем поля записано имя таблицы. Имена поля и таблицы отделяются точкой. Имя таблицы указывать необходимо, если имена полей повторяются для различных таблиц.
Если применить внутреннее соединение к таблицам, связанным по принципу «один-ко-многим», то результирующий набор может содержать избыточную информацию. Для устранения избыточности используют критерии отбора.
Пример 1 . Дана БД Sotrudniki, состоящая из двух таблиц:
Запрос внутреннего соединения таблиц, связанных отношением «один-ко-многим» имеет вид
Число записей в результирующем наборе данных равно произведению числа записей в таблице Sotrudniki на число записей в таблице Doljn. Результирующий набор данных имеет вид и содержит избыточную информацию:

Для ограничения числа записей в результирующем наборе данных применяют критерии отбора. Запрос в этом случае будет иметь вид
SELECT S_Fio,S_Birthday,D_Nazv FROM Sotrudniki, Doljn
WHERE S_Doljn=D_Code
Число записей в результирующем наборе данных будет равно числу записей в таблице Sotrudniki. p
Пример 2 . Требуется для БД Sotrudniki сформировать запрос, который позволит получить список сотрудников, имеющих должность «программист». Получим
SELECT S_fio, S_birthday FROM sotrudniki, doljn
WHERE S_doljn=D_code and D_nazv="программист"
В SQL-запросах допускается самообъединение таблицы. В этом случае одной таблице даются два псевдонима.
Например, для нахождения всех ровесников в таблице Sotrudniki можно написать запрос:
SELECT s1.s_fio, s2.s_fio, s1.s_birthday
FROM Sotrudniki s1, Sotrudniki s2
WHERE (EXTRACT(YEAR
FROM s1.s_birthday)=EXTRACT(YEAR
FROM s2.s_birthday))
AND (s1.s_fio!=s2.s_fio) AND (s1.s_fio Последнее условие упорядочивает фамилии и исключает дублирование результатов. При внутреннем соединении все таблицы, поля которых указаны в SQL-запросе, являются равноправными. То есть каждой записи в первой таблице находилась соответствующая ей запись во второй таблице. При внешнем объединении
(outer join
) в результирующий набор включаются записи независимо от того, есть ли соответствующее поле во второй таблице. Существует три типа внешнего объединения. 1) LEFT OUTER JOIN … ON –
левое, включает в результат все записи первой таблицы, даже те, для которых не имеется соответствия во второй. 2) RIGHT OUTER JOIN … ON
– правое, включает в результат все записи второй таблицы, даже те, для которых не имеется соответствия в первой. 3) FULL OUTER JOIN … ON
– полное, включает в результат объединение записей обеих таблиц, независимо от их соответствия. При внешнем соединении можно говорить о том, какая из таблиц является главной. В первом случае – левая, во втором – правая. Например.
Пусть в таблице Sotrudniki БД Sotrudniki есть фамилии, имеющие должность, не указанную в таблице Doljn, и есть должности в таблице Doljn, для которых нет фамилии в таблице Sotrudniki. Тогда 1) SELECT * FROM Sotrudniki LEFT OUTER JOIN Doljn ON S_doljn=D_code Результат включат все поля и таблицы Sotrudniki и таблицы Doljn. Число строк соответствует числу записей таблицы Sotrudniki. В строках, относящихся к записям, для которых в Doljn не нашлось соответствие, поля таблицы Doljn остаются пустыми. 2) SELECT * FROM Sotrudniki RIGHT OUTER JOIN Doljn ON S_doljn=D_code Число строк соответствует числу записей таблицы Doljn. В строках, относящихся к записям, для которых в Sotrudniki не нашлось соответствие, поля таблицы Sotrudniki остаются пустыми. 3) SELECT * FROM Sotrudniki FULL OUTER JOIN Doljn ON К строкам, относящимся к таблице Sotrudniki добавлены строки, относящиеся к таблице Doljn, для которых нет соответствия в таблице Sotrudniki. В SQL-запросе можно использовать запросы, вложенные в первый. Это можно применить и к операторам, возвращающих совокупные характеристики, и к операторам, возвращающим множество значений. Например, 1) Определить всех однофамильцев в таблицах Sotrudniki и Sotrudniki1, имеющих одинаковую структуру: SELECT * FROM Sotrudniki WHERE S_fio IN (SELECT S_fio FROM Sotrudniki1) Вложенный оператор SELECT возвращает множество фамилий из таблицы Sotrudniki1, а конструкция WHERE основного оператора SELECT отбирает в таблице Sotrudniki те записи, которые имеются во множестве фамилий из таблицы Sotrudniki1. 2) Вывести из БД Sotrudniki фамилию (фамилии) самого молодого сотрудника: SELECT S_Fio, EXTRACT(YEAR FROM S_Birthday) WHERE EXTRACT(YEAR FROM S_Birthday)= (SELECT max(EXTRACT(YEAR FROM S_Birthday)) FROM Sotrudniki) Вложенный оператор SELECT возвращает максимальный год рождения, который используется в условии WHERE основного оператора SELECT. 3) Вывести из БД Students все оценки конкретного студента, например, Петрова: SELECT S_fam, P_nazv, E_mark FROM Examination,Predm, Students WHERE E_student=(SELECT S_code FROM Students WHERE S_fam="Петров") AND E_Predm=P_code AND E_Student=S_code Во вложенной конструкции SELECT определяется код студента по фамилии "Петров", а последние условия обеспечивают исключение избыточности при внутреннем объединении таблиц. Связанные подзапросы.
Во внутреннем запросе можно ссылаться на таблицу, имя которой указано в предложении FROM
внешнего запроса. Такой связанный
подзапрос выполняется по одному разу для каждой строки таблицы основного запроса. Например,
получить сведения о предметах, по которым проводился экзамен конкретного числа, например, ‘14.01.2006’: SELECT * FROM Predm PR WHERE "14.01.2006" IN (SELECT E_date FROM Examination WHERE PR.P_code=E_predm) Эту же задачу можно решить с помощью операции соединения таблиц: SELECT DISTINCT P_nazv FROM Predm, Examination WHERE P_code=E_predm AND E_date= "14.01.2006" Пример.
Вывести фамилию (фамилии) студента, получившего на экзамене оценку выше среднего балла SELECT DISTINCT S_fam FROM Students, Examination E_mark>(SELECT AVG(E_mark) FROM Examination) AND S_code=E_student В условии WHERE при работе с множествами записей можно использовать ключевые слова ALL
и ANY. ALL
- условие выполняется для всех записей, ANY
- условие выполняется хотя бы для одной записи. Например
,
1) вывести фамилии сотрудников из таблицы Sotrudniki, которые не старше любого сотрудника в таблице Sotrudniki1: WHERE S_birthday>= ALL (SELECT S_birthday FROM Sotrudniki1) 2) вывести фамилии сотрудников из таблицы Sotrudniki, которые моложе хотя бы одного сотрудника в таблице Sotrudniki1: SELECT S_fio,S_birthday FROM Sotrudniki WHERE S_birthday> ANY (SELECT S_birthday FROM Sotrudniki1) Во вложенных конструкциях SELECT можно использовать ключевое слово EXISTS,
которое означает отбор только тех записей, для которых вложенный запрос возвращает одно или более значений. Например,
SELECT S_fio,S_birthday FROM Sotrudniki S1 WHERE EXISTS (SELECT S_fio,S_birthday FROM Sotrudniki S2 WHERE (S1.S_birthday=S2.S_birthday) AND (S1.S_code!=S2.S_code)) Получение списка сотрудников, которые имеют хотя бы одного сверстника. Язык SQL разрешает использовать в других операторах языка DML подзапросы
, которые являются внутренними запросами, определяемыми оператором SELECT
. Подзапрос
- очень мощное средство языка SQL. Он позволяет строить сложные
иерархии запросов, многократно выполняемые в процессе построения
результирующего набора или выполнения одного из операторов изменения
данных (DELETE
, INSERT
, UPDATE
). Условно подзапросы
иногда подразделяют на три типа, каждый из которых является сужением предыдущего: Подзапрос
позволяет решать следующие задачи: Hекоторые СУБД (например, СУБД Oracle) позволяют на основе подзапроса
создавать новые таблицы с помощью оператора CREATE TABLE
. Простым примером использования подзапроса
может служить следующий оператор: В данном операторе подзапрос
всегда должен возвращать единственное значение, которое будет проверяться в предикате. Если подзапрос
вернет более одного значения, то СУБД выдаст сообщение об ошибке выполнения SQL-оператора. В случае если подзапрос
не выберет ни одной строки, то предикат будет равен UNKNOWN
, что большинством СУБД интерпретируется как FALSE
. Стандарт определяет запись предиката в форме "значение оператор подзапрос
". Однако некоторые СУБД также позволяют записывать предикат в форме, указывающей подзапрос
слева от оператора сравнения. Например: Очень часто с подзапросами
используются агрегирующие функции, предоставляющие возможность сформулировать условие типа "больше, чем среднее по группе". Например: Если результатом подзапроса
становится группа строк (это случается всегда, когда условие не
гарантирует уникальности значения проверяемого предикатом внутреннего
запроса), то следует использовать оператор IN
, осуществляющий выбор одного значения из указываемого множества. Например: В этом случае предикат принимает значение TRUE
, если хотя бы одно из значений, возвращаемых подзапросом
, удовлетворяет условию. Однако применение оператора IN
имеет и некоторые смысловые недостатки: в запросе четко не
определяется, сколько строк должны быть результатом выполнения запроса.
При построении отношений для реальной модели данных это может приводить
к некоторой неоднозначности и зависимости от самих данных. В противном
случае, если модель данных предполагает в качестве постоянного
результата подзапроса
наличие только одной строки и, соответственно, использует оператор сравнения =
, а структура данных позволяет ввод значений, когда в результате подзапроса
будет более одной строки, то при использовании такого SQL-оператора в какой-то момент времени может проявиться ошибка. Если в запросе участвуют более двух таблиц, то для большей наглядности
имена полей иногда квалифицируют именами таблиц, указывая их через
точку. Стандарт позволяет не квалифицировать имя поля именем таблицы в
том случае, если не возникает неоднозначности (поле сначала ищется в
таблице, указанной фразой FROM
текущего запроса, затем внешнего запроса и т.д.). Очень часто вместо записи оператора SELECT
с использованием подзапроса
можно применять соединения. Однако на практике большинство СУБД подзапросы
выполняют более эффективно. Тем не менее, при проектировании комплекса
программ с критичными требованиями по быстродействию, разработчик
должен проанализировать план выполнения SQL-оператора для конкретной
СУБД. Наиболее продвинутые СУБД, такие как Oracle, предоставляют ряд
SQL-операторов, позволяющих оценить производительность выполнения
конкретного оператора языка SQL, а также определить уровень
оптимизации, применяемый для данного оператора. Подзапрос
может быть указан как в предикате, определяемом фразой WHERE
, так и в предикате по группам, определяемом фразой HAVING
. Например: В операторе SELECT
из внутреннего подзапроса
можно ссылаться на столбцы внешнего запроса, указанного во фразе SELECT
. Такой подзапрос
выполняется для каждой строки таблицы, определяя условие ее вхождения в формируемый результирующий набор. Например: В данном случае для каждой строки таблицы tbl1
будет проверяться условие, что значение поля f2
совпадает со значением строки таблицы tbl2
, где значение поля f3
равно значению поля f3
внешней таблицы (tbl1
). Это простейший пример коррелированного подзапроса
. Очень часто требуется, чтобы подзапрос
использовал те же данные, что и внешняя таблица. В этом случае обязательно применение алиасов. Например: В случае коррелированного подзапроса
во фразе HAVING
можно использовать только агрегирующие функции, так как каждый раз на момент выполнения подзапроса
в качестве проверяемой строки, к значениям которой имеет доступ подзапрос
, выступает результат группирования строк на основе агрегирующих функций основного запроса. Например: Если в предикате надо сравнить значение с некоторым множеством, то, как было показано выше, можно использовать оператор IN
. Для того чтобы проверить, существуют ли строки, удовлетворяющие конкретному условию подзапроса
, применяется оператор EXISTS
. Например: Этот запрос будет формировать не пустой результирующий набор только в том случае, если в какое-либо значение столбца f4
таблицы была занесена дата, например: "10/11/2003". Преимущество применения оператора EXISTS
с результатами подзапроса
состоит в том, что подзапрос
может возвращать как множество строк, так и множество столбцов. При коррелированном подзапросе
оператор EXISTS
будет вычисляться каждый раз для каждой строки внешнего запроса. В стандарте SQL-92 не предусмотрено использование в подзапросах
, к которым применяется оператор EXISTS
агрегирующих функций. Однако некоторые СУБД позволяют такой вид подзапросов
. Для использования результата подзапроса
в предикате также применяются операторы ANY
и ALL
, которые были подробно рассмотрены в предыдущих лекциях. Приведем пример использования оператора ANY
: Данный оператор определяет, что в результирующий набор будут включены все строки, значение столбца f3
которых присутствует в таблице tbl2
. К операторам языка DML, кроме оператора SELECT
, относятся операторы, позволяющие изменять данные в таблицах. Это оператор INSERT
, выполняющий добавление одной или нескольких строк в таблицу, оператор DELETE
, удаляющий из таблицы одну или несколько строк, и оператор UPDATE
, изменяющий значения столбцов таблицы. Оператор INSERT
INSERT INTO table_name
[ (field .,:) ]
{ VALUES (value .,:) }
| subquery
| {DEFAULT VALUES}; Оператор INSERT
может добавлять в таблицу как одну, так и несколько строк. Список полей (field .,:)
указывает имена полей и порядок занесения в них значений из списка значений, определяемого фразой VALUES
, или как результат выполнения подзапроса
. Список, определяемый фразой VALUES
, называется конструктором значений таблицы и указывается в круглых скобках через запятую. Если список полей (field .,:)
опущен, то порядок занесения значений будет соответствовать порядку столбцов, указанному в операторе CREATE TABLE
при создании данной таблицы. Если для столбцов, на которые установлено ограничение NOT NULL
, не указано добавляемых данных, то СУБД инициирует ошибку выполнения SQL-оператора. Следующий оператор INSERT
демонстрирует копирование строк таблицы tbl2
, выполняемое на основе подзапроса
: INSERT INTO tbl1(f1,f2,f3)
(SELECT f1,f2,f3 FROM tbl2); Очевидно, что количество полей, указываемое списком
полей, и типы данных этих полей должны совпадать с количеством полей и
их типами данных в конструкторе значений таблицы или в результирующем
наборе, формируемом подзапросом
. Оператор DELETE
в стандарте SQL-92 имеет следующее формальное описание: Оператор DELETE
используется для удаления из таблицы строк, указанных условием во фразе WHERE
(поисковое удаление, searched deletion) или WHERE CURRENT OF
(позиционное удаление, positioned deletion). Позиционное удаление, определяемое фразой WHERE CURRENT OF
, удаляя строки из курсора, соответственно удаляет их и из той таблицы базы данных, на базе которой был построен этот курсор. Если оператор DELETE
применяется к какому-либо представлению, то данные удаляются также из созданной на основе последнего таблицы базы данных. Никогда нельзя забывать, что если фраза WHERE
будет отсутствовать или предикат во фразе WHERE
будет всегда принимать значение TRUE
, то оператор DELETE
удалит из таблицы все строки. Оператор UPDATE
в стандарте SQL-92 имеет следующее формальное описание: Оператор UPDATE
применяется для внесения изменений в данные таблиц. Выражение expr
, используемое для вычисления значения столбца, может быть как простым выражением, так и подзапросом
,
возвращающим единственное значение. В выражении можно ссылаться на
старое значение изменяемого столбца и других столбцов текущей записи. При вычислении значений столбцов можно применять условное выражение CASE
и выражение CAST
для приведения типов. Например: Условное выражение CASE
позволяет выбрать одно из нескольких значений на основании указываемого условия. Условное выражение CASE
имеет следующее формальное описание: { CASE
{ expr WHEN expr THEN { expr | NULL }}
| { WHEN expr THEN { expr | NULL }}
[ ELSE { expr | NULL } ]
END}
| { NULLIF {expr1,expr2) }
| {COALESCE (expr .,:) } Условное выражение CASE
может быть записано, соответственно, в четырех формах: SELECT f1, CASE f3
WHEN "abc" THEN "1_abc" END FROM tbl1; SELECT f1, CASE
WHEN f3= "abc" THEN "1_abc"
ELSE f3 END FROM tbl1; INSERT INTO tbl1(f1,f2)
VALUES (1+ COALESCE(SELECT MAX(f1)
FROM tbl1, 0), 100); Для успешного выполнения оператора UPDATE
требуется ряд условий, включающий следующие: Рассмотрим, что такое вложенные запросы
в и для чего они нужны. Вложенный запрос практически ничем не отличается от обычного запроса. Он заключается в скобки и в нем доступны почти все методы и функции языка запросов 1С. А для вышестоящего запроса доступны все поля вложенного запроса. ВЫБРАТЬ
ИЗ
(ВЫБРАТЬ
ИЗ) КАК ВложенныйЗапрос
Конечно же в таком виде использование вложенного запроса не имеет смысла, т.к. можно сразу выбрать необходимые поля без использования вложенности. Здесь все предельно упрощено для простоты понимания. А теперь рассмотрим все вышесказанное на примере. И мы хотим выбрать из этой таблицы все подразделения, где работает более одного сотрудника. ВЫБРАТЬ
СотрудникиПодразделений.Подразделение КАК Подразделение,
КОЛИЧЕСТВО(СотрудникиПодразделений.Сотрудник) КАК КоличествоСотрудников
ИЗ
СотрудникиПодразделений КАК СотрудникиПодразделений
СГРУППИРОВАТЬ ПО
СотрудникиПодразделений.Подразделение
Если выполнить этот запрос, то в результате получим следующую таблицу Вторым шагом нам необходимо наложить на эту таблицу ограничение по количеству сотрудников. Для этого сделаем вышеприведенный запрос вложенным и в вышестоящем запросе пропишем соответствующее условие ВЫБРАТЬ
ВложенныйЗапрос.Подразделение КАК Подразделение
ИЗ
(ВЫБРАТЬ
СотрудникиПодразделений.Подразделение КАК Подразделение,
КОЛИЧЕСТВО(СотрудникиПодразделений.Сотрудник) КАК КоличествоСотрудников
ИЗ
СотрудникиПодразделений КАК СотрудникиПодразделений
СГРУППИРОВАТЬ ПО
СотрудникиПодразделений.Подразделение) КАК ВложенныйЗапрос
ГДЕ
ВложенныйЗапрос.КоличествоСотрудников > 1
Таким образом результат итогового запроса будет следующим Справедливости ради стоит отметить, что тот же результат можно достигнуть с помощью функции ИМЕЮЩИЕ
языка запросов 1С, а также с использованием временных таблиц.
Подзапросы
Коррелированные подзапросы
Построение предиката для подзапроса, возвращающего несколько строк
Применение подзапросов в операторах изменения данных
Оператор INSERT
Оператор DELETE
Оператор UPDATE
Условное выражение CASE
Часто встречается ситуация, когда над таблицей необходимо проделать несколько последовательных действий. Достаточно показательным является пример, когда сначала надо , а потом уже на сгруппированную таблицу наложить некоторое условие, либо соединить с другой таблицей. В таких случаях на помощь и приходят вложенные запросы
.
Структура самого примитивного вложенного запроса выглядит следующим образом
Пусть у нас есть таблица СотрудникиПодразделений:
На практике вы конечно же столкнетесь с более сложными вложенными запросами в которых может использоваться как , так и таблиц. А также может быть несколько уровней вложенности.
























