Dalam artikel ini, saya ingin melihat pelbagai teknik untuk mencari maklumat tentang peranti VoIP pada rangkaian, dan kemudian menunjukkan beberapa serangan terhadap VoIP.
pengenalan
Beberapa tahun kebelakangan ini telah menyaksikan kadar penggunaan Voice over Internet Protocol (VoIP) yang tinggi. Kebanyakan organisasi yang telah melaksanakan VoIP sama ada mengabaikan isu keselamatan dan pelaksanaan VoIP atau tidak menyedarinya. Seperti mana-mana rangkaian lain, rangkaian VoIP adalah sensitif kepada penggunaan yang tidak betul. Dalam artikel ini, saya ingin melihat pelbagai teknik untuk mencari maklumat tentang peranti VoIP pada rangkaian, dan kemudian menunjukkan beberapa serangan terhadap VoIP. Saya sengaja tidak turun ke butiran tahap protokol, kerana artikel ini ditujukan untuk pentester yang ingin mencuba teknik asas terlebih dahulu. Walau bagaimanapun, saya sangat mengesyorkan belajar tentang protokol yang digunakan dalam rangkaian VoIP.
Kemungkinan serangan pada VoIP
- Penafian Perkhidmatan (DoS)
- Mencuri dan memanipulasi data pendaftaran
- Serangan ke atas sistem pengesahan
- Penggantian (spoofing) ID Pemanggil
- Serangan Man-in-the-Middle
- "Shamanisme atas VLAN" (Vlan melompat)
- Mendengar pasif dan aktif
- Spam melalui telefon Internet (SPIT)
- pancingan data VoIP (Vishing)
Konfigurasi Makmal Ujian VoIP
Untuk menunjukkan isu keselamatan VoIP bagi tujuan artikel ini, saya menggunakan konfigurasi makmal berikut:
- Trixbox i(192.168.1.6) - pelayan IP-PBX sumber terbuka
- Backtrack 4 R2 (192.168.1.4) - OS pada mesin penyerang
- ZoIPer ii (192.168.1.3) - telefon lembut untuk Windows (pengguna A- mangsa)
- Linphone iii(192.168.1.8) - telefon lembut untuk Windows (pengguna B- mangsa)
Konfigurasi makmal kami

Gambar 1
Pertimbangkan rajah makmal yang dibentangkan di atas. Ini ialah konfigurasi rangkaian VoIP biasa organisasi kecil dengan penghala yang memperuntukkan alamat IP kepada peranti, sistem IP-PBX dan pengguna. Jika pengguna A rangkaian ini ingin menghubungi B, perkara berikut akan berlaku:
- Panggil A dihantar ke pelayan IP-PBX untuk pengesahan pengguna.
- Selepas pengesahan berjaya A Pelayan IP-PBX menyemak kehadiran sambungan pengguna (nombor sambungan) B. Jika sambungan ada, panggilan itu diubah hala B.
- Berdasarkan jawapan B(contohnya, menerima panggilan, meletakkan telefon, dll.) Pelayan IP-PBX bertindak balas kepada pengguna A.
- Jika semuanya baik-baik saja A mula berkomunikasi dengan B.
Sekarang kita mempunyai gambaran yang jelas tentang interaksi, mari kita beralih ke bahagian yang menyeronokkan - serangan VoIP.
Cari peranti VoIP
Penghitungan adalah asas bagi setiap serangan/pentest yang berjaya, kerana ia menyediakan penyerang dengan kedua-dua butiran yang diperlukan dan idea umum konfigurasi rangkaian. VoIP tidak terkecuali. Dalam rangkaian VoIP, maklumat tentang get laluan/pelayan VoIP, sistem IP-PBX, telefon lembut klien dan VoIP serta nombor pengguna (sambungan) akan berguna kepada kami sebagai penyerang. Mari kita lihat beberapa alat yang biasa digunakan untuk mencari peranti dan mencipta cap jari. Untuk memudahkan demonstrasi, mari kita anggap bahawa kita sudah mengetahui alamat IP peranti.
Smap
Smap iv mengimbas alamat IP individu atau subnet untuk peranti SIP yang didayakan. Mari gunakan smap terhadap pelayan IP-PBX. Rajah 2 menunjukkan bahawa kami dapat mencari pelayan dan mendapatkan maklumat Ejen Penggunanya.

Rajah 2
Svmap
Svmap ialah satu lagi pengimbas yang berkuasa daripada kit alat sipvicious v. Alat ini membolehkan anda menetapkan jenis permintaan yang digunakan semasa mencari peranti SIP. Jenis permintaan lalai ialah OPTIONS. Mari jalankan pengimbas untuk kumpulan 20 alamat. Seperti yang anda lihat, svmap boleh mengesan alamat IP dan maklumat Ejen Pengguna.

Rajah 3
Swar
Apabila mencari peranti VoIP, carian mengikut nombor pengguna boleh membantu menentukan sambungan SIP yang aktif. Svwar vi membolehkan anda mengimbas rangkaian penuh alamat IP. Rajah 4 menunjukkan hasil pengimbasan nombor pengguna dalam julat 200 hingga 300. Hasilnya, kami memperoleh sambungan pengguna yang didaftarkan pada pelayan IP-PBX.

Rajah 4
Jadi, kami telah melihat proses mencari peranti VoIP dan mendapat beberapa butiran konfigurasi yang menarik. Sekarang mari kita gunakan maklumat ini untuk menyerang rangkaian yang konfigurasinya baru kita periksa.
Serangan ke atas VoIP
Seperti yang telah dibincangkan, rangkaian VoIP terdedah kepada banyak ancaman dan serangan keselamatan. Dalam artikel ini, kita akan melihat tiga serangan kritikal terhadap VoIP yang boleh bertujuan untuk menjejaskan integriti dan kerahsiaan infrastruktur VoIP.
Serangan berikut ditunjukkan dalam bahagian berikut:
- Serangan pada pengesahan VoIP
- Mendengar melalui penipuan ARP
- Simulasikan ID Pemanggil
1. Serangan pada pengesahan VoIP
Apabila telefon VoIP baharu atau sedia ada menyertai rangkaian, ia menghantar permintaan REGISTER ke pelayan IP-PBX untuk mendaftarkan ID pengguna/sambungan yang dikaitkan dengan telefon. Permintaan pendaftaran ini mengandungi maklumat penting(seperti maklumat pengguna, data pengesahan, dsb.) yang mungkin menarik minat penyerang atau pentester. Rajah 5 menunjukkan paket permintaan pengesahan SIP yang ditangkap. Paket yang dipintas mengandungi maklumat berharga untuk penyerang. Mari gunakan data paket untuk menyerang pengesahan.

Rajah 5
Demonstrasi serangan
Senario Serangan

Rajah 6
Langkah 1: Untuk memudahkan demonstrasi, mari kita anggap bahawa kita mempunyai akses fizikal kepada rangkaian VoIP. Kini, menggunakan alat dan teknik yang diterangkan dalam bahagian artikel sebelumnya, kami akan mengimbas dan mencari peranti untuk mendapatkan maklumat berikut:
- Alamat IP pelayan SIP
- ID pengguna dan sambungan sedia ada
Langkah 2: Mari memintas beberapa permintaan pengelogan menggunakan wireshark vii. Kami akan menyimpannya dalam fail yang dipanggil auth.pcap. Rajah 7 menunjukkan fail wireshark dengan hasil tangkapan (auth.pcap).

Rajah 7
Langkah 3:
Kami kini menggunakan kit alat sipcrack viii. Set adalah sebahagian daripada Backtrack dan terletak dalam direktori /pentest/VoIP. Rajah 8 menunjukkan alatan dalam suite sipcrack.
Rajah 8
Langkah 4: Menggunakan sipdump, mari buang data pengesahan ke dalam fail yang dipanggil auth.txt. Rajah 9 menunjukkan fail tangkapan wireshark yang mengandungi bukti kelayakan pengesahan pengguna 200.

Rajah 9
Langkah 5: Data pengesahan ini termasuk ID pengguna, sambungan SIP, cincang kata laluan (MD5) dan alamat IP mangsa. Kami kini menggunakan sipcrack untuk memecahkan cincang kata laluan menggunakan serangan kamus yang disediakan. Rajah 10 menunjukkan bahawa fail wordlist.txt digunakan sebagai kamus untuk memecahkan cincang. Kami akan menyimpan hasil penggodaman dalam fail yang dipanggil auth.txt.

Rajah 10
Langkah 6: Hebat, kini kami mempunyai kata laluan untuk sambungan! Kami boleh menggunakan maklumat ini untuk mendaftar semula dengan pelayan IP-PBX daripada telefon SIP kami sendiri. Ini akan membolehkan kami melakukan perkara berikut:
- Menyamar sebagai pengguna yang sah dan hubungi pelanggan lain
- Dengar dan manipulasi panggilan keluar dan masuk yang sah ke sambungan mangsa (pengguna) A V dalam kes ini).
2. Mendengar melalui spoofing Arp
Setiap peranti rangkaian mempunyai alamat MAC yang unik. Seperti yang lain peranti rangkaian,Telefon VoIP terdedah kepada penipuan MAC/ARP. DALAM bahagian ini Kami akan melihat menghidu panggilan suara aktif dengan mendengar dan merakam perbualan VoIP secara langsung.
Demonstrasi serangan
Senario Serangan

Rajah 11
Langkah 1: Untuk tujuan demonstrasi, mari kita anggap bahawa kita telah pun menentukan alamat IP mangsa menggunakan teknik yang diterangkan sebelum ini. Seterusnya, menggunakan ucsniff ix Sebagai cara untuk menipu ARP, kami akan memalsukan alamat MAC mangsa.
Langkah 2: Adalah penting untuk menentukan alamat MAC sasaran yang perlu ditipu. Walaupun alat yang disebutkan sebelum ini dapat menentukan alamat MAC secara automatik, adalah amalan yang baik untuk menentukan MAC secara bebas, dengan cara yang berasingan. Mari gunakan nmap untuk ini x. Rajah 12 menunjukkan hasil pengimbasan alamat IP mangsa dan alamat MAC yang terhasil.
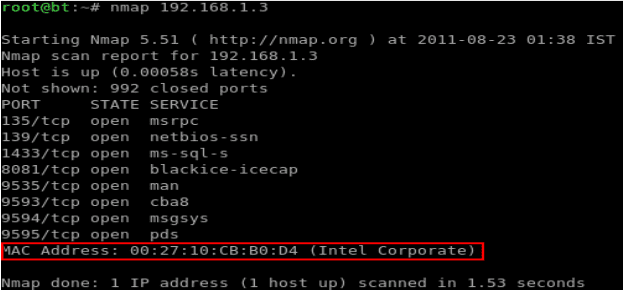
Rajah 12
Langkah 3: Sekarang setelah kita mempunyai alamat MAC mangsa, mari kita gunakan ucsniff untuk menipu MAC mereka. ucsniff menyokong beberapa mod spoofing (mod pemerhatian, mod belajar dan mod MiTM, iaitu "man-in-the-middle"). Mari gunakan mod MiTM dengan menyatakan alamat IP mangsa dan sambungan SIP dalam fail yang dipanggil targets.txt. Mod ini memastikan bahawa hanya panggilan (masuk dan keluar) mangsa (pengguna) dipantau A), tanpa menjejaskan trafik lain pada rangkaian. Rajah 13 dan 14 menunjukkan bahawa ucsniff telah menipu MAC pengguna A(dalam jadual ARP).

Rajah 13

Rajah 14
Langkah 4: Kami telah berjaya menggantikan alamat MAC mangsa dan kini bersedia untuk mendengar panggilan masuk dan keluar pengguna A melalui telefon VoIP.
Langkah 5: Sekarang bahawa pengguna B memanggil pengguna A dan memulakan dialog, ucsniff mula merakam perbualan mereka. Apabila panggilan tamat, ucsniff menyimpan keseluruhan perbualan yang dirakam ke fail wav. Rajah 15 menunjukkan bahawa ucsniff mengesan panggilan baharu daripada sambungan 200 hingga sambungan 202.
Rajah 15
Langkah 6: Apabila kami selesai, kami memanggil ucsniff sekali lagi dengan suis -q untuk menghentikan penipuan MAC pada sistem dan dengan itu memastikan bahawa segala-galanya berlaku sebaik sahaja serangan selesai.
Langkah 7: Fail audio yang disimpan boleh dimainkan menggunakan mana-mana pemain media yang terkenal seperti media tingkap pemain.
Penipuan ID Pemanggil
Ini adalah salah satu serangan paling mudah pada rangkaian VoIP. Penipuan ID Pelanggan sepadan dengan senario di mana pengguna yang tidak dikenali boleh berpura-pura menjadi pengguna sah rangkaian VoIP. Untuk melaksanakan serangan ini, perubahan mudah pada permintaan INVITE mungkin mencukupi. Terdapat banyak cara untuk menjana herot dengan cara yang betul SIP INVITE mesej (menggunakan scapy, SIPp, dsb.). Untuk demonstrasi kami menggunakan modul tambahan sip_invite_spoof daripada rangka kerja metasploit xi .
Senario Serangan

Rajah 16
Langkah 1: Mari jalankan metasploit dan muatkan modul pembantu voip/sip_invite_spoof.
Langkah 2: Seterusnya, tetapkan nilai pilihan MSG kepada Pengguna B. Ini akan memberi kita keupayaan untuk menyamar sebagai pengguna B. Mari kita tulis juga alamat IP pengguna A dalam pilihan RHOST. Selepas menyediakan modul, kami melancarkannya. Rajah 17 menunjukkan semua tetapan konfigurasi.

Rajah 17
Langkah 3: Modul pembantu akan menghantar permintaan jemputan yang diubah suai kepada mangsa (pengguna A). Mangsa akan menerima panggilan daripada telefon VoIP saya dan menjawabnya, menyangka dia sedang bercakap dengan pengguna B. Rajah 18 menunjukkan telefon VoIP mangsa ( A), yang menerima panggilan kononnya daripada pengguna B(tetapi sebenarnya dari saya).

Rajah 18
Langkah 4: Sekarang A percaya bahawa ia adalah panggilan biasa daripada B dan mula bercakap dengan seseorang yang memperkenalkan dirinya sebagai Pengguna B.
Kesimpulan
Banyak ancaman keselamatan sedia ada juga dikenakan pada VoIP. Menggunakan carian peranti, anda boleh mendapatkan maklumat kritikal yang berkaitan dengan rangkaian VoIP, ID/sambungan pengguna, jenis telefon, dll. Menggunakan alat khas, adalah mungkin untuk menjalankan serangan pengesahan, mencuri Panggilan VoIP, mencuri dengar, memanipulasi panggilan, menghantar spam VoIP, menjalankan pancingan data VoIP dan menjejaskan pelayan IP-PBX.
Saya harap artikel ini cukup bermaklumat untuk memberi kesedaran kepada isu keselamatan VoIP. Saya ingin meminta pembaca mengambil perhatian bahawa artikel ini tidak membincangkan semua alat dan teknik yang mungkin digunakan untuk mencari peranti VoIP pada rangkaian dan pentesting.
Mengenai Pengarang
Sohil Garg ialah pentester di PwC. Bidang minatnya termasuk membangunkan vektor serangan baharu dan ujian penembusan dalam persekitaran selamat. Beliau mengambil bahagian dalam penilaian keselamatan pelbagai aplikasi. Beliau telah membentangkan isu keselamatan VoIP di persidangan CERT-In yang dihadiri oleh pegawai kanan kerajaan dan pertahanan. Dia baru-baru ini menemui kelemahan dalam produk itu syarikat besar, yang memungkinkan untuk meningkatkan keistimewaan dan mengakses objek secara langsung.
Pautan
i http://fonality.com/trixbox/ii http://www.zoiper.com/
iii http://www.linphone.org/
iv http://www.wormulon.net/files/pub/smap-blackhat.tar.gz
v
vi http://code.google.com/p/sipvicious/
vii http://www.wireshark.org/
viii Alat ini boleh didapati dalam Backtrack 5 dalam direktori /pentest/voip/sipcrack/.
ix http://ucsniff.sourceforge.net/
x http://nmap.org/download.html
xi http://metasploit.com/download/
Sebaik sahaja pakej tiba di salah satu gudang kami di luar negara atau di Rusia, anda akan menerima pemberitahuan e-mel. Pada masa hadapan, anda akan dapat menjejak bungkusan anda di tapak web kami dalam bahagian "Penjejakan"; untuk melakukan ini, anda mesti memasukkan nombor penjejakan anda.
Sila pastikan anda telah memasukkan alamat mel anda dengan betul dalam profil IPS anda dan peti masuk e-mel anda tidak penuh.
Jika penjual anda (kedai dalam talian) memberitahu anda bahawa bungkusan anda telah tiba di salah satu pejabat kami, tetapi anda masih tidak dapat menjejakinya, sila hubungi kami, jika boleh, memberikan maklumat lengkap tentang bungkusan anda (nama kedai, penghantar dan alamat berlepas, nombor pengenalan, tarikh berlepas, dsb.).
- Anda mahu menerima satu atau dua bungkusan buat masa ini:
- Anda merancang untuk kerap (beberapa kali sebulan) menerima surat, majalah atau bungkusan dari luar negara:
- Tarif untuk perkhidmatan kami untuk pelanggan tetap kami adalah 10-30% lebih rendah daripada tarif untuk pelanggan bukan tetap (bergantung pada jenis perkhidmatan).
- Tarif untuk penghantaran bungkusan dari luar negara dikira mengikut berat sebenar bungkusan, dan bukan berdasarkan berat bulat kepada bilangan kilogram penuh.
- Diskaun terkumpul dikenakan.
- Pembungkusan dan pembungkusan semula surat/bungkusan untuk pelanggan tetap kami adalah percuma.
- Untuk pelanggan tetap, surat/bungkusan dihantar atau dimajukan daripada kami alamat asing ke mana-mana alamat antarabangsa lain atau ke tangan mana-mana orang di luar negara.
- Pelanggan tetap menerima maklumat tentang semua perubahan terlebih dahulu.
- Pelanggan tetap boleh memesan perkhidmatan bukan standard yang dia perlukan, walaupun perkhidmatan ini tidak ditunjukkan dalam senarai perkhidmatan IPS dan perlu dilakukan di luar Rusia.
- Penyimpanan surat/bungkusan jangka panjang percuma di pejabat asing kami.
- Ambil sendiri bungkusan anda di pejabat kami di luar negara.
-
Bolehkah saya menggunakan peti mel yang dilanggan di pejabat anda untuk menerima mel biasa, surat-menyurat, bil, langganan dari Moscow atau Rusia?
Sudah tentu. Yuran langganan kami lebih murah daripada di Russian Post. Dalam kes ini, selain daripada yuran langganan, anda tidak membayar apa-apa lagi.
Saya perlu menghantar bungkusan ke luar negara. Bagaimanakah perkhidmatan penghantaran IPS berbeza daripada syarikat kurier lain?
- Melalui kami, pelanggan boleh menghantar dalam 3 mod:
- mod pos - yang paling murah, tetapi juga yang paling perlahan - 10-12 hari bekerja;
- mod kurier purata kelajuan penghantaran – 4-5 hari bekerja (Express Smart);
- mod kurier dengan kelajuan penghantaran tertinggi - 1-2 hari perniagaan (Perniagaan ekspres).
- Kami menyediakan semua dokumen kastam secara bebas untuk pelanggan.
- Kami menyediakan perundingan percuma untuk mengoptimumkan proses logistik menghantar sebarang kargo ke mana-mana negara di dunia.
- Melalui kami, pelanggan boleh menghantar dalam 3 mod:
-
Saya mempunyai 4 bungkusan kecil. Bolehkah anda membungkus bungkusan ini menjadi satu?
Kita boleh. Kami akan menyediakan penyatuan bungkusan. Untuk pelanggan tetap (pelanggan peti mel) perkhidmatan ini adalah percuma.
Bagaimanakah saya boleh membayar untuk penghantaran?
Pada masa ini, kaedah pembayaran tunai dan bukan tunai tersedia.
Apakah pampasan yang akan saya bayar sekiranya pakej saya hilang?
Penghantaran kami sangat boleh dipercayai. Walau bagaimanapun, jika ini berlaku dan bungkusan itu telah diinsuranskan - jumlah penuh yang diinsuranskan.
Berapa lama masa yang diambil untuk menghantar pakej?
Penghantaran biasanya mengambil masa 7 hingga 12 hari dari tarikh bungkusan tiba di gudang kami di negara masing-masing.
Bolehkah saya menyimpan bungkusan saya di gudang anda di USA/UK/Jerman selama 1-2 bulan? Adakah terdapat bayaran tambahan untuk ini?
Jika anda tidak melanggan peti mel, IPS akan menyimpan bungkusan anda secara percuma hanya selama 7 hari dari tarikh penerimaan di gudang. Jika bungkusan itu disimpan lebih daripada 7 hari, bayaran tambahan akan dikenakan. IPS berhak, mengikut budi bicaranya, untuk melupuskan bungkusan yang disimpan di gudang selama lebih daripada 60 hari, yang pemiliknya belum membayar untuk penyimpanan.
Apakah faedah penghantaran dengan IPS?
Kelebihan penghantaran dengan IPS:
- kebolehpercayaan penghantaran;
- kos penghantaran yang munasabah dan boleh difahami;
- Masa penghantaran ialah 7-12 hari;
- kehadiran pejabat Moscow di mana mereka sentiasa bersedia untuk membantu;
- keupayaan untuk membeli barangan yang tidak terdapat di Rusia;
- keupayaan untuk membeli barang di kedai yang tidak menghantar barang ke Rusia;
- peluang untuk menjimatkan penghantaran dengan menggunakan perkhidmatan penyatuan penghantaran dan pembungkusan semula.
-
Apakah maklumat yang perlu saya nyatakan dalam medan "Alamat Penghantaran" semasa membeli barangan di kedai dalam talian?
Anda mesti memasukkan: alamat pejabat asing kami yang diberikan kepada anda oleh syarikat kami, Nama Keluarga dan Nama Pertama anda, nombor peti mel anda.
Perlukah saya memberitahu anda apa-apa selepas membuat pembelian dan menghantar pakej ke alamat yang diberikan kepada saya?
Selepas membuat pesanan, anda mesti memaklumkan kami tentang pesanan yang telah lengkap, berikan data pesanan - perihalan lampiran, beratnya, kosnya. Maklumat ini diperlukan untuk memproses bungkusan anda.
Adakah terdapat sebarang sekatan ke atas kemungkinan pelaburan?
Dengan IPS anda boleh menghantar bungkusan dengan sebarang lampiran yang tidak dilarang oleh perundangan Persekutuan Rusia.
Pelaburan yang dilarang termasuk:
- bahan letupan,
- barang mudah terbakar,
- bahan radioaktif,
- gas mampat,
- senjata api,
- sebarang item yang, mengikut sifat pembungkusan, boleh menyebabkan kecederaan kepada kakitangan IPS atau menyebabkan kerosakan pada item lain.
Anda boleh mendapatkan senarai lengkap lampiran yang dilarang.
Sebelum membuat pembelian di kedai dalam talian, sila pastikan pembelian anda tidak termasuk dalam kategori barangan berbahaya.
Adakah IPS menjamin ketulenan dan kualiti produk yang saya beli?
IPS tidak bertanggungjawab kepada pelanggan terhadap keaslian dan kualiti barangan yang dibeli olehnya. Untuk keselamatan anda sendiri, sila beli produk hanya dari kedai dalam talian yang dipercayai.
Bagaimana untuk membungkus bungkusan dengan betul?
Walau bagaimanapun, jika perlu, sila pastikan pakej anda dibungkus dengan betul, atau maklumkan kepada IPS bahawa pembungkusan tambahan diperlukan untuk pakej anda.
Kami tidak bertanggungjawab terhadap sebarang kehilangan atau kerosakan yang mungkin berlaku semasa pengendalian, pengangkutan atau penghantaran disebabkan pembungkusan yang tidak betul oleh pengirim.
Apakah dokumen yang perlu disediakan untuk mengesahkan anggaran kos penghantaran?
Invois yang disediakan oleh pengirim mesti disediakan dan amaun yang ditunjukkan mesti termasuk semua cukai serta semua caj lain yang mungkin.
Kedai dalam talian mana yang boleh saya beli?
Apakah yang perlu saya lakukan jika penjual menghantar produk yang salah/kuantiti yang salah?
Memandangkan syarikat IPS hanya menghantar bungkusan anda ke Rusia, semua soalan mengenai konfigurasi dan kesesuaian barangan, serta kemungkinan pertukaran atau pemulangan, mesti diselesaikan secara langsung dengan penjual atau pengirim.
saya nak beli barang kemas daripada logam berharga dengan batu berharga. Adakah ini mungkin?
Tidak. Kami tidak menghantar barangan yang diperbuat daripada logam berharga dan/atau batu berharga.
Bilakah saya akan tahu kos penghantaran akhir?
Hanya selepas bungkusan itu tiba di gudang asing kami yang anda pilih.
Setelah pakej anda telah diproses, anda akan dimaklumkan melalui e-mel mengenai masa penghantaran dan kos penghantaran akhir. Bungkusan anda akan diberikan nombor peribadi, anda boleh, mengikut arahan dalam surat, membayar kos penghantaran dan menjejaki status penghantaran anda.
Jika anda ingin menyatukan penghantaran anda, anda mesti membuat pembayaran selepas pembentukan akhir pakej.
Pelanggan yang melanggan peti mel tidak perlu membuat sebarang pembayaran sebelum menerima surat-menyurat/bungkusannya di pejabat IPS Moscow.
Jika saya memutuskan untuk menolak penghantaran ke Rusia bungkusan yang tiba atas nama saya di pejabat IPS asing, adakah sebarang jumlah akan ditahan daripada saya jika perlu memulangkan bungkusan itu kepada pengirim atau memusnahkannya?
Jika atas apa-apa sebab anda memutuskan untuk menghentikan penghantaran bungkusan anda ke Rusia, sila hubungi pengirim anda dengan segera supaya dia tidak menghantar bungkusan anda ke alamat IPS.
Jika bungkusan itu tiba di alamat gudang IPS, kami boleh, atas arahan anda, menghantar bungkusan itu kembali (atau hantar ke alamat lain) dengan bayaran pentadbiran $10, serta 100% daripada kos pemulangan/penghantaran bungkusan .
Kami juga boleh melupuskan bungkusan dengan potongan $10 yuran pentadbiran (untuk bungkusan tidak melebihi 15 kg). Jika pakej disimpan selama lebih daripada 21 hari, IPS akan mengenakan bayaran sebanyak $.50 sehari bagi setiap pakej.
Apakah berat minimum yang perlu dibayar bagi bungkusan yang dihantar?
Untuk pelanggan peti mel - berat boleh dicaj minimum ialah 1 paun, diikuti dengan kenaikan 0.1 paun.
Penghantaran parcel dari luar negara. Bagaimana ia berfungsi?
Kami menyediakan semua pelanggan kami (sama ada mereka pelanggan tetap atau pelanggan yang ingin menerima bungkusan sekali sahaja) dengan alamat pos di tiga bandar di seluruh dunia - London, New York dan Hanover. Kepada mana-mana daripada mereka, responden anda (kedai dalam talian, rakan, saudara, rakan sekerja, dll.) boleh menghantar bungkusan kepada anda dan 7-10 hari perniagaan selepas ia tiba di salah satu alamat ini, anda akan menerimanya di Moscow.
Bagaimanakah saya boleh mendapatkan alamat?
Terdapat dua pilihan:
Anda perlu membawa pasport anda ke pejabat IPS. Di sini mereka akan membuat salinan pasport anda dan mencatatkan anda Nombor telefon kenalan dan akan memberi anda alamat yang anda perlukan (di London, New York atau Hanover).
Masuk akal untuk anda membuat perjanjian perkhidmatan tetap. Untuk melakukan ini, anda perlu melanggan peti mel dan kerap membuat deposit bayaran langganan. Yuran langganan bulanan minimum ialah 755.2 rubel (termasuk VAT 18%). (Terdapat yuran langganan lain, ia bergantung pada set perkhidmatan percuma tambahan yang telah disertakan dalam perkhidmatan langganan). Dalam kes ini, anda menerima ketiga-tiga alamat dan boleh menggunakannya mengikut budi bicara anda.
Untuk mendapatkan alamat, bolehkah saya tidak datang kepada anda, tetapi menghantar salinan pasport saya melalui e-mel?
Anda boleh, tetapi kemudian anda memerlukan bayaran pendahuluan.
Dalam dua kes di atas (lihat soalan 2), kami menyediakan perkhidmatan kepada pelanggan secara tunai semasa penghantaran - kami menghantar (iaitu, menyediakan perkhidmatan dahulu), dan kemudian hanya menerima bayaran daripada pelanggan. Oleh itu, adalah penting bagi kami untuk memastikan bahawa pelanggan kami adalah orang yang sebenar.
Jika anda ingin menghantar salinan pasport anda kepada kami secara elektronik, maka bayaran pendahuluan daripada anda dalam jumlah sekurang-kurangnya 4000.0 rubel adalah penting untuk perkhidmatan selanjutnya. Jika, selepas menyediakan dan membayar perkhidmatan penghantaran, anda masih mempunyai baki, atas permintaan pertama anda, jumlah ini akan dikembalikan kepada anda kepada butiran yang anda hantarkan kepada kami. Atau pada masa hadapan anda boleh menggunakannya untuk membayar perkhidmatan di syarikat kami.
Mengapa berfaedah untuk melanggan peti mel?
Pelanggan yang melanggan peti mel menjadi pelanggan tetap kami.
Pelanggan tetap mempunyai faedah berikut:
Universiti Negeri St
Fakulti Filologi
Jabatan Linguistik Matematik
V.P. Zakharov
Pencarian maklumat
sistem
Manual pendidikan dan metodologi
Saint Petersburg
Pengulas:
doc. teknologi sains V.Sh. Rubashkin(Universiti Negeri St. Petersburg)
Ph.D. ped. sains O.A. Arbatskaya(Universiti Kebudayaan dan Seni Negeri St. Petersburg)
Dicetak melalui dekri
Majlis Editorial dan Penerbitan
Universiti Negeri St
Zakharov V.P.
Z-38 Sistem pencarian maklumat: Kaedah pendidikan. elaun. - St. Petersburg, 2005. - 48 p.
Manual yang dicadangkan mengandungi penerangan tentang asas dokumentari pencarian maklumat, program disiplin akademik "Teori Pengambilan Maklumat", yang dipelajari oleh pelajar tahun ke-3 Jabatan Linguistik Struktur dan Gunaan Universiti Negeri St. Petersburg, dan satu set kerja makmal (praktikal) dalam disiplin ini. Kerja makmal yang berasingan digunakan untuk mengajar pelajar kursus lain dan dalam disiplin lain. Manual ini berdasarkan aktiviti penyelidikan dan pengajaran penulis.
Bagi pelajar sarjana dan siswazah yang mengkhusus dalam bidang linguistik gunaan, sistem maklumat dan sistem pemprosesan teks automatik.
ã V.P. Zakharov, 2005
ã St. Petersburg
negeri
universiti, 2005
1. Pengenalan kepada teori dan amali
pencarian maklumat
1.1. Konsep asas pencarian maklumat
Sistem pencarian maklumat (IPS) ialah koleksi tertib dokumen (tatasusunan dokumen) dan teknologi maklumat yang direka untuk menyimpan dan mendapatkan maklumat - teks (dokumen) atau data (fakta). Sistem perolehan maklumat ialah sebarang repositori maklumat yang disusun dengan cara tertentu. Selain itu, sistem mendapatkan maklumat juga boleh menjadi tidak automatik. Perkara utama ialah Fungsi objektif: penyimpanan dan perolehan maklumat.
Bergantung pada objek penyimpanan dan jenis permintaan, dua jenis pengambilan maklumat dibezakan: dokumentari dan fakta - dan, dengan itu, dua jenis sistem perolehan maklumat - dokumentari dan fakta. Yang terakhir ini juga dipanggil sistem pencarian maklumat dan rujukan.
Dokumentari dipanggil sistem perolehan maklumat, yang melaksanakan carian untuk pertanyaan tematik dalam susunan dokumen atau teks dan kemudian memberikan pengguna subset dokumen ini atau salinannya. Konsep dokumen mungkin berbeza dari satu sistem ke satu sistem. Dalam kes umum, ini adalah objek maklumat tertentu, direkodkan (biasanya melalui beberapa sistem tanda) pada beberapa medium bahan (kertas, foto dan filem, ingatan magnet, dll.) dan bertujuan untuk penghantaran dalam ruang dan masa dalam sistem sosial komunikasi.
Fakta Sistem perolehan maklumat melaksanakan penyimpanan, carian dan pengeluaran data fakta secara langsung (ciri saintifik, teknikal, ekonomi dan sifat objek, proses, fenomena, alamat, nama, data kuantitatif, dll.).
Perbezaan utama dan penting antara carian dokumentari dan fakta ialah pendekatan kepada semantik dokumen. Sistem dokumentari menerangkan maksud dokumen secara keseluruhan dari sudut pandangan kandungan subjek tematiknya. Dalam kes ini, adalah penting untuk mengenal pasti dan menamakan (senarai) topik dan objek utama yang dokumen itu dikhaskan. Dalam sistem fakta, objek diterangkan, ciri-ciri mereka dan makna ciri-ciri ini direkodkan. Oleh itu perbezaan dalam bahasa penerangan dan kaedah menyimpan penerangan dalam sistem. Sehubungan itu, setiap jenis carian mempunyai alat carian sendiri.
Sistem fakta melibatkan pengumpulan dan carian dalam pelbagai dokumen dengan struktur yang dikawal ketat. Struktur sedemikian adalah sama ada hasil pemprosesan intelek awal dokumen semasa memasukkan maklumat ke dalam sistem, atau ketersediaan dokumen tersebut dalam bentuk siap dalam bidang tertentu aktiviti manusia, contohnya, borang perakaunan, borang, buku rujukan, jadual, dsb. . Terdapat sistem maklumat fakta yang menyediakan pengumpulan maklumat dan mencari hanya satu jenis objek dan hanya satu jenis pertanyaan. Terdapat juga sistem factographic yang lebih maju yang menyediakan penyimpanan dan pengambilan data yang pelbagai dalam kandungan dan struktur, tetapi kepelbagaian ini sentiasa terhad.
Pada masa yang sama, tiada perbezaan yang tidak dapat diatasi antara sistem dokumentari dan fakta. Selalunya, sistem perolehan maklumat sebenar adalah contoh sistem bercampur di mana maklumat fakta digunakan sebagai cara tambahan carian dokumentari, dan sebaliknya. Dalam sistem dokumentari, teks (dokumen) juga boleh distrukturkan, dibahagikan kepada serpihan atau medan, dan pemprosesan dan penyampaian maklumat dokumentari boleh dijalankan pada peringkat bidang individu.
Terdapat juga jenis sistem ketiga, yang dipanggil maklumat-logik. Ini adalah sistem yang bertindak balas terhadap permintaan yang terdapat dalam pangkalan maklumat secara eksplisit Tiada jawapan. Pangkalan pengetahuan ekstralinguistik dan maklumat yang dijana secara algoritma daripada perkara yang sedia ada (dokumentari atau fakta) membantu mendapatkan jawapan. ini maklumat baru sama ada dikeluarkan sebagai respons kepada permintaan, atau digunakan tambahan untuk carian.
Sistem mendapatkan maklumat jenis dokumen ialah koleksi dokumen yang tersusun, serta satu set alat dan kaedah yang direka untuk menyimpan, mencari dan mengeluarkan maklumat dokumentari atas permintaan. IPS dokumentari mengeluarkan dokumen yang sepadan dengan permintaan pada topik atau subjek. Dokumen yang subjek atau topik utamanya secara amnya sepadan dengan kandungan semantik permintaan maklumat dipanggil relevan , A sifat kedekatan semantik antara dua atau lebih teks (dalam kes ini, antara dokumen dan permintaan maklumat) - perkaitan . Relevan adalah konsep asas dalam teori pencarian maklumat. Mereka bercakap tentang dua jenis perkaitan: semantik dan formal. Korespondensi dokumen dengan kandungan permintaan maklumat dipanggil perkaitan semantik, dan korespondensi imej carian dokumen ini dengan preskripsi carian rasmi yang menyatakan ini permintaan informasi, - perkaitan formal. Perkaitan formal juga dipanggil perkaitan dokumen, dan perkaitan semantik ialah perkaitan maklumat (bermaksud "maklumat yang terkandung dalam dokumen").
Komponen sistem maklumat dipanggil subsistem. Pembahagian kepada subsistem adalah perlu dan berguna untuk tujuan pembangunan dan untuk menerangkan teknologi operasi sistem. Ia mungkin mempunyai asas yang berbeza. Biasanya, dua jenis pembahagian sistem maklumat kepada subsistem dipertimbangkan: mengikut prinsip fungsi (subsistem berfungsi) dan mengikut jenis cara (subsistem sokongan).
Pelbagai alat yang melaksanakan fungsi IPS dipanggil subsistem sokongan , atau "peruntukan". Subsistem berikut dibezakan: sokongan linguistik, sokongan maklumat, perkakasan, perisian, sokongan teknologi, kakitangan, dsb.
Sokongan Maklumat - ini ialah tatasusunan maklumat (dokumen, pertanyaan, metadata), serta alat dan kaedah untuk penerangan, pembinaan dan pengelasannya.
Sokongan linguistik - Ini adalah radas logik-semantik yang terdiri daripada bahasa pencarian maklumat, peraturan aplikasi (teknik pengindeksan), kriteria pengeluaran dan cara linguistik lain.
Perisian - ini adalah algoritma dan perisian, melaksanakan semua fungsi IPS yang dilakukan menggunakan komputer.
Sokongan teknikal - ini adalah cara teknikal (komputer, telekomunikasi) yang menyediakan penyimpanan, pengambilan dan penghantaran maklumat.
Sokongan teknologi - ini ialah satu set dan prosedur untuk melaksanakan proses dan prosedur automatik dan tidak automatik untuk memproses maklumat dalam sistem maklumat, termasuk penerangannya, gambar rajah teknologi maklumat dan bahan pengajaran.
Sokongan kakitangan (atau kakitangan). - ini adalah orang yang berinteraksi dengan sistem dan memastikan operasinya (kakitangan penyelenggaraan).
IPS juga dibahagikan kepada bahagian komponen (subsistem) mengikut fungsi, apabila setiap subsistem melaksanakan fungsi tertentu dalam proses teknologi: kemasukan dokumen, pengindeksan dokumen, kemasukan dan pembetulan pertanyaan, pengindeksan pertanyaan, carian, mengekalkan kamus, mengekalkan statistik, memproses carian keputusan, mengeluarkan dokumen, dsb. Bahagian sedemikian dipanggil subsistem berfungsi .
Konsep penting dalam pencarian maklumat ialah dokumen dan pertanyaan. Dokumen ditakrifkan sebagai satu cara untuk mengamankan dalam apa jua cara bahan khas sebarang maklumat tentang fakta, peristiwa, fenomena realiti objektif dan aktiviti mental manusia. Dokumen mempunyai bentuk persembahan yang berbeza. Dalam sistem perolehan maklumat dokumentari automatik, ini terutamanya maklumat teks dalam bahasa semula jadi dalam bentuk yang boleh dibaca oleh mesin.
Permintaan ialah keperluan maklumat yang dirumuskan dalam bahasa semula jadi. Hasil daripada "terjemahan" permintaan informasi dalam bahasa pencarian maklumat dipanggil imej pertanyaan carian (POZ) atau preskripsi carian (PP). Ini difahami sebagai ungkapan dalam bahasa pertanyaan , yang merangkumi kedua-dua FP itu sendiri dan kawalan carian. Sintaks dan semantik bahasa pertanyaan ditentukan oleh struktur dan kandungan dokumen dan tugas umum sistem.
Bahagian ketiga pembekalan maklumat ialah apa yang dipanggil "isu", hasil carian. Isu wujud dalam dua jenis: penerangan ringkas dokumen dan dokumen itu sendiri.
Komponen terpenting dalam sistem pencarian maklumat ialah bahasa pencarian maklumat. Untuk memilih dokumen yang diperlukan daripada pelbagai dokumen, seseorang mesti membaca atau melihat kandungannya. Untuk mempercepat dan memudahkan prosedur ini, pelbagai bentuk rakaman ringkasan kandungan dokumen telah muncul - anotasi, abstrak, katalog. Tetapi dalam semua kes ini, bahasa semula jadi digunakan untuk memilih dokumen berdasarkan huraian ringkasnya. "Keburukan" tanda linguistik seperti homonimi, sinonimi, dan polisemi adalah terkenal. Maksud sebenar banyak perkataan hanya boleh difahami dalam konteks. Ini menghalang penggunaan bahasa semula jadi untuk menangkap dan mengenal pasti maklumat konsep. Oleh itu, sistem formal yang direka untuk menyimpan maklumat dokumentari untuk tujuan perolehan seterusnya memerlukan penciptaan bahasa maklumat khas. Bahasa pencarian maklumat adalah sistem tanda dengan abjad, perbendaharaan kata, tatabahasa dan peraturan penggunaannya sendiri. Mari kita ambil perhatian bahawa semua bahasa buatan, dalam satu cara atau yang lain, dicipta dan dicipta berdasarkan bahasa semula jadi.
Apabila membandingkan dokumen dan permintaan, adalah perlu untuk menentukan kaitan dokumen berkenaan dengan permintaan dan membuat keputusan mengenai mengeluarkan atau tidak mengeluarkan dokumen untuk permintaan ini. Peraturan yang secara formal tahap perkaitan dokumen dan permintaan ditentukan, i.e. pematuhan dengan POD dan POS dipanggil kriteria korespondensi semantik (KSS), atau kriteria pengeluaran .
Model dan formula matematik untuk mengira pekali perkaitan boleh menjadi sangat berbeza. Dalam amalan, IPA dengan kriteria logik untuk mengeluarkan , apabila PP dibina menggunakan operator logik (Boolean) bagi konjungsi (&), pemecahan (\/), penolakan (~). Dalam kes ini, ungkapan pertanyaan logik ialah satu set elemen carian (biasanya kata kunci) digabungkan dengan pengendali logik dan kurungan yang diperlukan untuk menunjukkan susunan pengendali dilaksanakan. Kata kunci PP memainkan peranan pembolehubah Boolean yang mengambil nilai 1 (“benar”) jika perkataan yang diberikan terkandung dalam dokumen dan 0 (“salah”) apabila ia tiada. Dokumen dianggap relevan dengan pertanyaan jika formula logik pertanyaan secara keseluruhan menerima nilai "benar" untuk dokumen ini, dan tidak relevan jika hasil pengiraan formula logik adalah "palsu".
Simbol (&, \/, ~) yang digunakan dalam logik untuk menandakan konjungsi, disjungsi dan penolakan biasanya digantikan dalam carian maklumat oleh operator AND, OR dan NOT, masing-masing. Di Rusia, sebutan DAN, ATAU, BUKAN lebih kerap digunakan. Walau bagaimanapun, dalam kes umum, dalam setiap IRS tertentu, notasi untuk operator Boolean dipilih, dan kadangkala, untuk kemudahan pengguna, beberapa simbol diperkenalkan untuk operator yang sama (contohnya, dalam IRS Aport, operator gabungan boleh ditentukan dengan tanda-tanda berikut: &, ruang, DAN , Dan, +).
Penggunaan operator Boolean menyediakan logik mesra pengguna untuk membandingkan dokumen dan pertanyaan. Carian (pengiraan kebenaran untuk elemen PP), sebagai peraturan, dijalankan menggunakan fail indeks khas (terbalik) yang dibina berdasarkan perbendaharaan kata tatasusunan dokumentari, dan dicirikan oleh kelajuan tinggi. Kesederhanaan dan kejelasan CSS logik ini adalah sebab penggunaannya yang meluas.
Masalah menilai kecekapan carian adalah masalah yang kompleks, termasuk kedua-dua sisi teori dan praktikal. Penunjuk fungsian (teknikal) utama IRS berdasarkan perkaitan adalah kesempurnaan dan ketepatan, yang berdasarkan pembahagian dokumen kepada relevan dan tidak relevan, serta dikeluarkan dan tidak dikeluarkan.
Kesempurnaan carian (P) (Bahasa Inggeris Recall - R) ialah ukuran yang dikira sebagai nisbah kuantiti dikeluarkan berkaitan dokumen untuk jumlah bilangan yang berkaitan dokumen yang terkandung dalam tatasusunan maklumat.
Ketepatan carian (T) (Ketepatan Bahasa Inggeris - P) ialah nisbah kuantiti dikeluarkan berkaitan dokumen untuk jumlah dokumen yang dikeluarkan.
1.2. Carian maklumat di Internet
Peralihan kepada masyarakat maklumat abad ke-21 telah menimbulkan peningkatan yang tidak pernah berlaku sebelum ini dalam jumlah dan kepekatan maklumat dalam rangkaian komputer global. Ini telah memburukkan lagi masalah mewujudkan sistem pencarian maklumat (IRS) dan penggunaannya yang berkesan.
Sejarah sistem pencarian maklumat automatik bermula sejak setengah abad. Sistem perolehan maklumat biasa pada tahun-tahun awal ialah sistem mesin manusia, di mana analisis dan penerangan kandungan dokumen (pengindeksan) dilakukan secara manual, dan carian dijalankan oleh mesin. Pada mulanya, asas bahasa pencarian maklumat (IRL), unsur utamanya ialah kamus deskriptor dan tesaurus. Walau bagaimanapun, hari ini, kebanyakan sistem maklumat yang berfungsi tergolong dalam kelas sistem lisan jenis bukan tesaurus, apabila istilah pengindeksan dipilih terus daripada teks dokumen. Pertumbuhan seperti runtuhan salji dalam jumlah maklumat dokumentari elektronik, jenisnya, kepelbagaian tematik dan linguistik adalah punca krisis perolehan maklumat moden dan insentif untuk penambahbaikannya.
Masalah mencari sumber di Internet telah direalisasikan tidak lama lagi, dan sebagai tindak balas, pelbagai sistem dan alat perisian untuk carian muncul, antaranya sistem Gopher, Archie, Veronica, WAIS, WHOIS, dan lain-lain harus disebut. Kebelakangan ini Alat ini telah digantikan dengan "pelanggan" dan "pelayan" web seluruh dunia www.
Jika kita cuba mengklasifikasikan IPS Internet, kita boleh membezakan jenis utama berikut:
1. IRS jenis lisan (enjin carian)
2. Klasifikasi IRS (direktori)
3. Direktori elektronik (“kuning” halaman, dsb.)
4. Sistem pencarian maklumat khusus untuk spesies tertentu sumber
5. Agen pintar.
Perakaunan global semua sumber Internet disediakan oleh sistem pengelasan lisan dan sebahagiannya.
Klasifikasi IPS melaksanakan navigasi dalam ruang web berdasarkan petunjuk khas, yang merupakan "pokok" tematik yang dibina berdasarkan klasifikasi. Skim pengelasan sumber di Internet lazimnya ialah struktur pokok yang nodnya dinamakan dengan perkataan bahasa semula jadi. Pelbagai skim klasifikasi berbeza antara satu sama lain dalam skop dan metodologi penyusunannya. Salah satu kelemahan klasifikasi hierarki sejagat ialah ia bersifat konservatif dan ketinggalan daripada perkembangan sains, teknologi dan kehidupan secara amnya. Masalah utama perkhidmatan carian klasifikasi ialah automasi klasifikasi. Masih tugas pengelasan automatik Saya tidak menemui penyelesaian yang memuaskan. Pendaftaran laman web dan halaman web dalam direktori biasanya dilakukan oleh orang - pengindeks dan moderator sistem ini. Oleh itu, jumlah pangkalan data sistem jenis klasifikasi adalah agak kecil berbanding dengan kapasiti maklumat keseluruhan Internet.
Untuk menyelesaikan masalah liputan maksimum sumber Internet, sistem dipanggil metasearch(enjin metasearch). Mereka tidak mempunyai pangkalan data carian mereka sendiri, tidak mengandungi sebarang indeks, dan apabila mencari, gunakan sumber enjin carian lain. Disebabkan ini, kemungkinan mencari maklumat yang diperlukan meningkat. Untuk menghantar permintaan kepada enjin carian, ejen metasearch khas digunakan, yang bertanggungjawab untuk proses menyampaikan permintaan kepada sistem lain. Selepas memproses permintaan yang diterima, setiap sistem mengembalikan kepada ejen metasearch satu set perihalan dan pautan ke dokumen yang dianggapnya berkaitan permintaan ini. Walaupun semua daya tarikan enjin metasearch, anda juga harus ingat tentang keburukan dan keburukannya. Pertama sekali, kekurangan standard seragam bahasa pertanyaan tidak membenarkan metasistem mencapai daripada enjin carian yang melaksanakan pertanyaan enjin carian meta hasil yang sama yang boleh dicapai pengguna mahir apabila bekerja dengan setiap mesin secara berasingan.
Sistem pencarian maklumat global harus dianggap sebagai cara utama mencari maklumat di Internet hari ini. jenis lisan(enjin carian), pengindeksan (oleh sekurang-kurangnya, mendakwa ini) seluruh ruang Internet. Enjin carian utama jenis ini (terutamanya dari segi saiz pangkalan data) termasuk Google, Fast (AlltheWeb), AltaVista, HotBot, Inktomi, Teoma, WiseNut, MSN Search. Antara sistem Rusia yang utama ialah tiga: Yandex, Rambler dan Aport! (Aport). Kesempurnaan pangkalan data carian dan kecekapan mengindeks laman web adalah masalah utama semua sistem pencarian maklumat di Internet. Sebagai peraturan, sistem dengan volum pangkalan data yang lebih besar menyediakan hasil carian dan Kuantiti yang besar dokumen. Masalah besar, kedua-dua linguistik dan program, ialah multibahasa ruang maklumat Internet dan kepelbagaian format persembahan data. Walau bagaimanapun, sistem global utama menghadapi masalah ini.
IPS lisanlah yang diberi perhatian utama dalam bahagian praktikal manual. Pertama sekali, tahap pengguna dimodelkan, dinyatakan dalam bahasa pertanyaan dan antara muka permintaan-tindak balas. Analisis perbandingan bahasa pertanyaan pelbagai sistem pencarian maklumat di Internet dijalankan.
Keanehan sistem moden- carian teks penuh. Banyak sistem perolehan maklumat lisan di Internet mengira kaitan dokumen dengan pertanyaan dengan membandingkan elemen pertanyaan dengan teks penuh dokumen yang disiarkan di Internet. Bagi bahasa pencarian maklumat, sebagai peraturan, elemen carian adalah perkataan biasa bahasa semula jadi. Permintaan dirumus melalui antara muka khas, dilaksanakan dalam bentuk bentuk skrin dalam program penyemak imbas.
Adalah berguna untuk memahami cara sistem ini berfungsi. Terdapat tiga bahagian utama untuk mana-mana enjin carian.
robot - subsistem yang menyediakan penyemakan imbas (pengimbasan) Internet dan mengekalkan fail terbalik (pangkalan data indeks) sehingga kini. Pakej perisian ini adalah cara utama untuk mengumpul maklumat tentang ketersediaan dan status sumber maklumat rangkaian.
Cari pangkalan data - kononnya indeks - pangkalan data yang dianjurkan khas (pangkalan data indeks bahasa Inggeris), termasuk, pertama sekali, fail terbalik, yang terdiri daripada unit leksikal yang diambil daripada dokumen web yang diindeks dan mengandungi pelbagai maklumat tentang mereka (khususnya, kedudukan mereka dalam dokumen), serta tentang dokumen itu sendiri dan tapak secara amnya.
Sistem carian - subsistem carian yang memproses permintaan pengguna (urutan carian), mencari pangkalan data dan memberikan hasil carian kepada pengguna. Enjin carian berkomunikasi dengan pengguna melalui antara muka pengguna- bentuk skrin program penyemak imbas: antara muka untuk menjana pertanyaan dan antara muka untuk melihat hasil carian.
Fail indeks (atau ringkasnya indeks) ialah satu set fail yang saling berkaitan yang bertujuan untuk mencari data dengan pantas atas permintaan. Indeks sentiasa berdasarkan fail terbalik. Litar terbalik (terbalik). Organisasi tatasusunan carian adalah berdasarkan prinsip menyediakan akses kepada dokumen melalui pengecam kandungannya (ciri carian: deskriptor, kata kunci, istilah, ciri lain). Skim sedemikian diperoleh dengan memproses susunan dokumen yang berurutan untuk mencipta fail terbalik tambahan khas - titik akses.
Setiap rekod tatasusunan tambahan tersebut dikenal pasti oleh pengecam kandungan yang sepadan (deskriptor, kata kunci, hanya istilah, nama pengarang, nama organisasi, dll.) dan mengandungi nama (alamat storan) semua dokumen dalam imej carian yang mana ia terkandung. Untuk setiap pengecam kandungan (elemen data carian) dalam tatasusunan terbalik, bersama-sama dengan alamat (nombor, nama) dokumen, maklumat tambahan boleh disimpan (dan biasanya disimpan), seperti: nama medan, nombor ayat, di mana unsur ini ditemui dalam dokumen ini, nombor perkataan dalam ayat, dsb. Membetulkan kedudukan perkataan dalam teks dengan tepat kepada nombor ayat dan nombor perkataan ini dalam ayat membolehkan anda membina bahasa pertanyaan fleksibel yang membolehkan anda menetapkan jarak antara perkataan dan ayat dalam dokumen. Ciri-ciri kedudukan juga digunakan semasa mengira pekali perkaitan dan dokumen kedudukan dalam hasil carian.
Mencari dokumen yang diperlukan melalui fail terbalik dijalankan bukan dengan pengimbasan berterusan keseluruhan tatasusunan, tetapi dengan melihat hanya pengecam kandungan tersebut dalam fail terbalik yang dinyatakan dalam arahan carian, i.e. bilangan operasi perbandingan perkataan semasa carian adalah berkadar dengan bilangan istilah dalam preskripsi carian. Cara sistem pengendalian ini mengurangkan masa carian dan membolehkan anda menyampaikan maklumat kepada pengguna dalam masa nyata.
Carian indeks ialah operasi pada senarai pengecam elemen carian mengikut model carian dan kriteria padanan. Senarai dokumen yang berkaitan (dalam terminologi moden "tindak balas") yang terhasil, yang ditukar menjadi senarai kedudukan perihalan pendek dokumen, dilengkapi dengan pautan hiperteks dan ciri-ciri lain, dikembalikan kepada pengguna dalam program penyemak imbas kliennya. Mengklik pada tajuk dokumen dalam huraian ringkasnya (melalui hiperpautan) meminta dokumen itu sama ada terus dari pelayan di mana ia berada atau melalui pangkalan data enjin carian.
Komponen penting sistem maklumat moden ialah halaman web antara muka yang dipanggil, i.e. borang skrin di mana pengguna berkomunikasi dengan enjin carian. Terdapat dua jenis utama halaman hadapan: halaman pertanyaan dan halaman hasil carian.
pengindeksan teks penuh mungkin lebih laman web;
kerja "cekap" dengan bentuk perkataan - keupayaan IPS untuk mengenal pasti bentuk perkataan yang berbeza dari leksem yang sama, dengan cara yang berbeza, untuk menghasilkan bentuk kanonik - lemma, dan keupayaan untuk mengenal pasti bentuk tertentu di antara banyak bentuk perkataan;
cari perkataan dengan pemangkasan yang diberikan atau sewenang-wenangnya, kanan dan kiri;
bekerja dengan frasa - mengambil kira jarak antara perkataan dalam frasa dan susunan perkataan itu muncul;
algoritma yang berkesan untuk mengira pekali perkaitan semantik dan hasil carian kedudukan.
Maklumat dan dalam bentuk apa yang boleh diekstrak daripada antara muka keluaran IPS juga penting. Antara muka output (borang pembentangan keputusan) sistem yang berbeza termasuk parameter berikut: statistik perkataan daripada pertanyaan, bilangan dokumen yang ditemui, bilangan tapak, kawalan untuk mengisih dokumen dalam hasil carian, penerangan ringkas dokumen, dll. Penerangan setiap dokumen, seterusnya, boleh mengandungi: tajuk dokumen, URL (alamat dalam rangkaian), volum dokumen, tarikh penciptaan, nama pengekodan, anotasi, penonjolan fon perkataan daripada pertanyaan dalam anotasi, petunjuk halaman web lain yang berkaitan di tapak yang sama, pautan ke kategori katalog kepunyaan dokumen atau tapak yang ditemui, pekali perkaitan, keupayaan carian yang lain (cari dokumen yang serupa, cari yang ditemui). Turut menarik minat adalah ciri frekuensi- maklumat tentang bilangan dokumen yang ditemui dan unit bahasa yang dikenal pasti. Sesetengah sistem menyimpan log permintaan dengan keupayaan untuk mengulang carian dan memaparkan statistik permintaan. Berguna dan peluang menarik juga merupakan penyerahan dokumen kepada kelas tematik.
Kami akan menunjukkan ciri-ciri sistem yang berbeza, yang paling popular dan yang mempunyai sokongan linguistik yang paling maju (lihat Jadual, ms 14). Pertama sekali, ini adalah sistem perolehan maklumat Rusia Yandex, Rambler dan Aport. Mungkin alat linguistik yang paling berkuasa ialah IRS Artifact (syarikat Integrum-TECHNO, Moscow), tetapi sistem ini adalah komersil dan komposisi pangkalan datanya nyata berbeza daripada yang lain. Antara sistem Barat, yang kebanyakannya tidak membangunkan kaedah linguistik untuk menganalisis bahan teks, mari kita ambil IRS Google dan AltaVista yang terkenal. Mari kita terangkan secara ringkas ciri-ciri sistem ini (kehadiran atau ketiadaan keupayaan yang sepadan ditandakan dengan tanda "+" dan "-").
"Carian Lexeme" bermaksud bahawa hasil membandingkan perkataan dalam dokumen dan pertanyaan dianggap positif jika sebarang bentuk perkataan daripada pertanyaan terdapat dalam dokumen, yang dipastikan oleh mekanisme lemmatisasi automatik.
“Cari mengikut bentuk perkataan” bermakna hasil perbandingan dokumen dan pertanyaan dianggap positif jika terdapat bentuk perkataan dalam dokumen yang betul-betul sepadan dengan perkataan daripada pertanyaan, yang berlaku tanpa ketiadaan lemmatisasi automatik atau disediakan oleh khas mekanisme untuk mengambil kira bentuk perkataan.
“Kekerapan dokumen” bermaksud carian menghasilkan mesej tentang bilangan dokumen yang berkaitan, iaitu dokumen yang mengandungi perkataan (bentuk perkataan) atau frasa tertentu.
"Kekerapan perkataan demi perkataan" bermaksud bahawa hasil carian juga memberikan maklumat tentang jumlah bilangan kemunculan sesuatu leksem atau bentuk perkataan tertentu dalam pangkalan data carian (indeks).
Ciri-ciri enjin carian
Cari mengikut leksem | + (pertanyaan perkataan tunggal atau formula Boolean) | ||||
Cari mengikut bentuk perkataan | + (dalam syntagms: pertanyaan satu perkataan dalam petikan atau frasa dalam petikan) | ||||
Perakaunan untuk syntagma (frasa tidak boleh dipisahkan) | |||||
Perakaunan untuk huruf besar dan kecil | + (dalam syntagms) | ||||
Kekerapan perkataan | |||||
Dokumentari kekerapan |
1.3. Bahasa pertanyaan Internet IRS
Setelah menghubungi mana-mana perkhidmatan, pengguna, tanpa meninggalkan penyemak imbas, bekerja dengan "pelanggan" perkhidmatan ini, yang memberikan kami satu atau satu lagi bahasa pertanyaan. Sebagai peraturan, ini adalah bahasa tanpa kawalan perbendaharaan kata. Sebenarnya, kami berurusan dengan bahasa pengaturcaraan biasa yang dilaksanakan dalam seni bina pelayan-pelanggan, tetapi kami hanya melihat bahagian "overhead" bahasa pengaturcaraan ini - bahasa pertanyaan. Bahasa pertanyaan kebanyakan sistem termasuk kedua-dua pengendali Boolean tradisional dan pengendali kontekstual khas yang mengambil kira penstrukturan dokumen, susunan perkataan dalam teks dan jarak antara perkataan.
Bahasa pertanyaan menerangkan pertanyaan itu sendiri dan kadangkala bentuk di mana keputusan dibentangkan. Komponen utama berikut boleh dibezakan dalam bahasa pertanyaan IRS rangkaian.
1) Elemen carian sebenar (objek carian).
Ini sama ada kata kunci atau pengecam kandungan lain.
2) Operator carian.
Hampir semua bahasa pertanyaan menggunakan boolean pengendali logik DAN, ATAU, BUKAN. Bentuk di mana pengendali ini dinyatakan dalam permintaan sangat berbeza-beza, dan ia berbeza dalam perkhidmatan individu dan dalam jenis yang berbeza pertanyaan (mudah, kompleks).
3) Normalisasi elemen permintaan.
Unit leksikal yang sama dalam dokumen dan pertanyaan boleh dibentangkan dalam bentuk yang berbeza. Perkhidmatan carian mempunyai cara untuk menormalkan item leksikal tersebut. Normalisasi ini boleh ditentukan oleh pengguna (teknik yang dikenali sebagai pemangkasan atau kad bebas) atau dilakukan secara automatik (yang terakhir lebih disukai).
4) Tatabahasa linear: susunan elemen carian dan jarak antara mereka.
Pertama, ini adalah "frasa" (frasa tegar).
Kedua, terdapat pengendali kontekstual khas (kontekstual DAN), apabila syarat untuk kejadian bersama elemen pertanyaan dalam dokumen mesti dipenuhi dalam konteks dengan panjang tertentu.
5) Istilah carian tambahan.
Untuk mengurangkan volum keluaran dan meningkatkan ketepatan, pelbagai syarat-syarat tambahan carian, sesuatu seperti:
– cari dalam medan tertentu (bahagian) dokumen;
– mengehadkan kawasan carian mengikut pelbagai kriteria (tarikh, jenis data, format, dll.).
6) Keperluan untuk bentuk pembentangan hasil carian.
– keperluan untuk menyusun (kedudukan) hasil carian;
– jenis keputusan yang dihasilkan;
– bilangan dokumen yang dikeluarkan.
Untuk menerima (melihat) dokumen itu sendiri (halaman web) dan melihatnya, anda perlu pergi ke alamat http. Sebagai peraturan, sistem menyediakan peluang untuk melihat konteks - serpihan dokumen dengan kata kunci pertanyaan yang diserlahkan.
Semasa proses carian, pengguna biasanya diberi peluang untuk kembali kepada pertanyaan lama dan sama ada hanya menjelaskan, menyempitkannya atau bertukar kepada mod carian lain yang menyediakan alat carian yang lebih kompleks. Kaedah carian lain juga agak meluas - cari halaman yang serupa. Dalam kes ini, strategi carian dipilih oleh sistem itu sendiri.
2. Program disiplin akademik
"Teori Pencarian Maklumat"
2.1. Bahagian organisasi dan metodologi
Program disiplin disusun mengikut standard pendidikan negeri pendidikan profesional tinggi dalam arah 021800 - Linguistik.
Tujuan kursus adalah untuk memberi pelajar asas teori perolehan maklumat, terutamanya dokumentari, dan kemahiran menggunakan pelbagai sistem perolehan maklumat dokumentari, termasuk di Internet.
Objektif kursus:
membiasakan pelajar dengan konsep asas dan masalah pencarian maklumat automatik;
untuk membiasakan pelajar dengan prinsip asas organisasi dan fungsi sistem pencarian maklumat (IRS);
mengkaji pelbagai sistem maklumat, termasuk sistem maklumat Internet;
untuk membangunkan kemahiran penyelidikan dalam analisis dan perbandingan pelbagai sistem.
Tempat kursus dalam latihan profesional graduan: Kursus ini bersifat propaedeutik. Ia direka untuk pelbagai pelajar kemanusiaan dan direka bentuk untuk memberi mereka pemahaman asas tentang cara menyimpan dan mendapatkan maklumat.
Keperluan tahap penguasaan kandungan kursus
Hasil daripada latihan, pelajar:
mesti tahu:
konsep asas berkaitan sistem maklumat;
jenis utama sistem;
konsep bahasa pencarian maklumat;
konsep perkaitan dan kriteria korespondensi semantik;
enjin carian Internet utama;
bahasa pertanyaan dan antara muka sistem ini;
sepatutnya boleh:
carian di Internet;
membandingkan dan menganalisis sistem yang berbeza.
Bahagian kursus:
Asas Pencarian Maklumat
IPS Dokumentari
IRS fakta
Carian maklumat di Internet
Bahagian 1. Asas pencarian maklumat
Subjek, matlamat dan objektif kursus. Sambungan kursus dengan disiplin lain.
Maklumat, proses maklumat, sistem maklumat, aliran maklumat, teknologi maklumat. Jenis sistem maklumat (AIPS, ASNTI, ACS, ASNI, AOS, CAD, ES, pangkalan pengetahuan, dll.).
Konsep asas pencarian maklumat: maklumat, sistem maklumat, keperluan maklumat, perkaitan.
Data dan dokumen. Jenis dokumen maklumat. Dokumen teks. Penerangan dokumen.
Permintaan. Jenis permintaan. Carian subjek. Masalah utama automasi proses pemprosesan maklumat semantik.
Sistem pencarian maklumat (IRS). Jenis-jenis IPS. Ulasan ringkas jenis utama: dokumentari, fakta, intelektual.
Carian bibliografi. Pangkalan data bibliografi dan katalog elektronik. Sistem perpustakaan.
Sistem maklumat bukan teks (geografi, kartografi, dll.). Cari objek mengikut penerangannya ( fail grafik, fail muzik dan sebagainya.). Cari maklumat imej dan video.
Bahagian 2. IRS Dokumentari
Sejarah pembangunan sistem pencarian maklumat dokumentari automatik, peringkat pembangunan. Sistem bersepadu. ASNTI. Ciri-ciri pentas moden.
Komponen IPS. IPYA. . Cari model. IPS abstrak dan konkrit.
Struktur sistem maklumat dokumentari dan fakta. Subsistem berfungsi. Skim struktur IPS dokumentari.
Sistem dwi litar. IPS teks penuh. Sistem maklumat hiperteks.
Subsistem sokongan. Sokongan teknikal. Perisian. Jaringan komputer. Ciri-ciri membina sistem maklumat rangkaian.
Model matematik sistem pencarian maklumat dokumentari.
Organisasi tatasusunan carian dalam sistem mendapatkan maklumat.
Klasifikasi sistem perolehan maklumat dokumentari atas pelbagai alasan.
Bahagian 3. IRS Fakta
Maklumat fakta. Maklumat fakta yang tersusun dengan baik dan tidak tersusun dengan baik.
Jadual berciri objek.
Bahasa huraian semantik.
Keberkesanan IRS fakta.
Carian bibliografi sebagai sejenis penyelidikan fakta.
Bahagian 4. Sokongan linguistik untuk mendapatkan maklumat
Cara linguistik untuk mendapatkan maklumat. Komposisi sokongan linguistik IPS.
Konsep bahasa pencarian maklumat (IRL). ILP sebagai elemen utama alat logik-semantik IPS.
Bahasa pencarian maklumat: klasifikasi, tipologi. Bahasa berasaskan objek. Pengelasan. Subjek mengikut abjad dan klasifikasi faset.
Bahasa deskriptor. Bahasa lisan.
Bahasa semantik dan sintagmatik.
Cara untuk menerangkan bahasa. Komponen bahasa perolehan maklumat deskriptor (abjad, kamus, tatabahasa).
Penyeragaman kosa kata dalam IPS. Kamus deskriptor. Thesauri. Penciptaan kamus dan tesauri. Kawalan berwibawa sebagai elemen sokongan linguistik untuk sistem perpustakaan automatik.
Cara tatabahasa IPL. Hubungan paradigmatik dan sintagmatik.
Mengindeks dokumen dan pertanyaan. Cari imej dokumen dan pertanyaan.
Bahasa pertanyaan: konsep dan komposisi. Cara dan kaedah menyatakan keperluan maklumat. Arahan carian.
Cari model. Pengendali carian.
Cara normalisasi morfologi.
Bahasa bermaksud pembentangan dan penstrukturan dokumen elektronik (format, bahasa SGML, HTML, XML). Bahasa metadata (Dublin Core, GILS, dll.).
Sokongan linguistik sistem pencarian maklumat fakta. Unit asas IPL IPS fakta.
Bahagian 5. Fungsi dan pengendalian sistem maklumat
Sokongan maklumat, teknologi dan kakitangan.
Teknologi pemprosesan maklumat pra-mesin. Mengindeks dokumen dan pertanyaan. Ciri carian bergantung pada jenis dokumen.
Mod pengendalian IRS (IRI, carian retrospektif). Mod kumpulan dan dialog.
Ciri teknikal utama sistem perolehan maklumat dokumentari (kelengkapan, ketepatan). Faktor yang mempengaruhi kecekapan carian. Menilai keberkesanan IPS.
Cara dan kaedah untuk menyelesaikan masalah leksikal-semantik dalam IPS. Masalah merangka arahan carian. Maklum balas perkaitan.
Menyediakan hasil carian dengan dokumen utama. Penghantaran elektronik dokumen.
Bahagian 6. Carian maklumat di Internet
Maknanya jaringan komputer untuk organisasi perkhidmatan maklumat. Kaedah dan cara akses kepada tatasusunan dokumen jauh. Protokol Z39.50 (Cari/Pendapatan).
Rangkaian Internet, its penerangan ringkas tentang. Internet sebagai sistem pengangkutan elektronik. Internet sebagai ruang maklumat global.
Sumber maklumat internet. Pelayan FTP. GOPHER. WAIS.
Konsep hiperteks. Sistem hiperteks sebelum kemunculan Internet. pelayan WWW. Navigasi di web. Masalah mencari maklumat.
Sumber maklumat dokumentari. Dokumen elektronik. Format Persembahan maklumat teks di web (html, pdf, ps, doc, dll.). Penerbitan elektronik.
Bukan teks objek maklumat. Konsep perpustakaan elektronik.
Tipologi enjin carian di Internet. Pelbagai asas untuk pengelasan (mengikut keluasan liputan, mengikut ciri dalaman, mengikut jenis dokumen).
Tipologi enjin carian Internet. Sistem pencarian maklumat klasifikasi (katalog). Sistem mendapatkan maklumat lisan (teks, kamus) ( enjin carian).
Sistem pencarian maklumat global dan perkhidmatan Internet.
Bahasa semula jadi di Internet. IPS serantau. Versi serantau sistem global. Internet berbahasa Rusia.
Kaedah untuk mencipta pangkalan data carian dalam sistem global. Pengindeksan dan pendaftaran. Robot pengindeksan. Alat pengurusan pengindeksan (fail robots.txt, elemen META).
Ciri-ciri sokongan linguistik dan maklumat bagi sistem pencarian maklumat di Internet. IPL lisan. Cara tatabahasa IPL: syntagmatics. Operator kedudukan kontekstual ("frasa", operator jarak, dll.).
Masalah kedudukan dokumen dalam hasil carian. Cara menguruskan ranking.
Antara muka input. Bahasa pertanyaan (mudah, lanjutan). Komposisi mereka, contoh. Analisis perbandingan Bahasa pertanyaan IRS Internet. Menyimpan permintaan (sejarah sesi).
Antara muka keluaran. Pembentangan hasil carian. Perihalan dokumen (halaman web), perihalan tapak. Mengumpulkan dokumen mengikut tapak. Pengenalpastian dan penggabungan pendua.
Pengurusan carian. Statistik carian. Cari dalam apa yang ditemui. Cari mengikut persamaan.
Contoh IPS lisan. Analisis perbandingan enjin carian.
Bengkel mengenai pertanyaan penyahpepijatan dan carian dalam sistem maklumat lisan.
Klasifikasi IPS. Kaedah untuk membentuk pangkalan data dalam sistem klasifikasi. Pendaftaran, tapak pendaftaran khas. Cari mengikut kategori.
Bengkel pencarian dalam sistem maklumat klasifikasi.
Bahagian 7. Masa Kini dan Masa Depan Pencarian Maklumat
Pengkomersilan Internet secara umum dan perkhidmatan carian khususnya. Mengiklankan. Yuran pendaftaran dipercepatkan.
Pembangunan sistem maklumat tempatan.
Masalah penyatuan dan penyeragaman.
Maklum balas bermaksud. "Komuniti carian" tidak formal.
Pembangunan sokongan linguistik.
Sistem dengan seni bina teragih berpusat dan terpencar.
Intelektualisasi pencarian maklumat. Sistem maklumat pintar.
Elemen pemprosesan intelektual dalam sistem pencarian maklumat global di Internet. Ejen pintar.
Bahasa metadata bahasa XML, RDF, OWL dan alat penerangan kandungan lain.
2.3. Contoh soalan untuk kawalan diri
Berikan definisi:
Kriteria pengeluaran
Perkaitan
Tesaurus
Komponen IPS
Komposisi sokongan linguistik
Fail songsang
Pilih pilihan jawapan yang betul
Tanda “&” dalam Rambler IPS bermaksud operasi:
percanggahan (OR)
kata hubung (I)
jarak
tanda "|". dalam Yandex IPS bermaksud operasi:
mengikuti
kata hubung (I)
percanggahan (OR)
Subsistem berfungsi IPS ialah:
sokongan linguistik
perisian
sokongan teknikal
kemasukan dokumen
memasukkan pertanyaan
kriteria korespondensi semantik
bahasa pertanyaan
memaparkan hasil carian
fail terbalik
Jenis-jenis IPA ialah:
bahasa morfologi
bahasa deskriptor
bahasa semantik
bahasa klasifikasi
bahasa lisan
bahasa sekunder
bahasa berasaskan objek
Kaedah utama normalisasi morfologi dalam IPS:
berdasarkan morfoanalisis automatik
pemangkasan
bertopeng
awalan
Kriteria korespondensi semantik ialah:
peraturan pengindeksan
peraturan normalisasi
peraturan untuk mengira kesempurnaan
kaedah pemeringkatan
kaedah pengelasan
Pengindeksan ialah:
normalisasi morfologi
menyusun imej carian
terjemahan ke dalam bahasa logik matematik
terjemahan kepada IPYA
pengiraan perkaitan
menyusun kamus deskriptor
Subsistem sokongan IPS ialah:
sokongan linguistik
perisian
sokongan teknikal
kemasukan dokumen
memasukkan pertanyaan
kriteria korespondensi semantik
arahan carian
memaparkan hasil carian
fail terbalik
Jenis IPA:
bahasa berasaskan objek
bahasa klasifikasi
bahasa morfologi
bahasa semantik
bahasa lisan
bahasa sekunder
bahasa deskriptor
Kriteria pengeluaran ialah:
peraturan pengindeksan
peraturan normalisasi
peraturan pengiraan perkaitan
peraturan untuk mengira kesempurnaan
kaedah pemeringkatan
kaedah pengelasan
2.4. Anggaran topik laporan, abstrak,
kerja kursus
Analisis dan penerangan tentang IPS Internet (pemilihan topik sistem yang sesuai dengan guru)
Penciptaan bank data terminologi pada sistem mendapatkan maklumat (pengenalan, klasifikasi istilah dan tafsiran; hasilnya ialah indeks kamus hiperteks atau pangkalan data carian)
Penyelidikan tentang cara menggunakan kamus dan tesaurus dalam talian (contohnya, WordNet) untuk mengindeks pertanyaan dalam sistem mendapatkan maklumat
Analisis dan penerangan tentang mekanisme normalisasi morfologi dalam sistem pencarian maklumat
Mengambil kira sambungan sintagmatik sebagai cara untuk meningkatkan kecekapan carian dalam sistem perolehan maklumat teks penuh (kajian eksperimen)
Pengiraan perkaitan dalam sistem perolehan maklumat (kajian eksperimen)
Analisis kajian tentang keberkesanan perbandingan sistem perolehan maklumat teks penuh
Analisis sokongan linguistik sistem mendapatkan maklumat teks penuh
Kajian analitikal penerbitan dalam jurnal elektronik mengenai sistem pencarian maklumat Laporan Enjin Carian
2.5. Contoh senarai soalan peperiksaan
(kredit) untuk keseluruhan kursus
IPS abstrak dan konkrit (sebenar).
Sistem mendapatkan maklumat secara lisan (enjin carian). seni bina mereka. Contoh IPA lisan
Sistem maklumat global dan serantau di Internet. Contoh
Cara tatabahasa IPL. Cara-cara menyatakan hubungan tatabahasa
Kamus deskriptor. Tesaurus
Maklumat dokumentari di Internet. Dokumen teks. Alat bahasa untuk mempersembahkan dan menstruktur dokumen (dari sudut carian)
Mengindeks dokumen dan pertanyaan. Automasi pengindeksan
Sistem maklumat pintar
Internet sebagai persekitaran maklumat global. Sumber maklumat rangkaian. Masalah carian Internet
Keperluan maklumat, permintaan maklumat, preskripsi carian
Sistem pencarian maklumat (IRS). Jenis-jenis IPS. Gambaran ringkas tentang jenis utama
Bahasa pencarian maklumat: klasifikasi, tipologi
IPYA. Bahasa deskriptor. Bahasa lisan
IPYA. Bahasa klasifikasi
Sejarah pembangunan sistem pencarian maklumat dokumentari automatik, peringkat pembangunan. Ciri-ciri pentas moden
Sistem pencarian maklumat klasifikasi (katalog). Contoh klasifikasi IPS
Klasifikasi IRS dokumentari atas pelbagai alasan
Kriteria surat menyurat semantik. Cari Model
Cara linguistik untuk mendapatkan maklumat. Komposisi sokongan linguistik IPS
Kaedah untuk mencipta pangkalan data carian dalam sistem global (pengindeksan, pendaftaran)
Normalisasi morfologi perbendaharaan kata dalam IPS
Subsistem sokongan
Bahasa berasaskan objek
Organisasi tatasusunan carian dalam sistem mendapatkan maklumat
Ciri teknikal utama IRS dokumentari (kelengkapan, ketepatan)
Konsep bahasa pencarian maklumat (IRL). Klasifikasi (tipologi) IPL
Konsep "maklumat" dan "sistem". Proses dan sistem maklumat. Jenis sistem maklumat
Masalah carian Internet berbilang bahasa. Kaedah penyelesaian dalam sistem maklumat yang berbeza
Masalah mencari dokumen dalam bahasa Rusia. IPS berbahasa Rusia
Masalah merangka arahan carian. Maklum balas perkaitan
Sistem campuran (hibrid). Enjin metasearch. Contoh
Komponen bahasa perolehan maklumat deskriptor
Komponen IPS. Hubungan sistemik antara elemen IS
Intipati perolehan maklumat dokumentari. Konsep perkaitan
Bahasa semantik
Teknologi IPS dan mod operasi. IPS litar dua kali
Tipologi enjin carian Internet
IRS fakta
Gambar rajah fungsional dan struktur IPS. Subsistem berfungsi
Bahasa pertanyaan sistem pencarian maklumat Altavista. Antara muka persembahan hasil carian
Bahasa pertanyaan Google IRS. Antara muka persembahan hasil carian
Bahasa pertanyaan IRS "Aport". Antara muka persembahan hasil carian
Bahasa pertanyaan sistem mendapatkan maklumat Rambler. Antara muka persembahan hasil carian
Bahasa pertanyaan IRS Yandex. Antara muka persembahan hasil carian
Bahasa pertanyaan sistem pencarian maklumat moden. Analisis perbandingan
Bahasa pertanyaan. Arahan carian.
2.6. Pengagihan jam kursus mengikut topik
dan jenis kerja
Nama topik | Bilik Darjah termasuk | Kerja bebas |
|||
Seminari | |||||
Asas Pencarian Maklumat | |||||
IPS Dokumentari | |||||
IRS fakta | |||||
Sokongan linguistik untuk mendapatkan maklumat | |||||
Fungsi dan operasi sistem maklumat | |||||
Pencarian maklumat | |||||
Masa Kini dan Masa Depan Pencarian Maklumat | |||||
JUMLAH: | |||||
2.7. Bentuk kawalan semasa, pertengahan dan akhir
Semasa semester, pelajar menyediakan karya bertulis (abstrak) mengenai salah satu topik yang dipilih, yang "dipertahankan" pada akhir kursus dalam bentuk laporan. Pada akhir kursus terdapat ujian.
2.8. Sokongan pendidikan dan metodologi kursus
Sastera utama
Zakharov V.P. Sistem maklumat (carian dokumen). St. Petersburg, 2002.
Sains Komputer/ Ed. K.V. Tarakanova. M., 1986.
Lahuti D.G.. Sistem perolehan maklumat dokumentari-fakografi automatik // Keputusan Sains dan Teknologi. Sains Komputer. T. 12. M., 1988. ms 6–77.
Salton J. Perpustakaan dinamik dan sistem maklumat. M., 1979.
Salton G. Pemprosesan automatik, penyimpanan dan mendapatkan semula maklumat. M., 1973.
Cherny A.I.. Pengenalan kepada teori pencarian maklumat. M., 1975.
sastera tambahan
Avetisyan D.O. Masalah pencarian maklumat. M., 1991.
Arms W. Perpustakaan elektronik. M., 2001.
Beloozerov V.N. Piawaian baharu untuk terminologi mendapatkan maklumat // NTI. Ser. 1. 1997. Bil 11. ms 14–21.
Voiskunsky V.G. Carian dokumentari dan Maklum balas// Carian subjek dalam sistem perolehan maklumat tradisional dan bukan tradisional. St Petersburg, 1993. Isu. 11. ms 129–141.
Voiskunsky V.G., Zakharov V.P. Kompleks penyahpepijatan dialog // Linguistik struktur dan gunaan: Koleksi antara universiti. Vol. 4. St Petersburg, Universiti Negeri St. Petersburg, 1993, ms 197–211.
Decker S., Melnik S., Hermelen van F. Web Semantik: peranan XML dan RDF // Sistem terbuka. 2001. Bil 9. ms 23–33.
Zakharov V.P., Mordovchenko P.G., Sakharny L.V. Meningkatkan sokongan linguistik dalam sistem mendapatkan maklumat jenis "bebas tesaurus" // NTI. Ser. 2. 1980. No 6. ms 14–19.
Zakharov V.P., Pankov I.P. Sistem pencarian maklumat // Linguistik gunaan: Buku Teks / Ed. ed. A.S. Gerd. St Petersburg, Universiti Negeri St. Petersburg, 1996, ms 334–359.
Zakharov V.P., Pimenov E.N.. Pendekatan bahasa semula jadi untuk penciptaan sokongan linguistik untuk sistem pencarian maklumat // NTI. Ser. 2. 1997. No. 12.
Zmitrovich A.I. Sistem maklumat pintar. Minsk, 1997.
Kapustin V.A. Mencari maklumat di Internet // Dunia Internet. 1998. No. 9. ms 54–58.
Kapustin V.A. Sumber maklumat - bagaimana kita akan mencarinya? // Dunia Internet. 1998. No 9. ms 58–61.
Kapustin V.A. Asas mencari maklumat di Internet: Manual metodologi. St. Petersburg, 1999.
Kurnik A. carian internet. St. Petersburg, 2001.
Bermaklumat-enjin carian. M., 1972.
Lahuti D.G. Intelektualisasi sistem maklumat: Laporan saintifik... M., 2002.
Lyubarsky Yu.Ya. Sistem maklumat pintar. M., 1990.
Masevich A.Ts. Dua pendekatan kepada teori IPS berdasarkan konsep linguistik moden // Carian subjek dalam sistem perolehan maklumat tradisional dan bukan tradisional. L., 1989. Isu. 9. Hlm.25–49.
Moskovich V.A. Bahasa maklumat. M., 1971.
Parkhomenko V.F. Sistem untuk pengindeksan automatik dokumen BRACKETS OS EC // M., 1983
Digunakan Linguistik: Buku teks. St Petersburg, 1996. ms 59–67, 92–99, 360–388.
Rubashkin V.Sh. Perwakilan dan analisis makna dalam sistem maklumat pintar. M., 1989.
Sokolov A.V. Automasi carian bibliografi. - M., 1981.
Sokolov A.V.. Pengenalan kepada teori komunikasi sosial. St. Petersburg, 1996.
Sokolov A.V.. Bahan metodologi mengenai pembangunan tesauri pencarian maklumat. L., 1976.
Stepanov V. Carian bibliografi di Internet // Bibliografi. 1998. No 1. Hlm 5–10.
Khramtsov P.B.. Sistem pencarian maklumat Internet // Sistem terbuka. 1996. No 3. Hlm 46–49.
Khramtsov P.B.. Pemodelan dan analisis pengendalian sistem pencarian maklumat Internet // Sistem Terbuka. 1996. No 6. ms 46–56.
Shemakin Yu.I., Romanov A.A.. Semantik komputer. M., 1995.
Shemakin Yu.I. Tesaurus dalam kawalan automatik dan sistem pemprosesan maklumat. M., 1974.
Piawaian
tipikal penyelesaian reka bentuk untuk sistem automatik maklumat saintifik dan teknikal. M., 1983.
GOST 34.601-90. Teknologi maklumat. Satu set piawaian untuk sistem automatik. Peringkat mencipta sistem automatik.
GOST 34.602-89. Teknologi maklumat. Set piawaian untuk sistem automatik. Tugas teknikal untuk mencipta sistem automatik.
GOST 7.52-85. Format komunikasi untuk menukar data bibliografi pada pita magnetik. Cari imej dokumen.
GOST 7.74-96. Bahasa pencarian maklumat. Terma dan Definisi.
RD 34.003-90. Teknologi maklumat. Terma dan Definisi.
RD 34.201-89. Teknologi maklumat. Jenis, kelengkapan dan penetapan dokumen semasa membuat sistem automatik.
RD 34.680-88. Arahan berkaedah. Teknologi maklumat. Peruntukan asas.
RD 34.698-90. Arahan berkaedah. Teknologi maklumat. Keperluan untuk kandungan dokumen.
3. Bengkel (kerja makmal)
Arahan untuk melaksanakan kerja makmal
Hasil kerja makmal disimpan pada cakera keras dalam folder yang sesuai kerja makmal Lab#N, dengan N ialah nombor kerja. Selain itu, semua folder ini, seterusnya, disimpan dalam folder pelajar, yang mempunyai laluan berikut: DISK:\ Nama Akhir Guru\nnn-Fam\, dengan nnn ialah nombor kumpulan (pengecam), Fam ialah nama keluarga pelajar. Sebagai contoh, semua fail dan folder yang dibuat dan disimpan semasa kerja makmal No. 2 diletakkan dalam folder D:\Zakharov\ML_3kurs-Ivanova\Lab#2. Dalam tugasan makmal, folder pelajar semasa ini dipanggil " folder anda sendiri».
Dalam sesetengah kes, sebelum memulakan kerja, seperti yang diarahkan oleh guru, anda harus menyalin (dari komputer guru melalui "Kejiranan Rangkaian" atau dari cakera liut) fail tambahan yang diperlukan untuk menyelesaikan tugasan ke folder anda.
Laporan teks dengan hasil kerja yang sepadan dibuat dalam editor Word. Dalam tetingkap dokumen anda perlu memasukkan nama keluarga anda, nama pertama, nombor kumpulan/subkumpulan, nombor kerja makmal dan tarikh siap kerja. Kemudian tulis hasil kerja yang diperlukan ke dalam fail ini ( di bawah nombor item tugasan yang sepadan). Simpan data ini sebagai fail laporan bernama ReportN dalam folder anda, dengan N ialah nombor kerja. Untuk mengelakkan kehilangan data akibat kegagalan, fail yang dijana oleh pelajar semasa bekerja disyorkan untuk disimpan dengan kerap.
Untuk membentangkan hasil kerja anda kepada guru, letakkannya pada skrin dalam tetingkap berikut, melatakannya dari kiri ke kanan: kandungan folder kerja makmal yang dilindungi (dalam tetingkap Explorer), fail laporan dalam tetingkap Editor perkataan, tetingkap penyemak imbas (jika perlu).
Kerja makmal No 1
(Pengkelasan IPS)
Buka halaman enjin carian Aport (ROL, Russia On-Line). Biasakan diri anda dengan pengelas (categorizer) sistem ini. Salin tajuk peringkat atas ke dalam buku nota dan nomborkannya semula. Bergerak melalui tajuk rubrikator, cari dua muzium ("Muzium Sastera dan Memorial F.M. Dostoevsky" dan "Muzium Sejarah dan Memorial M.V. Lomonosov di kampung Lomonosovo, Wilayah Arkhangelsk"). Biasakan diri anda dengan borang untuk menyerahkan maklumat tentang tapak dalam direktori.
Untuk setiap muzium:
salin penerangan ringkas muzium yang ditentukan dalam katalog ke fail laporan Report1;
nyatakan indeks petikan (dalam bentuk nombor) dan liga (dalam bentuk nama lisan) untuk tapak muzium ini;
pergi ke laman web muzium dan salin halaman utama pertama dalam folder anda dalam format ;
buat "penanda halaman" untuk tapak web muzium dalam folder Kegemaran anda.
Buka halaman enjin carian Yandex. Biasakan diri anda dengan pengelas (categorizer) sistem ini. Salin tajuk peringkat atas ke dalam buku nota dan nomborkannya semula. Tandakan (bulatkan) tajuk yang bertepatan dengan tajuk Aport (secara keseluruhan atau sebahagian). Menelusuri tajuk rubrikator, cari “Muzium Sastera dan Memorial F.M. Dostoevsky" dan "Muzium Sejarah dan Memorial M.V. Lomonosov di kampung Lomonosovo, wilayah Arkhangelsk." Salin huraian mereka dalam rubrikator Yandex ke fail laporan.
Lawati Sistem Penarafan IPS Rambler. Biasakan diri anda dengan pengelas (categorizer) sistem ini. Rubrik yang bertepatan dengan rubrik Aport (secara keseluruhan atau sebahagian) hendaklah disalin ke dalam buku nota. Lihat penarafan tapak mengenai topik "Pendidikan". Biasakan diri anda dengan borang untuk menyampaikan maklumat dalam katalog. Salin nama tapak yang berada di kedudukan kelima, dengan penunjuk kuantitatifnya, ke dalam fail laporan Report1. Tengok statistik terperinci dan salin jadual statistik ke dalam fail laporan.
Ulangi perkara yang sama dalam sistem Yahoo.
Kerja makmal№ 2
(IPS lisan bahasa Rusia: analisis perbandingan)
Kerja ini terdiri daripada kajian perbandingan sistem Aport, Yandex, Rambler. Pelajar mesti mencerminkan hasil kajian dalam bentuk jadual (ms 34) dalam fail Report2 (orientasi jadual - landskap). Dalam sel, tuliskan cara dalam setiap sistem ini atau elemen bahasa pertanyaan atau antara muka input/output diwakili (semua kaedah yang sah). Dalam sesetengah kes, anda boleh menjawab dengan tanda “+” atau “–” (contohnya, “ Penerangan dokumen") atau teks percuma dalam perkataan anda sendiri (contohnya, « Halaman Berkaitan tapak yang sama" atau "Menyusun").
Pergi ke laman web enjin carian Aport (kemudian Yandex dan Rambler). Cari dalam setiap pautan sistem kepada penerangannya secara keseluruhan, kepada penerangan bahasa pertanyaan, antara muka (“Bantuan”, “Bantuan”, “Carian Terperinci” dan sebagainya . ). Dengan mengikuti pautan, teliti maklumat latar belakang dan semak secara ringkas perkara utama dalam buku kerja anda. Selepas ini, isikan sel jadual yang sepadan untuk setiap sistem (bahagian 1, 2).
Catatan. Jika teks jawapan tidak muat dalam sel jadual, adalah disyorkan untuk membuat nota kaki dan meneruskannya di bawah jadual. Sila ambil perhatian bahawa keupayaan sistem dalam carian mudah dan lanjutan berbeza. Tunjukkan ini dalam laporan. Beri perhatian kepada kehadiran bahagian "lain".
Kembali ke halaman utama enjin carian Aport (kemudian Yandex dan Rambler). Masukkan pertanyaan (contohnya, "Kaedah statistik dalam linguistik") dalam tetingkap pertanyaan teks dan carian. Simpan halaman dengan hasil carian dalam folder anda dalam format "html sahaja".
Kaji borang untuk membentangkan keputusan. Tulis secara ringkas dalam buku nota anda apa yang terkandung pada halaman web dengan hasil carian (struktur halaman web). Kaji bentuk pembentangan dokumen web individu (huraian ringkasnya dengan maklumat tambahan). Berdasarkan kajian keputusan yang diperolehi dan maklumat latar belakang yang dikaji sebelum ini, isikan sel jadual yang sesuai (bahagian 3).
Bentangkan hasil kerja anda kepada guru.
Hasil kajian perbandingan sistem Aport, Yandex, Rambler
№ | Pilihan | Aport | Yandex | Rambler |
Cari melalui teks | ||||
Operator logik: | ||||
kata hubung | ||||
perpecahan | ||||
Penafian | ||||
Pengendali sintagmatik: | ||||
frasa (frasa, perkataan berdekatan) | ||||
jarak dalam perkataan | ||||
jarak dalam ayat | ||||
Normalisasi morfologi (automatik, metakarakter digunakan) | ||||
Cari mengikut medan | ||||
mengikut tajuk | ||||
mengikut medan kata kunci | ||||
dengan ulasan kepada gambar (medan ALT) | ||||
mengikut teks hiperpautan | ||||
dengan alamat rujukan | ||||
dengan nama domain tapak (pelayan) | ||||
mengikut format | ||||
Antara muka isu (borang pembentangan keputusan) | ||||
statistik perkataan daripada pertanyaan | ||||
bilangan dokumen yang ditemui | ||||
bilangan tapak yang ditemui | ||||
bilangan dokumen setiap halaman hasil | ||||
menyusun dokumen pada halaman keluaran | ||||
carian dalam dijumpai | ||||
penerangan dokumen termasuk elemen berikut: | ||||
URL (alamat web) | ||||
saiz dokumen (volume) | ||||
tarikh penciptaan | ||||
pengekodan | ||||
abstrak (ringkasan) | ||||
menunjuk ke halaman web lain yang berkaitan di tapak yang sama | ||||
mencari dokumen yang serupa | ||||
Kerja makmal№ 3
(IPS lisan bahasa Rusia: carian)
Menyusun dan menyahpepijat pertanyaan topik
Buat permintaan dalam buku nota anda mengenai topik "Pertempuran tentera laut semasa Great Perang Patriotik" Pada masa yang sama, keluarkan perkataan yang tidak penting daripada topik, kembangkan pertanyaan dengan sinonim, cipta formula pertanyaan logik dengan penggunaan wajib operator kata hubung, disjungsi, jarak dan frasa (frasa tegar).
Tunjukkan permintaan kepada guru.
Kemudian tuliskan variannya dalam bahasa sistem Aport, Yandex, Rambler.
Nyahpepijat pertanyaan dalam mod carian sebenar, menjalankan sesi berurutan dalam ketiga-tiga sistem. Cuba ubah keperluan carian untuk mencapai prestasi carian yang optimum. Untuk melakukan ini, rekod dalam buku nota hasil yang diperolehi untuk setiap pilihan: ketepatan (untuk 20 dokumen pertama) dan kesempurnaan bersyarat (jumlah keluaran mutlak).
Kembali ke preskripsi carian terbaik dan salin teks pertanyaan melalui papan keratan daripada rentetan carian(tetingkap untuk memasukkan pertanyaan) ke dalam tetingkap fail laporan Report3 (satu demi satu dalam setiap sistem). Nyatakan petunjuk ketepatan dan kesempurnaan dalam laporan. Simpan halaman web pertama dengan hasil carian dalam setiap sistem dalam foldernya sendiri dalam format "html sahaja".
Memperkenalkan Carian Medan (Carian Terperinci)
Gunakan sistem Yandex untuk mencari dokumen khusus untuk Lev Gumilyov. Catatkan bilangan dokumen dan tapak yang ditemui dalam fail laporan. Simpan alamat (URL) dokumen pertama daripada senarai dalam Kegemaran dalam folder "Gumilyov".
Kemudian pergi ke mod carian lanjutan dan cari dokumen yang didedikasikan untuk Lev Gumilev dengan tarikh selepas 1 Oktober 2004. Tulis bilangan dokumen dan tapak baharu yang ditemui ke dalam fail laporan sekali lagi. Simpan dokumen pertama daripada senarai hasil carian dalam folder anda dalam format “arkib web, satu fail” (*.mht).
Cari dokumen mengenai topik "Ekonomi Kota Moscow" melalui sistem Rambler. Dalam kes ini, tetapkan volum carian (bilangan huraian dokumen pada halaman hasil) kepada 30. Isih hasil carian mengikut tarikh (menurun) dan simpan halaman web pertama dengan hasil carian dalam folder anda dalam format "html sahaja"
Pergi ke mod carian lanjutan dan cari dokumen mengenai topik yang sama, tetapi hanya terletak di tapak. Isih hasil carian mengikut tarikh (menaik) dan simpan halaman web pertama dengan hasil carian dalam folder anda dalam format "html sahaja". Catatkan bilangan dokumen dan tapak yang terdapat dalam fail laporan.
Cari dokumen mengenai topik "Pendidikan" melalui sistem Yandex, dari mana terdapat pautan ke tapak. Simpan halaman web pertama dengan hasil carian dalam folder anda dalam format "html sahaja". Catatkan bilangan dokumen dan tapak yang terdapat dalam fail laporan.
Muat turun salah satu dokumen yang ditemui, lihat kod htmlnya, cari di dalamnya pautan ke tapak dan salin elemen hiperpautan (dari awal hingga akhir tag A) ke fail laporan melalui papan keratan.
Dokumen dalam format mht, disimpan dalam perenggan 7 (tentang Lev Gumilyov), boleh dibaca dalam editor Word: pertama dalam format halaman web, kemudian dalam format "teks sahaja". Pada bacaan kedua, semak kandungan tetingkap input editor Word (terutamanya permulaan dan akhir fail), salin halaman pertama tetingkap input ke dalam fail laporan, dan bersedia untuk menerangkan format mht.
Catatan. Format mht dikodkan mengikut piawaian MIME (RFC2046 dan RFC2047).
Bentangkan hasil kerja anda kepada guru.
Kerja makmal No. 4
(IPA Verbal Global: Analisis Perbandingan)
Kerja ini terdiri daripada kajian perbandingan sistem maklumat Internet global jenis lisan yang diberikan.
Catatan. Set sistem dan nombornya mungkin berubah mengikut budi bicara guru.
Pergi ke tapak web enjin carian yang sepadan (selepas ini - nama domain sistem: www.nama_sistem.com). Cari dalam setiap pautan sistem kepada penerangannya secara keseluruhan, kepada perihalan bahasa pertanyaan, antara muka, mod pengendalian dan ciri lain sistem. Tulis secara ringkas penerangan setiap IPS dalam buku nota anda.
Menganalisis dan membandingkan keupayaan sistem dalam mod carian lanjutan. Simpan halaman antara muka carian lanjutan dalam folder anda sendiri.
Bentangkan hasil analisis dalam bentuk termampat dalam bentuk jadual pangsi (ms 38) dalam fail laporan Report4 (orientasi jadual - landskap). Saiz meja boleh ditambah. Jika sesuatu tidak sesuai dalam jadual, buat nota kaki dalam sel kepada teks di bawah jadual (jadual bukanlah satu bentuk persembahan hasil sebagai skema analisis).
Bentangkan hasil kerja anda kepada guru.
Hasil kajian perbandingan IPS verbal global
Pilihan | |||||
Pengendali logik(yang dan bagaimana ditanya) | |||||
Pengendali sintagmatik | |||||
Cari mengikut medan(susun senarai medan, perhatikan kehadiran/ketiadaannya dalam sistem tertentu) | |||||
bidang 1 | |||||
bidang 2 | |||||
……… | |||||
padang k | |||||
Memilih Pangkalan Data Carian | |||||
sumber 1 | |||||
sumber 2 | |||||
……… | |||||
sumber k | |||||
Format output mengandungi elemen berikut(di bawah jadual berikan contoh dari setiap sistem) | |||||
unsur 1 | |||||
unsur 2 | |||||
……… | |||||
unsur k | |||||
Ciri khas atau ciri khas |
Kerja makmal No. 5
(IPS Verbal Global: Kajian dan Carian)
Jalankan carian pada topik "Linguistik Pengiraan" dalam IRS global yang ditentukan ( set sistem dan bilangannya boleh berubah mengikut budi bicara guru). Preskripsi carian secara logik sepatutnya kelihatan seperti ini:
(kompaunutasionalVcomputingVcomputeh) &
lilmu inguistik.
Tanya permintaan dalam bahasa Inggeris dua kali, sebagai kata hubung dan sebagai frasa set (frasa), menggunakan kaedah menyatakan ciri pengendali bagi setiap sistem (untuk sistem yang tidak dikenali, cari maklumat rujukan yang sesuai). Simpan halaman web pertama dengan hasil setiap carian dalam folder anda sebagai "html sahaja". Keputusan kuantitatif ditunjukkan dalam jadual:
nama IPS | Dokumen/tapak ditemui | |||
Seminar
Reka bentuk sistem pengurusan dokumen
Konsep sistem pencarian maklumat (IRS).
Komposisi komponen dan teknologi bekerja dengan IPS.
Sedang berlangsung perusahaan moden peranan penting memainkan sumber maklumatnya, yang boleh difahami sebagai dokumentasi projek, surat-menyurat dengan rakan kongsi, pesanan dan arahan dalaman, data kewangan dan dokumen lain yang menjadi asas untuk membuat keputusan baharu dan digunakan dalam proses pengurusan perusahaan. Dan jika sistem maklumat khusus (seperti perakaunan atau sistem perdagangan atau perancangan sistem jabatan) berdasarkan penggunaan DBMS, maka untuk data tidak berstruktur kita memerlukan sistem tujuan umum - arkib elektronik yang beroperasi berdasarkan prinsip sistem perolehan maklumat.
Sistem pencarian maklumat (IRS) – ialah sistem yang direka untuk menyimpan dan mencari dokumen dengan teks, grafik, maklumat jadual mengenai atribut, kata kunci dokumen dan kandungan dalam mana-mana kawasan subjek. Terdapat dua jenis sistem maklumat: sistem fakta dan dokumengrafik. Sistem perolehan maklumat jenis fakta direka untuk menyimpan dan mendapatkan semula fakta, penunjuk, ciri mana-mana objek atau proses (contohnya, maklumat tentang pekerja, perusahaan, pemegang saham, dll.). Sistem maklumat dokumentografi berbeza kerana objek penyimpanan dan pengambilan semula dalam sistem ini ialah dokumen, laporan, abstrak, ulasan, jurnal, buku, dsb. Skrip untuk mencari dokumen menggunakan sistem mendapatkan maklumat biasanya datang untuk memasukkan pertanyaan carian yang terdiri daripada satu atau beberapa perkataan, selepas itu senarai nama dokumen yang ditemui dibentangkan. Pengguna boleh membuka mana-mana dokumen yang ditemui dan, jika sistem carian membenarkannya, kemunculan perkataan yang dicari dalam dokumen itu diserlahkan - "diserlahkan". Ciri-ciri organisasi berikut boleh dibezakan:
fungsi sistem maklumat dokumenografi, membezakannya daripada sistem pengurusan pangkalan data data berstruktur: – Dokumen boleh disimpan di atas kertas, media mikrografik atau wujud dalam format elektronik. Format mikrografik termasuk mikrofilem, mikrofik, slaid dan mikroform lain yang dihasilkan oleh pelbagai kamera dokumen. Format elektronik adalah lebih banyak dan termasuk dokumen yang disediakan pemproses perkataan, sistem E-mel dan program komputer lain, imej digital dokumen yang diimbas, dsb. Ini memerlukan penyimpanan mandatori kedua-dua salinan elektronik dokumen dan dokumen asalnya.
Jika dokumen besar dan lengkap salinan elektronik Ia tidak boleh dikeluarkan untuk dilihat atau disimpan, kemudian alamat storan elektronik untuk dokumen tersebut dibuat dan disimpan.
Pencarian dijalankan dengan mencari dokumen mengikut dua prinsip: oleh
atribut dokumen - tarikh penciptaan, saiz, pengarang, dll dan mengikutnya kandungan(teks). Biasanya, carian kandungan dokumen dilakukan dalam dua cara: dengan kata kunci dan oleh keseluruhan teks, yang dipanggil teks penuh, dengan itu menekankan bahawa keseluruhan teks dokumen digunakan untuk carian, dan bukan hanya butirannya.
Untuk mencari dokumen, imej carian mereka dibuat dan disimpan . Cari imej dokumen (SID) – satu set kod kata kunci utama (deskriptor) yang menerangkan maksud dan kandungan dokumen.
Kata kunci dan kodnya disimpan dalam kamus khas - tesaurus.
Untuk mencari dokumen, anda perlu membuat bahasa carian maklumat (IRL), yang merangkumi tesaurus dan tatabahasa bahasa, i.e. satu set peraturan untuk menentukan set pernyataan pada set kata kunci.
Untuk mencari dokumen, anda perlu menciptanya menggunakan IPA imej pertanyaan carian (POZ), iaitu satu set kata kunci yang dikodkan yang menerangkan dokumen yang perlu ditemui.
Gambar rajah interaksi komponen IPS ditunjukkan dalam Rajah. 1.
nasi. 1. Skim interaksi antara komponen IPS
IPS terdiri daripada subsistem sokongan berikut:
Sokongan linguistik, yang merangkumi bahasa pencarian maklumat;
Sokongan teknikal untuk sistem, termasuk komputer dan peranti untuk mencipta, menyimpan, membaca dan menghasilkan semula salinan di atas kertas, dalam mikroformat dan dalam bentuk elektronik;
Sokongan maklumat yang terdiri daripada pangkalan data dokumen (DB Doc.), alamat (DB Adr.) dan pangkalan data carian imej dokumen (DB DB) dan senarai deskriptor dan kodnya - tesaurus;
Perisian.
Perisian IPS direka untuk mengautomasikan fungsi utama berikut yang mesti dilaksanakan oleh sistem ini:
Menyusun, mengekod dan memuatkan pangkalan data AML;
Memuatkan pangkalan data dokumen dan alamat penyimpanannya;
Merangka, pengekodan POS;
Menjalankan operasi carian dan mengeluarkan respons kepada permintaan dalam bentuk dokumen atau alamat penyimpanan dokumen pada skrin komputer, di atas kertas, dalam fail;
Mengemas kini pangkalan data, dokumen dan alamat AML;
Mengemas kini tesaurus;
Pengeluaran sijil.
Mari kita pertimbangkan konsep asas yang digunakan dalam bidang carian dokumen.
Perkaitan - tahap surat-menyurat dokumen yang ditemui kepada permintaan . Dokumen yang ditemui melalui permintaan mungkin berkaitan dengan permintaan, iaitu, mengandungi maklumat yang diperlukan (diminta), atau ia mungkin tidak mempunyai sebarang kaitan. Dalam kes pertama, dokumen itu dipanggil relevan(dalam bahasa Inggeris berkaitan - "berkaitan"), pada yang kedua - tidak relevan, atau bunyi bising. Sebagai peraturan, dalam mana-mana enjin carian, atas permintaan, beberapa (biasanya banyak) dokumen yang ditemui dikembalikan. Ramai daripada mereka mungkin menceritakan kisah yang salah. Sebaliknya, beberapa dokumen penting yang berkaitan mungkin terlepas semasa carian. Adalah jelas bahawa kuantiti kedua-duanya menentukan kualiti carian, yang boleh ditentukan dengan agak tepat. Konsep utama dalam dunia alat carian ialah idea ketepatan dan kesempurnaan carian.
Ketepatan carian (T) ditentukan oleh bahagian maklumat yang dikembalikan sebagai tindak balas kepada permintaan yang berkaitan, i.e. berkaitan dengan pertanyaan ini dan merupakan parameter yang menunjukkan apakah perkadaran dokumen yang berkaitan dalam jumlah bilangan yang ditemui. Penunjuk ini dikira menggunakan formula:

Jika, sebagai contoh, semua dokumen yang dikeluarkan atas permintaan adalah berkaitan dengan kes itu, maka ketepatannya ialah 100%; jika, sebaliknya, semua dokumen bising, maka ketepatan carian adalah sifar.
Kesempurnaan carian (P)- parameter tambahan yang menunjukkan bahagian (atau peratusan) dokumen berkaitan yang terdapat dalam jumlah dokumen berkaitan, i.e. dicirikan oleh hubungan antara semua maklumat berkaitan yang tersedia dalam pangkalan data dan bahagian itu yang disertakan dalam respons dan dikira menggunakan formula:

Jika sebenarnya terdapat 100 dokumen dalam kawasan carian yang mengandungi maklumat yang diperlukan, dan pertanyaan mendapati hanya 30 daripadanya, maka kesempurnaan carian ialah 30%. Di samping itu, apabila menilai enjin carian, ia diambil kira jenis data yang boleh digunakan oleh sistem tertentu, dalam bentuk hasil carian yang dibentangkan, dan tahap latihan pengguna yang diperlukan untuk berfungsi dalam sistem ini. Perlu diingatkan bahawa ketepatan carian dan kesempurnaannya bergantung bukan sahaja pada sifat sistem carian, tetapi juga pada ketepatan pembinaan permintaan tertentu, serta pada idea subjektif pengguna tentang maklumat apa yang dia perlukan. Sekiranya terdapat masalah menilai beberapa sistem dan memilih yang paling berkesan, anda boleh mengira nilai purata kesempurnaan dan ketepatan sistem tertentu yang sedang dipertimbangkan dengan mengujinya pada pangkalan data rujukan dokumen.
Pengindeksan dokumen (iaitu penyediaan PML), yang bermaksud penyediaan awal teks untuk carian dan digunakan terutamanya untuk mempercepatkan carian; Sebagai peraturan, pangkalan data teks yang bertujuan untuk carian berulang diproses terlebih dahulu, mewujudkan apa yang dipanggil indeks(BAWAH ) . Apabila mengindeks, sistem carian menyusun senarai perkataan yang terdapat dalam teks dan memberikan setiap perkataan kodnya - koordinat dalam teks (selalunya nombor dokumen dan nombor perkataan dalam dokumen). Apabila mencari, perkataan itu dicari dalam indeks, dan mengikut koordinat yang ditemui, dokumen yang diperlukan. Jika terdapat beberapa perkataan dalam pertanyaan, operasi persilangan dilakukan pada koordinatnya . Jika banyak dokumen diisi semula, indeks juga perlu diisi semula.
Unit carian- ini ialah kuantum teks yang mana carian dijalankan dalam enjin carian tertentu, yang nilainya menentukan penunjuk ketepatan carian, jumlah bunyi dan masa tindak balas kepada permintaan. Unit carian boleh menjadi dokumen, ayat atau perenggan. Dalam teknologi menggunakan IPS, tiga kumpulan operasi boleh dibezakan:
Operasi yang berkaitan dengan mendapatkan imej carian dokumen (SID) yang menerangkan kandungan dokumen dan memuatkannya ke dalam pangkalan data (SID DB), serta memuatkan dokumen itu sendiri atau alamat penyimpanannya ke dalam BDDoc dan BDAdr.;
Operasi menyusun imej pertanyaan carian (SQI) menggunakan tesaurus, mencari dan mengeluarkan hasil untuk melihat dan memilih atau fail atau mencetak dokumen yang ditemui atau senarai alamat;
Operasi menyelenggara sistem pencarian maklumat, termasuk mengemas kini pangkalan data POD, BDDoc., BDAdr. dan tesaurus kerana kemunculan dan perlu menambah memori sistem dengan dokumen atau kata kunci baharu. Operasi mengekalkan IPS juga termasuk prosedur untuk mengeluarkan sijil tentang pengendalian sistem, strukturnya, kaedah carian dan kelas serta jenis dokumen yang disimpan u1076.
























