മിക്ക ആധുനിക വെബ് ആപ്ലിക്കേഷനുകളും ഡാറ്റാബേസുകളുമായി സംവദിക്കുന്നു, സാധാരണയായി ഒരു ഭാഷ ഉപയോഗിക്കുന്നു SQL. ഭാഗ്യവശാൽ, ഈ ഭാഷ പഠിക്കാൻ വളരെ എളുപ്പമാണ്. ഈ ലേഖനത്തിൽ നമ്മൾ ലളിതമായി നോക്കും SQL സംവദിക്കാൻ അവ എങ്ങനെ ഉപയോഗിക്കാമെന്ന് അന്വേഷണങ്ങൾ മനസിലാക്കുക MySQL ഡാറ്റാബേസ്.
നിങ്ങൾക്ക് എന്ത് ആവശ്യമായി വരും?
SQL (ഘടനാപരമായ അന്വേഷണ ഭാഷ) പോലുള്ള ഡാറ്റാബേസ് മാനേജ്മെന്റ് സിസ്റ്റങ്ങളുമായി ഇന്റർഫേസ് ചെയ്യാൻ പ്രത്യേകം രൂപകൽപ്പന ചെയ്ത ഒരു ഭാഷ MySQL, Oracle, Sqlite മറ്റുള്ളവരും... പൂർത്തിയാക്കാൻ SQL ഈ ലേഖനത്തിലെ അഭ്യർത്ഥനകൾ, ഇൻസ്റ്റാൾ ചെയ്യാൻ ഞാൻ നിങ്ങളെ ഉപദേശിക്കുന്നു MySQL നിങ്ങളുടെ പ്രാദേശിക കമ്പ്യൂട്ടറിലേക്ക്. ഉപയോഗിക്കാനും ഞാൻ ശുപാർശ ചെയ്യുന്നു phpMyAdmin ഒരു വിഷ്വൽ ഇന്റർഫേസ് ആയി.
എല്ലാവരുടെയും പ്രിയപ്പെട്ട ഡെൻവറിൽ ഇതെല്ലാം ലഭ്യമാണ്. അത് എന്താണെന്നും എവിടെ നിന്ന് കിട്ടുമെന്നും എല്ലാവരും അറിഞ്ഞിരിക്കണമെന്ന് ഞാൻ കരുതുന്നു :). കഴിയും WAMP അല്ലെങ്കിൽ MAMP എന്നിവയും ഉപയോഗിക്കുക.
ഡെൻവറിന് ഒരു ബിൽറ്റ്-ഇൻ ഉണ്ട് MySQL കൺസോൾ. ഇത് ഞങ്ങൾ ഉപയോഗിക്കും.
ഡാറ്റാബേസ് സൃഷ്ടിക്കുക:ഡാറ്റാബേസ് സൃഷ്ടിക്കൽ
ഇതാ ഞങ്ങളുടെ ആദ്യത്തെ അഭ്യർത്ഥന. തുടർന്നുള്ള പ്രവർത്തനത്തിനായി ഞങ്ങൾ ഞങ്ങളുടെ ആദ്യ ഡാറ്റാബേസ് സൃഷ്ടിക്കും.
ആരംഭിക്കുന്നതിന്, തുറക്കുക MySQL കൺസോൾ ചെയ്ത് ലോഗിൻ ചെയ്യുക. വേണ്ടി WAMP ഡിഫോൾട്ട് പാസ്വേഡ് ശൂന്യമാണ്. അതായത്, ഒന്നുമില്ല :). വേണ്ടി MAMP - "റൂട്ട്". ഡെൻവറിനെ സംബന്ധിച്ചിടത്തോളം, ഞങ്ങൾ വ്യക്തമാക്കേണ്ടതുണ്ട്.
ലോഗിൻ ചെയ്ത ശേഷം, ഇനിപ്പറയുന്ന വരി നൽകി ക്ലിക്കുചെയ്യുകനൽകുക:
ഡാറ്റാബേസ് സൃഷ്ടിക്കുക my_first_db;മറ്റ് ഭാഷകളിലെന്നപോലെ, ചോദ്യത്തിന്റെ അവസാനം ഒരു അർദ്ധവിരാമം (;) ചേർത്തിട്ടുണ്ടെന്ന് ശ്രദ്ധിക്കുക.
SQL-ലും കമാൻഡുകൾ കേസ് സെൻസിറ്റീവ്. ഞങ്ങൾ അവ വലിയ അക്ഷരങ്ങളിൽ എഴുതുന്നു.
ഓപ്ഷനുകൾ ഔപചാരികമായി: പ്രതീക സെറ്റ്ഒപ്പം സമാഹാരം
നിങ്ങൾക്ക് ഇൻസ്റ്റാൾ ചെയ്യണമെങ്കിൽപ്രതീക ഗണവും (പ്രതീക ഗണവും) കൂട്ടിച്ചേർക്കലും (താരതമ്യം) ആകാം ഇനിപ്പറയുന്ന കമാൻഡ് എഴുതുക:
ഡാറ്റാബേസ് സൃഷ്ടിക്കുക my_first_db ഡിഫോൾട്ട് ക്യാരക്ടർ സെറ്റ് utf8 COLLATE utf8_general_ci;പിന്തുണയ്ക്കുന്ന പ്രതീക സെറ്റുകളുടെ ഒരു ലിസ്റ്റ് കണ്ടെത്തുന്നു MySQL.
ഡാറ്റാബേസുകൾ കാണിക്കുക:എല്ലാ ഡാറ്റാബേസുകളുടെയും ഒരു ലിസ്റ്റ് പ്രദർശിപ്പിക്കുന്നു
ലഭ്യമായ എല്ലാ ഡാറ്റാബേസുകളും ലിസ്റ്റ് ചെയ്യാൻ ഈ കമാൻഡ് ഉപയോഗിക്കുന്നു.

ഡ്രോപ്പ് ഡാറ്റാബേസ്:ഒരു ഡാറ്റാബേസ് ഇല്ലാതാക്കുന്നു
ഈ ചോദ്യം ഉപയോഗിച്ച് നിങ്ങൾക്ക് നിലവിലുള്ള ഒരു ഡിബി ഇല്ലാതാക്കാം.

ഈ കമാൻഡ് മുന്നറിയിപ്പില്ലാതെ പ്രവർത്തിക്കുന്നതിനാൽ ശ്രദ്ധിക്കുക. നിങ്ങളുടെ ഡാറ്റാബേസിൽ ഡാറ്റ ഉണ്ടെങ്കിൽ, അതെല്ലാം ഇല്ലാതാക്കപ്പെടും.
ഉപയോഗിക്കുക:ഡാറ്റാബേസ് തിരഞ്ഞെടുക്കൽ
സാങ്കേതികമായി ഇതൊരു അന്വേഷണമല്ല, ഒരു പ്രസ്താവനയാണ്, അവസാനം ഒരു അർദ്ധവിരാമം ആവശ്യമില്ല.

ഇത് MySQL-നോട് പറയുന്നു നിലവിലെ സെഷനായി സ്ഥിരസ്ഥിതി ഡാറ്റാബേസ് തിരഞ്ഞെടുക്കുക. ഇപ്പോൾ ഞങ്ങൾ പട്ടികകൾ സൃഷ്ടിക്കാനും ഡാറ്റാബേസ് ഉപയോഗിച്ച് മറ്റ് കാര്യങ്ങൾ ചെയ്യാനും തയ്യാറാണ്.
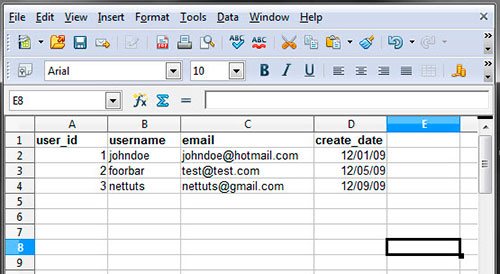
ഒരു ഡാറ്റാബേസിൽ ഒരു പട്ടിക എന്താണ്?
നിങ്ങൾക്ക് ഡാറ്റാബേസിലെ പട്ടികയെ ഇങ്ങനെ പ്രതിനിധീകരിക്കാംഎക്സൽ ഫയൽ.

ചിത്രത്തിലെന്നപോലെ, പട്ടികകൾക്ക് കോളത്തിന്റെ പേരുകളും വരികളും വിവരങ്ങളും ഉണ്ട്. ഉപയോഗിച്ച് SQL ചോദ്യങ്ങൾ നമുക്ക് അത്തരം പട്ടികകൾ സൃഷ്ടിക്കാൻ കഴിയും. ഞങ്ങൾക്ക് വിവരങ്ങൾ ചേർക്കാനും വായിക്കാനും അപ്ഡേറ്റ് ചെയ്യാനും ഇല്ലാതാക്കാനും കഴിയും.
പട്ടിക സൃഷ്ടിക്കുക: ഒരു മേശ ഉണ്ടാക്കുന്നു
സി ഈ ചോദ്യം ഉപയോഗിച്ച് നമുക്ക് ഡാറ്റാബേസിൽ പട്ടികകൾ സൃഷ്ടിക്കാൻ കഴിയും. നിർഭാഗ്യവശാൽ, ഡോക്യുമെന്റേഷൻ MySQL തുടക്കക്കാർക്ക് ഈ വിഷയത്തിൽ വളരെ വ്യക്തമല്ല. ഇത്തരത്തിലുള്ള അന്വേഷണത്തിന്റെ ഘടന വളരെ സങ്കീർണ്ണമായിരിക്കാം, എന്നാൽ ഞങ്ങൾ എളുപ്പമുള്ള എന്തെങ്കിലും ഉപയോഗിച്ച് ആരംഭിക്കാം.
ഇനിപ്പറയുന്ന ചോദ്യം 2 നിരകളുള്ള ഒരു പട്ടിക സൃഷ്ടിക്കും.
ടേബിൾ ഉപയോക്താക്കളെ സൃഷ്ടിക്കുക (ഉപയോക്തൃനാമം VARCHAR(20), create_date DATE);ഒന്നിലധികം വരികളിലും ഇൻഡന്റേഷനായി ടാബുകളിലും ഞങ്ങളുടെ ചോദ്യങ്ങൾ എഴുതാൻ കഴിയുമെന്നത് ശ്രദ്ധിക്കുക.
ആദ്യ വരി ലളിതമാണ്. ഞങ്ങൾ "ഉപയോക്താക്കൾ" എന്ന് വിളിക്കുന്ന ഒരു പട്ടിക സൃഷ്ടിക്കുന്നു. അടുത്തതായി, പരാൻതീസിസിൽ, കോമകളാൽ വേർതിരിച്ചത്, എല്ലാ നിരകളുടെയും ഒരു ലിസ്റ്റ് ആണ്. ഓരോ കോളത്തിന്റെ പേരിനും ശേഷം ഞങ്ങൾക്ക് VARCHAR അല്ലെങ്കിൽ DATE പോലുള്ള വിവര തരങ്ങളുണ്ട്.
VARCHAR(20) എന്നതിനർത്ഥം കോളം ടൈപ്പ് സ്ട്രിംഗാണെന്നും പരമാവധി 20 പ്രതീകങ്ങൾ ദൈർഘ്യമുണ്ടാകാമെന്നുമാണ്. ഇനിപ്പറയുന്ന ഫോർമാറ്റിൽ തീയതികൾ സംഭരിക്കുന്നതിന് ഉപയോഗിക്കുന്ന ഒരു വിവര തരം കൂടിയാണ് DATE: "YYYY - MM-DD".
പ്രൈമറി കീ ( പ്രാഥമിക കീh)
അടുത്ത ചോദ്യം റൺ ചെയ്യുന്നതിനുമുമ്പ്, "user_id" എന്നതിനായുള്ള ഒരു കോളം കൂടി ഉൾപ്പെടുത്തണം, അത് ഞങ്ങളുടെ പ്രാഥമിക കീ ആയിരിക്കും. ഒരു പട്ടികയിലെ ഓരോ വരിയും തിരിച്ചറിയാൻ ഉപയോഗിക്കുന്ന വിവരങ്ങളായി നിങ്ങൾക്ക് പ്രാഥമിക കീയെക്കുറിച്ച് ചിന്തിക്കാം.
ടേബിൾ ഉപയോക്താക്കൾ സൃഷ്ടിക്കുക (user_id INT AUTO_INCREMENT പ്രൈമറി കീ, ഉപയോക്തൃനാമം VARCHAR(20), create_date DATE);
INT ഒരു 32-ബിറ്റ് പൂർണ്ണസംഖ്യ ഉണ്ടാക്കുന്നു (ഉദാഹരണത്തിന്, സംഖ്യകൾ). AUTO_INCREMENT ഒരു പുതിയ മൂല്യം യാന്ത്രികമായി സൃഷ്ടിക്കുന്നുഐഡി ഓരോ തവണയും ഞങ്ങൾ പുതിയ വിവരങ്ങൾ ചേർക്കുന്നു. ഇത് ആവശ്യമില്ല, പക്ഷേ ഇത് മുഴുവൻ പ്രക്രിയയും എളുപ്പമാക്കുന്നു.
ഈ കോളം ഒരു പൂർണ്ണസംഖ്യയായിരിക്കണമെന്നില്ല, പക്ഷേ ഇത് മിക്കപ്പോഴും ഉപയോഗിക്കുന്നു. ഒരു പ്രാഥമിക കീ ഉണ്ടായിരിക്കുന്നതും ഓപ്ഷണൽ ആണ്, എന്നാൽ ഡാറ്റാബേസ് ആർക്കിടെക്ചറിനും പ്രകടനത്തിനും ശുപാർശ ചെയ്യുന്നു.
നമുക്ക് ചോദ്യം പ്രവർത്തിപ്പിക്കാം:

പട്ടികകൾ കാണിക്കുക:എല്ലാ പട്ടികകളും കാണിക്കുക
ഡാറ്റാബേസിൽ ഉള്ള പട്ടികകളുടെ ഒരു ലിസ്റ്റ് ലഭിക്കാൻ ഈ അന്വേഷണം നിങ്ങളെ അനുവദിക്കുന്നു.

വിശദീകരിക്കാൻ:പട്ടികയുടെ ഘടന കാണിക്കുക
നിലവിലുള്ള ഒരു പട്ടികയുടെ ഘടന കാണിക്കുന്നതിന്, നിങ്ങൾക്ക് ഈ ചോദ്യം ഉപയോഗിക്കാം.

എല്ലാ പ്രോപ്പർട്ടികളിലും കോളങ്ങൾ പ്രദർശിപ്പിക്കും.
ഡ്രോപ്പ് ടേബിൾ:പട്ടിക ഇല്ലാതാക്കുക
DROP ഡാറ്റാബേസുകൾക്ക് സമാനമാണ്, ഈ ചോദ്യം മുന്നറിയിപ്പില്ലാതെ പട്ടികയും അതിലെ ഉള്ളടക്കങ്ങളും ഇല്ലാതാക്കുന്നു.

ആൾട്ടർ ടേബിൾ: പട്ടിക മാറ്റുക
പട്ടികയിൽ വരുത്താൻ കഴിയുന്ന കൂടുതൽ മാറ്റങ്ങൾ കാരണം ഈ അന്വേഷണത്തിൽ സങ്കീർണ്ണമായ ഘടനയും അടങ്ങിയിരിക്കാം. ഉദാഹരണങ്ങൾ നോക്കാം.
(മുമ്പത്തെ ഘട്ടത്തിൽ നിങ്ങൾ പട്ടിക ഇല്ലാതാക്കിയെങ്കിൽ, ടെസ്റ്റുകൾക്കായി അത് വീണ്ടും സൃഷ്ടിക്കുക)
ഒരു കോളം ചേർക്കുന്നു
ALTER TABLE ഉപയോക്താക്കൾ ഉപയോക്തൃനാമത്തിന് ശേഷം VARCHAR(100) ഇമെയിൽ ചേർക്കുക;SQL-ന്റെ നല്ല വായനാക്ഷമതയുള്ളതിനാൽ, ഇത് വിശദമായി വിശദീകരിക്കുന്നതിൽ അർത്ഥമില്ലെന്ന് ഞാൻ കരുതുന്നു. "ഉപയോക്തൃനാമത്തിന്" ശേഷം ഞങ്ങൾ ഒരു പുതിയ കോളം "ഇമെയിൽ" ചേർക്കുന്നു.

ഒരു കോളം നീക്കംചെയ്യുന്നു

അതും വളരെ എളുപ്പമായിരുന്നു. ഈ അഭ്യർത്ഥന ജാഗ്രതയോടെ ഉപയോഗിക്കുക, കാരണം മുന്നറിയിപ്പില്ലാതെ നിങ്ങളുടെ ഡാറ്റ ഇല്ലാതാക്കപ്പെടാം.
കൂടുതൽ പരീക്ഷണങ്ങൾക്കായി നിങ്ങൾ ഇപ്പോൾ ഇല്ലാതാക്കിയ കോളം പുനഃസ്ഥാപിക്കുക.
ഒരു കോളത്തിൽ മാറ്റങ്ങൾ വരുത്തുന്നു
ചിലപ്പോൾ നിങ്ങൾ ഒരു നിരയുടെ ഗുണങ്ങളിൽ മാറ്റങ്ങൾ വരുത്താൻ ആഗ്രഹിച്ചേക്കാം, ഇത് ചെയ്യുന്നതിന് നിങ്ങൾ അത് പൂർണ്ണമായും ഇല്ലാതാക്കേണ്ടതില്ല.

ഈ ചോദ്യം ഉപയോക്തൃ നിരയെ "user_name" എന്ന് പുനർനാമകരണം ചെയ്യുകയും അതിന്റെ തരം VARCHAR(20) ൽ നിന്ന് VARCHAR(30) എന്നാക്കി മാറ്റുകയും ചെയ്തു. ഈ മാറ്റം പട്ടികയിലെ ഡാറ്റ മാറ്റാൻ പാടില്ല.
തിരുകുക: ഒരു പട്ടികയിലേക്ക് വിവരങ്ങൾ ചേർക്കുന്നു
ഇനിപ്പറയുന്ന ചോദ്യം ഉപയോഗിച്ച് പട്ടികയിലേക്ക് കുറച്ച് വിവരങ്ങൾ ചേർക്കാം.

നിങ്ങൾക്ക് കാണാനാകുന്നതുപോലെ, കോമകളാൽ വേർതിരിച്ച മൂല്യങ്ങളുടെ ഒരു ലിസ്റ്റ് VALUES() ൽ അടങ്ങിയിരിക്കുന്നു. എല്ലാ മൂല്യങ്ങളും ഒറ്റ നിരകളിൽ ഉൾപ്പെടുത്തിയിരിക്കുന്നു. മൂല്യങ്ങൾ പട്ടിക സൃഷ്ടിക്കുമ്പോൾ നിർവചിച്ച നിരകളുടെ ക്രമത്തിലായിരിക്കണം.
"user_id" എന്ന് വിളിക്കുന്ന പ്രൈമറി കീ ഫീൽഡിന്റെ ആദ്യ മൂല്യം NULL ആണെന്ന് ശ്രദ്ധിക്കുക. കോളത്തിന് AUTO_INCREMENT പ്രോപ്പർട്ടി ഉള്ളതിനാൽ, ഐഡി സ്വയമേവ ജനറേറ്റുചെയ്യുന്നതിനാണ് ഞങ്ങൾ ഇത് ചെയ്യുന്നത്. ആദ്യമായി വിവരങ്ങൾ ചേർക്കുമ്പോൾ ഐഡി 1 ആയിരിക്കും. അടുത്ത വരി 2 ആയിരിക്കും, അങ്ങനെ...
ഇതര ഓപ്ഷൻ
വരികൾ ചേർക്കുന്നതിന് മറ്റൊരു അന്വേഷണ ഓപ്ഷൻ ഉണ്ട്.

ഇത്തവണ ഞങ്ങൾ VALUES-ന് പകരം SET കീവേഡ് ഉപയോഗിക്കുന്നു, അതിന് പരാൻതീസിസുകളില്ല. നിരവധി സൂക്ഷ്മതകളുണ്ട്:
നിങ്ങൾക്ക് കോളം ഒഴിവാക്കാം. ഉദാഹരണത്തിന്, "user_id" എന്നതിന് ഞങ്ങൾ ഒരു മൂല്യം നൽകിയിട്ടില്ല, അത് അതിന്റെ AUTO_INCREMENT മൂല്യത്തിലേക്ക് സ്ഥിരസ്ഥിതിയായി മാറും. VARCHAR തരമുള്ള ഒരു കോളം നിങ്ങൾ ഒഴിവാക്കുകയാണെങ്കിൽ, ഒരു ശൂന്യമായ വരി ചേർക്കപ്പെടും.
ഓരോ കോളവും പേര് ഉപയോഗിച്ച് സൂചിപ്പിക്കണം. ഇക്കാരണത്താൽ, മുമ്പത്തെ പതിപ്പിൽ നിന്ന് വ്യത്യസ്തമായി ഏത് ക്രമത്തിലും അവ സൂചിപ്പിക്കാൻ കഴിയും.
ഇതര ഓപ്ഷൻ 2
ഇതാ മറ്റൊരു ഓപ്ഷൻ.

വീണ്ടും, നിരയുടെ പേരിലേക്ക് റഫറൻസുകൾ ഉള്ളതിനാൽ, നിങ്ങൾക്ക് ഏത് ക്രമത്തിലും മൂല്യങ്ങൾ സജ്ജമാക്കാൻ കഴിയും.
LAST_INSERT_ID()
നിലവിലെ സെഷന്റെ അവസാന വരിയിൽ AUTO_INCREMENT ആയിരുന്ന ഐഡി ലഭിക്കാൻ നിങ്ങൾക്ക് ഈ ചോദ്യം ഉപയോഗിക്കാം.

ഇപ്പോൾ()
അന്വേഷണങ്ങളിൽ നിങ്ങൾക്ക് MySQL ഫംഗ്ഷൻ എങ്ങനെ ഉപയോഗിക്കാമെന്ന് കാണിക്കാനുള്ള സമയമാണിത്.
NOW() ഫംഗ്ഷൻ നിലവിലെ തീയതി പ്രദർശിപ്പിക്കുന്നു. അതിനാൽ നിങ്ങൾ ഒരു പുതിയ വരി ചേർക്കുമ്പോൾ ഒരു കോളത്തിന്റെ തീയതി നിലവിലുള്ളതിലേക്ക് സ്വയമേവ സജ്ജീകരിക്കാൻ നിങ്ങൾക്ക് ഇത് ഉപയോഗിക്കാം.

ഞങ്ങൾക്ക് ഒരു മുന്നറിയിപ്പ് ലഭിച്ചുവെന്നത് ശ്രദ്ധിക്കുക, പക്ഷേ അത് അവഗണിക്കുക. ഇതിനുള്ള കാരണം, NOW() താൽക്കാലിക വിവരങ്ങൾ ഔട്ട്പുട്ട് ചെയ്യാൻ സഹായിക്കുന്നു എന്നതാണ്.

തിരഞ്ഞെടുക്കുക: ഒരു പട്ടികയിൽ നിന്ന് ഡാറ്റ വായിക്കുന്നു
ഞങ്ങൾ ഒരു പട്ടികയിലേക്ക് വിവരങ്ങൾ ചേർക്കുകയാണെങ്കിൽ, അത് എങ്ങനെ വായിക്കണമെന്ന് പഠിക്കുന്നത് യുക്തിസഹമായിരിക്കും. ഇവിടെയാണ് SELECT ചോദ്യം നമ്മെ സഹായിക്കുന്നത്.
ഒരു പട്ടിക വായിക്കാൻ സാധ്യമായ ഏറ്റവും ലളിതമായ SELECT ചോദ്യം ചുവടെയുണ്ട്.

ഈ സാഹചര്യത്തിൽ, നക്ഷത്രചിഹ്നം (*) അർത്ഥമാക്കുന്നത് ഞങ്ങൾ പട്ടികയിൽ നിന്ന് എല്ലാ ഫീൽഡുകളും അഭ്യർത്ഥിച്ചു എന്നാണ്. നിങ്ങൾക്ക് ചില കോളങ്ങൾ മാത്രം വേണമെങ്കിൽ, ചോദ്യം ഇതുപോലെ കാണപ്പെടും.

അവസ്ഥഎവിടെ
മിക്കപ്പോഴും, എല്ലാ നിരകളിലും ഞങ്ങൾക്ക് താൽപ്പര്യമില്ല, പക്ഷേ ചിലതിൽ മാത്രം. ഉദാഹരണത്തിന്, "nettuts" എന്ന ഉപയോക്താവിന് ഞങ്ങൾക്ക് ഒരു ഇമെയിൽ വിലാസം മാത്രമേ ആവശ്യമുള്ളൂ എന്ന് കരുതുക.

ഒരു ചോദ്യത്തിൽ വ്യവസ്ഥകൾ സജ്ജീകരിക്കാനും വിശദമായ തിരഞ്ഞെടുപ്പ് നടത്താനും നിങ്ങളെ എവിടെ അനുവദിക്കുന്നു.
സമത്വത്തിനായി, പ്രോഗ്രാമിങ്ങിലെ പോലെ രണ്ടല്ല, ഒരു തുല്യ ചിഹ്നം (=) ഉപയോഗിക്കുന്നു.
നിങ്ങൾക്ക് താരതമ്യങ്ങളും ഉപയോഗിക്കാം.

വ്യവസ്ഥകൾ സംയോജിപ്പിക്കാൻ AND അല്ലെങ്കിൽ OR ഉപയോഗിക്കാം:

സംഖ്യാ മൂല്യങ്ങൾ ഉദ്ധരണികളിൽ ആയിരിക്കരുത് എന്നത് ശ്രദ്ധിക്കുക.
IN()
ഒന്നിലധികം മൂല്യങ്ങളിൽ സാമ്പിൾ ചെയ്യാൻ ഇത് ഉപയോഗപ്രദമാണ്

ലൈക്ക് ചെയ്യുക
"വൈൽഡ്കാർഡ്" അഭ്യർത്ഥനകൾ നടത്താൻ നിങ്ങളെ അനുവദിക്കുന്നു

% ഐക്കൺ ഒരു "വൈൽഡ്കാർഡ്" ആയി ഉപയോഗിക്കുന്നു. അതായത്, എന്തും അതിന്റെ സ്ഥാനത്ത് ആകാം.
അവസ്ഥഓർഡർ പ്രകാരം
ഏതെങ്കിലും മാനദണ്ഡം അനുസരിച്ച് ഓർഡർ ചെയ്ത ഫോമിൽ നിങ്ങൾക്ക് ഫലം ലഭിക്കണമെങ്കിൽ

ഡിഫോൾട്ട് ഓർഡർ ASC ആണ് (ഏറ്റവും ചെറുത് മുതൽ വലുത്). വിപരീതമായി, DESC ഉപയോഗിക്കുന്നു.
പരിധി ... ഓഫ്സെറ്റ് ...
നിങ്ങൾക്ക് ലഭിച്ച ഫലങ്ങളുടെ എണ്ണം പരിമിതപ്പെടുത്താം.

LIMIT 2 ആദ്യ 2 ഫലങ്ങൾ മാത്രമേ എടുക്കൂ. LIMIT 1 OFFSET 2 ന് ആദ്യ 2 ന് ശേഷം 1 ഫലം ലഭിക്കും. LIMIT 2, 1 അർത്ഥമാക്കുന്നത് ഒരേ കാര്യമാണ് (ഓഫ്സെറ്റ് ആദ്യം വരികയും പിന്നീട് പരിമിതപ്പെടുത്തുകയും ചെയ്യുക).
അപ്ഡേറ്റ് ചെയ്യുക: പട്ടികയിലെ വിവരങ്ങളിൽ മാറ്റങ്ങൾ വരുത്തുക
ഒരു പട്ടികയിലെ വിവരങ്ങൾ മാറ്റാൻ ഈ ചോദ്യം ഉപയോഗിക്കുന്നു.

മിക്ക കേസുകളിലും, ഇത് WHERE ക്ലോസുമായി സംയോജിച്ച് ഉപയോഗിക്കുന്നു, കാരണം നിങ്ങൾ മിക്കവാറും ചില കോളങ്ങളിൽ മാറ്റങ്ങൾ വരുത്താൻ ആഗ്രഹിക്കുന്നു. WHERE ക്ലോസ് ഇല്ലെങ്കിൽ, മാറ്റങ്ങൾ എല്ലാ വരികളെയും ബാധിക്കും.
മാറ്റങ്ങൾ വരുത്തേണ്ട വരികളുടെ എണ്ണം പരിമിതപ്പെടുത്താനും നിങ്ങൾക്ക് LIMIT ഉപയോഗിക്കാം.

ഇല്ലാതാക്കുക: ഒരു പട്ടികയിൽ നിന്ന് വിവരങ്ങൾ നീക്കംചെയ്യുന്നു
അപ്ഡേറ്റ് പോലെ, ഈ ചോദ്യം WHERE എന്നതിനൊപ്പം ഉപയോഗിക്കുന്നു:

ഒരു പട്ടികയിലെ ഉള്ളടക്കങ്ങൾ ഇല്ലാതാക്കാൻ, നിങ്ങൾക്ക് ഇത് ചെയ്യാൻ കഴിയും:
ഉപയോക്താക്കളിൽ നിന്ന് ഇല്ലാതാക്കുക;
എന്നാൽ ഉപയോഗിക്കുന്നതാണ് നല്ലത്വെട്ടിച്ചുരുക്കുക

ഇല്ലാതാക്കുന്നതിനൊപ്പം, ഈ അഭ്യർത്ഥന മൂല്യങ്ങളും പുനഃസജ്ജമാക്കുന്നു AUTO_INCREMENT വീണ്ടും വരികൾ ചേർക്കുമ്പോൾ, പൂജ്യത്തിൽ നിന്ന് കൗണ്ട്ഡൗൺ ആരംഭിക്കും.ഇല്ലാതാക്കുക ഇത് ചെയ്യുന്നില്ല, കൗണ്ട്ഡൗൺ തുടരുന്നു.
ചെറിയക്ഷര മൂല്യങ്ങളും പ്രത്യേക വാക്കുകളും പ്രവർത്തനരഹിതമാക്കുന്നു
സ്ട്രിംഗ് മൂല്യങ്ങൾ
ചില പ്രതീകങ്ങൾ പ്രവർത്തനരഹിതമാക്കേണ്ടതുണ്ട് (എസ്കേപ്പ് ), അല്ലെങ്കിൽ പ്രശ്നങ്ങൾ ഉണ്ടാകാം.

ഇതിനായി ഒരു ബാക്ക്സ്ലാഷ് ഉപയോഗിക്കുന്നു.(\).
പ്രത്യേക വാക്കുകൾ
കാരണം MySQL-ൽ ധാരാളം പ്രത്യേക വാക്കുകൾ ഉണ്ട് (തിരഞ്ഞെടുക്കുക അല്ലെങ്കിൽ അപ്ഡേറ്റ് ചെയ്യുക ), അവ ഉപയോഗിക്കുമ്പോൾ പിശകുകൾ ഒഴിവാക്കാൻ, നിങ്ങൾ ഉദ്ധരണികൾ ഉപയോഗിക്കണം. എന്നാൽ സാധാരണ ഉദ്ധരണികളല്ല, ഇതുപോലെ(`).
അതായത്, നിങ്ങൾ " എന്ന പേരിൽ ഒരു കോളം ചേർക്കേണ്ടതുണ്ട്.ഇല്ലാതാക്കുക ", നിങ്ങൾ ഇത് ഇതുപോലെ ചെയ്യേണ്ടതുണ്ട്:

ഉപസംഹാരം
അവസാനം വരെ വായിച്ചതിന് നന്ദി. ഈ ലേഖനം നിങ്ങൾക്ക് സഹായകരമാണെന്ന് ഞാൻ പ്രതീക്ഷിക്കുന്നു. ഇത് ഇതുവരെ അവസാനിച്ചിട്ടില്ല! തുടരും:).
1 വോട്ട്എന്റെ ബ്ലോഗ് സൈറ്റിലേക്ക് സ്വാഗതം. ഇന്ന് നമ്മൾ തുടക്കക്കാർക്കുള്ള sql ചോദ്യങ്ങളെക്കുറിച്ച് സംസാരിക്കും. ചില വെബ്മാസ്റ്റർമാർക്ക് ഒരു ചോദ്യമുണ്ടാകാം. എന്തുകൊണ്ട് sql പഠിക്കണം? കടന്നു പോകാൻ പറ്റില്ലേ?
ഒരു പ്രൊഫഷണൽ ഇന്റർനെറ്റ് പ്രോജക്റ്റ് സൃഷ്ടിക്കാൻ ഇത് പര്യാപ്തമല്ലെന്ന് ഇത് മാറുന്നു. ഡാറ്റാബേസുകളിൽ പ്രവർത്തിക്കാനും വേർഡ്പ്രസ്സിനായി ആപ്ലിക്കേഷനുകൾ സൃഷ്ടിക്കാനും Sql ഉപയോഗിക്കുന്നു. ചോദ്യങ്ങൾ എങ്ങനെ ഉപയോഗിക്കാമെന്ന് കൂടുതൽ വിശദമായി നോക്കാം.
അത് എന്താണ്
Sql ഒരു ഘടനാപരമായ അന്വേഷണ ഭാഷയാണ്. ഡാറ്റയുടെ തരം നിർണ്ണയിക്കാനും അതിലേക്ക് ആക്സസ് നൽകാനും ചുരുങ്ങിയ സമയത്തിനുള്ളിൽ വിവരങ്ങൾ പ്രോസസ്സ് ചെയ്യാനും രൂപകൽപ്പന ചെയ്തിരിക്കുന്നു. ഇന്റർനെറ്റ് പ്രോജക്റ്റിൽ നിങ്ങൾ കാണാൻ ആഗ്രഹിക്കുന്ന ഘടകങ്ങളെയോ ചില ഫലങ്ങളെയോ ഇത് വിവരിക്കുന്നു.
ലളിതമായി പറഞ്ഞാൽ, ഡാറ്റാബേസിൽ വിവരങ്ങൾ ചേർക്കാനും മാറ്റാനും തിരയാനും പ്രദർശിപ്പിക്കാനും ഈ പ്രോഗ്രാമിംഗ് ഭാഷ നിങ്ങളെ അനുവദിക്കുന്നു. ഒരു ഡാറ്റാബേസിനെ അടിസ്ഥാനമാക്കിയുള്ള ഡൈനാമിക് ഇന്റർനെറ്റ് പ്രോജക്റ്റുകൾ സൃഷ്ടിക്കാൻ ഇത് ഉപയോഗിക്കുന്നു എന്നതാണ് mysql-ന്റെ ജനപ്രീതിക്ക് കാരണം. അതിനാൽ, ഒരു പ്രവർത്തനപരമായ ബ്ലോഗ് വികസിപ്പിക്കുന്നതിന്, നിങ്ങൾ ഈ ഭാഷ പഠിക്കേണ്ടതുണ്ട്.

അതിന് എന്ത് ചെയ്യാൻ കഴിയും
sql ഭാഷ നിങ്ങളെ അനുവദിക്കുന്നു:
- പട്ടികകൾ സൃഷ്ടിക്കുക;
- വിവിധ ഡാറ്റ സ്വീകരിക്കുന്നതിനും സംഭരിക്കുന്നതിനുമുള്ള മാറ്റം;
- വിവരങ്ങൾ ബ്ലോക്കുകളായി സംയോജിപ്പിക്കുക;
- ഡാറ്റ പരിരക്ഷിക്കുക;
- ആക്സസിൽ അഭ്യർത്ഥനകൾ സൃഷ്ടിക്കുക.
പ്രധാനം! നിങ്ങൾ sql മനസ്സിലാക്കിക്കഴിഞ്ഞാൽ, നിങ്ങൾക്ക് ഏത് സങ്കീർണ്ണതയുടെയും വേർഡ്പ്രസ്സിനായി ആപ്ലിക്കേഷനുകൾ എഴുതാം.
എന്ത് ഘടന
ഡാറ്റാബേസിൽ ഒരു എക്സൽ ഫയലായി അവതരിപ്പിക്കാൻ കഴിയുന്ന പട്ടികകൾ അടങ്ങിയിരിക്കുന്നു.
ഇതിന് ഒരു പേരും കോളങ്ങളും ചില വിവരങ്ങളുള്ള ഒരു വരിയും ഉണ്ട്. sql ചോദ്യങ്ങൾ ഉപയോഗിച്ച് നിങ്ങൾക്ക് അത്തരം പട്ടികകൾ സൃഷ്ടിക്കാൻ കഴിയും.
നിങ്ങൾ അറിയേണ്ടത്

Sql പഠിക്കാനുള്ള പ്രധാന പോയിന്റുകൾ
മുകളിൽ സൂചിപ്പിച്ചതുപോലെ, ടേബിളുകൾ അടങ്ങിയ ഒരു ഡാറ്റാബേസിലേക്ക് പുതിയ വിവരങ്ങൾ പ്രോസസ്സ് ചെയ്യുന്നതിനും നൽകുന്നതിനും അന്വേഷണങ്ങൾ ഉപയോഗിക്കുന്നു. ഓരോ വരിയും ഒരു പ്രത്യേക എൻട്രിയാണ്. അതിനാൽ, നമുക്ക് ഒരു ഡാറ്റാബേസ് ഉണ്ടാക്കാം. ഇത് ചെയ്യുന്നതിന്, കമാൻഡ് എഴുതുക:
'bazaname' എന്ന ഡാറ്റാബേസ് സൃഷ്ടിക്കുക
ഞങ്ങൾ ഡാറ്റാബേസ് നാമം ലാറ്റിനിൽ ഉദ്ധരണികളിൽ എഴുതുന്നു. അതിന് വ്യക്തമായ പേര് കൊണ്ടുവരാൻ ശ്രമിക്കുക. "111", "www" എന്നിവ പോലുള്ള ഒരു ഡാറ്റാബേസ് സൃഷ്ടിക്കരുത്.
ഡാറ്റാബേസ് സൃഷ്ടിച്ച ശേഷം, ഇൻസ്റ്റാൾ ചെയ്യുക:
'utf-8' പേരുകൾ സജ്ജീകരിക്കുക
സൈറ്റിലെ ഉള്ളടക്കം ശരിയായി പ്രദർശിപ്പിക്കുന്നതിന് ഇത് ആവശ്യമാണ്.
ഇനി നമുക്ക് ഒരു പട്ടിക ഉണ്ടാക്കാം:
'ബസാനാം' എന്ന പട്ടിക സൃഷ്ടിക്കുക. 'മേശ' (
ഐഡി INT(8) ശൂന്യമായ ഓട്ടോ_ഇൻക്രിമെന്റ് പ്രൈമറി കീ അല്ല,
ലോഗ് VARCHAR(10),
VARCHAR (10) കടന്നു
തീയതി DATE

രണ്ടാമത്തെ വരിയിൽ ഞങ്ങൾ മൂന്ന് ആട്രിബ്യൂട്ടുകൾ എഴുതി. അവ എന്താണ് അർത്ഥമാക്കുന്നത് എന്ന് നോക്കാം:
- NOT NULL ആട്രിബ്യൂട്ട് അർത്ഥമാക്കുന്നത് സെൽ ശൂന്യമായിരിക്കില്ല എന്നാണ് (ഫീൽഡ് ആവശ്യമാണ്);
- AUTO_INCREMENT മൂല്യം സ്വയമേവ പൂർത്തിയാക്കലാണ്;
- പ്രൈമറി കീ - പ്രാഥമിക കീ.
വിവരങ്ങൾ എങ്ങനെ ചേർക്കാം
സൃഷ്ടിച്ച പട്ടികയുടെ ഫീൽഡുകൾ മൂല്യങ്ങൾ ഉപയോഗിച്ച് പൂരിപ്പിക്കുന്നതിന്, INSERT സ്റ്റേറ്റ്മെന്റ് ഉപയോഗിക്കുന്നു. ഞങ്ങൾ കോഡിന്റെ ഇനിപ്പറയുന്ന വരികൾ എഴുതുന്നു:
'ടേബിളിൽ' തിരുകുക
(ലോഗിൻ, പാസ്, തീയതി) മൂല്യങ്ങൾ
('വാസ', '87654321', '2017-06-21 18:38:44');
ബ്രാക്കറ്റുകളിൽ ഞങ്ങൾ നിരകളുടെ പേരുകൾ സൂചിപ്പിക്കുന്നു, അടുത്തതിൽ - മൂല്യങ്ങൾ.
പ്രധാനം! നിരകളുടെ പേരുകളിലും മൂല്യങ്ങളിലും സ്ഥിരത നിലനിർത്തുക.
വിവരങ്ങൾ എങ്ങനെ അപ്ഡേറ്റ് ചെയ്യാം
ഇത് ചെയ്യുന്നതിന്, UPDATE കമാൻഡ് ഉപയോഗിക്കുക. ഒരു നിർദ്ദിഷ്ട ഉപയോക്താവിന്റെ പാസ്വേഡ് എങ്ങനെ മാറ്റാമെന്ന് നോക്കാം. ഞങ്ങൾ കോഡിന്റെ ഇനിപ്പറയുന്ന വരികൾ എഴുതുന്നു:
'ടേബിൾ' സെറ്റ് പാസ് = '12345678' എവിടെ ഐഡി = '1' അപ്ഡേറ്റ് ചെയ്യുക
ഇനി ‘12345678’ എന്ന പാസ്വേഡ് മാറ്റുക. "id"=1 എന്ന വരിയിൽ മാറ്റങ്ങൾ സംഭവിക്കുന്നു. നിങ്ങൾ WHERE കമാൻഡ് എഴുതിയില്ലെങ്കിൽ, എല്ലാ വരികളും മാറും, ഒരു നിർദ്ദിഷ്ട ഒന്നല്ല.
പുസ്തകം വാങ്ങാൻ ഞാൻ ശുപാർശ ചെയ്യുന്നു " ഡമ്മികൾക്കുള്ള SQL " അതിന്റെ സഹായത്തോടെ, നിങ്ങൾക്ക് ഘട്ടം ഘട്ടമായി ഡാറ്റാബേസ് ഉപയോഗിച്ച് പ്രൊഫഷണലായി പ്രവർത്തിക്കാൻ കഴിയും. എല്ലാ വിവരങ്ങളും ലളിതവും സങ്കീർണ്ണവുമായ തത്വമനുസരിച്ച് ക്രമീകരിച്ചിരിക്കുന്നു, മാത്രമല്ല അവ നന്നായി മനസ്സിലാക്കുകയും ചെയ്യും.

ഒരു എൻട്രി എങ്ങനെ ഇല്ലാതാക്കാം
നിങ്ങൾ എന്തെങ്കിലും തെറ്റ് എഴുതിയിട്ടുണ്ടെങ്കിൽ, DELETE കമാൻഡ് ഉപയോഗിച്ച് അത് ശരിയാക്കുക. UPDATE പോലെ തന്നെ പ്രവർത്തിക്കുന്നു. ഞങ്ങൾ ഇനിപ്പറയുന്ന കോഡ് എഴുതുന്നു:
'ടേബിളിൽ' നിന്ന് ഇല്ലാതാക്കുക എവിടെ ഐഡി = '1'
സാമ്പിൾ വിവരങ്ങൾ
ഡാറ്റാബേസിൽ നിന്ന് മൂല്യങ്ങൾ വീണ്ടെടുക്കാൻ, SELECT കമാൻഡ് ഉപയോഗിക്കുക. ഞങ്ങൾ ഇനിപ്പറയുന്ന കോഡ് എഴുതുന്നു:
'ടേബിളിൽ' നിന്ന് * തിരഞ്ഞെടുക്കുക എവിടെ ഐഡി = '1'
ഈ ഉദാഹരണത്തിൽ, പട്ടികയിൽ ലഭ്യമായ എല്ലാ ഫീൽഡുകളും ഞങ്ങൾ തിരഞ്ഞെടുക്കുന്നു. കമാൻഡിൽ നിങ്ങൾ ഒരു നക്ഷത്രചിഹ്നം "*" നൽകിയാൽ ഇത് സംഭവിക്കുന്നു. നിങ്ങൾക്ക് ചില സാമ്പിൾ മൂല്യം തിരഞ്ഞെടുക്കണമെങ്കിൽ, ഇത് എഴുതുക:
ലോഗ് തിരഞ്ഞെടുക്കുക, ടേബിളിൽ നിന്ന് കടന്നുപോകുക എവിടെ ഐഡി = '1'
ഡാറ്റാബേസുകളിൽ പ്രവർത്തിക്കാനുള്ള കഴിവ് മതിയാകില്ല എന്നത് ശ്രദ്ധിക്കേണ്ടതാണ്. ഒരു പ്രൊഫഷണൽ ഇന്റർനെറ്റ് പ്രോജക്റ്റ് സൃഷ്ടിക്കുന്നതിന്, ഒരു ഡാറ്റാബേസിൽ നിന്ന് പേജുകളിലേക്ക് ഡാറ്റ എങ്ങനെ ചേർക്കാമെന്ന് നിങ്ങൾ പഠിക്കേണ്ടതുണ്ട്. ഇത് ചെയ്യുന്നതിന്, PHP വെബ് പ്രോഗ്രാമിംഗ് ഭാഷയുമായി സ്വയം പരിചയപ്പെടുക. ഇത് നിങ്ങളെ സഹായിക്കും മിഖായേൽ റുസാക്കോവിന്റെ രസകരമായ കോഴ്സ് .

ഒരു പട്ടിക ഇല്ലാതാക്കുന്നു
ഒരു ഡ്രോപ്പ് അഭ്യർത്ഥന ഉപയോഗിച്ച് സംഭവിക്കുന്നു. ഇത് ചെയ്യുന്നതിന്, ഞങ്ങൾ ഇനിപ്പറയുന്ന വരികൾ എഴുതുന്നു:
ഡ്രോപ്പ് ടേബിൾ;
ഒരു നിർദ്ദിഷ്ട വ്യവസ്ഥയെ അടിസ്ഥാനമാക്കി ഒരു പട്ടികയിൽ നിന്ന് ഒരു റെക്കോർഡ് പ്രദർശിപ്പിക്കുന്നു
ഈ കോഡ് പരിഗണിക്കുക:
പട്ടികയിൽ നിന്ന് ഐഡി, രാജ്യം, നഗരം തിരഞ്ഞെടുക്കുക. എവിടെ ആളുകൾ>150000000
നൂറ്റമ്പത് ദശലക്ഷത്തിലധികം ജനസംഖ്യയുള്ള രാജ്യങ്ങളുടെ റെക്കോർഡുകൾ ഇത് പ്രദർശിപ്പിക്കും.
ഒരു അസോസിയേഷൻ
ജോയിൻ ഉപയോഗിച്ച് നിരവധി ടേബിളുകൾ ഒരുമിച്ച് ലിങ്ക് ചെയ്യാൻ സാധിക്കും. ഈ വീഡിയോയിൽ ഇത് എങ്ങനെ പ്രവർത്തിക്കുന്നുവെന്ന് കൂടുതൽ വിശദമായി കാണുക:
PHP, MySQL
ഒരു ഇന്റർനെറ്റ് പ്രോജക്റ്റ് സൃഷ്ടിക്കുമ്പോൾ അഭ്യർത്ഥനകൾ സാധാരണമാണെന്ന് ഒരിക്കൽ കൂടി ഞാൻ ഊന്നിപ്പറയാൻ ആഗ്രഹിക്കുന്നു. PHP പ്രമാണങ്ങളിൽ അവ ഉപയോഗിക്കുന്നതിന്, ഇനിപ്പറയുന്ന അൽഗോരിതം പിന്തുടരുക:
- mysql_connect() കമാൻഡ് ഉപയോഗിച്ച് ഡാറ്റാബേസിലേക്ക് ബന്ധിപ്പിക്കുക;
- mysql_select_db() ഉപയോഗിച്ച് ഞങ്ങൾ ആവശ്യമുള്ള ഡാറ്റാബേസ് തിരഞ്ഞെടുക്കുന്നു;
- mysql_fetch_array() ഉപയോഗിച്ച് ഞങ്ങൾ അഭ്യർത്ഥന പ്രോസസ്സ് ചെയ്യുന്നു;
- mysql_close() കമാൻഡ് ഉപയോഗിച്ച് കണക്ഷൻ അടയ്ക്കുക.
പ്രധാനം! ഒരു ഡാറ്റാബേസുമായി പ്രവർത്തിക്കുന്നത് ബുദ്ധിമുട്ടുള്ള കാര്യമല്ല. അഭ്യർത്ഥന ശരിയായി എഴുതുക എന്നതാണ് പ്രധാന കാര്യം.
തുടക്കക്കാരായ വെബ്മാസ്റ്റർമാർ അതിനെക്കുറിച്ച് ചിന്തിക്കും. ഈ വിഷയത്തിൽ നിങ്ങൾ എന്താണ് വായിക്കേണ്ടത്? മാർട്ടിൻ ഗ്രാബറിന്റെ പുസ്തകം ശുപാർശ ചെയ്യാൻ ഞാൻ ആഗ്രഹിക്കുന്നു " വെറും മനുഷ്യർക്കുള്ള SQL " തുടക്കക്കാർക്ക് എല്ലാം മനസ്സിലാകുന്ന തരത്തിലാണ് എഴുതിയിരിക്കുന്നത്. ഇത് ഒരു റഫറൻസ് പുസ്തകമായി ഉപയോഗിക്കുക.

എന്നാൽ ഇതൊരു സിദ്ധാന്തമാണ്. ഇത് പ്രായോഗികമായി എങ്ങനെ പ്രവർത്തിക്കുന്നു? വാസ്തവത്തിൽ, ഒരു ഇന്റർനെറ്റ് പ്രോജക്റ്റ് സൃഷ്ടിക്കുക മാത്രമല്ല, Google, Yandex എന്നിവയുടെ മുകളിലേക്ക് കൊണ്ടുവരികയും വേണം. വീഡിയോ കോഴ്സ് ഇതിന് നിങ്ങളെ സഹായിക്കും " വെബ്സൈറ്റ് സൃഷ്ടിക്കലും പ്രമോഷനും ».

വീഡിയോ നിർദ്ദേശം
ഇപ്പോഴും ചോദ്യങ്ങളുണ്ടോ? കൂടുതൽ വിവരങ്ങൾക്ക് ഓൺലൈൻ വീഡിയോ കാണുക.
ഉപസംഹാരം
അതിനാൽ, sql ചോദ്യങ്ങൾ എങ്ങനെ എഴുതാമെന്ന് കണ്ടെത്തുന്നത് തോന്നുന്നത്ര ബുദ്ധിമുട്ടുള്ള കാര്യമല്ല, എന്നാൽ ഏതൊരു വെബ്മാസ്റ്ററും ഇത് ചെയ്യേണ്ടതുണ്ട്. മുകളിൽ വിവരിച്ച വീഡിയോ കോഴ്സുകൾ ഇതിന് സഹായിക്കും. സബ്സ്ക്രൈബ് ചെയ്യുക എന്റെ VKontakte ഗ്രൂപ്പ് പുതിയ രസകരമായ വിവരങ്ങൾ ദൃശ്യമാകുമ്പോൾ ആദ്യം അറിയുക.
- ട്യൂട്ടോറിയൽ
ഈ ട്യൂട്ടോറിയൽ എന്തിനെക്കുറിച്ചാണ്?
ഈ ട്യൂട്ടോറിയൽ SQL ഭാഷയിലെ (DDL, DML) "എന്റെ മെമ്മറിയുടെ സ്റ്റാമ്പ്" പോലെയാണ്, അതായത്. ഇത് എന്റെ പ്രൊഫഷണൽ പ്രവർത്തനങ്ങളിൽ അടിഞ്ഞുകൂടിയതും എന്റെ തലയിൽ നിരന്തരം സംഭരിച്ചിരിക്കുന്നതുമായ വിവരങ്ങളാണ്. ഇത് എനിക്ക് മതിയായ മിനിമം ആണ്, ഇത് ഡാറ്റാബേസുകളിൽ പ്രവർത്തിക്കുമ്പോൾ മിക്കപ്പോഴും ഉപയോഗിക്കുന്നു. കൂടുതൽ പൂർണ്ണമായ SQL നിർമ്മാണങ്ങൾ ഉപയോഗിക്കേണ്ട ആവശ്യമുണ്ടെങ്കിൽ, സഹായത്തിനായി ഞാൻ സാധാരണയായി ഇന്റർനെറ്റിൽ സ്ഥിതിചെയ്യുന്ന MSDN ലൈബ്രറിയിലേക്ക് തിരിയുന്നു. എന്റെ അഭിപ്രായത്തിൽ, എല്ലാം നിങ്ങളുടെ തലയിൽ സൂക്ഷിക്കുന്നത് വളരെ ബുദ്ധിമുട്ടാണ്, ഇതിന് പ്രത്യേക ആവശ്യമില്ല. എന്നാൽ അടിസ്ഥാന ഘടനകൾ അറിയുന്നത് വളരെ ഉപയോഗപ്രദമാണ്, കാരണം... Oracle, MySQL, Firebird പോലെയുള്ള പല റിലേഷണൽ ഡാറ്റാബേസുകളിലും അവ ഏതാണ്ട് ഒരേ രൂപത്തിൽ ബാധകമാണ്. വ്യത്യാസങ്ങൾ പ്രധാനമായും ഡാറ്റ തരങ്ങളിലാണ്, അവ വിശദമായി വ്യത്യാസപ്പെടാം. നിരവധി അടിസ്ഥാന SQL നിർമ്മാണങ്ങൾ ഇല്ല, നിരന്തരമായ പരിശീലനത്തിലൂടെ അവ പെട്ടെന്ന് മനഃപാഠമാക്കപ്പെടുന്നു. ഉദാഹരണത്തിന്, ഒബ്ജക്റ്റുകൾ (പട്ടികകൾ, നിയന്ത്രണങ്ങൾ, സൂചികകൾ മുതലായവ) സൃഷ്ടിക്കുന്നതിന്, ഡാറ്റാബേസുമായി പ്രവർത്തിക്കാൻ ഒരു ടെക്സ്റ്റ് എഡിറ്റർ എൻവയോൺമെന്റ് (IDE) ഉണ്ടെങ്കിൽ മതിയാകും, കൂടാതെ പ്രവർത്തിക്കാൻ അനുയോജ്യമായ വിഷ്വൽ ടൂളുകൾ പഠിക്കേണ്ട ആവശ്യമില്ല. ഒരു പ്രത്യേക തരം ഡാറ്റാബേസ് (MS SQL, Oracle, MySQL, Firebird, ...). ഇതും സൗകര്യപ്രദമാണ്, കാരണം എല്ലാ വാചകങ്ങളും നിങ്ങളുടെ കണ്ണുകൾക്ക് മുന്നിലാണ്, കൂടാതെ ഒരു സൂചിക അല്ലെങ്കിൽ നിയന്ത്രണങ്ങൾ സൃഷ്ടിക്കുന്നതിന് നിങ്ങൾ നിരവധി ടാബുകൾ പ്രവർത്തിപ്പിക്കേണ്ടതില്ല. ഒരു ഡാറ്റാബേസുമായി നിരന്തരം പ്രവർത്തിക്കുമ്പോൾ, സ്ക്രിപ്റ്റുകൾ ഉപയോഗിച്ച് ഒരു ഒബ്ജക്റ്റ് സൃഷ്ടിക്കുന്നതും മാറ്റുന്നതും പുനർനിർമ്മിക്കുന്നതും നിങ്ങൾ വിഷ്വൽ മോഡിൽ ചെയ്യുന്നതിനേക്കാൾ പലമടങ്ങ് വേഗതയുള്ളതാണ്. സ്ക്രിപ്റ്റ് മോഡിലും (അതനുസരിച്ച്, കൃത്യമായ ശ്രദ്ധയോടെ), ഒബ്ജക്റ്റുകൾക്ക് പേരിടുന്നതിനുള്ള നിയമങ്ങൾ ക്രമീകരിക്കാനും നിയന്ത്രിക്കാനും എളുപ്പമാണ് (എന്റെ ആത്മനിഷ്ഠമായ അഭിപ്രായം). കൂടാതെ, ഒരു ഡാറ്റാബേസിൽ വരുത്തിയ മാറ്റങ്ങൾ (ഉദാഹരണത്തിന്, ടെസ്റ്റ്) അതേ രൂപത്തിൽ മറ്റൊരു ഡാറ്റാബേസിലേക്ക് (പ്രൊഡക്റ്റീവ്) മാറ്റേണ്ടിവരുമ്പോൾ സ്ക്രിപ്റ്റുകൾ ഉപയോഗിക്കാൻ സൗകര്യപ്രദമാണ്.SQL ഭാഷയെ പല ഭാഗങ്ങളായി തിരിച്ചിരിക്കുന്നു, ഇവിടെ ഞാൻ ഏറ്റവും പ്രധാനപ്പെട്ട 2 ഭാഗങ്ങൾ നോക്കും:
- DML - ഡാറ്റ മാനിപുലേഷൻ ലാംഗ്വേജ്, അതിൽ ഇനിപ്പറയുന്ന നിർമ്മാണങ്ങൾ അടങ്ങിയിരിക്കുന്നു:
- തിരഞ്ഞെടുക്കുക - ഡാറ്റ തിരഞ്ഞെടുക്കൽ
- INSERT - പുതിയ ഡാറ്റ ചേർക്കുന്നു
- അപ്ഡേറ്റ് - ഡാറ്റ അപ്ഡേറ്റ്
- ഇല്ലാതാക്കുക - ഡാറ്റ ഇല്ലാതാക്കുന്നു
- MERGE - ഡാറ്റ ലയനം
ഘട്ടം ഘട്ടമായുള്ള തത്വമനുസരിച്ചാണ് ഈ പാഠപുസ്തകം സൃഷ്ടിച്ചത്, അതായത്. നിങ്ങൾ അത് തുടർച്ചയായി വായിക്കുകയും വെയിലത്ത് ഉടനടി ഉദാഹരണങ്ങൾ പിന്തുടരുകയും വേണം. എന്നാൽ വഴിയിൽ നിങ്ങൾ ഒരു പ്രത്യേക കമാൻഡിനെക്കുറിച്ച് കൂടുതൽ വിശദമായി പഠിക്കേണ്ടതുണ്ടെങ്കിൽ, ഇന്റർനെറ്റിൽ ഒരു നിർദ്ദിഷ്ട തിരയൽ ഉപയോഗിക്കുക, ഉദാഹരണത്തിന്, MSDN ലൈബ്രറിയിൽ.
ഈ ട്യൂട്ടോറിയൽ എഴുതുമ്പോൾ, ഞാൻ MS SQL സെർവർ പതിപ്പ് 2014 ഡാറ്റാബേസ് ഉപയോഗിച്ചു, സ്ക്രിപ്റ്റുകൾ എക്സിക്യൂട്ട് ചെയ്യാൻ ഞാൻ MS SQL സെർവർ മാനേജ്മെന്റ് സ്റ്റുഡിയോ (SSMS) ഉപയോഗിച്ചു.
MS SQL സെർവർ മാനേജ്മെന്റ് സ്റ്റുഡിയോയെ (SSMS) കുറിച്ച് ചുരുക്കത്തിൽ
SQL സെർവർ മാനേജ്മെന്റ് സ്റ്റുഡിയോ (SSMS) എന്നത് മൈക്രോസോഫ്റ്റ് SQL സെർവറിന്റെ ഡാറ്റാബേസ് ഘടകങ്ങൾ കോൺഫിഗർ ചെയ്യുന്നതിനും കൈകാര്യം ചെയ്യുന്നതിനും നിയന്ത്രിക്കുന്നതിനുമുള്ള ഒരു യൂട്ടിലിറ്റിയാണ്. ഈ യൂട്ടിലിറ്റിയിൽ ഒരു സ്ക്രിപ്റ്റ് എഡിറ്ററും (ഞങ്ങൾ പ്രധാനമായും ഉപയോഗിക്കും) സെർവർ ഒബ്ജക്റ്റുകളിലും ക്രമീകരണങ്ങളിലും പ്രവർത്തിക്കുന്ന ഒരു ഗ്രാഫിക്കൽ പ്രോഗ്രാമും അടങ്ങിയിരിക്കുന്നു. SQL സെർവർ മാനേജ്മെന്റ് സ്റ്റുഡിയോയുടെ പ്രധാന ഉപകരണം ഒബ്ജക്റ്റ് എക്സ്പ്ലോറർ ആണ്, ഇത് സെർവർ ഒബ്ജക്റ്റുകൾ കാണാനും വീണ്ടെടുക്കാനും നിയന്ത്രിക്കാനും ഉപയോക്താവിനെ അനുവദിക്കുന്നു. ഈ വാചകം വിക്കിപീഡിയയിൽ നിന്ന് ഭാഗികമായി കടമെടുത്തതാണ്.
ഒരു പുതിയ സ്ക്രിപ്റ്റ് എഡിറ്റർ സൃഷ്ടിക്കാൻ, "പുതിയ ചോദ്യം" ബട്ടൺ ഉപയോഗിക്കുക:
നിലവിലെ ഡാറ്റാബേസ് മാറ്റുന്നതിന് നിങ്ങൾക്ക് ഡ്രോപ്പ്-ഡൗൺ ലിസ്റ്റ് ഉപയോഗിക്കാം:

ഒരു നിർദ്ദിഷ്ട കമാൻഡ് (അല്ലെങ്കിൽ കമാൻഡുകളുടെ ഗ്രൂപ്പ്) എക്സിക്യൂട്ട് ചെയ്യാൻ, അത് തിരഞ്ഞെടുത്ത് "എക്സിക്യൂട്ട്" ബട്ടണിൽ അല്ലെങ്കിൽ "F5" കീ അമർത്തുക. എഡിറ്ററിൽ നിലവിൽ ഒരു കമാൻഡ് മാത്രമേ ഉള്ളൂ എങ്കിലോ എല്ലാ കമാൻഡുകളും എക്സിക്യൂട്ട് ചെയ്യേണ്ടതുണ്ടെങ്കിൽ, നിങ്ങൾ ഒന്നും തിരഞ്ഞെടുക്കേണ്ടതില്ല.

സ്ക്രിപ്റ്റുകൾ പ്രവർത്തിപ്പിച്ചതിന് ശേഷം, പ്രത്യേകിച്ച് ഒബ്ജക്റ്റുകൾ (പട്ടികകൾ, നിരകൾ, സൂചികകൾ) സൃഷ്ടിക്കുന്നവ, മാറ്റങ്ങൾ കാണുന്നതിന്, അനുയോജ്യമായ ഗ്രൂപ്പ് (ഉദാഹരണത്തിന്, പട്ടികകൾ), പട്ടിക തന്നെ അല്ലെങ്കിൽ അതിലെ കോളങ്ങളുടെ ഗ്രൂപ്പിനെ ഹൈലൈറ്റ് ചെയ്ത് സന്ദർഭ മെനുവിൽ നിന്ന് പുതുക്കുക.

യഥാർത്ഥത്തിൽ, ഇവിടെ നൽകിയിരിക്കുന്ന ഉദാഹരണങ്ങൾ പൂർത്തിയാക്കാൻ നമ്മൾ അറിഞ്ഞിരിക്കേണ്ടത് ഇത്രമാത്രം. ബാക്കിയുള്ള SSMS യൂട്ടിലിറ്റി സ്വന്തമായി പഠിക്കാൻ എളുപ്പമാണ്.
ഒരു ചെറിയ സിദ്ധാന്തം
ഒരു റിലേഷണൽ ഡാറ്റാബേസ് (RDB, അല്ലെങ്കിൽ ഇനി മുതൽ സന്ദർഭത്തിൽ ലളിതമായി DB) പരസ്പരം ബന്ധിപ്പിച്ചിട്ടുള്ള പട്ടികകളുടെ ഒരു ശേഖരമാണ്. ഏകദേശം പറഞ്ഞാൽ, ഒരു ഘടനാപരമായ രൂപത്തിൽ ഡാറ്റ സംഭരിച്ചിരിക്കുന്ന ഒരു ഫയലാണ് ഡാറ്റാബേസ്.DBMS - ഡാറ്റാബേസ് മാനേജ്മെന്റ് സിസ്റ്റം, അതായത്. ഒരു പ്രത്യേക തരം ഡാറ്റാബേസിൽ (MS SQL, Oracle, MySQL, Firebird, ...) പ്രവർത്തിക്കുന്നതിനുള്ള ഒരു കൂട്ടം ടൂളാണിത്.
കുറിപ്പ്
കാരണം ജീവിതത്തിൽ, സംഭാഷണ സംഭാഷണത്തിൽ, ഞങ്ങൾ കൂടുതലും പറയുന്നു: "ഒറാക്കിൾ ഡിബി" അല്ലെങ്കിൽ "ഒറാക്കിൾ", യഥാർത്ഥത്തിൽ "ഒറാക്കിൾ ഡിബിഎംഎസ്" എന്നാണ് അർത്ഥമാക്കുന്നത്, ഈ പാഠപുസ്തകത്തിന്റെ സന്ദർഭത്തിൽ ഡിബി എന്ന പദം ചിലപ്പോൾ ഉപയോഗിക്കും. സന്ദർഭത്തിൽ നിന്ന്, നമ്മൾ കൃത്യമായി എന്താണ് സംസാരിക്കുന്നതെന്ന് വ്യക്തമാകുമെന്ന് ഞാൻ കരുതുന്നു.
നിരകളുടെ ഒരു ശേഖരമാണ് പട്ടിക. നിരകളെ ഫീൽഡുകൾ അല്ലെങ്കിൽ നിരകൾ എന്നും വിളിക്കാം; ഈ വാക്കുകളെല്ലാം ഒരേ കാര്യം പ്രകടിപ്പിക്കുന്ന പര്യായങ്ങളായി ഉപയോഗിക്കും.
പട്ടികയാണ് RDB-യുടെ പ്രധാന ഒബ്ജക്റ്റ്; എല്ലാ RDB ഡാറ്റയും പട്ടികയുടെ നിരകളിൽ വരി വരിയായി സംഭരിച്ചിരിക്കുന്നു. വരികളും രേഖകളും പര്യായപദങ്ങളാണ്.
ഓരോ ടേബിളിനും അതിലെ കോളങ്ങൾക്കുമായി, പിന്നീട് ആക്സസ് ചെയ്യപ്പെടുന്ന പേരുകൾ വ്യക്തമാക്കുന്നു.
MS SQL-ലെ ഒബ്ജക്റ്റ് നാമത്തിന് (പട്ടികയുടെ പേര്, കോളത്തിന്റെ പേര്, സൂചിക നാമം മുതലായവ) പരമാവധി 128 പ്രതീകങ്ങൾ ഉണ്ടായിരിക്കാം.
റഫറൻസിനായി- ORACLE ഡാറ്റാബേസിൽ, ഒബ്ജക്റ്റ് പേരുകൾക്ക് പരമാവധി 30 പ്രതീകങ്ങൾ ഉണ്ടായിരിക്കാം. അതിനാൽ, ഒരു നിർദ്ദിഷ്ട ഡാറ്റാബേസിനായി, പ്രതീകങ്ങളുടെ എണ്ണത്തിന്റെ പരിധി പാലിക്കുന്നതിന് ഒബ്ജക്റ്റുകൾക്ക് പേരിടുന്നതിന് നിങ്ങളുടേതായ നിയമങ്ങൾ വികസിപ്പിക്കേണ്ടതുണ്ട്.
ഒരു DBMS ഉപയോഗിച്ച് ഒരു ഡാറ്റാബേസ് അന്വേഷിക്കാൻ നിങ്ങളെ അനുവദിക്കുന്ന ഒരു ഭാഷയാണ് SQL. ഒരു നിർദ്ദിഷ്ട DBMS-ൽ, SQL ഭാഷയ്ക്ക് ഒരു പ്രത്യേക നിർവ്വഹണം ഉണ്ടായിരിക്കാം (അതിന്റെ സ്വന്തം ഭാഷ).
DDL ഉം DML ഉം SQL ഭാഷയുടെ ഒരു ഉപവിഭാഗമാണ്:
- ഡാറ്റാബേസ് ഘടന സൃഷ്ടിക്കുന്നതിനും പരിഷ്ക്കരിക്കുന്നതിനും DDL ഭാഷ ഉപയോഗിക്കുന്നു, അതായത്. പട്ടികകളും ബന്ധങ്ങളും സൃഷ്ടിക്കാൻ/പരിഷ്ക്കരിക്കാൻ/ഇല്ലാതാക്കാൻ.
- പട്ടിക ഡാറ്റ കൈകാര്യം ചെയ്യാൻ DML ഭാഷ നിങ്ങളെ അനുവദിക്കുന്നു, അതായത്. അവളുടെ വരികൾക്കൊപ്പം. പട്ടികകളിൽ നിന്ന് ഡാറ്റ തിരഞ്ഞെടുക്കാനും പട്ടികകളിലേക്ക് പുതിയ ഡാറ്റ ചേർക്കാനും നിലവിലുള്ള ഡാറ്റ അപ്ഡേറ്റ് ചെയ്യാനും ഇല്ലാതാക്കാനും ഇത് നിങ്ങളെ അനുവദിക്കുന്നു.
SQL-ൽ, നിങ്ങൾക്ക് 2 തരം കമന്റുകൾ ഉപയോഗിക്കാം (സിംഗിൾ-ലൈൻ, മൾട്ടി-ലൈൻ):
ഒരു വരി കമന്റ്
ഒപ്പം
/* മൾട്ടിലൈൻ അഭിപ്രായം */
യഥാർത്ഥത്തിൽ, ഇത് സിദ്ധാന്തത്തിന് മതിയാകും.
DDL - ഡാറ്റ ഡെഫനിഷൻ ഭാഷ
ഉദാഹരണത്തിന്, ഒരു പ്രോഗ്രാമർ അല്ലാത്ത ഒരു വ്യക്തിക്ക് പരിചിതമായ രൂപത്തിൽ ജീവനക്കാരെക്കുറിച്ചുള്ള ഡാറ്റയുള്ള ഒരു പട്ടിക പരിഗണിക്കുക:ഈ സാഹചര്യത്തിൽ, പട്ടികയുടെ നിരകൾക്ക് ഇനിപ്പറയുന്ന പേരുകളുണ്ട്: പേഴ്സണൽ നമ്പർ, മുഴുവൻ പേര്, ജനനത്തീയതി, ഇ-മെയിൽ, സ്ഥാനം, വകുപ്പ്.
ഈ കോളങ്ങൾ ഓരോന്നും അതിൽ അടങ്ങിയിരിക്കുന്ന ഡാറ്റയുടെ തരം അനുസരിച്ച് വിശേഷിപ്പിക്കാം:
- പേഴ്സണൽ നമ്പർ - പൂർണ്ണസംഖ്യ
- മുഴുവൻ പേര് - സ്ട്രിംഗ്
- ജനനത്തീയതി - തീയതി
- ഇമെയിൽ - സ്ട്രിംഗ്
- സ്ഥാനം - സ്ട്രിംഗ്
- വകുപ്പ് - ലൈൻ
ആരംഭിക്കുന്നതിന്, MS SQL-ൽ ഉപയോഗിക്കുന്ന ഇനിപ്പറയുന്ന അടിസ്ഥാന ഡാറ്റ തരങ്ങൾ മാത്രം ഓർത്താൽ മതിയാകും:
| അർത്ഥം | MS SQL-ലെ നൊട്ടേഷൻ | വിവരണം |
|---|---|---|
| വേരിയബിൾ നീളം സ്ട്രിംഗ് | varchar(N) ഒപ്പം nvarchar(N) |
N എന്ന സംഖ്യ ഉപയോഗിച്ച്, അനുബന്ധ കോളത്തിന് സാധ്യമായ പരമാവധി സ്ട്രിംഗ് ദൈർഘ്യം വ്യക്തമാക്കാം. ഉദാഹരണത്തിന്, “പേര്” നിരയുടെ മൂല്യത്തിൽ പരമാവധി 30 പ്രതീകങ്ങൾ അടങ്ങിയിരിക്കാമെന്ന് പറയണമെങ്കിൽ, അതിന്റെ തരം nvarchar(30) ആയി സജ്ജീകരിക്കേണ്ടതുണ്ട്. varchar ഉം nvarchar ഉം തമ്മിലുള്ള വ്യത്യാസം, ASCII ഫോർമാറ്റിൽ സ്ട്രിംഗുകൾ സംഭരിക്കുന്നതിന് varchar നിങ്ങളെ അനുവദിക്കുന്നു, അവിടെ ഒരു പ്രതീകം 1 ബൈറ്റ് ഉൾക്കൊള്ളുന്നു, കൂടാതെ nvarchar സ്ട്രിംഗുകൾ യൂണികോഡ് ഫോർമാറ്റിൽ സംഭരിക്കുന്നു, അവിടെ ഓരോ പ്രതീകവും 2 ബൈറ്റുകൾ ഉൾക്കൊള്ളുന്നു. ഈ ഫീൽഡിൽ യൂണികോഡ് പ്രതീകങ്ങൾ സംഭരിക്കേണ്ടതില്ലെന്ന് നിങ്ങൾക്ക് 100% ഉറപ്പുണ്ടെങ്കിൽ മാത്രമേ varchar തരം ഉപയോഗിക്കാവൂ. ഉദാഹരണത്തിന്, ഇമെയിൽ വിലാസങ്ങൾ സംഭരിക്കാൻ varchar ഉപയോഗിക്കാം കാരണം... അവയിൽ സാധാരണയായി ASCII പ്രതീകങ്ങൾ മാത്രമേ അടങ്ങിയിട്ടുള്ളൂ. |
| നിശ്ചിത നീളമുള്ള സ്ട്രിംഗ് | char(N) ഒപ്പം nchar(N) |
ഈ തരം ഒരു വേരിയബിൾ-ലെംഗ്ത്ത് സ്ട്രിംഗിൽ നിന്ന് വ്യത്യാസപ്പെട്ടിരിക്കുന്നു, സ്ട്രിംഗിന്റെ നീളം N പ്രതീകങ്ങളേക്കാൾ കുറവാണെങ്കിൽ, അത് എല്ലായ്പ്പോഴും വലതുവശത്ത് N-ന്റെ നീളത്തിൽ സ്പെയ്സുകളോടെ പാഡ് ചെയ്യുകയും ഡാറ്റാബേസിൽ ഈ രൂപത്തിൽ സംഭരിക്കുകയും ചെയ്യും, അതായത്. ഡാറ്റാബേസിൽ അത് കൃത്യമായി N പ്രതീകങ്ങൾ എടുക്കുന്നു (ഒരു പ്രതീകം char-ന് 1 ബൈറ്റും nchar-ന് 2 ബൈറ്റും എടുക്കുന്നു). എന്റെ പ്രയോഗത്തിൽ, ഈ തരം വളരെ അപൂർവമായി മാത്രമേ ഉപയോഗിക്കുന്നുള്ളൂ, അത് ഉപയോഗിക്കുകയാണെങ്കിൽ, അത് പ്രധാനമായും ചാർ (1) ഫോർമാറ്റിൽ ഉപയോഗിക്കുന്നു, അതായത്. ഒരു ഫീൽഡ് ഒരൊറ്റ പ്രതീകത്താൽ നിർവചിക്കുമ്പോൾ. |
| പൂർണ്ണസംഖ്യ | int | ഈ തരം കോളത്തിൽ പൂർണ്ണസംഖ്യകൾ മാത്രം ഉപയോഗിക്കാൻ ഞങ്ങളെ അനുവദിക്കുന്നു, പോസിറ്റീവ്, നെഗറ്റീവ്. റഫറൻസിനായി (ഇപ്പോൾ ഇത് ഞങ്ങൾക്ക് അത്ര പ്രസക്തമല്ല), int തരം അനുവദിക്കുന്ന സംഖ്യകളുടെ ശ്രേണി -2,147,483,648 മുതൽ 2,147,483,647 വരെയാണ്. സാധാരണയായി ഇത് ഐഡന്റിഫയറുകൾ വ്യക്തമാക്കാൻ ഉപയോഗിക്കുന്ന പ്രധാന തരമാണ്. |
| യഥാർത്ഥ അല്ലെങ്കിൽ യഥാർത്ഥ സംഖ്യ | ഫ്ലോട്ട് | ലളിതമായി പറഞ്ഞാൽ, ഇവ ഒരു ദശാംശ പോയിന്റ് (കോമ) അടങ്ങിയിരിക്കാവുന്ന സംഖ്യകളാണ്. |
| തീയതി | തീയതി | കോളത്തിന് മൂന്ന് ഘടകങ്ങൾ അടങ്ങുന്ന തീയതി മാത്രം സംഭരിക്കണമെങ്കിൽ: ദിവസം, മാസം, വർഷം. ഉദാഹരണത്തിന്, 02/15/2014 (ഫെബ്രുവരി 15, 2014). ഈ തരം കോളം "പ്രവേശന തീയതി", "ജനന തീയതി" മുതലായവയ്ക്ക് ഉപയോഗിക്കാം, അതായത്. തീയതി മാത്രം രേഖപ്പെടുത്തേണ്ടത് പ്രധാനമായ സന്ദർഭങ്ങളിൽ, അല്ലെങ്കിൽ സമയ ഘടകം ഞങ്ങൾക്ക് പ്രധാനമല്ലാത്തതും തള്ളിക്കളയാവുന്നതും അല്ലെങ്കിൽ അത് അറിയാത്തതുമായ സന്ദർഭങ്ങളിൽ. |
| സമയം | സമയം | കോളത്തിന് സമയ ഡാറ്റ മാത്രം സംഭരിക്കണമെങ്കിൽ ഈ തരം ഉപയോഗിക്കാം, അതായത്. മണിക്കൂർ, മിനിറ്റ്, സെക്കൻഡ്, മില്ലിസെക്കൻഡ്. ഉദാഹരണത്തിന്, 17:38:31.3231603 ഉദാഹരണത്തിന്, ദിവസേനയുള്ള "ഫ്ലൈറ്റ് പുറപ്പെടൽ സമയം". |
| തീയതിയും സമയവും | തീയതി സമയം | തീയതിയും സമയവും ഒരേസമയം സംരക്ഷിക്കാൻ ഈ തരം നിങ്ങളെ അനുവദിക്കുന്നു. ഉദാഹരണത്തിന്, 02/15/2014 17:38:31.323 ഉദാഹരണത്തിന്, ഇത് ഒരു ഇവന്റിന്റെ തീയതിയും സമയവും ആകാം. |
| പതാക | ബിറ്റ് | "അതെ"/"ഇല്ല" എന്ന ഫോമിന്റെ മൂല്യങ്ങൾ സംഭരിക്കുന്നതിന് ഈ തരം ഉപയോഗിക്കാൻ സൗകര്യപ്രദമാണ്, ഇവിടെ "അതെ" എന്നത് 1 ആയും "ഇല്ല" എന്നത് 0 ആയും സംഭരിക്കും. |
കൂടാതെ, ഫീൽഡ് മൂല്യം, അത് നിരോധിച്ചിട്ടില്ലെങ്കിൽ, വ്യക്തമാക്കിയേക്കില്ല; NULL കീവേഡ് ഈ ആവശ്യത്തിനായി ഉപയോഗിക്കുന്നു.
ഉദാഹരണങ്ങൾ പ്രവർത്തിപ്പിക്കുന്നതിന്, നമുക്ക് ടെസ്റ്റ് എന്ന ഒരു ടെസ്റ്റ് ഡാറ്റാബേസ് ഉണ്ടാക്കാം.
ഇനിപ്പറയുന്ന കമാൻഡ് പ്രവർത്തിപ്പിക്കുന്നതിലൂടെ ഒരു ലളിതമായ ഡാറ്റാബേസ് (അധിക പാരാമീറ്ററുകൾ വ്യക്തമാക്കാതെ) സൃഷ്ടിക്കാൻ കഴിയും:
ഡാറ്റാബേസ് ടെസ്റ്റ് സൃഷ്ടിക്കുക
കമാൻഡ് ഉപയോഗിച്ച് നിങ്ങൾക്ക് ഡാറ്റാബേസ് ഇല്ലാതാക്കാൻ കഴിയും (ഈ കമാൻഡ് ഉപയോഗിച്ച് നിങ്ങൾ വളരെ ശ്രദ്ധാലുവായിരിക്കണം):
ഡാറ്റാബേസ് ടെസ്റ്റ് ഡ്രോപ്പ് ചെയ്യുക
ഞങ്ങളുടെ ഡാറ്റാബേസിലേക്ക് മാറുന്നതിന്, നിങ്ങൾക്ക് കമാൻഡ് പ്രവർത്തിപ്പിക്കാൻ കഴിയും:
ടെസ്റ്റ് ഉപയോഗിക്കുക
പകരമായി, SSMS മെനു ഏരിയയിലെ ഡ്രോപ്പ്-ഡൗൺ ലിസ്റ്റിൽ നിന്ന് ടെസ്റ്റ് ഡാറ്റാബേസ് തിരഞ്ഞെടുക്കുക. ജോലി ചെയ്യുമ്പോൾ, ഡാറ്റാബേസുകൾക്കിടയിൽ മാറുന്നതിനുള്ള ഈ രീതി ഞാൻ പലപ്പോഴും ഉപയോഗിക്കുന്നു.
ഇപ്പോൾ ഞങ്ങളുടെ ഡാറ്റാബേസിൽ സ്പെയ്സുകളും സിറിലിക് പ്രതീകങ്ങളും ഉപയോഗിച്ച് വിവരണങ്ങൾ ഉപയോഗിച്ച് ഒരു പട്ടിക സൃഷ്ടിക്കാൻ കഴിയും:
ടേബിൾ സൃഷ്ടിക്കുക [ജീവനക്കാർ]([പേഴ്സണൽ നമ്പർ] ഇൻറ്റ്, [പേര്] nvarchar(30), [ജനന തീയതി] തീയതി, nvarchar(30), [സ്ഥാനം] nvarchar(30), [Department] nvarchar(30))
ഈ സാഹചര്യത്തിൽ, ഞങ്ങൾ ചതുര ബ്രാക്കറ്റുകളിൽ പേരുകൾ ചേർക്കേണ്ടിവരും […].
എന്നാൽ ഡാറ്റാബേസിൽ, കൂടുതൽ സൗകര്യത്തിനായി, എല്ലാ ഒബ്ജക്റ്റ് പേരുകളും ലാറ്റിനിൽ വ്യക്തമാക്കുന്നതാണ് നല്ലത്, പേരുകളിൽ സ്പെയ്സുകൾ ഉപയോഗിക്കരുത്. MS SQL-ൽ, സാധാരണയായി ഈ സാഹചര്യത്തിൽ ഓരോ വാക്കും ഒരു വലിയ അക്ഷരത്തിൽ ആരംഭിക്കുന്നു, ഉദാഹരണത്തിന്, "പേഴ്സണൽ നമ്പർ" ഫീൽഡിനായി, നമുക്ക് പേഴ്സണൽ നമ്പർ എന്ന പേര് സജ്ജീകരിക്കാം. നിങ്ങൾക്ക് പേരിൽ നമ്പറുകളും ഉപയോഗിക്കാം, ഉദാഹരണത്തിന്, PhoneNumber1.
ഒരു കുറിപ്പിൽ
ചില DBMS-കളിൽ, ഇനിപ്പറയുന്ന പേരിടൽ ഫോർമാറ്റ് "PHONE_NUMBER" കൂടുതൽ അഭികാമ്യമായിരിക്കും; ഉദാഹരണത്തിന്, ഈ ഫോർമാറ്റ് ORACLE ഡാറ്റാബേസിൽ ഉപയോഗിക്കാറുണ്ട്. സ്വാഭാവികമായും, ഒരു ഫീൽഡ് നാമം വ്യക്തമാക്കുമ്പോൾ, അത് ഡിബിഎംഎസിൽ ഉപയോഗിക്കുന്ന കീവേഡുകളുമായി പൊരുത്തപ്പെടുന്നില്ല എന്നത് അഭികാമ്യമാണ്.
ഇക്കാരണത്താൽ, നിങ്ങൾക്ക് സ്ക്വയർ ബ്രാക്കറ്റുകളുടെ വാക്യഘടനയെക്കുറിച്ച് മറക്കാനും [ജീവനക്കാർ] പട്ടിക ഇല്ലാതാക്കാനും കഴിയും:
ഡ്രോപ്പ് ടേബിൾ [ജീവനക്കാർ]
ഉദാഹരണത്തിന്, ജീവനക്കാരുള്ള ഒരു പട്ടികയ്ക്ക് "ജീവനക്കാർ" എന്ന് പേരിടാം, കൂടാതെ അതിന്റെ ഫീൽഡുകൾക്ക് ഇനിപ്പറയുന്ന പേരുകൾ നൽകാം:
- ഐഡി - പേഴ്സണൽ നമ്പർ (എംപ്ലോയി ഐഡി)
- പേര് - മുഴുവൻ പേര്
- ജന്മദിനം - ജനനത്തീയതി
- ഇമെയിൽ - ഇമെയിൽ
- സ്ഥാനം - സ്ഥാനം
- വകുപ്പ് - വകുപ്പ്
ഇനി നമുക്ക് നമ്മുടെ പട്ടിക ഉണ്ടാക്കാം:
ടേബിൾ ജീവനക്കാരെ സൃഷ്ടിക്കുക (ഐഡി ഇന്റ്, പേര് nvarchar(30), ജന്മദിന തീയതി, ഇമെയിൽ nvarchar(30), സ്ഥാനം nvarchar(30), വകുപ്പ് nvarchar(30))
ആവശ്യമായ നിരകൾ വ്യക്തമാക്കുന്നതിന്, NOT NULL ഓപ്ഷൻ ഉപയോഗിക്കാം.
നിലവിലുള്ള ഒരു പട്ടികയ്ക്കായി, ഇനിപ്പറയുന്ന കമാൻഡുകൾ ഉപയോഗിച്ച് ഫീൽഡുകൾ പുനർനിർവചിക്കാം:
അപ്ഡേറ്റ് ഐഡി ഫീൽഡ് ALTER TABLE ജീവനക്കാർ കോളം ഐഡിയിൽ മാറ്റം വരുത്തുക -- പേര് ഫീൽഡ് അപ്ഡേറ്റ് ചെയ്യുക പേര് ഫീൽഡ് ALTER TABLE ജീവനക്കാർ മാറ്റി കോളം പേര് nvarchar(30) NULL അല്ല
ഒരു കുറിപ്പിൽ
SQL ഭാഷയുടെ പൊതുവായ ആശയം മിക്ക DBMS-കൾക്കും സമാനമാണ് (കുറഞ്ഞത്, ഞാൻ പ്രവർത്തിച്ചിട്ടുള്ള DBMS-കളിൽ നിന്ന് എനിക്ക് വിലയിരുത്താൻ കഴിയുന്നത് ഇതാണ്). വ്യത്യസ്ത DBMS-കളിലെ DDL തമ്മിലുള്ള വ്യത്യാസങ്ങൾ പ്രധാനമായും ഡാറ്റ തരങ്ങളിലാണ് (അവരുടെ പേരുകൾ മാത്രമല്ല, അവ നടപ്പിലാക്കുന്നതിന്റെ വിശദാംശങ്ങളും വ്യത്യാസപ്പെട്ടിരിക്കാം), കൂടാതെ SQL ഭാഷയുടെ നിർവ്വഹണത്തിന്റെ പ്രത്യേകതകളും അല്പം വ്യത്യാസപ്പെട്ടിരിക്കാം (അതായത്, കമാൻഡുകളുടെ സാരാംശം ഒന്നുതന്നെയാണ്, പക്ഷേ ഭാഷയിൽ ചെറിയ വ്യത്യാസങ്ങൾ ഉണ്ടാകാം, അയ്യോ, പക്ഷേ ഒരു മാനദണ്ഡവുമില്ല). SQL-ന്റെ അടിസ്ഥാനകാര്യങ്ങൾ പഠിച്ചുകഴിഞ്ഞാൽ, നിങ്ങൾക്ക് ഒരു DBMS-ൽ നിന്ന് മറ്റൊന്നിലേക്ക് എളുപ്പത്തിൽ മാറാൻ കഴിയും, കാരണം... ഈ സാഹചര്യത്തിൽ, പുതിയ DBMS-ൽ കമാൻഡുകൾ നടപ്പിലാക്കുന്നതിന്റെ വിശദാംശങ്ങൾ മാത്രമേ നിങ്ങൾ മനസ്സിലാക്കേണ്ടതുള്ളൂ, അതായത്. മിക്ക കേസുകളിലും, ഒരു സാമ്യം വരച്ചാൽ മതിയാകും.ഒരു ടേബിൾ സൃഷ്ടിക്കുന്നു ടേബിൾ സൃഷ്ടിക്കുക ജീവനക്കാർ(ID int, -- ORACLE-ൽ int തരം തത്തുല്യമാണ് (റാപ്പർ) നമ്പറിന് (38) പേര് nvarchar2(30), -- ORACLE-ലെ nvarchar2 MS SQL ജന്മദിനത്തിലെ nvarchar-ന് തുല്യമാണ്, ഇമെയിൽ nvarchar2(30) , സ്ഥാനം nvarchar2(30), വകുപ്പ് nvarchar2(30)); -- ഐഡിയും നെയിം ഫീൽഡുകളും അപ്ഡേറ്റ് ചെയ്യുന്നു (ഇവിടെ ALTER കോളത്തിന് പകരം മോഡിഫൈ(...) ഉപയോഗിക്കുന്നു) ALTER TABLE Employees MODIFY(ID int NULL,Name nvarchar2(30) NULL അല്ല); -- PK ചേർക്കുന്നു (ഈ സാഹചര്യത്തിൽ നിർമ്മാണം MS SQL-ൽ ഉള്ളതുപോലെയാണ്, അത് താഴെ കാണിക്കും) ആൾട്ടർ ടേബിൾ ജീവനക്കാർ നിയന്ത്രണങ്ങൾ ചേർക്കുക PK_എംപ്ലോയീസ് പ്രൈമറി കീ(ഐഡി);
ORACLE-ന് varchar2 തരം നടപ്പിലാക്കുന്നതിൽ വ്യത്യാസങ്ങളുണ്ട്; അതിന്റെ എൻകോഡിംഗ് ഡാറ്റാബേസ് ക്രമീകരണങ്ങളെ ആശ്രയിച്ചിരിക്കുന്നു, ടെക്സ്റ്റ് സംരക്ഷിക്കാൻ കഴിയും, ഉദാഹരണത്തിന്, UTF-8 എൻകോഡിംഗിൽ. കൂടാതെ, ORACLE-ലെ ഫീൽഡ് ദൈർഘ്യം ബൈറ്റുകളിലും പ്രതീകങ്ങളിലും വ്യക്തമാക്കാം; ഇതിനായി, അധിക ഓപ്ഷനുകൾ BYTE, CHAR എന്നിവ ഉപയോഗിക്കുന്നു, അവ ഫീൽഡ് ദൈർഘ്യത്തിന് ശേഷം വ്യക്തമാക്കിയിരിക്കുന്നു, ഉദാഹരണത്തിന്:NAME varchar2(30 BYTE) -- ഫീൽഡ് ശേഷി 30 ബൈറ്റുകൾ ആയിരിക്കും NAME varchar2(30 CHAR) -- ഫീൽഡ് ശേഷി 30 പ്രതീകങ്ങൾ ആയിരിക്കും
ORACLE-ൽ varchar2(30) തരം വ്യക്തമാക്കുന്ന സാഹചര്യത്തിൽ, ഡിഫോൾട്ടായി BYTE അല്ലെങ്കിൽ CHAR ഏത് ഓപ്ഷനാണ് ഉപയോഗിക്കേണ്ടത്, ഡാറ്റാബേസ് ക്രമീകരണങ്ങളെ ആശ്രയിച്ചിരിക്കുന്നു, ചിലപ്പോൾ ഇത് IDE ക്രമീകരണങ്ങളിൽ സജ്ജമാക്കാം. പൊതുവേ, ചിലപ്പോൾ നിങ്ങൾക്ക് എളുപ്പത്തിൽ ആശയക്കുഴപ്പത്തിലാകാം, അതിനാൽ ORACLE-ന്റെ കാര്യത്തിൽ, varchar2 തരം ഉപയോഗിക്കുകയാണെങ്കിൽ (ഇത് ചിലപ്പോൾ ഇവിടെ ന്യായീകരിക്കപ്പെടുന്നു, ഉദാഹരണത്തിന്, UTF-8 എൻകോഡിംഗ് ഉപയോഗിക്കുമ്പോൾ), ഞാൻ CHAR (മുതൽ) വ്യക്തമായി എഴുതാൻ ആഗ്രഹിക്കുന്നു. അക്ഷരങ്ങളിൽ സ്ട്രിംഗിന്റെ നീളം കണക്കാക്കുന്നത് സാധാരണയായി കൂടുതൽ സൗകര്യപ്രദമാണ് ).
എന്നാൽ ഈ സാഹചര്യത്തിൽ, പട്ടികയിൽ ഇതിനകം കുറച്ച് ഡാറ്റ ഉണ്ടെങ്കിൽ, കമാൻഡുകൾ വിജയകരമായി നടപ്പിലാക്കുന്നതിന് പട്ടികയുടെ എല്ലാ വരികളിലും ഐഡിയും നെയിം ഫീൽഡുകളും പൂരിപ്പിക്കേണ്ടത് ആവശ്യമാണ്. നമുക്ക് ഇത് ഒരു ഉദാഹരണത്തിലൂടെ തെളിയിക്കാം: ഐഡി, സ്ഥാനം, ഡിപ്പാർട്ട്മെന്റ് ഫീൽഡുകളിലെ പട്ടികയിലേക്ക് ഡാറ്റ ചേർക്കുക; ഇനിപ്പറയുന്ന സ്ക്രിപ്റ്റ് ഉപയോഗിച്ച് ഇത് ചെയ്യാൻ കഴിയും:
ജീവനക്കാരെ ഉൾപ്പെടുത്തുക (ഐഡി, സ്ഥാനം, വകുപ്പ്) മൂല്യങ്ങൾ (1000,N"ഡയറക്ടർ",N"അഡ്മിനിസ്ട്രേഷൻ"), (1001,N"പ്രോഗ്രാമർ",N"IT"), (1002,N"അക്കൗണ്ടന്റ്",N"അക്കൗണ്ടിംഗ്" ), (1003,N"സീനിയർ പ്രോഗ്രാമർ",N"IT")
ഈ സാഹചര്യത്തിൽ, INSERT കമാൻഡും ഒരു പിശക് സൃഷ്ടിക്കും, കാരണം തിരുകുമ്പോൾ, ആവശ്യമായ നെയിം ഫീൽഡിന്റെ മൂല്യം ഞങ്ങൾ വ്യക്തമാക്കിയിട്ടില്ല.
ഒറിജിനൽ ടേബിളിൽ ഈ ഡാറ്റ ഞങ്ങൾക്കുണ്ടെങ്കിൽ, "ALTER TABLE Employees ALTER COLUMN ID int NULL" എന്ന കമാൻഡ് വിജയകരമായി നടപ്പിലാക്കും, കൂടാതെ "ALTER TABLE Employees ALTER COLUMN Name int NOT NULL" എന്ന കമാൻഡ് ഒരു പിശക് സന്ദേശം സൃഷ്ടിക്കും, നെയിം ഫീൽഡിൽ NULL (വ്യക്തമല്ലാത്ത) മൂല്യങ്ങൾ അടങ്ങിയിരിക്കുന്നു.
നമുക്ക് നെയിം ഫീൽഡിനായി മൂല്യങ്ങൾ ചേർത്ത് ഡാറ്റ വീണ്ടും പൂരിപ്പിക്കാം:
ഒരു പുതിയ പട്ടിക സൃഷ്ടിക്കുമ്പോൾ NOT NULL ഓപ്ഷനും നേരിട്ട് ഉപയോഗിക്കാം, അതായത്. CREATE TABLE കമാൻഡിന്റെ പശ്ചാത്തലത്തിൽ.
ആദ്യം, കമാൻഡ് ഉപയോഗിച്ച് പട്ടിക ഇല്ലാതാക്കുക:
ഡ്രോപ്പ് ടേബിൾ ജീവനക്കാർ
ഇപ്പോൾ നമുക്ക് ആവശ്യമായ ഐഡിയും നെയിം കോളങ്ങളും ഉള്ള ഒരു പട്ടിക ഉണ്ടാക്കാം:
ടേബിൾ ജീവനക്കാരെ സൃഷ്ടിക്കുക (ID int NULL, പേര് nvarchar(30) NULL അല്ല, ജന്മദിന തീയതി, ഇമെയിൽ nvarchar(30), സ്ഥാനം nvarchar(30), വകുപ്പ് nvarchar(30))
നിരയുടെ പേരിന് ശേഷം നിങ്ങൾക്ക് NULL എന്ന് എഴുതാനും കഴിയും, അതിനർത്ഥം അതിൽ NULL മൂല്യങ്ങൾ (നിർദ്ദിഷ്ടമല്ല) അനുവദിക്കും, എന്നാൽ ഇത് ആവശ്യമില്ല, കാരണം ഈ സ്വഭാവം സ്ഥിരസ്ഥിതിയായി സൂചിപ്പിച്ചിരിക്കുന്നു.
നേരെമറിച്ച്, നിലവിലുള്ള ഒരു നിര ഓപ്ഷണൽ ആക്കണമെങ്കിൽ, ഇനിപ്പറയുന്ന കമാൻഡ് വാക്യഘടന ഉപയോഗിക്കുക:
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ കോളത്തിന്റെ പേര് മാറ്റി nvarchar(30) NULL
അല്ലെങ്കിൽ ലളിതമായി:
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ കോളത്തിന്റെ പേര് മാറ്റി nvarchar(30)
ഈ കമാൻഡ് ഉപയോഗിച്ച് നമുക്ക് ഫീൽഡ് തരം മറ്റൊരു അനുയോജ്യമായ തരത്തിലേക്ക് മാറ്റാം അല്ലെങ്കിൽ അതിന്റെ ദൈർഘ്യം മാറ്റാം. ഉദാഹരണത്തിന്, നമുക്ക് നെയിം ഫീൽഡ് 50 പ്രതീകങ്ങളിലേക്ക് വികസിപ്പിക്കാം:
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ കോളത്തിന്റെ പേര് മാറ്റി nvarchar(50)
പ്രാഥമിക കീ
ഒരു പട്ടിക സൃഷ്ടിക്കുമ്പോൾ, അതിന് ഒരു അദ്വിതീയ കോളം അല്ലെങ്കിൽ അതിന്റെ ഓരോ വരികൾക്കും അദ്വിതീയമായ നിരകളുടെ ഒരു കൂട്ടം ഉണ്ടായിരിക്കുന്നത് അഭികാമ്യമാണ് - ഈ അദ്വിതീയ മൂല്യത്താൽ ഒരു റെക്കോർഡ് അദ്വിതീയമായി തിരിച്ചറിയാൻ കഴിയും. ഈ മൂല്യത്തെ പട്ടികയുടെ പ്രാഥമിക കീ എന്ന് വിളിക്കുന്നു. ഞങ്ങളുടെ എംപ്ലോയീസ് ടേബിളിന്, അത്തരമൊരു അദ്വിതീയ മൂല്യം ഐഡി കോളം ആയിരിക്കാം (അതിൽ "ജീവനക്കാരുടെ പേഴ്സണൽ നമ്പർ" അടങ്ങിയിരിക്കുന്നു - ഞങ്ങളുടെ കാര്യത്തിൽ ഈ മൂല്യം ഓരോ ജീവനക്കാരനും അദ്വിതീയമാണെങ്കിലും ആവർത്തിക്കാൻ കഴിയില്ല).കമാൻഡ് ഉപയോഗിച്ച് നിങ്ങൾക്ക് നിലവിലുള്ള ഒരു പട്ടികയിലേക്ക് ഒരു പ്രാഥമിക കീ സൃഷ്ടിക്കാൻ കഴിയും:
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ നിയന്ത്രണങ്ങൾ ചേർക്കുക PK_എംപ്ലോയീസ് പ്രൈമറി കീ(ഐഡി)
ഇവിടെ "PK_Employees" എന്നത് പ്രാഥമിക കീയുടെ ഉത്തരവാദിത്തമുള്ള നിയന്ത്രണത്തിന്റെ പേരാണ്. സാധാരണഗതിയിൽ, "PK_" എന്ന പ്രിഫിക്സ് ഉപയോഗിച്ചാണ് പ്രാഥമിക കീയ്ക്ക് പേര് നൽകിയിരിക്കുന്നത്, തുടർന്ന് പട്ടികയുടെ പേര്.
പ്രാഥമിക കീയിൽ നിരവധി ഫീൽഡുകൾ അടങ്ങിയിട്ടുണ്ടെങ്കിൽ, ഈ ഫീൽഡുകൾ കോമകളാൽ വേർതിരിച്ച പരാൻതീസിസിൽ ലിസ്റ്റ് ചെയ്യണം:
പട്ടികയുടെ പേര് മാറ്റുക
MS SQL-ൽ, പ്രാഥമിക കീയിൽ ഉൾപ്പെടുത്തിയിരിക്കുന്ന എല്ലാ ഫീൽഡുകൾക്കും NOT NULL സ്വഭാവം ഉണ്ടായിരിക്കണം എന്നത് ശ്രദ്ധിക്കേണ്ടതാണ്.
ഒരു പട്ടിക സൃഷ്ടിക്കുമ്പോൾ പ്രാഥമിക കീ നേരിട്ട് നിർണ്ണയിക്കാനും കഴിയും, അതായത്. CREATE TABLE കമാൻഡിന്റെ പശ്ചാത്തലത്തിൽ. നമുക്ക് പട്ടിക ഇല്ലാതാക്കാം:
ഡ്രോപ്പ് ടേബിൾ ജീവനക്കാർ
തുടർന്ന് ഇനിപ്പറയുന്ന വാക്യഘടന ഉപയോഗിച്ച് ഞങ്ങൾ ഇത് സൃഷ്ടിക്കും:
ജീവനക്കാരുടെ പട്ടിക സൃഷ്ടിക്കുക (ഐഡി പൂർണ്ണമല്ല, പേര് nvarchar(30) അസാധുവല്ല, ജന്മദിന തീയതി, ഇമെയിൽ nvarchar(30), സ്ഥാനം nvarchar(30), വകുപ്പ് nvarchar(30), പരിമിതപ്പെടുത്തുക PK_എംപ്ലോയീസ് PRIMARY KEY (PRIMARY KEY) ശേഷം വിവരിക്കുക എല്ലാ ഫീൽഡുകളും ഒരു പരിമിതിയായി)
സൃഷ്ടിച്ച ശേഷം, ഡാറ്റ ഉപയോഗിച്ച് പട്ടിക പൂരിപ്പിക്കുക:
ജീവനക്കാരെ ഉൾപ്പെടുത്തുക (ഐഡി, സ്ഥാനം, വകുപ്പ്, പേര്) മൂല്യങ്ങൾ (1000,N"ഡയറക്ടർ",N"അഡ്മിനിസ്ട്രേഷൻ",N"ഇവാനോവ് I.I."), (1001,N"പ്രോഗ്രാമർ",N"IT",N" പെട്രോവ് പി.പി." ), (1002,N"അക്കൗണ്ടന്റ്",N"അക്കൗണ്ടിംഗ്",N"സിഡോറോവ് എസ്.എസ്."), (1003,N"സീനിയർ പ്രോഗ്രാമർ",N"IT",N"ആന്ദ്രീവ് എ. എ.")
ഒരു പട്ടികയിലെ പ്രാഥമിക കീയിൽ ഒരു നിരയുടെ മൂല്യങ്ങൾ മാത്രമേ അടങ്ങിയിട്ടുള്ളൂ എങ്കിൽ, നിങ്ങൾക്ക് ഇനിപ്പറയുന്ന വാക്യഘടന ഉപയോഗിക്കാം:
ജീവനക്കാരുടെ പട്ടിക സൃഷ്ടിക്കുക (ഐഡി ഇൻറ്റ് ശൂന്യമായ നിയന്ത്രണമല്ല PK_Employees പ്രാഥമിക കീ, -- ഫീൽഡിന്റെ ഒരു സ്വഭാവമായി വ്യക്തമാക്കുക പേര് nvarchar(30) NULL അല്ല, ജന്മദിന തീയതി, ഇമെയിൽ nvarchar(30), സ്ഥാനം nvarcharn(30), )
വാസ്തവത്തിൽ, നിയന്ത്രണത്തിന്റെ പേര് നിങ്ങൾ വ്യക്തമാക്കേണ്ടതില്ല, ഈ സാഹചര്യത്തിൽ അതിന് ഒരു സിസ്റ്റം നാമം നൽകും ("PK__Employee__3214EC278DA42077" പോലെ):
ടേബിൾ ജീവനക്കാരെ സൃഷ്ടിക്കുക (ID int NULL, പേര് nvarchar(30) NULL അല്ല, ജന്മദിന തീയതി, ഇമെയിൽ nvarchar(30), പൊസിഷൻ nvarchar(30), വകുപ്പ് nvarchar(30), Primary KEY(ID))
അഥവാ:
ടേബിൾ ജീവനക്കാരെ സൃഷ്ടിക്കുക (ഐഡി ഇൻറ്റ് ശൂന്യമായ പ്രൈമറി കീ അല്ല, പേര് nvarchar(30) NULL അല്ല, ജന്മദിനം, ഇമെയിൽ nvarchar(30), സ്ഥാനം nvarchar(30), വകുപ്പ് nvarchar(30))
എന്നാൽ സ്ഥിരമായ പട്ടികകൾക്കായി നിങ്ങൾ എല്ലായ്പ്പോഴും നിയന്ത്രണത്തിന്റെ പേര് വ്യക്തമായി സജ്ജീകരിക്കാൻ ഞാൻ ശുപാർശ ചെയ്യുന്നു, കാരണം വ്യക്തമായി വ്യക്തമാക്കിയതും മനസ്സിലാക്കാവുന്നതുമായ പേര് ഉപയോഗിച്ച്, അത് പിന്നീട് കൈകാര്യം ചെയ്യുന്നത് എളുപ്പമായിരിക്കും; ഉദാഹരണത്തിന്, നിങ്ങൾക്ക് ഇത് ഇല്ലാതാക്കാം:
ആൾട്ടർ ടേബിൾ എംപ്ലോയീസ് പികെ_എംപ്ലോയീസ് നിയന്ത്രണം ഒഴിവാക്കുക
എന്നാൽ അത്തരം ഒരു ചെറിയ വാക്യഘടന, നിയന്ത്രണങ്ങളുടെ പേരുകൾ വ്യക്തമാക്കാതെ, താൽക്കാലിക ഡാറ്റാബേസ് പട്ടികകൾ സൃഷ്ടിക്കുമ്പോൾ ഉപയോഗിക്കാൻ സൗകര്യപ്രദമാണ് (താത്കാലിക പട്ടികയുടെ പേര് # അല്ലെങ്കിൽ ## ൽ ആരംഭിക്കുന്നു), അത് ഉപയോഗത്തിന് ശേഷം ഇല്ലാതാക്കപ്പെടും.
നമുക്ക് സംഗ്രഹിക്കാം
ഇതുവരെ ഞങ്ങൾ ഇനിപ്പറയുന്ന കമാൻഡുകൾ പരിശോധിച്ചു:- പട്ടിക സൃഷ്ടിക്കുക table_name (ഫീൽഡുകളുടെ ലിസ്റ്റിംഗ്, അവയുടെ തരങ്ങൾ, നിയന്ത്രണങ്ങൾ) - നിലവിലെ ഡാറ്റാബേസിൽ ഒരു പുതിയ പട്ടിക സൃഷ്ടിക്കാൻ ഉപയോഗിക്കുന്നു;
- ഡ്രോപ്പ് ടേബിൾ table_name - നിലവിലെ ഡാറ്റാബേസിൽ നിന്ന് ഒരു പട്ടിക ഇല്ലാതാക്കാൻ ഉപയോഗിക്കുന്നു;
- ആൾട്ടർ ടേബിൾപട്ടിക_പേര് കോളം മാറ്റുക column_name... – കോളം തരം അപ്ഡേറ്റ് ചെയ്യുന്നതിനോ അതിന്റെ ക്രമീകരണങ്ങൾ മാറ്റുന്നതിനോ ഉപയോഗിക്കുന്നു (ഉദാഹരണത്തിന്, NULL അല്ലെങ്കിൽ NULL സ്വഭാവം സജ്ജമാക്കാൻ);
- ആൾട്ടർ ടേബിൾപട്ടിക_പേര് നിയന്ത്രണം ചേർക്കുക constraint_name പ്രൈമറി കീ(ഫീൽഡ്1, ഫീൽഡ്2,...) - നിലവിലുള്ള ഒരു പട്ടികയിലേക്ക് ഒരു പ്രാഥമിക കീ ചേർക്കുന്നു;
- ആൾട്ടർ ടേബിൾപട്ടിക_പേര് ഡ്രോപ്പ് കൺസ്ട്രൈന്റ് constraint_name - പട്ടികയിൽ നിന്ന് ഒരു നിയന്ത്രണം നീക്കം ചെയ്യുന്നു.
താൽക്കാലിക പട്ടികകളെക്കുറിച്ച് കുറച്ച്
MSDN-ൽ നിന്ന് എക്സ്ട്രാക്റ്റ് ചെയ്യുക. MS SQL സെർവറിൽ രണ്ട് തരം താൽക്കാലിക ടേബിളുകളുണ്ട്: ലോക്കൽ (#), ഗ്ലോബൽ (##). SQL സെർവർ ഇൻസ്റ്റൻസിലേക്കുള്ള കണക്ഷൻ സെഷൻ ആദ്യം സൃഷ്ടിക്കപ്പെടുന്നത് വരെ അവയുടെ സ്രഷ്ടാക്കൾക്ക് മാത്രമേ പ്രാദേശിക താൽക്കാലിക പട്ടികകൾ ദൃശ്യമാകൂ. ഒരു ഉപയോക്താവ് SQL സെർവറിന്റെ ഉദാഹരണത്തിൽ നിന്ന് വിച്ഛേദിച്ചതിന് ശേഷം പ്രാദേശിക താൽക്കാലിക പട്ടികകൾ സ്വയമേവ ഇല്ലാതാക്കപ്പെടും. ഗ്ലോബൽ താൽക്കാലിക ടേബിളുകൾ എല്ലാ ഉപയോക്താക്കൾക്കും ആ പട്ടികകൾ സൃഷ്ടിച്ചതിന് ശേഷം ഏത് കണക്ഷൻ സെഷനുകളിലും ദൃശ്യമാകും, കൂടാതെ ആ പട്ടികകൾ പരാമർശിക്കുന്ന എല്ലാ ഉപയോക്താക്കളും SQL സെർവറിന്റെ ഉദാഹരണത്തിൽ നിന്ന് വിച്ഛേദിക്കുമ്പോൾ അവ ഇല്ലാതാക്കപ്പെടും.
tempdb സിസ്റ്റം ഡാറ്റാബേസിൽ താൽക്കാലിക പട്ടികകൾ സൃഷ്ടിച്ചിരിക്കുന്നു, അതായത്. അവ സൃഷ്ടിക്കുന്നതിലൂടെ ഞങ്ങൾ പ്രധാന ഡാറ്റാബേസ് തടസ്സപ്പെടുത്തുന്നില്ല; അല്ലാത്തപക്ഷം, താൽക്കാലിക ടേബിളുകൾ സാധാരണ പട്ടികകൾക്ക് സമാനമാണ്; അവ DROP TABLE കമാൻഡ് ഉപയോഗിച്ച് ഇല്ലാതാക്കാനും കഴിയും. ലോക്കൽ (#) താൽക്കാലിക ടേബിളുകളാണ് കൂടുതലായി ഉപയോഗിക്കുന്നത്.
ഒരു താൽക്കാലിക പട്ടിക സൃഷ്ടിക്കുന്നതിന്, നിങ്ങൾക്ക് CREATE TABLE കമാൻഡ് ഉപയോഗിക്കാം:
ടേബിൾ സൃഷ്ടിക്കുക #Temp(ID int, Name nvarchar(30))
MS SQL-ലെ ഒരു താൽക്കാലിക ടേബിൾ ഒരു സാധാരണ ടേബിളിന് സമാനമായതിനാൽ, DROP TABLE കമാൻഡ് ഉപയോഗിച്ച് ഇത് ഇല്ലാതാക്കാനും കഴിയും:
ഡ്രോപ്പ് ടേബിൾ #താപനില
നിങ്ങൾക്ക് ഒരു താൽക്കാലിക പട്ടിക സൃഷ്ടിക്കാനും കഴിയും (ഒരു സാധാരണ പട്ടിക പോലെ) കൂടാതെ SELECT ... INTO വാക്യഘടന ഉപയോഗിച്ച് ചോദ്യം നൽകുന്ന ഡാറ്റ ഉപയോഗിച്ച് ഉടൻ പൂരിപ്പിക്കുക:
ഐഡി തിരഞ്ഞെടുക്കുക, ജീവനക്കാരിൽ നിന്ന് #Temp-ലേക്ക് പേര്
ഒരു കുറിപ്പിൽ
വ്യത്യസ്ത DBMS-കളിൽ താൽക്കാലിക പട്ടികകൾ നടപ്പിലാക്കുന്നത് വ്യത്യസ്തമായിരിക്കാം. ഉദാഹരണത്തിന്, ORACLE, Firebird DBMS എന്നിവയിൽ, താൽക്കാലിക പട്ടികകളുടെ ഘടന ക്രിയേറ്റ് ഗ്ലോബൽ ടെമ്പററി ടേബിൾ കമാൻഡ് മുൻകൂട്ടി നിർണ്ണയിക്കണം, അതിൽ ഡാറ്റ സംഭരിക്കുന്നതിന്റെ പ്രത്യേകതകൾ സൂചിപ്പിക്കുന്നു, തുടർന്ന് ഉപയോക്താവ് അത് പ്രധാന പട്ടികകൾക്കിടയിൽ കാണുകയും അതിനോടൊപ്പം പ്രവർത്തിക്കുകയും ചെയ്യുന്നു. ഒരു സാധാരണ മേശ പോലെ.
ഡാറ്റാബേസ് നോർമലൈസേഷൻ - സബ്ടേബിളുകളായി (ഡയറക്ടറികൾ) വിഭജിക്കുകയും കണക്ഷനുകൾ തിരിച്ചറിയുകയും ചെയ്യുന്നു
ഞങ്ങളുടെ നിലവിലെ എംപ്ലോയീസ് ടേബിളിന് പോസിഷൻ, ഡിപ്പാർട്ട്മെന്റ് ഫീൽഡുകളിൽ ഉപയോക്താവിന് ഏത് വാചകവും നൽകാം, അത് പ്രാഥമികമായി പിശകുകൾ നിറഞ്ഞതാണ്, കാരണം ഒരു ജീവനക്കാരന് "ഐടി" ഡിപ്പാർട്ട്മെന്റായി സൂചിപ്പിക്കാൻ കഴിയും, രണ്ടാമത്തെ ജീവനക്കാരന് ഉദാഹരണത്തിന്, "ഐടി വകുപ്പ്" നൽകുക, മൂന്നാമത്തേതിൽ "ഐടി" ഉണ്ട്. തൽഫലമായി, ഉപയോക്താവ് എന്താണ് ഉദ്ദേശിച്ചതെന്ന് വ്യക്തമല്ല, അതായത്. ഈ ജീവനക്കാർ ഒരേ വകുപ്പിലെ ജീവനക്കാരാണോ, അതോ ഉപയോക്താവ് സ്വയം വിവരിച്ചതാണോ, ഇവ 3 വ്യത്യസ്ത വകുപ്പുകളാണോ? മാത്രമല്ല, ഈ സാഹചര്യത്തിൽ, ചില റിപ്പോർട്ടുകൾക്കായുള്ള ഡാറ്റ ശരിയായി ഗ്രൂപ്പുചെയ്യാൻ ഞങ്ങൾക്ക് കഴിയില്ല, അവിടെ ഓരോ വകുപ്പും ജീവനക്കാരുടെ എണ്ണം കാണിക്കേണ്ടത് ആവശ്യമായി വന്നേക്കാം.രണ്ടാമത്തെ പോരായ്മ ഈ വിവരങ്ങളുടെ സംഭരണത്തിന്റെ അളവും അതിന്റെ തനിപ്പകർപ്പുമാണ്, അതായത്. ഓരോ ജീവനക്കാരനും, ഡിപ്പാർട്ട്മെന്റിന്റെ പൂർണ്ണമായ പേര് സൂചിപ്പിച്ചിരിക്കുന്നു, ഡിപ്പാർട്ട്മെന്റ് നാമത്തിൽ നിന്ന് ഓരോ പ്രതീകവും സംഭരിക്കുന്നതിന് ഡാറ്റാബേസിൽ ഇടം ആവശ്യമാണ്.
മൂന്നാമത്തെ പോരായ്മ ഒരു സ്ഥാനത്തിന്റെ പേര് മാറുകയാണെങ്കിൽ ഈ ഫീൽഡുകൾ അപ്ഡേറ്റ് ചെയ്യുന്നതിനുള്ള ബുദ്ധിമുട്ടാണ്, ഉദാഹരണത്തിന്, നിങ്ങൾക്ക് “പ്രോഗ്രാമർ” എന്ന സ്ഥാനത്തെ “ജൂനിയർ പ്രോഗ്രാമർ” എന്ന് പുനർനാമകരണം ചെയ്യണമെങ്കിൽ. ഈ സാഹചര്യത്തിൽ, "പ്രോഗ്രാമർ" എന്നതിന് തുല്യമായ സ്ഥാനമുള്ള പട്ടികയുടെ ഓരോ വരിയിലും ഞങ്ങൾ മാറ്റങ്ങൾ വരുത്തേണ്ടതുണ്ട്.
ഈ പോരായ്മകൾ ഒഴിവാക്കാൻ, ഡാറ്റാബേസ് നോർമലൈസേഷൻ എന്ന് വിളിക്കപ്പെടുന്നവ ഉപയോഗിക്കുന്നു - ഇത് സബ്ടേബിളുകളിലേക്കും റഫറൻസ് ടേബിളുകളിലേക്കും വിഭജിക്കുന്നു. സിദ്ധാന്തത്തിന്റെ കാട്ടിൽ പോയി സാധാരണ രൂപങ്ങൾ എന്താണെന്ന് പഠിക്കേണ്ട ആവശ്യമില്ല; സാധാരണവൽക്കരണത്തിന്റെ സാരാംശം മനസ്സിലാക്കിയാൽ മതി.
നമുക്ക് 2 ഡയറക്ടറി ടേബിളുകൾ സൃഷ്ടിക്കാം “സ്ഥാനങ്ങൾ”, “ഡിപ്പാർട്ട്മെന്റുകൾ”, നമുക്ക് ആദ്യത്തെ സ്ഥാനങ്ങൾ എന്നും രണ്ടാമത്തേത് യഥാക്രമം വകുപ്പുകൾ എന്നും വിളിക്കാം:
പട്ടിക സ്ഥാനങ്ങൾ സൃഷ്ടിക്കുക (ഐഡി ഇൻറ്റ് ഐഡന്റിറ്റി(1,1) ശൂന്യമായ നിയന്ത്രണമല്ല PK_സ്ഥാനങ്ങൾ പ്രാഥമിക താക്കോൽ, പേര് nvarchar(30) ശൂന്യമല്ല) പട്ടിക വകുപ്പുകൾ സൃഷ്ടിക്കുക (ID int IDENTITY(1,1) KARNULL പേരുകൾ PKYNULL 0 ) ശൂന്യമല്ല)
ഇവിടെ ഞങ്ങൾ പുതിയ ഐഡന്റിറ്റി ഓപ്ഷൻ ഉപയോഗിച്ചുവെന്നത് ശ്രദ്ധിക്കുക, ഐഡി കോളത്തിലെ ഡാറ്റ സ്വയമേവ അക്കമിട്ട് നൽകപ്പെടും, 1 മുതൽ ആരംഭിക്കുന്നു, 1 ന്റെ വർദ്ധനവിൽ, അതായത്. പുതിയ റെക്കോർഡുകൾ ചേർക്കുമ്പോൾ, അവർക്ക് 1, 2, 3, മുതലായവ മൂല്യങ്ങൾ തുടർച്ചയായി നൽകും. അത്തരം ഫീൽഡുകളെ സാധാരണയായി ഓട്ടോ-ഇൻക്രിമെന്റിംഗ് എന്ന് വിളിക്കുന്നു. ഒരു പട്ടികയ്ക്ക് ഐഡന്റിറ്റി പ്രോപ്പർട്ടി ഉപയോഗിച്ച് നിർവചിച്ചിരിക്കുന്ന ഒരു ഫീൽഡ് മാത്രമേ ഉണ്ടാകൂ, സാധാരണയായി, പക്ഷേ ആ ഫീൽഡ് ആ പട്ടികയുടെ പ്രാഥമിക കീയാണ്.
ഒരു കുറിപ്പിൽ
വ്യത്യസ്ത ഡിബിഎംഎസുകളിൽ, ഒരു കൌണ്ടർ ഉപയോഗിച്ച് ഫീൽഡുകൾ നടപ്പിലാക്കുന്നത് വ്യത്യസ്തമായി ചെയ്യാവുന്നതാണ്. ഉദാഹരണത്തിന്, MySQL-ൽ, AUTO_INCREMENT ഓപ്ഷൻ ഉപയോഗിച്ചാണ് അത്തരമൊരു ഫീൽഡ് നിർവചിച്ചിരിക്കുന്നത്. ORACLE, Firebird എന്നിവയിൽ, ഈ പ്രവർത്തനം മുമ്പ് SEQUENCE ഉപയോഗിച്ച് അനുകരിക്കാമായിരുന്നു. എന്നാൽ എനിക്കറിയാവുന്നിടത്തോളം, ORACLE ഇപ്പോൾ GENERATED AS IDENTITY എന്ന ഓപ്ഷൻ ചേർത്തിട്ടുണ്ട്.
എംപ്ലോയീസ് ടേബിളിലെ പൊസിഷൻ, ഡിപ്പാർട്ട്മെന്റ് ഫീൽഡുകളിൽ രേഖപ്പെടുത്തിയിരിക്കുന്ന നിലവിലെ ഡാറ്റയെ അടിസ്ഥാനമാക്കി നമുക്ക് ഈ പട്ടികകൾ സ്വയമേവ പൂരിപ്പിക്കാം:
എംപ്ലോയീസ് ടേബിളിന്റെ പൊസിഷൻ ഫീൽഡിൽ നിന്ന് തനതായ മൂല്യങ്ങളോടെ പൊസിഷൻസ് ടേബിളിന്റെ നെയിം ഫീൽഡ് ഞങ്ങൾ പൂരിപ്പിക്കുന്നു, സ്ഥാനങ്ങൾ ചേർക്കുക (പേര്) സ്ഥാനങ്ങൾ അസാധുവല്ലാത്ത ജീവനക്കാരിൽ നിന്ന് വ്യത്യസ്ത സ്ഥാനം തിരഞ്ഞെടുക്കുക -- സ്ഥാനം വ്യക്തമാക്കാത്ത റെക്കോർഡുകൾ ഉപേക്ഷിക്കുക.
ഡിപ്പാർട്ട്മെന്റ് ടേബിളിനായി നമുക്ക് ഇത് ചെയ്യാം:
വകുപ്പുകൾ ചേർക്കുക (പേര്) ഡിപ്പാർട്ട്മെന്റ് ശൂന്യമല്ലാത്തിടത്ത് ജീവനക്കാരിൽ നിന്ന് വ്യത്യസ്തമായ വകുപ്പ് തിരഞ്ഞെടുക്കുക
നമ്മൾ ഇപ്പോൾ പൊസിഷനുകളും ഡിപ്പാർട്ട്മെന്റുകളും ടേബിളുകൾ തുറക്കുകയാണെങ്കിൽ, ഐഡി ഫീൽഡിനായി അക്കമിട്ട മൂല്യങ്ങളുടെ ഒരു കൂട്ടം നമുക്ക് കാണാം:
സ്ഥാനങ്ങളിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക
വകുപ്പുകളിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക
ഈ പട്ടികകൾ ഇപ്പോൾ സ്ഥാനങ്ങളും വകുപ്പുകളും വ്യക്തമാക്കുന്നതിനുള്ള റഫറൻസ് ബുക്കുകളുടെ പങ്ക് വഹിക്കും. ഞങ്ങൾ ഇപ്പോൾ ജോലി, ഡിപ്പാർട്ട്മെന്റ് ഐഡികൾ റഫർ ചെയ്യും. ഒന്നാമതായി, ഐഡന്റിഫയർ ഡാറ്റ സംഭരിക്കുന്നതിന് ജീവനക്കാരുടെ പട്ടികയിൽ പുതിയ ഫീൽഡുകൾ സൃഷ്ടിക്കാം:
പൊസിഷൻ ഐഡിക്ക് ഒരു ഫീൽഡ് ചേർക്കുക ആൾട്ടർ ടേബിൾ ജീവനക്കാർ പൊസിഷൻ ഐഡി ഇൻറ്റ് ചേർക്കുക -- ഡിപ്പാർട്ട്മെന്റ് ഐഡിക്ക് ഒരു ഫീൽഡ് ചേർക്കുക ആൾട്ടർ ടേബിൾ എംപ്ലോയീസ് ഡിപ്പാർട്ട്മെന്റ് ഐഡി ഇൻറ്റ് ചേർക്കുക
റഫറൻസ് ഫീൽഡുകളുടെ തരം ഡയറക്ടറികളിലെ പോലെ തന്നെ ആയിരിക്കണം, ഈ സാഹചര്യത്തിൽ ഇത് int ആണ്.
ഒരു കമാൻഡ് ഉപയോഗിച്ച് നിങ്ങൾക്ക് ഒരേസമയം നിരവധി ഫീൽഡുകൾ പട്ടികയിലേക്ക് ചേർക്കാനും കോമകളാൽ വേർതിരിച്ച ഫീൽഡുകൾ പട്ടികപ്പെടുത്താനും കഴിയും:
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ പൊസിഷൻ ഐഡി ഇൻറ്റ്, ഡിപ്പാർട്ട്മെന്റ് ഐഡി ഇൻറ്റ് ചേർക്കുക
ഇപ്പോൾ നമുക്ക് ഈ ഫീൽഡുകൾക്കായി ലിങ്കുകൾ (റഫറൻസ് നിയന്ത്രണങ്ങൾ - ഫോറിൻ കീ) എഴുതാം, അതിനാൽ ഡയറക്ടറികളിൽ കാണുന്ന ഐഡി മൂല്യങ്ങളിൽ ഉൾപ്പെടാത്ത ഈ ഫീൽഡുകളിലെ മൂല്യങ്ങൾ എഴുതാൻ ഉപയോക്താവിന് അവസരം ലഭിക്കില്ല.
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ നിയന്ത്രണങ്ങൾ ചേർക്കുക
രണ്ടാമത്തെ ഫീൽഡിനും ഞങ്ങൾ ഇത് ചെയ്യും:
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ നിയന്ത്രണങ്ങൾ ചേർക്കുക
ഇപ്പോൾ ഉപയോക്താവിന് ഈ ഫീൽഡുകളിലെ അനുബന്ധ ഡയറക്ടറിയിൽ നിന്ന് ഐഡി മൂല്യങ്ങൾ മാത്രമേ നൽകാൻ കഴിയൂ. അതനുസരിച്ച്, ഒരു പുതിയ വകുപ്പോ സ്ഥാനമോ ഉപയോഗിക്കുന്നതിന്, അവൻ ആദ്യം അനുബന്ധ ഡയറക്ടറിയിലേക്ക് ഒരു പുതിയ എൻട്രി ചേർക്കേണ്ടതുണ്ട്. കാരണം സ്ഥാനങ്ങളും വകുപ്പുകളും ഇപ്പോൾ ഡയറക്ടറികളിൽ ഒരൊറ്റ പകർപ്പിൽ സംഭരിച്ചിരിക്കുന്നു, അതിനാൽ പേര് മാറ്റാൻ, അത് ഡയറക്ടറിയിൽ മാത്രം മാറ്റിയാൽ മതിയാകും.
ഒരു റഫറൻസ് നിയന്ത്രണത്തിന്റെ പേര് സാധാരണയായി ഒരു സംയുക്ത നാമമാണ്, അതിൽ "FK_" എന്ന പ്രിഫിക്സ് അടങ്ങിയിരിക്കുന്നു, തുടർന്ന് പട്ടികയുടെ പേര്, തുടർന്ന് ഒരു അണ്ടർ സ്കോർ, തുടർന്ന് റഫറൻസ് ടേബിൾ ഐഡന്റിഫയറിനെ സൂചിപ്പിക്കുന്ന ഫീൽഡിന്റെ പേര്.
ഒരു ഐഡന്റിഫയർ (ഐഡി) സാധാരണയായി ബന്ധങ്ങൾക്ക് മാത്രം ഉപയോഗിക്കുന്ന ഒരു ആന്തരിക മൂല്യമാണ്, മാത്രമല്ല അവിടെ സംഭരിച്ചിരിക്കുന്ന മൂല്യം മിക്ക കേസുകളിലും പൂർണ്ണമായും നിസ്സംഗത പുലർത്തുന്നു, അതിനാൽ പ്രവർത്തിക്കുമ്പോൾ ഉണ്ടാകുന്ന സംഖ്യകളുടെ ക്രമത്തിലെ ദ്വാരങ്ങൾ ഒഴിവാക്കാൻ ശ്രമിക്കേണ്ടതില്ല. പട്ടികയ്ക്കൊപ്പം, ഉദാഹരണത്തിന്, ഡയറക്ടറിയിൽ നിന്ന് റെക്കോർഡുകൾ ഇല്ലാതാക്കിയ ശേഷം.
പട്ടികയുടെ മാറ്റുക
ഈ സാഹചര്യത്തിൽ, "റഫറൻസ്_ടേബിൾ" പട്ടികയിൽ, പ്രൈമറി കീ നിരവധി ഫീൽഡുകളുടെ സംയോജനത്താൽ പ്രതിനിധീകരിക്കുന്നു (ഫീൽഡ്1, ഫീൽഡ്2,...).
യഥാർത്ഥത്തിൽ, ഇപ്പോൾ നമുക്ക് പൊസിഷൻ ഐഡി, ഡിപ്പാർട്ട്മെന്റ് ഐഡി ഫീൽഡുകൾ ഡയറക്ടറികളിൽ നിന്ന് ഐഡി മൂല്യങ്ങൾ ഉപയോഗിച്ച് അപ്ഡേറ്റ് ചെയ്യാം. ഈ ആവശ്യത്തിനായി നമുക്ക് DML UPDATE കമാൻഡ് ഉപയോഗിക്കാം:
അപ്ഡേറ്റ് ചെയ്യുക ഇ സെറ്റ് പൊസിഷൻ ഐഡി=(പൊസിഷനുകളിൽ നിന്ന് ഐഡി തിരഞ്ഞെടുക്കുക എവിടെയാണ് പേര്=ഇ.സ്ഥാനം), ഡിപ്പാർട്ട്മെന്റ് ഐഡി=(ഡിപ്പാർട്ട്മെന്റുകളിൽ നിന്ന് ഐഡി തിരഞ്ഞെടുക്കുക എവിടെയാണ് പേര്=ഇ. ഡിപ്പാർട്ട്മെന്റ്) ജീവനക്കാരിൽ നിന്ന് ഇ
അഭ്യർത്ഥന പ്രവർത്തിപ്പിക്കുന്നതിലൂടെ എന്താണ് സംഭവിക്കുന്നതെന്ന് നമുക്ക് നോക്കാം:
ജീവനക്കാരിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക
അത്രയേയുള്ളൂ, പൊസിഷൻ ഐഡി, ഡിപ്പാർട്ട്മെന്റ് ഐഡി ഫീൽഡുകൾ സ്ഥാനങ്ങൾക്കും വകുപ്പുകൾക്കും അനുയോജ്യമായ ഐഡന്റിഫയറുകൾ കൊണ്ട് നിറഞ്ഞിരിക്കുന്നു; എംപ്ലോയീസ് ടേബിളിൽ സ്ഥാനവും ഡിപ്പാർട്ട്മെന്റ് ഫീൽഡുകളും ഇനി ആവശ്യമില്ല, നിങ്ങൾക്ക് ഈ ഫീൽഡുകൾ ഇല്ലാതാക്കാം:
ആൾട്ടർ ടേബിൾ എംപ്ലോയീസ് ഡ്രോപ്പ് കോളം സ്ഥാനം, വകുപ്പ്
ഇപ്പോൾ ഞങ്ങളുടെ പട്ടിക ഇതുപോലെ കാണപ്പെടുന്നു:
ജീവനക്കാരിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക
| ഐഡി | പേര് | ജന്മദിനം | ഇമെയിൽ | സ്ഥാനം ഐഡി | വകുപ്പ് ഐഡി |
|---|---|---|---|---|---|
| 1000 | ഇവാനോവ് I.I. | ശൂന്യം | ശൂന്യം | 2 | 1 |
| 1001 | പെട്രോവ് പി.പി. | ശൂന്യം | ശൂന്യം | 3 | 3 |
| 1002 | സിഡോറോവ് എസ്.എസ്. | ശൂന്യം | ശൂന്യം | 1 | 2 |
| 1003 | ആൻഡ്രീവ് എ.എ. | ശൂന്യം | ശൂന്യം | 4 | 3 |
ആ. അനാവശ്യമായ വിവരങ്ങൾ സംഭരിക്കുന്നതിൽ നിന്ന് ഞങ്ങൾ ഒടുവിൽ രക്ഷപ്പെട്ടു. ഇപ്പോൾ, ജോലിയുടെയും ഡിപ്പാർട്ട്മെന്റ് നമ്പറുകളുടെയും അടിസ്ഥാനത്തിൽ, റഫറൻസ് ടേബിളുകളിലെ മൂല്യങ്ങൾ ഉപയോഗിച്ച് നമുക്ക് അവരുടെ പേരുകൾ വ്യക്തമായി നിർണ്ണയിക്കാനാകും:
e.ID, e.Name,p.Name PositionName,d.Name DepartmentName from Employees e LEFT JoIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
ഒബ്ജക്റ്റ് ഇൻസ്പെക്ടറിൽ നൽകിയിരിക്കുന്ന പട്ടികയ്ക്കായി സൃഷ്ടിച്ച എല്ലാ വസ്തുക്കളും നമുക്ക് കാണാൻ കഴിയും. ഇവിടെ നിന്ന് നിങ്ങൾക്ക് ഈ ഒബ്ജക്റ്റുകൾ ഉപയോഗിച്ച് വിവിധ കൃത്രിമങ്ങൾ നടത്താം - ഉദാഹരണത്തിന്, ഒബ്ജക്റ്റുകളുടെ പേരുമാറ്റുക അല്ലെങ്കിൽ ഇല്ലാതാക്കുക.

പട്ടികയ്ക്ക് സ്വയം പരാമർശിക്കാൻ കഴിയുമെന്നതും ശ്രദ്ധേയമാണ്, അതായത്. നിങ്ങൾക്ക് ഒരു ആവർത്തന ലിങ്ക് സൃഷ്ടിക്കാൻ കഴിയും. ഉദാഹരണത്തിന്, ജീവനക്കാർക്കൊപ്പം ഞങ്ങളുടെ പട്ടികയിലേക്ക് മറ്റൊരു ഫീൽഡ് ManagerID ചേർക്കാം, ഇത് ഈ ജീവനക്കാരൻ റിപ്പോർട്ട് ചെയ്യുന്ന ജീവനക്കാരനെ സൂചിപ്പിക്കുന്നു. നമുക്ക് ഒരു ഫീൽഡ് സൃഷ്ടിക്കാം:
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ ManagerID int ചേർക്കുക
ഈ ഫീൽഡ് ഒരു NULL മൂല്യം അനുവദിക്കുന്നു; ഉദാഹരണത്തിന്, ജീവനക്കാരനെക്കാൾ മേലധികാരികൾ ഇല്ലെങ്കിൽ ഫീൽഡ് ശൂന്യമായിരിക്കും.
ഇനി നമുക്ക് എംപ്ലോയീസ് ടേബിളിനായി ഒരു ഫോറിൻ കീ ഉണ്ടാക്കാം:
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ നിയന്ത്രണങ്ങൾ ചേർക്കുക
നമുക്ക് ഇപ്പോൾ ഒരു ഡയഗ്രം സൃഷ്ടിച്ച് ഞങ്ങളുടെ പട്ടികകൾ തമ്മിലുള്ള ബന്ധങ്ങൾ അതിൽ എങ്ങനെ കാണപ്പെടുന്നുവെന്ന് നോക്കാം:


തൽഫലമായി, ഞങ്ങൾ ഇനിപ്പറയുന്ന ചിത്രം കാണും (എംപ്ലോയീസ് ടേബിൾ സ്ഥാനങ്ങളുമായും ഡിപ്പാർട്ട്മെന്റുകളുടേയും പട്ടികകളുമായി ബന്ധിപ്പിച്ചിരിക്കുന്നു, മാത്രമല്ല അത് തന്നെ സൂചിപ്പിക്കുന്നു):

അവസാനമായി, റഫറൻസ് കീകളിൽ ഡിലീറ്റ് കാസ്കേഡിലും അപ്ഡേറ്റ് കാസ്കേഡിലും അധിക ഓപ്ഷനുകൾ ഉൾപ്പെടുത്താൻ കഴിയുമെന്ന് പറയേണ്ടതാണ്, ഇത് റഫറൻസ് ടേബിളിൽ പരാമർശിച്ചിരിക്കുന്ന ഒരു റെക്കോർഡ് ഇല്ലാതാക്കുമ്പോഴോ അപ്ഡേറ്റ് ചെയ്യുമ്പോഴോ എങ്ങനെ പെരുമാറണമെന്ന് സൂചിപ്പിക്കുന്നു. ഈ ഓപ്ഷനുകൾ വ്യക്തമാക്കിയിട്ടില്ലെങ്കിൽ, മറ്റൊരു ടേബിളിൽ നിന്ന് റഫറൻസ് ചെയ്ത ഒരു റെക്കോർഡിനായി നമുക്ക് ഡയറക്ടറി ടേബിളിലെ ഐഡി മാറ്റാൻ കഴിയില്ല, മാത്രമല്ല ഈ റെക്കോർഡ് പരാമർശിക്കുന്ന എല്ലാ വരികളും ഇല്ലാതാക്കുന്നത് വരെ ഡയറക്ടറിയിൽ നിന്ന് അത്തരം ഒരു റെക്കോർഡ് ഇല്ലാതാക്കാനും ഞങ്ങൾക്ക് കഴിയില്ല. അല്ലെങ്കിൽ, ഈ വരികളിലെ റഫറൻസുകൾ മറ്റൊരു മൂല്യത്തിലേക്ക് അപ്ഡേറ്റ് ചെയ്യാം.
ഉദാഹരണത്തിന്, FK_Employees_DepartmentID എന്നതിനായുള്ള ON DELETE CASCADE ഓപ്ഷൻ വ്യക്തമാക്കുന്ന പട്ടിക വീണ്ടും സൃഷ്ടിക്കാം:
ഡ്രോപ്പ് ടേബിൾ ജീവനക്കാർ ടേബിൾ ജീവനക്കാരെ സൃഷ്ടിക്കുന്നു (ഐഡി ഇൻറ്റ് ശൂന്യമല്ല, പേര് nvarchar(30), ജന്മദിനം, ഇമെയിൽ nvarchar(30), പൊസിഷൻ ഐഡി ഇൻറ്റ്, ഡിപ്പാർട്ട്മെന്റ് ഐഡി, മാനേജർ ഐഡി, CONSTRAINT PK_Employees (പ്രൈമറി-പാർട്ട്മെന്റ്) N KEY(ഡിപ്പാർട്ട്മെന്റ് ഐഡി ) റഫറൻസ് ഡിപ്പാർട്ട്മെന്റുകൾ (ഐഡി) ഇല്ലാതാക്കുന്ന കാസ്കേഡ്, പരിമിതപ്പെടുത്തുക ജീവനക്കാർ (ഐഡി, പേര്, ജന്മദിനം, പൊസിഷൻ ഐഡി, ഡിപ്പാർട്ട്മെന്റ് ഐഡി, മാനേജർ ഐഡി )മൂല്യങ്ങൾ (1000,N"ഇവാനോവ് I.I.","19550219",2,1,NULL), (1001,N"Petrov P.P.","19831203",3,3,1003), (1002 ,N"Sidorov S.S. ","19760607",1,2,1000), (1003,N"ആന്ദ്രീവ് എ.എ.","19820417",4,3,1000)
ഡിപ്പാർട്ട്മെന്റ് പട്ടികയിൽ നിന്ന് ID 3 ഉള്ള ഡിപ്പാർട്ട്മെന്റ് ഇല്ലാതാക്കാം:
ഡിപ്പാർട്ട്മെന്റുകൾ ഇല്ലാതാക്കുക എവിടെ ID=3
ജീവനക്കാരുടെ പട്ടികയിലെ ഡാറ്റ നോക്കാം:
ജീവനക്കാരിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക
| ഐഡി | പേര് | ജന്മദിനം | ഇമെയിൽ | സ്ഥാനം ഐഡി | വകുപ്പ് ഐഡി | മാനേജർ ഐ.ഡി |
|---|---|---|---|---|---|---|
| 1000 | ഇവാനോവ് I.I. | 1955-02-19 | ശൂന്യം | 2 | 1 | ശൂന്യം |
| 1002 | സിഡോറോവ് എസ്.എസ്. | 1976-06-07 | ശൂന്യം | 1 | 2 | 1000 |
നിങ്ങൾക്ക് കാണാനാകുന്നതുപോലെ, എംപ്ലോയീസ് ടേബിളിൽ നിന്നുള്ള ഡിപ്പാർട്ട്മെന്റ് 3-നുള്ള ഡാറ്റയും ഇല്ലാതാക്കി.
ഓൺ അപ്ഡേറ്റ് കാസ്കേഡ് ഓപ്ഷൻ സമാനമായി പ്രവർത്തിക്കുന്നു, പക്ഷേ ഡയറക്ടറിയിലെ ഐഡി മൂല്യം അപ്ഡേറ്റ് ചെയ്യുമ്പോൾ ഇത് ഫലപ്രദമാണ്. ഉദാഹരണത്തിന്, പൊസിഷൻ ഡയറക്ടറിയിലെ ഒരു സ്ഥാനത്തിന്റെ ഐഡി ഞങ്ങൾ മാറ്റുകയാണെങ്കിൽ, ഈ സാഹചര്യത്തിൽ എംപ്ലോയീസ് ടേബിളിലെ ഡിപ്പാർട്ട്മെന്റ് ഐഡി ഡയറക്ടറിയിൽ ഞങ്ങൾ സജ്ജമാക്കിയ പുതിയ ഐഡി മൂല്യത്തിലേക്ക് അപ്ഡേറ്റ് ചെയ്യും. എന്നാൽ ഈ സാഹചര്യത്തിൽ ഇത് തെളിയിക്കാൻ കഴിയില്ല, കാരണം ഡിപ്പാർട്ട്മെന്റ് ടേബിളിലെ ഐഡി കോളത്തിന് ഐഡന്റിറ്റി ഓപ്ഷൻ ഉണ്ട്, അത് ഇനിപ്പറയുന്ന ചോദ്യം എക്സിക്യൂട്ട് ചെയ്യാൻ ഞങ്ങളെ അനുവദിക്കില്ല (ഡിപ്പാർട്ട്മെന്റ് ഐഡി 3 മുതൽ 30 വരെ മാറ്റുക):
ഡിപ്പാർട്ട്മെന്റുകൾ അപ്ഡേറ്റ് ചെയ്യുക സെറ്റ് ഐഡി=30 എവിടെ ഐഡി=3
ഡിലീറ്റ് കാസ്കേഡിലും അപ്ഡേറ്റ് കാസ്കേഡിലും ഈ 2 ഓപ്ഷനുകളുടെ സാരാംശം മനസ്സിലാക്കുക എന്നതാണ് പ്രധാന കാര്യം. ഞാൻ ഈ ഓപ്ഷനുകൾ വളരെ അപൂർവമായി മാത്രമേ ഉപയോഗിക്കുന്നുള്ളൂ, അവ ഒരു റഫറൻസ് പരിമിതിയിൽ വ്യക്തമാക്കുന്നതിന് മുമ്പ് നിങ്ങൾ ശ്രദ്ധാപൂർവ്വം ചിന്തിക്കാൻ ശുപാർശ ചെയ്യുന്നു, കാരണം നിങ്ങൾ ഒരു ഡയറക്ടറി പട്ടികയിൽ നിന്ന് അബദ്ധവശാൽ ഒരു എൻട്രി ഇല്ലാതാക്കുകയാണെങ്കിൽ, ഇത് വലിയ പ്രശ്നങ്ങളിലേക്ക് നയിക്കുകയും ഒരു ചെയിൻ റിയാക്ഷൻ സൃഷ്ടിക്കുകയും ചെയ്യും.
നമുക്ക് വകുപ്പ് 3 പുനഃസ്ഥാപിക്കാം:
IDENTITY മൂല്യം ചേർക്കുക/മാറ്റാൻ ഞങ്ങൾ അനുമതി നൽകുന്നു ഡിപ്പാർട്ട്മെന്റുകൾ IDENTITY_INSERT INSERT വകുപ്പുകളിൽ (ID,Name) VALUES(3,N"IT") -- IDENTITY മൂല്യം SET IDENTITY_INSERT ഡിപ്പാർട്ട്മെന്റുകൾ ഓഫാക്കി ചേർക്കുന്നത്/മാറ്റുന്നത് ഞങ്ങൾ നിരോധിക്കുന്നു
TRUNCATE TABLE കമാൻഡ് ഉപയോഗിച്ച് നമുക്ക് എംപ്ലോയീസ് ടേബിൾ പൂർണ്ണമായും മായ്ക്കാം:
വെട്ടിച്ചുരുക്കൽ പട്ടിക ജീവനക്കാർ
മുമ്പത്തെ INSERT കമാൻഡ് ഉപയോഗിച്ച് ഞങ്ങൾ വീണ്ടും അതിലേക്ക് ഡാറ്റ റീലോഡ് ചെയ്യും:
ജീവനക്കാരെ ചേർക്കുക (ഐഡി, പേര്, ജന്മദിനം, സ്ഥാന ഐഡി, ഡിപ്പാർട്ട്മെന്റ് ഐഡി, മാനേജർ ഐഡി) മൂല്യങ്ങൾ (1000, എൻ"ഇവാനോവ് ഐ.ഐ.","19550219",2,1,നല്ല), (1001,എൻ"പെട്രോവ് പി.പി." ,"198,312038,312038 ,3,1003), (1002,N"Sidorov S.S.","19760607",1,2,1000), (1003,N"Andreev A.A.","19820417" ,4,3,1000)
നമുക്ക് സംഗ്രഹിക്കാം
ഇപ്പോൾ, ഞങ്ങളുടെ അറിവിലേക്ക് നിരവധി DDL കമാൻഡുകൾ ചേർത്തു:- ഐഡന്റിറ്റി പ്രോപ്പർട്ടി ഒരു ഫീൽഡിലേക്ക് ചേർക്കുന്നു - ഈ ഫീൽഡ് പട്ടികയ്ക്കായി സ്വയമേവ പോപ്പുലേറ്റഡ് ഫീൽഡ് (കൌണ്ടർ ഫീൽഡ്) ആക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു;
- ആൾട്ടർ ടേബിൾപട്ടിക_പേര് ചേർക്കുക list_of_fields_with_characteristics - പട്ടികയിലേക്ക് പുതിയ ഫീൽഡുകൾ ചേർക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു;
- ആൾട്ടർ ടേബിൾപട്ടിക_പേര് ഡ്രോപ്പ് കോളം list_fields - പട്ടികയിൽ നിന്ന് ഫീൽഡുകൾ നീക്കംചെയ്യാൻ നിങ്ങളെ അനുവദിക്കുന്നു;
- ആൾട്ടർ ടേബിൾപട്ടിക_പേര് നിയന്ത്രണം ചേർക്കുക constraint_name വിദേശ കീ(ഫീൽഡുകൾ) റഫറൻസുകൾ table_reference (ഫീൽഡുകൾ) - പട്ടികയും റഫറൻസ് ടേബിളും തമ്മിലുള്ള ബന്ധം നിർവ്വചിക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു.
മറ്റ് നിയന്ത്രണങ്ങൾ - UNIQUE, DEFAULT, CHECK
ഒരു UNIQUE പരിമിതി ഉപയോഗിച്ച്, തന്നിരിക്കുന്ന ഫീൽഡിലെയോ ഫീൽഡുകളുടെ ഒരു കൂട്ടത്തിലെയോ ഓരോ വരിയുടെയും മൂല്യം അദ്വിതീയമായിരിക്കണം എന്ന് നിങ്ങൾക്ക് പറയാം. എംപ്ലോയീസ് ടേബിളിന്റെ കാര്യത്തിൽ, ഇമെയിൽ ഫീൽഡിൽ ഞങ്ങൾക്ക് അത്തരമൊരു നിയന്ത്രണം ഏർപ്പെടുത്താം. മൂല്യങ്ങൾ ഇതിനകം നിർവചിച്ചിട്ടില്ലെങ്കിൽ, ഇമെയിൽ മുൻകൂട്ടി പൂരിപ്പിക്കുക:എംപ്ലോയീസ് സെറ്റ് ഇമെയിൽ=" അപ്ഡേറ്റ് ചെയ്യുക [ഇമെയിൽ പരിരക്ഷിതം]"എവിടെ ഐഡി=1000 അപ്ഡേറ്റ് ജീവനക്കാർ ഇമെയിൽ സജ്ജമാക്കി=" [ഇമെയിൽ പരിരക്ഷിതം]"എവിടെ ഐഡി=1001 അപ്ഡേറ്റ് എംപ്ലോയീസ് സെറ്റ് ഇമെയിൽ=" [ഇമെയിൽ പരിരക്ഷിതം]"എവിടെ ഐഡി=1002 അപ്ഡേറ്റ് എംപ്ലോയീസ് സെറ്റ് ഇമെയിൽ=" [ഇമെയിൽ പരിരക്ഷിതം]"എവിടെ ഐഡി=1003
ഇപ്പോൾ നിങ്ങൾക്ക് ഈ ഫീൽഡിൽ ഒരു അദ്വിതീയ നിയന്ത്രണം ഏർപ്പെടുത്താം:
ALTER TABLE ജീവനക്കാർ നിയന്ത്രണങ്ങൾ ചേർക്കുക UQ_Employees_Email UNIQUE(ഇമെയിൽ)
ഇപ്പോൾ നിരവധി ജീവനക്കാർക്ക് ഒരേ ഇ-മെയിൽ നൽകാൻ ഉപയോക്താവിന് കഴിയില്ല.
ഒരു അദ്വിതീയ പരിമിതിയെ സാധാരണയായി ഇനിപ്പറയുന്ന രീതിയിൽ വിളിക്കുന്നു - ആദ്യം "UQ_" എന്ന പ്രിഫിക്സ് വരുന്നു, തുടർന്ന് പട്ടികയുടെ പേരും അണ്ടർ സ്കോറിന് ശേഷം ഈ പരിമിതി പ്രയോഗിച്ച ഫീൽഡിന്റെ പേരും വരുന്നു.
അതനുസരിച്ച്, പട്ടിക വരികളുടെ പശ്ചാത്തലത്തിൽ ഫീൽഡുകളുടെ സംയോജനം അദ്വിതീയമായിരിക്കണം എങ്കിൽ, ഞങ്ങൾ അവയെ കോമകളാൽ വേർതിരിച്ച് പട്ടികപ്പെടുത്തുന്നു:
പട്ടികയുടെ_നാമം മാറ്റുക
ഒരു ഫീൽഡിലേക്ക് ഒരു DEFAULT കൺസ്ട്രൈന്റ് ചേർക്കുന്നതിലൂടെ, ഒരു പുതിയ റെക്കോർഡ് ചേർക്കുമ്പോൾ, ഈ ഫീൽഡ് INSERT കമാൻഡിന്റെ ഫീൽഡുകളുടെ പട്ടികയിൽ ലിസ്റ്റ് ചെയ്തിട്ടില്ലെങ്കിൽ, പകരം വരുന്ന ഒരു സ്ഥിരസ്ഥിതി മൂല്യം നമുക്ക് വ്യക്തമാക്കാൻ കഴിയും. പട്ടിക സൃഷ്ടിക്കുമ്പോൾ ഈ നിയന്ത്രണം നേരിട്ട് സജ്ജമാക്കാൻ കഴിയും.
നമുക്ക് എംപ്ലോയീസ് ടേബിളിലേക്ക് ഒരു പുതിയ ഹയർ ഡേറ്റ് ഫീൽഡ് ചേർത്ത് അതിനെ HireDate എന്ന് വിളിക്കാം, ഈ ഫീൽഡിന്റെ ഡിഫോൾട്ട് മൂല്യം നിലവിലെ തീയതി ആയിരിക്കുമെന്ന് പറയാം:
മാറ്റുക
അല്ലെങ്കിൽ HireDate കോളം നിലവിലുണ്ടെങ്കിൽ, ഇനിപ്പറയുന്ന വാക്യഘടന ഉപയോഗിക്കാം:
മാറ്റുക
ഇവിടെ ഞാൻ നിയന്ത്രണത്തിന്റെ പേര് വ്യക്തമാക്കിയില്ല, കാരണം... DEFAULT-ന്റെ കാര്യത്തിൽ, ഇത് അത്ര നിർണായകമല്ലെന്ന് എനിക്ക് അഭിപ്രായമുണ്ട്. എന്നാൽ നിങ്ങൾ അത് നല്ല രീതിയിൽ ചെയ്യുകയാണെങ്കിൽ, നിങ്ങൾ മടിയനാകേണ്ടതില്ലെന്നും നിങ്ങൾ ഒരു സാധാരണ പേര് സജ്ജീകരിക്കണമെന്നും ഞാൻ കരുതുന്നു. ഇത് ഇനിപ്പറയുന്ന രീതിയിൽ ചെയ്യുന്നു:
മാറ്റുക
ഈ കോളം മുമ്പ് നിലവിലില്ലാത്തതിനാൽ, ഓരോ റെക്കോർഡിലേക്കും ഇത് ചേർക്കുമ്പോൾ, നിലവിലെ തീയതി മൂല്യം HireDate ഫീൽഡിൽ ചേർക്കും.
ഒരു പുതിയ എൻട്രി ചേർക്കുമ്പോൾ, നിലവിലെ തീയതിയും സ്വയമേവ ചേർക്കും, തീർച്ചയായും, ഞങ്ങൾ അത് വ്യക്തമായി സജ്ജീകരിച്ചില്ലെങ്കിൽ, അതായത്. നിരകളുടെ പട്ടികയിൽ ഞങ്ങൾ അത് സൂചിപ്പിക്കില്ല. ചേർത്ത മൂല്യങ്ങളുടെ പട്ടികയിൽ HireDate ഫീൽഡ് വ്യക്തമാക്കാതെ തന്നെ ഇത് ഒരു ഉദാഹരണം ഉപയോഗിച്ച് കാണിക്കാം:
ജീവനക്കാരെ ചേർക്കുക(ഐഡി, പേര്, ഇമെയിൽ) മൂല്യങ്ങൾ(1004,N"Sergeev S.S."," [ഇമെയിൽ പരിരക്ഷിതം]")
എന്താണ് സംഭവിച്ചതെന്ന് നമുക്ക് നോക്കാം:
ജീവനക്കാരിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക
| ഐഡി | പേര് | ജന്മദിനം | ഇമെയിൽ | സ്ഥാനം ഐഡി | വകുപ്പ് ഐഡി | മാനേജർ ഐ.ഡി | വാടക തീയതി |
|---|---|---|---|---|---|---|---|
| 1000 | ഇവാനോവ് I.I. | 1955-02-19 | [ഇമെയിൽ പരിരക്ഷിതം] | 2 | 1 | ശൂന്യം | 2015-04-08 |
| 1001 | പെട്രോവ് പി.പി. | 1983-12-03 | [ഇമെയിൽ പരിരക്ഷിതം] | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | സിഡോറോവ് എസ്.എസ്. | 1976-06-07 | [ഇമെയിൽ പരിരക്ഷിതം] | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | ആൻഡ്രീവ് എ.എ. | 1982-04-17 | [ഇമെയിൽ പരിരക്ഷിതം] | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | സെർജീവ് എസ്.എസ്. | ശൂന്യം | [ഇമെയിൽ പരിരക്ഷിതം] | ശൂന്യം | ശൂന്യം | ശൂന്യം | 2015-04-08 |
ഒരു ഫീൽഡിൽ ചേർത്തിരിക്കുന്ന മൂല്യങ്ങൾ പരിശോധിക്കാൻ ആവശ്യമുള്ളപ്പോൾ ചെക്ക് ചെക്ക് കൺസ്ട്രൈന്റ് ഉപയോഗിക്കുന്നു. ഉദാഹരണത്തിന്, നമുക്ക് ഒരു ജീവനക്കാരുടെ ഐഡന്റിഫയർ (ഐഡി) ആയ വ്യക്തികളുടെ നമ്പർ ഫീൽഡിൽ ഈ നിയന്ത്രണം ഏർപ്പെടുത്താം. ഈ നിയന്ത്രണം ഉപയോഗിച്ച്, പേഴ്സണൽ നമ്പറുകൾക്ക് 1000 മുതൽ 1999 വരെയുള്ള മൂല്യം ഉണ്ടായിരിക്കണമെന്ന് ഞങ്ങൾ പറയുന്നു:
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ CK_Employees_ID പരിശോധന ചേർക്കുക (1000 നും 1999 നും ഇടയിലുള്ള ഐഡി)
നിയന്ത്രണത്തിന് സാധാരണയായി അതേ പേര് നൽകാറുണ്ട്, ആദ്യം "CK_" എന്ന പ്രിഫിക്സ് ഉപയോഗിച്ച്, തുടർന്ന് പട്ടികയുടെ പേരും ഈ നിയന്ത്രണം ഏർപ്പെടുത്തിയിരിക്കുന്ന ഫീൽഡിന്റെ പേരും.
നിയന്ത്രണം പ്രവർത്തിക്കുന്നുണ്ടോയെന്ന് പരിശോധിക്കാൻ നമുക്ക് ഒരു അസാധുവായ റെക്കോർഡ് ചേർക്കാൻ ശ്രമിക്കാം (അനുബന്ധമായ പിശക് നമുക്ക് ലഭിക്കും):
ജീവനക്കാരുടെ (ഐഡി, ഇമെയിൽ) മൂല്യങ്ങൾ (2000," ചേർക്കുക [ഇമെയിൽ പരിരക്ഷിതം]")
ഇപ്പോൾ ചേർത്ത മൂല്യം 1500 ആക്കി മാറ്റി റെക്കോർഡ് ചേർത്തിട്ടുണ്ടെന്ന് ഉറപ്പാക്കാം:
ജീവനക്കാരുടെ (ഐഡി, ഇമെയിൽ) മൂല്യങ്ങൾ (1500," ചേർക്കുക [ഇമെയിൽ പരിരക്ഷിതം]")
ഒരു പേര് വ്യക്തമാക്കാതെ തന്നെ നിങ്ങൾക്ക് UNIQUE, CHECK നിയന്ത്രണങ്ങൾ സൃഷ്ടിക്കാനും കഴിയും:
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ അദ്വിതീയത ചേർക്കുക (ഇമെയിൽ) ഇതര പട്ടിക ജീവനക്കാർ ചെക്ക് ചേർക്കുക (1000 നും 1999 നും ഇടയിലുള്ള ഐഡി)
എന്നാൽ ഇത് വളരെ നല്ല രീതിയല്ല, കാരണം പരിമിതിയുടെ പേര് വ്യക്തമായി വ്യക്തമാക്കുന്നതാണ് നല്ലത്. ഇത് പിന്നീട് മനസിലാക്കാൻ, അത് കൂടുതൽ ബുദ്ധിമുട്ടായിരിക്കും, നിങ്ങൾ ഒബ്ജക്റ്റ് തുറന്ന് അതിന്റെ ഉത്തരവാദിത്തം എന്താണെന്ന് നോക്കേണ്ടതുണ്ട്.

ഒരു നല്ല പേരിനൊപ്പം, നിയന്ത്രണത്തെക്കുറിച്ചുള്ള ധാരാളം വിവരങ്ങൾ അതിന്റെ പേരിൽ നിന്ന് നേരിട്ട് മനസ്സിലാക്കാൻ കഴിയും.
കൂടാതെ, അതനുസരിച്ച്, ഒരു പട്ടിക സൃഷ്ടിക്കുമ്പോൾ ഈ നിയന്ത്രണങ്ങളെല്ലാം ഉടനടി സൃഷ്ടിക്കാൻ കഴിയും, അത് ഇതുവരെ നിലവിലില്ലെങ്കിൽ. നമുക്ക് പട്ടിക ഇല്ലാതാക്കാം:
ഡ്രോപ്പ് ടേബിൾ ജീവനക്കാർ
ഒരു CREATE TABLE കമാൻഡ് ഉപയോഗിച്ച് സൃഷ്ടിച്ച എല്ലാ നിയന്ത്രണങ്ങളും ഉപയോഗിച്ച് ഞങ്ങൾ ഇത് പുനർനിർമ്മിക്കും:
ടേബിൾ ജീവനക്കാരെ സൃഷ്ടിക്കുക (ID int NULL അല്ല, പേര് nvarchar(30), ജന്മദിന തീയതി, ഇമെയിൽ nvarchar(30), PositionID int, DepartmentID int, HireDate date NULL DEFAULT SYSDATETIME(), -- DEFAULT-ന് ഞാൻ PKNS_ETRAI-ഉം ഒരു അപവാദം ഉണ്ടാക്കും. പ്രൈമറി കീ (ഐഡി), പരിമിതമായ FK_Employees_DepartmentID വിദേശ കീ (DepartmentID) റഫറൻസ് വകുപ്പുകൾ(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) സ്ഥാനങ്ങൾ IQUE (ഇമെയിൽ), CK_Employees_ID പരിശോധിക്കുക (1000 നും 1999 നും ഇടയിലുള്ള ID))
ജീവനക്കാരെ ചേർക്കുക (ഐഡി, പേര്, ജന്മദിനം, ഇമെയിൽ, പൊസിഷൻ ഐഡി, ഡിപ്പാർട്ട്മെന്റ് ഐഡി) മൂല്യങ്ങൾ (1000,N"ഇവാനോവ് I.I.","19550219"," [ഇമെയിൽ പരിരക്ഷിതം]",2,1), (1001,N"പെട്രോവ് പി.പി.","19831203"," [ഇമെയിൽ പരിരക്ഷിതം]",3,3), (1002,N"Sidorov S.S.","19760607"," [ഇമെയിൽ പരിരക്ഷിതം]",1,2), (1003,N"ആന്ദ്രീവ് എ.എ.","19820417"," [ഇമെയിൽ പരിരക്ഷിതം]",4,3)
പ്രൈമറി കീയും അദ്വിതീയവുമായ നിയന്ത്രണങ്ങൾ സൃഷ്ടിക്കുമ്പോൾ സൃഷ്ടിച്ച സൂചികകളെക്കുറിച്ച് കുറച്ച്
മുകളിലെ സ്ക്രീൻഷോട്ടിൽ നിങ്ങൾക്ക് കാണാനാകുന്നതുപോലെ, പ്രാഥമിക കീയും തനതായ നിയന്ത്രണങ്ങളും സൃഷ്ടിക്കുമ്പോൾ, സമാന പേരുകളുള്ള സൂചികകൾ (PK_Employees, UQ_Employees_Email) സ്വയമേവ സൃഷ്ടിക്കപ്പെട്ടു. സ്ഥിരസ്ഥിതിയായി, പ്രാഥമിക കീയ്ക്കുള്ള സൂചിക CLUSTERED ആയും മറ്റെല്ലാ സൂചികകൾക്കായി NONCLUSTERED ആയും സൃഷ്ടിച്ചിരിക്കുന്നു. ഒരു ക്ലസ്റ്റർ സൂചിക എന്ന ആശയം എല്ലാ ഡിബിഎംഎസുകളിലും ലഭ്യമല്ലെന്ന് പറയേണ്ടതാണ്. ഒരു പട്ടികയ്ക്ക് ഒരു ക്ലസ്റ്റേഡ് സൂചിക മാത്രമേ ഉണ്ടാകൂ. ക്ലസ്റ്റേഡ് - ഈ സൂചിക പ്രകാരം പട്ടിക റെക്കോർഡുകൾ അടുക്കും എന്നാണ് അർത്ഥമാക്കുന്നത്, ഈ സൂചികയ്ക്ക് പട്ടികയിലെ എല്ലാ ഡാറ്റയിലേക്കും നേരിട്ട് ആക്സസ് ഉണ്ടെന്നും നമുക്ക് പറയാം. ഇത് പട്ടികയുടെ പ്രധാന സൂചികയാണ്, സംസാരിക്കാൻ. കൂടുതൽ ഏകദേശമായി പറഞ്ഞാൽ, ഇത് ഒരു പട്ടികയിൽ ഘടിപ്പിച്ചിരിക്കുന്ന ഒരു സൂചികയാണ്. ക്വറി ഒപ്റ്റിമൈസേഷനെ സഹായിക്കുന്ന വളരെ ശക്തമായ ഒരു ടൂളാണ് ക്ലസ്റ്റേർഡ് ഇൻഡക്സ്, എന്നാൽ നമുക്ക് ഇത് ഇപ്പോൾ ഓർക്കാം. ക്ലസ്റ്റേർഡ് ഇൻഡക്സ് പ്രൈമറി കീയിലല്ല, മറ്റൊരു ഇൻഡക്സിലാണെന്ന് പറയണമെങ്കിൽ, പ്രാഥമിക കീ സൃഷ്ടിക്കുമ്പോൾ നമ്മൾ NONCLUSTERED ഓപ്ഷൻ വ്യക്തമാക്കണം:പട്ടികയുടെ_നാമം മാറ്റുക.
ഉദാഹരണത്തിന്, നിയന്ത്രണ സൂചിക PK_Employees നോൺ-ക്ലസ്റ്റേർഡ് ആക്കാം, കൂടാതെ UQ_Employees_Email ക്ലസ്റ്റേർഡ് ഇൻഡെക്സ്. ആദ്യം, നമുക്ക് ഈ നിയന്ത്രണങ്ങൾ നീക്കംചെയ്യാം:
ആൾട്ടർ ടേബിൾ ജീവനക്കാർ പരിമിതപ്പെടുത്തുന്നു PK_Employees ALTER TABLE ജീവനക്കാർ DROP CONSTRAINT UQ_Employees_Email
ഇപ്പോൾ നമുക്ക് അവ ക്ലസ്റ്റേഡ്, നോൺക്ലസ്റ്റേർഡ് ഓപ്ഷനുകൾ ഉപയോഗിച്ച് സൃഷ്ടിക്കാം:
ALTER TABLE ജീവനക്കാർ PK_Employees പ്രൈമറി കീ നോൺക്ലസ്റ്റേഡ് (ID) ALTER TABLE ജീവനക്കാർ നിയന്ത്രണങ്ങൾ ചേർക്കുക UQ_Employees_Email UNIQUE CLUSTERED (ഇമെയിൽ)
ഇപ്പോൾ, എംപ്ലോയീസ് ടേബിളിൽ നിന്ന് തിരഞ്ഞെടുക്കുന്നതിലൂടെ, UQ_Employees_Email ക്ലസ്റ്റേർഡ് ഇൻഡക്സ് പ്രകാരം രേഖകൾ അടുക്കുന്നത് നമുക്ക് കാണാം:
ജീവനക്കാരിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക
| ഐഡി | പേര് | ജന്മദിനം | ഇമെയിൽ | സ്ഥാനം ഐഡി | വകുപ്പ് ഐഡി | വാടക തീയതി |
|---|---|---|---|---|---|---|
| 1003 | ആൻഡ്രീവ് എ.എ. | 1982-04-17 | [ഇമെയിൽ പരിരക്ഷിതം] | 4 | 3 | 2015-04-08 |
| 1000 | ഇവാനോവ് I.I. | 1955-02-19 | [ഇമെയിൽ പരിരക്ഷിതം] | 2 | 1 | 2015-04-08 |
| 1001 | പെട്രോവ് പി.പി. | 1983-12-03 | [ഇമെയിൽ പരിരക്ഷിതം] | 3 | 3 | 2015-04-08 |
| 1002 | സിഡോറോവ് എസ്.എസ്. | 1976-06-07 | [ഇമെയിൽ പരിരക്ഷിതം] | 1 | 2 | 2015-04-08 |
മുമ്പ്, ക്ലസ്റ്റേർഡ് സൂചിക PK_Employees സൂചിക ആയിരുന്നപ്പോൾ, സ്ഥിരസ്ഥിതിയായി ID ഫീൽഡ് പ്രകാരം റെക്കോർഡുകൾ അടുക്കി.
എന്നാൽ ഈ സാഹചര്യത്തിൽ, ഇത് ഒരു ക്ലസ്റ്റേർഡ് സൂചികയുടെ സത്ത കാണിക്കുന്ന ഒരു ഉദാഹരണം മാത്രമാണ്, കാരണം മിക്കവാറും, ഐഡി ഫീൽഡ് ഉപയോഗിച്ച് എംപ്ലോയീസ് ടേബിളിലേക്ക് അന്വേഷണങ്ങൾ നടത്താം, ചില സന്ദർഭങ്ങളിൽ, അത് തന്നെ ഒരു ഡയറക്ടറിയായി പ്രവർത്തിക്കും.
ഡയറക്ടറികൾക്കായി, പ്രാഥമിക കീയിൽ ക്ലസ്റ്റേർഡ് ഇൻഡക്സ് നിർമ്മിക്കുന്നത് സാധാരണയായി ഉചിതമാണ്, കാരണം അഭ്യർത്ഥനകളിൽ നമ്മൾ പലപ്പോഴും ഡയറക്ടറി ഐഡന്റിഫയറിലേക്ക് റഫർ ചെയ്യുന്നു, ഉദാഹരണത്തിന്, പേര് (സ്ഥാനം, വകുപ്പ്). ഒരു ക്ലസ്റ്റേർഡ് ഇൻഡക്സിന് ടേബിൾ വരികളിലേക്ക് നേരിട്ട് ആക്സസ് ഉണ്ടെന്ന് ഞാൻ മുകളിൽ എഴുതിയത് ഇവിടെ ഓർക്കാം, കൂടാതെ അധിക ഓവർഹെഡ് കൂടാതെ ഏത് നിരയുടെയും മൂല്യം നമുക്ക് ലഭിക്കും.
ഏറ്റവും കൂടുതൽ തവണ സാമ്പിൾ ചെയ്യുന്ന ഫീൽഡുകളിൽ ഒരു ക്ലസ്റ്റർ സൂചിക പ്രയോഗിക്കുന്നത് പ്രയോജനകരമാണ്.
ചിലപ്പോൾ ഒരു സറോഗേറ്റ് ഫീൽഡിനെ അടിസ്ഥാനമാക്കി ഒരു കീ ഉപയോഗിച്ച് പട്ടികകൾ സൃഷ്ടിക്കപ്പെടുന്നു; ഈ സാഹചര്യത്തിൽ, കൂടുതൽ അനുയോജ്യമായ ഒരു സൂചികയ്ക്കായി ക്ലസ്റ്റേർഡ് ഇൻഡക്സ് ഓപ്ഷൻ സേവ് ചെയ്യുകയും ഒരു സറോഗേറ്റ് പ്രൈമറി കീ സൃഷ്ടിക്കുമ്പോൾ നോൺക്ലസ്റ്റേർഡ് ഓപ്ഷൻ വ്യക്തമാക്കുകയും ചെയ്യുന്നത് ഉപയോഗപ്രദമാകും.
നമുക്ക് സംഗ്രഹിക്കാം
ഈ ഘട്ടത്തിൽ, എല്ലാ തരത്തിലുമുള്ള നിയന്ത്രണങ്ങളേയും അവയുടെ ഏറ്റവും ലളിതമായ രൂപത്തിൽ ഞങ്ങൾ പരിചയപ്പെട്ടു, അവ "ALTER TABLE table_name ADD CONSTRAINT constraint_name..." പോലെയുള്ള ഒരു കമാൻഡ് ഉപയോഗിച്ച് സൃഷ്ടിക്കപ്പെട്ടിരിക്കുന്നു:- പ്രൈമറി കീ- പ്രാഥമിക കീ;
- വിദേശ കീ- കണക്ഷനുകൾ സജ്ജീകരിക്കുകയും ഡാറ്റയുടെ റഫറൻഷ്യൽ സമഗ്രത നിരീക്ഷിക്കുകയും ചെയ്യുക;
- തനത്- അതുല്യത സൃഷ്ടിക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു;
- ചെക്ക്- നൽകിയ ഡാറ്റയുടെ കൃത്യത ഉറപ്പാക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു;
- ഡിഫോൾട്ട്- സ്ഥിരസ്ഥിതി മൂല്യം സജ്ജമാക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു;
- "" എന്ന കമാൻഡ് ഉപയോഗിച്ച് എല്ലാ നിയന്ത്രണങ്ങളും നീക്കം ചെയ്യാമെന്നതും ശ്രദ്ധിക്കേണ്ടതാണ്. ആൾട്ടർ ടേബിൾപട്ടിക_പേര് ഡ്രോപ്പ് കൺസ്ട്രൈന്റ് constraint_name".
ഒറ്റപ്പെട്ട സൂചികകൾ സൃഷ്ടിക്കുന്നു
ഇവിടെ സ്വതന്ത്രമെന്നാൽ ഞങ്ങൾ അർത്ഥമാക്കുന്നത് പ്രാഥമിക കീ അല്ലെങ്കിൽ തനതായ നിയന്ത്രണത്തിന് കീഴിൽ സൃഷ്ടിക്കാത്ത സൂചികകളാണ്.ഇനിപ്പറയുന്ന കമാൻഡ് ഉപയോഗിച്ച് ഒരു ഫീൽഡിലോ ഫീൽഡുകളിലോ സൂചികകൾ സൃഷ്ടിക്കാൻ കഴിയും:
ജീവനക്കാരുടെ ഇൻഡക്സ് IDX_Employees_Name (പേര്) സൃഷ്ടിക്കുക
കൂടാതെ ഇവിടെ നിങ്ങൾക്ക് CLUSTERED, NONCLUSTERED, UNIQUE എന്നീ ഓപ്ഷനുകൾ വ്യക്തമാക്കാൻ കഴിയും, കൂടാതെ ഓരോ വ്യക്തിഗത ഫീൽഡ് ASC (സ്ഥിരസ്ഥിതി) അല്ലെങ്കിൽ DESC എന്നിവയുടെ സോർട്ടിംഗ് ദിശയും നിങ്ങൾക്ക് വ്യക്തമാക്കാം:
ജീവനക്കാരിൽ യുക്യു_എംപ്ലോയീസ്_ഇമെയിൽ ഡെസ്ക് (ഇമെയിൽ ഡെസ്ക്) സൃഷ്ടിക്കുക.
ഒരു നോൺ-ക്ലസ്റ്റേർഡ് ഇൻഡക്സ് സൃഷ്ടിക്കുമ്പോൾ, NONCLUSTERED ഓപ്ഷൻ ഒഴിവാക്കാവുന്നതാണ്, കാരണം ഇത് സ്ഥിരസ്ഥിതിയായി സൂചിപ്പിക്കപ്പെടുന്നു, കമാൻഡിലെ ക്ലസ്റ്റേഡ് അല്ലെങ്കിൽ നോൺക്ലസ്റ്റേഡ് ഓപ്ഷന്റെ സ്ഥാനം സൂചിപ്പിക്കാൻ ഇവിടെ കാണിക്കുന്നു.
ഇനിപ്പറയുന്ന കമാൻഡ് ഉപയോഗിച്ച് നിങ്ങൾക്ക് സൂചിക ഇല്ലാതാക്കാം:
ജീവനക്കാരുടെ IDX_Employees_Name INDEX ഡ്രോപ്പ് ചെയ്യുക
CREATE TABLE കമാൻഡിന്റെ പശ്ചാത്തലത്തിൽ ലളിതമായ സൂചികകളും നിയന്ത്രണങ്ങളും സൃഷ്ടിക്കാൻ കഴിയും.
ഉദാഹരണത്തിന്, പട്ടിക വീണ്ടും ഇല്ലാതാക്കാം:
ഡ്രോപ്പ് ടേബിൾ ജീവനക്കാർ
ഒരു CREATE TABLE കമാൻഡ് ഉപയോഗിച്ച് സൃഷ്ടിച്ച എല്ലാ നിയന്ത്രണങ്ങളും സൂചികകളും ഉപയോഗിച്ച് ഞങ്ങൾ ഇത് പുനർനിർമ്മിക്കും:
ടേബിൾ ജീവനക്കാരെ സൃഷ്ടിക്കുക (ID int NULL, പേര് nvarchar(30), ജന്മദിന തീയതി, ഇമെയിൽ nvarchar(30), PositionID int, DepartmentID int, HireDate തീയതി നിയന്ത്രിതമല്ല DF_Employees_HireDate DEFAULT TIME, SYSCORP ARY കീ (ID ), CONSTRAINT FK_Employees_DepartmentID ഫോറിൻ കീ(DepartmentID) റഫറൻസ് വകുപ്പുകൾ(ID), പരിമിതമായ FK_Employees_PositionID ഫോറിൻ കീ(PositionID) REFERENCES സ്ഥാനങ്ങൾ മാനേജർഐഡി) റഫറൻസുകൾ ജീവനക്കാർ(ഐഡി), പരിമിതമായ UQ_Email ees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID ചെക്ക് (1000 നും 1999 നും ഇടയിലുള്ള ID), INDEX IDX_Employees_Name(Name))
അവസാനമായി, നമ്മുടെ ജീവനക്കാരെ പട്ടികയിലേക്ക് തിരുകാം:
ജീവനക്കാരെ ചേർക്കുക (ഐഡി, പേര്, ജന്മദിനം, ഇമെയിൽ, പൊസിഷൻ ഐഡി, ഡിപ്പാർട്ട്മെന്റ് ഐഡി, മാനേജർ ഐഡി) മൂല്യങ്ങൾ (1000,N"ഇവാനോവ് I.I.","19550219"," [ഇമെയിൽ പരിരക്ഷിതം]",2,1,NULL), (1001,N"പെട്രോവ് പി.പി.","19831203"," [ഇമെയിൽ പരിരക്ഷിതം]",3,3,1003), (1002,N"Sidorov S.S.","19760607"," [ഇമെയിൽ പരിരക്ഷിതം]",1,2,1000), (1003,N"ആന്ദ്രീവ് എ.എ.","19820417"," [ഇമെയിൽ പരിരക്ഷിതം]",4,3,1000)
കൂടാതെ, INCLUDE എന്നതിൽ വ്യക്തമാക്കുന്നതിലൂടെ നിങ്ങൾക്ക് ഒരു നോൺ-ക്ലസ്റ്റേർഡ് ഇൻഡക്സിൽ മൂല്യങ്ങൾ ഉൾപ്പെടുത്താനാകുമെന്നത് ശ്രദ്ധിക്കേണ്ടതാണ്. ആ. ഈ സാഹചര്യത്തിൽ, INCLUDE സൂചിക ഒരു ക്ലസ്റ്റേർഡ് സൂചികയെ അനുസ്മരിപ്പിക്കും, ഇപ്പോൾ സൂചിക പട്ടികയിൽ ഘടിപ്പിച്ചിട്ടില്ല, പക്ഷേ ആവശ്യമായ മൂല്യങ്ങൾ സൂചികയിൽ ഘടിപ്പിച്ചിരിക്കുന്നു. അതനുസരിച്ച്, അത്തരം സൂചികകൾക്ക് തിരഞ്ഞെടുക്കൽ അന്വേഷണങ്ങളുടെ (SELECT) പ്രകടനം വളരെയധികം മെച്ചപ്പെടുത്താൻ കഴിയും; ലിസ്റ്റുചെയ്ത എല്ലാ ഫീൽഡുകളും സൂചികയിലാണെങ്കിൽ, പട്ടികയിലേക്കുള്ള പ്രവേശനം ആവശ്യമില്ല. എന്നാൽ ഇത് സ്വാഭാവികമായും സൂചികയുടെ വലിപ്പം വർദ്ധിപ്പിക്കുന്നു, കാരണം ലിസ്റ്റുചെയ്ത ഫീൽഡുകളുടെ മൂല്യങ്ങൾ സൂചികയിൽ തനിപ്പകർപ്പാക്കിയിരിക്കുന്നു.
MSDN-ൽ നിന്ന് എക്സ്ട്രാക്റ്റ് ചെയ്യുക.സൂചികകൾ സൃഷ്ടിക്കുന്നതിനുള്ള പൊതുവായ കമാൻഡ് വാക്യഘടനസൃഷ്ടിക്കുക [അതുല്യ] [ക്ലസ്റ്റേഡ് | NONCLUSTERED ] INDEX index_name ഓണാണ്
നമുക്ക് സംഗ്രഹിക്കാം
സൂചികകൾക്ക് ഡാറ്റ വീണ്ടെടുക്കലിന്റെ വേഗത വർദ്ധിപ്പിക്കാൻ കഴിയും (SELECT), എന്നാൽ സൂചികകൾ പട്ടിക ഡാറ്റ പരിഷ്ക്കരണത്തിന്റെ വേഗത കുറയ്ക്കുന്നു, കാരണം ഓരോ പരിഷ്ക്കരണത്തിനും ശേഷം, സിസ്റ്റം ഒരു നിർദ്ദിഷ്ട പട്ടികയ്ക്കായി എല്ലാ സൂചികകളും പുനർനിർമ്മിക്കേണ്ടതുണ്ട്.ഓരോ സാഹചര്യത്തിലും, ഒപ്റ്റിമൽ സൊല്യൂഷൻ, സുവർണ്ണ ശരാശരി കണ്ടെത്തുന്നത് ഉചിതമാണ്, അതുവഴി സാംപ്ലിംഗും ഡാറ്റ മോഡിഫിക്കേഷൻ പ്രകടനവും ശരിയായ തലത്തിലായിരിക്കും. സൂചികകൾ സൃഷ്ടിക്കുന്നതിനുള്ള തന്ത്രവും സൂചികകളുടെ എണ്ണവും പട്ടികയിലെ ഡാറ്റ എത്ര തവണ മാറുന്നു എന്നതുപോലുള്ള പല ഘടകങ്ങളെ ആശ്രയിച്ചിരിക്കും.
DDL-നെക്കുറിച്ചുള്ള നിഗമനം
നിങ്ങൾക്ക് കാണാനാകുന്നതുപോലെ, DDL ഒറ്റനോട്ടത്തിൽ തോന്നിയേക്കാവുന്നത്ര സങ്കീർണ്ണമല്ല. മൂന്ന് ടേബിളുകൾ ഉപയോഗിച്ച് അതിന്റെ മിക്കവാറും എല്ലാ പ്രധാന ഘടനകളും ഇവിടെ കാണിക്കാൻ എനിക്ക് കഴിഞ്ഞു.പ്രധാന കാര്യം സാരാംശം മനസ്സിലാക്കുക എന്നതാണ്, ബാക്കിയുള്ളത് പരിശീലനത്തിന്റെ കാര്യമാണ്.
SQL എന്ന ഈ അത്ഭുതകരമായ ഭാഷയിൽ പ്രാവീണ്യം നേടിയതിൽ ഭാഗ്യം.
നമ്മൾ ഓരോരുത്തരും പതിവായി വിവിധ ഡാറ്റാബേസുകൾ കണ്ടുമുട്ടുകയും ഉപയോഗിക്കുകയും ചെയ്യുന്നു. ഞങ്ങൾ ഒരു ഇമെയിൽ വിലാസം തിരഞ്ഞെടുക്കുമ്പോൾ, ഞങ്ങൾ ഒരു ഡാറ്റാബേസുമായി പ്രവർത്തിക്കുന്നു. തിരയൽ സേവനങ്ങൾ, ഉപഭോക്തൃ ഡാറ്റ സംഭരിക്കുന്നതിന് ബാങ്കുകൾ മുതലായവ ഡാറ്റാബേസുകൾ ഉപയോഗിക്കുന്നു.
ഡാറ്റാബേസുകളുടെ നിരന്തരമായ ഉപയോഗം ഉണ്ടായിരുന്നിട്ടും, പല സോഫ്റ്റ്വെയർ സിസ്റ്റം ഡെവലപ്പർമാർക്കും ഒരേ പദങ്ങളുടെ വ്യത്യസ്ത വ്യാഖ്യാനങ്ങൾ കാരണം ഇപ്പോഴും നിരവധി ബ്ലൈൻഡ് സ്പോട്ടുകൾ ഉണ്ട്. SQL ഭാഷ കവർ ചെയ്യുന്നതിന് മുമ്പ് ഞങ്ങൾ അടിസ്ഥാന ഡാറ്റാബേസ് നിബന്ധനകളുടെ ഒരു ഹ്രസ്വ നിർവചനം നൽകും. അങ്ങനെ.
ഡാറ്റാബേസ് - ഓർഡർ ചെയ്ത ഡാറ്റ ഘടനകളും അവയുടെ ബന്ധങ്ങളും സംഭരിക്കുന്നതിനുള്ള ഒരു ഫയൽ അല്ലെങ്കിൽ ഫയലുകളുടെ ശേഖരം. മിക്കപ്പോഴും മാനേജ്മെന്റ് സിസ്റ്റത്തെ ഒരു ഡാറ്റാബേസ് എന്ന് വിളിക്കുന്നു - ഇത് ഒരു പ്രത്യേക ഫോർമാറ്റിലുള്ള വിവരങ്ങളുടെ ഒരു ശേഖരം മാത്രമാണ്, കൂടാതെ വിവിധ ഡിബിഎംഎസുകളിൽ പ്രവർത്തിക്കാനും കഴിയും.
മേശ - ഡോക്യുമെന്റുകൾ സംഭരിച്ചിരിക്കുന്ന ഒരു ഫോൾഡർ സങ്കൽപ്പിക്കുക, ഒരു പ്രത്യേക സ്വഭാവം അനുസരിച്ച് ഗ്രൂപ്പുചെയ്യുക, ഉദാഹരണത്തിന്, കഴിഞ്ഞ മാസത്തെ ഓർഡറുകളുടെ ഒരു ലിസ്റ്റ്. ഇതൊരു കമ്പ്യൂട്ടറിലെ ഒരു പട്ടികയാണ്. ഒരു പ്രത്യേക പട്ടികയ്ക്ക് അതിന്റേതായ തനതായ പേരുണ്ട്.
ഡാറ്റ തരം - ഒരു പ്രത്യേക നിരയിലോ വരിയിലോ സംഭരിക്കാൻ അനുവദിച്ചിരിക്കുന്ന വിവരങ്ങളുടെ തരം. ഇവ ഒരു നിശ്ചിത ഫോർമാറ്റിന്റെ നമ്പറുകളോ വാചകമോ ആകാം.
നിരയും നിരയും- ഞങ്ങളെല്ലാം സ്പ്രെഡ്ഷീറ്റുകൾ ഉപയോഗിച്ച് പ്രവർത്തിച്ചിട്ടുണ്ട്, അവയ്ക്ക് വരികളും നിരകളും ഉണ്ട്. ഏത് റിലേഷണൽ ഡാറ്റാബേസും സമാനമായ രീതിയിൽ പട്ടികകളുമായി പ്രവർത്തിക്കുന്നു. വരികളെ ചിലപ്പോൾ റെക്കോർഡുകൾ എന്ന് വിളിക്കുന്നു.
പ്രാഥമിക കീ- ഒരു ടേബിളിന്റെ ഓരോ വരിയിലും അത് അദ്വിതീയമായി തിരിച്ചറിയാൻ ഒന്നോ അതിലധികമോ നിരകൾ ഉണ്ടായിരിക്കും. ഒരു പ്രാഥമിക കീ ഇല്ലാതെ, പ്രസക്തമായ വരികൾ അപ്ഡേറ്റ് ചെയ്യാനും മാറ്റാനും ഇല്ലാതാക്കാനും വളരെ ബുദ്ധിമുട്ടാണ്.
എന്താണ് SQL?
SQL(ഇംഗ്ലീഷ് - ഘടനാപരമായ അന്വേഷണ ഭാഷ) ഡാറ്റാബേസുകളിൽ പ്രവർത്തിക്കുന്നതിനായി മാത്രം വികസിപ്പിച്ചെടുത്തതാണ്, നിലവിൽ എല്ലാ ജനപ്രിയ ഡിബിഎംഎസുകളുടെയും സ്റ്റാൻഡേർഡാണ്. ഭാഷാ വാക്യഘടനയിൽ ഒരു ചെറിയ എണ്ണം ഓപ്പറേറ്റർമാർ അടങ്ങിയിരിക്കുന്നു, പഠിക്കാൻ എളുപ്പമാണ്. എന്നാൽ, വ്യക്തമായ ലാളിത്യം ഉണ്ടായിരുന്നിട്ടും, ഏത് വലുപ്പത്തിലുമുള്ള ഡാറ്റാബേസ് ഉപയോഗിച്ച് സങ്കീർണ്ണമായ പ്രവർത്തനങ്ങൾക്കായി sql അന്വേഷണങ്ങൾ സൃഷ്ടിക്കാൻ ഇത് അനുവദിക്കുന്നു.
1992 മുതൽ, ANSI SQL എന്ന പൊതുവായി അംഗീകരിക്കപ്പെട്ട ഒരു സ്റ്റാൻഡേർഡ് ഉണ്ട്. ഇത് ഓപ്പറേറ്റർമാരുടെ അടിസ്ഥാന വാക്യഘടനയും പ്രവർത്തനങ്ങളും നിർവചിക്കുന്നു, കൂടാതെ ORACLE പോലുള്ള എല്ലാ DBMS മാർക്കറ്റ് ലീഡർമാരും പിന്തുണയ്ക്കുന്നു. ഒരു ചെറിയ ലേഖനത്തിൽ ഭാഷയുടെ എല്ലാ കഴിവുകളും പരിഗണിക്കുന്നത് അസാധ്യമാണ്, അതിനാൽ ഞങ്ങൾ അടിസ്ഥാന SQL അന്വേഷണങ്ങൾ മാത്രം പരിഗണിക്കും. ഉദാഹരണങ്ങൾ ഭാഷയുടെ ലാളിത്യവും കഴിവുകളും വ്യക്തമായി കാണിക്കുന്നു:
- ഡാറ്റാബേസുകളും പട്ടികകളും സൃഷ്ടിക്കുന്നു;
- ഡാറ്റ സാമ്പിൾ;
- രേഖകൾ ചേർക്കുന്നു;
- വിവരങ്ങളുടെ പരിഷ്ക്കരണവും ഇല്ലാതാക്കലും.
SQL ഡാറ്റ തരങ്ങൾ
ഒരു ഡാറ്റാബേസ് പട്ടികയിലെ എല്ലാ കോളങ്ങളും ഒരേ ഡാറ്റ തരം സംഭരിക്കുന്നു. SQL-ലെ ഡാറ്റ തരങ്ങൾ മറ്റ് പ്രോഗ്രാമിംഗ് ഭാഷകളുടേതിന് സമാനമാണ്.
ഞങ്ങൾ പട്ടികകളും ഡാറ്റാബേസുകളും സൃഷ്ടിക്കുന്നു

SQL-ൽ പുതിയ ഡാറ്റാബേസുകളും പട്ടികകളും മറ്റ് അന്വേഷണങ്ങളും സൃഷ്ടിക്കാൻ രണ്ട് വഴികളുണ്ട്:
- DBMS കൺസോൾ വഴിയുള്ള SQL പ്രസ്താവനകൾ
- ഡാറ്റാബേസ് സെർവറിൽ ഉൾപ്പെടുത്തിയിട്ടുള്ള ഇന്ററാക്ടീവ് അഡ്മിനിസ്ട്രേഷൻ ടൂളുകൾ ഉപയോഗിക്കുന്നു.
ഓപ്പറേറ്റർ ഒരു പുതിയ ഡാറ്റാബേസ് സൃഷ്ടിച്ചു ഡാറ്റാബേസ് സൃഷ്ടിക്കുക<наименование базы данных>; . നിങ്ങൾക്ക് കാണാനാകുന്നതുപോലെ, വാക്യഘടന ലളിതവും സംക്ഷിപ്തവുമാണ്.
ഇനിപ്പറയുന്ന പാരാമീറ്ററുകൾ ഉപയോഗിച്ച് ക്രിയേറ്റ് ടേബിൾ സ്റ്റേറ്റ്മെന്റ് ഉപയോഗിച്ച് ഞങ്ങൾ ഡാറ്റാബേസിനുള്ളിൽ പട്ടികകൾ സൃഷ്ടിക്കുന്നു:
- പട്ടികയുടെ പേര്
- കോളത്തിന്റെ പേരുകളും ഡാറ്റ തരങ്ങളും
ഒരു ഉദാഹരണമായി, ഇനിപ്പറയുന്ന നിരകളുള്ള ഒരു ചരക്ക് പട്ടിക സൃഷ്ടിക്കാം:
ഒരു പട്ടിക ഉണ്ടാക്കുക:
ടേബിൾ ചരക്ക് സൃഷ്ടിക്കുക
(commodity_id CHAR(15) NULL അല്ല,
vendor_id CHAR(15) ശൂന്യമല്ല,
ചരക്ക്_നാമം CHAR(254) NULL,
ചരക്ക്_വില ഡെസിമൽ(8,2) NULL,
commodity_desc VARCHAR(1000) NULL);
പട്ടികയിൽ അഞ്ച് നിരകൾ അടങ്ങിയിരിക്കുന്നു. പേര് വന്നതിന് ശേഷം ഡാറ്റ തരം, കോളങ്ങൾ കോമകളാൽ വേർതിരിക്കപ്പെടുന്നു. കോളം മൂല്യത്തിന് ശൂന്യമായ മൂല്യങ്ങൾ സ്വീകരിക്കാം (NULL) അല്ലെങ്കിൽ പൂരിപ്പിക്കണം (NULL), പട്ടിക സൃഷ്ടിക്കുമ്പോൾ ഇത് നിർണ്ണയിക്കപ്പെടുന്നു.
ഒരു പട്ടികയിൽ നിന്ന് ഡാറ്റ വീണ്ടെടുക്കുന്നു

ഏറ്റവും സാധാരണയായി ഉപയോഗിക്കുന്ന SQL അന്വേഷണമാണ് ഡാറ്റ ലഭ്യമാക്കൽ ഓപ്പറേറ്റർ. വിവരങ്ങൾ ലഭിക്കുന്നതിന്, അത്തരമൊരു പട്ടികയിൽ നിന്ന് എന്താണ് തിരഞ്ഞെടുക്കേണ്ടതെന്ന് ഞങ്ങൾ സൂചിപ്പിക്കണം. ആദ്യം ഒരു ലളിതമായ ഉദാഹരണം:
ചരക്കിൽ നിന്ന് commodity_name തിരഞ്ഞെടുക്കുക
SELECT പ്രസ്താവനയ്ക്ക് ശേഷം, വിവരങ്ങൾ ലഭിക്കുന്നതിന് കോളത്തിന്റെ പേര് ഞങ്ങൾ വ്യക്തമാക്കുന്നു, കൂടാതെ FROM പട്ടിക നിർവചിക്കുന്നു.
ഡാറ്റാബേസിൽ നൽകിയ ക്രമത്തിൽ Commodity_name മൂല്യങ്ങളുള്ള പട്ടികയുടെ എല്ലാ വരികളും അന്വേഷണത്തിന്റെ ഫലം ആയിരിക്കും, അതായത്. യാതൊരു തരംതിരിവുകളും ഇല്ലാതെ. ഫലം ക്രമപ്പെടുത്തുന്നതിന് ക്ലോസ് പ്രകാരം ഒരു അധിക ഓർഡർ ഉപയോഗിക്കുന്നു.
നിരവധി ഫീൽഡുകൾക്കായി അന്വേഷിക്കുന്നതിന്, ഇനിപ്പറയുന്ന ഉദാഹരണത്തിലെന്നപോലെ കോമകളാൽ വേർതിരിച്ച് പട്ടികപ്പെടുത്തുക:
ചരക്കിൽ നിന്ന് commodity_id, commodity_name, commodity_price എന്നിവ തിരഞ്ഞെടുക്കുക
ഒരു വരിയുടെ എല്ലാ നിരകളുടെയും മൂല്യം ഒരു അന്വേഷണ ഫലമായി ലഭിക്കുന്നത് സാധ്യമാണ്. ഇത് ചെയ്യുന്നതിന്, "*" ചിഹ്നം ഉപയോഗിക്കുക:
ചരക്കിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക
- കൂടാതെ SELECT പിന്തുണയ്ക്കുന്നു:
- ഡാറ്റ അടുക്കുന്നു (ഓപ്പറേറ്റർ പ്രകാരം ഓർഡർ ചെയ്യുക)
- വ്യവസ്ഥകൾ അനുസരിച്ച് തിരഞ്ഞെടുക്കൽ (എവിടെ)
- ഗ്രൂപ്പിംഗ് കാലാവധി (ഗ്രൂപ്പ് പ്രകാരം)
ഒരു വരി ചേർക്കുക

ഒരു പട്ടികയിലേക്ക് ഒരു വരി ചേർക്കുന്നതിന്, INSERT ഓപ്പറേറ്ററുമായുള്ള SQL അന്വേഷണങ്ങൾ ഉപയോഗിക്കുന്നു. കൂട്ടിച്ചേർക്കൽ മൂന്ന് തരത്തിൽ ചെയ്യാം:
- ഒരു പുതിയ മുഴുവൻ വരി ചേർക്കുക;
- ചരട് ഭാഗം;
- അന്വേഷണ ഫലങ്ങൾ.
ഒരു മുഴുവൻ വരി ചേർക്കുന്നതിന്, നിങ്ങൾ പട്ടികയുടെ പേരും പുതിയ വരിയുടെ നിരകളുടെ (ഫീൽഡുകൾ) മൂല്യങ്ങളും വ്യക്തമാക്കണം. ഒരു ഉദാഹരണം ഇതാ:
ചരക്ക് മൂല്യങ്ങളിലേക്ക് തിരുകുക ("106 ", "50", "കൊക്കകോള", "1.68", "ആൽക്കോഗോൾ ഇല്ല ,)
ഉദാഹരണം പട്ടികയിലേക്ക് ഒരു പുതിയ ഉൽപ്പന്നം ചേർക്കുന്നു. ഓരോ കോളത്തിനും VALUES എന്നതിന് ശേഷം മൂല്യങ്ങൾ ലിസ്റ്റ് ചെയ്തിരിക്കുന്നു. നിരയ്ക്ക് അനുബന്ധ മൂല്യമില്ലെങ്കിൽ, NULL വ്യക്തമാക്കണം. പട്ടിക സൃഷ്ടിക്കുമ്പോൾ വ്യക്തമാക്കിയ ക്രമത്തിൽ നിരകൾ മൂല്യങ്ങളാൽ നിറഞ്ഞിരിക്കുന്നു.
നിങ്ങൾ ഒരു വരിയുടെ ഭാഗം മാത്രം ചേർക്കുകയാണെങ്കിൽ, ഉദാഹരണത്തിലെന്നപോലെ നിരകളുടെ പേരുകൾ നിങ്ങൾ വ്യക്തമായി വ്യക്തമാക്കണം:
ചരക്കിലേക്ക് തിരുകുക (commodity_id, vendor_id, commodity_name)
മൂല്യങ്ങൾ("106 ", '50", "കൊക്കകോള",)
ഞങ്ങൾ ഉൽപ്പന്നത്തിന്റെയും വിതരണക്കാരന്റെയും അതിന്റെ പേരിന്റെയും ഐഡന്റിഫയറുകൾ മാത്രം നൽകി, ശേഷിക്കുന്ന ഫീൽഡുകൾ ശൂന്യമാക്കി.
അന്വേഷണ ഫലങ്ങൾ ചേർക്കുന്നു
വരികൾ കൂട്ടിച്ചേർക്കാൻ പ്രാഥമികമായി INSERT ഉപയോഗിക്കുന്നു, എന്നാൽ ഒരു SELECT പ്രസ്താവനയുടെ ഫലങ്ങൾ കൂട്ടിച്ചേർക്കാനും ഇത് ഉപയോഗിക്കാം.
ഡാറ്റ മാറ്റുന്നു

ഒരു ഡാറ്റാബേസ് പട്ടികയുടെ ഫീൽഡുകളിലെ വിവരങ്ങൾ മാറ്റുന്നതിന്, നിങ്ങൾ അപ്ഡേറ്റ് സ്റ്റേറ്റ്മെന്റ് ഉപയോഗിക്കണം. ഓപ്പറേറ്ററെ രണ്ട് തരത്തിൽ ഉപയോഗിക്കാം:
- പട്ടികയിലെ എല്ലാ വരികളും അപ്ഡേറ്റ് ചെയ്തു.
- ഒരു പ്രത്യേക ലൈനിന് മാത്രം.
അപ്ഡേറ്റ് മൂന്ന് പ്രധാന ഘടകങ്ങൾ ഉൾക്കൊള്ളുന്നു:
- മാറ്റങ്ങൾ വരുത്തേണ്ട പട്ടിക;
- ഫീൽഡ് നാമങ്ങളും അവയുടെ പുതിയ മൂല്യങ്ങളും;
- മാറ്റാൻ വരികൾ തിരഞ്ഞെടുക്കുന്നതിനുള്ള വ്യവസ്ഥകൾ.
നമുക്ക് ഒരു ഉദാഹരണം നോക്കാം. ID=106 ഉള്ള ഒരു ഉൽപ്പന്നത്തിന്റെ വില മാറിയെന്ന് പറയാം, അതിനാൽ ഈ ലൈൻ അപ്ഡേറ്റ് ചെയ്യേണ്ടതുണ്ട്. ഞങ്ങൾ ഇനിപ്പറയുന്ന ഓപ്പറേറ്റർ എഴുതുന്നു:
അപ്ഡേറ്റ് കമ്മോഡിറ്റി സെറ്റ് commodity_price = "3.2" എവിടെയാണ് commodity_id = "106"
ഞങ്ങൾ പട്ടികയുടെ പേര്, ഞങ്ങളുടെ കാര്യത്തിൽ, അപ്ഡേറ്റ് നടത്തുന്ന ചരക്ക്, തുടർന്ന് SET-ന് ശേഷം - കോളത്തിന്റെ പുതിയ മൂല്യം, WHERE എന്നതിൽ ആവശ്യമായ ഐഡി മൂല്യം വ്യക്തമാക്കി ആവശ്യമുള്ള റെക്കോർഡ് കണ്ടെത്തി.
ഒന്നിലധികം നിരകൾ മാറ്റുന്നതിന്, SET പ്രസ്താവനയ്ക്ക് ശേഷം കോമകളാൽ വേർതിരിച്ച ഒന്നിലധികം കോളം-മൂല്യ ജോഡികൾ. ഒരു ഉൽപ്പന്നത്തിന്റെ പേരും വിലയും അപ്ഡേറ്റ് ചെയ്യുന്ന ഒരു ഉദാഹരണം നോക്കാം:
കമ്മോഡിറ്റി സെറ്റ് അപ്ഡേറ്റ് ചെയ്യുക commodity_name=’Fanta’, commodity_price = "3.2" എവിടെയാണ് commodity_id = "106"
ഒരു നിരയിലെ വിവരങ്ങൾ നീക്കംചെയ്യുന്നതിന്, പട്ടിക ഘടന അനുവദിക്കുകയാണെങ്കിൽ നിങ്ങൾക്ക് NULL എന്ന മൂല്യം നൽകാം. NULL എന്നത് കൃത്യമായി "ഇല്ല" മൂല്യമാണെന്ന് ഓർമ്മിക്കേണ്ടതാണ്, കൂടാതെ വാചകത്തിന്റെയോ നമ്പറിന്റെയോ രൂപത്തിൽ പൂജ്യമല്ല. നമുക്ക് ഉൽപ്പന്ന വിവരണം നീക്കം ചെയ്യാം:
ചരക്ക് സെറ്റ് അപ്ഡേറ്റ് ചെയ്യുക commodity_desc = NULL എവിടെയാണ് commodity_id = "106"
വരികൾ നീക്കംചെയ്യുന്നു

ഒരു പട്ടികയിലെ വരികൾ ഇല്ലാതാക്കുന്നതിനുള്ള SQL അന്വേഷണങ്ങൾ DELETE സ്റ്റേറ്റ്മെന്റ് ഉപയോഗിച്ചാണ് നടപ്പിലാക്കുന്നത്. രണ്ട് ഉപയോഗ കേസുകളുണ്ട്:
- പട്ടികയിലെ ചില വരികൾ ഇല്ലാതാക്കി;
- പട്ടികയിലെ എല്ലാ വരികളും ഇല്ലാതാക്കി.
ഒരു പട്ടികയിൽ നിന്ന് ഒരു വരി ഇല്ലാതാക്കുന്നതിനുള്ള ഒരു ഉദാഹരണം:
commodity_id = "106" എവിടെ നിന്ന് ചരക്കിൽ നിന്ന് ഇല്ലാതാക്കുക
DELETE FROM എന്നതിന് ശേഷം വരികൾ ഇല്ലാതാക്കുന്ന പട്ടികയുടെ പേര് ഞങ്ങൾ സൂചിപ്പിക്കുന്നു. നീക്കം ചെയ്യുന്നതിനായി വരികൾ തിരഞ്ഞെടുക്കേണ്ട വ്യവസ്ഥ WHERE ക്ലോസിൽ അടങ്ങിയിരിക്കുന്നു. ഉദാഹരണത്തിൽ, ID=106 ഉള്ള ഉൽപ്പന്ന ലൈൻ ഞങ്ങൾ ഇല്ലാതാക്കുന്നു. എവിടെയാണെന്ന് വ്യക്തമാക്കുന്നത് വളരെ പ്രധാനമാണ് കാരണം ഈ പ്രസ്താവന ഒഴിവാക്കുന്നത് പട്ടികയിലെ എല്ലാ വരികളും ഇല്ലാതാക്കും. ഫീൽഡുകളുടെ മൂല്യം മാറ്റുന്നതിനും ഇത് ബാധകമാണ്.
DELETE പ്രസ്താവന കോളത്തിന്റെ പേരുകളോ മെറ്റാക്യാരാക്ടറുകളോ വ്യക്തമാക്കുന്നില്ല. ഇത് വരികൾ പൂർണ്ണമായും ഇല്ലാതാക്കുന്നു, പക്ഷേ ഇതിന് ഒരു കോളം പോലും ഇല്ലാതാക്കാൻ കഴിയില്ല.
Microsoft Access-ൽ SQL ഉപയോഗിക്കുന്നു

ടേബിളുകൾ, ഡാറ്റാബേസുകൾ, ഒരു ഡാറ്റാബേസിൽ ഡാറ്റ കൈകാര്യം ചെയ്യുന്നതിനും പരിഷ്ക്കരിക്കുന്നതിനും വിശകലനം ചെയ്യുന്നതിനും സൗകര്യപ്രദമായ ഒരു ഇന്ററാക്ടീവ് ക്വറി ഡിസൈനർ (ക്വറി ഡിസൈനർ) മുഖേന SQL ആക്സസ്സ് ക്വറികൾ നടപ്പിലാക്കുന്നതിനും സാധാരണയായി ഇന്ററാക്ടീവ് ആയി ഉപയോഗിക്കുന്നു.
സെർവർ ആക്സസ് മോഡും പിന്തുണയ്ക്കുന്നു, ഇതിൽ ആക്സസ് DBMS ഏത് ODBC ഡാറ്റാ ഉറവിടത്തിലേക്കും SQL അന്വേഷണങ്ങളുടെ ജനറേറ്ററായി ഉപയോഗിക്കാം. ഏത് ഫോർമാറ്റുമായും സംവദിക്കാൻ ആക്സസ് ആപ്ലിക്കേഷനുകളെ ഈ സവിശേഷത അനുവദിക്കുന്നു.
SQL വിപുലീകരണങ്ങൾ
ലൂപ്പുകൾ, ബ്രാഞ്ചിംഗ് മുതലായവ പോലുള്ള പ്രൊസീജറൽ പ്രോഗ്രാമിംഗ് ഭാഷകളുടെ എല്ലാ കഴിവുകളും SQL അന്വേഷണങ്ങൾക്ക് ഇല്ലാത്തതിനാൽ, DBMS നിർമ്മാതാക്കൾ വിപുലമായ കഴിവുകളോടെ SQL-ന്റെ സ്വന്തം പതിപ്പ് വികസിപ്പിക്കുന്നു. ഒന്നാമതായി, ഇത് സംഭരിച്ച നടപടിക്രമങ്ങൾക്കും നടപടിക്രമ ഭാഷകളുടെ സ്റ്റാൻഡേർഡ് ഓപ്പറേറ്റർമാർക്കുമുള്ള പിന്തുണയാണ്.
ഭാഷയുടെ ഏറ്റവും സാധാരണമായ ഭാഷാഭേദങ്ങൾ:
- ഒറാക്കിൾ ഡാറ്റാബേസ് - PL/SQL
- ഇന്റർബേസ്, ഫയർബേർഡ് - PSQL
- Microsoft SQL സെർവർ - ട്രാൻസാക്റ്റ്-SQL
- PostgreSQL - PL/pgSQL.
ഇന്റർനെറ്റിൽ SQL
MySQL DBMS സൗജന്യ ഗ്നു ജനറൽ പബ്ലിക് ലൈസൻസിന് കീഴിലാണ് വിതരണം ചെയ്യുന്നത്. ഇഷ്ടാനുസൃത മൊഡ്യൂളുകൾ വികസിപ്പിക്കാനുള്ള കഴിവുള്ള ഒരു വാണിജ്യ ലൈസൻസുണ്ട്. ഒരു ഘടകമെന്ന നിലയിൽ, XAMPP, WAMP, LAMP എന്നിവ പോലുള്ള ഇന്റർനെറ്റ് സെർവറുകളുടെ ഏറ്റവും ജനപ്രിയമായ അസംബ്ലികളിൽ ഇത് ഉൾപ്പെടുത്തിയിട്ടുണ്ട്, കൂടാതെ ഇന്റർനെറ്റിൽ ആപ്ലിക്കേഷനുകൾ വികസിപ്പിക്കുന്നതിനുള്ള ഏറ്റവും ജനപ്രിയമായ DBMS ആണ്.
ഇത് സൺ മൈക്രോസിസ്റ്റംസ് വികസിപ്പിച്ചെടുത്തു, നിലവിൽ ഒറാക്കിൾ കോർപ്പറേഷന്റെ പിന്തുണയുണ്ട്. 64 ടെറാബൈറ്റ് വലുപ്പമുള്ള ഡാറ്റാബേസുകൾ, SQL:2003 വാക്യഘടന നിലവാരം, ഡാറ്റാബേസുകളുടെ പകർപ്പ്, ക്ലൗഡ് സേവനങ്ങൾ എന്നിവ പിന്തുണയ്ക്കുന്നു.
ഇന്ന്, "ഡമ്മികൾക്കുള്ള" SQL കോഴ്സുകൾ കൂടുതൽ പ്രചാരത്തിലുണ്ട്. ഇത് വളരെ ലളിതമായി വിശദീകരിക്കാം, കാരണം ആധുനിക ലോകത്ത് നിങ്ങൾക്ക് "ഡൈനാമിക്" എന്ന് വിളിക്കപ്പെടുന്ന വെബ് സേവനങ്ങൾ കൂടുതലായി കണ്ടെത്താൻ കഴിയും. അവ തികച്ചും ഫ്ലെക്സിബിൾ ഷെൽ കൊണ്ട് വേർതിരിച്ചിരിക്കുന്നു, കൂടാതെ വെബ്സൈറ്റുകൾ സമർപ്പിക്കാൻ തീരുമാനിക്കുന്ന എല്ലാ തുടക്കക്കാരായ പ്രോഗ്രാമർമാരെയും അടിസ്ഥാനമാക്കിയുള്ളവയാണ്, ആദ്യം "ഡമ്മികൾക്കായി" SQL കോഴ്സുകളിൽ എൻറോൾ ചെയ്യുക.
എന്തുകൊണ്ടാണ് ഈ ഭാഷ പഠിക്കുന്നത്?
ഒന്നാമതായി, ഇന്നത്തെ ഏറ്റവും ജനപ്രിയമായ ബ്ലോഗ് എഞ്ചിനുകളിൽ ഒന്നായ WordPress-നായി വൈവിധ്യമാർന്ന ആപ്ലിക്കേഷനുകൾ സൃഷ്ടിക്കുന്നതിനാണ് SQL പഠിപ്പിക്കുന്നത്. കുറച്ച് ലളിതമായ പാഠങ്ങൾ പൂർത്തിയാക്കിയ ശേഷം, ഈ ഭാഷയുടെ ലാളിത്യം മാത്രം സ്ഥിരീകരിക്കുന്ന ഏത് സങ്കീർണ്ണതയുടെ അന്വേഷണങ്ങളും നിങ്ങൾക്ക് സൃഷ്ടിക്കാൻ കഴിയും.
എന്താണ് SQL?
അല്ലെങ്കിൽ ഒരു ഘടനാപരമായ അന്വേഷണ ഭാഷ, ഒരൊറ്റ ഉദ്ദേശ്യത്തിനായി സൃഷ്ടിച്ചതാണ്: വളരെ ചുരുങ്ങിയ സമയത്തിനുള്ളിൽ അവ നിർണ്ണയിക്കാനും ആക്സസ് നൽകാനും പ്രോസസ്സ് ചെയ്യാനും. നിങ്ങൾക്ക് SQL അർത്ഥം അറിയാമെങ്കിൽ, ഈ സെർവറിനെ "നടപടിക്രമേതര" ഭാഷ എന്ന് വിളിക്കപ്പെടുന്നതായി തരംതിരിച്ചിട്ടുണ്ടെന്ന് നിങ്ങൾ മനസ്സിലാക്കും. അതായത്, സൈറ്റിൽ നിങ്ങൾ ഭാവിയിൽ കാണാൻ ആഗ്രഹിക്കുന്ന ഏതെങ്കിലും ഘടകങ്ങളുടെയോ ഫലങ്ങളുടെയോ വിവരണം മാത്രമേ അതിന്റെ കഴിവുകളിൽ ഉൾപ്പെടുന്നുള്ളൂ. എന്നാൽ എപ്പോഴാണ് ഫലം ലഭിക്കാൻ പോകുന്നത് എന്ന് കൃത്യമായി സൂചിപ്പിക്കുന്നില്ല. ഈ ഭാഷയിലെ ഓരോ പുതിയ അഭ്യർത്ഥനയും ഒരു അധിക "സൂപ്പർസ്ട്രക്ചർ" പോലെയാണ്. അവ ഡാറ്റാബേസിൽ നൽകിയ ക്രമത്തിലാണ് അന്വേഷണങ്ങൾ നടപ്പിലാക്കുന്നത്.

ഈ ഭാഷ ഉപയോഗിച്ച് എന്ത് നടപടിക്രമങ്ങൾ നടത്താം?
അതിന്റെ ലാളിത്യം ഉണ്ടായിരുന്നിട്ടും, SQL ഡാറ്റാബേസ് വൈവിധ്യമാർന്ന അന്വേഷണങ്ങൾ സൃഷ്ടിക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു. ഈ പ്രധാനപ്പെട്ട പ്രോഗ്രാമിംഗ് ഭാഷ പഠിച്ചാൽ നിങ്ങൾക്ക് എന്തുചെയ്യാൻ കഴിയും?
- വൈവിധ്യമാർന്ന പട്ടികകൾ സൃഷ്ടിക്കുക;
- സ്വീകരിച്ച ഡാറ്റ സ്വീകരിക്കുക, സംഭരിക്കുക, പരിഷ്ക്കരിക്കുക;
- നിങ്ങളുടെ വിവേചനാധികാരത്തിൽ പട്ടിക ഘടനകൾ മാറ്റുക;
- ലഭിച്ച വിവരങ്ങൾ ഒറ്റ ബ്ലോക്കുകളായി സംയോജിപ്പിക്കുക;
- ലഭിച്ച ഡാറ്റ കണക്കാക്കുക;
- വിവരങ്ങളുടെ പൂർണ്ണമായ പരിരക്ഷ ഉറപ്പാക്കുക.

ഈ ഭാഷയിൽ ഏറ്റവും പ്രചാരമുള്ള കമാൻഡുകൾ ഏതാണ്?
നിങ്ങൾ ഡമ്മീസ് കോഴ്സിനായി ഒരു SQL എടുക്കാൻ തീരുമാനിക്കുകയാണെങ്കിൽ, അത് ഉപയോഗിച്ച് അന്വേഷണങ്ങൾ സൃഷ്ടിക്കുന്നതിന് ഉപയോഗിക്കുന്ന കമാൻഡുകളെക്കുറിച്ചുള്ള വിശദമായ വിവരങ്ങൾ നിങ്ങൾക്ക് ലഭിക്കും. ഇന്ന് ഏറ്റവും സാധാരണമായവ ഇവയാണ്:
- ഡാറ്റ നിർവചിക്കുന്ന ഒരു കമാൻഡാണ് DDL. ഡാറ്റാബേസിൽ വൈവിധ്യമാർന്ന ഒബ്ജക്റ്റുകൾ സൃഷ്ടിക്കാനും പരിഷ്ക്കരിക്കാനും ഇല്ലാതാക്കാനും ഇത് ഉപയോഗിക്കുന്നു.
- ഡാറ്റ കൈകാര്യം ചെയ്യുന്ന ഒരു കമാൻഡാണ് DCL. വ്യത്യസ്ത ഉപയോക്താക്കൾക്ക് ഡാറ്റാബേസിലെ വിവരങ്ങളിലേക്കുള്ള ആക്സസ് നൽകുന്നതിനും അതുപോലെ പട്ടികകളോ കാഴ്ചകളോ ഉപയോഗിക്കുന്നതിനും ഇത് ഉപയോഗിക്കുന്നു.
- വൈവിധ്യമാർന്ന ഇടപാടുകൾ കൈകാര്യം ചെയ്യുന്ന ഒരു ടീമാണ് TCL. ഇടപാടിന്റെ പുരോഗതി നിർണ്ണയിക്കുക എന്നതാണ് ഇതിന്റെ പ്രധാന ലക്ഷ്യം.
- DML - സ്വീകരിച്ച ഡാറ്റ കൈകാര്യം ചെയ്യുന്നു. ഡാറ്റാബേസിൽ നിന്ന് വിവിധ വിവരങ്ങൾ നീക്കാനോ അവിടെ നൽകാനോ ഉപയോക്താവിനെ അനുവദിക്കുക എന്നതാണ് ഇതിന്റെ ചുമതല.
ഈ സെർവറിൽ നിലനിൽക്കുന്ന പ്രത്യേകാവകാശങ്ങളുടെ തരങ്ങൾ
ഒരു പ്രത്യേക ഉപയോക്താവിന് അവന്റെ സ്റ്റാറ്റസിന് അനുസൃതമായി ചെയ്യാൻ കഴിയുന്ന പ്രവർത്തനങ്ങളെയാണ് പ്രത്യേകാവകാശങ്ങൾ സൂചിപ്പിക്കുന്നത്. ഏറ്റവും കുറഞ്ഞത്, തീർച്ചയായും, ഒരു സാധാരണ ലോഗിൻ ആണ്. തീർച്ചയായും, പ്രത്യേകാവകാശങ്ങൾ കാലത്തിനനുസരിച്ച് മാറിയേക്കാം. പഴയവ ഇല്ലാതാക്കുകയും പുതിയവ ചേർക്കുകയും ചെയ്യും. ഇന്ന്, SQL സെർവർ "ഫോർ ഡമ്മി" കോഴ്സുകൾ എടുക്കുന്ന എല്ലാവർക്കും, അനുവദനീയമായ നിരവധി പ്രവർത്തനങ്ങളുണ്ടെന്ന് അറിയാം:
- ഒബ്ജക്റ്റ് തരം - ഡാറ്റാബേസിൽ സ്ഥിതി ചെയ്യുന്ന ഒരു നിർദ്ദിഷ്ട ഒബ്ജക്റ്റുമായി ബന്ധപ്പെട്ട് മാത്രം ഏത് കമാൻഡ് എക്സിക്യൂട്ട് ചെയ്യാൻ ഉപയോക്താവിനെ അനുവദിച്ചിരിക്കുന്നു. അതേ സമയം, വ്യത്യസ്ത വസ്തുക്കൾക്ക് പ്രത്യേകാവകാശങ്ങൾ വ്യത്യാസപ്പെട്ടിരിക്കുന്നു. അവ ഒരു പ്രത്യേക ഉപയോക്താവുമായി മാത്രമല്ല, പട്ടികകളുമായും ബന്ധിപ്പിച്ചിരിക്കുന്നു. ആരെങ്കിലും തന്റെ കഴിവുകൾ ഉപയോഗിച്ച് ഒരു പട്ടിക സൃഷ്ടിച്ചാൽ, അവനെ അതിന്റെ ഉടമയായി കണക്കാക്കുന്നു. അതിനാൽ, അതിലെ വിവരങ്ങളുമായി ബന്ധപ്പെട്ട മറ്റ് ഉപയോക്താക്കൾക്ക് പുതിയ പ്രത്യേകാവകാശങ്ങൾ നൽകാനുള്ള അവകാശം അവനുണ്ട്.
- സിസ്റ്റം തരം ഡാറ്റ പകർപ്പവകാശം എന്ന് വിളിക്കപ്പെടുന്നതാണ്. അത്തരം പ്രത്യേകാവകാശങ്ങൾ ലഭിച്ച ഉപയോക്താക്കൾക്ക് ഡാറ്റാബേസിൽ വിവിധ വസ്തുക്കൾ സൃഷ്ടിക്കാൻ കഴിയും.

SQL-ന്റെ ചരിത്രം
1970-ൽ ഐബിഎം റിസർച്ച് ലബോറട്ടറിയാണ് ഈ ഭാഷ സൃഷ്ടിച്ചത്. അക്കാലത്ത്, അതിന്റെ പേര് അല്പം വ്യത്യസ്തമായിരുന്നു (SEQUEL), എന്നാൽ കുറച്ച് വർഷത്തെ ഉപയോഗത്തിന് ശേഷം അത് മാറ്റി, അത് ചെറുതാക്കി. ഇതൊക്കെയാണെങ്കിലും, ഇന്നും ലോകപ്രശസ്ത പ്രോഗ്രാമിംഗ് വിദഗ്ധർ ഇപ്പോഴും പഴയ രീതിയിലാണ് പേര് ഉച്ചരിക്കുന്നത്. SQL സൃഷ്ടിച്ചത് ഒരൊറ്റ ഉദ്ദേശ്യത്തോടെയാണ് - സാധാരണ ഇന്റർനെറ്റ് ഉപയോക്താക്കൾക്ക് പോലും ഒരു പ്രശ്നവുമില്ലാതെ പഠിക്കാൻ കഴിയുന്ന ഒരു ഭാഷ കണ്ടുപിടിക്കുക. രസകരമായ ഒരു വസ്തുത എന്തെന്നാൽ, അക്കാലത്ത് SQL അത്തരത്തിലുള്ള ഭാഷ മാത്രമായിരുന്നില്ല. കാലിഫോർണിയയിൽ, മറ്റൊരു കൂട്ടം സ്പെഷ്യലിസ്റ്റുകൾ സമാനമായ ഇൻഗ്രെസ് വികസിപ്പിച്ചെടുത്തു, പക്ഷേ അത് ഒരിക്കലും വ്യാപകമായില്ല. 1980-ന് മുമ്പ്, SQL-ന്റെ നിരവധി വ്യതിയാനങ്ങൾ പരസ്പരം അല്പം മാത്രം വ്യത്യസ്തമായിരുന്നു. ആശയക്കുഴപ്പം തടയുന്നതിന്, 1983-ൽ ഒരു സ്റ്റാൻഡേർഡ് പതിപ്പ് സൃഷ്ടിച്ചു, അത് ഇന്നും ജനപ്രിയമാണ്. "ഡമ്മികൾക്കുള്ള" SQL കോഴ്സുകൾ സേവനത്തെക്കുറിച്ച് കൂടുതൽ അറിയാനും ഏതാനും ആഴ്ചകൾക്കുള്ളിൽ അത് പൂർണ്ണമായി പഠിക്കാനും നിങ്ങളെ അനുവദിക്കുന്നു.










")










")


