ദൈനംദിന ജോലിയിൽ, ചോദ്യങ്ങൾ എഴുതുമ്പോൾ നിങ്ങൾക്ക് സമാനമായ പിശകുകൾ നേരിടേണ്ടിവരും.
ഈ ലേഖനത്തിൽ ചോദ്യങ്ങൾ എങ്ങനെ എഴുതരുത് എന്നതിന്റെ ഉദാഹരണങ്ങൾ നൽകാൻ ഞാൻ ആഗ്രഹിക്കുന്നു.
- എല്ലാ ഫീൽഡുകളും തിരഞ്ഞെടുക്കുക
പട്ടികയിൽ നിന്ന് * തിരഞ്ഞെടുക്കുകചോദ്യങ്ങൾ എഴുതുമ്പോൾ, എല്ലാ ഫീൽഡുകളുടെയും തിരഞ്ഞെടുക്കൽ ഉപയോഗിക്കരുത് - "*". നിങ്ങൾക്ക് ശരിക്കും ആവശ്യമുള്ള ഫീൽഡുകൾ മാത്രം ലിസ്റ്റ് ചെയ്യുക. ഇത് ലഭിച്ചതും അയച്ചതുമായ ഡാറ്റയുടെ അളവ് കുറയ്ക്കും. കൂടാതെ, ഇൻഡെക്സുകൾ മറയ്ക്കുന്നതിനെക്കുറിച്ച് മറക്കരുത്. നിങ്ങൾക്ക് യഥാർത്ഥത്തിൽ പട്ടികയിലെ എല്ലാ ഫീൽഡുകളും ആവശ്യമാണെങ്കിലും, അവ പട്ടികപ്പെടുത്തുന്നതാണ് നല്ലത്. ഒന്നാമതായി, ഇത് കോഡിന്റെ വായനാക്ഷമത മെച്ചപ്പെടുത്തുന്നു. ഒരു നക്ഷത്രചിഹ്നം ഉപയോഗിക്കുമ്പോൾ, അത് നോക്കാതെ പട്ടികയിൽ ഏതൊക്കെ ഫീൽഡുകൾ ഉണ്ടെന്ന് അറിയാൻ കഴിയില്ല. രണ്ടാമതായി, കാലക്രമേണ, നിങ്ങളുടെ ടേബിളിലെ നിരകളുടെ എണ്ണം മാറിയേക്കാം, ഇന്ന് അഞ്ച് INT കോളങ്ങൾ ഉണ്ടെങ്കിൽ, ഒരു മാസത്തിനുള്ളിൽ TEXT, BLOB ഫീൽഡുകൾ ചേർത്തേക്കാം, അത് തിരഞ്ഞെടുക്കലിനെ മന്ദഗതിയിലാക്കും.
- ഒരു സൈക്കിളിൽ അഭ്യർത്ഥനകൾ.
SQL ഒരു സെറ്റ് ഓപ്പറേറ്റിംഗ് ഭാഷയാണെന്ന് നിങ്ങൾ വ്യക്തമായി മനസ്സിലാക്കേണ്ടതുണ്ട്. ചില സമയങ്ങളിൽ നടപടിക്രമ ഭാഷകളിൽ ചിന്തിക്കാൻ ശീലിച്ച പ്രോഗ്രാമർമാർക്ക് അവരുടെ ചിന്തയെ സെറ്റുകളുടെ ഭാഷയിലേക്ക് മാറ്റുന്നത് ബുദ്ധിമുട്ടാണ്. ലളിതമായ ഒരു നിയമം സ്വീകരിച്ചുകൊണ്ട് ഇത് വളരെ ലളിതമായി ചെയ്യാൻ കഴിയും - "ഒരു ലൂപ്പിൽ അന്വേഷണങ്ങൾ ഒരിക്കലും എക്സിക്യൂട്ട് ചെയ്യരുത്." ഇത് എങ്ങനെ ചെയ്യാമെന്നതിന്റെ ഉദാഹരണങ്ങൾ:1. സാമ്പിളുകൾ
$news_ids = get_list("ഇന്നത്തെ_വാർത്തയിൽ നിന്ന് വാർത്ത_ഐഡി തിരഞ്ഞെടുക്കുക ");
അതേസമയം($news_id = get_next($news_ids))
$news = get_row("തലക്കെട്ട് തിരഞ്ഞെടുക്കുക, വാർത്തയിൽ നിന്ന് ബോഡി എവിടെ news_id = ". $news_id);നിയമം വളരെ ലളിതമാണ് - കുറച്ച് അഭ്യർത്ഥനകൾ, മികച്ചത് (ഏത് നിയമത്തെയും പോലെ ഇതിന് ഒഴിവാക്കലുകൾ ഉണ്ടെങ്കിലും). IN() നിർമ്മിതിയെ കുറിച്ച് മറക്കരുത്. മുകളിലുള്ള കോഡ് ഒരു ചോദ്യത്തിൽ എഴുതാം:
ശീർഷകം തിരഞ്ഞെടുക്കുക, ഇന്നത്തെ_വാർത്തയിൽ നിന്ന് ബോഡി തിരഞ്ഞെടുക്കുക.2. ഉൾപ്പെടുത്തലുകൾ
$ലോഗ് = parse_log();
അതേസമയം($റെക്കോർഡ് = അടുത്തത്($ലോഗ്))
ചോദ്യം("ലോഗുകളിലേക്ക് തിരുകുക സെറ്റ് മൂല്യം = ". $log["value"]);!}ഒരു ചോദ്യം സംയോജിപ്പിച്ച് നടപ്പിലാക്കുന്നത് കൂടുതൽ കാര്യക്ഷമമാണ്:
ലോഗുകളിലേക്ക് തിരുകുക (മൂല്യം) മൂല്യങ്ങൾ (...), (...)3. അപ്ഡേറ്റുകൾ
ചിലപ്പോൾ നിങ്ങൾ ഒരു പട്ടികയിൽ നിരവധി വരികൾ അപ്ഡേറ്റ് ചെയ്യേണ്ടതുണ്ട്. പുതുക്കിയ മൂല്യം ഒന്നുതന്നെയാണെങ്കിൽ, എല്ലാം ലളിതമാണ്:
വാർത്ത അപ്ഡേറ്റ് ചെയ്യുക SET ശീർഷകം="test" WHERE id IN (1, 2, 3).!}ഓരോ റെക്കോർഡിനും മാറ്റുന്ന മൂല്യം വ്യത്യസ്തമാണെങ്കിൽ, ഇനിപ്പറയുന്ന ചോദ്യം ഉപയോഗിച്ച് ഇത് ചെയ്യാൻ കഴിയും:
വാർത്താ സെറ്റ് അപ്ഡേറ്റ് ചെയ്യുക
തലക്കെട്ട് = കേസ്
എപ്പോൾ news_id = 1 അപ്പോൾ "aa"
എപ്പോൾ news_id = 2 അപ്പോൾ "bb" END
എവിടെ വാർത്ത_ഐഡി (1, 2)അത്തരം ഒരു അഭ്യർത്ഥന നിരവധി വ്യത്യസ്ത അഭ്യർത്ഥനകളേക്കാൾ 2-3 മടങ്ങ് വേഗതയുള്ളതാണെന്ന് ഞങ്ങളുടെ പരിശോധനകൾ കാണിക്കുന്നു.
- സൂചികയിലാക്കിയ ഫീൽഡുകളിൽ പ്രവർത്തനങ്ങൾ നടത്തുന്നു
ഉപയോക്താക്കളിൽ നിന്ന് user_id തിരഞ്ഞെടുക്കുക. blogs_count * 2 = $valueblogs_count കോളം സൂചികയിലാക്കിയാലും ഈ അന്വേഷണം സൂചിക ഉപയോഗിക്കില്ല. ഒരു സൂചിക ഉപയോഗിക്കുന്നതിന്, അന്വേഷണത്തിലെ സൂചികയിലുള്ള ഫീൽഡിൽ പരിവർത്തനങ്ങളൊന്നും നടത്തേണ്ടതില്ല. അത്തരം അഭ്യർത്ഥനകൾക്കായി, പരിവർത്തന പ്രവർത്തനങ്ങൾ മറ്റൊരു ഭാഗത്തേക്ക് നീക്കുക:
ഉപയോക്താക്കളിൽ നിന്ന് user_id തിരഞ്ഞെടുക്കുക. blogs_count = $value / 2;സമാനമായ ഉദാഹരണം:
TO_DAYS (CURRENT_DATE) മുതൽ TO_DAYS വരെ (രജിസ്റ്റർ ചെയ്തത്) ഉപയോക്താക്കളിൽ നിന്ന് user_id തിരഞ്ഞെടുക്കുക<= 10;രജിസ്റ്റർ ചെയ്ത ഫീൽഡിൽ ഒരു സൂചിക ഉപയോഗിക്കില്ല, അതേസമയം
രജിസ്റ്റർ ചെയ്ത ഉപയോക്താക്കളിൽ നിന്ന് user_id തിരഞ്ഞെടുക്കുക >= DATE_SUB(CURRENT_DATE, 10 ദിവസം ഇടവേള);
ചെയ്യും. - വരികളുടെ എണ്ണം എണ്ണാൻ വേണ്ടി മാത്രം
$ഫലം = mysql_query("പട്ടികയിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക", $ലിങ്ക്);
$num_rows = mysql_num_rows($result);
ഒരു നിശ്ചിത വ്യവസ്ഥ പാലിക്കുന്ന വരികളുടെ എണ്ണം നിങ്ങൾക്ക് തിരഞ്ഞെടുക്കണമെങ്കിൽ, ഉപയോഗിക്കുക ചോദ്യം തിരഞ്ഞെടുക്കുകപട്ടികയിൽ നിന്ന് COUNT(*) എണ്ണം, എല്ലാ വരികളും തിരഞ്ഞെടുക്കുന്നതിന് പകരം അവയുടെ എണ്ണം എണ്ണുക. - അധിക വരികൾ ലഭ്യമാക്കുന്നു
$ഫലം = mysql_query("ടേബിൾ1ൽ നിന്ന് * തിരഞ്ഞെടുക്കുക", $ലിങ്ക്);
അതേസമയം($റോ = mysql_fetch_assoc($ഫലം) && $i< 20) {
…
}
നിങ്ങൾക്ക് വരികൾ ലഭിക്കാൻ n ആവശ്യമുണ്ടെങ്കിൽ, ആപ്ലിക്കേഷനിലെ അധിക വരികൾ ഉപേക്ഷിക്കുന്നതിന് പകരം LIMIT ഉപയോഗിക്കുക. - RAND () പ്രകാരം ഓർഡർ ഉപയോഗിക്കുന്നു
തിരഞ്ഞെടുക്കുക * പട്ടികയിൽ നിന്ന് RAND () പരിധി 1 പ്രകാരം ഓർഡർ ചെയ്യുക;പട്ടികയിൽ 4-5 ആയിരത്തിലധികം വരികൾ ഉണ്ടെങ്കിൽ, RAND () പ്രകാരം ഓർഡർ ചെയ്യുന്നത് വളരെ സാവധാനത്തിൽ പ്രവർത്തിക്കും. രണ്ട് ചോദ്യങ്ങൾ പ്രവർത്തിപ്പിക്കുന്നത് കൂടുതൽ കാര്യക്ഷമമായിരിക്കും:
പട്ടികയിൽ ഒരു auto_increment പ്രാഥമിക കീയും വിടവുകളുമില്ലെങ്കിൽ:
$rnd = rand(1, query("ടേബിളിൽ നിന്ന് MAX(id) തിരഞ്ഞെടുക്കുക"));
$റോ = അന്വേഷണം ("പട്ടികയിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക * എവിടെ ഐഡി = ".$rnd);അഥവാ:
$cnt = അന്വേഷണം ("പട്ടികയിൽ നിന്ന് COUNT(*) തിരഞ്ഞെടുക്കുക");
$റോ = അന്വേഷണം ("ടേബിൾ പരിധിയിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക ".$cnt.", 1");
എന്നിരുന്നാലും, പട്ടികയിൽ വളരെയധികം വരികൾ ഉണ്ടെങ്കിൽ അത് മന്ദഗതിയിലാകും. - ധാരാളം ജോയിനുകൾ ഉപയോഗിക്കുന്നു
തിരഞ്ഞെടുക്കുക
v.video_id
ഒരു പേര്,
g.genre
നിന്ന്
വീഡിയോകൾ AS v
ഇടത് ചേരുക
link_actors_videos AS la ON la.video_id = v.video_id
ഇടത് ചേരുക
അഭിനേതാക്കൾ ഓൺ a.actor_id = la.actor_id
ഇടത് ചേരുക
link_genre_video AS lg ON lg.video_id = v.video_id
ഇടത് ചേരുക
g.genre_id = lg.genre_idടേബിളുകൾ ഒന്നിൽ നിന്ന് പലതിലേക്ക് ബന്ധിപ്പിക്കുമ്പോൾ, ഓരോ അടുത്ത ചേരുമ്പോഴും തിരഞ്ഞെടുക്കലിലെ വരികളുടെ എണ്ണം വർദ്ധിക്കും. അത്തരം സന്ദർഭങ്ങളിൽ, അത്തരം ഒരു ചോദ്യം നിരവധി ലളിതമായവയായി വിഭജിക്കുന്നത് വേഗത്തിലാണ്.
- LIMIT ഉപയോഗിക്കുന്നു
തിരഞ്ഞെടുക്കുക... പട്ടിക പരിധിയിൽ നിന്ന് $start, $per_pageഅത്തരമൊരു ചോദ്യം $per_page റെക്കോർഡുകൾ (സാധാരണയായി 10-20) തിരികെ നൽകുമെന്നും അതിനാൽ വേഗത്തിൽ പ്രവർത്തിക്കുമെന്നും പലരും കരുതുന്നു. ആദ്യത്തെ കുറച്ച് പേജുകളിൽ ഇത് വേഗത്തിൽ പ്രവർത്തിക്കും. എന്നാൽ റെക്കോർഡുകളുടെ എണ്ണം വലുതാണെങ്കിൽ, നിങ്ങൾ ഒരു SELECT എക്സിക്യൂട്ട് ചെയ്യേണ്ടതുണ്ട്... പട്ടികയിൽ നിന്ന് LIMIT 1000000, 1000020 ചോദ്യം, അങ്ങനെയുള്ള ഒരു ചോദ്യം എക്സിക്യൂട്ട് ചെയ്യാൻ, MySQL ആദ്യം 1000020 റെക്കോർഡുകൾ തിരഞ്ഞെടുത്ത് ആദ്യത്തെ മില്യൺ ഉപേക്ഷിച്ച് 20 തിരികെ നൽകും. ഇത് ഒട്ടും വേഗതയില്ലായിരിക്കാം. പ്രശ്നം പരിഹരിക്കാൻ നിസ്സാരമായ വഴികളൊന്നുമില്ല. പലരും അളവ് പരിമിതപ്പെടുത്തുന്നു ലഭ്യമായ പേജുകൾ ന്യായമായ സംഖ്യ. കവറിംഗ് ഇൻഡക്സുകൾ ഉപയോഗിച്ച് നിങ്ങൾക്ക് അത്തരം അന്വേഷണങ്ങൾ വേഗത്തിലാക്കാനും കഴിയും മൂന്നാം കക്ഷി പരിഹാരങ്ങൾ(ഉദാഹരണത്തിന് സ്ഫിങ്ക്സ്).
- ഡ്യൂപ്ലിക്കേറ്റ് കീ അപ്ഡേറ്റിൽ ഉപയോഗിക്കുന്നില്ല
$റോ = അന്വേഷണം ("തിരഞ്ഞെടുക്കുക * പട്ടികയിൽ നിന്ന് എവിടെയാണ് ഐഡി=1");എങ്കിൽ ($ വരി)
ചോദ്യം ("പട്ടിക സെറ്റ് കോളം അപ്ഡേറ്റ് ചെയ്യുക = കോളം + 1 എവിടെ ഐഡി = 1")
വേറെ
ചോദ്യം ("ടേബിൾ സെറ്റ് കോളം = 1, ഐഡി = 1");ഐഡി ഫീൽഡിനായി ഒരു പ്രാഥമിക അല്ലെങ്കിൽ അതുല്യമായ കീ ഉണ്ടെങ്കിൽ സമാനമായ ഒരു നിർമ്മാണം ഒരു ചോദ്യം ഉപയോഗിച്ച് മാറ്റിസ്ഥാപിക്കാം:
പട്ടികയിലേക്ക് തിരുകുക സെറ്റ് കോളം = 1, ഐഡി = 1 ഡ്യൂപ്ലിക്കേറ്റ് കീയിൽ അപ്ഡേറ്റ് കോളം = കോളം + 1
MySQL ഇപ്പോഴും ലോകത്തിലെ ഏറ്റവും ജനപ്രിയമായ റിലേഷണൽ ഡാറ്റാബേസാണ്, എന്നാൽ ഇത് ഏറ്റവും ഒപ്റ്റിമൈസ് ചെയ്തിട്ടുള്ളതാണ്. പലരും കൂടുതൽ ആഴത്തിൽ കുഴിക്കാതെ സ്ഥിരസ്ഥിതി ക്രമീകരണങ്ങളിൽ തുടരുന്നു. ഈ ലേഖനത്തിൽ, താരതമ്യേന അടുത്തിടെ പുറത്തുവന്ന ചില പുതിയ ഫീച്ചറുകൾക്കൊപ്പം ചില MySQL ഒപ്റ്റിമൈസേഷൻ നുറുങ്ങുകൾ ഞങ്ങൾ നോക്കാം.
കോൺഫിഗറേഷൻ ഒപ്റ്റിമൈസേഷൻ
പ്രകടനം മെച്ചപ്പെടുത്താൻ ഓരോ MySQL ഉപയോക്താവും ആദ്യം ചെയ്യേണ്ടത് കോൺഫിഗറേഷൻ മാറ്റുക എന്നതാണ്. എന്നിരുന്നാലും, മിക്ക ആളുകളും ഈ ഘട്ടം ഒഴിവാക്കുന്നു. ബി 5.7 ( നിലവിലുള്ള പതിപ്പ്) സ്ഥിരസ്ഥിതി ക്രമീകരണങ്ങൾ അതിന്റെ മുൻഗാമികളേക്കാൾ വളരെ മികച്ചതാണ്, പക്ഷേ അവ മെച്ചപ്പെടുത്തുന്നത് ഇപ്പോഴും സാദ്ധ്യവും എളുപ്പവുമാണ്.
നിങ്ങൾ Linux അല്ലെങ്കിൽ Vagrant -box (ഞങ്ങളുടെ ഹോംസ്റ്റേഡ് മെച്ചപ്പെടുത്തിയത് പോലെ) പോലുള്ള മറ്റെന്തെങ്കിലും ഉപയോഗിക്കുന്നുണ്ടെന്ന് ഞങ്ങൾ പ്രതീക്ഷിക്കുന്നു, അതനുസരിച്ച്, നിങ്ങളുടെ കോൺഫിഗറേഷൻ ഫയൽ /etc/mysql/my.cnf-ൽ സ്ഥിതിചെയ്യും. നിങ്ങളുടെ ഇൻസ്റ്റാളേഷൻ യഥാർത്ഥത്തിൽ ലോഡ് ആകാൻ സാധ്യതയുണ്ട് അധിക ഫയൽഇതിലെ കോൺഫിഗറേഷനുകൾ. അതിനാൽ നോക്കൂ, my.cnf ഫയലിൽ കൂടുതൽ അടങ്ങിയിട്ടില്ലെങ്കിൽ, /etc/mysql/mysql.conf.d/mysqld.cnf എന്നതിൽ നോക്കുക.
മാനുവൽ ട്യൂണിംഗ്
ഇനിപ്പറയുന്ന ക്രമീകരണങ്ങൾ ബോക്സിന് പുറത്ത് ചെയ്യണം. ഈ നുറുങ്ങുകൾ അനുസരിച്ച്, വിഭാഗത്തിലെ കോൺഫിഗറേഷൻ ഫയലിലേക്ക് ചേർക്കുക:
Innodb_buffer_pool_size = 1G # (ഇവിടെ ആകെ റാമിന്റെ 50%-70% മാറ്റുന്നു) innodb_log_file_size = 256M innodb_flush_log_at_trx_commit = 1 # എന്നത് 2 അല്ലെങ്കിൽ 0 ആയി മാറ്റാം innodb_DIRECT = O_DIDICT
- innodb_buffer_pool_size . മെമ്മറിയിൽ ഡാറ്റയും ഇൻഡക്സുകളും കാഷെ ചെയ്യുന്നതിനുള്ള ഒരുതരം "വെയർഹൗസ്" ആണ് ബഫർ പൂൾ. പതിവായി ആക്സസ് ചെയ്യപ്പെടുന്ന ഡാറ്റ മെമ്മറിയിൽ സൂക്ഷിക്കാൻ ഇത് ഉപയോഗിക്കുന്നു. നിങ്ങൾ ഒരു സമർപ്പിത അല്ലെങ്കിൽ വെർച്വൽ സെർവർ ഉപയോഗിക്കുമ്പോൾ, ഡാറ്റാബേസ് പലപ്പോഴും തടസ്സമാകുമ്പോൾ, റാമിന്റെ ഭൂരിഭാഗവും അതിന് നൽകുന്നത് അർത്ഥവത്താണ്. അതിനാൽ, മൊത്തം റാമിന്റെ 50-70% ഞങ്ങൾ ഇതിന് നൽകുന്നു. MySQL ഡോക്യുമെന്റേഷനിൽ ഈ പൂൾ സജ്ജീകരിക്കുന്നതിനുള്ള ഒരു ഗൈഡ് ഉണ്ട്.
- innodb_log_file_size . ലോഗ് ഫയൽ വലുപ്പം സജ്ജീകരിക്കുന്നത് നന്നായി വിവരിച്ചിരിക്കുന്നു, എന്നാൽ ചുരുക്കത്തിൽ ഇത് മായ്ക്കുന്നതിന് മുമ്പ് ലോഗുകളിൽ സംഭരിച്ചിരിക്കുന്ന ഡാറ്റയുടെ അളവാണ്. ഈ കേസിലെ ലോഗ് പിശക് റെക്കോർഡുകളല്ല, മറിച്ച് പ്രധാന innodb ഫയലുകളിൽ ഇതുവരെ ഡിസ്കിലേക്ക് ഫ്ലഷ് ചെയ്തിട്ടില്ലാത്ത മാറ്റങ്ങളുടെ ഒരു തരം ഡെൽറ്റ സ്നാപ്പ്ഷോട്ട് ആണെന്ന് ദയവായി ശ്രദ്ധിക്കുക. MySQL എഴുതുന്നു പശ്ചാത്തലം, എന്നാൽ ഇത് ഇപ്പോഴും റെക്കോർഡിംഗ് സമയത്തെ പ്രകടനത്തെ ബാധിക്കുന്നു. ഒരു വലിയ ലോഗ് ഫയൽ എന്നാൽ കൂടുതൽ അർത്ഥമാക്കുന്നു ഉയർന്ന പ്രകടനംചെറിയ എണ്ണം പുതിയതും ചെറുതുമായ ചെക്ക്പോസ്റ്റുകൾ സൃഷ്ടിച്ചതിനാൽ, അതേ സമയം ഒരു ക്രാഷ് ഉണ്ടായാൽ വീണ്ടെടുക്കൽ സമയം കൂടുതലാണ് (ഡാറ്റാബേസിലേക്ക് കൂടുതൽ ഡാറ്റ മാറ്റിയെഴുതണം).
- innodb_flush_log_at_trx_commit വിവരിക്കുകയും ലോഗ് ഫയലിന് എന്ത് സംഭവിക്കുമെന്ന് കാണിക്കുകയും ചെയ്യുന്നു. മൂല്യം 1 ആണ് ഏറ്റവും സുരക്ഷിതം, കാരണം ഓരോ ഇടപാടിനും ശേഷം ലോഗ് ഡിസ്കിലേക്ക് ഫ്ലഷ് ചെയ്യുന്നു. 0, 2 മൂല്യങ്ങൾക്കൊപ്പം, ACID കുറവ് ഉറപ്പുനൽകുന്നു, പക്ഷേ പ്രകടനം കൂടുതലാണ്. വ്യത്യാസം 1 ലെ സ്ഥിരത ആനുകൂല്യങ്ങളെ മറികടക്കാൻ പര്യാപ്തമല്ല.
- innodb_flush_method . ഡാറ്റ ഫ്ളഷ് ചെയ്യുന്നതിന്റെ കാര്യത്തിൽ, ഈ ക്രമീകരണം O_DIRECT-ലേക്ക് സജ്ജീകരിക്കേണ്ടതുണ്ട് - ഇരട്ട ബഫറിംഗ് ഒഴിവാക്കാൻ. I/O സിസ്റ്റം വളരെ മന്ദഗതിയിലായിരിക്കുമ്പോൾ എപ്പോഴും ഇത് ചെയ്യാൻ ഞാൻ നിങ്ങളെ ഉപദേശിക്കുന്നു. ഡിജിറ്റൽ ഓഷ്യൻ പോലുള്ള മിക്ക ഹോസ്റ്റിംഗുകളിലും നിങ്ങൾക്ക് SSD ഡ്രൈവുകൾ ഉണ്ടായിരിക്കും, അതിനാൽ I/O സിസ്റ്റം കൂടുതൽ ഉൽപ്പാദനക്ഷമതയുള്ളതായിരിക്കും.
ശേഷിക്കുന്ന പ്രശ്നങ്ങൾ സ്വയമേവ കണ്ടെത്താൻ ഞങ്ങളെ സഹായിക്കുന്ന ഒരു ടൂൾ പെർകോണയിൽ നിന്ന് ഉണ്ട്. ഈ സ്വമേധയാലുള്ള ക്രമീകരണം കൂടാതെ ഞങ്ങൾ ഇത് പ്രവർത്തിപ്പിക്കുകയാണെങ്കിൽ, 4 ക്രമീകരണങ്ങളിൽ 1 മാത്രമേ നിർവചിക്കുകയുള്ളൂ, കാരണം മറ്റ് 3 ഉപയോക്താവിന്റെ മുൻഗണനകളെ ആശ്രയിച്ചിരിക്കുന്നു. പരിസ്ഥിതിഅപേക്ഷകൾ.
വേരിയബിൾ ഇൻസ്പെക്ടർ
ഉബുണ്ടുവിൽ വേരിയബിൾ ഇൻസ്പെക്ടർ ഇൻസ്റ്റാൾ ചെയ്യുന്നു:
Wget https://repo.percona.com/apt/percona-release_0.1-4.$(lsb_release -sc)_all.deb sudo dpkg -i percona-release_0.1-4.$(lsb_release -sc)_all. deb sudo apt-get update sudo apt-get install percona-toolkit
മറ്റ് സിസ്റ്റങ്ങൾക്ക്, ഈ നിർദ്ദേശങ്ങൾ പാലിക്കുക.
തുടർന്ന് ടൂൾകിറ്റ് പ്രവർത്തിപ്പിക്കുക:
Pt-variable-advisor h=localhost,u=Homestad,p=secret
നിങ്ങൾ ഈ ഫലം കാണും:
# WARN delay_key_write: MyISAM സൂചിക ബ്ലോക്കുകൾ ആവശ്യം വരെ ഫ്ലഷ് ചെയ്യപ്പെടില്ല. # ശ്രദ്ധിക്കുക max_binlog_size: max_binlog_size 1GB യുടെ ഡിഫോൾട്ടിനെക്കാൾ ചെറുതാണ്. # ശ്രദ്ധിക്കുക സോർട്ട്_ബഫർ_സൈസ്-1: സോർട്ട്_ബഫർ_സൈസ് വേരിയബിൾ സാധാരണഗതിയിൽ അതിന്റെ ഡിഫോൾട്ടിൽ തന്നെ അത് മാറ്റേണ്ടതുണ്ടെന്ന് ഒരു വിദഗ്ദ്ധൻ തീരുമാനിക്കുന്നില്ലെങ്കിൽ. # ശ്രദ്ധിക്കുക innodb_data_file_path: InnoDB ഫയലുകൾ സ്വയമേവ നീട്ടുന്നത് പിന്നീട് വീണ്ടെടുക്കാൻ വളരെ ബുദ്ധിമുട്ടുള്ള ധാരാളം ഡിസ്ക് ഇടം ഉപയോഗിക്കും. # ലോഗ്_ബിൻ മുന്നറിയിപ്പ് നൽകുക: ബൈനറി ലോഗിംഗ് പ്രവർത്തനരഹിതമാക്കിയിരിക്കുന്നു, അതിനാൽ പോയിന്റ്-ഇൻ-ടൈം വീണ്ടെടുക്കൽ ഒപ്പംഅനുകരണം അല്ലസാധ്യമാണ്.
കുറിപ്പ് വിവർത്തകൻ:
എന്റെ മേൽ പ്രാദേശിക യന്ത്രം, ഇതുകൂടാതെ, ഇത് ഇനിപ്പറയുന്ന മുന്നറിയിപ്പും നൽകി:
innodb_flush_method പാരാമീറ്റർ O_DIRECT എന്നതിലേക്ക് സജ്ജീകരിക്കേണ്ടതുണ്ടെന്നും എന്തുകൊണ്ട് മുകളിൽ ചർച്ച ചെയ്തിരിക്കുന്നു എന്നതും. ലേഖനത്തിലെന്നപോലെ നിങ്ങൾ ട്യൂണിംഗ് സീക്വൻസ് പിന്തുടരുകയാണെങ്കിൽ, ഈ മുന്നറിയിപ്പ് നിങ്ങൾ കാണില്ല.
ഇതൊന്നുമല്ല ( ഏകദേശം: രചയിതാവ് സൂചിപ്പിച്ചത്) മുന്നറിയിപ്പുകൾ നിർണായകമല്ല, അവ തിരുത്തേണ്ട ആവശ്യമില്ല. തിരുത്താൻ കഴിയുന്ന ഒരേയൊരു കാര്യം, പകർപ്പിനും സ്നാപ്പ്ഷോട്ടുകൾക്കുമായി ഒരു ബൈനറി ലോഗ് സജ്ജീകരിക്കുക എന്നതാണ്.
ശ്രദ്ധിക്കുക: പുതിയ പതിപ്പുകളിൽ ഡിഫോൾട്ട് ബിൻലോഗ് വലുപ്പം 1G ആണ്, ഈ മുന്നറിയിപ്പ് ഉണ്ടാകില്ല.
Max_binlog_size = 1G log_bin = /var/log/mysql/mysql-bin.log server-id=master-01 binlog-format = "ROW"
- max_binlog_size . ബൈനറി ലോഗുകൾ എത്ര വലുതായിരിക്കുമെന്ന് നിർണ്ണയിക്കുന്നു. അവർ നിങ്ങളുടെ ഇടപാടുകളും അഭ്യർത്ഥനകളും രേഖപ്പെടുത്തുകയും ചെക്ക്പോസ്റ്റുകൾ ഉണ്ടാക്കുകയും ചെയ്യുന്നു. ഒരു ഇടപാട് പരമാവധി കവിഞ്ഞാൽ, ഡിസ്കിൽ സേവ് ചെയ്യുമ്പോൾ ലോഗ് അതിന്റെ വലിപ്പം കവിഞ്ഞേക്കാം; അല്ലെങ്കിൽ MySQL ഈ പരിധിക്കുള്ളിൽ അതിനെ പിന്തുണയ്ക്കും.
- ലോഗ്_ബിൻ. ഈ ഓപ്ഷൻ പൊതുവെ ബൈനറി ലോഗിംഗ് പ്രാപ്തമാക്കുന്നു. അതില്ലാതെ, സ്നാപ്പ്ഷോട്ടുകളോ പകർപ്പുകളോ അസാധ്യമാണ്. ഇത് നിങ്ങളുടെ ഡിസ്ക് സ്പേസിൽ വലിയ സ്വാധീനം ചെലുത്തുമെന്നത് ശ്രദ്ധിക്കുക. സെർവർ ഐഡി ആണ് ആവശ്യമായ ഓപ്ഷൻബൈനറി ലോഗിംഗ് പ്രവർത്തനക്ഷമമാക്കുമ്പോൾ, ഏത് സെർവറിൽ നിന്നാണ് അവ വന്നതെന്ന് ലോഗുകൾ "അറിയാം" (റെപ്ലിക്കേഷനായി), കൂടാതെ ബിൻലോഗ് ഫോർമാറ്റ് അവ എഴുതിയിരിക്കുന്ന രീതിയാണ്.
നിങ്ങൾക്ക് കാണാനാകുന്നതുപോലെ, പുതിയ MySQL-ന് ഡിഫോൾട്ടുകൾ ഉണ്ട്, അത് ഏതാണ്ട് പ്രൊഡക്ഷൻ തയ്യാറാണ്. തീർച്ചയായും, ഓരോ ആപ്ലിക്കേഷനും വ്യത്യസ്തമാണ് കൂടാതെ അതിന് ബാധകമായ അധിക തന്ത്രങ്ങളും ട്വീക്കുകളും ഉണ്ട്.
MySQL ട്യൂണർ
പിന്തുണയ്ക്കുന്ന ഉപകരണങ്ങൾ: തനിപ്പകർപ്പ് സൂചികകൾ തിരിച്ചറിയുന്നതിനുള്ള പെർകോണ ടൂൾകിറ്റ്
ഞങ്ങൾ മുമ്പ് ഇൻസ്റ്റാൾ ചെയ്ത Percona ടൂൾകിറ്റിന് തനിപ്പകർപ്പ് സൂചികകൾ കണ്ടെത്തുന്നതിനുള്ള ഒരു ടൂളും ഉണ്ട്, അത് മൂന്നാം കക്ഷി CMS-കൾ ഉപയോഗിക്കുമ്പോഴോ അല്ലെങ്കിൽ ആവശ്യമുള്ളതിനേക്കാൾ കൂടുതൽ സൂചികകൾ നിങ്ങൾ അബദ്ധവശാൽ ചേർത്തിട്ടുണ്ടോ എന്ന് സ്വയം പരിശോധിക്കുമ്പോഴോ ഉപയോഗപ്രദമാകും. ഉദാഹരണത്തിന്, സ്ഥിരസ്ഥിതി വേർഡ്പ്രസ്സ് ഇൻസ്റ്റാളേഷനിൽ wp_posts പട്ടികയിൽ തനിപ്പകർപ്പ് സൂചികകൾ ഉണ്ട്:
പിടി-ഡ്യൂപ്ലിക്കേറ്റ്-കീ-ചെക്കർ എച്ച്=ലോക്കൽഹോസ്റ്റ്, യു=ഹോംസ്റ്റെഡ്, പി=രഹസ്യം # ############################## ###########################################Homestead.wp_posts ##### ############################################## ################## # കീ ടൈപ്പ്_സ്റ്റാറ്റസ്_തീയതി അവസാനിക്കുന്നത് ക്ലസ്റ്റേർഡ് ഇൻഡക്സിന്റെ ഒരു പ്രിഫിക്സിലാണ് ,`ID`), # പ്രാഥമിക കീ (`ID`), # കോളം തരങ്ങൾ: # `post_type` varchar(20) collate utf8mb4_unicode_520_ci അസാധുവായ സ്ഥിരസ്ഥിതി "പോസ്റ്റ്" അല്ല # `post_status` varchar(20) collate utf8mb4_facode " " # `post_date` datetime null default അല്ല "0000-00-00 00:00:00" # `id` bigint(20) unsigned not null auto_increment # ഈ ഡ്യൂപ്ലിക്കേറ്റ് ക്ലസ്റ്റേർഡ് ഇൻഡക്സ് ചെറുതാക്കാൻ, എക്സിക്യൂട്ട് ചെയ്യുക: ALTER TABLE `homestead`. ` wp_posts` DROP INDEX `type_status_date`, INDEX ചേർക്കുക `type_status_date` (`post_type`,`post_status`,`post_date`);
നിന്ന് കാണാൻ കഴിയുന്നതുപോലെ അവസാന വരി, ഡ്യൂപ്ലിക്കേറ്റ് ഇൻഡക്സുകൾ എങ്ങനെ ഒഴിവാക്കാം എന്നതിനെക്കുറിച്ചുള്ള നുറുങ്ങുകളും ഈ ടൂൾ നിങ്ങൾക്ക് നൽകുന്നു.
സഹായ ഉപകരണങ്ങൾ: ഉപയോഗിക്കാത്ത സൂചികകൾക്കുള്ള പെർക്കോണ ടൂൾകിറ്റ്
പെർക്കോണ ടൂൾകിറ്റിന് ഉപയോഗിക്കാത്ത സൂചികകളും കണ്ടെത്താനാകും. നിങ്ങൾ മന്ദഗതിയിലുള്ള അന്വേഷണങ്ങളാണ് ലോഗ് ചെയ്യുന്നതെങ്കിൽ (ചുവടെയുള്ള തടസ്സങ്ങൾ വിഭാഗം കാണുക), നിങ്ങൾക്ക് യൂട്ടിലിറ്റി പ്രവർത്തിപ്പിക്കാൻ കഴിയും, കൂടാതെ ആ അന്വേഷണങ്ങൾ പട്ടികകളിൽ സൂചികകൾ ഉപയോഗിക്കുന്നുണ്ടോ എന്നും എങ്ങനെയെന്നും ഇത് പരിശോധിക്കും.
Pt-index-usage /var/log/mysql/mysql-slow.log
ഈ യൂട്ടിലിറ്റി ഉപയോഗിക്കുന്നതിനെക്കുറിച്ചുള്ള വിശദമായ വിവരങ്ങൾക്ക്, കാണുക.
ഇടുങ്ങിയ സ്ഥലങ്ങൾ
ഡാറ്റാബേസ് തടസ്സങ്ങൾ എങ്ങനെ കണ്ടെത്താമെന്നും നിരീക്ഷിക്കാമെന്നും ഈ വിഭാഗം വിവരിക്കുന്നു.
ആദ്യം, വേഗത കുറഞ്ഞ ചോദ്യങ്ങളുടെ ലോഗിംഗ് പ്രവർത്തനക്ഷമമാക്കാം:
Slow_query_log = /var/log/mysql/mysql-slow.log long_query_time = 1 log-queries-not-using-indexes = 1
മുകളിലുള്ള വരികൾ mysql കോൺഫിഗറേഷനിൽ ചേർക്കേണ്ടതാണ്. ഡാറ്റാബേസ് പൂർത്തിയാക്കാൻ 1 സെക്കൻഡിൽ കൂടുതൽ സമയമെടുത്ത അന്വേഷണങ്ങളുടെയും സൂചികകൾ ഉപയോഗിക്കാത്തവയുടെയും ട്രാക്ക് സൂക്ഷിക്കും.
ഈ ലോഗിൽ കുറച്ച് ഡാറ്റ ഉണ്ടെങ്കിൽ, മുകളിലുള്ള pt-index-usage യൂട്ടിലിറ്റി ഉപയോഗിച്ചോ അല്ലെങ്കിൽ pt-query-digest ഉപയോഗിച്ചോ നിങ്ങൾക്ക് സൂചിക ഉപയോഗത്തിനായി ഇത് വിശകലനം ചെയ്യാം, ഇത് ഇതുപോലുള്ള ഫലങ്ങൾ നൽകും:
Pt-query-digest /var/log/mysql/mysql-slow.log # 360ms ഉപയോക്തൃ സമയം, 20ms സിസ്റ്റം സമയം, 24.66M rss, 92.02M vsz # നിലവിലെ തീയതി: ഫെബ്രുവരി 13 22:39:29 2014 # ഹോസ്റ്റ്നാമം: * # ഫയലുകൾ: mysql-slow.log # മൊത്തത്തിൽ: 8 ആകെ, 6 അദ്വിതീയം, 1.14 QPS, 0.00x കൺകറൻസി ________________ # സമയ പരിധി: 2014-02-13 22:23:52 മുതൽ 22:23:59 വരെ # ആട്രിബ്യൂട്ട് ആകെ മിനിറ്റ് പരമാവധി ശരാശരി 95% stddev മീഡിയൻ # ================================================ == ============== # Exec time 3ms 267us 406us 343us 403us 39us 348us # ലോക്ക് സമയം 827us 88us 125us 103us 119us 12us 98us # Rows 5 1 850 അയച്ചു 51 34. ws എക്സാമിനർമാർ 87 4 30 10.88 28.75 7.37 7.70 # ചോദ്യ വലുപ്പം 2.15k 153 296 245.11 284.79 48.90 258.32 # === ================================= ==== ================ # പ്രൊഫൈൽ # റാങ്ക് ക്വറി ഐഡി പ്രതികരണ സമയം കോളുകൾ R/Call V/M ഇനം # ==== ==== ======= ===================================== # 1 0x728E539F7617C14D 0.0011 41.0% 3 0.0004 0.00 SELECT blog_article # 2 0x1290EEE0B201F3FF 0.0003 12.8% 1 0.0003 0.00 തിരഞ്ഞെടുക്കുക പോർട്ട്ഫോളിയോ_ ഇനം # 3 0x31DE4535BDBFA465 0.0003 12.6% 1 0.0000ഇ പോർട്ട്ഫോ 0.0003 SELECT40.0003 F47A5742 0.0003 12.1% 1 0.0003 0.00 തിരഞ്ഞെടുക്കുക portfolio_category # 5 0x8F848005A09C9588 0.0003 11.8% 1 0.0003 0.0003 0.0003 9.7% 1 0.0003 0.00 SELECT blog_article # ==== =========================================== == ===== ============== # ചോദ്യം 1: 0 QPS, 0x കൺകറൻസി, ID 0x728E539F7617C14D ബൈറ്റ് 736 ______ # സ്കോറുകൾ: V/M = 0.00 # സമയ പരിധി: എല്ലാ ഇവന്റുകളും 2014-02-13 22:23:52-ന് സംഭവിച്ചു # ആട്രിബ്യൂട്ട് pct മൊത്തം മിനിറ്റ് പരമാവധി ശരാശരി 95 % stddev മീഡിയൻ # ============================== ===== =================================== # എണ്ണം 37 3 # എക്സെക് സമയം 40 1മിസ് 352us 406us 375us 403us 22us 366us # ലോക്ക് സമയം 42 351us 103us 125us 117us 119us 9us 119us # വരികൾ അയച്ചു 25 9 1 4 3 3.89 1.37 3.80 പരീക്ഷ 72 72 3.81 7.70 # ചോദ്യ വലുപ്പം 47 1.02k 261 262 261.25 258.32 0 258.32 # സ്ട്രിംഗ്: # ലോക്കൽ ഹോസ്റ്റ് ഹോസ്റ്റ് ചെയ്യുന്നു# ഉപയോക്താക്കൾ * # ക്വറി_ടൈം ഡിസ്ട്രിബ്യൂഷൻ # 1ഉം # 10ഉം # 100ഉം ################################### ########################### # 1ms # 10ms # 100ms # 1s # 10s+ # പട്ടികകൾ # "ബ്ലോഗ്_ലേഖനം" പോലെ പട്ടിക സ്റ്റാറ്റസ് കാണിക്കുക\G # ക്രിയേറ്റ് ടേബിൾ കാണിക്കുക `ബ്ലോഗ്_ലേഖനം`\G # വിശദീകരിക്കുക /*!50100 പാർട്ടീഷനുകൾ*/ തിരഞ്ഞെടുക്കുക b0_.id AS id0, b0_.slug AS slug1, b0_.title AS title2, b0_.excerpt AS Excerpt, blink_0_. .വിവരണം AS വിവരണം5, b0_.സൃഷ്ടിച്ചത് പോലെ സൃഷ്ടിച്ചു6, b0_.അപ്ഡേറ്റ് ചെയ്തു
ഈ ലോഗുകൾ സ്വമേധയാ വിശകലനം ചെയ്യാൻ നിങ്ങൾ ആഗ്രഹിക്കുന്നുവെങ്കിൽ, നിങ്ങൾക്ക് ഇത് ചെയ്യാം, എന്നാൽ ആദ്യം നിങ്ങൾ ലോഗ് കൂടുതൽ പാർസബിൾ ഫോർമാറ്റിലേക്ക് കയറ്റുമതി ചെയ്യേണ്ടതുണ്ട്. ഇത് ഇതുപോലെ ചെയ്യാൻ കഴിയും:
Mysqldumpslow /var/log/mysql/mysql-slow.log
കൂടെ അധിക പാരാമീറ്ററുകൾനിങ്ങൾക്ക് ആവശ്യമുള്ളത് മാത്രം കയറ്റുമതി ചെയ്യാൻ നിങ്ങൾക്ക് ഡാറ്റ ഫിൽട്ടർ ചെയ്യാം. ഉദാഹരണത്തിന്, ശരാശരി എക്സിക്യൂഷൻ സമയം അനുസരിച്ച് അടുക്കിയ മികച്ച 10 ചോദ്യങ്ങൾ:
Mysqldumpslow -t 10 -s at /var/log/mysql/localhost-slow.log
ഉപസംഹാരം
ഈ സമഗ്രമായ MySQL ഒപ്റ്റിമൈസേഷൻ പോസ്റ്റിൽ, ഞങ്ങൾ കവർ ചെയ്തു വിവിധ രീതികൾഞങ്ങളുടെ MySQL പറക്കാനുള്ള സാങ്കേതികതകളും.
ഞങ്ങൾ കോൺഫിഗറേഷൻ ഒപ്റ്റിമൈസേഷൻ കണ്ടെത്തി, ഞങ്ങൾ സൂചികകൾ നവീകരിച്ചു, ചില തടസ്സങ്ങളിൽ നിന്ന് ഞങ്ങൾ രക്ഷപ്പെട്ടു. ഇതെല്ലാം മിക്കവാറും സിദ്ധാന്തമായിരുന്നു, എന്നിരുന്നാലും, ഇത് യഥാർത്ഥ ലോക ആപ്ലിക്കേഷനുകൾക്ക് ബാധകമാണ്.
രചയിതാവിൽ നിന്ന്:എന്റെ ഒരു സുഹൃത്ത് അവന്റെ കാർ ഒപ്റ്റിമൈസ് ചെയ്യാൻ തീരുമാനിച്ചു. ആദ്യം, അവൻ ഒരു ചക്രം എടുത്തു, അങ്ങനെ അവൻ മേൽക്കൂര മുറിച്ചു, പിന്നെ എഞ്ചിൻ ... പൊതുവേ, ഇപ്പോൾ അവൻ നടക്കുന്നു. ഇതെല്ലാം തെറ്റായ സമീപനത്തിന്റെ അനന്തരഫലങ്ങളാണ്! അതിനാൽ, നിങ്ങളുടെ ഡിബിഎംഎസ് പ്രവർത്തിക്കുന്നത് തുടരുന്നതിന്, MySQL ഒപ്റ്റിമൈസേഷൻ ശരിയായി ചെയ്യണം.
എപ്പോൾ ഒപ്റ്റിമൈസ് ചെയ്യണം, എന്തുകൊണ്ട്?
സെർവർ ക്രമീകരണങ്ങളിലേക്ക് പോയി വീണ്ടും പാരാമീറ്റർ മൂല്യങ്ങൾ മാറ്റുന്നത് വിലമതിക്കുന്നില്ല (പ്രത്യേകിച്ച് ഇത് എങ്ങനെ അവസാനിക്കുമെന്ന് നിങ്ങൾക്കറിയില്ലെങ്കിൽ). വെബ് ഉറവിടങ്ങളുടെ പ്രകടനം മെച്ചപ്പെടുത്തുന്നതിനുള്ള “ബെൽ ടവറിൽ” നിന്ന് ഈ വിഷയം ഞങ്ങൾ പരിഗണിക്കുകയാണെങ്കിൽ, അത് വളരെ വിപുലമാണ്, 7 വാല്യങ്ങളിലുള്ള ഒരു മുഴുവൻ ശാസ്ത്ര പ്രസിദ്ധീകരണവും അതിനായി സമർപ്പിക്കേണ്ടതുണ്ട്.
പക്ഷേ, ഒരു എഴുത്തുകാരൻ എന്ന നിലയിൽ എനിക്ക് അത്തരം ക്ഷമയില്ല, ഒരു വായനക്കാരൻ എന്ന നിലയിൽ നിങ്ങൾക്കും ഇല്ല. ഞങ്ങൾ ഇത് കൂടുതൽ ലളിതമായി ചെയ്യും കൂടാതെ MySQL സെർവറിന്റെയും അതിന്റെ ഘടകങ്ങളുടെയും ഒപ്റ്റിമൈസേഷന്റെ തണ്ടിലേക്ക് ചെറുതായി പരിശോധിക്കാൻ ശ്രമിക്കും. എല്ലാ DBMS പാരാമീറ്ററുകളും ഒപ്റ്റിമൽ ആയി സജ്ജീകരിക്കുന്നതിലൂടെ, നിരവധി ലക്ഷ്യങ്ങൾ കൈവരിക്കാൻ കഴിയും:
അന്വേഷണ നിർവ്വഹണ വേഗത വർദ്ധിപ്പിക്കുക.
പ്രമോട്ട് ചെയ്യുക മൊത്തത്തിലുള്ള പ്രകടനംസെർവർ.
ഉറവിട പേജുകൾ ലോഡ് ചെയ്യാനുള്ള കാത്തിരിപ്പ് സമയം കുറയ്ക്കുക.
ഹോസ്റ്റിംഗ് സെർവർ ശേഷിയുടെ ഉപഭോഗം കുറയ്ക്കുക.
ഉപയോഗിക്കുന്ന ഡിസ്ക് സ്ഥലത്തിന്റെ അളവ് കുറയ്ക്കുക.
ഒപ്റ്റിമൈസേഷന്റെ മുഴുവൻ വിഷയവും നിരവധി പോയിന്റുകളായി വിഭജിക്കാൻ ഞങ്ങൾ ശ്രമിക്കും, അതുവഴി "പാത്രം തിളപ്പിക്കുന്നത്" എന്താണെന്ന് കൂടുതലോ കുറവോ വ്യക്തമാകും.
എന്തിനാണ് ഒരു സെർവർ സജ്ജീകരിക്കുന്നത്
MySQL-ൽ, സെർവറിൽ നിന്ന് പ്രകടന ഒപ്റ്റിമൈസേഷൻ ആരംഭിക്കണം. ഒന്നാമതായി, നിങ്ങൾ അതിന്റെ പ്രവർത്തനം വേഗത്തിലാക്കുകയും അഭ്യർത്ഥനകൾ പ്രോസസ്സ് ചെയ്യുന്നതിന് എടുക്കുന്ന സമയം കുറയ്ക്കുകയും വേണം. മുകളിൽ പറഞ്ഞ എല്ലാ ലക്ഷ്യങ്ങളും നേടുന്നതിനുള്ള ഒരു സാർവത്രിക മാർഗം കാഷിംഗ് പ്രവർത്തനക്ഷമമാക്കുക എന്നതാണ്. "അത് എന്താണെന്ന്" അറിയില്ലേ? ഇപ്പോൾ ഞാൻ എല്ലാം വിശദീകരിക്കും.
നിങ്ങളുടെ സെർവർ ഉദാഹരണത്തിൽ കാഷിംഗ് പ്രവർത്തനക്ഷമമാക്കിയിട്ടുണ്ടെങ്കിൽ, പിന്നെ MySQL സിസ്റ്റംഉപയോക്താവ് നൽകിയ ചോദ്യം യാന്ത്രികമായി "ഓർമ്മിക്കുന്നു". അടുത്ത തവണ അത് വീണ്ടും സംഭവിക്കുന്നു ഈ ഫലംഅഭ്യർത്ഥന (സാമ്പിളിനായി) പ്രോസസ്സ് ചെയ്യില്ല, പക്ഷേ സിസ്റ്റം മെമ്മറിയിൽ നിന്ന് എടുത്തതാണ്. ഈ രീതിയിൽ സെർവർ ഒരു പ്രതികരണം നൽകുന്നതിനുള്ള സമയം "സംരക്ഷിക്കുന്നു", തൽഫലമായി, സൈറ്റിന്റെ പ്രതികരണ വേഗത വർദ്ധിക്കുന്നു. മൊത്തത്തിലുള്ള ഡൗൺലോഡ് വേഗതയ്ക്കും ഇത് ബാധകമാണ്.
MySQL-ൽ, ഈ DBMS, PHP എന്നിവയുടെ അടിസ്ഥാനത്തിൽ പ്രവർത്തിക്കുന്ന എഞ്ചിനുകൾക്കും CMS-നും അന്വേഷണ ഒപ്റ്റിമൈസേഷൻ ബാധകമാണ്. ഈ സാഹചര്യത്തിൽ, ഒരു പ്രോഗ്രാമിംഗ് ഭാഷയിൽ എഴുതിയ കോഡ്, ഒരു ഡൈനാമിക് വെബ് പേജ് സൃഷ്ടിക്കുന്നതിന്, ഡാറ്റാബേസിൽ നിന്ന് അതിന്റെ ഘടനാപരമായ ഭാഗങ്ങളും ഉള്ളടക്കങ്ങളും (രേഖകൾ, ആർക്കൈവുകൾ, മറ്റ് ടാക്സോണമികൾ) അഭ്യർത്ഥിക്കുന്നു.
MySQL-ൽ കാഷിംഗ് പ്രവർത്തനക്ഷമമാക്കിയതിന് നന്ദി, ഡിബിഎംഎസ് സെർവറിലേക്കുള്ള ചോദ്യങ്ങൾ എക്സിക്യൂട്ട് ചെയ്യുന്നത് വളരെ വേഗത്തിലാണ്. ഇതുമൂലം, മുഴുവൻ വിഭവങ്ങളുടെയും ലോഡിംഗ് വേഗത മൊത്തത്തിൽ വർദ്ധിക്കുന്നു. ഉപയോക്തൃ അനുഭവത്തിലും തിരയൽ ഫലങ്ങളിലെ സൈറ്റിന്റെ സ്ഥാനത്തിലും ഇത് നല്ല സ്വാധീനം ചെലുത്തുന്നു.
കാഷിംഗ് പ്രവർത്തനക്ഷമമാക്കുകയും കോൺഫിഗർ ചെയ്യുകയും ചെയ്യുക
എന്നാൽ "ബോറടിപ്പിക്കുന്ന" സിദ്ധാന്തത്തിൽ നിന്ന് രസകരമായ പരിശീലനത്തിലേക്ക് മടങ്ങാം. കൂടുതൽ ഒപ്റ്റിമൈസേഷൻ MySQL ഡാറ്റാബേസുകൾനിങ്ങളുടെ ഡാറ്റാബേസ് സെർവറിലെ കാഷിംഗ് നില പരിശോധിച്ചുകൊണ്ട് നമുക്ക് തുടരാം. ഇത് ചെയ്യുന്നതിന്, ഒരു പ്രത്യേക അഭ്യർത്ഥന ഉപയോഗിച്ച്, ഞങ്ങൾ എല്ലാ സിസ്റ്റം വേരിയബിളുകളുടെയും മൂല്യങ്ങൾ പ്രദർശിപ്പിക്കും:
തികച്ചും വ്യത്യസ്തമായ കാര്യമാണ്.
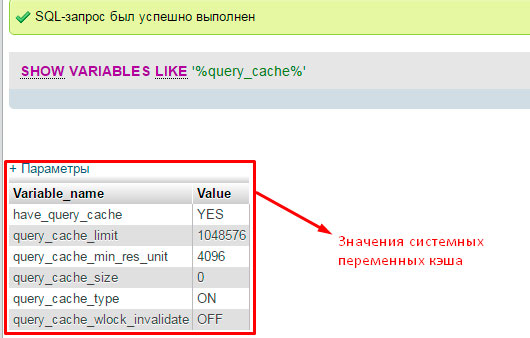
MySQL ഡാറ്റാബേസുകൾ ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിന് നമുക്ക് ഉപയോഗപ്രദമാകുന്ന, ലഭിച്ച മൂല്യങ്ങളുടെ ഒരു ചെറിയ അവലോകനം നടത്താം:
have_query_cache - ക്വറി കാഷിംഗ് "ഓൺ" ആണോ ഇല്ലയോ എന്ന് മൂല്യം സൂചിപ്പിക്കുന്നു.
query_cache_type - സജീവമായ കാഷെ തരം പ്രദർശിപ്പിക്കുന്നു. ഞങ്ങൾക്ക് "ഓൺ" മൂല്യം ആവശ്യമാണ്. എല്ലാത്തരം തിരഞ്ഞെടുപ്പുകൾക്കും കാഷിംഗ് പ്രവർത്തനക്ഷമമാക്കിയിട്ടുണ്ടെന്ന് ഇത് സൂചിപ്പിക്കുന്നു (SELECT കമാൻഡ്). SQL_NO_CACHE പരാമീറ്റർ ഉപയോഗിക്കുന്നവ ഒഴികെ (ഈ അന്വേഷണത്തെക്കുറിച്ചുള്ള വിവരങ്ങൾ സംരക്ഷിക്കുന്നത് വിലക്കുന്നു).
ഞങ്ങൾ എല്ലാ ക്രമീകരണങ്ങളും ശരിയായി സജ്ജീകരിച്ചിരിക്കുന്നു.
സൂചികകൾക്കും കീകൾക്കുമായി ഞങ്ങൾ കാഷെ അളക്കുന്നു
സൂചികകൾക്കും കീകൾക്കുമായി എത്ര റാം അനുവദിച്ചിട്ടുണ്ടെന്ന് ഇപ്പോൾ നിങ്ങൾ പരിശോധിക്കേണ്ടതുണ്ട്. MySQL ഡാറ്റാബേസ് ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിന് പ്രധാനപ്പെട്ട ഈ പരാമീറ്റർ സെർവറിന് ലഭ്യമായ റാമിന്റെ 20-30% ആയി സജ്ജീകരിക്കാൻ ശുപാർശ ചെയ്യുന്നു. ഉദാഹരണത്തിന്, ഒരു DBMS ഉദാഹരണത്തിനായി 4 "ഹെക്ടർ" അനുവദിച്ചിട്ടുണ്ടെങ്കിൽ, 32 "മീറ്റർ" സജ്ജമാക്കാൻ മടിക്കേണ്ടതില്ല. എന്നാൽ ഇതെല്ലാം ഒരു പ്രത്യേക ഡാറ്റാബേസിന്റെ സവിശേഷതകളെയും അതിന്റെ ഘടന (തരം) പട്ടികകളെയും ആശ്രയിച്ചിരിക്കുന്നു.
പാരാമീറ്റർ മൂല്യം സജ്ജമാക്കാൻ നിങ്ങൾ ഉള്ളടക്കം എഡിറ്റ് ചെയ്യേണ്ടതുണ്ട് കോൺഫിഗറേഷൻ ഫയൽ my.ini, ഡെൻവറിൽ സ്ഥിതി ചെയ്യുന്നത് ഇനിപ്പറയുന്ന പാതയിലാണ്: F:\Webserver\usr\local\mysql-5.5

നോട്ട്പാഡ് ഉപയോഗിച്ച് ഫയൽ തുറക്കുക. അതിനുശേഷം ഞങ്ങൾ അതിൽ key_buffer_size പാരാമീറ്റർ കണ്ടെത്തി നിങ്ങളുടെ പിസി സിസ്റ്റത്തിന് ഒപ്റ്റിമൽ വലുപ്പം സജ്ജമാക്കുക (റാമിന്റെ "ഹെക്ടർ" അനുസരിച്ച്). ഇതിനുശേഷം, നിങ്ങൾ ഡാറ്റാബേസ് സെർവർ പുനരാരംഭിക്കേണ്ടതുണ്ട്.

DBMS നിരവധി അധിക ഉപസിസ്റ്റങ്ങൾ ഉപയോഗിക്കുന്നു ( താഴ്ന്ന നില), കൂടാതെ അവരുടെ എല്ലാ അടിസ്ഥാന ക്രമീകരണങ്ങളും ഇതിൽ വ്യക്തമാക്കിയിട്ടുണ്ട് ഈ ഫയൽകോൺഫിഗറേഷനുകൾ. അതിനാൽ, നിങ്ങൾക്ക് MySQL InnoDB ഒപ്റ്റിമൈസ് ചെയ്യണമെങ്കിൽ, ഇവിടെ സ്വാഗതം. ഞങ്ങളുടെ അടുത്ത മെറ്റീരിയലുകളിലൊന്നിൽ ഞങ്ങൾ ഈ വിഷയം കൂടുതൽ വിശദമായി പഠിക്കും.
സൂചികകളുടെ നിലവാരം അളക്കുന്നു
പട്ടികകളിലെ സൂചികകളുടെ ഉപയോഗം, നൽകിയ ചോദ്യത്തിന് ഒരു ഡിബിഎംഎസ് പ്രതികരണം പ്രോസസ്സ് ചെയ്യുന്നതിനും സൃഷ്ടിക്കുന്നതിനുമുള്ള വേഗത ഗണ്യമായി വർദ്ധിപ്പിക്കുന്നു. MySQL ഓരോ ഡാറ്റാബേസിലെയും സൂചികയുടെ നിലവാരവും കീ ഉപയോഗവും നിരന്തരം "അളക്കുന്നു". ലഭിക്കുന്നതിന് നൽകിയ മൂല്യംചോദ്യം ഉപയോഗിക്കുക:
"handler_read%" പോലെ സ്റ്റാറ്റസ് കാണിക്കുക
"handler_read%" പോലെ സ്റ്റാറ്റസ് കാണിക്കുക |

ഫലമായുണ്ടാകുന്ന ഫലത്തിൽ, Handler_read_key ലൈനിലെ മൂല്യത്തിൽ ഞങ്ങൾക്ക് താൽപ്പര്യമുണ്ട്. അവിടെ സൂചിപ്പിച്ചിരിക്കുന്ന സംഖ്യ ചെറുതാണെങ്കിൽ, ഈ ഡാറ്റാബേസിൽ സൂചികകൾ മിക്കവാറും ഉപയോഗിച്ചിട്ടില്ലെന്ന് ഇത് സൂചിപ്പിക്കുന്നു. ഇത് മോശമാണ് (നമ്മുടേത് പോലെ).
→ ഒപ്റ്റിമൈസേഷൻ MySQL അന്വേഷണങ്ങൾ
MySQLവിവിധ തരംതിരിവുകൾക്കായി വിപുലമായ പ്രവർത്തനങ്ങളുണ്ട് ( ഓർഡർ പ്രകാരം), ഗ്രൂപ്പുകൾ ( ഗ്രൂപ്പ് പ്രകാരം), അസോസിയേഷനുകൾ ( ഇടത് ചേരുകഅഥവാ വലത് ചേരുക) ഇത്യാദി. അവയെല്ലാം തീർച്ചയായും സൗകര്യപ്രദമാണ്, പക്ഷേ ഒറ്റത്തവണ അഭ്യർത്ഥനകളുടെ സാഹചര്യങ്ങളിൽ. ഉദാഹരണത്തിന്, ഒരു കൂട്ടം പട്ടികകളും ലിങ്കുകളും ഉപയോഗിച്ച് നിങ്ങൾക്ക് വ്യക്തിപരമായി ഡാറ്റാബേസിൽ എന്തെങ്കിലും കണ്ടെത്തണമെങ്കിൽ, മുകളിലുള്ള പ്രവർത്തനങ്ങൾക്ക് പുറമേ നിങ്ങൾക്ക് സോപാധിക ഓപ്പറേറ്റർമാരെ ഉപയോഗിക്കാനും ഉപയോഗിക്കാനും കഴിയും. IF. പ്രധാന തെറ്റ്തുടക്കക്കാരായ പ്രോഗ്രാമർമാർക്കായി, സൈറ്റിന്റെ വർക്കിംഗ് കോഡിൽ അത്തരം ചോദ്യങ്ങൾ പ്രയോഗിക്കാനുള്ള ആഗ്രഹമാണിത്. ഈ സാഹചര്യത്തിൽ, സങ്കീർണ്ണമായ ഒരു ചോദ്യം തീർച്ചയായും മനോഹരമാണ്, പക്ഷേ ദോഷകരമാണ്. ഏതെങ്കിലും സോർട്ടിംഗ്, ഗ്രൂപ്പിംഗ്, യൂണിയൻ അല്ലെങ്കിൽ നെസ്റ്റഡ് ക്വറി ഓപ്പറേറ്റർമാർക്ക് റാമിൽ എക്സിക്യൂട്ട് ചെയ്യാൻ കഴിയില്ല എന്നതാണ് കാര്യം. HDDതാൽക്കാലിക പട്ടികകൾ സൃഷ്ടിക്കാൻ. ഹാർഡ് ഡ്രൈവ്, നിങ്ങൾക്കറിയാവുന്നതുപോലെ, സെർവറിന്റെ തടസ്സമാണ്.
mysql അന്വേഷണങ്ങൾ ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിനുള്ള നിയമങ്ങൾ
1. നെസ്റ്റഡ് ക്വറികൾ ഒഴിവാക്കുക
ഇതാണ് ഏറ്റവും ഗുരുതരമായ തെറ്റ്. ചൈൽഡ് പ്രോസസ്സ് പൂർത്തിയാകുന്നതുവരെ പാരന്റ് പ്രോസസ്സ് എപ്പോഴും കാത്തിരിക്കും, ഈ സമയത്ത് ഡാറ്റാബേസിലേക്ക് ഒരു കണക്ഷൻ സൂക്ഷിക്കുക, ഡിസ്ക് ഉപയോഗിക്കുക, iowait ലോഡ് ചെയ്യുക. ഡാറ്റാബേസിലേക്കുള്ള രണ്ട് സമാന്തര അഭ്യർത്ഥനകളും സെർവർ ഇന്റർപ്രെറ്ററിൽ ആവശ്യമായ ഫിൽട്ടറിംഗ് നടത്തുകയും ചെയ്യുന്നു ( പേൾ, PHP, മുതലായവ) നെസ്റ്റഡ് ചെയ്തതിനേക്കാൾ വേഗത്തിൽ മാഗ്നിറ്റ്യൂഡ് ഒരു ഓർഡർ എക്സിക്യൂട്ട് ചെയ്യും.
perl ലെ ഉദാഹരണങ്ങൾഎന്ത് ചെയ്യാൻ പാടില്ല:
എന്റെ $sth = $dbh->തയ്യാറ് ചെയ്യുക("എലമെന്റ് ഐഡി, എലമെന്റ് നാമം, ഗ്രൂപ്പ് ഐഡി തിരഞ്ഞെടുക്കുക ടിബിഎൽ എവിടെ ഗ്രൂപ്പ് ഐഡി IN(2,3,7)"); $sth-> എക്സിക്യൂട്ട്(); അതേസമയം (my @row = $sth->fetchrow_array()) ( my $groupNAME = $dbh->selectrow_array("ഗ്രൂപ്പുകളിൽ നിന്ന് ഗ്രൂപ്പ്NAME തിരഞ്ഞെടുക്കുക ഗ്രൂപ്പ് ഐഡി = $റോ"); ### നിങ്ങൾ പേരുകൾ ശേഖരിക്കണമെന്ന് പറയാം ഗ്രൂപ്പുകൾ ### കൂടാതെ അവയെ ഡാറ്റ അറേയുടെ അവസാനം ചേർക്കുക @row => $groupNAME; ### മറ്റെന്തെങ്കിലും ചെയ്യുക... )
അല്ലെങ്കിൽ ഇതുപോലെ ഒരു സാഹചര്യത്തിലും:
എന്റെ $sth = $dbh->തയ്യാറ് ചെയ്യുക("എലമെന്റ് ഐഡി, എലമെന്റ് NAME, ഗ്രൂപ്പ് ഐഡിയിൽ നിന്ന് tbl എവിടെ നിന്ന് ഗ്രൂപ്പ് ഐഡി തിരഞ്ഞെടുക്കുക (ഗ്രൂപ്പുകളിൽ നിന്ന് ഗ്രൂപ്പ് ഐഡി തിരഞ്ഞെടുക്കുക എവിടെ ഗ്രൂപ്പ് നാമം = "ആദ്യം" അല്ലെങ്കിൽ ഗ്രൂപ്പിന്റെ പേര് = "രണ്ടാം" അല്ലെങ്കിൽ ഗ്രൂപ്പിന്റെ പേര് = "ഏഴാമത്")");
അത്തരം പ്രവർത്തനങ്ങളുടെ ആവശ്യമുണ്ടെങ്കിൽ, എല്ലാ സാഹചര്യങ്ങളിലും ഒരു ഹാഷ്, അറേ അല്ലെങ്കിൽ മറ്റേതെങ്കിലും ഫിൽട്ടറിംഗ് പാത ഉപയോഗിക്കുന്നതാണ് നല്ലത്.
ഞാൻ സാധാരണയായി ചെയ്യുന്നതുപോലെ, perl-ലെ ഒരു ഉദാഹരണം:
എന്റെ %ഗ്രൂപ്പുകൾ; എന്റെ $sth = $dbh->തയ്യാറ് ചെയ്യുക("ഗ്രൂപ്പ് ഐഡി തിരഞ്ഞെടുക്കുക, ഗ്രൂപ്പ് ഐഡി എവിടെയാണ് ഗ്രൂപ്പ് ഐഡിയിൽ (2,3,7)"); $sth-> എക്സിക്യൂട്ട്(); അതേ സമയം (my @row = $sth->fetchrow_array()) ($groups($row) = $row; ) ### ഇപ്പോൾ നമുക്ക് my $sth2 = $dbh->തയ്യാറാക്കാതെ പ്രധാന കണ്ടെത്തൽ നടത്താം("SELECT) എലിമെന്റ് ഐഡി , എലമെന്റ് NAME, ഗ്രൂപ്പ് ഐഡി tbl എവിടെ ഗ്രൂപ്പ് ഐഡി IN(2,3,7)"); $sth2-> എക്സിക്യൂട്ട്(); അതേസമയം (my @row = $sth2->fetchrow_array()) (പുഷ് @റോ => $groups($row); ### നമുക്ക് മറ്റെന്തെങ്കിലും ചെയ്യാം...)
2. ഡാറ്റാബേസിൽ അടുക്കുകയോ ഗ്രൂപ്പുചെയ്യുകയോ ഫിൽട്ടർ ചെയ്യുകയോ ചെയ്യരുത്
സാധ്യമെങ്കിൽ, നിങ്ങളുടെ അന്വേഷണങ്ങളിൽ ഓർഡർ ബൈ, ഗ്രൂപ്പ് ബൈ, അല്ലെങ്കിൽ ജോയിൻ ഓപ്പറേറ്റർമാർ എന്നിവ ഉപയോഗിക്കരുത്. അവരെല്ലാം താൽക്കാലിക മേശകളാണ് ഉപയോഗിക്കുന്നത്. എലമെന്റുകൾ പ്രദർശിപ്പിക്കാൻ മാത്രം സോർട്ടിംഗ് അല്ലെങ്കിൽ ഗ്രൂപ്പിംഗ് ആവശ്യമാണെങ്കിൽ, ഉദാഹരണത്തിന് അക്ഷരമാലാക്രമത്തിൽ, ഈ പ്രവർത്തനങ്ങൾ ഇന്റർപ്രെറ്റർ വേരിയബിളുകളിൽ ചെയ്യുന്നതാണ് നല്ലത്.
എങ്ങനെ അടുക്കരുത് എന്നതിന്റെ പേൾ ഉദാഹരണങ്ങൾ:
എന്റെ $sth = $dbh->തയ്യാറ് ("എലമെന്റ് ഐഡി തിരഞ്ഞെടുക്കുക, tbl എവിടെ നിന്ന് ഗ്രൂപ്പ് ഐഡിയിൽ നിന്ന് എലമെന്റിന്റെ പേര് തിരഞ്ഞെടുക്കുക (2,3,7) എലമെന്റിന്റെ പേര് പ്രകാരം ഓർഡർ ചെയ്യുക"); $sth-> എക്സിക്യൂട്ട്(); അതേസമയം (my @row = $sth->fetchrow_array()) ( qq($row => $row);)
ഞാൻ സാധാരണയായി എങ്ങനെ അടുക്കുന്നു എന്നതിന്റെ perl-ലെ ഒരു ഉദാഹരണം:
എന്റെ $list = $dbh->selectall_arrayref("എലമെന്റ് ഐഡി തിരഞ്ഞെടുക്കുക, tbl എവിടെ നിന്ന് ഗ്രൂപ്പ് ഐഡി IN(2,3,7)"); foreach (sort ( $a-> cmp $b-> ) @$list)( പ്രിന്റ് qq($_-> => $_->);)
ഈ വഴി വളരെ വേഗതയുള്ളതാണ്. ധാരാളം ഡാറ്റ ഉണ്ടെങ്കിൽ വ്യത്യാസം പ്രത്യേകിച്ചും ശ്രദ്ധേയമാണ്. നിങ്ങൾ ക്രമപ്പെടുത്തേണ്ട സാഹചര്യത്തിൽ perlനിരവധി ഫീൽഡുകൾക്കായി, നിങ്ങൾക്ക് Schwartz സോർട്ട് പ്രയോഗിക്കാൻ കഴിയും. ക്രമരഹിതമായി അടുക്കൽ ആവശ്യമാണെങ്കിൽ RAND() പ്രകാരം ഓർഡർ ചെയ്യുക - perl-ൽ ക്രമരഹിതമായി അടുക്കുക.
3. സൂചികകൾ ഉപയോഗിക്കുക
ഡാറ്റാബേസിൽ അടുക്കുന്നത് ചില സന്ദർഭങ്ങളിൽ ഉപേക്ഷിക്കപ്പെടുമെങ്കിലും, എവിടെ സാധ്യമാകാൻ സാധ്യതയില്ല. അതിനാൽ, താരതമ്യം ചെയ്യുന്ന ഫീൽഡുകൾക്കായി, സൂചികകൾ സജ്ജമാക്കേണ്ടത് ആവശ്യമാണ്. അവ ചെയ്യാൻ എളുപ്പമാണ്.
ഈ അഭ്യർത്ഥനയോടെ:
ALTER TABLE `any_db`.`any_tbl` INDEX ചേർക്കുക `text_index`(`text_fld`(255));
ഇവിടെ 255 ആണ് കീ ദൈർഘ്യം. ചില ഡാറ്റ തരങ്ങൾക്ക് ഇത് ആവശ്യമില്ല. വിശദാംശങ്ങൾക്ക് MySQL ഡോക്യുമെന്റേഷൻ കാണുക.
ചിലപ്പോൾ നിങ്ങൾ ഒരു ചോദ്യം സൃഷ്ടിക്കുമ്പോൾ, നിങ്ങൾക്ക് പട്ടികയിൽ ഒരു അദ്വിതീയ വരി മാത്രമേ ആവശ്യമുള്ളൂ എന്ന് നിങ്ങൾക്ക് ഇതിനകം അറിയാം. ഒരു അദ്വിതീയ റെക്കോർഡിനെ അടിസ്ഥാനമാക്കി നിങ്ങൾക്ക് ഒരു തിരഞ്ഞെടുപ്പ് സൃഷ്ടിക്കാൻ കഴിയും. അല്ലെങ്കിൽ നിങ്ങളുടെ അവസ്ഥയെ തൃപ്തിപ്പെടുത്തുന്ന എന്തെങ്കിലും റെക്കോർഡുകൾ നിലവിലുണ്ടോ എന്നറിയാൻ നിങ്ങൾക്ക് ഒരു പരിശോധന നടത്താം.
അത്തരം സന്ദർഭങ്ങളിൽ, LIMIT 1 രീതി ഉപയോഗിച്ച് പ്രകടനം ഗണ്യമായി മെച്ചപ്പെടുത്താൻ കഴിയും:
// കാലിഫോർണിയയിൽ നിന്നുള്ള ആളുകൾക്ക് ഡാറ്റാബേസിൽ ഡാറ്റ ഉണ്ടോ? // ഇല്ല, ഒന്നുമില്ല!: $r = mysql_query("ഉപയോക്താവിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക * എവിടെ സംസ്ഥാനം = "കാലിഫോർണിയ""); എങ്കിൽ (mysql_num_rows($r) > 0) (// ... മറ്റ് കോഡ് ) // പോസിറ്റീവ് ഉത്തരം $r = mysql_query("ഉപയോക്താവിൽ നിന്ന് 1 തിരഞ്ഞെടുക്കുക സംസ്ഥാനം = "കാലിഫോർണിയ" പരിധി 1"); എങ്കിൽ (mysql_num_rows($r) > 0) ( // ...മറ്റ് കോഡ് )
2. ക്വറി കാഷെ പ്രോസസ്സിംഗ് ഉപയോഗിച്ച് ഡാറ്റാബേസുമായി പ്രവർത്തിക്കുന്നതിനുള്ള ഒപ്റ്റിമൈസേഷൻ
മിക്ക MySQL സെർവറുകളും ക്വറി കാഷിംഗ് പിന്തുണയ്ക്കുന്നു. ഇത് ഏറ്റവും കൂടുതൽ ഒന്നാണ് ഫലപ്രദമായ രീതികൾഡാറ്റാബേസ് എഞ്ചിൻ പ്രശ്നങ്ങളില്ലാതെ കൈകാര്യം ചെയ്യുന്ന പ്രകടന മെച്ചപ്പെടുത്തലുകൾ.
ഒരേ ചോദ്യം പലതവണ എക്സിക്യൂട്ട് ചെയ്യുമ്പോൾ, കാഷെയിൽ നിന്ന് ഫലം ലഭിക്കും. എല്ലാ ടേബിളുകളും വീണ്ടും പ്രോസസ്സ് ചെയ്യാതെ തന്നെ. ഇത് പ്രക്രിയയെ ഗണ്യമായി വേഗത്തിലാക്കുന്നു.
// അന്വേഷണ കാഷെ പിന്തുണയ്ക്കുന്നില്ലെങ്കിൽ $r = mysql_query("സൈൻഅപ്പ്_ഡേറ്റ് എവിടെ നിന്ന് ഉപയോക്തൃനാമം തിരഞ്ഞെടുക്കുക >= CURDATE()"); // കാഷെ പിന്തുണയ്ക്കുന്നു! $today_date = തീയതി("Y-m-d"); $r = mysql_query("സൈൻഅപ്പ്_ഡേറ്റ് എവിടെ നിന്ന് ഉപയോക്തൃനാമം തിരഞ്ഞെടുക്കുക >= "$today_date"");
3. ഇൻഡെക്സിംഗ് തിരയൽ ഫീൽഡുകൾ
സൂചികകൾ പ്രാഥമിക അല്ലെങ്കിൽ അദ്വിതീയ കീകളിലേക്ക് അസൈൻ ചെയ്യാൻ ഉദ്ദേശിച്ചുള്ളതല്ല. നിങ്ങൾ തിരയുന്ന ഒരു പട്ടികയിൽ നിരകൾ ഉണ്ടെങ്കിൽ, അവ മിക്കവാറും സൂചികയിലാക്കിയിരിക്കണം.
നിങ്ങൾക്ക് സങ്കൽപ്പിക്കാനാകുന്നതുപോലെ, ഈ നിയമം തിരയൽ സ്ട്രിംഗിന്റെ ഭാഗങ്ങൾക്കും ബാധകമാണ്: "Last_name LIKE '%'" പോലുള്ളവ. ഒരു വരിയുടെ തുടക്കത്തിൽ തിരയുമ്പോൾ, ആ കോളത്തിൽ MySQL-ന് ഇൻഡക്സിംഗ് ഉപയോഗിക്കാം.
ഏത് തരത്തിലുള്ള അന്വേഷണങ്ങൾക്ക് സാധാരണ സൂചികകൾ ഉപയോഗിക്കാൻ കഴിയില്ലെന്നും നിങ്ങൾ മനസ്സിലാക്കേണ്ടതുണ്ട്. ഉദാഹരണത്തിന്, ഒരു വാക്ക് തിരയുമ്പോൾ (ഉദാഹരണത്തിന്, "WHERE post_content LIKE '%tomato%""), ഒരു സാധാരണ സൂചിക ഉപയോഗിക്കുന്നത് നിങ്ങൾക്ക് ഒന്നും നൽകില്ല. ഈ സാഹചര്യത്തിൽ, ഉപയോഗിക്കുന്നതാണ് നല്ലത് MySQL തിരയൽപൂർണ്ണമായ പാലിക്കലിനായി അല്ലെങ്കിൽ നിങ്ങളുടെ സ്വന്തം സൂചിക സൃഷ്ടിക്കുക.
4. ചേരുമ്പോൾ ഒരേ തരത്തിലുള്ള നിരകൾ സൂചികയിലാക്കലും ഉപയോഗിക്കലും
നിങ്ങളുടെ ആപ്ലിക്കേഷനിൽ നിരവധി ജോയിൻ ചോദ്യങ്ങൾ അടങ്ങിയിട്ടുണ്ടെങ്കിൽ, നിങ്ങൾ ചേരുന്ന രണ്ട് പട്ടികകളിലെയും നിരകൾ സൂചികയിലാക്കിയിട്ടുണ്ടെന്ന് ഉറപ്പാക്കേണ്ടതുണ്ട്. ഇത് ആന്തരികത്തിന്റെ ഒപ്റ്റിമൈസേഷനെ ബാധിക്കുന്നു MySQL പ്രവർത്തനങ്ങൾഅസോസിയേഷൻ വഴി.
കൂടാതെ, ലയിപ്പിച്ച നിരകൾ ഒരേ തരത്തിലുള്ളതായിരിക്കണം. ഉദാഹരണത്തിന്, നിങ്ങൾ ഒരു ടേബിളിൽ നിന്ന് DECIMAL ടൈപ്പിന്റെ കോളവും മറ്റൊന്നിൽ നിന്ന് INT ടൈപ്പ് കോളവും ചേരുകയാണെങ്കിൽ, MySQL-ന് ഒന്നും ഉപയോഗിക്കാൻ കഴിയില്ല. ഇത്രയെങ്കിലുംസൂചികകളിൽ ഒന്ന്.
ചേരുന്ന നിരകളുടെ അനുബന്ധ വരികൾക്ക് പ്രതീക എൻകോഡിംഗ് പോലും ഒരേ തരത്തിലുള്ളതായിരിക്കണം.
// എന്റെ സംസ്ഥാനത്ത് സ്ഥിതി ചെയ്യുന്ന കമ്പനികൾക്കായി തിരയുന്നു $r = mysql_query("ഉപയോക്താക്കളിൽ നിന്ന് കമ്പനി_പേര് തിരഞ്ഞെടുക്കുക LEFT JOIN Company ON (users.state = companies.state) WHERE users.id = $user_id"); // രണ്ട് സംസ്ഥാന നിരകളും സൂചികയിലാക്കിയിരിക്കണം // അവ രണ്ടും ഒരേ തരവും അനുബന്ധ വരികൾക്കായി ഒരേ പ്രതീക എൻകോഡിംഗ് ഉണ്ടായിരിക്കുകയും വേണം // അല്ലെങ്കിൽ MySQL മുഴുവൻ പട്ടികയും സ്കാൻ ചെയ്യേണ്ടതുണ്ട്
5. സാധ്യമെങ്കിൽ, SELECT * ചോദ്യങ്ങൾ ഉപയോഗിക്കുന്നത് ഒഴിവാക്കുക
ഒരു ചോദ്യത്തിനിടയിൽ ഒരു പട്ടികയിലെ കൂടുതൽ ഡാറ്റ പ്രോസസ്സ് ചെയ്യപ്പെടുമ്പോൾ, ചോദ്യം തന്നെ മന്ദഗതിയിലാകും. സമയം അതിക്രമിച്ചിരിക്കുന്നു ഡിസ്ക് പ്രവർത്തനങ്ങൾ. കൂടാതെ, ഡാറ്റാബേസ് സെർവർ വെബ് സെർവറുമായി പങ്കിടുമ്പോൾ, സെർവറുകൾക്കിടയിൽ ഡാറ്റ കൈമാറുന്നതിൽ കാലതാമസമുണ്ടാകും.
// ആവശ്യമില്ലാത്ത ചോദ്യം $r = mysql_query ("ഉപയോക്താവിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക * എവിടെ user_id = 1"); $d = mysql_fetch_assoc($r); പ്രതിധ്വനി "സ്വാഗതം ($d["ഉപയോക്തൃനാമം"])"; // ഇനിപ്പറയുന്ന കോഡ് ഉപയോഗിക്കുന്നതാണ് നല്ലത്: $r = mysql_query("ഉപയോക്താവിൽ നിന്ന് ഉപയോക്തൃനാമം തിരഞ്ഞെടുക്കുക user_id = 1"); $d = mysql_fetch_assoc($r); പ്രതിധ്വനി "സ്വാഗതം ($d["ഉപയോക്തൃനാമം"])";
6. ഓർഡർ ബൈ RAND() അടുക്കൽ രീതി ഉപയോഗിക്കരുത്
ആദ്യം നല്ലതായി തോന്നുന്ന തന്ത്രങ്ങളിൽ ഒന്നാണിത്, കൂടാതെ പല പുതിയ പ്രോഗ്രാമർമാരും അതിൽ വീഴുന്നു. അന്വേഷണങ്ങളിൽ ഈ ഫിൽട്ടർ ഉപയോഗിക്കാൻ തുടങ്ങിയാൽ ഉടൻ തന്നെ നിങ്ങൾ സ്വയം എന്ത് കെണിയാണ് സജ്ജമാക്കുന്നതെന്ന് നിങ്ങൾക്ക് ഊഹിക്കാൻ പോലും കഴിയില്ല.
നിങ്ങളുടെ തിരയൽ ഫലങ്ങളിൽ ചില സ്ട്രിംഗുകൾ അടുക്കേണ്ടതുണ്ടെങ്കിൽ, അത് ചെയ്യാൻ കൂടുതൽ കാര്യക്ഷമമായ വഴികളുണ്ട്. നിങ്ങൾ ചേർക്കേണ്ടതുണ്ടെന്ന് പറയാം അധിക കോഡ്അഭ്യർത്ഥനയിലേക്ക്, പക്ഷേ ഈ കെണി കാരണം നിങ്ങൾക്ക് ഇത് ചെയ്യാൻ കഴിയില്ല, ഇത് ഡാറ്റാബേസിന്റെ വലുപ്പം വർദ്ധിക്കുന്നതിനനുസരിച്ച് ഡാറ്റ പ്രോസസ്സിംഗിന്റെ കാര്യക്ഷമത കുറയുന്നതിന് ഇടയാക്കും.
ടേബിളിലെ ഓരോ വരിയും അടുക്കുന്നതിന് മുമ്പ് MySQL ഒരു RAND() ഓപ്പറേഷൻ (സെർവർ കമ്പ്യൂട്ടിംഗ് റിസോഴ്സുകൾ ഉപയോഗിക്കുന്ന) നടത്തുമെന്നതാണ് പ്രശ്നം. ഈ സാഹചര്യത്തിൽ, ഒരു വരി മാത്രമേ തിരഞ്ഞെടുക്കൂ.
// എന്ത് കോഡ് ഉപയോഗിക്കാൻ പാടില്ല: $r = mysql_query("ഉപയോക്താവിൽ നിന്ന് ഉപയോക്തൃനാമം തിരഞ്ഞെടുക്കുക RAND() പരിധി 1 പ്രകാരം ഓർഡർ ചെയ്യുക"); // ഇനിപ്പറയുന്ന കോഡ് ഉപയോഗിക്കുന്നത് കൂടുതൽ ശരിയായിരിക്കും: $r = mysql_query("ഉപയോക്താവിൽ നിന്ന് എണ്ണം (*) തിരഞ്ഞെടുക്കുക"); $d = mysql_fetch_row($r); $rand = mt_rand(0,$d - 1); $r = mysql_query("ഉപയോക്തൃ പരിധി $rand, 1 എന്നതിൽ നിന്ന് ഉപയോക്തൃനാമം തിരഞ്ഞെടുക്കുക");
ഈ രീതിയിൽ, നിങ്ങൾ കുറച്ച് തിരയൽ ഫലങ്ങൾ തിരഞ്ഞെടുക്കും, അതിനുശേഷം നിങ്ങൾക്ക് പോയിന്റ് 1 ൽ വിവരിച്ചിരിക്കുന്ന LIMIT രീതി പ്രയോഗിക്കാൻ കഴിയും.
7. VARCHAR-ന് പകരം ENUM നിരകൾ ഉപയോഗിക്കുക
ENUM നിരകൾ വളരെ ഒതുക്കമുള്ളതിനാൽ പ്രോസസ്സ് ചെയ്യാൻ വേഗത്തിലാണ്. ഡാറ്റാബേസിനുള്ളിൽ, അവയുടെ ഉള്ളടക്കങ്ങൾ TINYINT ഫോർമാറ്റിൽ സംഭരിച്ചിരിക്കുന്നു, എന്നാൽ അവയ്ക്ക് ഏത് മൂല്യങ്ങളും ഉൾക്കൊള്ളാനും പ്രദർശിപ്പിക്കാനും കഴിയും. അതിനാൽ, അവയിൽ ചില ഫീൽഡുകൾ സജ്ജീകരിക്കുന്നത് വളരെ സൗകര്യപ്രദമാണ്.
നിങ്ങൾക്ക് നിരവധി ഫീൽഡുകൾ ഉണ്ടെങ്കിൽ വ്യത്യസ്ത അർത്ഥങ്ങൾഒരേ തരത്തിലുള്ള, VARCHAR നിരകൾക്ക് പകരം ENUM ഉപയോഗിക്കുന്നതാണ് നല്ലത്. ഉദാഹരണത്തിന്, ഇതൊരു "സ്റ്റാറ്റസ്" കോളമായിരിക്കാം, അതിൽ "സജീവ", "നിഷ്ക്രിയം", "തീർച്ചപ്പെടുത്താത്തത്", " എന്നിങ്ങനെയുള്ള മൂല്യങ്ങൾ മാത്രം അടങ്ങിയിരിക്കുന്നു കാലഹരണപ്പെട്ടു" തുടങ്ങിയവ.
പട്ടികയുടെ ഘടന മാറ്റാൻ MySQL നിങ്ങളോട് ആവശ്യപ്പെടുന്ന ഒരു സാഹചര്യം സജ്ജീകരിക്കുന്നത് പോലും സാധ്യമാണ്. നിങ്ങൾക്ക് ഒരു VARCHAR ഫീൽഡ് ഉള്ളപ്പോൾ, കോളം ഫോർമാറ്റ് ENUM-ലേക്ക് മാറ്റാൻ സിസ്റ്റം യാന്ത്രികമായി ശുപാർശ ചെയ്തേക്കാം. PROCEDURE ANALYSE() എന്ന ഫംഗ്ഷൻ വിളിച്ച് ഇത് ചെയ്യാം.
ഐപി വിലാസങ്ങൾ സംഭരിക്കുന്നതിന് ഫീൽഡുകൾ ഉപയോഗിക്കുക അൺസൈൻഡ് എന്ന് ടൈപ്പ് ചെയ്യുക INT
പല ഡെവലപ്പർമാരും ഈ ആവശ്യത്തിനായി VARCHAR(15) ഫീൽഡുകൾ സൃഷ്ടിക്കുന്നു, അതേസമയം IP വിലാസങ്ങൾ ഡാറ്റാബേസിൽ ദശാംശ സംഖ്യകളായി സംഭരിക്കാൻ കഴിയും. INT തരം ഫീൽഡുകൾ 4 ബൈറ്റുകൾ വരെ വിവരങ്ങൾ സംഭരിക്കാനുള്ള കഴിവ് നൽകുന്നു, അതേ സമയം അവ സജ്ജീകരിക്കാനും കഴിയും നിശ്ചിത വലിപ്പംവയലുകൾ.
IP വിലാസം 32 ബിറ്റുകളിൽ വ്യക്തമാക്കിയിരിക്കുന്നതിനാൽ, നിങ്ങളുടെ നിരകൾ അൺസൈൻ ചെയ്യാത്ത INT ഫോർമാറ്റിലാണെന്ന് ഉറപ്പാക്കണം.
അന്വേഷണങ്ങളിൽ, IP വിലാസങ്ങൾ പരിവർത്തനം ചെയ്യാൻ നിങ്ങൾക്ക് INET_ATON() പാരാമീറ്റർ ഉപയോഗിക്കാം ദശാംശ സംഖ്യകൾ, കൂടാതെ INET_NTOA() വിപരീതമാണ്. PHP യ്ക്ക് സമാനമായ മറ്റ് ഫംഗ്ഷനുകളുണ്ട് long2ip(), ip2long().
8. ലംബമായ വിഭജനം (വേർതിരിക്കൽ)
ഡാറ്റാബേസ് പ്രകടനം ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിനായി ഒരു പട്ടിക ഘടനയെ ലംബമായി വിഭജിക്കുന്ന പ്രക്രിയയാണ് ലംബ പാർട്ടീഷനിംഗ്.
ഉദാഹരണം 1: മറ്റ് കാര്യങ്ങൾക്കൊപ്പം, അവരുടെ വീട്ടുവിലാസങ്ങൾ അടങ്ങുന്ന ഉപയോക്താക്കളുടെ ഒരു പട്ടിക നിങ്ങളുടെ പക്കലുണ്ടെന്ന് പറയാം. ഈ വിവരങ്ങൾ വളരെ അപൂർവമായി മാത്രമേ ഉപയോഗിക്കുന്നുള്ളൂ. നിങ്ങൾക്ക് നിങ്ങളുടെ പട്ടിക വിഭജിച്ച് വിലാസ ഡാറ്റ മറ്റൊരു പട്ടികയിൽ സംഭരിക്കാം.
ഈ രീതിയിൽ, നിങ്ങളുടെ പ്രധാന ഉപയോക്തൃ പട്ടികയുടെ വലുപ്പം ഗണ്യമായി കുറയും. നിങ്ങൾക്കറിയാവുന്നതുപോലെ, ചെറിയ പട്ടികകൾ വേഗത്തിൽ പ്രോസസ്സ് ചെയ്യപ്പെടുന്നു.
ഉദാഹരണം 2: നിങ്ങളുടെ പട്ടികയിൽ "last_login" (അവസാന ലോഗിൻ) ഒരു ഫീൽഡ് ഉണ്ട്. ഉപയോക്താവ് അവരുടെ ഉപയോക്തൃനാമം ഉപയോഗിച്ച് ലോഗിൻ ചെയ്യുമ്പോഴെല്ലാം ഇത് അപ്ഡേറ്റ് ചെയ്യപ്പെടുന്നു. എന്നാൽ ഒരു ടേബിളിലെ ഓരോ മാറ്റവും ഡിസ്കിൽ സംഭരിച്ചിരിക്കുന്ന ആ ടേബിളിന്റെ അന്വേഷണ കാഷെയിൽ എഴുതിയിരിക്കുന്നു. നിങ്ങളുടെ പ്രധാന ഉപയോക്തൃ പട്ടികയിലേക്കുള്ള കോളുകളുടെ എണ്ണം കുറയ്ക്കുന്നതിന് നിങ്ങൾക്ക് ഈ ഫീൽഡ് മറ്റൊരു പട്ടികയിലേക്ക് നീക്കാവുന്നതാണ്.
എന്നിരുന്നാലും, പാർട്ടീഷനിംഗ് ഫലമായുണ്ടാകുന്ന രണ്ട് പട്ടികകളും ഭാവിയിൽ ഒരേപോലെ ഉപയോഗിക്കില്ലെന്ന് നിങ്ങൾക്ക് ഉറപ്പുണ്ടായിരിക്കണം. അല്ലെങ്കിൽ, ഇത് പ്രകടനത്തെ ഗണ്യമായി കുറയ്ക്കും.
9. ചെറിയ നിരകൾ വേഗതയുള്ളതാണ്
ഡാറ്റാബേസ് എഞ്ചിനുകൾക്കായി ഡിസ്ക് സ്പേസ്, ഒരുപക്ഷേ തടസ്സം. അതിനാൽ, കൂടുതൽ ഒതുക്കമുള്ള വിവരങ്ങൾ സംഭരിക്കുന്നത് പ്രകടന വീക്ഷണകോണിൽ നിന്ന് പൊതുവെ പ്രയോജനകരമാണ്. ഇത് ഡിസ്ക് ആക്സസുകളുടെ എണ്ണം കുറയ്ക്കുന്നു.
MySQL ഡോക്സ് നിരവധി സ്റ്റോറേജ് ആവശ്യകതകളുടെ രൂപരേഖ നൽകുന്നു വത്യസ്ത ഇനങ്ങൾഡാറ്റ. പട്ടികയിൽ വളരെയധികം റെക്കോർഡുകൾ അടങ്ങിയിരിക്കില്ലെന്ന് പ്രതീക്ഷിക്കുന്നെങ്കിൽ, INT, MEDIUMINT, SMALLINT, കൂടാതെ ഇൻ തുടങ്ങിയ ഫീൽഡുകളിൽ പ്രാഥമിക കീ സംഭരിക്കുന്നതിന് ഒരു കാരണവുമില്ല. ചില കേസുകളിൽ TINYINT പോലും. തീയതി ഫോർമാറ്റിൽ നിങ്ങൾക്ക് സമയ ഘടകങ്ങൾ (മണിക്കൂർ: മിനിറ്റ്) ആവശ്യമില്ലെങ്കിൽ, DATETIME എന്നതിന് പകരം DATE എന്ന തരത്തിലുള്ള ഫീൽഡുകൾ ഉപയോഗിക്കുക.
എന്നിരുന്നാലും, ഭാവിയിൽ വികസനത്തിന് ആവശ്യമായ ഇടം നിങ്ങൾ സ്വയം ഉപേക്ഷിക്കുന്നുവെന്ന് ഉറപ്പാക്കുക. അല്ലെങ്കിൽ, ഒരു ഘട്ടത്തിൽ ഒരു തകർച്ച പോലെ എന്തെങ്കിലും സംഭവിക്കാം.






 Xiaomi Mi Mix ഫാബ്ലെറ്റുകൾ")








 ഒരു ഹാർഡ് ഡ്രൈവ് എങ്ങനെ ബന്ധിപ്പിക്കാം ഒരു ലാപ്ടോപ്പിലേക്ക് ഒരു സാധാരണ എച്ച്ഡിഡി എങ്ങനെ ബന്ധിപ്പിക്കാം")








