പുതിയതും പുനർരൂപകൽപ്പന ചെയ്തതും എന്ന് വിളിക്കപ്പെടാൻ ഹാസ്വെലിൻ്റെ വാസ്തുവിദ്യ യോഗ്യമാണോ?
അഞ്ച് വർഷത്തിലേറെയായി, ഇൻ്റൽ ഒരു ടിക്ക്-ടോക്ക് തന്ത്രം പിന്തുടരുന്നു, ഒരു പുതിയ ആർക്കിടെക്ചറിൻ്റെ പ്രകാശനത്തോടെ ഒരു നിർദ്ദിഷ്ട വാസ്തുവിദ്യയെ കൂടുതൽ സങ്കീർണ്ണമായ സാങ്കേതിക മാനദണ്ഡങ്ങളിലേക്ക് മാറ്റുന്നു.
തൽഫലമായി, എല്ലാ വർഷവും നമുക്ക് ഒരു പുതിയ വാസ്തുവിദ്യ അല്ലെങ്കിൽ ഒരു പുതിയ സാങ്കേതിക പ്രക്രിയയിലേക്കുള്ള പരിവർത്തനം ലഭിക്കുന്നു. “അതിനാൽ” 2013 ലാണ് ആസൂത്രണം ചെയ്തത്, അതായത്, ഒരു പുതിയ വാസ്തുവിദ്യയുടെ പ്രകാശനം - ഹാസ്വെൽ. മുൻ തലമുറ ഐവി ബ്രിഡ്ജിൻ്റെ അതേ പ്രോസസ്സ് സാങ്കേതികവിദ്യ ഉപയോഗിച്ചാണ് പുതിയ ആർക്കിടെക്ചറിലുള്ള പ്രോസസ്സറുകൾ നിർമ്മിക്കുന്നത്: 22 nm, ട്രൈ-ഗേറ്റ്. സാങ്കേതിക പ്രക്രിയ മാറിയിട്ടില്ല, പക്ഷേ ട്രാൻസിസ്റ്ററുകളുടെ എണ്ണം വർദ്ധിച്ചു, അതിനർത്ഥം പുതിയ പ്രോസസറിൻ്റെ ക്രിസ്റ്റലിൻ്റെ അവസാന വിസ്തീർണ്ണവും വർദ്ധിച്ചു - അതിനുശേഷം വൈദ്യുതി ഉപഭോഗം.
പാരമ്പര്യങ്ങൾക്ക് അനുസൃതമായി, ഇൻ്റൽ ഉൽപ്പാദനക്ഷമവും മാത്രം അവതരിപ്പിച്ചു വിലകൂടിയ പ്രോസസ്സറുകൾകോർ i5, i7 ലൈനുകൾ. പ്രഖ്യാപനം ഡ്യുവൽ കോർ പ്രോസസ്സറുകൾജൂനിയർ ലൈനുകൾ, എല്ലായ്പ്പോഴും എന്നപോലെ, വൈകിയിരിക്കുന്നു. പുതിയ പ്രോസസ്സറുകൾക്കുള്ള വില അതേ നിലവാരത്തിൽ തന്നെ തുടരുന്നു എന്നത് ശ്രദ്ധിക്കേണ്ടതാണ് ഐവി പാലം.
വിവിധ തലമുറകളുടെ ക്വാഡ് കോർ പ്രോസസ്സറുകളുടെ ഡൈ ഏരിയകൾ താരതമ്യം ചെയ്യാം:
നിങ്ങൾക്ക് കാണാനാകുന്നതുപോലെ, ക്വാഡ് കോർ ഹാസ്വെല്ലിന് 177 എംഎം² വിസ്തീർണ്ണം മാത്രമേയുള്ളൂ, അതേസമയം അത് സംയോജിപ്പിച്ചിരിക്കുന്നു. വടക്കേ പാലം, കണ്ട്രോളർ റാൻഡം ആക്സസ് മെമ്മറിഒപ്പം ഗ്രാഫിക്സ് കോർ. അങ്ങനെ, ട്രാൻസിസ്റ്ററുകളുടെ എണ്ണം 200 ദശലക്ഷം വർദ്ധിച്ചു, വിസ്തീർണ്ണം 17 mm² വർദ്ധിച്ചു. ഹാസ്വെല്ലിനെ 32nm മായി താരതമ്യം ചെയ്താൽ മണൽ പാലം, തുടർന്ന് ട്രാൻസിസ്റ്ററുകളുടെ എണ്ണം 440 ദശലക്ഷം (38%) വർദ്ധിച്ചു, 22 nm പ്രോസസ്സ് സാങ്കേതികവിദ്യയിലേക്കുള്ള മാറ്റം കാരണം വിസ്തീർണ്ണം 39 mm² (18%) കുറഞ്ഞു. ഈ വർഷങ്ങളിലെല്ലാം താപ വിസർജ്ജനം ഏതാണ്ട് ഒരേ നിലയിൽ തന്നെ തുടരുന്നു (എസ്ബിക്ക് 95 W, ഹാസ്വെല്ലിന് 84 W), വിസ്തീർണ്ണം കുറഞ്ഞു.
സ്ഫടികത്തിൻ്റെ ഓരോ ചതുരശ്ര മില്ലിമീറ്ററിൽ നിന്നും കൂടുതൽ ചൂട് നീക്കം ചെയ്യേണ്ടതുണ്ടെന്ന വസ്തുതയിലേക്ക് ഇതെല്ലാം നയിച്ചു. നേരത്തെ 216 mm² ൽ നിന്ന് 95 W എടുക്കേണ്ടത് ആവശ്യമാണെങ്കിൽ, അതായത് 0.44 W / mm², ഇപ്പോൾ 177 mm² വിസ്തീർണ്ണത്തിൽ നിന്ന് 84 W - 0.47 W / mm² എടുക്കേണ്ടത് ആവശ്യമാണ്, ഇത് മുമ്പത്തേതിനേക്കാൾ 6.8% കൂടുതലാണ്. . ഈ പ്രവണത തുടരുകയാണെങ്കിൽ, അത്തരം ചെറിയ പ്രദേശങ്ങളിൽ നിന്ന് ചൂട് നീക്കം ചെയ്യുന്നത് ശാരീരികമായി ബുദ്ധിമുട്ടായിരിക്കും.
പൂർണ്ണമായും സൈദ്ധാന്തികമായി, 14 nm പ്രോസസ്സ് സാങ്കേതികവിദ്യ ഉപയോഗിച്ച് നിർമ്മിക്കുന്ന ബ്രോഡ്വെല്ലിൽ, 32 മുതൽ 22 nm വരെയുള്ള പരിവർത്തനത്തിലെന്നപോലെ ട്രാൻസിസ്റ്ററുകളുടെ എണ്ണം 21% വർദ്ധിക്കുമെന്നും വിസ്തീർണ്ണം 26 ആയി കുറയുമെന്നും നമുക്ക് അനുമാനിക്കാം. % (32 ൽ നിന്ന് 22 nm ലേക്ക് നീങ്ങുമ്പോൾ അതേ അളവിൽ), 131 mm² വിസ്തീർണ്ണത്തിൽ നമുക്ക് 1.9 ബില്യൺ ട്രാൻസിസ്റ്ററുകൾ ലഭിക്കും. താപ വിസർജ്ജനവും 19% കുറയുകയാണെങ്കിൽ, നമുക്ക് 68 W, അല്ലെങ്കിൽ 0.52 W/mm² ലഭിക്കും.
ഇവ സൈദ്ധാന്തിക കണക്കുകൂട്ടലുകളാണ്, പ്രായോഗികമായി ഇത് വ്യത്യസ്തമായിരിക്കും - 32 മുതൽ 22 nm വരെയുള്ള സാങ്കേതിക പ്രക്രിയയുടെ പരിവർത്തനം 3D ട്രാൻസിസ്റ്ററുകളുടെ ആമുഖവും അടയാളപ്പെടുത്തി, ഇത് ചോർച്ച പ്രവാഹങ്ങൾ കുറയ്ക്കുകയും അവയ്ക്കൊപ്പം താപ ഉൽപാദനം കുറയ്ക്കുകയും ചെയ്തു. എന്നിരുന്നാലും, 22 nm-ൽ നിന്ന് 14 nm-ലേക്കുള്ള പരിവർത്തനത്തെക്കുറിച്ച് ഇതുപോലൊന്ന് ഇതുവരെ കേട്ടിട്ടില്ല, അതിനാൽ പ്രായോഗികമായി താപ വിസർജ്ജന മൂല്യങ്ങൾ കൂടുതൽ മോശമായിരിക്കും, നിങ്ങൾ 0.52 W/mm² പ്രതീക്ഷിക്കേണ്ടതില്ല. എന്നിരുന്നാലും, താപ വിസർജ്ജന നില 0.52 W/mm² ആണെങ്കിൽപ്പോലും, പ്രാദേശിക അമിത ചൂടാക്കലിൻ്റെ പ്രശ്നവും ഒരു ചെറിയ ക്രിസ്റ്റലിൽ നിന്ന് ചൂട് നീക്കം ചെയ്യുന്നതിനുള്ള ബുദ്ധിമുട്ടും കൂടുതൽ രൂക്ഷമാകും.
വഴിയിൽ, 0.52 W/mm² എന്ന താപ വിസർജ്ജന നിലയിലുള്ള താപ വിസർജ്ജനത്തിലെ ബുദ്ധിമുട്ടുകളാണ് BGA-ലേക്ക് മാറാനുള്ള ഇൻ്റലിൻ്റെ ആഗ്രഹത്തിനോ സോക്കറ്റ് നിർത്തലാക്കാനുള്ള ശ്രമത്തിനോ അടിവരയിടുന്നത്. പ്രോസസർ മദർബോർഡിലേക്ക് ലയിപ്പിക്കുകയാണെങ്കിൽ, ഒരു ഇൻ്റർമീഡിയറ്റ് കവർ ഇല്ലാതെ ചൂട് നേരിട്ട് ചിപ്പിൽ നിന്ന് ഹീറ്റ്സിങ്കിലേക്ക് മാറ്റും. കവറുകൾക്ക് കീഴിൽ സോൾഡർ തെർമൽ പേസ്റ്റ് ഉപയോഗിച്ച് മാറ്റിസ്ഥാപിക്കുന്നതിൻ്റെ വെളിച്ചത്തിൽ ഇത് കൂടുതൽ പ്രസക്തമാണെന്ന് തോന്നുന്നു ആധുനിക പ്രോസസ്സറുകൾ. അത്ലോൺ എക്സ്പിയുടെ ഉദാഹരണം പിന്തുടർന്ന് തുറന്ന ക്രിസ്റ്റലുകളുള്ള "ബെയർ" പ്രൊസസറുകളുടെ രൂപം നമുക്ക് വീണ്ടും പ്രതീക്ഷിക്കാം, അതായത്, ഹീറ്റ് സിങ്കിലെ ഒരു ഇൻ്റർമീഡിയറ്റ് ലിങ്കായി ഒരു കവർ ഇല്ലാതെ.
ഇത് വളരെക്കാലമായി വീഡിയോ കാർഡുകളിൽ ചെയ്തുവരുന്നു, ക്രിസ്റ്റൽ ചിപ്പ് ചെയ്യുന്നതിനുള്ള അപകടം അതിന് ചുറ്റുമുള്ള ഇരുമ്പ് ഫ്രെയിമിലൂടെ ലഘൂകരിക്കുന്നു, അതിനാലാണ് വീഡിയോ കാർഡുകൾക്ക് അത്തരം " നിലവിലെ പ്രശ്നങ്ങൾ", പ്രോസസർ കവറിനു കീഴിലുള്ള തെർമൽ പേസ്റ്റ് പോലെ. എന്നിരുന്നാലും, ഓവർക്ലോക്കിംഗ് കൂടുതൽ ബുദ്ധിമുട്ടായിരിക്കും, കൂടാതെ ശരിയായ തണുപ്പിക്കൽ"നേർത്ത" പ്രോസസ്സറുകൾ ഏതാണ്ട് ഒരു ശാസ്ത്രമാണ്. ഇതെല്ലാം വളരെ വേഗം നമ്മെ കാത്തിരിക്കുന്നു, തീർച്ചയായും, ഒരു അത്ഭുതം സംഭവിച്ചില്ലെങ്കിൽ ...
എന്നാൽ നമുക്ക് ഭൂമിയിലേക്ക് ഇറങ്ങി ഹാസ്വെല്ലിനെക്കുറിച്ച് സംസാരിക്കാം. നമുക്കറിയാവുന്നതുപോലെ, സാൻഡി ബ്രിഡ്ജുമായി താരതമ്യപ്പെടുത്തുമ്പോൾ ഹാസ്വെല്ലിന് നിരവധി "മെച്ചപ്പെടുത്തലുകൾ/മാറ്റങ്ങൾ" ലഭിച്ചു (അതനുസരിച്ച്, ഐവി ബ്രിഡ്ജ്, ഇത് വലിയതോതിൽ, എസ്ബിയെ കൂടുതൽ സൂക്ഷ്മമായ സാങ്കേതിക പ്രക്രിയയിലേക്ക് മാറ്റുന്നതായിരുന്നു):
- ബിൽറ്റ്-ഇൻ വോൾട്ടേജ് റെഗുലേറ്റർ;
- പുതിയ ഊർജ്ജ സംരക്ഷണ മോഡുകൾ;
- ബഫറുകളുടെയും ക്യൂകളുടെയും അളവ് വർദ്ധിപ്പിക്കുക;
- കാഷെ ശേഷി വർദ്ധിപ്പിക്കുന്നു;
- വിക്ഷേപണ തുറമുഖങ്ങളുടെ എണ്ണം വർദ്ധിപ്പിക്കുക;
- സംയോജിത ഗ്രാഫിക്സ് കോറിൽ പുതിയ ബ്ലോക്കുകൾ, ഫംഗ്ഷനുകൾ, API-കൾ എന്നിവ ചേർക്കുന്നു;
- ഗ്രാഫിക്സ് കോറിലെ പൈപ്പ് ലൈനുകളുടെ എണ്ണം വർദ്ധിപ്പിക്കുന്നു.
അങ്ങനെ, പുതിയ പ്ലാറ്റ്ഫോമിൻ്റെ അവലോകനം മൂന്ന് ഭാഗങ്ങളായി തിരിക്കാം: പ്രോസസർ, സംയോജിത ഗ്രാഫിക്സ് ആക്സിലറേറ്റർ, ചിപ്സെറ്റ്.
പ്രോസസർ ഭാഗം
പ്രോസസറിലെ മാറ്റങ്ങളിൽ പുതിയ നിർദ്ദേശങ്ങളും പുതിയ പവർ സേവിംഗ് മോഡുകളും ചേർക്കുന്നത് ഉൾപ്പെടുന്നു, ഒരു വോൾട്ടേജ് റെഗുലേറ്റർ ഉൾപ്പെടുത്തൽ, അതുപോലെ തന്നെ പ്രോസസർ കോറിലെ മാറ്റങ്ങൾ എന്നിവ ഉൾപ്പെടുന്നു.
ഇൻസ്ട്രക്ഷൻ സെറ്റുകൾ
ഹാസ്വെൽ ആർക്കിടെക്ചർ പുതിയ ഇൻസ്ട്രക്ഷൻ സെറ്റുകൾ അവതരിപ്പിക്കുന്നു. അവയെ രണ്ട് വലിയ ഗ്രൂപ്പുകളായി തിരിക്കാം: വെക്റ്റർ പ്രകടനം വർദ്ധിപ്പിക്കാൻ ലക്ഷ്യമിടുന്നവയും സെർവർ സെഗ്മെൻ്റിനെ ലക്ഷ്യം വച്ചുള്ളവയും. ആദ്യത്തേതിൽ AVX, FMA3 എന്നിവ ഉൾപ്പെടുന്നു, രണ്ടാമത്തേത് - വിർച്ച്വലൈസേഷനും ഇടപാട് മെമ്മറിയും.
വിപുലമായ വെക്റ്റർ എക്സ്റ്റൻഷനുകൾ 2 (AVX2)
AVX സ്യൂട്ട് AVX 2.0 പതിപ്പിലേക്ക് വികസിപ്പിച്ചിരിക്കുന്നു. AVX2 കിറ്റ് നൽകുന്നു:
- 256-ബിറ്റ് ഇൻ്റിജർ വെക്റ്ററുകൾക്കുള്ള പിന്തുണ (മുമ്പ് 128-ബിറ്റിനുള്ള പിന്തുണ മാത്രമേ ഉണ്ടായിരുന്നുള്ളൂ);
- മെമ്മറിയിലെ തുടർച്ചയായ ഡാറ്റ ലൊക്കേഷൻ്റെ ആവശ്യകത നീക്കം ചെയ്യുന്ന നിർദ്ദേശങ്ങൾ ശേഖരിക്കുന്നതിനുള്ള പിന്തുണ; വ്യത്യസ്ത മെമ്മറി വിലാസങ്ങളിൽ നിന്ന് ഇപ്പോൾ ഡാറ്റ "ശേഖരിച്ചു" - ഇത് പ്രകടനത്തെ എങ്ങനെ ബാധിക്കുന്നുവെന്നത് രസകരമായിരിക്കും;
- ബിറ്റുകളിൽ കൃത്രിമത്വം/പ്രവർത്തനങ്ങൾക്കുള്ള നിർദ്ദേശങ്ങൾ ചേർക്കുന്നു.
പൊതുവെ, പുതിയ സെറ്റ്പൂർണ്ണസംഖ്യാ ഗണിതത്തിൽ കൂടുതൽ ശ്രദ്ധ കേന്ദ്രീകരിക്കുന്നു, കൂടാതെ AVX 2.0-ൽ നിന്നുള്ള പ്രധാന നേട്ടം പൂർണ്ണസംഖ്യ പ്രവർത്തനങ്ങളിൽ മാത്രമേ ദൃശ്യമാകൂ.
ഫ്യൂസ്ഡ് മൾട്ടിപ്ലൈ-ആഡ് (FMA3)
FMA എന്നത് രണ്ട് സംഖ്യകളെ ഗുണിച്ച് സഞ്ചിതത്തിലേക്ക് ചേർക്കുന്ന ഒരു സംയോജിത മൾട്ടിപ്ലൈ-ആഡ് ഓപ്പറേഷനാണ്. ഈ തരംപ്രവർത്തനങ്ങൾ വളരെ സാധാരണമാണ് കൂടാതെ വെക്റ്ററുകളുടെയും മെട്രിക്സുകളുടെയും ഗുണനം കൂടുതൽ കാര്യക്ഷമമായി നടപ്പിലാക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു. ഈ വിപുലീകരണത്തിനുള്ള പിന്തുണ വെക്റ്റർ പ്രവർത്തനങ്ങളുടെ പ്രകടനത്തെ ഗണ്യമായി വർദ്ധിപ്പിക്കണം. പിൽഡ്രൈവർ കോർ ഉള്ള എഎംഡി പ്രൊസസറുകളിൽ എഫ്എംഎ 3 ഇതിനകം പിന്തുണയ്ക്കുന്നു, ബുൾഡോസറിൽ എഫ്എംഎ 4 ഇതിനകം പിന്തുണയ്ക്കുന്നു.
FMA എന്നത് ഗുണനത്തിൻ്റെയും സങ്കലന പ്രവർത്തനത്തിൻ്റെയും സംയോജനമാണ്: a=b×c+d.
FMA3 നെ സംബന്ധിച്ചിടത്തോളം, ഇവ മൂന്ന്-ഓപ്പറാൻറ് നിർദ്ദേശങ്ങളാണ്, അതായത്, നിർദ്ദേശത്തിൽ പങ്കെടുക്കുന്ന മൂന്ന് ഓപ്പറണ്ടുകളിൽ ഒന്നിലേക്ക് ഫലം എഴുതിയിരിക്കുന്നു. തൽഫലമായി, നമുക്ക് a=b×c+a, a=a×b+c, a=b×a+c എന്നിങ്ങനെയുള്ള ഒരു ഓപ്പറേഷൻ ലഭിക്കും.
FMA4 എന്നത് നാലാമത്തെ ഓപ്പറണ്ടിലേക്ക് എഴുതിയ ഫലത്തോടുകൂടിയ നാല്-ഓപ്പറാൻറ് നിർദ്ദേശങ്ങളാണ്. നിർദ്ദേശം ഫോം എടുക്കുന്നു: a=b×c+d.
FMA3-നെ കുറിച്ച് പറയുമ്പോൾ: ഈ നൂതനമായ കോഡ് FMA3-ന് അനുയോജ്യമാണെങ്കിൽ ഉൽപ്പാദനക്ഷമത 30%-ൽ അധികം വർദ്ധിപ്പിക്കും. ഹസ്വെൽ ഇപ്പോഴും ചക്രവാളത്തിൽ ആയിരുന്നപ്പോൾ, FMA3-ന് പകരം FMA4 നടപ്പിലാക്കാൻ ഇൻ്റൽ പദ്ധതിയിട്ടിരുന്നു, എന്നാൽ പിന്നീട് FMA3-ന് അനുകൂലമായി തീരുമാനം മാറ്റി. മിക്കവാറും, അതുകൊണ്ടാണ് ബുൾഡോസർ FMA4 പിന്തുണയോടെ പുറത്തുവന്നത്: അവർ പറയുന്നു, അത് ഇൻ്റലിലേക്ക് പരിവർത്തനം ചെയ്യാൻ അവർക്ക് സമയമില്ല (എന്നാൽ Piledriver FMA3 ഉപയോഗിച്ച് പുറത്തിറങ്ങി). കൂടാതെ, തുടക്കത്തിൽ 2007-ൽ ബുൾഡോസർ FMA3 ഉപയോഗിച്ച് ആസൂത്രണം ചെയ്തിരുന്നു, എന്നാൽ 2008-ൽ FMA4 അവതരിപ്പിക്കാനുള്ള ഇൻ്റലിൻ്റെ പദ്ധതികളുടെ പ്രഖ്യാപനത്തിന് ശേഷം വർഷം എഎംഡി FMA4 ഉപയോഗിച്ച് ബുൾഡോസർ പുറത്തിറക്കി മനസ്സ് മാറ്റി. FMA3 നെ അപേക്ഷിച്ച് FMA4-ൽ നിന്നുള്ള നേട്ടം ചെറുതായതിനാൽ, ഇലക്ട്രിക്കലിൻ്റെ സങ്കീർണതകൾ കാരണം ഇൻ്റൽ അതിൻ്റെ പ്ലാനുകളിൽ FMA4-നെ FMA3 ആക്കി മാറ്റി. ലോജിക് സർക്യൂട്ടുകൾ- പ്രധാനപ്പെട്ടത്, ഇത് ട്രാൻസിസ്റ്റർ ബജറ്റും വർദ്ധിപ്പിക്കുന്നു.
AVX2, FMA3 എന്നിവയിൽ നിന്നുള്ള നേട്ടങ്ങൾ സോഫ്റ്റ്വെയർ ഈ ഇൻസ്ട്രക്ഷൻ സെറ്റുകളുമായി പൊരുത്തപ്പെട്ടുകഴിഞ്ഞാൽ ദൃശ്യമാകും, അതിനാൽ "ഇവിടെയും ഇപ്പോളും" പ്രകടന നേട്ടങ്ങളൊന്നും നിങ്ങൾ പ്രതീക്ഷിക്കേണ്ടതില്ല. സോഫ്റ്റ്വെയർ നിർമ്മാതാക്കൾ തികച്ചും നിഷ്ക്രിയരായതിനാൽ, "അധിക" പ്രകടനം കാത്തിരിക്കേണ്ടിവരും.
ഇടപാട് മെമ്മറി
മൈക്രോപ്രൊസസ്സറുകളുടെ പരിണാമം ത്രെഡുകളുടെ എണ്ണത്തിൽ വർദ്ധനവിന് കാരണമായി - ഒരു ആധുനിക ഡെസ്ക്ടോപ്പ് പ്രോസസ്സറിന് അവയിൽ എട്ടോ അതിലധികമോ ഉണ്ട്. ഒരു വലിയ സംഖ്യമൾട്ടി-ത്രെഡ് മെമ്മറി ആക്സസ് നടപ്പിലാക്കുമ്പോൾ ത്രെഡുകൾ കൂടുതൽ കൂടുതൽ ബുദ്ധിമുട്ടുകൾ സൃഷ്ടിക്കുന്നു. റാമിലെ വേരിയബിളുകളുടെ പ്രസക്തി നിയന്ത്രിക്കേണ്ടത് ആവശ്യമാണ്: ചില ത്രെഡുകൾക്ക് സമയബന്ധിതമായി എഴുതുന്നതിന് ഡാറ്റ തടയേണ്ടത് ആവശ്യമാണ്, കൂടാതെ മറ്റ് ത്രെഡുകൾക്കായി ഡാറ്റ വായിക്കാനോ മാറ്റാനോ അനുവദിക്കുക. ഇതൊരു ബുദ്ധിമുട്ടുള്ള കാര്യമാണ്, മൾട്ടി-ത്രെഡഡ് പ്രോഗ്രാമുകളിൽ ഡാറ്റ ഫ്രഷ് ആയി നിലനിർത്താൻ ട്രാൻസാക്ഷൻ മെമ്മറി വികസിപ്പിച്ചെടുത്തു. എന്നാൽ മുമ്പ് ഇന്ന്ഇത് സോഫ്റ്റ്വെയറിൽ നടപ്പിലാക്കി, ഇത് പ്രകടനം കുറച്ചു.
ഹാസ്വെല്ലിന് ഒരു പുതിയ ട്രാൻസാക്ഷണൽ സിൻക്രൊണൈസേഷൻ എക്സ്റ്റൻഷനുകൾ (ടിഎസ്എക്സ്) ഉണ്ട് - ട്രാൻസാക്ഷനൽ മെമ്മറി, ഇത് മൾട്ടി-ത്രെഡഡ് പ്രോഗ്രാമുകൾ കാര്യക്ഷമമായി നടപ്പിലാക്കുന്നതിനും അവയുടെ വിശ്വാസ്യത വർദ്ധിപ്പിക്കുന്നതിനും രൂപകൽപ്പന ചെയ്തിട്ടുള്ളതാണ്. "ഹാർഡ്വെയറിൽ" ട്രാൻസാഷണൽ മെമ്മറി നടപ്പിലാക്കാൻ ഈ വിപുലീകരണം നിങ്ങളെ അനുവദിക്കുന്നു, അതുവഴി മൊത്തത്തിലുള്ള പ്രകടനം വർദ്ധിപ്പിക്കുന്നു.
എന്താണ് ട്രാൻസാക്ഷൻ മെമ്മറി? പങ്കിട്ട ഡാറ്റയിലേക്ക് ആക്സസ് നൽകുന്നതിന് സമാന്തര പ്രക്രിയകൾ കൈകാര്യം ചെയ്യുന്നതിനുള്ള ഒരു സംവിധാനമുള്ള മെമ്മറിയാണിത്. TSX വിപുലീകരണത്തിൽ രണ്ട് ഘടകങ്ങൾ അടങ്ങിയിരിക്കുന്നു: ഹാർഡ്വെയർ ലോക്ക് എലിഷൻ (HLE), നിയന്ത്രിത ഇടപാട് മെമ്മറി (ആർടിഎം).
ഒരു ഇടപാട് ആരംഭിക്കുന്നതിനും അവസാനിപ്പിക്കുന്നതിനും നിർത്തലാക്കുന്നതിനും ഒരു പ്രോഗ്രാമർക്ക് ഉപയോഗിക്കാനാകുന്ന നിർദ്ദേശങ്ങളുടെ ഒരു കൂട്ടമാണ് RTM ഘടകം. TSX പിന്തുണയില്ലാതെ പ്രോസസ്സറുകൾ അവഗണിക്കുന്ന പ്രിഫിക്സുകൾ HLE ഘടകം അവതരിപ്പിക്കുന്നു. പ്രിഫിക്സുകൾ വേരിയബിൾ ലോക്കിംഗ് നൽകുന്നു, ലോക്ക് ചെയ്ത വേരിയബിളുകൾ ഉപയോഗിക്കാനും (വായിക്കാൻ) മറ്റ് പ്രോസസ്സുകളെ അനുവദിക്കുകയും ലോക്ക് ചെയ്ത ഡാറ്റ റൈറ്റ് വൈരുദ്ധ്യം സംഭവിക്കുന്നത് വരെ അവയുടെ കോഡ് എക്സിക്യൂട്ട് ചെയ്യുകയും ചെയ്യുന്നു.
ഓൺ ഈ നിമിഷംഈ വിപുലീകരണം ഉപയോഗിക്കുന്ന അപ്ലിക്കേഷനുകൾ ഇതിനകം പ്രത്യക്ഷപ്പെട്ടു.
വെർച്വലൈസേഷൻ
വെർച്വലൈസേഷൻ്റെ പ്രാധാന്യം നിരന്തരം വർദ്ധിച്ചുകൊണ്ടിരിക്കുന്നു: ധാരാളം ഉണ്ട് വെർച്വൽ സെർവറുകൾഒരു ഫിസിക്കൽ ഒന്നിൽ സ്ഥിതിചെയ്യുന്നു, ക്ലൗഡ് സേവനങ്ങൾ കൂടുതൽ വ്യാപകമാവുകയാണ്. അതിനാൽ, വിർച്ച്വലൈസേഷൻ സാങ്കേതികവിദ്യകളുടെയും വിർച്വലൈസ്ഡ് എൻവയോൺമെൻ്റുകളുടെയും വേഗത വർദ്ധിപ്പിക്കുക എന്നത് സെർവർ വിഭാഗത്തിൽ വളരെ അടിയന്തിരമായ ഒരു കടമയാണ്. വിർച്വലൈസ്ഡ് എൻവയോൺമെൻ്റുകളുടെ പ്രകടനം വർദ്ധിപ്പിക്കുന്നതിന് പ്രത്യേകമായി ലക്ഷ്യമിട്ടുള്ള നിരവധി മെച്ചപ്പെടുത്തലുകൾ ഹസ്വെല്ലിൽ അടങ്ങിയിരിക്കുന്നു. നമുക്ക് അവയെ പട്ടികപ്പെടുത്താം:
- ഗസ്റ്റ് സിസ്റ്റങ്ങളിൽ നിന്ന് ഹോസ്റ്റ് സിസ്റ്റത്തിലേക്ക് മാറാൻ എടുക്കുന്ന സമയം കുറയ്ക്കുന്നതിനുള്ള മെച്ചപ്പെടുത്തലുകൾ;
- എക്സ്റ്റെൻഡഡ് പേജ് ടേബിളിലേക്ക് (ഇപിടി) ആക്സസ് ബിറ്റുകൾ ചേർത്തു;
- TLB ആക്സസ് സമയം കുറച്ചു;
- vmexit കമാൻഡ് എക്സിക്യൂട്ട് ചെയ്യാതെ ഹൈപ്പർവൈസറിനെ വിളിക്കുന്നതിനുള്ള പുതിയ നിർദ്ദേശങ്ങൾ;
തൽഫലമായി, വിർച്വലൈസ്ഡ് എൻവയോൺമെൻ്റുകൾക്കിടയിലുള്ള പരിവർത്തന സമയം 500 പ്രൊസസർ സൈക്കിളുകളിൽ താഴെയായി കുറച്ചിരിക്കുന്നു. ഇത് വെർച്വലൈസേഷനുമായി ബന്ധപ്പെട്ട മൊത്തത്തിലുള്ള പെർഫോമൻസ് ഓവർഹെഡിൽ കുറവുണ്ടാക്കും. പുതിയ Xeon E3-12xx-v3 ഈ ക്ലാസ് ടാസ്ക്കുകളിൽ Xeon E3-12xx-v2 നേക്കാൾ വേഗതയുള്ളതായിരിക്കും.
ബിൽറ്റ്-ഇൻ വോൾട്ടേജ് റെഗുലേറ്റർ
ഹസ്വെല്ലിൽ, പ്രോസസർ കവറിനു കീഴിലുള്ള മദർബോർഡിൽ നിന്ന് വോൾട്ടേജ് റെഗുലേറ്റർ നീക്കി. മുമ്പ് (സാൻഡി ബ്രിഡ്ജ്) പ്രോസസറിലേക്ക് വ്യത്യസ്ത വോൾട്ടേജുകൾ നൽകേണ്ടത് ആവശ്യമാണ് ഗ്രാഫിക്സ് കോർ, സിസ്റ്റം ഏജൻ്റിന്, പ്രോസസർ കോറുകൾ മുതലായവ. ഇപ്പോൾ ഒരു വോൾട്ടേജ് Vccin 1.75 V മാത്രമേ സോക്കറ്റിലൂടെ പ്രോസസറിലേക്ക് വിതരണം ചെയ്യുന്നുള്ളൂ, അത് ബിൽറ്റ്-ഇൻ വോൾട്ടേജ് റെഗുലേറ്ററിലേക്ക് വിതരണം ചെയ്യുന്നു. വോൾട്ടേജ് റെഗുലേറ്ററിൽ 20 സെല്ലുകൾ അടങ്ങിയിരിക്കുന്നു, ഓരോ സെല്ലും 25 എ മൊത്തം കറൻ്റുള്ള 16 ഘട്ടങ്ങൾ സൃഷ്ടിക്കുന്നു. മൊത്തത്തിൽ, നമുക്ക് 320 ഘട്ടങ്ങൾ ലഭിക്കും, ഇത് ഏറ്റവും സങ്കീർണ്ണമായ മദർബോർഡുകളേക്കാൾ വളരെ കൂടുതലാണ്. ഈ സമീപനം മദർബോർഡുകളുടെ ലേഔട്ട് ലളിതമാക്കാൻ മാത്രമല്ല (അതിനാൽ അവയുടെ വില കുറയ്ക്കാനും) മാത്രമല്ല, പ്രോസസറിനുള്ളിലെ വോൾട്ടേജുകൾ കൂടുതൽ കൃത്യമായി നിയന്ത്രിക്കാനും ഇത് അനുവദിക്കുന്നു, ഇത് കൂടുതൽ ഊർജ്ജ ലാഭത്തിലേക്ക് നയിക്കുന്നു.
പഴയ LGA1155 സോക്കറ്റുമായി ഹാസ്വെല്ലിന് ശാരീരികമായി പൊരുത്തപ്പെടാൻ കഴിയാത്തതിൻ്റെ പ്രധാന കാരണങ്ങളിലൊന്നാണിത്. അതെ, എല്ലാ വർഷവും ഒരു പുതിയ പ്ലാറ്റ്ഫോം പുറത്തിറക്കി പണം സമ്പാദിക്കാനുള്ള ഇൻ്റലിൻ്റെ ആഗ്രഹത്തെക്കുറിച്ച് നമുക്ക് സംസാരിക്കാം ( പുതിയ ചിപ്സെറ്റ്) കൂടാതെ ഓരോ രണ്ട് വർഷത്തിലും - ഒരു പുതിയ സോക്കറ്റ്, എന്നാൽ ഈ സാഹചര്യത്തിൽ ഉണ്ട് വസ്തുനിഷ്ഠമായ കാരണങ്ങൾ: ശാരീരിക/വൈദ്യുത പൊരുത്തക്കേട്.
എന്നിരുന്നാലും, എല്ലാം ഒരു വിലയിൽ വരുന്നു. വോൾട്ടേജ് റെഗുലേറ്ററാണ് പുതിയ പ്രൊസസറിലെ താപത്തിൻ്റെ മറ്റൊരു ശ്രദ്ധേയമായ ഉറവിടം. ഹാസ്വെൽ അതിൻ്റെ മുൻഗാമിയായ ഐവി ബ്രിഡ്ജിൻ്റെ അതേ പ്രോസസ്സ് സാങ്കേതികവിദ്യ ഉപയോഗിച്ചാണ് നിർമ്മിച്ചിരിക്കുന്നത് എന്നതിനാൽ, പ്രോസസർ കൂടുതൽ ചൂടായിരിക്കുമെന്ന് ഞങ്ങൾ പ്രതീക്ഷിക്കണം.

പൊതുവേ, ഈ മെച്ചപ്പെടുത്തൽ മൊബൈൽ സെഗ്മെൻ്റിൽ കൂടുതൽ പ്രയോജനകരമാകും: വേഗതയേറിയതും കൂടുതൽ കൃത്യവുമായ വോൾട്ടേജ് മാറ്റങ്ങൾ വൈദ്യുതി ഉപഭോഗം കുറയ്ക്കും, അതുപോലെ തന്നെ പ്രോസസർ കോറുകളുടെ ആവൃത്തിയെ കൂടുതൽ ഫലപ്രദമായി നിയന്ത്രിക്കും. പ്രത്യക്ഷത്തിൽ, ഇതൊരു ശൂന്യമായ മാർക്കറ്റിംഗ് പ്രസ്താവനയല്ല, കാരണം ഇൻ്റൽ വളരെ കുറഞ്ഞ പവർ ഉപഭോഗമുള്ള മൊബൈൽ പ്രോസസ്സറുകൾ പ്രഖ്യാപിക്കാൻ പോകുന്നു.
പുതിയ ഊർജ്ജ സംരക്ഷണ മോഡുകൾ
ഹാസ്വെല്ലിന് പുതിയ S0ix സ്ലീപ്പ് സ്റ്റേറ്റുകൾ ഉണ്ട്, അവ S3/S4 സ്റ്റേറ്റുകൾക്ക് സമാനമാണ്, എന്നാൽ വളരെ വേഗത്തിലുള്ള CPU പരിവർത്തന സമയമുണ്ട്. ജോലി സാഹചര്യം. ഒരു പുതിയ C7 നിഷ്ക്രിയ അവസ്ഥയും ചേർത്തു.
സ്ക്രീനിലെ ചിത്രം സജീവമായി തുടരുമ്പോൾ, പ്രോസസ്സറിൻ്റെ പ്രധാന ഭാഗം ഓഫ് ചെയ്യുന്നതിനൊപ്പം C7 മോഡും ഉണ്ട്.
പ്രോസസ്സറുകളുടെ ഏറ്റവും കുറഞ്ഞ നിഷ്ക്രിയ ആവൃത്തി 800 മെഗാഹെർട്സ് ആണ്, ഇത് വൈദ്യുതി ഉപഭോഗം കുറയ്ക്കുകയും വേണം.
പ്രോസസ്സർ ആർക്കിടെക്ചർ


ഫ്രണ്ട് എൻഡ്

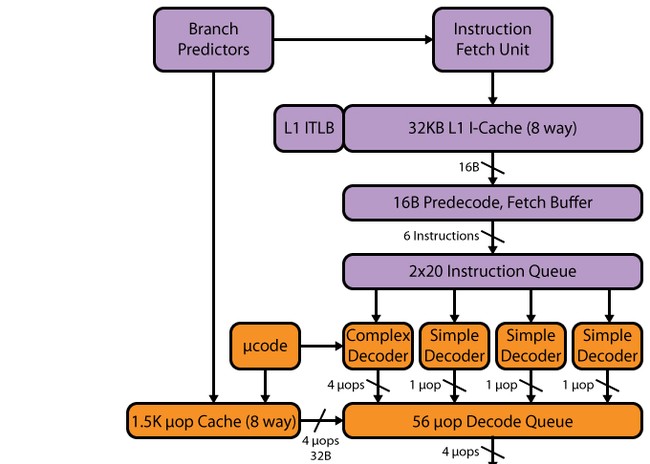
എസ്ബിയിലെ പോലെ ഹസ്വെൽ പൈപ്പ്ലൈനിന് 14-19 ഘട്ടങ്ങളുണ്ട്: ഒരു µop കാഷെ ഹിറ്റിന് 14 ഘട്ടങ്ങൾ, ഒരു മിസ്സിനായി 19 ഘട്ടങ്ങൾ. SB - 1536 µop നെ അപേക്ഷിച്ച് µop കാഷെയുടെ വലിപ്പം മാറിയിട്ടില്ല. uop കാഷെയുടെ ഓർഗനൈസേഷൻ SB-യിലെ പോലെ തന്നെ തുടർന്നു - എട്ട് വരികളുള്ള 32 സെറ്റുകൾ, ഓരോന്നിനും ആറ് uops. എന്നിരുന്നാലും, എക്സിക്യൂഷൻ ഉപകരണങ്ങളുടെ എണ്ണത്തിലുണ്ടായ വർദ്ധനയും uop കാഷെയ്ക്ക് ശേഷമുള്ള തുടർന്നുള്ള ബഫറുകളും കാരണം, uop കാഷെയിൽ വർദ്ധനവ് പ്രതീക്ഷിക്കാം - 1776 uops വരെ (എന്തുകൊണ്ട് കൃത്യമായി ഈ വോള്യം ചുവടെ ചർച്ചചെയ്യും).
ഡീകോഡർ
ഡീകോഡർ മാറിയിട്ടില്ലെന്ന് ഒരാൾ പറഞ്ഞേക്കാം - ഇത് എസ്ബിയെപ്പോലെ നാല്-വഴിയായി തുടരുന്നു. ഇതിൽ നാല് സമാന്തര ചാനലുകൾ അടങ്ങിയിരിക്കുന്നു: ഒരു സങ്കീർണ്ണ വിവർത്തകനും (സങ്കീർണ്ണമായ ഡീകോഡറും) മൂന്ന് ലളിതവും (ലളിതമായ ഡീകോഡർ). ഒരു സങ്കീർണ്ണ വിവർത്തകന് ഒന്നിലധികം uop സൃഷ്ടിക്കുന്ന സങ്കീർണ്ണ നിർദ്ദേശങ്ങൾ പ്രോസസ്സ്/ഡീകോഡ് ചെയ്യാൻ കഴിയും. ബാക്കിയുള്ള മൂന്ന് ചാനലുകൾ ഡീകോഡ് ചെയ്തു ലളിതമായ നിർദ്ദേശങ്ങൾ. വഴിയിൽ, മാക്രോ-ഓപ്പറേഷനുകളുടെ ലയനത്തിൻ്റെ സാന്നിധ്യം കാരണം, എക്സിക്യൂഷൻ, അൺലോഡിംഗ് നിർദ്ദേശങ്ങൾ എന്നിവ ഉപയോഗിച്ച് ലോഡുചെയ്യുന്നത് സൃഷ്ടിക്കുന്നു, ഉദാഹരണത്തിന്, ഒരു uop കൂടാതെ "ലളിതമായ" ഡീകോഡർ ചാനലുകളിൽ ഡീകോഡ് ചെയ്യാനും കഴിയും. എസ്എസ്ഇ നിർദ്ദേശങ്ങൾഒരു uop ജനറേറ്റുചെയ്യുക, അതിനാൽ അവ മൂന്ന് ലളിതമായ ചാനലുകളിൽ ഏതിലും ഡീകോഡ് ചെയ്യാൻ കഴിയും. 256-ബിറ്റ് എവിഎക്സ്, എഫ്എംഎ 3, ട്രിഗർ പോർട്ടുകളുടെയും ഫംഗ്ഷൻ ഉപകരണങ്ങളുടെയും വർദ്ധിച്ച എണ്ണം എന്നിവ കണക്കിലെടുക്കുമ്പോൾ, ഈ ഡീകോഡർ വേഗത മതിയാകില്ല - മാത്രമല്ല ഇത് ഒരു തടസ്സമായി മാറിയേക്കാം. ഭാഗികമായി, ഈ തടസ്സം L0m uop കാഷെ "വികസിപ്പിച്ചിരിക്കുന്നു", എന്നിട്ടും, 8 ലോഞ്ച് പോർട്ടുകളുള്ള ഒരു പ്രോസസർ ഉള്ളതിനാൽ, ഡീകോഡർ വികസിപ്പിക്കുന്നതിനെക്കുറിച്ച് ഇൻ്റൽ ചിന്തിക്കണം - പ്രത്യേകിച്ചും, സങ്കീർണ്ണമായ ചാനലുകളുടെ എണ്ണം വർദ്ധിപ്പിക്കുന്നത് ഉപദ്രവിക്കില്ല.
ഷെഡ്യൂളർ, ബഫർ പുനഃക്രമീകരിക്കൽ, എക്സിക്യൂഷൻ യൂണിറ്റുകൾ


ഡീകോഡറിന് ശേഷം ഡീകോഡ് ചെയ്ത നിർദ്ദേശങ്ങളുടെ ഒരു ക്യൂ വരുന്നു, ഇവിടെ നമ്മൾ ആദ്യത്തെ മാറ്റം കാണുന്നു. എസ്ബിക്ക് 28 എൻട്രികളുള്ള രണ്ട് ക്യൂകൾ ഉണ്ടായിരുന്നു - ഒരു വെർച്വൽ ഹൈപ്പർ-ത്രെഡിംഗ് (HT) ത്രെഡിന് ഒരു ക്യൂ. ഹസ്വെല്ലിൽ, 56 എൻട്രികളുള്ള രണ്ട് എച്ച്ടി ത്രെഡുകൾക്കായി രണ്ട് ക്യൂകൾ പൊതുവായ ഒന്നായി സംയോജിപ്പിച്ചു, അതായത്, ക്യൂവിൻ്റെ അളവ് മാറിയില്ല, പക്ഷേ ആശയം മാറി. ഇപ്പോൾ 56 റെക്കോർഡുകളുടെ മുഴുവൻ വോളിയവും ഒരു ത്രെഡിന് ഒരു സെക്കൻഡിൻ്റെ അഭാവത്തിൽ ലഭ്യമാണ് - അതിനാൽ, ലോ-ത്രെഡുള്ള ആപ്ലിക്കേഷനുകളിലും മൾട്ടി-ത്രെഡുള്ള ആപ്ലിക്കേഷനുകളിലും വർദ്ധനവ് പ്രതീക്ഷിക്കാം (രണ്ട് ത്രെഡുകൾക്ക് ഉപയോഗിക്കാനാകുമെന്നതാണ് ഇതിന് കാരണം. ഒറ്റ ക്യൂ കൂടുതൽ കാര്യക്ഷമമായി).
പുനഃക്രമീകരിക്കുന്ന ബഫറും മാറ്റി - ഇത് 168 ൽ നിന്ന് 192 എൻട്രികളായി ഉയർത്തി. പരസ്പരം "സ്വതന്ത്രമായ" uops ഉണ്ടാകാനുള്ള സാധ്യത കാരണം ഇത് HT യുടെ കാര്യക്ഷമത മെച്ചപ്പെടുത്തും. ഡീകോഡ് ചെയ്ത മൈക്രോ-ഓപ് ക്യൂ 54-ൽ നിന്ന് 60 ആക്കി. എസ്ബിയിൽ പ്രത്യക്ഷപ്പെട്ട ഫിസിക്കൽ രജിസ്റ്റർ ഫയലുകളും വർദ്ധിപ്പിച്ചിട്ടുണ്ട് - ഇൻ്റിജർ ഓപ്പറാൻഡുകൾക്ക് 160-ൽ നിന്ന് 168 രജിസ്റ്ററുകളായും, ഫ്ളോട്ടിംഗ് പോയിൻ്റ് ഓപ്പറണ്ടുകൾക്ക് 144-ൽ നിന്ന് 168 ആയും, പോസിറ്റീവ് ഉണ്ടായിരിക്കണം. വെക്റ്റർ കണക്കുകൂട്ടലുകളുടെ പ്രകടനത്തെ ബാധിക്കുന്നു.
ബഫറുകളിലെയും ക്യൂകളിലെയും മാറ്റങ്ങളെക്കുറിച്ചുള്ള എല്ലാ ഡാറ്റയും ഒരൊറ്റ പട്ടികയിലേക്ക് സംഗ്രഹിക്കാം.
തത്വത്തിൽ, ഹസ്വെല്ലിലെ പാരാമീറ്ററുകളിലെ മാറ്റങ്ങൾ വളരെ പ്രതീക്ഷിച്ചതായി തോന്നുന്നു പൊതുവായ യുക്തിഇൻ്റൽ പ്രോസസർ ആർക്കിടെക്ചറിൻ്റെ വികസനം. അതേ യുക്തിയുടെ അടിസ്ഥാനത്തിൽ, അടുത്ത തലമുറയിൽ അത് നമുക്ക് അനുമാനിക്കാം കോർ വലുപ്പങ്ങൾബഫറുകളും ക്യൂകളും 14% ൽ കൂടുതൽ വർദ്ധിക്കില്ല, അതായത്, പുനഃക്രമീകരിക്കുന്ന ബഫറിൻ്റെ വലുപ്പം ഏകദേശം 218 ആയിരിക്കും. എന്നാൽ ഇവ തികച്ചും സൈദ്ധാന്തിക അനുമാനങ്ങളാണ്.
ഡീകോഡ് ചെയ്ത പ്രവർത്തനങ്ങളുടെ ക്യൂവിന് ശേഷം, ട്രിഗർ പോർട്ടുകളും അവയിൽ ഘടിപ്പിച്ചിരിക്കുന്ന പോർട്ടുകളും. പ്രവർത്തന ഉപകരണങ്ങൾ. ഈ ഘട്ടത്തിൽ ഞങ്ങൾ കൂടുതൽ വിശദമായി വസിക്കും.
നമുക്കറിയാവുന്നതുപോലെ, സാൻഡി ബ്രിഡ്ജിന് ആറ് വിക്ഷേപണ തുറമുഖങ്ങൾ ഉണ്ടായിരുന്നു, അത് നെഹാലേമിൽ നിന്ന് പാരമ്പര്യമായി ലഭിച്ചു, അത് കോൺറോയിൽ നിന്ന്. അതായത്, 2006 മുതൽ, പെൻ്റിയം 4-ൽ ലഭ്യമായ നാലിലേക്ക് രണ്ട് പോർട്ടുകൾ കൂടി ഇൻ്റൽ ചേർത്തപ്പോൾ, ലോഞ്ച് പോർട്ടുകളുടെ എണ്ണം മാറിയിട്ടില്ല - പുതിയ ഫങ്ഷണൽ ഉപകരണങ്ങൾ മാത്രമേ ചേർത്തിട്ടുള്ളൂ. എന്നിരുന്നാലും, P4-ന് ഒരുതരം യഥാർത്ഥ നെറ്റ്ബർസ്റ്റ് ആർക്കിടെക്ചർ ഉണ്ടായിരുന്നു എന്നത് എടുത്തുപറയേണ്ടതാണ്, അതിൽ രണ്ട് പോർട്ടുകൾക്കും ഒരു ക്ലോക്ക് സൈക്കിളിൽ രണ്ട് പ്രവർത്തനങ്ങൾ നടത്താൻ കഴിയും (എല്ലാ പ്രവർത്തനങ്ങളിലും ഇല്ലെങ്കിലും). എന്നാൽ P4 ൻ്റെ ഉദാഹരണം ഉപയോഗിക്കാതെ, PIII ൻ്റെ ഉദാഹരണം ഉപയോഗിച്ച് ലോഞ്ച് പോർട്ടുകളുടെ എണ്ണത്തിൻ്റെ പരിണാമം കണ്ടെത്തുന്നത് ഏറ്റവും ശരിയായിരിക്കും, കാരണം P4- ന് ഒരു നീണ്ട പൈപ്പ്ലൈൻ ഉണ്ട്, കൂടാതെ "ഇരട്ട" പ്രകടനവും ഒരു ട്രെയ്സ് കാഷും ഉള്ള പോർട്ടുകൾ സമാരംഭിക്കുന്നു. , അതിൻ്റെ മുഴുവൻ വാസ്തുവിദ്യയും പൊതുവായി അംഗീകരിക്കപ്പെട്ടതിൽ നിന്ന് വ്യത്യസ്തമാണ്. കോൺറോയിലേക്കുള്ള ലോഞ്ച് പോർട്ടുകളുടെ ഫംഗ്ഷണൽ സ്കീമിൻ്റെ കാര്യത്തിൽ പെൻ്റിയം III വളരെ അടുത്താണ്, കൂടാതെ ഒരു ചെറിയ കണ്ടെയ്നറും ഉണ്ട്. അതിനാൽ, പൊതുവേ, പിഐഐയുടെ നേരിട്ടുള്ള പിൻഗാമിയാണ് കോൺറോയെന്ന് നമുക്ക് പറയാം. ഇതിൻ്റെ അടിസ്ഥാനത്തിൽ, അഞ്ച് വിക്ഷേപണ തുറമുഖങ്ങളുള്ള പിഐഐയെ അപേക്ഷിച്ച് 2006 ൽ ഒരു ലോഞ്ച് പോർട്ട് മാത്രമേ ചേർത്തിട്ടുള്ളൂ എന്ന് പ്രസ്താവിക്കാം.
അങ്ങനെ, ലോഞ്ച് പോർട്ടുകളുടെ എണ്ണം വളരെ സാവധാനത്തിൽ വളരുകയാണ്, പുതിയവ ചേർത്താൽ, ഒരു സമയം. ഹാസ്വെൽ ഒരേസമയം രണ്ടെണ്ണം ചേർത്തു, ആകെ എട്ട് പോർട്ടുകൾ നൽകി - കുറച്ച് കൂടി, ഞങ്ങൾ ഇറ്റാനിയത്തിലേക്ക് പോകും. അതനുസരിച്ച്, 8 UOPs/സൈക്കിളിൻ്റെ എക്സിക്യൂഷൻ പാതയിൽ ഹാസ്വെൽ ഒരു സൈദ്ധാന്തിക പ്രകടനം കാണിക്കുന്നു, അതിൽ 4 UOP-കൾ ഗണിത പ്രവർത്തനങ്ങൾക്കായി ചെലവഴിക്കുന്നു, ശേഷിക്കുന്ന 4 മെമ്മറി പ്രവർത്തനങ്ങളിലാണ്. കോൺറോ/നെഹാലം/എസ്ബിക്ക് 6 മോപ്സ്/സ്ട്രോക്ക് ഉണ്ടായിരുന്നുവെന്ന് ഓർക്കുക: 3 മോപ്സ് ഗണിത പ്രവർത്തനങ്ങൾകൂടാതെ 3 മെമ്മറി ഓപ്പറേഷൻ മൊഡ്യൂളുകളും. ഈ മെച്ചപ്പെടുത്തൽ ഐപിസി സ്കോർ ഉയർത്തും, അതിനാൽ ഇൻ്റലിൻ്റെ വികസന പദ്ധതിയിൽ അതിൻ്റെ സ്ഥാനം "അങ്ങനെ" എന്ന് പൂർണ്ണമായും ന്യായീകരിക്കുന്ന ഹാസ്വെൽ ആർക്കിടെക്ചറിൽ വളരെ ഗുരുതരമായ മാറ്റങ്ങൾ ഉണ്ട്.
ഹസ്വെല്ലിലെ FU മാറ്റങ്ങൾ

ആക്യുവേറ്ററുകളുടെ എണ്ണവും വർധിപ്പിച്ചിട്ടുണ്ട്. പുതിയ ആറാമത്തെ (ഏഴാമത്തെ) പോർട്ട് രണ്ട് അധിക ആക്യുവേറ്ററുകൾ ചേർത്തു - ഒരു പൂർണ്ണസംഖ്യ ഗണിതവും ഷിഫ്റ്റ് ഉപകരണവും ഒരു ബ്രാഞ്ച് പ്രവചന ഉപകരണവും. വിലാസം അൺലോഡ് ചെയ്യുന്നതിനുള്ള ഉത്തരവാദിത്തം ഏഴാമത്തെ (എട്ടാമത്തെ) പോർട്ട് ആണ്.
അങ്ങനെ, നമുക്ക് നാല് പൂർണ്ണസംഖ്യകളുടെ ഗണിത നിർവ്വഹണ യൂണിറ്റുകൾ ലഭിക്കുന്നു, എന്നാൽ സാൻഡി ബ്രിഡ്ജ് ഞങ്ങൾക്ക് നൽകിയത് മൂന്ന് മാത്രമാണ്. അതിനാൽ, പൂർണ്ണസംഖ്യകളുടെ ഗണിതത്തിൻ്റെ വേഗതയിൽ വർദ്ധനവ് നമുക്ക് പ്രതീക്ഷിക്കാം. കൂടാതെ, സിദ്ധാന്തത്തിൽ, ഫ്ലോട്ടിംഗ് പോയിൻ്റും പൂർണ്ണസംഖ്യയും ഒരേസമയം കണക്കുകൂട്ടാൻ ഇത് ഞങ്ങളെ അനുവദിക്കും, ഇത് NT യുടെ കാര്യക്ഷമത വർദ്ധിപ്പിക്കും. എസ്ബിയിൽ, പൂർണ്ണസംഖ്യ ഫംഗ്ഷൻ ഉപകരണങ്ങൾ ഉപയോഗിച്ച അതേ പോർട്ടുകളിൽ ഫ്ലോട്ടിംഗ് പോയിൻ്റ് കണക്കുകൂട്ടലുകൾ നടത്തി, അതിനാൽ വലിയ തടയൽ സംഭവിച്ചു, അതായത് നിങ്ങൾക്ക് ഒരു "വിജാതീയ" ലോഡ് ഉണ്ടാകില്ല. കൂട്ടിച്ചേർക്കുന്നു എന്നതും ശ്രദ്ധിക്കേണ്ടതാണ് അധിക ഉപകരണംഹസ്വെല്ലിലെ സംക്രമണം ഗണിത കണക്കുകൂട്ടലുകളിൽ "തടയാതെ" പരിവർത്തനം പ്രവചിക്കുന്നത് സാധ്യമാക്കും - മുമ്പ്, പൂർണ്ണസംഖ്യ കണക്കാക്കുമ്പോൾ, ഒരേയൊരു ബ്രാഞ്ച് പ്രെഡിക്റ്റർ തടഞ്ഞു, അതായത്, ഗണിത നിർവ്വഹണ യൂണിറ്റോ പ്രവചനമോ പ്രവർത്തിപ്പിക്കാൻ സാധ്യമായിരുന്നു. പോർട്ടുകൾ 0, 1 എന്നിവയും മാറ്റങ്ങൾക്ക് വിധേയമായി - അവ ഇപ്പോൾ FMA3-നെ പിന്തുണയ്ക്കുന്നു. ഏഴാമത് (എട്ടാമത്) ഇൻ്റൽ പോർട്ട്കാര്യക്ഷമത വർദ്ധിപ്പിക്കുന്നതിനും "തടയൽ" നീക്കം ചെയ്യുന്നതിനുമായി അവതരിപ്പിച്ചു - രണ്ടാമത്തെയും മൂന്നാമത്തെയും പോർട്ടുകൾ ലോഡിംഗിനായി പ്രവർത്തിക്കുമ്പോൾ, ഏഴാമത്തെ (എട്ടാമത്തെ) പോർട്ട് അൺലോഡിംഗിൽ ഏർപ്പെടാൻ കഴിയും, അത് മുമ്പ് അസാധ്യമായിരുന്നു. AVX/FMA3 കോഡിൻ്റെ ഉയർന്ന എക്സിക്യൂഷൻ വേഗത ഉറപ്പാക്കാൻ ഈ പരിഹാരം ആവശ്യമാണ്.
പൊതുവേ, അത്തരമൊരു വിശാലമായ എക്സിക്യൂട്ടീവ് പാത എച്ച്ടിയിൽ ഒരു മാറ്റത്തിലേക്ക് നയിച്ചേക്കാം - ഇത് നാല്-ത്രെഡുകളാക്കി മാറ്റുന്നു. കൂട്ടത്തിൽ ഇൻ്റൽ പ്രോസസ്സറുകൾവളരെ ഇടുങ്ങിയ HT എക്സിക്യൂഷൻ പാതയുള്ള Xeon Pi നാല്-ത്രെഡുകളുള്ളതാണ്, കൂടാതെ പഠനങ്ങളും പരിശോധനകളും കാണിക്കുന്നത് പോലെ, കോപ്രൊസസർ സ്കെയിൽ നന്നായി പ്രവർത്തിക്കുന്നു. അതായത്, ഒരു ഇടുങ്ങിയ നിർവ്വഹണ പാത പോലും, തത്വത്തിൽ, നാല് ത്രെഡുകൾ ഉപയോഗിച്ച് ഫലപ്രദമായി പ്രവർത്തിക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു. എട്ട് ലോഞ്ച് പോർട്ടുകളുള്ള ഒരു പാതയ്ക്ക് നാല് ത്രെഡുകൾ കാര്യക്ഷമമായി പ്രവർത്തിപ്പിക്കാൻ കഴിയും, കൂടാതെ, നാല് ത്രെഡുകളുടെ സാന്നിധ്യത്തിന് എട്ട് ലോഞ്ച് പോർട്ടുകൾ മികച്ച രീതിയിൽ ലോഡ് ചെയ്യാൻ കഴിയും. ശരിയാണ്, കൂടുതൽ കാര്യക്ഷമതയ്ക്കായി, "സ്വതന്ത്ര" ഡാറ്റയുടെ കൂടുതൽ സാധ്യതയ്ക്കായി ബഫറുകൾ (പ്രാഥമികമായി പുനഃക്രമീകരിക്കുന്ന ബഫർ) വർദ്ധിപ്പിക്കേണ്ടത് ആവശ്യമാണ്.
ഹാസ്വെൽ L1-L2 ത്രൂപുട്ടും ഇരട്ടിയാക്കി, അതേ ലേറ്റൻസി മൂല്യങ്ങൾ നിലനിർത്തി. എട്ട് ലോഞ്ച് പോർട്ടുകളുടെയും 256-ബിറ്റ് എവിഎക്സ്, എഫ്എംഎ 3 എന്നിവയുടെ സാന്നിധ്യം കണക്കിലെടുക്കുമ്പോൾ 32-ബൈറ്റ് എഴുത്തും 16-ബൈറ്റ് വായനയും മതിയാകില്ല എന്നതിനാൽ ഈ അളവ് വളരെ അത്യാവശ്യമായിരുന്നു.
| മണൽ പാലം | ഹാസ്വെൽ | |
| L1i | 32k, 8-വഴി | 32k, 8-വഴി |
| L1d | 32k, 8-വഴി | 32k, 8-വഴി |
| ലേറ്റൻസി | 4 അളവുകൾ | 4 അളവുകൾ |
| ഡൗൺലോഡ് വേഗത | 32 ബൈറ്റുകൾ/ക്ലോക്ക് | 64 ബൈറ്റുകൾ/ക്ലോക്ക് |
| എഴുത്ത് വേഗത | 16 ബൈറ്റുകൾ/സൈക്കിൾ | 32 ബൈറ്റുകൾ/ക്ലോക്ക് |
| L2 | 256k, 8-വഴി | 256k, 8-വഴി |
| ലേറ്റൻസി | 11 ബാറുകൾ | 11 ബാറുകൾ |
| L2-നും L1-നും ഇടയിലുള്ള ബാൻഡ്വിഡ്ത്ത് | 32 ബൈറ്റുകൾ/ക്ലോക്ക് | 64 ബൈറ്റുകൾ/ക്ലോക്ക് |
| L1i TLB | 4k: 128, 4-വേ 2M/4M: 8/ത്രെഡ് | 4k: 128, 4-വേ 2M/4M: 8/ത്രെഡ് |
| L1d TLB | 4k: 128, 4-വേ 2M/4M: 7/ത്രെഡ് 1G: 4, 4-വേ | 4k: 128, 4-വേ 2M/4M: 7/ത്രെഡ് 1G: 4, 4-വേ |
| L2 TLB | 4k: 512, 4-വേ | 4k+2M പങ്കിട്ടു: 1024, 8-വേ |
TLB L2 1024 എൻട്രികളായി ഉയർത്തി, രണ്ട് മെഗാബൈറ്റ് പേജുകൾക്കുള്ള പിന്തുണ പ്രത്യക്ഷപ്പെട്ടു. TLB L2 ൻ്റെ വർദ്ധനവ് അസോസിയേറ്റിവിറ്റിയിൽ നാലിൽ നിന്ന് എട്ടിലേക്ക് വർദ്ധനവിന് കാരണമായി.
മൂന്നാം ലെവൽ കാഷെ സംബന്ധിച്ചിടത്തോളം, അതിനുള്ള സാഹചര്യം അവ്യക്തമാണ്: പുതിയ പ്രോസസ്സറിൽ, സമന്വയ നഷ്ടങ്ങൾ കാരണം ആക്സസ് ലേറ്റൻസി വർദ്ധിക്കണം, കാരണം ഇപ്പോൾ L3 കാഷെ അതിൻ്റെ സ്വന്തം ആവൃത്തിയിലാണ് പ്രവർത്തിക്കുന്നത്, അല്ലാതെ പ്രോസസ്സർ കോറുകളുടെ ആവൃത്തിയിലല്ല, മുമ്പത്തെപ്പോലെ. ഒരു ക്ലോക്ക് സൈക്കിളിൽ 32 ബൈറ്റുകളിൽ ഇപ്പോഴും ആക്സസ് നടക്കുന്നുണ്ടെങ്കിലും. മറുവശത്ത്, സിസ്റ്റം ഏജൻ്റിലേക്കുള്ള മാറ്റങ്ങളെക്കുറിച്ചും ലോഡ് ബാലൻസർ ബ്ലോക്കിലെ മെച്ചപ്പെടുത്തലുകളെക്കുറിച്ചും ഇൻ്റൽ സംസാരിക്കുന്നു, ഇതിന് ഇപ്പോൾ ഒന്നിലധികം L3 കാഷെ അഭ്യർത്ഥനകൾ സമാന്തരമായി പ്രോസസ്സ് ചെയ്യാനും അവയെ ഡാറ്റയും നോൺ-ഡേറ്റാ അഭ്യർത്ഥനകളും ആയി വേർതിരിക്കാനും കഴിയും. ഇത് L3 കാഷെയുടെ ത്രൂപുട്ട് വർദ്ധിപ്പിക്കണം (ചില പരിശോധനകൾ ഇത് സ്ഥിരീകരിക്കുന്നു, L3 കാഷെ ബാൻഡ്വിഡ്ത്ത് IB-യെക്കാൾ അല്പം കൂടുതലാണ്).
ഹസ്വെല്ലിലെ എൽ 3 കാഷെയുടെ പ്രവർത്തന തത്വം നെഹലേമിന് സമാനമാണ്. നെഹാലെമിൽ, എൽ 3 കാഷെ അൺകോറിൽ സ്ഥിതിചെയ്യുന്നു, അതിന് അതിൻ്റേതായ നിശ്ചിത ആവൃത്തി ഉണ്ടായിരുന്നു, എസ്ബിയിൽ എൽ 3 കാഷെ പ്രോസസർ കോറുകളുമായി ബന്ധിപ്പിച്ചിരിക്കുന്നു - അതിൻ്റെ ആവൃത്തി പ്രോസസർ കോറുകളുടെ ആവൃത്തിക്ക് തുല്യമായി. ഇക്കാരണത്താൽ, പ്രശ്നങ്ങൾ ഉയർന്നു - ഉദാഹരണത്തിന്, ലോഡ് ഇല്ലാത്തപ്പോൾ പ്രോസസർ കോറുകൾ കുറഞ്ഞ ആവൃത്തികളിൽ പ്രവർത്തിക്കുമ്പോൾ (ഒപ്പം LLC "ഉറങ്ങി"), കൂടാതെ GPU- ന് ഉയർന്ന LLC PS ആവശ്യമാണ്. അതായത്, ഈ സൊല്യൂഷൻ GPU-ൻ്റെ പ്രകടനത്തെ പരിമിതപ്പെടുത്തി, കൂടാതെ LLC-യെ ഉണർത്താൻ മാത്രം പ്രോസസ്സർ കോറുകൾ നിഷ്ക്രിയാവസ്ഥയിൽ നിന്ന് പുറത്തുകൊണ്ടുവരേണ്ടതും ആവശ്യമാണ്. വൈദ്യുതി ഉപഭോഗവും കാര്യക്ഷമതയും മെച്ചപ്പെടുത്താൻ പുതിയ പ്രൊസസർ GPU പ്രവർത്തനംമേൽപ്പറഞ്ഞ സാഹചര്യങ്ങളിൽ, L3 കാഷെ അതിൻ്റെ ആവൃത്തിയിൽ പ്രവർത്തിക്കുന്നു. ഡെസ്ക്ടോപ്പ് സൊല്യൂഷനുകളേക്കാൾ മൊബൈൽ ഈ പരിഹാരത്തിൽ നിന്ന് ഏറ്റവും കൂടുതൽ പ്രയോജനം നേടണം.
കാഷെ വലുപ്പങ്ങൾക്ക് ഒരു നിശ്ചിത ആശ്രിതത്വം ഉണ്ടെന്നത് ശ്രദ്ധിക്കേണ്ടതാണ്. മൂന്നാമത്തെ ലെവൽ കാഷെ ഓരോ കോറിനും രണ്ട് മെഗാബൈറ്റ് ആണ്, രണ്ടാമത്തെ ലെവൽ കാഷെ 256 KB ആണ്, ഇത് ഒരു കോറിന് L3 വോളിയത്തേക്കാൾ എട്ട് മടങ്ങ് കുറവാണ്. ആദ്യ ലെവൽ കാഷെയുടെ വോളിയം, L2 നേക്കാൾ എട്ട് മടങ്ങ് ചെറുതാണ്, 32 KB ആണ്. uop കാഷെ ഈ ആശ്രിതത്വത്തിലേക്ക് തികച്ചും യോജിക്കുന്നു: അതിൻ്റെ 1536 uops വോളിയം L1 നേക്കാൾ 7-9 മടങ്ങ് ചെറുതാണ് (ഇത് കൃത്യമായി നിർണ്ണയിക്കാൻ കഴിയില്ല, കാരണം ഒരു uop-ൻ്റെ ബിറ്റ് വലുപ്പം അജ്ഞാതമാണ്, കൂടാതെ ഇൻ്റൽ ഈ വിഷയത്തിൽ വിപുലീകരിക്കാൻ സാധ്യതയില്ല. ). അതാകട്ടെ, 168 uops-ൻ്റെ പുനഃക്രമീകരിക്കുന്ന ബഫർ, 1536 uops-ൻ്റെ uop കാഷെയേക്കാൾ എട്ട് മടങ്ങ് ചെറുതാണ്, എന്നിരുന്നാലും, ബഫറുകളിലും ക്യൂകളിലും വ്യാപകമായ വർദ്ധനവിനെ അടിസ്ഥാനമാക്കി, uop കാഷെയിൽ 14% വർദ്ധനവ് പ്രതീക്ഷിക്കാം, അതായത്, 1776 വരെ. അങ്ങനെ, ബഫറുകളുടെയും കാഷെകളുടെയും വോള്യങ്ങൾക്ക് ആനുപാതികമായ വലുപ്പങ്ങളുണ്ട്. ഇൻ്റൽ L1/L2 കാഷെകൾ വർദ്ധിപ്പിക്കാത്തതിൻ്റെ മറ്റൊരു കാരണം ഇതാണ്, ഓരോ ഏരിയാ വർദ്ധനയിലും പ്രകടനം വർദ്ധിപ്പിക്കുന്നതിന് വോള്യങ്ങളിലെ അത്തരം അനുപാതങ്ങൾ ഏറ്റവും ഫലപ്രദമാണ്. ബിൽറ്റ്-ഇൻ ടോപ്പ്-എൻഡ് ഗ്രാഫിക്സ് കോർ ഉള്ള പ്രോസസ്സറുകൾക്ക് വിശാലമായ ആക്സസ് ബസ് ഉള്ള ഇൻ്റർമീഡിയറ്റ് ഫാസ്റ്റ് മെമ്മറി ഉണ്ടെന്നത് ശ്രദ്ധിക്കേണ്ടതാണ്, അത് റാമിലേക്കുള്ള എല്ലാ അഭ്യർത്ഥനകളും കാഷെ ചെയ്യുന്നു - പ്രോസസ്സറും വീഡിയോ ആക്സിലറേറ്ററും. ഈ മെമ്മറിയുടെ അളവ് 128 MB ആണ്. പ്രോസസർ കോറുകൾക്കായി, ഈ മെമ്മറി L4 കാഷെ ആയി കണക്കാക്കുകയാണെങ്കിൽ, വോളിയം 64 മെഗാബൈറ്റ് ആയിരിക്കണം, കൂടാതെ ഒരു ഗ്രാഫിക്സ് കോർ ചേർക്കുമ്പോൾ, 128 MB ഉപയോഗം തികച്ചും യുക്തിസഹമായി തോന്നുന്നു.
മെമ്മറി കൺട്രോളറിനെ സംബന്ധിച്ചിടത്തോളം, ഇതിന് ചാനലുകളുടെ എണ്ണത്തിൽ വർദ്ധനവോ റാമിൻ്റെ പ്രവർത്തനത്തിൻ്റെ ആവൃത്തിയിലെ വർദ്ധനവോ ലഭിച്ചില്ല, അതായത്, 1600 മെഗാഹെർട്സ് ആവൃത്തിയിൽ ഡ്യുവൽ-ചാനൽ ആക്സസ് ഉള്ള അതേ മെമ്മറി കൺട്രോളറാണ് ഇത്. ഈ തീരുമാനം വിചിത്രമായി തോന്നുന്നു, കാരണം എസ്ബിയിൽ നിന്ന് ഐബിയിലേക്കുള്ള മാറ്റം ഐസിപിയുടെ പ്രവർത്തന ആവൃത്തി 1333 മെഗാഹെർട്സിൽ നിന്ന് 1600 മെഗാഹെർട്സായി വർദ്ധിപ്പിച്ചു, എന്നിരുന്നാലും ഇത് ഒരു പുതിയ സാങ്കേതിക പ്രക്രിയയിലേക്കുള്ള ആർക്കിടെക്ചറിൻ്റെ മാറ്റം മാത്രമായിരുന്നു. ഇപ്പോൾ ഞങ്ങൾക്ക് ഒരു പുതിയ ആർക്കിടെക്ചർ ഉണ്ട്, അതേസമയം മെമ്മറി പ്രവർത്തനത്തിൻ്റെ ആവൃത്തി അതേ തലത്തിൽ തന്നെ തുടരുന്നു.
ഗ്രാഫിക്സ് കോറിലെ മെച്ചപ്പെടുത്തലുകൾ ഞങ്ങൾ ഓർക്കുകയാണെങ്കിൽ ഇത് കൂടുതൽ അപരിചിതമായി തോന്നുന്നു - എല്ലാത്തിനുമുപരി, IB-യിലെ ലോ-എൻഡ് HD2500 വീഡിയോ കാർഡ് പോലും 25 GB/s ബാൻഡ്വിഡ്ത്ത് പൂർണ്ണമായും ഉപയോഗിച്ചുവെന്ന് ഞങ്ങൾ ഓർക്കുന്നു. ഇപ്പോൾ സിപിയു പ്രകടനവും ഗ്രാഫിക്സ് പ്രകടനവും വർദ്ധിച്ചു, അതേസമയം മെമ്മറി ബാൻഡ്വിഡ്ത്ത് അതേ തലത്തിൽ തന്നെ തുടരുന്നു. വിശാലമായ സ്കെയിലിൽ, എതിരാളി അതിൻ്റെ APU-കളിൽ മെമ്മറി ബാൻഡ്വിഡ്ത്ത് നിരന്തരം വർദ്ധിപ്പിക്കുന്നു, ഇത് ഇൻ്റലിൻ്റെതിനേക്കാൾ ഉയർന്നതാണ്. 1866 മെഗാഹെർട്സ് അല്ലെങ്കിൽ 2133 മെഗാഹെർട്സ് ആവൃത്തിയിലുള്ള മെമ്മറിയെ ഹാസ്വെൽ പിന്തുണയ്ക്കുമെന്ന് പ്രതീക്ഷിക്കുന്നത് യുക്തിസഹമാണ്, ഇത് ബാൻഡ്വിഡ്ത്ത് യഥാക്രമം 30, 34 GB/s ആയി വർദ്ധിപ്പിക്കും.
തൽഫലമായി, ഇൻ്റലിൻ്റെ ഈ തീരുമാനം പൂർണ്ണമായും വ്യക്തമല്ല. ആദ്യം, ഒരു എതിരാളി ഇല്ലാതെ വേഗതയേറിയ മെമ്മറിക്കുള്ള പിന്തുണ അവതരിപ്പിച്ചു പ്രത്യേക പ്രശ്നങ്ങൾ. രണ്ടാമതായി, 1866 MHz ആവൃത്തിയിൽ പ്രവർത്തിക്കുന്ന മെമ്മറി മൊഡ്യൂളുകളുടെ വില 1600 MHz മൊഡ്യൂളുകളുമായി താരതമ്യപ്പെടുത്തുമ്പോൾ വളരെ കൂടുതലല്ല, കൂടാതെ, 1866 MHz മെമ്മറി വാങ്ങാൻ ആരും ബാധ്യസ്ഥരല്ല - തിരഞ്ഞെടുക്കൽ ഉപയോക്താവിന് ആയിരിക്കും. മൂന്നാമതായി, 1866 മെഗാഹെർട്സ് മാത്രമല്ല, 2133 മെഗാഹെർട്സും പിന്തുണയ്ക്കുന്നതിൽ പ്രശ്നങ്ങളൊന്നും ഉണ്ടാകില്ല: ഹാസ്വെല്ലിൻ്റെ പ്രഖ്യാപനം മുതൽ, റാം ഓവർക്ലോക്കുചെയ്യുന്നതിനുള്ള ലോക റെക്കോർഡുകൾ സജ്ജീകരിച്ചിട്ടുണ്ട്, അതായത്, ഐകെപിക്ക് വേഗത്തിലുള്ള മെമ്മറി കൈകാര്യം ചെയ്യാൻ കഴിയുമായിരുന്നു. എന്തെങ്കിലും പ്രശ്നം. നാലാമതായി, Xeon E5-2500 V2 (Ivy Bridge-EP) സെർവർ ലൈൻ 1866 MHz-നുള്ള പിന്തുണ ക്ലെയിം ചെയ്യുന്നു, എന്നാൽ ഡെസ്ക്ടോപ്പ് സൊല്യൂഷനുകളേക്കാൾ വളരെ വൈകിയാണ് ഇൻ്റൽ സാധാരണയായി ഈ വിപണിയിൽ വേഗതയേറിയ മെമ്മറി മാനദണ്ഡങ്ങൾക്കുള്ള പിന്തുണ അവതരിപ്പിക്കുന്നത്.
തത്വത്തിൽ, മത്സരത്തിൻ്റെ അഭാവത്തിൽ, ഇൻ്റലിന് അതിൻ്റെ പേശികൾ കെട്ടിപ്പടുക്കുകയും അതിൻ്റെ മികവ് വർദ്ധിപ്പിക്കുകയും ചെയ്യേണ്ട ആവശ്യമില്ലെന്ന് ഒരാൾക്ക് അനുമാനിക്കാം, എന്നാൽ ഈ അനുമാനം തികച്ചും തെറ്റാണ്, കാരണം മെമ്മറി ബാൻഡ്വിഡ്ത്ത് വർദ്ധിക്കുന്നത് ചട്ടം പോലെ വർദ്ധിക്കുന്നു. സംയോജിത ഗ്രാഫിക്സ് കോറിൻ്റെ പ്രകടനം, പ്രോസസർ പ്രകടനം മിക്കവാറും വർദ്ധിപ്പിക്കില്ല. അതേ സമയം, ഗ്രാഫിക്സ് പ്രകടനത്തിൽ ഇൻ്റൽ ഇപ്പോഴും എഎംഡിയെക്കാൾ പിന്നിലാണ് കഴിഞ്ഞ വർഷങ്ങൾഇൻ്റൽ തന്നെ ഗ്രാഫിക്സിൽ കൂടുതൽ കൂടുതൽ ശ്രദ്ധ ചെലുത്തുന്നു, അതിൻ്റെ മെച്ചപ്പെടുത്തലിൻ്റെ നിരക്ക് പ്രോസസർ കോറിനേക്കാൾ വളരെ കൂടുതലാണ്. കൂടാതെ, മെമ്മറി ബാൻഡ്വിഡ്ത്തിലെ വർദ്ധനവ് ഗ്രാഫിക്സ് പ്രകടനത്തിൽ 30% വരെ വർദ്ധനവിന് കാരണമാകുമെന്ന് കാണിക്കുന്ന മുൻ തലമുറ HD4000 ൻ്റെ സംയോജിത ഗ്രാഫിക്സ് കോർ പരിശോധിക്കുന്നതിൻ്റെ ഫലങ്ങളെ ഞങ്ങൾ ആശ്രയിക്കുകയാണെങ്കിൽ, കൂടാതെ പുതിയത് ഗ്രാഫിക്സ് കോർ HD4600, HD4000 നേക്കാൾ വേഗതയേറിയതാണ്, അപ്പോൾ PSP-യിൽ നിന്നുള്ള ഗ്രാഫിക്സ് കോർ പ്രകടനത്തെ ആശ്രയിക്കുന്നത് കൂടുതൽ വ്യക്തമാകും. "ഇടുങ്ങിയ" മെമ്മറി ബാൻഡ്വിഡ്ത്ത് കൊണ്ട് പുതിയ ഗ്രാഫിക്സ് കോർ കൂടുതൽ പരിമിതപ്പെടുത്തും. എല്ലാ വസ്തുതകളും സംഗ്രഹിച്ചാൽ, ഇൻ്റലിൻ്റെ തീരുമാനം പൂർണ്ണമായും മനസ്സിലാക്കാൻ കഴിയാത്തതാണ്: കമ്പനി തന്നെ അതിൻ്റെ ഗ്രാഫിക്സ് "ഞെരിച്ചു", പക്ഷേ ബാൻഡ്വിഡ്ത്ത് വർദ്ധനവ് അതിൻ്റെ പ്രകടനം മെച്ചപ്പെടുത്തും.
കാഷെകളുടെ ആർക്കിടെക്ചറിലേക്ക് മടങ്ങുമ്പോൾ, നമുക്ക് ഒരു ചിന്തയെ ശൂന്യതയിലേക്ക് വലിച്ചെറിയാം: ഒരു ഇൻ്റർമീഡിയറ്റ് കാഷെ (മോപ്പ് കാഷെ) ചേർത്തതിനാൽ, ഏകദേശം 4-8 കെബി വലുപ്പവും കുറഞ്ഞ ആക്സസ്സും ഉള്ള ഒരു ഇൻ്റർമീഡിയറ്റ് ഡാറ്റ കാഷെ എന്തുകൊണ്ട് ചേർക്കരുത്. P4 (uop കാഷെ എന്ന ആശയം Netburst-ൽ നിന്ന് എടുത്തതിനാൽ) പോലെ L1d കാഷെയ്ക്കും എക്സിക്യൂട്ടീവ് ഉപകരണങ്ങൾക്കും ഇടയിലുള്ള ലേറ്റൻസി? P4-ൽ ഈ ഇൻ്റർമീഡിയറ്റ് ഡാറ്റ കാഷെയ്ക്ക് രണ്ട് ക്ലോക്ക് സൈക്കിളുകളുടെ ആക്സസ് സമയമുണ്ടെന്നും ഒരു P4 സൈക്കിൾ ഒരു പരമ്പരാഗത പ്രോസസ്സറിൻ്റെ ഏകദേശം 0.75 ക്ലോക്ക് സൈക്കിളുകൾക്ക് തുല്യമാണെന്നും ഓർക്കുക, അതായത് ആക്സസ് സമയം ഏകദേശം ഒന്നര ക്ലോക്ക് സൈക്കിളുകളായിരുന്നു. എന്നിരുന്നാലും, സമാനമായ എന്തെങ്കിലും നമ്മൾ വീണ്ടും കണ്ടേക്കാം - നന്നായി മറന്നുപോയ പഴയ കാര്യങ്ങൾ ഓർക്കാൻ ഇൻ്റൽ ഇഷ്ടപ്പെടുന്നു.
നിങ്ങൾക്ക് കാണാനാകുന്നതുപോലെ, AVX/FMA3 കോഡിൻ്റെ പ്രകടനം വർദ്ധിപ്പിക്കുന്നതിനാണ് ഇൻ്റൽ മിക്ക വാസ്തുവിദ്യാ മാറ്റങ്ങളും ലക്ഷ്യമിട്ടത്: ഇതിൽ കാഷെ ത്രൂപുട്ടിലെ വർദ്ധനവ്, പോർട്ടുകളുടെ എണ്ണത്തിലെ വർദ്ധനവ്, അപ്ലോഡ്/ലോഡ് നിരക്കിലെ വർദ്ധനവ് എന്നിവ ഉൾപ്പെടുന്നു. നിർവ്വഹണ പാത. തൽഫലമായി, പ്രധാന പ്രകടന നേട്ടം AVX/FMA3 ഉപയോഗിച്ച് എഴുതിയ സോഫ്റ്റ്വെയറിൽ നിന്നായിരിക്കണം. തത്വത്തിൽ, പരിശോധനാ ഫലങ്ങൾ വിലയിരുത്തുമ്പോൾ, ഇത് അങ്ങനെയാണെന്ന് തോന്നുന്നു. "പഴയ" ആപ്ലിക്കേഷനുകളിലെ അതേ ഫ്രീക്വൻസിയിൽ ഡ്രൈ പെർഫോമൻസ് മുമ്പത്തെ കാമ്പിനെ അപേക്ഷിച്ച് ഏകദേശം 10% വർദ്ധനവ് ലഭിച്ചു, കൂടാതെ പുതിയ ഇൻസ്ട്രക്ഷൻ സെറ്റുകൾ ഉപയോഗിച്ച് എഴുതിയ ആപ്ലിക്കേഷനുകൾ 30% ത്തിലധികം വർദ്ധനവ് കാണിക്കുന്നു. പുതിയ ഇൻസ്ട്രക്ഷൻ സെറ്റുകൾക്കായി ആപ്ലിക്കേഷനുകൾ ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിനാൽ ഹാസ്വെൽ ആർക്കിടെക്ചറിൻ്റെ നേട്ടങ്ങൾ വെളിപ്പെടുത്തും. അപ്പോഴാണ് എസ്ബിയേക്കാൾ ഹാസ്വെലിൻ്റെ മികവ് വ്യക്തമാകുന്നത്.
നവീകരണത്തിൻ്റെ ഒരു പ്രധാന ഭാഗത്തിൻ്റെ പ്രധാന നേട്ടം മൊബൈൽ ഉപകരണങ്ങളായിരിക്കും. L3 കാഷെയിലേക്കുള്ള ഒരു പുതിയ സമീപനം, ഒരു ബിൽറ്റ്-ഇൻ വോൾട്ടേജ് റെഗുലേറ്റർ, പുതിയ സ്ലീപ്പ് മോഡുകൾ, പ്രോസസർ കോറുകളുടെ കുറഞ്ഞ പ്രവർത്തന ആവൃത്തികൾ എന്നിവ അവരെ സഹായിക്കും.
ഉപസംഹാരം (പ്രോസസർ ഭാഗം)
ഹാസ്വെലിൽ നിന്ന് നിങ്ങൾക്ക് എന്ത് പ്രതീക്ഷിക്കാം?
ലോഞ്ച് പോർട്ടുകളുടെ എണ്ണത്തിലുള്ള വർദ്ധനവ് കാരണം, ഐപിസിയിൽ വർദ്ധനവ് പ്രതീക്ഷിക്കാം, അതിനാൽ ഒപ്റ്റിമൈസ് ചെയ്യാത്ത സോഫ്റ്റ്വെയറിൽ പോലും, അതേ ആവൃത്തിയിൽ സാൻഡി ബ്രിഡ്ജിനെക്കാൾ പുതിയ ഹാസ്വെൽ ആർക്കിടെക്ചറിന് നേരിയ നേട്ടമുണ്ടാകും. AVX2/FMA3 നിർദ്ദേശങ്ങൾ ഭാവിയിലേക്കുള്ള ഒരു അടിത്തറയാണ്, ഈ ഭാവി സോഫ്റ്റ്വെയർ ഡെവലപ്പർമാരെ ആശ്രയിച്ചിരിക്കുന്നു: അവർ എത്ര വേഗത്തിൽ അവരുടെ ആപ്ലിക്കേഷനുകൾ പൊരുത്തപ്പെടുത്തുന്നുവോ അത്രയും വേഗത്തിൽ അന്തിമ ഉപയോക്താവ്ഒരു പെർഫോമൻസ് ബൂസ്റ്റ് ലഭിക്കും. എന്നിരുന്നാലും, എല്ലാത്തിലും എല്ലായിടത്തും നിങ്ങൾ വളർച്ച പ്രതീക്ഷിക്കരുത്: മൾട്ടിമീഡിയ ഡാറ്റയ്ക്കൊപ്പം പ്രവർത്തിക്കുന്നതിലും ശാസ്ത്രീയ കണക്കുകൂട്ടലുകളിലും SIMD നിർദ്ദേശങ്ങൾ പ്രധാനമായും ഉപയോഗിക്കുന്നു, അതിനാൽ ഈ ജോലികളിൽ പ്രകടന വളർച്ച പ്രതീക്ഷിക്കണം. ഊർജ്ജ കാര്യക്ഷമത വർദ്ധിപ്പിക്കുന്നതിൽ നിന്നുള്ള പ്രധാന നേട്ടം മൊബൈൽ സിസ്റ്റങ്ങളിലായിരിക്കും, ഈ പ്രശ്നം ശരിക്കും പ്രധാനമാണ്. അതിനാൽ, പുതിയ ഇൻ്റൽ ഹാസ്വെൽ ആർക്കിടെക്ചർ പ്രയോജനപ്പെടുത്തുന്ന രണ്ട് പ്രധാന മേഖലകൾ വർദ്ധിച്ച SIMD പ്രകടനവും വർദ്ധിച്ച ഊർജ്ജ കാര്യക്ഷമതയുമാണ്.
പുതിയ ഹാസ്വെൽ പ്രോസസറുകളുടെ പ്രയോഗക്ഷമതയെ സംബന്ധിച്ചിടത്തോളം, അവയുടെ ഉപയോഗത്തിനായി നിരവധി വ്യത്യസ്ത ഓപ്ഷനുകൾ പരിശോധിക്കുന്നത് മൂല്യവത്താണ്: ഡെസ്ക്ടോപ്പ് കമ്പ്യൂട്ടറുകളിൽ, സെർവറുകളിൽ, മൊബൈൽ സൊല്യൂഷനുകളിൽ, ഗെയിമർമാർക്കായി, ഓവർക്ലോക്കറുകൾക്കായി.
ഡെസ്ക്ടോപ്പ്
ഒരു ഡെസ്ക്ടോപ്പ് പ്രൊസസറിന് വൈദ്യുതി ഉപഭോഗം ഒരു പ്രധാന വശമല്ല, അതിനാൽ ചെലവേറിയ വൈദ്യുതി ഉള്ള യൂറോപ്പിൽ പോലും, ഇക്കാരണത്താൽ ആരും മുൻ തലമുറകളിൽ നിന്ന് ഹാസ്വെല്ലിലേക്ക് മാറാൻ സാധ്യതയില്ല. മാത്രമല്ല, ഹസ്വെല്ലിൻ്റെ ടിഡിപി ഐബിയേക്കാൾ ഉയർന്നതാണ്, അതിനാൽ മിനിമം ലോഡുകളുടെ കാര്യത്തിൽ മാത്രമേ സേവിംഗ്സ് ഉണ്ടാകൂ. ചോദ്യം ഈ രീതിയിൽ ഉന്നയിക്കുമ്പോൾ, സംശയമില്ല - അത് വിലമതിക്കുന്നില്ല.
ഒരു പ്രകടന വീക്ഷണകോണിൽ നിന്ന്, പരിവർത്തനവും അത്തരമൊരു ലാഭകരമായ ഇടപാട് പോലെ തോന്നുന്നില്ല: പ്രോസസർ ടാസ്ക്കുകളിലെ പരമാവധി വേഗത വർദ്ധനവ് ഇപ്പോൾ 10% ൽ കൂടുതലായിരിക്കില്ല. സാൻഡി ബ്രിഡ്ജിൽ നിന്നോ ഐവി ബ്രിഡ്ജിൽ നിന്നോ ഹാസ്വെല്ലിലേക്ക് മാറുന്നത് നിങ്ങൾ FMA3, AVX2 എന്നിവയ്ക്കുള്ള സമർത്ഥമായ പിന്തുണയോടെ അപ്ലിക്കേഷനുകൾ ഉപയോഗിക്കാൻ ആഗ്രഹിക്കുന്നുവെങ്കിൽ മാത്രമേ ന്യായീകരിക്കപ്പെടുകയുള്ളൂ: FMA3 പിന്തുണ ചില ആപ്ലിക്കേഷനുകളിൽ 30% മുതൽ 70% വരെ വർദ്ധനവ് നൽകും. വിർച്ച്വലൈസേഷനുമായി ബന്ധപ്പെട്ട മെച്ചപ്പെടുത്തലുകളും ട്രാൻസാഷണൽ മെമ്മറി നടപ്പിലാക്കുന്നതും ഡെസ്ക്ടോപ്പിന് താൽപ്പര്യമില്ലാത്തതും ഉപയോഗപ്രദവുമാണ്.
സെർവറുകളും വർക്ക്സ്റ്റേഷനുകളും
സെർവറുകൾ ദിവസത്തിൽ 24 മണിക്കൂറും തുടർച്ചയായി പ്രവർത്തിക്കുന്നതിനാൽ, പ്രോസസറിൽ ഉയർന്ന സ്ഥിരമായ ലോഡ് ഉണ്ടെന്ന് കണക്കിലെടുക്കുമ്പോൾ, ശുദ്ധമായ ഊർജ്ജ ഉപഭോഗത്തിൻ്റെ കാര്യത്തിൽ ഹാസ്വെൽ IB-യെക്കാൾ മികച്ചതായിരിക്കാൻ സാധ്യതയില്ല, എന്നിരുന്നാലും ഇത് വാട്ട് പെർഫോമൻസ് കണക്കിലെടുത്ത് കുറച്ച് നേട്ടം നൽകിയേക്കാം. AVX2/FMA3 പിന്തുണ സെർവറുകളിൽ ഉപയോഗപ്രദമാകാൻ സാധ്യതയില്ല, പക്ഷേ ശാസ്ത്രീയ കണക്കുകൂട്ടലുകളിൽ ഉൾപ്പെട്ടിരിക്കുന്ന വർക്ക്സ്റ്റേഷനുകളിൽ. ഈ പിന്തുണവളരെ വളരെ ഉപകാരപ്രദമായിരിക്കും - എന്നാൽ ഉപയോഗിക്കുന്ന സോഫ്റ്റ്വെയറിൽ പുതിയ നിർദ്ദേശങ്ങൾ പിന്തുണയ്ക്കുന്നുവെങ്കിൽ മാത്രം. ഇടപാട് മെമ്മറി വളരെ ഉപയോഗപ്രദമായ കാര്യമാണ്, പക്ഷേ എല്ലായ്പ്പോഴും അല്ല: മൾട്ടി-ത്രെഡ് പ്രോഗ്രാമുകളിലും ഡാറ്റാബേസുകളിൽ പ്രവർത്തിക്കുന്ന പ്രോഗ്രാമുകളിലും ഇതിന് വർദ്ധനവ് നൽകാൻ കഴിയും, പക്ഷേ അതിനായി. ഫലപ്രദമായ ഉപയോഗംസോഫ്റ്റ്വെയർ ഒപ്റ്റിമൈസേഷനും ആവശ്യമാണ്.
എന്നാൽ വിർച്ച്വലൈസേഷനുമായി ബന്ധപ്പെട്ട എല്ലാ മെച്ചപ്പെടുത്തലുകളും മിക്കവാറും നല്ല ഫലം നൽകും, കാരണം വെർച്വൽ പരിതസ്ഥിതികൾ ഇപ്പോൾ വളരെ സജീവമായി ഉപയോഗിക്കുന്നു, മാത്രമല്ല മിക്കവയിലും ഫിസിക്കൽ സെർവറുകൾനിരവധി വെർച്വലുകളിൽ പ്രവർത്തിക്കുന്നു. കൂടാതെ, വിർച്ച്വലൈസേഷൻ്റെ വ്യാപനം പ്രകടനത്തിൻ്റെ അടിസ്ഥാനത്തിൽ ഒരു വെർച്വൽ പരിതസ്ഥിതിയുടെ ചെലവ് ഗണ്യമായി കുറയ്ക്കുന്നതിലൂടെ മാത്രമല്ല, സാമ്പത്തിക കാര്യക്ഷമതയിലും വിശദീകരിക്കുന്നു: ഒരു ഫിസിക്കൽ ഒന്നിൽ നിരവധി വെർച്വൽ സെർവറുകൾ പരിപാലിക്കുന്നത് വിലകുറഞ്ഞതും കൂടുതൽ കാര്യക്ഷമമാക്കാൻ അനുവദിക്കുന്നു. പ്രോസസ്സർ ഉറവിടങ്ങൾ ഉൾപ്പെടെയുള്ള വിഭവങ്ങളുടെ ഉപയോഗം.
ഉടൻ സെർവർ മാർക്കറ്റ്ഹാസ്വെല്ലിൻ്റെ രൂപം പോസിറ്റീവായി അഭിവാദ്യം ചെയ്യണം. Xeon E3-1200v1, Xeon E3-1200v2 എന്നിവ അടിസ്ഥാനമാക്കിയുള്ള സെർവറുകൾ Xeon E3-1200v3 (Haswell) ഉള്ള സെർവറുകളിലേക്ക് മാറ്റിയ ശേഷം, നിങ്ങൾക്ക് ഉടൻ തന്നെ കാര്യക്ഷമതയിൽ വർദ്ധനവ് ലഭിക്കും, കൂടാതെ AVX2/FMA3, ട്രാൻസാഷണൽ മെമ്മറി എന്നിവയ്ക്കായുള്ള സോഫ്റ്റ്വെയർ ഒപ്റ്റിമൈസ് ചെയ്ത ശേഷം, പ്രകടനം വർദ്ധിക്കും. അതിലും കൂടുതൽ.
മൊബൈൽ പരിഹാരങ്ങൾ
മൊബൈൽ സെഗ്മെൻ്റിൽ ഹസ്വെൽ അവതരിപ്പിച്ചതിൻ്റെ പ്രധാന നേട്ടം തീർച്ചയായും മെച്ചപ്പെട്ട വൈദ്യുതി ഉപഭോഗത്തിൻ്റെ മേഖലയിലാണ്. ഇൻ്റലിൻ്റെ അവതരണങ്ങളും ഇൻറർനെറ്റിൽ ഇതിനകം ദൃശ്യമാകുന്ന ടെസ്റ്റ് ഫലങ്ങളും വിലയിരുത്തുമ്പോൾ, ശരിക്കും ഒരു ഫലമുണ്ട്, കൂടാതെ ശ്രദ്ധേയമായ ഒന്ന്.
ശുദ്ധമായ പ്രകടനത്തിൻ്റെ കാര്യത്തിൽ, ഐവി ബ്രിഡ്ജിൽ നിന്ന് ഹാസ്വെല്ലിലേക്ക് മാറുന്നത് അത്ര ന്യായമായ ഒരു സംരംഭമായി തോന്നുന്നില്ല: അറ്റ നേട്ടം താരതമ്യേന ചെറുതായിരിക്കണം, കൂടാതെ മെച്ചപ്പെടുത്തലുകൾ വ്യക്തിഗത ഘടകങ്ങൾ(അതേ വെർച്വലൈസേഷൻ അല്ലെങ്കിൽ മൾട്ടിമീഡിയ നിർദ്ദേശങ്ങൾ) ഒരു മൊബൈൽ സിസ്റ്റത്തിൻ്റെ ഉപയോക്താവിന് കൂടുതൽ നൽകാൻ സാധ്യതയില്ല, കാരണം അവർ ലാപ്ടോപ്പുകളിലും ടാബ്ലെറ്റുകളിലും പരിസ്ഥിതികളോ സങ്കീർണ്ണമായ ശാസ്ത്രീയ കണക്കുകൂട്ടലുകളോ അപൂർവ്വമായി സൃഷ്ടിക്കുന്നു.
പൊതുവേ, പ്രോസസർ പ്രകടനത്തിൻ്റെ കാര്യത്തിൽ, നിങ്ങൾ വളരെയധികം പ്രതീക്ഷിക്കേണ്ടതില്ല, പക്ഷേ മൊബൈൽ സിസ്റ്റങ്ങൾ തീർച്ചയായും ഗ്രാഫിക്സ് കോറിൻ്റെ പ്രകടനത്തിൽ വർദ്ധനവ് ആവശ്യപ്പെടും. അതിനാൽ, ഊർജ്ജ ഉപഭോഗ പ്രശ്നങ്ങൾ നിങ്ങൾക്ക് നിർണായകമല്ലെങ്കിൽ, സാൻഡി ബ്രിഡ്ജിൽ നിന്നോ ഐവി ബ്രിഡ്ജിൽ നിന്നോ നവീകരിക്കുന്നത് നിങ്ങൾ ഗൗരവമായി പരിഗണിക്കേണ്ടതില്ല - നിലവിലുള്ള സിസ്റ്റങ്ങൾ പൂർണ്ണമായും കാലഹരണപ്പെടുന്നതുവരെ പ്രവർത്തിക്കുന്നത് തുടരുന്നതാണ് നല്ലത്. നിങ്ങൾ പലപ്പോഴും ബാറ്ററികളിൽ പ്രവർത്തിക്കുകയാണെങ്കിൽ, ഹാസ്വെല്ലിന് ബാറ്ററി ലൈഫിൽ ഗണ്യമായ വർദ്ധനവ് നൽകാൻ കഴിയും.
കളിക്കാർ
റഷ്യയിലെ ഗെയിമർമാർക്കിടയിൽ energy ർജ്ജ ഉപഭോഗത്തിൻ്റെ പ്രശ്നം, ഒരു ചട്ടം പോലെ, ഒരു പ്രശ്നമല്ല - ഗെയിമിംഗ് വീഡിയോ കാർഡുകൾ 200 വാട്ടുകളോ അതിൽ കൂടുതലോ ഉപയോഗിക്കുമ്പോൾ അത് എന്തുകൊണ്ട് ആയിരിക്കണം? ഗെയിമർമാർക്ക് വെർച്വലൈസേഷനും ഇടപാട് മെമ്മറിയും ആവശ്യമില്ല. AVX2/FMA3 ഗെയിമുകൾക്കായി പ്രത്യേകമായി ഡിമാൻഡിലായിരിക്കുമെന്നത് ഒരു വസ്തുതയല്ല, എന്നിരുന്നാലും അവ ഭൗതികശാസ്ത്ര കണക്കുകൂട്ടലുകളിൽ ഉപയോഗപ്രദമാകുമെങ്കിലും. പ്രോസസറിൻ്റെ ശുദ്ധമായ പ്രകടനമാണ് അവശേഷിക്കുന്നത്, ഇവിടെ അതേ ഐവി ബ്രിഡ്ജുമായുള്ള വ്യത്യാസം ചെറുതാണ്. തൽഫലമായി, ഈ വിഭാഗം ഉപയോക്താക്കൾക്ക് എസ്ബിയിൽ നിന്നോ ഐബിയിൽ നിന്നോ ഹാസ്വെല്ലിലേക്കുള്ള നേരിട്ടുള്ള പരിവർത്തനവും പ്രസക്തമാണെന്ന് തോന്നുന്നില്ല. എന്നാൽ നെഹാലെമിൽ നിന്നും ലിനിഫീൽഡിൽ നിന്നും പുതിയ പ്രോസസറുകളിലേക്ക് മാറുന്നത് യുക്തിസഹമാണ്, അതിലുപരിയായി കോൺറോ.
ഓവർക്ലോക്കറുകൾ
ഓവർക്ലോക്കറുകൾക്ക്, പുതിയ പ്രോസസർ (എന്നാൽ, തീർച്ചയായും, അതിൻ്റെ "അൺലോക്ക് ചെയ്ത" കെ-പതിപ്പ്) രസകരമായിരിക്കാം, പ്രത്യേകിച്ചും അത് "തലയോട്ടി" സാധ്യമാണെങ്കിൽ, അതായത്, മെറ്റൽ കവർ നീക്കം ചെയ്ത് ക്രിസ്റ്റൽ നേരിട്ട് തണുപ്പിക്കുക. ഇത് ചെയ്തില്ലെങ്കിൽ, ഓവർക്ലോക്കിംഗ് ഫലങ്ങൾ ഐവി ബ്രിഡ്ജിനേക്കാൾ മിതമായതായി കാണപ്പെടും. കൂടാതെ, സംയോജിത വോൾട്ടേജ് റെഗുലേറ്റർ ഒരു പരിമിത ഘടകമാണ്. ഇതിനെക്കുറിച്ച് കൂടുതൽ വായിക്കുക
ഞങ്ങൾ വിവർത്തനം ചെയ്യുന്നു... ചൈനീസ് (ലളിതമാക്കിയ) ചൈനീസ് (പരമ്പരാഗത) ഇംഗ്ലീഷ് ഫ്രഞ്ച് ജർമ്മൻ ഇറ്റാലിയൻ പോർച്ചുഗീസ് റഷ്യൻ സ്പാനിഷ് ടർക്കിഷ് വിവർത്തനം ചെയ്യുക
നിർഭാഗ്യവശാൽ, ഞങ്ങൾക്ക് ഇപ്പോൾ ഈ വിവരങ്ങൾ വിവർത്തനം ചെയ്യാൻ കഴിയുന്നില്ല - ദയവായി പിന്നീട് വീണ്ടും ശ്രമിക്കുക.
ആമുഖം
ആശയവിനിമയത്തിനും ഡാറ്റാ കൈമാറ്റത്തിനുമായി രൂപകൽപ്പന ചെയ്തിരിക്കുന്ന സോഫ്റ്റ്വെയറിന് വളരെ ഉയർന്ന പ്രകടനം ആവശ്യമാണ്, കാരണം അത് വലിയ അളവിലുള്ള ചെറിയ ഡാറ്റ പാക്കറ്റുകൾ കൈമാറുന്നു. വിർച്ച്വലൈസേഷൻ ആപ്ലിക്കേഷൻ വികസനത്തിൻ്റെ സവിശേഷതകളിൽ ഒന്ന് നെറ്റ്വർക്ക് പ്രവർത്തനങ്ങൾ(NFV) എന്നത് സാധ്യമായ പരമാവധി വിർച്ച്വലൈസേഷൻ ഉപയോഗിക്കേണ്ടത് ആവശ്യമാണ്, എന്നാൽ അതേ സമയം ആവശ്യമായ കേസുകൾഉപയോഗിച്ച ഹാർഡ്വെയറിനായുള്ള ആപ്ലിക്കേഷനുകൾ ഒപ്റ്റിമൈസ് ചെയ്യുക.
ഈ ലേഖനത്തിൽ, NFV ആപ്ലിക്കേഷനുകളുടെ പ്രകടനം ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിന് ഉപയോഗപ്രദമായ Intel® പ്രോസസറുകളുടെ മൂന്ന് സവിശേഷതകൾ ഞാൻ ഹൈലൈറ്റ് ചെയ്യും: Cache Allocation Technologies (CAT), Intel® Advanced Vector Extensions 2 (Intel® AVX2) വെക്റ്റർ പ്രോസസ്സിംഗിനായി, Intel® ട്രാൻസാക്ഷണൽ സിൻക്രൊണൈസേഷൻ എക്സ്റ്റൻഷനുകൾ (Intel® TSX).
CAT ഉപയോഗിച്ച് മുൻഗണനാ വിപരീത പ്രശ്നം പരിഹരിക്കുന്നു
കുറഞ്ഞ മുൻഗണനയുള്ള ഫംഗ്ഷൻ ഉയർന്ന മുൻഗണനയുള്ള ഫംഗ്ഷനിൽ നിന്ന് വിഭവങ്ങൾ മോഷ്ടിക്കുമ്പോൾ, ഞങ്ങൾ ഇതിനെ "മുൻഗണന വിപരീതം" എന്ന് വിളിക്കുന്നു.
എല്ലാം അല്ല വെർച്വൽ പ്രവർത്തനങ്ങൾതുല്യമായി പ്രാധാന്യമുള്ളത്. ഉദാഹരണത്തിന്, പ്രോസസ്സിംഗ് സമയത്തിനും പ്രകടനത്തിനും റൂട്ടിംഗ് ഫംഗ്ഷൻ പ്രധാനമാണ്, അതേസമയം മീഡിയ എൻകോഡിംഗ് ഫംഗ്ഷൻ അത്ര പ്രധാനമല്ല. വീഡിയോ ഫ്രെയിം റേറ്റ് സെക്കൻഡിൽ 20 മുതൽ 19 ഫ്രെയിമുകൾ വരെ കുറയുന്നത് ആരും ശ്രദ്ധിക്കാത്തതിനാൽ, ഉപയോക്തൃ അനുഭവത്തെ ബാധിക്കാതെ ഇടയ്ക്കിടെ പാക്കറ്റുകൾ ഡ്രോപ്പ് ചെയ്യാൻ ഈ സവിശേഷതയെ അനുവദിക്കും.
ഏറ്റവും സജീവമായ ഉപഭോക്താവിന് അത് ലഭിക്കുന്ന തരത്തിലാണ് ഡിഫോൾട്ട് കാഷെ രൂപകൽപ്പന ചെയ്തിരിക്കുന്നത് ഏറ്റവും വലിയ ഭാഗം. എന്നാൽ ഏറ്റവും സജീവമായ ഉപഭോക്താവ് എല്ലായ്പ്പോഴും ഏറ്റവും പ്രധാനപ്പെട്ട ആപ്ലിക്കേഷനല്ല. വാസ്തവത്തിൽ, വിപരീതമാണ് പലപ്പോഴും ശരി. ഉയർന്ന മുൻഗണനയുള്ള ആപ്ലിക്കേഷനുകൾ ഒപ്റ്റിമൈസ് ചെയ്തു, അവയുടെ ഡാറ്റ വോളിയം സാധ്യമായ ഏറ്റവും ചെറിയ സെറ്റിലേക്ക് ചുരുക്കിയിരിക്കുന്നു. കുറഞ്ഞ മുൻഗണനയുള്ള ആപ്ലിക്കേഷനുകൾക്ക് അത്രയും ഒപ്റ്റിമൈസേഷൻ ശ്രമം ആവശ്യമില്ല, അതിനാൽ അവ കൂടുതൽ മെമ്മറി ഉപയോഗിക്കുന്നു. ഈ ഫംഗ്ഷനുകളിൽ ചിലത് ധാരാളം മെമ്മറി ഉപയോഗിക്കുന്നു. ഉദാഹരണത്തിന്, സ്റ്റാറ്റിസ്റ്റിക്കൽ വിശകലനത്തിനായുള്ള പാക്കറ്റ് വാച്ച് ഫംഗ്ഷന് കുറഞ്ഞ മുൻഗണനയുണ്ട്, പക്ഷേ ധാരാളം മെമ്മറി ഉപയോഗിക്കുകയും കാഷെ തീവ്രവുമാണ്.
ഒരു പ്രത്യേക കേർണലിൽ ഉയർന്ന മുൻഗണനയുള്ള ഒരു ആപ്ലിക്കേഷൻ ഇടുകയാണെങ്കിൽ, ആപ്ലിക്കേഷൻ അവിടെ സുരക്ഷിതമായിരിക്കും, കുറഞ്ഞ മുൻഗണനയുള്ള ആപ്ലിക്കേഷനുകൾ ബാധിക്കപ്പെടില്ലെന്ന് ഡെവലപ്പർമാർ പലപ്പോഴും അനുമാനിക്കുന്നു. നിർഭാഗ്യവശാൽ, അങ്ങനെയല്ല. ഓരോ കോറിനും അതിൻ്റേതായ ലെവൽ 1 കാഷെ (L1, ഏറ്റവും വേഗതയേറിയതും എന്നാൽ ചെറുതുമായ കാഷെ) ഒരു ലെവൽ 2 കാഷെ (L2, അൽപ്പം വലുതും എന്നാൽ വേഗത കുറഞ്ഞതും) ഉണ്ട്. ഡാറ്റയ്ക്കും (L1D) പ്രോഗ്രാം കോഡിനും (L1I, "I" എന്നത് നിർദ്ദേശങ്ങൾക്കായി പ്രത്യേകം L1 കാഷെ ഏരിയകൾ ഉണ്ട്). മൂന്നാം ലെവൽ കാഷെ (ഏറ്റവും മന്ദഗതിയിലുള്ളത്) എല്ലാ പ്രോസസർ കോറുകൾക്കും സാധാരണമാണ്. ബ്രോഡ്വെൽ കുടുംബം ഉൾപ്പെടെയുള്ള Intel® പ്രോസസർ ആർക്കിടെക്ചറുകളിൽ, L3 കാഷെ പൂർണ്ണമായും ഉൾക്കൊള്ളുന്നു, അതായത് L1, L2 കാഷെകളിൽ അടങ്ങിയിരിക്കുന്ന എല്ലാം ഇതിൽ അടങ്ങിയിരിക്കുന്നു. ഇൻക്ലൂസീവ് കാഷെ പ്രവർത്തിക്കുന്ന രീതി കാരണം, മൂന്നാം ലെവൽ കാഷെയിൽ നിന്ന് എന്തെങ്കിലും നീക്കം ചെയ്താൽ, അത് ബന്ധപ്പെട്ട ഒന്നും രണ്ടും ലെവൽ കാഷെകളിൽ നിന്നും നീക്കം ചെയ്യപ്പെടും. ഇതിനർത്ഥം, L3 കാഷെയിൽ ഇടം ആവശ്യമുള്ള ഒരു കുറഞ്ഞ മുൻഗണനയുള്ള ആപ്ലിക്കേഷന്, അത് മറ്റൊരു കാമ്പിൽ പ്രവർത്തിക്കുന്നുണ്ടെങ്കിൽപ്പോലും, ഉയർന്ന മുൻഗണനയുള്ള ആപ്ലിക്കേഷൻ്റെ L1, L2 കാഷെകളിൽ നിന്നുള്ള ഡാറ്റ സ്ഥാനഭ്രഷ്ടനാക്കും.
മുൻകാലങ്ങളിൽ, ഈ പ്രശ്നം പരിഹരിക്കാൻ "വാം-അപ്പ്" എന്ന ഒരു സമീപനം ഉണ്ടായിരുന്നു. L3 കാഷെയിലേക്കുള്ള ആക്സസ് മത്സരിക്കുമ്പോൾ, "വിജയി" എന്നത് മിക്കപ്പോഴും മെമ്മറി ആക്സസ് ചെയ്യുന്ന ആപ്ലിക്കേഷനാണ്. അതിനാൽ, നിഷ്ക്രിയമായിരിക്കുമ്പോൾ പോലും, ഉയർന്ന മുൻഗണനയുള്ള ഫംഗ്ഷൻ കാഷെ നിരന്തരം ആക്സസ് ചെയ്യുക എന്നതാണ് പരിഹാരം. ഇത് വളരെ ഗംഭീരമായ ഒരു പരിഹാരമല്ല, പക്ഷേ ഇത് പലപ്പോഴും സ്വീകാര്യമാണ്, അടുത്തിടെ വരെ ഇതരമാർഗങ്ങളൊന്നും ഉണ്ടായിരുന്നില്ല. എന്നാൽ ഇപ്പോൾ ഒരു ബദലുണ്ട്: Intel® Xeon® E5 v3 പ്രോസസർ കുടുംബം കാഷെ അലോക്കേഷൻ ടെക്നോളജി (CAT) അവതരിപ്പിക്കുന്നു, ഇത് ആപ്ലിക്കേഷനുകളുടെയും സേവനത്തിൻ്റെ ക്ലാസുകളുടെയും അടിസ്ഥാനത്തിൽ കാഷെ അനുവദിക്കാനുള്ള കഴിവ് നൽകുന്നു.
മുൻഗണന വിപരീതത്തിൻ്റെ ആഘാതം
മുൻഗണനാ വിപരീതത്തിൻ്റെ ആഘാതം പ്രകടിപ്പിക്കാൻ, ഞാൻ ഒരു ലളിതമായ മൈക്രോബെഞ്ച് എഴുതി, അത് ഉയർന്ന മുൻഗണനയുള്ള ത്രെഡിൽ ഇടയ്ക്കിടെ ഒരു ലിങ്ക് ചെയ്ത ലിസ്റ്റ് ട്രാവർസൽ പ്രവർത്തിപ്പിക്കുന്നു, അതേസമയം കുറഞ്ഞ മുൻഗണനയുള്ള ത്രെഡ് മെമ്മറി കോപ്പി ഫംഗ്ഷൻ നിരന്തരം പ്രവർത്തിപ്പിക്കുന്നു. ഈ ത്രെഡുകൾ ഒരേ പ്രോസസറിൻ്റെ വ്യത്യസ്ത കോറുകളിലേക്ക് അസൈൻ ചെയ്തിരിക്കുന്നു. ഇത് റിസോഴ്സ് തർക്കത്തിനുള്ള ഏറ്റവും മോശം സാഹചര്യത്തെ അനുകരിക്കുന്നു: പകർപ്പ് പ്രവർത്തനത്തിന് ധാരാളം മെമ്മറി ആവശ്യമാണ്, അതിനാൽ ഇത് ലിസ്റ്റ് ആക്സസ് ചെയ്യുന്ന കൂടുതൽ പ്രധാനപ്പെട്ട ത്രെഡിനെ തടസ്സപ്പെടുത്താൻ സാധ്യതയുണ്ട്.
സിയിലെ കോഡ് ഇതാ.
// സ്യൂഡോ-റാൻഡം പാറ്റേൺ void init_pool (list_item *head, int N, int A, int B) (int C = B; list_item *current = head; എന്നതിന് (int i = 0; i< N - 1; i++) { current->ടിക്ക് = 0; C = (A*C + B) % N; നിലവിലുള്ളത്->അടുത്തത് = (list_item*)&(head[C]); നിലവിലെ = നിലവിലെ->അടുത്തത്; ) // ലിങ്ക് ചെയ്ത ലിസ്റ്റിലെ ആദ്യ N ഘടകങ്ങൾ സ്പർശിക്കുക അസാധുവാണ് warmup_list(list_item* current, int N) ( bool write = (N > POOL_SIZE_L2_LINES) ? true: false; for(int i = 0; i< N - 1; i++) { current = current->അടുത്തത്; എങ്കിൽ (എഴുതുക) നിലവിലുള്ളത്->ടിക്ക്++; ) അസാധുവായ അളവ് (list_item* head, int N) ( ഒപ്പിടാത്ത __നീണ്ട നീളമുള്ള i1, i2, ശരാശരി = 0; (int j = 0; j< 50; j++) { list_item* current = head; #if WARMUP_ON while(in_copy) warmup_list(head, N); #else while(in_copy) spin_sleep(1); #endif i1 = __rdtsc(); for(int i = 0; i < N; i++) { current->ടിക്ക് ++; നിലവിലെ = നിലവിലെ->അടുത്തത്; ) i2 = __rdtsc(); ശരാശരി += (i2-i1)/50; in_copy = true; ) ഫലങ്ങൾ=ശരാശരി/N )
ഇതിൽ മൂന്ന് പ്രവർത്തനങ്ങൾ അടങ്ങിയിരിക്കുന്നു.
- init_pool() ഫംഗ്ഷൻ ഒരു വലിയ അലോക്കേറ്റഡ് ഫ്രീ മെമ്മറി ഏരിയയിൽ ലിങ്ക് ചെയ്ത ലിസ്റ്റ് ആരംഭിക്കുന്നു ലളിതമായ ജനറേറ്റർവ്യാജ സംഖ്യകൾ. ഇത് ലിസ്റ്റ് ഇനങ്ങളെ മെമ്മറിയിൽ പരസ്പരം അടുത്ത് നിൽക്കുന്നത് തടയുന്നു, ഇത് സ്പേഷ്യൽ ലൊക്കലിറ്റി സൃഷ്ടിക്കും, ഇത് ചില ഇനങ്ങൾ സ്വയമേവ മുൻകൈ എടുക്കുന്നതിനാൽ ഞങ്ങളുടെ അളവുകളെ ബാധിക്കും. ഓരോ ലിസ്റ്റ് ഘടകവും കൃത്യമായി ഒരു കാഷെ ലൈൻ ആണ്.
- വാംഅപ്പ്() ഫംഗ്ഷൻ നിർമ്മിച്ച ലിസ്റ്റിൽ തുടർച്ചയായി ആവർത്തിക്കുന്നു. കാഷെയിൽ ഉണ്ടായിരിക്കേണ്ട നിർദ്ദിഷ്ട ഡാറ്റ ആക്സസ് ചെയ്യേണ്ടതുണ്ട്, അതിനാൽ ഈ ഫംഗ്ഷൻ മറ്റ് ത്രെഡുകളെ L3 കാഷെയിൽ നിന്ന് കമ്പോസ് ചെയ്ത ലിസ്റ്റ് ഒഴിവാക്കുന്നതിൽ നിന്ന് തടയുന്നു.
- അളവ്() ഫംഗ്ഷൻ ഒരു ലിസ്റ്റ് എലമെൻ്റിൻ്റെ ട്രാവേസൽ അളക്കുന്നു, തുടർന്ന് ഒന്നുകിൽ 1 മില്ലിസെക്കൻഡ് ഉറങ്ങുന്നു അല്ലെങ്കിൽ ഞങ്ങൾ ഏത് ടെസ്റ്റ് നടത്തുന്നു എന്നതിനെ ആശ്രയിച്ച് വാംഅപ്പ്() ഫംഗ്ഷനെ വിളിക്കുന്നു. അളവ്() ഫംഗ്ഷൻ ഫലങ്ങളെ ശരാശരിയാക്കുന്നു.
5th Gen Intel® Core™ i7 പ്രോസസറിലെ മൈക്രോബെഞ്ച്മാർക്ക് ഫലങ്ങൾ ചുവടെയുള്ള ഗ്രാഫിൽ കാണിച്ചിരിക്കുന്നു, ഇവിടെ X-അക്ഷം എന്നത് ലിങ്ക് ചെയ്ത ലിസ്റ്റിലെ മൊത്തം കാഷെ ലൈനുകളുടെ എണ്ണവും Y-അക്ഷം ഓരോന്നിനും CPU സൈക്കിളുകളുടെ ശരാശരി എണ്ണമാണ്. ലിങ്ക്-ലിസ്റ്റ് ആക്സസ്. ലിങ്ക് ചെയ്ത ലിസ്റ്റിൻ്റെ വലുപ്പം കൂടുന്നതിനനുസരിച്ച്, അത് ആദ്യ ലെവൽ ഡാറ്റാ കാഷെയിൽ നിന്ന് രണ്ടാം ലെവലിലേക്കും പിന്നീട് മൂന്നാം ലെവൽ കാഷിലേക്കും തുടർന്ന് പ്രധാന മെമ്മറിയിലേക്കും നീങ്ങുന്നു.
അടിസ്ഥാന സൂചകം ചുവപ്പ്-തവിട്ട് വരയാണ്, ഇത് മെമ്മറിയിൽ കോപ്പി ത്രെഡ് ഇല്ലാത്ത ഒരു പ്രോഗ്രാമുമായി യോജിക്കുന്നു, അതായത്, തർക്കമില്ലാതെ. മുൻഗണനാ വിപരീതത്തിൻ്റെ അനന്തരഫലങ്ങൾ നീല വര കാണിക്കുന്നു: മെമ്മറി കോപ്പി ഫംഗ്ഷൻ കാരണം, ലിസ്റ്റ് ആക്സസ് ചെയ്യുന്നതിന് വളരെയധികം സമയമെടുക്കുന്നു. ഹൈ-സ്പീഡ് L1 അല്ലെങ്കിൽ L2 കാഷെയിൽ ലിസ്റ്റ് യോജിച്ചാൽ ആഘാതം വളരെ വലുതാണ്. ലിസ്റ്റ് വളരെ വലുതാണെങ്കിൽ, അത് മൂന്നാം ലെവൽ കാഷെയിൽ ചേരുന്നില്ലെങ്കിൽ, ആഘാതം നിസ്സാരമാണ്.
മെമ്മറി കോപ്പി ഫംഗ്ഷൻ പ്രവർത്തിക്കുമ്പോൾ ഗ്രീൻ ലൈൻ വാം-അപ്പ് പ്രഭാവം കാണിക്കുന്നു: ആക്സസ് സമയം കുത്തനെ കുറയുകയും അടിസ്ഥാന മൂല്യത്തെ സമീപിക്കുകയും ചെയ്യുന്നു.
ഞങ്ങൾ CAT പ്രവർത്തനക്ഷമമാക്കുകയും ഓരോ കോറിനും പ്രത്യേക ഉപയോഗത്തിനായി L3 കാഷെയുടെ ഭാഗങ്ങൾ അനുവദിക്കുകയും ചെയ്താൽ, ഫലങ്ങൾ അടിസ്ഥാനരേഖയ്ക്ക് വളരെ അടുത്തായിരിക്കും (ഡയഗ്രാമിൽ കാണിക്കാൻ വളരെ അടുത്ത്), അതാണ് ഞങ്ങളുടെ ലക്ഷ്യം.
ഉൾപ്പെടുത്തൽCAT
ഒന്നാമതായി, പ്ലാറ്റ്ഫോം CAT-നെ പിന്തുണയ്ക്കുന്നുവെന്ന് ഉറപ്പാക്കുക. CAT ലഭ്യത സൂചിപ്പിക്കുന്നതിന് വിലാസം ലീഫ് 7, സബ്ലീഫ് 0 എന്നിവ പരിശോധിച്ചുകൊണ്ട് നിങ്ങൾക്ക് CPUID നിർദ്ദേശം ഉപയോഗിക്കാം.
CAT സാങ്കേതികവിദ്യ പ്രവർത്തനക്ഷമമാക്കുകയും പിന്തുണയ്ക്കുകയും ചെയ്താൽ, അനുവദിക്കുന്നതിന് പ്രോഗ്രാം ചെയ്യാവുന്ന MSR രജിസ്റ്ററുകൾ ഉണ്ട് വിവിധ ഭാഗങ്ങൾവ്യത്യസ്ത കോറുകൾക്കായുള്ള മൂന്നാം ലെവൽ കാഷെ.
ഓരോ പ്രോസസർ സോക്കറ്റിനും MSR രജിസ്റ്ററുകൾ IA32_L3_MASKn ഉണ്ട് (ഉദാഹരണത്തിന്, 0xc90, 0xc91, 0xc92, 0xc93). ഓരോ ക്ലാസ് സേവനത്തിനും (COS) എത്ര L3 കാഷെ അനുവദിക്കണമെന്ന് സൂചിപ്പിക്കുന്ന ഒരു ബിറ്റ് മാസ്ക് ഈ രജിസ്റ്ററുകൾ സംഭരിക്കുന്നു. 0xc90 COS0, COS1-ന് 0xc91 മുതലായവയ്ക്കുള്ള കാഷെ അലോക്കേഷൻ സംഭരിക്കുന്നു.
ഉദാഹരണത്തിന്, ഈ ഡയഗ്രം, കാഷെ എങ്ങനെ വിഭജിക്കാമെന്ന് കാണിക്കാൻ വിവിധ തരം സേവനങ്ങൾക്കായി സാധ്യമായ ചില ബിറ്റ് മാസ്കുകൾ കാണിക്കുന്നു: COS0-ന് പകുതിയും, COS1-ന് നാലിലൊന്നും, COS2, COS3 എന്നിവയ്ക്കും എട്ടാമത്തേത് ലഭിക്കും. ഉദാഹരണത്തിന്, 0xc90-ൽ 11110000, 0xc93-ൽ 00000001 എന്നിവ അടങ്ങിയിരിക്കും.
ഡയറക്ട് ഡാറ്റ ഇൻപുട്ട്/ഔട്ട്പുട്ട് (ഡിഡിഐഒ) അൽഗോരിതത്തിന് അതിൻ്റേതായ മറഞ്ഞിരിക്കുന്ന ബിറ്റ് മാസ്ക് ഉണ്ട്, അത് നെറ്റ്വർക്ക് അഡാപ്റ്ററുകൾ പോലുള്ള ഉയർന്ന വേഗതയുള്ള പിസിഐഇ ഉപകരണങ്ങളിൽ നിന്നുള്ള ഡാറ്റ ഫ്ലോ L3 കാഷെയുടെ പ്രത്യേക മേഖലകളിലേക്ക് മാറ്റാൻ അനുവദിക്കുന്നു. നിർവചിച്ചിരിക്കുന്ന സേവന ക്ലാസുകളുമായി വൈരുദ്ധ്യമുണ്ടാകാനുള്ള സാധ്യതയുണ്ട്, അതിനാൽ ഉയർന്ന ത്രൂപുട്ട് NFV ആപ്ലിക്കേഷനുകൾ സൃഷ്ടിക്കുമ്പോൾ ഇത് കണക്കിലെടുക്കണം. പൊരുത്തക്കേടുകൾ പരിശോധിക്കുന്നതിന്, കാഷെ മിസ്സുകൾ കണ്ടെത്തുന്നതിന് ഉപയോഗിക്കുക. ചില BIOS-ന് DDIO മാസ്ക് കാണാനും മാറ്റാനും നിങ്ങളെ അനുവദിക്കുന്ന ഒരു ക്രമീകരണം ഉണ്ട്.
ഓരോ കോറിനും ഒരു MSR രജിസ്റ്റർ IA32_PQR_ASSOC (0xc8f) ഉണ്ട്, ആ കോറിന് ഏത് തരം സേവനമാണ് ബാധകമെന്ന് സൂചിപ്പിക്കുന്നത്. സേവനത്തിൻ്റെ ഡിഫോൾട്ട് ക്ലാസ് 0 ആണ്, അതായത് MSR 0xc90-ലെ ബിറ്റ്മാസ്ക് ഉപയോഗിക്കുന്നു. (ഡിഫോൾട്ടായി, പരമാവധി കാഷെ ലഭ്യത ഉറപ്പാക്കാൻ ബിറ്റ്മാസ്ക് 0xc90 1 ആയി സജ്ജീകരിച്ചിരിക്കുന്നു.)
ഏറ്റവും ലളിതമായ മോഡൽ NFV-യിൽ CAT ഉപയോഗിക്കുന്നത്, ഒറ്റപ്പെട്ട ബിറ്റ് മാസ്ക്കുകൾ ഉപയോഗിച്ച് വ്യത്യസ്ത കോറുകളിലേക്ക് L3 കാഷെ ചങ്കുകൾ അനുവദിക്കുകയും തുടർന്ന് കോറുകളിലേക്ക് ത്രെഡുകളോ വെർച്വൽ മെഷീനുകളോ നൽകുകയും ചെയ്യുന്നു. എക്സിക്യൂട്ട് ചെയ്യുന്നതിന് VM-കൾക്ക് കോറുകൾ പങ്കിടണമെങ്കിൽ, OS ഷെഡ്യൂളറിൽ ഒരു നിസ്സാരമായ പരിഹാരം ഉണ്ടാക്കാനും VM-കൾ പ്രവർത്തിക്കുന്ന ത്രെഡുകളിലേക്ക് ഒരു കാഷെ മാസ്ക് ചേർക്കാനും എല്ലാ ഷെഡ്യൂളിംഗ് ഇവൻ്റുകളിലും ചലനാത്മകമായി അത് പ്രവർത്തനക്ഷമമാക്കാനും കഴിയും.
കാഷെയിൽ ഡാറ്റ ലോക്ക് ചെയ്യാൻ CAT ഉപയോഗിക്കുന്നതിന് മറ്റൊരു അസാധാരണ മാർഗമുണ്ട്. ആദ്യം, ഒരു സജീവ കാഷെ മാസ്ക് സൃഷ്ടിക്കുകയും അത് എൽ3 കാഷെയിലേക്ക് ലോഡുചെയ്യുന്നതിന് മെമ്മറിയിലെ ഡാറ്റ ആക്സസ് ചെയ്യുകയും ചെയ്യുക. ഭാവിയിൽ ഉപയോഗിക്കുന്ന ഏത് CAT ബിറ്റ്മാസ്കിലും L3 കാഷെയുടെ ഈ ഭാഗത്തെ പ്രതിനിധീകരിക്കുന്ന ബിറ്റുകൾ പ്രവർത്തനരഹിതമാക്കുക. മൂന്നാം ലെവൽ കാഷെയിൽ ഡാറ്റ ലോക്ക് ചെയ്യപ്പെടും, കാരണം അത് അവിടെ നിന്ന് പുറത്താക്കുന്നത് ഇപ്പോൾ അസാധ്യമാണ് (DDIO കൂടാതെ). ഒരു NFV ആപ്ലിക്കേഷനിൽ, സ്ഥിരമായ ആക്സസ് ഉറപ്പാക്കുന്നതിന്, റൂട്ടിംഗിനും പാക്കറ്റ് പാഴ്സിംഗിനുമുള്ള ഇടത്തരം വലിപ്പത്തിലുള്ള ലുക്ക്അപ്പ് ടേബിളുകൾ L3 കാഷെയിൽ ലോക്ക് ചെയ്യാൻ ഈ സംവിധാനം അനുവദിക്കുന്നു.
വെക്റ്റർ പ്രോസസ്സിംഗിനായി Intel AVX2 ഉപയോഗിക്കുന്നു
SIMD (ഒരു നിർദ്ദേശം, നിരവധി ഡാറ്റ) നിർദ്ദേശങ്ങൾ ഒരേ സമയം വ്യത്യസ്ത ഡാറ്റകളിൽ ഒരേ പ്രവർത്തനം നടത്താൻ നിങ്ങളെ അനുവദിക്കുന്നു. ഫ്ലോട്ടിംഗ് പോയിൻ്റ് കണക്കുകൂട്ടലുകൾ വേഗത്തിലാക്കാൻ ഈ നിർദ്ദേശങ്ങൾ പലപ്പോഴും ഉപയോഗിക്കാറുണ്ട്, എന്നാൽ നിർദ്ദേശങ്ങളുടെ പൂർണ്ണസംഖ്യ, ബൂളിയൻ, ഡാറ്റ പതിപ്പുകളും ലഭ്യമാണ്.
നിങ്ങൾ ഉപയോഗിക്കുന്ന പ്രോസസ്സറിനെ ആശ്രയിച്ച്, നിങ്ങൾക്ക് SIMD നിർദ്ദേശങ്ങളുടെ വ്യത്യസ്ത കുടുംബങ്ങൾ ലഭ്യമാകും. കമാൻഡുകൾ പ്രോസസ്സ് ചെയ്യുന്ന വെക്റ്ററിൻ്റെ വലുപ്പവും വ്യത്യസ്തമായിരിക്കും:
- SSE 128-ബിറ്റ് വെക്റ്ററുകൾ പിന്തുണയ്ക്കുന്നു.
- Intel AVX2 256-ബിറ്റ് വെക്ടറുകൾക്കുള്ള പൂർണ്ണസംഖ്യ നിർദ്ദേശങ്ങളെ പിന്തുണയ്ക്കുകയും പ്രവർത്തനങ്ങൾ ശേഖരിക്കുന്നതിനുള്ള നിർദ്ദേശങ്ങൾ നടപ്പിലാക്കുകയും ചെയ്യുന്നു.
- ഭാവിയിൽ AVX3 വിപുലീകരണങ്ങളിൽ ഇൻ്റൽ ആർക്കിടെക്ചറുകൾ® 512-ബിറ്റ് വെക്റ്ററുകൾ പിന്തുണയ്ക്കും.
രണ്ട് 64-ബിറ്റ് വേരിയബിളുകൾക്കും നാല് 32-ബിറ്റ് വേരിയബിളുകൾക്കും അല്ലെങ്കിൽ എട്ട് 16-ബിറ്റ് വേരിയബിളുകൾക്കും (ഉപയോഗിക്കുന്ന SIMD നിർദ്ദേശങ്ങൾ അനുസരിച്ച്) ഒരു 128-ബിറ്റ് വെക്റ്റർ ഉപയോഗിക്കാം. വലിയ വെക്ടറുകൾ കൂടുതൽ ഡാറ്റ ഘടകങ്ങളെ ഉൾക്കൊള്ളും. NFV ആപ്ലിക്കേഷനുകളുടെ ഉയർന്ന ത്രൂപുട്ട് ആവശ്യകതകൾ കണക്കിലെടുത്ത്, നിങ്ങൾ എല്ലായ്പ്പോഴും ഏറ്റവും ശക്തമായ SIMD നിർദ്ദേശങ്ങൾ (അനുബന്ധ ഹാർഡ്വെയർ) ഉപയോഗിക്കണം, നിലവിൽ Intel AVX2.
ചിത്രത്തിൽ കാണിച്ചിരിക്കുന്നതുപോലെ, മൂല്യങ്ങളുടെ വെക്റ്ററിൽ ഒരേ പ്രവർത്തനം നടത്താൻ SIMD നിർദ്ദേശങ്ങൾ മിക്കപ്പോഴും ഉപയോഗിക്കുന്നു. ഇവിടെ X1opY1 മുതൽ X4opY4 വരെയുള്ള ക്രിയേഷൻ ഓപ്പറേഷൻ ഒരൊറ്റ നിർദ്ദേശമാണ്, ഒരേസമയം X1 മുതൽ X4 വരെയുള്ള ഡാറ്റാ ഇനങ്ങളും Y1 മുതൽ Y4 വരെ പ്രോസസ്സ് ചെയ്യുന്നു. ഈ ഉദാഹരണത്തിൽ, നാല് ഓപ്പറേഷനുകൾ ഒരേസമയം പ്രോസസ്സ് ചെയ്യുന്നതിനാൽ സ്പീഡ് സാധാരണ (സ്കെലാർ) എക്സിക്യൂഷനേക്കാൾ നാലിരട്ടി വേഗത്തിലായിരിക്കും. SIMD വെക്റ്റർ വലുതായിരിക്കുന്നതിനാൽ വേഗതയും വലുതായിരിക്കും. NFV ആപ്ലിക്കേഷനുകൾ പലപ്പോഴും ഒരേ രീതിയിൽ ഒന്നിലധികം പാക്കറ്റ് സ്ട്രീമുകൾ പ്രോസസ്സ് ചെയ്യുന്നു, അതിനാൽ SIMD നിർദ്ദേശങ്ങൾ പ്രകടനം ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിനുള്ള ഒരു സ്വാഭാവിക മാർഗം നൽകുന്നു.
ലളിതമായ ലൂപ്പുകൾക്കായി, നൽകിയിരിക്കുന്ന സിപിയുവിന് (നിങ്ങൾ ശരിയായ കമ്പൈലർ ഫ്ലാഗുകൾ ഉപയോഗിക്കുകയാണെങ്കിൽ) ലഭ്യമായ ഏറ്റവും പുതിയ SIMD നിർദ്ദേശങ്ങൾ ഉപയോഗിച്ച് കംപൈലർ പലപ്പോഴും സ്വയമേവ പ്രവർത്തനങ്ങളെ വെക്ടറൈസ് ചെയ്യും. റൺടൈമിൽ ഹാർഡ്വെയർ പിന്തുണയ്ക്കുന്ന ഏറ്റവും ആധുനിക ഇൻസ്ട്രക്ഷൻ സെറ്റ് ഉപയോഗിക്കുന്നതിന് നിങ്ങളുടെ കോഡ് ഒപ്റ്റിമൈസ് ചെയ്യാം അല്ലെങ്കിൽ ഒരു നിർദ്ദിഷ്ട ടാർഗെറ്റ് ആർക്കിടെക്ചറിനായി നിങ്ങൾക്ക് കോഡ് കംപൈൽ ചെയ്യാം.
SIMD പ്രവർത്തനങ്ങൾ മെമ്മറി ലോഡുകളെ പിന്തുണയ്ക്കുന്നു, മെമ്മറിയിൽ നിന്ന് ഒരു രജിസ്റ്ററിലേക്ക് 32 ബൈറ്റുകൾ (256 ബിറ്റുകൾ) പകർത്തുന്നു. മെമ്മറിക്കും രജിസ്റ്ററുകൾക്കുമിടയിൽ ഡാറ്റ കൈമാറ്റം ചെയ്യാനും കാഷെ ഒഴിവാക്കാനും മെമ്മറിയിലെ വിവിധ സ്ഥലങ്ങളിൽ നിന്ന് ഡാറ്റ ശേഖരിക്കാനും ഇത് അനുവദിക്കുന്നു. നിങ്ങൾക്ക് വെക്റ്ററുകൾ ഉപയോഗിച്ച് വിവിധ പ്രവർത്തനങ്ങൾ നടത്താനും (ഒരു രജിസ്റ്ററിൽ ഡാറ്റ മാറ്റാനും) വെക്റ്ററുകൾ സംഭരിക്കാനും (ഒരു രജിസ്റ്ററിൽ നിന്ന് മെമ്മറിയിലേക്ക് 32 ബൈറ്റുകൾ വരെ എഴുതാം).
REP MOV നിർദ്ദേശങ്ങൾ വളരെ മന്ദഗതിയിലായതിനാൽ തുടക്കം മുതൽ SIMD നിർദ്ദേശങ്ങൾ ഉപയോഗിച്ച് നടപ്പിലാക്കിയ അടിസ്ഥാന ദിനചര്യകളുടെ അറിയപ്പെടുന്ന ഉദാഹരണങ്ങളാണ് Memcpy, memmov എന്നിവ. memcpy കോഡ് പതിവായി അപ്ഡേറ്റ് ചെയ്തു സിസ്റ്റം ലൈബ്രറികൾഏറ്റവും പുതിയ SIMD നിർദ്ദേശങ്ങൾ ഉപയോഗിക്കുന്നതിന്. ഏറ്റവും പുതിയ പതിപ്പുകളിൽ ഏതൊക്കെ ഉപയോഗത്തിന് ലഭ്യമാണ് എന്നതിനെക്കുറിച്ചുള്ള വിവരങ്ങൾ ലഭിക്കാൻ CPUID മാനേജർ പട്ടിക ഉപയോഗിച്ചു. അതേ സമയം, ലൈബ്രറികളിൽ പുതിയ തലമുറയിലെ SIMD നിർദ്ദേശങ്ങൾ നടപ്പിലാക്കുന്നത് സാധാരണയായി വൈകും.
ഉദാഹരണത്തിന്, അടുത്ത നടപടിക്രമംലളിതമായ ഒരു ലൂപ്പ് ഉപയോഗിക്കുന്ന memcpy, ബിൽറ്റ്-ഇൻ ഫംഗ്ഷനുകളെ അടിസ്ഥാനമാക്കിയുള്ളതാണ് (ലൈബ്രറി കോഡിന് പകരം), അതിനാൽ കമ്പൈലറിന് SIMD നിർദ്ദേശങ്ങളുടെ ഏറ്റവും പുതിയ പതിപ്പിനായി ഇത് ഒപ്റ്റിമൈസ് ചെയ്യാൻ കഴിയും.
Mm256_store_si256((__m256i*) (dest++), (__m256i*) (src++))
ഇത് ഇനിപ്പറയുന്ന അസംബ്ലി കോഡിലേക്ക് കംപൈൽ ചെയ്യുന്നു കൂടാതെ സമീപകാല ലൈബ്രറികളുടെ ഇരട്ടി പ്രകടനവുമുണ്ട്.
C5 fd 6f 04 04 vmovdqa (%rsp,%rax,1),%ymm0 c5 fd 7f 84 04 00 00 vmovdqa%ymm0.0x10000(%rsp,%rax,1)
ലഭ്യമായ ഏറ്റവും പുതിയ SIMD നിർദ്ദേശങ്ങൾ ഉപയോഗിച്ച് ഒരു ഇൻലൈൻ ഫംഗ്ഷനിൽ നിന്നുള്ള അസംബ്ലി കോഡ് 32 ബൈറ്റുകൾ (256 ബിറ്റുകൾ) പകർത്തും, അതേസമയം SSE ഉപയോഗിക്കുന്ന ലൈബ്രറി കോഡ് 16 ബൈറ്റുകൾ (128 ബിറ്റുകൾ) മാത്രമേ പകർത്തൂ.
NFV ആപ്ലിക്കേഷനുകൾ പലപ്പോഴും തുടർച്ചയായി ഇല്ലാത്ത വ്യത്യസ്ത മെമ്മറി ലൊക്കേഷനുകളിൽ ഒന്നിലധികം ലൊക്കേഷനുകളിൽ നിന്ന് ഡാറ്റ ലോഡ് ചെയ്തുകൊണ്ട് ഒരു ശേഖരണ പ്രവർത്തനം നടത്തേണ്ടതുണ്ട്. ഉദാഹരണത്തിന്, ഒരു നെറ്റ്വർക്ക് അഡാപ്റ്ററിന് DDIO ഉപയോഗിച്ച് ഇൻകമിംഗ് പാക്കറ്റുകൾ കാഷെ ചെയ്യാൻ കഴിയും. ഒരു NFV ആപ്ലിക്കേഷൻ്റെ ഭാഗത്തേക്ക് മാത്രമേ ആക്സസ്സ് ആവശ്യമുള്ളൂ നെറ്റ്വർക്ക് തലക്കെട്ട്ലക്ഷ്യസ്ഥാന ഐപി വിലാസത്തിനൊപ്പം. ശേഖരിക്കുന്ന പ്രവർത്തനത്തിലൂടെ, ഒരേ സമയം 8 പാക്കറ്റുകളുടെ ഡാറ്റ ശേഖരിക്കാൻ അപ്ലിക്കേഷന് കഴിയും.
ശേഖരണ പ്രവർത്തനത്തിനായി ഇൻലൈൻ ഫംഗ്ഷനുകളോ അസംബ്ലി കോഡോ ഉപയോഗിക്കേണ്ടതില്ല, കാരണം മെമ്മറിയിലെ കപട-റാൻഡം ലൊക്കേഷനുകളിൽ നിന്നുള്ള ഒരു ടെസ്റ്റ് സംമ്മിംഗ് നമ്പറുകളെ അടിസ്ഥാനമാക്കി, ചുവടെ കാണിച്ചിരിക്കുന്ന പ്രോഗ്രാമിന് കോഡ് വെക്ടറൈസ് ചെയ്യാൻ കംപൈലറിന് കഴിയും.
Int a; int b; (i = 0; i< 1024; i++) a[i] = i; for (i = 0; i < 64; i++) b[i] = (i*1051) % 1024; for (i = 0; i < 64; i++) sum += a]; // This line is vectorized using gather.
അവസാന വരി ഇനിപ്പറയുന്ന അസംബ്ലി കോഡിലേക്ക് സമാഹരിച്ചിരിക്കുന്നു.
C5 fe 6f 40 80 vmovdqu -0x80(%rax),%ymm0 c5 ed fe f3 vpaddd %ymm3,%ymm2,%ymm6 c5 e5 ef db vpxor %ymm3,%ymm3,%ymm3 c5 d5% 76 qd ymm5,%ymm5 c4 e2 55 90 3c a0 vpgatherdd %ymm5,(%rax,%ymm4,4),%ymm7
ഒരൊറ്റ ശേഖരണ പ്രവർത്തനം ഡൗൺലോഡുകളുടെ ഒരു ശ്രേണിയേക്കാൾ വളരെ വേഗതയുള്ളതാണ്, എന്നാൽ ഡാറ്റ ഇതിനകം കാഷെയിലാണെങ്കിൽ മാത്രമേ ഇത് അർത്ഥമാക്കൂ. അല്ലെങ്കിൽ, നൂറുകണക്കിന് അല്ലെങ്കിൽ ആയിരക്കണക്കിന് സിപിയു സൈക്കിളുകൾ ആവശ്യമായ മെമ്മറിയിൽ നിന്ന് ഡാറ്റ എടുക്കേണ്ടിവരും. ഡാറ്റ കാഷെയിലാണെങ്കിൽ, 10x സ്പീഡ് അപ്പ് സാധ്യമാണ്
(അതായത് 1000%). ഡാറ്റ കാഷെയിൽ ഇല്ലെങ്കിൽ, വേഗത 5% മാത്രമാണ്.
ഇതുപോലുള്ള സാങ്കേതിക വിദ്യകൾ ഉപയോഗിക്കുമ്പോൾ, തടസ്സങ്ങൾ തിരിച്ചറിയുന്നതിനും ആപ്ലിക്കേഷൻ ഡാറ്റ പകർത്തുന്നതിനോ ശേഖരിക്കുന്നതിനോ കൂടുതൽ സമയം ചെലവഴിക്കുന്നുണ്ടോ എന്ന് മനസിലാക്കാൻ ആപ്ലിക്കേഷൻ വിശകലനം ചെയ്യേണ്ടത് പ്രധാനമാണ്. നിങ്ങൾക്ക് ഉപയോഗിക്കാം.
Intel AVX2-ലും മറ്റ് SIMD പ്രവർത്തനങ്ങളിലും NFV-യ്ക്കുള്ള മറ്റൊരു ഉപയോഗപ്രദമായ സവിശേഷത ബിറ്റ്വൈസ് ആണ് ലോജിക്കൽ പ്രവർത്തനങ്ങൾ. നിലവാരമില്ലാത്ത എൻക്രിപ്ഷൻ കോഡ് വേഗത്തിലാക്കാൻ അവ ഉപയോഗിക്കുന്നു, കൂടാതെ ബിറ്റ് ചെക്കിംഗ് ASN.1 ഡവലപ്പർമാർക്ക് സൗകര്യപ്രദമാണ് കൂടാതെ ടെലികമ്മ്യൂണിക്കേഷനിലെ ഡാറ്റയ്ക്കായി ഇത് പലപ്പോഴും ഉപയോഗിക്കുന്നു. MPSSEF പോലുള്ള നൂതന അൽഗോരിതങ്ങൾ ഉപയോഗിച്ച് വേഗതയേറിയ സ്ട്രിംഗ് താരതമ്യത്തിനായി Intel AVX2 ഉപയോഗിക്കാം.
Intel AVX2 വിപുലീകരണങ്ങൾ നന്നായി പ്രവർത്തിക്കുന്നു വെർച്വൽ മെഷീനുകൾ. പ്രകടനം സമാനമാണ് കൂടാതെ തെറ്റായ വിർച്ച്വൽ മെഷീൻ എക്സിറ്റുകളൊന്നുമില്ല.
ഉയർന്ന സ്കേലബിളിറ്റിക്കായി Intel TSX ഉപയോഗിക്കുന്നു
പ്രശ്നങ്ങളിലൊന്ന് സമാന്തര പ്രോഗ്രാമുകൾഒന്നിലധികം ത്രെഡുകൾ ഒരേ ഡാറ്റ ഇനം ഉപയോഗിക്കാൻ ശ്രമിക്കുമ്പോൾ ഒരു ത്രെഡെങ്കിലും ഡാറ്റ മാറ്റാൻ ശ്രമിക്കുമ്പോൾ സംഭവിക്കാവുന്ന ഡാറ്റ കൂട്ടിയിടികൾ ഒഴിവാക്കുക എന്നതാണ്. പ്രവചനാതീതമായ ആവൃത്തി ഫലങ്ങൾ ഒഴിവാക്കാൻ, ലോക്കിംഗ് ഉപയോഗിക്കുന്നു: ഒരു ഡാറ്റാ ഇനം ഉപയോഗിക്കുന്ന ആദ്യ ത്രെഡ് അതിൻ്റെ ജോലി പൂർത്തിയാകുന്നതുവരെ മറ്റ് ത്രെഡുകളിൽ നിന്ന് അതിനെ തടയുന്നു. എന്നാൽ പതിവായി മത്സരിക്കുന്ന ലോക്കുകൾ ഉണ്ടെങ്കിലോ ലോക്കുകൾ യഥാർത്ഥത്തിൽ ആവശ്യമുള്ളതിനേക്കാൾ വലിയ മെമ്മറി ഏരിയയെ നിയന്ത്രിക്കുന്നെങ്കിലോ ഈ സമീപനം ഫലപ്രദമാകണമെന്നില്ല.
ഇൻ്റൽ ട്രാൻസാക്ഷണൽ സിൻക്രൊണൈസേഷൻ എക്സ്റ്റൻഷനുകൾ (ടിഎസ്എക്സ്) ഹാർഡ്വെയർ മെമ്മറിയിലെ ഇടപാടുകളിലെ ലോക്കുകൾ മറികടക്കാൻ പ്രോസസർ നിർദ്ദേശങ്ങൾ നൽകുന്നു. ഇത് ഉയർന്ന സ്കേലബിളിറ്റി കൈവരിക്കാൻ സഹായിക്കുന്നു. മെമ്മറി ലൊക്കേഷനുകൾ പരിരക്ഷിക്കുന്നതിന് Intel TSX ഉപയോഗിക്കുന്ന ഒരു വിഭാഗത്തിലേക്ക് ഒരു പ്രോഗ്രാം പ്രവേശിക്കുമ്പോൾ, എല്ലാ മെമ്മറി ആക്സസ് ശ്രമങ്ങളും റെക്കോർഡ് ചെയ്യപ്പെടും, കൂടാതെ സംരക്ഷിത സെഷൻ്റെ അവസാനം അവ യാന്ത്രികമായി പ്രതിജ്ഞാബദ്ധമാവുകയോ അല്ലെങ്കിൽ യാന്ത്രികമായി പിൻവലിക്കുകയോ ചെയ്യും എന്നതാണ് ഇത് പ്രവർത്തിക്കുന്ന രീതി. മറ്റൊരു ത്രെഡിൽ നിന്ന് എക്സിക്യൂട്ട് ചെയ്യുമ്പോൾ, ഒരു റേസ് അവസ്ഥയ്ക്ക് കാരണമായേക്കാവുന്ന ഒരു മെമ്മറി ആക്സസ് വൈരുദ്ധ്യമുണ്ടെങ്കിൽ (ഉദാഹരണത്തിന്, മറ്റൊരു ഇടപാട് ഡാറ്റ വായിക്കുന്ന സ്ഥലത്തേക്ക് എഴുതുന്നത്) ഒരു റോൾബാക്ക് നടത്തുന്നു. Intel TSX നടപ്പിലാക്കുന്നതിന് മെമ്മറി ആക്സസ് റെക്കോർഡ് വളരെ വലുതായാൽ, ഒരു I/O നിർദ്ദേശമോ സിസ്റ്റം കോളോ ഉണ്ടെങ്കിലോ അല്ലെങ്കിൽ ഒഴിവാക്കലുകൾ തള്ളപ്പെടുകയോ അല്ലെങ്കിൽ വെർച്വൽ മെഷീനുകൾ ഷട്ട് ഡൗൺ ചെയ്യുകയോ ചെയ്താൽ ഒരു റോൾബാക്ക് സംഭവിക്കാം. I/O കോളുകൾ ബാഹ്യ ഇടപെടൽ കാരണം ഊഹക്കച്ചവടത്തിൽ എക്സിക്യൂട്ട് ചെയ്യാൻ കഴിയാതെ വരുമ്പോൾ പിൻവലിക്കപ്പെടും. സിസ്റ്റം കോൾ- വളയങ്ങളും മെമ്മറി ഡിസ്ക്രിപ്റ്ററുകളും മാറ്റുന്ന വളരെ സങ്കീർണ്ണമായ പ്രവർത്തനം, അത് തിരികെ കൊണ്ടുവരുന്നത് വളരെ ബുദ്ധിമുട്ടാണ്.
Intel TSX-നുള്ള ഒരു സാധാരണ ഉപയോഗ കേസ് ഒരു ഹാഷ് ടേബിളിലെ ആക്സസ് കൺട്രോളാണ്. സാധാരണഗതിയിൽ, കാഷെ ടേബിളിലേക്കുള്ള ആക്സസ് ഉറപ്പുനൽകാൻ ഒരു കാഷെ ടേബിൾ ലോക്ക് ഉപയോഗിക്കുന്നു, എന്നാൽ ഇത് ആക്സസിനായി മത്സരിക്കുന്ന ത്രെഡുകളുടെ ലേറ്റൻസി വർദ്ധിപ്പിക്കുന്നു. ലോക്കിംഗ് പലപ്പോഴും വളരെ പരുക്കനാണ്: മുഴുവൻ ടേബിളും ലോക്ക് ചെയ്തിരിക്കുന്നു, എന്നിരുന്നാലും ത്രെഡുകൾ ഒരേ ഘടകങ്ങൾ ആക്സസ് ചെയ്യാൻ ശ്രമിക്കുന്നത് വളരെ അപൂർവമാണ്. കോറുകളുടെ എണ്ണം (ത്രെഡുകളും) വർദ്ധിക്കുന്നതിനനുസരിച്ച്, നാടൻ ലോക്കിംഗ് സ്കേലബിളിറ്റിയെ തടസ്സപ്പെടുത്തുന്നു.
ചുവടെയുള്ള ഡയഗ്രാമിൽ കാണിച്ചിരിക്കുന്നതുപോലെ, ത്രെഡുകൾ വ്യത്യസ്ത ഘടകങ്ങൾ ഉപയോഗിക്കുന്നുണ്ടെങ്കിലും, ഒരു ത്രെഡ് മറ്റൊരു ത്രെഡ് ഹാഷ് ടേബിൾ റിലീസ് ചെയ്യുന്നതിനായി കാത്തിരിക്കുന്നതിന് കാരണമാകും. ഇൻ്റൽ ടിഎസ്എക്സിൻ്റെ ഉപയോഗം രണ്ട് ത്രെഡുകളും പ്രവർത്തിക്കാൻ അനുവദിക്കുന്നു, ഇടപാടിൻ്റെ അവസാനം വിജയകരമായി എത്തിയതിന് ശേഷം അവയുടെ ഫലങ്ങൾ രേഖപ്പെടുത്തുന്നു. ഹാർഡ്വെയർ ഈച്ചയിലെ വൈരുദ്ധ്യങ്ങൾ കണ്ടെത്തുകയും കുറ്റകരമായ ഇടപാടുകൾ നിർത്തലാക്കുകയും ചെയ്യുന്നു. ഇൻ്റൽ ടിഎസ്എക്സ് ഉപയോഗിക്കുമ്പോൾ, ത്രെഡ് 2 കാത്തിരിക്കേണ്ടതില്ല, രണ്ട് ത്രെഡുകളും വളരെ നേരത്തെ തന്നെ എക്സിക്യൂട്ട് ചെയ്യുന്നു. ഹാഷ് ടേബിളുകളിലെ ലോക്കിംഗ് ഫൈൻ-ട്യൂൺ ചെയ്ത ലോക്കിംഗിലേക്ക് പരിവർത്തനം ചെയ്യപ്പെടുന്നു, ഇത് മെച്ചപ്പെട്ട പ്രകടനത്തിന് കാരണമാകുന്നു. ഒരൊറ്റ കാഷെ ലൈനിൻ്റെ (64 ബൈറ്റുകൾ) തലത്തിലുള്ള തർക്ക ട്രാക്കിംഗ് കൃത്യതയെ ഇൻ്റൽ ടിഎസ്എക്സ് പിന്തുണയ്ക്കുന്നു.
ഇടപാടുകൾ നടത്തുന്നതിന് കോഡിൻ്റെ വിഭാഗങ്ങൾ വ്യക്തമാക്കുന്നതിന് Intel TSX രണ്ട് പ്രോഗ്രാമിംഗ് ഇൻ്റർഫേസുകൾ ഉപയോഗിക്കുന്നു.
- ഹാർഡ്വെയർ ലോക്ക് ബൈപാസ് (HLE) ബാക്ക്വേർഡ് കോംപാറ്റിബിൾ ആണ്, ലോക്ക് ലൈബ്രറിയിൽ വലിയ മാറ്റങ്ങൾ വരുത്താതെ സ്കേലബിളിറ്റി മെച്ചപ്പെടുത്താൻ ഇത് എളുപ്പത്തിൽ ഉപയോഗിക്കാം. തടഞ്ഞ നിർദ്ദേശങ്ങൾക്കായി HLE-ൽ ഇപ്പോൾ പ്രിഫിക്സുകൾ ഉണ്ട്. എച്ച്എൽഇ നിർദ്ദേശ പ്രിഫിക്സ് ഹാർഡ്വെയറിനെ അത് ഏറ്റെടുക്കാതെ തന്നെ ലോക്കിൻ്റെ അവസ്ഥ നിരീക്ഷിക്കാൻ സിഗ്നൽ നൽകുന്നു. മുകളിലെ ഉദാഹരണത്തിൽ, വിവരിച്ച ഘട്ടങ്ങൾ എടുക്കുന്നത്, ഹാഷ് ടേബിളിൽ സംഭരിച്ചിരിക്കുന്ന ഒരു മൂല്യത്തിലേക്ക് വൈരുദ്ധ്യമുള്ള എഴുത്ത് ആക്സസ് ഇല്ലെങ്കിൽ മറ്റ് ഹാഷ് ടേബിൾ എൻട്രികളിലേക്കുള്ള ആക്സസ് മേലിൽ ഒരു ലോക്കിന് കാരണമാകില്ലെന്ന് ഉറപ്പാക്കും. തൽഫലമായി, ആക്സസ് സമാന്തരമാക്കും, അതിനാൽ നാല് ത്രെഡുകളിലും സ്കേലബിളിറ്റി വർദ്ധിപ്പിക്കും.
- RTM ഇൻ്റർഫേസിൽ ആരംഭിക്കുന്നതിനുള്ള വ്യക്തമായ നിർദ്ദേശങ്ങൾ (XBEGIN), പ്രതിബദ്ധത (XEND), റദ്ദാക്കൽ (XABORT), ഇടപാടുകളുടെ അവസ്ഥ (XTEST) എന്നിവ ഉൾപ്പെടുന്നു. ഈ നിർദ്ദേശങ്ങൾ ലോക്കിംഗ് ലൈബ്രറികൾക്ക് ലോക്ക് ബൈപാസിംഗ് നടപ്പിലാക്കുന്നതിനുള്ള കൂടുതൽ വഴക്കമുള്ള മാർഗ്ഗം നൽകുന്നു. ആർടിഎം ഇൻ്റർഫേസ് ലൈബ്രറികളെ ഫ്ലെക്സിബിൾ ട്രാൻസാക്ഷൻ ക്യാൻസലേഷൻ അൽഗോരിതങ്ങൾ ഉപയോഗിക്കാൻ അനുവദിക്കുന്നു. മെച്ചപ്പെടുത്താൻ ഈ ഫീച്ചർ ഉപയോഗിക്കാം ഇൻ്റൽ പ്രകടനംശുഭാപ്തിവിശ്വാസമുള്ള ഇടപാട് പുനരാരംഭിക്കൽ, ഇടപാട് റോൾബാക്കുകൾ, മറ്റ് നൂതന സാങ്കേതിക വിദ്യകൾ എന്നിവ ഉപയോഗിച്ച് TSX. CPUID നിർദ്ദേശം ഉപയോഗിച്ച്, ഉപയോക്തൃ-ലെവൽ കോഡുമായി ബാക്ക്വേർഡ് കോംപാറ്റിബിലിറ്റി നിലനിർത്തിക്കൊണ്ട് ലൈബ്രറിക്ക് നോൺ-ആർടിഎം ലോക്കുകളുടെ പഴയ നിർവ്വഹണത്തിലേക്ക് മടങ്ങാൻ കഴിയും.
- ലഭിക്കുന്നതിന് അധിക വിവരം HLE, RTM എന്നിവയെക്കുറിച്ചുള്ള ഇൻ്റൽ ഡെവലപ്പർ സോൺ പോർട്ടലിൽ ഇനിപ്പറയുന്ന ലേഖനങ്ങൾ വായിക്കാൻ ഞാൻ ശുപാർശ ചെയ്യുന്നു.
HLE അല്ലെങ്കിൽ RTM ഉപയോഗിച്ച് സിൻക്രൊണൈസേഷൻ പ്രിമിറ്റീവുകൾ ഒപ്റ്റിമൈസ് ചെയ്യുന്നത് പോലെ, ഡാറ്റാ പ്ലെയിൻ ഡെവലപ്മെൻ്റ് കിറ്റ് (DPDK) ഉപയോഗിക്കുമ്പോൾ NFV ഡാറ്റ പ്ലാൻ ഫീച്ചറുകൾക്ക് ഇൻ്റൽ TSX-ൽ നിന്ന് പ്രയോജനം ലഭിക്കും.
Intel TSX ഉപയോഗിക്കുമ്പോൾ, പ്രധാന വെല്ലുവിളി ഈ വിപുലീകരണങ്ങൾ നടപ്പിലാക്കുന്നതിലല്ല, മറിച്ച് അവയുടെ പ്രകടനം വിലയിരുത്തുന്നതിലും നിർണ്ണയിക്കുന്നതിലുമാണ്. ഉപയോഗിക്കാവുന്ന പ്രകടന കൗണ്ടറുകൾ ഉണ്ട് ലിനക്സ് പ്രോഗ്രാമുകൾ* perf, കൂടാതെ Intel TSX എക്സിക്യൂഷൻ്റെ വിജയം വിലയിരുത്തുന്നതിന് (പൂർത്തിയായതിൻ്റെ എണ്ണവും റദ്ദാക്കിയ സൈക്കിളുകളുടെ എണ്ണവും).
Intel TSX ജാഗ്രതയോടെ ഉപയോഗിക്കുകയും NFV ആപ്ലിക്കേഷനുകളിൽ ശ്രദ്ധാപൂർവം പരീക്ഷിക്കുകയും വേണം, കാരണം Intel TSX സംരക്ഷിച്ചിരിക്കുന്ന ഒരു ഏരിയയിലെ I/O പ്രവർത്തനങ്ങളിൽ എപ്പോഴും റോൾബാക്ക് ഉൾപ്പെടുന്നു, കൂടാതെ പല NFV ഫീച്ചറുകളും ധാരാളം I/O ഓപ്പറേഷനുകൾ ഉപയോഗിക്കുന്നു. NFV ആപ്ലിക്കേഷനുകളിൽ കൺകറൻ്റ് ലോക്കിംഗ് ഒഴിവാക്കണം. ലോക്കുകൾ ആവശ്യമാണെങ്കിൽ, ലോക്ക് ബൈപാസ് അൽഗോരിതം സ്കേലബിളിറ്റി മെച്ചപ്പെടുത്താൻ സഹായിക്കും.
എഴുത്തുകാരനെ കുറിച്ച്
ഇൻ്റൽ കോർപ്പറേഷൻ്റെ സോഫ്റ്റ്വെയർ ആൻഡ് സർവീസസ് ഗ്രൂപ്പിൽ ആപ്ലിക്കേഷൻ ഡെവലപ്മെൻ്റ് എഞ്ചിനീയറായി അലക്സാണ്ടർ കൊമറോവ് പ്രവർത്തിക്കുന്നു. കഴിഞ്ഞ 10 വർഷമായി, നിലവിലുള്ളതും ഭാവിയിലുള്ളതുമായ ഇൻ്റൽ സെർവർ പ്ലാറ്റ്ഫോമുകളിൽ ഏറ്റവും ഉയർന്ന പ്രകടനം നേടുന്നതിന് കോഡ് ഒപ്റ്റിമൈസ് ചെയ്യുക എന്നതാണ് അലക്സാണ്ടറിൻ്റെ പ്രധാന ജോലി. പ്രൊഫൈലറുകൾ, കംപൈലറുകൾ, ലൈബ്രറികൾ, ഏറ്റവും പുതിയ ഇൻസ്ട്രക്ഷൻ സെറ്റുകൾ, നാനോ ആർക്കിടെക്ചർ, ഏറ്റവും പുതിയ x86 പ്രോസസറുകൾക്കും ചിപ്സെറ്റുകൾക്കും വേണ്ടിയുള്ള ആർക്കിടെക്ചറൽ മെച്ചപ്പെടുത്തലുകൾ തുടങ്ങിയ ഇൻ്റൽ സോഫ്റ്റ്വെയർ ഡെവലപ്മെൻ്റ് ടൂളുകളുടെ ഉപയോഗം ഈ വർക്കിൽ ഉൾപ്പെടുന്നു.
അധിക വിവരം
NFV-യെക്കുറിച്ചുള്ള കൂടുതൽ വിവരങ്ങൾക്ക്, ഇനിപ്പറയുന്ന വീഡിയോകൾ കാണുക.
#സിയോൺമിക്കപ്പോഴും, ഒരു സിംഗിൾ-പ്രോസസർ സെർവർ അല്ലെങ്കിൽ വർക്ക്സ്റ്റേഷൻ തിരഞ്ഞെടുക്കുമ്പോൾ, ഏത് പ്രോസസ്സർ ഉപയോഗിക്കണമെന്ന ചോദ്യം ഉയർന്നുവരുന്നു - ഒരു സെർവർ Xeon അല്ലെങ്കിൽ ഒരു സാധാരണ Core ix. ഈ പ്രോസസറുകൾ ഒരേ കോറുകളിൽ നിർമ്മിച്ചതാണെന്ന് കണക്കിലെടുക്കുമ്പോൾ, തിരഞ്ഞെടുപ്പ് പലപ്പോഴും വീഴുന്നു ഡെസ്ക്ടോപ്പ് പ്രോസസ്സറുകൾ, സമാനമായ പ്രകടനത്തോടെ സാധാരണയായി കുറഞ്ഞ ചിലവുണ്ട്. എന്തുകൊണ്ടാണ് ഇൻ്റൽ Xeon E3 പ്രോസസറുകൾ പുറത്തിറക്കുന്നത്? നമുക്ക് അത് കണ്ടുപിടിക്കാം.
സ്പെസിഫിക്കേഷനുകൾ
ആരംഭിക്കുന്നതിന്, നിലവിലെ മോഡൽ ശ്രേണിയിൽ നിന്ന് Xeon പ്രോസസറിൻ്റെ ജൂനിയർ മോഡൽ എടുക്കാം - Xeon E3-1220 V3. എതിരാളി ആയിരിക്കും കോർ പ്രൊസസർ i5-4440. രണ്ട് പ്രോസസ്സറുകളും ഹസ്വെൽ കോർ അടിസ്ഥാനമാക്കിയുള്ളതാണ്, ഒരേ അടിസ്ഥാന ക്ലോക്ക് വേഗതയും സമാന വിലകളുമുണ്ട്. ഈ രണ്ട് പ്രോസസ്സറുകൾ തമ്മിലുള്ള വ്യത്യാസങ്ങൾ പട്ടികയിൽ അവതരിപ്പിച്ചിരിക്കുന്നു:സംയോജിത ഗ്രാഫിക്സിൻ്റെ ലഭ്യത. ഒറ്റനോട്ടത്തിൽ, Core i5 ന് ഒരു നേട്ടമുണ്ട്, എന്നാൽ എല്ലാ സെർവർ മദർബോർഡുകൾക്കും ഒരു സംയോജിത ഗ്രാഫിക്സ് കാർഡ് ഉണ്ട്, അത് പ്രോസസറിൽ ഗ്രാഫിക്സ് ചിപ്പ് ആവശ്യമില്ല, കൂടാതെ വർക്ക്സ്റ്റേഷനുകൾ അവയുടെ താരതമ്യേന കുറഞ്ഞ പ്രകടനം കാരണം സംയോജിത ഗ്രാഫിക്സ് ഉപയോഗിക്കുന്നില്ല.
ECC പിന്തുണ. ഉയർന്ന വേഗതയും വലിയ അളവിലുള്ള റാമും സാധ്യത വർദ്ധിപ്പിക്കുന്നു സോഫ്റ്റ്വെയർ പിശകുകൾ. സാധാരണഗതിയിൽ, അത്തരം പിശകുകൾ അദൃശ്യമാണ്, എന്നാൽ ഇതൊക്കെയാണെങ്കിലും, അവ ഡാറ്റ മാറ്റങ്ങളിലേക്കോ സിസ്റ്റം ക്രാഷുകളിലേക്കോ നയിച്ചേക്കാം. ആണെങ്കിൽ ഡെസ്ക്ടോപ്പ് കമ്പ്യൂട്ടറുകൾഅപൂർവ്വമായി സംഭവിക്കുന്നതിനാൽ അത്തരം പിശകുകൾ അപകടകരമല്ലെങ്കിലും, വർഷങ്ങളോളം മുഴുവൻ സമയവും പ്രവർത്തിക്കുന്ന സെർവറുകളിൽ അവ അസ്വീകാര്യമാണ്. അവ ശരിയാക്കാൻ, ECC (പിശക്-തിരുത്തൽ കോഡ്) സാങ്കേതികവിദ്യ ഉപയോഗിക്കുന്നു, ഇതിൻ്റെ കാര്യക്ഷമത 99.988% ആണ്.
തെർമൽ ഡിസൈൻ പവർ (ടിഡിപി). അടിസ്ഥാനപരമായി, പരമാവധി ലോഡിൽ പ്രോസസ്സറിൻ്റെ ഊർജ്ജ ഉപഭോഗം. Xeons ന് സാധാരണയായി ഒരു ചെറിയ തെർമൽ എൻവലപ്പും മികച്ച പവർ സേവിംഗ് അൽഗോരിതങ്ങളും ഉണ്ട്, ഇത് ആത്യന്തികമായി കുറഞ്ഞ വൈദ്യുതി ബില്ലുകൾക്കും കൂടുതൽ കാര്യക്ഷമമായ തണുപ്പിനും കാരണമാകുന്നു.
L3 കാഷെ. കാഷെ മെമ്മറി പ്രോസസറിനും റാമിനും ഇടയിലുള്ള ഒരു തരം പാളിയാണ്, ഇതിന് വളരെ ഉയർന്ന വേഗതയുണ്ട്. കാഷെ വലുപ്പം കൂടുന്തോറും പ്രോസസർ വേഗത്തിൽ പ്രവർത്തിക്കുന്നു, കാരണം വളരെ വേഗതയേറിയ റാം പോലും കാഷെ മെമ്മറിയേക്കാൾ വളരെ മന്ദഗതിയിലാണ്. Xeon പ്രോസസ്സറുകൾക്ക് സാധാരണയായി വലിയ കാഷെ വലുപ്പങ്ങളുണ്ട്, അവ വിഭവ-ഇൻ്റൻസീവ് ആപ്ലിക്കേഷനുകൾക്ക് അഭികാമ്യമാക്കുന്നു.
TurboBoost മോഡിൽ ഫ്രീക്വൻസി / ഫ്രീക്വൻസി. ഇവിടെ എല്ലാം ലളിതമാണ് - ഉയർന്ന ആവൃത്തി, പ്രോസസ്സർ വേഗത്തിൽ പ്രവർത്തിക്കുന്നു, മറ്റെല്ലാ കാര്യങ്ങളും തുല്യമാണ്. അടിസ്ഥാന ആവൃത്തി, അതായത്, പൂർണ്ണ ലോഡിന് കീഴിൽ പ്രോസസ്സറുകൾ പ്രവർത്തിക്കുന്ന ആവൃത്തി സമാനമാണ്, എന്നാൽ ടർബോ ബൂസ്റ്റ് മോഡിൽ, അതായത്, മൾട്ടി-കോർ പ്രോസസ്സറുകൾക്കായി രൂപകൽപ്പന ചെയ്തിട്ടില്ലാത്ത ആപ്ലിക്കേഷനുകളിൽ പ്രവർത്തിക്കുമ്പോൾ, Xeon വേഗതയുള്ളതാണ്.
ഇൻ്റൽ TSX-NI പിന്തുണ. ഇൻ്റൽ ട്രാൻസാക്ഷണൽ സിൻക്രൊണൈസേഷൻ എക്സ്റ്റൻഷനുകൾ പുതിയ നിർദ്ദേശങ്ങൾ (ഇൻ്റൽ ടിഎസ്എക്സ്-എൻഐ) മൾട്ടി-ത്രെഡഡ് ആപ്ലിക്കേഷനുകളുടെ എക്സിക്യൂഷൻ എൻവയോൺമെൻ്റ് ഒപ്റ്റിമൈസ് ചെയ്യുന്ന പ്രോസസ്സർ കാഷെ സിസ്റ്റത്തിലേക്കുള്ള ഒരു ആഡ്-ഓൺ സൂചിപ്പിക്കുന്നു, പക്ഷേ, തീർച്ചയായും, ഈ ആപ്ലിക്കേഷനുകൾ ഉപയോഗിക്കുകയാണെങ്കിൽ മാത്രം സോഫ്റ്റ്വെയർ ഇൻ്റർഫേസുകൾ TSX-NI. ബിഗ് ഡാറ്റയും ഡാറ്റാബേസുകളും ഉപയോഗിച്ചുള്ള പ്രവർത്തനം കൂടുതൽ കാര്യക്ഷമമായി നടപ്പിലാക്കാൻ ടിഎസ്എക്സ്-എൻഐ നിർദ്ദേശ സെറ്റുകൾ നിങ്ങളെ അനുവദിക്കുന്നു - പല ത്രെഡുകൾ ഒരേ ഡാറ്റ ആക്സസ് ചെയ്യുന്ന സന്ദർഭങ്ങളിലും ത്രെഡ് തടയുന്ന സാഹചര്യങ്ങളിലും. TSX-ൽ നടപ്പിലാക്കിയിട്ടുള്ള ഊഹക്കച്ചവട ഡാറ്റ ആക്സസ്, പങ്കിട്ട ഡാറ്റ ആക്സസ്സുചെയ്യുമ്പോൾ വൈരുദ്ധ്യങ്ങൾ പരിഹരിച്ച് ഒരേസമയം എക്സിക്യൂട്ട് ചെയ്ത ത്രെഡുകളുടെ എണ്ണം വർദ്ധിപ്പിക്കുമ്പോൾ അത്തരം ആപ്ലിക്കേഷനുകൾ കൂടുതൽ കാര്യക്ഷമമായും കൂടുതൽ ചലനാത്മകമായും സ്കെയിൽ പെർഫോമൻസ് നിർമ്മിക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു.

വിശ്വസനീയമായ നിർവ്വഹണ പിന്തുണ. ഇൻ്റൽ ട്രസ്റ്റഡ് എക്സിക്യൂഷൻ ടെക്നോളജി, പ്രോസസ്സറുകളിലേക്കും ഹാർഡ്വെയറുകളിലേക്കും ഹാർഡ്വെയർ മെച്ചപ്പെടുത്തലിലൂടെ സുരക്ഷിതമായ കമാൻഡ് എക്സിക്യൂഷൻ മെച്ചപ്പെടുത്തുന്നു. ഇൻ്റൽ ചിപ്പുകൾ. ഈ സാങ്കേതികവിദ്യ ഡിജിറ്റൽ ഓഫീസ് പ്ലാറ്റ്ഫോമുകൾക്ക് അളന്ന ആപ്ലിക്കേഷൻ ലോഞ്ച്, സുരക്ഷിത കമാൻഡ് എക്സിക്യൂഷൻ തുടങ്ങിയ സുരക്ഷാ ഫീച്ചറുകൾ നൽകുന്നു. സിസ്റ്റത്തിലെ മറ്റ് ആപ്ലിക്കേഷനുകളിൽ നിന്ന് ഒറ്റപ്പെട്ട് പ്രവർത്തിക്കുന്ന ഒരു അന്തരീക്ഷം സൃഷ്ടിക്കുന്നതിലൂടെ ഇത് നേടാനാകും.
പഴയ Xeon പ്രോസസറുകളുടെ ഗുണങ്ങളിൽ ഇതിലും വലിയ L3 കപ്പാസിറ്റി, 45 MB വരെ, കൂടുതൽ കോറുകൾ, 18 വരെ, കൂടുതൽ പിന്തുണയുള്ള RAM എന്നിവ ഉൾപ്പെടുന്നു, ഓരോ പ്രോസസ്സറിന് 768 GB വരെ. അതേ സമയം, ഉപഭോഗം 160 W കവിയരുത്. ഒറ്റനോട്ടത്തിൽ, ഇത് വളരെ വലിയ മൂല്യമാണ്, എന്നിരുന്നാലും, അത്തരം പ്രോസസ്സറുകളുടെ പ്രകടനം 80 W ൻ്റെ TDP ഉള്ള അതേ Xeon E3-1220 V3 ൻ്റെ പ്രകടനത്തേക്കാൾ പലമടങ്ങ് കൂടുതലാണെന്ന് കണക്കിലെടുക്കുമ്പോൾ, സേവിംഗ്സ് വ്യക്തമാകും. പ്രോസസറുകളൊന്നും ഇല്ലെന്നതും ശ്രദ്ധിക്കേണ്ടതാണ് പ്രധാന കുടുംബംമൾട്ടിപ്രോസസിംഗിനെ പിന്തുണയ്ക്കുന്നില്ല, അതായത്, ഒരു കമ്പ്യൂട്ടറിൽ ഒന്നിൽ കൂടുതൽ പ്രോസസ്സറുകൾ ഇൻസ്റ്റാൾ ചെയ്യാൻ സാധ്യമല്ല. സെർവറുകൾക്കും വർക്ക്സ്റ്റേഷനുകൾക്കുമുള്ള മിക്ക ആപ്ലിക്കേഷനുകളും കോറുകൾ, ത്രെഡുകൾ, ഫിസിക്കൽ പ്രോസസ്സറുകൾ എന്നിവയിലുടനീളം നന്നായി സ്കെയിൽ ചെയ്യുന്നു, അതിനാൽ രണ്ട് പ്രോസസ്സറുകൾ ഇൻസ്റ്റാൾ ചെയ്യുന്നത് പ്രകടനത്തിൽ ഏകദേശം ഇരട്ടി വർദ്ധനവ് നൽകും.
തീയതി: 2014-08-13 22:26
2007-ൽ തിരിച്ചെത്തി എഎംഡി കമ്പനിഒരു പുതിയ തലമുറയെ പുറത്തിറക്കി ഫെനോം പ്രോസസ്സറുകൾ. ഈ പ്രോസസ്സറുകൾ, പിന്നീട് തെളിഞ്ഞതുപോലെ, TLB ബ്ലോക്കിൽ ഒരു പിശക് അടങ്ങിയിരിക്കുന്നു (വിവർത്തന ലുക്ക്-അസൈഡ് ബഫർ വേഗത്തിലുള്ള പരിവർത്തനംഭൗതിക വിലാസങ്ങളിലേക്കുള്ള വെർച്വൽ വിലാസങ്ങൾ). ഒരു ബയോസ് പാച്ചിൻ്റെ രൂപത്തിലുള്ള ഒരു പാച്ചിലൂടെ ഈ പ്രശ്നം പരിഹരിക്കുകയല്ലാതെ കമ്പനിക്ക് മറ്റ് മാർഗമില്ലായിരുന്നു, എന്നാൽ ഇത് പ്രോസസറിൻ്റെ പ്രകടനം ഏകദേശം 15% കുറച്ചു.
സമാനമായ ചിലത് ഇപ്പോൾ ഇൻ്റലിന് സംഭവിച്ചിരിക്കുന്നു. ഹാസ്വെൽ ജനറേഷൻ പ്രൊസസറുകളിൽ, കമ്പനി ടിഎസ്എക്സ് (ട്രാൻസക്ഷണൽ സിൻക്രൊണൈസേഷൻ എക്സ്റ്റൻഷൻ) നിർദ്ദേശങ്ങൾക്കുള്ള പിന്തുണ നടപ്പിലാക്കി. മൾട്ടി-ത്രെഡഡ് ആപ്ലിക്കേഷനുകൾ ത്വരിതപ്പെടുത്തുന്നതിനാണ് അവ രൂപകൽപ്പന ചെയ്തിരിക്കുന്നത്, അവ പ്രാഥമികമായി സെർവർ സെഗ്മെൻ്റിൽ ഉപയോഗിച്ചിരിക്കണം. ഹാസ്വെൽ സിപിയുകൾ വളരെക്കാലമായി വിപണിയിലുണ്ടെങ്കിലും, ഈ സെറ്റ്പ്രായോഗികമായി നിർദ്ദേശങ്ങളൊന്നും ഉപയോഗിച്ചിട്ടില്ല. പ്രത്യക്ഷത്തിൽ, അത് സമീപഭാവിയിൽ സംഭവിക്കില്ല.
TSX നിർദ്ദേശങ്ങളിൽ കമ്പനി തന്നെ വിളിക്കുന്നതുപോലെ ഇൻ്റൽ ഒരു "അക്ഷരത്തെറ്റ്" ഉണ്ടാക്കി എന്നതാണ് വസ്തുത. പിശക്, വഴി, പ്രോസസർ ഭീമനിൽ നിന്നുള്ള സ്പെഷ്യലിസ്റ്റുകൾ കണ്ടെത്തിയില്ല. ഇത് സിസ്റ്റം അസ്ഥിരതയിലേക്ക് നയിച്ചേക്കാം. തീരുമാനിക്കുക ഈ പ്രശ്നംഈ നിർദ്ദേശങ്ങളുടെ കൂട്ടം പ്രവർത്തനരഹിതമാക്കുന്ന BIOS അപ്ഡേറ്റ് ചെയ്യുന്നതിലൂടെ കമ്പനിക്ക് ഇത് ഒരു വിധത്തിൽ മാത്രമേ ചെയ്യാൻ കഴിയൂ.
വഴിയിൽ, ടിഎസ്എക്സ് നടപ്പിലാക്കുന്നത് മാത്രമല്ല ഹാസ്വെൽ പ്രോസസ്സറുകൾ, മാത്രമല്ല കോർ എം എന്ന പേരിൽ പ്രത്യക്ഷപ്പെടേണ്ട ആദ്യത്തെ ബ്രോഡ്വെൽ സിപിയു മോഡലുകളിലും, ഭാവിയിൽ അതിൻ്റെ അടുത്ത ഉൽപ്പന്നങ്ങളിൽ TSX നിർദ്ദേശങ്ങളുടെ "പിശക് രഹിത" പതിപ്പ് നടപ്പിലാക്കാൻ ഇൻ്റൽ ഉദ്ദേശിക്കുന്നതായി ഒരു കമ്പനി പ്രതിനിധി സ്ഥിരീകരിച്ചു.
ടാഗുകൾ: അഭിപ്രായം
മുൻ വാർത്ത
2014-08-13 22:23
സോണി എക്സ്പീരിയ Z2 ഉപ്പിട്ട കുളത്തിൻ്റെ അടിയിൽ ആറാഴ്ചത്തെ താമസത്തിന് ശേഷം "അതിജീവിച്ചു"
സ്മാർട്ട്ഫോണുകൾ പലപ്പോഴും അവിശ്വസനീയമായ കഥകളുടെ നായകന്മാരാകുന്നു, അതിൽ അവർ പോക്കറ്റ് ബോഡി കവചത്തിൻ്റെ വേഷം പരീക്ഷിക്കുകയും ബുള്ളറ്റ് നിർത്തുകയും സംരക്ഷിക്കുകയും ചെയ്യുന്നു.
2014-08-13 21:46
ഐഫോൺ 6 അവസാന പരീക്ഷണ ഘട്ടത്തിലേക്ക് പ്രവേശിച്ചു
ഏറ്റവും പുതിയ ഡാറ്റ പ്രകാരം വാർത്താ ഏജൻസി Gforgames, iPhone 6, ഉൽപ്പാദനത്തിലേക്ക് പുതിയ സ്മാർട്ട്ഫോണിൻ്റെ വൻതോതിലുള്ള ലോഞ്ച് ചെയ്യുന്നതിന് മുമ്പായി അവസാന പരീക്ഷണ ഘട്ടത്തിലേക്ക് പ്രവേശിച്ചു. ഐഫോൺ 6 ചൈനയിലെ ഫാക്ടറികളിൽ അസംബിൾ ചെയ്യുമെന്ന് ഞങ്ങൾ നിങ്ങളെ ഓർമ്മിപ്പിക്കട്ടെ...
2014-08-12 16:38
Octa-core iRU M720G ടാബ്ലെറ്റ് രണ്ട് സിം കാർഡുകൾ പിന്തുണയ്ക്കുന്നു
ടാബ്ലെറ്റിന് 2 ജിബി റാമും 16 ജിബി ബിൽറ്റ്-ഇൻ ഫ്ലാഷ് മെമ്മറിയും ഉണ്ട്. ബോർഡിൽ രണ്ട് ക്യാമറകളുണ്ട്: പ്രധാന 8 മെഗാപിക്സലും മുൻവശത്ത് 2 മെഗാപിക്സലും. iRU M720G-ൽ 3G, GPS, Wi-Fi, ബ്ലൂടൂത്ത്, FM റേഡിയോ മൊഡ്യൂളുകൾ, കൂടാതെ രണ്ട് സിം കാർഡുകൾക്കുള്ള സ്ലോട്ടും സജ്ജീകരിച്ചിരിക്കുന്നു, അത് പ്രവർത്തിക്കാൻ അനുവദിക്കുന്നു...
2014-08-10 18:57
എൽജി റഷ്യയിൽ വിലകുറഞ്ഞ സ്മാർട്ട്ഫോൺ എൽ60 പുറത്തിറക്കി
വലിയ ആഡംബരവും ആർഭാടവുമില്ലാതെ, റഷ്യയിൽ അവതരിപ്പിച്ച എൽജി ഇലക്ട്രോണിക്സ് പുതിയ മോഡൽ L സീരീസ് III - LG L60. ഈ വിലകുറഞ്ഞ സ്മാർട്ട്ഫോൺ അവതരിപ്പിക്കുന്നത് വില പരിധിഏറ്റവും വലിയ റഷ്യൻ ഭാഷയിൽ നിന്ന് 4 മുതൽ 5 ആയിരം റൂബിൾ വരെ ...
ഓരോ പുതിയ തലമുറയിലും, ഇൻ്റൽ പ്രോസസ്സറുകൾ കൂടുതൽ കൂടുതൽ സാങ്കേതികവിദ്യകളും പ്രവർത്തനങ്ങളും ഉൾക്കൊള്ളുന്നു. അവരിൽ ചിലർ അറിയപ്പെടുന്നവരാണ് (ഉദാഹരണത്തിന്, ആർക്കാണ് ഹൈപ്പർത്രെഡിംഗിനെക്കുറിച്ച് അറിയില്ല?), മിക്ക നോൺ-സ്പെഷ്യലിസ്റ്റുകൾക്കും മറ്റുള്ളവരുടെ നിലനിൽപ്പിനെക്കുറിച്ച് പോലും അറിയില്ല. നമുക്കത് എല്ലാവർക്കും തുറന്നു കൊടുക്കാം അറിയപ്പെടുന്ന അടിസ്ഥാനംഇൻ്റൽ ഓട്ടോമേറ്റഡ് റിലേഷണൽ നോളജ് ബേസ് (ARK) ഉൽപ്പന്നങ്ങളെക്കുറിച്ചുള്ള അറിവ് അവിടെ ഒരു പ്രോസസർ തിരഞ്ഞെടുക്കുക. സവിശേഷതകളുടേയും സാങ്കേതികവിദ്യകളുടേയും ഒരു വലിയ ലിസ്റ്റ് നമുക്ക് കാണാം - അവയുടെ നിഗൂഢമായ മാർക്കറ്റിംഗ് പേരുകൾക്ക് പിന്നിലെന്താണ്? പ്രശ്നം കൂടുതൽ ആഴത്തിൽ പരിശോധിക്കാൻ ഞങ്ങൾ നിങ്ങളെ ക്ഷണിക്കുന്നു പ്രത്യേക ശ്രദ്ധഅധികം അറിയപ്പെടാത്ത സാങ്കേതികവിദ്യകളിൽ - തീർച്ചയായും രസകരമായ ഒരുപാട് കാര്യങ്ങൾ അവിടെ ഉണ്ടാകും.
ഇൻ്റൽ ഡിമാൻഡ് ബേസ്ഡ് സ്വിച്ചിംഗ്
മെച്ചപ്പെടുത്തിയ ഇൻ്റൽ സ്പീഡ് സ്റ്റെപ്പ് ടെക്നോളജിക്കൊപ്പം, പ്രോസസർ ഇവിടെ പ്രവർത്തിക്കുന്നുവെന്ന് ഉറപ്പാക്കുന്നതിന് ഇൻ്റൽ ഡിമാൻഡ് ബേസ്ഡ് സ്വിച്ചിംഗ് സാങ്കേതികവിദ്യയ്ക്ക് ഉത്തരവാദിത്തമുണ്ട്. ഒപ്റ്റിമൽ ഫ്രീക്വൻസിആവശ്യത്തിന് വൈദ്യുതോർജ്ജം ലഭിച്ചു: ആവശ്യത്തിൽ കൂടുതലോ കുറവോ ഇല്ല. ഇത് ഊർജ്ജ ഉപഭോഗവും താപ ഉൽപാദനവും കുറയ്ക്കുന്നു, ഇത് മാത്രമല്ല പ്രധാനമാണ് പോർട്ടബിൾ ഉപകരണങ്ങൾ, മാത്രമല്ല സെർവറുകൾക്കും - അവിടെയാണ് ഡിമാൻഡ് ബേസ്ഡ് സ്വിച്ചിംഗ് ഉപയോഗിക്കുന്നത്.
ഇൻ്റൽ ഫാസ്റ്റ് മെമ്മറി ആക്സസ്
റാം പ്രകടനം ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിനുള്ള മെമ്മറി കൺട്രോളർ പ്രവർത്തനം. കമാൻഡ് ക്യൂവിൻ്റെ ആഴത്തിലുള്ള വിശകലനത്തിലൂടെ, "ഓവർലാപ്പുചെയ്യുന്ന" കമാൻഡുകൾ (ഉദാഹരണത്തിന്, അതേ മെമ്മറി പേജിൽ നിന്ന് വായിക്കുന്നത്) തിരിച്ചറിയാനും യഥാർത്ഥ എക്സിക്യൂഷൻ പുനഃക്രമീകരിക്കാനും അനുവദിക്കുന്ന സാങ്കേതികവിദ്യകളുടെ സംയോജനമാണിത്. ഒന്നിനുപുറകെ ഒന്നായി വധിച്ചു. കൂടാതെ, റീഡ് ക്യൂ ശൂന്യമാകുമെന്ന് പ്രവചിക്കപ്പെടുന്ന സമയങ്ങളിൽ ലോവർ പ്രയോറിറ്റി മെമ്മറി റൈറ്റ് കമാൻഡുകൾ ഷെഡ്യൂൾ ചെയ്യപ്പെടുന്നു, ഇത് മെമ്മറി റൈറ്റ് പ്രക്രിയയെ വായനാ വേഗതയിൽ കൂടുതൽ നിയന്ത്രണത്തിലാക്കുന്നു.
ഇൻ്റൽ ഫ്ലെക്സ് മെമ്മറി ആക്സസ്
മെമ്മറി കൺട്രോളറിൻ്റെ മറ്റൊരു പ്രവർത്തനം, അത് ഒരു പ്രത്യേക ചിപ്പ് ആയിരുന്ന കാലത്ത്, 2004 ൽ വീണ്ടും പ്രത്യക്ഷപ്പെട്ടു. ഒരേസമയം രണ്ട് മെമ്മറി മൊഡ്യൂളുകൾ ഉപയോഗിച്ച് സിൻക്രണസ് മോഡിൽ പ്രവർത്തിക്കാനുള്ള കഴിവ് നൽകുന്നു, കൂടാതെ മുമ്പുണ്ടായിരുന്ന ലളിതമായ ഡ്യുവൽ-ചാനൽ മോഡിൽ നിന്ന് വ്യത്യസ്തമായി, മെമ്മറി മൊഡ്യൂളുകൾ ആകാം വ്യത്യസ്ത വലുപ്പങ്ങൾ. ഈ രീതിയിൽ, കമ്പ്യൂട്ടറിനെ മെമ്മറി ഉപയോഗിച്ച് സജ്ജീകരിക്കുന്നതിൽ വഴക്കം കൈവരിച്ചു, അത് പേരിൽ പ്രതിഫലിക്കുന്നു.
ഇൻ്റൽ ഇൻസ്ട്രക്ഷൻ റീപ്ലേ
ഇൻ്റൽ ഇറ്റാനിയം പ്രോസസറുകളിൽ ആദ്യമായി പ്രത്യക്ഷപ്പെട്ട വളരെ ആഴത്തിലുള്ള സാങ്കേതികവിദ്യ. പ്രൊസസർ പൈപ്പ്ലൈനുകളുടെ പ്രവർത്തന സമയത്ത്, നിർദ്ദേശങ്ങൾ ഇതിനകം തന്നെ നടപ്പിലാക്കുമ്പോൾ ഒരു സാഹചര്യം ഉണ്ടാകാം, പക്ഷേ ആവശ്യമായ ഡാറ്റ ഇതുവരെ ലഭ്യമല്ല. തുടർന്ന് നിർദ്ദേശം "വീണ്ടും പ്ലേ" ചെയ്യേണ്ടതുണ്ട്: കൺവെയറിൽ നിന്ന് നീക്കം ചെയ്ത് അതിൻ്റെ തുടക്കത്തിൽ പ്രവർത്തിപ്പിക്കുക. കൃത്യമായി എന്താണ് സംഭവിക്കുന്നത്. മറ്റൊന്ന് പ്രധാന പ്രവർത്തനം IRT - പ്രോസസ്സർ പൈപ്പ്ലൈനുകളിൽ ക്രമരഹിതമായ പിശകുകളുടെ തിരുത്തൽ. വളരെ രസകരമായ ഈ സവിശേഷതയെക്കുറിച്ച് കൂടുതൽ വായിക്കുക.
ഇൻ്റൽ മൈ വൈഫൈ ടെക്നോളജി
നിലവിലുള്ള ഫിസിക്കൽ ഒന്നിലേക്ക് ഒരു വെർച്വൽ വൈഫൈ അഡാപ്റ്റർ ചേർക്കാൻ നിങ്ങളെ അനുവദിക്കുന്ന വിർച്ച്വലൈസേഷൻ സാങ്കേതികവിദ്യ; അതിനാൽ, നിങ്ങളുടെ അൾട്രാബുക്ക് അല്ലെങ്കിൽ ലാപ്ടോപ്പ് ഒരു പൂർണ്ണ ആക്സസ് പോയിൻ്റോ റിപ്പീറ്ററോ ആകാം. സോഫ്റ്റ്വെയർ ഘടകങ്ങൾഎൻ്റെ വൈഫൈ ഇൻ്റൽ പ്രോസെറ്റ് വയർലെസ് സോഫ്റ്റ്വെയർ ഡ്രൈവർ പതിപ്പ് 13.2-ലും അതിലും ഉയർന്നതിലും ഉൾപ്പെടുത്തിയിട്ടുണ്ട്; ചില വൈഫൈ അഡാപ്റ്ററുകൾ മാത്രമേ സാങ്കേതികവിദ്യയുമായി പൊരുത്തപ്പെടുന്നുള്ളൂ എന്നത് ഓർമിക്കേണ്ടതാണ്. ഇൻസ്റ്റലേഷൻ നിർദ്ദേശങ്ങളും സോഫ്റ്റ്വെയർ, ഹാർഡ്വെയർ അനുയോജ്യത എന്നിവയുടെ ഒരു ലിസ്റ്റും ഇൻ്റൽ വെബ്സൈറ്റിൽ കാണാം.
ഇൻ്റൽ സ്മാർട്ട് ഐഡൽ ടെക്നോളജി
മറ്റൊരു ഊർജ്ജ സംരക്ഷണ സാങ്കേതികവിദ്യ. നിലവിൽ ഉപയോഗിക്കാത്ത പ്രോസസർ ബ്ലോക്കുകൾ പ്രവർത്തനരഹിതമാക്കാനോ അവയുടെ ആവൃത്തി കുറയ്ക്കാനോ നിങ്ങളെ അനുവദിക്കുന്നു. ഒരു സ്മാർട്ട്ഫോൺ സിപിയുവിന് ഒഴിച്ചുകൂടാനാവാത്ത ഒരു കാര്യം, അത് പ്രത്യക്ഷപ്പെട്ടിടത്താണ് - ഇൻ്റൽ ആറ്റം പ്രോസസ്സറുകളിൽ.
ഇൻ്റൽ സ്റ്റേബിൾ ഇമേജ് പ്ലാറ്റ്ഫോം
സാങ്കേതികവിദ്യയെക്കാൾ ബിസിനസ് പ്രക്രിയകളെ സൂചിപ്പിക്കുന്ന ഒരു പദം. കോർ പ്ലാറ്റ്ഫോം ഘടകങ്ങളും ഡ്രൈവറുകളും കുറഞ്ഞത് 15 മാസമെങ്കിലും മാറ്റമില്ലാതെ തുടരുന്നുവെന്ന് ഉറപ്പാക്കിക്കൊണ്ട് Intel SIPP പ്രോഗ്രാം സോഫ്റ്റ്വെയർ സ്ഥിരത ഉറപ്പാക്കുന്നു. അങ്ങനെ, കോർപ്പറേറ്റ് ഉപഭോക്താക്കൾഈ കാലയളവിൽ വിന്യസിച്ചിരിക്കുന്ന അതേ സിസ്റ്റം ഇമേജുകൾ ഉപയോഗിക്കാനുള്ള അവസരമുണ്ട്.
ഇൻ്റൽ ക്വിക്ക് അസിസ്റ്റ്
വലിയ അളവിലുള്ള കമ്പ്യൂട്ടേഷൻ ആവശ്യമായ ഹാർഡ്വെയർ നടപ്പിലാക്കിയ ഫംഗ്ഷനുകളുടെ ഒരു കൂട്ടം, ഉദാഹരണത്തിന്, എൻക്രിപ്ഷൻ, കംപ്രഷൻ, പാറ്റേൺ തിരിച്ചറിയൽ. ഡവലപ്പർമാർക്ക് ഫങ്ഷണൽ ബിൽഡിംഗ് ബ്ലോക്കുകൾ നൽകി അവരുടെ ആപ്ലിക്കേഷനുകൾ വേഗത്തിലാക്കി കാര്യങ്ങൾ എളുപ്പമാക്കുക എന്നതാണ് QuickAssist-ൻ്റെ ലക്ഷ്യം. മറുവശത്ത്, ഏറ്റവും ശക്തമായ പ്രോസസറുകളല്ല, "കനത്ത" ജോലികൾ ഏൽപ്പിക്കാൻ സാങ്കേതികവിദ്യ നിങ്ങളെ അനുവദിക്കുന്നു, ഇത് പ്രകടനത്തിലും വൈദ്യുതി ഉപഭോഗത്തിലും ഗുരുതരമായി പരിമിതപ്പെടുത്തിയിരിക്കുന്ന എംബഡഡ് സിസ്റ്റങ്ങളിൽ പ്രത്യേകിച്ചും വിലപ്പെട്ടതാണ്.
ഇൻ്റൽ ക്വിക്ക് റെസ്യൂം
അടിസ്ഥാനമാക്കി കമ്പ്യൂട്ടറുകൾക്കായി വികസിപ്പിച്ച സാങ്കേതികവിദ്യ ഇൻ്റൽ പ്ലാറ്റ്ഫോമുകൾടിവി റിസീവറുകൾ അല്ലെങ്കിൽ ഡിവിഡി പ്ലെയറുകൾ പോലെ തൽക്ഷണം ഓണാക്കാനും ഓഫാക്കാനും അവരെ അനുവദിച്ച Viiv; അതേ സമയം, "ഓഫ്" അവസ്ഥയിൽ, കമ്പ്യൂട്ടറിന് ഉപയോക്തൃ ഇടപെടൽ ആവശ്യമില്ലാത്ത ചില ജോലികൾ ചെയ്യുന്നത് തുടരാം. പ്ലാറ്റ്ഫോം തന്നെ മറ്റ് രൂപങ്ങളിലേക്ക് സുഗമമായി പരിവർത്തനം ചെയ്തെങ്കിലും അതിനോടൊപ്പമുള്ള സംഭവവികാസങ്ങൾ, ലൈൻ ഇപ്പോഴും ARK- ൽ ഉണ്ട്, കാരണം അത് വളരെക്കാലം മുമ്പായിരുന്നില്ല.
ഇൻ്റൽ സെക്യൂർ കീ
ഡിജിറ്റൽ റാൻഡം നമ്പർ ജനറേറ്ററിൻ്റെ (DRNG) ഹാർഡ്വെയർ നടപ്പിലാക്കൽ ഉപയോഗിക്കുന്ന 32-, 64-ബിറ്റ് RDRAND നിർദ്ദേശങ്ങൾക്കുള്ള ഒരു പൊതു നാമം. മനോഹരവും ഉയർന്ന നിലവാരമുള്ളതുമായ റാൻഡം കീകൾ സൃഷ്ടിക്കുന്നതിന് ക്രിപ്റ്റോഗ്രാഫിക് ആവശ്യങ്ങൾക്കായി നിർദ്ദേശം ഉപയോഗിക്കുന്നു.
ഇൻ്റൽ TSX-NI
ഇൻ്റൽ ട്രാൻസാക്ഷണൽ സിൻക്രൊണൈസേഷൻ എക്സ്റ്റൻഷനുകൾ എന്ന സങ്കീർണ്ണ നാമമുള്ള സാങ്കേതികവിദ്യ - പുതിയ നിർദ്ദേശങ്ങൾ പ്രോസസർ കാഷെ സിസ്റ്റത്തിലേക്കുള്ള ഒരു ആഡ്-ഓൺ സൂചിപ്പിക്കുന്നു, അത് മൾട്ടി-ത്രെഡഡ് ആപ്ലിക്കേഷനുകളുടെ എക്സിക്യൂഷൻ എൻവയോൺമെൻ്റ് ഒപ്റ്റിമൈസ് ചെയ്യുന്നു, പക്ഷേ, തീർച്ചയായും, ഈ ആപ്ലിക്കേഷനുകൾ TSX-NI പ്രോഗ്രാമിംഗ് ഇൻ്റർഫേസുകൾ ഉപയോഗിക്കുകയാണെങ്കിൽ മാത്രം. ഉപയോക്താവിൻ്റെ ഭാഗത്ത് നിന്ന് ഈ സാങ്കേതികവിദ്യനേരിട്ട് കാണാനാകില്ല, എന്നാൽ ആർക്കും അതിൻ്റെ വിവരണം വായിക്കാൻ കഴിയും ആക്സസ് ചെയ്യാവുന്ന ഭാഷസ്റ്റെപാൻ കോൾട്സോവിൻ്റെ ബ്ലോഗിൽ.
ഉപസംഹാരമായി, Intel ARK ഒരു വെബ്സൈറ്റ് എന്ന നിലയിൽ മാത്രമല്ല, iOS, Android എന്നിവയ്ക്കായുള്ള ഒരു ഓഫ്ലൈൻ ആപ്ലിക്കേഷനായും നിലവിലുണ്ടെന്ന് ഒരിക്കൽ കൂടി നിങ്ങളെ ഓർമ്മിപ്പിക്കാൻ ഞങ്ങൾ ആഗ്രഹിക്കുന്നു. വിഷയത്തിൽ തുടരുക!
























