ഈ ചെറിയ ലേഖനത്തിൽ നമ്മൾ MySQL, സാമ്പിൾ, കൗണ്ടിംഗ് എന്നിവയിലെ ഡാറ്റാബേസുകളെ കുറിച്ച് സംസാരിക്കും. ഡാറ്റാബേസുകളിൽ പ്രവർത്തിക്കുമ്പോൾ, ഒരു നിശ്ചിത വ്യവസ്ഥയോടുകൂടിയോ അല്ലാതെയോ നിങ്ങൾ COUNT() വരികളുടെ എണ്ണം കണക്കാക്കേണ്ടതുണ്ട്; ഇനിപ്പറയുന്ന ചോദ്യം ഉപയോഗിച്ച് ഇത് ചെയ്യാൻ വളരെ എളുപ്പമാണ്
കോഡ് കാണുക MYSQL
ചോദ്യം പട്ടികയിലെ വരികളുടെ എണ്ണമുള്ള ഒരു മൂല്യം നൽകും.
വ്യവസ്ഥയോടെ എണ്ണുന്നു
കോഡ് കാണുക MYSQL
ഈ വ്യവസ്ഥയെ തൃപ്തിപ്പെടുത്തുന്ന പട്ടികയിലെ വരികളുടെ എണ്ണം ഉപയോഗിച്ച് ചോദ്യം ഒരു മൂല്യം നൽകും: var = 1
വ്യത്യസ്ത വ്യവസ്ഥകളുള്ള ഒന്നിലധികം വരി എണ്ണൽ മൂല്യങ്ങൾ ലഭിക്കുന്നതിന്, നിങ്ങൾക്ക് നിരവധി ചോദ്യങ്ങൾ ഒന്നൊന്നായി പ്രവർത്തിപ്പിക്കാൻ കഴിയും, ഉദാഹരണത്തിന്
കോഡ് കാണുക MYSQL
എന്നാൽ ചില സന്ദർഭങ്ങളിൽ, ഈ സമീപനം പ്രായോഗികമോ അനുയോജ്യമോ അല്ല. അതിനാൽ, ഒരു അന്വേഷണത്തിൽ ഒരേസമയം നിരവധി ഫലങ്ങൾ ലഭിക്കുന്നതിന് നിരവധി ഉപചോദ്യങ്ങളുള്ള ഒരു ചോദ്യം സംഘടിപ്പിക്കുന്നത് പ്രസക്തമാകും. ഉദാഹരണത്തിന്
കോഡ് കാണുക MYSQL
അതിനാൽ, ഡാറ്റാബേസിലേക്ക് ഒരു ചോദ്യം മാത്രം എക്സിക്യൂട്ട് ചെയ്യുന്നതിലൂടെ, നിരവധി നിബന്ധനകൾക്കുള്ള വരികളുടെ എണ്ണത്തിൻ്റെ ഒരു ഫലം നമുക്ക് ലഭിക്കും, ഉദാഹരണത്തിന്, നിരവധി എണ്ണം മൂല്യങ്ങൾ അടങ്ങിയിരിക്കുന്നു.
കോഡ് കാണുകവാചകം
| c1|c2|c3 -------- 1 |5 |8 |
നിരവധി വ്യത്യസ്ത ചോദ്യങ്ങളുമായി താരതമ്യം ചെയ്യുമ്പോൾ സബ്ക്വറികൾ ഉപയോഗിക്കുന്നതിൻ്റെ പോരായ്മ, എക്സിക്യൂഷൻ്റെ വേഗതയും ഡാറ്റാബേസിലെ ലോഡുമാണ്.
ഒരു MySQL ചോദ്യത്തിൽ ഒന്നിലധികം COUNT-കൾ അടങ്ങിയ ഒരു ചോദ്യത്തിൻ്റെ ഇനിപ്പറയുന്ന ഉദാഹരണം അല്പം വ്യത്യസ്തമായാണ് നിർമ്മിച്ചിരിക്കുന്നത്, അത് IF(കണ്ടീഷൻ, മൂല്യ1, മൂല്യം2) കൺസ്ട്രക്റ്റുകളും SUM() ഉം ഉപയോഗിക്കുന്നു. ഒരു ചോദ്യത്തിനുള്ളിൽ നിർദ്ദിഷ്ട മാനദണ്ഡങ്ങൾക്കനുസൃതമായി ഡാറ്റ തിരഞ്ഞെടുക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു, തുടർന്ന് അവയെ സംഗ്രഹിച്ച് അതിൻ്റെ ഫലമായി നിരവധി മൂല്യങ്ങൾ പ്രദർശിപ്പിക്കുക.
കോഡ് കാണുക MYSQL
അഭ്യർത്ഥനയിൽ നിന്ന് കാണാൻ കഴിയുന്നതുപോലെ, ഇത് വളരെ സംക്ഷിപ്തമായി നിർമ്മിച്ചതാണ്, പക്ഷേ അതിൻ്റെ നിർവ്വഹണ വേഗതയും സന്തോഷകരമായിരുന്നില്ല, ഈ അഭ്യർത്ഥനയുടെ ഫലം ഇനിപ്പറയുന്നതായിരിക്കും,
കോഡ് കാണുകവാചകം
| ആകെ|c1|c2|c3 ------------- 14 |1 |5 |8 |
അടുത്തതായി, നിരവധി COUNT() തിരഞ്ഞെടുക്കുന്നതിനുള്ള മൂന്ന് അന്വേഷണ ഓപ്ഷനുകളുടെ നിർവ്വഹണ വേഗതയെക്കുറിച്ചുള്ള താരതമ്യ സ്ഥിതിവിവരക്കണക്കുകൾ ഞാൻ നൽകും. അന്വേഷണ നിർവ്വഹണത്തിൻ്റെ വേഗത പരിശോധിക്കുന്നതിനായി, ഓരോ തരത്തിലുമുള്ള 1000 അന്വേഷണങ്ങൾ നിർവ്വഹിച്ചു, ഒരു പട്ടികയിൽ മൂവായിരത്തിലധികം റെക്കോർഡുകൾ അടങ്ങിയിരിക്കുന്നു. മാത്രമല്ല, ഓരോ തവണയും അഭ്യർത്ഥനയിൽ SQL_NO_CACHE അടങ്ങിയിരിക്കുന്നു, ഡാറ്റാബേസ് വഴി ഫലങ്ങൾ കാഷെ ചെയ്യുന്നത് അപ്രാപ്തമാക്കും.
നിർവ്വഹണ വേഗത
മൂന്ന് വ്യത്യസ്ത അഭ്യർത്ഥനകൾ: 0.9 സെ
സബ്ക്വറികളുള്ള ഒരു ചോദ്യം: 0.95 സെ
IF, SUM നിർമ്മാണത്തോടുകൂടിയ ഒരു അഭ്യർത്ഥന: 1.5 സെ
ഉപസംഹാരം. അതിനാൽ, നിരവധി COUNT() ഉള്ള MySQL ഡാറ്റാബേസിലേക്ക് ചോദ്യങ്ങൾ നിർമ്മിക്കുന്നതിന് ഞങ്ങൾക്ക് നിരവധി ഓപ്ഷനുകൾ ഉണ്ട്, പ്രത്യേക ചോദ്യങ്ങളുള്ള ആദ്യ ഓപ്ഷൻ വളരെ സൗകര്യപ്രദമല്ല, എന്നാൽ മികച്ച വേഗത ഫലം ഉണ്ട്. സബ്ക്വറികളുള്ള രണ്ടാമത്തെ ഓപ്ഷൻ കുറച്ചുകൂടി സൗകര്യപ്രദമാണ്, പക്ഷേ അതിൻ്റെ എക്സിക്യൂഷൻ വേഗത അല്പം കുറവാണ്. അവസാനമായി, ഏറ്റവും സൗകര്യപ്രദമെന്ന് തോന്നുന്ന IF, SUM കൺസ്ട്രക്റ്റുകളുള്ള അന്വേഷണത്തിൻ്റെ മൂന്നാമത്തെ ലാക്കോണിക് പതിപ്പിന് ഏറ്റവും കുറഞ്ഞ എക്സിക്യൂഷൻ വേഗതയുണ്ട്, ഇത് ആദ്യ രണ്ട് ഓപ്ഷനുകളേക്കാൾ ഏകദേശം രണ്ട് മടങ്ങ് കുറവാണ്. അതിനാൽ, ഒരു ഡാറ്റാബേസിൻ്റെ പ്രവർത്തനം ഒപ്റ്റിമൈസ് ചെയ്യുമ്പോൾ, COUNT() ഉള്ള സബ്ക്വറികൾ അടങ്ങിയ അന്വേഷണത്തിൻ്റെ രണ്ടാമത്തെ പതിപ്പ് ഉപയോഗിക്കാൻ ഞാൻ ശുപാർശ ചെയ്യുന്നു, ഒന്നാമതായി, അതിൻ്റെ നിർവ്വഹണ വേഗത ഏറ്റവും വേഗതയേറിയ ഫലത്തോട് അടുത്താണ്, രണ്ടാമതായി, ഒരു അന്വേഷണത്തിനുള്ളിൽ അത്തരമൊരു ഓർഗനൈസേഷൻ വളരെ സൗകര്യപ്രദമാണ്. .
കഴിഞ്ഞ പാഠത്തിൽ ഞങ്ങൾ ഒരു അസൗകര്യം നേരിട്ടു. "സൈക്കിളുകൾ" എന്ന വിഷയം ആരാണ് സൃഷ്ടിച്ചതെന്ന് അറിയാൻ ഞങ്ങൾ ആഗ്രഹിച്ചപ്പോൾ, ഞങ്ങൾ ഒരു അനുബന്ധ അഭ്യർത്ഥന നടത്തി:
രചയിതാവിൻ്റെ പേരിനുപകരം, ഞങ്ങൾക്ക് അവൻ്റെ ഐഡൻ്റിഫയർ ലഭിച്ചു. ഇത് മനസ്സിലാക്കാവുന്നതേയുള്ളൂ, കാരണം ഞങ്ങൾ ഒരു ടേബിളിലേക്ക് ഒരു അന്വേഷണം നടത്തി - വിഷയങ്ങൾ, വിഷയ രചയിതാക്കളുടെ പേരുകൾ മറ്റൊരു പട്ടികയിൽ സംഭരിച്ചിരിക്കുന്നു - ഉപയോക്താക്കൾ. അതിനാൽ, വിഷയ രചയിതാവിൻ്റെ ഐഡൻ്റിഫയർ കണ്ടെത്തി, ഞങ്ങൾ മറ്റൊരു അന്വേഷണം നടത്തേണ്ടതുണ്ട് - ഉപയോക്തൃ പട്ടികയിലേക്ക് അവൻ്റെ പേര് കണ്ടെത്താൻ:

അവയിലൊന്ന് ഒരു സബ്ക്വറി (നെസ്റ്റഡ് ക്വറി) ആക്കി മാറ്റിക്കൊണ്ട് അത്തരം അന്വേഷണങ്ങളെ ഒന്നായി സംയോജിപ്പിക്കാനുള്ള കഴിവ് SQL നൽകുന്നു. അതിനാൽ, "സൈക്കിളുകൾ" എന്ന വിഷയം ആരാണ് സൃഷ്ടിച്ചതെന്ന് കണ്ടെത്താൻ, ഞങ്ങൾ ഇനിപ്പറയുന്ന അന്വേഷണം നടത്തും:
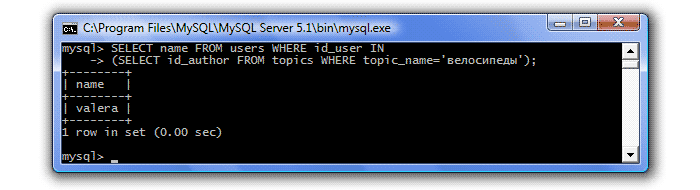
അതായത്, കീവേഡിന് ശേഷം എവിടെ, ഞങ്ങൾ മറ്റൊരു അഭ്യർത്ഥന വ്യവസ്ഥയിൽ എഴുതുന്നു. MySQL ആദ്യം സബ്ക്വറി പ്രോസസ്സ് ചെയ്യുന്നു, id_author=2 നൽകുന്നു, ഈ മൂല്യം ക്ലോസിലേക്ക് കൈമാറുന്നു. എവിടെബാഹ്യ അഭ്യർത്ഥന.
ഒരു ചോദ്യത്തിൽ നിരവധി ഉപചോദ്യങ്ങൾ ഉണ്ടാകാം, അത്തരം ഒരു ചോദ്യത്തിനുള്ള വാക്യഘടന ഇപ്രകാരമാണ്: ഉപചോദ്യങ്ങൾക്ക് ഒരു കോളം മാത്രമേ തിരഞ്ഞെടുക്കാനാകൂ എന്നത് ശ്രദ്ധിക്കുക, അവയുടെ മൂല്യങ്ങൾ ബാഹ്യ അന്വേഷണത്തിലേക്ക് മടങ്ങും. ഒന്നിലധികം നിരകൾ തിരഞ്ഞെടുക്കാൻ ശ്രമിക്കുന്നത് ഒരു പിശകിന് കാരണമാകും.
ഇത് ഏകീകരിക്കുന്നതിന്, നമുക്ക് മറ്റൊരു അഭ്യർത്ഥന നടത്താം കൂടാതെ ഫോറത്തിൽ "സൈക്കിൾ" വിഷയത്തിൻ്റെ രചയിതാവ് എന്ത് സന്ദേശങ്ങളാണ് നൽകിയതെന്ന് കണ്ടെത്താം:

ഇപ്പോൾ നമുക്ക് ചുമതല സങ്കീർണ്ണമാക്കാം, "സൈക്കിൾ" വിഷയത്തിൻ്റെ രചയിതാവ് ഏത് വിഷയത്തിലാണ് സന്ദേശങ്ങൾ അയച്ചതെന്ന് കണ്ടെത്തുക:

ഇത് എങ്ങനെ പ്രവർത്തിക്കുന്നുവെന്ന് നമുക്ക് കണ്ടെത്താം.
- MySQL ആദ്യം ഏറ്റവും ആഴത്തിലുള്ള ചോദ്യം എക്സിക്യൂട്ട് ചെയ്യും:
- തത്ഫലമായുണ്ടാകുന്ന ഫലം (id_author=2) ഒരു ബാഹ്യ അഭ്യർത്ഥനയിലേക്ക് കൈമാറും, അത് ഫോം എടുക്കും:
- തത്ഫലമായുണ്ടാകുന്ന ഫലം (id_topic:4,1) ഒരു ബാഹ്യ അഭ്യർത്ഥനയിലേക്ക് കൈമാറും, അത് ഫോം എടുക്കും:
- ഇത് അന്തിമ ഫലം നൽകും (വിഷയ_നാമം: മത്സ്യബന്ധനത്തെക്കുറിച്ച്, മത്സ്യബന്ധനത്തെക്കുറിച്ച്). ആ. "സൈക്കിൾ" വിഷയത്തിൻ്റെ രചയിതാവ് സെർജി സൃഷ്ടിച്ച "മത്സ്യബന്ധനത്തെക്കുറിച്ച്" വിഷയത്തിലും (id=1) സ്വെറ്റ സൃഷ്ടിച്ച "മത്സ്യബന്ധനത്തെക്കുറിച്ച്" വിഷയത്തിലും (id=4) സന്ദേശങ്ങൾ അയച്ചു.
- മൂന്നിൽ കൂടുതൽ നെസ്റ്റിംഗ് ഡിഗ്രി ഉള്ള അന്വേഷണങ്ങൾ സൃഷ്ടിക്കാൻ ശുപാർശ ചെയ്യുന്നില്ല. ഇത് എക്സിക്യൂഷൻ സമയവും കോഡ് മനസ്സിലാക്കുന്നതിലെ ബുദ്ധിമുട്ടും വർദ്ധിപ്പിക്കുന്നു.
- നെസ്റ്റഡ് അന്വേഷണങ്ങൾക്കായി നൽകിയിരിക്കുന്ന വാക്യഘടന ഒരുപക്ഷേ ഏറ്റവും സാധാരണമാണ്, എന്നാൽ ഒരേയൊരു കാര്യമല്ല. ഉദാഹരണത്തിന്, ചോദിക്കുന്നതിനുപകരം
എഴുതുക
ആ. WHERE കീവേഡ് ഉപയോഗിച്ച് ഉപയോഗിക്കുന്ന ഏത് ഓപ്പറേറ്റർമാരെയും നമുക്ക് ഉപയോഗിക്കാം (അവസാന പാഠത്തിൽ ഞങ്ങൾ അവരെ പഠിച്ചു).
- MySQL
ദൈനംദിന ജോലിയിൽ, ചോദ്യങ്ങൾ എഴുതുമ്പോൾ നിങ്ങൾക്ക് സമാനമായ പിശകുകൾ നേരിടേണ്ടിവരും.
ഈ ലേഖനത്തിൽ ചോദ്യങ്ങൾ എങ്ങനെ എഴുതരുത് എന്നതിൻ്റെ ഉദാഹരണങ്ങൾ നൽകാൻ ഞാൻ ആഗ്രഹിക്കുന്നു.
- എല്ലാ ഫീൽഡുകളും തിരഞ്ഞെടുക്കുക
പട്ടികയിൽ നിന്ന് * തിരഞ്ഞെടുക്കുകചോദ്യങ്ങൾ എഴുതുമ്പോൾ, എല്ലാ ഫീൽഡുകളുടെയും തിരഞ്ഞെടുക്കൽ ഉപയോഗിക്കരുത് - "*". നിങ്ങൾക്ക് ശരിക്കും ആവശ്യമുള്ള ഫീൽഡുകൾ മാത്രം ലിസ്റ്റ് ചെയ്യുക. ഇത് ലഭിച്ചതും അയച്ചതുമായ ഡാറ്റയുടെ അളവ് കുറയ്ക്കും. കൂടാതെ, ഇൻഡെക്സുകൾ മറയ്ക്കുന്നതിനെക്കുറിച്ച് മറക്കരുത്. നിങ്ങൾക്ക് യഥാർത്ഥത്തിൽ പട്ടികയിലെ എല്ലാ ഫീൽഡുകളും ആവശ്യമാണെങ്കിലും, അവ പട്ടികപ്പെടുത്തുന്നതാണ് നല്ലത്. ഒന്നാമതായി, ഇത് കോഡിൻ്റെ വായനാക്ഷമത മെച്ചപ്പെടുത്തുന്നു. ഒരു നക്ഷത്രചിഹ്നം ഉപയോഗിക്കുമ്പോൾ, അത് നോക്കാതെ പട്ടികയിൽ ഏതൊക്കെ ഫീൽഡുകൾ ഉണ്ടെന്ന് അറിയാൻ കഴിയില്ല. രണ്ടാമതായി, കാലക്രമേണ, നിങ്ങളുടെ ടേബിളിലെ നിരകളുടെ എണ്ണം മാറിയേക്കാം, ഇന്ന് അഞ്ച് INT കോളങ്ങൾ ഉണ്ടെങ്കിൽ, ഒരു മാസത്തിനുള്ളിൽ TEXT, BLOB ഫീൽഡുകൾ ചേർത്തേക്കാം, അത് തിരഞ്ഞെടുക്കലിനെ മന്ദഗതിയിലാക്കും.
- ഒരു സൈക്കിളിൽ അഭ്യർത്ഥനകൾ.
SQL ഒരു സെറ്റ് ഓപ്പറേറ്റിംഗ് ഭാഷയാണെന്ന് നിങ്ങൾ വ്യക്തമായി മനസ്സിലാക്കേണ്ടതുണ്ട്. ചില സമയങ്ങളിൽ നടപടിക്രമ ഭാഷകളിൽ ചിന്തിക്കാൻ ശീലിച്ച പ്രോഗ്രാമർമാർക്ക് അവരുടെ ചിന്തയെ സെറ്റുകളുടെ ഭാഷയിലേക്ക് മാറ്റുന്നത് ബുദ്ധിമുട്ടാണ്. ലളിതമായ ഒരു നിയമം സ്വീകരിച്ചുകൊണ്ട് ഇത് വളരെ ലളിതമായി ചെയ്യാൻ കഴിയും - "ഒരു ലൂപ്പിൽ അന്വേഷണങ്ങൾ ഒരിക്കലും എക്സിക്യൂട്ട് ചെയ്യരുത്." ഇത് എങ്ങനെ ചെയ്യാമെന്നതിൻ്റെ ഉദാഹരണങ്ങൾ:1. സാമ്പിളുകൾ
$news_ids = get_list("ഇന്നത്തെ_വാർത്തയിൽ നിന്ന് വാർത്ത_ഐഡി തിരഞ്ഞെടുക്കുക ");
അതേസമയം($news_id = get_next($news_ids))
$news = get_row("തലക്കെട്ട് തിരഞ്ഞെടുക്കുക, വാർത്തയിൽ നിന്ന് ബോഡി എവിടെ news_id = ". $news_id);നിയമം വളരെ ലളിതമാണ് - കുറച്ച് അഭ്യർത്ഥനകൾ, മികച്ചത് (ഏത് നിയമത്തെയും പോലെ ഇതിന് ഒഴിവാക്കലുകൾ ഉണ്ടെങ്കിലും). IN() നിർമ്മിതിയെ കുറിച്ച് മറക്കരുത്. മുകളിലുള്ള കോഡ് ഒരു ചോദ്യത്തിൽ എഴുതാം:
ശീർഷകം തിരഞ്ഞെടുക്കുക, ഇന്നത്തെ_വാർത്തയിൽ നിന്ന് ബോഡി തിരഞ്ഞെടുക്കുക.2. ഉൾപ്പെടുത്തലുകൾ
$ലോഗ് = parse_log();
അതേസമയം($റെക്കോർഡ് = അടുത്തത്($ലോഗ്))
ചോദ്യം("ലോഗുകളിലേക്ക് തിരുകുക സെറ്റ് മൂല്യം = ". $log["value"]);!}ഒരു ചോദ്യം സംയോജിപ്പിച്ച് നടപ്പിലാക്കുന്നത് കൂടുതൽ കാര്യക്ഷമമാണ്:
ലോഗുകളിലേക്ക് തിരുകുക (മൂല്യം) മൂല്യങ്ങൾ (...), (...)3. അപ്ഡേറ്റുകൾ
ചിലപ്പോൾ നിങ്ങൾ ഒരു പട്ടികയിൽ നിരവധി വരികൾ അപ്ഡേറ്റ് ചെയ്യേണ്ടതുണ്ട്. പുതുക്കിയ മൂല്യം ഒന്നുതന്നെയാണെങ്കിൽ, എല്ലാം ലളിതമാണ്:
വാർത്ത അപ്ഡേറ്റ് ചെയ്യുക SET ശീർഷകം="test" WHERE id IN (1, 2, 3).!}ഓരോ റെക്കോർഡിനും മാറ്റുന്ന മൂല്യം വ്യത്യസ്തമാണെങ്കിൽ, ഇനിപ്പറയുന്ന ചോദ്യം ഉപയോഗിച്ച് ഇത് ചെയ്യാൻ കഴിയും:
വാർത്താ സെറ്റ് അപ്ഡേറ്റ് ചെയ്യുക
തലക്കെട്ട് = കേസ്
എപ്പോൾ news_id = 1 അപ്പോൾ "aa"
എപ്പോൾ news_id = 2 അപ്പോൾ "bb" END
എവിടെ വാർത്ത_ഐഡി (1, 2)അത്തരം ഒരു അഭ്യർത്ഥന നിരവധി വ്യത്യസ്ത അഭ്യർത്ഥനകളേക്കാൾ 2-3 മടങ്ങ് വേഗതയുള്ളതാണെന്ന് ഞങ്ങളുടെ പരിശോധനകൾ കാണിക്കുന്നു.
- സൂചികയിലാക്കിയ ഫീൽഡുകളിൽ പ്രവർത്തനങ്ങൾ നടത്തുന്നു
ഉപയോക്താക്കളിൽ നിന്ന് user_id തിരഞ്ഞെടുക്കുക. blogs_count * 2 = $valueblogs_count കോളം സൂചികയിലാക്കിയാലും ഈ അന്വേഷണം സൂചിക ഉപയോഗിക്കില്ല. ഒരു സൂചിക ഉപയോഗിക്കുന്നതിന്, അന്വേഷണത്തിലെ സൂചികയിലുള്ള ഫീൽഡിൽ പരിവർത്തനങ്ങളൊന്നും നടത്തേണ്ടതില്ല. അത്തരം അഭ്യർത്ഥനകൾക്കായി, പരിവർത്തന പ്രവർത്തനങ്ങൾ മറ്റൊരു ഭാഗത്തേക്ക് നീക്കുക:
ഉപയോക്താക്കളിൽ നിന്ന് user_id തിരഞ്ഞെടുക്കുക. blogs_count = $value / 2;സമാനമായ ഉദാഹരണം:
TO_DAYS (CURRENT_DATE) - TO_DAYS (രജിസ്റ്റർ ചെയ്തത്) = DATE_SUB(CURRENT_DATE, INTERVAL 10 ദിവസം) ഉപയോക്താക്കളിൽ നിന്ന് user_id തിരഞ്ഞെടുക്കുക;
ചെയ്യും. - അവയുടെ എണ്ണം എണ്ണാൻ വേണ്ടി മാത്രം വരികൾ എടുക്കുന്നു
$ഫലം = mysql_query("പട്ടികയിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക", $ലിങ്ക്);
$num_rows = mysql_num_rows($result);
ഒരു നിശ്ചിത വ്യവസ്ഥ പാലിക്കുന്ന വരികളുടെ എണ്ണം നിങ്ങൾക്ക് തിരഞ്ഞെടുക്കണമെങ്കിൽ, വരികളുടെ എണ്ണം കണക്കാക്കാൻ എല്ലാ വരികളും തിരഞ്ഞെടുക്കുന്നതിനുപകരം പട്ടിക ചോദ്യത്തിൽ നിന്ന് SELECT COUNT(*) ഉപയോഗിക്കുക. - അധിക വരികൾ ലഭ്യമാക്കുന്നു
$ഫലം = mysql_query("ടേബിൾ1ൽ നിന്ന് * തിരഞ്ഞെടുക്കുക", $ലിങ്ക്);
അതേസമയം($റോ = mysql_fetch_assoc($ഫലം) && $i< 20) {
…
}
നിങ്ങൾക്ക് വരികൾ ലഭിക്കാൻ n ആവശ്യമുണ്ടെങ്കിൽ, ആപ്ലിക്കേഷനിലെ അധിക വരികൾ ഉപേക്ഷിക്കുന്നതിന് പകരം LIMIT ഉപയോഗിക്കുക. - RAND () പ്രകാരം ഓർഡർ ഉപയോഗിക്കുന്നു
തിരഞ്ഞെടുക്കുക * പട്ടികയിൽ നിന്ന് RAND () പരിധി 1 പ്രകാരം ഓർഡർ ചെയ്യുക;പട്ടികയിൽ 4-5 ആയിരത്തിലധികം വരികൾ ഉണ്ടെങ്കിൽ, RAND () പ്രകാരം ഓർഡർ ചെയ്യുന്നത് വളരെ സാവധാനത്തിൽ പ്രവർത്തിക്കും. രണ്ട് ചോദ്യങ്ങൾ പ്രവർത്തിപ്പിക്കുന്നത് കൂടുതൽ കാര്യക്ഷമമായിരിക്കും:
പട്ടികയിൽ ഒരു auto_increment പ്രാഥമിക കീയും വിടവുകളുമില്ലെങ്കിൽ:
$rnd = rand(1, query("ടേബിളിൽ നിന്ന് MAX(id) തിരഞ്ഞെടുക്കുക"));
$റോ = അന്വേഷണം ("പട്ടികയിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക * എവിടെ ഐഡി = ".$rnd);അഥവാ:
$cnt = അന്വേഷണം ("പട്ടികയിൽ നിന്ന് COUNT(*) തിരഞ്ഞെടുക്കുക");
$റോ = അന്വേഷണം ("ടേബിൾ പരിധിയിൽ നിന്ന് * തിരഞ്ഞെടുക്കുക ".$cnt.", 1");
എന്നിരുന്നാലും, പട്ടികയിൽ വളരെയധികം വരികൾ ഉണ്ടെങ്കിൽ അത് മന്ദഗതിയിലാകും. - ഒരു വലിയ സംഖ്യ ജോയിനുകൾ ഉപയോഗിക്കുന്നു
തിരഞ്ഞെടുക്കുക
v.video_id
ഒരു പേര്,
g.genre
നിന്ന്
വീഡിയോകൾ AS v
ഇടത് ചേരുക
link_actors_videos AS la ON la.video_id = v.video_id
ഇടത് ചേരുക
അഭിനേതാക്കൾ ഓൺ a.actor_id = la.actor_id
ഇടത് ചേരുക
link_genre_video AS lg ON lg.video_id = v.video_id
ഇടത് ചേരുക
g.genre_id = lg.genre_idടേബിളുകൾ ഒന്നിൽ നിന്ന് പലതിലേക്ക് ബന്ധിപ്പിക്കുമ്പോൾ, ഓരോ അടുത്ത ചേരുമ്പോഴും തിരഞ്ഞെടുക്കലിലെ വരികളുടെ എണ്ണം വർദ്ധിക്കും. അത്തരം സന്ദർഭങ്ങളിൽ, അത്തരം ഒരു ചോദ്യം നിരവധി ലളിതമായവയായി വിഭജിക്കുന്നത് വേഗത്തിലാണ്.
- LIMIT ഉപയോഗിക്കുന്നു
തിരഞ്ഞെടുക്കുക... പട്ടിക പരിധിയിൽ നിന്ന് $start, $per_pageഅത്തരമൊരു ചോദ്യം $per_page റെക്കോർഡുകൾ (സാധാരണയായി 10-20) തിരികെ നൽകുമെന്നും അതിനാൽ വേഗത്തിൽ പ്രവർത്തിക്കുമെന്നും പലരും കരുതുന്നു. ആദ്യത്തെ കുറച്ച് പേജുകളിൽ ഇത് വേഗത്തിൽ പ്രവർത്തിക്കും. എന്നാൽ റെക്കോർഡുകളുടെ എണ്ണം വലുതാണെങ്കിൽ, നിങ്ങൾ ഒരു SELECT എക്സിക്യൂട്ട് ചെയ്യേണ്ടതുണ്ട്... പട്ടികയിൽ നിന്ന് LIMIT 1000000, 1000020 ചോദ്യം, അങ്ങനെയുള്ള ഒരു ചോദ്യം എക്സിക്യൂട്ട് ചെയ്യാൻ, MySQL ആദ്യം 1000020 റെക്കോർഡുകൾ തിരഞ്ഞെടുത്ത് ആദ്യത്തെ മില്യൺ ഉപേക്ഷിച്ച് 20 തിരികെ നൽകും. ഇത് ഒട്ടും വേഗതയില്ലായിരിക്കാം. പ്രശ്നം പരിഹരിക്കാൻ നിസ്സാരമായ വഴികളൊന്നുമില്ല. പലരും ലഭ്യമായ പേജുകളുടെ എണ്ണം ന്യായമായ സംഖ്യയായി പരിമിതപ്പെടുത്തുന്നു. കവറിംഗ് ഇൻഡക്സുകളോ മൂന്നാം കക്ഷി സൊല്യൂഷനുകളോ ഉപയോഗിച്ച് നിങ്ങൾക്ക് അത്തരം അന്വേഷണങ്ങൾ വേഗത്തിലാക്കാം (ഉദാഹരണത്തിന് സ്ഫിൻക്സ്).
- ഡ്യൂപ്ലിക്കേറ്റ് കീ അപ്ഡേറ്റിൽ ഉപയോഗിക്കുന്നില്ല
$റോ = അന്വേഷണം ("തിരഞ്ഞെടുക്കുക * പട്ടികയിൽ നിന്ന് എവിടെയാണ് ഐഡി=1");എങ്കിൽ ($ വരി)
ചോദ്യം ("പട്ടിക സെറ്റ് കോളം അപ്ഡേറ്റ് ചെയ്യുക = കോളം + 1 എവിടെ ഐഡി = 1")
വേറെ
ചോദ്യം ("ടേബിൾ സെറ്റ് കോളം = 1, ഐഡി = 1");ഐഡി ഫീൽഡിനായി ഒരു പ്രാഥമിക അല്ലെങ്കിൽ അതുല്യമായ കീ ഉണ്ടെങ്കിൽ സമാനമായ ഒരു നിർമ്മാണം ഒരു ചോദ്യം ഉപയോഗിച്ച് മാറ്റിസ്ഥാപിക്കാം:
പട്ടികയിലേക്ക് തിരുകുക സെറ്റ് കോളം = 1, ഐഡി = 1 ഡ്യൂപ്ലിക്കേറ്റ് കീയിൽ അപ്ഡേറ്റ് കോളം = കോളം + 1
























