Je li Haswellova arhitektura vrijedna naziva se novom i redizajniranom?
Više od pet godina Intel je slijedio strategiju tik-tak, izmjenjujući prijelaz specifične arhitekture na sofisticiranije tehnološke norme s izdavanjem nove arhitekture.
Kao rezultat toga, svake godine dobivamo ili novu arhitekturu ili prijelaz na novi tehnički proces. Za 2013. planirano je “tako”, odnosno izlazak nove arhitekture - Haswell. Procesori s novom arhitekturom proizvode se koristeći istu procesnu tehnologiju kao prethodna generacija Ivy Bridge: 22 nm, Tri-gate. Tehnički proces se nije promijenio, ali je povećan broj tranzistora, što znači da je povećana i završna površina kristala novog procesora - a nakon toga i potrošnja energije.
Pridržavajući se tradicije, Intel je predstavio samo produktivne i skupi procesori Core i5 i i7 linije. Obavijest dvojezgreni procesori juniorske linije, kao i uvijek, kasne. Vrijedno je napomenuti da su cijene novih procesora ostale na istoj razini kao Ivy Bridge.
Usporedimo područja matrice različitih generacija četverojezgrenih procesora:
Kao što vidite, četverojezgreni Haswell ima površinu od samo 177 mm², dok je integriran Sjeverni most, kontrolor RAM memorija i grafička jezgra. Tako se broj tranzistora povećao za 200 milijuna, a površina se povećala za 17 mm². Ako usporedimo Haswell sa 32nm Pješčani most, tada se broj tranzistora povećao za 440 milijuna (38%), a površina zbog prelaska na 22 nm procesnu tehnologiju smanjila se za 39 mm² (18%). Disipacija topline ostala je gotovo ista razina svih ovih godina (95 W za SB i 84 W za Haswell), a površina se smanjila.
Sve je to dovelo do činjenice da se sa svakog kvadratnog milimetra kristala mora ukloniti više topline. Ako je ranije od 216 mm² trebalo uzeti 95 W, odnosno 0,44 W/mm², sada je od površine od 177 mm² potrebno uzeti 84 W - 0,47 W/mm², što je 6,8% više nego prije . Ako se ovaj trend nastavi, uskoro će biti jednostavno fizički teško odvoditi toplinu s tako malih površina.
Čisto teoretski, možemo pretpostaviti da će se u Broadwellu, koji će se proizvoditi 14 nm procesnom tehnologijom, broj tranzistora povećati za 21%, kao pri prijelazu s 32 na 22 nm, a površina će se smanjiti za 26 % (u istom iznosu kao i kod prelaska s 32 na 22 nm), dobivamo 1,9 milijardi tranzistora na površini od 131 mm². Ako i rasipanje topline padne za 19%, tada dobivamo 68 W, odnosno 0,52 W/mm².
Ovo su teoretski izračuni, u praksi će biti drugačije - prijelaz tehnološkog procesa s 32 na 22 nm obilježen je i uvođenjem 3D tranzistora, čime su smanjene struje curenja, a s njima i stvaranje topline. Međutim, još se ništa slično nije čulo o prijelazu s 22 nm na 14 nm, tako da će u praksi vrijednosti rasipanja topline najvjerojatnije biti još gore, a ne treba se nadati 0,52 W/mm². Međutim, čak i ako je razina rasipanja topline 0,52 W/mm², problem lokalnog pregrijavanja i poteškoća s odvođenjem topline s malog kristala postat će još akutniji.
Usput, upravo poteškoće s rasipanjem topline s razinom rasipanja topline od 0,52 W/mm² mogu biti u pozadini Intelove želje da prijeđe na BGA ili pokušaja ukidanja utičnice. Ako je procesor zalemljen na matičnu ploču, toplina će se izravno prenositi s čipa na hladnjak bez međupoklopca. Ovo izgleda još relevantnije u svjetlu zamjene lemljenja termalnom pastom ispod poklopaca moderni procesori. Ponovno možemo očekivati pojavu “golih” procesora s otvorenim kristalima po uzoru na Athlon XP, odnosno bez poklopca kao međukarike u hladnjaku.
To se radi na video karticama već duže vrijeme, a opasnost od krhotina kristala je ublažena željeznim okvirom oko njega, zbog čega video kartice nemaju takav “ trenutni problemi", poput termalne paste ispod poklopca procesora. Međutim, overclocking će postati još teži, i pravilno hlađenje“tanji” procesori su gotovo znanost. A sve nas to čeka vrlo brzo, ako se, naravno, ne dogodi čudo...
No, spustimo se na zemlju i vratimo se razgovoru o Haswellu. Kao što znamo, Haswell je primio brojna "poboljšanja/promjene" u odnosu na Sandy Bridge (i, sukladno tome, Ivy Bridge, što je uglavnom bio prijenos SB-a na suptilniji tehnički proces):
- ugrađeni regulator napona;
- novi načini uštede energije;
- povećanje volumena međuspremnika i redova čekanja;
- povećanje kapaciteta predmemorije;
- povećanje broja lansirnih otvora;
- dodavanje novih blokova, funkcija, API-ja u integriranu grafičku jezgru;
- povećanje broja cjevovoda u grafičkoj jezgri.
Dakle, pregled nove platforme može se podijeliti u tri dijela: procesor, integrirani grafički akcelerator, čipset.
Procesorski dio
Promjene na procesoru uključuju dodavanje novih uputa i novih načina za uštedu energije, uključivanje regulatora napona, kao i promjene na samoj jezgri procesora.
Setovi instrukcija
Arhitektura Haswell ima nove skupove instrukcija. Mogu se podijeliti u dvije velike skupine: one usmjerene na povećanje performansi vektora i one usmjerene na segment poslužitelja. Prvi uključuju AVX i FMA3, drugi - virtualizaciju i transakcijsku memoriju.
Napredna vektorska proširenja 2 (AVX2)
AVX paket je proširen na verziju AVX 2.0. Komplet AVX2 pruža:
- podrška za 256-bitne cjelobrojne vektore (prije je postojala samo podrška za 128-bitne);
- podrška za instrukcije prikupljanja, koje uklanjaju zahtjev za kontinuiranom lokacijom podataka u memoriji; sada se podaci “prikupljaju” s različitih memorijskih adresa - bit će zanimljivo vidjeti kako to utječe na performanse;
- dodavanje uputa za manipulaciju/operacije na bitovima.
općenito, novi set je više fokusiran na cjelobrojnu aritmetiku, a glavna korist od AVX 2.0 bit će vidljiva samo u cjelobrojnim operacijama.
Fused Multiply-Add (FMA3)
FMA je kombinirana operacija množenja i zbrajanja u kojoj se dva broja množe i dodaju akumulatoru. Ovaj tip operacije su prilično uobičajene i omogućuju učinkovitiju implementaciju množenja vektora i matrica. Podrška za ovo proširenje trebala bi značajno povećati performanse vektorskih operacija. FMA3 je već podržan u AMD procesorima s Piledriver jezgrom, a FMA4 je već podržan u Bulldozeru.
FMA je kombinacija operacije množenja i zbrajanja: a=b×c+d.
Što se tiče FMA3, to su instrukcije od tri operanda, odnosno rezultat se upisuje u jedan od tri operanda koji sudjeluju u instrukciji. Kao rezultat, dobivamo operaciju poput a=b×c+a, a=a×b+c, a=b×a+c.
FMA4 su instrukcije s četiri operanda s rezultatom upisanim u četvrti operand. Instrukcija ima oblik: a=b×c+d.
Govoreći o FMA3: ova će inovacija povećati produktivnost za više od 30% ako se kôd prilagodi FMA3. Vrijedno je napomenuti da je Intel planirao implementirati FMA4 umjesto FMA3, dok je Haswell još bio daleko na horizontu, ali je kasnije promijenio svoju odluku u korist FMA3. Najvjerojatnije je upravo zbog toga Bulldozer izašao s podrškom za FMA4: kažu, nisu ga imali vremena pretvoriti u Intel (ali Piledriver je izašao s FMA3). Štoviše, u početku je Bulldozer 2007. bio planiran s FMA3, ali nakon objave Intelovih planova za uvođenje FMA4 2008. godine AMD predomislio se izdavanjem Buldožera s FMA4. I Intel je zatim promijenio FMA4 u FMA3 u svojim planovima, budući da je dobit od FMA4 u usporedbi s FMA3 mala, a komplikacije električnih logički sklopovi- značajno, što također povećava proračun tranzistora.
Dobici od AVX2 i FMA3 pojavit će se nakon što se softver prilagodi tim skupovima uputa, tako da ne biste trebali očekivati nikakve dobitke u performansama "ovdje i sada". A budući da su proizvođači softvera prilično inertni, "dodatne" performanse će morati pričekati.
Transakcijska memorija
Evolucija mikroprocesora dovela je do porasta broja niti - moderni desktop procesor ima ih osam ili više. Veliki broj niti stvara sve više i više poteškoća pri implementaciji višenitnog pristupa memoriji. Potrebno je kontrolirati relevantnost varijabli u RAM-u: potrebno je pravodobno blokirati podatke za upisivanje za neke niti, a omogućiti čitanje ili promjenu podataka za druge niti. Ovo je težak zadatak, a transakcijska memorija razvijena je kako bi se podaci održavali svježima u programima s više niti. Ali prije danas implementiran je u softver, što je smanjilo performanse.
Haswell ima nove Transactional Synchronization Extensions (TSX) - transakcijsku memoriju, koja je dizajnirana za učinkovitu implementaciju višenitnih programa i povećanje njihove pouzdanosti. Ovo proširenje vam omogućuje implementaciju transakcijske memorije "u hardveru", čime se povećava ukupna izvedba.
Što je transakcijska memorija? Ovo je memorija koja u sebi ima mehanizam za upravljanje paralelnim procesima kako bi se omogućio pristup zajedničkim podacima. TSX proširenje sastoji se od dvije komponente: Hardware Lock Elision (HLE) i Restricted Transaction Memory (RTM).
RTM komponenta je skup instrukcija koje programer može koristiti za pokretanje, završetak i prekid transakcije. HLE komponenta uvodi prefikse koje ignoriraju procesori bez TSX podrške. Prefiksi omogućuju zaključavanje varijabli, dopuštajući drugim procesima da koriste (čitaju) zaključane varijable i izvršavaju svoj kod dok ne dođe do sukoba upisa zaključanih podataka.
Na ovaj trenutak Aplikacije koje koriste ovo proširenje već su se pojavile.
Virtualizacija
Važnost virtualizacije neprestano raste: sve ih je više virtualni poslužitelji smješteni na jednom fizičkom, a usluge u oblaku sve su raširenije. Stoga je povećanje brzine virtualizacijskih tehnologija i virtualiziranih okruženja vrlo hitan zadatak u segmentu poslužitelja. Haswell sadrži nekoliko poboljšanja usmjerenih posebno na povećanje performansi virtualiziranih okruženja. Nabrojimo ih:
- poboljšanja za smanjenje vremena potrebnog za prijelaz sa gostujućih sustava na glavni sustav;
- dodani pristupni bitovi proširenoj tablici stranica (EPT);
- Vrijeme pristupa TLB-u je smanjeno;
- nove upute za pozivanje hipervizora bez izvršavanja naredbe vmexit;
Kao rezultat toga, vrijeme prijelaza između virtualiziranih okruženja smanjeno je na manje od 500 procesorskih ciklusa. To bi trebalo rezultirati smanjenjem ukupnih opterećenja performansi povezanih s virtualizacijom. A novi Xeon E3-12xx-v3 će vjerojatno biti brži u ovoj klasi zadataka od Xeon E3-12xx-v2.
Ugrađeni regulator napona
U Haswellu je regulator napona premješten s matične ploče ispod poklopca procesora. Prethodno (Sandy Bridge) bilo je potrebno napajati različite napone procesora grafička jezgra, za agenta sustava, za jezgre procesora itd. Sada se preko utičnice na procesor dovodi samo jedan napon Vccin 1,75 V, koji se dovodi na ugrađeni regulator napona. Regulator napona sastoji se od 20 ćelija, svaka ćelija stvara 16 faza s ukupnom strujom od 25 A. Ukupno dobivamo 320 faza, što je znatno više od čak i najsofisticiranijih matičnih ploča. Ovaj pristup omogućuje ne samo pojednostavljenje rasporeda matičnih ploča (a time i smanjenje njihove cijene), već i točniju regulaciju napona unutar procesora, što zauzvrat dovodi do veće uštede energije.
Ovo je jedan od glavnih razloga zašto Haswell ne može biti fizički kompatibilan sa starim LGA1155 utičnicom. Da, možemo govoriti o Intelovoj želji da zaradi izdavanjem nove platforme svake godine ( novi čipset) i svake dvije godine - nova utičnica, ali u ovom slučaju postoji objektivni razlozi: fizička/električna nekompatibilnost.
Međutim, sve ima svoju cijenu. Regulator napona još je jedan primjetan izvor topline u novom procesoru. A s obzirom na to da se Haswell proizvodi koristeći istu procesnu tehnologiju kao i njegov prethodnik Ivy Bridge, trebali bismo očekivati da će procesor biti topliji.

Općenito, ovo će poboljšanje biti korisnije u mobilnom segmentu: brže i preciznije promjene napona smanjit će potrošnju energije, kao i učinkovitiju kontrolu frekvencije procesorskih jezgri. I očito, ovo nije prazna marketinška izjava, jer Intel će najaviti mobilne procesore s ultra niskom potrošnjom energije.
Novi načini za uštedu energije
Haswell ima nova S0ix stanja mirovanja, koja su slična S3/S4 stanjima, ali s mnogo bržim vremenom prijelaza CPU-a radni uvjeti. Dodano je i novo stanje mirovanja C7.
C7 način rada prati gašenje glavnog dijela procesora, dok slika na ekranu ostaje aktivna.
Minimalna frekvencija mirovanja procesora je 800 MHz, što bi također trebalo smanjiti potrošnju energije.
Arhitektura procesora


Front-end

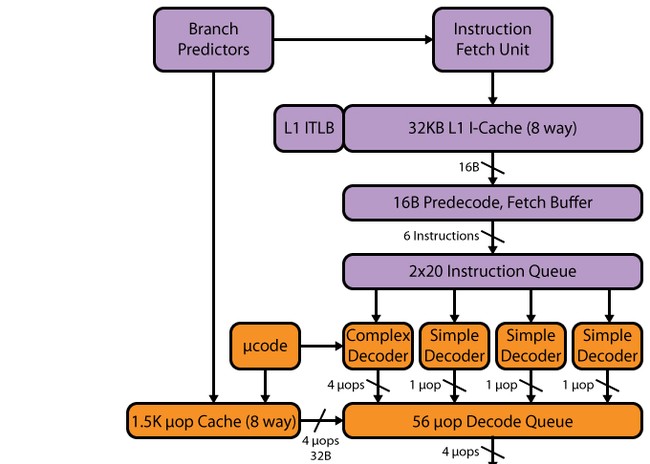
Haswellov cjevovod, kao iu SB-u, ima 14-19 stupnjeva: 14 stupnjeva za pogodak µop cachea, 19 za promašaj. Veličina predmemorije µop nije se promijenila u usporedbi sa SB - 1536 µop. Organizacija uop cachea ostala je ista kao u SB - 32 seta od osam redaka, svaki sa šest uops. Iako bi se zbog povećanja broja izvršnih uređaja, kao i naknadnih međuspremnika nakon uop cachea, moglo očekivati povećanje uop cachea - do 1776 uops (zašto baš ovaj volumen, bit će riječi u nastavku).
Dekoder
Dekoder se, moglo bi se reći, nije promijenio - ostaje četverosmjerni, poput SB-a. Sastoji se od četiri paralelna kanala: jednog složenog prevoditelja (složeni dekoder) i tri jednostavna (jednostavni dekoder). Složeni prevoditelj može obraditi/dekodirati složene upute koje generiraju više od jednog uop-a. Preostala tri kanala su dekodirana jednostavne upute. Usput, zbog prisutnosti spajanja makrooperacija, učitavanje s izvršavanjem i istovar instrukcija generiraju, na primjer, jedan uop i mogu se dekodirati u "jednostavnim" dekoderskim kanalima. SSE upute također generiraju jedan uop, tako da se mogu dekodirati u bilo kojem od tri jednostavna kanala. S obzirom na pojavu 256-bitnog AVX-a, FMA3, kao i povećanog broja okidačkih priključaka i funkcijskih uređaja, ova brzina dekodera možda jednostavno neće biti dovoljna - i može postati usko grlo. Djelomično je ovo usko grlo "prošireno" L0m uop predmemorijom, ali ipak, imajući procesor s 8 portova za pokretanje, Intel bi trebao razmisliti o proširenju dekodera - posebno ne bi škodilo povećati broj složenih kanala.
Planer, međuspremnik za preuređivanje, izvršne jedinice


Nakon dekodera dolazi red dekodiranih instrukcija i tu vidimo prvu promjenu. SB je imao dva reda od 28 unosa - jedan red po virtualnoj Hyper-Threading (HT) niti. U Haswellu su dva reda čekanja spojena u jedan zajednički za dvije HT dretve s 56 unosa, odnosno volumen reda se nije mijenjao, ali se mijenjao koncept. Sada je cijeli volumen od 56 zapisa dostupan jednoj niti u odsutnosti druge - stoga možemo očekivati porast u aplikacijama s niskim nitima i onima s više niti (to je zbog činjenice da dvije niti mogu koristiti jedan red čekanja učinkovitije).
Međuspremnik za preuređivanje je također promijenjen - povećan je sa 168 na 192 unosa. To bi trebalo poboljšati učinkovitost HT-a zbog veće vjerojatnosti postojanja uop-ova koji su međusobno “neovisni”. Red čekanja za dekodirane mikro operacije povećan je s 54 na 60. Datoteke fizičkog registra koje su se pojavile u SB također su povećane - sa 160 na 168 registara za cijele operande i sa 144 na 168 za operande s pomičnim zarezom, koji bi trebali imati pozitivan učinak na izvedbu vektorskih izračuna.
Sažmimo sve podatke o promjenama u međuspremnicima i redovima u jednu tablicu.
U principu, promjene parametara u Haswellu izgledaju sasvim očekivano, s obzirom opća logika razvoj procesorske arhitekture Intel. Na temelju iste logike možemo pretpostaviti da u sljedećoj generaciji Veličine jezgri međuspremnici i redovi neće se povećati za više od 14%, odnosno veličina međuspremnika za preuređivanje bit će oko 218. Ali to su čisto teoretske pretpostavke.
Nakon niza dekodiranih operacija slijede priključci okidača i priključci koji su im pripojeni. funkcionalni uređaji. U ovoj fazi ćemo se detaljnije zadržati.
Kao što znamo, Sandy Bridge je imao šest lansirnih otvora, koje je naslijedio od Nehalema, a ovaj od Conroea. Odnosno, od 2006. godine, kada je Intel dodao još dva priključka na četiri dostupna za Pentium 4, broj priključaka za pokretanje nije se promijenio - dodani su samo novi funkcionalni uređaji. Međutim, vrijedno je spomenuti da je P4 imao neku vrstu originalne NetBurst arhitekture, u kojoj su njegova dva porta mogla izvesti dvije operacije u jednom taktu (iako ne sa svim operacijama). Ali bilo bi najispravnije pratiti evoluciju broja portova za pokretanje ne koristeći primjer P4, već koristeći primjer PIII, budući da P4 ima dugi cjevovod i portove za pokretanje s "dvostrukom" izvedbom i predmemoriju praćenja , a njegova cjelokupna arhitektura primjetno se razlikuje od općeprihvaćene. A Pentium III je vrlo blizu Conroeu u smislu funkcionalne sheme lansirnih otvora, a također ima kratki spremnik. Dakle, općenito možemo reći da je Conroe izravni nasljednik PIII. Na temelju toga može se konstatirati da je 2006. godine dodan samo jedan lansirni otvor u odnosu na PIII koji je imao pet lansirnih otvora.
Dakle, broj portova za lansiranje raste prilično sporo, a ako se dodaju novi, onda jedan po jedan. Haswell je dodao dva odjednom, dajući ukupno osam portova - još samo malo, i doći ćemo do Itaniuma. Sukladno tome, Haswell pokazuje teoretsku izvedbu na putu izvršenja od 8 UOP-a/ciklusu, od čega se 4 UOP-a troše na aritmetičke operacije, a preostala 4 su na memorijske operacije. Prisjetite se da je Conroe/Nehalem/SB imao 6 mopova po udaru: 3 mopa aritmetičke operacije i 3 modula za rad s memorijom. Ovo poboljšanje trebalo bi podići IPC ocjenu, a time doista postoje vrlo ozbiljne promjene u Haswell arhitekturi koje u potpunosti opravdavaju njezino mjesto kao “tako” u Intelovom razvojnom planu.
FU promjene u Haswellu

Povećan je i broj aktuatora. Novi šesti (sedmi) priključak dodao je dva dodatna aktuatora - uređaj za cjelobrojnu aritmetiku i pomak te uređaj za predviđanje grananja. Sedmi (osmi) port je odgovoran za istovar adrese.
Tako dobivamo četiri jedinice za izvršavanje cjelobrojne aritmetike, dok nam je Sandy Bridge dao samo tri. Stoga možemo očekivati povećanje brzine cjelobrojne aritmetike. Osim toga, u teoriji, ovo bi nam trebalo omogućiti da istovremeno izvodimo proračune s pomičnim zarezom i cjelobrojnim izračunima, što bi zauzvrat moglo povećati učinkovitost NT-a. U SB-u su izračuni s pomičnim zarezom provedeni na istim priključcima gdje su korišteni uređaji s cjelobrojnom funkcijom, pa je uglavnom došlo do blokiranja, tj. niste mogli imati „heterogeno“ opterećenje. Također treba napomenuti da dodavanje dodatni uređaj prijelaz u Haswellu omogućit će predviđanje prijelaza bez "blokiranja" tijekom aritmetičkih izračuna - prethodno je, tijekom cjelobrojnih izračuna, jedini prediktor grana bio blokiran, tj. bilo je moguće upravljati ili aritmetičkom izvršnom jedinicom ili prediktorom. Portovi 0 i 1 također su doživjeli promjene - sada podržavaju FMA3. sedmi (osmi) Intel priključak uveden za povećanje učinkovitosti i uklanjanje "blokiranja" - kada drugi i treći priključak rade za utovar, sedmi (osmi) priključak može se uključiti u istovar, što je prije bilo jednostavno nemoguće. Ovo rješenje je neophodno kako bi se osigurala velika brzina izvršavanja AVX/FMA3 koda.
Općenito, tako širok izvršni put može dovesti do promjene u HT-u - čineći ga četveronitnim. U ko Intel procesori Xeon Phi s mnogo užim HT izvršnim putem ima četiri niti, a kao što studije i testovi pokazuju, koprocesor se prilično dobro mjeri. To jest, čak i uži put izvršenja, u načelu, omogućuje vam učinkovit rad s četiri niti. A staza s osam portova za pokretanje može prilično učinkovito pokrenuti četiri niti, štoviše, prisutnost četiri niti može bolje učitati osam portova za pokretanje. Istina, za veću učinkovitost bit će potrebno povećati međuspremnike (prvenstveno međuspremnik za preuređivanje) za veću vjerojatnost "neovisnih" podataka.
Haswell je također udvostručio propusnost L1-L2, zadržavajući iste vrijednosti latencije. Ova mjera je jednostavno bila neophodna, budući da 32-bajtno pisanje i 16-bajtno čitanje jednostavno ne bi bilo dovoljno s obzirom na prisutnost osam portova za pokretanje, kao i 256-bitni AVX i FMA3.
| Pješčani most | Haswell | |
| L1i | 32k, 8-smjerni | 32k, 8-smjerni |
| L1d | 32k, 8-smjerni | 32k, 8-smjerni |
| Latencija | 4 mjere | 4 mjere |
| Brzina skidanja | 32 bajta/sat | 64 bajta/sat |
| Brzina pisanja | 16 bajtova po ciklusu | 32 bajta/sat |
| L2 | 256k, 8-smjerni | 256k, 8-smjerni |
| Latencija | 11 mjera | 11 mjera |
| Širina pojasa između L2 i L1 | 32 bajta/sat | 64 bajta/sat |
| L1i TLB | 4k: 128, 4-smjerni 2M/4M: 8/navoj | 4k: 128, 4-smjerni 2M/4M: 8/navoj |
| L1d TLB | 4k: 128, 4-smjerni 2M/4M: 7/navoj 1G: 4, 4-smjerni | 4k: 128, 4-smjerni 2M/4M: 7/navoj 1G: 4, 4-smjerni |
| L2 TLB | 4k: 512, 4-smjerni | 4k+2M podijeljeno: 1024, 8-smjerni |
TLB L2 povećan je na 1024 unosa, a pojavila se i podrška za stranice od dva megabajta. Povećanje TLB L2 također je povlačilo za sobom povećanje asocijativnosti s četiri na osam.
Što se tiče predmemorije treće razine, situacija s njom je dvosmislena: u novom procesoru latencija pristupa trebala bi se povećati zbog gubitaka sinkronizacije, jer sada L3 predmemorija radi na vlastitoj frekvenciji, a ne na frekvenciji procesorskih jezgri, kao što je bilo prije. Iako se pristup još uvijek izvodi na 32 bajta po taktu. S druge strane, Intel govori o promjenama System Agenta i poboljšanjima Load Balancer bloka, koji sada može paralelno obraditi više L3 cache zahtjeva i razdvojiti ih na podatkovne i nepodatkovne zahtjeve. Ovo bi trebalo povećati propusnost L3 predmemorije (neki testovi to potvrđuju, propusnost L3 predmemorije nešto je veća od IB-a).
Princip rada L3 predmemorije u Haswellu donekle je sličan Nehalemu. U Nehalemu je L3 predmemorija bila smještena u Uncoreu i imala je vlastitu fiksnu frekvenciju, dok je u SB-u L3 predmemorija bila vezana za procesorske jezgre - njena je frekvencija postala jednaka frekvenciji procesorskih jezgri. Zbog toga su se pojavili problemi - na primjer, kada su jezgre procesora radile na smanjenim frekvencijama bez opterećenja (a LLC je "zaspao"), a GPU je trebao visok LLC PS. To jest, ovo je rješenje ograničilo performanse GPU-a, a također je zahtijevalo da se jezgre procesora izvedu iz stanja mirovanja samo da bi se probudio LLC. Novi procesor za poboljšanje potrošnje energije i učinkovitosti GPU rad u gornjim situacijama L3 predmemorija radi na vlastitoj frekvenciji. Mobilna umjesto stolna rješenja trebala bi imati najviše koristi od ovog rješenja.
Vrijedno je napomenuti da veličine predmemorije imaju određenu ovisnost. Treća razina predmemorije je dva megabajta po jezgri, druga razina predmemorije je 256 KB, što je osam puta manje od L3 volumena po jezgri. Volumen predmemorije prve razine je pak osam puta manji od L2 i iznosi 32 KB. Uop cache savršeno se uklapa u ovu ovisnost: njegov volumen od 1536 uops je 7-9 puta manji od L1 (to je nemoguće točno odrediti, budući da je bitna veličina uopsa nepoznata, a Intel vjerojatno neće proširiti ovu temu ). S druge strane, međuspremnik za preuređivanje od 168 uops točno je osam puta manji od uop predmemorije od 1536 uops, iako bi se, na temelju široko rasprostranjenog povećanja u međuspremnicima i redovima čekanja, moglo očekivati povećanje uop predmemorije za 14%, tj. do 1776. Dakle, volumeni međuspremnika i predmemorija imaju proporcionalne veličine. Ovo je vjerojatno još jedan razlog zašto Intel ne povećava L1/L2 predmemorije, smatrajući takve omjere u volumenima najučinkovitijima u smislu povećanja performansi po povećanju područja. Vrijedno je napomenuti da procesori s ugrađenom vrhunskom grafičkom jezgrom imaju srednju brzu memoriju sa širokom pristupnom sabirnicom, koja sprema sve zahtjeve u RAM - i procesor i video akcelerator. Količina ove memorije je 128 MB. Za procesorske jezgre, ako ovu memoriju promatramo kao L4 cache, volumen je trebao biti 64 megabajta, a uz dodatak grafičke jezgre korištenje 128 MB izgleda sasvim logično.
Što se tiče memorijskog kontrolera, on nije dobio ni povećanje broja kanala niti povećanje frekvencije rada RAM-a, odnosno i dalje je isti memorijski kontroler s dvokanalnim pristupom na frekvenciji od 1600 MHz. Ova odluka izgleda prilično čudno, jer je prijelaz sa SB na IB povećao radnu frekvenciju ICP-a sa 1333 MHz na 1600 MHz, iako je to bio samo prijelaz arhitekture na novi tehnički proces. I sada imamo novu arhitekturu, dok je frekvencija rada memorije ostala na istoj razini.
Ovo izgleda još čudnije ako se prisjetimo poboljšanja u grafičkoj jezgri – uostalom, sjetimo se da je čak i jeftinija HD2500 video kartica u IB-u u potpunosti iskoristila propusnost od 25 GB/s. Sada su i performanse CPU-a i performanse grafike porasle, dok je propusnost memorije ostala na istoj razini. Na širem planu, konkurent stalno povećava memorijsku širinu pojasa u svojim APU-ima, a ona je veća od Intelove. Bilo bi logično očekivati da Haswell podržava memoriju s frekvencijom od 1866 MHz ili 2133 MHz, što bi povećalo propusnost na 30 odnosno 34 GB/s.
Kao rezultat toga, ova odluka Intela nije sasvim jasna. Najprije je konkurent uveo podršku za bržu memoriju bez posebni problemi. Drugo, cijena memorijskih modula koji rade na frekvenciji od 1866 MHz nije puno veća u usporedbi s modulima od 1600 MHz, a osim toga nitko nije obvezan kupiti memoriju od 1866 MHz - izbor bi bio na korisniku. Treće, ne može biti problema s podrškom ne samo za 1866 MHz, već i za 2133 MHz: od same najave Haswella postavljeni su svjetski rekordi u overklokiranju RAM-a, odnosno IKP bi mogao podnijeti bržu memoriju i bez ima li problema. Četvrto, linija poslužitelja Xeon E5-2500 V2 (Ivy Bridge-EP) tvrdi da podržava 1866 MHz, ali Intel obično uvodi podršku za brže memorijske standarde na ovom tržištu mnogo kasnije nego stolna rješenja.
U principu, moglo bi se pretpostaviti da u nedostatku konkurencije Intel ne treba “tek tako” nagomilavati svoje mišiće i dalje povećavati svoju nadmoć, ali ta je pretpostavka apsolutno netočna, budući da povećanje propusnosti memorije u pravilu povećava performanse integrirane grafičke jezgre i gotovo ne povećava performanse procesora. U isto vrijeme, Intel još uvijek zaostaje za AMD-om u grafičkim performansama, i posljednjih godina Sam Intel posvećuje sve više pažnje grafici, a stopa poboljšanja za nju je mnogo veća nego za jezgru procesora. Osim toga, ako se oslonimo na rezultate testiranja integrirane grafičke jezgre prethodne generacije HD4000, koji su pokazali da povećanje propusnosti memorije dovodi do povećanja grafičkih performansi do 30%, a također uzimajući u obzir da novi grafička jezgra HD4600 je primjetno brža od HD4000, a ovisnost performansi grafičke jezgre o PSP-u postaje još očiglednija. Nova grafička jezgra bit će još više ograničena "uskom" memorijskom propusnošću. Sumirajući sve činjenice, odluka Intela potpuno je neshvatljiva: tvrtka je sama "zadavila" svoju grafiku, ali bi povećanje propusnosti moglo poboljšati njezine performanse.
Vraćajući se na arhitekturu predmemorije, samo izbacimo jednu misao u prazno: budući da je dodan srednji predmemorija (mop cache), zašto ne dodati međupredmemoriju podataka veličine oko 4-8 KB i s nižim pristupom latencija između L1d predmemorije i izvršnih uređaja, kao iz P4 (budući da je koncept uop predmemorije preuzet iz Netbursta)? Podsjetimo se da je u P4 ova međupredmemorija podataka imala vrijeme pristupa od dva ciklusa takta, a jedan ciklus P4 bio je jednak otprilike 0,75 ciklusa takta konvencionalnog procesora, odnosno vrijeme pristupa je bilo oko jedan i pol ciklusa takta. Ipak, možda opet vidimo nešto slično – Intel se voli prisjećati dobro zaboravljenih starih stvari.
Kao što možete vidjeti, Intel je većinu arhitektonskih promjena usmjerio na povećanje performansi AVX/FMA3 koda: to je uključivalo povećanje propusnosti predmemorije, povećanje broja portova i povećanje stope učitavanja/učitavanja u put izvršenja. Kao rezultat toga, glavni dobitak performansi trebao bi doći od softvera napisanog pomoću AVX/FMA3. U principu, sudeći prema rezultatima testiranja, čini se da je tako. Suhe performanse na istoj frekvenciji u "starim" aplikacijama dobile su povećanje od oko 10% u usporedbi s prethodnom jezgrom, a aplikacije napisane pomoću novih skupova instrukcija pokazuju povećanje od više od 30%. Tako će se prednosti Haswell arhitekture otkriti kako se aplikacije optimiziraju za nove skupove instrukcija. Tada će Haswellova nadmoć nad SB-om postati očita.
Glavna korist od značajnog dijela inovacija bit će mobilni uređaji. U tome će im pomoći novi pristup L3 cacheu, ugrađeni regulator napona, novi načini mirovanja te niže minimalne radne frekvencije procesorskih jezgri.
Zaključak (procesorski dio)
Što možete očekivati od Haswella?
Zbog povećanja broja launch portova možemo očekivati porast IPC-a, pa će nova Haswell arhitektura već sada na istoj frekvenciji imati blagu prednost u odnosu na Sandy Bridge, čak i uz neoptimiziran softver. Instrukcije AVX2/FMA3 su temelj za budućnost, a ta budućnost ovisi o programerima softvera: što brže prilagode svoje aplikacije, brže krajnji korisnik dobit će poboljšanje performansi. Međutim, ne treba očekivati rast u svemu i svugdje: SIMD upute se uglavnom koriste u radu s multimedijskim podacima iu znanstvenim izračunima, tako da treba očekivati rast performansi u tim zadacima. Glavna korist od povećanja energetske učinkovitosti bit će u mobilnim sustavima, gdje je ovo pitanje zaista važno. Dakle, dva glavna područja u kojima nova Intel Haswell arhitektura ima značajne koristi su povećane SIMD performanse i povećana energetska učinkovitost.
Što se tiče primjenjivosti novih Haswell procesora, vrijedi ispitati nekoliko različitih opcija za njihovu upotrebu: u stolnim računalima, u poslužiteljima, u mobilnim rješenjima, za igrače, za overclockere.
Radna površina
Potrošnja energije nije ključan aspekt za desktop procesor, pa čak i u Europi sa skupom strujom, teško da će itko samo zbog toga prijeći na Haswell iz prethodnih generacija. Štoviše, TDP Haswella veći je od TDP-a IB-a, tako da će ušteda biti samo u slučaju minimalnih opterećenja. Kad se pitanje postavi na ovaj način, nema sumnje - ne isplati se.
Sa stajališta performansi, prijelaz također ne izgleda kao tako isplativ posao: maksimalno povećanje brzine procesorskih zadataka sada neće biti veće od 10%. Prelazak na Haswell sa Sandy Bridge ili Ivy Bridge bit će opravdan samo ako planirate koristiti aplikacije s kompetentnom podrškom za FMA3 i AVX2: podrška za FMA3 može dati povećanje u nekim aplikacijama od 30% do 70%. Poboljšanja vezana uz virtualizaciju i implementaciju transakcijske memorije su od malog interesa i koristi za desktop.
Poslužitelji i radne stanice
Uzimajući u obzir da poslužitelji rade kontinuirano 24 sata dnevno i imaju prilično visoko konstantno opterećenje procesora, Haswell vjerojatno neće biti bolji od IB-a u pogledu čiste potrošnje energije, iako bi mogao pružiti određeni dobitak u pogledu performansi po vatu. Malo je vjerojatno da će podrška za AVX2/FMA3 biti korisna u poslužiteljima, ali u radnim stanicama uključenim u znanstvene izračune. ova podrška bit će vrlo, vrlo koristan - ali samo ako su nove upute podržane u korištenom softveru. Transakcijska memorija je vrlo korisna stvar, ali ne uvijek: može dati povećanje u višenitnim programima iu programima koji rade s bazama podataka, ali za učinkovito korištenje nužna je i optimizacija softvera.
Ali sva poboljšanja povezana s virtualizacijom najvjerojatnije će dati dobar učinak, budući da se virtualna okruženja sada vrlo aktivno koriste i na većini fizičkih poslužitelja radi na nekoliko virtualnih. Štoviše, prevalencija virtualizacije se objašnjava ne samo primjetnim smanjenjem troškova virtualnog okruženja u smislu performansi, već i ekonomskom učinkovitošću: jeftinije je održavati više virtualnih poslužitelja na jednom fizičkom i omogućuje učinkovitije korištenje resursa, uključujući resurse procesora.
Tako dalje tržište poslužitelja Haswellov nastup treba pozdraviti pozitivno. Nakon promjene poslužitelja temeljenih na Xeon E3-1200v1 i Xeon E3-1200v2 na poslužitelje s Xeon E3-1200v3 (Haswell), odmah ćete dobiti povećanje učinkovitosti, a nakon optimizacije softvera za AVX2/FMA3 i transakcijsku memoriju, performanse će se povećati još više.
Mobilna rješenja
Glavna korist od uvođenja Haswella u mobilni segment, naravno, leži u području poboljšane potrošnje energije. Sudeći po Intelovim prezentacijama, ali i rezultatima testova koji se već pojavljuju na internetu, učinka doista ima, i to primjetnog.
U smislu čistih performansi, prijelaz s Ivy Bridgea na Haswell ne čini se tako razumnim pothvatom: neto dobit trebala bi biti relativno mala, a poboljšanja u pojedinačne komponente(ista virtualizacija ili multimedijske upute) vjerojatno neće puno dati korisniku mobilnog sustava, budući da rijetko stvaraju okruženja ili složene znanstvene izračune na prijenosnim računalima i tabletima.
Općenito, što se tiče performansi procesora, ne biste trebali očekivati puno, ali će mobilni sustavi sigurno zahtijevati povećanje performansi grafičke jezgre. Stoga, ako vam problemi s potrošnjom energije nisu kritično važni, ne biste trebali ozbiljno razmišljati o nadogradnji s Sandy Bridgea ili Ivy Bridgea - bolje je nastaviti s radom na postojećim sustavima dok potpuno ne zastare. Ako često radite na baterije, Haswell može pružiti značajno povećanje trajanja baterije.
Igrači
Pitanje potrošnje energije među igračima u Rusiji u pravilu nije problem - a zašto bi bio kada video kartice za igranje troše 200 vata ili više? Igrači također ne trebaju virtualizaciju i transakcijsku memoriju. Nije činjenica da će AVX2/FMA3 biti tražen posebno za igre, iako bi mogli biti korisni u fizičkim proračunima. Ono što ostaje je čista izvedba procesora, a ovdje je razlika s istim Ivy Bridgeom mala. Kao rezultat toga, za ovu kategoriju korisnika izravan prijelaz sa SB ili IB na Haswell također se ne čini relevantnim. Ali ima smisla prijeći na nove procesore Nehalem i Lynifield, a još više Conroe.
Overklokeri
Za overklokere bi novi procesor (ali, naravno, samo njegova “otključana” K-verzija) mogao biti zanimljiv, pogotovo ako ga je moguće “skalpirati”, odnosno skinuti metalni poklopac i izravno ohladiti kristal. Ako se to ne učini, rezultati overclockinga izgledaju još skromnije od onih kod Ivy Bridgea. Osim toga, integrirani regulator napona može biti ograničavajući faktor. Pročitajte više o ovome
We translate... Prevedi kineski (pojednostavljeni) kineski (tradicionalni) engleski francuski njemački talijanski portugalski ruski španjolski turski
Nažalost, trenutno ne možemo prevesti ove informacije - pokušajte ponovno kasnije.
Uvod
Softver dizajniran za komunikaciju i prijenos podataka zahtijeva vrlo visoke performanse jer prenosi ogroman broj malih paketa podataka. Jedna od značajki razvoja virtualizacijskih aplikacija mrežne funkcije(NFV) je da je potrebno koristiti virtualizaciju u najvećoj mogućoj mjeri, ali u isto vrijeme potrebnih slučajeva optimizirati aplikacije za korišteni hardver.
U ovom ću članku istaknuti tri značajke Intel® procesora koje su korisne za optimiziranje performansi NFV aplikacija: Tehnologije dodjele predmemorije (CAT), Intel® Advanced Vector Extensions 2 (Intel® AVX2) za vektorsku obradu i Intel® Transactional Synchronization Extensions (Intel® TSX).
Rješavanje problema inverzije prioriteta pomoću CAT-a
Kada funkcija niskog prioriteta krade resurse od funkcije visokog prioriteta, to nazivamo "inverzija prioriteta".
Ne sve virtualne funkcije jednako važno. Na primjer, funkcija usmjeravanja važna je za vrijeme obrade i performanse, dok funkcija kodiranja medija nije toliko važna. Ovoj se značajci vrlo lako može dopustiti da povremeno ispušta pakete bez utjecaja na korisničko iskustvo, budući da nitko ionako neće primijetiti smanjenje brzine sličica u sekundi s 20 na 19 sličica u sekundi.
Zadana predmemorija dizajnirana je na takav način da je prima najaktivniji korisnik najveći dio. Ali najaktivniji potrošač nije uvijek i najvažnija aplikacija. Zapravo, često je točno suprotno. Aplikacije visokog prioriteta su optimizirane, njihov volumen podataka smanjen je na najmanji mogući skup. Aplikacije niskog prioriteta ne zahtijevaju toliko truda u optimizaciji, pa obično zauzimaju više memorije. Neke od ovih funkcija zauzimaju puno memorije. Na primjer, funkcija praćenja paketa za statističku analizu ima nizak prioritet, ali troši puno memorije i intenzivno koristi predmemoriju.
Programeri često pretpostavljaju da ako stave jednu aplikaciju visokog prioriteta u određeni kernel, tada će aplikacija tamo biti sigurna i na nju neće utjecati aplikacije niskog prioriteta. Nažalost, nije. Svaka jezgra ima svoju predmemoriju razine 1 (L1, najbrža, ali najmanja predmemorija) i predmemoriju razine 2 (L2, nešto veća, ali sporija). Postoje odvojena područja L1 predmemorije za podatke (L1D) i programski kod (L1I, "I" označava upute). Treća razina predmemorije (najsporija) zajednička je svim procesorskim jezgrama. Na procesorskim arhitekturama Intel® do i uključujući obitelj Broadwell, L3 predmemorija je potpuno uključena, što znači da sadrži sve što je sadržano u L1 i L2 predmemorije. Zbog načina na koji radi predmemorija uključivanja, ako se nešto ukloni iz predmemorije treće razine, također će se ukloniti iz odgovarajuće predmemorije prve i druge razine. To znači da aplikacija niskog prioriteta kojoj je potreban prostor u L3 predmemorije može istisnuti podatke iz L1 i L2 predmemorije aplikacije visokog prioriteta, čak i ako radi na drugoj jezgri.
U prošlosti je postojao pristup za rješavanje ovog problema koji se zvao "zagrijavanje". Kada se pristup L3 predmemorije natječe, "pobjednik" je aplikacija koja najčešće pristupa memoriji. Stoga je rješenje imati funkciju visokog prioriteta koja stalno pristupa predmemoriji, čak i kada je u stanju mirovanja. Ovo nije baš elegantno rješenje, ali je često bilo sasvim prihvatljivo, a donedavno nije bilo alternative. Ali sada postoji alternativa: obitelj procesora Intel® Xeon® E5 v3 uvodi tehnologiju dodjele predmemorije (CAT), koja vam daje mogućnost dodjele predmemorije na temelju aplikacija i klasa usluge.
Utjecaj inverzije prioriteta
Kako bih demonstrirao utjecaj inverzije prioriteta, napisao sam jednostavan mikrobench koji povremeno pokreće prolazak povezane liste na niti visokog prioriteta, dok nit niskog prioriteta stalno pokreće funkciju memorijskog kopiranja. Te su niti dodijeljene različitim jezgrama istog procesora. Ovo simulira najgori mogući scenarij za nadmetanje resursa: operacija kopiranja zahtijeva puno memorije, pa je vjerojatno da će poremetiti važniju nit koja pristupa popisu.
Evo koda u C-u.
// Izgradite povezani popis veličine N s pseudo-slučajnim uzorkom void init_pool(list_item *head, int N, int A, int B) ( int C = B; list_item *current = head; for (int i = 0; i< N - 1; i++) { current->kvačica = 0; C = (A*C + B) % N; trenutno->sljedeće = (stavka_liste*)&(glava[C]); trenutni = trenutni->sljedeći; ) ) // Dodirnite prvih N elemenata u povezanom popisu void warmup_list(list_item* current, int N) ( bool write = (N > POOL_SIZE_L2_LINES) ? true: false; for(int i = 0; i< N - 1; i++) { current = current->Sljedeći; if (pisati) trenutni->kvačica++; ) ) void mjera(list_item* head, int N) ( unsigned __long long i1, i2, avg = 0; for (int j = 0; j< 50; j++) { list_item* current = head; #if WARMUP_ON while(in_copy) warmup_list(head, N); #else while(in_copy) spin_sleep(1); #endif i1 = __rdtsc(); for(int i = 0; i < N; i++) { current->označiti++; trenutni = trenutni->sljedeći; ) i2 = __rdtsc(); prosj. += (i2-i1)/50; in_copy = istina; ) rezultati=prosjek/N )
Sadrži tri funkcije.
- Funkcija init_pool() inicijalizira povezani popis u velikom dodijeljenom slobodnom memorijskom području koristeći jednostavan generator pseudoslučajni brojevi. Ovo sprječava da stavke popisa budu blizu jedna drugoj u memoriji, što bi stvorilo prostornu lokalitet, što bi utjecalo na naša mjerenja jer bi se neke stavke automatski unaprijed dohvatile. Svaki element popisa je točno jedan redak predmemorije.
- Funkcija warmup() kontinuirano ponavlja konstruirani popis. Postoji potreba za pristupom određenim podacima koji bi trebali biti u predmemorije, tako da ova funkcija sprječava druge niti da izbace sastavljeni popis iz L3 predmemorije.
- Funkcija measure() mjeri obilazak jednog elementa popisa, zatim ili spava 1 milisekundu ili poziva funkciju warmup(), ovisno o tome koji test izvodimo. Funkcija izmjere() tada izračunava prosjek rezultata.
Rezultati mikrobenchmarka na procesoru Intel® Core™ i7 5. generacije prikazani su na grafikonu ispod, gdje je X-os ukupan broj redaka predmemorije na povezanom popisu, a Y-os je prosječan broj CPU ciklusa po pristup popisu veza. Kako se veličina povezanog popisa povećava, on se pomiče iz predmemorije podataka prve razine u predmemoriju druge i zatim treće razine, a zatim u glavnu memoriju.
Osnovni indikator je crveno-smeđa linija, ona odgovara programu bez niti kopiranja u memoriji, odnosno bez sukoba. Plava linija prikazuje posljedice inverzije prioriteta: zbog funkcije memorijskog kopiranja pristupanje popisu traje znatno dulje. Utjecaj je posebno velik ako popis stane u L1 ili L2 predmemoriju velike brzine. Ako je popis toliko velik da ne stane u predmemoriju treće razine, utjecaj je zanemariv.
Zelena linija pokazuje učinak zagrijavanja kada radi funkcija kopiranja memorije: vrijeme pristupa naglo se smanjuje i približava se osnovnoj vrijednosti.
Ako omogućimo CAT i dodijelimo dijelove L3 predmemorije svakoj jezgri za isključivu upotrebu, rezultati će biti vrlo blizu osnovnoj liniji (preblizu da bi se prikazali na dijagramu), što je naš cilj.
Uključenje, UbrajanjeMAČKA
Prije svega, provjerite podržava li platforma CAT. Možete koristiti CPUID instrukciju provjerom adresnog lista 7, podlist 0 koji je dodan da označi dostupnost CAT-a.
Ako je CAT tehnologija omogućena i podržana, postoje MSR registri koji se mogu programirati za dodjelu različite dijelove predmemorija treće razine za različite jezgre.
Svaka procesorska utičnica ima MSR registre IA32_L3_MASKn (na primjer, 0xc90, 0xc91, 0xc92, 0xc93). Ovi registri pohranjuju bitnu masku koja pokazuje koliko L3 predmemorije treba dodijeliti za svaku klasu usluge (COS). 0xc90 pohranjuje dodjelu predmemorije za COS0, 0xc91 za COS1, itd.
Na primjer, ovaj dijagram prikazuje neke moguće maske bitova za različite klase usluga kako bi se pokazalo kako se predmemorija može podijeliti: COS0 dobiva polovicu, COS1 dobiva četvrtinu, a COS2 i COS3 dobivaju svaki osminu. Na primjer, 0xc90 bi sadržavao 11110000, a 0xc93 bi sadržavao 00000001.
Algoritam izravnog unosa/izlaza podataka (DDIO) ima vlastitu skrivenu masku bitova koja omogućuje prijenos podataka s PCIe uređaja velike brzine kao što su mrežni adapteri u određena područja L3 predmemorije. Postoji mogućnost sukoba s klasama usluga koje se definiraju, pa se to mora uzeti u obzir pri izradi NFV aplikacija visoke propusnosti. Za testiranje sukoba koristite za otkrivanje promašaja predmemorije. Neki BIOS-i imaju postavku koja vam omogućuje pregled i promjenu DDIO maske.
Svaka jezgra ima MSR registar IA32_PQR_ASSOC (0xc8f) koji pokazuje koja se klasa usluge odnosi na tu jezgru. Zadana klasa usluge je 0, što znači da se koristi bitmaska u MSR 0xc90. (Prema zadanim postavkama bitmaska 0xc90 postavljena je na 1 kako bi se osigurala maksimalna dostupnost predmemorije.)
Najviše jednostavan model Korištenje CAT-a u NFV-u je dodjeljivanje L3 dijelova predmemorije različitim jezgrama pomoću izoliranih bitnih maski, a zatim dodjeljivanje niti ili virtualnih strojeva jezgrama. Ako VM-ovi trebaju dijeliti jezgre za izvršavanje, također je moguće napraviti trivijalni popravak za planer OS-a, dodati masku predmemorije nitima na kojima VM-ovi rade i dinamički je omogućiti pri svakom događaju raspoređivanja.
Postoji još jedan neobičan način korištenja CAT-a za zaključavanje podataka u predmemoriju. Najprije stvorite masku aktivne predmemorije i pristupite podacima u memoriji da biste ih učitali u L3 predmemoriju. Zatim onemogućite bitove koji predstavljaju ovaj dio L3 predmemorije u bilo kojoj CAT bitmaski koja će se koristiti u budućnosti. Podaci će biti zaključani u L3 predmemoriju jer ih je sada nemoguće izbaciti (osim DDIO). U NFV aplikaciji ovaj mehanizam omogućuje zaključavanje tablica pretraživanja srednje veličine za usmjeravanje i analizu paketa u L3 predmemoriju kako bi se osigurao trajni pristup.
Korištenje Intel AVX2 za vektorsku obradu
SIMD (jedna instrukcija, mnogo podataka) instrukcije omogućuju izvođenje iste operacije na različitim dijelovima podataka u isto vrijeme. Ove se instrukcije često koriste za ubrzavanje izračuna s pomičnim zarezom, ali dostupne su i integerske, booleove i podatkovne verzije instrukcija.
Ovisno o procesoru koji koristite, imat ćete različite obitelji SIMD instrukcija koje su vam dostupne. Veličina vektora obrađenog naredbama također će se razlikovati:
- SSE podržava 128-bitne vektore.
- Intel AVX2 podržava integer upute za 256-bitne vektore i implementira upute za operacije skupljanja.
- U AVX3 proširenjima u budućnosti Intelove arhitekture® Bit će podržani 512-bitni vektori.
Jedan 128-bitni vektor može se koristiti za dvije 64-bitne varijable, četiri 32-bitne varijable ili osam 16-bitnih varijabli (ovisno o SIMD uputama koje se koriste). Veći vektori će prihvatiti više podatkovnih elemenata. S obzirom na visoke zahtjeve za propusnost NFV aplikacija, uvijek biste trebali koristiti najmoćnije SIMD upute (i pridruženi hardver), trenutno Intel AVX2.
SIMD instrukcije se najčešće koriste za izvođenje iste operacije na vektoru vrijednosti, kao što je prikazano na slici. Ovdje je operacija kreiranja X1opY1 do X4opY4 jedna instrukcija, koja istovremeno obrađuje podatkovne stavke X1 do X4 i Y1 do Y4. U ovom primjeru, ubrzanje će biti četiri puta brže od normalnog (skalarnog) izvođenja jer se četiri operacije obrađuju istovremeno. Ubrzanje može biti onoliko koliko je velik SIMD vektor. NFV aplikacije često obrađuju više tokova paketa na isti način, tako da SIMD upute pružaju prirodan način za optimizaciju performansi.
Za jednostavne petlje, prevodilac će često automatski vektorizirati operacije korištenjem najnovijih SIMD instrukcija dostupnih za dani CPU (ako koristite prave oznake prevoditelja). Možete optimizirati svoj kod za korištenje najsuvremenijeg skupa instrukcija koji podržava hardver tijekom izvođenja ili možete kompajlirati kod za određenu ciljnu arhitekturu.
SIMD operacije također podržavaju memorijska opterećenja, kopiranje do 32 bajta (256 bita) iz memorije u registar. To omogućuje prijenos podataka između memorije i registara, zaobilazeći predmemoriju, te prikupljanje podataka s različitih mjesta u memoriji. Također možete izvoditi razne operacije s vektorima (mijenjanje podataka unutar jednog registra) i pohranjivanje vektora (zapisivanje do 32 bajta iz registra u memoriju).
Memcpy i memmov dobro su poznati primjeri osnovnih rutina koje su od početka implementirane korištenjem SIMD instrukcija jer je instrukcija REP MOV bila prespora. Kod memcpy redovito je ažuriran u knjižnice sustava koristiti najnovije SIMD upute. Tablica CPUID upravitelja korištena je za dobivanje informacija o tome koja je od najnovijih verzija dostupna za korištenje. Istodobno, implementacija novih generacija SIMD instrukcija u knjižnicama obično kasni.
Na primjer, sljedeći postupak memcpy, koji koristi jednostavnu petlju, temelji se na ugrađenim funkcijama (umjesto knjižničnog koda), tako da ga kompajler može optimizirati za najnoviju verziju SIMD instrukcija.
Mm256_store_si256((__m256i*) (dest++), (__m256i*) (src++))
Prevodi u sljedeći asemblerski kod i ima dvostruko bolju izvedbu od nedavnih biblioteka.
C5 fd 6f 04 04 vmovdqa (%rsp,%rax,1),%ymm0 c5 fd 7f 84 04 00 00 vmovdqa %ymm0.0x10000(%rsp,%rax,1)
Asemblerski kod iz ugrađene funkcije kopirat će 32 bajta (256 bita) korištenjem najnovijih dostupnih SIMD uputa, dok će knjižnični kod koji koristi SSE kopirati samo 16 bajtova (128 bita).
NFV aplikacije često moraju izvršiti operaciju prikupljanja učitavanjem podataka s više lokacija na različitim memorijskim lokacijama koje nisu susjedne. Na primjer, mrežni adapter može predmemorirati dolazne pakete koristeći DDIO. NFV aplikacija može trebati pristup samo dijelu mrežno zaglavlje s odredišnom IP adresom. Uz operaciju collect, aplikacija može prikupiti podatke za 8 paketa u isto vrijeme.
Nema potrebe za korištenjem ugrađenih funkcija ili asemblerskog koda za operaciju prikupljanja jer prevodilac može vektorizirati kod, kao za program prikazan u nastavku, na temelju testa zbrajanja brojeva iz pseudoslučajnih lokacija u memoriji.
Int a; int b; za (i = 0; i< 1024; i++) a[i] = i; for (i = 0; i < 64; i++) b[i] = (i*1051) % 1024; for (i = 0; i < 64; i++) sum += a]; // This line is vectorized using gather.
Posljednji redak je kompajliran u sljedeći asemblerski kod.
C5 fe 6f 40 80 vmovdqu -0x80(%rax),%ymm0 c5 ed fe f3 vpaddd %ymm3,%ymm2,%ymm6 c5 e5 ef db vpxor %ymm3,%ymm3,%ymm3 c5 d5 76 ed vpcmpeqd %ymm5,% ymm5,%ymm5 c4 e2 55 90 3c a0 vpgatherdd %ymm5,(%rax,%ymm4,4),%ymm7
Pojedinačna operacija prikupljanja znatno je brža od slijeda preuzimanja, ali to ima smisla samo ako su podaci već u predmemoriji. U suprotnom, podaci će se morati dohvatiti iz memorije, što zahtijeva stotine ili tisuće CPU ciklusa. Ako su podaci u cacheu, moguće je 10x ubrzanje
(tj. 1000%). Ako podaci nisu u cacheu, ubrzanje je samo 5%.
Pri korištenju ovakvih tehnika važno je analizirati aplikaciju kako bi se identificirala uska grla i shvatilo troši li aplikacija previše vremena na kopiranje ili prikupljanje podataka. Možeš koristiti .
Još jedna korisna značajka za NFV u Intel AVX2 i drugim SIMD operacijama je bitwise and logičke operacije. Koriste se za ubrzavanje nestandardnog enkripcijskog koda, a provjera bitova prikladna je za ASN.1 programere i često se koristi za podatke u telekomunikacijama. Intel AVX2 može se koristiti za brže usporedbe nizova pomoću naprednih algoritama kao što je MPSSEF.
Intel AVX2 proširenja rade dobro virtualni strojevi. Performanse su iste i nema pogrešnih izlaza iz virtualnog stroja.
Korištenje Intel TSX za veću skalabilnost
Jedan od problema paralelni programi je izbjegavanje kolizija podataka, do kojih može doći kada više niti pokušava koristiti istu podatkovnu stavku, a barem jedna nit pokušava promijeniti podatke. Kako bi se izbjegli rezultati nepredvidive učestalosti, koristi se zaključavanje: prva nit koja koristi podatkovnu stavku blokira je od ostalih niti dok njezin rad ne završi. Ali ovaj pristup možda neće biti učinkovit ako postoje česta konkurentska zaključavanja ili ako zaključavanja kontroliraju veće područje memorije nego što je zapravo potrebno.
Intel Transactional Synchronization Extensions (TSX) pružaju procesorske upute za zaobilaženje zaključavanja transakcija u hardverskoj memoriji. To pomaže u postizanju veće skalabilnosti. Način na koji to radi je da kada program uđe u odjeljak koji koristi Intel TSX za zaštitu memorijskih lokacija, svi pokušaji pristupa memoriji se bilježe, a na kraju zaštićene sesije automatski se predaju ili se automatski vraćaju. Vraćanje se izvodi ako je tijekom izvođenja iz druge niti došlo do sukoba pristupa memoriji koji bi mogao uzrokovati stanje utrke (na primjer, pisanje na lokaciju s koje druga transakcija čita podatke). Povratak se također može dogoditi ako zapis o pristupu memoriji postane prevelik za implementaciju Intel TSX, ako postoji I/O instrukcija ili sistemski poziv, ili ako se izbace iznimke ili se virtualni strojevi isključe. I/O pozivi se vraćaju unatrag kada se ne mogu spekulativno izvršiti zbog vanjskih smetnji. Sistemski poziv- vrlo složena operacija koja mijenja prstenove i deskriptore memorije, vrlo ju je teško vratiti.
Uobičajeni slučaj upotrebe za Intel TSX je kontrola pristupa na hash tablici. Obično se zaključavanje tablice predmemorije koristi za jamčenje pristupa tablici predmemorije, ali to povećava latenciju za niti koje se natječu za pristup. Zaključavanje je često pregrubo: cijela tablica je zaključana, iako je izuzetno rijetko da niti pokušavaju pristupiti istim elementima. Kako se broj jezgri (i niti) povećava, grubo zaključavanje ometa skalabilnost.
Kao što je prikazano na donjem dijagramu, grubo blokiranje može uzrokovati da jedna nit čeka drugu nit da oslobodi hash tablicu, čak iako niti koriste različite elemente. Korištenje Intel TSX-a omogućuje rad obje niti, njihovi se rezultati bilježe nakon uspješnog završetka transakcije. Hardver detektira sukobe u hodu i prekida transakcije koje vrijeđaju. Kada koristite Intel TSX, nit 2 ne mora čekati, obje se niti izvršavaju mnogo ranije. Zaključavanje hash tablica pretvara se u fino podešeno zaključavanje, što rezultira poboljšanom izvedbom. Intel TSX podržava preciznost praćenja sukoba na razini jedne retke predmemorije (64 bajta).
Intel TSX koristi dva programska sučelja za određivanje dijelova koda za izvođenje transakcija.
- Hardware Lock Bypass (HLE) kompatibilan je unatrag i može se jednostavno koristiti za poboljšanje skalabilnosti bez velikih promjena u biblioteci zaključavanja. HLE sada ima prefikse za blokirane instrukcije. HLE prefiks instrukcije signalizira hardveru da prati stanje zaključavanja bez preuzimanja. U gornjem primjeru, poduzimanje opisanih koraka osigurat će da pristup drugim unosima hash tablice više neće rezultirati zaključavanjem osim ako postoji sukobljeni pristup pisanju vrijednosti pohranjene u hash tablici. Kao rezultat toga, pristup će biti paraleliziran, tako da će se skalabilnost povećati u sve četiri niti.
- RTM sučelje uključuje eksplicitne upute za pokretanje (XBEGIN), predaju (XEND), otkazivanje (XABORT) i testiranje stanja (XTEST) transakcija. Ove upute daju bibliotekama za zaključavanje fleksibilniji način implementacije zaobilaženja zaključavanja. RTM sučelje omogućuje knjižnicama korištenje fleksibilnih algoritama za otkazivanje transakcija. Ova se značajka može koristiti za poboljšanje Intelove performanse TSX koji koristi optimistična ponovna pokretanja transakcija, vraćanja transakcija u prethodno stanje i druge napredne tehnike. Korištenjem instrukcije CPUID, knjižnica se može vratiti na stariju implementaciju ne-RTM zaključavanja dok zadržava kompatibilnost unatrag s kodom na razini korisnika.
- Za dobivanje dodatne informacije Preporučujem čitanje sljedećih članaka na portalu Intel Developer Zone o HLE i RTM.
Poput optimizacije sinkronizacijskih primitiva pomoću HLE ili RTM, NFV značajke podatkovnog plana mogu imati koristi od Intel TSX-a kada se koristi Data Plane Development Kit (DPDK).
Kada koristite Intel TSX, glavni izazov nije implementacija ovih proširenja, već procjena i određivanje njihove izvedbe. Postoje brojači performansi koji se mogu koristiti u Linux programi* perf, te za procjenu uspješnosti izvršavanja Intel TSX (broj dovršenih i broj otkazanih ciklusa).
Intel TSX treba koristiti s oprezom i pažljivo testirati u NFV aplikacijama jer I/O operacije u području zaštićenom Intel TSX-om uvijek uključuju vraćanje, a mnoge NFV značajke koriste mnogo I/O operacija. Istodobno zaključavanje treba izbjegavati u NFV aplikacijama. Ako su zaključavanja neophodna, tada će algoritmi zaobilaženja zaključavanja pomoći u poboljšanju skalabilnosti.
o autoru
Alexander Komarov radi kao inženjer za razvoj aplikacija u Grupi za softver i usluge tvrtke Intel Corporation. Tijekom proteklih 10 godina, Alexanderov glavni rad bio je optimiziranje koda za postizanje najviših performansi na postojećim i budućim Intelovim poslužiteljskim platformama. Ovaj rad uključuje korištenje Intelovih alata za razvoj softvera kao što su profileri, kompajleri, biblioteke, najnoviji skupovi instrukcija, nanoarhitektura i arhitektonska poboljšanja najnovijih x86 procesora i skupova čipova.
dodatne informacije
Za više informacija o NFV-u pogledajte sljedeće videozapise.
#XeonČesto se pri odabiru jednoprocesorskog poslužitelja ili radne stanice postavlja pitanje koji procesor koristiti - poslužiteljski Xeon ili obični Core ix. S obzirom da su ovi procesori izgrađeni na istim jezgrama, izbor često pada na desktop procesori, koji obično imaju nižu cijenu sa sličnim performansama. Zašto onda Intel izdaje Xeon E3 procesore? Hajdemo shvatiti.
Tehnički podaci
Za početak, uzmimo mlađi model Xeon procesora iz trenutne serije modela - Xeon E3-1220 V3. Protivnik će biti Jezgreni procesor i5-4440. Oba procesora temelje se na Haswell jezgri, imaju isti osnovni takt i slične cijene. Razlike između ova dva procesora prikazane su u tablici:Dostupnost integrirane grafike. Na prvi pogled, Core i5 ima prednost, ali sve matične ploče poslužitelja imaju integriranu grafičku karticu koja ne zahtijeva grafički čip u procesoru, a radne stanice obično ne koriste integriranu grafiku zbog njihove relativno niske performanse.
ECC podrška. Velika brzina i velike količine RAM-a povećavaju vjerojatnost softverske greške. Obično su takve pogreške nevidljive, ali unatoč tome mogu dovesti do promjene podataka ili pada sustava. Ako za desktop računala Iako takve pogreške nisu opasne zbog svoje rijetke pojave, neprihvatljive su u poslužiteljima koji rade 24 sata dnevno nekoliko godina. Za njihovo ispravljanje koristi se ECC (engl. error-correcting code) tehnologija čija je učinkovitost 99,988%.
Toplinska projektirana snaga (TDP). U biti, potrošnja energije procesora pri maksimalnom opterećenju. Xeoni obično imaju manju toplinsku ovojnicu i pametnije algoritme za uštedu energije, što u konačnici rezultira nižim računima za struju i učinkovitijim hlađenjem.
L3 predmemorija. Cache memorija je vrsta sloja između procesora i RAM-a, koji ima vrlo veliku brzinu. Što je veća veličina predmemorije, to brže radi procesor, budući da je čak i vrlo brz RAM značajno sporiji od predmemorije. Xeon procesori obično imaju veću veličinu predmemorije, što ih čini poželjnijim za aplikacije koje zahtijevaju velike resurse.
Frekvencija / Frekvencija u TurboBoost modu. Ovdje je sve jednostavno - što je veća frekvencija, to brže radi procesor, sve ostale stvari su jednake. Osnovna frekvencija, odnosno frekvencija na kojoj procesori rade pod punim opterećenjem je ista, ali u Turbo Boost modu, odnosno pri radu s aplikacijama koje nisu predviđene za višejezgrene procesore, Xeon je brži.
Podrška za Intel TSX-NI. Intel Transactional Synchronization Extensions New Instructions (Intel TSX-NI) podrazumijeva dodatak sustavu predmemorije procesora koji optimizira okruženje izvršavanja multi-threaded aplikacija, ali, naravno, samo ako te aplikacije koriste softverska sučelja TSX-NI. Skupovi instrukcija TSX-NI omogućuju vam učinkovitiju implementaciju rada s velikim podacima i bazama podataka - u slučajevima kada mnoge niti pristupaju istim podacima i dolazi do situacija blokiranja niti. Spekulativni pristup podacima, koji je implementiran u TSX-u, omogućuje učinkovitiju izgradnju takvih aplikacija i dinamičnije skaliranje performansi pri povećanju broja istovremeno izvedenih niti rješavanjem sukoba prilikom pristupa zajedničkim podacima.

Trusted Execution podrška. Intel Trusted Execution Technology poboljšava sigurno izvršavanje naredbi kroz hardverska poboljšanja procesora i hardvera Intel čipovi. Ova tehnologija pruža digitalnim uredskim platformama sigurnosne značajke kao što su izmjereno pokretanje aplikacija i sigurno izvršavanje naredbi. To se postiže stvaranjem okruženja u kojem se aplikacije izvode izolirano od drugih aplikacija u sustavu.
Prednosti starijih Xeon procesora uključuju još veći L3 kapacitet, do 45 MB, više jezgri, do 18, i više podržanog RAM-a, do 768 GB po procesoru. U isto vrijeme, potrošnja ne prelazi 160 W. Na prvi pogled, to je vrlo velika vrijednost, međutim, s obzirom da su performanse takvih procesora nekoliko puta veće od performansi istog Xeon E3-1220 V3 s TDP-om od 80 W, ušteda postaje očita. Također treba napomenuti da nijedan od procesora Osnovna obitelj ne podržava višeprocesiranje, odnosno moguće je instalirati najviše jedan procesor u jedno računalo. Većina aplikacija za poslužitelje i radne stanice dobro se skalira po jezgrama, nitima i fizičkim procesorima, tako da će instaliranje dva procesora dati gotovo dvostruko povećanje performansi.
Datum: 2014-08-13 22:26
Davne 2007. godine tvrtka AMD izdao novu generaciju Phenom procesori. Ti su procesori, kako se kasnije pokazalo, sadržavali pogrešku u TLB bloku (translation look-aside buffer brza pretvorba virtualne adrese u fizičke). Tvrtka nije imala drugog izbora nego riješiti ovaj problem kroz zakrpu u obliku zakrpe za BIOS, ali to je smanjilo performanse procesora za oko 15%.
Nešto slično sada se dogodilo Intelu. U procesorima Haswell generacije tvrtka je implementirala podršku za TSX (Transactional Synchronization Extension) instrukcije. Osmišljeni su za ubrzavanje višenitnih aplikacija i trebali su se koristiti prvenstveno u segmentu poslužitelja. Unatoč činjenici da su Haswell CPU-i već dosta dugo na tržištu, ovaj skup Upute praktički nisu korištene. Po svemu sudeći, to se neće dogoditi u bliskoj budućnosti.
Činjenica je da je Intel napravio "tipsku pogrešku", kako to sama kompanija naziva, u uputama za TSX. Pogrešku, usput, nisu otkrili stručnjaci iz procesorskog diva. Može dovesti do nestabilnosti sustava. Odlučiti ovaj problem Tvrtka to može učiniti samo na jedan način, ažuriranjem BIOS-a, čime se onemogućuje ovaj skup uputa.
Usput, TSX se implementira ne samo u Haswell procesori, ali i u prvim modelima Broadwell CPU-a, koji bi se trebali pojaviti pod imenom Core M. Predstavnik tvrtke potvrdio je da Intel namjerava implementirati verziju TSX instrukcija “bez grešaka” u svoje sljedeće proizvode u budućnosti.
Oznake: komentar
Prethodne vijesti
2014-08-13 22:23
Sony Xperia Z2 je “preživio” nakon šest tjedana boravka na dnu slane bare
Pametni telefoni često postaju junaci nevjerojatnih priča u kojima se okušavaju u ulozi džepnog pancira, zaustavljanja metka i spašavanja
2014-08-13 21:46
IPhone 6 je ušao u finalnu fazu testiranja
Prema posljednjim podacima novinska agencija Gforgames, iPhone 6 je ušao u završnu fazu testiranja prije masovnog lansiranja novog pametnog telefona u proizvodnju. Podsjetimo, iPhone 6 će se sklapati u tvornicama u Kini...
2014-08-12 16:38
Osmojezgreni iRU M720G tablet podržava dvije SIM kartice
Tablet ima 2 GB RAM-a i 16 GB ugrađene flash memorije. Na brodu su dvije kamere: glavna od 8 megapiksela i prednja od 2 megapiksela. iRU M720G opremljen je 3G, GPS, Wi-Fi, Bluetooth, FM radio modulima, kao i utorom za dvije SIM kartice, što mu omogućuje obavljanje...
2014-08-10 18:57
LG je u Rusiji izdao jeftin pametni telefon L60
Bez puno pompe i pompe LG Electronics predstavio se u Rusiji novi model L serija III - LG L60. Ovaj jeftini pametni telefon predstavljen je u Raspon cijena od 4 do 5 tisuća rubalja od najvećih ruskih...
Sa svakom novom generacijom Intel procesori uključuju sve više tehnologija i funkcija. Neki od njih su dobro poznati (tko, na primjer, ne zna za hiperthreading?), dok većina nespecijalista uopće ne zna za postojanje drugih. Otvorimo ga za sve poznata baza znanja o Intelovim proizvodima Automated Relational Knowledge Base (ARK) i tamo odaberite procesor. Vidjet ćemo pozamašan popis značajki i tehnologija - što se krije iza njihovih tajanstvenih marketinških naziva? Pozivamo vas da dublje istražite problem, okrećući se Posebna pažnja o malo poznatim tehnologijama - tamo će sigurno biti puno zanimljivih stvari.
Intel Demand Based Switching
Zajedno s poboljšanom Intel SpeedStep tehnologijom, Intel Demand Based Switching tehnologija odgovorna je za osiguravanje da procesor radi na optimalna frekvencija i dobivao odgovarajuću električnu energiju: ni više ni manje od potrebne. Time se smanjuje potrošnja energije i proizvodnja topline, što je važno ne samo za prijenosni uređaji, ali i za poslužitelje - tu se koristi Demand Based Switching.
Intelov brzi pristup memoriji
Funkcija kontrolera memorije za optimizaciju rada s RAM-om. To je kombinacija tehnologija koja omogućuje, kroz dubinsku analizu reda naredbi, identificiranje naredbi koje se "preklapaju" (na primjer, čitanje s iste memorijske stranice), a zatim mijenja redoslijed stvarnog izvršenja tako da se naredbe "preklapaju" pogubljeni jedan za drugim. Osim toga, naredbe za upisivanje u memoriju nižeg prioriteta raspoređuju se za vremena kada se predviđa da će se red čekanja za čitanje isprazniti, čineći proces pisanja u memoriju još manje restriktivnim u pogledu brzine čitanja.
Intel Flex pristup memoriji
Još jedna funkcija memorijskog kontrolera, koja se pojavila još u danima kada je bio zaseban čip, još 2004. godine. Pruža mogućnost rada u sinkronom načinu rada s dva memorijska modula istovremeno, a za razliku od jednostavnog dvokanalnog načina rada koji je postojao prije, memorijski moduli se mogu različite veličine. Na ovaj način postignuta je fleksibilnost u opremanju računala memorijom, što se očituje iu nazivu.
Intel Instruction Replay
Vrlo duboka tehnologija koja se prvi put pojavila u Intel Itanium procesorima. Tijekom rada procesorskih cjevovoda može se dogoditi situacija kada su instrukcije već došle za izvršenje, ali potrebni podaci još nisu dostupni. Uputu zatim treba "ponovno reproducirati": ukloniti je s pokretne trake i pokrenuti na početku. Što se upravo i događa. Još jedan važna funkcija IRT – ispravljanje slučajnih grešaka na cjevovodima procesora. Pročitajte više o ovoj vrlo zanimljivoj značajki.
Tehnologija Intel My WiFi
Tehnologija virtualizacije koja vam omogućuje dodavanje virtualnog WiFi adaptera na postojeći fizički; stoga vaš ultrabook ili prijenosno računalo može postati potpuna pristupna točka ili repetitor. Softverske komponente Moj WiFi uključen je u upravljački program Intel PROSet Wireless Software verzije 13.2 i novije; Treba imati na umu da su samo neki WiFi adapteri kompatibilni s tehnologijom. Upute za instalaciju, kao i popis kompatibilnosti softvera i hardvera, mogu se pronaći na Intelovoj web stranici.
Tehnologija Intel Smart Idle
Još jedna tehnologija za uštedu energije. Omogućuje vam da onemogućite trenutno neiskorištene blokove procesora ili smanjite njihovu frekvenciju. Neizostavna stvar za CPU pametnog telefona, koja se upravo tamo i pojavila - u Intel Atom procesorima.
Intel Stable Image Platform
Pojam koji se odnosi na poslovne procese, a ne na tehnologiju. Program Intel SIPP osigurava stabilnost softvera osiguravajući da osnovne komponente platforme i upravljački programi ostanu nepromijenjeni najmanje 15 mjeseci. Tako, korporativni klijenti imaju priliku koristiti iste raspoređene slike sustava tijekom tog razdoblja.
Intel QuickAssist
Skup hardverski implementiranih funkcija koje zahtijevaju velike količine računanja, na primjer, šifriranje, kompresija, prepoznavanje uzoraka. Svrha QuickAssista je olakšati stvari razvojnim programerima pružajući im funkcionalne sastavne dijelove i ubrzati njihove aplikacije. S druge strane, tehnologija vam omogućuje da "teške" zadatke povjerite ne najsnažnijim procesorima, što je posebno vrijedno u ugrađenim sustavima koji su ozbiljno ograničeni u performansama i potrošnji energije.
Intel Quick Resume
Tehnologija razvijena za računala temeljena na Intelove platforme Viiv, koji im je omogućio uključivanje i isključivanje gotovo trenutno, poput TV prijemnika ili DVD playera; u isto vrijeme, u stanju "isključeno", računalo je moglo nastaviti obavljati neke zadatke koji nisu zahtijevali intervenciju korisnika. I iako je sama platforma glatko prešla u druge oblike zajedno s razvojem koji ju je pratio, linija je još uvijek prisutna u ARK-u, jer to nije bilo tako davno.
Intelov sigurnosni ključ
Generički naziv za 32- i 64-bitne RDRAND instrukcije koje koriste hardversku implementaciju Digital Random Number Generator (DRNG). Uputa se koristi u kriptografske svrhe za generiranje lijepih i visokokvalitetnih slučajnih ključeva.
Intel TSX-NI
Tehnologija složenog naziva Intel Transactional Synchronization Extensions – New Instructions podrazumijeva dodatak sustavu predmemorije procesora koji optimizira izvršno okruženje višenitnih aplikacija, ali, naravno, samo ako te aplikacije koriste TSX-NI programska sučelja. Sa strane korisnika ovu tehnologiju nije izravno vidljiv, ali svatko može pročitati njegov opis pristupačan jezik na blogu Stepana Koltsova.
Zaključno, želimo vas još jednom podsjetiti da Intel ARK postoji ne samo kao web stranica, već i kao offline aplikacija za iOS i Android. Ostanite na temi!
























