Испытание приборов, файлы конфигурации и файлы журналов все должны быть понятны для человека. YAML (YAML Не Markup Language) имеет менее подробные данные, чем формат сериализации XML и стал популярным форматом среди разработчиков программного обеспечения главным образом потому, что он легче для человеческого понимания. YAML файлы просто текстовые файлы, содержащие данные, записанные в соответствии с правилом YAML синтаксиса и, как правило, имеет расширение файла.yml. В этой статье вы познакомитесь с основами YAML и как вы можете интегрировать PHP парсер YAML в ваших проектах.
Использовать YAML для проектов PHP
Понимание синтаксиса YAML
YAML поддерживает расширенные функции, такие как ссылки и пользовательских типов данные, но и как разработчик PHP, большую часть времени вы будете заинтересованы в том, как YAML представляет перечисленных массивов (последовательности в YAML терминологии) и ассоциативные массивы (отображений).
Вот как представляет перечисление в массиве YAML:
- "Уильям О"Нил" - false
Каждый элемент массива представлен после дефиса и пробела. Его синтаксис для представления значений похож на PHP (цитируя строки и т.д.)
Выше, эквивалентно следующему PHP:
Как правило, каждый элемент появляться на ее собственную линию в YAML, но перечисленные массивы могут быть выражены на одной линии с помощью скобок:
[ 2, "Уильям О"Нил", false ]
Следующий код показывает, как представляет собой ассоциативный массив, в YAML:
Id: 2 name: "Уильям О"Нил" isActive: false
Первый ключ элемента указывает двоеточие и один или несколько пробелов, а затем значение указано. Имея только один пробел после двоеточия достаточно, но вы можете использовать больше пространства для лучшей читаемости, если хотите.
Эквивалентный массив PHP из вышеперечисленных YAML это:
2, "name" => "Уильям О"Нил", "isActive" => false);?>
И похоже на перечисленные массивы, вы можете выразить ассоциативных массивов на одной линии с использованием фигурных скобок:
{ id: 2, name: "Уильям О"Нил", isActive: false }
С одним или несколькими пробелами для отступа, вы можете представлять собой многомерный массив следующим образом:
Выше блока YAML это эквивалентно следующему PHP:
array(0 => array("id" => 1, "name" => "Брэд Тейлор", "isActive" => true), 1 => array("id" => 2, "name" => "Уильям О"Нил", "isActive" => false)));?>
YAML также позволяет представить коллекцию элементов данных в одном документе, не требуя корневого узла. В следующем примере содержимое article.yml , который показывает несколько многомерных массивов в одном файле.
Author: 0: { id: 1, name: "Брэд Тейлор", isActive: true } 1: { id: 2, name: "Уильям О"Нил", isActive: false } category: 0: { id: 1, name: "PHP" } 1: { id: 2, name: "YAML" } 2: { id: 3, name: "XML" } article: 0: id: 1 title: "Как использовать YAML в Проекте PHP" content: > YAML-менее многословен сериализации данных формат. За ним стоит "YAML не Язык Разметки". YAML была популярной сериализации данных формата среди разработчики программного обеспечения, главным образом, потому, что это понятно для человека. author: 1 status: 2 articleCategory: 0: { articleId: 1, categoryId: 1 } 1: { articleId: 1, categoryId: 2 }
Хотя в большинстве синтаксис YAML является интуитивно понятным и простым для запоминания, есть одно важное правило, на которое следует обратить внимание. Выравнивание должно быть сделано с одним или несколькими пробелами; вкладки не допускается. Вы можете настроить IDE, чтобы вставить пробелы вместо вкладки при нажатии клавиши табуляции, которая является общей конфигурацией среди разработчиков программного обеспечения, чтобы убедиться, код с правильным отступом и отображается при просмотре в других редакторах.
Вы можете узнать более сложные функций и синтаксис, и что YAML поддерживает, читая официальные документы , Symfony или Вики .
YAML не должен быть альтернативой XML
Если вы исследовании YAML с вашей любимой поисковой системе, вы, несомненно, тему «YAML против XML", и, естественно, когда вы впервые увидите YAML, вы, как правило, предпочтете его, а на XML, потому что его легче читать и писать. Тем не менее, YAML должен быть еще одним инструментом в арсенале разработчика и не должен быть альтернативой XML. Вот некоторые преимущества YAML и XML.
Преимущества YAML
- Менее подробен, легко составить и более удобным для чтения
- Не имеет древовидную структуру с одним узлом родителей
Преимущества XML
- Более встроенная поддержка PHP по сравнению с YAML
- XML стал стандартом де-факто для связи между приложениями связи
- XML-теги могут иметь атрибуты предоставление более подробной информации о закрытых данных
Несмотря на многословие, XML является более удобным для чтения и сопровождения, когда иерархия элементов глубокая по сравнению с пространством-ориентированное представление иерархии в YAML.
Принимая во внимание преимущества в обоих языках, YAML, кажется, больше подходит для коллекции различных наборов данных, и когда люди также являются одними из данных потребителей.
Выбор Parser PHP YAML
Парсер YAML, имеет две функциональные возможности, своего рода нагрузки для функции, которая преобразует YAML в массив, и свалка функции, которые преобразует массив в YAML.
Настоящее время YAML парсер PHP, доступен как расширение PECL и не поставляется вместе с PHP. Кроме того, есть анализаторы написан на чистом PHP, которые были бы чуть медленнее по сравнению с расширением PECL.
Ниже приведены несколько парсеров YAML для PHP:
- Не поставляется вместе с PHP
- Потребуется корневой доступ к серверу для установки
- Реализованные в PHP
- Будет работать в PHP 5.2.4 +
- Необходимо извлечь рамки из Symfony
- Реализованные в PHP
- Будет работать в PHP 5.3.2 +
- Реализованные в PHP
- Будет работать в PHP 5 +
Я предпочитаю выбрать компоненты Symfony 1,4 YAML из-за мобильности (он работает с PHP 5.2.4 +) и погашения (Symfony 1.4 и установлены рамки PHP). После того как вы извлекли архив YAML компонентов Symfony, YAML классы доступны под lib/yaml . Статические методы load() и dump() доступны с класса sfYaml.
Интеграция в проект Parser PHP YAML
Всякий раз, когда вам интегрировать сторонние классы или библиотеку в ваш проект PHP, это хорошая практика, чтобы создать оболочку и тесты. Изменение сторонней библиотеки с минимальными изменениями в проекте код (к коду проекта должна относиться только оболочка) и с уверенностью, что изменения не будут тормозить любую функциональность (тестов).
Ниже приводится тест (YamlParserTest.php) были созданы для своего класса-оболочки (YamlParser.php). Необходимо для запуска и поддержания теста. Вы можете добавить несколько тестов, если вы хотите, за неправильное имена файлов и расширений файлов, кроме.yml , и другие тесты, основанные на сценариях вы столкнетесь в своём проекте.
yamlParser = new YamlParser(); } public function testMainArrayKeys() { $parsedYaml = $this->yamlParser->load("article.yml"); $mainArrayKeys = array_keys($parsedYaml); $expectedKeys = array("author", "category", "article", "articleCategory"); $this->assertEquals($expectedKeys, $mainArrayKeys); } public function testSecondLevelElement() { $parsedYaml = $this->yamlParser->load("article.yml"); $actualArticle = $parsedYaml["article"]; $title = "How to Use YAML in Your Next PHP Project"; $content = "YAML is a less-verbose data serialization format. " . "It stands for \"YAML Ain"t Markup Language\". " . "YAML has been a popular data serialization format among " . "software developers mainly because it"s human-readable.\n"; $expectedArticle = array("id" => 1, "title" => $title, "content" => $content, "author" => 1, "status" => 2); $this->assertEquals($expectedArticle, $actualArticle); } /** * @expectedException YamlParserException */ public function testExceptionForWrongSyntax() { $this->yamlParser->load("wrong-syntax.yml"); } }?>
А вот класс оболочки (wrapper):
getMessage(), $e->getCode(), $e); } } public function dump($array) { try { return sfYaml::dump($array); } catch (Exception $e) { throw new YamlParserException($e->getMessage(), $e->getCode(), $e); } } } class YamlParserException extends Exception { public function __construct($message = "", $code = 0, $previous = NULL) { if (version_compare(PHP_VERSION, "5.3.0") < 0) { parent::__construct($message, $code); } else { parent::__construct($message, $code, $previous); } } }?>
P.S.
Так что теперь у вас есть знания о том, что такое YAML, и как представлять PHP массивы в YAML, а также интегрировать PHP парсер YAML в ваших проектах. Потратив немного времени с синтаксис YAML, вы сможете понять, потенциал возможностей которые он предоставляет. Вы также можете рассмотреть возможность изучения Symfony 1.4 и 2, которые широко использует YAML.
Пришел день, и конфигурационные файлы для нашего приложения стали настолько большими, что менеджеры намекнули что в JSON-конфигах получается подозрительно много фигурных и не фигурных скобочек, и им хотелось бы от них избавиться. Был дан тонкий намек, что неплохо бы приглядеться к YAML, ведь ходят слухи что он очень человекочитаемый. И скобочек никаких там нет. И списки красивые. Не внять старшим мы естественно не могли, вынуждены были изучать вопрос, искать разницу, плюсы и минусы обоих форматов. Очевидно, что такие сравнения затеваются лишь для того, чтобы подтвердить мнение руководителей или даже если не подтвердить, то они найдут почему они правы и почему стоит делать изменения:)
Уверен, что многие с данными форматами знакомы, но все же приведу краткое описание с википедии:
JSON (англ. JavaScript Object Notation) - текстовый формат обмена данными, основанный на JavaScript и обычно используемый именно с этим языком. Как и многие другие текстовые форматы, JSON легко читается людьми. Несмотря на происхождение от JavaScript (точнее, от подмножества языка стандарта ECMA-262 1999 года), формат считается языконезависимым и может использоваться практически с любым языком программирования. Для многих языков существует готовый код для создания и обработки данных в формате JSON.
YAML - человекочитаемый формат сериализации данных, концептуально близкий к языкам разметки, но ориентированный на удобство ввода-вывода типичных структур данных многих языков программирования. Название YAML представляет собой рекурсивный акроним YAML Ain"t Markup Language («YAML - не язык разметки»). В названии отражена история развития: на ранних этапах язык назывался Yet Another Markup Language («Ещё один язык разметки») и даже рассматривался как конкурент XML, но позже был переименован с целью акцентировать внимание на данных, а не на разметке документов.
И так, что нам нужно:
- сделать одинаковый сложный JSON и YAML
- определить параметры по каким будем сравнивать
- десериализовать в Java объекты около 30 раз
- сравнить результат по скорости
- сравнить читаемость файлов
- сравнить удобство работы с форматом
Очевидно, что писать собственные парсеры мы не будем, поэтому для начала выберем для каждого формата по уже существующему парсеру.
Для json будем использовать gson (от google), а для yaml - snakeyaml (от не-знаю-кого).
Как видим все просто, нужно только создать достаточно сложную модель, которая будет имитировать сложность конфиг-файлов, и написать модуль который будет тестировать yaml и json парсеры. Приступим.
Нужна модель примерно такой сложности: 20 атрибутов разных типов + 5 коллекций по 5-10 элементов + 5 вложенных объектов по 5-10 элементов и 5 коллекций.
Этот этап всего сравнения смело можно назвать самым нудным и неинтересным. Были созданы классы, с незвучными именами типа Model, Emdedded1, и т.д. Но мы не гонимся за читаемостью кода (как минимум в этой части), поэтому так и оставим.
file.json
"embedded2": { "strel1": "el1", "strel2": "el2", "strel4": "el4", "strel5": "el5", "strel6": "el6", "strel7": "el7", "intel1": 1, "intel2": 2, "intel3": 3, "list1": [ 1, 2, 3, 4, 5 ], "list2": [ 1, 2, 3, 4, 5, 6, 7 ], "list3": [ "1", "2", "3", "4" ], "list4": [ "1", "2", "3", "4", "5", "6" ], "map1": { "3": 3, "2": 2, "1": 1 }, "map2": { "1": "1", "2": "2", "3": "3" } }
file.yml
embedded2: intel1: 1 intel2: 2 intel3: 3 list1: - 1 - 2 - 3 - 4 - 5 list2: - 1 - 2 - 3 - 4 - 5 - 6 - 7 list3: - "1" - "2" - "3" - "4" list4: - "1" - "2" - "3" - "4" - "5" - "6" map1: "3": 3 "2": 2 "1": 1 map2: 1: "1" 2: "2" 3: "3" strel1: el1 strel2: el2 strel4: el4 strel5: el5 strel6: el6 strel7: el7
Соглашусь, что человекочитаемость параметр достаточно субъективный. Но все таки, на мой взгяд, yaml немного более приятен взгляду и более интуитивно понятен.
yaml parser
public class BookYAMLParser implements Parser
json parser
public class BookJSONParser implements Parser
Как мы видим, оба формата имеют поддержку в java. Но для json выбор намного шире, это бесспорно.
Парсеры гоотовы, теперь рассмотрим реализацию сравнения. Тут тоже все предельно просто и очевидно. Есть простой метод, который 30 раз десериализует объекты из файла. Если кому интересно - код под спойлером.
testing code
public static void main(String args) { String jsonFilename = "file.json"; String yamlFilename = "file.yml"; BookJSONParser jsonParser = new BookJSONParser(jsonFilename); jsonParser.serialize(new Book(new Author("name", "123-123-123"), 123, "dfsas")); BookYAMLParser yamlParser = new BookYAMLParser(yamlFilename); yamlParser.serialize(new Book(new Author("name", "123-123-123"), 123, "dfsas")); //json deserialization StopWatch stopWatch = new StopWatch(); stopWatch.start(); for (int i = 0; i < LOOPS; i++) { Book e = jsonParser.deserialize(); } stopWatch.stop(); System.out.println("json worked: " + stopWatch.getTime()); stopWatch.reset(); //yaml deserialization stopWatch.start(); for (int i = 0; i < LOOPS; i++) { Book e; e = yamlParser.deserialize(); } stopWatch.stop(); System.out.println("yaml worked: " + stopWatch.getTime()); }
В реультате получаем следующий результат:
json worked: 278
yaml worked: 669

Как видно, json файлы парсятся примерно в три раза быстрее. Но абсолютная разница не является критичной, в наших масштабах. Поэтому это не сильный плюс в пользу json.
Это происходит потому что json парсится «на лету», то есть считывается посимвольно и сразу сохраняется в объект. Получается объект формируется за один проход по файлу. На самом деле я не знаю как работает именно этот парсер, но в общем схема такая.
А yaml, в свою очередь, более размеренный. Этап обработки данных делится на 3 этапа. Сначала строится дерево объектов. Потом оно еще каким-то образом преобразовывается. И только после этого этапа конвертируется в нужные структуры данных.
Небольшая сравнительная таблица ("+" - преимущество, "-" - отставание, "+-" - нет явного преимущества):
Как это можно подытожить?
Тут все очевидно, если вам важна скорость - тогда json, если человекочитаемость - yaml. Нужно просто решить, что важнее. Для нас оказалось - второе.
На самом деле, тут можно привести еще множество различных доводов в пользу каждого из форматов, но я считаю, что самые важные все таки эти два пункта.
Далее, при работе с yaml мне пришлось столкнусть с не очень красивой обработкой исключений, особенно при синтаксических ошибках. Также, пришлось протестировать различные yaml библиотеки. Еще, в завершение нужно было написать какую-нибудь валидацию. Были опробованы валидацию при помощи схем (там приходилось вызывать руби гемы), и bean-валидация на основе jsr-303. Если вас интересует какая-либо из этих тем - буду рад ответить на вопросы.
Спасибо за внимание:)
P.S.
Уже под конец написания статьи наткнулся на следующее сравнение yaml и json.
Станислав Шашалевич

Парсер контента – наше глобальное и передовое решение, которое позволяет парсить каталоги, страницы и rss ленты. Казалось бы, что еще можно требовать от данного модуля?! Но не тут-то было. Наши клиенты не стоят на месте и постоянно требуют от нас развития решения. А мы этому только рады. И вот теперь мы хотим сообщить, что удовлетворили еще одну очень важную просьбу наших клиентов: Парсинг XML файлов. Теперь Парсер может работать не только с rss, page, catalog
типами данных, но и с xml
. И что самое главное: внедрение такого полезного функционала никак не повлияет на стоимость решения. Цена решения в 14
990 руб.
останется неизменной.
Парсинг xml файлов позволяет парсить и такой полезный для интернет-магазинов формат, как YML файлы. Именно поэтому xml парсер по умолчанию настроен для парсинга yml выдачи. Но тут же у наших клиентов может возникнуть вопрос: А чем же ваша загрузка YML файлов отличается от аналогичных решений в Маркетплейсе. Вот список некоторых преимуществ нашего модуля над аналогами:
- возможность конвертации и пересчета валют
- возможность изменения цен
- возможность редактирования названия и свойств товаров
- возможность указания свойств по умолчанию
- возможность авторизации на стороннем сервере
- выполнять различные действия над элементами, которые отсутствуют в текущей выгрузке(ничего не делать, удалить, деактивировать)
- автоматический перевод текста
- возможность периодического запуска (агенты, крон)
- возможность указания полей и свойств для обновления
- возможность использования прокси-сервера
Суть парсинга осталась аналогичная: обработка xml файла идет по селекторам и атрибутам. Так что, если вы уже настраивали парсер catalog , то настройка парсера нового типа для Вас пройдет просто и легко.
А теперь давайте подробнее рассмотри функциональность нового типа данных:
Вкладка Парсер:

Тип парсера – соответственно и есть тип парсера: rss, page, catalog, xml
Режим парсера – режим, в котором работает парсер. Существует два режима работы: debug и work. По умолчанию для отладки используется debug режим. Именно в этом режиме необходимо настраивать парсер. В debug режиме осуществляется парсинг первых 30 элементов XML файла.
Стоит отметить, что, если вы используете модуль «Парсер контента» в триал версии, то парсер работает только в дебаг режиме.
Дополнительные урлы XML файлов - вы можете также включить в выгрузку и другие урлы xml файлов. Для этого просто укажите их с новой строки.
ID инфоблока-каталога – инфоблок, в который будет осуществляться загрузка разделов и товаров.
ID раздела – раздел инфоблока, в который будет осуществляться загрузка разделов и товаров.
Количество товаров, выгружаемых за один шаг парсера – количество товаров, который парсер обрабатывает за один шаг. По умолчанию 300
Шаг парсера – понятие, которое имеет место при ручном режиме запуска парсера. В этом случае каждый шаг происходит отключение и новое подключение к каналу выгрузки. Варьируйте это значение в зависимости от возможностей вашего хостинга. Если парсер работает от агента(крон), то шаг парсера игнорируется, и выгрузка осуществляется одним запросом.
Активен, Сортировка, Название, Время последнего запуска – интуитивно понятные поля и в комментариях не нуждаются.
Кодировка - кодировка xml файла. Устаревшее поле. На данный момент кодировка определяется автоматически, но, если возникают какие-то проблемы с кодировкой, то рекомендуется указать вручную.
Вкладка Основные настройки - Категории

Пример XML файла для категорий:

Селектор-атрибут названия категории – указывается путь к названию категории. Если пусто, то название берется из значения самой категории
Селектор-атрибут, содержащий id категории – путь к id категории.
Селектор-атрибут, содержащий id родительской категории – для организации вложенности разделов необходимо указать пусть к значению родительского id категории.
Вкладка Основные настройки - Товары

Пример XML файла для товаров:

Селектор конкретного товара – путь к контейнеру конкретного товара
Селектор-атрибут, содержащий id товара – путь к id товара
Селектор-атрибут названия товара – путь к наименованию товара
Селектор-атрибут цены – контейнер, содержащий значение цены товара
Селектор-атрибут описания – содержит описание товара
Селектор-атрибут превью картинки – путь к картинке
Селектор-атрибут детальной картинки – путь к картинке
Вкладка Свойства

Свойство доп. картинок – если есть доп. картинки, то необходимо указать поля, в которые будет осуществляться выгрузка картинок.
Селектор-атрибут перечисления доп. картинок – указывается селектор и атрибут доп. картинок. Пример picture. Указывается относительно селектора товара.
Значения свойств по умолчанию – можно указать значения свойств, которые будут заноситься по умолчанию автоматически при создании товаров
Парсинг по селектору – вы можете указать конкретный селектор свойства, который находится внутри селектора товара в xml. Например: vendor, barcode
Удалять символы – также вы можете удалять лишние символы в свойствах(единицы измерения и прочее)
Парсинг свойств и автоматическое создание - позволяет автоматически создавать, заполнять и обновлять свойства, которые идут списком в xml файле.
Уникализация свойств в данном случае идет по наименованию.
Автоматическое создание свойств – если галочка отмечена, то, в случае отсутствия свойства, оно будет создавать. Если свойство уже есть
Селектор-атрибут перечисления свойств – общий селектор, в котором находятся информация о свойстве
Селектор-атрибут названия свойства – путь расположения названия свойства. Напоминаем, что это важный параметр, так как уникализация в данном случае идет именно по этому параметру.
Селектор-атрибут значения свойства – путь к значению свойства. Если ничего не задано, то значение берется непосредственно из селектора свойства
Выберите тип создаваемых свойств – если свойства не создавались, то они будут созданы. Необходимо выбрать тип новых свойств из значений: Список или Строка.
Удалять символы – позволяет удалять лишние символы из свойств.
Добавление/удаление символов полей и свойств – функционал, позволяющий добавлять и удалять символы и названия товара, а также у его свойств.
Вкладки Торговый каталог, Дополнительные настройки, Обновления/уникальность, Логи, Видео-инструкци идентичны парсеру типа catalog . Поэтому подробно их рассматривать не будем.
Вкладка Торговый Каталог

Вкладка позволяет гибко работать с ценами:
Указывать параметры цены и валюты
Конвертировать валюту
Изменять цены
Округлять цены
Вкладка Дополнительные настройки:
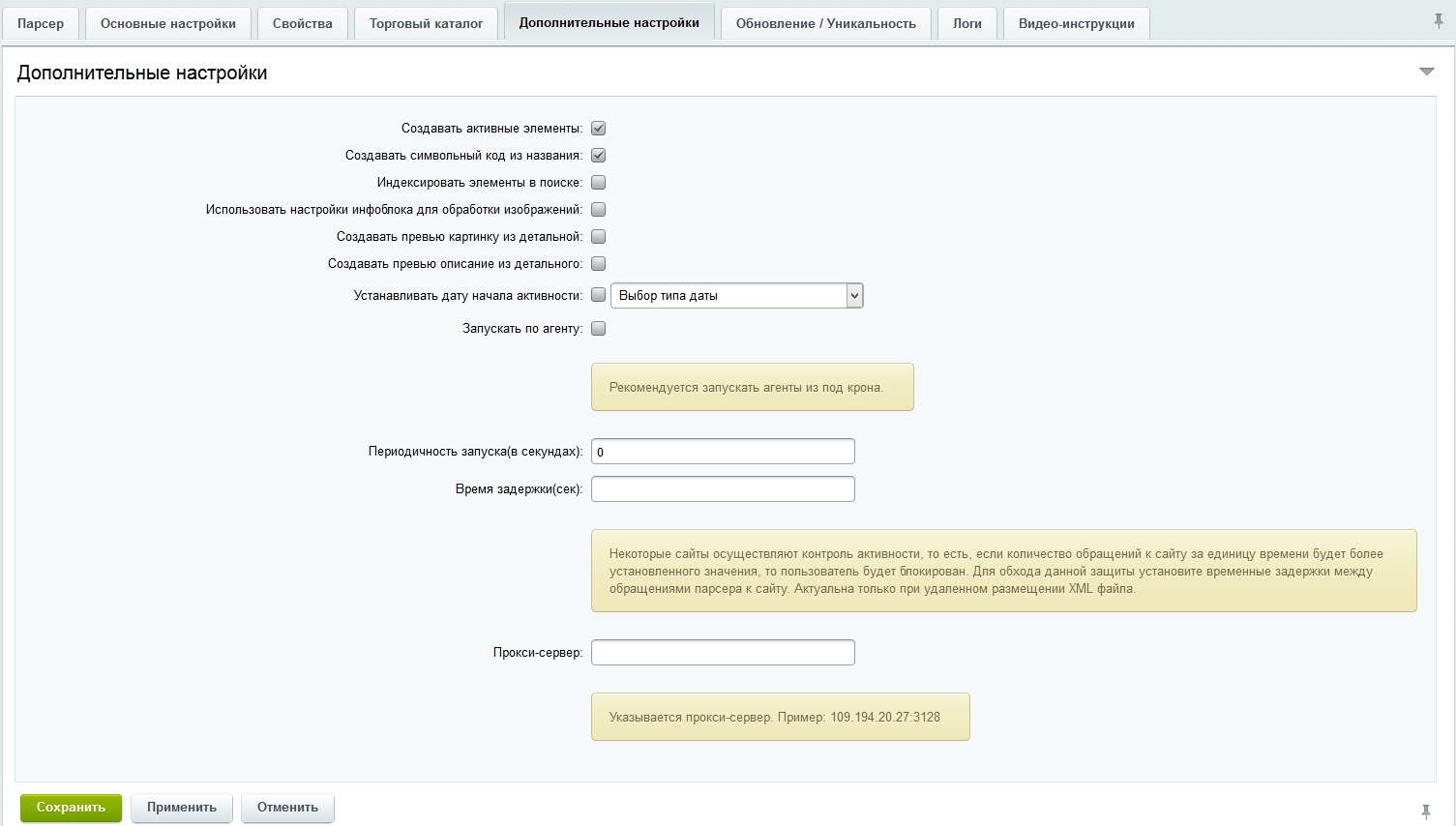
Вкладка Обновление/Уникальность:

Вкладка позволяет задать параметры уникализации, а также настроить обновление полей товаров.
(PECL yaml >= 0.4.0)
yaml_parse — Разбирает поток YAML
Описание
yaml_parse (string $input [, int $pos = 0 [, int &$ndocs [, array $callbacks = NULL ]]]) : mixed
Конвертирует весь поток YAML или его часть и записывает в переменную.
Список параметров
Строка для парсинга как поток YAML.
Документ для разбора (-1 для всех документов, 0 для первого документа, ...).
Если ndocs найден, тогда он будет заменен на количество документов в потоке YAML.
Возвращаемые значения
Возвращает значение, закодированое в input , в соответствующем типе PHP или FALSE в случае возникновения ошибки. Если параметр pos равен -1 , будет возвращен массив, содержащий по одной записи для каждого документа, найденого в потоке.
Примеры
Пример #1 Пример использования yaml_parse()
$yaml
= <<
invoice: 34843
date: "2001-01-23"
bill-to: &id001
given: Chris
family: Dumars
address:
lines: |-
458 Walkman Dr.
Suite #292
city: Royal Oak
state: MI
postal: 48046
site: zxibit.esy.es
ship-to: *id001
product:
- sku: BL394D
quantity: 4
description: Basketball
price: 450
- sku: BL4438H
quantity: 1
description: Super Hoop
price: 2392
tax: 251.420000
total: 4443.520000
comments: Late afternoon is best. Backup contact is Nancy Billsmer @ 338-4338.
...
EOD;
$parsed
=
yaml_parse
($yaml
);
var_dump
($parsed
);
?>
Результатом выполнения данного примера будет что-то подобное:
array(8) { ["invoice"]=> int(34843) ["date"]=> string(10) "2001-01-23" ["bill-to"]=> &array(3) { ["given"]=> string(5) "Chris" ["family"]=> string(6) "Dumars" ["address"]=> array(4) { ["lines"]=> string(34) "458 Walkman Dr. Suite #292" ["city"]=> string(9) "Royal Oak" ["state"]=> string(2) "MI" ["postal"]=> int(48046) } } ["ship-to"]=> &array(3) { ["given"]=> string(5) "Chris" ["family"]=> string(6) "Dumars" ["address"]=> array(4) { ["lines"]=> string(34) "458 Walkman Dr. Suite #292" ["city"]=> string(9) "Royal Oak" ["state"]=> string(2) "MI" ["postal"]=> int(48046) } } ["product"]=> array(2) { => array(4) { ["sku"]=> string(6) "BL394D" ["quantity"]=> int(4) ["description"]=> string(10) "Basketball" ["price"]=> int(450) } => array(4) { ["sku"]=> string(7) "BL4438H" ["quantity"]=> int(1) ["description"]=> string(10) "Super Hoop" ["price"]=> int(2392) } } ["tax"]=> float(251.42) ["total"]=> float(4443.52) ["comments"]=> string(68) "Late afternoon is best. Backup contact is Nancy Billsmer @ 338-4338." }
Плагин позволяет импортировать товары из других магазинов через Yandex XML feed, который используется магазинами для торговли на Яндекс.Маркете.
Товары импортируются в структуру плагина магазина WP Shop. Работает автоматическая синхронизация товаров с источником, которую можно запускать как вручную, так и через крон.
Незаменимый инструмент для:
1. Переноса магазина с любых других движков на WordPress WP-Shop
2. Построения партнерских магазинов, для зарабатывания на партнерской комиссии по модели CPS
Для работы приложения требуется IonCube Loader!
Arbitrary section 1
Часто задаваемые вопросы
Installation Instructions- Upload plugin «WP Shop YML Parser» to the /wp-content/plugins/ directory
- Activate the plugin «WP Shop YML Parser» through the ‘Plugins’ menu in WordPress
- See full userguide how to set up your «WP Shop YML Parser»
Visit the site wp-shop.ru for help.
Отзывы
Ни в коем случае не связывайтесь с этими разработчиками и ничего у них не покупайте. Тот функционал, который они обещают в про версии - обман. Они просто возьмут с вас деньги, а потом от всего откажутся, в том числе от поддержки. Просто посмотрите их кривой сайт и полуживую документацию и сами всё поймёте!
Журнал изменений
Version: 0.9
-project_as_field
-id_as_field
Version: 0.8
-template_price (custom price tag)
Version: 0.7
-fields_update — new setting to update custom fields in projects
Version: 0.6
-Sample xml parser replaced by SAX parser that better for memory management
Version: 0.5
-improovments
Version: 0.4
-bulk analizing
-clone project by category
Version: 0.3
-link to docs
Version: 0.2
-local feeds enable
— source as file enable
— addition yml options
Version: 0.1
-initial relese
























