Ensiklopedik YouTube
-
1 / 5
Statistikada bu termin ilk dəfə Frensis Qalton (1886) tərəfindən insanın fiziki xüsusiyyətlərinin irsiyyətinin öyrənilməsi ilə bağlı istifadə edilmişdir. Xüsusiyyətlərdən biri kimi insan boyu götürülüb; məlum olub ki, ümumiyyətlə, uzunboylu ataların oğulları, təəccüblü deyil ki, qısaboy ataların oğullarından hündür olublar. Daha maraqlısı o idi ki, oğulların boyunun dəyişməsi ataların boyunun dəyişməsindən daha kiçik idi. Oğulların boylarının orta səviyyəyə qayıtma tendensiyası belə özünü göstərirdi ( ortalığa doğru geriləmə), yəni “reqressiya”. Bu fakt, boyu 56 düym olan ata oğullarının orta boyunun hesablanması, 58 düym uzunluğunda olan ata oğullarının orta boyunun hesablanması və s. yolu ilə nümayiş etdirildi. Daha sonra nəticələr müstəvidə, ordinat boyunca çəkildi. bunlardan oğulların orta boyu, x oxunda isə ataların orta boyunun dəyərləri çəkilmişdir. Nöqtələr (təxminən) müsbət meyl bucağı 45°-dən az olan düz xətt üzərində yerləşir; reqressiyanın xətti olması vacibdir.
Təsvir
Tutaq ki, bir cüt təsadüfi dəyişənlərin ikidəyişənli paylanmasından bir nümunəmiz var ( X, Y). Təyyarədə düz xətt ( x, y) funksiyanın seçmə analoqu idi
g (x) = E (Y ∣ X = x) . (\ displaystyle g (x) = E (Y \ orta X = x).) E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) , (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac () \sigma _(2))(\sigma _(1))))(x-\mu _(1)),)v a r (Y ∣ X = x) = σ 2 2 (1 − ϱ 2) . (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) Bu nümunədə reqressiya Y haqqında (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) Bu nümunədə reqressiya Y xətti fərqlidir, onda verilmiş tənliklər həqiqi reqressiya tənliyinin xətti yaxınlaşmasıdır.
Ümumiyyətlə, bir təsadüfi dəyişənin digərinə reqressiyası mütləq xətti deyil. Özünüzü bir neçə təsadüfi dəyişənlə məhdudlaşdırmaq da lazım deyil. Statistik reqressiya problemləri reqressiya tənliyinin ümumi formasının müəyyən edilməsini, reqressiya tənliyinə daxil olan naməlum parametrlərin təxminlərinin qurulmasını və reqressiya haqqında statistik fərziyyələrin sınaqdan keçirilməsini əhatə edir. Bu problemlər reqressiya təhlili çərçivəsində həll edilir.
Sadə bir reqressiya nümunəsi (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) By Y arasındakı əlaqədir (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) Və Y, bu əlaqə ilə ifadə olunur: (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).)=u(Y)+ε, harada u(x)=E((\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) | Y=x) və təsadüfi dəyişənlər Y və ε müstəqildir. Bu təqdimat funksional əlaqəni öyrənmək üçün eksperiment tərtib edərkən faydalıdır y=u(x) təsadüfi olmayan kəmiyyətlər arasında y Və x. Təcrübədə adətən tənlikdə reqressiya əmsalları. y=u(x) naməlumdur və eksperimental məlumatlardan təxmin edilir.
Xətti reqressiya
Gəlin asılılığı təsəvvür edək y-dan x birinci dərəcəli xətti model şəklində:
y = β 0 + β 1 x + ε.(\displaystyle y=\beta _(0)+\beta _(1)x+\varepsilon.) x Biz bu dəyərləri fərz edəcəyik xətasız müəyyən edilir, β 0 və β 1 model parametrləri, ε isə paylanması sıfır orta qiymət və σ 2 sabit sapma ilə normal qanuna tabe olan xətadır. β parametrlərinin dəyərləri əvvəlcədən məlum deyil və bir sıra eksperimental dəyərlərdən müəyyən edilməlidir (), i=1, …, x i, y i n
. Beləliklə yaza bilərik:y i ^ = b 0 + b 1 x i , i = 1 , … , n (\displaystyle (\widehat (y_(i)))=b_(0)+b_(1)x_(i),i=1,\ nöqtələr, n) y burada model tərəfindən proqnozlaşdırılan dəyər deməkdir x, verilmişdir b verilmişdir 0 və 1 - model parametrlərinin nümunə qiymətləndirmələri. Biz də müəyyən edək e i = y i − y i ^ (\displaystyle e_(i)=y_(i)-(\widehat (y_(i)))) - üçün yaxınlaşma xətasının dəyəri i (\displaystyle i)
ci müşahidə.
Ən kiçik kvadratlar metodu verilmiş modelin parametrlərini və onların sapmalarını hesablamaq üçün aşağıdakı düsturları verir: b 1 = ∑ i = 1 n (x i − x ¯) (y i − y ¯) ∑ i = 1 n (x i − x ¯) 2 = c o v (x , y) σ x 2 ; (\displaystyle b_(1)=(\frac (\sum _(i=1)^(n)(x_(i)-(\bar (x)))(y_(i)-(\bar (y)) )))(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))=(\frac (\mathrm (cov) (x,y) ))(\sigma _(x)^(2)));) s b 0 = s e 1 n + x ¯ 2 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s_(b_(0))=s_(e)(\sqrt ((\frac (1)(n))+(\frac ((\bar (x))^(2))(\sum _) (i=1)^(n)(x_(i)-(\bar (x)))^(2)))));)s b 1 = s e 1 ∑ i = 1 n (x i − x ¯) 2 , (\displaystyle s_(b_(1))=s_(e)(\sqrt (\frac (1)(\sum _(i=1) )^(n)(x_(i)-(\bar (x)))^(2)),) burada orta dəyərlər həmişəki kimi müəyyən edilir:, x ¯ = ∑ i = 1 n x i n (\displaystyle (\bar (x))=(\frac (\sum _(i=1)^(n)x_(i))(n))) Və y ¯ = ∑ i = 1 n y i n (\displaystyle (\bar (y))=(\frac (\sum _(i=1)^(n)y_(i))(n))) s e
2 reqressiya qalığını ifadə edir, əgər model düzgündürsə, bu, σ 2 dispersiyasının təxminidir. Reqressiya əmsallarının standart xətaları orta göstəricinin standart xətası kimi istifadə olunur - etimad intervallarını tapmaq və hipotezləri yoxlamaq üçün. Biz, məsələn, reqressiya əmsalının sıfıra bərabər olduğu, yəni model üçün əhəmiyyətsiz olduğu fərziyyəsini yoxlamaq üçün Tələbə testindən istifadə edirik. Tələbə statistikası: t = b / s b (\displaystyle t=b/s_(b)) x i, y i. Əgər əldə edilən dəyər üçün ehtimal və<0,05 - гипотеза отвергается. Напротив, если нет оснований отвергнуть гипотезу о равенстве нулю, скажем, −2 sərbəstlik dərəcəsi olduqca kiçikdir, məsələn, b 1 (\displaystyle b_(1)) - ən azı bu formada arzu olunan reqressiyanın mövcudluğu və ya əlavə müşahidələr toplamaq haqqında düşünməyə əsas var. Sərbəst müddət sıfıra bərabərdirsə b 0 (\displaystyle b_(0))
, onda düz xətt başlanğıcdan keçir və yamacın təxmini dəyəri bərabərdir,b = ∑ i = 1 n x i y i ∑ i = 1 n x i 2 (\displaystyle b=(\frac (\sum _(i=1)^(n)x_(i)y_(i))(\sum _(i=) 1)^(n)x_(i)^(2))))
və onun standart xətasıs b = s e 1 ∑ i = 1 n x i 2 . verilmişdir b verilmişdir(\displaystyle s_(b)=s_(e)(\sqrt (\frac (1)(\sum _(i=1)^(n)x_(i)^(2)))).) x Adətən β 0 və β 1 reqressiya əmsallarının həqiqi dəyərləri məlum deyil. Yalnız onların təxminləri məlumdur y 1. Başqa sözlə, həqiqi reqressiya xətti nümunə məlumatlarından qurulandan fərqli işləyə bilər. Siz reqressiya xətti üçün güvən bölgəsini hesablaya bilərsiniz. İstənilən dəyər üçün uyğun dəyərlər normal paylanmışdır. Orta reqressiya tənliyinin qiymətidir
y ^ (\displaystyle (\widehat (y)))İndi nöqtədə reqressiya tənliyinin dəyəri üçün -faiz etibar intervalını hesablaya bilərsiniz x:
y ^ − t (1 − α / 2 , n − 2) s y ^< y < y ^ + t (1 − α / 2 , n − 2) s y ^ {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{\widehat {y}}Harada t(1−α/2, x i, y i−2) - t- Tələbə paylanmasının dəyəri. Şəkildə 10 nöqtədən (bərk nöqtələr) istifadə edilməklə qurulmuş reqressiya xətti, həmçinin reqressiya xəttinin nöqtəli xətlərlə məhdudlaşan 95% etibarlılıq bölgəsi göstərilir. 95% ehtimalla deyə bilərik ki, həqiqi xəttin haradasa bu ərazinin daxilində yerləşir. Və ya əks halda, oxşar məlumat dəstlərini (dairələrlə işarələnmiş) toplasaq və onların üzərində reqressiya xətləri qursaq (mavi rənglə göstərilmişdir), onda 100-dən 95-də bu düz xətlər etimad bölgəsini tərk etməyəcəkdir. (Vizual etmək üçün şəklin üzərinə klikləyin) Nəzərə alın ki, bəzi məqamlar etibarlılıq zonasından kənarda idi. Bu, tamamilə təbiidir, çünki biz dəyərlərin özündən deyil, reqressiya xəttinin etimad bölgəsindən danışırıq. Dəyərlərin yayılması reqressiya xətti ətrafında dəyərlərin yayılmasından və bu xəttin özünün mövqeyinin qeyri-müəyyənliyindən ibarətdir, yəni:
s Y = s e 1 m + 1 n + (x − x ¯) 2 ∑ i = 1 n (x i − x ¯) 2 ;(\displaystyle s_(Y)=s_(e)(\sqrt ((\frac (1)(m))+(\frac (1)(n))+(\frac ((x-(\bar (x)) )))^(2))(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))));) Burada m y burada model tərəfindən proqnozlaşdırılan dəyər deməkdir x- ölçmə tezliyi . VƏ 100 ⋅ (1 − α 2) (\displaystyle 100\cdot \left(1-(\frac (\alpha )(2))\sağ)) Burada dəyərlər y-ortalama üçün faiz etibar intervalı (proqnoz intervalı).
edəcək:< y < y ^ + t (1 − α / 2 , n − 2) s Y {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{Y}y ^ − t (1 − α / 2 , n − 2) s Y BuradaŞəkildə bu 95% güvən bölgəsində y=1 bərk xətlərlə məhdudlaşır. Kəmiyyətin bütün mümkün dəyərlərinin 95%-i bu sahəyə düşür x.
tədqiq olunan dəyərlər diapazonunda
Daha bir neçə statistika Əgər şərti gözlənti olarsa, bunu qəti şəkildə sübut etmək olar E (Y ∣ X = x) (\displaystyle E(Y\mid X=x)) X, Y bəzi iki ölçülü təsadüfi dəyişən ( ) xətti funksiyasıdır x (\displaystyle x) , onda bu şərti gözlənti mütləq formada təmsil olunur E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac (\) sigma _(2))(\sigma _(1)))(x-\mu _(1))) E(Y, Harada E((\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).))=μ 1, Y)=μ 2 , var( (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).))=σ 1 2 , var( X, Y)=ρ.
)=σ 2 2 , cor( Üstəlik, əvvəllər qeyd olunan xətti model üçün Y = β 0 + β 1 X + ε (\displaystyle Y=\beta _(0)+\beta _(1)X+\varepsilon ) , Harada X (\displaystyle X) və müstəqil təsadüfi dəyişənlərdir vəε (\displaystyle \varepsilon) E (Y ∣ X = x) = β 0 + β 1 x (\displaystyle E(Y\mid X=x)=\beta _(0)+\beta _(1)x). Sonra, əvvəllər göstərilən bərabərlikdən istifadə edərək və üçün düsturları əldə edə bilərik: β 1 = ϱ σ 2 σ 1 (\displaystyle \beta _(1)=\varrho (\frac (\sigma _(2))(\sigma _(1)))),
β 0 = μ 2 − β 1 μ 1 (\displaystyle \beta _(0)=\mu _(2)-\beta _(1)\mu _(1))
Əgər bir yerdən apriori məlumdursa ki, müstəvidəki təsadüfi nöqtələr dəsti xətti model tərəfindən yaradılır, lakin əmsalları naməlumdur. β 0 (\displaystyle \beta _(0)) Və β 1 (\displaystyle \beta _(1)), siz göstərilən düsturlardan istifadə edərək bu əmsalların nöqtə təxminlərini əldə edə bilərsiniz. Bunun üçün təsadüfi dəyişənlərin riyazi gözləntiləri, dispersiyaları və korrelyasiyaları əvəzinə bu düsturlar Y Və (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) onların qərəzsiz qiymətləndirmələrini əvəz etməliyik. Alınan qiymətləndirmə düsturları ən kiçik kvadratlar metodu əsasında alınan düsturlarla tam üst-üstə düşəcək.
Reqressiya təhlilinin əsas məqsədi effektiv xarakteristikanın dəyişməsinin bir və ya bir neçə amil xarakteristikasının təsiri nəticəsində baş verdiyi və effektiv xarakteristikaya da təsir edən bütün digər amillərin məcmusunun sabit və orta qiymətlər kimi qəbul edildiyi analitik ünsiyyət formasının müəyyən edilməsindən ibarətdir.
Reqressiya təhlili problemləri:
a) Asılılıq formasının müəyyən edilməsi. Hadisələr arasındakı əlaqənin xarakteri və formasına gəldikdə, müsbət xətti və qeyri-xətti və mənfi xətti və qeyri-xətti reqressiya arasında fərq qoyulur.
b) Bu və ya digər tipli riyazi tənlik şəklində reqressiya funksiyasının müəyyən edilməsi və izahlı dəyişənlərin asılı dəyişənə təsirinin müəyyən edilməsi.
c) Asılı dəyişənin naməlum qiymətlərinin qiymətləndirilməsi. Reqressiya funksiyasından istifadə edərək, izahlı dəyişənlərin müəyyən edilmiş dəyərləri intervalında asılı dəyişənin dəyərlərini təkrar edə bilərsiniz (yəni, interpolyasiya problemini həll edin) və ya müəyyən edilmiş intervaldan kənarda prosesin gedişatını qiymətləndirə bilərsiniz (yəni, ekstrapolyasiya problemini həll edin). Nəticə asılı dəyişənin dəyərinin qiymətləndirilməsidir.Qoşalaşmış reqressiya iki y və x dəyişəni arasında əlaqə üçün tənlikdir: , burada y asılı dəyişəndir (nəticə atributudur); x müstəqil izahlı dəyişəndir (xüsusiyyət faktoru).
Xətti və qeyri-xətti reqressiyalar var.
Təxmin edilən parametrlərə görə qeyri-xətti olan reqressiyalar: Reqressiya tənliyinin qurulması onun parametrlərinin qiymətləndirilməsinə gəlir. Parametrlərdə xətti reqressiyaların parametrlərini qiymətləndirmək üçün ən kiçik kvadratlar metodundan (OLS) istifadə olunur. Ən kiçik kvadratlar metodu belə parametr qiymətləndirmələrini əldə etməyə imkan verir ki, nəticədə y xarakteristikasının faktiki dəyərlərinin nəzəri olanlardan kvadratik sapmalarının cəmi minimaldır, yəni.
Xətti reqressiya: y = a + bx + ε
Qeyri-xətti reqressiyalar iki sinfə bölünür: təhlilə daxil edilən izahedici dəyişənlərə görə qeyri-xətti, lakin təxmin edilən parametrlərə görə xətti olan reqressiyalar və təxmin edilən parametrlərə görə qeyri-xətti olan reqressiyalar.
İzahedici dəyişənlərdə qeyri-xətti olan reqressiyalar: .
.
Xətti və qeyri-xətti tənliklər üçün a və b-yə nisbətdə aşağıdakı sistem həll edilir:
Bu sistemdən gələn hazır düsturlardan istifadə edə bilərsiniz:
Öyrənilən hadisələr arasında əlaqənin yaxınlığı xətti reqressiya üçün cüt korrelyasiya xətti əmsalı ilə qiymətləndirilir:
və korrelyasiya indeksi - qeyri-xətti reqressiya üçün:
Qurulmuş modelin keyfiyyəti təyinetmə əmsalı (indeksi), eləcə də yaxınlaşmanın orta xətası ilə qiymətləndiriləcəkdir.
Orta yaxınlaşma xətası - hesablanmış dəyərlərin faktiki olanlardan orta sapması: .
.
Dəyərlərin icazə verilən həddi 8-10% -dən çox deyil.
Orta elastiklik əmsalı x faktoru orta dəyərdən 1% dəyişdikdə y nəticəsinin orta dəyərdən neçə faiz dəyişəcəyini göstərir:
.Dispersiya təhlilinin məqsədi asılı dəyişənin dispersiyasını təhlil etməkdir:
,
kvadratik kənarlaşmaların ümumi cəmi haradadır;
- reqressiya (izah edilmiş) və ya “faktorial”) ilə bağlı kvadratik kənarlaşmaların cəmi;
- kvadrat sapmaların qalıq cəmi.
Nəticə xarakteristikası y-nin ümumi dispersiyasında reqressiya ilə izah edilən dispersiyanın payı R2 təyini əmsalı (indeksi) ilə xarakterizə olunur:
Determinasiya əmsalı əmsalın və ya korrelyasiya indeksinin kvadratıdır.F-testi - reqressiya tənliyinin keyfiyyətinin qiymətləndirilməsi - reqressiya tənliyinin statistik əhəmiyyətsizliyi və əlaqənin yaxınlığının göstəricisi haqqında №-li fərziyyənin sınaqdan keçirilməsindən ibarətdir. Bunun üçün faktiki F faktı ilə Fisher F-meyarının kritik (cədvəl) F cədvəl dəyərləri arasında müqayisə aparılır. F faktı bir sərbəstlik dərəcəsi üçün hesablanmış amil və qalıq dispersiyaların dəyərlərinin nisbətindən müəyyən edilir:
 ,
,
burada n - əhali vahidlərinin sayı; m, x dəyişənləri üçün parametrlərin sayıdır.
F cədvəli verilmiş sərbəstlik dərəcələrində və a əhəmiyyətlilik səviyyəsində təsadüfi amillərin təsiri altında meyarın mümkün olan maksimum qiymətidir. Əhəmiyyət səviyyəsi a doğru olduğunu nəzərə alsaq, düzgün fərziyyənin rədd edilməsi ehtimalıdır. Adətən a 0,05 və ya 0,01-ə bərabər alınır.
Əgər F cədvəli< F факт, то Н о - гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если F табл >F fakt, onda H o hipotezi rədd edilmir və reqressiya tənliyinin statistik əhəmiyyətsizliyi və etibarsızlığı tanınır.
Reqressiya və korrelyasiya əmsallarının statistik əhəmiyyətini qiymətləndirmək üçün hər bir göstərici üçün Student t-testi və etimad intervalları hesablanır. Göstəricilərin təsadüfi təbiəti haqqında fərziyyə irəli sürülür, yəni. onların sıfırdan əhəmiyyətsiz fərqi haqqında. Tələbənin t-testindən istifadə edərək reqressiya və korrelyasiya əmsallarının əhəmiyyətinin qiymətləndirilməsi onların dəyərlərini təsadüfi xətanın böyüklüyü ilə müqayisə etməklə həyata keçirilir:
; ; .
Xətti reqressiya parametrlərinin və korrelyasiya əmsalının təsadüfi səhvləri düsturlarla müəyyən edilir:
T-statistikanın faktiki və kritik (cədvəl) dəyərlərini - t cədvəli və t faktını müqayisə edərək, H o hipotezini qəbul edirik və ya rədd edirik.
Fisher F-testi ilə Student t-statistikası arasındakı əlaqə bərabərliklə ifadə edilir
Əgər t cədvəli< t факт то H o отклоняется, т.е. a, b и не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора х. Если t табл >t bir faktdır ki, H o hipotezi rədd edilmir və a, b və ya əmələ gəlməsinin təsadüfi xarakteri qəbul edilir.
Etibar intervalını hesablamaq üçün hər bir göstərici üçün maksimum D səhvini təyin edirik:
, .
Etibar intervallarının hesablanması üçün düsturlar aşağıdakılardır:
; ;
; ;
Sıfır etimad intervalına düşürsə, yəni. Aşağı həddi mənfi, yuxarı həddi isə müsbətdirsə, eyni vaxtda həm müsbət, həm də mənfi dəyərləri qəbul edə bilmədiyi üçün təxmin edilən parametr sıfır olaraq qəbul edilir.
Proqnoz dəyəri müvafiq (proqnozlaşdırılan) dəyərin reqressiya tənliyinə əvəz edilməsi ilə müəyyən edilir. Proqnozun orta standart səhvi hesablanır: ,
,
Harada
və proqnoz üçün etimad intervalı qurulur: ;
;  ;
; 
Harada .
.Nümunə həlli
Tapşırıq №1. 199X-ci ildə Ural bölgəsinin yeddi ərazisi üçün iki xüsusiyyətin dəyəri məlumdur.
Cədvəl 1.
Tələb olunur: 1. y-nin x-dən asılılığını xarakterizə etmək üçün aşağıdakı funksiyaların parametrlərini hesablayın:
a) xətti;
b) güc (əvvəlcə hər iki hissənin loqarifmini götürərək dəyişənlərin xəttiləşdirmə prosedurunu yerinə yetirməlisiniz);
c) nümayiş etdirici;
d) bərabərtərəfli hiperbola (həmçinin bu modeli necə əvvəlcədən xəttiləşdirməyi başa düşməlisiniz).
2. Orta yaxınlaşma xətası və Fişerin F testindən istifadə edərək hər bir modeli qiymətləndirin.Həlli (Variant №1)
Xətti reqressiyanın a və b parametrlərini hesablamaq üçün (hesablama kalkulyatordan istifadə etməklə edilə bilər).
üçün normal tənliklər sistemini həll edin A Və b:
İlkin məlumatlara əsasən hesablayırıq :
:
y x yx x 2 y 2 A i l 68,8 45,1 3102,88 2034,01 4733,44 61,3 7,5 10,9 2 61,2 59,0 3610,80 3481,00 3745,44 56,5 4,7 7,7 3 59,9 57,2 3426,28 3271,84 3588,01 57,1 2,8 4,7 4 56,7 61,8 3504,06 3819,24 3214,89 55,5 1,2 2,1 5 55,0 58,8 3234,00 3457,44 3025,00 56,5 -1,5 2,7 6 54,3 47,2 2562,96 2227,84 2948,49 60,5 -6,2 11,4 7 49,3 55,2 2721,36 3047,04 2430,49 57,8 -8,5 17,2 Cəmi 405,2 384,3 22162,34 21338,41 23685,76 405,2 0,0 56,7 Çərşənbə. məna (Cəmi/n) 57,89 54,90 3166,05 3048,34 3383,68 Y Y 8,1 s 5,74 5,86 Y Y Y Y Y Y s 2 32,92 34,34 Y Y Y Y Y Y 

Reqressiya tənliyi: y = 76,88 - 0,35X. Orta gündəlik əmək haqqının 1 rubl artması ilə. ərzaq məhsullarının alınması xərclərinin xüsusi çəkisi orta hesabla 0,35% bənd azalır.
Xətti cüt korrelyasiya əmsalını hesablayaq:
Əlaqə orta səviyyədədir, tərsdir.
Determinasiya əmsalını təyin edək: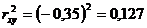
Nəticənin 12,7% dəyişməsi x faktorunun dəyişməsi ilə izah olunur. Həqiqi dəyərləri reqressiya tənliyinə əvəz etmək X, nəzəri (hesablanmış) qiymətləri müəyyən edək . Orta yaxınlaşma xətasının qiymətini tapaq:
Orta hesabla, hesablanmış dəyərlər faktiki olanlardan 8,1% kənara çıxır.
F kriteriyasını hesablayaq:
1-dən< F < ¥ , nəzərə alınmalıdır F -1 .
Yaranan dəyər fərziyyənin qəbul edilməsinin zəruriliyini göstərir Amma oh müəyyən edilmiş asılılığın təsadüfi xarakteri və tənliyin parametrlərinin statistik əhəmiyyətsizliyi və əlaqənin yaxınlığının göstəricisi.
1b. Güc modelinin qurulmasından əvvəl dəyişənlərin xəttiləşdirilməsi proseduru aparılır. Nümunədə xəttiləşdirmə tənliyin hər iki tərəfinin loqarifmlərini götürməklə həyata keçirilir:
HaradaY=lg(y), X=lg(x), C=lg(a).Hesablamalar üçün cədvəldəki məlumatlardan istifadə edirik. 1.3.
Cədvəl 1.3
(\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) Y YX Y2 X 2 A i 1 1,8376 1,6542 3,0398 3,3768 2,7364 61,0 7,8 60,8 11,3 2 1,7868 1,7709 3,1642 3,1927 3,1361 56,3 4,9 24,0 8,0 3 1,7774 1,7574 3,1236 3,1592 3,0885 56,8 3,1 9,6 5,2 4 1,7536 1,7910 3,1407 3,0751 3,2077 55,5 1,2 1,4 2,1 5 1,7404 1,7694 3,0795 3,0290 3,1308 56,3 -1,3 1,7 2,4 6 1,7348 1,6739 2,9039 3,0095 2,8019 60,2 -5,9 34,8 10,9 7 1,6928 1,7419 2,9487 2,8656 3,0342 57,4 -8,1 65,6 16,4 Cəmi 12,3234 12,1587 21,4003 21,7078 21,1355 403,5 1,7 197,9 56,3 Orta dəyər 1,7605 1,7370 3,0572 3,1011 3,0194 Y Y 28,27 8,0 σ 0,0425 0,0484 Y Y Y Y Y Y Y σ 2 0,0018 0,0023 Y Y Y Y Y Y Y C və b-ni hesablayaq:
Xətti tənlik alırıq: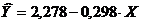 .
.
Onun gücləndirilməsini həyata keçirərək, əldə edirik:
Bu tənliyə faktiki dəyərləri əvəz etmək X, nəticənin nəzəri qiymətlərini alırıq. Onlardan istifadə edərək göstəriciləri hesablayacağıq: əlaqənin sıxlığı - korrelyasiya indeksi və orta yaxınlaşma xətası
Güc qanunu modelinin xüsusiyyətləri onun əlaqəni xətti funksiyadan bir qədər yaxşı təsvir etdiyini göstərir.1c. Eksponensial əyrinin tənliyinin qurulması
tənliyin hər iki tərəfinin loqarifmlərini götürərək dəyişənləri xəttiləşdirmə prosedurundan əvvəl:

Hesablamalar üçün cədvəl məlumatlarından istifadə edirik.(\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) x Yx Y2 x 2 A i 1 1,8376 45,1 82,8758 3,3768 2034,01 60,7 8,1 65,61 11,8 2 1,7868 59,0 105,4212 3,1927 3481,00 56,4 4,8 23,04 7,8 3 1,7774 57,2 101,6673 3,1592 3271,84 56,9 3,0 9,00 5,0 4 1,7536 61,8 108,3725 3,0751 3819,24 55,5 1,2 1,44 2,1 5 1,7404 58,8 102,3355 3,0290 3457,44 56,4 -1,4 1,96 2,5 6 1,7348 47,2 81,8826 3,0095 2227,84 60,0 -5,7 32,49 10,5 7 1,6928 55,2 93,4426 2,8656 3047,04 57,5 -8,2 67,24 16,6 Cəmi 12,3234 384,3 675,9974 21,7078 21338,41 403,4 -1,8 200,78 56,3 Çərşənbə. zn. 1,7605 54,9 96,5711 3,1011 3048,34 Y Y 28,68 8,0 σ 0,0425 5,86 Y Y Y Y Y Y Y σ 2 0,0018 34,339 Y Y Y Y Y Y Y A və reqressiya parametrlərinin dəyərləri IN təşkil edib:
Nəticə xətti tənlik belədir: .
Əldə edilən tənliyi gücləndirək və adi formada yazaq:
.
Əldə edilən tənliyi gücləndirək və adi formada yazaq:
Əlaqənin yaxınlığını korrelyasiya indeksi ilə qiymətləndirəcəyik:
HESABAT
Tapşırıq: 23 daşınmaz əmlaka dair məlumatlara (satış qiyməti və yaşayış sahəsi) əsaslanan reqressiya təhlili prosedurunu nəzərdən keçirin.
“Reqressiya” iş rejimi xətti reqressiya tənliyinin parametrlərini hesablamaq və tədqiq olunan proses üçün adekvatlığını yoxlamaq üçün istifadə olunur.
MS Excel-də reqressiya təhlili problemini həll etmək üçün menyudan seçin Xidmət komanda Məlumatların təhlili və təhlil aləti" Reqressiya".
Görünən informasiya qutusunda aşağıdakı parametrləri təyin edin:
1. Giriş intervalı Y- bu, yaranan atribut üçün məlumat diapazonudur. Bir sütundan ibarət olmalıdır.
2. Daxiletmə intervalı X amillərin (müstəqil dəyişənlərin) dəyərlərini ehtiva edən bir sıra hüceyrələrdir. Giriş diapazonlarının (sütunların) sayı 16-dan çox olmamalıdır.
3. Qeyd qutusu Teqlər, aralığın birinci sətirində başlıq varsa təyin edilir.
4. Qeyd qutusu Etibarlılıq səviyyəsi yanındakı sahədə standartdan fərqli bir etibarlılıq səviyyəsini daxil etməlisinizsə aktivləşdirilir. R2 təyin əmsalının və reqressiya əmsallarının əhəmiyyətini yoxlamaq üçün istifadə olunur.
5. Sabit sıfır.Əgər reqressiya xətti mənbədən keçməlidirsə (və 0 =0) bu qeyd qutusu yoxlanılmalıdır.
6. Çıxış intervalı/ Yeni iş vərəqi/ Yeni iş kitabı -çıxış diapazonunun yuxarı sol xanasının ünvanını təyin edin.
7. Yoxlama qutuları qrupda Qalıqlar müvafiq sütunları və ya qrafikləri çıxış diapazonuna daxil etmək lazım olduqda təyin edilir.
8. Müşahidə olunan Y dəyərlərinin avtomatik yaradılan faiz intervallarından asılılığının səpələnmə qrafikini göstərmək istəyirsinizsə, Normal Ehtimal Qrafiki qeyd qutusu aktivləşdirilməlidir.
Çıxış diapazonunda OK düyməsini basdıqdan sonra hesabat alırıq.
Bir sıra məlumatların təhlili alətlərindən istifadə edərək mənbə məlumatlarının reqressiya təhlilini həyata keçirəcəyik.
Reqressiya təhlili aləti ən kiçik kvadratlar metodundan istifadə edərək reqressiya tənliyinin parametrlərini uyğunlaşdırmaq üçün istifadə olunur. Reqressiya bir və ya bir neçə müstəqil dəyişənin dəyərlərinin bir asılı dəyişənə təsirini təhlil etmək üçün istifadə olunur.
CƏDVƏL REQRESSİYA STATİSTİKASI
Böyüklük cəm R təyin əmsalının köküdür (R-kvadrat). Buna korrelyasiya indeksi və ya çoxlu korrelyasiya əmsalı da deyilir. Müstəqil dəyişənlərin (X1, X2) və asılı dəyişənin (Y) asılılıq dərəcəsini ifadə edir və təyin əmsalının kvadrat kökünə bərabərdir, bu dəyər sıfırdan birə qədər olan dəyərləri qəbul edir; Bizim vəziyyətimizdə 0,7-yə bərabərdir ki, bu da dəyişənlər arasında əhəmiyyətli əlaqəni göstərir.
Böyüklük R-kvadrat (təyin etmə əmsalı), həmçinin əminlik ölçüsü adlanır, nəticədə reqressiya xəttinin keyfiyyətini xarakterizə edir. Bu keyfiyyət mənbə məlumatları ilə reqressiya modeli (hesablanmış verilənlər) arasında uyğunluq dərəcəsi ilə ifadə edilir. Əminlik ölçüsü həmişə interval daxilindədir.
Bizim vəziyyətimizdə R-kvadrat dəyəri 0,48-dir, yəni. demək olar ki, 50%, bu, reqressiya xəttinin orijinal məlumatlara zəif uyğunluğunu göstərir tapılmış dəyər R-kvadrat = 48%<75%, то, следовательно, также можно сделать вывод о невозможности прогнозирования с помощью найденной регрессионной зависимости. Таким образом, модель объясняет всего 48% вариации цены, что говорит о недостаточности выбранных факторов, либо о недостаточном объеме выборки.
Normallaşdırılmış R-kvadrat eyni təyin əmsalıdır, lakin nümunənin ölçüsünə uyğunlaşdırılır.
Normal R-kvadrat=1-(1-R-kvadrat)*((n-1)/(n-k)),
reqressiya təhlili xətti tənlik
burada n - müşahidələrin sayı; k - parametrlərin sayı. Yeni reqressorlar (amillər) əlavə edilərkən normallaşdırılmış R-kvadratdan istifadə edilməsinə üstünlük verilir, çünki onlar artdıqca R-kvadrat dəyəri də artacaq, lakin bu, modeldə təkmilləşməni göstərməyəcək. Bizim vəziyyətimizdə nəticədə alınan dəyər 0,43 olduğundan (bu, R-kvadratından cəmi 0,05 ilə fərqlənir), R-kvadrat əmsalına yüksək inamdan danışmaq olar.
Standart səhv müşahidə nəticələrinin yaxınlaşması (yaxınlaşması) keyfiyyətini göstərir. Bizim vəziyyətimizdə səhv 5.1-dir. Faizlə hesablayaq: 5,1/(57,4-40,1)=0,294? 29% (Standart səhv olduqda model daha yaxşı hesab olunur<30%)
Müşahidələr- müşahidə edilən dəyərlərin sayı göstərilir (23).
VARIANSIN CƏDVƏL TƏHLİLİ
Reqressiya tənliyini əldə etmək üçün reqressiya tənliyi ilə izah edilən asılı dəyişənin dispersiyasının həmin hissəsinin izah olunmayan (qalıq) hissəsinə nisbəti olan reqressiya tənliyinin düzgünlüyünün xarakteristikası -statistika müəyyən edilir. variasiyadan.
df sütununda- sərbəstlik dərəcələrinin sayı k verilir.
Reqressiya üçün bu, reqressorların (faktorların) sayıdır - X1 (sahə) və X2 (bal), yəni. k=2.
Qalanları üçün bu, n-(m+1) bərabər dəyərdir, yəni. ilkin xalların sayı (23) minus əmsalların sayı (2) və sərbəst müddət (1) çıxılmaqla.
SS sütununda- yaranan xarakteristikanın orta qiymətindən kvadrat kənara çıxanların cəmi. Təqdim edir:
Reqressiya tənliyi ilə hesablanmış nəzəri dəyərlərin nəticə xarakteristikasının orta dəyərindən kvadrat sapmaların reqressiya cəmi.
Orijinal dəyərlərin nəzəri dəyərlərdən sapmalarının qalıq cəmi.
İlkin dəyərlərin ortaya çıxan xarakteristikadan kvadrat sapmalarının ümumi cəmi.
Kvadrat sapmaların reqressiya cəmi nə qədər böyük olarsa (və ya qalıq cəmi nə qədər kiçik olarsa), reqressiya tənliyi ilkin nöqtələrin buluduna bir o qədər yaxşı yaxınlaşır. Bizim vəziyyətimizdə qalıq məbləğ təxminən 50% təşkil edir. Nəticə etibarilə, reqressiya tənliyi başlanğıc nöqtələrin buluduna çox zəif yaxınlaşır.
MS sütununda- qərəzsiz seçmə dispersiyaları, reqressiya və qalıq.
F sütununda Reqressiya tənliyinin əhəmiyyətini yoxlamaq üçün kriteriya statistikasının dəyəri hesablanmışdır.
Reqressiya tənliyinin əhəmiyyətinin statistik sınağını həyata keçirmək üçün dəyişənlər arasında əlaqənin olmaması haqqında sıfır fərziyyə tərtib edilir (dəyişənlər üçün bütün əmsallar sıfıra bərabərdir) və əhəmiyyət səviyyəsi seçilir.
Əhəmiyyət səviyyəsi test nəticəsində düzgün sıfır fərziyyənin rədd edilməsi - I tip səhvin edilməsinin məqbul ehtimalıdır. Bu halda, I tip xəta etmək, nümunədə populyasiyada dəyişənlər arasında əlaqənin olduğunu etiraf etmək deməkdir, halbuki əslində heç biri yoxdur. Tipik olaraq əhəmiyyət səviyyəsi 5% olaraq qəbul edilir. Alınan = 9,4 qiymətini cədvəl qiyməti = 3,5 (sərbəstlik dərəcələrinin sayı müvafiq olaraq 2 və 20-dir) ilə müqayisə etsək, reqressiya tənliyinin əhəmiyyətli olduğunu deyə bilərik (F>Fcr).
Əhəmiyyət sütununda F kriteriya statistikasının alınan qiymətinin ehtimalı hesablanır. Bizim vəziyyətimizdə 0,05-dən az olan bu dəyər = 0,00123 olduğundan, reqressiya tənliyinin (asılılığın) 95% ehtimalla əhəmiyyətli olduğunu deyə bilərik.
Yuxarıda təsvir olunan iki sütun bütövlükdə modelin etibarlılığını göstərir.
Aşağıdakı cədvəl reqressorlar üçün əmsalları və onların təxminlərini ehtiva edir.
Y-kəsici xətti heç bir reqressorla əlaqəli deyil, bu, sərbəst əmsaldır;
Sütunda ehtimallar Reqressiya tənliyi əmsallarının dəyərləri qeyd olunur. Beləliklə, tənlik əldə edildi:
Y=25,6+0,009X1+0,346X2
Reqressiya tənliyi ilkin nöqtələr buludunun mərkəzindən keçməlidir: 13.02? 38.26
Sonra, sütun dəyərlərini cüt-cüt müqayisə edin Əmsallar və Standart Xəta. Görünür ki, bizim vəziyyətimizdə əmsalların bütün mütləq dəyərləri standart səhvləri üstələyir. Bu, reqressorların əhəmiyyətini göstərə bilər, lakin bu kobud təhlildir. t-statistik sütunu əmsalların əhəmiyyətinin daha dəqiq qiymətləndirilməsini təmin edir.
t-statistik sütunda formula ilə hesablanmış t-test dəyərlərini ehtiva edir:
t=(əmsal)/(Standart xəta)
Bu testin sərbəstlik dərəcələrinin sayı ilə Tələbə paylanması var
n-(k+1)=23-(2+1)=20
Tələbə cədvəlindən istifadə edərək ttable = 2.086 dəyərini tapırıq. Müqayisə edir
t cədvəli ilə biz tapırıq ki, X2 reqressor əmsalı əhəmiyyətsizdir.
Sütun p-dəyəri test statistikasının kritik dəyərinin (Tələbənin t statistik göstəricisi) seçmədən hesablanmış dəyərini aşması ehtimalını təmsil edir. Bu vəziyyətdə müqayisə edirik p-dəyərləri seçilmiş əhəmiyyətlilik səviyyəsi ilə (0.05). Görünür ki, yalnız X2=0,08>0,05 reqressor əmsalı əhəmiyyətsiz hesab edilə bilər.
Aşağı 95% və yuxarı 95% sütunlar 95% inamla etimad intervalı limitlərini təmin edir. Hər bir əmsalın öz məhdudiyyətləri var: Əmsal cədvəli*Standart xəta
Etibar intervalları yalnız statistik əhəmiyyətli dəyərlər üçün qurulur.
Əvvəlki yazılarda təhlil çox vaxt qarşılıqlı fondun gəlirləri, veb səhifənin yüklənmə müddətləri və ya sərinləşdirici içki istehlakı kimi tək ədədi dəyişənə diqqət yetirirdi. Bu və sonrakı qeydlərdə biz bir və ya bir neçə digər ədədi dəyişənin dəyərlərindən asılı olaraq ədədi dəyişənin dəyərlərinin proqnozlaşdırılması üsullarına baxacağıq.
Material kəsişən bir nümunə ilə təsvir ediləcəkdir. Geyim mağazasında satış həcminin proqnozlaşdırılması. Sunflowers endirimli geyim mağazalar şəbəkəsi 25 ildir ki, daim genişlənir. Bununla belə, şirkətdə hazırda yeni satış məntəqələrinin seçilməsinə sistemli yanaşma yoxdur. Bir şirkətin yeni mağaza açmaq niyyətində olduğu yer subyektiv mülahizələrə əsasən müəyyən edilir. Seçim meyarları əlverişli icarə şərtləri və ya menecerin ideal mağaza yeri haqqında fikirləridir. Təsəvvür edin ki, siz xüsusi layihələr və planlaşdırma şöbəsinin rəhbərisiniz. Sizə yeni mağazalar açmaq üçün strateji plan hazırlamaq tapşırılıb. Bu plana yeni açılan mağazalar üçün illik satış proqnozu daxil edilməlidir. Siz pərakəndə satış sahəsinin birbaşa gəlirlə əlaqəli olduğuna inanırsınız və bunu qərar qəbuletmə prosesinizdə nəzərə almaq istəyirsiniz. Yeni mağazanın ölçüsünə əsaslanaraq illik satışları proqnozlaşdırmaq üçün statistik modeli necə inkişaf etdirirsiniz?
Tipik olaraq, reqressiya təhlili dəyişənin dəyərlərini proqnozlaşdırmaq üçün istifadə olunur. Onun məqsədi ən azı bir müstəqil və ya izahedici dəyişənin dəyərlərindən asılı dəyişənin və ya cavabın dəyərlərini proqnozlaşdıra bilən statistik model hazırlamaqdır. Bu qeyddə sadə xətti reqressiyaya baxacağıq - asılı dəyişənin dəyərlərini proqnozlaşdırmağa imkan verən statistik bir üsul (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) müstəqil dəyişən qiymətlərlə Y. Sonrakı qeydlər müstəqil dəyişənin dəyərlərini proqnozlaşdırmaq üçün hazırlanmış çoxlu reqressiya modelini təsvir edəcəkdir (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) bir neçə asılı dəyişənin dəyərlərinə əsaslanaraq ( X 1, X 2, …, X k).
Qeydi və ya formatda yükləyin, nümunələri formatda
Reqressiya modellərinin növləri
Harada ρ 1 – avtokorrelyasiya əmsalı; Əgər ρ 1 = 0 (avtokorrelyasiya yoxdur), D≈ 2; Əgər ρ 1 ≈ 1 (müsbət avtokorrelyasiya), D≈ 0; Əgər ρ 1 = -1 (mənfi avtokorrelyasiya), D ≈ 4.
Praktikada Durbin-Vatson kriteriyasının tətbiqi dəyərin müqayisəsinə əsaslanır D tənqidi nəzəri dəyərlərlə dL Və dU müəyyən sayda müşahidələr üçün x i, y i, modelin müstəqil dəyişənlərinin sayı k(sadə xətti reqressiya üçün k= 1) və əhəmiyyət səviyyəsi α. Əgər D< d L , təsadüfi kənarlaşmaların müstəqilliyi haqqında fərziyyə rədd edilir (deməli, müsbət avtokorrelyasiya mövcuddur); Əgər D>dU, hipotez rədd edilmir (yəni avtokorrelyasiya yoxdur); Əgər d L< D < d U , qərar qəbul etmək üçün kifayət qədər əsas yoxdur. Hesablanmış dəyər olduqda D 2-dən çox, sonra ilə dL Və dU Müqayisə olunan əmsalın özü deyil D, və ifadə (4 - D).
Excel-də Durbin-Watson statistikasını hesablamaq üçün Şəkil 1-də aşağı cədvələ müraciət edək. 14 Balansın çıxarılması. (10) ifadəsindəki pay =SUMMAR(massiv1;massiv2), məxrəc isə =SUMMAR(massiv) funksiyasından istifadə etməklə hesablanır (şək. 16).

düyü. 16. Durbin-Vatson statistikasının hesablanması üçün düsturlar
Bizim nümunəmizdə D= 0,883. Əsas sual budur: Durbin-Vatson statistikasının hansı dəyəri müsbət avtokorrelyasiyanın mövcud olduğu qənaətinə gəlmək üçün kifayət qədər kiçik hesab edilməlidir? D dəyərini kritik dəyərlərlə əlaqələndirmək lazımdır ( dL Və dU), müşahidələrin sayından asılı olaraq x i, y i və əhəmiyyət səviyyəsi α (şək. 17).

düyü. 17. Durbin-Watson statistikasının kritik dəyərləri (cədvəl fraqmenti)
Beləliklə, malları evə çatdıran bir mağazada satış həcmi problemində bir müstəqil dəyişən var ( k= 1), 15 müşahidə ( x i, y i= 15) və əhəmiyyətlilik səviyyəsi α = 0,05. Beləliklə, dL= 1.08 və dU= 1.36. ildən D = 0,883 < dL= 1.08, qalıqlar arasında müsbət avtokorrelyasiya var, ən kiçik kvadratlar metodundan istifadə etmək olmaz.
Yamac və korrelyasiya əmsalı haqqında fərziyyələrin yoxlanılması
Yuxarıda, reqressiya yalnız proqnozlaşdırma üçün istifadə edilmişdir. Reqressiya əmsallarını təyin etmək və dəyişənin qiymətini proqnozlaşdırmaq (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) verilmiş dəyişən dəyər üçün YƏn kiçik kvadratlar metodundan istifadə edilmişdir. Bundan əlavə, biz qiymətləndirmənin kök orta kvadrat səhvini və qarışıq korrelyasiya əmsalını araşdırdıq. Əgər qalıqların təhlili ən kiçik kvadratlar metodunun tətbiqi şərtlərinin pozulmadığını və sadə xətti reqressiya modelinin adekvat olduğunu təsdiq edərsə, seçmə məlumatlarına əsaslanaraq, dəyişənlər arasında xətti əlaqənin olduğunu iddia etmək olar. əhali.
Ərizət - yamac üçün meyarlar.Əhali yamacının β 1 sıfıra bərabər olub olmadığını yoxlayaraq, dəyişənlər arasında statistik əhəmiyyətli əlaqənin olub olmadığını müəyyən edə bilərsiniz. Y Və (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).). Bu fərziyyə rədd edilərsə, dəyişənlər arasında olduğu iddia edilə bilər Y Və (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) xətti əlaqə mövcuddur. Sıfır və alternativ fərziyyələr aşağıdakı kimi tərtib edilmişdir: H 0: β 1 = 0 (xətti asılılıq yoxdur), H1: β 1 ≠ 0 (xətti asılılıq var). Tərifinə görə t-statistika seçmə meyli ilə populyasiya yamacının hipotetik dəyəri arasındakı fərqə bərabərdir və yamacın təxmininin kök orta kvadrat səhvinə bölünür:
(11) t = (verilmişdir 1 – β 1 ) / Sb 1
Harada verilmişdir 1 – nümunə məlumatları üzrə birbaşa reqressiyanın mailliyi, β1 – birbaşa əhalinin hipotetik mailliyi,
 , və test statistikası t var t- ilə paylanması n – 2 sərbəstlik dərəcələri.
, və test statistikası t var t- ilə paylanması n – 2 sərbəstlik dərəcələri.α = 0.05-də mağaza ölçüsü ilə illik satış arasında statistik əhəmiyyətli əlaqənin olub olmadığını yoxlayaq. t-kriteriya istifadə edildikdə digər parametrlərlə birlikdə göstərilir Analiz paketi(seçim Reqressiya). Analiz Paketinin tam nəticələri Şəkildə göstərilmişdir. 4, t-statistika ilə əlaqəli fraqment - Şəkildə. 18.
düyü. 18. Müraciət nəticələri t
Mağazaların sayından bəri x i, y i= 14 (bax. Şəkil 3), kritik dəyər t- α = 0,05 əhəmiyyət səviyyəsində olan statistik düsturdan istifadə etməklə tapıla bilər: tL=STUDENT.ARV(0.025,12) = –2.1788, burada 0.025 əhəmiyyət səviyyəsinin yarısıdır və 12 = x i, y i – 2; t U=TƏLƏBƏ.OBR(0.975,12) = +2.1788.
ildən t-statistika = 10,64 > t U= 2.1788 (Şəkil 19), sıfır hipotezi H 0 rədd edildi. Digər tərəfdən, r- üçün dəyər X=1-STUDENT.DIST(D3,12,DOĞRU) düsturu ilə hesablanan = 10.6411, təqribən sıfıra bərabərdir, ona görə də hipotez H 0 yenidən rədd edildi. Fakt budur ki r-demək olar ki, sıfır dəyəri o deməkdir ki, mağaza ölçüsü ilə illik satışlar arasında həqiqi xətti əlaqə olmasaydı, xətti reqressiyadan istifadə edərək onu aşkar etmək praktiki olaraq qeyri-mümkün olardı. Buna görə də, orta illik mağaza satışları ilə mağaza ölçüsü arasında statistik əhəmiyyətli xətti əlaqə var.

düyü. 19. Əhali yamacı haqqında fərziyyənin 0,05 və 12 sərbəstlik dərəcəsi əhəmiyyətlilik səviyyəsində sınaqdan keçirilməsi
ƏrizəF - yamac üçün meyarlar. Sadə xətti reqressiyanın mailliyi haqqında fərziyyələri yoxlamaq üçün alternativ yanaşma istifadə etməkdir F-meyarlar. Bunu xatırladaq F-test iki variasiya arasındakı əlaqəni yoxlamaq üçün istifadə olunur (ətraflı məlumat üçün bax). Yamac fərziyyəsini sınaqdan keçirərkən təsadüfi səhvlərin ölçüsü səhv dispersiyasıdır (sərbəstlik dərəcələrinin sayına bölünmüş kvadrat səhvlərin cəmi), buna görə də F-kriteriya reqressiya ilə izah edilən dispersiya nisbətindən istifadə edir (yəni dəyər SSR, müstəqil dəyişənlərin sayına bölünür k), səhv fərqinə ( MSE = S YX 2 ).
Tərifinə görə F-statistika orta reqressiyanın kvadratına (MSR) bərabərdir, səhv dispersiyaya (MSE) bölünür: F = MSR/ MSE E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac (\) sigma _(2))(\sigma _(1)))(x-\mu _(1))) MSR =SSR / k, MSE =SSE/(x i, y i– k – 1), k– reqressiya modelində müstəqil dəyişənlərin sayı. Test statistikası F var F- ilə paylanması k Və x i, y i– k – 1 sərbəstlik dərəcələri.
Verilmiş əhəmiyyət səviyyəsi α üçün qərar qaydası aşağıdakı kimi tərtib edilir: əgər F>FU, sıfır hipotezi rədd edilir; əks halda rədd edilmir. Dispersiya təhlilinin xülasə cədvəli şəklində təqdim olunan nəticələr Şəkildə göstərilmişdir. 20.

düyü. 20. Reqressiya əmsalının statistik əhəmiyyəti haqqında fərziyyənin yoxlanılması üçün dispersiya cədvəlinin təhlili.
Eynilə t-meyar F- istifadə edildikdə meyar cədvəldə göstərilir Analiz paketi(seçim Reqressiya). İşin tam nəticələri Analiz paketiŞəkildə göstərilir. 4 ilə əlaqəli fraqment F-statistika - Şəkildə. 21.

düyü. 21. Ərizə nəticələri F-Excel Analiz Paketindən istifadə etməklə əldə edilən meyarlar
F-statistikası 113,23 və r-qiymət sıfıra yaxın (xana ƏhəmiyyətiF). Əhəmiyyət səviyyəsi α 0,05 olarsa, kritik dəyəri təyin edin F-düsturdan istifadə etməklə bir və 12 sərbəstlik dərəcəsi olan paylamalar əldə edilə bilər F U=F.OBR(1-0,05;1;12) = 4,7472 (şək. 22). ildən F = 113,23 > F U= 4.7472 və r- 0-a yaxın dəyər< 0,05, нулевая гипотеза H 0 rədd edilir, yəni. Mağazanın ölçüsü onun illik satışları ilə sıx bağlıdır.

düyü. 22. Əhali yamac hipotezinin bir və 12 sərbəstlik dərəcələri ilə 0,05 əhəmiyyətlilik səviyyəsində sınaqdan keçirilməsi
Yamac β 1 olan etibarlılıq intervalı. Dəyişənlər arasında xətti əlaqənin olması ilə bağlı fərziyyəni yoxlamaq üçün β 1 yamacını ehtiva edən etibarlılıq intervalı qura və β 1 = 0 hipotetik dəyərinin bu intervala aid olduğunu yoxlaya bilərsiniz. β 1 yamacını ehtiva edən inam intervalının mərkəzi nümunənin yamacıdır verilmişdir 1 , və onun sərhədləri kəmiyyətlərdir b 1 ±tn –2 Sb 1
Şəkildə göstərildiyi kimi. 18, verilmişdir 1 = +1,670, x i, y i = 14, Sb 1 = 0,157. t 12 =TƏLƏBƏ.ARV(0.975,12) = 2.1788. Beləliklə, b 1 ±tn –2 Sb 1 = +1,670 ± 2,1788 * 0,157 = +1,670 ± 0,342 və ya + 1,328 ≤ β 1 ≤ +2,012. Beləliklə, əhalinin yamacının +1,328 - +2,012 (yəni, 1,328,000 - 2,012,000) intervalında olması 0,95 ehtimalı var. Bu dəyərlər sıfırdan böyük olduğundan, illik satış və mağaza sahəsi arasında statistik əhəmiyyətli xətti əlaqə var. Etibar intervalı sıfırdan ibarət olsaydı, dəyişənlər arasında heç bir əlaqə olmazdı. Bundan əlavə, etimad intervalı o deməkdir ki, hər mağaza sahəsi 1000 kv. ft orta satış həcminin 1,328,000 dollardan 2,012,000 dollara qədər artması ilə nəticələnir.
İstifadəsit -korrelyasiya əmsalı üçün meyarlar. korrelyasiya əmsalı tətbiq edilmişdir r, iki ədədi dəyişən arasındakı əlaqənin ölçüsüdür. İki dəyişən arasında statistik əhəmiyyətli əlaqənin olub olmadığını müəyyən etmək üçün istifadə edilə bilər. Hər iki dəyişənin populyasiyaları arasındakı korrelyasiya əmsalını ρ simvolu ilə işarə edək. Sıfır və alternativ fərziyyələr aşağıdakı kimi formalaşdırılır: H 0: ρ = 0 (korrelyasiya yoxdur), H 1: ρ ≠ 0 (korrelyasiya var). Bir əlaqənin mövcudluğunun yoxlanılması:

Harada r = + , Əgər verilmişdir 1 > 0, r = – , Əgər verilmişdir 1 < 0. Тестовая статистика t var t- ilə paylanması n – 2 sərbəstlik dərəcələri.
Sunflowers mağazalar şəbəkəsi ilə bağlı problemdə r 2= 0.904, a b 1- +1,670 (bax. Şəkil 4). ildən b 1> 0, illik satış və mağaza ölçüsü arasında korrelyasiya əmsalı r= +√0,904 = +0,951. Bu dəyişənlər arasında korrelyasiya olmadığına dair sıfır fərziyyəni istifadə edərək yoxlayaq t-statistika:

α = 0.05 əhəmiyyətlilik səviyyəsində sıfır hipotezi rədd edilməlidir, çünki t= 10,64 > 2,1788. Beləliklə, illik satış və mağaza ölçüsü arasında statistik əhəmiyyətli əlaqənin olduğunu iddia etmək olar.
Əhali yamacı ilə bağlı nəticələr müzakirə edilərkən, etimad intervalları və fərziyyə testləri bir-birini əvəz edən mənada istifadə olunur. Bununla belə, korrelyasiya əmsalını ehtiva edən etimad intervalını hesablamaq daha çətin olur, çünki statistik göstəricilərin seçmə paylanması növü r həqiqi korrelyasiya əmsalından asılıdır.
Riyazi gözləntilərin qiymətləndirilməsi və fərdi dəyərlərin proqnozlaşdırılması
Bu bölmədə cavabın riyazi gözləntisini qiymətləndirmək üsulları müzakirə olunur (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) və fərdi dəyərlərin proqnozları (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) dəyişənin verilmiş dəyərləri üçün Y.
Etibar intervalının qurulması. 2-ci misalda (yuxarıdakı bölməyə baxın Ən kiçik kvadratlar üsulu) reqressiya tənliyi dəyişənin qiymətini proqnozlaşdırmağa imkan verdi (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) Y. Pərakəndə satış nöqtəsi üçün yer seçmək problemində 4000 kv.m sahəsi olan bir mağazada orta illik satış həcmi. fut 7,644 milyon dollara bərabər idi, lakin ümumi əhalinin riyazi gözləntisinin bu təxminləri nöqtəlidir. Əhalinin riyazi gözləntilərini qiymətləndirmək üçün etimad intervalı konsepsiyası təklif edilmişdir. Eynilə, konsepsiyanı təqdim edə bilərik cavabın riyazi gözləntisi üçün inam intervalı verilmiş dəyişən dəyər üçün Y:
Harada
 , =
verilmişdir 0
+
verilmişdir 1
X i– proqnozlaşdırılan dəyər dəyişkəndir (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) saat Y = X i, S YX- kök orta kvadrat xətası, x i, y i- nümunə ölçüsü, Yi- dəyişənin müəyyən edilmiş dəyəri Y, µ
Y|X =
Xi– dəyişənin riyazi gözləntisi (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) saat X = X i, SSX =
, =
verilmişdir 0
+
verilmişdir 1
X i– proqnozlaşdırılan dəyər dəyişkəndir (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) saat Y = X i, S YX- kök orta kvadrat xətası, x i, y i- nümunə ölçüsü, Yi- dəyişənin müəyyən edilmiş dəyəri Y, µ
Y|X =
Xi– dəyişənin riyazi gözləntisi (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) saat X = X i, SSX = 
Düsturun (13) təhlili göstərir ki, etimad intervalının eni bir neçə amildən asılıdır. Müəyyən bir əhəmiyyət səviyyəsində, orta kvadrat xətadan istifadə etməklə ölçülən reqressiya xətti ətrafında dalğalanmaların amplitüdünün artması intervalın eninin artmasına səbəb olur. Digər tərəfdən, gözlənildiyi kimi, nümunə ölçüsünün artması intervalın daralması ilə müşayiət olunur. Bundan əlavə, intervalın eni dəyərlərdən asılı olaraq dəyişir Yi. Əgər dəyişən dəyər (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) miqdarlar üçün proqnozlaşdırılır Y, orta qiymətə yaxındır , etimad intervalı ortadan uzaq olan dəyərlər üçün cavab proqnozlaşdırıldığından daha dar olur.
Deyək ki, mağaza yeri seçərkən, sahəsi 4000 kvadratmetr olan bütün mağazaların orta illik satışları üçün 95% etibarlılıq intervalı qurmaq istəyirik. ayaqları:

Buna görə, sahəsi 4000 kv.m olan bütün mağazalarda orta illik satış həcmi. fut, 95% ehtimalı ilə 6.971 ilə 8.317 milyon dollar arasındadır.
Proqnozlaşdırılan dəyər üçün etibarlılıq intervalını hesablayın. Dəyişənin verilmiş dəyəri üçün cavabın riyazi gözləntiləri üçün inam intervalına əlavə olaraq Y, tez-tez proqnozlaşdırılan dəyər üçün inam intervalını bilmək lazımdır. Belə bir güvən intervalının hesablanması düsturu (13) düsturuna çox bənzəsə də, bu intervalda parametrin qiymətləndirilməsi deyil, proqnozlaşdırılan dəyəri var. Proqnozlaşdırılan cavab üçün interval (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).)X = Xi müəyyən bir dəyişən dəyər üçün Yi düsturla müəyyən edilir:

Tutaq ki, pərakəndə satış məntəqəsi üçün yer seçərkən, sahəsi 4000 kvadratmetr olan bir mağaza üçün proqnozlaşdırılan illik satış həcmi üçün 95% inam intervalı qurmaq istəyirik. ayaqları:

Beləliklə, 4000 kv.m sahəsi olan bir mağaza üçün proqnozlaşdırılan illik satış həcmi. fut, 95% ehtimalı ilə 5,433 ilə 9,854 milyon dollar arasındadır. Bunun səbəbi, fərdi dəyərlərin proqnozlaşdırılmasındakı dəyişkənliyin riyazi gözləntiləri qiymətləndirməkdən qat-qat böyük olmasıdır.
Reqressiyadan istifadə ilə bağlı tələlər və etik problemlər
Reqressiya təhlili ilə bağlı çətinliklər:
- Ən kiçik kvadratlar metodunun tətbiqi şərtlərinin nəzərə alınmaması.
- Ən kiçik kvadratlar metodunun tətbiqi şərtlərinin səhv qiymətləndirilməsi.
- Ən kiçik kvadratlar metodunun tətbiqi şərtləri pozulduqda alternativ üsulların düzgün seçilməməsi.
- Tədqiqat mövzusunu dərindən bilmədən reqressiya analizinin tətbiqi.
- İzahedici dəyişənin diapazonundan kənarda reqressiyanın ekstrapolyasiyası.
- Statistik və səbəb əlaqələri arasında qarışıqlıq.
Elektron cədvəllərin və statistik proqram təminatının geniş yayılması reqressiya analizinin istifadəsinə mane olan hesablama problemlərini aradan qaldırdı. Lakin bu, reqressiya analizinin kifayət qədər ixtisas və biliyə malik olmayan istifadəçilər tərəfindən istifadə edilməsinə səbəb oldu. Əgər onların bir çoxunun ən kiçik kvadratlar metodunun tətbiqi şərtləri haqqında heç bir təsəvvürü yoxdursa və onların həyata keçirilməsini necə yoxlamaq lazım olduğunu bilmirlərsə, istifadəçilər alternativ metodlar haqqında necə məlumat əldə edə bilərlər?
Tədqiqatçı rəqəmlərin cırılması ilə - sürüşmə, yamac və qarışıq korrelyasiya əmsalının hesablanması ilə məşğul olmamalıdır. Onun daha dərin biliyə ehtiyacı var. Bunu dərsliklərdən götürülmüş klassik nümunə ilə izah edək. Anscombe göstərdi ki, Şəkil 1-də göstərilən bütün dörd məlumat dəsti. 23, eyni reqressiya parametrlərinə malikdir (şək. 24).

düyü. 23. Dörd süni verilənlər toplusu

düyü. 24. Dörd süni məlumat dəstinin reqressiya təhlili; ilə edilir Analiz paketi(Şəkili böyütmək üçün şəklin üzərinə klikləyin)
Beləliklə, reqressiya təhlili baxımından bütün bu məlumat dəstləri tamamilə eynidir. Təhlil orada bitsəydi, çox faydalı məlumatları itirərdik. Bunu bu məlumat dəstləri üçün qurulmuş səpələnmə qrafikləri (Şəkil 25) və qalıq qrafiklər (Şəkil 26) sübut edir.

düyü. 25. Dörd verilənlər dəsti üçün səpələnmə qrafikləri
Səpələnmə qrafikləri və qalıq qrafiklər bu məlumatların bir-birindən fərqləndiyini göstərir. Düz xətt boyunca paylanmış yeganə çoxluq A çoxluğudur. A çoxluğundan hesablanan qalıqların qrafikində heç bir nümunə yoxdur. Bunu B, C və D çoxluqları haqqında demək olmaz. B çoxluğu üçün çəkilmiş səpilmə qrafası aydın kvadratik nümunəni göstərir. Bu nəticə parabolik formaya malik olan qalıq süjeti ilə təsdiqlənir. Səpələnmə qrafiki və qalıq qrafiki B məlumat dəstinin kənar göstərici ehtiva etdiyini göstərir. Bu vəziyyətdə, məlumat dəstindən kənar göstəricini çıxarmaq və təhlili təkrarlamaq lazımdır. Müşahidələrdə kənar göstəricilərin aşkar edilməsi və aradan qaldırılması üsulu təsir təhlili adlanır. Həddindən artıq göstərici aradan qaldırıldıqdan sonra modelin yenidən qiymətləndirilməsinin nəticəsi tamamilə fərqli ola bilər. G dəstindəki məlumatlardan tərtib edilmiş səpələnmə qrafiki empirik modelin fərdi cavabdan əhəmiyyətli dərəcədə asılı olduğu qeyri-adi vəziyyəti göstərir ( X 8 = 19, (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) 8 = 12.5). Belə reqressiya modelləri xüsusilə diqqətlə hesablanmalıdır. Beləliklə, səpilmə və qalıq qrafiklər reqressiya təhlili üçün vacib vasitədir və onun ayrılmaz hissəsi olmalıdır. Bunlar olmadan reqressiya təhlili etibarlı deyil.

düyü. 26. Dörd məlumat dəsti üçün qalıq qrafiklər
Reqressiya təhlilində tələlərdən necə qaçmaq olar:
- Dəyişənlər arasında mümkün əlaqələrin təhlili Y Və (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).) həmişə səpələnmə xəttini çəkməklə başlayın.
- Reqressiya təhlilinin nəticələrini şərh etməzdən əvvəl onun tətbiqi şərtlərini yoxlayın.
- Müstəqil dəyişənə qarşı qalıqların qrafikini qurun. Bu, empirik modelin müşahidə nəticələrinə nə dərəcədə uyğun olduğunu müəyyən etməyə və dispersiya sabitliyinin pozulmasını aşkar etməyə imkan verəcəkdir.
- Normal xəta paylanması fərziyyəsini yoxlamaq üçün histoqramlardan, gövdə və yarpaq qrafiklərindən, qutu qrafiklərindən və normal paylanma qrafiklərindən istifadə edin.
- Ən kiçik kvadratlar metodunun tətbiqi şərtləri yerinə yetirilmirsə, alternativ üsullardan istifadə edin (məsələn, kvadrat və ya çoxlu reqressiya modelləri).
- Ən kiçik kvadratlar metodunun tətbiqi şərtləri yerinə yetirilərsə, reqressiya əmsallarının statistik əhəmiyyəti haqqında fərziyyəni yoxlamaq və riyazi gözləntiləri və proqnozlaşdırılan cavab dəyərini ehtiva edən etimad intervallarını qurmaq lazımdır.
- Müstəqil dəyişənin diapazonundan kənarda asılı dəyişənin dəyərlərini proqnozlaşdırmaqdan çəkinin.
- Unutmayın ki, statistik əlaqələr həmişə səbəb-nəticə deyil. Unutmayın ki, dəyişənlər arasında korrelyasiya onlar arasında səbəb-nəticə əlaqəsinin olması demək deyil.
CV. Blok diaqramda göstərildiyi kimi (Şəkil 27) qeyddə sadə xətti reqressiya modeli, onun tətbiqi şərtləri və bu şərtlərin sınaqdan keçirilməsi üsulları təsvir edilmişdir. Hesab olunur t-reqressiya yamacının statistik əhəmiyyətinin yoxlanılması meyarı. Asılı dəyişənin dəyərlərini proqnozlaşdırmaq üçün reqressiya modelindən istifadə edilmişdir. İllik satış həcminin mağaza sahəsindən asılılığının araşdırıldığı pərakəndə satış məntəqəsi üçün yer seçimi ilə bağlı bir nümunə nəzərdən keçirilir. Əldə edilən məlumat mağaza üçün yeri daha dəqiq seçməyə və onun illik satış həcmini proqnozlaşdırmağa imkan verir. Aşağıdakı qeydlər reqressiya təhlilinin müzakirəsini davam etdirəcək və həmçinin çoxsaylı reqressiya modellərinə baxacaq.

düyü. 27. Qeydin struktur diaqramı
Levin et al kitabının materiallarından istifadə olunur. – M.: Williams, 2004. – s. 792–872
Əgər asılı dəyişən kateqoriyalıdırsa, logistik reqressiyadan istifadə edilməlidir.
Reqressiya nədir?
İki davamlı dəyişəni nəzərdən keçirin x=(x 1 , x 2 , .., x n), y=(y 1 , y 2 , ..., y n).
Nöqtələri ikiölçülü səpələnmə xəttinə yerləşdirək və bizdə olduğunu söyləyək xətti əlaqə, əgər verilənlər düz xətt ilə təxmini olarsa.
Buna inansaq y asılıdır x, və dəyişikliklər y dəyişiklikləri ilə əlaqədardır x, reqressiya xəttini təyin edə bilərik (reqressiya y Bu nümunədə reqressiya x), bu iki dəyişən arasındakı xətti əlaqəni ən yaxşı təsvir edir.
Reqressiya sözünün statistik istifadəsi Ser Francis Galtona (1889) aid edilən orta səviyyəyə geriləmə kimi tanınan fenomendən irəli gəlir.
O, göstərdi ki, hündürboy atalar uzun boylu oğullara sahib olsalar da, oğulların orta boyu hündürboy atalarından daha qısadır. Oğulların orta boyu əhalinin bütün atalarının orta boylarına doğru “geriləşdi” və “geriyə doğru getdi”. Beləliklə, orta hesabla, uzun boylu ataların daha qısa (lakin hələ də kifayət qədər uzun) oğulları var və qısa ataların daha uzun (lakin hələ də kifayət qədər qısa) oğulları var.
Reqressiya xətti
Sadə (cüt) xətti reqressiya xəttini qiymətləndirən riyazi tənlik:
x müstəqil dəyişən və ya proqnozlaşdırıcı adlanır.
(\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).)- asılı dəyişən və ya cavab dəyişəni. Bu, gözlədiyimiz dəyərdir y(orta hesabla) dəyərini bilsək x, yəni. bu "proqnozlaşdırılan dəyər" y»
- a- qiymətləndirmə xəttinin sərbəst üzvü (kəsişməsi); mənası budur (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).), Nə vaxt x=0(Şəkil 1).
- verilmişdir- təxmin edilən xəttin mailliyi və ya qradiyenti; olan məbləği ifadə edir Y artırsaq orta hesabla artır x bir vahid üçün.
- a Və verilmişdir təxmin edilən xəttin reqressiya əmsalları adlanır, baxmayaraq ki, bu termin çox vaxt yalnız üçün istifadə olunur verilmişdir.
Cütlü xətti reqressiya birdən çox müstəqil dəyişəni daxil etmək üçün genişləndirilə bilər; bu halda kimi tanınır çoxlu reqressiya.
Şəkil 1. a kəsişməsini və b yamacını göstərən xətti reqressiya xətti (x bir vahid artdıqca Y miqdarı artır)
Ən kiçik kvadratlar üsulu
Müşahidələr nümunəsindən istifadə edərək reqressiya təhlili aparırıq a Və verilmişdir- populyasiyada (ümumi əhali) xətti reqressiya xəttini müəyyən edən həqiqi (ümumi) parametrlərin, α və β-nın nümunə qiymətləndirmələri.
Əmsalları təyin etmək üçün ən sadə üsul a Və verilmişdir edir ən kiçik kvadratlar üsulu(MNC).
Uyğunluq qalıqlara baxmaqla qiymətləndirilir (hər bir nöqtənin xəttdən şaquli məsafəsi, məsələn, qalıq = müşahidə olunur) y- proqnozlaşdırılır y, Düyü. 2).
Ən yaxşı uyğunluq xətti elə seçilir ki, qalıqların kvadratlarının cəmi minimal olsun.

düyü. 2. Hər bir nöqtə üçün təsvir edilmiş qalıqları olan xətti reqressiya xətti (şaquli nöqtəli xətlər).
Xətti reqressiya fərziyyələri
Beləliklə, hər bir müşahidə olunan dəyər üçün qalıq fərqə bərabərdir və hər bir qalıq müsbət və ya mənfi ola bilər.
Xətti reqressiyanın arxasında aşağıdakı fərziyyələri yoxlamaq üçün qalıqlardan istifadə edə bilərsiniz:
- Qalıqlar normal olaraq sıfır orta ilə paylanır;
Xəttilik, normallıq və/və ya sabit dispersiya ilə bağlı fərziyyələr şübhə doğurursa, biz bu fərziyyələrin ödənildiyi yeni reqressiya xəttini çevirə və ya hesablaya bilərik (məsələn, loqarifmik çevrilmədən istifadə etmək və s.).
Qeyri-adi dəyərlər (xarici göstəricilər) və təsir nöqtələri
"Nüfuzlu" müşahidə, buraxılmadıqda, bir və ya bir neçə model parametrinin təxminlərini (yəni, yamac və ya kəsişmə) dəyişir.
Bir kənar göstərici (verilənlər dəstindəki dəyərlərin əksəriyyətinə uyğun olmayan müşahidə) "nüfuzlu" müşahidə ola bilər və ikidəyişənli səpələnmə və ya qalıq sahəsini yoxlayaraq vizual olaraq asanlıqla aşkar edilə bilər.
Həm kənar göstəricilər, həm də “təsirli” müşahidələr (nöqtələr) üçün modellər həm daxil edilmiş, həm də daxil edilmədən istifadə olunur və qiymətləndirmələrdəki dəyişikliklərə (reqressiya əmsalları) diqqət yetirilir.
Təhlil apararkən, kənar göstəriciləri və ya təsir nöqtələrini avtomatik olaraq atmamalısınız, çünki sadəcə onlara məhəl qoymamaq əldə edilən nəticələrə təsir göstərə bilər. Həmişə bu kənar göstəricilərin səbəblərini öyrənin və təhlil edin.
Xətti reqressiya hipotezi
Xətti reqressiyanın qurulması zamanı sıfır fərziyyə yoxlanılır ki, β reqressiya xəttinin ümumi mailliyi sıfıra bərabərdir.
Xəttin mailliyi sıfırdırsa, və arasında xətti əlaqə yoxdur: dəyişiklik təsir etmir
Həqiqi yamacın sıfır olduğu sıfır hipotezini yoxlamaq üçün aşağıdakı alqoritmdən istifadə edə bilərsiniz:
əmsalın standart xətası olan sərbəstlik dərəcələri ilə paylanmaya məruz qalan nisbətə bərabər olan test statistikasını hesablayın.

 ,
, - qalıqların dispersiyasının qiymətləndirilməsi.
- qalıqların dispersiyasının qiymətləndirilməsi.Tipik olaraq, əhəmiyyət səviyyəsinə çatdıqda, sıfır hipotezi rədd edilir.

ikitərəfli test ehtimalını verən sərbəstlik dərəcələri ilə paylanmanın faiz nöqtəsi haradadır
Bu, 95% ehtimalı ilə ümumi yamacı ehtiva edən intervaldır.
Böyük nümunələr üçün, deyək ki, 1,96 dəyəri ilə təqribən hesab edə bilərik (yəni, test statistikası normal paylanmağa meyllidir)
Xətti reqressiyanın keyfiyyətinin qiymətləndirilməsi: təyinetmə əmsalı R 2
Çünki xətti əlaqə və bunun dəyişməsini gözləyirik , və onu reqressiya ilə bağlı olan və ya onunla izah edilən variasiya adlandırın. Qalıq variasiya mümkün qədər kiçik olmalıdır.
Əgər bu doğrudursa, onda variasiyanın çoxu reqressiya ilə izah ediləcək və nöqtələr reqressiya xəttinə yaxın yerləşəcək, yəni. xətt məlumatlara yaxşı uyğun gəlir.
Ümumi dispersiyanın reqressiya ilə izah edilən nisbəti deyilir təyin əmsalı, adətən faizlə ifadə edilir və işarələnir R 2(qoşalaşmış xətti reqresiyada bu kəmiyyətdir r 2, korrelyasiya əmsalının kvadratı), reqressiya tənliyinin keyfiyyətini subyektiv qiymətləndirməyə imkan verir.
Fərq reqressiya ilə izah edilə bilməyən dispersiya faizini ifadə edir.
Reqressiya xəttinin uyğunluğunu müəyyən etmək üçün subyektiv mühakimələrə etibar etməliyik.
Proqnoz üçün Reqressiya Xəttinin Tətbiqi
Müşahidə olunan diapazonun həddindən artıq sonundakı dəyərdən bir dəyəri proqnozlaşdırmaq üçün reqressiya xəttindən istifadə edə bilərsiniz (heç vaxt bu hədləri aşan ekstrapolyasiya etməyin).
Müəyyən bir dəyərə malik olan müşahidə olunanların orta qiymətini həmin dəyəri reqressiya xəttinin tənliyinə daxil etməklə proqnozlaşdırırıq.
Beləliklə, əgər biz kimi təxmin etsək, bu proqnozlaşdırılan dəyəri və onun standart xətasını həqiqi populyasiya ortalaması üçün inam intervalını qiymətləndirmək üçün istifadə edin.
Bu proseduru müxtəlif dəyərlər üçün təkrarlamaq bu xətt üçün inam limitlərini qurmağa imkan verir. Bu, məsələn, 95% etibarlılıq səviyyəsində həqiqi xətti ehtiva edən band və ya sahədir.
Sadə reqressiya planları
Sadə reqressiya dizaynları bir davamlı proqnozlaşdırıcıdan ibarətdir. Əgər 7, 4 və 9 kimi proqnozlaşdırıcı dəyərləri olan P olan 3 müşahidə varsa və dizayn birinci dərəcəli təsirə malikdirsə, onda dizayn matrisi X olacaq.

və X1 üçün P istifadə edərək reqressiya tənliyidir
Y = b0 + b1 P
Sadə bir reqressiya dizaynı kvadrat effekt kimi P-yə daha yüksək səviyyəli effekti ehtiva edirsə, dizayn matrisində X1 sütunundakı dəyərlər ikinci dərəcəyə qaldırılacaqdır:

və tənlik formasını alacaq
Y = b0 + b1 P2
Siqma ilə məhdudlaşdırılmış və həddindən artıq parametrləşdirilmiş kodlaşdırma üsulları sadə reqressiya dizaynlarına və yalnız davamlı proqnozlaşdırıcıları ehtiva edən digər dizaynlara tətbiq edilmir (çünki sadəcə olaraq heç bir kateqoriyalı proqnozlaşdırıcılar yoxdur). Seçilmiş kodlaşdırma metodundan asılı olmayaraq, davamlı dəyişənlərin dəyərləri müvafiq olaraq artırılır və X dəyişənləri üçün dəyərlər kimi istifadə olunur. Bu halda, yenidən kodlaşdırma aparılmır. Bundan əlavə, reqressiya planlarını təsvir edərkən, dizayn matrisi X-i nəzərdən qaçıra və yalnız reqressiya tənliyi ilə işləyə bilərsiniz.
Nümunə: Sadə reqressiya təhlili
Bu nümunə cədvəldə təqdim olunan məlumatlardan istifadə edir:

düyü. 3. İlkin məlumatların cədvəli.
Təsadüfi olaraq seçilmiş 30 əyalətdə 1960 və 1970-ci illərin siyahıyaalınmasının müqayisəsindən tərtib edilmiş məlumatlar. Rayon adları müşahidə adları kimi təqdim olunur. Hər bir dəyişənlə bağlı məlumat aşağıda təqdim olunur:

düyü. 4. Dəyişən spesifikasiyalar cədvəli.
Tədqiqat problemi
Bu misal üçün yoxsulluq səviyyəsi ilə yoxsulluq həddindən aşağı olan ailələrin faizini proqnozlaşdıran dərəcə arasındakı əlaqə təhlil ediləcək. Buna görə də 3 (Pt_Poor) dəyişənini asılı dəyişən kimi qəbul edəcəyik.
Biz bir fərziyyə irəli sürə bilərik: əhalinin sayındakı dəyişikliklər və yoxsulluq həddindən aşağı olan ailələrin faiz nisbəti bir-birinə bağlıdır. Yoxsulluğun xaricə miqrasiyaya səbəb olmasını gözləmək ağlabatan görünür, ona görə də yoxsulluq həddindən aşağı olan insanların faizi ilə əhalinin dəyişməsi arasında mənfi korrelyasiya olacaq. Buna görə də, biz dəyişəni 1 (Pop_Chng) proqnozlaşdırıcı dəyişən kimi qəbul edəcəyik.
Nəticələrə baxın
Reqressiya əmsalları

düyü. 5. Pop_Chng-də Pt_Poor-un reqressiya əmsalları.
Pop_Chng sıra ilə Param sütununun kəsişməsində.<.05 . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на.65.
Pop_Chng-də Pt_Poor-un reqressiyası üçün standartlaşdırılmamış əmsalı -0,40374-dür. Bu o deməkdir ki, əhalinin hər vahid azalmasına görə yoxsulluq səviyyəsinin .40374 artımı var. Bu qeyri-standart əmsal üçün yuxarı və aşağı (defolt) 95% etibarlılıq hədləri sıfırı əhatə etmir, ona görə də reqressiya əmsalı p səviyyəsində əhəmiyyətlidir.
Dəyişən paylama

Məlumatlarda böyük kənar göstəricilər varsa, korrelyasiya əmsalları əhəmiyyətli dərəcədə həddən artıq qiymətləndirilə və ya aşağı qiymətləndirilə bilər. Pt_Poor asılı dəyişəninin rayonlar üzrə paylanmasını öyrənək. Bunun üçün Pt_Poor dəyişəninin histoqramını quraq.
düyü. 6. Pt_Poor dəyişəninin histoqramı.

Gördüyünüz kimi, bu dəyişənin paylanması normal paylanmadan kəskin şəkildə fərqlənir. Bununla belə, hətta iki əyalətdə (iki sağ sütunda) yoxsulluq həddinin altında olan ailələrin faiz nisbəti normal bölgüdə gözlənildiyindən daha yüksək olsa da, onlar “diapazonda” görünür.
düyü. 7. Pt_Poor dəyişəninin histoqramı.
Bu mühakimə bir qədər subyektivdir. Əsas qayda ondan ibarətdir ki, müşahidə (və ya müşahidələr) intervala (ortalama ± 3 dəfə standart sapma) daxil deyilsə, kənar göstəricilər nəzərə alınmalıdır. Bu halda, onların əhali üzvləri arasında korrelyasiyaya böyük təsir göstərməməsini təmin etmək üçün kənar göstəricilərlə və olmadan təhlili təkrar etməyə dəyər.
Dağılma qrafiki

Əgər fərziyyələrdən biri verilmiş dəyişənlər arasındakı əlaqəyə dair aprioridirsə, onda onu müvafiq səpələnmə qrafiki üzərində yoxlamaq faydalıdır.
düyü. 8. Dağılma diaqramı.
Dağılma qrafiki iki dəyişən arasında aydın mənfi korrelyasiya (-.65) göstərir. O, həmçinin reqressiya xətti üçün 95% etimad intervalını göstərir, yəni reqressiya xəttinin iki nöqtəli əyri arasında olması 95% ehtimalı var.

Əhəmiyyətlilik meyarları
Pop_Chng reqressiya əmsalı testi təsdiq edir ki, Pop_Chng Pt_Poor, p ilə sıx bağlıdır.<.001 .
Alt xətt
Bu nümunə sadə reqressiya dizaynının necə təhlil ediləcəyini göstərdi. Standartlaşdırılmamış və standartlaşdırılmış reqressiya əmsallarının şərhləri də təqdim edilmişdir. Asılı dəyişənin cavab paylanmasının öyrənilməsinin vacibliyi müzakirə edilir və proqnozlaşdırıcı ilə asılı dəyişən arasındakı əlaqənin istiqamətini və gücünü təyin etmək üçün texnika nümayiş etdirilir.
























